Abstract
The widespread adoption of Internet of Things (IoT) technology has significantly expanded the scale at which devices are connected, posing new challenges to maintaining symmetry in network management. Traditional centralized identification architectures adopt a symmetric processing paradigm in which all device data are uniformly transmitted to the cloud for processing. However, this rigid symmetric structure fails to accommodate the asymmetric distribution typical of IoT edge devices. To address these challenges, this paper proposes an asymmetric identification framework based on cloud–edge collaboration, exploring a high-performance, resource-efficient, and privacy-preserving solution for IoT device identification. The proposed region-specific personalized algorithm (FedRP) introduces a region-specific, personalized identification approach grounded in federated learning principles. Firstly, FedRP leverages a decentralized processing framework to enhance data security by processing data locally. Secondly, it employs a personalized federated learning framework to optimize local models, thus improving identification accuracy and effectiveness. Finally, FedRP strategically separates the personalized parameters of transformer-based blocks from shared parameters and selectively transmits them, reducing the burden on network resources. Comprehensive comparative experiments demonstrate the efficacy of the proposed approach for large-scale IoT environments, which are characterized by numerous devices and complex network conditions.
1. Introduction
With the rapid advancement and widespread adoption of Internet of Things (IoT) technologies, the number of edge devices has grown substantially. While this proliferation strengthens human connectivity, the increasing diversity and number of connected devices also pose significant challenges for network management [1]. As IoT networks continue to expand in both size and complexity, effective device identification has emerged as a pressing necessity [2,3].
In recent years, deep learning has gained substantial attention in the field of IoT device recognition due to its high efficiency and accuracy. By learning the characteristics and behavioral patterns of devices, deep learning models can achieve fine-grained and precise classification [4]. Traditional deep learning-based training paradigms can be broadly categorized as using either centralized or distributed approaches. In centralized training, data must be uploaded to a central server, which becomes inefficient and bandwidth-intensive when handling massive amounts of data from edge devices. Distributed training mitigates some of these issues by enabling parallel computation across nodes; however, it still falls short in ensuring data privacy and security, especially in the face of increasingly frequent and sophisticated network attacks [5,6]. These limitations underscore the need for a learning paradigm that can simultaneously preserve data privacy while supporting distributed training. As an emerging paradigm in distributed learning, Federated Learning (FL) has demonstrated significant potential for privacy-preserving model training [7,8,9]. FL enables collaborative model optimization by training local models on client devices and aggregating model updates on a central server—without transferring raw data—thus ensuring data privacy while achieving global model convergence [10,11].
However, the substantial heterogeneity of IoT devices and their complex behavioral patterns often demand that personalization strategies be differentiated across datasets and deployment scenarios, a need that intensifies the generalization difficulties faced by federated learning (FL) algorithms [12,13]. Under conditions of non-independent and identically distributed (non-IID) data, model performance across clients tends to vary significantly, making it challenging to strike a balance between global model performance and local adaptability. This challenge is further compounded by the limited computational capabilities of edge devices and stringent privacy-preservation requirements, both of which restrict the design space for efficient trade-offs between personalized modeling and shared model parameters. Despite the demonstrated advantages of FL in preserving privacy and enabling collaborative learning across distributed nodes, its practical adoption in real-world IoT environments remains fraught with challenges. Most existing FL methods assume homogeneous data distributions across clients—a condition seldom met in heterogeneous IoT ecosystems, which are characterized by diverse data modalities and behavioral variability. Furthermore, prevailing personalized FL approaches predominantly target user-level customization, neglecting the region- or scenario-level heterogeneity that is commonly encountered in real-world IoT deployments such as smart homes, industrial control systems, and geographically dispersed networks. Compounding these issues is the limited volume of labeled data typically available on individual devices, which significantly hampers the capacity of deep learning models to extract meaningful statistical patterns and to contribute effectively to optimization of a global model.
In summary, this paper aims to design a distributed learning framework that enables efficient and accurate identification of IoT devices while rigorously preserving user data privacy. It is important to note that IoT devices span a wide range of application domains, including smart home appliances (e.g., smart locks, thermostats), wearable health monitors, and industrial control sensors. These devices exhibit significant variations in traffic patterns, communication protocols, and behavioral characteristics, introducing a high degree of heterogeneity into the learning environment and limiting the effectiveness of unified modeling approaches. Against this backdrop, several key challenges remain to be addressed. First, the diverse and non-IID nature of data in IoT ecosystems demands the use of models with strong generalization capabilities—those that can achieve high recognition accuracy while maintaining computational efficiency. One promising direction involves incorporating large-scale pretrained language models, which offer powerful feature extraction and transfer capabilities well-suited to the complex traffic patterns of IoT networks. Second, federated learning must demonstrate robustness across heterogeneous datasets and deployment scenarios. It is critical not only to achieve strong global model performance, but also to enable effective personalization for each client, particularly in situations in which only limited labeled data are available locally, thus ensuring reliable deployment in real-world, resource-constrained environments.
In this paper, we address the aforementioned challenges by proposing a novel distributed learning framework designed to enhance the recognition and identification of IoT devices while ensuring the security and privacy of client data. Our contributions are summarized as follows:
- We propose a hybrid federated learning framework, the region-specific personalized algorithm (FedRP), which combines federated learning with advanced personalization techniques, enhancing global model generalization and client-specific fine-tuning.
- Our approach leverages transformer-based blocks to explore data representation in multiple dimensions, accommodating the fluctuating packet lengths characteristic of traffic flows with different devices.
- Our framework employs differential privacy and secure multiparty computation to ensure data security during training and updates.
- We design lightweight, resource-efficient algorithms suitable for the varying computational capacities of IoT devices.
- Extensive experiments on diverse IoT datasets validate our framework’s ability to maintain high accuracy, generalization, personalization, and efficiency while maintaining data privacy.
By addressing these critical challenges, our proposed distributed learning model sets a new standard for IoT device recognition, balancing accuracy, efficiency, personalization, and data privacy. Our contributions pave the way for more secure and effective IoT network management, fostering the continued growth and integration of IoT technologies in various applications and industries.
2. Related Work
2.1. IoT Device Identification
Device identification is a fundamental technology for addressing IoT security challenges and has long been a focal point of research in this field [14]. Methods for device identification can primarily be classified into two categories: active identification of signals emitted by IoT devices and passive identification based on IoT device-generated traffic using deep learning-based approaches [15]. The former requires actively probing for unique device characteristics, which can consume significant computational resources and face challenges in identifying encrypted or privacy-protected traffic. In contrast, deep learning-based methods automatically learn and extract device features from large-scale data, offering superior adaptability and scalability while significantly reducing computational overhead.
