1. Introduction
The last two decades have seen a significant increase in research into metaheuristic algorithms. The procedure of a metaheuristic algorithm can be divided into four steps: initialization, movement, replacement, and iteration [
1]. The most popular metaheuristic algorithms to date are the particle swarm optimization (PSO) [
2,
3], genetic algorithm (GA) [
4,
5,
6], and ant colony optimization (ACO) [
7,
8,
9].
PSO was introduced by Kennedy and Eberhart in 1995 [
10,
11]. It imitates the foraging behavior of birds and fish, and provides a population-based search procedure, where each individual is abstracted as a “particle” that flies around in a multidimensional search space. The best positions encountered by a particle and its neighbors determine the particle’s trajectory, along with other PSO parameters. In other words, a PSO system attempts to balance exploration and exploitation by combining global and local search methods [
12].
The GA has been widely investigated since Holland proposed it in 1960 [
13,
14]. The GA was developed from Darwinian evolution. Based on the concept of natural genetics and evolutionary principles, GA is a stochastic search technique that can search the near optimum solution in a large and complicated space. As Gordini [
15] points out, “the GA differs from other non-linear optimization techniques in that it searches by maintaining a population of solutions from which better solutions are created, rather than making incremental changes to a single solution to a problem.” The GA is consisted of three operators: reproduction, crossover, and mutation [
16]. Reproduction is a process of survival-of-the-fittest selection. Crossover is the partial swap between two parent strings in order to produce two offspring strings. Mutation is the occasional random inversion of bit values in order to generate a non-recursive offspring. One importance of the GA is that several metaheuristic algorithms have been developed from the GA, such as the honey-bee mating optimization (HBMO) algorithm [
17] and the harmony search (HS) algorithm [
16].
The harmony search (HS) algorithm is a modern metaheuristic intelligent evolution algorithm [
18], and was inspired by the music improvisation process where musicians improvise their instruments’ pitches searching for a perfect state of harmony [
19]. The HS algorithm simulates the principle of the music improvisation process in the same way that the GA simulates biological evolution, the simulated annealing algorithm (SA) [
20] simulates physical annealing, and the PSO algorithm simulates the swarm behavior of birds and fish [
18], etc. The HS algorithm has excellent exploitation capabilities. However, the HS algorithm suffers a very serious limitation of premature convergence if one or more initially generated harmonies are in the vicinity of local optimal [
21]. As Assad and Deep [
22] point out, “The efficiency of evolutionary algorithms depends on the extent of balance between diversification and intensification during the course of the search. Intensification, also called exploitation, is the ability of an algorithm to exploit the search space in the vicinity of the current good solution, whereas diversification, also called exploration, is the process of exploring the new regions of a large search space and thus allows dissemination of the new information into the population. Proper balance between these two contradicting characteristics is a must to enhance the performance of the algorithm.”
Therefore, in order to eradicate the aforementioned limitation, several improved HS algorithms have been proposed, such as the improved harmony search (IHS) algorithm [
23], the self-adaptive global best harmony search (SHGS) [
24], the novel global harmony search (NGHS) [
25], the intelligent global harmony search (IGHS) algorithm [
19], and so on. Of these algorithms, the IHS algorithm is the first to propose using the adjustment strategy to tune the pitch adjusting rate (PAR) and bandwidth (BW) parameters. In the HS algorithm, according to the value of PAR, the musicians will determine to adjust their instruments’ pitches or not. Besides, the musicians will adjust the pitches within the BW distance. The PAR and BW values change dynamically with generation number, as shown in
Figure 1. In Mahdavi’s paper [
23], the adjustment strategy was proofed; it can enhance the searching ability of the harmony search algorithm. In other words, the importance of the appropriate parameters was proofed in his paper.
Appropriate parameters can enhance the searching ability of a metaheuristic algorithm; their importance has been described in many studies. First, Pan et al. demonstrated that a good set of parameters can enhance an algorithm’s ability to search for the global optimum or near optimum region with a high convergence rate [
19,
24]. Second, in the NGHS algorithm, the new trial solutions are generated by the parameter
. Therefore, Zou et al. [
25,
26] showed that the most reasonable design for
in the NGHS algorithm can guarantee that the proposed algorithm has strong global search ability in the early optimization stage, and strong local search ability in the late optimization stage. In addition, a dynamically adjusted
maintains a balance between the global search and the local search. In another paper, Zou et al. [
27] demonstrated that an appropriate harmony memory considering rate (HMCR) and PAR value in the SGHS algorithm can be gradually learned to suit the particular problem and the particular phases of the search process. In addition, there is no single choice for the genetic mutation probability (
) in the NGHS algorithm; it should be adjusted according to practical optimization problems. Last, Valian, Tavakoli, and Mohanna [
28] observed that there can be no single choice for HMCR in the IGHS algorithm, and it should be adjusted according to the given optimization problems.
However, in the NGHS algorithm, the value of the genetic mutation probability (
) is a fixed value that is given in the initialization step. According to the result of Mahdavi’s paper [
23], we supposed that the adjustment strategy could enhance the searching ability. Therefore, a dynamic adjusting novel global harmony search (DANGHS) algorithm was proposed in this paper. In the DANGHS algorithm, the mutation probability adjusts dynamically with the generation number by the adjustment strategy. However, we can adjust the mutation probability using different strategies. Therefore, this paper used 16 different strategies in the DANGHS algorithm in 14 well-known benchmark optimization problems. In other words, the performance of different strategies in the DANGHS algorithm for different problems was investigated. Besides, in general, one important characteristic of the metaheuristic algorithm is to be fast and efficient. A better metaheuristic algorithm cannot only search the more exact solution but also use less iterations than other algorithms. Therefore, we discuss the efficiency of the DANGHS algorithm in this paper. According to the numerical results, the DANGHS algorithm had better searching performance in comparison with other HS algorithms in most problems.
The remainder of this paper is arranged as follows. In
Section 2, the HS, IHS, SGHS, and NGHS algorithms are introduced.
Section 3 describes the DANGHS algorithm. A large number of experiments are carried out to test and compare the performance of 16 different strategies in the DANGHS algorithm in
Section 4. Conclusions and suggestions for future research are given in
Section 5.
2. HS, IHS, SGHS, and NGHS
In this section, the HS, the IHS, the SGHS, and the NGHS are reviewed.
