Abstract
In this paper, we first develop an active set identification technique, and then we suggest a modified nonmonotone line search rule, in which a new parameter formula is introduced to control the degree of the nonmonotonicity of line search. By using the modified line search and the active set identification technique, we propose a global convergent method to solve the NMF based on the alternating nonnegative least squares framework. In addition, the larger step size technique is exploited to accelerate convergence. Finally, a large number of numerical experiments are carried out on synthetic and image datasets, and the results show that our presented method is effective in calculating speed and solution quality.
1. Introduction
As a typical nonnegative data dimensionality reduction technology, nonnegative matrix factorization (NMF) [1,2,3,4,5] can efficiently mine hidden information from data, so it has been gradually applied to research into high-dimensional data. This method as a data reduction technique appears in many applications, such as image processing [2], text mining [6], blind source separation [7], clustering [8], music analysis [9], and hyperspectral imaging unmixing [10], to name a few. Generally speaking, the fundamental NMF problem can be summarized as follows: given an data matrix with and a predetermined positive integer , then NMF plans to find two nonnegative matrices and such that
Our visualization illustration of NMF is shown in Figure 1.
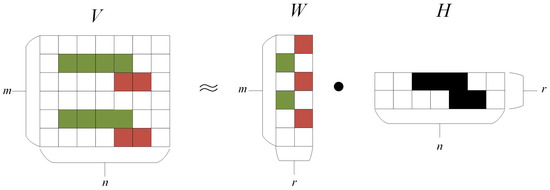
Figure 1.
Visualization illustration of NMF.
One of the most commonly used models of NMF (1) is
where is the Frobenius norm.
The project Barzilai-Borwein (PBB) algorithm is regarded as a popular and effective method for solving (2) which was originated by Barzilai and Borwein [11]. In recent years, a large number of studies [12,13,14,15,16] have shown that the PBB algorithm is a very effective algorithm in solving optimal problems. The PBB algorithm has the characteristics of simple calculation and high efficiency, so it has been paid attention to by various disciplines. So far, the research results based on the PBB have been widely used in the field of NMF (see [17,18,19,20,21]).
In view of the perfect symmetry of the interaction between W and H, we will focus on the updating of matrix W based on the PBB algorithm. Remember that is an approximate value of H after kth update, and there are
Original cost function (4) is the most frequently used form in the PBB method for NMF and has been widely and deeply researched [17,20,21,22,23]. But the major disadvantage of (4) is that it is not strongly convex [24,25,26,27,28], and we can only hope that this method can find a stationary point, rather than a global or local minimizer. To overcome this drawback, a proximal modification of cost function (4) is presented in [18,19], namely, the proximal cost function (5).
At present, the proximal cost function (5) has been used with the PBB method for NMF in [18,19]. When the cost function (5) is a strongly convex quadratic optimization problem, their lower bound is zero, so the subproblem (5) has a unique minimizer. In [18], the authors present a quadratic regularization nonmonotone PBB algorithm to solve (5) and established its global convergence result under mild conditions. Recently, it is revisited in [19] for the monotone PBB method and is also shown to converge globally to a stationary point of (3), and through the analysis of numerical experiments, it is proved that the monotone PBB method can win over the nonmonotone one under certain conditions. However, when solving the problems (4) and (5), the existing gradient methods based on the PBB converge slowly due to the nonnegative conditions. Therefore, this project intends to develop a new fast NMF algorithm.
In this paper, we introduce a prox-linear approximation of at based on which is the cost function (6). And then we propose an active set identification technique. Next, we present a modified nonmonotone line search technique so as to improve the efficiency of nonmonotone line search, in which a new parameter formula is presented to attempt to control the degree of the nonmonotonicity of line search, and thus improve both the possibility of finding the global optimal solution and the convergence speed. By using the active set identification strategy and the modified nonmonotone line search, a global convergent method is proposed to solve (6) based on the alternating nonnegative least squares framework. In particular, in each iteration, identification techniques are used to determine active and free variables. We take or to update some active variables, while using a projected Barzilai-Borwein method to update the free variables and some active variables. The calculation speed is improved by using the method of larger step size. Finally, through the numerical experiments of simulation data and image data, it is proved that the proposed algorithm is effective.
This paper is organized in the following manner. In Section 3, we introduce our estimation of active set, put forward an efficient NMF algorithm, and present the global convergence results of this method. The experimental results are given in Section 4. Finally, Section 5 is the conclusion of the thesis.
2. A Fast PBB Algorithm
In this section, we present an efficient algorithm for solving the NMF and establish the global convergence of our algorithm. Now, let us first introduce some main results of the objective function that we know.