In recent years, machine learning techniques have garnered considerable attention as approaches for device identification. Sivanathan et al. [16] utilized the Naive Bayesian method to achieve high-precision classification of 28 types of commercial IoT devices based solely on domain names, port numbers, and cipher suite information. AUDI [17] established device fingerprints by extracting features from periodic traffic flows and employed a supervised k-Nearest Neighbors (kNN) classifier to automatically identify device types. Using a large dataset containing 33 typical commercial IoT devices, this method achieved an impressive accuracy rate of 98.2%. Yair et al. [18] applied the Random Forest algorithm to features extracted from network traffic, successfully identifying 99% of device types on the whitelist and identifying unknown devices not on the whitelist in 96% of cases. Aksoy and Gunes [19] leveraged genetic algorithms to identify relevant features and applied various machine learning algorithms to classify IoT device types. Desai et al. [20] addressed the challenge of feature selection from IoT network traffic, focusing on the relevance of each feature to the objectives of machine learning models. Yousef et al. [21] proposed the FedAP algorithm, which relies on each client independently training its model and then performing parameter updates through global aggregation.
While machine learning methods often require manual feature design and selection, which limits their generalization capabilities, deep learning (DL) methods can autonomously learn features from raw data. As a result, deep learning approaches have gained significant attention in the field of IoT device identification. Hamdaoui et al. [22] proposed an integrated approach combining supervised and unsupervised learning techniques, enabling secondary classification of unfamiliar device types. In [23], a deep learning-based classification method was introduced to model the behavior of malicious traffic in detail, facilitating DDoS detection at the access edge. Yang et al. [24] utilized a CNN+BiLSTM deep learning architecture to develop an end-to-end system for IoT device identification. Pedro et al. [25] proposed an LSTM–CNN architecture that incorporates hardware performance behavior for individual device identification, utilizing adversarial training and model distillation defense techniques to enhance the model’s resilience against evasion attacks. In [26], an enhanced DL framework was introduced by integrating zero-bias layers into deep neural networks to improve robustness and interoperability. However, existing methods often overlook the high heterogeneity of IoT devices, assuming consistent data distributions across devices. At the same time, IoT networks involve a variety of devices that generate diverse types of data, making such assumptions problematic. Furthermore, many device-identification methods rely on unencrypted traffic patterns and thus may not be applicable in modern IoT environments, where encryption is widely used. This leads to challenges in accurately identifying devices in real-world scenarios.
2.2. Federate Learning
Federated learning represents an advanced, encrypted form of distributed machine learning technology [7]. In the current landscape, where IoT devices place a strong emphasis on data privacy and protection, federated learning has gained significant attention and recognition. Google was the first company to introduce federated learning technology, aiming to solve the data silo problem while ensuring data privacy. In federated learning, multiple clients (such as IoT devices) collaboratively train a shared model while keeping their data stored locally. Rather than sending raw data to a central server, clients compute model updates based on their local data and send only the model parameters to the server. This approach helps preserve data privacy and reduces the risks associated with data leakage or exposure. The core concept of federated learning is model aggregation. The central server initializes a global model and distributes it to the client devices. Clients then train the model on their local data and send the updated model weights to the central server. The server aggregates these updates to improve the global model. This process is repeated over multiple communication rounds. FedAvg [27], as the first and most widely adopted federated learning algorithm, is responsible for aggregating the locally trained models at the central server at the end of each communication round. Initially, the server initializes a global model and distributes it to the client devices. After each training round, the selected client models are averaged and aggregated, and the result is returned to the server model.
Several new methods have been proposed to enhance the performance of the FedAvg model. FedProx [28] introduced a proximal term to mitigate inconsistencies caused by non-IID data and heterogeneous local updates. Wang et al. [29] introduced the FedNova algorithm, which employs a normalization-based averaging technique to address objective inconsistencies and ensure rapid error convergence. Wu et al. [30] proposed FedAMD, a novel federated learning framework centered on anchor sampling to improve model performance. FedLaw [31] introduced an effective federated learning method that learns aggregation weights, significantly enhancing the generalization of the global model. Palihawadana et al. [32] proposed a similarity-guided algorithm to further enhance model performance.
In recent years, federated learning has been widely adopted in applications such as device identification due to its exceptional privacy-preserving capabilities [33]. He et al. [34] introduced a federated learning-based EDI (FedeEDI) method to ensure faster training speeds and a more secure training environment. Zhang et al. [35] proposed a novel Centroid Distance Weighted Federated Averaging (CDW-FedAvg) algorithm and evaluated it based on feasibility, accuracy, and performance. Mothukuri et al. [36] introduced a federated learning-based anomaly-detection method to ensure user privacy and security. Recent research has also provided valuable insights into enhancing privacy protection and model performance. Xu et al. [37] proposed the RAT Ring protocol, which addresses data confidentiality and security issues in the Industrial Internet of Things (IIoT) by utilizing traceable ring signatures. This method significantly enhances data-privacy protection and can be applied to strengthen privacy preservation in federated learning. Cao et al. [38] conducted an in-depth exploration of non-contrastive learning methods, analyzing their potential for optimizing the dimensional efficiency of federated learning models. Their theoretical analysis provides critical insights for improving the performance of federated learning. However, these algorithms often overlook issues such as data imbalance and client unreliability, typically assuming consistent data distribution and reliability across clients. Given the complexity and heterogeneity of IoT devices, such assumptions can lead to poor model generalization and accuracy. Therefore, to improve the model’s generalization ability, we introduce an innovative normalization strategy and divide the aggregation process into local and global components.
3. Problem Definition
In IoT device identification, concerns about user privacy have been raised in association with the capturing of device traffic [39]. Researchers have developed methods to prevent privacy leakage [40], particularly in Wide Area Networks (WANs), whereas Local Area Networks (LANs) are generally considered more trustworthy. We assume trusted IoT systems, such as smart homes and industrial IoT, where the possibility that malicious attacks may confuse the model is disregarded, as in previous studies. Due to the difficulty of directly accessing operational nodes for device identification, we leverage communication behavior to identify connected IoT devices. The traffic set S of the IoT device is defined as follows:
where represents the set of device traffic flows and is the set of sensing devices that generate these flows. is the -th flow and is composed of a series of packets , and is the length of the traffic sequence. Packets within the same flow share the same five-tuple (source IP, source port, destination IP, destination port, transport layer protocol). is the payload information of the packets. Our goal is to build an end-to-end system to predict the label , which is exactly the real device type (i.e., ).
