Multimedia Data Modelling Using Multidimensional Recurrent Neural Networks


Abstract
1. Introduction
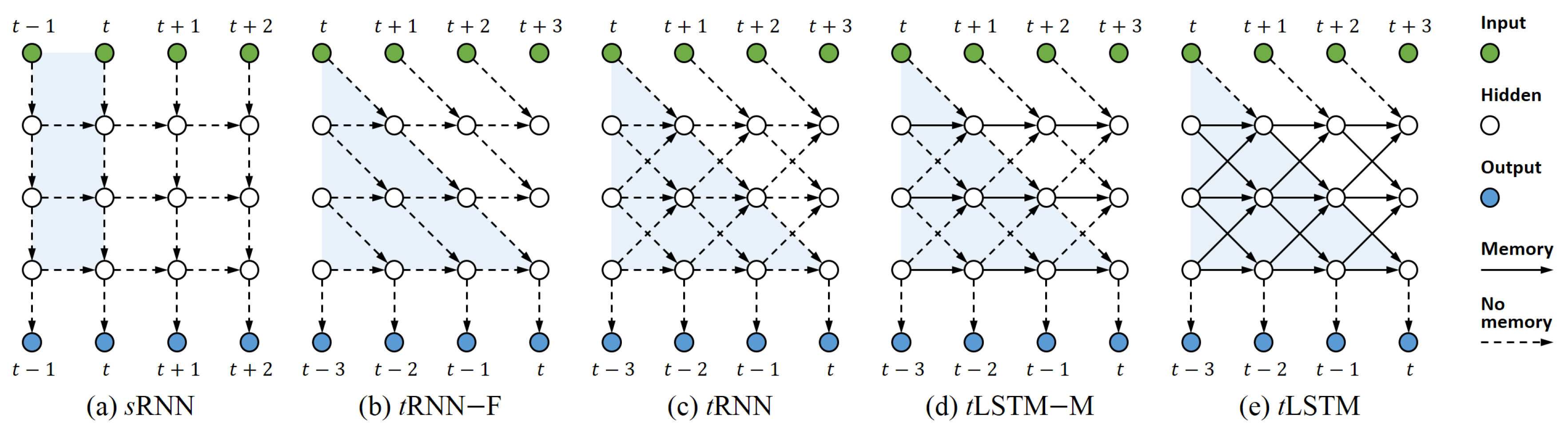
- We represent RNN hidden states as multidimensional arrays (tensors) to allow more flexible parameter sharing, thereby being able to efficiently widen the network without extra parameters.
- We use the temporal computations of the RNN to absorb its deep computations in order that we can deepen it without extra runtime. We call this novel RNN as the Tensor RNN (tRNN).
- We propose a memory cell convolution and apply it to the tRNN in order to mitigate gradient vanishing and explosion, obtaining a Tensor LSTM (tLSTM).
