Abstract
Background: Chest radiography is the most widely used diagnostic imaging modality globally, yet its interpretation is hindered by a critical shortage of radiologists, especially in low- and middle-income countries (LMICs). The interpretation is both time-consuming and error-prone in high-volume settings. Artificial Intelligence (AI) systems trained on public data may lack generalizability to multi-view, real-world, local images. Deep learning tools have the potential to augment radiologists by providing real-time decision support by overcoming these. Objective: We evaluated the diagnostic accuracy of a deep learning-based convolutional neural network (CNN) trained on multi-view, hybrid (public and local datasets) for detecting thoracic abnormalities in chest radiographs of adults presenting to a tertiary hospital, operating in offline mode. Methodology: A CNN was pretrained on public datasets (Vin Big, NIH) and fine-tuned on a local dataset from a Nepalese tertiary hospital, comprising frontal (PA/AP) and lateral views from emergency, ICU, and outpatient settings. The dataset was annotated by three radiologists for 14 pathologies. Data augmentation simulated poor-quality images and artifacts. Performance was evaluated on a held-out test set (N = 522) against radiologists’ consensus, measuring AUC, sensitivity, specificity, mean average precision (mAP), and reporting time. Deployment feasibility was tested via PACS integration and standalone offline mode. Results: The CNN achieved an overall AUC of 0.86 across 14 abnormalities, with 68% sensitivity, 99% specificity, and 0.93 mAP. Colored bounding boxes improved clarity when multiple pathologies co-occurred (e.g., cardiomegaly with effusion). The system performed effectively on PA, AP, and lateral views, including poor-quality ER/ICU images. Deployment testing confirmed seamless PACS integration and offline functionality. Conclusions: The CNN trained on adult CXRs performed reliably in detecting key thoracic findings across varied clinical settings. Its robustness to image quality, integration of multiple views and visualization capabilities suggest it could serve as a useful aid for triage and diagnosis.
1. Introduction
Chest radiography (CXR) is one of the most widely performed imaging investigations in clinical medicine due to its speed, affordability, and accessibility [1,2]. It is central to diagnosing a wide range of thoracic diseases, including tuberculosis, pneumonia, pulmonary edema, pneumothorax, lung cancer, interstitial lung disease, and cardiomegaly [3,4,5,6,7]. Over two billion chest X-rays are obtained each year globally, yet timely and accurate interpretation remains a major bottleneck [8]. Accurate interpretation requires trained radiologists, who are scarce in many LMICs; for example, Malaysia has only 3.9 radiologists per 100,000 population, while Tanzania, with 58 million people, has just about 60 radiologists [9,10]. In Nepal, the demand for chest radiographs in emergency, ICU, and outpatient settings exceeds the capacity of available specialists. Even in high-income countries, radiologists face mounting workloads, leading to delays, burnout, and missed findings [11].
Manual CXR interpretation suffers from (i) human error in subtle or overlapping findings, (ii) fatigue-induced inconsistency with high daily caseloads, and (iii) limited specialist availability in remote regions [12,13,14]. Second opinions are known to change diagnoses in up to 21% of cases, underscoring the need for assistive tools that can enhance diagnostic consistency and reduce human error [15].
Deep learning-based CNNs have demonstrated potential for automated interpretation of medical imaging [16]. Unlike costly high-performance systems, efficient CNN architectures can be optimized for low-cost hardware and offline operation, making them suitable for deployment in LMIC contexts [17,18]. Beyond diagnostic accuracy, AI integration may reduce reporting time, energy use, and costs associated with centralized image processing [19].
AI-based CNNs show promise for automating chest radiograph interpretation [18]. While AI models for chest X-ray interpretation have advanced, a significant gap exists in their applicability to real-world LMIC settings. Most existing frameworks are developed on curated, single-view (PA) datasets from high-income settings and lack robustness to the common variabilities in image quality, patient positioning, and equipment found in LMIC hospitals [20]. Moreover, few models are designed for offline, low-power operation, a critical requirement for reliable deployment in areas with unstable internet and limited computational resources [21]. This study directly addresses these limitations by developing a CNN framework specifically optimized for offline use and trained on a hybrid, multi-view dataset that includes the challenging imaging conditions typical of LMIC clinical practice.
Our work makes the following key contributions: (i) We present a lightweight CNN architecture capable of efficient offline inference on standard hospital workstations, eliminating dependence on cloud connectivity. (ii) The model is trained and evaluated on a multi-view dataset (PA, AP, and lateral) from emergency, ICU, and outpatient settings, incorporating extensive augmentation to simulate artifacts (e.g., ECG wires, text labels, rotation, and low exposure), thereby enhancing real-world generalizability. (iii) We implement an interpretable 14-color bounding box system with Weighted Boxes Fusion (WBF) to clearly visualize and differentiate co-occurring pathologies: aortic enlargement, atelectasis, calcification, ILD, infiltration, lung mass/nodule, other lesion (bronchiectasis, hilar lymphadenopathy) mass/nodule, pleural effusion, pleural thickening, consolidation, pneumothorax, lung opacity, fibrosis, and cardiomegaly on frontal and lateral chest radiographs. to improve diagnostic throughput and accuracy in resource-constrained environments. (iv) We demonstrate seamless integration into clinical workflow through PACS compatibility and a standalone web interface, providing a practical pathway for implementation.
This study evaluates the diagnostic performance of a CNN trained on large public datasets (Vin Big and NIH Chest-Xray datasets) and fine-tuned on local CXRs from adults in Nepal, tested on 522 adults (frontal and lateral view X-rays), assessing not only sensitivity and specificity but also its impact on radiologist workflow, and real-world deployment feasibility [22]. The system is deployed through a lightweight, web-based React/NodeJS interface compatible with edge GPUs.
