Abstract
The performance of witness-based random search algorithms is highly influenced by the distribution density of witnesses. To optimize this distribution, we propose a novel method based on the symmetric folding of the objective dataset. Our approach involves establishing mathematical models for symmetrically folding points and regions in two-dimensional space and deriving a set of rigorously proven properties for folding operations on matrix-formed datasets, complete with computational formulations. Theoretical analysis and numerical experiments demonstrate that the proposed symmetric folding technique can nearly double the probability of successfully identifying a target element via random sampling. The efficacy of the method is validated by a case study on identifying a nontrivial divisor of an odd composite integer, demonstrating that the symmetric folding of the structured dataset can significantly improve the efficiency of randomized search procedures.
Keywords:
symmetric folding; mathematical modeling; random search; witness abundance; computational efficiency PACS:
89.20.Ff; 02.90.+p; 87.55.kd; 07.05.Kf; 89.70.Eg; 45.10.-b; 05.40.Fb
MSC:
68P15; 68Q10; 68Q99; 68T20
1. Introduction
Witness-based random search algorithms gained prominence in the early 1970s owning to their groundbreaking success in addressing problems in number theory, such as primality testing and compositeness certification. Since then, their applications have expanded significantly, spanning diverse domains including decision-making [1,2], data structures [3], network design [4], data mining [5], coding theory [6], data-flow analysis [7], IoT systems [8], cryptography [9], software verification [10], and quantum entanglement research [11].
The efficiency of a witness-based random search algorithm is largely determined by the abundance of witnesses distributed throughout the search space, as established in both classical books (e.g., [12,13,14]) and more recent literature (e.g., [15,16]). Notably, Hromkovič J. emphasized in his seminal work [17] that the concept of witness abundance is a significant gem in the design of randomized algorithms due to its deep connection with nontrivial discoveries in computer science and mathematics.
Given that witnesses are typically dispersed across a large search space that cannot be exhaustively explored [18], enhancing their distribution density constitutes a promising research direction. In light of this consideration, this paper proposes an innovative method to turn sparsely distributed witnesses closer. This method is inspired by the physical act of folding a paper sheet, as illustrated in Figure 1, which demonstrates a paper sheet is folded to by symmetrically folding. Suppose that several points, referred to as witnesses and marked with blue and red dots, are randomly distributed and affixed to one surface of the paper. When the paper sheet is folded along its axis of symmetry, aligning the two halves precisely, these witnesses are brought into closer proximity. Figure 1 simultaneously shows that folding can not only enhance the local density of the witnesses, but also reduce the gaps between non-witnesses. This is undoubtedly a benefit of witness-based random searches, as gaps can be traversed more quickly and there are more opportunities to encounter a witness.
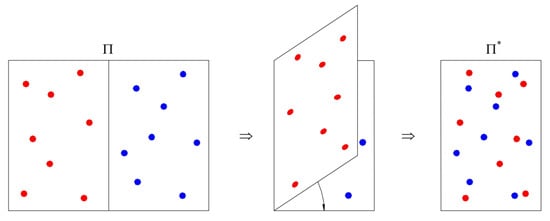
Figure 1.
Symmetrical folding brings witnesses into closer proximity.
Inspired by this phenomenon, we introduced the concept of symmetric folding and conducted a preliminary investigation in [19]. However, as an initial exploration, that paper neither provided a comprehensive analysis of the properties of symmetric folding nor established a method for its calculation. This paper hence aims to present a systematic extension and formalization of the study, providing a complete method for symmetrically folding datasets to enhance the efficiency of random search. Through rigorous mathematical reasoning, we derive a set of fundamental properties of symmetric folding, formulate the laws governing the folding process, and prove that symmetric folding can significantly enhance the probability of locating a witness. Furthermore, we apply the principle of symmetric folding to datasets employed in [20,21], showing that search efficiency is considerably improved as a result.
This paper is organized as follows: Section 1 provides an overview of the research context. Section 2 establishes formal definitions and notational conventions. Section 3 synthesizes our main theoretical results, including two theorems, five corollaries, and their corresponding proofs. Section 4 presents application instances. Section 5 concludes the paper by discussing the implications of the findings and suggesting potential directions for future research.
2. Terminologies, Notations, and Definitions
This section presents the necessary symbols, notations, and definitions for subsequent mathematical reasoning.
