Abstract
Our main focus in this work is the classical variational inequality problem with Lipschitz continuous and pseudo-monotone mapping in real Hilbert spaces. An adaptive reflected subgradient-extragradient method is presented along with its weak convergence analysis. The novelty of the proposed method lies in the fact that only one projection onto the feasible set in each iteration is required, and there is no need to know/approximate the Lipschitz constant of the cost function a priori. To illustrate and emphasize the potential applicability of the new scheme, several numerical experiments and comparisons in tomography reconstruction, Nash–Cournot oligopolistic equilibrium, and more are presented.
Keywords:
subgradient-extragradient; reflected step; variational inequality; pseudo-monotone mapping; Lipschitz mapping MSC:
47H09; 47J20; 47J05; 47J25
1. Introduction
In this paper, we focus on the classical variational inequality (VI) problem, as can be found in Fichera [1,2], Stampacchia [3], and Kinderlehrer and Stampacchia [4], defined in real Hilbert space H. Given a nonempty, closed, and convex set of and a continuous mapping , the variational inequality (VI) problem consists of finding a point such that:
is used to denote the solution set of VIP(1) for simplicity. A wide range of mathematical and applied sciences rely heavily on variational inequalities in both theory and algorithms. Due to the importance of the variational inequality problem and many of its applications in different fields, several notable researchers have extensively studied this class of problems in the literature, and many more new ideas are emerging in connection with the problems. In the case of finite-dimensional setting, the current state-of-the-art results can be found in [5,6,7] including the substantial references therein.
Many algorithms (iterative methods) for solving the variational inequality (1) have been developed and well studied; see [5,6,7,8,9,10,11,12,13,14,15] and the references therein. One of the famous methods is the so-called extragradient method (EGM), which was developed by Korpelevich [16] (also by Antipin [17] independently) in the finite-dimensional Euclidean space for a monotone and Lipschitz continuous operator. The extragradient method has been modified in different ways and later was extended to infinite-dimensional spaces. Many of these extensions were well studied in [18,19,20,21,22,23] and the references therein.
One feature that renders the Korpelevich algorithm less acceptable has to do with the fact that two projections onto the feasible set are required in every iteration. For this reason, there is a need to solve a minimum distance problem twice every iteration. Therefore, the efficiency of this method (Korpelevich algorithm) is affected, which limits its application as well.
A remedy to the second drawback was presented in Censor et al. [18,19,20]. The authors introduced the subgradient-extragradient method (SEGM). Given ,
In this algorithm, A is an L-Lipschitz-continuous and monotone mapping and . One of the novelties in the proposed SEGM (2) is the replacement of the second projection onto a feasible set with a projection onto a half-space. Recently, weak and strong convergence results of SEGM (2) have been obtained in the literature; see [24,25] and the references therein.
Thong and Hieu in [26] came up with inertial subgradient-extragradient method in the following algorithm. Given ,
The authors proved the weak convergence of the sequence generated by (3) to a solution of variational inequality (VI), Equation (1), for the case where A is monotone and an L-Lipschitz-continuous mapping. For some:
the parameter is chosen to satisfy:
The sequence is non-decreasing with .
Malitsky in [21] introduced the following projected reflected gradient method, which solves VI (1) when A is Lipschitz continuous and monotone: choose :
where , and we obtain weak convergence results in real Hilbert spaces.
Recently, Bo̧t et al. [27] introduced Tseng’s forward-backward-forward algorithm with relaxation parameters in Algorithm 1 to solve VI (1).
In [28], the following adaptive golden ratio method in Algorithm 2 for solving VI (1) was proposed.
| Algorithm 1: Tseng’s forward-backward-forward algorithm with relaxation parameters. | |
| Initialization: Choose with the given parameters and . Let be arbitrary.Iterative steps: is calculated, with the current iterate given as follows: Step 1. Compute: Step 2. Compute: | |
| Algorithm 2: Adaptive golden ratio method. | |
| Initialization: Choose . Set . Iterative steps: is calculated, with the current iterate given as follows: Step 1. Compute: | |
Motivated by the recent works in [18,19,20,21,26,27,28], our aim in this paper is to introduce a reflected subgradient-extragradient method that solves variational inequalities and obtain weak convergence in the case where the cost function is Lipschitz continuous and a pseudo-monotone operator in real Hilbert spaces. This pseudo-monotone operator is in the sense of Karamardian [29]. Our method uses self-adaptive step sizes, and the convergence of the proposed algorithm is proven without any assumption of prior knowledge of the Lipschitz constant of the cost function.
The outline of the paper is as follows. We start with recalling some basic definitions and results in Section 2. Our algorithm and weak convergence analysis are presented in Section 3. In Section 4, we give some numerical experiments to demonstrate the performances of our method compared with other related algorithms.
2. Preliminaries
In this section, we provide necessary definitions and results needed in the sequel.
Definition 1.
An operator is said to be L-Lipschitz continuouswith if the following inequality is satisfied:
Definition 2.
An operator is said to bemonotoneif the following inequality is satisfied:
Definition 3.
An operator is said to be pseudo-monotone if the following inequality implies the other:
Definition 4.
An operator is said to besequentially weakly continuousif for each sequence , we have that converges weakly to x, which implies that converges weakly to .
Recall that for any given point x chosen in H, denotes the unique nearest point in C. This operator has been shown to be nonexpansive, that is,
The operator is known as the metric projection of H onto C.
Lemma 1
([30]). Given and with C a nonempty, closed, and convex subset of a real Hilbert space H, then:
Lemma 2
([30,31]). Given , a real Hilbert space and letting C be a closed and convex subset of H, then the following inequalities are true:
- 1.
- 2.
Lemma 3
([32]). Given and , , and letting , then, for all , the projection is defined by:
In particular, if , then:
The explicit formula provided in Lemma 3 is very important in computing the projection of any point onto a half-space.
Lemma 4
([33], Lemma 2.1). Let be continuous and pseudo-monotone where C is a nonempty, closed, and convex subset of a real Hilbert space H. Then, is a solution of if and only if:
Lemma 5
([34]). Let be a sequence in H and C a nonempty subset of H with the following conditions satisfied:
- (i)
- every sequential weak cluster point of is in C;
- (ii)
- exists for every .
Then, the sequence converges weakly to a point in C.
The following lemmas were given in [35].
Lemma 6.
Let h be a real-valued function on a real Hilbert space H, and define . If h is Lipschitz continuous on H with modulus and K is nonempty, then:
where is the distance function from x to K.
Lemma 7.
Let H be a real Hilbert space. The following statements are satisfied.
- (i)
- For all , ;
- (ii)
- For all , ;
- (iii)
- For all , .
Lemma 8
(Maingé [36]). Let , , and be sequences defined in satisfying the following:
and there exists θ, a real number, with for all Then, the following hold:
- (i)
- where
- (ii)
- there exists such that
In the work that follows, as denotes the strong convergence of to a point x, and as denotes the weak convergence of to a point x.
3. Main Results
We first provide the following conditions upon which the convergence analysis of our method is based and then present our method in Algorithm 3.
Condition 1.
The feasible set C is a nonempty, closed, and convex subset of H.
Condition 2.
The VI (1) associated operator is pseudo-monotone, sequentially weakly and Lipschitz continuous on a real Hilbert space H.
Condition 3.
The solution set of VI (1) is nonempty, that is .
