Abstract
We investigate the model of gene expression in the form of Iterated Function System (IFS), where the probability of choice of any iterated map depends on the state of the phase space. Random jump times of the process mark activation periods of the gene when pre-mRNA molecules are produced before mRNA and protein processing phases occur. The main idea is inspired by the continuous-time piecewise deterministic Markov process describing stochastic gene expression. We show that for our system there exists a unique invariant limit measure. We provide full probabilistic description of the process with a comparison of our results to those obtained for the model with continuous time.
Keywords:
stochastic gene expression; pre-mRNA; iterated function system; limit measure; gene expression process simulation MSC:
47D06
1. Introduction
An interesting problem in the field of modeling of biological processes [1] has been to understand the interactions in gene regulatory networks. Information on various approaches to describe relations between genes can be found in the paper [2]. Numerous methods based on chemical networks [3], logical networks [4] or dynamical systems [5] are used. As [6] suggests, piecewise deterministic stochastic processes can be used to may model genetic patterns. Our paper belongs to this methodology, but it investigates a discrete-time analogue of the ordinary differential equation case. A more common approach would be to use Markov jump processes, which lead to chemical master equations (CME) considered in discrete state spaces [7]. There are several methods to solve CME’s, including finding exact solution (i.e., by means of Poisson representation) or approximation methods. Unfortunately, all these methods can only approximate the solution of the CME or they can be applied in particular cases. Moreover, most of related studies generally focus on the translation phase, without putting any importance to the transcription phase or the intermediate mRNA processing. The main advantage of the analysis derived from piecewise deterministic stochastic processes is the potential to extend a model simply by adding new types of particles to the stochastic reaction network. Our approach, dependent on piecewise deterministic stochastic process combines deterministic approach represented by dynamical systems with stochastic effects represented by Markov processes. In many cases, discrete time or continuous-time dynamical systems became two alternative ways to describe the dynamics of a network. The formalism of discrete-time systems does not concentrate on instantaneous changes in the level of gene expression but rather on the overall change in a given time interval. This may be the right approach to model processes where some reactions must be integrated over a short timeline for the purpose of revealing more important interactions affecting expression levels with respect to a larger time perspective. Another aspect is that the experimental data obtained from living cells are undoubtedly discrete in time and because of the costs we are limited only to relatively small sets of samples [8]. In recent years, difference equation models appeared (see [9,10,11]). In this work we concentrate on the gene expression process with four stages: activation of the gene, being followed then by pre-mRNA and mRNA and protein processing [12].
Basically, after a gene is activated at a random time moment, mature mRNA is produced in the nucleus, then it is transported to the cytoplasm, where the protein translation follows. However, it is known that translated mRNA molecules must get through further processing first, before a new protein particle is formed. Besides that, many sources [13] claim that at least one additional phase, primary transcript (pre-mRNA) processing also takes place. Actually, in the world of eukaryotic genes, after activation at a random time point, the DNA is transformed into some certain pre-mRNA form of transcript. Then, the non-coding sequences (introns) of transcript are removed and the coding (exons) regions are combined. This process is called mRNA splicing. In addition to the splicing step, pre-mRNA processing also includes at least three other processes: addition of the m7G cap at the end to increase the stability, polyadenylation at the -UTR which affects the miRNA regulation and RNA degradation, and post-transcriptional modifications (methylation). In some genes, there is an extra step of RNA editing. Multiple other genetic modifications take place under the general term called RNA processing. In such a situation we finally get a functional form of mRNA, which is transferred into the cytoplasm, where in the translation phase, mRNA is decoded into a protein. Of course, both mRNA and protein undergo biological degradation. The presence of a random component in our model, responsible for switching between active and inactive states of the gene in the random time moments has been identified in the continuous case as a piecewise deterministic Markov process (PDMP) [14]. This class of stochastic processes can be considered to be randomly switching dynamical systems with the intensities of the consecutive jumps dependent on the current state of the phase. However, if we consider discrete-time scale, then we must investigate iterated function systems (IFS’s) with place-dependent probabilities, see [15] or [16]. We are going to unify a common approach for both time continuous and time discrete dynamical systems with random jumps. We will investigate the existence of stationary distributions for time discrete dynamical systems with random jumps and compare its form with the continuous-time case. Here we introduce jump intensity functions, which play crucial role in the distribution of waiting time for the jump [17] and for this purpose we provide an appropriate cumulative distribution function. Specifically, instead of in the continuous case (see [17]), we justify the formula for the life-span function in the discrete case. In this way we obtain certain IFS corresponding to a discrete-time Markov process with jumps characterized by jump intensity functions.