- We generalise the tLSTM so that it can process not only non-structured time series (series of vectors) [20], but also structured time series (series of tensors, such as videos).
- We show by experiments that our model is well-suited for various multimedia data modelling tasks, including text generation, text calculation, image classification, and video prediction.
2. Method
2.1. Tensor Representation
2.2. Deep Computation through Time
2.3. Using LSTMs
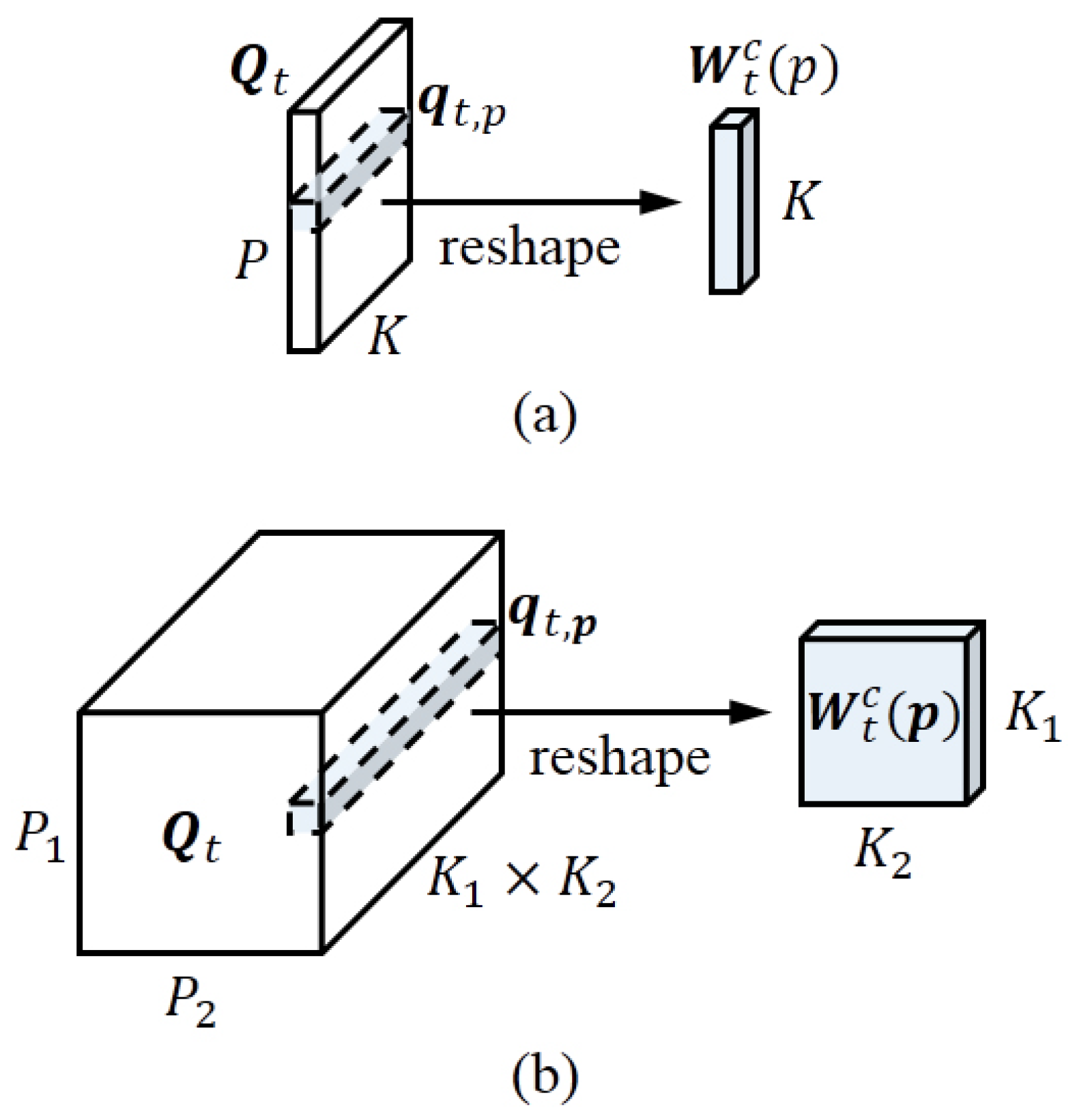
2.3.1. Memory Cell Convolution
2.3.2. Channel Normalisation
2.3.3. Leveraging Higher-Dimensional Tensors
2.4. Handling Structured Inputs
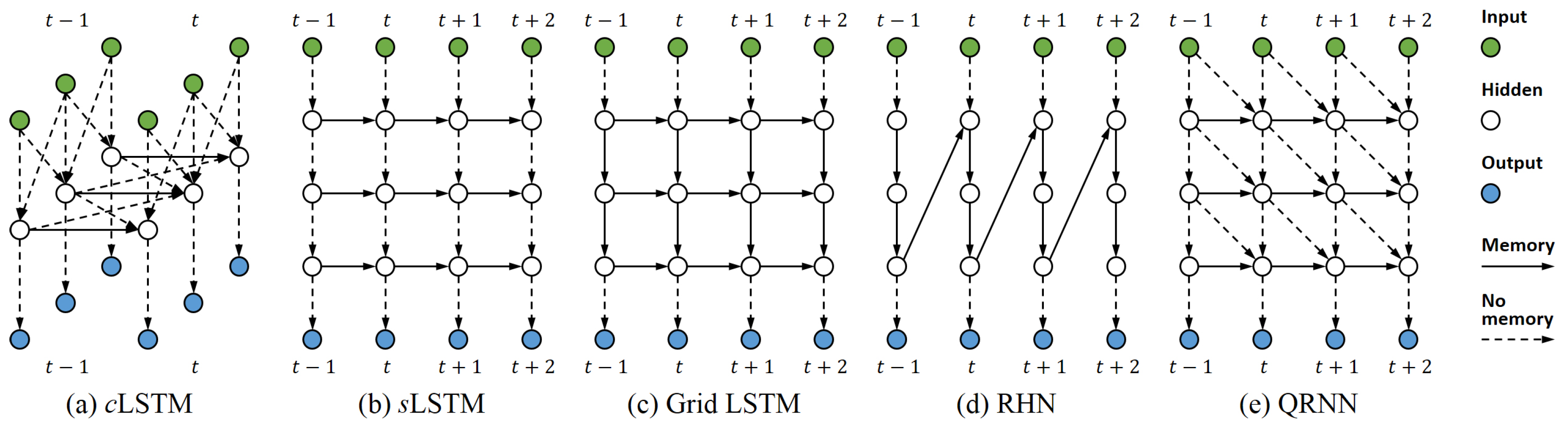
3. Related Work
3.1. Convolutional LSTMs
3.2. Deep LSTMs
3.3. Other Parallelisation Methods
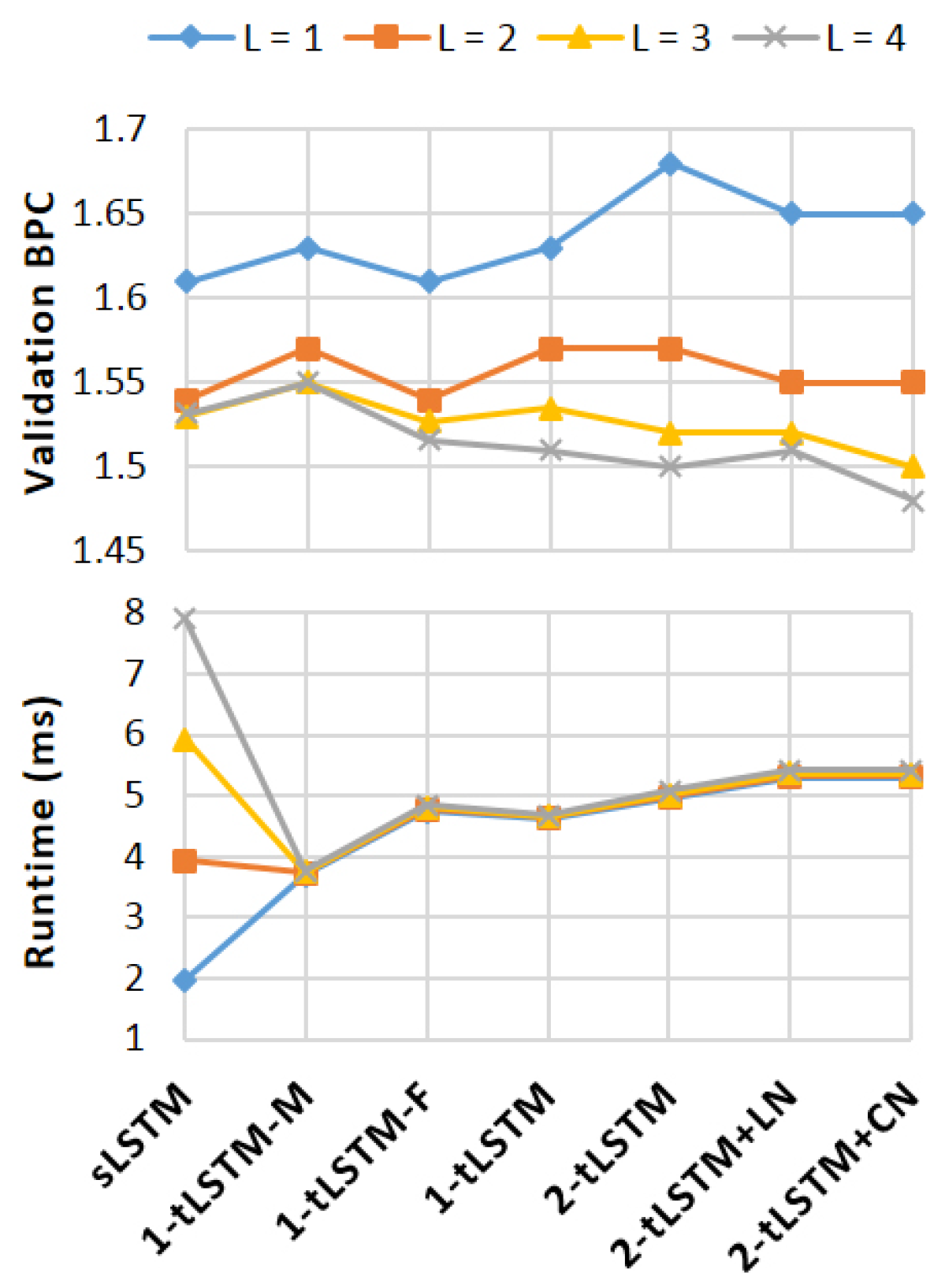
