Abstract
Unrelated parallel machine scheduling problems (UPMSP) with various processing constraints have been considered fully; however, a UPMSP with deteriorating preventive maintenance (PM) and sequence-dependent setup time (SDST) is seldom considered. In this study, a new differentiated shuffled frog-leaping algorithm (DSFLA) is presented to solve the problem with makespan minimization. The whole search procedure consists of two phases. In the second phase, quality evaluation is done on each memeplex, then the differentiated search processes are implemented between good memeplexes and other ones, and a new population shuffling is proposed. We conducted a number of experiments. The computational results show that the main strategies of DSFLA were effective and reasonable and DSFLA was very competitive at solving UPMSP with deteriorating PM and SDST.
1. Introduction
The parallel machine scheduling problem (PMSP) is a typical scheduling problem that can be categorized into three types: identical PMSP, uniform PMSP, and unrelated PMSP (UPMSP). As the generalization of the other two types, UPMSP has attracted great attention, and a number of results have been obtained to solve UPMSP with various processing constraints, such as random breakdown and random rework [1,2,3,4].
Preventive maintenance (PM) often exists in many actual manufacturing cases, can effectively prevent potential failures and serious accidents in parallel machines, and is often required to be considered in UPMSP. Regarding UPMSP with maintenance, Yang et al. [5] studied UPMSP with aging effects and PM to minimize the total machine load and proved that the problem remained polynomially solvable when a maintenance frequency on every machine is given.
Tavana et al. [4] presented a three-stage maintenance scheduling model for UPMSP with aging effects and multi-maintenance activities. Wang and Liu [6] proposed an improved non-dominated sorting genetic algorithm-II for multi-objective UPMSP with multi-resources PM. Gara-Ali et al. [7] provided several performance criteria and different maintenance systems and gave a new method to solve the problem with deteriorating and maintenance. Lei and Liu [8] proposed an artificial bee colony (ABC) with division for distributed UPMSP with PM.
Deteriorating maintenance means that the length of maintenance activity is not constant and depends on the running time of the machine. UPMSP with deteriorating maintenance has also been studied. Cheng et al. [9] and Hsu et al. [10] provided some polynomial solutions. Lu et al. [11] considered UPMSP with parallel-batching processing, deteriorating jobs, and deteriorating maintenance and presented a mixed integer programming model and a hybrid ABC with tabu search (TS).
In many real-life industries, such as the chemical, printing, metal processing, and semiconductor industries, SDST often cannot be ignored [12]. UPMSP with SDST has been extensively addressed since the pioneering work of Parker et al. [13]. Kurz and Askin [14] proposed several heuristics. Arnaout et al. [15] designed an improved ant colony optimization with a pheromone re-initialization method. Vallada and Ruiz [16] presented a genetic algorithm to minimize the makespan. Lin and Ying [17] developed a hybrid ABC for UPMSP with machine-dependent setup times and SDST.
Caniyilmaz et al. [18] applied an ABC algorithm to solve UPMSP with processing set restrictions, an SDST, and a due date. Diana et al. [19] presented an improved immune algorithm by introducing a local search and a new selection operator. Wang and Zheng [20] proposed an estimation of distribution algorithm and gave five local search strategies. Ezugwu and Akutsah [21] proposed an improved firefly algorithm refined with a local search. Fanjul-Peyro et al. [22] presented an exact algorithm. Bektur and Sarac [23] introduced a TS and a simulated annealing algorithm for UPMSP with SDST, machine eligibility restrictions and a common server. Cota et al. [24] developed a multi-objective smart pool search algorithm for green UPMSP with SDST.
For UPMSP with PM and SDST, Avalos-Rosales et al. [25] developed an efficient meta-heuristic based on a multi-start strategy to minimize the makespan, and Wang and Pan [26] presented a novel imperialist competitive algorithm with an estimation of distribution algorithm to optimize the makespan and total tardiness.
SDST and deteriorating maintenance are common processing constraints and often exist simultaneously in the real-life production process; however, the previous works mainly deal with UPMSP with one of these two constraints, few papers focus on UPMSP with maintenance and SDST [25,26] and UPMSP with deteriorating PM and SDST is hardly studied. It is necessary to investigate UPMSP with deteriorating PM and SDST due to their extensive existences in production. On the other hand, meta-heuristics, including ABC, have been applied to solve UPMSP with various processing constraints, such as PM and SDST. As a meta-heuristic, by observing, imitating, and modeling the search behavior of frogs for the location with the maximum amount of available food, the shuffled frog-leaping algorithm (SFLA) is seldom used to handle UPMSP.