Lemma 1
is Lipschitz continuous with the constant .
([29]). The following two statements are valid.
- (i)
- The objective function of (3) is convex.
- (ii)
- The gradient
In order to facilitate the discussion, we mainly focus on (6) and then rewrite it. Note that the cost function (7) is closely related to the one in Xu et al. [30], but has the following difference: matrix U is in our cost function (7), however, to [30] the matrix U is an extrapolation point in .
where the fixed matrix .
According to (ii) of the Lemma 1, is strictly convex in W for any given U. In each iteration, we will first solve the following strongly convex quadratic minimization problem, so as to obtain a value
Because the objective function of the problem (8) is strongly convex, the solution of the problem is unique and closed-form
Here, the operator projects all negative terms of X to zero.
Let , where is the direction which is obtained by (23) with being the BB stepsize [11], whereby we see that the convergence of can not be guaranteed. Therefore, a global optimization strategy is proposed based on the modified Armiji line search [31].
Therefore, a globalization strategy based on the modified Armiji line search [31] has been proposed, that is, we ask for a step size , so that
here . Owing to the maximum function, a good function value obtained in any iteration will be discarded, and the numerical performance depends largely on the selection of M in some cases (see [32]).
So as to overcome these shortcomings and obtain a large step size in each procedure, we present a modified nonmonotone line search rule. The modified line search is as follows: for the known iteration point and search direction at , we select , where , , where , , , and , to find a satisfying the following inequality:
where is defined as
Similar to M in (10), the selection in (12) is an important factor in determining the degree of nonmonotonicity (see [33]). Thus, to improve the efficiency of a nonmonotone line search, Ahookhosh et al. [34] choose a varying value for the parameter by using a simple formula. Later, Nosratipour et al. [35] decided that should be related to a suitable criterion to measure the distance to the optimal solution. Thus, they defined by
However, we found that if the iterative sequence is trapped in a narrow curved valley, then it can lead to , from which we can obtain , so the nonmonotone line search is reduced to the standard Armijo line search, which is inefficient owing to the generation of very short or zigzagging steps. To overcome this drawback, we suggest the following :
It is obvious that is large when the function value decreases rapidly, and then will also be large, so therefore the nonmonotone strategy will be stronger. However, when is close to the optimal solution, we can obtain which tends toward zero, and then also tends toward zero, so then the nonmonotone rule will be weaker and it tends to be a monotone rule.
As was observed in [16], the active set method can enhance the efficiency of the local convergence algorithm and reduce the computing cost. There-in-after, we will recommend an active set recognition technology to approximate the right sustain of the solution points. In our context, we deal with the active set which is considered as the subset of zero components of . Now, we introduce the active set L as the index set corresponding to the zero component. Meanwhile, the inactive set F is to be the support of .
Definition 1.
Let and be a stationary point of (3). We define the active set as follows:
We further define an inactive set F which is a complementary set of L,
where .
Then, for any , we define the following approximations and as and , respectively,
where is the BB step size. For simplicity, we abbreviate and as and , respectively. Similar to the Lemma 1 in [21], we have that if the strict complementarity is satisfied at , then coincides with the active set if is sufficiently close to .
In order to obtain a well estimate of the active set, the active set is further subdivided into two sets
and
here is a constant.
Obviously, is the index set of variables with the first-order necessary condition. Therefore, we have reason to set the variables with indices in to 0. In addition, because is an index set that does not satisfy the first-order necessary condition, we further subdivide into two subsets
and
When a variable is with indices in , we consider the direction of the form 0. And for the variables of the indexs in , we consider the direction of the form , so as to to improve the corresponding components. Thus, through the above discussion, we define this direction in the following compact form:
where is the BB stepsize.
Finally, we let
where is the step size which is found by using a nonmonotonic line search (11).
It is known from [36] that the larger step size technique can significantly accelerate the rate of convergence of the algorithm, so by adding a relaxation factor s to the update rule of (24), we modify the update rule (24) as
for relaxation factor . We show that the optimal parameter s in (25) is by number experiments in Section 4.4.
Based on the above discussion, we develop a nonmonotone projected Barzilai-Borwein method based on the active set strategy proposed in Section 3 and outline the proposed algorithm in Algorithm 1. We can follow a similar procedure for updating H.
| Algorithm 1 Nonmonotone projected Barzilai-Borwein algorithm (NMPBB). |
|
Remark 1.
According to (11), from the definition of , we obtain
Since , we can find that (11) equals
If and are close to 0 and 1, respectively, and , then (11) reduces to the Gu’s line search in [33] with and , which implies that the linear search condition of Gu in [33] can be regarded as a special case of (11). In addition, when and , the line search rule (11) can be reduced to the Armijo line search rule.