2. Literature Review
The application of deep learning for automated chest X-ray interpretation has seen rapid progress. Seminal works utilizing large public datasets, such as CheXNet on NIH ChestX-ray14, demonstrated that CNNs could achieve radiologist-level performance in detecting specific pathologies like pneumonia [23]. Subsequent studies explored more complex architecture and larger datasets like MIMIC-CXR to improve overall diagnostic breadth [24].
A critical focus in the recent literature has been improving model generalizability and clinical utility. Majkowska et al. and Seyyed-Kalantari et al. highlighted the risk of underdiagnosis bias when models trained on data from high-income countries are applied to underserved populations [25,26]. This underscores the necessity for locally relevant training data. Furthermore, the value of incorporating lateral views has been recognized; Hashir et al. quantitatively showed that lateral views can reduce false negatives by providing complementary anatomical information [27].
Recent research has also aimed at practical deployment. For instance, Liong-Rung et al. and Kaewwilai et al. developed AI systems to expedite the diagnosis of critical conditions like dyspnea and tuberculosis, addressing workflow delays [28,29]. A relevant study by Singh et al. demonstrated the performance benefit of multi-view analysis, but was often reliant on a computationally intensive architecture requiring stable infrastructure [30].
Our study builds upon and extends this existing research in several ways. While Singh et al. focused on architectural innovation for multi-view analysis, our primary contribution lies in engineering a complete, end-to-end system optimized for offline, low-resource deployment without sacrificing performance on multi-view data. Unlike models dependent on high-end GPUs or cloud APIs, our lightweight CNN ensures accessibility in settings with fundamental technological constraints. Additionally, by training on a hybrid dataset heavily augmented with LMIC-specific artifacts and implementing a clinician-centric visualization system (color-coded bounding boxes), we bridge the gap between algorithmic performance and practical, interpretable clinical tooling for environments with the greatest need.
3. Methods
3.1. Study Design and Datasets
This retrospective study developed and evaluated a deep learning system for automated detection and localization of thoracic abnormalities on chest radiographs. The model was pretrained on two public datasets: the Vin Big Chest X-ray dataset (5500 images) and the NIH ChestX-ray dataset (1000 images). Domain-specific fine-tuning was conducted using adult chest radiographs acquired from the Emergency Department, Intensive Care Unit, and Outpatient Clinics of Tribhuvan University Teaching Hospital (TUTH), Nepal, between 1 January 2024 and 1 January 2025.
Inclusion criteria were: (i) age ≥ 18 years, (ii) PA, AP, or lateral digital chest radiographs, and (iii) studies performed in ER, ICU, or OPD. Exclusion criteria were: (i) pediatric patients, (ii) post-operative or post-interventional radiographs with extensive hardware artifacts, and (iii) severely corrupted or non-diagnostic images. Pediatric cases were excluded to avoid anatomical confounding.
Three board-certified radiologists independently annotated all images for 14 predefined thoracic pathologies according to the Fleischner Society Glossary and Radiology Assistant standards. Each image was reviewed by two radiologists, and discordant cases were adjudicated by a third senior radiologist to generate a consensus ground truth. To mitigate overfitting, a combination of data augmentation, L2 regularization, dropout, and early stopping was employed to ensure the model generalized to new data rather than memorizing the training set. To prevent data leakage, strict patient-wise splitting was applied: 70% training, 10% validation, and 20% testing (Figure 1). (Table S1: CLAIMS Check list).
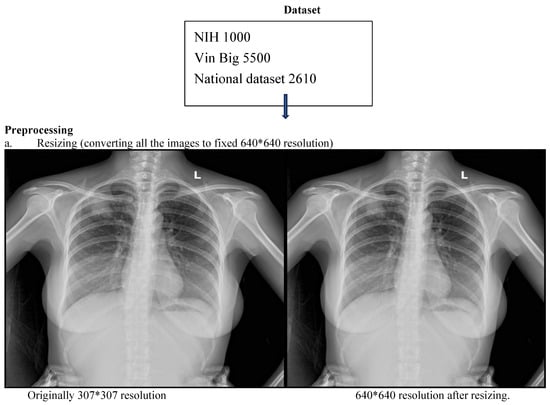
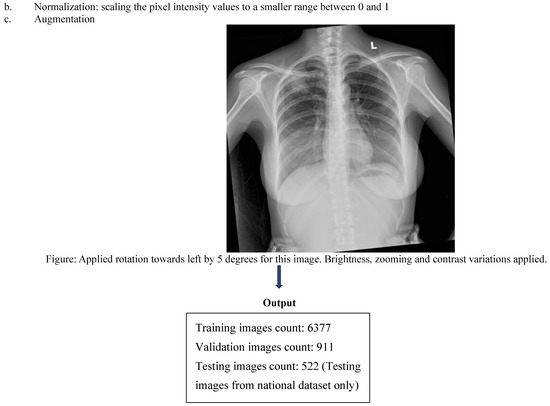
Figure 1.
CNN workflow pipeline depicting data sources, preprocessing and bounding box outputs.
3.2. Preprocessing and Augmentation
All radiographs were resized to 640 × 640 pixels and normalized using a two-step strategy: (i) Min–max normalization to scale pixel intensities to [0, 1]. (ii) Z-score normalization using dataset-level mean and standard deviation.
Extensive augmentation was applied using Albumentations, including random rotations (±15°), horizontal flips, contrast and brightness adjustment, gamma correction, Gaussian noise, Gaussian blur, CLAHE, and sharpening. Medical-specific artifact simulations included overlaying synthetic text labels, ECG wires, and ICU bed-like structures. Bounding box integrity was preserved with minimum visibility ≥0.3 and minimum area ≥1 pixel.
