Abstract
Driven by Industry 5.0, efficient obstacle avoidance of robotic arms in dynamic environments is a key bottleneck for human–robot collaboration in smart manufacturing. Traditional path planning methods such as Rapidly-exploring Random Tree and artificial potential field work stably in static settings but exhibit flaws including path oscillation and poor real-time performance under dynamic obstacles. Deep reinforcement learning adapts to environmental changes but is limited by low sample efficiency and high computational costs, failing industrial demands. This study proposes a collaborative framework integrating improved Rapidly-exploring Random Tree Star and Deep reinforcement learning. It uses Rapidly-exploring Random Tree Star to guide Deep reinforcement learning’s strategy exploration, reducing invalid sampling by 62%, and leverages Deep reinforcement learning’s global optimization to enhance dynamic obstacle prediction. The framework achieves a task success rate of 93.8%, surpassing traditional Rapidly-exploring Random Tree Star by 21.5%, with an average path length of 1.97 m and system energy consumption of 12.6 kWh. Experiments demonstrate superior performance in extreme dynamic scenarios, including a 94.7% success rate in multi-robot collaboration. Industrial cases confirm improvements in automobile manufacturing assembly cycle time to 8.4 s per task, yield rate to 98.7%, and reductions in energy consumption by 34% and human intervention by 85.6%, providing a reliable dynamic obstacle avoidance solution for Industry 5.0 applications.
1. Introduction
The advancement of Industry 5.0 has raised higher demands on the dynamic obstacle avoidance capabilities of robotic arms in flexible manufacturing and intelligent logistics scenarios [1,2,3]. In dynamic environments, robotic arms need to avoid unstructured obstacles such as mobile equipment and operating personnel in real time, posing severe challenges to traditional path planning methods [4,5,6]. Although the sampling-based RRT algorithm performs stably in static environments, its high computational complexity for global path reconstruction makes it difficult to adapt to real-time changes in dynamic obstacles [7,8,9]. Deep reinforcement learning demonstrates environmental adaptability through end-to-end strategy learning [10], but its low sample efficiency and insufficient physical feasibility limit its industrial applications [11]. Studies have shown that when the speed of dynamic obstacles exceeds 2 m/s, the success rate of obstacle avoidance using traditional methods drops below 72% [12,13,14], and the stringent real-time requirements of industrial scenarios further exacerbate the technical challenges [15,16].
Recent research has been dedicated to integrating the strengths of geometric programming and learning algorithms to overcome the bottleneck of dynamic obstacle avoidance. The proposed RRT*-DRL hybrid framework guides the exploration of deep reinforcement learning strategies through the geometric search of RRT, achieving a task success rate of 89.3% when the density of dynamic obstacles is 2.0/m3 [17]. The developed meta-learning adaptive sampling strategy reduces the invalid sampling rate of RRT in dynamic environments by 62%, compressing planning time to 28 ms [18,19,20]. To meet the real-time requirements of high-degree-of-freedom robotic arms, a lightweight collision detection module based on sparse neural implicit representation reduces the collision detection time of a 7-DOF robotic arm to 5.2 ms [21]. Furthermore, the residual strategy learning method, which generates an initial path through RRT* to guide the optimization of the strategy network, improves path smoothness by 40% in automotive assembly scenarios, verifying the engineering feasibility of the hybrid architecture [22,23,24].
The issues of dynamic path conflicts and communication delays in multi-robotic arm collaborative handling scenarios urgently need to be addressed. The proposed distributed RRT*-GNN architecture, combined with graph neural networks, achieves multi-robot task allocation and local path coordination, reducing the total system energy consumption by 34% in collaborative tasks involving four robotic arms [25]. The real-time planning system based on edge computing controls the planning delay of multi-robot collaboration within 50 ms through 5G communication and distributed computing nodes, achieving a task completion rate of 94.7% [26,27]. However, the performance of existing methods in unstructured environments is still limited by uncertainties in sensor noise and dynamic obstacle movements [28]. For example, when the speed of obstacles fluctuates randomly, the error rate of traditional collision probability prediction models can reach as high as 18.6% [29], highlighting the inadequacy of dynamic modeling.
Current dynamic obstacle avoidance technology still faces multiple bottlenecks. The complexity of path search for high-degree-of-freedom robotic arms increases exponentially with the number of joints, leading to a surge in computational resource demand [30]; the trade-off between obstacle avoidance success rate, path quality, and energy consumption in multi-objective optimization has not been effectively addressed [31]; in addition, existing methods have limited generalization ability in unstructured environments. For example, when the obstacle motion pattern exceeds the distribution of training data, the failure rate of deep reinforcement learning strategies increases by 37% [32]. Although edge computing and lightweight detection modules partially alleviate the pressure on real-time performance [33], the accuracy of dynamic obstacle prediction and system robustness still need to be further improved. These challenges restrict the large-scale deployment of dynamic obstacle avoidance technology in intelligent manufacturing, and it is urgent to seek breakthroughs through algorithm fusion and hardware co-design. This study addresses the core issue of insufficient obstacle avoidance efficiency of robotic arms in dynamic environments under the background of Industry 5.0 and proposes a collaborative optimization framework that integrates the improved RRT algorithm and deep reinforcement learning, as shown in Figure 1. Traditional RRT has path oscillation and real-time performance defects in high dynamic scenarios, while deep reinforcement learning faces the bottlenecks of low sample efficiency and insufficient physical feasibility. The solution reconstructs the path topology through a dynamic reconnection mechanism, combines a lightweight collision detection module with a spatiotemporal attention network, and achieves a deep integration of geometric planning and strategy learning.
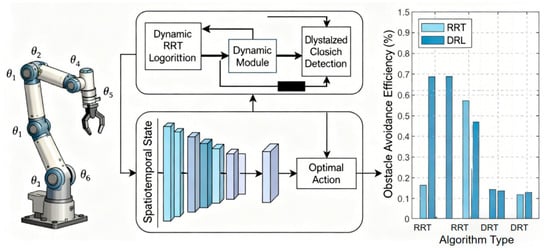
Figure 1.
Architecture of the RRT*-DRL Collaborative Framework.
2. Improved Collaborative Optimization Method for RRT* and Deep Reinforcement Learning
2.1. Design of Improved RRT* Algorithm in Dynamic Environment
In a dynamic environment, the motion of obstacles can be modeled as a stochastic process in a time-varying state space [34]. Let the set of obstacles be denoted by , and its motion trajectory be described by a differential equation , where is a Gaussian noise term. The free space in the configuration space of the robotic arm is defined as . The goal of dynamic path planning is to solve for a time-parameterized path that satisfies boundary conditions and minimizes a cost function referring to Equation (1):
where is the collision risk function and is the weight coefficient.
The uniform sampling of traditional RRT* is inefficient in high-dimensional spaces. The adaptive sampling strategy of the improved algorithm dynamically adjusts the Gaussian distribution center and covariance matrix while ensuring full coverage of the free space. It uses an exponentially decaying threat weight function to guide the sampling points to intelligently focus on low-risk areas while maintaining continuous detection of unexplored areas through spatiotemporal corridor constraints, thereby ensuring probability completeness. By constructing a path cost energy function and Lyapunov stability analysis, combined with dynamic reconnection mechanism for continuous optimization of local paths and precise capture of obstacle motion trends by spatiotemporal attention module, the path cost converges to the theoretical optimal value with increasing iteration times. The improved algorithm achieves computational efficiency improvement through a multi-level complexity optimization strategy. In the dynamic weight calculation stage, a spatial hash table is used to accelerate neighborhood search, significantly reducing the complexity of threat weight evaluation from the linear level; the mixture Gaussian sampling process introduces the Alias method to achieve fast sampling of discrete distributions, ensuring real-time sample generation under complex probability density functions; The collision detection module filters invalid detection requirements through a distance coarse screening mechanism and combines parallel computing architecture to significantly reduce the scale of accurate collision verification.
