
Fitting Non-Parametric Mixture of Regressions: Introducing an EM-Type Algorithm to Address the Label-Switching Problem




Abstract
:1. Introduction
2. Materials and Methods
2.1. Model Definition
2.2. Local-Likelihood Estimation and the Label-Switching Problem
2.2.1. Local-Likelihood Estimation
| Algorithm 1 The EM algorithm for fitting non-parametric mixtures of regression. |
| Step 1: (Initialization) Provide the initial values for , and for all and . Step 2: (E-Step) At the iteration, use expression (6) to compute the local responsibilities for each grid point . Step 3: (M-Step) Let be a vector of local responsibilities at grid point associated with the component. Compute , and , for each and , using expressions (8)–(10). Step 4: Alternate between the E- and the M-Step until convergence. |
2.2.2. Label-Switching Problem
2.3. Modified Estimation Procedure
2.3.1. Regularity Assumptions
2.3.2. The Proposed Algorithm
| Algorithm 2 Modified EM algorithm for fitting the NPGMRs model. |
| Step 1: Perform local likelihood estimation using Algorithm 1. For each grid point , consider the local responsibilities , for , obtained at convergence. Step 2: For each grid point , use the local responsibilities, , for , to calculate the non-parametric mixture regression functions using (8)–(10) for all . Thus obtaining the following set of non-parametric mixture of regression functions Step 3: Let and choose, as the final estimated non-parametric mixture of regression functions, the subset of functions , where denotes that the functions in the set are defined over the set of values , such that Let the set of random sample data. To obtain the set we, respectively, interpolate the function values in the set . |
3. Simulation Study
3.1. Choosing the Bandwidth and Number of Components
- (1)
- For each , find the best bandwidth using the cross-validation approach, where is the largest number of components to consider.
- (2)
- For each of the models in (1) based on the best bandwidth, choose as a final model the one that minimizes the BIC