In addition, we also make the following parameter choices. .
Remark 1.
| Algorithm 3: Adaptive projected reflected subgradient extragradient method. | |
| Initialization: Given , let be arbitrary Iterative steps: Given the current iterate , calculate as follows: Step 1. Compute: Step 2. Compute: | |
The first step towards the convergence proof of Algorithm 3 is to show that the sequence generated by (9) is well defined. This is done using similar arguments as in [25].
Lemma 9.
The sequence generated by (9) is a nonincreasing sequence and:
Proof.
Clearly, by (9), is nonincreasing since for all . Next, using the fact that A is L-Lipschitz continuous, we have:
Therefore, the sequence is nonincreasing and lower bounded. Therefore, there exists □
Lemma 10.
Proof.
Using Lemma 4 and the fact that denotes a solution of Problem (1), we obtain the following:
It follows from (10) and that:
Hence, the proof of the first claim of Lemma 10 is achieved. Next, we proceed to the proof of the second claim. Clearly, from the definition of , the following inequality is true:
In fact, Inequality (11) is satisfied if . Otherwise, it implies from (9) that:
Thus,
Hence, we can conclude from the above that Inequality (11) is true for and .
Remark 2.
Lemma 10 implies that with . Based on Lemma 3, we can write in the form:
We present the following result using similar arguments in [14], Theorem 3.1.
Lemma 11.
Let be a sequence generated by Algorithm 3, and assume that Conditions 1–3 hold. Let be a sequence generated by Algorithm 3. If there exists , a subsequence of such that converges weakly to and , then
Proof.
From and , we have .Furthermore, we have:
Thus,
Equivalently, we have:
From this, we obtain:
We have that is a bounded sequence and A is Lipschitz continuous on H, and we get that is bounded and . Taking in (12), since , we get:
On the other hand, we have:
Since and A is Lipschitz continuous on H, we get:
which, together with (13) and (14), implies that:
Next, we show that .
Next, a decreasing sequence, , of positive numbers, which tends to zero, is chosen. We denote by , for each k, the smallest positive integer satisfying the inequality:
It should be noted that the existence of is guaranteed by (15). Clearly, the sequence is increasing from the fact that is decreasing. Furthermore, for each k, since , we can suppose . We get:
where:
We can infer from (16) that for each k:
Using the pseudo-monotonicity of the operator A on H, we obtain:
Hence, we have:
Next, we show that:
Using the fact that and we get . Furthermore, for A sequentially weakly continuous on C, converges weakly to . We can suppose , since otherwise, z is a solution. Using the fact that the norm mapping is sequentially weakly lower semicontinuous, we obtain:
Since and as , we get:
This in fact means
Next, letting , then the right-hand side of (17) tends to zero by A being Lipschitz continuous, are bounded, and:
Hence, we obtain:
Therefore, for all , we get:
Finally, using Lemma 4, we have , which completes the proof. □
Remark 3.
Imposing the sequential weak continuity on A is not necessary when A is a monotone function; see [24].
Theorem 4.
Any sequence that is generated using Algorithm 3 converges weakly to an element of when Conditions 1–3 are satisfied.
Proof.
Claim 1. is a bounded sequence. Define , and let . Then, we have:
Furthermore,
This implies that:
which in turn implies that:
Note that:
and this implies:
Using (22) in (21), we obtain:
Furthermore, by Lemma 7 (iii),
Using (24) in (23):
Define:
Since , we have:
Now, using (25) in (26), one gets:
Observe that:
Using (28) in (27), we get:
Hence, is non-increasing. In a similar way, we obtain:
Note that:
From (30), we have:
Consequently,
and this means from (31) that:
By (29) and (32), we get:
This then implies that:
Hence, We also have from Algorithm 3 that:
From (25), we obtain:
Using Lemma 8 in (36) (noting (34)), we get:
This implies that exists. Therefore, the sequence is bounded, and so is .
Claim 2. There exists such that:
We know that are bounded using the fact that are bounded. Hence, there exists such that:
Therefore, for all , we obtain:
Then, we have that is M-Lipschitz continuous on H. From Lemma 6, we get:
from which, together with Lemma 10, we get:
Combining (19) and (38), we obtain:
This complete the proof of Claim 2.
Claim 3. The sequence converges weakly to an element of Indeed, since is a bounded sequence, there exists the subsequence of such that . Since and are bounded, there exists such that , and we have from (39):
From (40), we have:
Consequently,
Furthermore, of converges weakly to . This implies from Lemma 11 and (41) that . Therefore, we proved that if , then exists, and each sequential weak cluster point of the sequence is in . By Lemma 5, the sequence converges weakly to an element of □
4. Numerical Illustrations
In this section, we consider many examples in which some are real-life applications for numerical implementations of our proposed Algorithm 3. For a broader overview of the efficiency and accuracy of our proposed algorithm, we investigate and compare the performance of the proposed Algorithm 3 with Algorithm 1 proposed by Boţ et al. in [27] (Bot Alg.), Algorithm 2 proposed by Malitsky in [28] (Malitsky Alg.), the algorithm proposed by Shehu and Iyiola in [37] (Shehu Alg.), the subgradient-extragradient method (SEM) (2), and the extragradient method (EGM) in [16].
Example 1

(Tomography reconstruction model). In this example, we consider the linear inverse problem:
where is the unknown image, is the projection matrix, and is the given sinogram (set of projections). The aim then is to recover a slice image of an object from a sinogram. To be realistic, we consider noisy , where . Problem (42) can be presented as a convex feasibility problem (CFP) with the sets (hyper-planes) . Since, in practice, the projection matrix B is often rank-deficient, so range(B); thus, we may assume that the CFP has no solution (also called inconsistent), so we consider the least squares model .
Recall that the projection onto the hyper-plane has a closed formula . Therefore, the evaluation of reduces to a matrix-vector multiplication, and this can be realized very efficiently, where and . Note that our approach only exploits feasibility constraints, which is definitely not a state-of-the-art model for tomography reconstruction. More involved methods would solve this problem with the use of some regularization techniques, but we keep such a simple model for illustration purposes only.
As a particular problem, we wish to reconstruct the Shepp–Logan phantom image (thus, with ) from the far less measurement . We generate the matrix randomly and define , where is a random vector, whose entries are drawn from .