SFLA has a fast convergence speed and effective algorithm structure containing local search and global information exchanges [27]. It has been widely applied to solve various optimization problems, such as topology optimization and production scheduling problems [28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45]. The existing works on scheduling problems revealed that SFLA has great potential in solving UPMSP with deteriorating PM and SDST. On the other hand, the same search process and parameters are adopted in all memeplexes, and the differentiated search process is seldom used, which can effectively intensify the exploration ability and avoid falling local optima; thus, it is necessary to investigate the possible applications of SFLA with new optimization mechanisms for UPMSP with SDST and PM.
In this study, UPMSP with deteriorating PM and SDST is considered, and a new differentiated shuffled frog-leaping algorithm (DSFLA) is applied to minimize the makespan. The entire search procedure is composed of two phases. In the second phase, the memeplex quality is evaluated on each memeplex to divide all memeplexes into good memeplexes and others, then the differentiated search processes are implemented between good memeplexes and others, and a new population shuffling is proposed. We conduct experiments to test the effect of the main strategies and the search advantages for DSFLA.
The remainder of the paper is organized as follows. The problem is described in Section 2 followed by an introduction to SFLA in Section 3. DSFLA for the considered problem is reported in Section 4. Numerical experiments on DSFLA are reported in Section 5, the conclusions are summarized in the final section, and some topics of future research are provided.
2. Problem Description
UPMSP with deteriorating PM and SDST is composed of n jobs and m unrelated parallel machines . Each job can be processed on any one of m machines. The processing time of job depends on the performance of its processing machine . The processing times on different machines are usually different.
On machine , job is processed in a time interval between two consecutive maintenance activities, and the length of the interval is indicated as , and denotes the duration of each maintenance. For deteriorating maintenance, is not constant and depends on and the starting time of maintenance, , where are constant, and indicates the starting time of maintenance on . There are some intervals for processing on each machine. If the processing of a job cannot be completed in a processing interval, the job cannot be processed in the current interval and should be moved to the next interval.
For SDST, is the setup time for processing job after job on machine , indicates the setup time of machine to process the first job after a maintenance activity, and is the setup time of machine to perform a maintenance activity after the job .
There have the following constraints on jobs and machines.
- ■
- Each job and machine is available at time zero.
- ■
- Each job can be processed on only one machine at a time.
- ■
- Operations cannot be interrupted.
- ■
- Preemption is not allowed.
The problem is composed of the scheduling sub-problem and machine assignment sub-problem. The goal of the problem is to minimize the makespan.
Let be a completion time of job j in schedule , and the makespan can be defined by . Thus, the objective is to find a schedule that minimizes the makespan , where is the set of all feasible schedules .
An illustrative example is provided. Table 1 and Table 2 give the processing time and setup time. There are two machines and eight jobs. Data on deteriorating PM are shown in Figure 1, where and for all machines.

Table 1.
Processing time.
Table 2.
Setup times and .
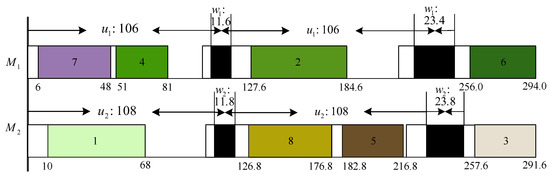
Figure 1.
A schedule of the example.
When no PM is considered, any two jobs on any one machine are symmetrical, that is, exchanging them does not change the makespan. When PM is handled, any two jobs on a machine between time 0 and the first PM or two consecutive PMs, because of the above, are reasonable; thus, the consideration of PM has impact on the optimization of the considered UPMSP.
3. Introduction to SFLA
In SFLA, a solution is defined as the position of a frog, and there is a population of possible solutions defined by a set of virtual frogs. After the initial population P is produced, the following steps, which are population division, memeplex search, and population shuffling, are repeated until the stopping condition is met.
Population division is as follows. After all solutions are sorted, suppose that , and then solution is allocated into memeplex , where indicates the remainder of , is the fitness of solution , and s indicates the number of memeplexes.
The search process in memeplex is shown below. is used as optimization object, then a new solution is produced by Equation (2) with and . If the new one is better than , then replace with ; otherwise, and are used to generate a solution by Equation (3). If has better fitness than , then becomes the new ; otherwise, a randomly obtained solution directly substitutes for , where , and are the worst solution and best solution in memeplex and the best solution of P.
where is a random number following uniform distribution in [0.1].
A new population P is constructed by shuffling all evolved memeplexes.
