

A Study on Network Anomaly Detection Using Fast Persistent Contrastive Divergence

 ,
,  and
and 
Abstract
1. Introduction
2. Related Works
2.1. Deep-Learning-Based Network Intrusion Detection
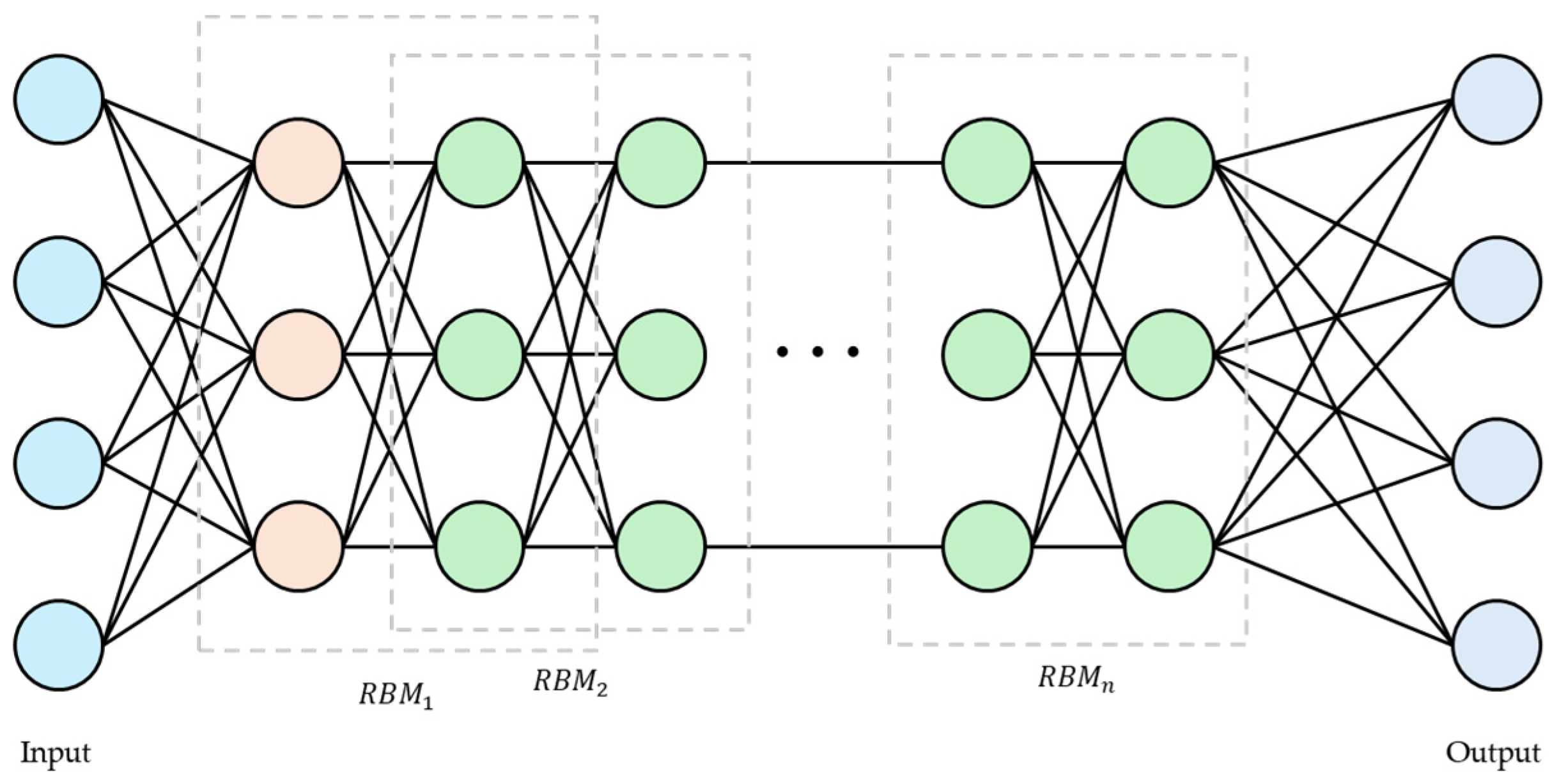
2.2. Deep Belief Network
2.3. Contrastive Divergence
3. Fast-Persistent-Contrastive-Divergence-Method-Based Deep Belief Network
3.1. Dataset Preprocessing
3.2. Training FPCD-DBN
