Abstract
Object detection in complex scenarios such as construction sites, electric power operations, and resource exploration often suffers from low accuracy and frequent missed or false detections. To address these challenges, this study proposes a modified You Only Look Once version 8 nano (YOLOv8n)-based algorithm, termed YOLOv8n-ASA, for safety-helmet-wearing detection. The proposed method introduces structural asymmetry into the network to enhance feature representation and detection robustness. Specifically, an Adaptive Kernel Convolution (AKConv) module is incorporated into the backbone, in which asymmetric kernels are used to better capture features of irregularly shaped objects. The Simple Attention Module (SimAM) further sharpens the focus on critical regions, while the Asymptotic Feature Pyramid Network (AFPN) replaces the symmetric top–down fusion pathway of the traditional FPN with a progressive and asymmetric feature integration strategy. These asymmetric designs mitigate semantic gaps between non-adjacent layers and enable more effective multi-scale fusion. Extensive experiments demonstrate that YOLOv8n-ASA achieves superior accuracy and robustness compared to several benchmarks, validating its effectiveness for safety-helmet-wearing detection in complex real-world scenarios.
1. Introduction
Construction environments in such industries as building sites, electric power operations, and resource exploration are generally complex and hazardous, posing constant threats such as falls from height, being struck by objects, and machinery collisions. Accordingly, ensuring adequate and effective head protection comprises a non-negotiable link of operational safety. Safety helmets, a kind of core and basic protective equipment, can effectively cushion impacts in the event of an accident, substantially mitigating the risk of head injuries for workers, which thus serve as a vital barrier for protecting life safety [1]. In construction scenarios, therefore, real-time and accurate detection of personnel’s safety helmet wearing has become an integral and critical component of the safety production management system. Traditionally, safety-helmet-wearing detection primarily relies on manual inspection. This approach demands significant human resources and time while exhibiting inherent limitations such as low efficiency, poor real-time performance, and susceptibility to the subjective state of inspectors, ultimately falling short of the demands of large-scale and highly dynamic construction scenarios. Automatic detection based on object detection, characterized by efficiency and objectivity, has gradually replaced the traditional approach due to the rapid development of computer vision technologies, and emerged as a mainstream technological approach for safety production management in construction sites.
In the task of safety-helmet-wearing detection, You Only Look Once (YOLO) series algorithms have been recognized as the mainstream fundamental framework due to their advantages on both detection speed and accuracy. In some extreme scenarios, however, they fail to meet the actual demands for detection accuracy owing to such problems as complex background interference (occlusion by equipment and building materials), object occlusion (head overlapping in crowded scenes), and diversity of safety helmet colors and sizes (different brands and models) [2]. This challenge has prompted numerous researchers to explore accuracy optimization in YOLO algorithms, resulting in a series of dedicated improvement schemes. For instance, Ku et al. [3] designed a YO-LO version 4 (YOLOv4)-based real-time detection architecture to enhance the detection accuracy for small objects on construction sites by integrating an image super-resolution module and optimizing the Cross Stage Partial DarkNet53 (CSPDarknet53) Backbone Network. Meanwhile, it alleviates the problem of sample class imbalance by introducing foreground–background-balanced loss function. However, this architecture still suffers from certain limitations: On the one hand, the effectiveness of the image super-resolution module is highly dependent on the quality of original images, leading to limited performance gains in low-resolution or blurry scenarios. On the other hand, while the loss function demonstrates strong adaptability, it requires parameter adjustment based on the distribution characteristics of objects in different construction scenarios. Overall, the architecture’s environmental adaptability and detection efficiency still require further optimization. Qin et al. [4] developed an LT-YOLO model for safety-helmet-wearing detection based on the Tiny-YOLOv3 algorithm. This model fulfills the requirement for real-time detection through a lightweight design while ensuring detection accuracy. However, its experimental verification was conducted primarily on specific data sets, and construction scenarios with different lighting conditions and complex backgrounds were not sufficiently incorporated, hindering its generalization and necessitating additional parameter testing and model optimization for cross-scenario applications. Li et al. [5] proposed a YOLOv5s-PSG algorithm, with strengthened extraction and expression abilities for object features by constructing a multi-branch feature extraction structure and introducing the simple attention module (SimAM) and GSconv convolutional layer. However, the introduction of the multi-branch structure and the convolutional layer possibly results in redundancy or loss of feature information, affecting the detection stability of the algorithm. In addition, this algorithm employs a relatively simplistic design in its feature fusion, easily leading to insufficient feature fusion in scenarios with severe object occlusion or intense background interference, thereby affecting the detection accuracy. Deng et al. [6] put forward an enhanced detection scheme based on YOLOv5, which can perceive cross-scale global features through the fused transformer module. In addition, dynamic convolution and coordinate attention mechanisms are integrated therein to construct a feature enhancement network, the model structure is optimized using the decoupled detection head and anchor-free strategy, and bounding box precision is enhanced by introducing the EIoU loss function. This scheme effectively improves the detection performance for dense small targets, but in complex scenarios, the detection accuracy is prone to fluctuations due to insufficient consideration of the spatial correlations between objects and the background suppression during structural optimization, especially in regions with dense personnel and severe occlusion. Yin et al. [7] proposed an algorithm integrating coordinate attention and soft non-maximal suppression (NMS) for safety-helmet-wearing detection. The coordinate attention mechanism is introduced to focus on the key feature areas of safety helmets, the soft NMS is integrated to enhance the accuracy of filtering the confidence of candidate bounding boxes, and the WIoU loss function is introduced to optimize the bounding box regression and enhance the generalization ability. While this algorithm demonstrates significant improvements in overall performance, it is still not accurate enough in extracting features under conditions with complex backgrounds and overlapping objects, easily giving rise to missed or false detection. To address missed and false detections for dense and small objects in scenarios like smart parks, Shan et al. [8] designed an enhanced YOLOv5 architecture, which integrates the efficient channel attention (ECA) mechanism to optimize feature channels, establishes a weighted bidirectional feature pyramid to increase the efficiency of cross-scale feature fusion, and employs the decoupled detection head to facilitate algorithm convergence. This architecture displays improved accuracy for small object detection, but its weighted feature pyramid is unstable in processing extremely small or large objects, and its decoupled head remains susceptible to positioning bias for safety helmets in complex backgrounds. YOLOX, a feature-enhanced algorithm for safety helmet detection proposed by Wang et al. [9], introduces the soft space pyramid pooling (SPP) module in the Backbone Network to reduce the loss of feature information and retain more contextual information. Additionally, it employs a feature fusion module