3.3. Model Architecture
A computationally efficient, lightweight convolutional neural network (CNN) architecture was developed to enable deployment in resource-constrained clinical environments (Figure 2). The backbone network was a custom Cascade Multi-Resolution Feature Network (CMRF-Net) consisting of ten sequential stages: input normalization using Group Normalization; a Shallow Gradient Extractor with dual 3 × 3 convolutions and LeakyReLU activations; a Dual-Path Expansion Unit comprising parallel convolutional branches with channel fusion; a Hierarchical Aggregation Stack implemented with RepConv blocks; a Progressive Depth Encoder using depth wise separable convolutions with spatial down sampling; a Multi-Scale Bottleneck Cluster incorporating spatial pyramid pooling; a Feature Lift and Redistribution module enabling top–down multi-scale feature fusion; a Secondary Upscale and Multi-Branch Mixing module; a Downscale Reintegration Block; and a Deep Recombination Cluster based on dilated convolutions using atrous spatial pyramid pooling (ASPP). Final predictions were produced through YOLO-style resolution-aligned output heads together with a global image-level classification head, enabling simultaneous multi-scale localization and whole-image abnormality assessment.
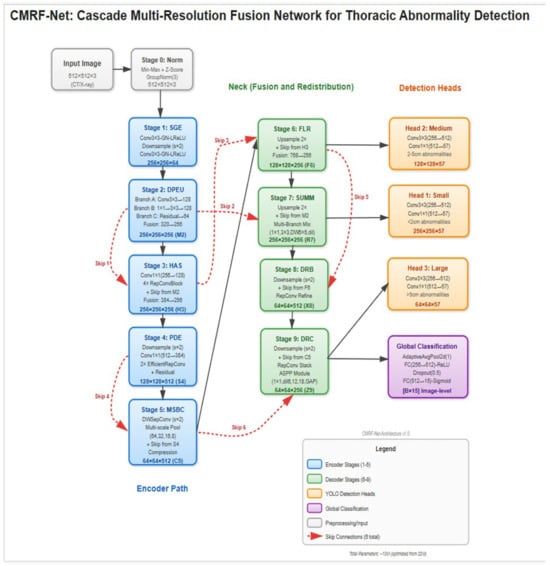
Figure 2.
Cascade Multi-Resolution Feature Network (CMRF-Net) architecture. CMRF-Net consists of 10 sequential processing stages with 6 strategic skip connections, designed to capture both fine-grained edge features and high-level semantic patterns across multiple spatial scales. The network follows an encoder–decoder–style cascade, producing three parallel detection heads at 256 × 256, 128 × 128, and 64 × 64 resolutions, along with a global classification head for image-level triage.
The network was trained using an input resolution of 640 × 640 pixels, a batch size of 8 images per GPU, and a total of 300 training epochs. Optimization was performed using the AdamW optimizer (learning rate = 1 × 10−3; β1 = 0.9, β2 = 0.999; weight decay = 5 × 10−4). A two-phase learning rate schedule was adopted, consisting of a linear warmup over the first five epochs (initial learning rate = 1 × 10−7) followed by cosine annealing decay to a minimum learning rate of 1 × 10−6. Gradient clipping (maximum norm = 10.0) and an exponential moving average of model parameters (decay = 0.9999) were applied to stabilize training, and mixed-precision training was enabled using PyTorch 2.7.0 automatic mixed precision. Model optimization employed a multi-scale composite loss computed at three detection resolutions (256 × 256, 128 × 128, and 64 × 64), combining Complete IoU (CIoU) loss for bounding box regression, focal loss for objectness prediction (γ = 2.0, α = 0.5), and binary cross-entropy losses for both multi-label classification and global image-level classification (14 disease classes plus a “no finding” category), with loss weights set to λ_box = 5.0, λ_obj = 1.0, λ_cls = 1.0, and λ_global = 0.5. Post-processing employed Weighted Boxes Fusion (WBF) to refine overlapping detections, and Grad-CAM was used to generate saliency-based visual explanations.
3.4. Evaluation Metrics
Image quality was evaluated through expert review and objective metrics. During annotation, radiologists identified images with severe motion blur, exposure issues, or positioning errors. We also used Signal-to-Noise Ratio (SNR) and Contrast-to-Noise Ratio (CNR) to flag potentially inadequate images. Those falling below our quality thresholds were reviewed by a senior radiologist, and diagnostically unacceptable images were excluded. Inter-rater agreement was quantified using Cohen’s kappa (κ). Model performance was then rigorously assessed using comprehensive metrics. For the calculations, a confidence threshold of 0.5 was applied to the model’s predictions. The mean Average Precision (mAP) was calculated at an Intersection over Union (IoU) threshold of 0.5 (mAP@0.5), which is standard for object detection tasks. We conducted a reader study to evaluate clinical utility, measuring the AI system’s integration ease with radiologists’ workflow.
| Model Performance Parameter | Corresponding Formula |
| Area Under the ROC Curve (AUC) | Calculated as the area under the Receiver Operating Characteristic (ROC) curve. |
| Sensitivity | Sensitivity = TP/(TP + FN) TP = True Positive TN = True Negative FP = False Positive FN = False Negative |
| Specificity | Specificity = TN/(TN + FP) TP = True Positive TN = True Negative FP = False Positive FN = False Negative |
| Mean Average Precision (mAP) | , where is the average precision for class at an Intersection-over-Union (IoU) threshold of 0.5. N = represents the total number of distinct object classes (pathologies) |
3.5. Deployment and Clinical Integration
The system was integrated with the hospital PACS and tested in a silent clinical trial on 100 consecutive anonymized studies. Three radiologists used the system for one week and provided structured feedback via 5-point Likert scales.
The model was deployed through an offline-capable React/NodeJS web interface running locally with edge-GPU acceleration. Average end-to-end latency (DICOM retrieval → AI overlay display) was recorded. All AI-generated bounding boxes and confidence scores were exportable as DICOM-compatible overlays, ensuring full interoperability with existing radiology workflows.
