Abstract
Applications in medical technology have a massive contribution to the treatment of patients. One of the attractive tools is ball bearings. These balls support the load of the application as well as minimize friction between the surfaces. If a heavy load is applied to a ball bearing, there is the risk that the balls may be damaged and cause the bearing to fail earlier. Hence, we aim to study the model of the failure times of ball bearings. A hybrid Type-II censoring scheme is recommended to minimize the experimental time and cost where the components are following alpha power inverse Weibull distribution. A ball bearing is one example; the other is the resistance of guinea pigs exposed to dosages of virulent tubercle bacilli. We use different estimation methods to obtain point and interval estimates of the unknown parameters of the distribution; consequently, estimating statistical functions such as the hazard rate and the survival functions are observed. The maximum likelihood method and the maximum product spacing methods are used, in addition to the Bayesian estimation method, in which symmetric and asymmetric loss functions are utilized. Interval estimators are obtained for the unknown parameters using three different criteria: approximate, credible, and bootstrap confidence intervals. The performance of the parameters’ estimation is accomplished via simulation analysis and numerical methods such as Newton–Raphson and Monte Carlo Markov chains. Finally, results and conclusions support the suitability of alpha power inverse Weibull distribution under a hybrid Type-II censoring scheme for modeling real biomedical data.
1. Introduction
Many bearing types and styles provide an extensive range of solutions that are useful for applications across various industries, including mechanical, medical, global aerospace, and others. In biomaterials, ball bearing technology is used for “Hip Joint Replacement”, where it is necessary for a patient’s life suffering from arthritis; for more details, refer to [1]. When ball bearings are operating, they can be inclined to spoil for different reasons; it can be due to lack of lubrication, changeable load, vibration, or pollutants. All can cause a fast failure time of the bearings. Accordingly, modeling components’ lifetimes have considerable attention in many applied sciences.
Another important application in the biomedical area is studying the resistance of living organs to a certain kind of bacteria. Tuberculosis is still considered one of the main health problems, taking millions of lives annually. The World Health Organization reported that 30% of the world’s population had been infected with the tubercle bacillus, and the risk of infection is still increasing; see [2]. We considered a sample of guinea pigs that were exposed to dosages of virulent tubercle bacilli (VTB), and their resistance was recorded with respect to their living times. Modeling the lifetimes of guinea pigs is our second purpose in this work.
Dealing with samples in real-life experiments may confront obstacles such as missing or eliminating components during the experiment and/or lack of money and time; therefore, statisticians are spending considerable effort in investigating components’ breakdown times (failures) as the main structure of the performing systems in industry and mechanics. The researchers usually analyze the observation of operating unit failure, the recorded lifetimes of those units, and their application of statistical analysis methods from data obtained to data collected for the whole system. However, certain experimental units are costly and highly efficient, requiring to decrease in the number of tested components and their lifetimes. A measurement system that can save time and resources for all outputs is the main requirement. It will subsequently be taken into consideration because the composite data show the exact times of failure of such damaged components. Failure data should be fitted to an appropriate parametric statistical distribution to estimate its unknown parameters and furthermore to estimate its reliability and hazard functions. Estimating the reliability and hazard functions helps statisticians predict and make the right decision about the survival factor or hazard factor of these models in probabilistic meaning with a high level of confidence that may reach .
In this paper, some statistical inference approaches are handled, such as the maximum likelihood, the maximum product spacing, and the Bayesian methods.
A system of censoring schemes that can balance (i) the total experimental time spent, (ii) the number of test components, and (iii) the efficiency of the experimental statistical inference is of great concern and is highly evaluated. A hybrid censoring scheme is a consolidation between the two types of censoring schemes (Type-I and Type-II), which may be explained by using similar elements. The analysis is decided with the failure of r units, or reaching a specified time in the experiment. If the i-th ordered failure time is symbolized by , the test may be ended at or at . Time means the end of the experiment for hybrid Type-I censoring () test units. is the end time for hybrid Type-II censored () test units. Epstein [3] suggested the and studied a lifetime experiment that assumes the life cycle of every component to be exponentially distributed.
Many researchers have worked on , such as Ebrahimi [4]. One of the disadvantages of is that a small number of failures may occur until after a fixed period T under . Childs et al. [5] developed , which assures a minimum of r failures. If r failures actually occurred before T, the experiment would remain until the r-th failure occurred, and we would see failures of the data exactly at this point. The applications of the have been discussed by several authors, and the reader can refer to Mansour and Ramadan [6], Salah et al. [7], Yousef et al. [8], Yadav et al. [9], Mahmoud et al. [10], Aldahlan et al. [11], Mohamed et al. [12], Ramadan et al. [13] and Nassr et al. [14].