Next, we prove that the improved nonmonotone line search is well-defined. Before presenting this fact, we state the scaled projected gradient direction by
for all and .
For each and . The next Lemma 2 is very important in our proof.
Lemma 2
([37]). For each , ,
- (i)
- ,
- (ii)
- The stationary point of (3) is at W if and only if
The lemma that follows states that is true if and only if the stationary point of problem (3) is the iteration point .
Lemma 3.
Let be calculated by (23), then if and only if is a stationary point of problem (3).
Proof.
Let . It is obvious that is a stationary point of problem (3) when . If , we have
The above inequality implies that . By the KKT condition, we can find that is a stationary point of problem (3). If , by (ii) of Lemma 2, we know that is a stationary point of problem (3).
Assume that is a stationary point of (3). From the KKT condition, (17) and (18), we have
By the definition of , we have for all . And then from the (ii) of Lemma 2, we have for all . Therefore, we have for all . For another case, since , for , and is a feasible point, from the definition of , we have . □
The next Lemma 4 is very important in our proof.
Lemma 4.
Sequence produced by Algorithm 1, we have
Proof.
By (23), we know
If , it is obvious that holds.
If , from (i) of Lemma 2, we have
Thus, we now only need to prove that
If , the inequality (32) holds. If , for all , from (21), we have
which lead to
The above deduction implies that the inequality (29) holds for . Combining (13) and (33), we obtain that (29) holds. By means of the Cauchy equality, from (29), we obtain (30). □
The following lemma is borrowed from Lemma 3 [18].
Lemma 5
([18]). Suppose Algorithm 1 generates and , there is
Now, we will show the nice property of our line search.
Lemma 6.
Suppose Algorithm 1 generates sequences and , there is
Proof.
Based on the definition of , we have
where the last inequality from Lemma 2 and . From , it concludes that , i.e., .
Therefore, if , from (12), we have
where the last inequality follows from (36). Thus, (37) indicates
In addition, if , we have . □
It follows from Lemma 6 that
In addition, for any initial iterate , Algorithm 1 generates sequences and that are both included in the level set.
Again, from Lemma 6, the theorem shown below can be easily obtained.
Theorem 1.
Assume that the level set is bounded, so the sequence is convergent.
Proof.
First, we show that . Apparently, according to (35) we have
Therefore, we obtain that for all .
From (39), we can obtain that
that is, the sequence has a lower bound. Since the sequence is nonincreasing, the sequence is convergent. □
Next, we will exhibit that the line search (11) is well-defined.
Theorem 2.
Assume Algorithm 1 generates sequences and , so step 5 of the Algorithm 1 is well-defined.
Proof.
For this purpose, we prove that the line search stops at a limited value of steps. To establish a contradiction, we suppose that such that (26) does not exist, and then for all adequately large positive integers m, according to Lemmas 5 and 6, we have
According to (40), from the definition of , we have
Since , we can find that (40) is equivalent to
From Lemmas 5 and 6, we have
Due to , thus,
According to the mean-theorem, there is a such that
that is,
When , we find that
Since , is correct. This is not consistent with the fact that . Therefore, step 5 of Algorithm 1 is well-defined. □
3. Convergence Analysis
In this part, we prove the global convergence of NMPBB. To establish the global convergence of NMPBB, we firstly present the following result.
Lemma 7.
Suppose that Algorithm 1 generates a step size , if the stationary point of (3) is not , so there is a constant that will cause .
Proof.
For the resulting step size , if does not satisfy (26), namely,
where Lemmas 5 and 6 lead to the final inequality. Thus,
By the mean-value theorem, we can find an that makes
where is the Lipschitz constant of .
Substitute the last inequality we obtained from (43) into (42) to find
From and , we have
□
Lemma 8.
Assume that Algorithm 1 generates the sequence , for the given level set , if it is considered bounded, so there is
(i)
(ii) there is a positive constant δ makes
Proof.
(i) By the definition of , for we have
Since , and for all t,
According to Theorem 1, as ,
which implies that
(ii) From (11) and Lemma 2 (i), we have
where . □
The global convergence of Algorithm 1 is proved by the theorem shown below.
Theorem 3.
Suppose that Algorithm 1 generates sequences and , so we obtain
Proof.
According to Lemma 8 (ii), we have
Based on Lemma 8 (i), as , we can obtain
□
According to Theorem 3, Lemma 3, and (25), we will exhibit the main convergence results we find as follows.
Theorem 4.