A consequence of the stochastic expression is the diversity of the population in terms of the composition of individual proteins and gene expression profiles [13]. Stochastic gene expression causes expression variability within the same organism or tissue, which has effect on biological function.
This work is organized as follows. In Section 3 we present the model, and we give the definition of our process. In Section 4 and Section 5 we investigate its properties and we describe it as an IFS with place-dependent probabilities. In Section 6, we use the classical result of Barnsley [18], to show that our process converges in distribution to a unique invariant measure when the number of iterations converges to infinity and we describe the properties of this measure in Section 7. A complete step-by-step description of the whole process, summing up all the information from the earlier sections, is provided in Section 8. A computer simulation of trajectories of the process, is the content of Section 9, with the source code available in GitHub [19]. In Section 10 presents the derivation of formulas for the support of the invariant measure. Summary is the last section of this paper.
2. Methods
In this paper, we investigate a model which is based on IFS with place-dependent probabilities. Compared to the model presented in [17], we replace ordinary differential equations (ODEs) by the system of difference equations, which leads to the investigation of discrete-time model, but can be generalized into continuous case. The question therefore arises how we justify the usage of difference equations in our model. Our justification is that our results remain consistent with the work from [17] which can be considered as an alternative way of description of such systems. Discrete approach is an attempt to mathematical formulation of the problem using different tools. This paper provides discussion between different approaches (sometimes different than standard accepted principles).
3. Stochastic Gene Expression—Discrete Case
Gene expression is a very complex biological process including multiple essential subprocesses. In the continuous case, Lipniacki et al. [6] introduced a model based mathematically on piecewise deterministic Markov process which includes three crucial phases: gene activation, mRNA and protein processing.
Let denote the number of pre-mRNA molecules at time , denote the number of mRNA molecules at time , denote the number of protein molecules at time , where in general . Analogically to the solution of continuous model, we can introduce the symbol , where . A discrete-time model would evaluate after starting from .
The difference equation then could be given by equation of the following kind:
Thus, our approach is based on particular translation . In the paper we fix the value of . For the sake of simplicity, we denote . Let , typically in the theory of linear difference equations, we define . In our model, we take , hence is a time step, instead of unity. Please note that one could use the basic techniques of scaling variables to get unity, instead of . We consider the following model being represented by the system of difference equations in the form.
where ; is the speed of synthesis of pre-mRNA molecules if the gene is active; is the rate of converting pre-mRNA into active mRNA molecules; is the pre-mRNA degradation rate; is the mRNA degradation rate; is the rate of converting mRNA into protein molecules and is the protein degradation rate (see Figure 1). Provided the time step is small enough, , , , R, C, and P will be independent of , see [10]. Here such that
where denotes the moment of first jump of this process, where the distribution of is described by life-span function in Section 3.1.
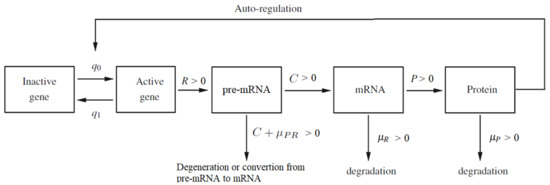
Figure 1.
The diagram of auto-regulated gene expression with pre-mRNA, mRNA and protein contribution. Description of the parameters: and are switching intensity functions; R is the speed of synthesis of pre-mRNA molecules if the gene is active; C is the rate of converting pre-mRNA into active mRNA molecules; P is the rate of converting mRNA into protein molecules; is the pre-mRNA degradation rate; is the mRNA degradation rate; is the protein degradation rate. The sum should be treated as a total degradation rate of the pre-mRNA particles.
The values of the coefficients are scaled simultaneously to the interval so that their relative importance in the model can be more easily seen. Basically, there is no biological reason behind imposing any restrictions on the values of the parameters. However, we need this step to perform mathematical analysis of the asymptotic behavior of this system. We can transform almost any system in such way. An exception is the case when the system (1) reduces to less than three equations. It can happen, when some coefficients are equal to zero or they are equal one to another. We do not analyze such cases here. An open question then remains, what happens, for example, when or and other similar situations, described below. To avoid degenerate cases, we will assume in the model (1) that:
since the number of degraded molecules cannot exceed the current number of corresponding molecules.