2.1. Terminologies and Notations
The terms axis symmetry and point symmetry are consistently employed in this work, as defined in standard elementary geometry textbooks such as [22,23,24]. Symbol means n-dimensional real space. Symbol means A can derive B, and means A and B can derive each other. Symbol means x in interval [a, b]. Symbols and are, respectively, the floor and ceiling functions of real x such that , the details of which can be referred to in [25]. Particularly, the following identity (1), which is derived from (3.11) of [25], will be used in the subsequent reasoning.
Unless otherwise stated, the term "point" refers to a geometric point, which can be described with coordinates within a coordinate system. Abstract datasets are occasionally represented using specific geometric entities to provide concise descriptions. For example, a strip represents a one-dimensional set with uniformly distributed points, while a sheet denotes a two-dimensional set characterized by uniform distribution. Particularly, a segment is a part of a strip. A segment s starting at x and ending at y is denoted by an expression .
For an odd composite integer N with divisors p and q satisfying , any integer smaller than N and sharing a nontrivial common divisor with N is said to be a witness of N’s divisors, or simply a witness of N. Obviously, a divisor of N, p or q, can be obtained by computing the greatest common divisor (GCD) between N and any one of its witnesses.
It is important to note that all sets analyzed in this paper are finite, countable, and planar unless explicitly specified otherwise.
2.2. Definitions
Definition 1
(Symmetric folding of points). Assume that X and Y are two movable points. If X is moved to the position where Y locates, or conversely, Y is moved to the position where X locates, the two points are said to be superimposed (or overlaid) and denoted by the symbol . The operation of moving X to Y is said to be a superimposition of X on (onto) Y, denoted by , which means that Y is the reference or base. Hence, means folding Y on (onto) X. The symmetric folding of two points refers to the superimposition that moves one of the two points to the other with their bisector as the symmetric axis. If ignoring the base, the symmetric folding of X onto Y is denoted by . Under the meaning of the symmetric folding, X and Y are called symmetric counterparts or mirror images of each other.
By Definition 1, the number of points involved in the symmetric folding must generally exceed one. Although a single point could be symmetric to itself theoretically, this scenario lacks physical and practical significance. Hence, we assume that more than one point is involved in the symmetric folding unless specific theoretical requirements dictate otherwise. Since points are always within a planar region, we have the following Definition 2.
Definition 2
(Symmetric folding of planar regions). Let Π and be two finite planar regions that have the same shape; the operation that superimposes Π onto to make the two completely coincide is called a superimposition of Π to (onto) , denoted by , meaning is the base. If is the symmetric counterpart of Π across a mirror axis m, the symmetric folding of Π to (onto) particularly refers to the superimposition that folds each point of Π to (onto) its symmetric counterpart in with respect to m. In this case, is referred to as the base. If ignoring the base, the symmetric folding of Π to is denoted by and simply said to fold Π to along m.
There are a variety of planar regions. However, our interest in this paper is in the symmetric folding of strips and rectangular sheets, as described in Definitions 3 and 4.
Definition 3
(Symmetric folding of strips). Let and be two strips, where n is a positive integer; the symmetric folding of P to (onto) Q, denoted by , meaning Q is the base, is given by
If ignoring the base, the symmetric folding of P to Q is simply denoted by , where P and Q are called symmetric counterparts, or mirror images of each other.
Definition 4
(Symmetric folding of a rectangular sheet). Given a rectangular sheet S with horizontal mirror axis h and vertical mirror axis v, the symmetric horizontal folding of S, denoted by h-fold, folds S along the h-axis; the symmetric vertical folding of S, denoted by v-fold, folds S along the v-axis. Folding S first with an h-fold and then the folded result with a v-fold is denoted by -fold; folding S first with a v-fold and then the folded result with an h-fold is denoted by -fold. The -fold and -fold are called mixed folds or hybrid folds.
In addition to the coordinates that describe the position (location), a point may also be associated with certain external properties. For instance, it can be marked red or assigned a numerical label. This leads to the following Definition 5.
Definition 5
(Imprint of a point). An imprint of a point, or simply an imprint, refers to an external property, e.g., a mark or an identifier, associated with the point. A point with an imprint i is referred to as an imprinted point, denoted by . The imprint of a point can be superimposed by the rule . A strip consisting of imprinted points is an imprinted strip, and a sheet consisting of imprinted points is an imprinted sheet.
Remark 1.