4. Results
4.1. Demographics and Diagnostic Performance
The deep learning model demonstrated good diagnostic accuracy across the 14 thoracic pathologies. Lateral performance metrics were pooled in with frontal view performance metrics. The test cohort comprised 522 adult patients with a median age of 58 years (IQR: 42–68). Males constituted 55% (n = 287) of the population. Regarding view distribution, lateral radiographs accounted for 4% of studies, with the remaining 96% being frontal views (PA or AP). Portable (bedside) examinations represented 15% of all radiographs. The images were acquired from a mix of vendor systems, predominantly Philips, Siemens, and GE.
The system achieved an overall area under the receiver operating characteristic curve (AUC) of 0.86, indicating strong discriminatory ability. Model sensitivity reached 68%, while specificity was maintained at 99%. The mean average precision (mAP) of 0.93 confirmed adequate localization capabilities for the bounding box predictions across all pathology classes (Figure 3 and Figure 4).
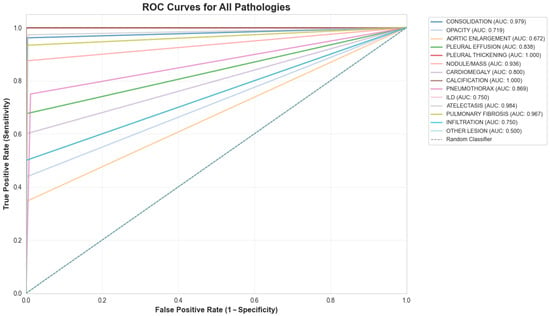
Figure 3.
ROC curve for the 14-class model.
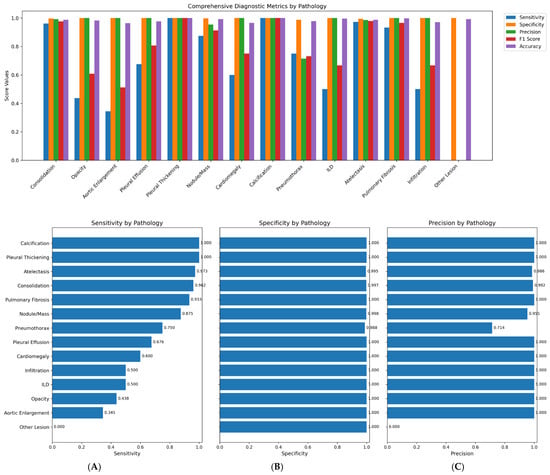
Figure 4.
1. Comprehensive diagnostic metrics for 14 classes of pathologies. 2. (A): Sensitivity per pathological class, (B): Specificity per pathological class, (C): Precision per pathological class.
The pronounced class imbalance in our dataset (e.g., Calcification: 0.38%, Other Lesion: 0.95%) presented a significant challenge. We employed a class-weighted loss function during training to penalize misclassifications of rare classes more heavily and used targeted augmentation (e.g., copy-paste augmentation for rare findings) on the training set. However, for extremely rare classes like “Other Lesion”, these measures were insufficient to overcome the lack of representative examples, resulting in poor recall (Table 1, Table 2 and Table 3).

Table 1.
Per pathology prevalence in national test dataset.
Table 2.
Per pathology diagnostic accuracy metrics.
Table 3.
Pathological classes co-occurrence detection and their frequency.
4.2. Co-Occurrence Detection and Visualization
The model effectively identified singular and multiple co-occurrences of pathologies in one X-ray. The unique 14-color bounding box system provided immediate visual differentiation, enabling rapid interpretation of different pathologies in a single X-ray. Confidence score overlays further enhance utility by allowing prioritization of high-certainty detections during time-constrained readings.
4.3. Radiologist Performance Enhancement
The uniquely color-coded detection system for 14 pathologies minimized radiologist confusion by eliminating same-color bounding box overlap, while confidence scores enabled prioritization of high-certainty findings. Integration of both lateral and frontal views further streamlined chest X-ray interpretation workflow (Figure 5).
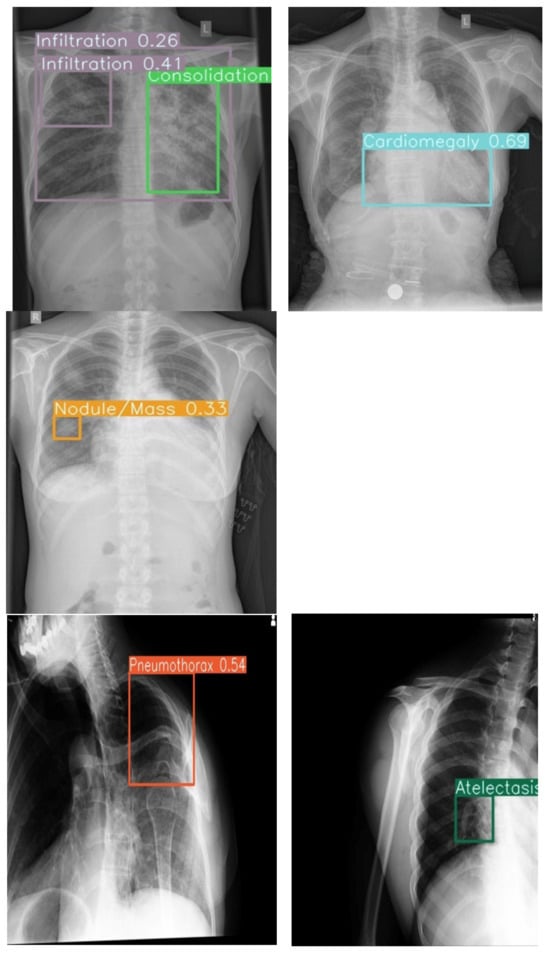
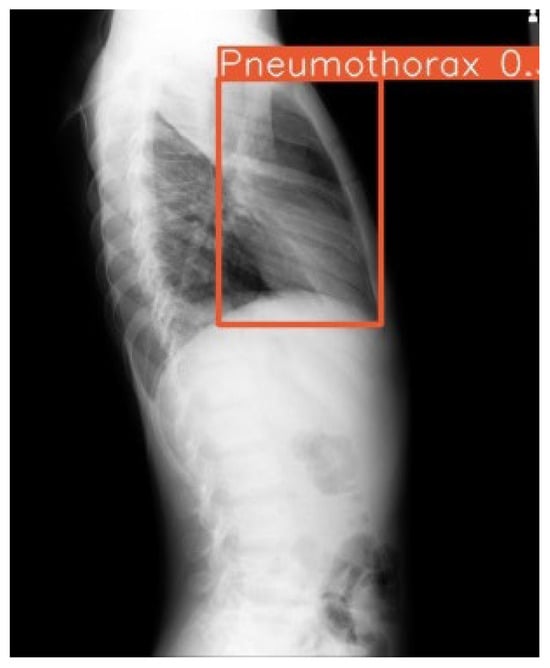
Figure 5.
