

Enhancing Oracle Bone Character Category Discovery via Character Component Distillation and Self-Merged Pseudo-Label

Abstract
1. Introduction
- We propose an OBC category discovery method with a symmetrical structure that effectively recognizes novel OBC categories from unlabeled data.
- To reinforce the learned representation, we propose a character component distillation procedure that distills character components in symmetrical views by extracting spatial-disjoint components from foreground masks based on K-means clustering.
- To compensate for the asymmetrical supervision, we propose a self-merged pseudo-label based on the predictions of the model and a symmetrical teacher for known and novel categories as stable and robust supervision for unlabeled data.
2. Related Research
2.1. Oracle Bone Character Recognition
2.2. Generalized Category Discovery
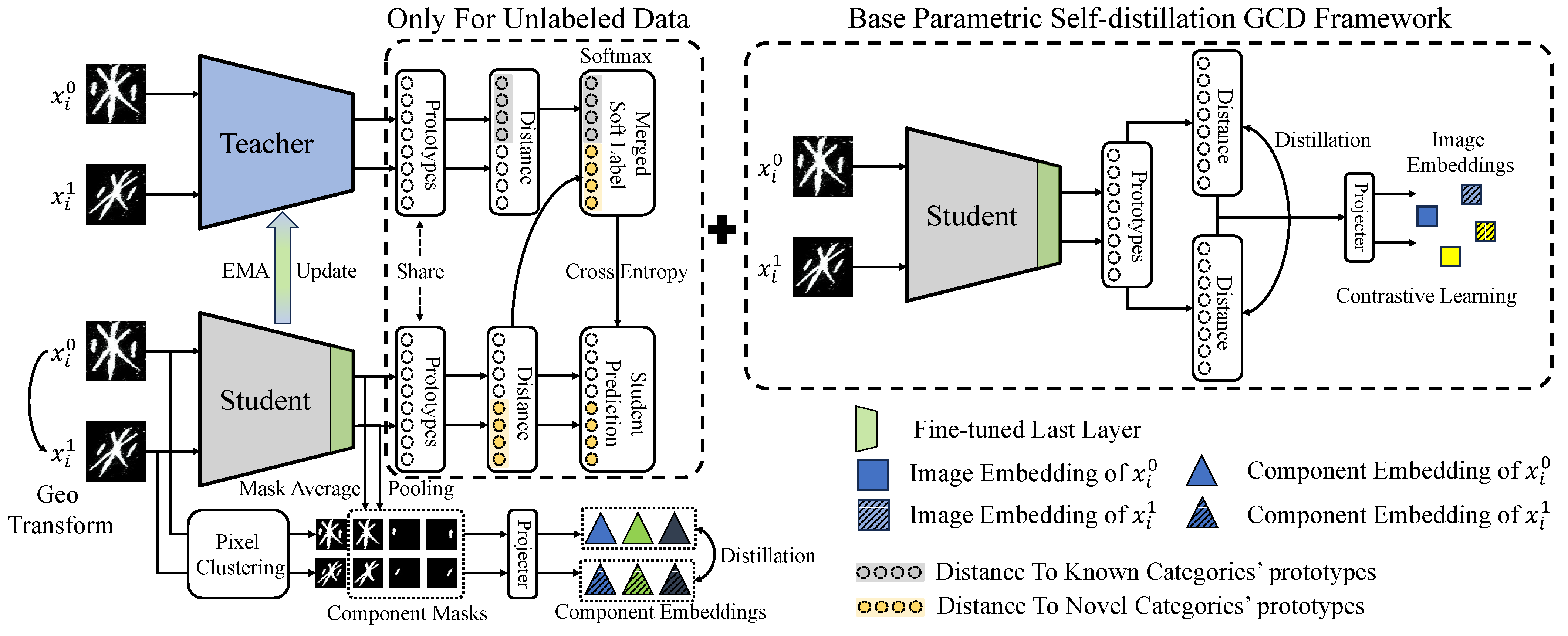
3. Proposed Method
3.1. Preliminary
3.2. Geometric Transforms for Generating Contrastive Views
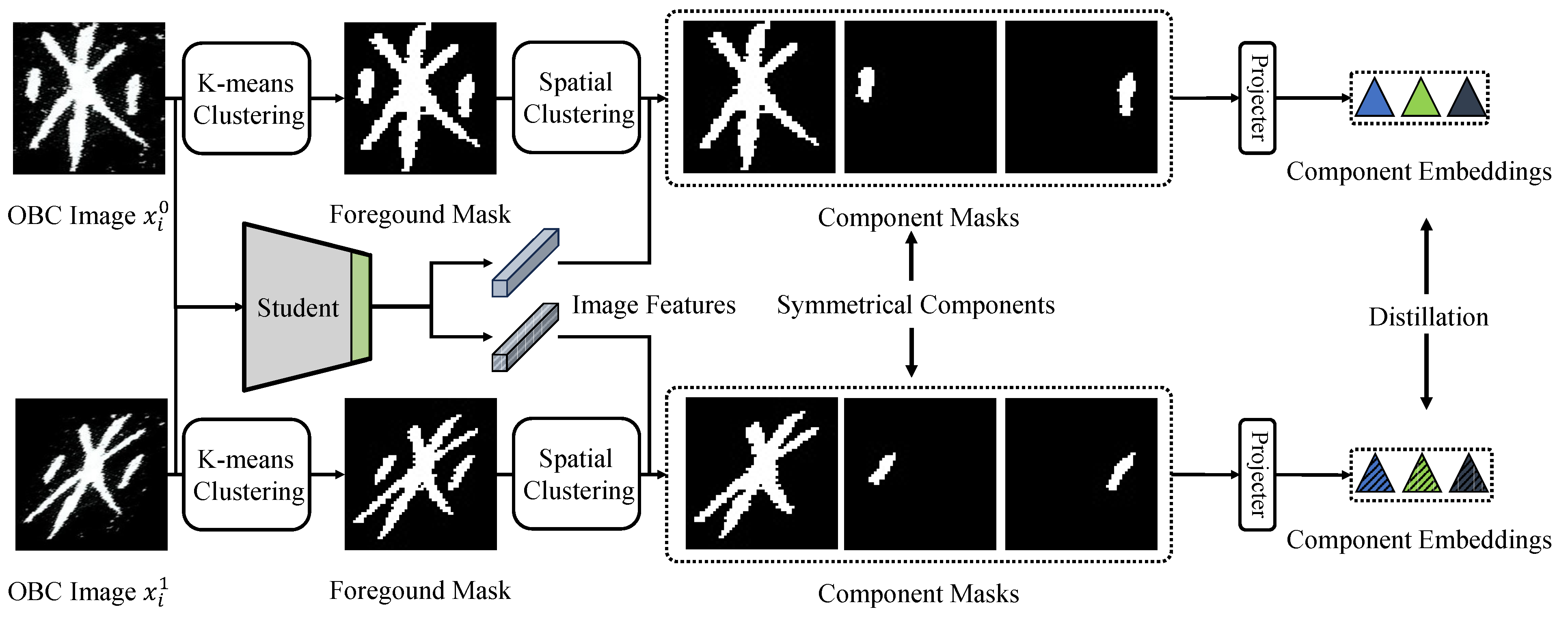
3.3. Character Component Distillation
3.4. Self-Merged Pseudo-Label
4. Experiments
4.1. Datasets and Evaluation
4.2. Implementation Details
4.3. Comparison with State-of-the-Art Methods
4.4. Ablation Study
4.5. Time Complexity
5. Discussion
5.1. Methodology
5.2. The Opted Teacher–Student Framework
5.3. Limitations and Future Research
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Gao, F.; Zhang, J.; Liu, Y.; Han, Y. Image Translation for Oracle Bone Character Interpretation. Symmetry 2022, 14, 743. [Google Scholar] [CrossRef]
- Guan, H.; Yang, H.; Wang, X.; Han, S.; Liu, Y.; Jin, L.; Bai, X.; Liu, Y. Deciphering Oracle Bone Language with Diffusion Models. arXiv 2024, arXiv:2406.00684. [Google Scholar]
- Zhang, Z.; Guo, A.; Li, B. Internal Similarity Network for Rejoining Oracle Bone Fragment Images. Symmetry 2022, 14, 1464. [Google Scholar] [CrossRef]
- Gao, F.; Chen, X.; Li, B.; Liu, Y.; Jiang, R.; Han, Y. Linking unknown characters via oracle bone inscriptions retrieval. Multimed. Syst. 2024, 30, 125. [Google Scholar] [CrossRef]
- Hu, Z.; Cheung, Y.M.; Zhang, Y.; Zhang, P.; Tang, P.L. Component-Level Oracle Bone Inscription Retrieval. In Proceedings of the International Conference on Multimedia Retrieval, Phuket, Thailandp, 10–14 June 2024; pp. 647–656. [Google Scholar]
- Qiao, R.; Yang, L.; Pang, K.; Zhang, H. Making Visual Sense of Oracle Bones for You and Me. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle WA, USA, 17–21 June 2024; pp. 12656–12665. [Google Scholar]
