
Spatiotemporal Deformation Prediction Model for Retaining Structures Integrating ConvGRU and Cross-Attention Mechanism

Abstract
1. Introduction
2. Methodology
2.1. Convolutional GRU Neural Networks
2.1.1. Convolutional Layer
2.1.2. GRU Layer
2.1.3. ConvGRU Model
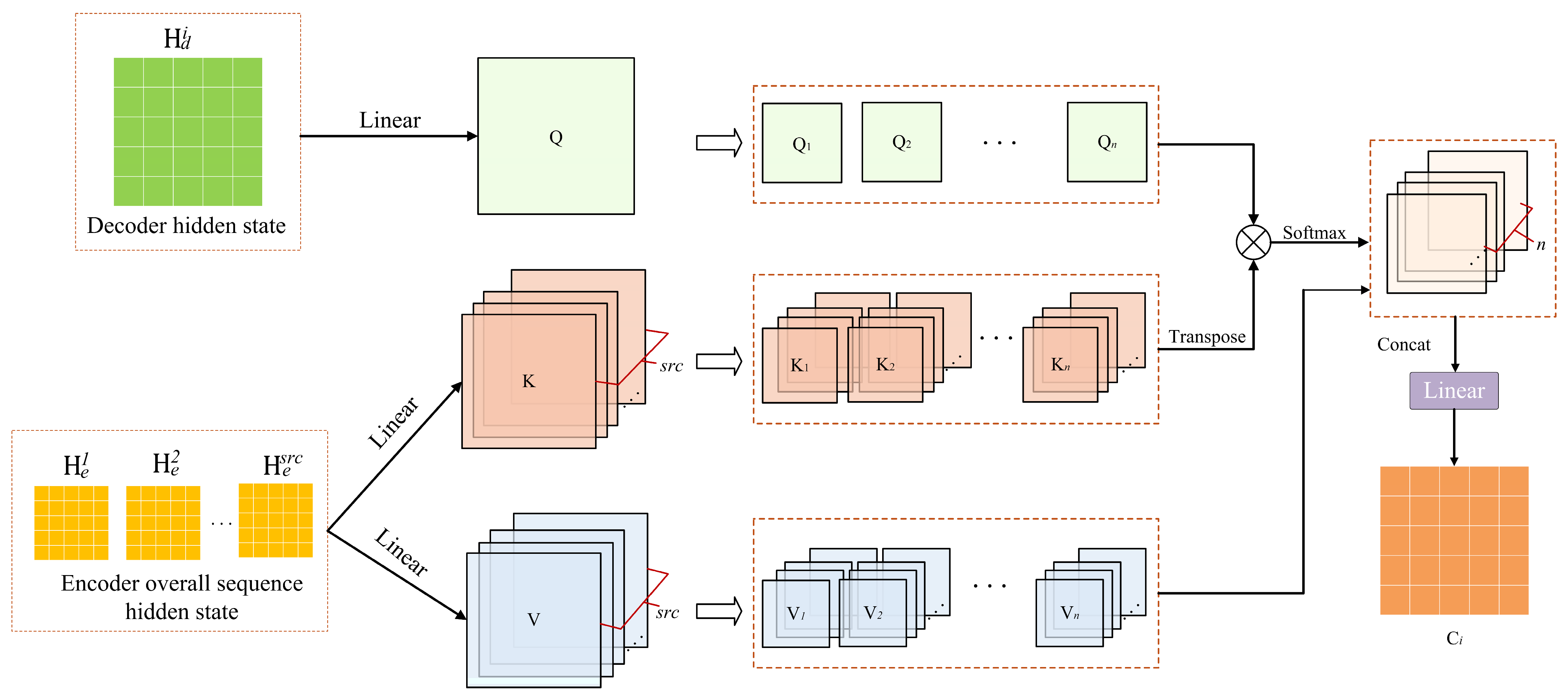
2.2. Cross-Attention Mechanism
2.3. Structure of the Proposed CGCA Model
2.3.1. Spatiotemporal Dimensions of the Model Input and Output