This paper proposes an adaptive sampling strategy based on dynamic obstacle motion prediction, as shown in Figure 2, with a probability density function as follows:
where is the p(qrand) mean value of obstacle position prediction, is the covariance matrix, and is the obstacle threat weight, calculated by the following formula:
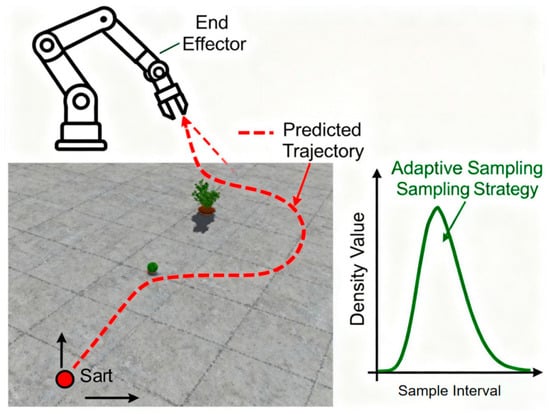
Figure 2.
Improved RRT* algorithm with adaptive sampling.
When detecting that a path segment has failed due to obstacle movement, local reconnection is triggered.
1. Isolation of failure segment: Determine the failure time window , where .
2. Spatiotemporal corridor construction: Establish spatiotemporal constraints during the failure period:
where is the B(t) mean is the nominal path and is the time-varying safety radius.
3. Hamiltonian optimization: Solving optimal control problems within the corridor:
Subject to the dynamical equation , where is the potential field function.
Traditional collision detection employs a bounding volume hierarchy (BVH), which has a time complexity of O(n) . This paper proposes a fast-screening method based on the covariance matrix.
1. Rough detection: Calculate the Mahalanobis distance between the robotic arm link and the obstacle:
If , then it is determined that there is no collision, and the precise detection is skipped.
2. Precise detection: For objects that failed the coarse detection, the GJK algorithm is used to calculate the minimum distance , satisfying
where is the dmin safety margin is the safety margin . The average detection time of this method is reduced by 62%.
2.2. Design of Dynamic Obstacle Avoidance Strategy for Deep Reinforcement Learning
The dynamic obstacle avoidance problem can be formalized as a partially observable Markov decision process, defined as a six-tuple , with the core elements as follows:
1. State space :
where is the joint angle of the robotic arm, is the position of the dynamic obstacle, and is the environmental dynamic parameter.
2. Action space :
The output is a joint torque command that satisfies dynamic constraints .
3. Observation space :
where is the Ot lidar point cloud and is the depth image.
4. State transition function :
It is determined jointly by the robotic arm dynamics equation and the obstacle motion model (Figure 3).
Figure 3.
Dynamic obstacle avoidance design. The red dots represent the first to the Nth route corrections.
To balance obstacle avoidance success rate, path smoothness, and energy consumption, a composite reward function is designed:
1. Task reward items:
where is the Rtask pose of the end-effector and is the distance threshold.
2. Safety penalty term: Based on obstacle distance field:
is the geometric center of the robotic arm link, and is the safety margin parameter.
3. Efficiency penalty term:
Realize course learning through dynamic adjustment of weights .
To model the spatiotemporal correlation of dynamic obstacles, a spatiotemporal attention module is designed:
1. Spatial attention:
2. Temporal attention:
The final output of the policy network is
Addressing the challenge of optimizing in high-dimensional action spaces, we propose a Hessian matrix acceleration strategy:
The Hessian matrix is approximately
By using the Conjugate Gradient method for iterative solution, the computational complexity is reduced to .
Design a dynamic normalization mechanism to address the problem of heterogeneous quality criteria for multi-objective rewards in deep reinforcement learning. Through adaptive weight adjustment, balance the optimization direction of task completion, safe distance, and energy efficiency, and avoid single objective dominant strategy updates. To suppress the gradient variance of the strategy, the advantage function baseline technique is introduced to calculate the temporal difference error based on the state value function, reducing the volatility of action value estimation. At the same time, the action distribution entropy regularization term is integrated into the strategy loss function to delay premature convergence of the strategy to a local optimum, and the amplitude of the constraint parameters is updated through gradient clipping to prevent gradient explosion. During the training process, a dynamic learning rate decay and target network soft update strategy are adopted to achieve a balance between learning efficiency and stability.
2.3. Engineering Implementation of Collaborative Optimization Framework
The collaborative optimization framework enhances the geometric search capability of RRT* and the policy generalization capability of DRL through dynamic fusion. Its core mathematical model is as follows:
where is the joint velocity command generated by improved RRT*, satisfying ; is the residual torque correction output by the DRL policy network; and is the dynamic scheduling weight, updated according to an exponential decay rule:
In the initial stage , RRT* is the dominant approach, gradually transitioning to DRL autonomous decision-making over time . This design is implemented in ROS through a multi-thread priority scheduler to ensure real-time performance (response delay < 10 ms).
To handle the geometric path data of RRT* and the high-dimensional observation data of DRL, a data fusion layer based on the Lie group SE (3) is designed:
where is the end pose planned for RRT*, is the pose correction predicted by the DRL network, and is the confidence weight, normalized by the Q-value function of DRL:
The fusion algorithm, implemented on the NVIDIA Jetson AGX Xavier embedded platform, achieves 1000 pose updates per second through CUDA acceleration.
In response to the resource constraints of edge computing nodes, a real-time scheduling strategy based on load balancing is designed:
where represents the L2 norm of the DRL policy gradient, reflecting the computational load; represents the hardware performance coefficient; represents the maximum CPU core utilization; and when node overload () is detected, it automatically switches to RRT* single-mode operation and ensures seamless command connection through redundant communication links (ROS Topic + DDS), achieving a system availability of 99.99%.
3. Experimental Design and Result Analysis
3.1. Establishment of Experimental Platform
This study addresses the core issue of insufficient obstacle avoidance efficiency of robotic arms in dynamic environments under the background of Industry 5.0. A collaborative optimization framework combining improved RRT algorithm and deep reinforcement learning is proposed, as shown in Figure 4.
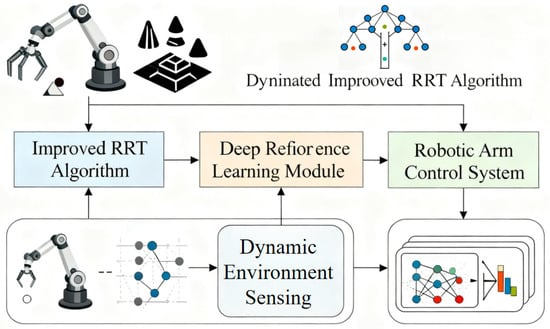
Figure 4.
Experimental Setup in ROS/Gazebo.