In this article, alpha power inverse Weibull (APIW) distribution is used to model the ball-bearing lifetimes and the resistance of VTB. APIW distribution was first proposed by [15]. Let X be a random variable with an APIW distribution; then, the cumulative distribution function (CDF) and the probability density function () are determined as
and
respectively. The survival and the hazard functions of APIW distribution are
and
respectively. The APIW statistical characteristics were discussed recently by [15]. It was shown that the of APIW is unimodal; it can be either symmetric or skewed to the right depending on the parameter values. In addition, the hazard rate function can be an increasing or decreasing curve. Hence, this model is a good candidate for describing several real data which can be symmetric or asymmetric (positively skewed).
Point and interval estimation of the unknown parameters were explored on the basis of a complete sample. Not much work handled the hybrid Type-II censoring for the alpha power family of distribution and used it for modeling biological issues; hence, we aim to study the APIW lifetimes under using classical estimation methods in addition to the Bayesian method based on informative priors with symmetric and asymmetric loss functions. A simulation analysis using R software is performed to compare the different methods of estimation and test the quality of the new model under sampling when fitting it to some real-life data. The Newton–Raphson method of maximization is used in the “maxLik” software to compute the MLE and MPS. Additionally, the ‘CODA’ package, which analyzes Markov chain Monte Carlo (MCMC) outputs and diagnoses lack of convergence, is used to compute the Bayesian estimation.
The rest of this article is prepared accordingly: In Section 2, the maximum likelihood estimators are obtained for the APIW parameters, and hence, estimations of the hazard rate and reliability functions are obtained. In Section 3, estimates are observed using the MPS method. Bayesian estimation is derived in Section 4 under various loss functions, including the squared error loss function () and the linear exponential loss function (). Confidence intervals are evaluated in Section 5. In Section 6, the actual data set is tested and analyzed. Simulation analysis is observed in Section 7 to study and evaluate the quality of the various estimators studied in this research. Conclusions and related results are reported in Section 8.
2. The Maximum Likelihood Estimator
The classical well-known maximum likelihood estimation (MLE) method is used in this section. Point estimations of the parameters are performed assuming the censoring . Hence, let n be identical components that are placed in an experiment and assume their lifetimes follow the APIW distribution with as in Equation (2). The experiment is stopped at the pre-fixed time (T) and at a pre-specified number of failures () whichever comes later; therefore, the experiment is stopped at the max(,T ), in which denotes the r-th failure. Under , the random failures are achieved according to the cases:
Case 1: if
Case 2: if
m: The number of units that fail before time T and
The likelihood function for case 1 is
For case 2, the likelihood function is
The combined likelihood function can be represented as
where , H indicates the number of failures, if H and if H
The MLEs of the parameters denoted by and can be attained by solving the simultaneous nonlinear log-likelihood equations as follows, respectively:
and
An implicit solution is not an easy task for solving the above system. Hence, some numerical techniques will be helpful to find a numerical approximate solution. The Newton–Raphson technique is used to find a numerical solution. The Newton–Raphson algorithm is described in detail in EL-Sagheer [16].
Furthermore, using the invariant property of the MLEs, we can find the MLEs of and , after replacing and by and in Equations (3) and (4); hence, we obtain
and
3. Maximum Product Spacing
The maximum product spacing method (MPS) is an alternative efficient estimation method that demonstrates improvements compared with other point estimation methods; one may refer to Cheng and Amin [17] for more details. The MPS is performed to estimate the unknown parameters of APIW distribution. Once again, it is necessary to deal with a system of nonlinear equations; these equations are emanated from the partial derivatives of the logarithm of the product spacing function , which is written as:
where is the geometric mean of the product spacing function that is defined as
4. Bayes Estimation
A Bayesian approach, which is highly effective in reliability analysis, is created by the capacity to combine prior information within the test, as the restricted availability of data is a significant difficulty in relation with reliability analysis. The unknown , and parameters versus the functions of loss for and are estimates of Bayesian. Suppose that the unknown parameters and have Gamma prior distributions independently.
where the hyper-parameters and are the hyper-parameters that contain the prior information. Many authors, such as Kundu and Howlader [18], Dey and Dey [19], Dey et al. [20] and Dey et al. [21] developed Bayesian estimation for their parameter models using informative gamma priors. The posterior distribution of and is defined by and can be procured by combining the likelihood function Equation (5) with the prior Equation (17) and can be written as
A square error loss (SEL) function, which is a commonly used function, is a symmetric loss function, which is defined as
here, is an estimate of .
The Bayes estimate of any function of and , say under the SEL function can be determined as
where
The function is the most universally used asymmetric loss function. The asymmetric loss function is considered more comprehensive in many respects; see Varian [22]. It is
where is a loss function scale parameter. The LINEX loss function is nearly the same as the SEL function for the option of positive or negative values of (close to zero).