For a given level set , assume that it is bounded, hence Algorithm 1 computes the generated sequence , and any accumulation point obtained is a stationary point of (3).
4. Numerical Experiments
In the following content, by using synthetic datasets and real-world datasets (ORL image database and Yale image database (Both ORL and Yale image datasets in MATLAB format are available at http://www.cad.zju.edu.cn/home/dengcai/Data/FaceData.html (accessed on 26 December 2023))), we exhibit the main numerical experiments to compare the performance of NMPBB with that of the other five efficient methods including the NeNMF [29], the projected BB method (APBB2 [17]) (The code is available at http://homepages.umflint.edu/∼lxhan/software.html (accessed on 26 December 2023)), QRPBB [18], hierarchical alternating least squares (HALS) [38], and block coordinate descent (BCD) method [39]. All of the reported numerical results are performed using MATLAB v8.1 (R2013a) on a Lenovo laptop.
4.1. Stopping Criterion
According to the Karush-Kuhn-Tucker (KKT) conditions optimized by existing constraints, we know that is a stationary point of NMF (2) if and only if and are simultaneously satisfied, here
and is also written as shown above. Hence, we employ the stopping criteria shown below, which is also used in [40] in numerical experiments:
here is a tolerance. When employing the stop criterion (52), we need to pay attention to the scale degrees of freedom of the NMF solution, as discussed in [41].
4.2. Synthetic Data
In this section, first the NMPBB method and the other three ANLS-based methods are tested on synthetic datasets. Since the matrix V in this test happens to be a low-rank matrix, it will be rewritten as , and here we generate the L and R by using the MATLAB commands and , respectively.
For NMPBB, in a later experiment we adopt the parameters shown below:
The settings are identical with those of APBB2 and QRPBB. Take for NMPBB, the reason of selecting relaxation factor is given in Section 4.4, and take for all comparison algorithms. In addition, for NMPBB we choose and the update by the following recursive formula
We unify the maximum number of iterations of all algorithms to 50,000. All other parameters of APBB2, NeNMF, and QRPBB are unified as default values.
For all the problems we are considering, casually generated 10 diverse starting values, and the average outcomes obtained from using these starting points are presented in Table 1. The item iter represents that the number of iterations required to satisfy the termination condition (52) is met. The item niter represents the total number of sub-iterations for solving W and H. is relative error, is the final value of the projected gradient norm, and CPU time (in seconds) separately measures performance.

Table 1.
Experimental results on synthetic datasets.
Table 1 clearly indicates that all methods met the condition of convergence within a reasonable number of iterations. Table 1 also clearly indicates that our ANMPBB needs the least execution time and the least number of sub-iterations among all methods, particularly in the case of large-scale problems.
Since the NMPBB method is closely related to the QRPBB method, as we all know that the hierarchical ALS (HALS) algorithm for NMF is the most effective upon most occasions, we use the coordinate descent method to solve subproblems in NMF. We further examine algorithms of NMPBB, QRPBB, HALS, and BCD. We show that these four methods compare on eight randomly generated independent Gaussian noise measures when the signal-to-noise ratio which is 30 dB in Figure 2, Figure 3 and Figure 4 is terminated when the stopping criterion said by the inequality in (52) satisfies or the maximum number of iterations is more than 30. Figure 2 shows the value of the objective function compared to the number of iterations. From Figure 2, for most of the test problems, we will draw a conclusion that NMPBB decreases the objective function much quicker than the other three methods in 30 iterations. This may be because our NMPBB exploits an efficient modified nonmonotone line search and adds a relaxing factor s to the update rules of and . Hence our NMPBB significantly outperforms the other three methods. Figure 3 shows the relationship between the relative residual errors and the number of iterations. Figure 4 exhibits the relative residual errors versus CPU time. The results shown in Figure 3 and Figure 4 are consistent with those shown in Figure 2.