2.1. Harmony Search Algorithm
The HS algorithm was proposed by Geem, Kim, and Loganathan in 2001 [
16]. HS is similar in concept to other metaheuristic algorithms such as GA, PSO, and ACO in terms of combining the rules of randomness to imitate the process that inspired it. However, HS draws its inspiration not from biological or physical processes but from the improvisation process of musicians, such as that found in a Jazz trio [
19,
29].
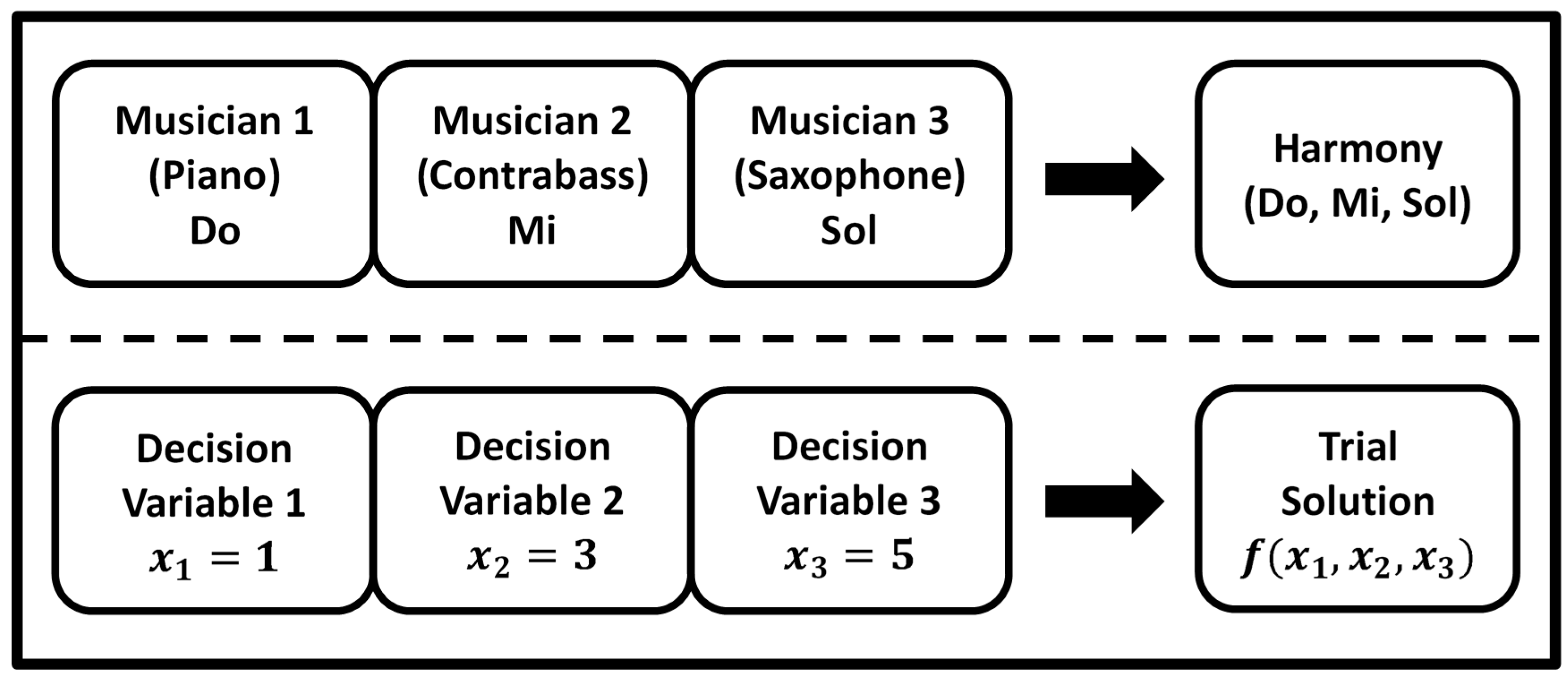
In the musical improvisation process, each musician sounds any pitch within a possible range, and then together they make a single harmony. If all the pitches make a pleasing harmony, the experience is stored in each player’s memory, and the possibility of making a more pleasing harmony the next time is increased [
30]. Similarly, in engineering optimization, each decision variable initially chooses any value within a possible range, together making one solution vector [
27]. In the HS algorithm, each harmony, which means the trial solution for the problem, is represented by a D-dimension real vector, and a pleasing harmony means the good trial solution for the problem [
19]. If all the decision variable values make a good solution, then that experience is stored in each variable’s memory, and the possibility of making a good solution the next time is also increased [
27].
Figure 2 shows the comparison between music improvisation and engineering optimization. In
Figure 2, there is a Jazz trio consisting of three musicians. Each musician plays an instrument at the same time to make a single harmony. The pitches of the three instruments mean the values of the three decision variables.
In general, the HS algorithm works as follows [
27]:
Step 1. Initialization: the algorithm and problem parameters
In this step, the parameters of the HS algorithm are determined. The parameters are the harmony memory size (m), the harmony memory considering rate (HMCR), the pitch adjusting rate (PAR), the bandwidth (BW), the current iteration (k = 1), and the maximum number of iterations (NI). Furthermore, the D-dimensional optimization problem is defined as Minimize f(x) subject to . and are the lower and upper bounds for decision variables .
Step 2. Initialization: the decision variable values and the harmony memory
The initial decision variable values
are generated by Equation (1). The harmony memory (HM) is as shown in Equation (2).
In Equation (1), is the uniformly generated random numbers in the region of [0, 1].
Step 3. Movement: improvise a new harmony
Movement step is the most important step of any algorithm. The performance of global exploration and local exploitation are related to the design of the movement step. In the HS algorithm, the movement step is improvisation. The new harmony vector is generated by memory consideration, pitch adjustment, and random selection mechanisms in this step. The HS movement steps (Pseudocode 1) are shown in Algorithm 1.
| Algorithm 1 The Movement Steps of HS (Pseudocode 1) |
| 1: | For do |
| 2: | If then |
| 3: | % memory consideration |
| 4: | If then |
| 5: | % pitch adjustment |
| 6: | If then |
| 7: | |
| 8: | Else if then |
| 9: | |
| 10: | End |
| 11: | End |
| 12: | Else |
| 13: | % random selection |
| 14: | End |
| 15: | End |
Here, is the jth component of . is an uniformly generated random number in [1, m], and is the jth component of the ith candidate solution vector in the HM. , , and are the uniformly generated random numbers in the region of [0, 1], and BW is a given distance bandwidth.