4. Experiments
4.1. Datasets
4.2. Performance Evaluation
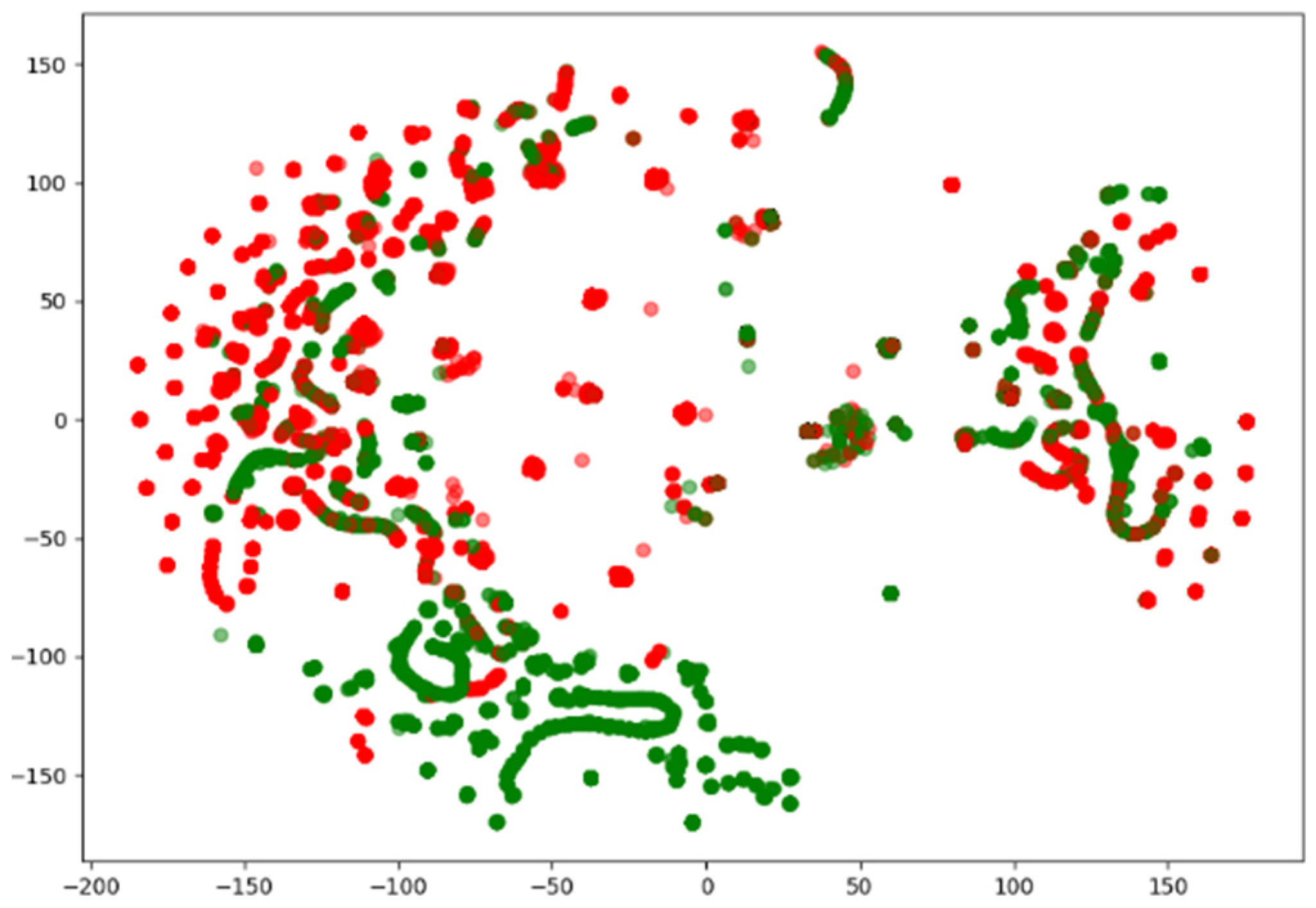
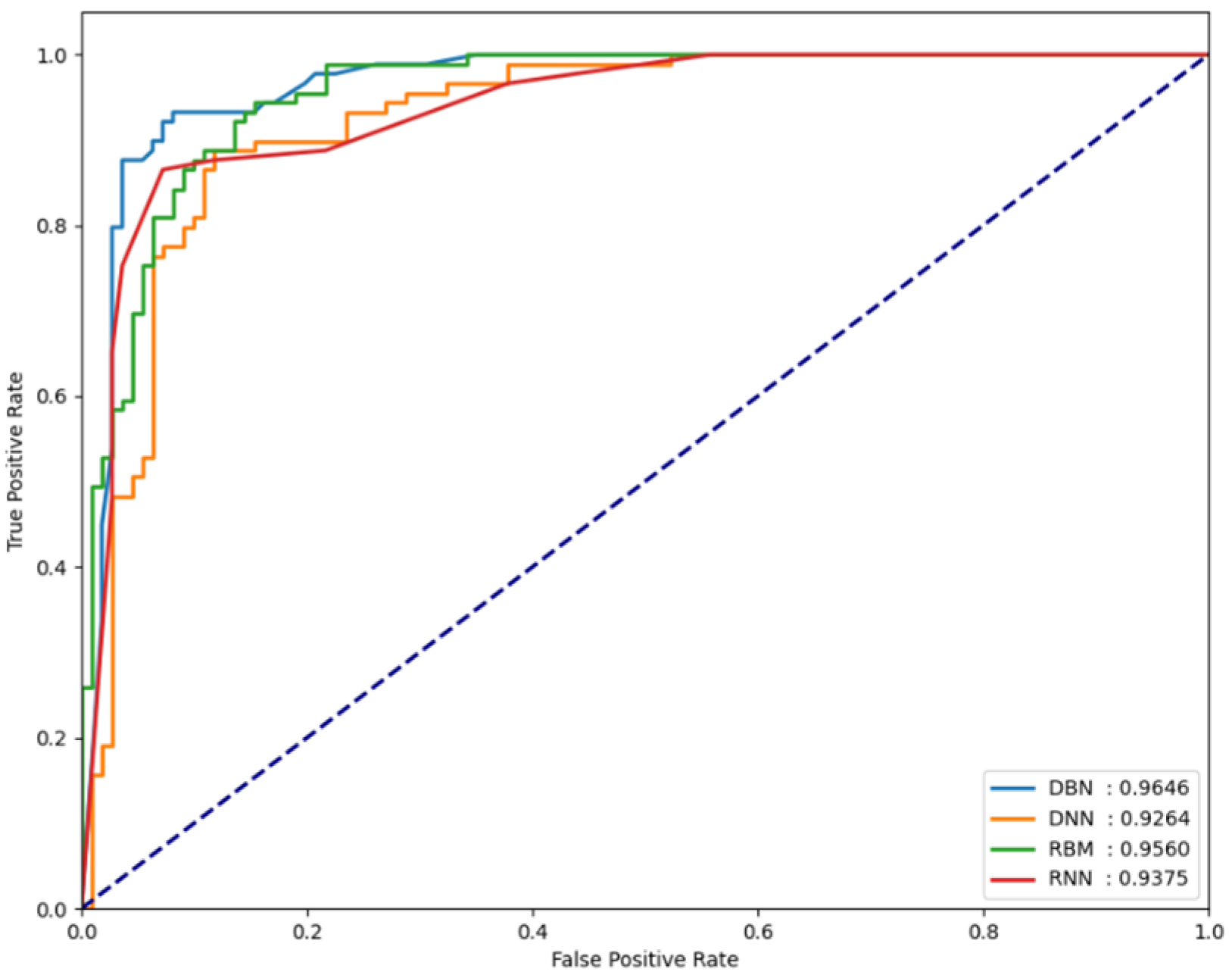
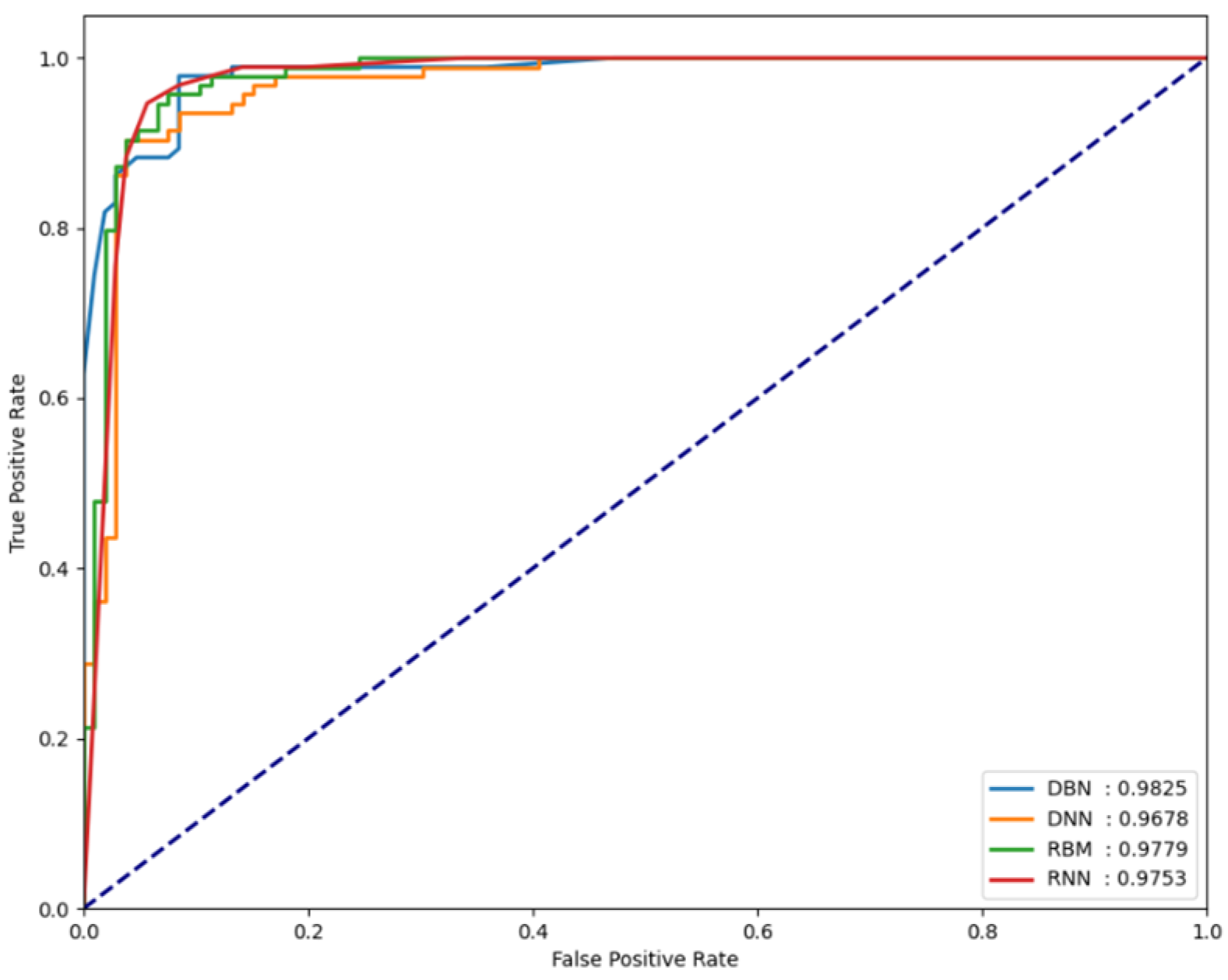
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Barbir, A.; Murphy, S.; Yang, Y. RFC 4593: Generic Threats to Routing Protocols. Available online: http://www.ietf.org/rfc/rfc4593.txt (accessed on 3 September 2024).