integrating the ECA mechanism to enhance the learning and fusion efficiency of object features and reduce the false detection rate. The algorithm exhibits improvements in detection accuracy, but in scenarios with complex backgrounds or overlapped objects, its soft SPP module fails to preserve key feature details adequately, and its attention mechanism’s weight allocation is susceptible to the interference from background noise, potentially resulting in false or missed detection. Wang et al. [10] proposed an enhanced architecture YOLOv7-tiny, which introduces the efficient multi-scale attention (EMSA) module to guide the algorithm to focus on the key feature areas of safety helmets, employs the dynamic attention detection head to optimize feature expression, and integrates the Wise-IoU loss function to alleviate the positioning bias caused by personnel occlusion. Though this algorithm enhances feature extraction to achieve higher accuracy, the adaptability of its multi-scale attention mechanism requires further optimization for scenarios with highly varied object scales. Lin et al. [11] developed the YOLOv8n-SLIM-CA algorithm employing Mosaic data augmentation to generate samples rich in dense and small objects, embedding a coordinate attention mechanism to amplify feature responses from safety helmets, utilizing a slim-neck structure for efficient multi-scale feature fusion, and introducing a small object detection layer to improve the recognition capability for dense objects. Despite the fact that this algorithm has significantly better detection performance in complex scenarios, the feature extraction and positioning accuracy require further improvements for extremely large objects or small objects at long distances. Aiming at addressing safety accidents caused by the lack of personal protective equipment in coal mine operations, Cheng et al. [12] put forward an SMT-YOLOv8s detection algorithm for simultaneously detecting the wearing of safety helmets and safety vests. In this algorithm, a scale-aware modulation module is introduced to enhance image feature extraction ability, a cross-channel enhanced attention module is designed to highlight object features, and an enhanced complete IoU (CIoU) is incorporated to accurately calculate the positional deviation between the predicted bounding box and the ground truth bounding box. Such a modified algorithm possesses high detection accuracy and computational efficiency in the complex environment of coal mines, characterized by low illumination and high dust concentrations. Lin et al. [13] designed a multi-scale convolution group (MSCG)-YOLO algorithm, where the multi-head self-attention mechanism is integrated into the connection layer between the Backbone Network and the Neck Network to enhance the global vision of the model and its ability to detect small and occluded objects. In addition, a new Neck structure and an enhanced detection head are designed to optimize the feature transmission and object recognition process. Despite higher detection accuracy, this algorithm is less capable of suppressing background noise in scenarios with dense objects or complex backgrounds, easily leading to false or missed detection.
In addition to these representative improvements, several recent studies have further expanded the applicability of YOLO-based helmet detection in complex scenarios. For example, lightweight optimization has become an important research direction, as demonstrated by LS-YOLOv8n, which employs a simplified backbone and pruning strategy to significantly reduce model size while maintaining competitive detection accuracy, making it suitable for edge deployment [14]. Meanwhile, YOLOv8n_H introduces SCConv-based feature refinement, coordinate attention, and a lightweight decoupled detection head to enhance small-object perception and reduce computational overhead [15]. Furthermore, the URD-YOLOv8 framework improves multi-scale representation and occlusion robustness through DySample upsampling, RFAConv, and an enhanced aggregation structure, achieving superior performance in dense and cluttered environments [16]. These recent works collectively highlight the ongoing trend toward balancing detection accuracy, robustness, and computational efficiency in safety helmet detection tasks.
To sum up, current research on the YOLO series-based safety-helmet-wearing detection using the YOLO series has made remarkable progress in structural optimization, feature enhancement, and loss function refinement, significantly elevating the detection accuracy, but three critical challenges remain unresolved when evaluated against the practical demands of real construction scenarios: First, some algorithms have unstable detection performance in scenarios with dense, overlapped or seriously occluded objects, leading to high missed and false detection rates. Second, while various attention mechanisms and feature enhancement strategies have strengthened the expression of object features, but they fail to adequately capture detailed features, especially in low-resolution and complex backgrounds. Third, although multi-scale fusion and feature pyramid structure improve the ability to detect objects of different scales, it is hard to maintain detection stability in complex backgrounds or for extremely small objects. Therefore, a central research focus for optimizing safety-helmet-wearing detection technologies lies in enhancing the robustness of algorithms in complex scenarios while maintaining both detection accuracy and real-time performance, particularly in maintaining high efficiency on edge devices with limited computational resources.
To address the aforementioned challenges, this study proposes an enhanced detection framework termed YOLOv8 nano–Adaptive Spatial Attention (YOLOv8n-ASA). The central motivation is to overcome the inherent limitations of conventional symmetric feature extraction mechanisms, which often lack flexibility when encountering irregular object geometries, multi-scale variations, and severe occlusion in real-world industrial scenes. By introducing controlled architectural asymmetry, the proposed framework aims to strengthen feature representation adaptability, thereby improving the stability and accuracy of safety helmet detection under complex and dynamic operational environments.
The YOLOv8n-ASA framework integrates three essential components—adaptive kernel convolution (AKConv), the simple attention module (SimAM), and an asymptotic feature pyramid network (AFPN)—into the baseline YOLOv8n architecture. The AKConv module dynamically adjusts convolutional kernel configurations to enhance sensitivity to objects with varying scales and orientations. SimAM selectively emphasizes informative spatial regions while suppressing irrelevant background noise, effectively improving feature discriminability. Meanwhile, the AFPN employs a progressive multi-scale fusion strategy to facilitate more efficient cross-layer information exchange and mitigate feature degradation during transmission. Collectively, these components introduce purposeful structural asymmetry and substantially enhance the model’s robustness in detecting small, occluded, and visually ambiguous safety helmet targets.
The primary contributions of this work are as follows:
- (1)
- Through introduction of the variable convolutional kernel AKConv module into the Backbone Network, the algorithm’s adaptive ability to safety helmet objects of different scales and orientations was enhanced by dynamically adjusting the scale and shape of convolutional kernels, thereby enhancing feature extraction accuracy in complex scenarios.
- (2)
- Through integration of the SimAM module, it is positioned between the Backbone Network and Neck Network layers, the pertinence and effectiveness of object feature extraction were effectively improved by mining the key information areas in the feature map, thus guiding the network to focus on relevant features of safety helmet objects, and suppressing background noise interference.
- (3)
- Through introduction of the AFPN structure for Neck Network optimization, the efficiency of information exchange across different layers of features was improved by the progressive feature fusion strategy, alleviating the problem of information loss during feature transfer and further enhancing the detection efficiency for multi-scale objects (especially small objects and occluded objects).