Step 4. Replacement: update harmony memory
If the fitness value of the new harmony vector is better than that of the worst harmony in the HM, replace the worst harmony vector by .
Step 5. Iteration: check the stopping criterion
If the stopping criterion (maximum number of iterations NI) is satisfied, the computation is terminated; otherwise, the current iteration k = k + 1 and go back to step 3.
2.2. Improved Harmony Search Algorithm
The IHS algorithm was proposed by Mahdavi, Fesanghary, and Damangir in 2007 for solving optimization problems [
23]. In their paper, they noted that PAR and BW are very important parameters in the HS algorithm when fine-tuning optimized solution vectors, and can be potentially useful in adjusting the convergence rate of the algorithm to the optimal solution. Fine adjustment of these parameters is therefore of particular interest. The key difference between the IHS and the traditional HS method is thus in the way PAR and BW are adjusted in each iteration by Equations (3) and (4):
In Equation (3),
is the pitch adjustment rate in the current iteration k;
and
are the minimum and maximum adjustment rates, respectively. In Equation (4),
is the distance bandwidth in current iteration k,
is the minimum bandwidth, and
is the maximum bandwidth.
Figure 1 shows that the PAR and BW values change dynamically with the iteration number.
2.3. Self-Adaptive Global Best Harmony Search Algorithm
The SGHS algorithm was presented by Pan et al. in 2010 for continuous optimization problems [
24].
In the SGHS algorithm, the HMCR and PAR were dynamically adapted by the normal distribution and the BW was adjusted in each iteration. The value of
was generated by the mean
and the standard deviation. In the same way, the value of
was generated by the mean
and the standard deviation. Pan et al. assumed that the dynamic mean
is in the range of [0.9, 1.0] and the static standard deviation is 0.01; the dynamic mean
. is in the range of [0.0, 1.0] and the static standard deviation is 0.05. Furthermore, the
and
were recorded by their historic values when the generated harmony successfully replaced the worst harmony in the harmony memory. After a specified learning period (LP), the
and
were recalculated by averaging all the recorded
and
values during this period respectively. In the subsequent iterations, new
and
values were generated with the new mean
and
and the given standard deviation. In addition, the
is decreased in each iteration by Equation (5).
In general, the SGHS algorithm works as follows:
Step 1. Initialization: the problem and algorithm parameters
Set parameters m, LP, NI, , , , , the current iteration k = 1, and iteration counter lp = 1.
Step 2. Initialization: the decision variable values and the harmony memory
The initial decision variable values is generated by Equation (1). The harmony memory (HM) is as shown in Equation (2).
Step 3. Movement: generate the algorithm parameters
Generate and with and by the normal distribution respectively. Generate with and by Equation (5).
Step 4. Movement: improvise a new harmony
Improvise a new harmony . The SGHS movement step (Pseudocode 2) is shown in Algorithm 2.
| Algorithm 2 The Movement Steps of SGHS (Pseudocode 2) [24] |
| 1: | For do |
| 2: | If then |
| 3: | |
| 4: | If then |
| 5: | |
| 6: | Else if then |
| 7: | |
| 8: | End |
| 9: | If then |
| 10: | |
| 11: | End |
| 12: | Else |
| 13: | % random selection |
| 14: | End |
| 15: | End |
Here, is the jth component of . is an uniformly generated random number in [1, m], and is the jth component of the ith candidate solution vector in the HM. is the jth component of the best candidate solution vector in the HM. , , and are uniformly generated random numbers in [0, 1]. is used for position updating, determines the distance of the BW, is used for pitch adjustment, and is used for random selection.
Step 5. Replacement: update harmony memory
If the fitness value of the new harmony vector is better than that of the worst harmony in the HM, replace the worst harmony vector by and record the values of and .
Step 6. Replacement: update and
If lp = LP, recalculate and by averaging all the recorded and values respectively and reset lp = 1; otherwise, lp = lp +1.
Step 7. Iteration: check the stopping criterion
If NI is completed, return the best harmony vector in the HM; otherwise, the current iteration k = k + 1 and go back to step 3.
2.4. Novel Global Harmony Search Algorithm
The NGHS algorithm [
25,
26] is an improved algorithm that combines HS, PSO, and GA. A prominent characteristic of PSO is that individual particles attempt to imitate the social experience. It means the particles are affected by other better particles in the PSO algorithm. A prominent characteristic of GA is that it is possible for the trial solution to escape from the local optimum by mutation. In other words, NGHS tries to generate a new solution by moving the worst solution toward the best solution or by mutation.
Figure 3 is used to illustrate the principle of position updating.
is defined as an adaptive step of the j
th decision variable. This adaptive step can dynamically balance the performance of global exploration and local exploitation in the NGHS algorithm. As Zou et al. [
26] points out, “In the early stage of optimization, all solution vectors are sporadic in the solution space, so most adaptive steps are large, and most trust regions are wide, which is beneficial to the global search of NGHS. However, in the late stage of optimization, all non-best solution vectors are inclined to move to the global best solution vector, so most solution vectors are close to each other. In this case, most adaptive steps are small and most trust regions are narrow, which is beneficial to the local search of NGHS.”
According to this prominent characteristic, NGHS modifies the movement step of HS therefore the NGHS algorithm can imitate the current best harmony in the HM. In general, the NGHS algorithm works as follows:
Step 1. Initialization: the algorithm and problem parameters
- (1)
Set parameters m, NI, and the current iteration k = 1.
- (2)
The genetic mutation probability () is included in NGHS, while the harmony memory considering rate (HMCR), pitch adjusting rate (PAR) and the bandwidth (BW) are excluded from NGHS.
Step 2. Initialization: the decision variable values and the harmony memory
The initial decision variable values are generated by Equation (1). The HM is as shown in Equation (2).