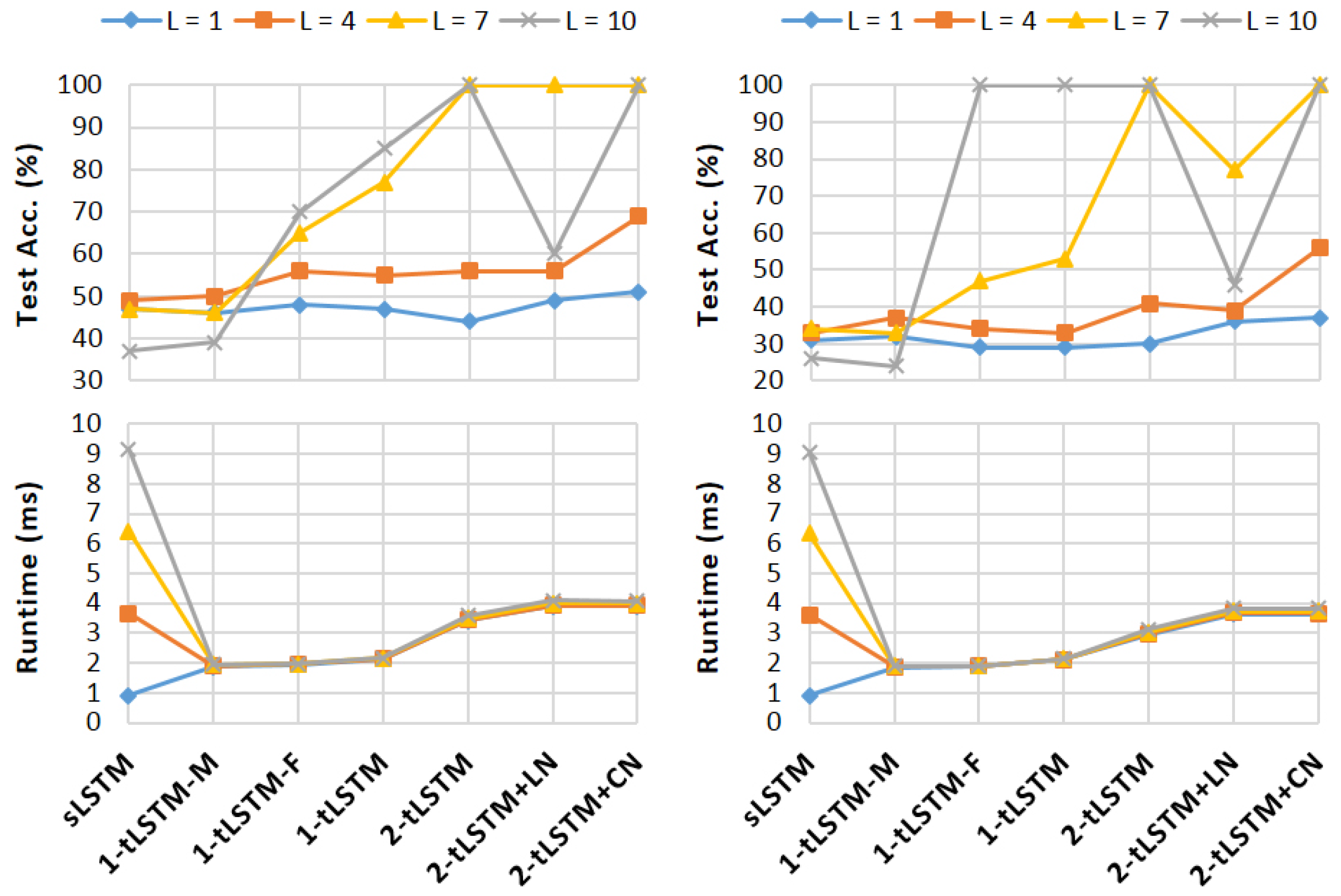
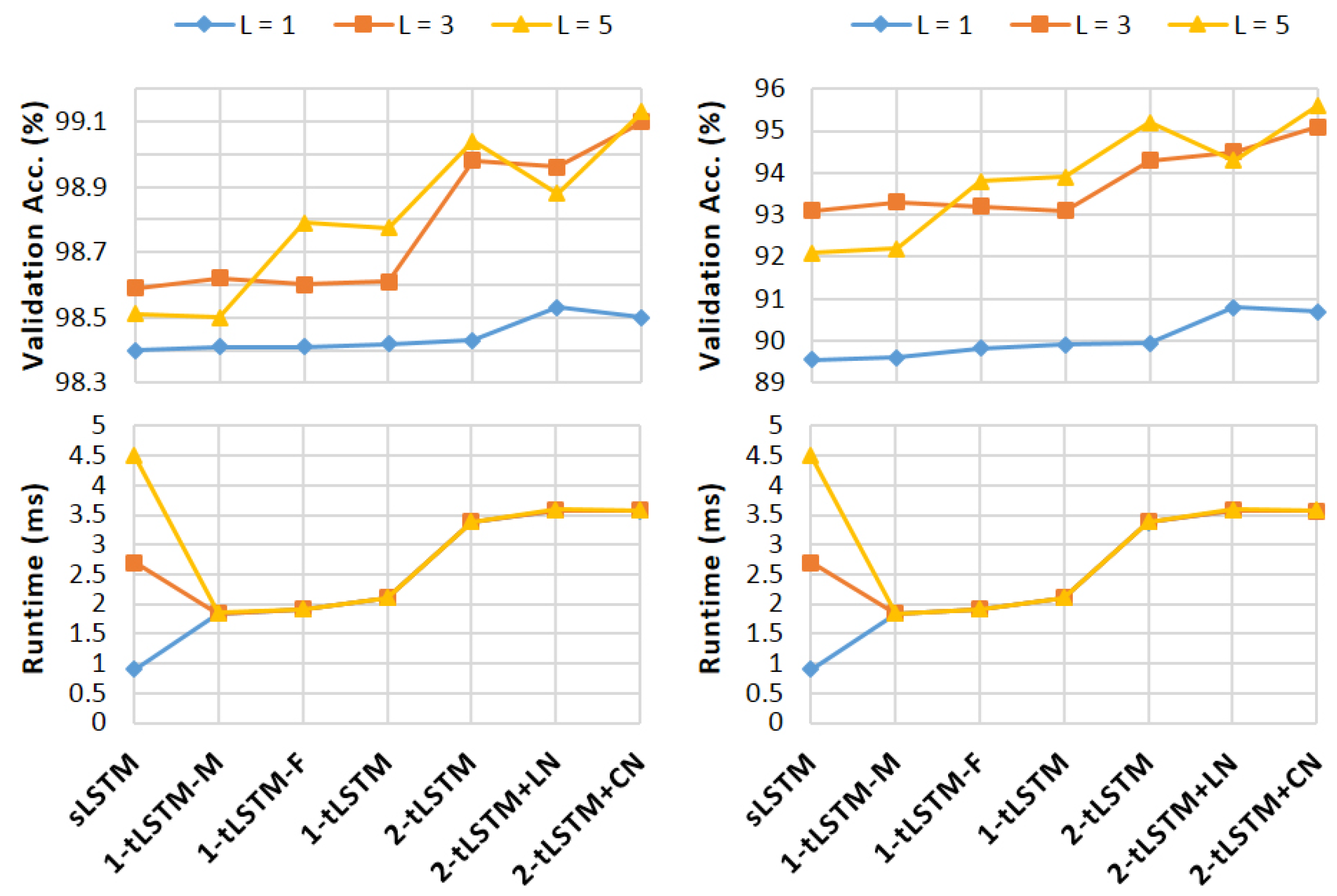
4. Experiments
- sLSTM: We implement the sLSTM [45] and share the parameters for different layers. This configuration is served as our baseline.
- 1-tLSTM–F: 1-tLSTM with no feedback connection (–F).
4.1. Text Generation
4.2. Text Calculation
- (i)
- Addition: The goal of this task is adding two integers of 15-digit. The model firstly reads both integers, after which it predicts their sum, both in a sequential manner (i.e., one digit per time step). Following [46], we use the symbol ‘-’ to delimit integers and pad the input and target sequences, e.g.,
- (ii)
- Copy: The copy task is to reproduce 20 random symbols presented as a sequence, where 65 different symbols are used. As in the addition task, the symbol ‘-’ is also used as a delimiter, e.g.,
4.3. Image Classification
- (i)
- Sequential MNIST: In this task, the model first sequentially reads the pixels in a scanline order, and then outputs the class of the digit contained in the image [62]. It is a time series task of 784 time steps, where we generate the output from the last time step, thereby requiring to capture very long term temporal dependencies.
- (ii)
- Sequential Permuted MNIST: To make the problem even harder, we generate a permuted MNIST (pMNIST) [63] by permuting the original image pixels with a fixed random order so that the long-term dependency can also exist in neighbouring pixels.