- Zhang, Y.K.; Zhang, H.; Liu, Y.G.; Yang, Q.; Liu, C.L. Oracle Character Recognition by Nearest Neighbor Classification with Deep Metric Learning. In Proceedings of the International Conference on Document Analysis and Recognition, Sydney, Australia, 20–25 September 2019; pp. 309–314. [Google Scholar]
- Chen, S.; Xu, H.; Weize, G.; Xuxin, L.; Bofeng, M. A classification method of oracle materials based on local convolutional neural network framework. IEEE Comput. Graph. Appl. 2020, 40, 32–44. [Google Scholar] [CrossRef]
- Liu, M.; Liu, G.; Liu, Y.; Jiao, Q. Oracle Bone Inscriptions Recognition based on Deep Convolutional Neural Network. J. Image Graph. 2020, 8, 114–119. [Google Scholar] [CrossRef]
- Gan, J.; Chen, Y.; Hu, B.; Leng, J.; Wang, W.; Gao, X. Characters as Graphs: Interpretable Handwritten Chinese Character Recognition via Pyramid Graph Transformer. Pattern Recognit. 2023, 137, 109317. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W.; Liu, C.L. Unsupervised Structure-Texture Separation Network for Oracle Character Recognition. IEEE Trans. Image Process. 2022, 31, 3137–3150. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Deng, W.; Su, S. Oracle Character Recognition using Unsupervised Discriminative Consistency Network. Pattern Recognit. 2024, 148, 110180. [Google Scholar] [CrossRef]
- Yue, X.; Li, H.; Fujikawa, Y.; Meng, L. Dynamic Dataset Augmentation for Deep Learning-Based Oracle Bone Inscriptions Recognition. ACM J. Comput. Cult. Herit. 2022, 15, 1–20. [Google Scholar]
- Wang, W.; Zhang, T.; Zhao, Y.; Jin, X.; Mouchere, H.; Yu, X. Improving Oracle Bone Characters Recognition via A CycleGAN-Based Data Augmentation Method. In Proceedings of the International Conference on Neural Information Processing, IIT, Indore, India, 22–26 November 2022; pp. 88–100. [Google Scholar]
- Li, J.; Wang, Q.F.; Huang, K.; Yang, X.; Zhang, R.; Goulermas, J.Y. Towards Better Long-tailed Oracle Character Recognition with Adversarial Data Augmentation. Pattern Recognit. 2023, 140, 109534. [Google Scholar] [CrossRef]
- Vaze, S.; Han, K.; Vedaldi, A.; Zisserman, A. Generalized Category Discovery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 8–24 June 2022; pp. 7482–7491. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. K-means++: The Advantages of Careful Seeding. In Proceedings of the SODA, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Pu, N.; Zhong, Z.; Sebe, N. Dynamic Conceptional Contrastive Learning for Generalized Category Discovery. In Proceedings of the Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7579–7588. [Google Scholar]