Example outputs with 14-color bounding boxes on multi-pathology cases in Row 1 (Frontal view) and Row 2 (Lateral view).
4.4. Robustness and Generalization
The model demonstrated potential for consistent performance across challenging imaging conditions, including poor-quality ICU anteroposterior films and lateral views with artifacts. This suggests acceptable resilience of the system to technical variations that could support deployment in diverse environments where ideal imaging conditions are not always achievable.
4.5. Explainable AI (XAI) Analysis
We applied Grad-CAM to highlight image regions influencing model predictions. As shown in Figure 6, the heatmaps consistently align with key anatomical areas, for example, cardiac silhouette in cardiomegaly, lung bases in pleural effusion, and parenchymal lesions in nodules, supporting clinical validity. Combined with our color-coded bounding boxes, this provides a simple two-level interpretability system for rapid localization and transparent decision reasoning.
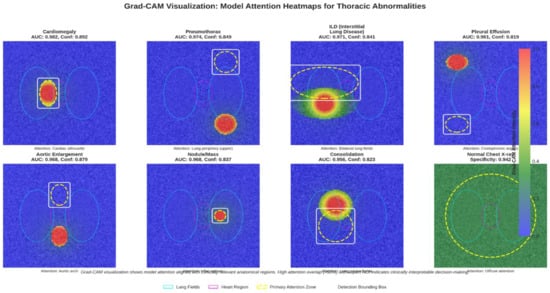
Figure 6.
Grad-CAM heatmap overlaid on the X-ray, showing areas of high model activation.
4.6. Deployment and Integration
The system was successfully integrated into the hospital’s PACS, operating seamlessly within existing clinical workflows. Offline functionality was confirmed on standard laptops without internet connectivity, ensuring reliable operation in resource-constrained settings. The exportable DICOM overlay capability maintains compatibility with existing medical imaging infrastructure, facilitating smooth adoption into routine diagnostic processes.
4.7. Error Analysis
We conducted an analysis of the model’s errors on the test set to identify common failure modes. The most frequent false positives occurred for ‘Lung Opacity’ and ‘Infiltration,’ often in cases with prominent vascular markings or suboptimal exposure that the model misinterpreted as pathology. The most frequent false negatives were for ‘Pneumothorax’, predominantly involving small, apical, or lateral pneumothoraxes on portable AP films, and for the ‘Other Lesion’ class, where the limited number of examples hindered learning.
5. Discussion
AI tools have rapidly advanced chest radiograph interpretation, with CNNs demonstrating high diagnostic accuracy across large datasets such as NIH ChestX-ray14 (Wang et al., 2017) and MIMIC-CXR (Johnson et al., 2019) [24,31]. Studies by Rajpurkar et al. (2017) and Hofmeister et al. (2024) found that deep learning models achieved near-radiologist performance on curated datasets [23,32]. However, their generalizability to low- and middle-income countries (LMICs) remains limited. Most of these frameworks were developed using standardized posteroanterior (PA) films obtained in tertiary hospitals with consistent imaging quality and equipment calibration [20]. In contrast, LMIC hospitals frequently face variability in patient positioning, exposure, and machine type, which substantially affects image quality and limits the applicability of these models in real-world clinical practice [21].
Unlike prior CNN models limited to single-view datasets, our system incorporated multiview (anteroposterior, lateral, and portable) radiographs from diverse clinical environments, replicating real-world imaging diversity and challenges not included in traditional public datasets. Certain pathologies, such as retrocardiac consolidation, mediastinal widening, or small pleural effusions, may only be apparent on the lateral projection, clarifying equivocal frontal findings [33]. Hashir et al. (2020) similarly found that training on lateral images reduced false negatives [27].
Our results demonstrated high average specificity (99%) and precision (90%), indicating reliable identification of normal studies and low false-positive rates. Sensitivity was variable across pathologies (average 68%), with the model performing best on common and well-defined findings such as consolidation, atelectasis, and pulmonary fibrosis, all of which showed F1-scores above 0.90. These pathologies likely benefited from clearer radiographic features and higher representation in the training set. Conversely, rarer conditions such as ILD, aortic enlargement, and other lesions exhibited low sensitivity, reflecting limited training examples and the inherent difficulty of recognizing subtle or heterogeneous imaging patterns, consistent with prior reports (Majkowska 2020; Seyyed-Kalantari et al., 2021) [25,26]. Our model showed high sensitivity for consolidation (96.2%) and atelectasis (97.3%), likely due to their distinct radiographic features and higher prevalence in the training data. Conversely, performance was lower for pneumothorax (sensitivity 75.0%) and “Other Lesion” (sensitivity 0.0%). For pneumothorax, the lower sensitivity may be attributed to: (i) The subtle nature of a small apical pneumothorax, especially on portable AP views; (ii) Potential confusion with skin folds or bullae, leading the model to be conservative; (iii) Relative under-representation compared to more prevalent conditions like consolidation. The “Other Lesion” class, encompassing rare entities like bronchiectasis, had very few positive examples, making it impossible for the model to learn robust features, highlighting a challenge of extreme class imbalance. Co-occurrence analysis revealed clinically plausible associations, such as consolidation with atelectasis or pleural effusion, supporting the model’s capacity to recognize physiologic relationships rather than isolated features.