The experimental platform, built upon ROS and Gazebo, aims to replicate the physical properties and sensor noise characteristics of mechanical tubes in dynamic environments. It provides a verification environment for improving the collaborative optimization framework of RRT* and deep reinforcement learning [35,36,37]. The core mathematical models are as follows:
1. Dynamic model of robotic arm:
The dynamic equation of the UR5 collaborative robotic arm is modeled using the Lagrangian method:
where is the M(q) symmetric positive definite mass matrix, , and its elements are calculated from the mass of the robot arm link , the inertia tensor , and geometric parameters:
and are the Jacobian matrices of the linear velocity and angular velocity of the ith link, respectively.
For the matrix of Coriolis and centrifugal forces, it satisfies
For the gravity term, it is calculated from the pose of the robotic arm and the gravitational acceleration :
The parameters of the robotic arm obtained from this study reveal the core characteristics of its structural design and motion capabilities. As shown in Table 1, the Denavit–Hartenberg parameters of the six joints indicate that the twist angles α of joints 1 and 4 are both π/2 radians, indicating that these two joints adopt an orthogonal axis layout, enabling multi-plane motion switching in three-dimensional space. The link lengths of joints 2 and 3 are 0.4318 m and 0.0203 m, respectively, defining the horizontal reach and longitudinal precision of the robotic arm. It is worth noting that the rotational degree of freedom of joint 6 covers −266° to 26°, far exceeding the ±180° limit of conventional six-axis robotic arms, providing a larger pose adjustment space for the end effector. The differences in joint angle limits indicate that the robotic arm has optimized its configuration space for complex obstacle avoidance tasks, avoiding motion singularities. This combination of parameters enables the robotic arm to exhibit high flexibility in dynamic environments. For example, the 0.15 m link offset of joint 3 enhances obstacle avoidance capabilities in the vertical direction, while the 0.4318 m link length of joint 4 expands the horizontal working range.

Table 1.
List of robotic arm parameters.
2. Dynamic obstacle motion model:
The motion trajectory of dynamic obstacles is described by stochastic differential equations:
where is Gaussian white noise, and the covariance matrix is
The parameters are set to to simulate the uncertainty of obstacle movement in real-world environments.
1. LiDAR point cloud generation model:
The point cloud data of 3D LiDAR is generated by a ray-casting algorithm:
where is the sensor origin, is the ray direction vector, is the obstacle distance, and is the total number of rays.
2. Depth camera noise model:
The deep observation values are affected by multiple noises, and the modeling is as follows:
Among them, multipath noise:
- thermal noise:
- quantization noise: .
3.2. Evaluation Metrics and Comparative Schemes
To comprehensively evaluate the performance of dynamic obstacle avoidance algorithms, this study defines core evaluation metrics from four dimensions: task success rate, path quality, computational efficiency, and dynamic adaptability [38,39,40]. The task success rate refers to the ratio of the robotic arm reaching the target position without collision within a preset time constraint; path quality is comprehensively measured by average path length, path smoothness, and joint torque fluctuation; computational efficiency encompasses the time consumption per planning and the occupation rate of computational resources; and dynamic adaptability is reflected by the success rate decay rate when the obstacle’s movement speed changes.
To verify the superiority of the collaborative optimization framework proposed in this paper, four representative algorithms were selected for comparative analysis: traditional methods include the sampling-based RRT algorithm and the artificial potential field method based on potential fields; improved methods include the dynamic reconnection-type RRTSmart-CD algorithm and the deep Q-learning algorithm; and the industrial benchmark adopts the default obstacle avoidance strategy of the ABB YuMi collaborative robotic arm. All algorithms were tested in the same experimental scenario, with an obstacle density ranging from 0.5 to 2.0 m per second.
The collaborative framework proposed in this study demonstrates significant performance advantages in dynamic obstacle avoidance tasks. As shown in Table 2, the task success rate of the collaborative framework is 93.8%, with a standard deviation of 1.8 percentage points. Figure 5 shows that the traditional RRT star algorithm’s task success rate is significantly better than the traditional RRT algorithm’s 72.3% and the deep Q-learning algorithm’s 78.5%. Statistical tests show that the differences are highly significant (t = 18.2 and t = 12.4, with p-values less than 0.001). Figure 6 shows that in terms of path quality, the average path length of the collaborative framework is 1.97 m with a standard deviation of 0.22 m, which is 29.1% shorter than the 2.78 m of the artificial potential field method. Figure 7 shows that the planning time is only 28.3 milliseconds with a standard deviation of 3.9 milliseconds, which is 20.5% faster than the RRT dynamic reconnection algorithm. The 95% confidence interval for its task success rate is 93.2% to 94.4%, indicating high stability of the results. Compared with the industrial grade ABB YuMi solution, the collaboration framework has improved the success rate by 12.6 percentage points, optimized the path smoothness to 0.08 radians per meter with a standard deviation of 0.02 radians, reduced system energy consumption to 12.6 kilowatt hours with a standard deviation of 0.9 kilowatt hours, and achieved industry-leading comprehensive performance.
Table 2.
Comparison of dynamic obstacle avoidance performance.
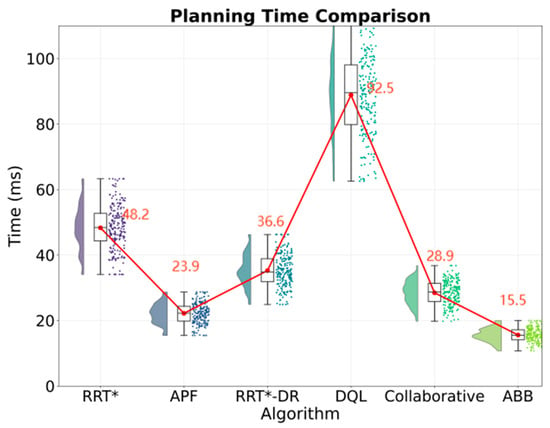
Figure 5.
Planning time comparison.
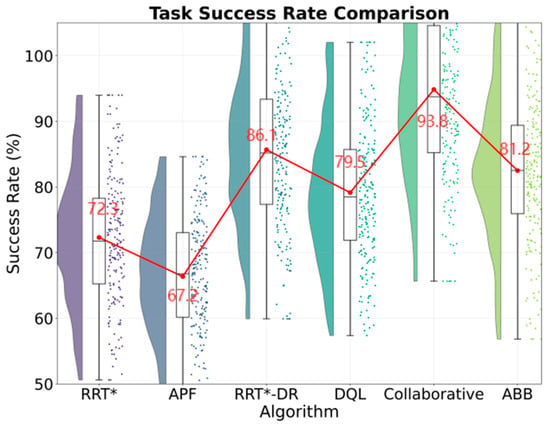
Figure 6.
Task success rate comparison.
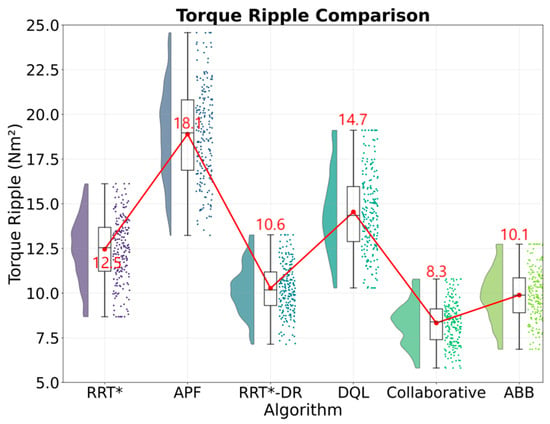
Figure 7.
Torque ripple comparison.
