Abstract
In this paper, the inverse gamma power series (IGPS) class of distributions asymmetric is introduced. This family is obtained by compounding inverse gamma and power series distributions. We present the density, survival and hazard functions, moments and the order statistics of the IGPS. Estimation is first discussed by means of the quantile method. Then, an EM algorithm is implemented to compute the maximum likelihood estimates of the parameters. Moreover, a simulation study is carried out to examine the effectiveness of these estimates. Finally, the performance of the new class is analyzed by means of two asymmetric real data sets.
1. Introduction
In the last few decades, several papers have discussed the derivation of new probabilistic families by compounding different distributions with the power series (PS) model. For example, the exponential geometric (EG, Adamidis and Loukas [1]), exponential Poisson (EP, Kus [2]) and exponential logarithmic (EL, Tahmasbi and Rezaei [3]) distributions. The exponential PS is introduced in Chahkandi and Ganjali [4], Morais and Barreto-Souza [5] presented the Weibull PS (WPS) class of distributions, Mahmoudi and Jafari [6] defined the generalized exponential PS (GEPS) distributions, Silva et al. [7], the extended Weibull PS (EWPS) and Bagheri et al. [8], the generalized modified Weibull PS distribution (GMWPS). More recently, Warahena-Liyanage and Pararai [9] introduce the Lindley PS distributions (LPS), Alizadeh et al. [10] study the exponentiated power Lindley PS class of distributions, Elbatal et al. [11] propose and study a new family of exponential Pareto PS and finally the Generalized Burr XII PS distribution was given by Elbatal et al. [12].
In this work, we propose to study the resulting model obtained by compounding the inverse gamma (IG) and the PS distribution introduced by Noack [13].
We say that a random variable X follows an IG distribution with shape parameter and scale parameter (henceforward, the notation will be used) if its probability density function (pdf) is given by
and its survival function is
where represents the survival function for the gamma distribution with shape parameter a and scale 1 and is the upper incomplete gamma function. Please note that . The rth non-central moment for this distribution is given by , in particular for we have , and so for , .
The remainder of the work is organized as follows. In Section 2, the Inverse Gamma PS (IGPS) probabilistic family is introduced and some properties including the density, survival and hazard functions, moments and statistical ordering are examined. Furthermore, some particular cases of this family are analyzed. Parameter estimation is discussed in Section 3, where quantile-matching estimation method and Expectation-Maximization (EM) algorithm are considered. In Section 4, a simulation analysis is carried out to test the performance of the estimates. Then, this family is applied to two real data sets. Section 5 concludes the paper.
2. The Model
Let be the number of concurrent causes producing the event of interest in a subject. For instance, in a cancer context, M represents the number of carcinogenic cells that a patient has and, as a result of this number, it might trigger the metastasis process. In electronic circuits connected in series, M represents the number of components that the circuit has, so if one of those components fails, the entire circuit will fail. In credit scoring, M represents the number of different factors for which a customer stops paying their bills (economic, psychological, family, etc.). Let us also assume that M follows a PS distribution (Noack [13]) with probability mass function (pmf) given by
where , is called the power parameter and the series function . We highlight that the pmf in Equation (2) also corresponds to the generalized Power distribution discussed in Patil [14]. However, many works that have discussed this distribution referred to this model as PS model (see for instance, Adamidis and Loukas [1]; Morais and Barreto-Souza [5]). Hereafter, (2) will be denoted as PS. In Table 1, for four members of the PS family, the values of , and parameter space are illustrated.

Table 1.
Special cases of the PS distribution. For Binomial distribution q is considered known.
Let the random variable denote the time when the ath concurrent causes produce the event of interest. , , are assumed conditionally independent and identically distributed given M with common distribution IG. The inverse gamma PS (henceforth, IGPS) model is defined as the marginal distribution of . The survival function for the IGPS model is given by
and its corresponding density function is provided by
The hazard function is
Figure 1 shows the density and hazard functions for the inverse gamma Poisson (IGP), inverse gamma logarithmic (IGL), inverse gamma geometric (IGG) and inverse gamma binomial (IGB) distributions, respectively.