3.2. Initializing the Fitting Algorithm
- (1)
- For each , we estimate 20 degree polynomial GMLRs models.
- (2)
- Choose the model that minimizes the BIC in (1) to initialize the model.
3.3. Performance Measures
- (a)
- Root of the Average Squared Errors (RASE)where is a non-parametric function for the component and is its estimate.
- (b)
- Maximum Absolute Error (MAE)
- (c)
- Model Classification StrengthLet D be the set of observed data and the corresponding component indicator variable. Define as an matrix with the element if and and zero otherwise. That is, observations i and are co-members of the same component.Definewhere is an indicator function taking value one if A is true and zero otherwise. In (17), is the true component indicator variable and is the estimated version. That is,
- (d)
- Coefficient of Determination () We use the following to calculate the proportion of variation in the response explained by the fitted NPGMRs modelwhere the terms on the right hand side are as defined in Ingrassia and Punzo [19]
- (e)
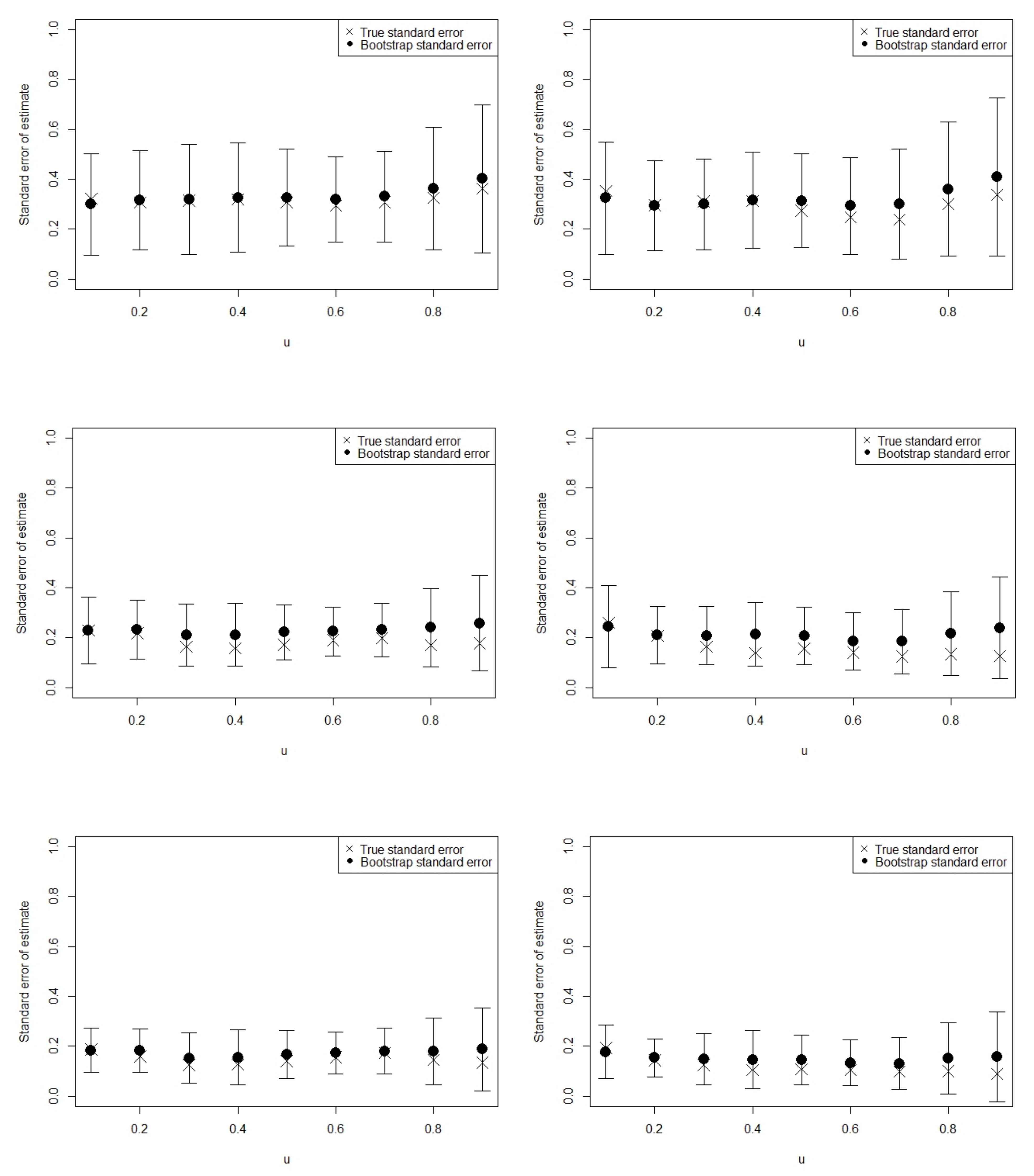
- Standard Errors and Confidence IntervalsWe use the bootstrap approach to approximate the point-wise standard errors of the estimates as well as the confidence intervals for the model parameter functions. For a given we use the estimated model to generate the corresponding ; this way we generate the bootstrap sample denoted by . We generate such samples to produce bootstrap fitted models to approximate the point-wise standard errors and confidence intervals.
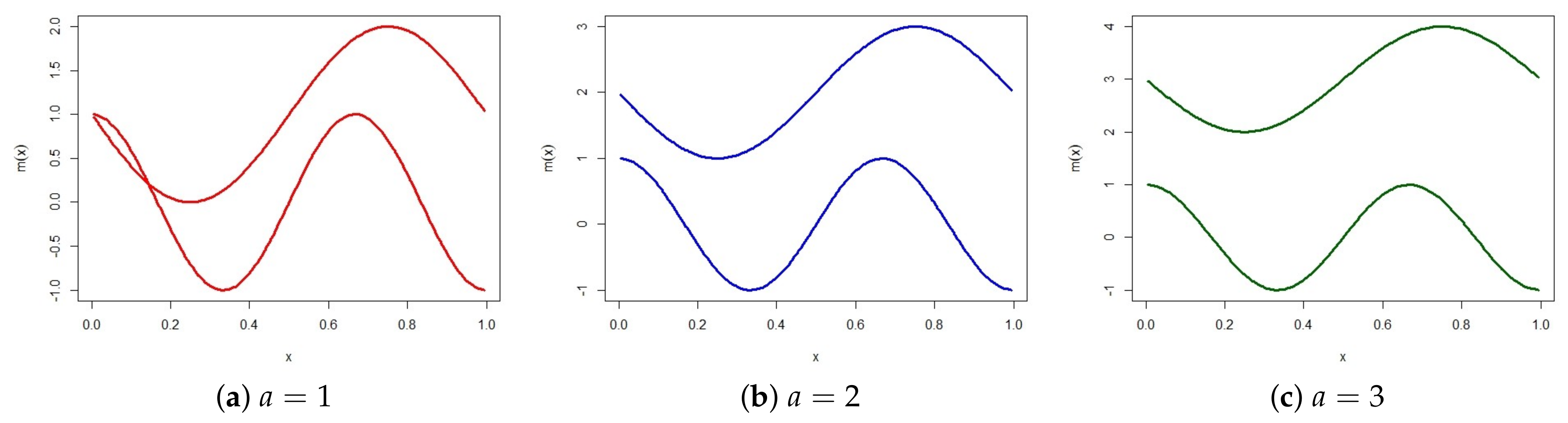
3.4. Simulation Studies
4. Application
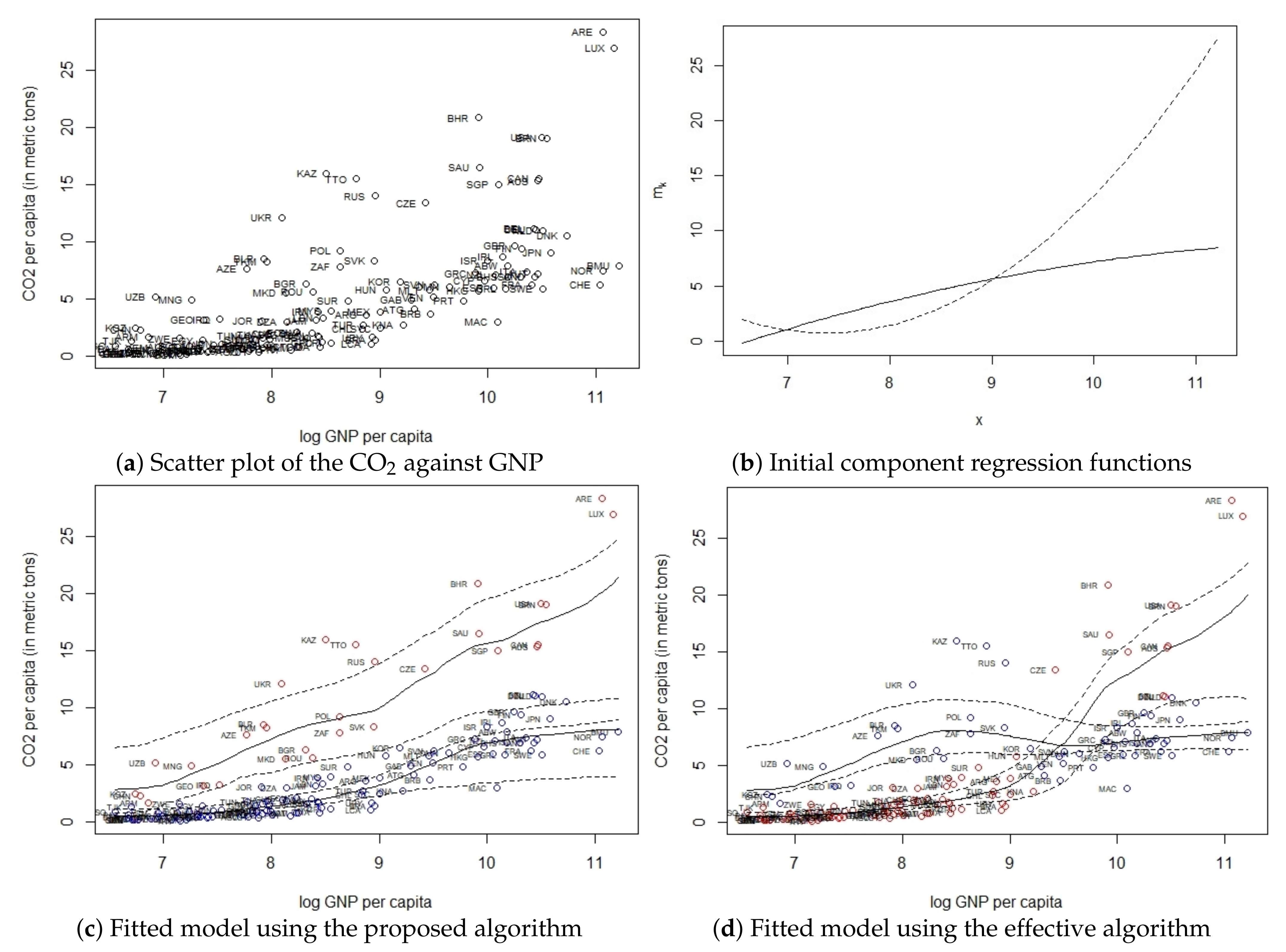
4.1. Problem and Data Description
4.2. Modelling and Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BIC | Bayesian Information Criterion |
| EM | Expectation-Maximization |
| GMLRs | Gaussian Mixture of Linear Regressions |
| LLFs | Local-Likelihood Functions |
| NPGMRs | Non-parametric Gaussian Mixture of Regressions |