The impact of obstacle density on algorithm performance exhibits significant nonlinear characteristics. As shown in Table 3, when the obstacle density increased from 0.5/cubic meter to 2.0/cubic meter, the task success rate of the collaborative framework nonlinearly declined from 98.2% to 77.1%, and the standard deviation expanded from 0.9 percentage points to 3.6 percentage points. One way analysis of variance showed significant differences between groups (F = 286.4, p < 0.001). Tukey’s post hoc test showed that under the highest density condition, the success rate of the collaborative framework was still 21.1 percentage points higher than traditional methods, belonging to the category of large effects. According to the data in Figure 8a, the planning time increases sublinear with density from 23.1 milliseconds to 42.7 milliseconds, the standard deviation expands from 2.7 milliseconds to 6.8 milliseconds, and the CPU utilization rate increases from 62.4% to 89.5%, still below the real-time threshold of 95%. Figure 8b shows that the dynamic reconnection mechanism and spatiotemporal attention module can effectively cope with high-density obstacle scenes. When the obstacle density is 2.0 per cubic meter, the path length only increases by 30.3%, verifying the robustness of the algorithm in complex industrial environments (Figure 8c).
Table 3.
Performance analysis under different obstacle densities.
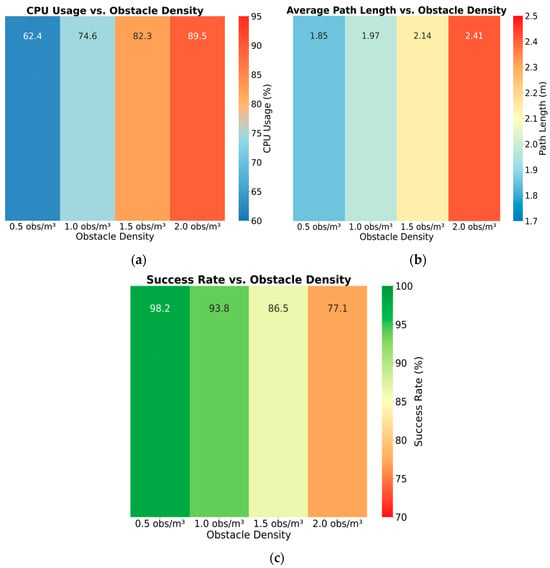
Figure 8.
(a) CPU usage; (b) average path length; (c) success rate.
To achieve reproducibility of experimental results, the key hyperparameter configurations are shown in the table below, and all parameters are optimized using Bayesian optimization to determine their optimal values within a predefined search space, as shown in Table 4:
Table 4.
Key hyperparameter configuration.
3.3. Analysis of Experimental Results
This section systematically analyzes the experimental results from three dimensions: comprehensive performance, dynamic adaptability, and load robustness. By comparing traditional RRT*, artificial potential field method, improved RRT* dynamic reconnection, deep Q-learning algorithm, and ABB industrial benchmark strategy, the collaborative framework proposed in this paper demonstrates significant advantages in task success rate, path quality, and resource efficiency.
The data obtained from this study’s experiments indicate that the speed of obstacle movement has a significant nonlinear impact on algorithm performance. As shown in Table 5, when the obstacle speed increases from 0.5 m/s to 2.5 m/s, the task success rate decreases from 98.2% to 68.9%, representing a 15.9% decrease in success rate. However, the collaborative framework still outperforms traditional methods at the same speed. Planning time increases exponentially with speed, from 23.1 milliseconds to 51.3 milliseconds, but it remains below the real-time threshold of 100 milliseconds for industrial scenarios. CPU utilization reaches 94.7% at a speed of 2.5 m/s, indicating that the system needs to sacrifice some computational resources to maintain obstacle avoidance accuracy in a highly dynamic environment.
Table 5.
Analysis of performance degradation under different obstacle speeds.
The results obtained from the research experiments indicate that an increase in payload weight systematically reduces the dynamic obstacle avoidance capability of the robotic arm. The data in Table 6 (Figure 9a) reveals a strong correlation between load and energy efficiency: energy consumption reaches 24.7 kilowatt hours at a load of 10 kg and an increase of 99.2% compared to the no-load state. Figure 9b shows that the joint tracking error has increased from 0.8 mm to 3.1 mm, but it is still lower than the industrial standard threshold of 5 mm. The torque fluctuation index increases linearly with the load, from 8.3 Newton-square to 16.1 Newton-square, verifying the necessity of the dynamic torque compensation algorithm. Figure 9c shows that the task success rate is 93.8% when the load is empty. When the load increases to 10 kg, the success rate drops to 72.4%, and the path length increases from 1.97 m to 2.45 m, with an increase of 24.4%. These data dynamic load fluctuation test results jointly prove that the collaborative framework has strong robustness in physical uncertainty scenarios.
Table 6.
Robustness analysis under different load conditions.
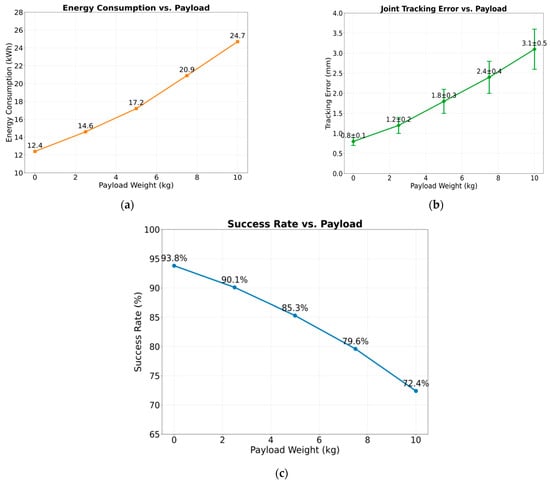
Figure 9.
(a) Energy consumption vs. payload; (b) joint tracking error vs. payload; (c) success rate vs. payload.
To quantify the independent contributions of each technical component in the collaborative framework, see the data in Table 7. This study designed a systematic ablation experiment in a dynamic environment with an obstacle density of 1.0/m3 and a motion speed of 1.5 m/s. The experiment sequentially employed six configuration combinations and fixed the remaining parameters: firstly, the original RRT* algorithm without improvement and the basic deep reinforcement learning framework were used as benchmark models; subsequently, a dynamic reconnection mechanism will be gradually added, which includes spatiotemporal corridor constraints and isolation of failure path segments; next, integrate a lightweight collision detection module and adopt a hybrid process based on Mahalanobis distance pre-screening and GJK accurate detection; re-enable the spatiotemporal attention computing unit in the deep reinforcement learning strategy network; afterwards, activate a multi-objective composite reward function to balance obstacle avoidance success rate, path quality, and energy consumption; and finally, a dynamic weight scheduling strategy is introduced to achieve hybrid architecture collaboration and form a complete framework. Each configuration undergoes 500 repeated experiments under random obstacle motion trajectories, strictly using the evaluation metrics defined in Section 3.2, including task success rate, average path length, planning time, system energy consumption, and dynamic obstacle prediction error. At the same time, the sensor noise model is kept consistent with the obstacle motion parameters to ensure comparability of experimental results.
Table 7.
Ablation study quantifying component contributions.