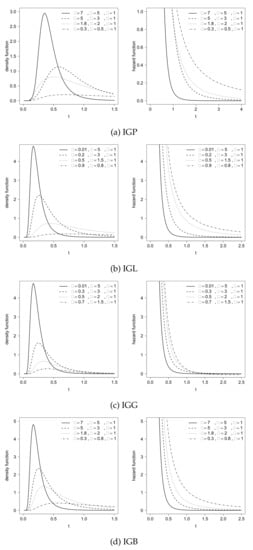
Figure 1.
Density and hazard functions for the IGP, IGL, IGG and IGB distributions with different combinations for parameters.
In the following, we will examine some properties of the probability density function (4).
Proposition 1.
The IG distribution for is a limiting special case of the IGPS model when .
Proof.
We have that the cumulative distribution function (cdf) of the IG distribution for is given by , where . Therefore,
using the proof given by Morais and Barreto-Souza [5] such limit is given by
□
The probability density function of IGPS have the following interesting representation.
Proposition 2.
Let . By inserting the latter expression in (4), it is satisfied that
where is conditional pdf of given the value of M for the IG distribution. Therefore, this density function can be expressed as an infinite linear combination of the inverse gamma distribution.
The following proposition illustrates the moments of the IGPS model.
Proposition 3.
The rth moment of an IGPS distribution is given by
Proof.
By taking expression (6) and using the Monotone Convergence Theorem, the rth moment of the random variable T is calculated as follows
□
3. Estimation
In this section, we discuss two different methods to estimate the parameters of the IGPS distribution. The first one is based on matching theoretical and sample quantiles for the IGPS and the second is based on the EM algorithm (see Dempster et al. [16]).
3.1. Quantile-Matching Estimation Method
A first set of estimates for is obtained by matching the first, second and third sample quartiles (denoted as and respectively) with their theoretical counterpart. In this case, the resulting equations are
By solving for , we have
Therefore, the system is reduced to the following equations that can be solved numerically,
3.2. EM-Type Algorithm
For a sample from the IGPS model, the (observed) log-likelihood function for is given by
Direct maximization of (11) can be hard. For this reason, since the distribution given in (4) is obtained through a mixing process, we propose an EM-type algorithm to perform the parameter estimation. In this problem, the vector is unobservable and the vector represents the observable data. Thus, the vector represents the complete data. Up to a constant, the complete log-likelihood function for is given by
Let be the estimate of at the kth iteration and denote as the conditional expectation of given the observed data and . Therefore,
where . Please note that can be computed using the Proposition 1 in Gallardo et al. [17] considering , for .
We also note that the maximization in relation to can be performed independently from the values of and . However, the maximization in relation to () can be performed conditioning on the value of (), producing a conditioning maximization (CM) step (see Meng and Rubin [18] for details).
In summary, the kth iteration of the EM algorithm have the following form:
- E-step: For , define and compute
- M-step I: Update as the solution for the non-linear equationwith the sum of the vector .
- CM-step II: Given , update as
- CM-step III: Given , update as the solution for the non-linear equation
- If some convergence condition is satisfied then stop iterating, otherwise move back to the E-step for another iteration.The standard errors of the estimates can be estimated using the method given by Louis [19]. Here, we use the observed information matrix instead of the Fisher’s information matrix and replace the missing values by the corresponding pseudo-values calculated in the last iteration of the ECM algorithm.
3.3. Randomized Quantile Residuals
As a graphical method of model diagnosis, we use QQ-plots of the randomized quantile residuals (see Dunn and Smyth [20]). The ith randomized quantile residual is defined as
where is the cdf of the model specified by (4) and the cdf of the standard normal distribution. If the model is correctly specified, are a random sample from the standard normal distribution. In particular the expression for the ith randomized quantile residual of the IGPS distribution is given by
The latter expression will be used to sketch the QQ-plots in the applications section.