In traditional federated learning, the client plays a crucial role and independently trains its local model [7]. Generally, the central server initially deploys a base model upon which the clients train using their local data. Once training is complete, clients send model updates rather than raw data to the central server for aggregation. To illustrate the algorithm model in detail, this paper assumes a large-scale IoT system with m heterogeneous intelligent local area networks acting as gateways, i.e., clients. Each client aims to preserve its own data privacy while effectively leveraging the knowledge derived from other clients’ data, thus incorporating the federated learning framework for collaborative training. During the federated learning phase, the IoT cloud center is responsible for coordinating and managing the entire learning process, including global model initialization, parameter aggregation, and model evaluation. Additionally, the collection of device traffic data that client i can store is denoted as:
where represents unidirectional flow data, represents device type labels, is the current number of flow data instances owned by the client, and represents the set of device types within the current edge node. Assuming that the model parameters of the local model are and that denotes the loss function evaluated by the client’s model for a single data instance , the overall loss function for the local model across all data instances of the i-th device can be expressed as follows:
The objective of traditional federated learning can be simplified into an optimization problem, as shown in Equation (3), below:
This objective minimizes the average local loss across all clients, ensuring that the global model converges to a solution that performs well on all clients.
Federated learning yields high-performance models by minimizing the total loss function, making its distributed training crucial in cloud–edge collaborative environments. However, in IoT systems, edge nodes may struggle to obtain optimal models due to limitations in local data or computational capabilities. Centralizing all data in the cloud introduces privacy and security risks. Federated learning addresses this by exchanging information through a cloud center, leveraging local data patterns for model training. Nevertheless, the high heterogeneity of data from different sources can result in poor model performance on certain clients, affecting overall performance and fairness. Therefore, personalized federated learning has been proposed to retain each node’s data characteristics while enhancing the model’s generalization ability and adaptability.
This paper adopts personalized federated learning as the foundational approach, optimizing models locally to better meet the specific requirements and data characteristics of each client. This approach achieves true model convergence while preserving data privacy. The optimization objective of modern personalized federated learning techniques can be summarized as follows:
In this equation, represents the regularization parameter and denotes the reference model used for calibrating and adjusting the personalized model. Both the parameter set contained in the local model and the reference parameter set must be stored by the client to generate the personalized model. The additional parameter sets not only increase communication costs but also waste edge storage space by storing redundant information. Inspired by traditional centralized deep learning, where heterogeneous data distributed across different tasks can be used to train a universal representation that requires only a small subset of parameters for learning specific tasks, this paper proposes communicating only the globally shared universal parameters, retaining the personalized parameters locally. This approach eliminates the need for the reference parameter set typically required in personalized federated learning. Therefore, the optimization problem in equation (5) can be rewritten as:
where s represents the shared parameters that are common across all clients and facilitate the cloud–edge model interaction, while denotes the personalized parameters specific to client i. The optimization involves adjusting both the shared parameters s and the personalized parameters for each client.
4. Methodology
This study proposes a region-personalized federated learning framework, termed FedRP, to address the challenges of IoT device classification. By leveraging the powerful feature-extraction capabilities of large-scale pretrained transformer models, FedRP enables accurate and robust device categorization. Unlike traditional centralized processing paradigms, FedRP effectively mitigates concerns related to data privacy and high hardware-based resource demands. Moreover, it improves communication efficiency and is well-suited for deployment on resource-constrained edge devices. A detailed framework of the FedRP model is illustrated in Figure 1.
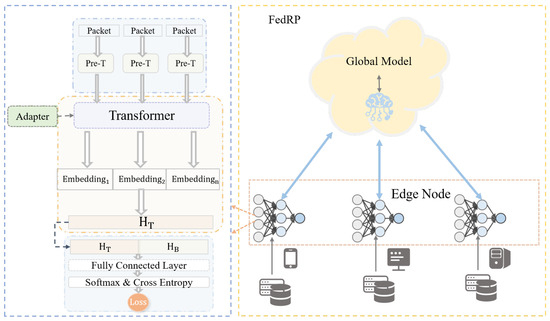
Figure 1.
The overview of the FedRP model.
4.1. Model Architecture
IoT device traffic is inherently sequential and stream-oriented, with strong temporal dependencies between adjacent packets. Therefore, in order to effectively identify devices under specific scenarios, the pretrained network must learn the interpacket associations present in labeled traffic inputs. This learning paradigm, widely employed in natural language processing (NLP), is commonly referred to as “fine-tuning.” Since the pretrained encoder is device-agnostic, it can be reused across various device types after fine-tuning.
Additionally, traffic flows generated by different IoT devices often exhibit fluctuations in packet lengths, introducing diversity in traffic patterns. To address this, we employ transformer-based modules to extract multidimensional representations from the input sequences. Specifically, we use pretrained transformer blocks to capture byte-level dependencies in device traffic. Let denote the tokenized and labeled input data, which are first projected into the input embedding space using a trainable matrix , as follows:
We then augment with positional embeddings to form the final embedding matrix E, which is passed through a stack of M transformer encoders. The operation of the th encoder block, where , begins by taking the input (with ) and applying linear projections to generate the corresponding key, query, and value vectors:
where , , and are the respective learnable projection matrices. These vectors are used to compute the core component of the transformer: the multi-head self- attention mechanism:
where denotes the dimensionality of K and is the output of the i-th attention head. is a learnable projection matrix used to combine the outputs of all heads. This is followed by a residual connection and layer normalization, after which a feed-forward network (FFN) with F hidden units is applied to produce the final encoder output, as follows:
where , , , and are learnable parameters of the FFN and denotes the ReLU activation function. The output embedding serves either as input to the next encoder or as the final representation used for device classification.
As shown in Figure 2, each transformer encoder module consists of two key components: the multi-head attention layer and the feed-forward network. Both are connected via linear projection layers that map the feature space and are followed by residual connections and normalization layers. To enable local data-driven personalization, we insert lightweight adapter modules within each sublayer to support customized adaptation.
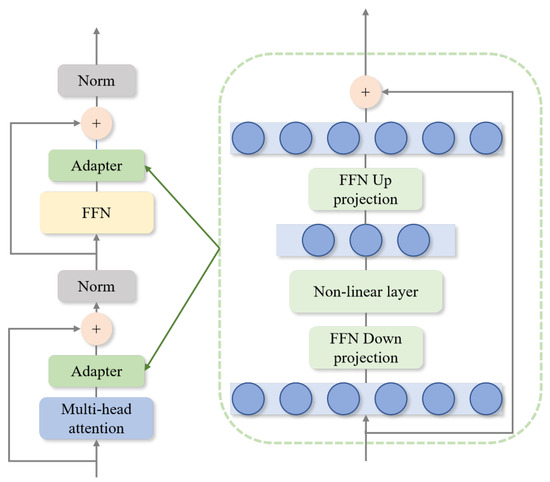
Figure 2.