- Yang, X.; Pan, X.; King, I.; Xu, Z. Generalized Category Discovery with Clustering Assignment Consistency. In Proceedings of the International Conference on Neural Information Processing, Changsha, China, 20–23 November 2023. [Google Scholar]
- Wen, X.; Zhao, B.; Qi, X. Parametric Classification for Generalized Category Discovery: A Baseline Study. In Proceedings of the International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 16590–16600. [Google Scholar]
- Wang, H.; Vaze, S.; Han, K. SPTNet: An Efficient Alternative Framework for Generalized Category Discovery with Spatial Prompt Tuning. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Choi, S.; Kang, D.; Cho, M. Contrastive Mean-Shift Learning for Generalized Category Discovery. In Proceedings of the Computer Vision and Pattern Recognition, Seattle WA, USA, 17–21 June 2024; pp. 23094–23104. [Google Scholar]
- Guo, J.; Wang, C.; Roman-Rangel, E.; Chao, H.; Rui, Y. Building hierarchical representations for oracle character and sketch recognition. IEEE Tran. Image Process. 2015, 25, 104–118. [Google Scholar] [CrossRef] [PubMed]
- Meng, L.; Fujikawa, Y.; Ochiai, A.; Izumi, T.; Yamazaki, K. Recognition of Oracular Bone Inscriptions using Template Matching. Int. J. Comput. Theory Eng. 2016, 8, 53. [Google Scholar] [CrossRef]
- Yuan, J.; Chen, S.; Mo, B.; Ma, Y.; Zheng, W.; Zhang, C. R-GNN: Recurrent graph neural networks for font classification of oracle bone inscriptions. Herit. Sci. 2024, 12, 30. [Google Scholar] [CrossRef]
- Xu, Y.; Feng, Y.; Liu, J.; Song, S.; Xu, Z.; Zhang, L. Conf-UNet: A Model for Speculation on Unknown Oracle Bone Characters. In Proceedings of the Knowledge Science, Engineering and Management; Springer Nature: Cham, Switzerland, 2023; pp. 89–103. [Google Scholar] [CrossRef]
- Caron, M.; Bojanowski, P.; Joulin, A.; Douze, M. Deep Clustering for Unsupervised Learning of Visual Features. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 139–156. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised Contrastive Learning. In Proceedings of the Advances in Neural Information Processing Systems, virtual, 6–12 December 2020. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G.E. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the International Conference on Machine Learning, Addis Ababa, Ethiopia, 26–30 April 2020; Volume 119, pp. 1597–1607. [Google Scholar]