4. Simulation Study
In the following, we study the behavior of the maximum likelihood estimates (MLE) in finite samples, to empirically verify that these estimates satisfy desirable properties (unbiased, asymptotically efficient, normally asymptotic distributed). For this purpose, the EM algorithm was used to compute the estimates and their corresponding standard errors by means of the Hessian matrix. This process is replicated 1000 times with a sample size for the parameters in the Poisson model and in Geometric model. The values and are maintained for both models. Then, for each estimate we calculated its average bias (bias), average standard error (se), root of the mean squared error (RMSE) as shown in Table 2. We observed that the averages are close to the true values for the IGP and IGG models. Additionally, as expected, the bias and RMSEs decrease as the sample size increases.
Table 2.
Simulation study for IGP and IGG models.
5. Real Data Illustration
In this section, we apply the IGPS distribution to two real data sets.
5.1. Repair Times Data Set
The first data set appears in Von Alven [21]. It illustrates the active repair times in hours of an airborne communication transceiver. The observed times are 0.2, 0.3, 0.5, 0.5, 0.5, 0.5, 0.6, 0.6, 0.7, 0.7, 0.7, 0.8, 0.8, 1.0, 1.0, 1.0, 1.0, 1.1, 1.3, 1.5, 1.5, 1.5, 1.5, 2.0, 2.0, 2.2, 2.5, 2.7, 3.0, 3.0, 3.3, 3.3, 4.0, 4.0, 4.5, 4.7, 5.0, 5.4, 5.4, 7.0, 7.5, 8.8, 9.0, 10.3, 22.0, 24.5.
We first use the quantile-matching estimation method to find the estimates of the IGP, IGL and IGG distributions, obtaining , and for the IGP model, , and for the IGL model and , and for the IGG model respectively. Then, by taking those figures as starting values, we estimate the parameters via the aforementioned EM algorithm. For model comparison, we have also fitted the WPS model discussed in Morais and Barreto-Souza [5] and EG, EP and EL by Adamidis and Loukas [1], Kus [2] and Tahmasbi and Rezaei [3], respectively. Table 3 exhibits three measures of model selection, the maximum of the log-likelihood function (), Akaike’s information criterion (AIC) (see Akaike [22]) and Bayesian information criterion (BIC) (see Schwarz [23]), for the repair times data set. For the first measure of model validation a larger value is preferable whereas for last two measure of model selection a lower figure is desirable. Table 4 shows the estimates and standard errors (in brackets) for the three models of the EPS, WPS and IGPS families with a lower AIC and BIC statistics. In addition, it is useful to express the fit of the model to the data in terms of distribution functions. In particular, it is suggested to use the following three empirical distribution function (EDF) goodness-of-fit measures to quantify the “distance” between the empirical distribution function constructed from the data and the cumulative distribution function of the fitted models. In this paper, we propose the use of the Anderson-Darling (AD) test statistics. We also are interested in testing for normality by means of the Shapiro–Francia (SF) and Shapiro–Wilk tests. For the AD test, smaller values of the test statistics indicate a better fit of the model to the data. With respect to the SF and SW tests under the null hypothesis the data are drawn from a normal distribution. As judged by the figures of p-value of the corresponding test statistics presented in Table 4, it can be seen that none of the models are rejected at the 5% significance level, validating that the models are statistically legitimate candidates to explain this data set. Furthermore, we have plotted in Figure 2 the histogram and the estimated density functions for this data set. Finally, the QQ-plot of the randomized quantile residuals is illustrated in Figure 3. A perfect alignment with the 45 line implies the residuals are normally distributed. It is observable that the residuals for the IGG distribution underestimate the lower part and overestimate the upper part of the distribution of residuals.
Table 3.
Maximum of the log-likelihood function , AIC and BIC for EPS, WPS and IGPS models in the repair times data set.
Table 4.
Estimates, standard errors (in brackets) and p-values associated with the AD, SF and SW statistics for IGG, WG and EP models in the repair times data set.
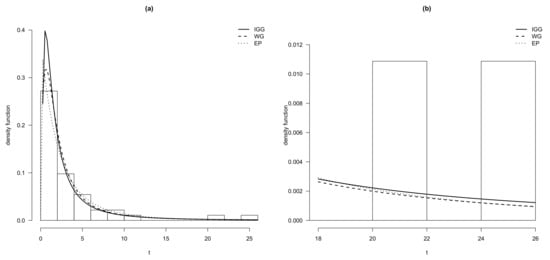
Figure 2.