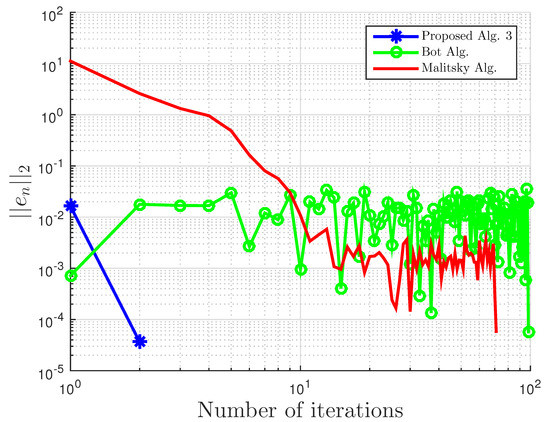
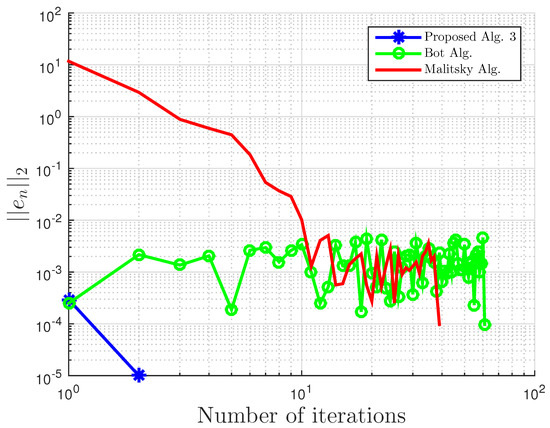
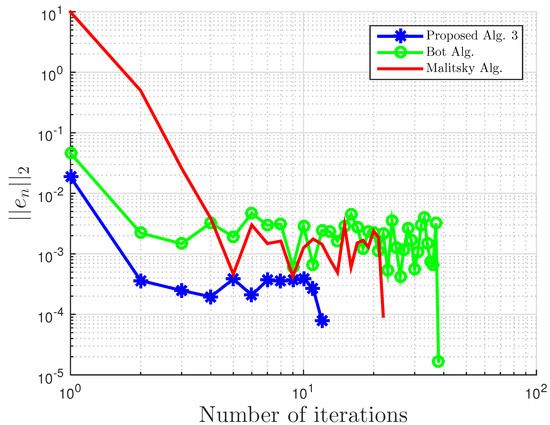
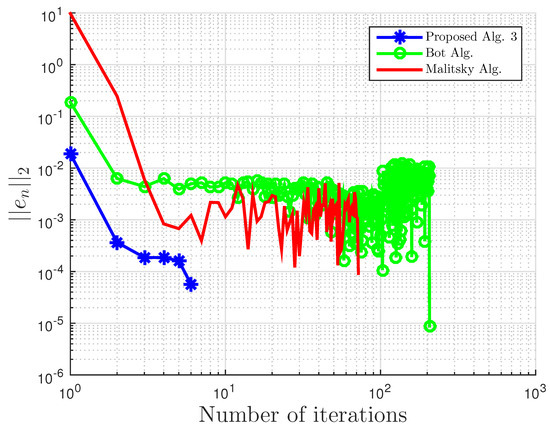
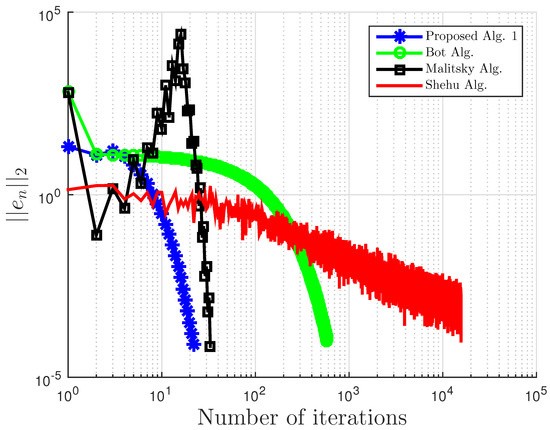
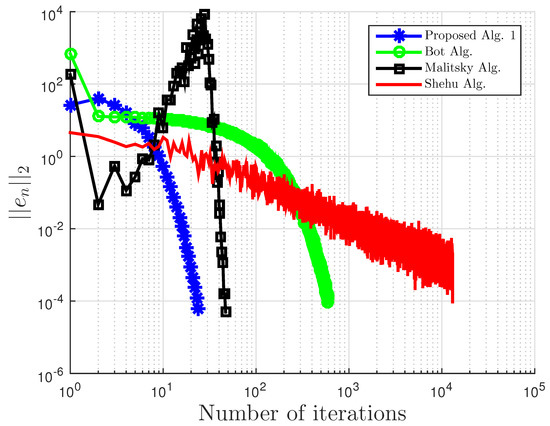
Using this example, we give some comparisons of our proposed Algorithm 3, Algorithm 1 proposed by Boţ et al. in [27] (Bot Alg.), and Algorithm 2 proposed by Malitsky et al. in [28] (Malitsky Alg.) using the residual , where , as our stopping criterion. For our proposed algorithm, the starting point is chosen randomly with and for Boţ et al., the starting point and , while for Malitsky et al., the starting point with randomly chosen, and . All results are reported in Table 1 and Table 2 and Figure 1, Figure 2, Figure 3, Figure 4, Figure 5 and Figure 6.
Table 1.
Example 1 comparison: proposed Algorithm 3, Bot Algorithm 1, and Malitsky Algorithm 2 with .
Table 2.
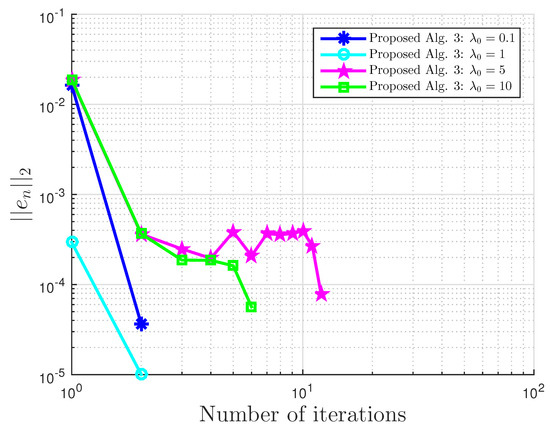
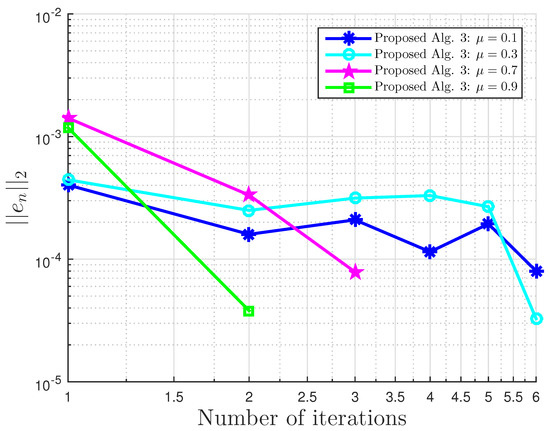
Example 1: proposed Algorithm 3 with for different values.
Figure 1.
Example 1: and . Alg., Algorithm.
Figure 2.
Example 1: and .
Figure 3.
Example 1: and .
Figure 4.
Example 1: and .
Figure 5.
Example 1: .
Figure 6.
Example 1: .
Example 2
(Equilibrium-optimization model). Here, we consider the Nash–Cournot oligopolistic equilibrium model in electricity markets. Given m companies, such that the i-th company possesses generating units, denote by x the power vector, that is each of its j-th entries corresponds to the power generated by unit j. Assume that the price function is an affine decreasing function of where N is the number of all generating units. Therefore, . We can now present the profit of company i as , where is the cost for generating by generating unit j. Denote by the strategy set of the i-th company i. Clearly, for each i, and the overall strategy set is .
The Nash equilibrium concept with regards to the above data is that each company wishes to maximize its profit by choosing the corresponding production level under the presumption that the production of the other companies is a parametric input.
Recall that is an equilibrium point if:
where the vector stands for the vector obtained from by replacing with . Define:
with:
Therefore, finding a Nash equilibrium point is formulated as:
Suppose for every j, the cost for production and the environmental fee g are increasingly convex functions. This convexity assumption implies that (43) is equivalent to (see [38]):
where:
Note that is differentiable convex for every j.