The Bayes estimate of any function of and , say under the LINEX function can be determined as
It is noticed that the ratio of multiple integrals in Equations (21) and (24) cannot be obtained in an explicit form.
MCMC is developed to create samples of the joint posterior function in Equation (18). The MCMC mechanism is primarily concerned with calculating an estimated integral value. We consider the Gibbs in the Metropolis–Hasting sampler approach in order to implement the MCMC technique. From Equations (5) and (17), the joint posterior distribution can be written as
We rewrite conditionals for and as follows:
and
The conditional posteriors of and in Equations (26)–(28) thus do not have normal forms. As a result, the MCMC method will be used to compute the Bayesian estimates of and in addition to the Bayesian estimates of the survival function and hazard function as well as the related credible intervals. See Robert [23,24] for a detailed description of the MCMC method.
5. Confidence Intervals
In this section, we study three types of confidence intervals. A numerical analysis is performed to compare the efficacy of these intervals with respect to interval length and coverage probability.
5.1. Approximate Confidence Intervals
This subsection will present the observed Fisher’s information matrix, which is frequently used to construct asymptotic confidence intervals (ACIs). The principle of missing information is as follows:
Observed information = Complete information − Missing information.
The MLEs are approximately bivariate normal with a mean and variance matrix . Here, is the observed Fisher information matrix, and it is defined as
where
and
As a result, the approximate (or observed) asymptotic variance-covariance matrix for MLEs is derived by inverting the observed information matrix or equivalent
It is well known that is approximately distributed as multivariate normal with mean and covariance matrix under some regularity conditions, see Lawless [25]. The two-sided confidence intervals can be given by
where is the percentile of the standard normal distribution with right-tail probability .
The delta method is used to obtain approximate estimates of the variances of and . Greene [26] explained a general approach to computing CIs for functions of MLEs. The variance of and can be estimated using this method, respectively.
where and are, respectively, the gradient of and with respect to and as follows:
and
where
and
Then, the two-sided confidence intervals of and can be given, respectively, by
A disadvantage of an approximate confidence interval is that it can produce a negative lower bound even if the parameter only accepts positive values. The negative value is modified by zero in this case. Optionally, Meeker and Escobar [27] proposed using a log transformation to obtain approximate confidence intervals for parameters with positive values. Thus, the approximate two-sided confidence interval derived in this manner for is provided by
where
5.2. Credible CI
The credible confidence interval (CCI) is obtained by using the algorithm of Metropolis-Hastings within the Gibbs sampling technique. We summarized these algorithm steps as follows:
- (1)
- Start with initial guess
- (2)
- Set
- (3)
- From the normal proposal distributions and , generate and from , and and from the main crossways in inverse Fisher information matrix can be obtained and .
- (4)
- From , and generate proposals , and .
- (i)
- Evaluate the acceptance probabilities
- (ii)
- From a uniform distribution, generate , and .
- (iii)
- If , accept and set ; else, set .
- (iv)
- If , accept and set ; else, set .
- (v)
- If , accept and set ; else, set
- (5)
- Set
- (6)
- Repeat Steps (3)–(5) N times and obtain and
- (7)
- To compute the CRs ofas then, the of is
The first simulated M variations will be eliminated in order to promote convergence and devote attention to the selection of initial values. The samples have chosen , an approximate posterior sample generated for sufficiently large N, which may be required to develop the inferences of Bayes.
The approximate Bayes estimates of based on the function are obtained by
The approximate Bayes estimates for based on the loss function are obtained by
5.3. Bootstrap CI
When the sample size is small, the percentile bootstrap (Boot-p) and the bootstrap-t (Boot-t) confidence interval presented by [28,29,30,31] allows for the computation of the confidence interval for the parameters of interest. Two parametric bootstrap algorithms are offered to calculate the bootstrap confidence intervals of and . Bootstrap-t was created using a studentized ‘pivot’ and requires an estimator of the variance of the MLE of and .
5.3.1. Parametric Boot-p
- (1)
- Based on obtain and by maximizing Equations (7)–(9).
- (2)
- Generate from the APIW distribution with parameters and based on hybrid Type-II censoring, using the algorithm described in [32].
- (3)
- Obtain the bootstrap estimate , by the MLEs under the bootstrap sample.
- (4)
- Repeat Steps (2) and (3) boot times, and obtain , where,
- (5)
- Obtain by arrange in ascending orders.
Define for given z, where is the cumulative distribution function of The approximate bootstrap-p CI of is given by
5.3.2. Parametric Boot-t
- (1)
- Repeat the steps of the parametric Boot-p from (1) to (3).