2.3.2. CGCA Model
2.4. Collaborative Optimization Strategy
2.5. Flowchart of the Proposed Method
3. Case Study
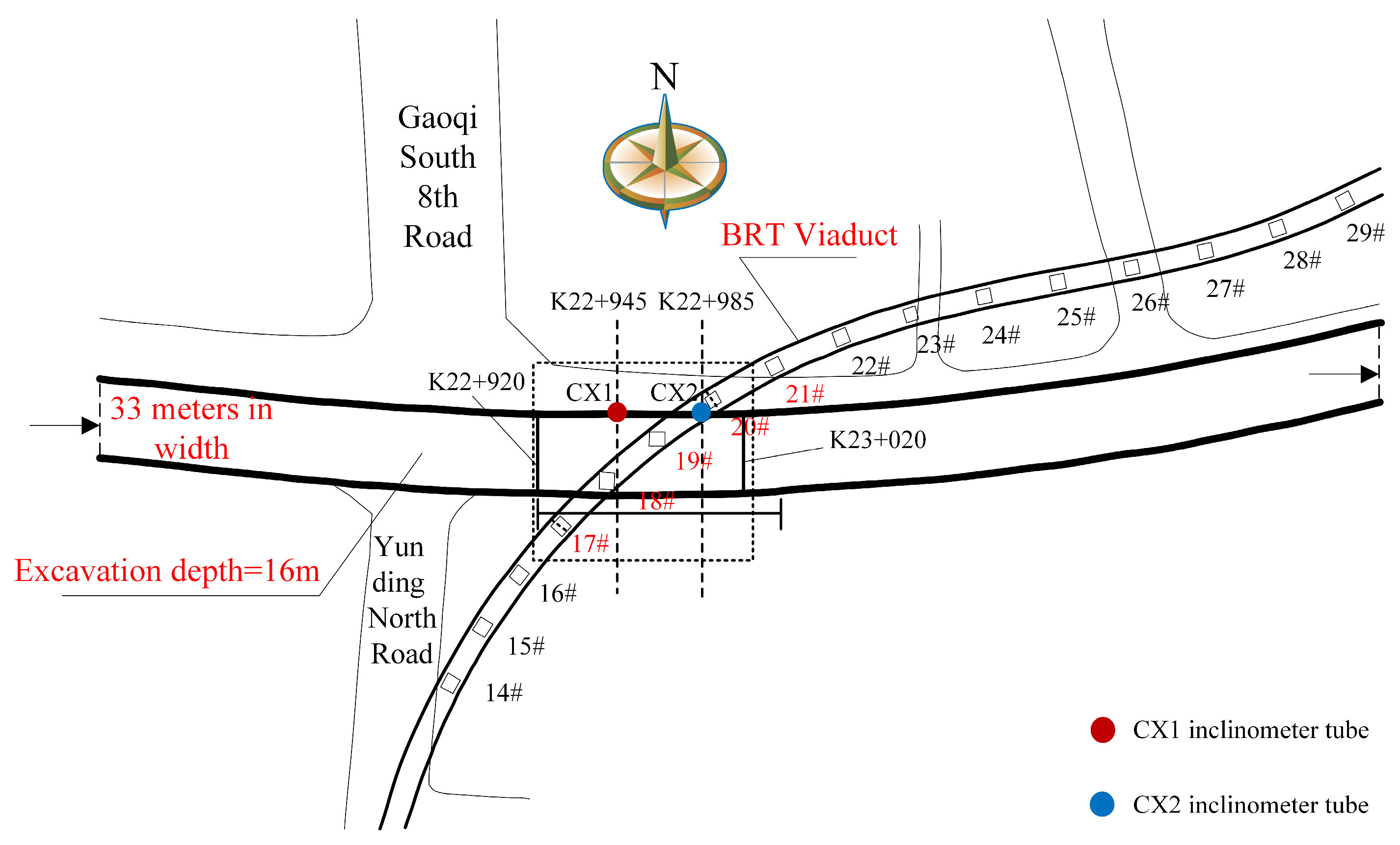
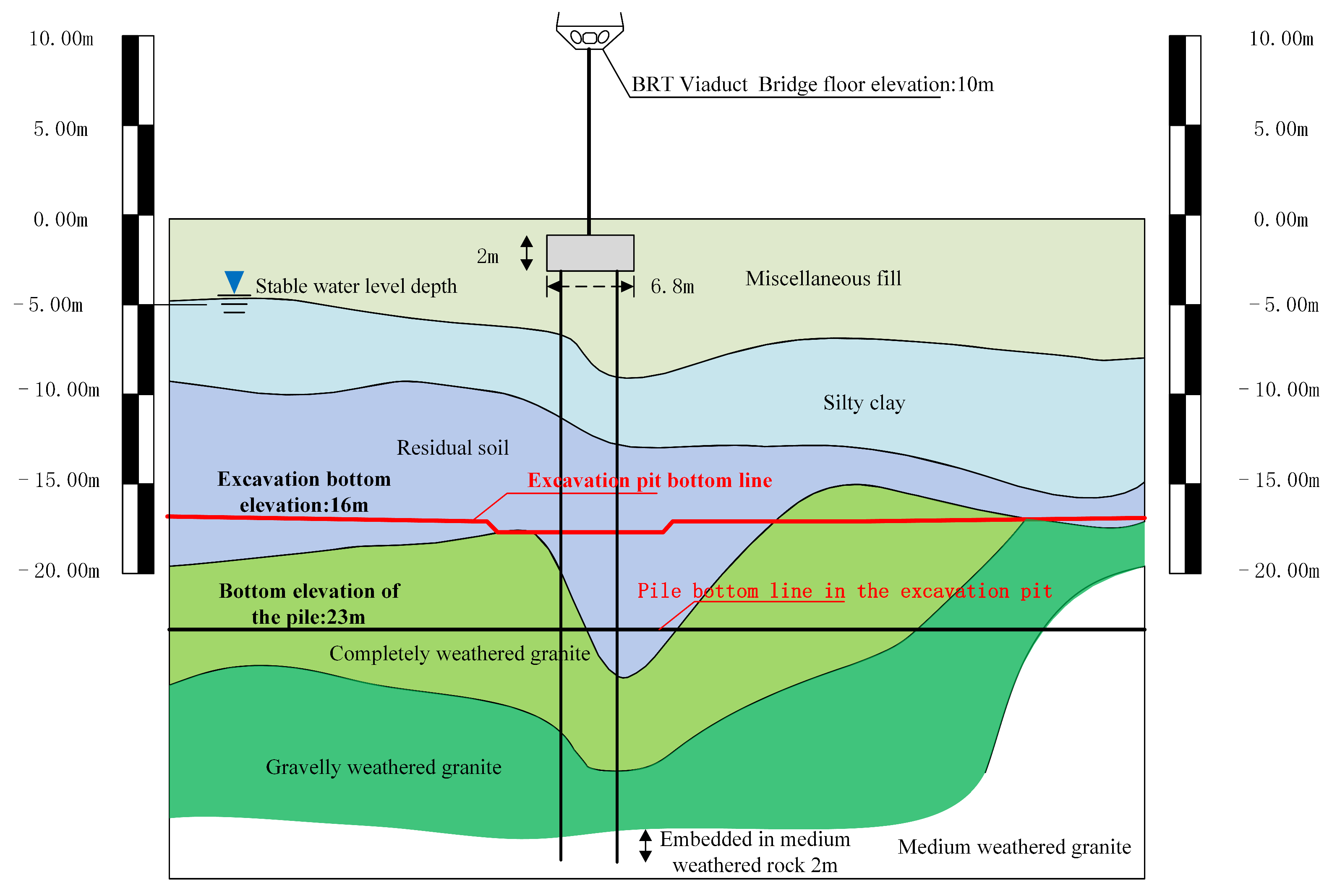
3.1. Project Overview
3.2. Data Acquisition
4. Construction of CGCA Model
5. Results
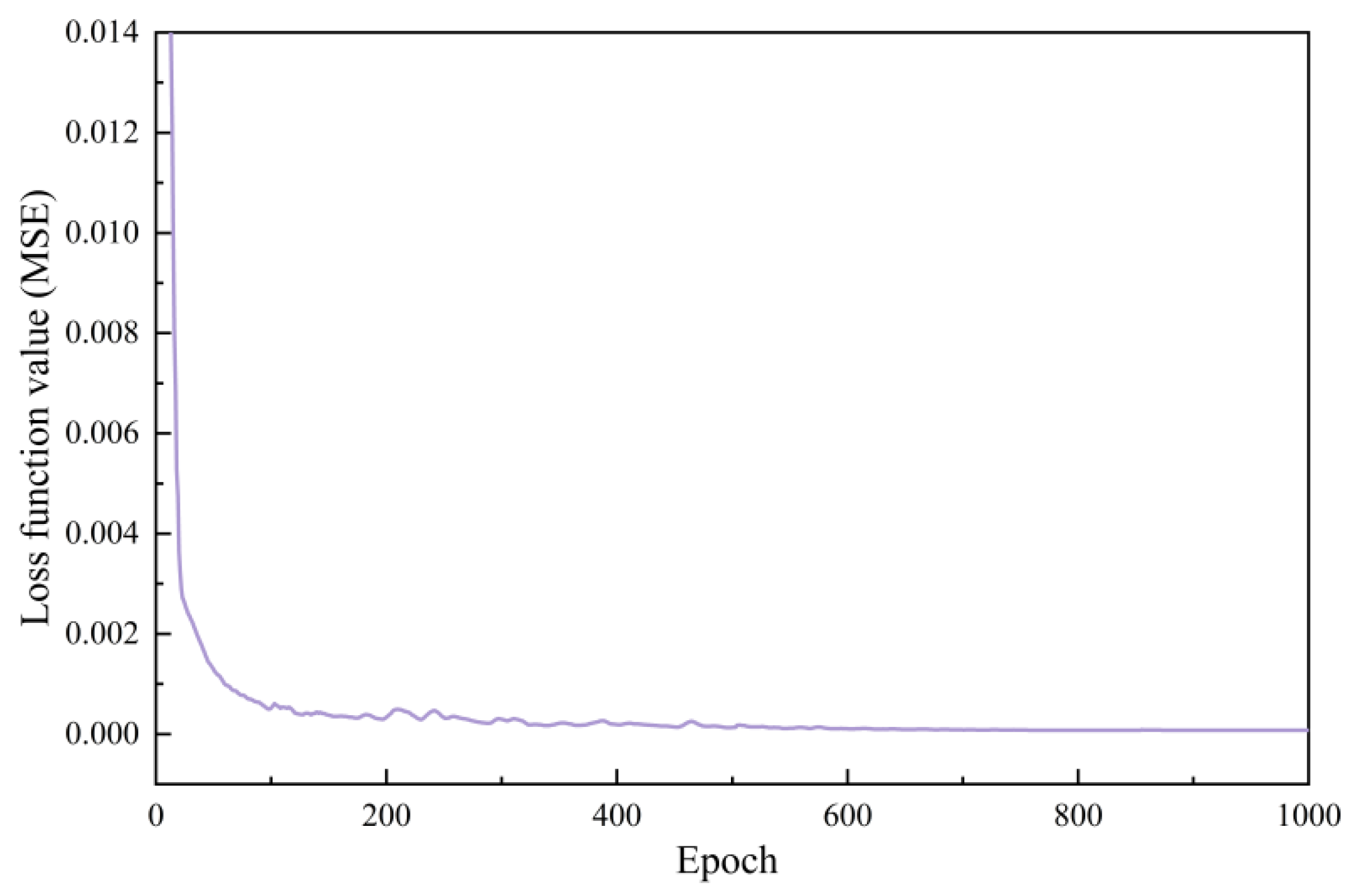
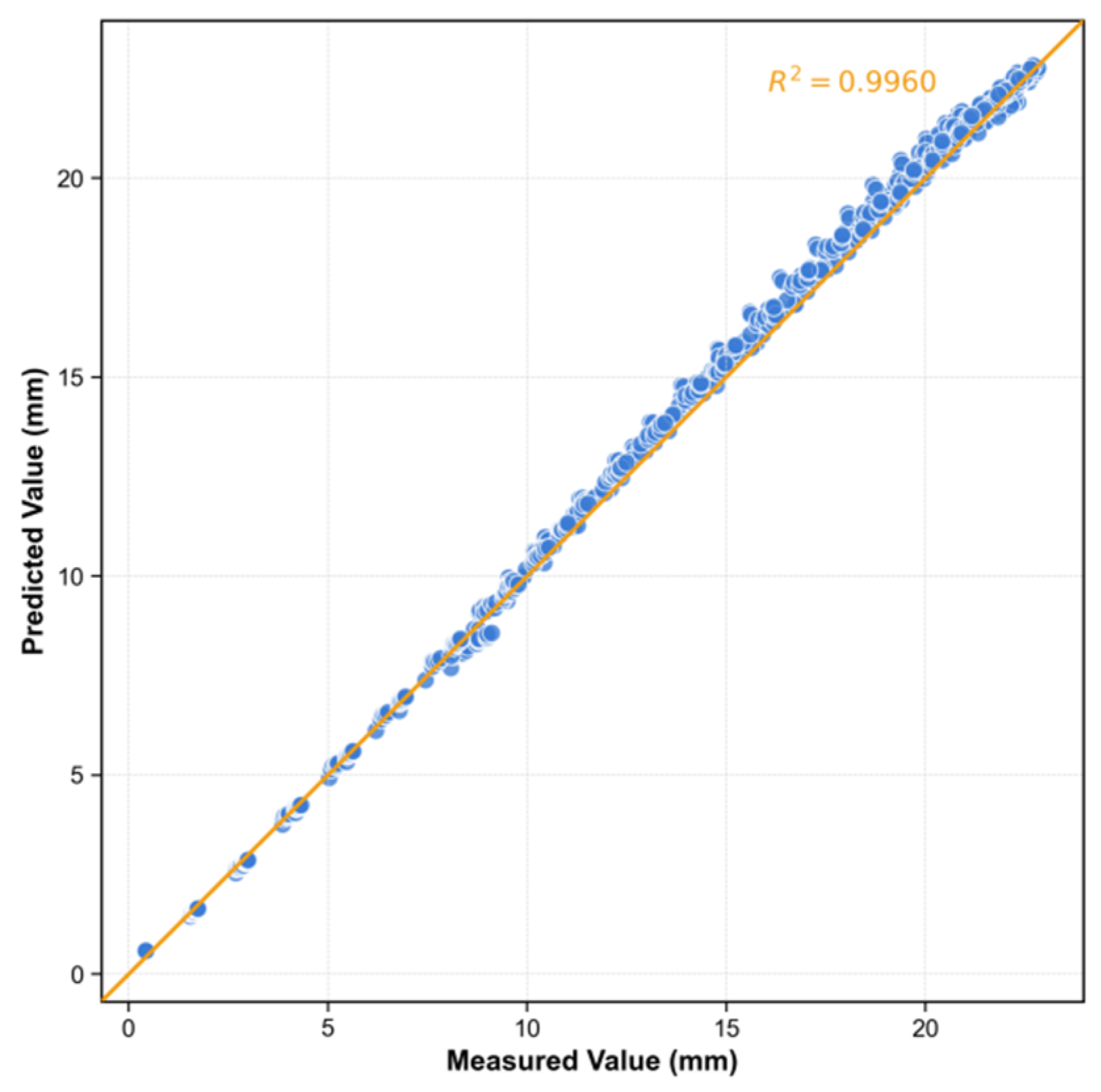
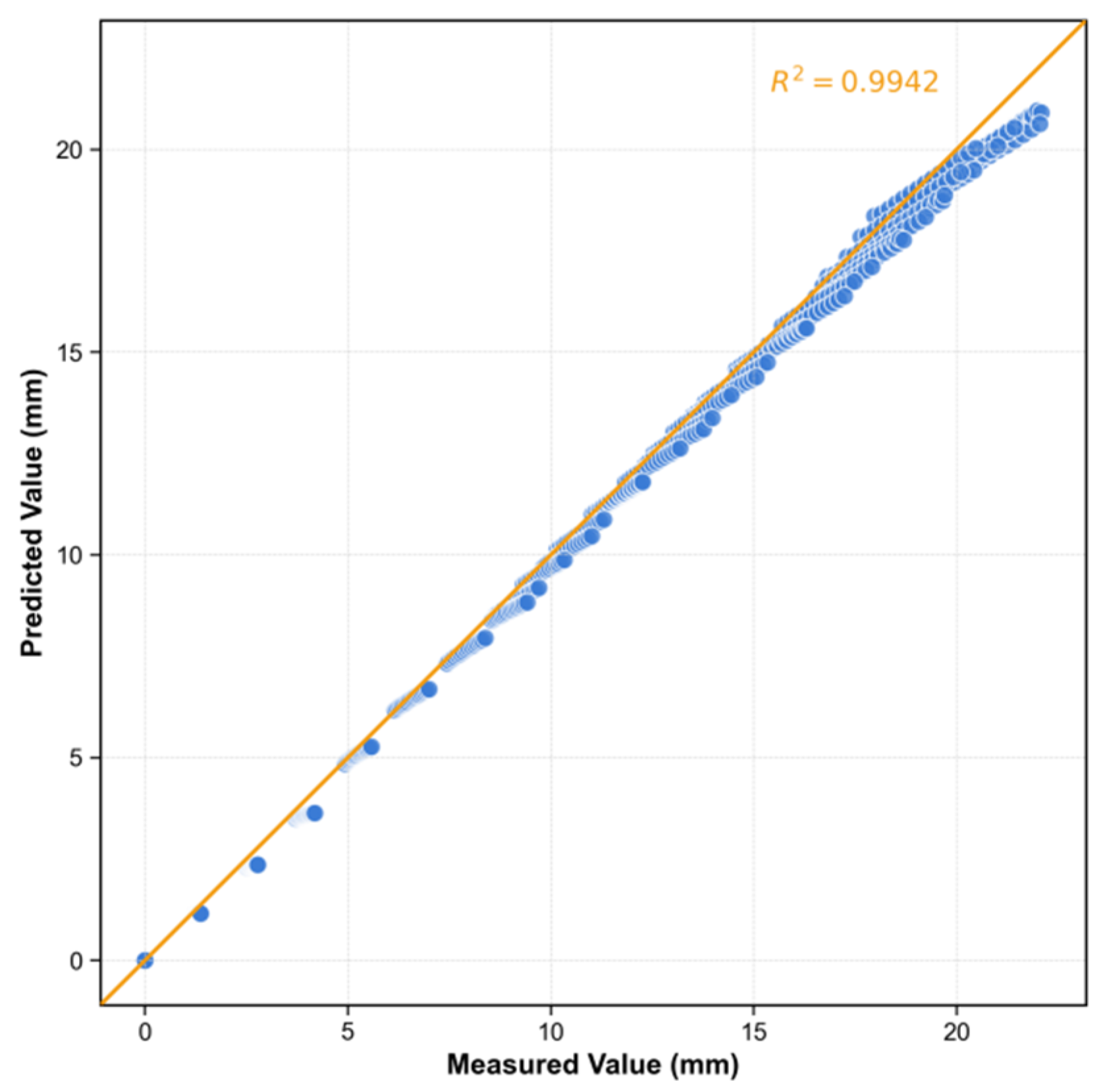