If we assume that we obtain the following system of linear difference equations:
with initial condition where .
Please note that .
Example 1.
Let us consider the system (4) with the values of parameters , In this case, the solutions of (4) are:
Please note that this formula is valid for any hence we could also extend the solutions (5) to the continuous-time case.
In the Figure 2, we show these trajectories for (left panel) and (right panel).
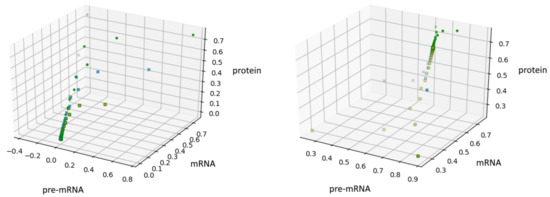
Figure 2.
A solution of Equation (4) for with on the left and on the right.
If we assume that is constant, then the system (1) takes the form (4) which can be rewritten in the following form:
with the initial condition
Remark 1.
We assumed that i is constant, but important is to explain the way our process behaves after the next switch.
For the purpose of calculation of we need to use the value of not in consistency with the formula (1).
If (3) hold and , then the solutions of the system (4) are:
We can extend this formula from to , since the formula (7) is valid not only for but also for .
Using the formula (7) we denote by
the solutions of the system (6), where we assume that Also note that:
where . One can rewrite (9) in the following form:
see also [17]. For the rest of the paper we assume and (to avoid “degenerative” cases).
After substituting where and in the system (6) and taking:
we obtain equivalent system of difference equations:
with initial condition . We will return to system (12) in Section 4 and Section 10.
3.1. Life-Span Function
Let f be a function defined on the set of non-negative integers with values in . We define . Analogically to description from [20] we investigate the following system of equations:
Let and be a time when the process changes its state th time, , . Let be a discrete trajectory of the process from time to . Let be a solution of the Equation (13) with the initial condition . Now we define as the intensity function with parameter x which means that after small fixed natural time our process changes its state with probability . Let B be a Borel subset of and
For any the distribution function of the difference is given by , where is a survival function, i.e., the probability of duration between consecutive changes of states by the process.
Please note that . If , then is a probability that the process will change its state for the first time after time . Then we have
Hence, by taking we obtain the following formulas:
Therefore,
assuming lies in the sufficiently small neighborhood of zero, since . Similar formula has been derived in the continuous case (see 1.7 [20]), but in the Formula (17) we use sum instead of integral operator. Above considerations are justified by using the following definition.
Definition 1.
We define life-span function by the following formula:
where is a bounded switching intensity function and t is a non-negative integer number. In our case, if we can take
Hence, instead of in the continuous case (the formula used in the paper [17]), we justify the formula for the life-span function in the discrete case.
3.2. Piecewise Deterministic Markov Process
In this subsection we introduce basic characteristics of the Markov process represented by the system (4) that will be needed for further considerations. Here, we assume that . Let and be positive and continuous functions on the set . Let . Using our Definition 1 of the life-span function, we can define the distribution function of the difference , namely
where as before, is a time when the process changes its state th time. Please note that .
The explicit expressions for the solutions of the system (4) were found in (7). Hence,
for the arbitrary choice of . It is known [20] that such description gives us piecewise deterministic Markov process
on the state space with two switching intensity functions , and the transition measure given by Dirac Delta Function concentrated at the point . Please note that by the definition of the system (1), the set is invariant with respect to the process , i.e., if
then
for all .
The technical proof of this fact, which is based on the usage of formulas (7), is omitted. In the fourth chapter, we introduce Iterated Function Systems to investigate the existence of invariant measure and its support.
4. Iterated Function System
For we define the mappings given by the formulas
We can reformulate then the system (12) in the form
where .
The family is an iterated function system if for every the mapping is a contraction on the complete Euclidean metric space .
We can see that
Hence the mapping is a contraction with the constant equal to .
Definition 2.
Let be an iterated function system. We define the operator on the set by the formula .
The transformation introduced above corresponds to the function (30) in the model from [17]. We will describe an invariant compact set K such that .
Remark 2.