Step 3. Movement: improvise a new harmony
NGHS modifies the movement step in HS. The NGHS movement step (Pseudocode 3) is shown in Algorithm 3.
| Algorithm 3 The Movement Steps of NGHS (Pseudocode 3) [25,26,27]. |
| 1: | For do |
| 2: | |
| 3: | If then |
| 4: | |
| 5: | Else if then |
| 6: | |
| 7: | End |
| 8: | % position updating |
| 9: | If then |
| 10: | % genetic mutation |
| 11: | End |
| 12: | End |
Here, and are the best harmony and the worst harmony in the HM, respectively. , and are uniformly generated random numbers in [0, 1]. is used for position updating, determines whether NGHS should carry out genetic mutation, and is used for genetic mutation.
Genetic mutation with a small probability is carried out for the current worst harmony in the HM after position updating [
25,
26,
27].
Step 4. Replacement: update harmony memory
NGHS replaces the worst harmony in the HM by the new harmony , even if the new harmony is worse than the worst harmony.
Step 5. Iteration: check the stopping criterion
If the stopping criterion (maximum number of iterations NI) is satisfied, the computation is terminated; otherwise, the current iteration k = k + 1 and go back to step 3.
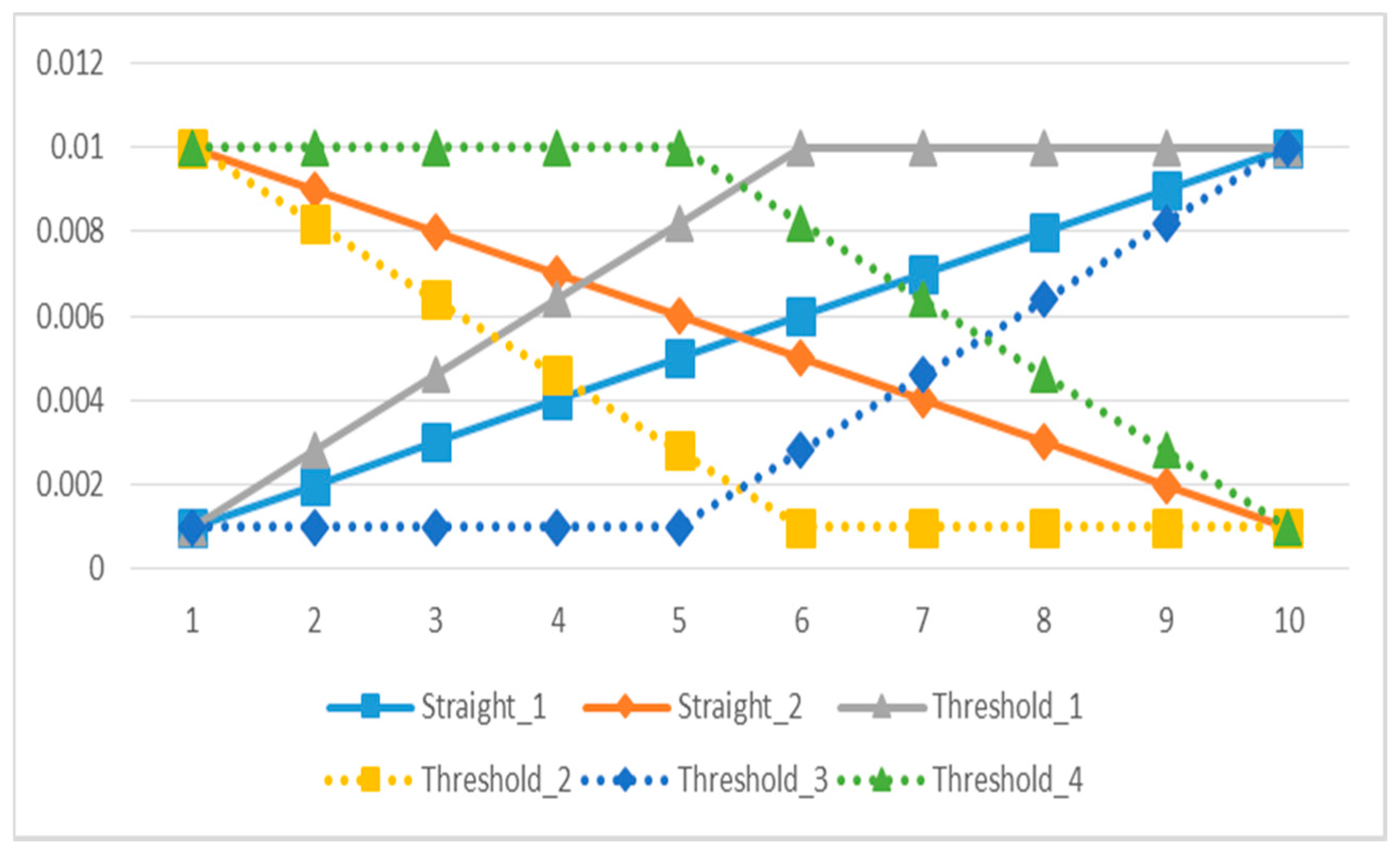
3. Dynamic Adjusting Novel Global Harmony Search (DANGHS) Algorithm
Appropriate parameters can enhance the searching ability of a metaheuristic algorithm. Inspired by this concept, a dynamic adjusting NGHS (DANGHS) is presented in this section. In the DANGHS, the genetic mutation probability (
) is dynamically adjusted in each iteration. However, we can enhance the searching ability of the NGHS algorithm by many kinds of dynamic adjustment strategies. Therefore, we introduced 16 dynamic adjustment strategies in this paper. All 16 strategies are shown as follows, and
Figure 4,
Figure 5 and
Figure 6 are used to illustrate the 16 strategies.
- (1)
Straight linear increasing strategy (Straight_1):
The genetic mutation probability is increased by Equation (6), which is a linear function.
Here,
is the minimum genetic mutation probability, and
is the maximum genetic mutation probability.
- (2)
Straight linear decreasing strategy (Straight_2):
The genetic mutation probability is decreased by Equation (7), which is a linear function.
- (3)
Threshold linear prior increasing strategy (Threshold_1):
The genetic mutation probability is increased by Equation (8), which is a linear function with a threshold. The genetic mutation probability is raised before the threshold, but the genetic mutation probability is a fixed maximum value after the threshold.
- (4)
Threshold linear prior decreasing strategy (Threshold_2):
The genetic mutation probability is decreased by Equation (9), which is a linear function with a threshold. The genetic mutation probability is reduced before the threshold, but the genetic mutation probability is a fixed minimum value after the threshold.