5.1. Performance of CGCA
5.2. The Effect of Encoder Length on Model Performance
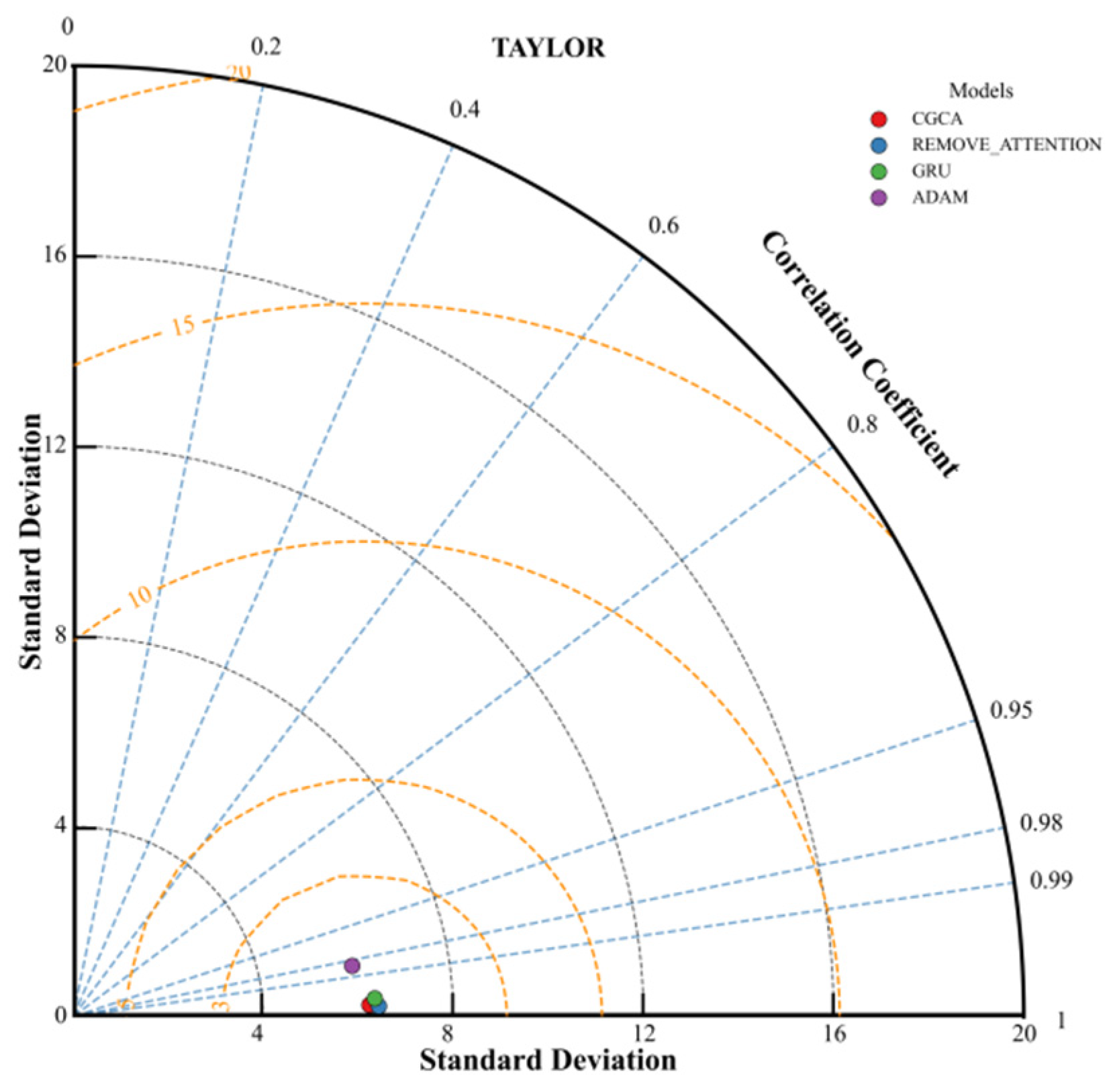
5.3. Comparative Experiment
6. Conclusions
- (1)
- Based on the measured data from the deep foundation pit project of the open-cut underpass for elevated bridges along Xiamen’s Second East Passage, the CGCA model demonstrated excellent prediction accuracy on the test set: with a root mean square error (RMSE) of 0.385 mm, a mean absolute error (MAE) of 0.314 mm, and a coefficient of determination (R2) of 0.996. This confirms the model’s strong capability to capture the spatiotemporal deformation characteristics of retaining structures, providing technical support for “millimeter-level early warning + dynamic decision-making” in high-risk foundation pit projects within densely populated urban areas.
- (2)
- Effectiveness of architecture design and optimization strategy: Comparative experiments show that the performance of the CGCA model is significantly better than other benchmark models. After eliminating the cross-attention mechanism, the performance of the model decreased (MAE increased to 0.53 mm, R2 decreased to 0.989), which verified the key role of the mechanism in long-term dependence modeling through step-length feature fusion. The combined optimization strategy of AdamW and Lookahead reduces the prediction error by 54% compared with the single Adam optimizer, highlighting the advantages of the weight update mechanism in suppressing overfitting and improving generalization. Compared with the GRU model with parameter isomorphism, the CGCA model shows higher correlation and lower dispersion, which confirms its superiority in spatio-temporal feature extraction.