2. YOLOv8n Network Structure
2.1. Overall Network Architecture
The YOLOv8 algorithm, constructed upon the established strengths of the YOLO series, introduces novel modules and architectural optimizations, achieving a dual improvement in both detection accuracy and inference speed [17]. YOLOv8 is categorized into five distinct versions based on model depth and parameter count: YOLOv8n, YOLOv8 small (YOLOv8s), YOLOv8m, YOLOv8l, and YOLOv8x. Among them, YOLOv8n is characterized by minimal parameter size and fastest inference speed, which can fulfill the demands of lightweight deployment scenarios such as edge devices and mobile terminals for real-time performance [18]. Considering the requirements of industrial construction safety scenarios, i.e., real-time detection of safety helmet wearing under limited computational power, YOLOv8n was selected as the basic algorithm and was subjected to optimization and module reconstruction based on its detection shortcomings in complex scenarios.
YOLOv8 adopts a “layered and progressive” network design principle, with its architecture comprising four core modules: Input, Backbone Network for feature extraction, Neck Network for feature fusion, and Head Network for final output. These modules work in concert to execute a complete detection process: “raw image input → multi-scale feature extraction → feature integration and refinement → object classification and positioning”, ensuring robust recognition capability for objects of varying sizes across diverse scenarios. The overall network architecture of YOLOv8 is illustrated in Figure 1.
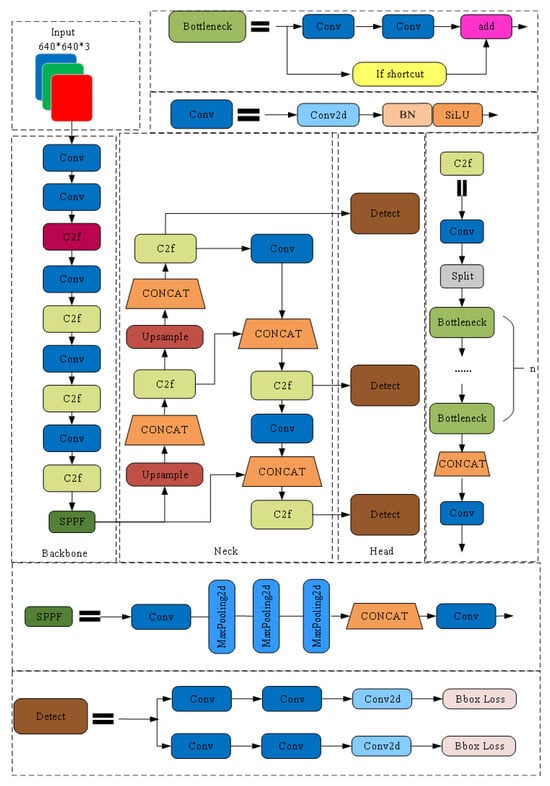
Figure 1.
Traditional YOLOv8 network architecture.
2.2. Core Module Design and Function
The Backbone Network of YOLOv8 is established based on a modified CSPDarknet53 architecture and then subjected to five down-sampling stages to generate feature maps at five different scales for multi-layer feature extraction. Unlike the C3 module used in YOLOv5, C2f, a novel module introduced in YOLOv8, integrates design concepts from both C3 and effective long-range aggregation network (ELAN), offering improved gradient flow capability and feature fusion efficiency. Within the C2f module, the input is first processed by a Conv-BatchNorm-SiLU (CBS) structure to ensure stable feature distribution and smooth information stream propagation. Next, a Bottleneck structure is formed therein with stacked small convolutional kernels, mitigating vanishing gradient problem leveraging residual connections, and thus increasing network depth while effectively controlling parameter growth [19].
In terms of feature fusion, YOLOv8’s Neck Network adopts a hybrid structure fusing feature pyramid network (FPN) and path aggregation network (PAN). The former is responsible for propagating deep semantic features upward to the shallow layer, thus enhancing the semantic expression of high-resolution features. By contrast, the latter offers a bottom–up path to strengthen spatial positioning cues in features within the shallow layer. Compared to the traditional FPN structure, YOLOv8 streamlines its PAN module by eliminating certain redundant convolution operations after up-sampling steps, enhancing overall feature fusion efficiency.
Through the above architectural design, YOLOv8’s Neck Network effectively integrates spatial and semantic features from different layers, thereby enhancing its detection capability for multi-scale objects, especially small objects. This fusion strategy combines both top–down and bottom–up paths, enabling the algorithm to maintain high precision while achieving excellent real-time performance and demonstrate stronger adaptive ability when confronted with complex scenarios [20].
Regarding the Head Network, YOLOv8 adopts a decoupled structural design to separate the object classification task and the bounding box regression task into two independent branches, thus reducing the mutual interference between tasks and enhancing the overall training stability. The classification branch employs the binary cross entropy (BCE) loss function, focusing on the prediction of the probability distribution of object classes. The regression branch utilizes both the distribution focus loss and CIoU loss to achieve precise regression of object positions.
In terms of positive–negative sample assignment strategies, YOLOv8n introduces the Task-Aligned Assigner method, which comprehensively evaluates the matching degree between the predicted bounding box and the ground truth bounding box by integrating the classification confidence and positioning accuracy, thereby dynamically adjusting the positive–negative sample allocation to enhance the generalization ability of the algorithm. The corresponding computational expression is shown in Formula (1):
where s is a predicted class value, u is the CIoU value between the predicted bounding box and the ground truth bounding box, α and β are weighted hyper-parameters, and t is a weighted score, with values approaching 1 indicating higher conformity to the positive sample criterion.
3. Design of YOLOv8n-ASA Algorithm
3.1. Structure of YOLOv8n-ASA Algorithm
While YOLOv8n algorithm possesses advantages including lightweight design and high speed that make it suitable for deployment in industrial settings, its practical application in safety-helmet-wearing detection still faces performance bottlenecks in complex scenarios: When construction environments involve crowded personnel, significant variations in safety helmet sizes, or severe background interference, the algorithm easily encounters such problems as insufficient feature extraction and inadequate object focus since it is constrained by its limited parameter scale and basic network architecture, which ultimately elevate the false and missed detection rates [21]. The specific limitations can be summarized as follows:
- (1)
- Limited adaptability of fixed convolutional kernels. The Backbone Network of YOLOv8n algorithm employs fixed-size convolutional kernels (mainly 3 × 3) for feature extraction. This design performs stably in scenarios with relatively uniform object scales and shapes, but it fails to flexibly match object features for safety helmets with large size ranges and different shapes, easily resulting in the loss of detailed information and affecting the detection accuracy.
- (2)
- Lack of targeted attention mechanisms. The original network architecture does not incorporate effective attention modules. Consequently, in scenarios with complex backgrounds or occluded objects, the algorithm fails to actively focus on safety helmet regions, easily leading to false detection of background noise or missed detections of occluded safety helmets.