- (2)
- The variance–covariance matrix and the approximate estimates of the variance and based on the asymptotic variance–covariance matrix and delta method are computed.
- (3)
- The statistic is defined as
- (4)
- Obtain from repeating steps 2–5, NBoot times
- (5)
- Obtain the ordered sequences by arranging in in ascending order.
Define , where is the cumulative distribution function of for a given z.
Then, the approximate bootstrap-t CI of is obtained by
6. Application to Real-Life Data
Two real data examples are discussed in this section. We aim to model the failure times of a sample of ball bearings using APIW distribution, and the resistances in a sample of guinea pigs are modeled using APIW distribution. A goodness of fit measure is utilized for that purpose. Point and interval estimations are performed via numerical methods using suitable R-codes.
6.1. Data Set I
Leiblein et al. [33] employ the suggested approaches in this section to determine how many millions of spins a large sample of 23 ball bearings can withstand before failing. The data are shown in Table 1. The difference between the empirical Kolmogorov–Smirnov (KSD) distribution and the CDF for the APIW distribution is 0.0937, and the p-value (PVKS) is 0.9876, which indicates the goodness of fit using the APIW model. Therefore, the APIW distribution is consistent with the information supplied.

Table 1.
Failure times for a group of 23 ball bearings in a life endurance test.
Table 2 details the MLE, the MPS, and the Bayesian estimates of the parameters with the standard errors (SE) and describes the Kolmogorov–Smirnov goodness of fit test for data set I. While analyzing data set I, it was discovered that the Bayesian estimates have lower SE values for estimating , while the MPS has less SE when estimating and . The best goodness of fit with respect to KSD is attained for its minimum value, and this is achieved under Bayesian estimation; similarly, the highest PVKS is obtained under Bayesian estimation. Therefore, according to Bayesian estimations, the APIW distribution offers a better fit. Figure 1 illustrates the APIW distribution’s theoretical and empirical , CDF, and P-P plot using data set I, and it can be seen that the APIW is fitting data set I very well.
Table 2.
MLE, MPS, and Bayesian estimates with SE values and KS test.
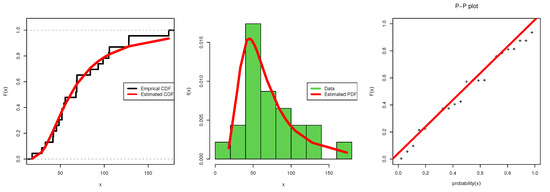
Figure 1.
Estimated CDF, pdf, and pp-plot: data set I.
To check the performance of the MLE, we plot the profile likelihood function, where the x-label is one parameter with different values and the y-label is the log-likelihood value keeping the other parameters to be fixed. The profile likelihood of data set I is sketched in Figure 2, where the blue line is a log-likelihood values with different value of parameter and dot is the MLE estimator of parameter with max log-likelihood value, and it confirms that the MLE estimates have maximum values for data set I, which is consistent with the values of MLE observed in Table 2, and it is also clear that data set I behave very well as the three roots of the parameter are global maxima.
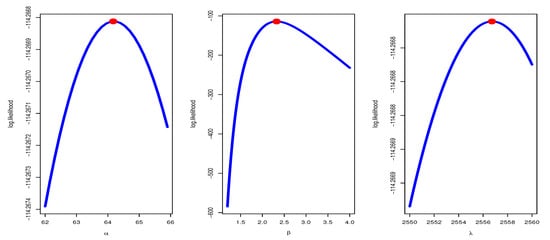
Figure 2.
The Profile likelihood curve with maximum point for data set I.
The plots of the MCMC trace, the auto-correlation (ACF) tests, the posterior sample histogram, and the convergence of MCMC are all performed to diagnose the issues related to MCMC samples. An essential tool for evaluating a chain’s mixing is a trace plot. The auto-correlation plot, also known as the ACF plot, shows the serial correlation in time-varying data. Therefore, we plot MCMC trace, ACF plot, and a histogram of posterior density of MCMC results, and the convergence of the MCMC results for data set I are presented in Figure 3, Figure 4, Figure 5 and Figure 6, respectively.
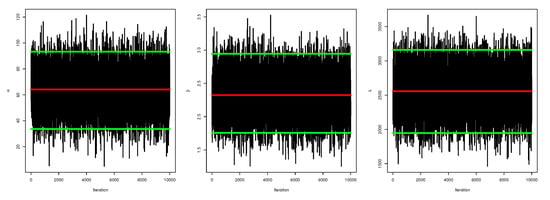
Figure 3.
MCMC trace: data set I.