Our proposed scheme is tested with the following cost function:
The parameters for all , matrix D, and vector d were generated randomly in the interval , , and , respectively.
The numerical experiments involve the initial points and generated randomly in and . The stopping role of the algorithm is chosen as , where . Let us assume that each company has the same lower production bound one and upper production bound 40, that is,
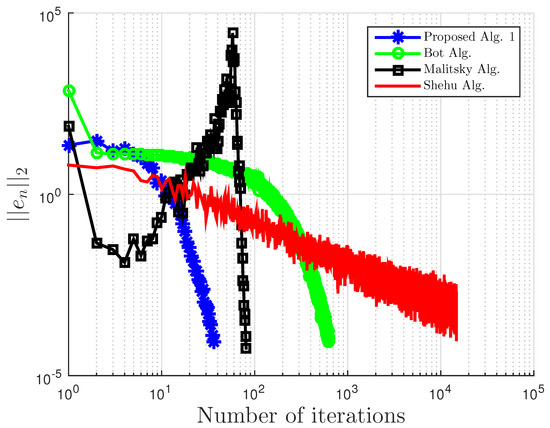
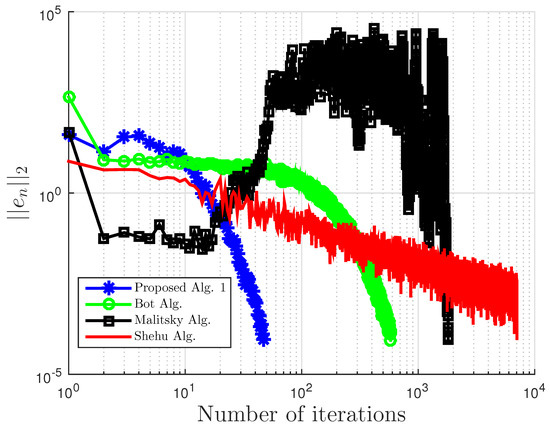
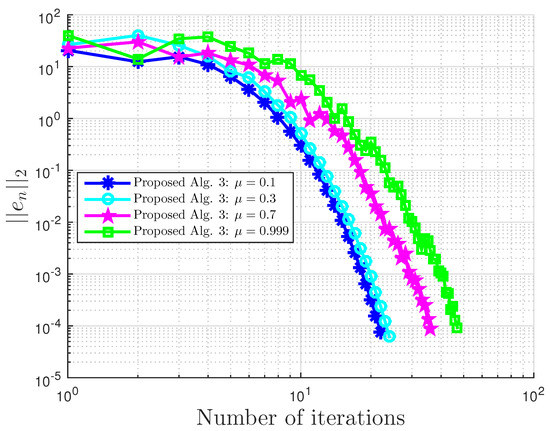
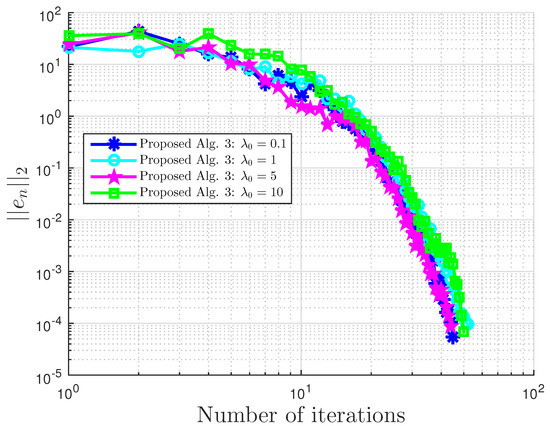
We compare our proposed Algorithm 3 with Algorithm 1 proposed by Boţ et al. in [27] (Bot Alg.), Algorithm 2 proposed by Malitsky et al. in [28] (Malitsky Alg.), and Shehu and Iyiola’s proposed Algorithm 3.2 in [37] (Shehu Alg.). For our proposed algorithm, we choose for Boţ et al., for Malitsky et al., the starting point and , while for Shehu and Iyiola, and All results are reported in Table 3 and Table 4 and Figure 7, Figure 8, Figure 9, Figure 10, Figure 11 and Figure 12.
Table 3.
Example 2 comparison: proposed Algorithm 3, Bot Algorithm 1, Malitsky Algorithm 2, and Shehu Alg. [37] with and .
Table 4.
Example 2: proposed Algorithm 3 with for different values.
Figure 7.
Example 2: and .
Figure 8.
Example 2: and .
Figure 9.
Example 2: and .
Figure 10.
Example 2: and .
Figure 11.
Example 2: .
Figure 12.
Example 2: .
Example 3.
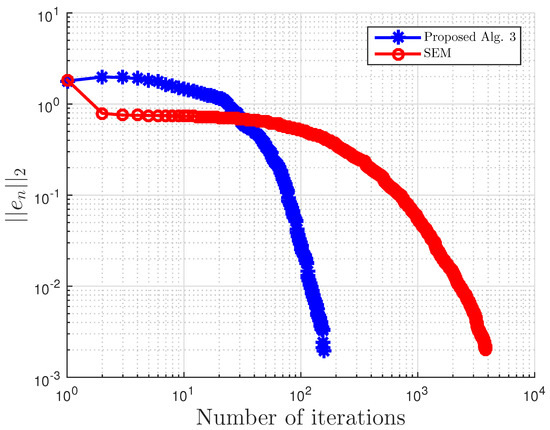
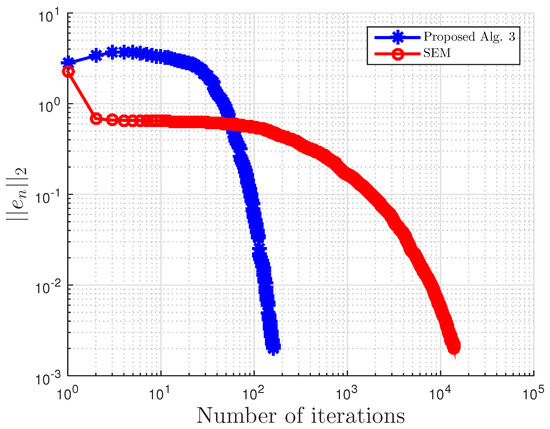
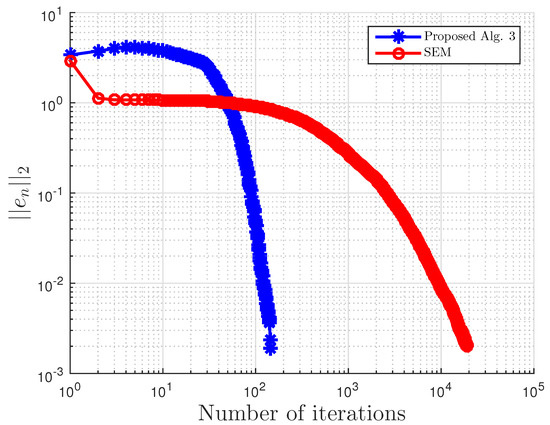
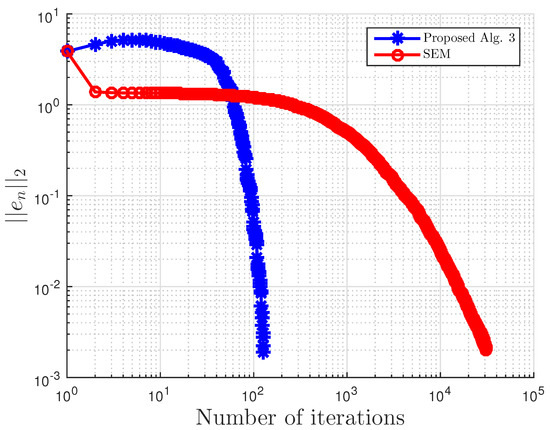
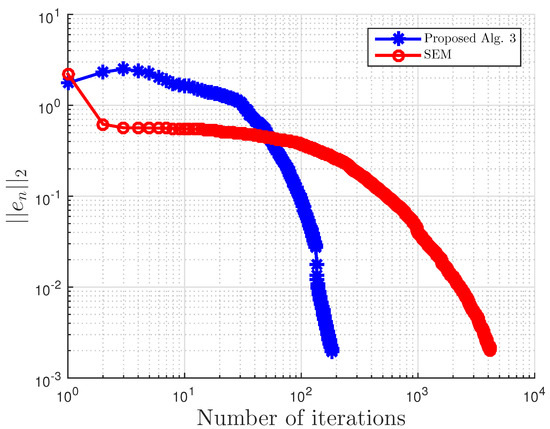
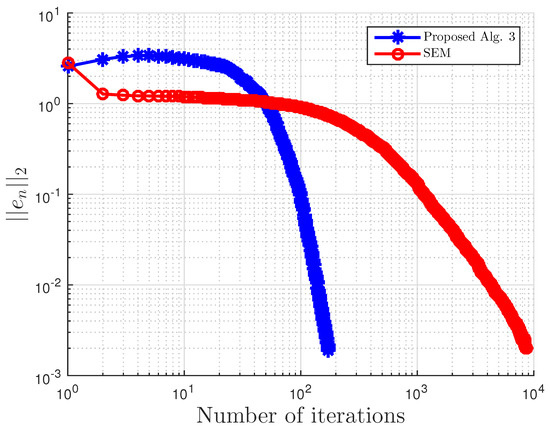
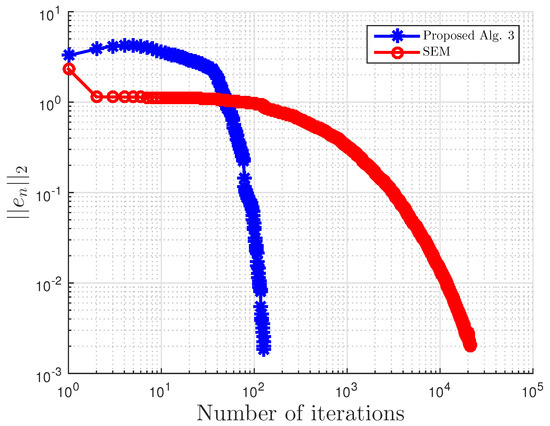
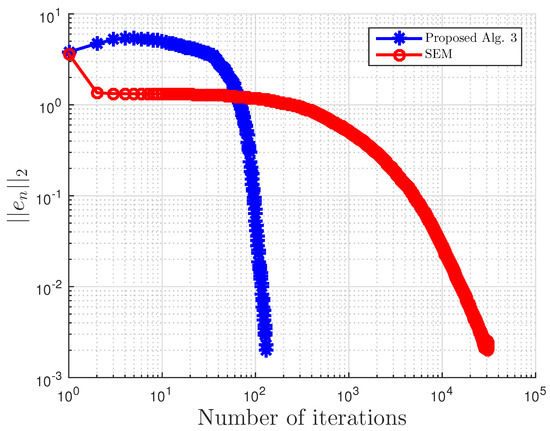
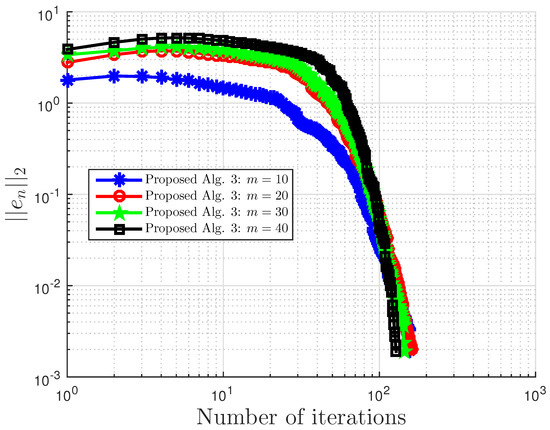