- (3)
- The model shows excellent performance under different data sets, and still maintains high robustness under dynamic interference conditions (such as the CX2 section adjacent to the BRT bridge): Although the data nonlinearity is enhanced by the coupling of traffic dynamic load and soil-structure interaction, the model still maintains a high-precision prediction of MAE < 0.36 mm through multi-dimensional information fusion (burial depth, working condition) and attention weighting mechanism, which fully verifies its universality and robustness in complex engineering environments.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huang, J.; Liu, J.; Guo, K.; Wu, C.; Yang, S.; Luo, M.; Lu, Y. Numerical Simulation Study on the Impact of Deep Foundation Pit Excavation on Adjacent Rail Transit Structures—A Case Study. Buildings 2024, 14, 1853. [Google Scholar] [CrossRef]
- Xu, Q.; Xie, J.; Lu, L.; Wang, Y.; Wu, C.; Meng, Q. Numerical and Theoretical Analysis on Soil Arching Effect of Prefabricated Piles as Deep Foundation Pit Supports. Undergr. Space 2024, 16, 314–330. [Google Scholar] [CrossRef]
- Cheng, K.; Riqing, X.; Ying, H.; Cungang, L.; Gan, X. Simplified Method for Calculating Ground Lateral Displacement Induced by Foundation Pit Excavation. Eng. Comput. 2020, 37, 2501–2516. [Google Scholar] [CrossRef]
- Zhu, Y.; Wang, W.; Xu, Z.; Chen, J.; Zhang, J. Hydro-Mechanical Numerical Analysis of a Double-Wall Deep Excavation in a Multi-Aquifer Strata Considering Soil–Structure Interaction. Buildings 2025, 15, 989. [Google Scholar] [CrossRef]
- Han, G.; Zhang, Y.; Zhang, J.; Zhang, H. Numerical Analysis and Optimization of Displacement of Enclosure Structure Based on MIDAS Finite Element Simulation Software. Buildings 2025, 15, 1462. [Google Scholar] [CrossRef]
- Hong, C.; Luo, G.; Chen, W. Safety Analysis of a Deep Foundation Ditch Using Deep Learning Methods. Gondwana Res. 2023, 123, 16–26. [Google Scholar] [CrossRef]
- Hu, H.; Hu, X.; Gong, X. Predicting the Strut Forces of the Steel Supporting Structure of Deep Excavation Considering Various Factors by Machine Learning Methods. Undergr. Space 2024, 18, 114–129. [Google Scholar] [CrossRef]
- Wang, X.; Pan, Y.; Chen, J.; Li, M. A Spatiotemporal Feature Fusion-Based Deep Learning Framework for Synchronous Prediction of Excavation Stability. Tunn. Undergr. Space Technol. 2024, 147, 105733. [Google Scholar] [CrossRef]
- Zhou, X.; Pan, Y.; Qin, J.; Chen, J.-J.; Gardoni, P. Spatio-Temporal Prediction of Deep Excavation-Induced Ground Settlement: A Hybrid Graphical Network Approach Considering Causality. Tunn. Undergr. Space Technol. 2024, 146, 105605. [Google Scholar] [CrossRef]
- Deng, Z.; Xu, L.; Su, Q.; He, Y.; Li, Y. A Novel Method for Subgrade Cumulative Deformation Prediction of High-Speed Railways Based on Empiricism-Constrained Neural Network and SHapley Additive exPlanations Analysis. Transp. Geotech. 2024, 49, 101438. [Google Scholar] [CrossRef]
- Fayaz, J.; Medalla, M.; Torres-Rodas, P.; Galasso, C. A Recurrent-Neural-Network-Based Generalized Ground-Motion Model for the Chilean Subduction Seismic Environment. Struct. Saf. 2023, 100, 102282. [Google Scholar] [CrossRef]
- Yang, J.; Liu, Y.; Yagiz, S.; Laouafa, F. An Intelligent Procedure for Updating Deformation Prediction of Braced Excavation in Clay Using Gated Recurrent Unit Neural Networks. J. Rock Mech. Geotech. Eng. 2021, 13, 1485–1499. [Google Scholar] [CrossRef]
- Hong, S.; Ko, S.J.; Woo, S.I.; Kwak, T.Y.; Kim, S.R. Time-Series Forecasting of Consolidation Settlement Using LSTM Network. Appl. Intell. 2024, 54, 1386–1404. [Google Scholar] [CrossRef]
- Yang, B.; Yin, K.; Lacasse, S.; Liu, Z. Time Series Analysis and Long Short-Term Memory Neural Network to Predict Landslide Displacement. Landslides 2019, 16, 677–694. [Google Scholar] [CrossRef]
- Zhang, W.S.; Yuan, Y.; Long, M.; Yao, R.H.; Jia, L.; Liu, M. Prediction of Surface Settlement around Subway Foundation Pits Based on Spatiotemporal Characteristics and Deep Learning Models. Comput. Geotech. 2024, 168, 106149. [Google Scholar] [CrossRef]