Schematic diagram of the adapter module.
Given the resource limitations on edge devices, each adapter adopts a bottleneck architecture to minimize computational overhead. As shown in Figure 2, the adapter comprises two feed-forward layers: the first compresses the original D-dimensional feature into a lower M-dimensional subspace for task-specific adaptation, and the second projects it back to D dimensions. By ensuring , the adapter achieves efficient parameter usage while maintaining compatibility with edge hardware. A residual connection is also integrated to approximate identity mapping during early training stages, thereby preserving model stability and facilitating effective personalization.
4.2. The Proposed FedRP Method
The regional personalized federated learning algorithm proposed in this paper involves combining the regional personalized updates of local models with the generation of a global recognition model. Algorithm 1 presents the pseudocode implementation of the FedRP algorithm. Algorithm 2 presents the implementation of local parameter updates in FedRP. Specifically, FedRP comprises the following steps. First, the cloud server utilizes the global model as the initialization model and distributes this original model to each client i. Next, each client i uses its local dataset for local training, thereby updating the shared parameters of the local model. The local update of the shared parameters by client i in the t-th communication round is represented as follows:
where represents the shared parameters of client i in the t-th communication round and is the learning rate.
Each client i also updates the personalized parameters of the local model using its local dataset . The local update of the personalized parameters by client i in the t-th communication round is represented as follows:
| Algorithm 1 Regional Personalized Federated Learning (FedRP) |
|
| Algorithm 2 ClientUpdate |
|
Each client uploads the updated shared parameters to the IoT cloud center server while retaining the personalized parameters locally. The cloud center receives the shared parameter sets provided by each client. These parameters contain coarse-grained representations of the data from each client. The cloud center aggregates them by averaging in the t-th communication round. The aggregation of the shared parameters by the cloud center in the t-th communication round is represented as follows:
After undergoing local model training, each edge LAN client obtains shared parameters and personalized parameters that can be used to update local personalized models. This process iterates multiple times, repeating these steps. Eventually, the personalized models obtained by each client can be used for edge-node device management, while the global model can be utilized for macroscopic monitoring by the cloud center. The number of clients is denoted as m. The dataset of client traffic is represented as . The communication rounds are denoted as T. The initial value of personalized parameters is . The number of client updates, learning rate, and other parameters are also defined in the context of the algorithm.
5. Evaluation
5.1. Datasets
The experiments in this section are primarily based on the UNSW-2016 IoT dataset curated by Sivanathan et al. [28], which captures network traffic from a wide range of IoT devices in a real-world environment. TP-Link routers were used as gateways, with traffic collected using the TCPdump tool and stored in PCAP format over a continuous 20-day period. The dataset includes 23 commonly used IoT device types. However, several devices were associated with extremely limited traffic, which may lead to significant class imbalance and reduced experimental stability. To ensure robustness and reproducibility, we excluded three device types with insufficient data and focused on the remaining twenty for training and evaluation. Additionally, the traffic flows were labeled according to device type, and MAC addresses were omitted to protect user privacy. The mapping between device labels and MAC addresses is shown in Table 1.

Table 1.
UNSW-2016 DATASET.
To further validate the effectiveness and generalizability of the proposed approach, we introduced the USTC-TFC2016 dataset as a supplementary benchmark. This dataset was compiled by researchers at the University of Science and Technology of China (USTC) between 2011 and 2015 from real-world network environments. It consists of two parts: the first includes samples of ten types of malicious traffic, and the second includes ten types of benign traffic. USTC-TFC2016 comprises a total of 119,820 traffic records, from which we randomly selected 100,000 samples for training and evaluation. The details of the composition of the dataset are provided in Table 2.
Table 2.
USTC-TFC2016 DATASET.
However, due to the use of federated learning, certain operations need to be performed on the dataset construction. To realistically simulate data heterogeneity in real-world IoT systems, this experiment employs three commonly used non-independent and identically distributed (non-IID) data patterns from the federated learning literature to simulate heterogeneous scenarios:
- Balanced Dirichlet Distribution: Each client receives an equal number of samples, but the label distribution varies across clients, following a Dirichlet distribution with parameter . In this experiment, is set to 0.01 or 0.1. The datasets generated from this distribution are labeled as , , , and and are distributed to the clients.
- Unbalanced Dirichlet Distribution: Each client receives a different number of samples, and the label distribution varies, also following a Dirichlet distribution with parameter . In this experiment, is set to 0.1 or 1.0. The datasets generated from this distribution are labeled as , , , and and are distributed to the clients.
- Pathological Non-IID Distribution: Each client may have a different total number of samples, but the key feature is that each client possesses only samples from two completely distinct categories. The datasets generated from this distribution are labeled as , , , and and are distributed to the clients.
Compared to the pathological non-IID setting, the unbalanced Dirichlet distribution more closely resembles real-world IoT applications. In practical IoT environments, each client participating in personalized federated learning typically has devices from a variety of categories, with potential overlap in categories between clients with different data volumes. This scenario is common in practice. However, the data distribution in the pathological non-IID setting is more extreme, as it contains only two categories, which creates a more challenging scenario for research purposes compared to the balanced and unbalanced Dirichlet distributions.
5.2. Experimental Settings
All experiments in this section were conducted on the Windows 11 operating system. The server configuration featured an Intel Core i9-13900KF processor, 128 GB of RAM, and an RTX-4090 GPU with CUDA 11.3 for parallel training acceleration. Python 3.9 was used as the programming language, and PyTorch 1.11.0 was employed as the deep learning framework. In all experiments, the Adam optimizer was used for training, with the learning rate set to 0.0001 and values set to (0.9, 0.999). The dimension M of the FFN in the adapter was set to 64, which is consistent with widely adopted settings in the literature. Four clients participated in the federated learning process, with each client performing five local update rounds and 100 communication rounds between the server and the clients.
5.3. Metrics
To evaluate the performance of IoT device identification, we use several key metrics: Accuracy (Acc), macro-averaged score (), average precision (Pre), and average recall (Rec). These metrics are defined as follows:
Accuracy (Acc) measures the overall correctness of the model by computing the ratio of correctly predicted instances to the total number of instances.