References
- Titterington, D.M.; Smith, A.F.M.; Makov, U.E. Statistical Analysis of Finite Mixture Distributions; John Wiley and Sons: Hoboken, NJ, USA, 1985. [Google Scholar]
- Frühwirth-Schnatter, S.; Celeux, G.; Robert, C.P. Handbook of Mixture Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 2019. [Google Scholar]
- Quandt, R.E. A New Approach to Estimating Switching Regressions. J. Am. Stat. Assoc. 1972, 67, 306–310. [Google Scholar] [CrossRef]
- Goldfeld, S.M.; Quandt, R.E. A Markov model for switching regressions. J. Econom. 1973, 1, 3–15. [Google Scholar] [CrossRef]
- Quandt, R.E.; Ramsey, J.B. Estimating Mixtures of Normal Distributions and Switching Regressions. J. Am. Stat. Assoc. 1978, 73, 730–738. [Google Scholar] [CrossRef]
- Frühwirth-Schnatter, S. Finite Mixture and Markov Switching Models; Springer Science & Business Media: New York, NY, USA, 2006. [Google Scholar]
- Hurn, M.; Justel, A.; Robert, C.P. Estimating mixtures of regressions. J. Comput. Graph. Stat. 2003, 12, 55–79. [Google Scholar] [CrossRef]
- Huang, M.; Li, R.; Wang, S. Nonparametric mixture of regression models. J. Am. Stat. Assoc. 2013, 108, 929–941. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xiang, S.; Yao, W. Semi-parametric mixtures of non-parametric regressions. Ann. Inst. Stat. Math. 2018, 70, 131–154. [Google Scholar] [CrossRef]
- Wu, X.; Liu, T. Estimation and testing for semiparametric mixtures of partially linear models. Commun. Stat.-Theory Methods 2017, 46, 8690–8705. [Google Scholar] [CrossRef]
- Zhang, Y.; Zheng, Q. Semiparametric mixture of additive regression models. Commun. Stat.-Theory Methods 2018, 47, 681–697. [Google Scholar] [CrossRef]
- Zhang, Y.; Pan, W. Estimation and inference for mixture of partially linear additive models. Commun.-Stat.-Theory Methods 2020, 51, 2519–2533. [Google Scholar] [CrossRef]
- Xiang, S.; Yao, W. Semi-parametric mixtures of regressions with single-index for model based clustering. Adv. Data Anal. Classif. 2020, 14, 261–292. [Google Scholar] [CrossRef] [Green Version]