- (5)
Threshold linear posterior increasing strategy (Threshold_3):
The genetic mutation probability is increased by Equation (10), which is a linear function with a threshold. The genetic mutation probability is a fixed minimum value before the threshold, but the genetic mutation probability is raised after the threshold.
- (6)
Threshold linear posterior decreasing strategy (Threshold_4):
The genetic mutation probability is decreased by Equation (11), which is a linear function with a threshold. The genetic mutation probability is a fixed maximum value before the threshold, but the genetic mutation probability is reduced after the threshold.
- (7)
Natural exponential increasing strategy (Exponential_1):
The genetic mutation probability is increased by Equation (12), which is a non-linear function.
- (8)
Natural exponential decreasing strategy (Exponential_2):
The genetic mutation probability is decreased by Equation (13), which is a non-linear function.
- (9)
Exponential increasing strategy:
The genetic mutation probability is increased by Equation (14), which is a non-linear function. We can control the increasing rate by the modification rate (
).
In this paper, the
is equal to 0.01 or 0.001. Therefore, in this paper, the 9th strategy (Exponential_3) is the exponential increasing strategy with
, and the 10th strategy (Exponential_5) is the exponential increasing strategy with
.
- (10)
Exponential decreasing strategy:
The genetic mutation probability is decreased by Equation (15), which is a non-linear function. We can control the decreasing rate by the modification rate (
).
In this paper, the
is equal to 0.01 or 0.001. Therefore, in this paper, the 11th strategy (Exponential_4) is the exponential decreasing strategy with
, and the 12th strategy (Exponential_6) is the exponential decreasing strategy with
.
- (11)
Concave cosine strategy:
The genetic mutation probability is changed by Equation (16), which is a periodic function. The shape of this function is a concave, and we can control the cycle time of this function by the coefficient of cycle (cc).
In this paper, the
is equal to 1 or 3. Therefore, in this paper, the 13th strategy (Cosine_1) is the concave cosine strategy with
, and the 14th strategy (Cosine_3) is the concave cosine strategy with
.
- (12)
Convex cosine strategy:
The genetic mutation probability is changed by Equation (17), which is a periodic function. The shape of this function is a convex, and we can control the cycle time of this function by the coefficient of cycle (cc).
In this paper, the
is equal to 1 or 3. Therefore, in this paper, the 15th strategy (Cosine_2) is the convex cosine strategy with
, and the 16th strategy (Cosine_4) is the convex cosine strategy with
.
In general, the DANGHS algorithm works as follows:
Step 1. Initialization: the problem and algorithm parameters
The parameters are the harmony memory size (m), the current iteration k = 1, and the maximum number of iterations (NI).
Step 2. Initialization: the decision variable values and the harmony memory
The initial decision variable values is generated by Equation (1). The HM is as shown in Equation (2).
Step 3. Movement: generate the algorithm parameters
Generate the genetic mutation probability () in each iteration by dynamic adjustment strategies.
Step 4. Movement: improvise a new harmony
The DANGHS movement step (Pseudocode 4) is shown in Algorithm 4.
| Algorithm 4 The Movement Steps of DANGHS (Pseudocode 4) |
| 1: | For do |
| 2: | If then |
| 3: |
|
| 4: | If then |
| 5: | |
| 6: | Else if then |
| 7: | |
| 8: | End |
| 9: | % position updating |
| 10: | Else |
| 11: | % genetic mutation |
| 12: | End |
| 13: | End |
Here, and are the best harmony and the worst harmony in the HM, respectively. , and are uniformly generated random numbers in [0, 1]. determines whether DANGHS should carry out genetic mutation, is used for position updating, and is used for genetic mutation.
Step 5. Replacement: update harmony memory
DANGHS replaces the worst harmony in the HM by the new harmony , even if the new harmony is worse than the worst harmony.
Step 6. Iteration: check the stopping criterion
If the stopping criterion (maximum number of iterations NI) is satisfied, terminate the computation and return the best harmony vector in the HM; otherwise, the current iteration k = k + 1 and go back to step 3.
4. Experiments and Analysis
In order to verify the performance of the 16 dynamic adjustment strategies in the DANGHS algorithm, 14 well-known benchmark optimization problems [
24,
28,
31] are considered, as shown in
Table 1. This study used Python 3.6.2 (64-bit) as the complier to write the program for finding the solution. The solution-finding equipment was an Intel Core (TM) i7-4720HQ (2.6 GHz) CPU, 8G of memory, and Windows 10 home edition (64-bit) OS.
Problems 1–4, 10 and 11, which are Sphere function, Step function, Schwefel’s problem 2.22, Rotated hyper-ellipsoid function, Shifted Sphere function, and Shifted Rotated hyper-ellipsoid function, are unimodal problems. Problems 5–9 and 12–14, which are Griewank function, Ackley’s function, Rosenbrock function, Rastrigin function, Schwefel’s problem 2.26, Shifted Rotated Griewank function, Shifted Rosenbrock function, and Shifted Rastrigin function, are difficult multimodal problems; i.e., there are several local optima in these problems and the number of local optima increases with the problem dimension (D) [
24].
In order to verify the performance of the DANGHS algorithm, this paper compared the extensive experiment results of the DANGHS algorithm with other different HS algorithms. In the experiments, the parameters of the compared HS algorithms are shown in
Table 2 [
28].
In all HS algorithms, the harmony memory size (m) is 5. For each problem, two different dimension sizes (D) are tested, and they are equal to 30 and 100. Therefore, the iteration number are equal to 60,000 and 150,000, respectively. Thirty independent experiments (n) are carried out for each problem. The experimental results obtained using the 16 proposed adjustment strategies in the DANGHS algorithms and those obtained using different HS algorithms are shown in
Table 3 and
Table 4, respectively. In the two tables, SD represents the standard deviation.
In
Table 3, several experimental results are given. First of all, the best results given by the same strategy for different dimension sizes are obtained for problems 1, 3, 6, 9 and 13. Among these problems, the decreasing strategy can find the best objective function value for problems 1, 3, 6, and 9. According to the experimental results, the exponential decreasing strategy with mr = 0.001 (Exponential_6) can find the best objective function value for problems 1 (1.8344 × 10
−31; 1.2209 × 10
−14), 3 (1.9511 × 10
−18 7.9778 × 10
−9) and 6 (9.6308 × 10
−14; 9.3030 × 10
−9); the threshold linear prior decreasing strategy (Threshold_2) can find the best objective function value for problem 9 (3.8183 × 10
−4; 1.2728 × 10
−3). More specifically, the convex cosine strategy with k = 3 (Cosine_4), which is the periodic strategy, can find the best objective function value for problem 13 (3.9875 × 10
2; 5.3644 × 10
2).