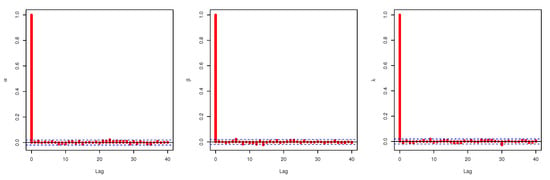
Figure 4.
Auto-correlation test: data set I.
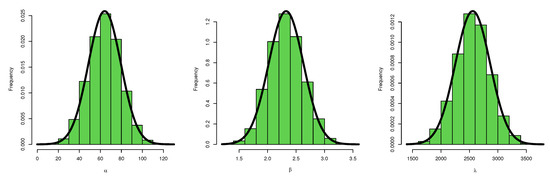
Figure 5.
Histogram of posterior density: data set I.
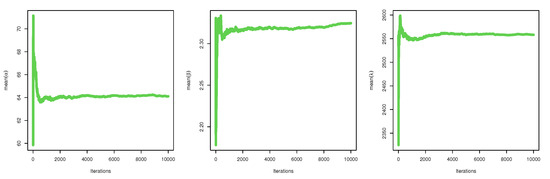
Figure 6.
Convergence of MCMC results: data set I.
Figure 3, Figure 5, and Figure 6 confirm that the MCMC trace has normal results and convergence measures for data set I. Furthermore, this shows the histograms for the marginal posterior density estimates of the parameters based on 5000 chain values and the Gaussian kernel. The estimation in Figure 5 clearly indicates that all generated posteriors are symmetric with respect to the theoretical posterior density function. Figure 4 explores the auto-correlation test which revealed that the auto-correlation test for the MCMC is the correlation between an iteration series with a decreased version of itself. The auto-correlation function started to slow down at zero, which represents the correlation of the iteration series with itself, and then, it resulted in a correlation of one.
Table 3 provides the MLE, the MPS, and the Bayesian estimates for parameters of APIW distribution based on hybrid censored samples for data set I. Table 4 presents the survival and hazard of APIW distribution based on hybrid censored samples with data set I.
Table 3.
MLE, MPS, and Bayesian estimates based on hybrid censored samples: data set I.
Table 4.
Survival and hazard based on hybrid censored samples: data set I.
It is observed from the numerical results in Table 3 that the Bayesian estimators act better than alternative methods for estimating the parameter , while the MPS is the best choice for estimating the parameters and . Table 4 demonstrates the efficiency of the MPS estimation method since the survival estimation is maximized and the hazard rate estimation is minimized under the MPS estimation method.
6.2. Data Set II
A real data set II from Okash et al. [34] is considered. To demonstrate the reliability of the APIW distribution to fit these data, 72 observations of resistance in guinea pigs were exposed to various dosages of virulent tubercle bacilli. The observed data set II has been shown in Table 5.
Table 5.
Survival times (in days) of resistance in guinea pigs exposed to various dosages of virulent tubercle bacilli.
Table 6 details MLE, MPS, and Bayesian estimates with SE and DKS goodness of fit test for data set II. While analyzing data set II, it is realized that the MPS estimates have lower SE values for the estimated APIW parameters. For modeling purposes, the Bayesian estimation has the minimum KSD (0.1091) and highest PVKS (0.3581); hence, the APIW distribution offers a better fit under Bayesian estimation. Figure 7 illustrates the APIW distribution’s theoretical and empirical , CDF, and P-P plot using data set II, and it can be seen that the APIW is suitable and reliable for fitting data set II.
Table 6.
MLE, MPS, and Bayesian estimates with SE values and KS test: data set II.
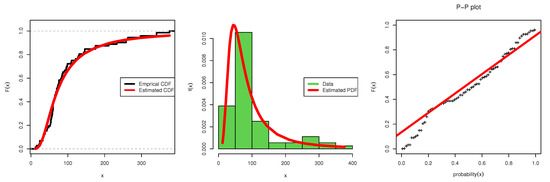
Figure 7.
Estimated CDF, pdf and pp-plot: data set II.
Figure 8 confirms that the MLE estimates have the maximum likelihood values for data set II for the estimated parameter values that coincide with the MLE estimates in Table 6. Figure 9, describing the trace of the MCMC and its convergence. Figure 10 states that there is no auto-correlation for the MCMC series; the values started with zero and end up with one. In Figure 11, it is emphasized that the MCMC results have a normal curve with symmetric histograms of the posterior density, while Figure 12 shows that the MCMC trace has convergence results. Table 7 summarizes the MLE, the MPS, and the Bayesian estimates for parameters of APIW distribution based on hybrid censored samples for data set II with different values of T and r. The Bayesian estimators are better for estimating the parameter , while the MPS is the best choice for estimating the parameters and . Table 8 shows the estimated values of the survival and the hazard of APIW distribution based on the hybrid censored samples with data set II with different values of T and r. It is clear that the maximum survival is attained under MPS estimation and also the minimum hazard rate is obtained under MPS estimation, which supports the selection of the MPS method for efficient failure data analysis.