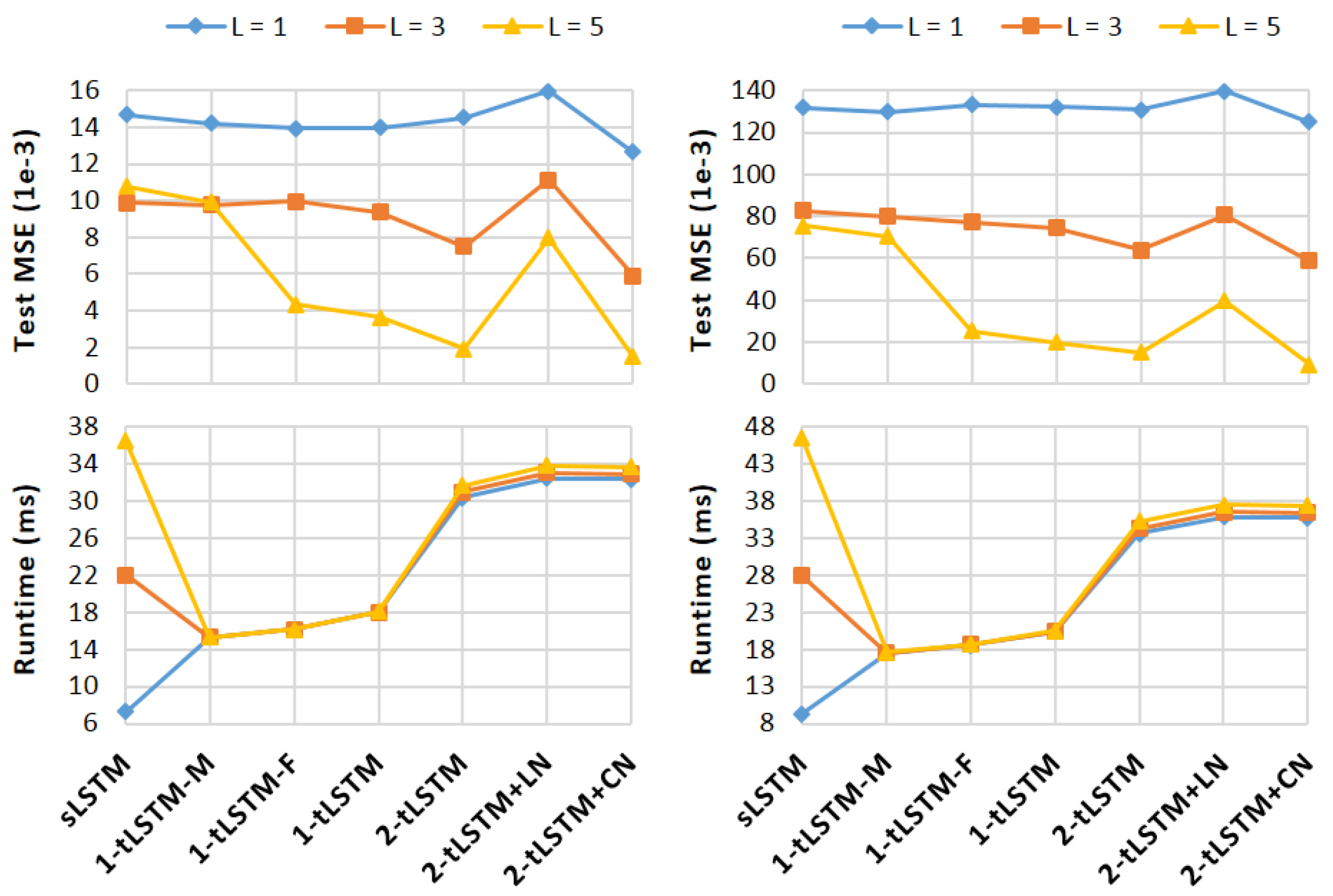
4.4. Video Prediction
- (i)
- KTH [67]: The dataset consists of 600 real videos with 25 subjects performing six actions (walking, running, jogging, hand-clapping, hand-waving, and boxing). It has been split into a training set (subjects 1–16) and a test set (subjects 17–25), resulting in 383 and 216 sequences, respectively. We resize all frames to .
- (ii)
- UCF101 [68]: The dataset consists of 13,320 real videos of resolution with 101 human actions that could be split into five types (sports, playing musical instruments, human-human interaction, body-motion only, and human-object interaction). It is currently the most challenging dataset of actions. Following [69], we train our models on Sports-1M [70] dataset and test them on UCF-101.
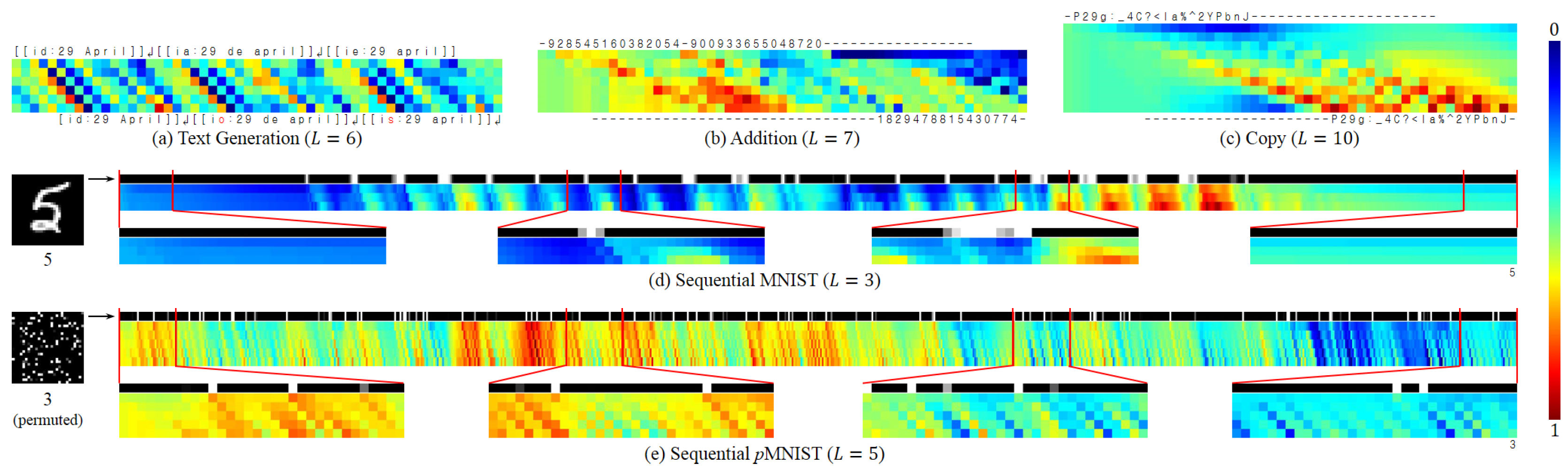
4.5. Analysis
- Text Generation: If the next character is largely determined by the current input, the input content can be preserved with less modification when it arrives at the output location, and vice versa.
- Addition: Two integers are gradually compressed into the memory and then interact with each other, generating their summation.
- Copy: The model acts as a shift register, continuing to move the input symbols to their output locations.
- Seq. MNIST: The model seems more sensitive to pixel value changes (which represent contours, or the digit topology); it gradually accumulates evidence to generate the final output.
