
Machine Learning Approach to Predict Physical Properties of Polypropylene Composites: Application of MLR, DNN, and Random Forest to Industrial Data

 ,
,
Abstract
:1. Introduction
- This study proposed and compared prediction models by training recipe-based data from a real PP composites plant.
- Categorization is applied as data preprocessing to overcome the overfitting issue.
- This is the first study to propose a suitable model according to physical properties.
2. Related Work
3. Materials and Methods
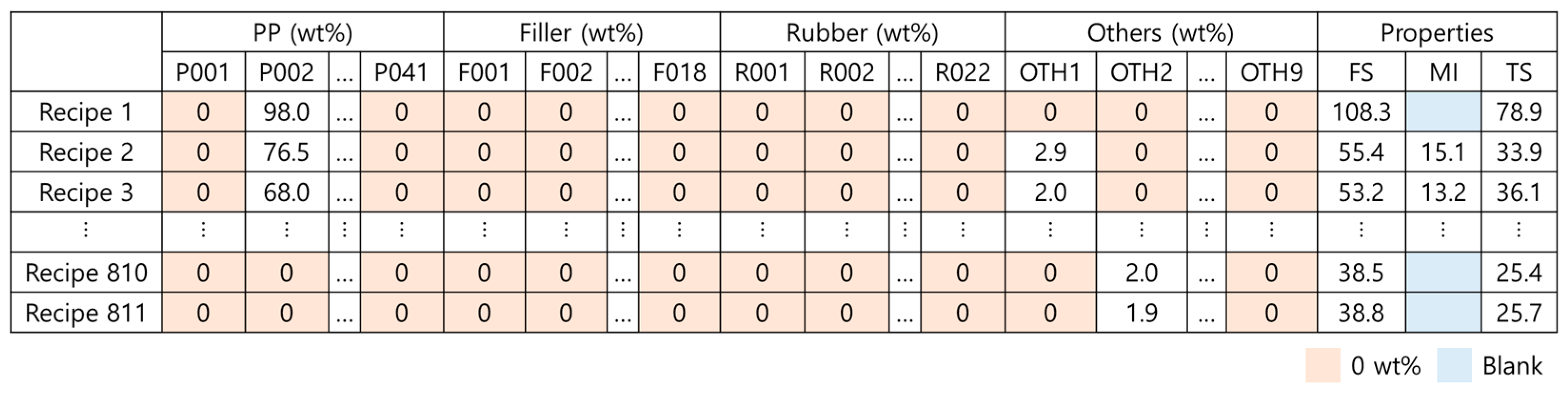
3.1. Dataset
3.2. Multiple Linear Regression
3.3. Deep Neural Network
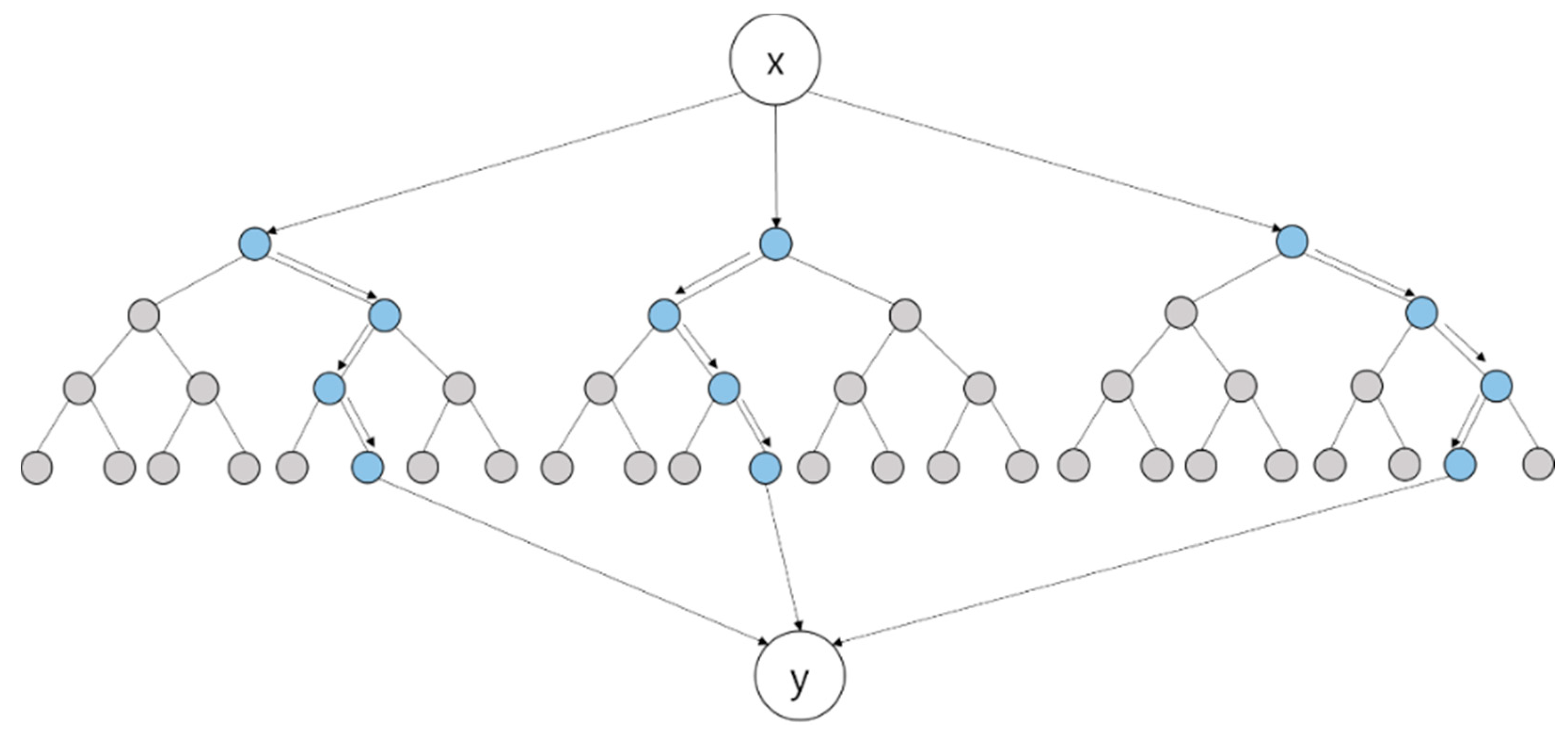
3.4. Random Forest
4. Machine Learning Model Development
4.1. Overview of Model Development
4.2. Data Categorization
4.3. Preprocessing
4.4. Modeling
5. Results and Discussion
5.1. Validation of Categorization
5.2. Comparison of Prediction Model Performance
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Du, Y.; Li, D.; Liu, L.; Gai, G. Recent achievements of self-healing graphene/polymer composites. Polymers 2018, 10, 114. [Google Scholar] [CrossRef] [PubMed]
- Dikobe, D.G.; Luyt, A.S. Morphology and properties of polypropylene/ethylene vinyl acetate copolymer/wood powder blend composites. Express Polym. Lett. 2009, 3, 190–199. [Google Scholar] [CrossRef]
- Ismail, H. Thermoplastic elastomers based on polypropylene/natural rubber and polypropylene/recycle rubber blends. Polym. Test. 2002, 21, 389–395. [Google Scholar] [CrossRef]
- Zhang, M.; Liu, X. A soft sensor based on adaptive fuzzy neural network and support vector regression for industrial melt index prediction. Chem. Intell. Lab. Syst. 2013, 126, 83–90. [Google Scholar] [CrossRef]
- Jiang, H.; Xiao, Y.; Li, J.; Liu, X. Prediction of the melt index based on the relevance vector machine with modified particle swarm optimization. Chem. Eng. Technol. 2012, 35, 819–826. [Google Scholar] [CrossRef]
- Liu, W.; Li, M.; Zhang, M.; Wang, D.; Guo, Z.; Long, S.; Yang, S.; Wang, H.; Li, W.; Hu, Y.K.; et al. Estimating leaf mercury content in Phragmites australis based on leaf hyperspectral reflectance. Ecosyst. Health Sustain. 2020, 6, 1726211. [Google Scholar] [CrossRef]
- Ali, M.; Prasad, R.; Xiang, Y.; Deo, R.C. Near real-time significant wave height forecasting with hybridized multiple linear regression algorithms. Renew. Sustain. Energy Rev. 2020, 132, 110003. [Google Scholar] [CrossRef]