(a) Density function for IGG, WG and EP models and (b) for the right tail in repair times data set.
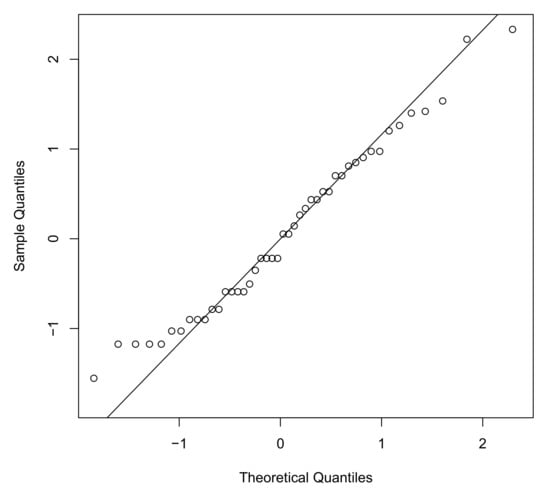
Figure 3.
QQ-plot of the randomized quantile residuals of IGG distribution for repair times data set.
5.2. Gauge Lengths Data Set
The second data set was originally reported by Badar and Priest [24] and it also discussed in Kundu and Raqab [25]. It deals with the strength measured in GPA for single carbon fibers and impregnated 1000-carbon fiber tows. Single fibers were tested under tension at gauge lengths of 10 mm (). The data set consists of the following observations: 1.901, 2.132, 2.203, 2.228, 2.257, 2.350, 2.361, 2.396, 2.397, 2.445, 2.454, 2.474, 2.518, 2.522, 2.525, 2.532, 2.575, 2.614, 2.616, 2.618, 2.624, 2.659, 2.675, 2.738, 2.740, 2.856, 2.917, 2.928, 2.937, 2.937, 2.977, 2.996, 3.030, 3.125, 3.139, 3.145, 3.220, 3.223, 3.235, 3.243, 3.264, 3.272, 3.294, 3.332. 3.346, 3.377, 3.408, 3.435, 3.493, 3.501, 3.537, 3.554, 3.562, 3.628, 3.852, 3.871, 3.886, 3.971, 4.024, 4.027, 4.225, 4.395, 5.020.
We use again the quantile-matching estimation method to find the estimates of the IGP, IGL and IGG distributions, obtaining , and for the IGP model, , and for the IGL model and , and for the IGG model respectively. Next, we estimate the parameters by means of the EM algorithm using those numbers as initial values. For the sake of model comparison, we have also fitted the WPS model, EG, EP and EL, respectively. Table 5 exhibits three measures of model selection, the maximum of the log-likelihood function (), AIC and BIC criteria, for the gauge lengths data set. Table 6 shows the estimates and standard errors (in brackets) for the three models of the EPS, WPS and IGPS families with a lower AIC and BIC statistics. Moreover, we propose again the use of the Anderson-Darling (AD) test statistics. We also are interested in testing for normality by means of the Shapiro–Francia (SF) and Shapiro–Wilk tests. For the AD test, smaller values of the test statistics indicate a better fit of the model to the data. With respect to the SF and SW tests under the null hypothesis the data are drawn from a normal distribution. As judged by the figures of p-value of the corresponding test statistics presented in Table 6, it can be seen that none of the models are rejected at the 5% significance level, validating that the models are statistically legitimate candidates to explain this data set. Once again, we have plotted in Figure 4 the histogram and the estimated density functions for this data set. Finally, the QQ-plot of the randomized quantile residuals is now displayed in Figure 5. It is again noticeable that the residuals for the IGG distribution underestimate the lower part and overestimate the upper part of the distribution of residuals.
Table 5.
Maximum of the log-likelihood function , AIC and BIC for EPS, WPS and IGPS models in the gauge lengths data set.
Table 6.
Estimates, standard errors (in brackets) and p-values associated with the AD, SF and SW statistics for IGG, WG and EP models in the gauge lengths data set.