On the other hand, the best results given by different strategies for different dimension sizes are obtained for problems 4, 5, 7, 8, 10, 11, 12, and 14. Among these problems, the increasing strategy can find the best objective function value for problem 7. According to the experimental results, the straight linear increasing strategy (Straight_1) can find the best objective function value for problem 7 with D = 30 (1.0089 × 101). However, the threshold linear posterior increasing strategy (Threshold_3) can find the best objective function value for problem 7 with D = 100 (6.1559 × 101). Besides, the decreasing strategy can find the best objective function value for problems 4, 5, 10, 11, 12, and 14. According to the experimental results, the threshold linear posterior decreasing strategy (Threshold_4) can find the best objective function value for problems 4 (6.0249 × 101), 5 (3.1209 × 10−2) and 11 (−3.7419 × 102) with D = 30. However, the natural exponential decreasing strategy (Exponential_2) can find the best objective function value for problems 4 (8.6301 × 103), 5 (6.4754 × 10−3), and 11 (1.1471 × 104) with D = 100. The natural exponential decreasing strategy (Exponential _2) can find the best objective function value for problem 10 with D = 30 (−4.5000 × 102). However, the threshold linear prior decreasing strategy (Threshold_2) can find the best objective function value for problem 10 with D = 100 (−4.5000 × 102). The straight linear decreasing strategy (Straight_2) can find the best objective function value for problem 12 with D = 30 (−1.7821 × 102). However, the exponential decreasing strategy with = 0.001 (Exponential_6) can find the best objective function value for problem 12 with D = 100 (−1.6037 × 102). The straight linear decreasing strategy (Straight_2) can find the best objective function value for problem 14 with D = 30 (−3.3000 × 102). However, the exponential decreasing strategy with = 0.01 (Exponential_4) can find the best objective function value for problem 14 with D = 100 (−3.2997 × 102).
Particularly, for problem 8, the decreasing strategy can find the best objective function value when D = 30, however the increasing strategy can find the best objective function value when D = 100. In other words, the threshold linear prior decreasing strategy (Threshold_2) can find the best objective function value for problem 8 with D = 30 (0.0000). However, the exponential increasing strategy with = 0.01 (Exponential_3) can find the best objective function value for problem 8 with D = 100 (2.7729 × 10−2).
In
Table 3, the best results are presented by the boldface type. For example, the Threshold_2 strategy had the best minimum objective function value for problems 1 with D = 30 (7.1381 × 10
−39). The Exponential_6 strategy had the best maximum objective function value (3.7601 × 10
−30) and had the minimum standard deviation value (7.0604 × 10
−31) for problems 1 with D = 30.
In
Table 4, among all problems for D = 30, the DANGHS algorithm can find the best objective function value for problems 1–3, 6–10, and 14. The SGHS algorithm can find the best objective function value for problems 2, 4, and 11. The NGHS algorithm can find the best objective function value for problems 2, 12, and 13. The IHS algorithm can find the best objective function value for problem 5. The best algorithms and the best results are presented by the boldface type in
Table 4.
On the other hand, among all problems for D = 100, the DANGHS algorithm can find the best objective function value for problems 1–14. The NGHS algorithm can find the best objective function value for problem 2.
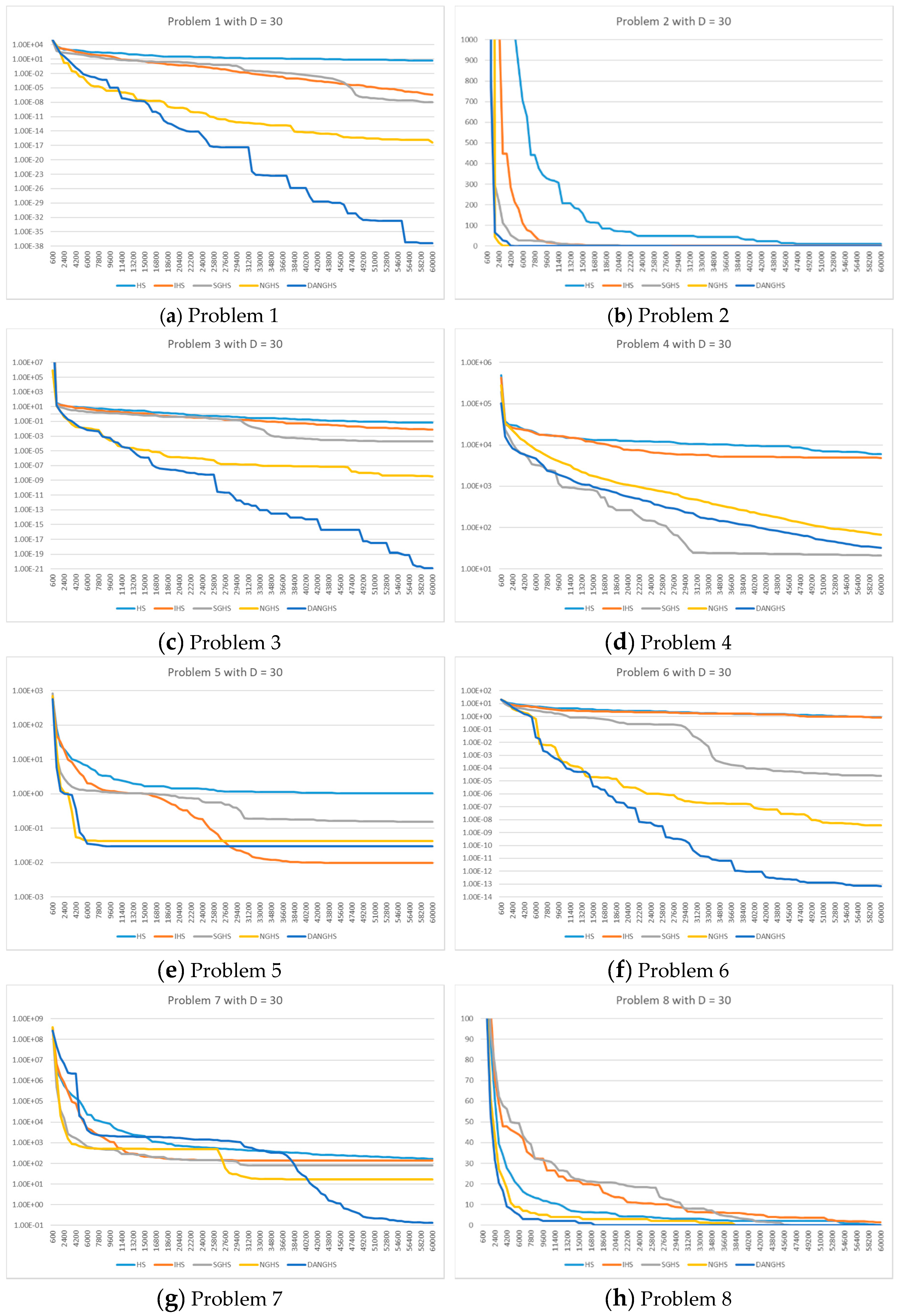
Figure 7 presents a typical solution history graph of five different algorithms along iterations for problems 1 to 8 with D = 30, and
Figure 8 presents a typical solution history graph of five different algorithms along iterations for problems 9 to 14 with D = 30.