- Chen, L.; Pilania, L.; Batra, R.; Huan, T.D.; Kim, C.; Kuenneth, C.; Ramprasad, R. Polymer informatics: Current status and critical next steps. Mater. Sci. Eng. R. 2021, 144, 100595. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Asteris, P.G. A comparative study of ANN and ANFIS models for the prediction of cement-based mortar materials compressive strength. In Neural Computing and Applications; Springer: London, UK, 2020; Volume 4. [Google Scholar] [CrossRef]
- Belalia Douma, O.; Boukhatem, B.; Ghrici, M.; Tagnit-Hamou, A. Prediction of properties of self-compacting concrete containing fly ash using artificial neural network. Neural Comput. Appl. 2017, 28, 707–718. [Google Scholar] [CrossRef]
- Kuhe, A.; Achirgbenda, V.T.; Agada, M. Global solar radiation prediction for Makurdi, Nigeria, using neural networks ensemble. Energy Source Part A Recovery Util. Environ. Eff. 2021, 43, 1373–1385. [Google Scholar] [CrossRef]
- Yılmaz, O.; Bas, E.; Egrioglu, E. The training of pi-sigma artificial neural networks with differential evolution algorithm for forecasting. Comput. Econ. 2021, 59, 1699–1711. [Google Scholar] [CrossRef]
- Tran, H.D.; Kim, C.; Chen, L.; Chandrasekaran, A.; Batra, R.; Ventatram, S.; Kamla, D.; Lightstone, J.P.; Curnani, R.; Shetty, P.; et al. Machine-learning predictions of polymer properties with Polymer Genome. J. Appl. Phys. 2020, 128, 171104. [Google Scholar] [CrossRef]
- De Sousa, I.C.; Nascimento, M.; Silva, G.N.; Nascimento, A.C.C.; Cruz, C.D.; Silva, F.F.; De Almeida, D.P.; Pestana, K.N.; Azevedo, C.F.; Zambolim, L.; et al. Genomic prediction of leaf rust resistance to Arabica coffee using machine learning algorithms. Sci. Agric. 2021, 78, 4. [Google Scholar] [CrossRef]
- Du, J.; Yang, T.; Chen, X.; Chai, J.; Zhao, Y.; Shi, S. A CNN-based cost-effective modulation format identification scheme by low-bandwidth direct detecting and low rate sampling for elastic optical networks. Opt. Commun. 2020, 471, 126007. [Google Scholar] [CrossRef]
- Singh, G.; Pal, M.; Yadav, Y.; Singla, T. Deep neural network-based predictive modeling of road accidents. Neural Comput. Appl. 2020, 32, 12417–12426. [Google Scholar] [CrossRef]