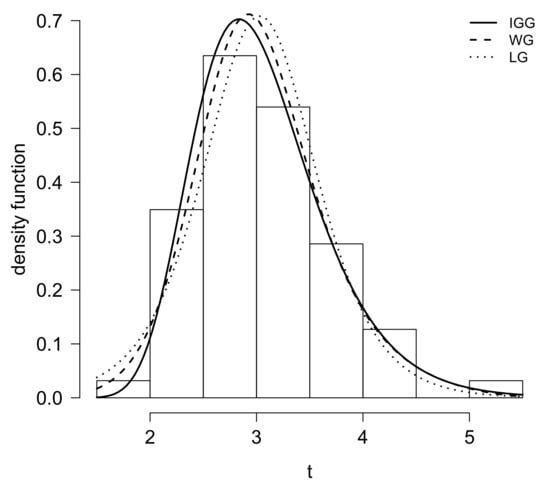
Figure 4.
Density function for IGG, WG and LG models in gauge lengths data set.
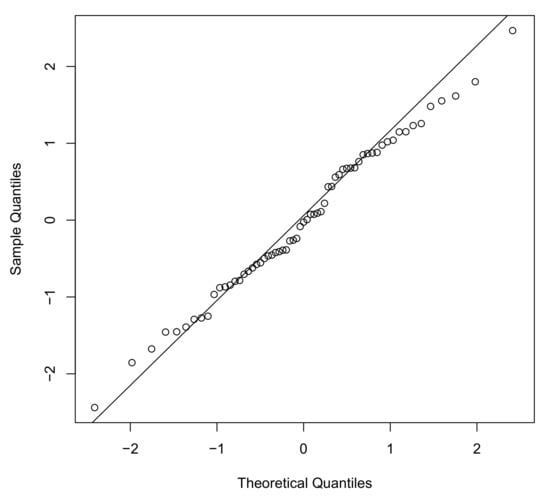
Figure 5.
QQ-plot of the randomized quantile residuals of IGG distribution for gauge lengths data set.
6. Conclusions
In this paper, the inverse gamma power series (IGPS) family of probabilistic distribution has been introduced. This family has been obtained by mixing the inverse gamma and power series distributions. Moreover, four particular members of this family has been derived and examined. Some of its most relevant properties has been studied including the probability density function, survival and hazard functions, and the order statistics. The issue of parameter estimation was first discussed by means of the quantile-matching estimation method. Then, the estimates obtained by the latter method were used as initial values in a novel EM algorithm to carry out maximum likelihood estimation. Furthermore, a simulation study was performed to examine the efficiency of these estimates.
Author Contributions
Conceptualization, D.I.G. and H.W.G.; formal analysis, P.A.R., E.C.-O., D.I.G. and H.W.G.; investigation, P.A.R., E.C.-O., D.I.G. and H.W.G.; methodology, D.I.G. and H.W.G.; software, P.A.R. and D.I.G.; supervision, E.C.-O. and H.W.G.; validation, D.I.G. and E.C.-O.; visualization, H.W.G. All authors have read and agreed to the published version of the manuscript.
Funding
The research of H.W. Gómez was supported by SEMILLERO UA-2021 project, Chile.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used in Section 5.1 and Section 5.2 appear directly in the manuscript.