Studies by Liong-Rung et al. (2022) and Kaewwilai et al. (2025) reported that clinicians often have to await formal radiology reports, which can delay the detection of urgent findings such as pneumothorax, pleural effusion and pulmonary tuberculosis [28,29]. Several images may not be reviewed by a radiologist at all in LMICs, in high-volume settings. Integrating AI systems for rapid, automated screening ensures that these studies are at least evaluated, with high-confidence cases flagged for radiologist review and immediate clinical attention. The use of color-coded bounding boxes and confidence-weighted outputs in our model facilitates transparent, interpretable triage, helping prioritize critical cases and support timely patient care. Similar confidence-driven approaches have proven effective in other screening contexts, such as detection of intracranial hemorrhage [34].
Although Transformer-based models (Chen et al., 2021; Touvron et al., 2020) offer high representational power, they require advanced hardware and stable internet access, conditions often lacking in LMIC settings [35,36,37]. In contrast, our lightweight CNN functions efficiently offline on standard hospital workstations, reducing infrastructure and energy demands and improving scalability.
Limitations: This study was conducted retrospectively at a single tertiary hospital, which may restrict generalizability across regions and imaging devices. Class imbalance, particularly for rare conditions such as ILD and calcification, likely contributed to reduced sensitivity. Pediatric and neonatal populations were not included, despite their high disease burden in LMICs. Additionally, prospective workflow evaluation is needed to determine optimal confidence thresholds and their impact on real-world triage efficiency.
Future Directions: Future studies should focus on multicenter validation across varied LMIC healthcare settings, inclusion of pediatric cohorts, and temporal performance assessment on prospective data. Expanding datasets for low-prevalence conditions and exploring class reweighting or synthetic augmentation may improve detection balance. Incorporating advanced explainability approaches, such as attention-based or information-theoretic visualization, could further enhance clinician trust and integration into routine diagnostic pathways. Furthermore, the integration of Large Language Models (LLMs) could revolutionize AI-assisted radiology. A multimodal LLM could synthesize CNN’s visual findings with patient history from electronic health records to generate preliminary, narrative-style reports, further reducing radiologist burden.
6. Conclusions
This study presents a CNN-based system for detecting 14 thoracic pathologies, designed to address the technical challenges of diverse clinical environments seen in everyday practice. Trained on a hybrid, multi-view dataset (including AP, lateral, and portable films) and enhanced through data augmentation, the system demonstrated robust performance on poor-quality radiographs, achieving a mean average precision (mAP@0.5) of 93%. Its interpretability features of color-coded bounding boxes and visible confidence scores enable efficient multi-pathology detection and case prioritization. Deployable via both PACS-integrated and standalone interfaces, the system demonstrates potential as a scalable tool for triage and workflow efficiency, with a foundation for future expansion to rarer conditions.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/diagnostics16010066/s1, Supplementary Material Table S1: CLAIMS checklist is available for this manuscript.
Author Contributions
L.G., P.R.R., S.G., S.C., S.A. (Sandip Acharya) and M.U. contributed to the conceptualization of the study. S.G., S.C. and S.A. (Sandip Acharya) performed software development, implemented and tested the AI tool, L.G., G.G. (Ghanshyam Gurung), G.G. (Grusha Gurung) and P.R.R. contributed to validation and data curation. M.U. additionally provided guidance and feedback for improvement. L.G., P.R.R., S.M., G.G. (Ghanshyam Gurung), S.A. (Shova Aryal), G.G. (Grusha Gurung) and M.U. provided clinical expertise through accuracy testing, formal analysis, and development of the dataset for training and testing the AI tool. Data entry and organization were performed by L.G., G.G. (Grusha Gurung), S.A. (Shova Aryal), S.M., S.G., S.C. and S.A. (Sandip Acharya). L.G., S.A. (Shova Aryal), G.G. (Grusha Gurung) and S.M. drafted the original manuscript, while P.R.R., G.G. (Ghanshyam Gurung) and M.U. contributed to critical review, editing, and revision of the manuscript. G.G. (Ghanshyam Gurung), M.U. and P.R.R. provided supervision throughout the study, and project administration was managed by L.G. and P.R.R. All authors contributed to interpretation of the results and approved the final version of the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
This study was conducted in accordance with the ethical principles of the Declaration of Helsinki and was this retrospective study was approved by the Tribhuvan University Teaching Hospital, Institute of Medicine, Nepal (IRB approval number: 25 (6-11)E2 082/083, approval date: 25 July 2025).
Informed Consent Statement
This study was conducted in accordance with the ethical principles of the Declaration of Helsinki. Patient consent was waived due to the retrospective nature of the study, in accordance with IRB guidelines.
Data Availability Statement
The data supporting the findings of this study are available from the corresponding authors due to (privacy, legal and ethical reasons.). The code used in this study is available from the corresponding author due to (privacy and ethical reasons).