According to Definition 5, an imprinted point may possess more than one imprint. This can be analogized to a colored ball labeled with a number. The concept of the imprint coming into being, a point can either be geometric or imprinted. Regarding the purpose of this paper, the term ’point’ by default refers to the imprint point hereafter. Based on Corollary 2 in [19], when a source point is folded onto a target point, it ceases to exist geometrically while transferring its imprints to the target point. This phenomenon gives rise to the concept of "folding by imprints," formally stated in Definition 6.
Definition 6
(Folding by imprints). Folding by imprints refers to the folding of an imprinted strip or sheet, emphasizing the transformation of points’ imprints rather than their coordinates.
Remark 2.
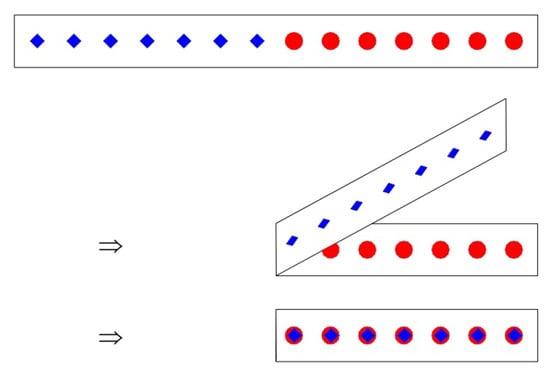
Symmetric folding of two strips, imprints of a point, and folding by imprints can be depicted with Figure 2. In the figure, two different imprints, the blue squares and red circular dots on a trip, are superimposed after performing a symmetric folding on the strip.
Figure 2.
Imprints and folding of them.
Imprints can act as witnesses in identifying certain characteristics of points. This derives the following Definition 7.
Definition 7
(Witness by imprint). If an imprint of a point can be utilized to characterize that point, that imprint is referred to as a witness to the point. In such a case, the point itself is termed a witness point.
The concept of witness by imprint permits the association of a geometric point with a specific value. For instance, we can establish a rule for generating an imprint, say an integer, for each lattice in a planar region, and then determine whether a randomly chosen lattice is associated with a multiple of a prime number. By this means, the problem of identifying a divisor of a composite integer is converted into randomly searching certain lattices in the region, as Section 4 deals with.
3. Theoretical Results
The theoretical results include two theorems and five corollaries, which are stated and proved below.
Theorem 1.
Given n points on a strip, where is an integer, then for an arbitrary integer , the symmetric folding of the strip superimposes the point onto the point or vice versa, resulting in a total of distinct overlaid points on the folded strip.
Proof.
When n is even, let with k being an integer; it follows . Denote the n points by a set
By Definition 3, is symmetric to ; hence, the symmetric folding results in , where , saying that the theorem holds in the case of n being an even number.
If n is odd, letting with k being an integer follows and
This time, is symmetric to itself and each element is symmetric to with respect to , where . Namely, the symmetric folding also results in for , showing that the theorem holds when n is an odd number. Consequently, the theorem holds in all cases. □
Corollary 1.
Given n points on a strip, where is an integer, let be the set of these n points, namely,
Assume is the set of the symmetric folding of ; then,
Proof.
This corollary is the alternative statement of Theorem 1. □
Remark 3.
Let
and
then, (6) says each element is associated with one element and one element . Keeping such symmetric folding by partitioning and into their respective symmetric counterparts, each partitioned subset contributes one of its elements to an element in the last folded result. Specifically, every element in the last folded result is associated with a partitioned subset exactly once.
Corollary 2.
Given points on a strip with being an integer, let be the set of these points, namely,
Denote to be the set after performing k times of symmetric folding on and to be the element of , where ; then,
where
and .
Proof.
By Corollary 1, the symmetric folding of yields
where and the index j satisfies .
Likewise, the symmetric folding of yields
where and the index s satisfies .
Since and , it follows
In general, let ; then, the symmetric folding of is given by
where and the index t satisfies .
With detail calculations it follows
Remark 4.
It is seen from (14) that is superimposed from points of . Obviously , saying all the points in are superimposed onto the first point after performing m times of symmetric folding. By Corollary 1, m times of symmetric folding also fold all the points onto the last point.
Corollary 3.
Given n points on a strip with n being a positive integer, it takes at least and at most times of symmetric folding to fold all these n points onto the first one or the last one.
Proof.
If it happens to have an such that , then Corollary 2 ensures that Corollary 3 holds because . Otherwise, there must exist a k such that . That is leading to . By Theorem 1 and identity (1), k times of the symmetric folding yields points. Since , the corollary holds. □
Corollary 4.