Acknowledgments
We thank the editors and the anonymous reviewers for their constructive comments, which helped us to improve the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Adamidis, K.; Loukas, S. A Lifetime Distribution with Decreasing Failure Rate. Stat. Probab. Lett. 1998, 39, 35–42. [Google Scholar] [CrossRef]
- Kus, C. A new lifetime distribution. Comput. Stat. Data Anal. 2007, 51, 4497–4509. [Google Scholar] [CrossRef]
- Tahmasbi, R.; Rezaei, S. A two-parameter lifetime distribution with decreasing failure rate. Comput. Stat. Data Anal. 2008, 52, 3889–3901. [Google Scholar] [CrossRef]
- Chahkandi, M.; Ganjali, M. On some lifetime distributions with decreasing failure rate. Comput. Stat. Data Anal. 2009, 53, 4433–4440. [Google Scholar] [CrossRef]
- Morais, A.L.; Barreto-Souza, W. A compound class of Weibull and power series distribution. Comput. Stat. Data Anal. 2011, 55, 1410–1425. [Google Scholar] [CrossRef]
- Mahmoudi, E.; Jafari, A.A. Generalized exponential power series distributions. Comput. Stat. Data Anal. 2012, 56, 4047–4066. [Google Scholar] [CrossRef]
- Silva, R.B.; Bourguignon, M.; Dias, C.R.B.; Cordeiro, G.M. The compound family of extended Weibull power series distributions. Comput. Stat. Data Anal. 2013, 58, 352–367. [Google Scholar] [CrossRef]
- Bagheri, S.F.; Samani, E.B.; Ganjali, M. The generalized modified Weibull power series distribution: Theory and applications. Comput. Stat. Data Anal. 2016, 94, 136–160. [Google Scholar] [CrossRef]
- Warahena-Liyanage, G.; Pararai, M. The Lindley Power Series Class of Distributions: Model. Properties and Applications. J. Comput. Model. 2015, 5, 35–80. [Google Scholar]
- Alizadeh, M.; Bagheri, S.F.; Bahrami-Samani, E.; Ghobadi, S.; Nadarajah, S. Exponentiated power Lindley power series class of distributions: Theory and applications. Commun.-Stat.-Simul. Comput. 2018, 47, 2499–2531. [Google Scholar] [CrossRef]
- Elbatal, I.; Zayedm, M.; Rasekhi, M.; Butt, N.S. The Exponential Pareto Power Series Distribution: Theory and Applications. Pak. J. Stat. Oper. Res. 2017, 13, 603–615. [Google Scholar] [CrossRef][Green Version]
- Elbatal, I.; Altun, E.; Afify, A.Z.; Ozel, G. The Generalized Burr XII Power Series Distributions with Properties and Applications. Ann. Data Sci. 2019, 6, 571–597. [Google Scholar] [CrossRef]
- Noack, A. On a class of discrete random variables. Ann. Math. Stat. 1950, 21, 127–132. [Google Scholar] [CrossRef]
- Patil, G.P. Certain Properties of the Generalized Power Series Distribution. Ann. Math. Stat. 1962, 21, 179–182. [Google Scholar] [CrossRef]
- Barakat, H.M.; Abdelkader, Y.H. Computing the moments of order statistics from nonidentical random variables. Stat. Methods Appl. 2004, 13, 15–26. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubim, D.B. Maximum likelihood from incomplete data via the EM algorithm (with discussion). J. R. Stat. Soc. Ser. B 1977, 39, 1–38. [Google Scholar]
- Gallardo, D.I.; Romeo, J.S.; Meyer, R. A simplified estimation procedure based on the EM algorithm for the power series cure rate model. Commun. Stat.-Simul. Comput. 2017, 46, 6342–6359. [Google Scholar] [CrossRef]
- Meng, X.; Rubin, D. Maximum Likelihood Estimation via the ECM Algorithm: A General Framework. Biometrika 1993, 80, 267–278. [Google Scholar] [CrossRef]
- Louis, T. Finding the observed information matrix when using the EM algorithm. J. R. Stat. Soc. Ser. B 1982, 44, 226–233. [Google Scholar]
- Dunn, P.K.; Smyth, G.K. Randomized Quantile Residuals. J. Comput. Graph. Stat. 1996, 5, 236–244. [Google Scholar]
- Von Alven, W.H. Reliability Engineering by ARINC; Prentice Hall: Upper Saddle River, NJ, USA, 1964. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the Dimension of a Model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Badar, M.G.; Priest, A.M. Statistical aspects of fiber and bundle strength in hybrid composites. In Progress in Science and Engineering Composites; Hayashi, T., Kawata, K., Umekawa, S., Eds.; ICCM-IV: Tokyo, Japan, 1982; pp. 1129–1136. [Google Scholar]
- Kundu, D.; Raqab, M.Z. Estimation of R = P(Y < X) for three-parameter Weibull distribution. Stat. Probab. Lett. 2009, 79, 1839–1846. [Google Scholar]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).