- Cisco Annual Internet Report (2018–2023) White Paper. Available online: https://www.cisco.com/c/en/us/solutions/collateral/executive-perspectives/annual-internet-report/white-paper-c11-741490.html (accessed on 3 September 2024).
- Bace, R.G.; Mell, P. Intrusion Detection Systems; Special Publication (NIST SP), Report Number 800-31; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2001. Available online: https://www.nist.gov/publications/intrusion-detection-systems (accessed on 9 September 2024).
- Liao, H.J.; Lin, C.H.R.; Lin, Y.C.; Tung, K.Y. Intrusion detection system: A comprehensive review. J. Netw. Comput. Appl. 2013, 36, 16–24. [Google Scholar] [CrossRef]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep learning for anomaly detection: A review. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Hasib, K.M.; Iqbal, M.S.; Shah, F.M.; Mahmud, J.A.; Popel, M.H.; Showrov, M.I.H.; Ahmed, S.; Rahman, O. A survey of methods for managing the classification and solution of data imbalance problem. J. Comput. Sci. 2020, 16, 1546–1557. [Google Scholar] [CrossRef]
- Fischer, A.; Igel, C. An introduction to restricted Boltzmann machines. In Proceedings of the Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications: 17th Iberoamerican Congress, CIARP 2012, Buenos Aires, Argentina, 3–6 September 2012; pp. 14–36. [Google Scholar] [CrossRef]
- Hinton, G.E. Deep belief networks. Scholarpedia 2009, 4, 5947. [Google Scholar] [CrossRef]
- Xiao, C.; Gou, Z.; Tai, W.; Zhang, K.; Zhou, F. Imputation-based time-series anomaly detection with conditional weight-incremental diffusion models. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Long Beach, CA, USA, 4 August 2023; pp. 2742–2751. [Google Scholar] [CrossRef]
- Xu, J.; Wu, H.; Wang, J.; Long, M. Anomaly transformer: Time series anomaly detection with association discrepancy. arXiv 2021, arXiv:2110.02642. [Google Scholar] [CrossRef]
- Yang, Y.; Zheng, K.; Wu, C.; Yang, Y. Improving the classification effectiveness of intrusion detection by using improved conditional variational autoencoder and deep neural network. Sensors 2019, 19, 2528. [Google Scholar] [CrossRef]
- Radford, B.J.; Apolonio, L.M.; Trias, A.J.; Simpson, J.A. Network traffic anomaly detection using recurrent neural networks. arXiv 2018, arXiv:1803.10769. [Google Scholar] [CrossRef]
- Kim, J.; Kim, J.; Kim, H.; Shim, M.; Choi, E. CNN-based network intrusion detection against denial-of-service attacks. Electronics 2020, 9, 916. [Google Scholar] [CrossRef]
- Tian, Y.; Mirzabagheri, M.; Bamakan, S.M.H.; Wang, H.; Qu, Q. Ramp loss one-class support vector machine; a robust and effective approach to anomaly detection problems. Neurocomputing 2018, 310, 223–235. [Google Scholar] [CrossRef]
- Zavarak, S.; Iskefiyeli, M. Anomaly-based intrusion detection from network flow features using variational autoencoder. IEEE Access 2020, 8, 108346–108358. [Google Scholar] [CrossRef]
- Kim, G.; Yi, H.; Lee, J.; Paek, Y.; Yoon, S. LSTM-based system-call language modeling and robust ensemble method for designing host-based intrusion detection systems. arXiv 2016, arXiv:1611.01726. [Google Scholar] [CrossRef]
- Aldwairi, T.; Perera, D.; Novotny, M.A. An evaluation of the performance of Restricted Boltzmann Machines as a model for anomaly network intrusion detection. Comput. Netw. 2018, 144, 111–119. [Google Scholar] [CrossRef]
- Sharma, H.S.; Singh, K.J. A feed forward deep neural network model using feature selection for cloud intrusion detection system. Concurr. Comput. Pract. Exp. 2024, 36, e8001. [Google Scholar] [CrossRef]
- Sharma, H.S.; Singh, K.J. Intrusion detection system: A deep neural network-based concatenated approach. J. Supercomput. 2024, 80, 13918–13948. [Google Scholar] [CrossRef]
- Carreira-Perpinan, M.A.; Hinton, G. On contrastive divergence learning. In Proceedings of the International Workshop on Artificial Intelligence and Statistics, Bridgetown, Barbados, 6–8 January 2005; Volume R5, pp. 33–40. Available online: https://proceedings.mlr.press/r5/carreira-perpinan05a.html (accessed on 3 September 2024).