As stated above, all memeplexes are often evolved by the same search process and parameters [29,32,33] and the differentiated search in memeplexes is seldom considered. When the differentiated search operators and parameters are introduced, the search ability will be intensified, and local optima can be effectively avoided, as a result, the search efficiency is greatly improved. In this study, DSFLA is presented to solve UPMSP with deteriorating PM and SDST.
4. DSFLA for UPMSP with Deteriorating PM and SDST
DSFLA is composed of two phases, and the differentiated search is implemented in the second phase.
4.1. Initialization, Population Division, and the First Phase
UPMSP consists of two sub-problems: machine assignment and scheduling, and two-string representation is often applied to indicate the solution of UPMSP [46,47]; however, two strings are often dependent each other, and it is difficult to design and apply global search or local search on each string independently. In this study, a solution of the problem is represented as a machine assignment string and a scheduling string , where is the assigned parallel machine for job , , and is real number and corresponds to . These two strings are independent.
Lei and Liu [8] analyzed why a scheduling string is introduced because of the above mentioned changes of symmetry. The decoding process is described below. First, we decide on a machine for each job according to each machine assignment string, and then on each machine , for all jobs allocated on —that is, . The processing sequence of these jobs is decided by the ascending order of , and they process jobs and deal with maintenance on sequentially.
After the initial population P is randomly produced, population division is performed in the following way. Decide the best s solutions from P and sort them in the descending order of their objective. Then, the first solution is allocated into memeplex , the second solution is assigned into , and so on. Then, binary tournament selection is used to allocate other solutions into memeplexes: randomly select two solutions and , and then, if () is better than (). Then, () is included into . If two solutions have the same objective, then stochastically choose one of them and add it into . The unchosen solution goes back to population P. Repeat the above steps for deciding a solution for , , , and then repeat the above procedure until all solutions are assigned. Obviously, , where denotes the size of each memeplex.
There are two phases in the search process of DSFLA. The steps of the first phase are identical with SFLA in Section 3. The search process in is shown below. Repeat the following steps times: decide , execute two-point crossover on machine assignment string of and , if the obtained solution x is better than , then replace with x; otherwise, apply two-point crossover on a scheduling string between and . If the generated solution x has a smaller makespan than , x becomes the new , where is an integer.
In the first phase, global search is only used because of its good exploration ability in the early search stage. In the second phase, the differentiated search processes are implemented based on memeplex quality evaluation.
4.2. The Second Phase
The evaluation of memeplex quality is seldom considered in SFLA. In this study, memeplex quality is evaluated according to solution quality and evolution quality. For memeplex , its quality is defined by
where are real number, and indicate solution quality and evolution quality of , respectively, , , and represent the maximum and minimum evolution quality of all memeplexes, respectively.
After all solutions in are sorted in the ascending order of makespan, let indicate the set of the first solutions except and is the set of the remained solutions in ,
where is the average makespan of all solutions in , , is a real number.
Solutions of are better than those of ; therefore, we set to reflect this feature. and are obtained by experiments.
Let indicate the improved number of x between the first generation and the current generation. When is chosen as an optimization object, such as , in general SFLA, if an obtained solution is better than x, then . is the total search times from the first generation to the current generation.
For solution , its is used to evaluate its evolution quality and is computed by
The second phase is shown as follows.
- (1)
- Perform population division, compute for all memeplexes, sort them in descending order of , and construct set .
- (2)
- For each memeplex , , repeat the following steps times if , execute global search between and a randomly chosen ; else perform global search between and a solution with for all .
- (3)
- For each memeplex ,
- 1
- sort all solutions in in the ascending order of makespan, suppose , and construct a set .
- 2
- Repeat the following steps times, and randomly choose a solution ; if , then select a solution by roulette selection based on , execute global search between and y, and update memory ; else execute global search between and a solution z with for all and update memory .
- (4)
- Execute multiple neighborhood searches on each solution .
- (5)
- Perform new population shuffling.
where is defined for each solution and is the average value of all in . is a real number and set to be 0.4 by experiments, indicates the average quality of all memeplexes, is the set of good memeplexes, and is a probability and defined by
where is an integer and decided by ranking according to makespan in the first step of step (3) in the above Algorithm.
In the second phase, after all memeplexes are sorted in the descending order of , suppose .
Memory is used to store the intermediate solutions. The maximum size is given in advance. We set to be 200 by experiments. When the number of solutions exceeds , a solution x can be added into when x is better than the worst solution of and substitutes for the worst one.