- (3)
- Feature fusion efficiency requires improvement. Although the PAN-FPN structure in YOLOv8n algorithm enables multi-scale feature fusion, there exists relatively direct interaction between low-layer and high-layer features during propagation. This design fails to fully account for the complementary nature of information across different layers, easily causing insufficient semantic richness in low-layer features and poor positioning in high-layer features, especially inadequate support for small object detection.
To address the above limitations, YOLOv8n-ASA algorithm, an enhanced YOLOv8n algorithm integrating AKConv, SimAM and AFPN modules, was designed in this paper, which employs a three-layer optimization strategy of “enhancing feature extraction flexibility via AKConv → strengthening object focus through SimAM → improving information utilization using AFPN” to improve the performance in safety-helmet-wearing detection in complex construction scenarios. The overall structure of the YOLOv8n-ASA algorithm is illustrated in Figure 2.
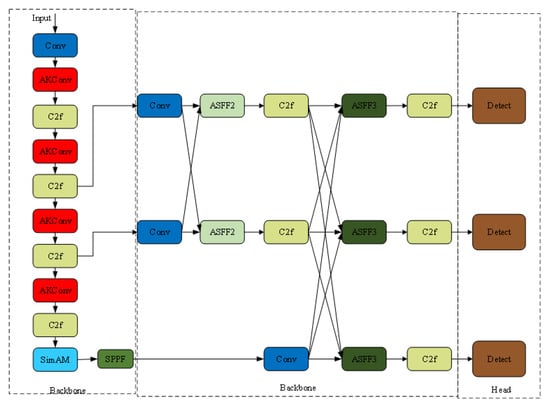
Figure 2.
Architecture of the proposed YOLOv8n-ASA network.
3.2. Core Module Optimization
In the task of safety-helmet-wearing detection in industrial construction scenarios, objects often face such challenges as dynamic scale variations, irregular shapes, and occlusion interference. The fixed-size and fixed-shape convolutional kernels in traditional convolutional neural networks exhibit significant limitations in feature extraction: First, the receptive field of fixed convolutional kernels cannot flexibly match objects of different scales, easily resulting in the loss of detailed information on small objects and the redundancy of local features for large ones. Secondly, its fixed sampling mode can hardly adapt to irregular object shapes or occluded scenarios, failing to accurately capture key features of safety helmets and ultimately affecting the detection accuracy.
In face of these problems, the AKConv module was introduced in this paper, which innovatively integrates the core advantages of both dynamic convolution and deformable convolution. In other words, this module not only maintains the flexibility of dynamic convolution in adaptively adjusting kernel parameters with input features, but also possesses the spatial perception capability of deformable convolution to break through the limitations of fixed sampling grids and adapt to geometric deformations of objects. This effectively compensates for the shortcomings of a single convolutional mechanism and enables precise feature extraction for safety helmet objects in complex scenarios [22]. Its improvements concern the following aspects: (1) Parameter configuration for flexible convolutional kernel: The AKConv module endows convolutional kernels with a flexible number of parameters, so that the size and shape can be adjusted based on actual needs, thus better adapting to object changes. (2) Optimization algorithm for initial sampling coordinate: The AKConv module introduces a novel algorithm to generate initial sampling coordinates for convolutional kernels of different sizes, further enhancing the flexibility in processing multi-scale objects. (3) Adaptive sampling position offset adjustment: To adapt to different object changes, the AKConv module adjusts the sampling position of irregular convolutional kernels based on obtained offsets, thereby improving the accuracy of feature extraction.
The structure of the designed AKConv module is shown in Figure 3. Assuming that the input image dimensions are (C, H, W), where C represents the number of channels, H stands for image height, and W corresponds to image width, the complete workflow consisted of the following four steps.
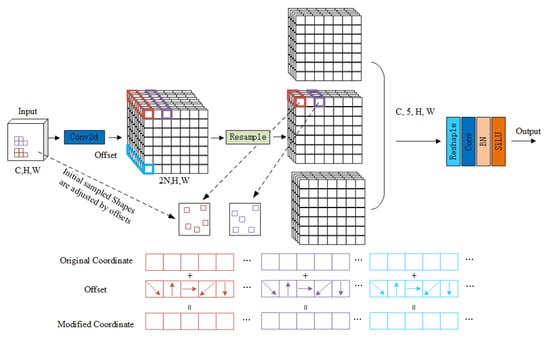
Figure 3.
AKConv architecture.
- (1)
- Feature preprocessing and initial sampling: The input feature maps first underwent preliminary feature mapping through the standard Conv2D convolutional layer to unify the dimension and distribution of features. Then, based on the optimization algorithm for initial sampling coordinates described above, an initial sampling coordinate grid was generated for preset basic convolutional kernels to determine the initial range of feature extraction.
- (2)
- Offset prediction and sampling position adjustment: The preprocessed feature maps were input to the offset prediction branch, which output an offset matrix corresponding to initial sampling coordinates by learning the geometric deformation and position information of objects. The offset matrix was then superimposed with the initial sampling coordinates to yield corrected sampling coordinates, enabling sampling points to adaptively fit the actual shape and position of safety helmets.
- (3)
- Feature resampling and dimension integration: Based on the corrected sampling coordinates, the feature maps were resampled using bilinear interpolation to extract local features that aligned with the object shape. Next, the resampled features were subjected to dimension restructuring to ensure that feature dimensions matched with subsequent convolutional layers.
- (4)
- Feature output and activation. The restructured features were normalized by the BatchNorm layer to eliminate differences in feature distribution. Finally, a nonlinear transformation was introduced through the SiLU activation function to enhance feature expression and output the final feature maps.
In this study, the introduced AKConv module significantly enhanced the flexibility and spatial perception of feature extraction without increasing excessive computational cost through self-adjustment of the sampling range and convolutional kernel layout based on the actual size, shape and distribution characteristics of objects in input images. This mechanism enables the AKConv module to dynamically adjust the sampling pattern according to the local features in images, accurately covering the key feature areas of safety helmets and significantly improving the efficiency and accuracy of feature extraction.
3.3. Introduction of SimAM Module
The attention mechanisms focus on more discriminative key information by assigning differentiated weights to different features in input images, thus enhancing the detection accuracy, performance and generalization ability of algorithms. Existing mainstream attention modules, such as channel attention mechanism and spatial attention mechanism, usually generate one- or two-dimensional weight maps and apply these weights to feature representation. However, such methods often constrain attention to a single dimension, failing to achieve collaborative modeling using multi-dimensional information such as channels, spaces, and layers.