- Berglund, M.; Raiko, T. Stochastic gradient estimate variance in contrastive divergence and persistent contrastive divergence. arXiv 2013, arXiv:1312.6002. [Google Scholar] [CrossRef]
- Tieleman, T.; Hinton, G. Using fast weights to improve persistent contrastive divergence. In Proceedings of the 26th Annual International Conference on Machine Learning Held in Conjunction with the 2007 International Conference on Inductive Logic Programming, Montreal, QC, Canada, 14–18 June 2009; pp. 1033–1040. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. NSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Stiawan, D.; Idris, M.Y.B.; Bamhdi, A.M.; Budiarto, R. CICIDS-2017 Dataset Feature Analysis With Information Gain for Anomaly Detection. IEEE Access 2020, 8, 132911–132921. [Google Scholar] [CrossRef]
- Aygun, R.C.; Yavuz, A.G. Network anomaly detection with stochastically improved autoencoder based models. In Proceedings of the 2017 IEEE 4th International Conference on Cyber Security and Cloud Computing (CSCloud), New York, NY, USA, 26–28 June 2017; pp. 193–198. [Google Scholar] [CrossRef]
- Zhou, X.; Hu, Y.; Liang, W.; Ma, J.; Jin, Q. Variational LSTM enhanced anomaly detection for industrial big data. IEEE Trans. Ind. Inform. 2020, 17, 3469–3477. [Google Scholar] [CrossRef]
- Min, B.; Yoo, J.; Kim, S.; Shin, D.; Shin, D. Network anomaly detection using memory-augmented deep autoencoder. IEEE Access 2021, 9, 104695–104706. [Google Scholar] [CrossRef]
- Tang, T.A.; Mhamdi, L.; McLernon, D.; Zaidi, S.A.R.; Ghogho, M. Deep learning approach for network intrusion detection in software defined networking. In Proceedings of the 2016 International Conference on Wireless Networks and Mobile Communications (WINCOM), Fez, Morocco, 26–29 October 2016; pp. 258–263. [Google Scholar] [CrossRef]
- Yin, C.; Zhu, Y.; Fei, J.; He, X. A deep learning approach for intrusion detection using recurrent neural networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Aggarwal, P.; Sharma, S.K. Analysis of KDD dataset attributes-class wise for intrusion detection. Procedia Comput. Sci. 2015, 57, 842–851. [Google Scholar] [CrossRef]
- Naseer, S.; Saleem, Y.; Khalid, S.; Bashir, M.K.; Han, J.; Iqbal, M.M.; Han, K. Enhanced network anomaly detection based on deep neural networks. IEEE Access 2018, 6, 48231–48246. [Google Scholar] [CrossRef]
- Khan, F.A.; Gumaei, A. A comparative study of machine learning classifiers for network intrusion detection. In Proceedings of the Artificial Intelligence and Security: 5th International Conference, ICAIS 2019, New York, NY, USA, 26–28 July 2019; pp. 75–86. [Google Scholar] [CrossRef]