- Assran, M.; Caron, M.; Misra, I.; Bojanowski, P.; Bordes, F.; Vincent, P.; Joulin, A.; Rabbat, M.; Ballas, N. Masked Siamese Networks for Label-efficient Learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 456–473. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R.B. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9726–9735. [Google Scholar]
- Guan, T.; Shen, W.; Yang, X.; Feng, Q.; Jiang, Z.; Yang, X. Self-Supervised Character-to-Character Distillation for Text Recognition. In Proceedings of the International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 19473–19484. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean Teachers are Better Role Models: Weight-averaged Consistency Targets Improve Semi-supervised Deep Learning Results. In Proceedings of the International Conference on Learning Representations (Workshop), Toulon, France, 24–26 April 2017. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.; Cubuk, E.D.; Kurakin, A.; Li, C. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence. In Proceedings of the Advances in Neural Information Processing Systems, virtual, 6–12 December 2020. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging Properties in Self-Supervised Vision Transformers. In Proceedings of the International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 9630–9640. [Google Scholar]
- van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Oracle-241 | Oracle-241-Hand | OBI125 | |
|---|---|---|---|
| # Labeled Classes | 120 | 120 | 62 |
| # Unlabeled Classes | 241 | 241 | 125 |
| # Labeled Images | 12,136 | 2570 | 840 |
| # Unlabeled Images | 38,032 | 8291 | 2291 |
| Oracle-241 | Oracle-241-Hand | OBI125 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | All | Known | Novel | All | Known | Novel | All | Known | Novel |
| K-means [19] | 9.35 | 9.51 | 9.20 | 41.45 | 39.33 | 43.35 | 21.51 | 21.88 | 21.07 |
| GCD [18] | 56.88 | 64.84 | 53.15 | 67.87 | 77.13 | 63.71 | 26.98 | 42.62 | 17.92 |
| SimGCD [22] | 68.53 | 74.87 | 62.61 | 78.55 | 84.89 | 72.85 | 41.78 | 58.78 | 21.96 |
| SPT [23] | 64.47 | 78.84 | 51.05 | 70.16 | 79.57 | 61.69 | 50.14 | 67.43 | 29.97 |
| CMS [24] | 70.37 | 78.04 | 63.20 | 78.34 | 90.49 | 67.40 | 39.32 | 54.45 | 21.66 |
| Ours | 71.41 | 76.08 | 67.05 | 80.54 | 85.80 | 75.80 | 64.66 | 81.17 | 45.40 |
| Oracle-241 | Oracle-241-Hand | OBI125 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CDT | SST | All | Known | Novel | All | Known | Novel | All | Known | Novel |
| ✗ | ✗ | 66.82 | 76.32 | 57.94 | 80.11 | 87.55 | 73.41 | 55.48 | 77.61 | 29.67 |
| ✓ | ✗ | 67.28 | 76.30 | 58.85 | 80.24 | 87.15 | 74.02 | 56.71 | 78.37 | 31.45 |
| ✗ | ✓(plain) | 70.72 | 75.42 | 66.34 | 79.17 | 85.51 | 73.46 | 59.18 | 79.13 | 35.91 |