In the paper [21] it was shown that for the metric space an iterated function system has a unique non-empty compact fixed set K such that One way of generating such set K is to start with a compact set (which can contain a single point, called a seed) and iterate the mapping using the formula . This iteration converges to the attractor , i.e., the distance between K and converges to 0 in the Hausdorff metric, see [21].
Another way to generate some fractal objects was presented by Barnsley in [22]. The set of such points is called an IFS-attractor. In our case, an example of the attractor is shown in Figure 3, see also Section 10. The source code has been added to GitHub [19].
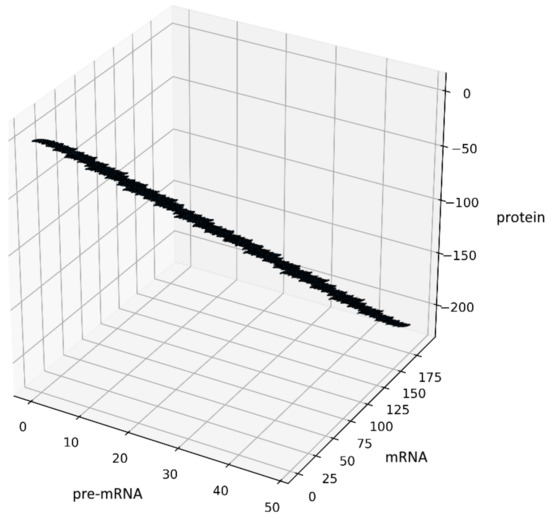
Figure 3.
Figure presents the results obtained for the system (12) with , , the initial conditions and constant probabilities after 100,000 iterations.
5. Iterated Function Systems with Place-Dependent Probabilities
In this section, similarly to the paper [23], we provide a description of IFS generated by the family of mappings with being a probability of a choice of a mapping . We assume that . Let be two Borel measurable non-singular functions, while let be two non-negative Borel measurable functions such that .
If and is a Borel subset, then the transition probability from x to B is defined by
where is the indicator function of the set B. We can define the mapping
where T is a Markov operator on space of the bounded Borel measurable real-valued functions (which forms the Banach space with the supremum norm). Then . Let be the space of finite signed Borel measures on . By we denote the set of all probability measures from .
We define the operator by the formula
showing how a probability distribution on X of the process is transformed in one step. Here, the operators are classical Frobenius–Perron operators for the transformation , respectively (see [20], Section 2.1.5). Let be the set of bounded real-valued continuous functions on . A Borel invariant probability measure (i.e., ) is called attractive iff for all and for all we have . In other words, that means converges to in distribution. For the rest of the section, we will use the theory of Markov processes (see p. 369 in [18]) to describe this IFS. Let be the Markov process with initial distribution equal to and transition probability from point x to Borel subset . If is a Dirac measure concentrated at , then we denote the process . A transition probability P provides the following interpretation. We have . If has a distribution , then is the distribution of which means that . It is known that
where f is a bounded Borel measurable real-valued function.
Hence, . In the next section we investigate long-term behavior of the process .
6. Convergence of the System to Invariant Measure
In this section we assume that . In classical work [18], Barnsley considered a discrete-time Markov process on a locally compact metric space X obtained by a family of randomly iterating Lipschitz maps . For any i the probability of choosing map at each step is given by . Assume that:
- Sets of finite diameter in X have compact closure.
- For any i the mappings are average-contractive, i.e., uniformly in x and y, (for details see paper [18]).
- For every i the mappings are Hölder continuous.
Under these assumptions, the Markov process converges in distribution to a unique invariant measure. In our regime, we can formulate a weaker version of the theorem above (see also [18], p. 372).
Theorem 1.
Let be a Markov process on the space . We assume that the initial distribution of this process is given by and its transition probability is given by (26). Let the probability of choosing contractive map at each step be Hölder continuous function and moreover
Then the Markov process converges in distribution to a unique invariant measure when .
To illustrate this theorem, we will investigate transition probability in the case of the stochastic process , see (22). We assume that the state space of our process is . For we define the jump transformation by the formula .
Each jump transformation , defined on the state space is non-singular with respect to the product measure of the Lebesgue measure on and the counting measure on the set . We define the positive and continuous jump intensity rate functions by the formulas and on . Here, is the jump intensity rate from the state i to the state , where see Figure 1. Let . The following equation holds:
Please note that .
Let be two Borel measurable non-singular functions. If and is a Borel subset, then the transition probability is defined by:
Please note that .