- Xiang, S.; Yao, W.; Yang, G. An Overview of Semi-parametric Extensions of Finite Mixture Models. Stat. Sci. 2019, 34, 391–404. [Google Scholar] [CrossRef] [Green Version]
- Tibshirani, R.; Hastie, T. Local likelihood estimation. J. Am. Stat. Assoc. 1987, 82, 559–567. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B Methodol. 1977, 39, 1–38. [Google Scholar]
- Stephens, M. Dealing with label switching in mixture models. J. R. Stat. Soc. Ser. B Stat. Methodol. 2000, 62, 795–809. [Google Scholar] [CrossRef]
- Tibshirani, R.; Walther, G. Cluster validation by prediction strength. J. Comput. Graph. Stat. 2005, 14, 511–528. [Google Scholar] [CrossRef]
- Ingrassia, S.; Punzo, A. Cluster validation for mixtures of regressions via the total sum of squares decomposition. J. Classif. 2020, 37, 526–547. [Google Scholar] [CrossRef]
- Dinda, S. Environmental Kuznets curve hypothesis: A survey. Ecol. Econ. 2004, 49, 431–455. [Google Scholar] [CrossRef] [Green Version]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Functions | Component (k) | |
|---|---|---|
| 1 | 2 | |
| ) | ||
| Scenario | ||||||
|---|---|---|---|---|---|---|
| a = 1 | a = 2 | a = 3 | ||||
| RASEm | R2 | RASEm | R2 | RASEm | R2 | |
| Proposed Algorithm | 0.3604 (0.0849) | 69.7196 (5.0879) | 0.2546 (0.0683) | 77.7391 (3.6825) | 0.2026 (0.043) | 86.2399 (2.0393) |
| Effective Algorithm | 0.4339 (0.1374) | 68.7144 (5.4797) | 0.299 (0.1723) | 77.3533 (4.0877) | 0.2122 (0.0743) | 86.2229 (2.1173) |
| Proposed Algorithm | 0.3018 (0.0678) | 69.1957 (3.7468) | 0.1929 (0.0427) | 77.7333 (2.6144) | 0.1545 (0.0296) | 86.3577 (1.2879) |
| Effective Algorithm | 0.3987 (0.1359) | 67.7125 (4.0693) | 0.2132 (0.0696) | 77.3875 (2.7089) | 0.157 (0.0396) | 86.3374 (1.3074) |
| Proposed Algorithm | 0.2533 (0.0494) | 68.9866 (2.7873) | 0.1485 (0.0278) | 77.8396 (1.9831) | 0.059 (0.0119) | 86.3538 (0.9668) |
| Effective Algorithm | 0.3905 (0.1502) | 67.3622 (3.3621) | 0.1671 (0.0439) | 77.5533 (2.0859) | 0.1197 (0.0305) | 86.3476 (0.9778) |