Given distinct points in a strip, where m and n are finite positive integers, then all these points are folded to the first or the last n points after performing m times of symmetric folding one after another.
Proof.
Let be the points; kept in their original orders, subgroup them into clusters, say , and ; then, each cluster contains n elements of . Namely, can be rewritten by
Regard each cluster as a point in space; then, by Corollary 2, all the clusters are superimposed onto or after performing m times of symmetric folding. This immediately validates Corollary 4. □
Remark 5.
Corollary 5.
Given a rectangular sheet containing rows and columns, where m and n are finite positive integers, assume is the set of points on the sheet, namely,
Or
Then, the following conclusions (C1),(C2), and (C3) are true.
(C1) For a positive integer k satisfying , let be the set after performing k times of h-fold on and be its element at the row and column; then,
where and .
(C2) For a positive integer l satisfying , let be the set after performing l times of v-fold on and be its element at the row and column; then,
where and .
(C3) For positive integers k and l satisfying and , let be the set after performing a symmetric mixed fold on by k times of h-fold and l times of v-fold; denote to be the element at the row and column of ; then,
where , and .
Proof.
Regarding each row as a point in , (C1) is true by referring to Corollary 2. Likewise, (C2) is true by regarding each column as a point in . With the recursive principle, (C3) is obtained. □
Remark 6.
By (18), all the rows of are superimposed onto the first row after performing m times of h-fold; by(19), all the columns of are superimposed onto the first column after performing n times of v-fold; by (20), all the elements of are superimposed onto or after performing symmetric mixed folds of by k h-folds and l v-folds.
Theorem 2.
The symmetric folding nearly doubles the probability of randomly selecting a witness point in a strip or sheet.
Proof.
Consider the case of symmetrically folding a strip to . Partition into two symmetric halves, say and ; then, . Suppose Sl contains wl witness points, Sr contains wr witness points, and S0 totally contains n points. Let p1 denote the probability of randomly selecting a witness point in S1, and p0 represent the probability of randomly selecting a witness point across S0.
Then, in the case n is even, say n = 2m, it
leads to . According to Definitions 1, 3, 5, and Corollary 2 in [20], the number of points on S1 is reduced to half that on S0 while the total number of witness points remains
unchanged. Hence, .
If n is odd, say n = 2m + 1, the intermediate point, say M, is on the perpendicular bisector. Assume M is not a witness and it belongs to either of and ; then, and . Because , the theorem holds for this case. Likewise, if M is a witness, then and , leading to the same result as the case that M is not a witness.
The case of symmetrically folding a sheet can be proven similarly, showing that the theorem holds. □
4. Applications for Folding and Searching Rectangular Datasets
Based on the theoretical findings, this section demonstrates the folding of two distinct sheets, denoted as and , which were employed in [20] and [21], respectively. These sheets are specifically designed to identify a divisor of an odd composite integer N through the application of the Monte Carlo algorithm. Both sheets exhibit a structural characteristic wherein witnesses are locally accumulated within a large, sparse lattice space, resulting in significant gaps between non-witnesses. Such a configuration can lead to high search efficiency in certain cases but significantly reduced performance in others. For instance, when N comprises 23 decimal digits, the maximum computational time reaches 30,481.30 s, whereas the minimum is recorded at 3054.51 s, as illustrated in the tables in Section 4. This variability stems from the fact that the search process may frequently require extensive time traversing the large gaps between non-witnesses. Since folding has the potential to increase the witness distribution density and simultaneously reduce the gaps between non-witnesses, its application to these sheets is expected to improve search effectiveness. Motivated by this consideration, we investigate the strategies and methodologies for implementing the folding.
4.1. Folding and Searching Dataset
This subsection elaborates on the folding characteristics of , outlines a folding strategy, and proposes a method to implement the folding process.
4.1.1. Structure and Folding Characteristics of
For an odd composite integer N and a parameter g, the dataset is a lattice set described by
where , , and the lattice point is associated with an imprint given by
is geometrically a rectangular sheet containing rows and columns, a total of elements. Expressed with imprints and by (22), each row of is identical to the others. For example, taking and yields as shown in Figure 3.

Figure 3.
Dataset generated by and .
Using a solid circle • to denote a witness and an empty circle ∘ to denote a non-witness, we have the distribution pattern of witnesses and non-witnesses illustrated in Figure 4, which comes from Figure 3.

Figure 4.
Witness and non-witness in generated by and .