Assume now that the initial distribution of the process is given by and its transition probability is given by (30). The process is both Markov and IFS such that the probability of random choice of one of two functions depends on the space part of a state. By Theorem 1 the Markov process converges in distribution to a unique invariant measure when .
7. Properties of an Invariant Measure
In this section we assume that (for the sake of simplicity, we assume here that ). By Theorem 1, we know that the process converges in distribution to a unique invariant measure. A classical result of Hutchinson [21] states that there exists a unique non-empty compact set K such that .
Theorem 2.
Consider the stochastic process such that with and transition probability given by (30). Then
where d is the Euclidean distance in .
Proof.
For any set we denote and for . Consider . From the Theorem 3.1 (Ch. 3, p. viii) of [21] it follows then converges to K in the Hausdorff metric uniformly when . Using our notion, converges to 0 uniformly when . Please note that is a trajectory of our process which depends on the probabilities , see (30). Hence, we get , since the choice of was arbitrary.□
Moreover, if , then . Hence, K is an invariant set for this process.
8. Jump Distribution
Remark 3.
Let . With an analogy to the description of PDMP in the book [14], we will define the function as a cumulative distribution function of the first jump of the process which starts at at some point . Let and we define then the process on the random interval as follows:
After time the process starts again, but with new initial condition equal to .
This process evolves with respect to the points obtained by the solution (12) with given value of i until time of the next jump . Then, this step repeats infinitely many times. Please note that
Hence, for all , because is a bounded function.
Also, for all , because is positive function.
Hence, . Analogically, for all , where . All these considerations are true with the probability being equal to .
Let . Next, by (20) we get for all . Please note that independently from the values of , where . Hence, .
Therefore, . We also get that
where . Please note that is the expected value of the number of jumps of our process up to the time .
Now we will gather all the facts about the process considered in this paper.
Definition of the process
- 1.
- Denote the state space .
- 2.
- According to the reaction scheme Figure 1, the reactions which occur in our process are as follows:Outcome (A)Outcome (B)Outcome (A) and (B)where is the concentration level of all the substances at time t.Consider the simplified version of this system (12) with being two Borel measurable non-singular functions defined by (23).
- 3.
- Let be two non-negative Borel measurable functions such that
- 4.
- In addition, let and and be two non-negative functions defined on .
- 5.
- From now, by we denote the solutions of the system (12), i.e.,Despite the fact that we consider discrete-time Markov process, we can assume that (see comment above Equation (8)). We consider two cases, where or which corresponds to the functions and respectively.
- 6.
- Let be a Markov process on the space with initial distribution of the process given by and its transition probability is given by (30).
- 7.
- Here, .
- 8.
- is both Markov process and IFS such that the probability of random choice of one of two functions depends on the space part of a state.
- 9.
- With an analogy to the description in the book [14], we define the function as a cumulative distribution function of the first jump of our process which starts at at some point .
- 10.
- We say that and we define then the process on the random interval as follows:
- 11.
- After time we start the process X again, but with new initial conditions being equal to . This process evolves with respect to the points obtained by the solution (12) with given value of i till time of the next jump . Then, we repeat this step infinitely many times. Since .
- 12.
- From the definition of the process both of the intensity functions and depend on two non-negative Borel measurable functions .
Summary of the properties of the process is both Markov process and IFS such that the probability of random choice of one of two functions depends on the space part of a state. By Theorem 1 the Markov process converges in distribution to a unique invariant measure when . This theorem means that the trajectories of this process after sufficiently long time are arbitrarily close to K independent from the probability distribution. In addition, if , then . Hence, K is invariant. It is worth noting that the life-span function of the process is equal to unlike the continuous case studied in [17].
9. Stochastic Simulations
To visualize the behavior of the stochastic process (4), we performed stochastic simulation of the process (Figure 4). The code was developed in Python (3.7.4). The parameter values are with Borel measurable probability functions and and initial conditions .
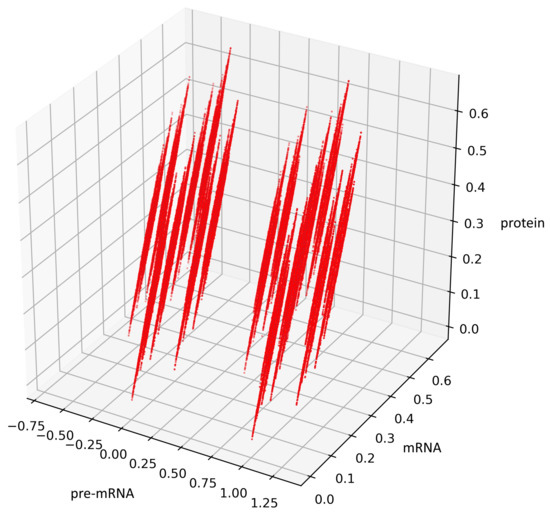
Figure 4.