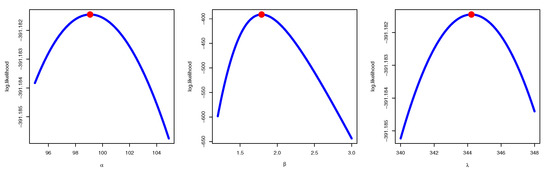
Figure 8.
The Profile likelihood curve with the maximum point for data set II.
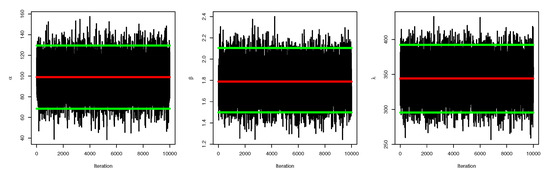
Figure 9.
MCMC trace: data set II.
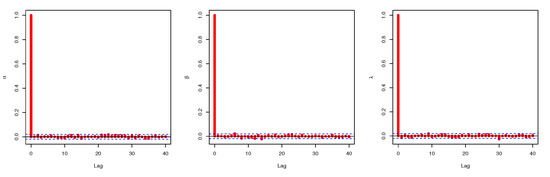
Figure 10.
Auto-correlation test: data set II.
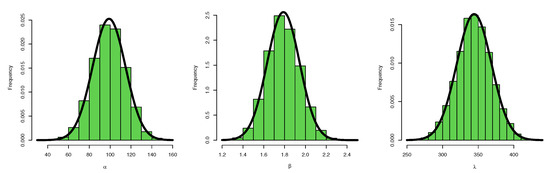
Figure 11.
Histogram of posterior density: data set II.
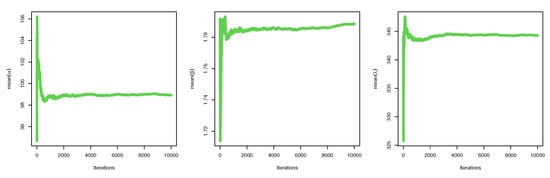
Figure 12.
Convergence of MCMC results: data set II.
Table 7.
MLE, MPS, and Bayesian estimates based on hybrid censored samples: data set II.
Table 8.
Survival and hazard based on hybrid censored samples: data set II.
7. A Simulation Study
A simulation analysis was carried out using 5000 iterations for hybrid Type-II censored samples. For the generated simulated sample from APIW distribution, descriptive statistics are computed to evaluate the consistency of this simulated data, Table 9 summarizes some measures in addition to skewness and kurtosis measures. Each simulation compares the APIW distribution parameter estimators by likelihood, product spacing, and Bayesian. Censored APIW samples are with the initial values:
Table 9.
Summary of simulated data from APIW distribution.
- In Table 10: and .
Table 10. Bayesian and non-Bayesian estimation for parameters of APIW distribution based on hybrid censored samples where .
- In Table 11: and .
Table 11. Bayesian and non-Bayesian estimation for parameters of APIW distribution based on hybrid censored samples where .
- In Table 12: and .
Table 12. Bayesian and non-Bayesian estimation for parameters of APIW distribution based on hybrid censored samples where .
For the development of a hybrid censored sample, we selected different sample sizes as n = 50 and 100 and different censored sample sizes as r = 30, 40, and 50 for n = 50, r = 70, 90, and 100 for n = 100.
The relative bias (RB), mean square error (MSE), length of asymptotic confidence intervals (LACI), length of bootstrap-p (LBP), and length of bootstrap-t (LBT) are calculated, and a comparison was considered between the different approaches of the resulting estimators with respect to the RB of , and . In addition, the MSE was utilized for the same purpose such that where is the number of simulated samples, and . Overall, of the CIs are obtained from asymptotic distributions from MLEs and CRIs and are also compared with a further criterion. The comparison is between the average confidence interval length (ACL). In order to assess the type of prior, estimates of the parameters in the Bayes technique are computed from informative priors. The hyperparameters in the case of informative priors are chosen by elective hyperparameters using MLE information to show the results of estimated parameters.
From the simulation analysis, we point out the following results:
- In almost all cases, the Bayes estimates perform better than the MLEs with respect to RB, MSE, LACI, LBP, and LBT.
- In most cases, the MPS estimates are better than the MLE with respect to MSE.
- The performance increases when the censored sample size r increases, such that the sample size n and the time of the hybrid censored sample are kept fixed.
- The performance increases when the time of a hybrid censored sample increases when keeping sample size n and censored sample size r as fixed values.