Six neighborhood structures are used. is shown below. Randomly select a job from the machine with the largest and move it into the machine with the smallest , where and are the completion time of the last processed job on and , respectively. is performed in the following way. Decide on a machine with the largest and a job with the largest processing time on , randomly choose a machine and a job with the largest and exchange and between and .
is described as follows. Randomly select two machines and and exchange a job with the largest and a job with the largest between these two machines. only act on the machine assignment string.
,, are performed on a scheduling string by swapping two randomly chosen genes, inserting a randomly selected gene into a new randomly decided position, and inverting genes between two stochastically positions .
Multiple neighborhood search is performed in the following way. For solution x, let , repeat the following steps V times: produce a solution , , let if , and if z is better than x, then replace x with z and .
Global search is executed in the same way of the first phase.
In the existing SFLA [29,32,33], a new population P is constructed by using s evolved memeplexes. In this study, new population shuffling is done in the following way: best solutions of and s memeplexes are added into new population P, and worst solutions of P are removed. We test by experiments and set .
Some worst solutions of P can be updated by solutions of , that is, solutions of P can be improved by memeplex search or shuffling.
In the second phase, the set is composed of good memeplexes with better quality than other memeplexes, in the search process for a good memeplex, a global search of optimization object x is implemented according to , and then multiple neighborhood search acts on the solutions in . Only global search is executed for other memeplexes; moreover, different parameters, , are used, and, as a result, differentiated search is implemented.
4.3. Algorithm Description
The detailed steps of DSFLA are shown below.
- (1)
- Initialization. Randomly produce initial population P with N solutions, and let initial be empty.
- (2)
- Population division. execute search process within each memeplex.
- (3)
- Perform population shuffling.
- (4)
- If the stopping condition of the first phase is not met, then go to step (2).
- (5)
- Execute the second phase until the stopping condition is met.
The computational complexity is , where L is the repeated number of steps 2–3.
Unlike the previous SFLA [29,32,33], DSFLA has the following features. (1) Quality evaluation is done for all memeplexes according to the solution quality and evolution quality and all memeplexes are categorized into two types: good memeplexes and other memeplexes. (2) The differentiated search is implemented by different search strategies and parameters for two types of memeplexes; as a result, the exploration ability is intensified; and the possibility of falling into local optima diminishes greatly.
5. Computational Experiments
Extensive experiments were conducted on a set of instances to test the performance of DSFLA for UPMSP with deteriorating PM and SDST. All experiments were implemented by using Microsoft Visual C++ 2019 and run on 8.0 G RAM 2.30 GHz CPU PC.
5.1. Instances and Comparative Algorithms
We used 70 instances, which has and , or and , , setup time from [5,10], , , and for machine .
We proposed a hybrid particle swarm optimization and genetic algorithm (HPSOGA) [48] for UPMSP. It can be applied to our UPMSP after the decoding procedure of DSFLA is adopted, and thus we selected it as a comparative algorithm. Lu et al. [11] presented ABC-TS for an unrelated parallel-batching machine scheduling problem with deteriorating jobs and maintenance. Avalos-Rosales et al. [25] applied a multi-start algorithm (MSA) to solve UPMSP with PM and SDST. These two algorithms can be directly used to solve UPMSP with SDST and deteriorating PM and possess good performance; therefore, they are chosen as comparative algorithms.
The general SFLA in Section 3 was also implemented, in which global search between two solutions is performed in the same way as the first stage of DSFLA. The comparison between DSFLA and SFLA is to show the effect of the main strategies of DSFLA.
5.2. Parameter Settings
In DSFLA, the stopping condition is the maximum number of objective function evaluations. We found that DSFLA can converge fully. We also tested this condition for other comparative algorithms when is . We also found that the above was appropriate; thus, we used this stopping condition.
DSFLA possesses other main parameters: N, s, , , V, and , where denotes the maximum number of objective function evaluations in the first phase.
The Taguchi method [49] was used to decide the settings for parameters. We selected instance for parameter tuning. The levels of each parameter are shown in Table 3. There were 27 parameter combinations according to the orthogonal array .
Table 3.
Parameters and their levels.
DSFLA with each combination run 10 times independently for the chosen instance. The results of and the ratio are shown in Figure 2, in which the ratio is defined as and is the best solution found in 10 runs. From Figure 2, DSFLA with following combination , , , , and obtained better results than DSFLA with other combinations; therefore, the above combination was adopted.