Obviously, such a distribution pattern will leave a significant ‘trap’ for a random search, as the search may frequently fall into the big areas occupied by non-witnesses.
Performing one, two, and three times of v-folds on results in Figure 5, among which Figure 5a has 6 rows and 9 columns, Figure 5b has 6 rows and 5 columns, and Figure 5c has 6 rows and 3 columns. It can be observed that the lattice position of the folded sheet wraps 2, 4, and 8 elements from with respect to the 1 v-fold, 2 v-folds, and 3 v-folds. Particularly, seen in Figure 5c, each point is associated with at least two witnesses, greatly increasing the probability of finding a witness.

Referring to (10) in [20], the probability P of randomly selecting a witness in is estimated by
Assume ; then, by Theorem 2, times of v-fold of can lead to a significantly big probability to select a witness randomly.
4.1.2. A Strategy for Folding and Searching
For a big N, both and are large numbers. As observed from (22), rows of are identical, implying that is essentially a large sheet consisting of duplicated long strips aligned up together. Hence, applying v-folding to an individual strip is computationally more efficient than folding the entire large sheet. Meanwhile, the large value of suggests that the number of points in the folded strip will remain substantially high. Therefore, partitioning the long strip into a sequence of smaller segments and utilizing parallel computing techniques to process these segments can improve the computational efficiency. Consequently, performing v-fold on an individual long strip, in conjunction with the parallel technique, constitutes the general strategy for folding and searching .
4.1.3. An Approach for Folding and Searching
There are various styles of folding a long strip. For example, a two-folded folding (symmetric folding) folds it by two halves, a three-folded folding folds it by three parts of equal length, and a multiple-folded folding folds it by more than three parts of equal length, as shown in Figure 6, where the arrows indicate the folding directions and the dashed lines mean the original configurations of the folded parts.
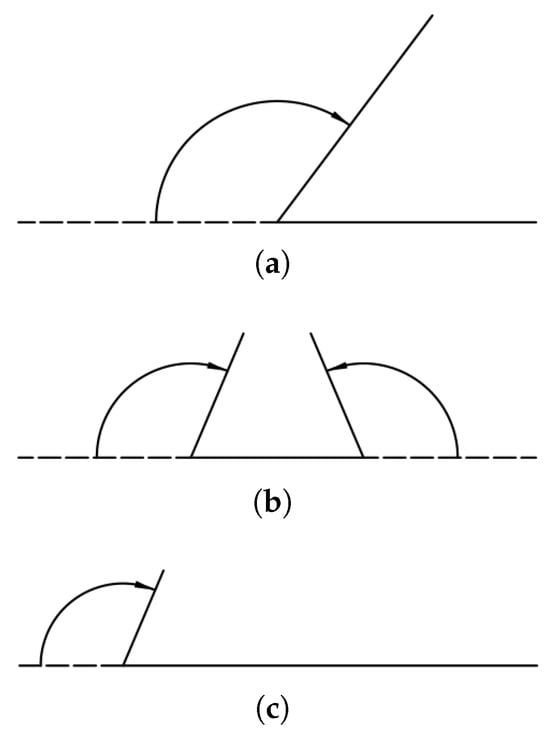
Figure 6.
Various folding styles. (a) Two-folded folding. (b) Three-folded folding. (c) Multiple-folded folding.
Herein, we introduce a method that folds a long strip into a specified number of smaller segments and performs synchronized searches on these folded segments. Assume a strip S persists n points; express n in the form , namely,
where M, W, and R are integers such that and .
Then S can be partitioned segments. Among these segments, the shortest one contains R points, and the remaining ones collectively consist of points. Obviously, each segment can be searched independently by either a parallel or a sequential technique. However, due to the characteristic of witnesses’ local accumulation within a global sparsity, some segments might contain no witnesses. Under such circumstances, folding these segments with v-folding is a reasonable measure to reduce the occurrence of the vanity in the segments. Because the shortest segment contains the fewest points, it can be searched first. If the search does not find an expected result, according to Corollary 4 and Remark 6, for any integer k satisfying , the segments can be folded onto segments, each containing exactly W points available for further searching.
Let be the strip of the segments; assume is the strip obtained after k times of the v-folds of ; then, it follows by (16)
where and .
Assume is the starting Y-coordinate of ; then, for an integer j satisfying , the segment of is given by
4.2. Folding and Searching Dataset
This subsection outlines the folding characteristic of , proposes a method for folding and searching it.