Visualization of the stochastic process (4), depending on two non-negative Borel measurable functions and .
10. The Derivation of the Formula for the Attractor
We consider the system which simplifies both systems (1) and (6), namely (12):
with the initial condition . We also assume that the values of the parameters are pairwise distinct.
In the case of , we will find a set for the process described by the system (36), i.e., the smallest invariant set for the process, for which almost all trajectories of the process enter in a finite time.
Remark 4.
Let us observe that if we consider only integer values of t then the attractor generated by the composition of the systems (36) is a discrete set (see Figure 3 for , ) and it is contained inside the attractor obtained for real values . Hence, now we only proceed with real values of .
Let . Let denote the solutions of (36) at time t with the initial condition . Namely
where by we denote the vector
We obtain
This gives us the following formulas:
for all times . Hence
Using the formulas (38) we get
If , we can assume . Hence,
where . These equations are similar to the ones obtained in the continuous case [17], therefore the attractor will adopt analogous form as in that case.
Taking as the initial points in the Formula (41) and in the Formula (42), we get a parametric equations for the surfaces and which we will found out as the boundaries of attractor :
Please note that both sets are symmetric to each other with respect to the point , since . This means that the boundary of (and so is the attractor ) is symmetric to itself with respect to the point . Moreover, it can be shown that
Now we are going to describe the attractor . It appears that two changes of i are sufficient to get to any arbitrary point in . The composition of three flows and is given by the following formulas:
Figure 5 presents trajectories of the processes (44) and (45), where are drawn from uniform distribution on the interval . Both show the contour of the attractor . For parameters chosen to create Figure 5, the density of colors intensity (i.e., red intensity, blue intensity) and Equations (39) and (40) may suggest bistability (in the sense of bimodality of the stationary distribution, see [17]). We are convinced that there is a need for further research about bistability in a discrete case. Please note that for deterministic linear systems, bistability cannot hold, hence such phenomenon in a stochastic linear system would be interesting.
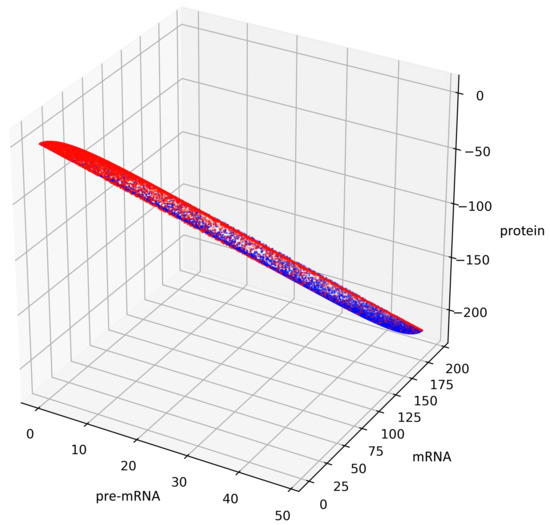
Figure 5.
This figure presents all states of the stochastic process (36) with after two switches. The red color represents the states given by the Formula (45) representing trajectories of the process starting with while the blue color represents the states given by the Formula (44) representing trajectories of the process starting with .
We will start with description of the set, which we can reach in two changes of . In analogy to the above, in the case of double superposition, we define in a new way. If , we can assume and hence we get equations:
where and
We can assume that because if in Equations (46) and (47) then we get:
(the values of above states can be also obtained taking and after appropriate substitution to ). Please note that these states belong correspondingly to the boundaries and . Hence is a case when the trajectory is on the boundary of the attractor .
Let
where
The set consist of all points from (47), where we take .
Equivalently using the Equation (46) we get an alternative formula for the set .
where
In the light of Equation (43), descriptions (48) and (51) are equivalent. Analogically to the description of (48), we provide a plot of an attractor in the case of description (50).
For the geometric reasons two Formulas (48) and (50) describe the same set , see Figure 6 and Figure 7, compare also with Figure 5.