Precision (Pre) is the ratio of true positive predictions to the total number of positive predictions, averaged across all classes.
Recall (Rec) is the ratio of true positive predictions to the total number of actual positive instances, averaged across all classes.
Macro-averaged Score () is the harmonic mean of Precision and Recall, calculated for each class and then averaged.
In these formulas, , , , and denote true positives, true negatives, false positives, and false negatives, respectively. The division by 20 indicates averaging across 20 classes, reflecting a multi-class classification problem.
5.4. Experimental Results
To validate the effectiveness of FedRP, this experiment selects four categories of federated learning algorithms and fully local training as baselines. They are +FedAvg [27], PACFL [41], FedProto [42], FedAP [43], and LOCAL. To validate the effectiveness of transformer-based blocks in IoT device identification, this experiment selected five existing ML- and DL-based identification algorithms as benchmarks: NB [44], SVM [45], CNN [26], Audi [17], and DEFT [46]. To ensure fairness, each model is re-implemented with the parameters and configurations described in the corresponding research, thereby reproducing the results of these approaches. Additionally, all models are trained on the same training set and evaluated on the same test set.
5.4.1. Quantitative Evaluation
This section presents the experimental evaluation of the FedRP algorithm on the UNSW-2016 and USTC-TFC2016 datasets. The average accuracy across all client test sets is used as the evaluation criterion, with results presented in Table 3 and Table 4. The experimental results show that the FedRP algorithm outperforms other baseline methods on both datasets.
Table 3.
Average accuracy and performance improvement on UNSW-2016.
Table 4.
Average accuracy and performance improvement on USTC-TFC2016.
On the UNSW-2016 dataset, FedRP demonstrates superior performance in most cases, especially under conditions of pathological distributions. In such cases, the average accuracy of FedRP reaches 95.13%, which is significantly higher than those of FedAvg and other personalized federated learning methods. When is set to 0.01, the accuracy of FedRP is 93.03%, further validating its ability to handle data heterogeneity and imbalanced distributions effectively. On the USTC-TFC2016 dataset, all algorithms perform significantly better than they do on the UNSW-2016 dataset, primarily because the UNSW-2016 dataset contains more noise, such as nonattack traffic or mixed traffic, which can interfere with model performance. Nonetheless, FedRP still performs very well on this dataset. Compared to FedAvg, FedRP shows a significant improvement in accuracy across all data distributions. For example, under pathological conditions, FedRP’s accuracy is 98.13%, approximately 7.22% higher than that of FedAvg. The results from both datasets demonstrate that FedRP consistently achieves high accuracy across different data distributions, confirming its effectiveness and stability in diverse scenarios.
Furthermore, while FedAP also achieves good performance on both datasets, it relies on additional local data to generate pretrained models to guide the personalization of local models. In contrast, FedRP assesses the relationships between clients without requiring extra local data. Unlike FedAvg or FedAP, FedRP does not aggregate parameters globally across all clients. Instead, it first performs local aggregation of shared parameters within regions to form regional representations; then, each client uses the adapter module for lightweight personalization. This approach retains the locality of the data while avoiding the overhead of large-scale parameter synchronization, making it more suitable for deployment on resource-constrained edge devices. Thus, FedRP is more efficient in environments with limited resources.
5.4.2. Local Comparison
In this chapter, we compare the FedRP method with other local centralized learning methods in terms of their performance on the UNSW-2016 dataset. The local methods are based on the first dataset , which is constructed using a balanced Dirichlet distribution (). As shown in Figure 3, the personalized FedRP model demonstrates significant improvements across various performance metrics compared to methods such as NB, SVM, CNN, and others. Specifically, compared to NB and SVM, FedRP achieves improvements of over 40% in both accuracy and F1 score. When compared to DEFT, the FedRP model shows improvements of more than 10% in accuracy and over 11% in F1 score. Furthermore, the performance of locally trained models is comparable to that of the FedRP models, further confirming the strong device-recognition capabilities of the LLM model itself. This demonstrates that within the federated learning framework, FedRP is capable of achieving efficient and accurate device recognition.
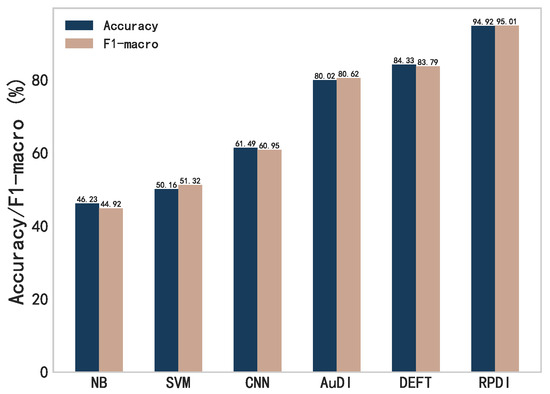
Figure 3.
The recognition accuracy and F1 score of local centralized learning on UNSW-2016.
5.4.3. Error Analysis
This section analyzes the recognition performance of FedRP across different datasets and data distributions, with error analysis conducted using confusion matrices. Figure 4 and Figure 5 present the average confusion matrices of FedRP on the UNSW-2016 and USTC-TFC2016 datasets under imbalanced Dirichlet distributions ( and ). As shown in the figures, FedRP accurately identifies most device types, achieving recognition accuracies exceeding 90% in many cases. Misclassifications are sparse and occur with low probability. Notably, the recognition performance under is slightly better than that under , which may be attributed to the fact that increased data heterogeneity enhances the benefits of personalization, allowing models to better capture task-specific features. Although performance may slightly decline under more heterogeneous distributions, the recognition accuracy for most devices remains consistently high. This robustness is largely attributed to the strong representational and generalization capabilities of the global model within the federated learning framework, which enables local personalized models to achieve competitive recognition results even when the degree of personalization is moderate.
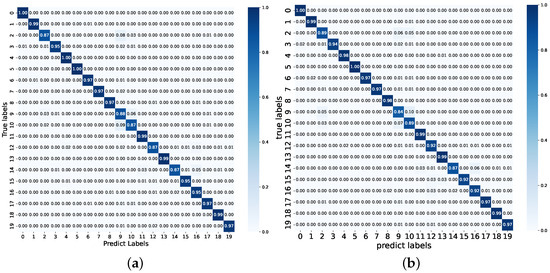
Figure 4.
Average confusion matrix on UNSW-2016. (a) The result under the imbalanced Dirichlet distribution with . (b) The result under the imbalanced Dirichlet distribution with .