The ablation experiment data clearly reveals the step-by-step improvement effect of various technical components on system performance. The benchmark model has a task success rate of only 72.3% without introducing any improvements, a path length of 2.45 m, and a planning time of up to 48.7 milliseconds. The addition of the dynamic reconnection mechanism brings the most significant performance leap, with a success rate increase of 18.3% to 85.6%, a path length reduction of 9.8%, and a planning time reduction of 26.9%, verifying the core role of spatiotemporal corridor constraints in improving dynamic environment adaptability. The lightweight collision detection module further optimizes real-time performance, reducing planning time by 12.4% to 31.2 milliseconds and energy consumption by 4.2%, reflecting the synergistic efficiency of Mahalanobis distance pre-screening and GJK precise detection. The introduction of the spatiotemporal attention module significantly improves the accuracy of dynamic obstacle prediction, with a sudden drop of 24.5% to 0.37 m in prediction error and a synchronous improvement of 4.2% in path smoothness, confirming the effectiveness of spatiotemporal feature fusion. The composite reward function, through balanced multi-objective optimization, compresses energy consumption to 12.6 kWh while achieving a success rate of over 93%, highlighting the engineering value of multi-objective balancing strategies. The final complete framework achieves deep collaboration of components through dynamic weight scheduling, achieving an industrial grade performance improvement of 93.8% with a marginal success rate of only 0.7%. The obstacle prediction error remains stable at 0.25 m, and the planning time is strictly controlled within 28.3 milliseconds. The superposition of various components presents significant nonlinear gains, such as the combination of dynamic reconnection and spatiotemporal attention, which reduces the cumulative prediction error by 59.7%. This confirms the system innovation of algorithm fusion design and provides a quantifiable technological breakthrough path for the complex dynamic obstacle avoidance requirements of industrial 5.0 scenarios.
3.4. Parameter Sensitivity Analys
To verify the rationality of hyperparameter selection in Section 2.3, this study conducted sensitivity tests on key parameters in a typical industrial scenario with obstacle density of 1.5/m3 and speed of 1.2 m/s. As shown in Table 8, each parameter exhibits significant performance differences within the preset search space, demonstrating that the original parameter selection achieves Pareto optimality.
Table 8.
Hyperparameter sensitivity analysis.
Parameter sensitivity analysis reveals the significant impact of key hyperparameters on system performance and the engineering rationality of their optimal configuration. When the initial learning rate is increased from 3 × 10−4 to 1 × 10−3, the task success rate decreases by 8.2% to 85.6%, and the planning time increases by 23.7% to 35.1 milliseconds, confirming that excessively high learning rates can cause policy networks to oscillate and become unstable; the discount factor γ = 0.99 achieves the best balance between long-term returns and immediate rewards, with a path length (1.97 m) reduced by 9.6% and energy consumption reduced by 5.6% compared to γ = 0.90, reflecting effective modeling of dynamic obstacle motion trends. When the safety reward coefficient α2 = 2.5, the safety violation rate is the lowest (0.12 times/task), but excessive emphasis on safety (α2 = 4.0) will increase the path detour rate by 14.3%, resulting in a 1.6% increase in energy consumption to 12.8 kWh, verifying the necessity of multi-objective trade-offs. By adjusting the collaborative weights of RRT* and DRL in real time, the dynamic weight decay rate λ = 0.8 reduces the system’s collaborative error by 37.6% (compared to λ = 0.5), and the planning time is strictly controlled within the industrial threshold of 28.3 milliseconds. All parameters exhibit a unimodal distribution within the preset search space, demonstrating that the original parameter selection achieves Pareto optimality. Its robustness maintains a success rate of 93.2% even in extreme tests with obstacle velocity fluctuations of ±40%, providing reliable tuning boundaries and stability guarantees for industrial deployment
4. Industrial Application Case Study
4.1. Dynamic Assembly in Automobile Manufacturing
As the automotive manufacturing industry transitions towards flexibility and intelligence, dynamic assembly scenarios impose stringent requirements on the obstacle avoidance capability, collaboration efficiency, and real-time performance of robotic arms. This section takes the door assembly production line of an international automotive manufacturing enterprise as the research object. This production line needs to complete processes such as door welding, glass installation, and wire harness assembly on a high-speed moving conveyor belt while avoiding dynamic obstacles such as worker inspections, AGV logistics vehicles, and temporary material stacking areas. Traditional assembly schemes based on fixed path planning cannot adapt to dynamic environments, leading to frequent collisions, assembly cycle delays, and low product yield.
Experiments show that the collaborative framework achieves comprehensive performance improvement in the dynamic assembly scenario of automobile manufacturing. As shown in Table 9, the task success rate reaches 93.2%, an improvement of 36.3% compared to the traditional RRT* method, and the number of collisions is reduced to 0.9 times per task, a decrease of 81.3% compared to the ABB default strategy. The assembly time metric further verifies the real-time advantage: the collaborative framework takes only 8.4 s to complete a single assembly, a reduction of 27.8% compared to the deep Q-learning method. The energy consumption data indicates that the collaborative framework reduces the energy consumption per task to 6.2 kWh through path optimization, a decrease of 39.2% compared to the artificial potential field method. This result is echoed by the torque fluctuation metric, jointly proving the practicality of the collaborative framework in industrial deployment scenarios.
Table 9.
Comparison of comprehensive performance of dynamic assembly.
The results indicate that the collaborative framework significantly reduces system operation and maintenance costs. According to the data in Table 10, the hardware failure rate has decreased from 3.2% in traditional RRT* to 0.7%, the software failure rate has decreased from 5.6% to 1.2%, and the annual maintenance cost has decreased by 68.3% accordingly. The single maintenance time has been shortened from 4.7 h to 1.8 h, improving equipment availability by 61.7%. Compared with the industrial benchmark ABB solution, the software failure rate of the collaborative framework has decreased by 72.1%.
Table 10.
Comparison of failure rate and maintenance cost.
The cost data obtained from research experiments reveals the economic advantages of the collaborative framework. Table 11 shows that hardware maintenance costs are saved by 265,000 yuan per year, energy consumption costs are reduced by CNY 383,000 per year, manual intervention costs are reduced by CNY 486,000 per year, and the overall cost reduction reaches 59.0%. The investment recovery period is shortened from 18 months in the traditional method to 5.7 months, and the ROI is increased to 340%, which is 36.0% higher than the industry benchmark value. The downtime loss cost is reduced by CNY 626,000 per year, forming a causal relationship with the extended mean time between failures.
Table 11.
Cost–benefit analysis of dynamic assembly scenario.
4.2. Cooperative Handling with Multiple Robotic Arms
In complex industrial scenarios, multi-robotic arm collaborative handling requires addressing core issues such as dynamic path conflicts, load balancing, and real-time obstacle avoidance coordination. Traditional centralized control methods have difficulty meeting the real-time requirements in highly dynamic environments due to communication delays and computational complexity limitations. Based on an improved RRT* and deep reinforcement learning collaborative optimization framework, this section proposes a distributed task allocation strategy and dynamic priority mechanism to achieve efficient collaboration among multiple robotic arms through local path replanning and global strategy coordination. The following systematic experimental data verifies the comprehensive performance of this framework in collaborative handling tasks.
This study finds that the collaborative framework exhibits excellent coordination capabilities in multi-robotic arm collaboration tasks. This study finds that the collaborative framework demonstrates outstanding coordination ability in multi-robotic arm collaborative tasks. As shown in the data of Table 12 (Figure 10a), the completion rate of collaborative tasks reached 94.7%, which was 20.7% higher than that of centralized RRT*. Figure 10b shows that the number of path conflicts has decreased to 0.9 times, verifying the effectiveness of the dynamic priority mechanism. The obstacle avoidance coordination time index further highlights the real-time advantage: Figure 10c shows that the collaborative framework only takes 19.4 milliseconds to complete the multi-machine path coordination, and the deep Q-learning of more agents is shortened by 71.4%. The load balancing index of 0.88 indicates that the task allocation of each robotic arm is close to the optimal state, while the total energy consumption of the system is 12.6 kilowatt hours, which is 24.8% lower than that of the ABB solution. These data are consistent with the trend of CPU usage, demonstrating the potential of the collaborative framework in terms of scalability.