To address the above limitations and improve the efficiency and accuracy of attention modeling in the task of safety-helmet-wearing detection, the SimAM module was adopted in this study, with its structure shown in Figure 4. The SimAM module calculates the minimum energy value for each neuron by minimizing the energy function [23]. A lower energy value signifies a greater difference between the neuron and the surrounding area, reflecting higher importance. Assigning specific attention weights to each neuron enables more accurate distinction between safety helmet features and background interference features.
Figure 4.
SimAM architecture.
The minimum energy function for each neuron in the SimAM module was calculated using Formulas (2)–(4):
where and are mean and variance of neurons (i.e., object pixels) in the channel, respectively, represents the hyper-parameter of regulation, and E is the minimum energy of object neurons.
A lower energy value hints that the neuron (or pixel) is more distinct from its surrounding pixels, reflecting its higher importance in visual processing. Therefore, the significance of each neuron could be quantitatively evaluated by 1/E.
The SimAM module finally incorporated a sigmoid function to limit the oversized E values. The output characteristics of the SimAM module could be calculated based on Formula (5):
where and stand for the output feature map and the input, respectively, represents the dot product operation, and Sigmoid () is the attention weight formed by sigmoid-mapped 1/E into the value between [0,1].
Finally, the attention weight of each neuron was used to weight the input feature maps to yield the feature information with a heightened focus on safety helmet regions.
3.4. Introduction of AFPN
Multi-scale feature extraction is a vital task of deep learning-based object detection tasks. YOLOv8 integrates traditional FPN in its feature pyramid structure. As a typical pyramid structure, FPN achieves feature fusion through a top–down or bottom–up path. However, an inherent limitation exists in such symmetric pyramid structures: High-layer features at the top of the pyramid must propagate across multiple intermediate layers to fuse with low-layer ones. During this process, the semantic information of high-layer features is prone to degradation or loss, and the detailed information of low-layer features may also become diluted. This is fundamentally attributed to the significant semantic gap between non-adjacent layers, particularly the substantial disparity between the lowest and highest layers.
To overcome the above limitation, AFPN [24] was introduced in this paper, with its structure shown in Figure 5. AFPN adopts a progressive and asymmetric feature fusion strategy to integrate deep semantic information while retaining shallow spatial details, thereby effectively avoiding the aforementioned problems. To further refine the fusion process, AFPN explicitly divides feature integration into hierarchical stages, ensuring that low, middle, and high-layer features contribute according to their semantic relevance. By incorporating adaptive spatial feature fusion (ASFF), AFPN assigns spatially adaptive weights to different feature layers, enabling the network to emphasize the most informative scales at each location and mitigate conflicts arising from heterogeneous feature responses. Additionally, the asymmetric fusion mechanism allows shallow high-resolution features to maintain dominance when processing tiny or overlapping objects, preventing fine details from being overshadowed by deeper semantic representations and enhancing the separability of densely distributed targets. As shown in Figure 5, after extracting features by the Backbone Network through a bottom–up path, AFPN integrates low-layer features, middle-layer features, and high-layer features in order, with the black arrow representing the convolution operation, and the blue arrow representing ASFF. ASFF refers to an adaptive spatial fusion technology that assigns differentiated weights to different layers of features to enhance the contribution of key feature layers and simultaneously alleviate conflicts between different object features. In this paper, the AFPN structure was embedded in the Neck Network of the YOLOv8n algorithm, breaking the symmetric propagation pattern of traditional FPNs and introducing structural asymmetry to enhance multi-scale representation, thereby effectively bridging the semantic gap between non-adjacent layers and improving the efficiency and robustness of feature fusion.
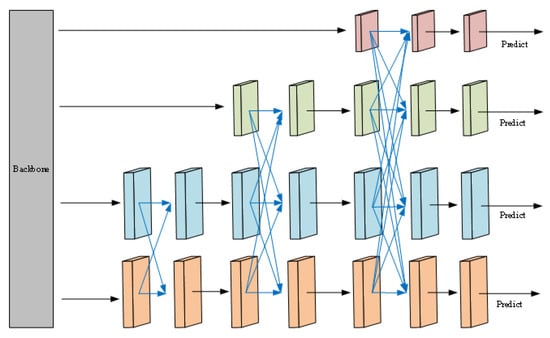
Figure 5.
AFPN architecture.
4. Experimental Design and Result Analysis
4.1. Datasets
In this experiment, a custom-built safety-helmet-wearing detection dataset was utilized. The dataset was constructed by collecting safety helmet images through web crawling and video frame extraction, followed by manual annotation using the LabelImg tool. It comprised a total of 8983 images, covering various complex scenarios including building sites, power plants, factories, aerial work and offshore operations, as well as all-day periods including morning, noon and night. The dataset was divided into a training set (6288 images), a validation set (1797 images), and a test set (898 images) at a ratio of 7:2:1. The annotations included Person, Head, and Helmet, with related definitions and descriptions detailed in Table 1a,b.

Table 1.
(a) Tag name and number of instances. (b) Scene distribution.
4.2. Evaluation Indicators
The primary indicators used to assess network performance included precision (P), recall (R), average precision (AP), and mean average accuracy (mAP), which were calculated based on Formulas (6)–(9).
In the formulas, P measures the proportion of true positive samples among all samples predicted as positive. R is the number of objects that can be accurately detected by the model, TP represents the number of positive samples predicted by the model correctly, FP and FN are the number of positive and negative samples predicted incorrectly, respectively, and N stands for the number of classes in the data.
4.3. Model Training Parameters and Results
The experiments in this study were conducted on PC platforms with Windows 11 operating system and the following hardware configuration: Intel i7-12700H processor and NVIDIA GeForce RTX 3060 graphics card, together with the software environment of CUDA 12.3 and the PyTorch 2.00 framework. The training was performed under the following parameters: input image resolution: 640 × 640, model optimization equipment: stochastic gradient descent (SGD) optimizer, epochs: 300, batch size: 8, number of worker threads: 8, and other parameters: default, the parameter settings are shown in Table 2.
Table 2.
Training hyperparameters and data-augmentation settings.
The YOLOv8n-ASA model was evaluated upon the completion of model training, with results shown in Figure 6. The values of loss functions fully reflected the basic performance of the model: The bounding box loss (box_loss) was maintained at a low level, suggesting high prediction precision of the model for the spatial position of target objects, and excellent overlap between the predicted bounding box and the ground truth annotation box. The classification loss (cls_loss) successfully converged to a lower value, proving that the model not only accurately locates the target but also accurately identifies its class. The concurrent optimization and collective decline of these loss functions serve as a key indicator of improvements in the overall performance of the model.