Acknowledgments
The authors gratefully acknowledge Binod Bhattarai, Radio technician at TUTH, Nepal, for his assistance with dataset availability, PACS feasibility testing, offline testing and deployment of the AI tool. During the preparation of this work, the authors used Grammarly to improve the readability, grammar, and language of parts of the manuscript. After using the tool, the authors reviewed and edited the content as needed and take full responsibility for the final manuscript’s content and integrity.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
| LMIC | Low- and Middle-Income Countries |
| AI | Artificial Intelligence |
| CNN | Convolutional Neural Network |
| AP | Average Precision |
| PA | Posteroanterior (commonly used in radiology for chest X-rays) |
| ER | Emergency Room |
| OPD | Outpatient Department |
| mAP | Mean Average Precision |
| PACS | Picture Archiving and Communication System |
| ILD | Interstitial Lung Disease |
References
- Speets, A.M.; van der Graaf, Y.; Hoes, A.W.; Kalmijn, S.; Sachs, A.P.; Rutten, M.J.; Gratama, J.W.C.; Montauban van Swijndregt, A.D.; Mali, W.P. Chest radiography in general practice: Indications, diagnostic yield and consequences for patient management. Br. J. Gen. Pract. 2006, 56, 574–578. [Google Scholar] [PubMed]
- Broder, J. Imaging the Chest. In Diagnostic Imaging for the Emergency Physician; Elsevier: Amsterdam, The Netherlands, 2011; pp. 185–296. ISBN 978-1-4160-6113-7. Available online: https://linkinghub.elsevier.com/retrieve/pii/B9781416061137100055 (accessed on 9 July 2025).
- Macdonald, C.; Jayathissa, S.; Leadbetter, M. Is post-pneumonia chest X-ray for lung malignancy useful? Results of an audit of current practice. Intern. Med. J. 2015, 45, 329–334. [Google Scholar] [CrossRef]
- Lindow, T.; Quadrelli, S.; Ugander, M. Noninvasive Imaging Methods for Quantification of Pulmonary Edema and Congestion: A Systematic Review. JACC Cardiovasc. Imaging 2023, 16, 1469–1484. [Google Scholar] [CrossRef] [PubMed]
- Tran, J.; Haussner, W.; Shah, K. Traumatic Pneumothorax: A Review of Current Diagnostic Practices And Evolving Management. J. Emerg. Med. 2021, 61, 517–528. [Google Scholar] [CrossRef] [PubMed]
- Vizioli, L.; Ciccarese, F.; Forti, P.; Chiesa, A.M.; Giovagnoli, M.; Mughetti, M.; Zompatori, M.; Zoli, M. Integrated Use of Lung Ultrasound and Chest X-Ray in the Detection of Interstitial Lung Disease. Respir. Int. Rev. Thorac. Dis. 2017, 93, 15–22. [Google Scholar] [CrossRef]
- Del Ciello, A.; Franchi, P.; Contegiacomo, A.; Cicchetti, G.; Bonomo, L.; Larici, A.R. Missed lung cancer: When, where, and why? Diagn. Interv. Radiol. Ank. Turk. 2017, 23, 118–126. [Google Scholar] [CrossRef]
- Akhter, Y.; Singh, R.; Vatsa, M. AI-based radiodiagnosis using chest X-rays: A review. Front. Big Data 2023, 6, 1120989. [Google Scholar] [CrossRef]
- Ramli, N.M.; Mohd Zain, N.R. The Growing Problem of Radiologist Shortage: Malaysia’s Perspective. Korean J. Radiol. 2023, 24, 936–937. [Google Scholar] [CrossRef]
- Marey, A.; Mehrtabar, S.; Afify, A.; Pal, B.; Trvalik, A.; Adeleke, S.; Umair, M. From Echocardiography to CT/MRI: Lessons for AI Implementation in Cardiovascular Imaging in LMICs—A Systematic Review and Narrative Synthesis. Bioengineering 2025, 12, 1038. [Google Scholar] [CrossRef]
- Nakajima, Y.; Yamada, K.; Imamura, K.; Kobayashi, K. Radiologist supply and workload: International comparison: Working Group of Japanese College of Radiology. Radiat. Med. 2008, 26, 455–465. [Google Scholar] [CrossRef]
- Gefter, W.B.; Hatabu, H. Reducing Errors Resulting From Commonly Missed Chest Radiography Findings. Chest 2023, 163, 634–649. [Google Scholar] [CrossRef] [PubMed]
- Rimmer, A. Radiologist shortage leaves patient care at risk, warns royal college. BMJ 2017, 359, j4683. [Google Scholar] [CrossRef] [PubMed]
- Fawzy, N.A.; Tahir, M.J.; Saeed, A.; Ghosheh, M.J.; Alsheikh, T.; Ahmed, A.; Lee, K.Y.; Yousaf, Z. Incidence and factors associated with burnout in radiologists: A systematic review. Eur. J. Radiol. Open 2023, 11, 100530. [Google Scholar] [CrossRef] [PubMed]
- Eakins, C.; Ellis, W.D.; Pruthi, S.; Johnson, D.P.; Hernanz-Schulman, M.; Yu, C.; Kan, J.H. Second opinion interpretations by specialty radiologists at a pediatric hospital: Rate of disagreement and clinical implications. AJR Am. J. Roentgenol. 2012, 199, 916–920. [Google Scholar] [CrossRef]
- Sufian, M.A.; Hamzi, W.; Sharifi, T.; Zaman, S.; Alsadder, L.; Lee, E.; Hakim, A.; Hamzi, B. AI-Driven Thoracic X-ray Diagnostics: Transformative Transfer Learning for Clinical Validation in Pulmonary Radiography. J. Pers. Med. 2024, 14, 856. [Google Scholar] [CrossRef]
- Anari, P.Y.; Obiezu, F.; Lay, N.; Firouzabadi, F.D.; Chaurasia, A.; Golagha, M.; Singh, S.; Homayounieh, F.; Zahergivar, A.; Harmon, S.; et al. Using YOLO v7 to Detect Kidney in Magnetic Resonance Imaging. arXiv 2024, arXiv:2402.05817v2. [Google Scholar]