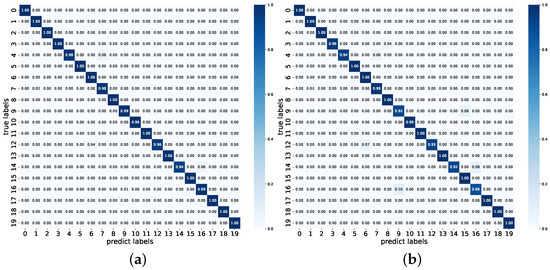
Figure 5.
Average confusion matrix on USTC-TFC2016. (a) The result under the imbalanced Dirichlet distribution with . (b) The result under the imbalanced Dirichlet distribution with .
5.4.4. Train Validation
Figure 6 illustrates the training loss curves of four representative devices in FedRP under a balanced Dirichlet distribution with . For better visualization, only the first 350 training epochs are displayed. As observed, all four devices exhibit rapid convergence, with loss values consistently decreasing over time. This downward trend indicates that the model is progressively learning meaningful representations from the data during training. Moreover, the absence of pronounced signs of overfitting or underfitting suggests that the personalized federated learning approach effectively mitigates model drift and maintains training stability. A closer inspection of the curves reveals periodic small peaks occurring every five epochs. These fluctuations correspond to the communication rounds between clients and the central server. During these rounds, the server distributes updated global parameters, prompting local models to adjust accordingly and thus resulting in transient instability. Nevertheless, the curves quickly return to stable trajectories after each communication round, reflecting the robustness and adaptability of the FedRP framework.
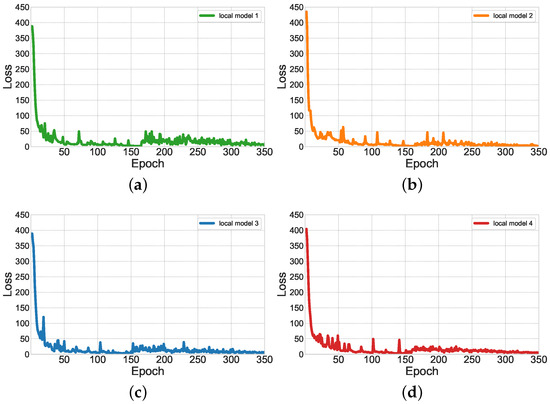
Figure 6.
Loss functions of local models under a balanced Dirichlet distribution with : (a) local model 1; (b) local model 2; (c) local model 3; (d) local model 4.
5.4.5. Ablation Study
This section investigates the impact of different local training epochs and learning rates on the performance of the FedRP model. Table 5 presents the average performance of FedRP on the UNSW-2016 dataset under a balanced Dirichlet distribution with . From Table 5, it can be observed that as the number of local update rounds increases, the performance metrics of FedRP first improve and then decrease. The primary reason for this trend may be twofold: on the one hand, when the number of local updates increases, each client conducts multiple training sessions on its local dataset, which can lead to overfitting; on the other hand, due to the significant heterogeneity of the local data, as the number of local training rounds increases, clients are more likely to focus on updating and learning personalized parameters, leading to a phenomenon known as “knowledge forgetting,” particularly with small sample sizes. This leads the model to forget previously learned knowledge, which hinders the development of effective personalized models. Therefore, this experiment adopts five local training rounds.
Table 5.
Performance comparison of FedRP under different local epochs (%).
Figure 7 presents a performance comparison of FedRP under different learning rates, with the dataset being UNSW-2016. The experimental results show that the performance of the model exhibits significant changes as the learning rate increases. From the figure, it can be seen that the model performs best when the learning rate is set to , achieving an accuracy of 94.92% and an F1 score of 0.9501. Specifically, lower learning rates (such as and ) result in relatively high accuracy but do not correspond to similarly high F1 scores (0.9326 and 0.9221, respectively), indicating a possible underfitting phenomenon. Further observation reveals that when the learning rate is , although the accuracy is 82.32%, the F1 score is only 0.8342, suggesting that the model may have overfitted at this high learning rate, leading to a decrease in performance. Therefore, when selecting the learning rate, it is crucial to consider both the model’s generalization ability and the stability of the training process.
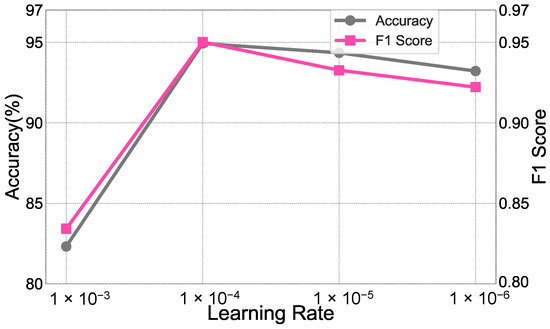
Figure 7.
Performance comparison of FedRP under different learning rates on UNSW-2016.
6. Conclusions
This study proposed a privacy-preserving personalized IoT device-identification model suitable for cloud–edge collaborative systems, aiming to achieve high-precision classification and data-privacy security. Through the construction of a cloud–edge collaborative system model, the identification algorithm was deployed at both edge nodes and central nodes. The FedRP model, based on federated learning and personalized fine-tuning, ensured efficient performance and protection of data privacy. FedRP utilized a federated learning framework to gather comprehensive information from multiple participants, addressing functional differences and data heterogeneity across network nodes. By incorporating adapters into the transformer model, FedRP obtained personalized and shared parameters, uploading only the shared parameters to reduce communication overhead. Experimental results demonstrated that FedRP struck a balance between performance in device identification and privacy security, making it suitable for device-identification tasks in large-scale cloud–edge collaborative IoT systems.