- Seq. pMNIST: The model seems more sensitive to high value pixels (which come from the digit); our conjecture is that the permutation has destroyed the digit topology, and thereby made each high value pixel potentially important.
- At each time step, different locations of the tensor possess markedly different values, which implies that a tensor of a larger size could encode more content, requiring less effort for compressing.
- The value becomes more and more distinct from the input to output and is shifted along the time axis, which reveals that the model indeed simultaneously performs the deep and temporal computations, with the memory cell carrying the long-term dependency.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Mathematical Definition for Cross-Layer Convolutions
Appendix A.1. Hidden State Convolution
Appendix A.2. Memory Cell Convolution
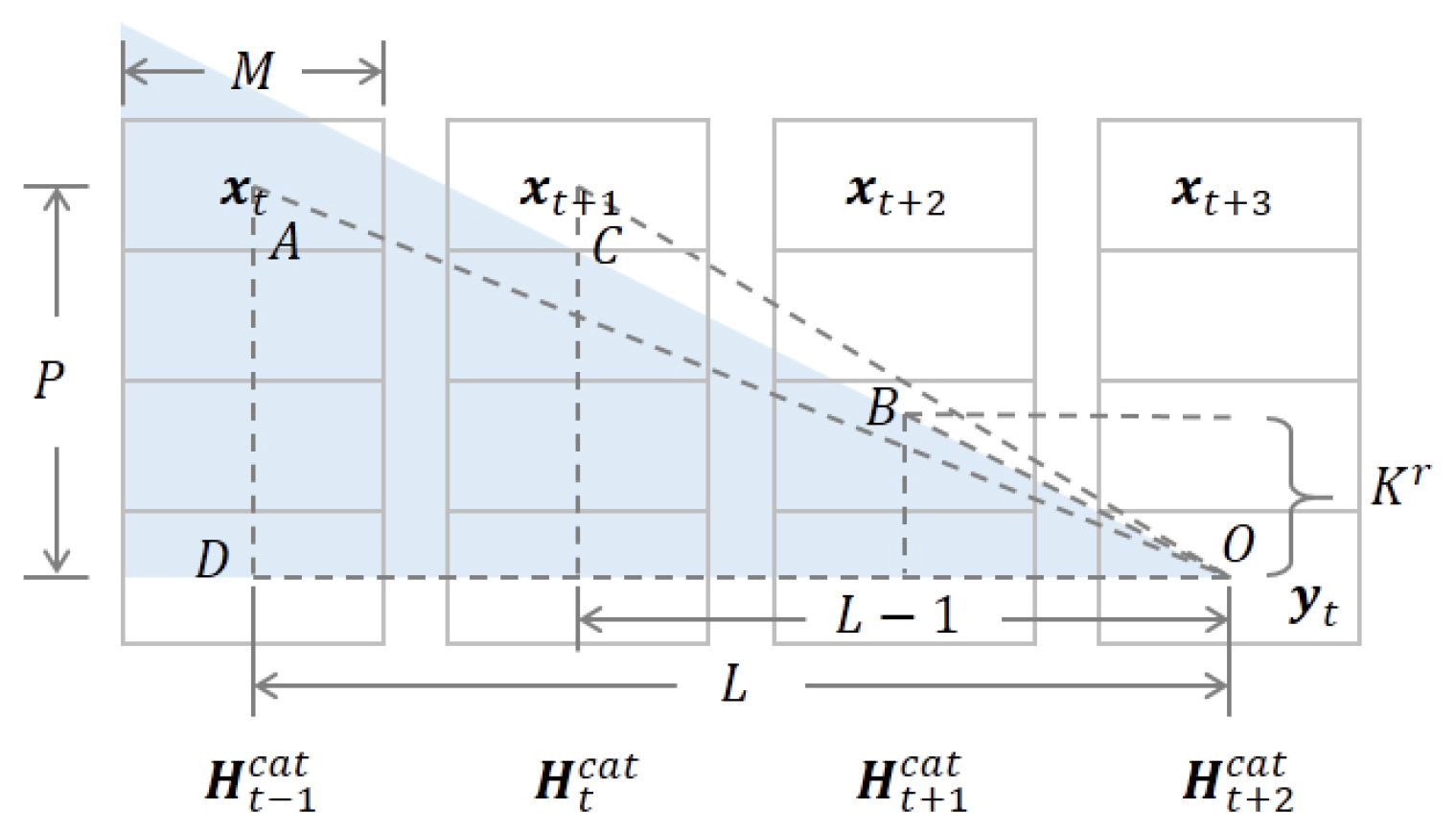
Appendix B. Derivation for the Constraint of L, P, and K

Appendix C. MemConv Mitigates the Gradient Vanishing/Explosion
References
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013. [Google Scholar]
- Santos, C.D.; Zadrozny, B. Learning character-level representations for part-of-speech tagging. In Proceedings of the 31st International Conference on International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the International Conference on Learning Representations 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Iyyer, M.; Boyd-Graber, J.; Claudino, L.; Socher, R.; Daumé, H., III. A neural network for factoid question answering over paragraphs. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Byeon, W.; Breuel, T.M.; Raue, F.; Liwicki, M. Scene labeling with lstm recurrent neural networks. In Proceedings of the 28th IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Kumar, A.C.; Bhandarkar, S.M.; Prasad, M. Depthnet: A recurrent neural network architecture for monocular depth prediction. In Proceedings of the 2018 Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Van den Oord, A.; Kalchbrenner, N.; Kavukcuoglu, K. Pixel Recurrent Neural Networks. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Huang, Y.; Wang, W.; Wang, L. Bidirectional recurrent convolutional networks for multi-frame super-resolution. In Proceedings of the Twenty-ninth Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Milan, A.; Rezatofighi, S.H.; Dick, A.R.; Reid, I.D.; Schindler, K. Online Multi-Target Tracking Using Recurrent Neural Networks. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Tokmakov, P.; Alahari, K.; Schmid, C. Learning Video Object Segmentation with Visual Memory. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Ranzato, M.; Szlam, A.; Bruna, J.; Mathieu, M.; Collobert, R.; Chopra, S. Video (language) modeling: A baseline for generative models of natural videos. arXiv, 2014; arXiv:1412.6604. [Google Scholar]
- Villegas, R.; Yang, J.; Hong, S.; Lin, X.; Lee, H. Decomposing motion and content for natural video sequence prediction. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Elman, J.L. Finding structure in time. Cognit. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y. Learning deep architectures for AI. In Foundations and Trends® in Machine Learning; University of California, Berkeley: Berkeley, CA, USA, 2009. [Google Scholar]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 38th International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–30 May 2013. [Google Scholar]
- He, Z.; Gao, S.; Xiao, L.; Liu, D.; He, H.; Barber, D. Wider and Deeper, Cheaper and Faster: Tensorized LSTMs for Sequence Learning. In Proceedings of the Thirty-first Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Taylor, G.W.; Hinton, G.E. Factored conditional restricted Boltzmann machines for modeling motion style. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009. [Google Scholar]
- Sutskever, I.; Martens, J.; Hinton, G.E. Generating text with recurrent neural networks. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Denil, M.; Shakibi, B.; Dinh, L.; de Freitas, N.; Ranzato, M.A. Predicting parameters in deep learning. In Proceedings of the Twenty-seventh Conference on Neural Information Processing Systems, Stateline, NV, USA, 5–10 December 2013. [Google Scholar]