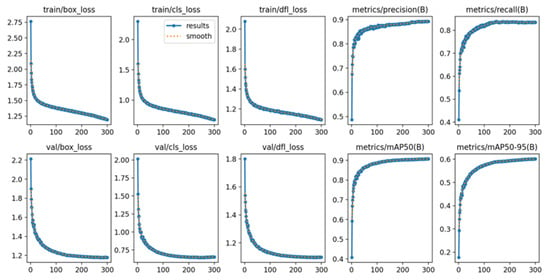
Figure 6.
YOLOv8n-ASA model training evaluation results.
As to P indicator validation, the mAP@0.5 index reached a high level, indicating that the model has extremely high object detection and classification accuracy and strong practicability under the loose condition of the IoU threshold of 0.5. Moreover, mAP@0.5:0.95 serves as a more rigorous comprehensive evaluation metric, making its strong performance particularly critical. This indicator represents the AP across 10 different IoU thresholds ranging from 0.5 to 0.95 (with a step size of 0.05). The excellent results demonstrate not only high R of the model but also superior predicted bounding box precision, highlighting the model’s strong generalization ability and robustness. Such models display enhanced adaptability in actual complex scenarios (including partial occlusion or deformation of objects).
Therefore, the trained model demonstrated outstanding performance in object positioning accuracy, recognition confidence, classification ability and overall mAP. The model successfully balances the positioning and classification subtasks in detection, forming a highly synergistic system showing the potential for practical application in complex visual detection scenarios, especially in resource-constrained scenarios.
Precision–recall (PR) curves act as a widely used method for assessing model performance. Figure 7 shows the PR curve of the model proposed in this study, with R and P as the horizontal axis and vertical axis, respectively. The curve intuitively reflected the variations in the model’s P at different R levels. A PR curve closer to the upper-right corner indicated a better P-R balance, signifying superior overall performance.
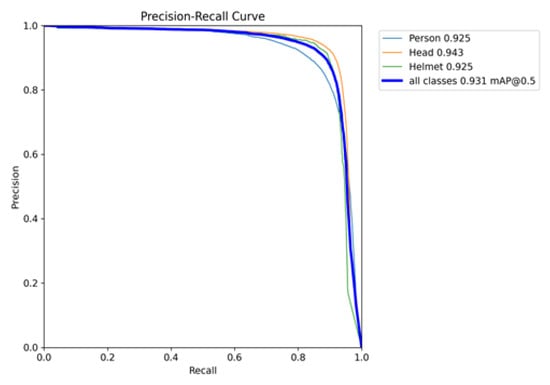
Figure 7.
PR curve.
According to the PR curve in Figure 7, the object detection model proposed in this study exhibited excellent overall performance in terms of the P-R balance. The PR curve as a whole showed a distribution pattern significantly closer to the upper-right corner, and the coverage area under the curve was maintained at a high level, implying that the model has a satisfactory precision while maintaining a high R. When R varied in a wide range from 0 to 0.8, the model’s P was consistently maintained at a high level. This feature fully proved that the model can maintain reliable detection performance in most application scenarios. In particular, when R reached the critical interval of 0.6–0.7, P was still maintained above 0.85, demonstrating the model’s effectiveness in handling imbalanced positive and negative samples. Collectively, the model achieved a good balance between P and R, two mutually restrictive indicators, along with robust overall detection performance and high practical application value, making it well-suited for object detection in complex scenarios.
4.4. Ablation Experiments and Analysis
To validate and analyze the influence of different improvement modules on the detection performance of the algorithm, four sets of ablation experiments were conducted, all trained and tested on the proprietary dataset. With YOLOv8n as the benchmark model, partial convolution in the Backbone Network was firstly replaced with the AKConv module, the SimAM was then introduced into the network model (called model B), and finally AFPN was introduced into the model (called model C). The results of ablation experiments are stated in Table 3.
Table 3.
Ablation experiment.
The results revealed that, compared with the benchmark YOLOv8n, the finally modified YOLOv8n-ASA model displayed significant improvements in mAP@0.5, P and R, with increases of 4.7%, 3.5% and 3.9%, respectively. The ablation experiments proved the positive contribution of AKConv, SimAM and AFPN modules to model performance as well as the superiority of YOLOv8n-ASA algorithm over the original algorithm in the task of safety-helmet-wearing detection.
4.5. Comparative Experiments
4.5.1. Comparative Study of Convolutional Methods
To verify the improvement effect of the AKConv module introduced in this study, the Backbone Network of the YOLOv8n model as the baseline model was replaced with traditional convolution (Conv), dynamic convolution (DyConv), deformable convolution (DCN) and AKConv proposed in this study. Table 4 shows the results of the comparative experiments on each model, revealing that the YOLOv8n + AKConv model had an improvement of 0.8%, 1.3% and 0.6% in mAP@0.5 compared with YOLOv8n, YOLOv8n + DyConv and YOLOv8n + DCN models, respectively. Thus, the introduction of AKConv module in the Backbone Network effectively enhances the precision of feature extraction, proving its effectiveness in object detection tasks.
Table 4.
Convolution comparison experiment.
4.5.2. Comparative Study of Different Attention Module Improvements
To validate the improvement effect of the SimAM introduced in this study, the model introducing the AKConv module (YOLOv8n + AKConv model) was employed as a benchmark to compare the effects of multiple attention mechanisms on algorithm performance, with results listed in Table 5. The results revealed that the detection precision of the SimAM used in the network was higher than that of other popular attention mechanisms. Compared with those of the YOLOv8n + AKConv model, mAP@0.5 reached 90.8%, and P and R rose by 1.8% and 2.1%, respectively, in the YOLOv8n + AKConv + SimAM model, proving the effectiveness of SimAM in enhancing the performance of object detection models.
Table 5.
Attention module comparison experiment.
4.5.3. Comparative Study of Feature Pyramid Networks
To verify the improvement effect of AFPN introduced in this study, the YOLOv8 + AKConv + SimA model was adopted as the baseline model, and then its feature pyramid network was replaced with the bidirectional feature pyramid network (BiFPN) and the AFPN proposed in this study. The results in Table 6 uncovered that both BiFPN and AFPN improved the detection performance of the model, but the improvement by AFPN was more significant, with mAP@0.5 reaching 91.2%. This demonstrated that AFPN enables more effective fusion of multi-scale features, enhancing the model’s ability to extract key information and thus greatly improving its detection performance.
Table 6.
Feature pyramid network comparison experiment.
Building upon this observation, the individual contributions of the three core modules can be further articulated. AKConv empowers the backbone with adaptive kernel modulation, enabling dynamic adjustment of convolutional scales and shapes to better accommodate safety-helmet-wearing targets with diverse sizes, poses, and deformation patterns. SimAM enhances the network’s ability to emphasize semantically informative regions through parameter-free attention estimation, effectively suppressing background interference and improving the distinctiveness of target features in cluttered environments. AFPN, through its progressive and bidirectional feature-aggregation mechanism, strengthens cross-scale feature interaction and mitigates semantic attenuation during feature propagation, providing notable advantages for detecting small, densely distributed, and partially occluded targets.