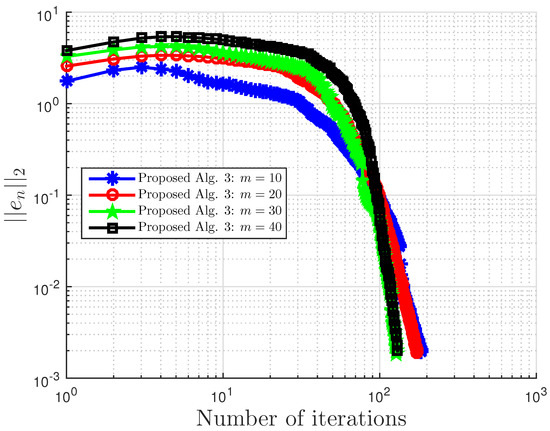
This example is taken from [39]. First, generate the following matrices randomly B, S, D in where S is skew-symmetric and D is a positive definite diagonal matrix. Then, define the operator A by with . The symmetric property of S implies that the operator does not arise from an optimization problem, and the positive definiteness of D implies the uniqueness of the solution to the corresponding variational inequality problem.
We choose here . Choose random matrix and with nonnegative entries, and define the VI feasible set C by . Clearly, the origin is in C, and it is the unique solution of the corresponding variational inequality. Projections onto C are computed via the MATLAB routine fmincon, and thus, it is costly. We test the algorithm’s performances (number of iterations and CPU time in seconds) for different m’s and inequality constraints k.
For this example, the stopping criterion is chosen as , where We experiment with different values of k and m. We randomly generate vector b and matrices B, S, and D. We choose and μ appropriately in Algorithm 3. In (2), is used. Algorithm 3 proposed in this paper is compared with the subgradient-extragradient method (SEM) (2). For our proposed algorithm, we choose and while for SEM, All results are reported in Table 5 and Figure 13, Figure 14, Figure 15, Figure 16, Figure 17, Figure 18, Figure 19, Figure 20, Figure 21 and Figure 22.
Table 5.
Comparison of proposed Algorithm 3 and the subgradient-extragradient method (SEM) (2) for Example 3.
Figure 13.
Example 3: and .
Figure 14.
Example 3: and .
Figure 15.
Example 3: and .
Figure 16.
Example 3: and .
Figure 17.
Example 3: and .
Figure 18.
Example 3: and .
Figure 19.
Example 3: and .
Figure 20.
Example 3: and .
Figure 21.
Example 3: .
Figure 22.
Example 3: .
Example 4.