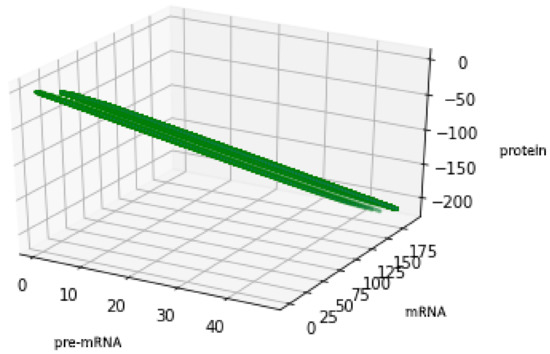
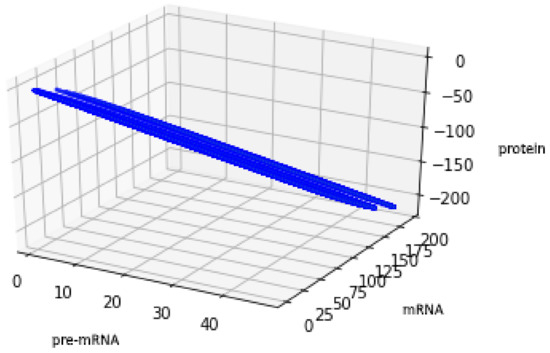
Figure 7.
Figure presents the set described by Formula (50) with the values of parameters: , , .
Now, let and be given as follows:
where we use the notion taken from (49). As with the considerations in Appendix A in the paper [17] we prove that the function f is a local diffeomorphism. Hence (see Equations (46) and (47)) is an open set. Moreover, is the interior of . Please note that
Hence set is bounded by the surfaces , which are built from the trajectories of the system (36), where i was switched only once. The set is indeed the support of stationary distribution when time goes to infinity. For this purpose, it is sufficient to show that:
- (1)
- after more than two switches the trajectories of the process do not leave ,
- (2)
- we cannot find any invariant subset of not equal to . To satisfy the second condition it is sufficient to show that all the states in communicate with each other, i.e., we can join any two arbitrary states by some trajectory of the process. The proof follows the same lines as in [17], (pp. 31–33).
11. Conclusions
We developed a model of gene expression using IFS with place-dependent probabilities. As a novelty, in this paper, we introduced new formulas for life-span functions, suitable for discrete case. Moreover, we have shown that asymptotic behavior of the model is in line with the results presented in the paper [17]. We have been able to perform extensive numerical simulations and describe a support of the invariant measure of this process. Both continuous-time and discrete-time system are asymptotically stable. We believe further research could find a relationship between supports of respective invariant measures. Fitting suitable values of parameters can allow use of this model along with experimental data obtained in the laboratory conditions, realistically for selected values in some time interval.
Author Contributions
Conceptualization, M.Z. and A.T; methodology, M.Z. and A.T.; software, A.T.; validation, M.Z. and A.T.; formal analysis, M.Z. and A.T.; investigation, M.Z. and A.T.; writing—original draft preparation M.Z. and A.T.; writing—review and editing, M.Z. and A.T.; visualization, M.Z. and A.T.; supervision, M.Z. and A.T. All authors have read and agreed to the published version of the manuscript.
Funding
This paper was partially supported by the National Science Centre (Poland) Grant No. 2017/27/B/ST1/00100.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors are grateful to Ryszard Rudnicki (IMPAN Katowice, Poland) for his comments.
Conflicts of Interest
The authors declare no conflict of interest.