- Lim, J.; Jeong, S.; Kim, J. Deep neural network-based optimal selection and blending ratio of waste seashells as an alternative to high-grade limestone depletion for SO X capture and utilization. Chem. Eng. J. 2021, 431, 133244. [Google Scholar] [CrossRef]
- Qiao, C.; Gao, B.; Shi, Y. SRS-DNN: A deep neural network with strengthening response sparsity. Neural Comput. Appl. 2020, 32, 8127–8142. [Google Scholar] [CrossRef]
- Franco, B.M.; Hernández-Callejo, L.; Navas-Gracia, L.M. Virtual weather stations for meteorological data estimations. Neural Comput. Appl. 2020, 32, 12801–12812. [Google Scholar] [CrossRef]
- Shen, F.; Liu, Y.; Wang, R.; Zhou, W. A dynamic financial distress forecast model with multiple forecast results under unbalanced data environment. Knowl.-Based Syst. 2020, 192, 105365. [Google Scholar] [CrossRef]
- Mannodoi-Kanakkithodi, A.; Pilanial, G.; Huan, T.D.; Lookman, T.; Ramprasad, R. Machine Learning Strategy for Accelerated Design of Polymer Dielectrics. Sci. Rep. 2016, 6, 20952. [Google Scholar] [CrossRef]
- Chen, L.; Shen, Z.; Lyer, A.; Ghumman, U.F.; Tang, S.; Bi, J.; Chen, W.; Li, Y. Machine-Learning-Assisted De Novo Design of Organic Molecules and Polymers: Opportunities and Challenges. Polymers 2020, 12, 163. [Google Scholar] [CrossRef] [PubMed]
- Hibino, Y.; Oyane, A.; Shitomi, K.; Miyaji, H. Technique for simple apatite coating on a dental resin composite with light-curing through a micro-rough apatite layer. Mater. Sci. Eng. C 2020, 116, 111146. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Cheng, L.; Ye, F.; Zhang, L.; Liu, Y.; Cui, X.; Fu, Z. Effects of heat treatment on mechanical and dielectric properties of 3D Si3N4f/BN/Si3N4 composites by CVI. J. Eur. Ceram. Soc. 2020, 40, 5305–5315. [Google Scholar] [CrossRef]
- Chan, L.L.T.; Chen, J. Melt index prediction with a mixture of Gaussian process regression with embedded clustering and variable selections. J. Appl. Polym. Sci. 2017, 134, 45237. [Google Scholar] [CrossRef]
- Kim, Y.S.; Kim, J.K.; Jeon, E.S. Effect of the compounding conditions of polyamide 6, carbon fiber, and Al2O3 on the mechanical and thermal properties of the composite polymer. Materials 2019, 12, 3047. [Google Scholar] [CrossRef]
- Li, J.; Heap, A.D.; Potter, A.; Daniell, J.J. Application of machine learning methods to spatial interpolation of environmental variables. Environ. Modell. Softw. 2011, 26, 1647–1659. [Google Scholar] [CrossRef]