Author Contributions
Conceptualization, Y.J. and B.X.; methodology, B.C.; validation, B.Z. and Y.L.; formal analysis, J.W. (Jiacheng Wang) and F.G.; investigation, Y.J.; writing—original draft preparation, B.C. and J.W. (Junfei Wang); writing—review and editing, Y.L. and B.X.; visualization, Y.L.; supervision, J.W. (Junfei Wang) and Y.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded in part by the Key Research and Development Program of Hubei Province, China under Grants 2024BAB031, 2024BAB016.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Kim, H.; Feamster, N. Improving network management with software defined networking. IEEE Commun. Mag. 2013, 51, 114–119. [Google Scholar] [CrossRef]
- Ghimire, B.; Rawat, D.B. Recent Advances on Federated Learning for Cybersecurity and Cybersecurity for Federated Learning for Internet of Things. IEEE Internet Things J. 2022, 9, 8229–8249. [Google Scholar] [CrossRef]
- Peng, K.; Wang, L.; He, J.; Cai, C.; Hu, M. Joint Optimization of Service Deployment and Request Routing for Microservices in Mobile Edge Computing. IEEE Trans. Serv. Comput. 2024, 17, 1016–1028. [Google Scholar] [CrossRef]
- Zha, Z.; He, J.; Zhen, L.; Yu, M.; Dong, C.; Li, Z.; Wu, G.; Zuo, H.; Peng, K. A BiGRU Model Based on the DBO Algorithm for Cloud-Edge Communication Networks. Appl. Sci. 2024, 14, 10155. [Google Scholar] [CrossRef]
- Baccour, E.; Mhaisen, N.; Abdellatif, A.A.; Erbad, A.; Mohamed, A.; Hamdi, M.; Guizani, M. Pervasive AI for IoT Applications: A Survey on Resource-Efficient Distributed Artificial Intelligence. IEEE Commun. Surv. Tutor. 2022, 24, 2366–2418. [Google Scholar] [CrossRef]
- Deng, T.; Xu, X.; Zou, Z.; Liu, W.; Wang, D.; Hu, M. Multidrone Parcel Delivery via Public Vehicles: A Joint Optimization Approach. IEEE Internet Things J. 2024, 11, 9312–9323. [Google Scholar] [CrossRef]
- Arisdakessian, S.; Wahab, O.A.; Mourad, A.; Otrok, H.; Guizani, M. A Survey on IoT Intrusion Detection: Federated Learning, Game Theory, Social Psychology, and Explainable AI as Future Directions. IEEE Internet Things J. 2023, 10, 4059–4092. [Google Scholar] [CrossRef]
- Xu, B.; Guo, J.; Ma, F.; Hu, M.; Liu, W.; Peng, K. On the Joint Design of Microservice Deployment and Routing in Cloud Data Centers. J. Grid Comput. 2024, 22, 42. [Google Scholar] [CrossRef]
- Peng, K.; Xie, J.; Wei, L.; Hu, J.; Hu, X.; Deng, T.; Hu, M. Clustering-Based Collaborative Storage for Blockchain in IoT Systems. IEEE Internet Things J. 2024, 11, 33847–33860. [Google Scholar] [CrossRef]
- Hu, M.; Guo, Z.; Wen, H.; Wang, Z.; Xu, B.; Xu, J.; Peng, K. Collaborative Deployment and Routing of Industrial Microservices in Smart Factories. IEEE Trans. Ind. Inform. 2024, 20, 12758–12770. [Google Scholar] [CrossRef]
- Wang, L.; Li, Z.; Wang, C.; Li, J.; Hu, M.; Liu, W.; Peng, K. Obstacle-Aware Multicast Routing Algorithm for Large-Scale LEO Constellations. IEEE Trans. Netw. Sci. Eng. 2024, 11, 4551–4563. [Google Scholar] [CrossRef]
- Habbal, A.; Ali, M.K.; Abuzaraida, M.A. Artificial Intelligence Trust, Risk and Security Management (AI TRiSM): Frameworks, applications, challenges and future research directions. Expert Syst. Appl. 2024, 240, 122442. [Google Scholar] [CrossRef]
- Peng, K.; He, J.; Guo, J.; Liu, Y.; He, J.; Liu, W.; Hu, M. Delay-Aware Optimization of Fine-Grained Microservice Deployment and Routing in Edge via Reinforcement Learning. IEEE Trans. Netw. Sci. Eng. 2024, 11, 6024–6037. [Google Scholar] [CrossRef]
- Kebande, V.R.; Awad, A.I. Industrial Internet of Things Ecosystems Security and Digital Forensics: Achievements, Open Challenges, and Future Directions. ACM Comput. Surv. 2024, 56, 1–37. [Google Scholar] [CrossRef]
- Xu, Q.; Zheng, R.; Saad, W.; Han, Z. Device Fingerprinting in Wireless Networks: Challenges and Opportunities. IEEE Commun. Surv. Tutor. 2016, 18, 94–104. [Google Scholar] [CrossRef]
- Sivanathan, A.; Gharakheili, H.H.; Sivaraman, V. Detecting Behavioral Change of IoT Devices Using Clustering-Based Network Traffic Modeling. IEEE Internet Things J. 2020, 7, 7295–7309. [Google Scholar] [CrossRef]
- Marchal, S.; Miettinen, M.; Nguyen, T.D.; Sadeghi, A.R.; Asokan, N. AuDI: Toward Autonomous IoT Device-Type Identification Using Periodic Communication. IEEE J. Sel. Areas Commun. 2019, 37, 1402–1412. [Google Scholar] [CrossRef]
- Meidan, Y.; Bohadana, M.; Shabtai, A.; Ochoa, M.; Tippenhauer, N.O.; Guarnizo, J.D.; Elovici, Y. Detection of Unauthorized IoT Devices Using Machine Learning Techniques. arXiv 2017, arXiv:1709.04647. [Google Scholar]
- Aksoy, A.; Gunes, M.H. Automated IoT Device Identification using Network Traffic. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar]
- Desai, B.A.; Divakaran, D.M.; Nevat, I.; Peter, G.W.; Gurusamy, M. A feature-ranking framework for IoT device classification. In Proceedings of the 2019 11th International Conference on Communication Systems & Networks (COMSNETS), Bengaluru, India, 7–11 January 2019; pp. 64–71. [Google Scholar]
- Yeganeh, Y.; Farshad, A.; Boschmann, J.; Gaus, R.; Frantzen, M.; Navab, N. FedAP: Adaptive Personalization in Federated Learning for Non-IID Data. In Distributed, Collaborative, and Federated Learning, and Affordable AI and Healthcare for Resource Diverse Global Health; Albarqouni, S., Bakas, S., Bano, S., Cardoso, M.J., Khanal, B., Landman, B., Li, X., Qin, C., Rekik, I., Rieke, N., et al., Eds.; Springer: Cham, Switzerland, 2022; pp. 17–27. [Google Scholar]
- Bao, J.; Hamdaoui, B.; Wong, W.K. IoT Device Type Identification Using Hybrid Deep Learning Approach for Increased IoT Security. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 565–570. [Google Scholar]