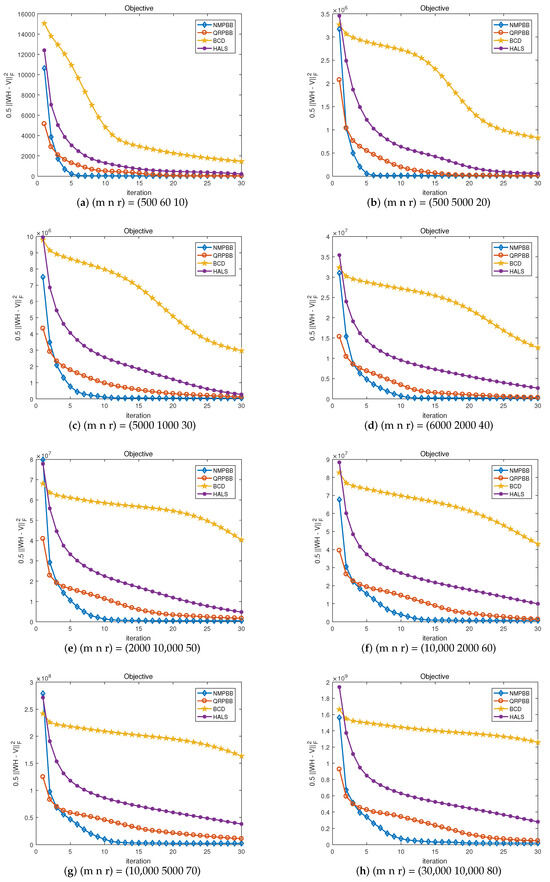
Figure 2.
Objective value versus iteration on random problem .
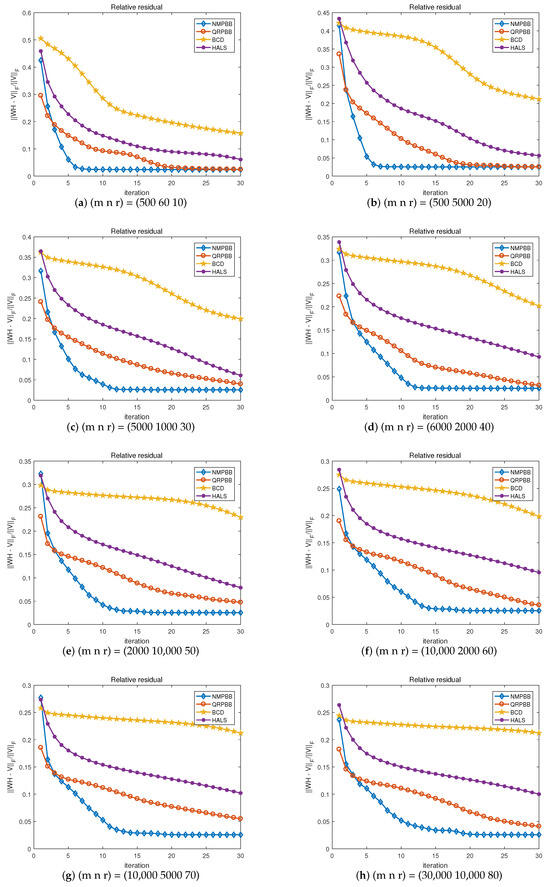
Figure 3.
Residual value versus iteration on random problem .
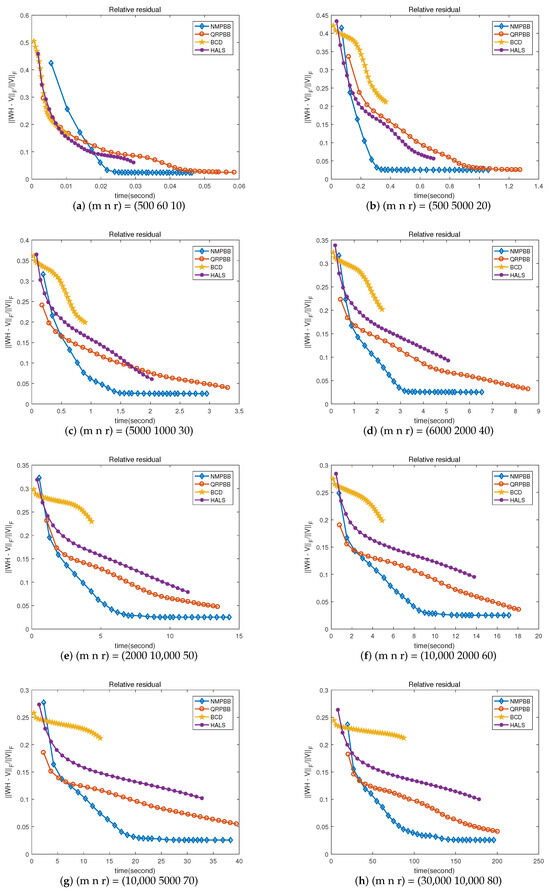
Figure 4.
Residual value versus CPU time on random problem .
4.3. Image Data
The ORL image database is a collection of 400 images of people’s faces belonging to 40 individuals representing 10 each. The dataset includes variations in lighting conditions, facial expressions (including whether they open their eyes, whether they smile), and facial details including whether they wear glasses. Some subjects have multiple photos taken at different times. The images were captured with the subject positioned upright and facing forward (allowing for slight movement to the sides). The background used was uniformly dark and even. All the images were taken against a dark homogeneous background with the subjects in an upright frontal position (with tolerance for some side movement). The pictures used are represented by the columns of the matrix V, and V has 400 rows and 1024 columns.