- Do, D.T.T.; Lee, D.; Lee, J. Material optimization of functionally graded plates using deep neural network and modified symbiotic organisms search for eigenvalue problems. Compos. Part B Eng. 2019, 159, 300–326. [Google Scholar] [CrossRef]
- Do, D.T.T.; Nguyen-Xuan, H.; Lee, J. Material optimization of tri-directional functionally graded plates by using deep neural network and isogeometric multimesh design approach. Appl. Math. Modell. 2020, 87, 501–533. [Google Scholar] [CrossRef]
- Li, F.; Pang, X.; Yang, Z. Motor current signal analysis using deep neural networks for planetary gear fault diagnosis. Meas. J. Int. Meas. Confed. 2019, 145, 45–54. [Google Scholar] [CrossRef]
- Park, C.; Ha, J.; Park, S. Prediction of Alzheimer’s disease based on deep neural network by integrating gene expression and DNA methylation dataset. Expert Syst. Appl. 2020, 140, 112873. [Google Scholar] [CrossRef]
- Arısoy, E.; Sainath, T.N.; Kingsbury, B.; Ramabhadran, B. Deep neural network language models. In Proceedings of the NAACL-HLT 2012 Workshop: Will We Ever Really Replace the N-gram Model? On the Future of Language Modeling for HLT, Montr´eal, QC, Canada, 8 June 2012; pp. 20–28. [Google Scholar]
- Du, S.S.; Lee, J.D.; Li, H.; Wang, L.; Zhai, X. Gradient descent finds global minima of deep neural networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 3003–3048. [Google Scholar]
- Zhang, Y.; Gao, J.; Zhou, H. Breeds classification with deep convolutional neural network. In Proceedings of the 2020 12th International Conference on Machine Learning and Computing, Shenzhen, China, 15–17 February 2020; ACM International Conference Proceeding Series. pp. 145–151. [Google Scholar] [CrossRef]
- Baptista, M.L.; Henriques, E.M.P.; Goebel, K. More effective prognostics with elbow point detection and deep learning. Mech. Syst. Signal Process. 2020, 146, 106987. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Joo, C.; Park, H.; Kim, J. Development of physical property prediction models for polypropylene composites with optimizing random forest hyperparameters. Int. J. Intell. Syst. 2022, 37, 3625–3653. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | PP | Filler | Rubber | Others | Total |
|---|---|---|---|---|---|
| Number of materials | 41 | 18 | 22 | 9 | 90 |
| Number of Recipes | Number of Composite Types | |