- The MSEs and the widths of the confidence intervals of the ACI, BP, and BT of the MLEs, MPS, and Bayes estimations decrease as the number of failures r increases for a fixed sample size n.
- As the sample size n increases, the average length of all intervals decreases. On average, the credible CI estimates are better than the ACI.
- As the sample size n increases, the bootstrap CI estimates are better than the traditional CI.
8. Conclusions
Modeling some biomedical data was performed in this study, the new APIW continuous distribution was utilized and the hybrid Type-II censoring scheme was recommended. Three estimation methods were performed to estimate the unknown parameters of the APIW distribution and hence estimate the survival and hazard functions. In real data analysis, the classical alternative (MPS) for the well-known MLE method confirmed the power fullness of the MPS over the MLE for estimating parameters, survival, and hazard function. In simulation analysis, the Bayesian approach for the inference of APIW parameters was relatively acting much better compared to the classical methods. A comparison was conducted with respect to the mean squared error and relative bias, and all results were summarized in tables and plotted in figures. The MCMC approach was employed as estimates from Bayesian are not directly obtainable. The model was applied to two real-life data sets, including failure statistical data for certain ball-bearing components and the resistance in guinea pigs exposed to various dosages of virulent tubercle bacilli.
Author Contributions
Conceptualization, D.A.R. and H.H.A.; methodology, D.A.R. and E.M.A.; software, E.M.A.; validation, D.A.R., H.H.A. and A.R.; formal analysis, E.M.A.; investigation, D.A.R.; resources, H.H.A.; data curation, A.R.; writing—original draft preparation, D.A.R. and E.M.A.; writing—review and editing, D.A.R., H.H.A. and E.M.A. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Deanship of Scientific Research, Vice Presidency for Graduate Studies and Scientific Research, King Faisal University, Saudi Arabia [Grant No. 2245].
Data Availability Statement
Data are available in this paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ghalme, S.G.; Mankar, A.; Bhalerao, Y. Biomaterials in Hip Joint Replacement. Int. J. Mater. Sci. Eng. 2016, 4, 113–125. [Google Scholar] [CrossRef]
- Kochi, A. The global tuberculosis situation and the new control strategy of the World Health Organization. Tubercle 1991, 72, 1–6. [Google Scholar] [CrossRef]
- Epstein, B. Truncated life tests in the exponential case. Ann. Socite Pol. Math. 1954, 25, 555–564. [Google Scholar] [CrossRef]
- Ebrahimi, N. Estimating the parameters of an exponential distribution from hybrid life test. J. Stat. Plan. Inference 1986, 14, 255–261. [Google Scholar] [CrossRef]
- Childs, A.; Chand Rasekhar, B.; Balakrishnan, N.; Kundu, D.E. Likelihood inference based on type-I and type-II hybrid censored samples from the exponential distribution. Ann. Inst. Stat. Math. 2003, 55, 319–330. [Google Scholar] [CrossRef]
- Mansour, M.M.M.; Ramadan, D.A. Statistical inference of the parameters of the modified extended exponential distribution under the type-II hybrid censoring scheme. J. Appl. Probab. Stat. 2020, 15, 19–44. [Google Scholar]
- Salah, M.M.; Ahmed, E.A.; Alhussain, Z.A.; Ahmed, H.H.; El-Morshedy, M.; Eliwa, M.S. Statistical inferences for type-II hybrid censoring data from the alpha power exponential distribution. PLoS ONE 2021, 16, e0244316. [Google Scholar] [CrossRef] [PubMed]
- Yousef, M.M.; Almetwally, E.M. Bayesian Inference for the Parameters of Exponential Chen Distribution Based on Hybrid Censoring. Pak. J. Stat. 2022, 38, 145–164. [Google Scholar]
- Yadav, A.S.; Singh, S.K.; Singh, U. On hybrid censored inverse Lomax distribution: Application to the survival data. Statistica 2016, 76, 185–203. [Google Scholar]
- Mahmoud, M.A.W.; Ramadan, D.A.; Mansour, M.M.M. Estimation of lifetime parameters of the modified extended exponential distribution with application to a mechanical model. Commun. Stat. Simul. Comput. 2020, 51, 7005–7018. [Google Scholar] [CrossRef]
- Aldahlan, M.A.; Bakoban, R.A.; Alzahrani, L.S. On Estimating the Parameters of the Beta Inverted Exponential Distribution under Type-II Censored Samples. Mathematics 2022, 10, 506. [Google Scholar] [CrossRef]