The Yale face database was created at the Yale Center for Computational Vision and Control. It consists of 165 gray-scale images, with each person in the database having 11 images associated with them. In total, there are 15 people. The facial images in question were captured under different lighting conditions (left-light, center-light, right-light), with various facial expressions (calm, cheerful, sorrowful, amazed, and blinking), and with or without glasses. The pictures used are represented by the rows of the matrix V, and V has 165 rows and 1024 columns.
For all the databases we used in (52), we performed a diverse casually generated starting iteration with , the maximum number of iterations (maxit) for all algorithms is set to 50,000, and the average results are presented in Table 2. From Table 2, we conclude that the QRPBB method converges in fewer iterations and CPU times than APBB2 and NeNMF, and in contrast to QRPBB, our NMPBB method requires 1/4 CPU time to satisfy the set tolerance. Although the residuals by NMPBB are not the smallest among all algorithms appearing for all the databases we use, the results of mean that solutions by NMPBB are nearer to the point of stationary.
Table 2.
Experimental results on Yale and ORL datasets.
4.4. The Importance of Relaxation Factor s
In the following content, the clear experimental results indicate that relaxation factor s is used for updating rules of and . We implement NMPBB using diverse s given on synthetic datasets which are the same as those in Section 4.2. We set the required maximum number of iterations to 30, and the other parameters required in the experiment will have the same values as those in Section 4.2. Figure 5 shows the relationship between the relative residuals error and the run-time results. In Figure 5, we can see that the relaxation factor s fails to accelerate the convergence when and increasing constant s significantly accelerates the convergence when . As for NMPBB, it seems that s = 1.7 is the best compared with other experimental values in terms of speed of convergence, and hence s = 1.7 was used as our NMPBB in all experiments.
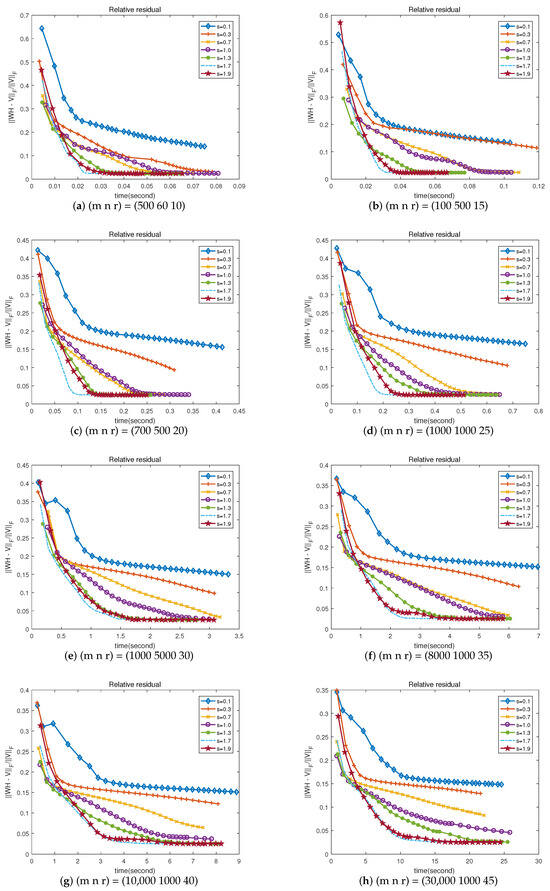
Figure 5.
Residual value versus CPU time on random problem .
5. Conclusions
In this paper, a prox-linear quadratic regularization objective function is presented, and the prox-linear term leads to strongly convex quadratic subproblems. Then, we propose a new line search technique based on the idea of [33]. According to the new line search, we put forward a global convergent method with larger step size to solve the subproblems. Finally, a series of numerical results are given to show that the method is a promising tool for NMF.
Symmetric nonnegative matrix factorization is a special but important class of NMF which has found numerous applications in data analysis such as various clustering tasks. Therefore, a direction for future research would be to extend the proposed algorithm to solve symmetric nonnegative matrix factorization problems.
Author Contributions
W.L.: supervision, methodology, formal analysis, writing—original draft, writing—review and editing. X.S.: software, data curation, conceptualization, visualization, formal analysis, writing—original draft. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Natural Science Foundation of China under grant No. 12201492.