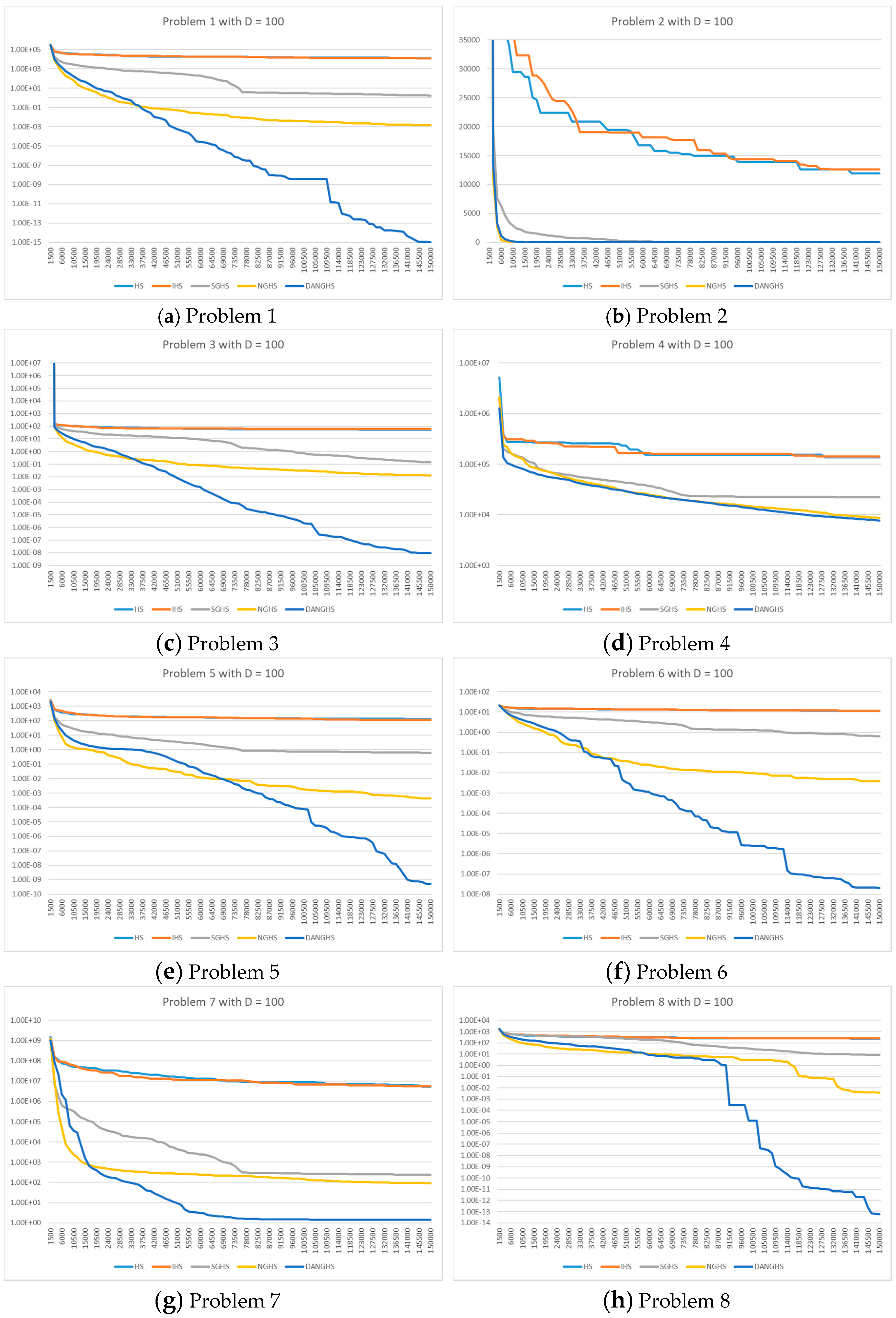
Figure 9 presents a typical solution history graph of five different algorithms along iterations for problems 1 to 8 with D = 100, and
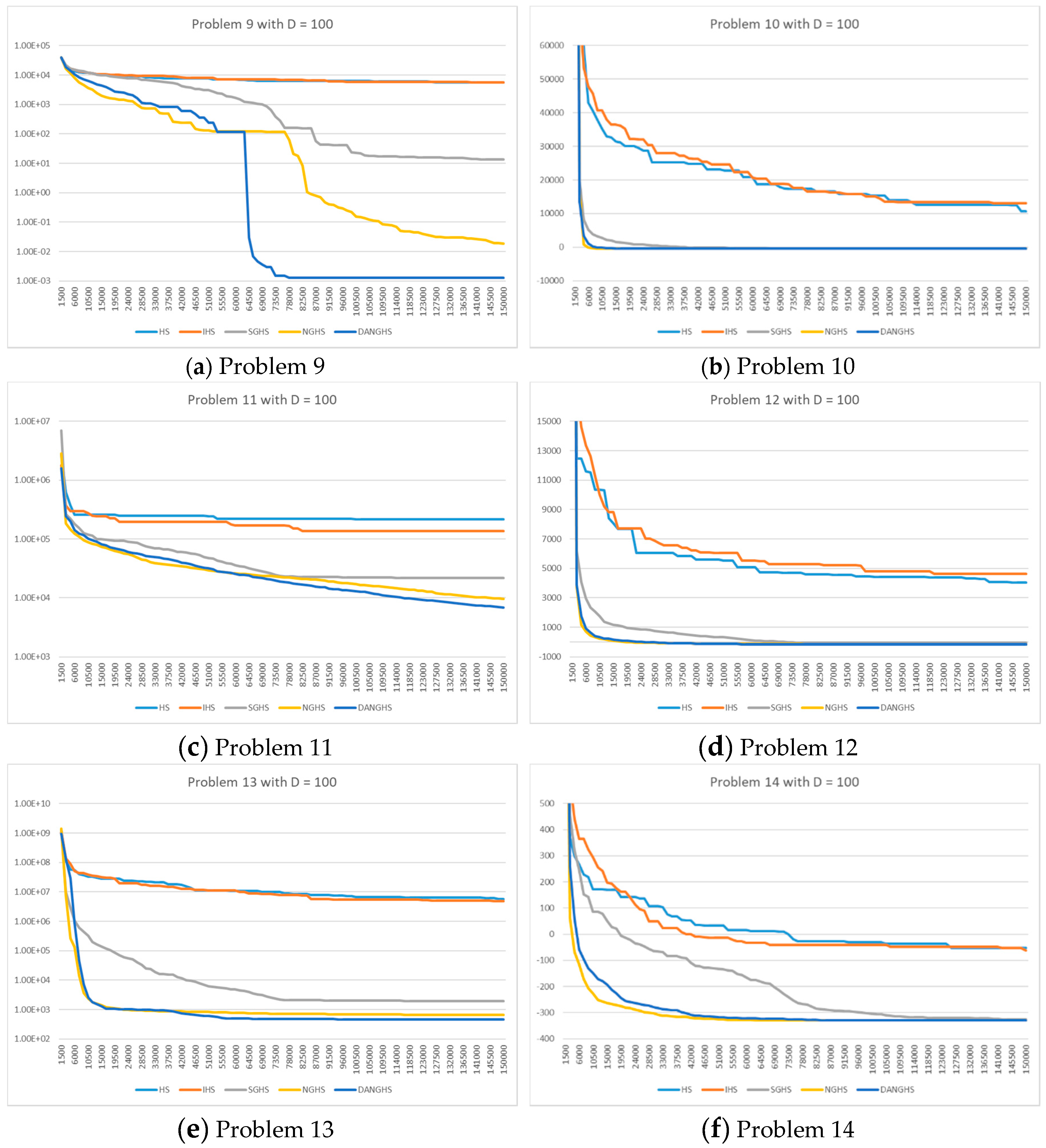
Figure 10 presents a typical solution history graph of five different algorithms along iterations for problems 9 to 14 with D = 100.
Finally, we will discuss and analyze the efficiency of the DANGHS algorithm. In
Figure 7,
Figure 8,
Figure 9 and
Figure 10, we can easily find out that the DANGHS algorithm obviously had the better searching performance and convergence ability than other algorithms in most low-dimensional problems and in all high-dimensional problems. In other words, the DANGHS algorithm can use the less iterations to solve the problem and is more efficient than other HS algorithms. Besides, according to the experimental results, the DANGHS with Pseudocode 3 spent 603.5025 seconds to run 30 experiments; while the DANGHS with Pseudocode 4 spent 532.7705 seconds only to run 30 experiments. The DANGHS algorithm with Pseudocode 4 reduces 11.72% of the running time, as compared with Pseudocode 3. Therefore, the DANGHS algorithm with the proposed Pseudocode 4 is more efficient than with Pseudocode 3.
5. Conclusions
We presented a DANGHS algorithm, which combines NGHS and the dynamic adjustment strategy for genetic mutation probability. Moreover, the extensive computational experiments and comparisons were carried out for 14 benchmark continuous optimization problems. According to the extensive computational results, there are several findings in this paper worth summarizing.
First, different strategies are suitable for different problems.
The decreasing dynamic adjustment strategies should be applied to some problems in which the DANGHS algorithm needs a larger, , in the early iterations, in order to have a larger probability of finding a better trial solution around the current one.
The increasing dynamic adjustment strategies should be applied to other problems. For these problems, if the current solution is trapped in a local optimum, the DANGHS algorithm requires a larger probability, , in later iterations in order to avoid the local optima.