4.2.1. Structure and Folding Characteristics of
For an odd composite integer N and a parameter g, the dataset defined in [21] is mathematically described by
where , , and the imprint of the lattice point is given by
contains rows and columns, a total of elements. Figure 7 shows the imprints of generated by and .

Figure 7.
Dataset generated by and .
Seen in [21], itself is symmetric with respect to its center and the witnesses in it distribute in a right-down pattern (in the direction parallel to the line ), also accumulating locally within global sparsity. Figure 8 depicts the witnesses and non-witnesses in Figure 7.
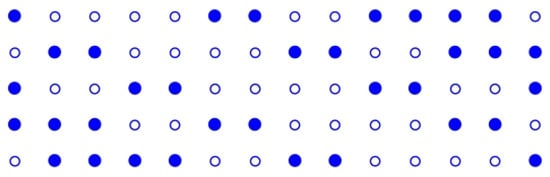
Figure 8.
Witness and non-witness in of and .
With such a distribution, both v-folds and h-folds are needed to obtain a denser distribution of the witnesses. Take the case of Figure 8 as an example; after an h-fold, it is turned into Figure 9.

Figure 9.
Result of folding Figure 8 by an h-fold.
Performing 2 times of v-folds turns Figure 9 into Figure 10a and Figure 10b, respectively. It is seen that the last fold leads to quite a high probability of randomly selecting a point of witness.
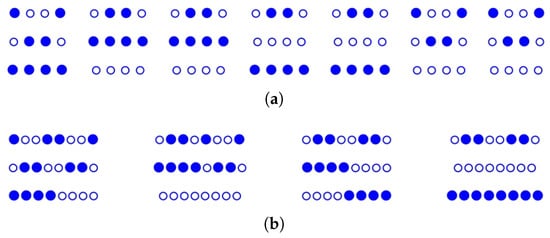
The probability of randomly selecting a witness in has been estimated in [21] by
which is approximately for a large N
Hence, for a given N satisfying , applying iterations of h-folds or v-folds, or iterations of -folds, where positive integers s and t satisfy the condition , can significantly increase the probability of randomly selecting a witness.
4.2.2. A Strategy for Folding and Searching
It has been shown in [19] that one -fold of generates the same resulting sheet as one -fold, with witnesses distributed in an approximately random manner across the resultant sheet. Meanwhile, the study [26] has proven that the first and last rows contain an identical number of witnesses, and that number is the maximum count across all rows. Based on these findings, a two-step folding and searching strategy is drawn as follows:
- (1)
- Conduct an h-fold of the last row onto the first row to obtain a folded strip S.
- (2)
- Fold and search S with the same approach as folding and searching a strip of .
4.2.3. An Approach Folding and Searching
Because is a vast number for a big N, the h-fold of the last row onto the first row requires pre-partitioning the rows into smaller segments, similar to partitioning the long strip of . This can be achieved by still referring to Formula (24).
Consider each of the first and last rows is partitioned into segments, among which the shortest one contains R points and the other ones contain collectively points, where and . If the shortest segment is searched without an expected result, let , be the two strips formed by the consecutive segments from the first and last rows, respectively, and be the strip folded by the h-fold of onto ; then,
where the superscript j ranges from 1 to .
Denote to be the strip from being symmetrically folded by k times; it follows
where the superscript k satisfies and i ranges from 1 to .
4.3. Superimposing on and Searching It
Restrict X and Y by
Then, and contain the same number of rows and columns for a given , and thus the two can be superimposed on each other. Denote the superimposed result with the symbol , namely, ; then, the witnesses in are more than in either or . Figure 11 exhibits the witnesses and non-witnesses within that are produced by taking , and . This time, utilizing on the SPRSA searching method introduced in [20] generally brings a higher efficiency than on .

Figure 11.
Witnesses and non-witnesses in by and .
4.4. Numerical Experiments
Numerical experiments were conducted using computers equipped with an Intel(R) Core(TM) i5-10500 CPU @ 3.10 GHz, 16 GB of RAM, and the Windows 10 operating system, implemented in Python 3. The experimental data were sourced from [20,21], originally presented in [27]. The results are summarized in Table 1, Table 2, Table 3, Table 4 and Table 5. In these tables, the column labeled “Integer N” denotes the semi-prime integers to be factored; the “Digits” column indicates the number of decimal digits in N; “Time 1” represents the computational time reported in [20]; “Time 2” corresponds to the time reported in [21]; “Time 3” is the time after folding ; “Time 4” is the time after folding ; and “Time 5” refers to the time after superimposing onto . All the times are measured in seconds, and the Monte Carlo search method was employed throughout, consistent with the approach used in [20,21]. The results demonstrate that folding and superimposing operations yield improved computational efficiency, thereby supporting the theoretical analysis.