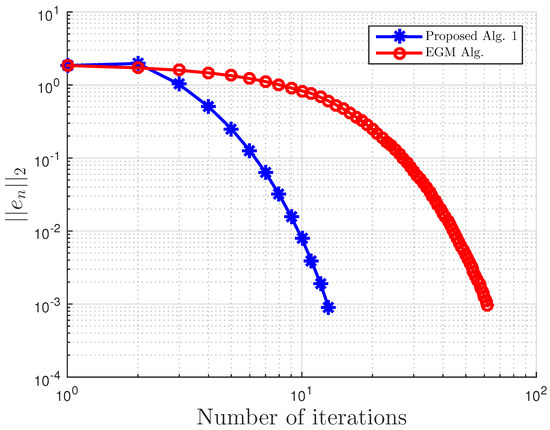
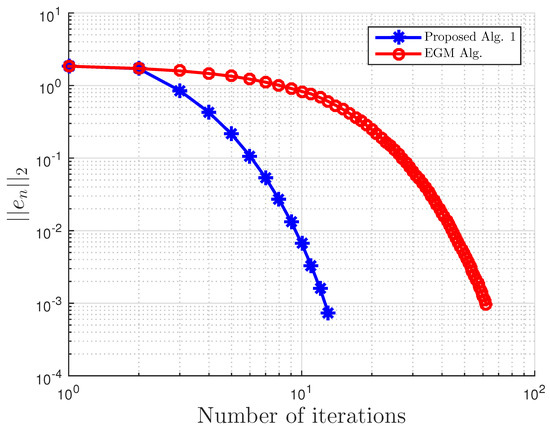
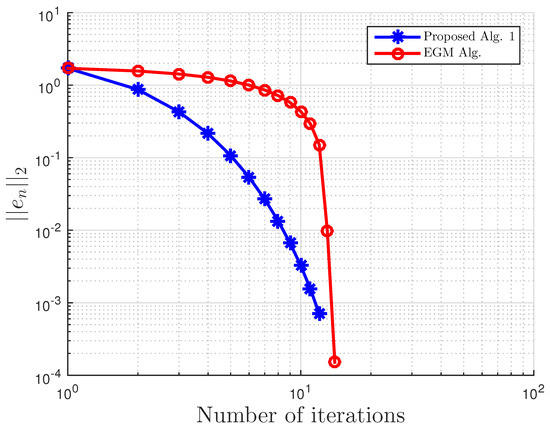
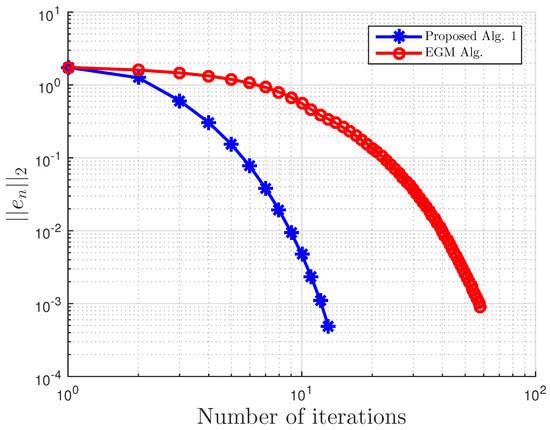
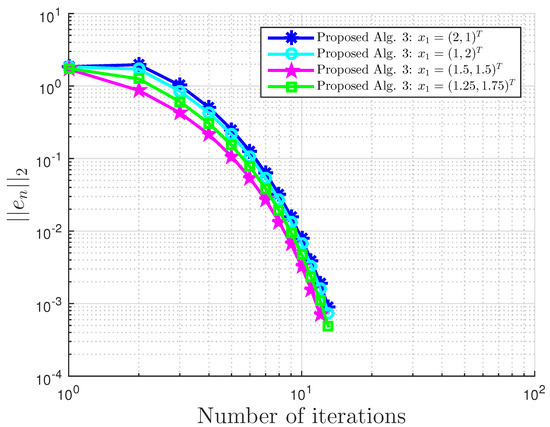
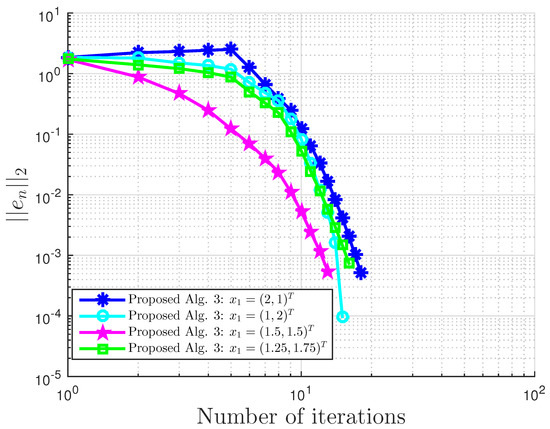
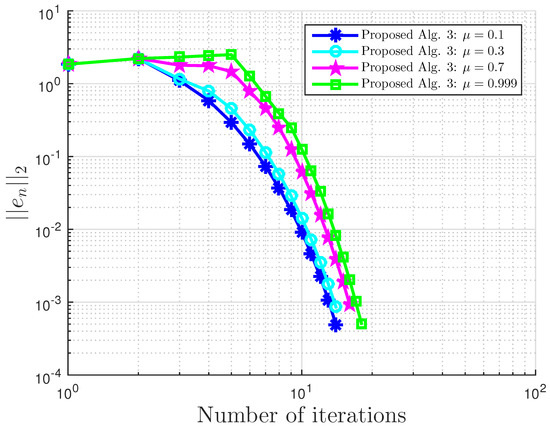
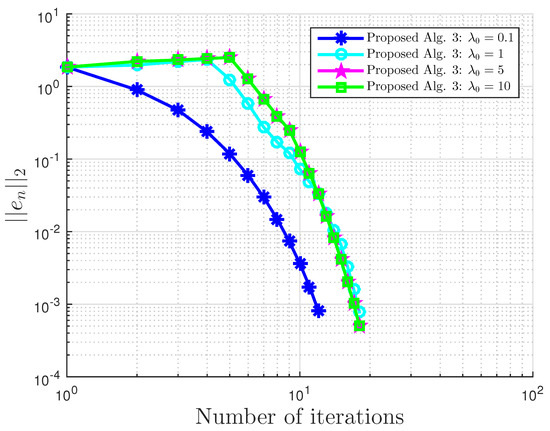
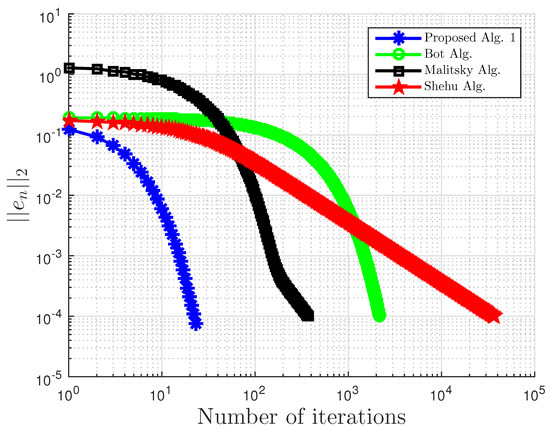
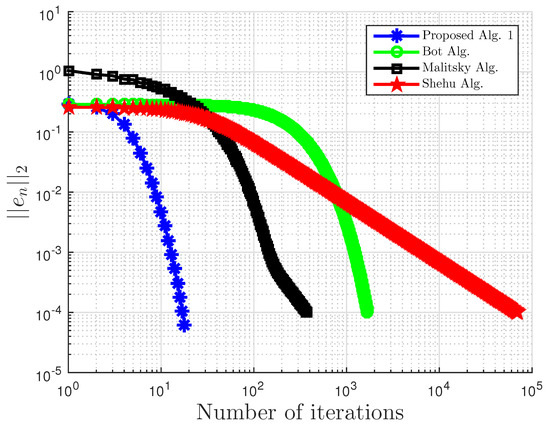
Consider VI(1) with:
and:
Then, A is not monotone on C, but pseudo-monotone. Furthermore, VI (1) has the unique solution . A comparison of our method is made with the extragradient method [16]. We denote the parameter in EGM [16] as to differentiate it from in our proposed Algorithm 3. We terminate the iterations if:
with . In this, our proposed Algorithm 3 is compared with the extragradient method (EGM) in [16]. For our proposed algorithm, we choose and , while for EGM, . All results are reported in Table 6, Table 7 and Table 8 and Figure 23, Figure 24, Figure 25, Figure 26, Figure 27, Figure 28, Figure 29, Figure 30, Figure 31 and Figure 32.