- Malaiya, R.K.; Kwon, D.; Suh, S.C.; Kim, H.; Kim, I.; Kim, J. An empirical evaluation of deep learning for network anomaly detection. IEEE Access 2019, 7, 140806–140817. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Hidden Layer Dimension | 12-6-3 |
| Batch Size | 64 |
| Momentum | 0.9 |
| Activation Function | ReLU, Sigmoid |
| Optimizer/Learning Rate | Adam/0.001 |
| Loss Function | MSE |
| Title 1 | Train Dataset | Test Dataset | ||
|---|---|---|---|---|
| Benign | Attack | Benign | Attack | |
| NSL-KDD | 67,343 | 58,630 | 12,833 | 9711 |
| UNSW-NB15 | 119,341 | 56,000 | 45,332 | 37,000 |
| CIC-IDS-2017 | 1,704,822 | 418,234 | 568,275 | 139,412 |
| Predicted | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual | Positive | True Positive (TP) | False Negative (FN) |
| Negative | False Positive (FP) | True Negative (TN) | |
| Parameter | Value | ||
|---|---|---|---|
| NSL-KDD | UNSW-NB15 | CIC-IDS-2017 | |
| DBN | 0.9637 | 0.9646 | 0.9825 |
| DNN | 0.9437 | 0.9262 | 0.9678 |
| RBM | 0.9127 | 0.9560 | 0.9779 |
| RNN | 0.9301 | 0.9375 | 0.9753 |
| Methods | Metrics | |||
|---|---|---|---|---|
| Accuracy | Precision | Recall | F1 Score | |
| DNN [28] | 0.7575 | - | - | - |
| RNN-IDS [29] | 0.8129 | - | - | - |
| RT [30] | 0.8621 | 0.8078 | 0.9416 | 0.8696 |
| AE [25] | 0.8828 | 0.9123 | 0.8786 | 0.8951 |
| DAE [25] | 0.8865 | 0.9648 | 0.8308 | 0.8928 |
| LSTM [31] | 0.8900 | - | - | - |
| FPCD-DBN | 0.8939 | 0.8951 | 0.8983 | 0.8972 |
| Methods | Metrics | |||
|---|---|---|---|---|
| Accuracy | Precision | Recall | F1 Score | |
| NB [32] | 0.7639 | 0.7820 | 0.7640 | 0.7729 |
| SVM [33] | 0.8190 | 0.9730 | 0.7560 | 0.8210 |
| RF [26] | 0.8363 | 0.8690 | 0.8360 | 0.8522 |
| SSAE [26] | - | 0.7310 | 0.9630 | 0.8320 |
| MemAE [27] | 0.8530 | 0.8774 | 0.8530 | 0.8526 |
| FPCD-DBN | 0.8662 | 0.8841 | 0.8816 | 0.8828 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, J.; Park, S.; Lim, J.; Kang, J.; Shin, D.; Shin, D. A Study on Network Anomaly Detection Using Fast Persistent Contrastive Divergence. Symmetry 2024, 16, 1220. https://doi.org/10.3390/sym16091220
Jeong J, Park S, Lim J, Kang J, Shin D, Shin D. A Study on Network Anomaly Detection Using Fast Persistent Contrastive Divergence. Symmetry. 2024; 16(9):1220. https://doi.org/10.3390/sym16091220
Chicago/Turabian StyleJeong, Jaeyeong, Seongmin Park, Joonhyung Lim, Jiwon Kang, Dongil Shin, and Dongkyoo Shin. 2024. "A Study on Network Anomaly Detection Using Fast Persistent Contrastive Divergence" Symmetry 16, no. 9: 1220. https://doi.org/10.3390/sym16091220
APA StyleJeong, J., Park, S., Lim, J., Kang, J., Shin, D., & Shin, D. (2024). A Study on Network Anomaly Detection Using Fast Persistent Contrastive Divergence. Symmetry, 16(9), 1220. https://doi.org/10.3390/sym16091220