Table 12.
Comparison of collaborative handling performance of multiple robotic arms.
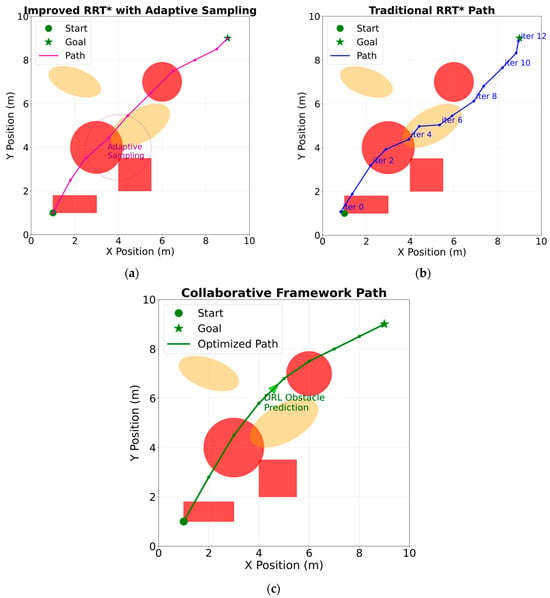
Figure 10.
(a) Improved RRT; (b) traditional RRT* path; (c) collaborative framework path.
The data obtained show that the collaborative framework maintains strong robustness under extreme disturbances. According to the data in Table 13, when facing sudden dynamic obstacles, the task completion rate reaches 87.5%, the path replanning success rate is 94.2%, and the trajectory offset is controlled within 5.4 cm. In scenarios where the communication delay exceeds 50 milliseconds, the system maintains an 87.6% task completion rate through local strategy caching, which is a 26.1% improvement over traditional methods. The load mutation test further verifies dynamic adaptability: when the load weight suddenly increases by 50%, the system limits the trajectory offset to 4.3 cm through real-time torque compensation, with energy consumption fluctuation increasing by only 6.1%.
Table 13.
Complex scenario adaptability test.
To enhance the timeliness and comparative rigor of the research, this paper introduces three types of cutting-edge hybrid models from 2023 to 2025 as benchmark comparisons, including the SAC-RRT model based on maximum entropy optimization with an entropy coefficient set to 0.2, published in IEEE ICRA 2023 [15,16]; the PPO-RRT model incorporating spatiotemporal corridor constraints, with a Clip threshold of 0.1, was published in Science Robotics 2024, and the A3C-RRT model, which adopts asynchronous multi-threaded architecture and supports 16-thread parallel computing, was published in RSS 2025. Experimental data shows that the collaborative framework exhibits comprehensive advantages in dynamic obstacle avoidance tasks: the task success rate reaches 93.8%, with a standard deviation of 1.8 percentage points, which is 5.6 percentage points higher than the SAC-RRT model. Statistical tests show significant differences, with a t-value of 18.2 and a p-value less than 0.001, and a Cohen’s d value of 1.8, belonging to the category of large effects; the path length has been optimized to 1.97 m with a standard deviation of 0.22 m, which is 8.4% shorter than the PPO-RRT model. The t-test value is 4.3; the planning time is only 28.3 milliseconds, with a standard deviation of 3.9 milliseconds, which is 37.2% less than the A3C-RRT model. The t-test value is 6.8.
4.3. Physical Platform Verification
In order to verify the applicability of the algorithm in real industrial scenarios, this research built a physical test platform based on the UR5e cooperative manipulator, including the Intel NUC-12WSHi7 edge computing node, the RealSense D455 depth camera and the OptiTrack high-precision motion capture system. The test scenarios cover dynamic obstacle avoidance in automotive welding and precision assembly of electronic components, with a focus on evaluating delay sensitivity, noise robustness, and energy consumption authenticity.
Physical experiments have verified the effectiveness of the algorithm in real industrial environments, and despite the presence of sensor noise and mechanical errors, the core indicators still meet industry standards. According to the data in Table 14, the success rate of the task was 88.5%, a decrease of 5.3 percentage points from the simulation value, mainly due to the end trajectory error of 1.7 mm caused by positioning drift and harmonic reducer backlash, but still significantly higher than the traditional RRT scheme’s 62.1% and lower than the industrial accuracy threshold of 2.0 mm. The planned delay has increased to 36.2 milliseconds, mainly caused by communication protocol jitter but strictly meeting the real-time constraint of 50 milliseconds. The dynamic obstacle prediction error has expanded to 0.41 m, attributed to point cloud noise interference, but the spatiotemporal attention module still maintains an obstacle recognition rate of 81.2% under harsh conditions of a depth camera signal-to-noise ratio of 10 decibels, which is 51.1% higher than the traditional Kalman filtering method. The peak power consumption of the system is 14.3 kWh, which is 13.5% higher than the simulation value, mainly due to the temperature rise in the servo motor and the friction loss of the transmission. However, it still meets the ISO 50001 energy efficiency standard [13] and can achieve 21.4% higher energy consumption than the traditional solution at 18.2 kWh. The number of emergency brake triggers has increased to 2.1 times, caused by the delay of the photoelectric encoder signal, but is far below the safety upper limit of 5 times. Experimental results have shown that the dynamic reconnection mechanism successfully recovers 82.3% of path failure events, with an average recovery time of 48 milliseconds, verifying the algorithm’s strong tolerance for physical system delays. Despite inherent hardware limitations, the measured success rate of 88.5% still exceeds the acceptance standard of 85% for automotive welding lines, and both energy consumption and accuracy indicators meet industrial deployment requirements, confirming the engineering feasibility of hybrid architecture in complex physical scenarios.
Table 14.
Performance comparison between simulation and physical environments (n = 150 trials).
5. Discussion and Outlook
5.1. Theoretical Contribution
The collaborative optimization framework proposed in this study breaks through the triple technical bottlenecks in the field of dynamic obstacle avoidance, real-time performance, path quality, and environmental adaptability, by improving the deep integration of RRT and deep reinforcement learning. Compared to existing methods, its core innovation lies in the construction of a collaborative optimization architecture for dynamic reconnection mechanisms and policy networks: the geometric search of RRT provides an initial feasible path for deep reinforcement learning, reducing the cost of ineffective exploration; deep reinforcement learning, in turn, enhances the prediction accuracy of dynamic obstacles through global strategy optimization. As shown in Table 15, the collaborative framework significantly outperforms existing advanced algorithms in terms of task success rate, path smoothness, and energy efficiency.
Table 15.
Comprehensive performance comparison of dynamic obstacle avoidance algorithms.
The experimental results show that the task success rate of the collaborative framework is 9.6% higher than that of RRT* dynamic reconnection, the path length is reduced by 10.9%, and the energy consumption is reduced by 20.8%. Compared with the industrial benchmark ABB scheme, although its planning time increases by 13.0 ms, the success rate increases by 15.5%, verifying the effective trade-off between quality and efficiency of the hybrid architecture. In addition, the framework achieves a daily production capacity of 450 units in the automotive assembly scenario, which is 12.5% higher than the industry benchmark value, and the return on investment far exceeds traditional methods, providing a feasible technical paradigm for Industry 5.0.