Table 1.
Comparison of Time Consumption in Group 1.
Table 2.
Comparison of Time Consumption in Group 2.
Table 3.
Comparison of Time Consumption in Group 3.
Table 4.
Comparison of Time Consumption in Group 4.
Table 5.
Comparison of Time Consumption in Group 5.
4.5. More Application Scenarios
The method of symmetric folding can be applied to more scenarios than just identifying a divisor of a composite integer, which is an essential topic in cryptography. Since the folding operations are actually performed on the indices of the elements in a matrix-formed dataset, as expressed in the formulations (5)–(20), the method can be generally applied to any countable, structured dataset. Here are some examples.
- Blind search issue. A blind search searches for objectives within a restricted area without previously assigning information about them. A concrete example of such a search is fault diagnosis in industry, such as detecting the fault spot within a material through data analysis, identifying the faulty component in a large-scale integrated circuit, and so on. Those detections are always performed with an embedded diagnosis system. By structuring the source data, folding can improve the computational efficiency of the system.
- Database issue. A database is a structured repository for storing and frequently accessing large volumes of data. Each database can be conceptualized as a sheet composed of rows and columns. According to Remarks 4 and 6, applying k iterations of symmetric folding results in a single cell in the folded sheet corresponding to distinct cells in the original database. As a result, querying a single cell in the folded sheet provides simultaneous access to cells in the original database, thereby significantly improving search efficiency.
- Engineering optimization issue. Engineering optimization constantly searches for a solution in a large computational domain. Partitioning the domain first and then folding the partitioned result, as we do with and , can lead to multiple subdomains being synchronically searched, thus enhancing computational efficiency.
5. Conclusions and Future Work
Based on the physical principle that symmetric folding can bring points on a paper sheet closer together, we have developed mathematical models for symmetrically folding a dataset represented in matrix form and have formulated the corresponding computational procedures. Since this folding process both increases the density of witnesses and reduces the gaps between non-witnesses, a witness-based randomized approach can either efficiently identify a witness or rapidly traverse a non-witness, thereby improving overall search efficiency. The mathematical analysis, grounded in an abstract countable dataset, ensures that our theoretical results and computational formulations can be applied to any arbitrary finite countable dataset. Although our practical examples demonstrate the method by identifying a divisor of an odd composite integer, our framework remains general.
Nevertheless, certain aspects remain for future investigation, such as the development of random search algorithms on two-dimensional regions formed through multiple hybrid folding operations and how such techniques further enhance random search efficiency. Furthermore, researches on multi-dimensional folding, finding a optimal folding sequence, and folding an irregular dataset also challenge our future work. We hope that more young researchers will engage in this area to produce even deeper and more valuable results.
Funding
This research was supported by Natural Science Foundation of Guangdong Province (2024A1515010021) and Guangzhou University of Software (KY202501).
Data Availability Statement
The source codes of the numerical experiments are accessed at the Python forum thread: https://python-forum.io/thread-45621-post-188242.html#pid188242 (accessed on 30 October 2025).
Conflicts of Interest
The author declares no conflicts of interest.