- Jin, J.; Jin, Q.; Chen, J.; Wang, C.; Li, M.; Yu, L. Prediction of the Tunnelling Advance Speed of a Super-Large-Diameter Shield Machine Based on a KF-CNN-BiGRU Hybrid Neural Network. Measurement 2024, 230, 114517. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Yuan, Y.; Lin, L.; Huo, L.-Z.; Kong, Y.-L.; Zhou, Z.-G.; Wu, B.; Jia, Y. Using an Attention-Based LSTM Encoder–Decoder Network for near Real-Time Disturbance Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1819–1832. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, P.; Yu, Y.; Li, X.; Biancardo, S.A.; Zhang, J. Missing Data Repairs for Traffic Flow with Self-Attention Generative Adversarial Imputation Net. IEEE Trans. Intell. Transp. Syst. 2022, 23, 7919–7930. [Google Scholar] [CrossRef]
- Yang, M.; Song, M.; Guo, Y.; Lyv, Z.; Chen, W.; Yao, G. Prediction of Shield Tunneling-Induced Ground Settlement Using LSTM Architecture Enhanced by Multi-Head Self-Attention Mechanism. Tunn. Undergr. Space Technol. 2025, 161, 106536. [Google Scholar] [CrossRef]
- Fan, G.; He, Z.; Li, J. Structural Dynamic Response Reconstruction Using Self-Attention Enhanced Generative Adversarial Networks. Eng. Struct. 2023, 276, 115334. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Tao, Y.; Zeng, S.; Sun, H.; Cai, Y.; Zhang, J.; Pan, X. A Spatiotemporal Deep Learning Method for Excavation-Induced Wall Deflections. J. Rock Mech. Geotech. Eng. 2024, 16, 3327–3338. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Zhang, M.R.; Lucas, J.; Hinton, G.; Ba, J. Lookahead Optimizer: K Steps Forward, 1 Step Back. arXiv 2019, arXiv:1907.08610. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Category | Specific Parameters | Data Sources | Model Function |
|---|---|---|---|
| Inclinometer data | Horizontal displacement of the inclinometer tube | On-site monitoring | Capture the spatiotemporal features of deformation |
| Buried depth | Depth coordinates of monitoring points | Design drawing of the inclinometer tube | Correlation between structural location and deformation |
| Excavation conditions | Excavation depth | Construction Log | Reflect the immediate impact of construction dynamics on deformation |
| Phase | Project Profile | Construction Time | Period/Day |
|---|---|---|---|
| 1 | Sloped excavation was conducted to a depth of −2.5 m, followed by casting the first layer of concrete support. | 13 October 2021~30 October 2021 | 17 |
| 2 | Excavate to −7 m in turn, and set up the second steel support. | 30 October 2021~20 November 2021 | 21 |
| 3 | Excavate to −12 m, and set up the third steel support. | 20 November 2021~16 December 2021 | 26 |
| 4 | Excavating to the bottom of the pit −16 m. | 16 December 2021~26 December 2021 | 10 |
| 5 | The cushion is applied, and the bottom plate is poured. | 26 December 2021~13 January 2022 | 18 |
| Symbol | Meaning Description | Specification |
|---|---|---|
| Encoder hidden layer dimension | 256 | |
| Decoder hidden layer dimension | 256 | |
| Encoder neural network layers | 2 | |
| Decoder neural network layers | 2 | |
| src | Encoder length | 5 |
| trg | Decoder length | 1 |
| Batch size | The size of a training sample | 4 |
| The first-order momentum coefficient | 0.9 | |
| Second-order momentum coefficient | 0.99 | |
| Weight attenuation coefficient | 0.001 | |
| Parameter update interval | 10 | |
| Weighting coefficient of historical parameters | 0.5 | |
| The maximum number of training iteration rounds | 1000 |
| Model | MAE | RMSE | R2 |
|---|---|---|---|
| CGCA | 0.31 | 0.39 | 0.996 |
| REMOVE_ATTENTION | 0.53 | 0.63 | 0.989 |
| ADAM | 0.90 | 1.14 | 0.966 |
| GRU | 0.60 | 0.72 | 0.986 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Y.; Xiao, Z.; Gong, Z.; Huang, S.; Zhu, H. Spatiotemporal Deformation Prediction Model for Retaining Structures Integrating ConvGRU and Cross-Attention Mechanism. Buildings 2025, 15, 2537. https://doi.org/10.3390/buildings15142537
Gao Y, Xiao Z, Gong Z, Huang S, Zhu H. Spatiotemporal Deformation Prediction Model for Retaining Structures Integrating ConvGRU and Cross-Attention Mechanism. Buildings. 2025; 15(14):2537. https://doi.org/10.3390/buildings15142537
Chicago/Turabian StyleGao, Yanyong, Zhaoyun Xiao, Zhiqun Gong, Shanjing Huang, and Haojie Zhu. 2025. "Spatiotemporal Deformation Prediction Model for Retaining Structures Integrating ConvGRU and Cross-Attention Mechanism" Buildings 15, no. 14: 2537. https://doi.org/10.3390/buildings15142537
APA StyleGao, Y., Xiao, Z., Gong, Z., Huang, S., & Zhu, H. (2025). Spatiotemporal Deformation Prediction Model for Retaining Structures Integrating ConvGRU and Cross-Attention Mechanism. Buildings, 15(14), 2537. https://doi.org/10.3390/buildings15142537