References
- DiStefano, J., III. Dynamic Systems Biology Modeling and Simulation, 1st ed.; Academic Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Smolen, P.; Baxter, D.A.; Byrne, J.H. Mathematical modeling of gene networks. Neuron 2000, 26, 567–580. [Google Scholar] [CrossRef]
- Schnoerr, D.; Sanguinetti, G.; Grima, R. Approximation and inference methods for stochastic biochemical kinetics—A tutorial review. J. Phys. A Math. Theor. 2017, 50, 93–101. [Google Scholar] [CrossRef]
- Somogyi, R.; Sniegoski, C. Modeling the complexity of genetic networks. Understanding multigenic and pleiotropic regulation. Complexity 1996, 1, 46–53. [Google Scholar] [CrossRef]
- May, R.M. Biological Populations Obeying Difference equations: Stable Points, stable cycles, and chaos. J. Theor. Biol. 1975, 51, 511–524. [Google Scholar] [CrossRef]
- Lipniacki, T.; Paszek, P.; Marciniak-Czochra, A.; Brasier, A.R.; Kimmel, M. Transcriptional stochasticity in gene expression. J. Theor. Biol. 2006, 238, 348–367. [Google Scholar] [CrossRef] [PubMed]
- Grima, R.; Schmidt, T.; Newman, T. Steady-state fluctuations of a genetic feedback loop: An exact solution. J. Chem. Phys. 2012, 137, 35–104. [Google Scholar] [CrossRef] [PubMed]
- Cacace, F.; Farina, L.; Germani, A.; Palumbo, P. Discrete-time models for gene transcriptional regulation networks. In Proceedings of the 49th IEEE Conference on Decision and Control, CDC, Atlanta, GA, USA, 15–17 December 2010. [Google Scholar]
- Levine, H.A.; Yeon-Jung, S.; Nilsen-Hamilton, M. A discrete dynamical system arising in molecular biology. Discret. Contin. Dyn. Syst. B 2012, 17, 2091–2151. [Google Scholar] [CrossRef]
- D’Haeseleer, P.; Wen, X.; Fuhrman, S.; Somogyi, R. Linear modeling of mRNA expression levels during CNS development and injury. In Proceedings of the Pacific Symposium on Biocomputing 1999, Mauna Lani, HI, USA, 4–9 January 1999; pp. 41–52. [Google Scholar]
- Song, M.J.; Ouyang, Z.; Liu, Z.L. Discrete Dynamical System Modeling for Gene Regulatory Networks of HMF Tolerance for Ethanologenic Yeast. IET Syst. Biol. 2009, 3, 203–218. [Google Scholar] [CrossRef] [PubMed]
- Cobb, M. 60 years ago, Francis Crick changed the logic of biology. PLoS Biol. 2017, 15, e2003243. [Google Scholar] [CrossRef] [PubMed]
- Lodish, H.; Berk, A.; Kaiser, C.; Krieger, M.; Bretscher, A.; Ploegh, A.; Amon, A.; Martin, K. Molecular Cell Biology, 8th ed.; W.H. Freeman: New York, NY, USA, 2016. [Google Scholar]
- Davis, M.H.A. Piecewise-deterministic Markov processes: A general class of nondiffusion stochastic models. J. R. Stat. Soc. Ser. B 1984, 46, 353–388. [Google Scholar] [CrossRef]
- Barany, B. On Iterated Function Systems with place-dependent probabilities. Proc. Am. Math. Soc. 1993, 143, 419–432. [Google Scholar] [CrossRef]
- Ladjimi, F.; Peigné, M. Iterated function systems with place dependent probabilities and application to the Diaconis-Friedman’s chain on [0,1]. arXiv 2017, arXiv:1707.07237. [Google Scholar]
- Rudnicki, R.; Tomski, A. On a stochastic gene expression with pre-mRNA, mRNA and protein contribution. J. Theor. Biol. 2015, 387, 54–67. [Google Scholar] [CrossRef] [PubMed]
- Barnsley, M.F.; Demko, S.G.; Elton, J.H.; Geronimo, J.S. Invariant measures for Markov processes arising from iterated function systems with place-dependent probabilities. Ann. l’Inst. Henri Poincare Probab. Stat. 1988, 24, 367–394. [Google Scholar]
- Tomski, A. Stochastic Gene Expression Revisited simulations. Available online: https://github.com/AndrzejTomski/Stochastic_Gene_Expression_Revisited (accessed on 18 April 2021).
- Rudnicki, R.; Tyran-Kamińska, M. Piecewise Deterministic Processes in Biological Models, 1st ed.; Springer International Publishing: Cham, Switzerland, 2017. [Google Scholar]
- Hutchinson, J.; John, E. Fractals and self similarity. Indiana Univ. Math. J. 1981, 30, 713–747. [Google Scholar] [CrossRef]
- Barnsley, M.F.; Rising, H. Fractals Everywhere; Academic Press Professional: Boston, MA, USA, 1993. [Google Scholar]
- Kwiecińska, A.; Słomczyński, W. Random dynamical systems arising from iterated function systems with place-dependent probabilities. Stat. Probab. Lett. 2000, 50, 401–407. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).