Data Availability Statement
The datasets generated or analyzed during this study are available in the face databases in matlab format at http://www.cad.zju.edu.cn/home/dengcai/Data/FaceData.html (accessed on 26 December 2023).
Conflicts of Interest
The authors declare that they have no conflicts of interest.
References
- Gong, P.H.; Zhang, C.S. Efficient nonnegative matrix factorization via projected Newton method. Pattern Recognit. 2012, 45, 3557–3565. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef] [PubMed]
- Lee, D.D.; Seung, H.S. Algorithms for non-negative matrix factorization. Adv. Neural Process. Inf. Syst. 2001, 13, 556–562. [Google Scholar]
- Kim, D.; Sra, S.; Dhillon, I.S. Fast Newton-type methods for the least squares nonnegative matrix approximation problem. SIAM Int. Conf. Data Min. 2007, 1, 38–51. [Google Scholar]
- Paatero, P.; Tapper, U. Positive matrix factorization: A non-negative factor model with optimal utilization of error estimates of data values. Environmetrics 1994, 5, 111–126. [Google Scholar] [CrossRef]
- Ding, C.; Li, T.; Peng, W. On the equivalence between non-negative matrix factorization and probabilistic latent semantic indexing. Comput. Stat. Data Anal. 2008, 52, 3913–3927. [Google Scholar] [CrossRef]
- Chan, T.H.; Ma, W.K.; Chi, C.Y.; Wang, Y. A convex analysis framework for blind separation of nonnegative sources. IEEE Trans. Signal Process. 2008, 56, 5120–5134. [Google Scholar] [CrossRef]
- Ding, C.; He, X.; Simon, H. On the Equivalence of Nonnegative Matrix Factorization and Spectral Clustering. SIAM Int. Conf. Data Min. (SDM’05) 2005, 606–610. [Google Scholar]
- Févotte, C.; Bertin, N.; Durrieu, J.L. Nonnegative matrix factorization with the Itakura-Saito divergence: With application to music analysis. Neural Comput. 2009, 21, 793–830. [Google Scholar]
- Ma, W.K.; Bioucas-Dias, J.; Chan, T.H.; Gillis, N.; Gader, P.; Plaza, A.; Ambikapathi, A.; Chi, C.Y. A Signal Processing Perspective on Hyperspectral Unmixing. IEEE Signal Process. Mag. 2014, 31, 67–81. [Google Scholar] [CrossRef]
- Barzilai, J.; Borwein, J.M. Two-point step size gradient methods. IMA J. Numer. Anal. 1988, 8, 141–148. [Google Scholar] [CrossRef]
- Dai, Y.H.; Liao, L.Z. R-Linear convergence of the Barzilai-Borwein gradient method. IMA J. Numer. Anal. 2002, 22, 1–10. [Google Scholar] [CrossRef]
- Raydan, M. On the Barzilai-Borwein choice of steplength for the gradient method. IMA J. Numer. Anal. 1993, 13, 321–326. [Google Scholar] [CrossRef]
- Raydan, M. The Barzilai and Borwein gradient method for the large-scale unconstrained minimization problem. SIAM J. Optim. 1997, 7, 26–33. [Google Scholar] [CrossRef]
- Xiao, Y.H.; Hu, Q.J. Subspace Barzilai-Borwein gradient method for large-scale bound constrained optimization. Appl. Math. Optim. 2008, 58, 275–290. [Google Scholar] [CrossRef]
- Xiao, Y.H.; Hu, Q.J.; Wei, Z.X. Modified active set projected spectral gradient method for bound constrained optimization. Appl. Math. Model. 2011, 35, 3117–3127. [Google Scholar] [CrossRef]
- Han, L.X.; Neumann, M.; Prasad, U. Alternating projected Barzilai-Borwein methods for nonnegative matrix factorization. Electron. Trans. Numer. Anal. 2009, 36, 54–82. [Google Scholar]
- Huang, Y.K.; Liu, H.W.; Zhou, S.S. Quadratic regularization projected alternating Barzilai-Borwein method for nonnegative matrix factorization. Data Min. Knowl. Discov. 2015, 29, 1665–1684. [Google Scholar] [CrossRef]
- Huang, Y.K.; Liu, H.W.; Zhou, S.S. An efficint monotone projected Barzilai-Borwein method for nonnegative matrix factorization. Appl. Math. Lett. 2015, 45, 12–17. [Google Scholar] [CrossRef]
- Li, X.L.; Liu, H.W.; Zheng, X.Y. Non-monotone projection gradient method for non-negative matrix factorization. Comput. Optim. Appl. 2012, 51, 1163–1171. [Google Scholar] [CrossRef]