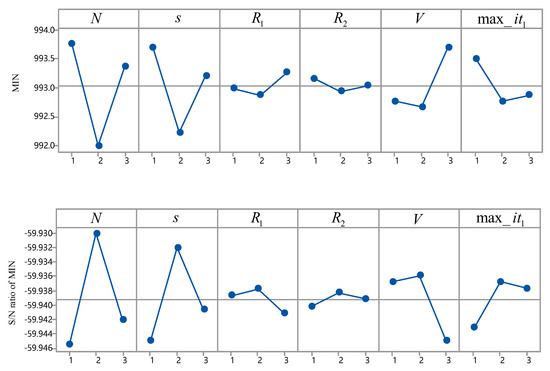
Figure 2.
Results of and the ratio.
5.3. Results and Analyses
DSFLA was compared with SFLA, ABC-TS, HPSOGA, and MSA. All parameters except the stopping conditions of ABC-TS, HPSOGA, and MSA were directly adopted from the original references. For SFLA, there were no and , and the other parameters were given the same settings as DSFLA. Each algorithm randomly ran 10 times for each instance. Table 4, Table 5 and Table 6 show the computational results of all algorithms, in which is the average value of the obtained 10 elite solutions in 10 runs, and is the standard deviation of 10 elite solutions.
Table 4.
Computational results of five algorithms on the metric MIN.
Table 5.
Computational results of five algorithms on the metric AVG.
Table 6.
Computational results of five algorithms on the metric SD.
Table 7 describes the computational times of DSFLA and its comparative algorithms, in which the unit of time is seconds. Figure 3 gives a box plot of all algorithms, in which () () indicates the () () of an algorithm minus the () () of DSFLA. Figure 4 reveals the convergence curves of two instances.
Table 7.
The computational times of DSFLA, HPSOGA, ABC-TS, and MSA.
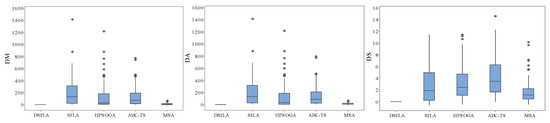
Figure 3.
Box plot of all algorithms.
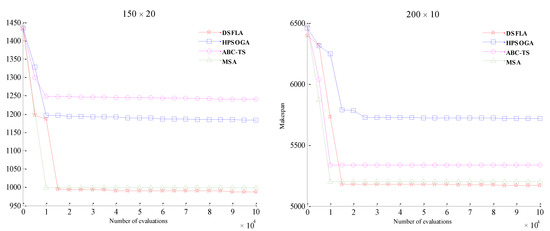
Figure 4.
Convergence curves of DSFLA and its comparative algorithms.
As shown in Table 4, Table 5 and Table 6, SFLA could not produce better than DSFLA on any instances and obtains bigger than SFLA by at least 100 for most instances. DSFLA had better convergent performance than SFLA. DSFLA generated smaller than SFLA on all instances, and the differences of between the two algorithms were significant.
DSFLA performed better than SFLA for the average performance. The of SFLA was also worse than that of DSFLA for most instances, and SFLA was inferior to DSFLA regarding search stability. DSFLA performed notably better when compared with SFLA. This conclusion can also be drawn from Figure 3; thus, new strategies, such as differentiated search, had a positive impact on the performance of DSFLA.
It can be seen from Table 4 that DSFLA produced smaller compared with HPSOGA and ABC-TS for nearly all instances and generated a worse than MSA for only 11 instances. DSFLA converged better than its comparative algorithms. The convergence performance differences between DSFLA and its comparative algorithm can also be seen from the box plot and convergence curves in Figure 3 and Figure 4.
The results in Table 5 show that DSFLA obtained a better over HPSOGA and ABC-TS for nearly all instances and possessed a smaller than MSA for most instances. DSFLA had a better average performance than its three comparative algorithms. This conclusion can also be drawn from Figure 3. Table 6 and Figure 3 reveal that DSFLA had better stability than its three comparative algorithms; thus, we concluded that DSFLA can provide promising results for solving UPMSP with deteriorating PM and SDST.
The good performances of DSFLA mainly resulted from its new strategies in the second phase. The differentiated search was implemented by memeplex quality evaluation and different search combinations of global search and multiple neighborhood search. These strategies effectively intensified the exploration ability and avoided the search falling into local optima. As a result, a high search efficiency was obtained; thus, DSFLA is a very competitive method for the considered UPMSP.
6. Conclusions
UPMSP with various processing constraints has been extensively considered. This paper addressed UPMSP with deteriorating PM and SDST and provided a new algorithm named DSFLA to minimize the makespan. In DSFLA, two search phases exist, memeplex quality evaluation is performed, and the differentiated search processes between two kind of memeplexes are implemented in the second phase. A new population shuffling was also presented. A number of computational experiments were conducted. The computational results demonstrated that DSFLA had promising advantages, such as good convergence and stability in solving the considered UPMSP.