Table 6.
Comparison of proposed Algorithm 3 and the extragradient method (EGM) [16] for Example 4 with and .
Table 7.
Proposed Algorithm 3 for Example 4 with and .
Table 8.
Example 4: proposed Algorithm 3 with for different and values.
Figure 23.
Example 4: and .
Figure 24.
Example 4: and .
Figure 25.
Example 4: and .
Figure 26.
Example 4: and .
Figure 27.
Example 4: and .
Figure 28.
Example 4: and .
Figure 29.
Example 4: and .
Figure 30.
Example 4: and .
Figure 31.
Example 5: , and .
Figure 32.
Example 5: , and .
Example 5.
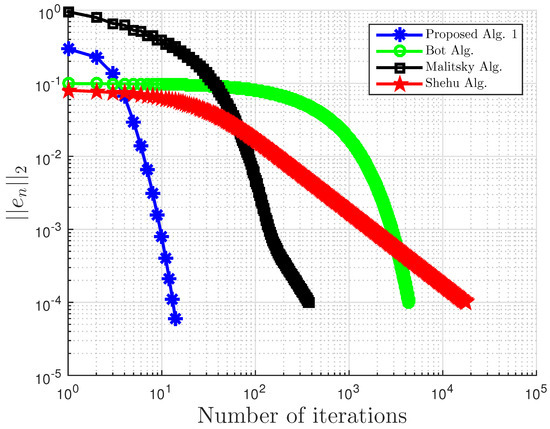
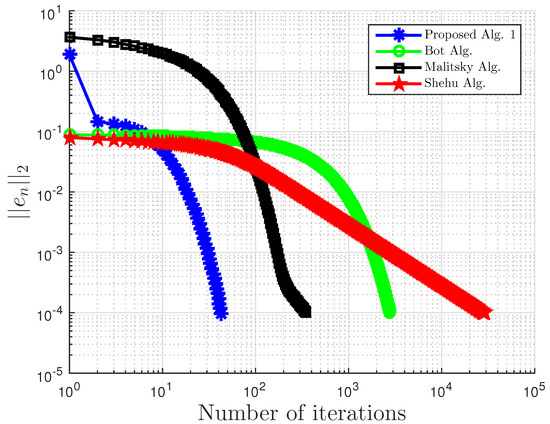
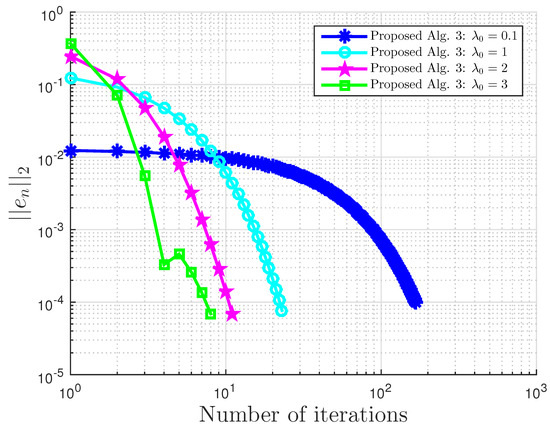
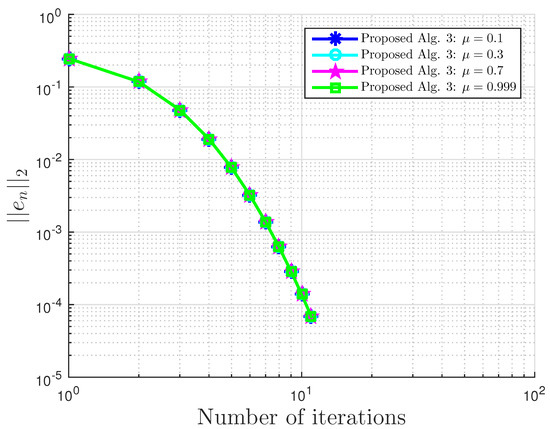
Consider and . Define by:
It can also be shown that A is pseudo-monotone, but not monotone on H, Lipschitz continuous with , and sequentially weakly-to-weak;y continuous on H (see Example 2.1 of [27]).
Our proposed Algorithm 3 is compared with Algorithm 1 proposed by Boţ et al. in [27] (Bot Alg.), Algorithm 2 proposed by Malitsky et al. in [28] (Malitsky Alg.), and Shehu and Iyiola’s proposed Algorithm 3.2 in [37] (Shehu Alg.). For our proposed algorithm, we choose and for Boţ et al., for Malitsky et al., and , while for Shehu and Iyiola, , and All algorithms are terminated using the stopping criterion with . All results are reported in Table 9 and Table 10 and Figure 33, Figure 34, Figure 35 and Figure 36.
Table 9.
Example 5 comparison: proposed Algorithm 3, Bot Algorithm 1, Malitsky Algorithm 2, and Shehu Alg. [37] with and .
Table 10.
Example 5: proposed Algorithm 3 with for different and values.
Figure 33.
Example 5: , and .
Figure 34.
Example 5: , and .
Figure 35.
Example 5: .
Figure 36.
Example 5: .
5. Discussion
The weak convergence analysis of the reflected subgradient-extragradient method for variational inequalities in real Hilbert spaces is obtained in this paper. We provide and intensive numerical illustration and comparison with related works for several applications such as tomography reconstruction and Nash–Cournot oligopolistic equilibrium models. Our result is one of the few results on the subgradient-extragradient method with the reflected step in the literature. Our next project is to modify our results to bilevel variational inequalities.