References
- Littman, M.L. The Witness Algorithm: Solving Partially Observable Markov Decision Processes; Technical report; Brown University: Providence, RI, USA, 1994. [Google Scholar]
- Poupart, P. Exploiting Structure to Efficiently Solve Large-Scale Partially Observable Decision Processes. Ph.D. Dissertation, The University of Toronto, Toronto, ON, Canada, 2005. [Google Scholar]
- Alon, N.; Naor, M. Derandomization, witnesses for Boolean matrix multiplication and construction of perfect hash functions. Algorithmica 1996, 16, 434–449. [Google Scholar] [CrossRef]
- Du, W.; Deng, J.; Han, Y.S.; Varshney, P.K. A witness-based approach for data fusion assurance in wireless sensor networks. In Proceedings of the IEEE Global Telecommunications Conference, San Francisco, CA, USA, 1–5 December 2003. [Google Scholar] [CrossRef]
- Frederix, D. Starting in the Middle: Witness-Based Itemset Mining. Master’s Thesis, Kargolieke University, Leuven, Belgium, 2014. [Google Scholar]
- Chini, P.; Massoud, R.; Meyer, R.; Saivasan, P. Fast Witness Counting. arXiv 2018, arXiv:1807.05777. [Google Scholar] [CrossRef]
- Saan, S. Witness Generation for Data-Flow Analysis. Master’s Thesis, University of Tartu, Tartu, Estonia, 2020. [Google Scholar]
- Nguyen, L.D.; Leyva-Mayorga, I.; Popovski, P. Witness-based Approach for Scaling Distributed Ledgers to Massive IoT Scenarios. In Proceedings of the 2020 IEEE 6th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 2–16 June 2020. [Google Scholar] [CrossRef]
- Xie, X.; Chen, Y.C.; Wang, J.R.; Wu, Y. Witness-Based Searchable Encryption with Aggregative Trapdoor. In Security with Intelligent Computing and Big-Data Services (SICBS 2018); Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Ayaziova, P.; Beyer, D.; Lingsch-Rosenfeld, M.; Spiessl, M.; Strejcek, J. Software Verification Witnesses 2.0. In Model Checking Software; Neele, T., Wijs, A., Eds.; Springer: Cham, Switzerland, 2025; pp. 184–203. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, T.; Huang, X.; Fei, S. Witness based nonlinear detection of quantum entanglement. arXiv 2025, arXiv:2502.02868. [Google Scholar] [CrossRef] [PubMed]
- Richard, M.K. An introduction to randomized algorithms. Discret. Appl. Math. 1991, 34, 165–201. [Google Scholar] [CrossRef]
- Motwani, R.; Raghavan, P. Randomized algorithms. ACM Comput. Surv. 1995, 28, 33–37. [Google Scholar] [CrossRef]
- Hromkovič, J. Algorithmic Adventures: From Knowledge to Magic; Springer: Berlin/Heidelberg, Germany, 2009; p. 210. [Google Scholar] [CrossRef]
- Ronald, T.K. The Art of Randomness: Randomized Algorithms in the Real World; No Starch Press: San Francisco, CA, USA, 2024; p. 638. [Google Scholar]
- Aspnes, J. Notes on Randomized Algorithms. arXiv 2024, arXiv:2003.01902. [Google Scholar] [CrossRef]
- Hromkovič, J. Design and Analysis of Randomized Algorithms; Springer: Berlin/Heidelberg, Germany, 2005; p. 183. [Google Scholar] [CrossRef]
- Sharma, K.; Garg, D. Randomized Algorithms: Methods and Techniques. Int. J. Comput. Appl. 2011, 28, 29–32. [Google Scholar] [CrossRef]
- Huang, Y.; Wang, X. A Property of Point Symmetry Under Symmetric Folding Transformation. Asian Res. J. Math. 2025, 21, 43–50. [Google Scholar] [CrossRef]
- Li, H.; Liu, Z.; Wang, X. A Dataset and A Dynamic Distributed Parallel Network for Identifying Divisors of Odd Composite Integers. J. Adv. Math. Comput. Sci. 2025, 40, 104–129. [Google Scholar] [CrossRef]
- Liu, Z.; Li, H.; Wang, X. A Novel Dataset and Algorithm for Identifying Divisors of an Odd Composite Integer Using Distributed Parallel Network. J. Adv. Math. Comput. Sci. 2025, 40, 105–120. [Google Scholar] [CrossRef]
- The Math Forum Drexel University and Jessica Wolk-Stanley. In Dr. Math Introduces Geometry; John Wiley & Sons: Hoboken, NJ, USA, 2004; p. 137.
- Umble, R.N.; Han, Z. Transformational Plane Geometry; CRC Press: Boca Raton, FL, USA, 2015; p. 133. [Google Scholar]
- MathBitsNotebook Symmetry in Geometry; Mathbitsnotebook: New York, NY, USA, 2025.
- Graham, R.L.; Knuth, E.E.; Patashnik, O. Concrete Mathematics: A Foundation for Computer Science, 2nd ed.; Addison-Wesley Publishing Company: Boston, MA, USA, 1994; pp. 67–101. [Google Scholar]
- Liu, Y.; Wang, X. A Boundary Property of Dataset ΠC. Int. J. Math. Trends Technol. 2025, 71, 28–32. [Google Scholar] [CrossRef]
- Mahadee, A.M.; Kamrujjaman, M. Cryptanalysis of RSA Cryptosystem: Prime Factorization using Genetic Algorithm. arXiv 2024, arXiv:2407.05944. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).