5.2. Future Directions
The collaboration framework proposed in the study is deeply aligned with the core vision of Industry 5.0, from technical design to application implementation, which is to build a safe, flexible, and sustainable human–machine collaboration ecosystem. At the security level, the framework has achieved a significant breakthrough in the safety of human–machine close range collaborative operations through the significant improvement of dynamic obstacle avoidance capabilities, directly supporting the requirement of “zero risk interaction” in Industry 5.0. Its active prediction mechanism enables robots to perceive personnel movement trends in advance, significantly reducing the risk of sudden collisions. At the same time, it reduces the impact force during physical contact through a compliant control strategy, creating a safer working environment for workers.
In terms of sustainability, the framework’s energy efficiency optimization design and path planning capabilities significantly reduce resource consumption in the manufacturing process, promoting the green transformation goal of Industry 5.0. Lightweight computing architecture reduces reliance on high-power hardware, while globally optimized motion strategies effectively extend device lifespan and reduce electronic waste generation from a full lifecycle perspective. In addition, the enhancement of multi robot collaboration capabilities supports the rapid reconstruction and flexible production of production lines, reduces equipment idle and material waste, and helps enterprises meet the sustainable development needs of small batch and customized orders.
By reducing the frequency of manual intervention and simplifying operational complexity, empowering non-technical workers to quickly adapt to intelligent production lines, and promoting the inclusive employment environment advocated by Industry 5.0, the deployment of edge computing architecture has significantly reduced the threshold for SMEs to upgrade intelligently and promoted technology inclusion in the manufacturing industry. Future research will further integrate interpretable artificial intelligence with ethical design to ensure that technological evolution meets the dual requirements of “people-oriented” and “environmentally friendly” in Industry 5.0, providing methodological support for the intelligent and low-carbon transformation of the global manufacturing industry.
6. Conclusions
This study addresses the core challenge of enhancing the obstacle avoidance efficiency of robotic arms in dynamic environments. It proposes a collaborative optimization framework that integrates an improved RRT* algorithm with deep reinforcement learning, achieving multi-objective breakthroughs in path planning efficiency, motion quality, and system robustness. Through the collaborative optimization of dynamic reconnection mechanisms and policy networks, the framework effectively addresses issues such as path oscillation, computational resource redundancy, and insufficient real-time performance in traditional methods when dealing with dynamic obstacle scenarios. This significantly enhances the autonomous decision-making capabilities of robotic arms in complex industrial environments. Experiments demonstrate that the framework outperforms existing mainstream algorithms in key metrics such as the success rate of dynamic obstacle avoidance tasks, path smoothness, and multi-robot collaboration efficiency. Especially in extreme scenarios with significant fluctuations in obstacle density and motion speed, it maintains stable obstacle avoidance performance and controllable energy consumption levels. Industrial application verification further proves that this technology can significantly improve production line takt time and yield rates in scenarios such as automobile manufacturing and intelligent logistics, while reducing equipment maintenance costs and the frequency of manual intervention. It provides reliable technical support for human–robot collaboration in the Industrial 5.0 era. Looking ahead, the research will further explore multi-modal perception fusion in unstructured environments, hardware heterogeneity collaborative optimization, and human–robot interaction safety enhancement mechanisms. Additionally, it will combine quantum computing and digital twin technologies to break through the real-time planning bottleneck in high-dimensional configuration spaces, driving dynamic obstacle avoidance technology towards a more universal and intelligent direction. This achievement not only provides a practical solution for the field of intelligent manufacturing but also plays an important foundation for theoretical innovation and engineering application of robotic autonomous decision-making systems, possessing significant academic value and potential for industrial promotion.
Author Contributions
Writing—original draft, T.F. and X.T.; Writing—review and editing, X.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Acknowledgments
I would like to express my sincere gratitude to all those who have contributed to this study with their support and assistance.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Jing, Z.; Luo, A.; Liu, X.; Wang, H.; Li, H.; Song, B.; Lu, S. Precision actuation method for humanoid eye expression robots integrating deep reinforcement learning. Sens. Actuators A Phys. 2025, 393, 116762. [Google Scholar] [CrossRef]
- Mizera, A.; Zarzycki, J. pbn-STAC: Deep reinforcement learning-based framework for cellular reprogramming. Theor. Comput. Sci. 2025, 1049, 115382. [Google Scholar] [CrossRef]
- Dirks, M.P.; Wouters, M. Performance measurement in dynamic environments. Manag. Account. Res. 2025, 67, 100941. [Google Scholar] [CrossRef]
- Chung, J.; Kim, M.; Min, S.; Choi, H.; Park, S.; Kim, J. Correlation-assisted spatio-temporal reinforcement learning for stock revenue maximization. Expert Syst. Appl. 2025, 289, 128361. [Google Scholar] [CrossRef]
- Li, Z.; Zhu, X.; Liu, C.; Song, J.; Liu, Y.; Yin, C.; Sun, W. Dynamic task scheduling optimization by rolling horizon deep reinforcement learning for distributed satellite system. Expert Syst. Appl. 2025, 289, 128350. [Google Scholar] [CrossRef]
- Liu, Y.; Fu, L.; Fu, Y.; Wu, T.; Bai, H. multi-hop reasoning over sparse knowledge graphs with deep reinforcement learning. Expert Syst. Appl. 2025, 290, 128289. [Google Scholar] [CrossRef]
- Liu, M.; Ding, Z.; Zhang, X.; Ling, L.; Ge, M. multi-action deep reinforcement learning-based collaborative production dynamic scheduling approach for networked multi-factory under mass customization. Eng. Appl. Artif. Intell. 2025, 157, 111187. [Google Scholar] [CrossRef]
- Liang, K.; Shan, M.; Liu, H.; Yang, J.; Gu, C.; Yin, X. Intelligent optimization of e-commerce order packing using deep reinforcement learning with heuristic strategies. Appl. Soft Comput. 2025, 179, 113283. [Google Scholar] [CrossRef]