Author Contributions
Writing—review and editing, A.G., O.S.I., L.A. and Y.S. All authors contributed equally to this work which included mathematical theory and analysis and code implementation. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The study does not report any data.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| VI | variational inequality problem |
| EGM | extragradient method |
| SEGM | subgradient-extragradient method |
References
- Fichera, G. Sul problema elastostatico di Signorini con ambigue condizioni al contorno. Atti Accad. Naz. Lincei VIII Ser. Rend. Cl. Sci. Fis. Mat. Nat. 1963, 34, 138–142. [Google Scholar]
- Fichera, G. Problemi elastostatici con vincoli unilaterali: Il problema di Signorini con ambigue condizioni al contorno. Atti Accad. Naz. Lincei Mem. Cl. Sci. Fis. Mat. Nat. Sez. I VIII Ser. 1964, 7, 91–140. [Google Scholar]
- Stampacchia, G. Formes bilineaires coercitives sur les ensembles convexes. C. R. Acad. Sci. 1964, 258, 4413–4416. [Google Scholar]
- Kinderlehrer, D.; Stampacchia, G. An Introduction to Variational Inequalities and Their Applications; Academic: New York, NY, USA, 1980. [Google Scholar]
- Facchinei, F.; Pang, J.S. Finite-Dimensional Variational Inequalities and Complementarity Problems. Volume I; Springer Series in Operations Research; Springer: New York, NY, USA, 2003. [Google Scholar]
- Facchinei, F.; Pang, J.S. Finite-Dimensional Variational Inequalities and Complementarity Problems. Volume II; Springer Series in Operations Research; Springer: New York, NY, USA, 2003. [Google Scholar]
- Konnov, I.V. Combined Relaxation Methods for Variational Inequalities; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Iusem, A.N. An iterative algorithm for the variational inequality problem. Comput. Appl. Math. 1994, 13, 103–114. [Google Scholar]
- Iusem, A.N.; Svaiter, B.F. A variant of Korpelevich’s method for variational inequalities with a new search strategy. Optimization 1997, 42, 309–321. [Google Scholar] [CrossRef]
- Kanzow, C.; Shehu, Y. Strong convergence of a double projection-type method for monotone variational inequalities in Hilbert spaces. J. Fixed Point Theory Appl. 2018, 20, 51. [Google Scholar] [CrossRef]
- Khobotov, E.N. Modifications of the extragradient method for solving variational inequalities and certain optimization problems. USSR Comput. Math. Math. Phys. 1987, 27, 120–127. [Google Scholar] [CrossRef]
- Maingé, P.E. A hybrid extragradient-viscosity method for monotone operators and fixed point problems. SIAM J. Control Optim. 2008, 47, 1499–1515. [Google Scholar] [CrossRef]
- Marcotte, P. Application of Khobotov’s algorithm to variational inequalities and network equilibrium problems. Inf. Syst. Oper. Res. 1991, 29, 258–270. [Google Scholar] [CrossRef]
- Vuong, P.T. On the weak convergence of the extragradient method for solving pseudo-monotone variational inequalities. J. Optim. Theory Appl. 2018, 176, 399–409. [Google Scholar] [CrossRef]
- Shehu, Y.; Iyiola, O.S. Weak convergence for variational inequalities with inertial-type method. Appl. Anal. 2020, 2020, 1–25. [Google Scholar] [CrossRef]
- Korpelevich, G.M. The extragradient method for finding saddle points and other problems. Ekon. Matematicheskie Metody 1976, 12, 747–756. [Google Scholar]
- Antipin, A.S. On a method for convex programs using a symmetrical modification of the Lagrange function. Ekon. Matematicheskie Metody 1976, 12, 1164–1173. [Google Scholar]
- Censor, Y.; Gibali, A.; Reich, S. The subgradient-extragradient method for solving variational inequalities in Hilbert space. J. Optim. Theory Appl. 2011, 148, 318–335. [Google Scholar] [CrossRef]
- Censor, Y.; Gibali, A.; Reich, S. Strong convergence of subgradient-extragradient methods for the variational inequality problem in Hilbert space. Optim. Methods Softw. 2011, 26, 827–845. [Google Scholar] [CrossRef]
- Censor, Y.; Gibali, A.; Reich, S. Extensions of Korpelevich’s extragradient method for the variational inequality problem in Euclidean space. Optimization 2011, 61, 1119–1132. [Google Scholar] [CrossRef]
- Malitsky, Y.V. Projected reflected gradient methods for monotone variational inequalities. SIAM J. Optim. 2015, 25, 502–520. [Google Scholar] [CrossRef]
- Malitsky, Y.V.; Semenov, V.V. A hybrid method without extrapolation step for solving variational inequality problems. J. Glob. Optim. 2015, 61, 193–202. [Google Scholar] [CrossRef]
- Solodov, M.V.; Svaiter, B.F. A new projection method for variational inequality problems. SIAM J. Control Optim. 1999, 37, 765–776. [Google Scholar] [CrossRef]
- Denisov, S.V.; Semenov, V.V.; Chabak, L.M. Convergence of the modified extragradient method for variational inequalities with non-Lipschitz operators. Cybern. Syst. Anal. 2015, 51, 757–765. [Google Scholar] [CrossRef]
- Yang, J.; Liu, H. Strong convergence result for solving monotone variational inequalities in Hilbert space. Numer. Algorithms 2019, 80, 741–752. [Google Scholar] [CrossRef]
- Thong, D.V.; Hieu, D.V. Modified subgradient-extragradient method for variational inequality problems. Numer. Algorithms 2018, 79, 597–610. [Google Scholar] [CrossRef]
- Boţ, R.I.; Csetnek, E.R.; Vuong, P.T. The forward-backward-forward method from discrete and continuous perspective for pseudomonotone variational inequalities in Hilbert spaces. Eur. J. Oper. Res. 2020, 287, 49–60. [Google Scholar] [CrossRef]
- Malitsky, Y.V. Golden ratio algorithms for variational inequalities. Math. Program. 2020, 184, 383–410. [Google Scholar] [CrossRef]
- Karamardian, S. Complementarity problems over cones with monotone and pseudo-monotone maps. J. Optim. Theory Appl. 1976, 18, 445–454. [Google Scholar] [CrossRef]
- Goebel, K.; Reich, S. Uniform Convexity, Hyperbolic Geometry, and Nonexpansive Mappings; Marcel Dekker: New York, NY, USA, 1984. [Google Scholar]
- Kopecká, E.; Reich, S. A note on alternating projections in Hilbert spaces. J. Fixed Point Theory Appl. 2012, 12, 41–47. [Google Scholar] [CrossRef]
- Cegielski, A. Iterative Methods for Fixed Point Problems in Hilbert Spaces; Lecture Notes in Mathematics; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Cottle, R.W.; Yao, J.C. Pseudo-monotone complementarity problems in Hilbert space. J. Optim. Theory Appl. 1992, 75, 281–295. [Google Scholar] [CrossRef]
- Opial, Z. Weak convergence of the sequence of successive approximations for nonexpansive mappings. Bull. Am. Math. Soc. 1967, 73, 591–597. [Google Scholar] [CrossRef]
- He, Y.R. A new double projection algorithm for variational inequalities. J. Comput. Appl. Math. 2006, 185, 166–173. [Google Scholar] [CrossRef]
- Maingé, P.E. Convergence theorems for inertial KM-type algorithms. J. Comput. Appl. Math. 2008, 219, 223–236. [Google Scholar] [CrossRef]
- Shehu, Y.; Iyiola, O.S. Iterative algorithms for solving fixed point problems and variational inequalities with uniformly continuous monotone operators. Numer. Algorithms 2018, 79, 529–553. [Google Scholar] [CrossRef]
- Yen, L.H.; Muu, L.D.; Huyen, N.T.T. An algorithm for a class of split feasibility problems: Application to a model in electricity production. Math. Methods Oper. Res. 2016, 84, 549–565. [Google Scholar] [CrossRef]
- Harker, P.T.; Pang, J.-S. A damped-Newton method for the linear complementarity problem. In Computational Solution of Nonlinear Systems of Equations, Lectures in Applied Mathematics; Allgower, G., Georg, K., Eds.; AMS: Providence, RI, USA, 1990; Volume 26, pp. 265–284. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).