UPMSP with at least two actual constraints, such as PM, SDST, and learning effects, may attract attention. We will continue to focus on these UPMSP by using meta-heuristics, including ABC and the imperialist competitive algorithm. Uncertainty often cannot be neglected and should be added into scheduling problems. UPMSP with uncertainty and energy-related elements, etc. is our future topic. Reinforcement learning has been used to solve scheduling problems and we will pay attention to meta-heuristics with reinforcement learning for UPMSP with various processing constraints.
Author Contributions
Conceptualization, D.L.; software, T.Y.; writing—original draft preparation, D.L.; writing—review and editing, D.L. Both authors have read and agreed to the published version of the manuscript.
Funding
This paper was supported by the National Natural Science Foundation of China (61573264).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Kim, Y.-H.; Kim, R.-S. Insertion of new idle time for unrelated parallel machine scheduling with job splititing and machine breakdown. Comput. Ind. Eng. 2020, 147, 106630. [Google Scholar] [CrossRef]
- Wang, X.M.; Li, Z.T.; Chen, Q.X.; Mao, N. Meta-heuristics for unrelated parallel machines scheduling with random rework to minimize expected total weighted tardiness. Comput. Ind. Eng. 2020, 145, 106505. [Google Scholar] [CrossRef]
- Ding, J.; Shen, L.J.; Lu, Z.P.; Peng, B. Parallel machine scheduling with completion-time based criteria and sequence-dependent deterioration. Comput. Oper. Res. 2019, 103, 35–45. [Google Scholar] [CrossRef]
- Tavana, M.; Zarook, Y.; Santos-Arteaga, F.J. An integrated three-stage maintenance scheduling model for unrelated parallel machines with aging effect and multimaintenance activities. Comput. Ind. Eng. 2015, 83, 226–236. [Google Scholar] [CrossRef]
- Yang, D.L.; Cheng, T.C.E.; Yang, S.J.; Hsu, C.J. Unrelated parallel-machine scheduling with aging effects and multi-maintenance activities. Comput. Oper. Res. 2013, 39, 1458–1464. [Google Scholar] [CrossRef]
- Wang, S.J.; Liu, M. Multi-objective optimization of parallel machine scheduling integrated with multi-resources preventive maintenance planning. J. Manuf. Syst. 2015, 37, 182–192. [Google Scholar] [CrossRef]
- Gara-Ali, A.; Finke, G.; Espinouse, M.L. Parallel-machine scheduling with maintenance: Praising the assignment problem. Eur. J. Oper. Res. 2016, 252, 90–97. [Google Scholar] [CrossRef]
- Lei, D.M.; Liu, M.Y. An artificial bee colony with division for distributed unrelated parallel machine scheduling with preventive maintenance. Comput. Ind. Eng. 2020, 141, 106320. [Google Scholar] [CrossRef]
- Cheng, T.C.E.; Hsu, C.-J.; Yang, D.-L. Unrelated parallel-machine scheduling with deteriorating maintenance activities. Comput. Ind. Eng. 2011, 60, 602–605. [Google Scholar] [CrossRef]
- Hsu, C.-J.; Ji, M.; Guo, J.Y.; Yang, D.-L. Unrelated parallel-machine scheduling problems with aging effects and deteriorating maintenance activities. Infor. Sci. 2013, 253, 163–169. [Google Scholar] [CrossRef]
- Lu, S.J.; Liu, X.B.; Pei, J.; Thai, M.T.; Pardalos, P.M. A hybrid ABC-TS algorithm for the unrelated parallel-batching machines scheduling problem with deteriorating jobs and maintenance activity. Appl. Soft. Comput. 2018, 66, 168–182. [Google Scholar] [CrossRef]
- Allahverdi, A.; Gupta, J.N.; Aldowaisan, T. A review of scheduling research involving setup considerations. Omega 1999, 27, 219–239. [Google Scholar] [CrossRef]
- Parker, R.G.; Deana, R.H.; Holmes, R.A. On the use of a vehicle routing algorithm for the parallel processor problem with sequence dependent changeover costs. IIE Trans. 1977, 9, 155–160. [Google Scholar] [CrossRef]
- Kurz, M.; Askin, R. Heuristic scheduling of parallel machines with sequence-dependent set-up times. Int. J. Prod. Res. 2001, 39, 3747–3769. [Google Scholar] [CrossRef]