- Liu, H.W.; Li, X. Modified subspace Barzilai-Borwein gradient method for non-negative matrix factorization. Comput. Optim. Appl. 2013, 55, 173–196. [Google Scholar] [CrossRef]
- Bonettini, S. Inexact block coordinate descent methods with application to non-negative matrix factorization. IMA J. Numer. Anal. 2011, 31, 1431–1452. [Google Scholar] [CrossRef]
- Zdunek, R.; Cichocki, A. Fast nonnegative matrix factorization algorithms using projected gradient approaches for large-scale problems. Comput. Intell. Neurosci. 2008, 2008, 939567. [Google Scholar] [CrossRef]
- Bai, J.C.; Bian, F.M.; Chang, X.K.; Du, L. Accelerated stochastic Peaceman-Rachford method for empirical risk minimization. J. Oper. Res. Soc. China 2023, 11, 783–807. [Google Scholar] [CrossRef]
- Bai, J.C.; Han, D.R.; Sun, H.; Zhang, H.C. Convergence on a symmetric accelerated stochastic ADMM with larger stepsizes. CSIAM Trans. Appl. Math. 2022, 3, 448–479. [Google Scholar]
- Bai, J.C.; Hager, W.W.; Zhang, H.C. An inexact accelerated stochastic ADMM for separable convex optimization. Comput. Optim. Appl. 2022, 81, 479–518. [Google Scholar] [CrossRef]
- Bai, J.C.; Li, J.C.; Xu, F.M.; Zhang, H.C. Generalized symmetric ADMM for separable convex optimization. Comput. Optim. Appl. 2018, 70, 129–170. [Google Scholar] [CrossRef]
- Bai, J.C.; Zhang, H.C.; Li, J.C. A parameterized proximal point algorithm for separable convex optimization. Optim. Lett. 2018, 12, 1589–1608. [Google Scholar] [CrossRef]
- Guan, N.Y.; Tao, D.C.; Luo, Z.G.; Yuan, B. NeNMF: An optimal gradient method for nonnegative matrix factorization. IEEE Trans. Signal Process. 2012, 60, 2882–2898. [Google Scholar] [CrossRef]
- Xu, Y.Y.; Yin, W.T. A globally convergent algorithm for nonconvex optimization based on block coordinate update. J. Sci. Comput. 2017, 72, 700–734. [Google Scholar] [CrossRef]
- Zhang, H.C.; Hager, W.W. A nonmonotone line search technique and its application to unconstrained optimization. SIAM J. Optim. 2004, 14, 1043–1056. [Google Scholar] [CrossRef]
- Dai, Y.H. On the nonmonotone line search. J. Optim. Theory Appl. 2002, 112, 315–330. [Google Scholar] [CrossRef]
- Gu, N.Z.; Mo, J.T. Incorporating nonmonotone strategies into the trust region method for unconstrained optimization. Comput. Math. Appl. 2008, 55, 2158–2172. [Google Scholar] [CrossRef]
- Ahookhosh, M.; Amini, K.; Bahrami, S. A class of nonmonotone Armijo-type line search method for unconstrained optimization. Optimization 2012, 61, 387–404. [Google Scholar] [CrossRef]
- Nosratipour, H.; Borzabadi, A.H.; Fard, O.S. On the nonmonotonicity degree of nonmonotone line searches. Calcolo 2017, 54, 1217–1242. [Google Scholar] [CrossRef]
- Glowinski, R. Numerical Methods for Nonlinear Variational Problems; Springer: New York, NY, USA, 1984. [Google Scholar]
- Birgin, E.G.; Martinez, J.M.; Raydan, M. Nonmonotone spectral projected gradient methods on convex sets. SIAM J. Optim. 2000, 10, 1196–1211. [Google Scholar] [CrossRef]
- Cichocki, A.; Zdunek, R.; Amari, S.I. Hierarchical ALS Algorithms for Nonnegative Matrix and 3D Tensor Factorization. Lect. Notes Comput. Sci. Springer 2007, 4666, 169–176. [Google Scholar]
- Xu, Y.Y.; Yin, W.T. A block coordinate descent method for regularized multi-convex optimization with applications to nonnegative tensor factorization and completion. SIAM J. Imaging Sci. 2015, 6, 1758–1789. [Google Scholar] [CrossRef]
- Lin, C.J. Projected Gradient Methods for non-negative matrix factorization. Neural Comput. 2007, 19, 2756–2779. [Google Scholar] [CrossRef] [PubMed]
- Gillis, N. The why and how of nonnegative matrix factorization. arXiv 2015, arXiv:1401.5226v2. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).