| ✗ | ✓ | 71.15 | 75.09 | 67.47 | 80.48 | 87.27 | 74.38 | 63.42 | 79.13 | 45.10 |
| ✓ | ✓ | 71.41 | 76.08 | 67.05 | 80.54 | 85.80 | 75.80 | 64.66 | 81.17 | 45.40 |
| Oracle-241 | Oracle-241-Hand | OBI125 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| All | Known | Novel | All | Known | Novel | All | Known | Novel | |
| 0.000025 | 66.29 | 76.06 | 57.16 | 79.44 | 87.66 | 72.03 | 56.16 | 75.06 | 34.12 |
| 0.00005 | 67.28 | 76.30 | 58.85 | 79.25 | 87.83 | 71.52 | 56.44 | 76.84 | 32.64 |
| 0.0001 | 65.86 | 76.50 | 55.91 | 80.24 | 87.15 | 74.02 | 56.71 | 78.37 | 31.45 |
| 0.0002 | 65.65 | 77.20 | 54.86 | 78.61 | 88.74 | 69.49 | 56.03 | 76.84 | 31.75 |
| Oracle-241 | Oracle-241-Hand | OBI125 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| All | Known | Novel | All | Known | Novel | All | Known | Novel | |
| immediate | 63.16 | 74.93 | 52.17 | 70.99 | 83.25 | 59.96 | 60.14 | 75.32 | 42.43 |
| 10 | 65.88 | 75.22 | 57.16 | 74.05 | 86.02 | 63.27 | 63.42 | 79.13 | 45.10 |
| 20 | 69.06 | 77.13 | 61.53 | 78.74 | 87.27 | 71.06 | 61.10 | 78.12 | 41.25 |
| 30 | 70.57 | 76.95 | 64.61 | 80.40 | 85.91 | 75.45 | 60.82 | 79.13 | 39.47 |
| 40 | 70.33 | 76.09 | 64.95 | 80.48 | 87.27 | 74.38 | 59.45 | 77.35 | 38.58 |
| 50 | 70.57 | 76.23 | 65.28 | 79.76 | 86.08 | 74.07 | 58.49 | 77.35 | 36.50 |
| 60 | 70.98 | 76.68 | 65.65 | 80.00 | 86.13 | 74.48 | 56.99 | 76.84 | 33.83 |
| 70 | 71.15 | 75.09 | 67.47 | 80.40 | 86.13 | 75.24 | 55.89 | 77.86 | 30.27 |
| Methods | GCD | SimGCD | SPT | CMS | Ours |
|---|---|---|---|---|---|
| Time | 101 s | 121 s | 145 s | 235 s | 170 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, X.; Li, Z.; Pan, S.; Fang, Y. Enhancing Oracle Bone Character Category Discovery via Character Component Distillation and Self-Merged Pseudo-Label. Symmetry 2024, 16, 1098. https://doi.org/10.3390/sym16091098
Wan X, Li Z, Pan S, Fang Y. Enhancing Oracle Bone Character Category Discovery via Character Component Distillation and Self-Merged Pseudo-Label. Symmetry. 2024; 16(9):1098. https://doi.org/10.3390/sym16091098
Chicago/Turabian StyleWan, Xiuan, Zhengchen Li, Shouyong Pan, and Yuchun Fang. 2024. "Enhancing Oracle Bone Character Category Discovery via Character Component Distillation and Self-Merged Pseudo-Label" Symmetry 16, no. 9: 1098. https://doi.org/10.3390/sym16091098
APA StyleWan, X., Li, Z., Pan, S., & Fang, Y. (2024). Enhancing Oracle Bone Character Category Discovery via Character Component Distillation and Self-Merged Pseudo-Label. Symmetry, 16(9), 1098. https://doi.org/10.3390/sym16091098