- Irsoy, O.; Cardie, C. Modeling compositionality with multiplicative recurrent neural networks. In Proceedings of the International Conference on Learning Representations 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Novikov, A.; Podoprikhin, D.; Osokin, A.; Vetrov, D.P. Tensorizing neural networks. In Proceedings of the Twenty-ninth Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Wu, Y.; Zhang, S.; Zhang, Y.; Bengio, Y.; Salakhutdinov, R. On Multiplicative Integration with Recurrent Neural Networks. In Proceedings of the Thirtieth Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Bertinetto, L.; Henriques, J.F.; Valmadre, J.; Torr, P.; Vedaldi, A. Learning feed-forward one-shot learners. In Proceedings of the Thirtieth Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Garipov, T.; Podoprikhin, D.; Novikov, A.; Vetrov, D. Ultimate tensorization: Compressing convolutional and FC layers alike. In Proceedings of the Thirtieth Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Krause, B.; Lu, L.; Murray, I.; Renals, S. Multiplicative LSTM for sequence modelling. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Appleyard, J.; Kocisky, T.; Blunsom, P. Optimizing Performance of Recurrent Neural Networks on GPUs. arXiv, 2016; arXiv:1604.01946. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Gated Feedback Recurrent Neural Networks. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Leifert, G.; Strauß, T.; Grüning, T.; Wustlich, W.; Labahn, R. Cells in multidimensional recurrent neural networks. J. Mach. Learn. Res. 2016, 17, 3313–3349. [Google Scholar]
- Schmidhuber, J. Learning to control fast-weight memories: An alternative to dynamic recurrent networks. Neural Comput. 1992, 4, 131–139. [Google Scholar] [CrossRef]
- De Brabandere, B.; Jia, X.; Tuytelaars, T.; Van Gool, L. Dynamic filter networks. In Proceedings of the Thirtieth Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Ha, D.; Dai, A.; Le, Q.V. HyperNetworks. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv, 2016; arXiv:1607.06450. [Google Scholar]
- Xingjian, S.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Twenty-ninth Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Romera-Paredes, B.; Torr, P.H.S. Recurrent instance segmentation. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Patraucean, V.; Handa, A.; Cipolla, R. Spatio-temporal video autoencoder with differentiable memory. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Wu, L.; Shen, C.; Hengel, A.V.D. Deep Recurrent Convolutional Networks for Video-based Person Re-identification: An End-to-End Approach. arXiv, 2016; arXiv:1606.01609. [Google Scholar]
- Stollenga, M.F.; Byeon, W.; Liwicki, M.; Schmidhuber, J. Parallel multi-dimensional LSTM, with application to fast biomedical volumetric image segmentation. In Proceedings of the Twenty-ninth Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Chen, J.; Yang, L.; Zhang, Y.; Alber, M.; Chen, D.Z. Combining Fully Convolutional and Recurrent Neural Networks for 3D Biomedical Image Segmentation. In Proceedings of the Thirtieth Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Graves, A. Generating sequences with recurrent neural networks. arXiv, 2013; arXiv:1308.0850. [Google Scholar]
- Kalchbrenner, N.; Danihelka, I.; Graves, A. Grid long short-term memory. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Zilly, J.G.; Srivastava, R.K.; Koutník, J.; Schmidhuber, J. Recurrent Highway Networks. In Proceedings of the 34th International Conference on Machine Learning (ICML 2017), Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Bradbury, J.; Merity, S.; Xiong, C.; Socher, R. Quasi-recurrent neural networks. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Graves, A. Adaptive Computation Time for Recurrent Neural Networks. arXiv, 2016; arXiv:1603.08983. [Google Scholar]
- Mujika, A.; Meier, F.; Steger, A. Fast-Slow Recurrent Neural Networks. In Proceedings of the Thirty-first Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Diamos, G.; Sengupta, S.; Catanzaro, B.; Chrzanowski, M.; Coates, A.; Elsen, E.; Engel, J.; Hannun, A.; Satheesh, S. Persistent RNNs: Stashing Recurrent Weights On-Chip. In Proceedings of the 33rd International Conference on Machine Learning (ICML 2016), New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Kaiser, Ł.; Sutskever, I. Neural gpus learn algorithms. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Kaiser, Ł.; Bengio, S. Can Active Memory Replace Attention? In Proceedings of the Thirtieth Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv, 2016; arXiv:1609.03499. [Google Scholar]
- Lei, T.; Zhang, Y. Training RNNs as Fast as CNNs. arXiv, 2017; arXiv:1709.02755. [Google Scholar]
- Chang, S.; Zhang, Y.; Han, W.; Yu, M.; Guo, X.; Tan, W.; Cui, X.; Witbrock, M.; Hasegawa-Johnson, M.; Huang, T. Dilated Recurrent Neural Networks. In Proceedings of the Thirty-first Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Jozefowicz, R.; Zaremba, W.; Sutskever, I. An Empirical Exploration of Recurrent Network Architectures. In Proceedings of the 32nd International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015. [Google Scholar]
- Collobert, R.; Kavukcuoglu, K.; Farabet, C. Torch7: A matlab-like environment for machine learning. In Proceedings of the Twenty-fifth Conference on Neural Information Processing Systems, Sierra Nevada, Spain, 12–17 December 2011. [Google Scholar]
- Hutter, M. The Human Knowledge Compression Contest. 2012. Available online: http://prize.hutter1.net (accessed on 13 July 2018).