| Algorithm | RASE | |
|---|---|---|
| Proposed Algorithm | 0.1944 (0.0445) | 1 |
| Effective Algorithm | 0.2539 (0.0715) | 325 |
| Model | K | h | BIC |
|---|---|---|---|
| NPGMRs | 1 | 0.95 | 770.7226 |
| 3 | 0.945 | 766.3612 | |
| 4 | 0.95 | 819.9092 | |
| 5 | 0.9 | 916.5939 | |
| GMLRs | 1 | 810.1633 | |
| 1 | 811.2591 | ||
| 2 | 760.8051 | ||
| 3 | 754.7527 | ||
| 4 | 788.4389 |
| Algorithm | Performance Measures | ||||
|---|---|---|---|---|---|
| BIC | R | ||||
| Estimated | Bootstrap Mean (Std) | 95% (Lower) Bootstrap | 95% (Upper) Bootstrap | ||
| Proposed Algorithm | 83.3556 | 80.7076 (6.1293) | 63.8578 | 89.1703 | |
| Effective Algorithm | 718.4571 | 73.8182 | 70.0673 (5.8218) | 57.9395 | 80.5303 |
| Algorithm | Component 1 | Component 2 | ||
|---|---|---|---|---|
| Test Statistic | p-Value | Test Statistic | p-Value | |
| Proposed Algorithm | 0.1622 | 0.3690 | 0.1069 | 0.1441 |
| Effective Algorithm | 0.2589 | <0.0001 | 0.1733 | 0.0690 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Skhosana, S.B.; Kanfer, F.H.J.; Millard, S.M. Fitting Non-Parametric Mixture of Regressions: Introducing an EM-Type Algorithm to Address the Label-Switching Problem. Symmetry 2022, 14, 1058. https://doi.org/10.3390/sym14051058
Skhosana SB, Kanfer FHJ, Millard SM. Fitting Non-Parametric Mixture of Regressions: Introducing an EM-Type Algorithm to Address the Label-Switching Problem. Symmetry. 2022; 14(5):1058. https://doi.org/10.3390/sym14051058
Chicago/Turabian StyleSkhosana, Sphiwe B., Frans H. J. Kanfer, and Salomon M. Millard. 2022. "Fitting Non-Parametric Mixture of Regressions: Introducing an EM-Type Algorithm to Address the Label-Switching Problem" Symmetry 14, no. 5: 1058. https://doi.org/10.3390/sym14051058
APA StyleSkhosana, S. B., Kanfer, F. H. J., & Millard, S. M. (2022). Fitting Non-Parametric Mixture of Regressions: Introducing an EM-Type Algorithm to Address the Label-Switching Problem. Symmetry, 14(5), 1058. https://doi.org/10.3390/sym14051058