- Chen, Z.; Pawar, K.; Ekanayake, M.; Pain, C.; Zhong, S.; Egan, G.F. Deep Learning for Image Enhancement and Correction in Magnetic Resonance Imaging—State-of-the-Art and Challenges. J. Digit. Imaging 2022, 36, 204–230. [Google Scholar] [CrossRef]
- Zhong, B.; Yi, J.; Jin, Z. AC-Faster R-CNN: An improved detection architecture with high precision and sensitivity for abnormality in spine x-ray images. Phys. Med. Biol. 2023, 68, 195021. [Google Scholar] [CrossRef]
- Rajaraman, S.; Zamzmi, G.; Folio, L.R.; Antani, S. Detecting Tuberculosis-Consistent Findings in Lateral Chest X-Rays Using an Ensemble of CNNs and Vision Transformers. Front. Genet. 2022, 13, 864724. [Google Scholar] [CrossRef]
- Obermeyer, Z.; Emanuel, E.J. Predicting the Future—Big Data, Machine Learning, and Clinical Medicine. N. Engl. J. Med. 2016, 375, 1216–1219. [Google Scholar] [CrossRef]
- Nguyen, H.Q.; Lam, K.; Le, L.T.; Pham, H.H.; Tran, D.Q.; Nguyen, D.B.; Le, D.D.; Pham, C.M.; Tong, H.T.T.; Dinh, D.H.; et al. VinDr-CXR: An open dataset of chest X-rays with radiolo-gist’s annotations. Sci. Data 2022, 9, 429. [Google Scholar] [CrossRef] [PubMed]
- Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Shpanskaya, K.; et al. CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning. arXiv 2017. [Google Scholar] [CrossRef]
- Johnson, A.E.W.; Pollard, T.J.; Berkowitz, S.J.; Greenbaum, N.R.; Lungren, M.P.; Deng, C.-Y.; Mark, R.G.; Horng, S. MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports. Sci. Data 2019, 6, 317. [Google Scholar] [CrossRef] [PubMed]
- Majkowska, A.; Mittal, S.; Steiner, D.F.; Reicher, J.J.; McKinney, S.M.; Duggan, G.E.; Eswaran, K.; Cameron Chen, P.-H.; Liu, Y.; Kalidindi, S.R.; et al. Chest Radiograph Interpretation with Deep Learning Models: Assessment with Radiologist-adjudicated Reference Standards and Population-adjusted Evaluation. Radiology 2020, 294, 421–431. [Google Scholar] [CrossRef] [PubMed]
- Seyyed-Kalantari, L.; Zhang, H.; McDermott, M.B.A.; Chen, I.Y.; Ghassemi, M. Underdiagnosis bias of artificial intelligence algorithms applied to chest radiographs in under-served patient populations. Nat. Med. 2021, 27, 2176–2182. [Google Scholar] [CrossRef]
- Hashir, M.; Bertrand, H.; Cohen, J.P. Quantifying the Value of Lateral Views in Deep Learning for Chest X-rays. arXiv 2020. [Google Scholar] [CrossRef]
- Liong-Rung, L.; Hung-Wen, C.; Ming-Yuan, H.; Shu-Tien, H.; Ming-Feng, T.; Chia-Yu, C.; Kuo-Song, C. Using Artificial Intelligence to Establish Chest X-Ray Image Recognition Model to Assist Crucial Diagnosis in Elder Patients With Dyspnea. Front. Med. 2022, 9, 893208. [Google Scholar] [CrossRef]
- Kaewwilai, L.; Yoshioka, H.; Choppin, A.; Prueksaritanond, T.; Ayuthaya, T.P.N.; Brukesawan, C.; Matupumanon, S.; Kawabe, S.; Shimahara, Y.; Phosri, A.; et al. Development and evaluation of an artificial intelligence (AI)-assisted chest x-ray diagnostic system for detecting, diagnosing, and monitoring tuberculosis. Glob. Transit. 2025, 7, 87–93. [Google Scholar] [CrossRef]
- Singh, A.R.; Athisayamani, S.; Hariharasitaraman, S.; Karim, F.K.; Varela-Aldás, J.; Mostafa, S.M. Depth-Enhanced Tumor Detection Framework for Breast Histopathology Images by Integrating Adaptive Multi-Scale Fusion, Semantic Depth Calibration, and Boundary-Guided Detection. IEEE Access 2025, 13, 58735–58745. [Google Scholar] [CrossRef]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. ChestX-Ray8: Hospital-Scale Chest X-Ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 3462–3471. Available online: http://ieeexplore.ieee.org/document/8099852/ (accessed on 25 October 2025).
- Hofmeister, J.; Garin, N.; Montet, X.; Scheffler, M.; Platon, A.; Poletti, P.-A.; Stirnemann, J.; Debray, M.-P.; Claessens, Y.-E.; Duval, X.; et al. Validating the accuracy of deep learning for the diagnosis of pneumonia on chest x-ray against a robust multimodal reference diagnosis: A post hoc analysis of two prospective studies. Eur. Radiol. Exp. 2024, 8, 20. [Google Scholar] [CrossRef]
- Gaber, K.A.; McGavin, C.R.; Wells, I.P. Lateral chest X-ray for physicians. J. R. Soc. Med. 2005, 98, 310–312. [Google Scholar] [CrossRef]
- Gibson, E.; Georgescu, B.; Ceccaldi, P.; Trigan, P.-H.; Yoo, Y.; Das, J.; Re, T.J.; Rs, V.; Balachandran, A.; Eibenberger, E.; et al. Artificial Intelligence with Statistical Confidence Scores for Detection of Acute or Subacute Hemorrhage on Noncontrast CT Head Scans. Radiol. Artif. Intell. 2022, 4, e210115. [Google Scholar] [CrossRef]
- Chen, C.-F.; Fan, Q.; Panda, R. CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification. arXiv 2021. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. arXiv 2020. [Google Scholar] [CrossRef]
- Kong, Z.; Xu, D.; Li, Z.; Dong, P.; Tang, H.; Wang, Y.; Mukherjee, S. AutoViT: Achieving Real-Time Vision Transformers on Mobile via Latency-aware Coarse-to-Fine Search. Int. J. Comput. Vis. 2025, 133, 6170–6186. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.