- Chung, J.; Ahn, S.; Bengio, Y. Hierarchical multiscale recurrent neural networks. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Le, Q.V.; Jaitly, N.; Hinton, G.E. A simple way to initialize recurrent networks of rectified linear units. arXiv, 2015; arXiv:1504.00941. [Google Scholar]
- Arjovsky, M.; Shah, A.; Bengio, Y. Unitary Evolution Recurrent Neural Networks. In Proceedings of the 33rd International Conference on Machine Learning (ICML 2016), New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Wisdom, S.; Powers, T.; Hershey, J.; Le Roux, J.; Atlas, L. Full-capacity unitary recurrent neural networks. In Proceedings of the Thirtieth Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Zhang, S.; Wu, Y.; Che, T.; Lin, Z.; Memisevic, R.; Salakhutdinov, R.R.; Bengio, Y. Architectural Complexity Measures of Recurrent Neural Networks. In Proceedings of the Thirtieth Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Cooijmans, T.; Ballas, N.; Laurent, C.; Courville, A. Recurrent Batch Normalization. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv, 2012; arXiv:1212.0402. [Google Scholar]
- Mathieu, M.; Couprie, C.; LeCun, Y. Deep multi-scale video prediction beyond mean square error. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, N.; Mansimov, E.; Salakhudinov, R. Unsupervised learning of video representations using lstms. In Proceedings of the 32nd International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015. [Google Scholar]
- Lotter, W.; Kreiman, G.; Cox, D. Deep predictive coding networks for video prediction and unsupervised learning. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | #Parameters | BPC |
|---|---|---|
| MI-LSTM [26] | ≈17 M | 1.44 |
| mLSTM [29] | ≈20 M | 1.42 |
| HyperLSTM+LN [37] | 26.5 M | 1.34 |
| HM-LSTM+LN [61] | ≈35 M | 1.32 |
| Large RHN [47] | ≈46 M | 1.27 |
| Large FS-LSTM-4 [50] | ≈47 M | 1.245 |
| 2 × Large FS-LSTM-4 [50] | ≈94 M | 1.198 |
| 2-tLSTM+CN (, ) | 50.1 M | 1.264 |
| Method | Addition | Copy | ||
|---|---|---|---|---|
| #Samples | Accuracy | #Samples | Accuracy | |
| sLSTM [45] | 5 M | 51% | 900 K | >50% |
| Grid LSTM [46] | 550 K | >99% | 150 K | >99% |
| 2-tLSTM+CN () | 298 K | >99% | 115 K | >99% |
| 2-tLSTM+CN () | 317 K | >99% | 54 K | >99% |
| Method | MNIST | pMNIST |
|---|---|---|
| iRNN [62] | 97.0 | 82.0 |
| LSTM [63] | 98.2 | 88.0 |
| uRNN [63] | 95.1 | 91.4 |
| Full-capacity uRNN [64] | 96.9 | 94.1 |
| sTANH [65] | 98.1 | 94.0 |
| BN-LSTM [66] | 99.0 | 95.4 |
| Dilated GRU [56] | 99.2 | 94.6 |
| Dilated CNN [54] in [56] | 98.3 | 96.7 |
| 2-tLSTM+CN () | 99.2 | 94.9 |
| 2-tLSTM+CN () | 99.0 | 95.7 |
| Method | KTH | UCF101 | ||||
|---|---|---|---|---|---|---|
| MSE ↓ | PSNR ↑ | SSIM ↑ | MSE ↓ | PSNR ↑ | SSIM ↑ | |
| Composite LSTM [72] | 0.01021 | 20.893 | 0.77958 | 0.16342 | 9.877 | 0.50363 |
| Beyond MSE [69] | 0.00193 | 28.465 | 0.88234 | 0.00987 | 22.133 | 0.81254 |
| PredNet [73] | 0.00384 | 27.954 | 0.90052 | 0.01672 | 18.945 | 0.80827 |
| MCnet [12] | 0.00190 | 30.179 | 0.91228 | 0.00979 | 22.861 | 0.84392 |
| 2-tLSTM+CN () | 0.00148 | 31.053 | 0.93316 | 0.00925 | 22.785 | 0.85941 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Z.; Gao, S.; Xiao, L.; Liu, D.; He, H. Multimedia Data Modelling Using Multidimensional Recurrent Neural Networks. Symmetry 2018, 10, 370. https://doi.org/10.3390/sym10090370
He Z, Gao S, Xiao L, Liu D, He H. Multimedia Data Modelling Using Multidimensional Recurrent Neural Networks. Symmetry. 2018; 10(9):370. https://doi.org/10.3390/sym10090370
Chicago/Turabian StyleHe, Zhen, Shaobing Gao, Liang Xiao, Daxue Liu, and Hangen He. 2018. "Multimedia Data Modelling Using Multidimensional Recurrent Neural Networks" Symmetry 10, no. 9: 370. https://doi.org/10.3390/sym10090370
APA StyleHe, Z., Gao, S., Xiao, L., Liu, D., & He, H. (2018). Multimedia Data Modelling Using Multidimensional Recurrent Neural Networks. Symmetry, 10(9), 370. https://doi.org/10.3390/sym10090370