Collectively, these components exhibit strong complementarity: AKConv enhances adaptive feature encoding, SimAM refines salient semantic representation, and AFPN improves multi-scale feature integration. Their synergistic combination substantially elevates the robustness and generalization capability of the proposed detection framework across complex and diverse safety-monitoring scenarios.
4.5.4. Comparative Study of Mainstream Algorithms
For comprehensive performance evaluation of the YOLOv8n-ASA algorithm proposed in this study, experimental comparisons were made with other mainstream algorithms like two-stage detection algorithm Faster-RCNN, single-stage detection algorithms (including SSD, YOLOv5, and YOLOv7) and the modified MSCG-YOLO algorithm. To ensure fairness and reproducibility of the comparison, all models—including Faster R-CNN, SSD, YOLOv5, YOLOv7, and MSCG-YOLO—were evaluated under strictly consistent experimental conditions. The input resolution, training methodology, and data-augmentation techniques were kept completely identical across all experiments.
The results in Table 7 revealed that the two-stage algorithm Faster-RCNN had the lowest AP and the slowest detection speed, making it not suitable for safety-helmet-wearing detection tasks with high requirements for real-time performance. The YOLOv8n-ASA algorithm proposed in this study outperformed SSD, YOLOv5n, YOLOv5s and YOLOv7-tiny algorithms in AP, with increases of 13.5%, 4.5%, 2.7% and 3.8%, respectively, in mAP@0.5. Compared with the modified MSCG-YOLO algorithm, the YOLOv8n-ASA algorithm had an increase of 2.2% in mAP@0.5. In contrast with the original algorithm YOLOv8n, the YOLOv8n-ASA algorithm had a significant increase of 3.9% in mAP@0.5 despite increased number of parameters caused by elevated structural complexity. In addition, following the reviewer’s suggestion, the inference speed (FPS) of each model had been incorporated into the comparison. This additional metric, alongside mAP, enables a more comprehensive evaluation of the real-world applicability and real-time performance of the proposed algorithm. Therefore, the YOLOv8n-ASA algorithm significantly enhances the precision of safety helmet wearing recognition and effectively reduces the risk of missed and false detections, displaying obvious advantages in object detection performance.
Table 7.
Comparison experiment of mainstream algorithms.
4.5.5. Visual Comparison
To further verify the effect of the improved algorithm in this study, the YOLOv8n-ASA algorithm, MSCG-YOLO algorithm and original YOLOv8n algorithm were selected for visual comparison, with specific detection effectiveness and corresponding detection results shown in Figure 8 and Table 7, respectively. Figure 8 presents a visual comparison of detection results from three algorithms: from left to right, the original YOLOv8n, the MSCG-YOLO, and the YOLOv8n-ASA proposed in this study.


Figure 8.
Comparison chart of detection effects.
According to Figure 8 and Table 8, in Scenario 1, all three algorithms accurately detected all objects, with YOLOv8n-ASA algorithm showing a high confidence level. In Scenario 2, the original YOLOv8n algorithm and the MSCG-YOLO algorithm had missed detections. In the small-object scenario, the original YOLOv8n algorithm missed two objects, the MSCG-YOLO algorithm missed one object, and the YOLOv8n-ASA algorithm detected all objects. In the complex lighting scenario, the original YOLOv8n algorithm had false detection, whereas the YOLOv8n-ASA algorithm and MSCG-YOLO algorithm detected all objects correctly, with YOLOv8n-ASA exhibiting a high confidence level.
Table 8.
Detection effectiveness of each algorithm.
4.6. Generalization Performance Evaluation Experiments
To validate the generalization performance of the YOLOv8n-ASA algorithm, the public Safety Helmet Wearing Dataset (SHWD) was selected for generalization experiments. The SHWD dataset is a public dataset for safety-helmet-wearing detection, containing 7581 images from multiple application scenarios. The images contain objects with and without safety helmets in different lighting conditions, backgrounds, and occlusion conditions. The dataset contains two types of annotations: heads without safety helmets and heads with safety helmets. The dataset was divided into a training set, a validation set and a test set at the ratio of 7:2:1. In the training phase, Mosaic data enhancement technology was used to improve sample diversity and relieve class imbalance. This dataset has a relatively balanced scale distribution of objects, dominated by small- and medium-sized objects, and includes some occlusion conditions, making it closer to actual application scenarios.
The original YOLOv8n algorithm and the YOLOv8n-ASA algorithm were compared on the SHWD dataset under the same equipment and experimental environment, with the results shown in Table 9. It was found that on the SHWD dataset, the mAP@0.5 of the YOLOv8n-ASA algorithm reached 93.8%, suggesting significantly improved detection performance. In contrast with the original YOLOv8n algorithm, the YOLOv8n-ASA algorithm exhibited better detection performance, fully proving its favorable generalization ability on different safety-helmet-wearing detection datasets.
Table 9.
Generalization experiment results.
4.7. Experiments on Real Scenario Detection Effectiveness
To validate the detection performance of YOLOv8n-ASA algorithm in real construction site scenarios, experimental investigation was conducted in real construction scenes. As can be seen from Figure 9, the algorithm improved the P of feature extraction and detection by introducing attention mechanism and progressive feature pyramid network (PFPN) and effectively strengthened its perception of object regions. During actual detection, YOLOv8n-ASA algorithm precisely identified safety helmet objects of different sizes, colors and orientations. Even under challenging conditions such as partial occlusion of objects, rapid worker movement, or strong background interference, it still demonstrates excellent positioning and classification accuracy, exhibiting favorable environmental adaptability and robustness.

Figure 9.
Actual detection scene diagram.
5. Conclusions
Challenged by massive algorithm parameters, low detection precision and poor real-time performance in the object detection task of safety helmet wearing in complex scenarios, a detection algorithm was proposed in this study based on modified YOLOv8n algorithm, namely YOLOv8n-ASA. The YOLOv8n-ASA algorithm introduces the AKConv module into the Backbone Network to adaptively adjust the shape and size of convolutional kernels, thereby enhancing the feature extraction ability and detection performance of the algorithm. In addition, it employs SimAM to improve its attention to key image information, thus enhancing the accuracy of safety helmet feature capture. Moreover, it integrates AFPN to solve the problem of feature loss in non-adjacent layers, achieving more effective extraction and fusion of features across different layers.