- Arnaout, J.P.; Rabad, G.; Musa, R. A two-stage ant colony optimization algorithm to minimize the makespan on unrelated parallel machines with sequence-dependent setup times. J. Intell. Manuf. 2010, 21, 693–701. [Google Scholar] [CrossRef]
- Vallada, E.; Ruiz, R. A genetic algorithm for the unrelated machine scheduling problem with sequence dependent setup times. Eur. J. Oper. Res. 2011, 211, 612–622. [Google Scholar] [CrossRef] [Green Version]
- Lin, S.W.; Ying, K.-C. ABC-based manufacturing scheduling for unrelated parallel machines with machine-dependent and job sequence-dependent setup times. Comput. Oper. Res. 2014, 51, 172–181. [Google Scholar] [CrossRef]
- Caniyilmaz, E.; Benli, B.; IIkay, M.S. An artificial bee colony algorithm approach for unrelated parallel machine scheduling with processing set restrictions, job sequence-dependent setup times, and due date. Int. J. Adv. Manuf. Technol. 2015, 77, 2105–2115. [Google Scholar] [CrossRef]
- Diana, R.O.M.; Filho, M.F.D.F.; Souza, S.R.D.; Vitor, J.F.D.A. An immune-inspired algorithm for an unrelated parallel machines scheduling problem with sequence and machine dependent setup-times for makespan minimisation. Neurocomputing 2015, 163, 94–105. [Google Scholar] [CrossRef]
- Wang, L.; Zheng, X.L. A hybrid estimation of distribution algorithm for unrelated parallel machine scheduling with sequence-dependent setup times. IEEE-CAA J. Autom. 2016, 3, 235–246. [Google Scholar]
- Ezugwu, A.E.; Akutsah, F. An improved firefly algorithm for the unrelated parallel machines scheduling problem with sequence-dependent setup times. IEEE Acc. 2018, 4, 54459–54478. [Google Scholar] [CrossRef]
- Fanjul-Peyro, L.; Ruiz, R.; Perea, F. Reformulations and an exact algorithm for unrelated parallel machine scheduling problems with setup times. Comput. Oper. Res. 2019, 10, 1173–1182. [Google Scholar] [CrossRef]
- Bektur, G.; Sarac, T. A mathematical model and heuristic algorithms for an unrelated parallel machine scheduling problem with sequence-dependent setup times, machine eligibility restrictions and a common server. Comput. Oper. Res. 2019, 103, 46–63. [Google Scholar] [CrossRef]
- Cota, L.P.; Coelho, V.N.; Guimaraes, F.G.; Souza, M.F. Bi-criteria formulation for green scheduling with unrelated parallel machines with sequence-depedent setup times. Int. Trans. Oper. Res. 2021, 28, 996–1007. [Google Scholar] [CrossRef]
- Avalos-Rosales, O.; Angel-Bello, F.; Alvarez, A.; Cardona-Valdes, Y. Including preventive maintenance activities in an unrelated parallel machine environment with dependent setup times. Comput. Ind. Eng. 2018, 123, 364–377. [Google Scholar] [CrossRef]
- Wang, M.; Pan, G.H. A novel imperialist competitive algoirthm with multi-elite individuals guidance for multi-objective unrelated parallel machine scheduling problem. IEEE Acc. 2019, 7, 121223–121235. [Google Scholar] [CrossRef]
- Eusuff, M.M.; Lansey, K.E.; Pasha, F. Shuffled frog-leaping algorithm: A memetic meta-heuristic for discrete optimization. Eng. Optim. 2006, 38, 129–154. [Google Scholar] [CrossRef]
- Rahimi-Vahed, A.; Mirzaei, A.H. Solving a bi-criteria permutation flow-shop problem using shuffled frog-leaping algorithm. Appl. Soft. Comput. 2008, 12, 435–452. [Google Scholar] [CrossRef]
- Pan, Q.K.; Wang, L.; Gao, L.; Li, J.Q. An effective shuffled frog-leaping algorithm for lot-streaming flow shop scheduling problem. Int. J. Adv. Manuf. Technol. 2011, 52, 699–713. [Google Scholar] [CrossRef]
- Li, J.Q.; Pan, Q.K.; Xie, S.X. An effective shuffled frog-leaping algorithm for multi-objective flexible job shop scheduling problems. Appl. Math. Comput. 2012, 218, 9353–9371. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, L.; Liu, M.; Wang, S.Y. An effective shuffled frog-leaping algorithm for hybrid flow-shop scheduling with multiprocessor tasks. Int. J. Adv. Manuf. Technol. 2013, 68, 1529–1537. [Google Scholar] [CrossRef]