- Xu, H.; Zhang, Z.; Yu, X.; Wu, Y.; Zha, Z.; Xu, B.; Xu, W.; Hu, M.; Peng, K. Targeted Training Data Extraction—Neighborhood Comparison-Based Membership Inference Attacks in Large Language Models. Appl. Sci. 2024, 14, 7118. [Google Scholar] [CrossRef]
- Yin, F.; Yang, L.; Wang, Y.; Dai, J. IoT ETEI: End-to-End IoT Device Identification Method. In Proceedings of the 2021 IEEE Conference on Dependable and Secure Computing (DSC), Fukushima, Japan, 30 January–2 February 2021; pp. 1–8. [Google Scholar]
- Sánchez Sánchez, P.M.; Huertas Celdrán, A.; Bovet, G.; Martínez Pérez, G. Adversarial attacks and defenses on ML- and hardware-based IoT device fingerprinting and identification. Future Gener. Comput. Syst. 2024, 152, 30–42. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, J.; Li, J.; Song, H.; Yang, T.; Niu, S.; Ming, Z. Zero-Bias Deep Learning for Accurate Identification of Internet-of-Things (IoT) Devices. IEEE Internet Things J. 2021, 8, 2627–2634. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.y. Communication-Efficient Learning of Deep Networks from Decentralized Data. Proc. Mach. Learn. Res. 2017, 54, 1273–1282. [Google Scholar]
- Feng, K.; Luo, L.; Xia, Y.; Luo, B.; He, X.; Li, K.; Zha, Z.; Xu, B.; Peng, K. Optimizing Microservice Deployment in Edge Computing with Large Language Models: Integrating Retrieval Augmented Generation and Chain of Thought Techniques. Symmetry 2024, 16, 1470. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Q.; Liang, H.; Joshi, G.; Poor, H.V. Tackling the Objective Inconsistency Problem in Heterogeneous Federated Optimization. Adv. Neural Inf. Process. Syst. 2020, 33, 7611–7623. [Google Scholar]
- Wu, F.; Guo, S.; Qu, Z.; He, S.; Liu, Z.; Gao, J. Anchor Sampling for Federated Learning with Partial Client Participation. Proc. Mach. Learn. Res. 2023, 202, 37379–37416. [Google Scholar]
- Li, Z.; Lin, T.; Shang, X.; Wu, C. Revisiting Weighted Aggregation in Federated Learning with Neural Networks. Proc. Mach. Learn. Res. 2023, 202, 19767–19788. [Google Scholar]
- Palihawadana, C.; Wiratunga, N.; Wijekoon, A.; Kalutarage, H. FedSim: Similarity guided model aggregation for Federated Learning. Neurocomputing 2022, 483, 432–445. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated Learning in Mobile Edge Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef]
- He, Z.; Yin, J.; Wang, Y.; Gui, G.; Adebisi, B.; Ohtsuki, T.; Gacanin, H.; Sari, H. Edge Device Identification Based on Federated Learning and Network Traffic Feature Engineering. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 1898–1909. [Google Scholar] [CrossRef]
- Zhang, W.; Lu, Q.; Yu, Q.; Li, Z.; Liu, Y.; Lo, S.K.; Chen, S.; Xu, X.; Zhu, L. Blockchain-Based Federated Learning for Device Failure Detection in Industrial IoT. IEEE Internet Things J. 2021, 8, 5926–5937. [Google Scholar] [CrossRef]
- Mothukuri, V.; Khare, P.; Parizi, R.M.; Pouriyeh, S.; Dehghantanha, A.; Srivastava, G. Federated-Learning-Based Anomaly Detection for IoT Security Attacks. IEEE Internet Things J. 2022, 9, 2545–2554. [Google Scholar] [CrossRef]
- Xu, G.; Xu, S.; Fan, X.; Cao, Y.; Mao, Y.; Xie, Y.; Chen, X.B. RAT Ring: Event Driven Publish/Subscribe Communication Protocol for IIoT by Report and Traceable Ring Signature. IEEE Trans. Ind. Inform. 2025, 1–9. [Google Scholar] [CrossRef]
- Cao, Z.; Huang, L.; Wang, T.; Wang, Y.; Shi, J.; Zhu, A.; Shi, T.; Snoussi, H. Understanding the Dimensional Need of Noncontrastive Learning. IEEE Trans. Cybern. 2025, 1–14. [Google Scholar] [CrossRef]
- Peng, K.; Liao, T.; Liao, X.; Xie, J.; Xu, B.; Deng, T.; Hu, M. DCMM: Dynamic Cluster-Based Mobile Node Migration Scheme for Blockchain Collaborative Storage in Mobile IoT Networks. IEEE Trans. Netw. Sci. Eng. 2025, 12, 584–598. [Google Scholar] [CrossRef]
- Alneyadi, S.; Sithirasenan, E.; Muthukkumarasamy, V. A survey on data leakage prevention systems. J. Netw. Comput. Appl. 2016, 62, 137–152. [Google Scholar] [CrossRef]
- Vahidian, S.; Morafah, M.; Wang, W.; Kungurtsev, V.; Chen, C.; Shah, M.; Lin, B. Efficient Distribution Similarity Identification in Clustered Federated Learning via Principal Angles between Client Data Subspaces. Proc. AAAI Conf. Artif. Intell. 2023, 37, 10043–10052. [Google Scholar] [CrossRef]
- Tan, Y.; Long, G.; Liu, L.; Zhou, T.; Lu, Q.; Jiang, J.; Zhang, C. FedProto: Federated Prototype Learning across Heterogeneous Clients. Proc. AAAI Conf. Artif. Intell. 2022, 36, 8432–8440. [Google Scholar] [CrossRef]
- Lu, W.; Wang, J.; Chen, Y.; Qin, X.; Xu, R.; Dimitriadis, D.; Qin, T. Personalized Federated Learning with Adaptive Batchnorm for Healthcare. arXiv 2022, arXiv:2112.00734. [Google Scholar] [CrossRef]
- Chakraborty, B.; Divakaran, D.M.; Nevat, I.; Peters, G.W.; Gurusamy, M. Cost-Aware Feature Selection for IoT Device Classification. IEEE Internet Things J. 2021, 8, 11052–11064. [Google Scholar] [CrossRef]
- Hamad, S.A.; Zhang, W.E.; Sheng, Q.Z.; Nepal, S. IoT Device Identification via Network-Flow Based Fingerprinting and Learning. In Proceedings of the 2019 18th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/13th IEEE International Conference on Big Data Science And Engineering (TrustCom/BigDataSE), Rotorua, New Zealand, 5–8 August 2019; pp. 103–111. [Google Scholar]
- Thangavelu, V.; Divakaran, D.M.; Sairam, R.; Bhunia, S.S.; Gurusamy, M. DEFT: A Distributed IoT Fingerprinting Technique. IEEE Internet Things J. 2019, 6, 940–952. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).