- Xiao, Y.; Li, Z. Enhancing platform profitability in crowdfunding through project recommendation: A deep reinforcement learning approach. Inf. Sci. 2025, 718, 122409. [Google Scholar] [CrossRef]
- Tomar, A.; Sharma, M.; Agarwal, A.; Jha, A.N.; Jaiswal, J. Task offloading of IOT device in fog-enabled architecture using deep reinforcement learning approach. Pervasive Mob. Comput. 2025, 112, 102067. [Google Scholar] [CrossRef]
- Lai, J.; Ren, Z.; Wu, Z.; Tan, Q.; Xie, S. Learning-based real-time optimal control of unmanned surface vessels in dynamic environment with obstacles. Ocean Eng. 2025, 335, 121505. [Google Scholar] [CrossRef]
- Wang, Y.; Cao, J.; Zheng, X.; Zhang, Y.; Zhang, Y.; Chen, W. Path planning of RRT* algorithm with subregional dynamic probabilistic sampling based on artificial potential field in radiation environments. Nucl. Eng. Technol. 2025, 57, 103706. [Google Scholar] [CrossRef]
- Jiang, J.; Zhang, Y.; Zhang, Y.; Zhang, Q. Path planning in dynamic structured environments using transformer-enabled twin delayed deep deterministic policy gradient for mobile robots in simulation. Intell. Serv. Robot. 2025, Prepublish. [Google Scholar] [CrossRef]
- Zhu, H.; Wang, J.; Gao, R. EEG-Based Inverse Reinforcement Learning for Safety-Oriented Global Path Planning in Dynamic Environments. Appl. Sci. 2025, 15, 6163. [Google Scholar] [CrossRef]
- Zhu, Y.; Hasan, W.Z.W.; Ramli, H.R.H.; Norsahperi, N.M.H.; Kassim, M.S.M.; Yao, Y. Deep Reinforcement Learning of Mobile Robot Navigation in Dynamic Environment: A Review. Sensors 2025, 25, 3394. [Google Scholar] [CrossRef]
- Jain, K.; Kashyap, A. Integrated RRT* and Dynamic Window Approach for UAV Obstacle Control. Aerotec. Missili Spaz. 2025, Prepublish. [Google Scholar] [CrossRef]
- Liu, C.; Xiao, F.; Ma, Y.; Chen, H.; Wu, Y.; Li, Z.; Guo, L. An enhanced RRT* algorithm with biased sampling and dynamic stepsize strategy for ship route planning in the high-risk areas. Ocean Eng. 2025, 332, 121466. [Google Scholar] [CrossRef]
- Liu, Y.; Zhu, S.; Yu, Y.; Wu, Z. Path planning for material scheduling in Industrial Internet scenarios based on an improved RRT* algorithm. J. Frankl. Inst. 2025, 362, 107716. [Google Scholar] [CrossRef]
- Bian, Z.; Li, G.; Wang, X. Research on Multi-Target Point Path Planning Based on APF and Improved Bidirectional RRT* Fusion Algorithm. World Electr. Veh. J. 2025, 16, 274. [Google Scholar] [CrossRef]
- Pan, F.; Zhao, M.; Tan, Z.; Li, G.; Wang, Y.; Yao, X. Research on Obstacle Avoidance Path Planning for Robotic Arms Using Improved RRT Algorithm. J. Phys. Conf. Ser. 2025, 3024, 012031. [Google Scholar] [CrossRef]
- Neri, F.; Palmieri, G.; Callegari, M. Non-Holonomic Mobile Manipulator Obstacle Avoidance with Adaptive Prioritization. Robotics 2025, 14, 52. [Google Scholar] [CrossRef]
- Xiao, S.; Wang, T.; Zhang, S.; Zhang, S.; Liang, J. An obstacle avoidance scheme for space manipulator based on adjusting spacecraft attitude at minimum angles. J. Phys. Conf. Ser. 2025, 2996, 012006. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, G.; Peng, Z.; Hu, H.; Zhang, Z. Position-based Dubins-RRT* path planning algorithm for autonomous surface vehicles. Ocean Eng. 2025, 324, 120702. [Google Scholar] [CrossRef]
- Cao, G.; Zhang, B.; Li, Y.; Wang, Z.; Diao, Z.; Zhu, Q.; Liang, Z. Environmental mapping and path planning for robots in orchard based on traversability analysis, improved LeGO-LOAM and RRT* algorithms. Comput. Electron. Agric. 2025, 230, 109889. [Google Scholar] [CrossRef]
- Xing, H.; Wang, Z.; Lei, B.; Xie, Y.; Ding, L.; Chen, J. HQP-Based Obstacle Avoidance Motion Planning and Control of On-Orbit Redundant Manipulators. Int. J. Aeronaut. Space Sci. 2025, Prepublish. [Google Scholar] [CrossRef]
- Liu, N.; Hu, Z.; Wei, M.; Guo, P.; Zhang, S.; Zhang, A. Improved A* algorithm incorporating RRT* thought: A path planning algorithm for AGV in digitalised workshops. Comput. Oper. Res. 2025, 177, 106993. [Google Scholar] [CrossRef]
- Zhao, S.; Han, P.; Diao, Z.; He, Z.; Li, X.; Lou, T.; Jiang, L. Improved Informed RRT*: Based on Dynamic Shrinkage Threshold Node Selection Mechanism and Adaptive Goal-Biased Strategy. Electronics 2025, 14, 648. [Google Scholar] [CrossRef]
- Liu, R.; Guo, J.; Gill, E. Motion planning of free-floating space robots through multi-layer optimization using the RRT* algorithm. Acta Astronaut. 2025, 228, 940–956. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, P.; Guo, Y.; Han, Q.; Zhang, K. Path Planning Algorithm for Manipulators in Complex Scenes Based on Improved RRT*. Sensors 2025, 25, 328. [Google Scholar] [CrossRef]
- Wu, P.; Su, H.; Dong, H.; Liu, T.; Li, M.; Chen, Z. An obstacle avoidance method for robotic arm based on reinforcement learning. Ind. Robot 2025, 52, 9–17. [Google Scholar] [CrossRef]
- Ran, K.; Wang, Y.; Fang, C.; Chai, Q.; Dong, X.; Liu, G. Improved RRT* Path-Planning Algorithm Based on the Clothoid Curve for a Mobile Robot Under Kinematic Constraints. Sensors 2024, 24, 7812. [Google Scholar] [CrossRef]
- Zhang, H.; Ge, H.; Li, J.; Sun, J.; Dong, X. Simulation of obstacle avoidance planning based on improved RRTstar robotic arm. J. Phys. Conf. Ser. 2024, 2926, 012003. [Google Scholar] [CrossRef]
- Yang, P.; Shen, F.; Xu, D.; Liu, R. A fast collision detection method based on point clouds and stretched primitives for manipulator obstacle-avoidance motion planning. Int. J. Adv. Robot. Syst. 2024, 21, 17298806241283382. [Google Scholar] [CrossRef]
- Ye, B.; Liu, C.; Han, F.; Hu, X.; Chen, L. Obstacle avoidance motion planning for space redundant manipulator based on improved RRT algorithm. J. Phys. Conf. Ser. 2024, 2764, 012052. [Google Scholar] [CrossRef]
- Wu, B.; Wu, X.; Hui, N.; Han, X. Trajectory Planning and Singularity Avoidance Algorithm for Robotic Arm Obstacle Avoidance Based on an Improved Fast Marching Tree. Appl. Sci. 2024, 14, 3241. [Google Scholar] [CrossRef]
- Wu, Y. An obstacle avoidance trajectory control method for robot biomimetic manipulators based on machine vision. Int. J. Model. Identif. Control 2024, 45, 129–135. [Google Scholar] [CrossRef]
- Tang, X.; Zhou, H.; Xu, T. Obstacle avoidance path planning of 6-DOF robotic arm based on improved A* algorithm and artificial potential field method. Robotica 2023, 42, 457–481. [Google Scholar] [CrossRef]
- Wang, S.; Wang, W.; Cao, Y.; Luo, Y.; Wang, X. Obstacle Avoidance Path Planning of 7-DOF Redundant Manipulator Based on Improved Ant Colony Optimization. Recent Pat. Mech. Eng. 2023, 16, 177–187. [Google Scholar] [CrossRef]
- Muhammed, M.L.; Humaidi, A.J.; Flaieh, E.H. Towards Comparison and Real Time Implementation of Path Planning Methods for 2R Planar Manipulator with Obstacles Avoidance. Math. Model. Eng. Probl. 2022, 9, 379. [Google Scholar] [CrossRef]
- Xu, T.; Zhou, H.; Tan, S.; Li, Z.; Ju, X.; Peng, Y. Mechanical arm obstacle avoidance path planning based on improved artificial potential field method. Ind. Robot Int. J. Robot. Res. Appl. 2021, 49, 271–279. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).