The periodic dynamic adjustment strategy can find the best objective function value for problem 13. These particular results show that there are not only two kinds of adjustment strategies, decreasing and increasing strategies, which are suitable for all problems. This viewpoint is different from the common views: the adjustment strategy is as small as possible or as large as possible with a generation number. For a specific problem, the periodic dynamic adjustment strategy could have better performance in comparison with other decreasing or increasing strategies. Therefore, these results inspire us to further investigate this kind of periodic dynamic adjustment strategy in future experiments.
Second, the extensive experimental results showed that the DANGHS algorithm had better searching performance in comparison with other HS algorithms for D = 30 and 100 in most problems. Particularly for D = 100, the DANGHS algorithm could search the best objective function value in all 14 problems. In other words, the DANGHS had superior searching performance in high-dimensional problems. According to the numerical results, we proofed that algorithms with dynamic parameters, such as the DANGHS algorithm and the IHS algorithm, could have better searching performance than algorithms without dynamic parameters, such as the NGHS algorithm and the HS algorithm. Moreover, according to these results, we proofed that the viewpoint presented in previous studies is suitable for the NGHS algorithm. This viewpoint states that appropriate parameters can enhance the searching ability of a metaheuristic algorithm.
Finally, the DANGHS algorithm using Pseudocode 4 was more efficient than that using Pseudocode 3. In Pseudocode 3, the algorithm generates a new harmony, and then with probability, the algorithm abandoned it to generate a mutated harmony. Obviously, it was redundant and inefficient. Therefore, we modified the procedure in Pseudocode 3 and presented a more efficient Pseudocode 4 in this paper. In conclusion, the DANGHS algorithm is a more efficient and effective algorithm.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}