- Lei, D.M.; Guo, X.P. A shuffled frog-leaping algorithm for hybrid flow shop scheduling with two agents. Expert Syst. Appl. 2015, 42, 9333–9339. [Google Scholar] [CrossRef]
- Lei, D.M.; Guo, X.P. A shuffled frog-leaping algorithm for job shop scheduling with outsourcing options. Int. J. Prod. Res. 2016, 54, 4793–4804. [Google Scholar] [CrossRef]
- Lei, D.M.; Zheng, Y.L.; Guo, X.P. A shuffled frog-leaping algorithm for flexible job shop scheduling with the consideration of energy consumption. Int. J. Prod. Res. 2017, 55, 3126–3140. [Google Scholar] [CrossRef]
- Lei, D.M.; Wang, T. Solving distributed two-stage hybrid flowshop scheduling using a shuffled frog-leaping algorithm with memeplex grouping. Eng. Optim. 2020, 52, 1461–1474. [Google Scholar] [CrossRef]
- Cai, J.C.; Zhou, R.; Lei, D.M. Dynamic shuffled frog-leaping algorithm for distributed hybrid flow shop scheduling with multiprocessor tasks. Eng. Appl. Artif. Intell. 2020, 90, 103540. [Google Scholar] [CrossRef]
- Kong, M.; Liu, X.B.; Pei, J.; Pardalos, P.M.; Mladenovic, N. Parallel-batching scheduling with nonlinear processing times on a single and unrelated parallel machines. J. Glob. Optim. 2020, 78, 693–715. [Google Scholar] [CrossRef]
- Lu, K.; Ting, L.; Keming, W.; Hanbing, Z.; Makoto, T.; Bin, Y. An improved shuffled frog-leaping algorithm for flexible job shop scheduling problem. Algorithms 2015, 8, 19–31. [Google Scholar] [CrossRef] [Green Version]
- Fernez, G.S.; Krishnasamy, V.; Kuppusamy, S.; Ali, J.S.; Ali, Z.M.; El-Shahat, A.; Abdel Aleem, S.H. Optimal dynamic scheduling of electric vehicles in a parking lot using particle swarm optimization and shuffled frog leaping algorithm. Energies 2020, 13, 6384. [Google Scholar]
- Yang, W.; Ho, S.L.; Fu, W. A modified shuffled frog leaping algorithm for the topology optimization of electromagnet devices. Appl. Sci. 2020, 10, 6186. [Google Scholar] [CrossRef]
- Moayedi, H.; Bui, D.T.; Thi Ngo, P.T. Shuffled frog leaping algorithm and wind-driven optimization technique modified with multilayer perceptron. Appl. Sci. 2020, 10, 689. [Google Scholar] [CrossRef] [Green Version]
- Hsu, H.-P.; Chiang, T.-L. An improved shuffled frog-leaping algorithm for solving the dynamic and continuous berth allocation problem (DCBAP). Appl. Sci. 2019, 9, 4682. [Google Scholar] [CrossRef] [Green Version]
- Mora-Melia, D.; Iglesias-Rey, P.L.; Martínez-Solano, F.J.; Muñoz-Velasco, P. The efficiency of setting parameters in a modified shuffled frog leaping algorithm applied to optimizing water distribution networks. Water 2016, 8, 182. [Google Scholar] [CrossRef] [Green Version]
- Amiri, B.; Fathian, M.; Maroosi, A. Application of shuffled frog-leaping algorithm on clustering. Int. J. Adv. Manuf. Technol. 2009, 45, 199–209. [Google Scholar] [CrossRef]
- Elbeltagi, E.; Hegazy, T.; Grierson, D. A modified shuffled frog-leaping optimization algorithm: Applications to project management. Struct. Infrastruct. Eng. 2007, 3, 53–60. [Google Scholar] [CrossRef]
- Gao, J.Q.; He, G.X.; Wang, Y.S. A new parallel genetic algorithm for solving multiobjective scheduling problems subjected to special process constraint. Int. J. Adv. Manuf. Technol. 2009, 43, 151–160. [Google Scholar] [CrossRef]
- Afzalirad, M.; Rezaein, J. A realistic variant of bi-objective unrelated parallel machine scheduling problem NSGA-II and MOACO approaches. Appl. Soft Comput. 2017, 50, 109–123. [Google Scholar] [CrossRef]
- Mir, M.S.S.; Rezaeian, J. A robust hybrid approach based on particle swarm optimization and genetic algorithm to minimize the total machine load on unrelated parallel machines. Appl. Soft Comput. 2016, 41, 488–504. [Google Scholar]
- Taguchi, G. Introduction to Quality Engineering; Asian Productivity Organization: Tokyo, Japan, 1986. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).