- Mohammed, H.S.; Nassar, M.; Alotaibi, R.; Elshahhat, A. Analysis of Adaptive Progressive Type-II Hybrid Censored Dagum Data with Applications. Symmetry 2022, 14, 2146. [Google Scholar] [CrossRef]
- Ramadan, D.A.; Aboshady, M.S.; Mansour, M.M.M. Inference for modified extended exponential distribution based on progressively Type-I hybrid censored data with application to some mechanical models. J. Appl. Probab. Stat. 2022, 17, 69–88. [Google Scholar]
- Nassr, S.G.; Almetwally, E.M.; El Azm, W.S.A. Statistical inference for the extended weibull distribution based on adaptive type-II progressive hybrid censored competing risks data. Thail. Stat. 2021, 19, 547–564. [Google Scholar]
- Ramadan, D.A.; Magdy, W.A. On the alpha-power inverse Weibull. Int. J. Comput. Appl. 2018, 181, 975–8887. [Google Scholar]
- El-Sagheer, R.M. Estimation of parameters of Weibull-Gamma distribution based on progressively censored data. Stat. Pap. 2018, 59, 725–757. [Google Scholar] [CrossRef]
- Cheng, R.C.H.; Amin, N.A.K. Estimating parameters in continuous univariate distributions with a shifted origin. J. R. Stat. Soc. Ser. B Methodol. 1983, 45, 394–403. [Google Scholar] [CrossRef]
- Kundu, D.; Howlader, H. Bayesian inference and prediction of the inverse Weibull distribution for Type-II censored data. Comput. Stat. Data Anal. 2010, 54, 1547–1558. [Google Scholar] [CrossRef]
- Dey, S.; Dey, T. On progressively censored generalized inverted exponential distribution. J. Appl. Stat. 2014, 41, 2557–2576. [Google Scholar] [CrossRef]
- Dey, S.; Ali, S.; Park, C. Weighted exponential distribution: Properties and different methods of estimation. J. Stat. Comput. Simul. 2015, 85, 3641–3661. [Google Scholar] [CrossRef]
- Dey, S.; Singh, S.; Tripathi, Y.M.; Asgharzadeh, A. Estimation and prediction for a progressively censored generalized inverted exponential distribution. Stat. Methodol. 2016, 32, 185–202. [Google Scholar] [CrossRef]
- Varian, H.R. Bayesian approach to real estate assessment. In Studies in Bayesian Econometrics and Statistics in Honor of L.J. Savage; Feinderg, S.E., Zellner, A., Eds.; North-Holland: Amsterdam, The Netherlands, 1975; pp. 195–208. [Google Scholar]
- Robert, C.P. Monte Carlo Statistical Methods; Springer: New York, NY, USA, 2004. [Google Scholar]
- Tolba, A. Bayesian and Non-Bayesian Estimation Methods for Simulating the Parameter of the Akshaya Distribution. Comput. J. Math. Stat. Sci. 2022, 1, 13–25. [Google Scholar] [CrossRef]
- Lawless, J.F. Statistical Models and Methods for Lifetime Data; John Wiley and Sons: New York, NY, USA, 1982. [Google Scholar]
- Greene, W.H. Econometric Analysis, 4th ed.; Prentice-Hall: NewYork, NY, USA, 2000. [Google Scholar]
- Meeker, W.Q.; Escobar, L.A. Statistical Methods for Reliability Data; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Efron, B. The bootstrap and other resampling plans. In CBMS-NSF Regional Conference Series in Applied Mathematics; SIAM: Philadelphia, PA, USA, 1982. [Google Scholar]
- Hall, P. Theoretical Comparison of Bootstrap Confidence Intervals. Ann. Stat. 1988, 16, 927–953. [Google Scholar] [CrossRef]
- Almongy, H.M.; Almetwally, E.M.; Alharbi, R.; Alnagar, D.; Hafez, E.H.; Mohie El-Din, M.M. The Weibull generalized exponential distribution with censored sample: Estimation and application on real data. Complexity 2021, 2021, 6653534. [Google Scholar] [CrossRef]
- Muhammed, H.Z.; Almetwally, E.M. Bayesian and non-Bayesian estimation for the bivariate inverse weibull distribution under progressive type-II censoring. Ann. Data Sci. 2020, 1–32. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Sandhu, R.A. Best linear unbiased and maximum likelihood estimation for exponential distributions under general progressive Type-ll censored samples. Indian J. Stat. Ser. B 1996, 58, 1–9. [Google Scholar]
- Leiblein, J.; Zelen, M. Statistical investigation of fatigue life of deep groove ball bearings. Res. Natl. Bur. Stand. 1956, 57, 273–316. [Google Scholar] [CrossRef]
- Okasha, H.M.; El-Baz, A.H.; Tarabia, A.M.K.; Basheer, A.M. Extended inverse weibull distribution with reliability application. J. Egypt. Math. Soc. 2017, 25, 343–349. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).