Furthermore, ablation experiments, comparative study of different algorithms, generalization performance evaluation experiments and real scenario detection effectiveness experiments were conducted, proving the superiority of the proposed algorithm. It was found that compared with the original YOLOv8n algorithm, the proposed YOLOv8n-ASA algorithm had a slight increase in parameters due to the increase in structural complexity, but it exhibited significantly improved accuracy in detecting safety helmet wearing, effectively avoiding missed and false detections. Overall, the YOLOv8n-ASA algorithm had better detection performance.
The YOLOv8n-ASA algorithm requires continuous optimization and improvement in the future. While ameliorating the detection speed and computational workload, its ability to extract features and to capture subtle features should be further enhanced, with focus on improving the detection precision for extremely small objects, so as to enhance its practical value.
Author Contributions
Conceptualization, L.Z.; methodology, S.W. and H.M.; software, H.M. and J.Z.; validation, S.W.; formal analysis, L.Z. and H.M.; writing—original draft preparation, S.W. and H.M.; writing—review and editing, L.Z. and J.Z.; supervision, L.Z.; All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China (61741303).
Data Availability Statement
The data that support the findings of this study are available from the corresponding author, [L.Z.], upon reasonable request.
Acknowledgments
The authors would like to express their gratitude for the valuable feedback and suggestions provided by all the anonymous reviewers and the editorial team.
Conflicts of Interest
The authors declare no conflicts of interest to report regarding the present study.
References
- Zhang, Y.; Lin, C.; Chen, G. Efficient Helmet Detection Based on Deep Learning and Pruning Methods. J. Electron. Imaging 2025, 34, 023006. [Google Scholar] [CrossRef]
- Xu, Z.; Qian, Y.; Yan, F. GCW-YOLOv8n: Lightweight Safety Helmet Wearing Detection Algorithm. Comput. Eng. Appl. 2025, 61, 144–154. [Google Scholar] [CrossRef]
- Ku, B.; Kim, K.; Jeong, J. Real-Time ISR-YOLOv4 Based Small Object Detection for Safe Shop Floor in Smart Factories. Electronics 2022, 11, 2348. [Google Scholar] [CrossRef]
- Qin, Z.; Ming, L.; Song, W.; Zhang, W. Helmet Detection Method Based on Lightweight Deep Learning Model. Sci. Technol. Eng. 2022, 22, 5659–5665. [Google Scholar]
- Li, Y.; Shi, X.; Xu, X.; Zhang, H.; Yang, F. Yolov5s-PSG: Improved Yolov5s-Based Helmet Recognition in Complex Scenes. IEEE Access 2025, 13, 34915–34924. [Google Scholar] [CrossRef]
- Deng, Z.; Xiong, Y.; Yang, R.; Chen, Y. Improved YOLOv5 Helmet Wearing Detection Algorithm for Small Targets. Comput. Eng. Appl. 2024, 60, 78–87. [Google Scholar] [CrossRef]
- Yin, X.; Su, N.; Xie, Y.; Qu, S. Dense safety helmet detection based on coordinate attention and soft NMS. Mod. Electron. Technol. 2025, 48, 153–161. [Google Scholar] [CrossRef]
- Shan, C.; Liu, H.; Yu, Y. Research on Improved Algorithm for Helmet Detection Based on YOLOv5. Sci. Rep. 2023, 13, 18056. [Google Scholar] [CrossRef]
- Wang, X.; Wang, L. Safety Helmet Detection Algorithm with Feature Enhancement in Low Light Blasting Scenes. Comput. Eng. 2025, 51, 252–260. [Google Scholar] [CrossRef]
- Wang, S.; Wu, P.; Wu, Q. Safety Helmet Detection Based on Improved YOLOv7-Tiny with Multiple Feature Enhancement. J. Real-Time Image Process. 2024, 21, 120. [Google Scholar] [CrossRef]
- Lin, B. Safety Helmet Detection Based on Improved YOLOv8. IEEE Access 2024, 12, 28260–28272. [Google Scholar] [CrossRef]
- Cheng, L.; Zhang, J.; Jing, G.; Wang, M. Detection algorithm of safety hat and safety vest in coal mine based on YOLOv8. J. Saf. Sci. Technol. 2025, 21, 115–121. [Google Scholar] [CrossRef]
- Lin, C.; Zhang, Y.; Chen, G. Intelligent Detection of Safety Helmets and Reflective Vests Based on Deep Learning. J. Real-Time Image Process. 2025, 22, 5. [Google Scholar] [CrossRef]
- Wang, M.; Qiu, H.; Wang, J. Helmet detection algorithm based on lightweight improved YOLOv8. Signal Image Video Process. 2025, 19, 20. [Google Scholar] [CrossRef]
- Chen, X.; Jiao, Z.; Liu, Y. Improved YOLOv8n based helmet wearing inspection method. Sci. Rep. 2025, 15, 1945. [Google Scholar] [CrossRef] [PubMed]
- Song, C.; Li, Y. A YOLOv8 algorithm for safety helmet wearing detection in complex environment. Sci. Rep. 2025, 15, 24236. [Google Scholar] [CrossRef]
- Chen, Y.; Yuan, X.; Wang, J.; Wu, R.; Li, X.; Hou, Q.; Cheng, M.-M. YOLO-MS: Rethinking Multi-Scale Representation Learning for Real-Time Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 4240–4252. [Google Scholar] [CrossRef]
- Chen, J.; Er, M.J. Dynamic YOLO for Small Underwater Object Detection. Artif. Intell. Rev. 2024, 57, 165. [Google Scholar] [CrossRef]
- Guo, W.; Fan, Y.; Li, X.; Zhang, X.; Wang, M. Detection of Nonstandard Wearing of Safety Helmet Based on Improved YOLO. Ordnance Ind. Autom. 2024, 43, 33–36+42. [Google Scholar] [CrossRef]
- Tan, H.; Yang, J. Lightweight Convolutional Neural Network Object Detection for Remote Sensing Images. Remote Sens. Technol. Appl. 2025, 40, 167–176. [Google Scholar]
- Wang, Q.; Xia, L.; Chen, T.; Han, H.; Wang, L. Detection of underground personnel safety helmet wearing based on improved YOLOv8n. J. Mine Autom. 2024, 50, 124–129. [Google Scholar] [CrossRef]
- Zhang, X.; Song, Y.; Song, T.; Yang, D.; Ye, Y.; Zhou, J.; Zhang, L. LDConv: Linear Deformable Convolution for Improving Convolutional Neural Networks. Image Vis. Comput. 2024, 149, 105190. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Online, 18–24 July 2021; Volume 139, pp. 11863–11874. [Google Scholar]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic feature pyramid network for object detection. In Proceedings of the 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Oahu, HI, USA, 1–4 October 2023; IEEE: New York, NY, USA, 2023; pp. 2184–2189. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).