|---|---|---|
| FS | 811 → 803 | 496 → 494 |
| MI | 811 → 480 | 496 → 339 |
| TS | 811 → 801 | 496 → 493 |
| Number of Recipes in a Type | Number of Training Datasets | Number of Validation Datasets | Number of Testing Datasets |
|---|---|---|---|
| 1 | 1 | 0 | 0 |
| 2 | 1 | 0 | 1 |
| 3 | 1 | 1 | 1 |
| 4 | 2 | 1 | 1 |
| 5 | 3 | 1 | 1 |
| 6 | 3 | 1 | 2 |
| 7 | 4 | 1 | 2 |
| 8 | 5 | 1 | 2 |
| 9 | 6 | 1 | 2 |
| 10 | 7 | 1 | 2 |
| 11 | 8 | 1 | 2 |
| 12 | 9 | 1 | 2 |
| Property | Training Data | Validation Data | Testing Data |
|---|---|---|---|
| FS | 71.6% | 8.3% | 20.1% |
| MI | 73.6% | 6% | 20.4% |
| TS | 71.2% | 8.4% | 20.4% |
| Hyperparameter | Value | ||
|---|---|---|---|
| MLR | Intercept fitting | True | |
| DNN | Type | Regressor | |
| Number of nodes in hidden layer1 | 45 | ||
| Number of nodes in hidden layer2 | 10 | ||
| Number of nodes in hidden layer3 | 10 | ||
| Optimizer | Adam | ||
| Learning rate | 0.001 | ||
| Batch size | 3 | ||
| Loss | mean_squared _error | ||
| Epochs | earlystopping | ||
| earlystopping | monitor | val_loss | |
| patience | 10 | ||
| verbose | 1 | ||
| RF | Type | Regressor | |
| Number of estimators | 100 | ||
| Bootstrap | True | ||
| Max depth | 10 | ||
| Min samples leaf | 3 | ||
| Algorithm | Property | Training Data | Validation Data |
|---|---|---|---|
| MLR | FS | 0.9717 | 0.9793 |
| MI | 0.9193 | 0.9426 | |
| TS | 0.9559 | 0.9445 | |
| DNN | FS | 0.9796 | 0.9850 |
| MI | 0.9854 | 0.9321 | |
| TS | 0.9801 | 0.9472 | |
| RF | FS | 0.9852 | 0.9862 |
| MI | 0.9607 | 0.8904 | |
| TS | 0.9837 | 0.9585 |
| FS | MI | TS | ||||
|---|---|---|---|---|---|---|
| RMSE | R2 | RMSE | R2 | RMSE | R2 | |
| MLR | 8.3122 | 0.9291 | 2.4072 | 0.9406 | 6.2689 | 0.9334 |
| DNN | 8.5404 | 0.9254 | 3.3413 | 0.9297 | 4.9358 | 0.9587 |
| RF | 9.9609 | 0.8981 | 4.9732 | 0.8442 | 5.9648 | 0.9397 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Joo, C.; Park, H.; Kwon, H.; Lim, J.; Shin, E.; Cho, H.; Kim, J. Machine Learning Approach to Predict Physical Properties of Polypropylene Composites: Application of MLR, DNN, and Random Forest to Industrial Data. Polymers 2022, 14, 3500. https://doi.org/10.3390/polym14173500
Joo C, Park H, Kwon H, Lim J, Shin E, Cho H, Kim J. Machine Learning Approach to Predict Physical Properties of Polypropylene Composites: Application of MLR, DNN, and Random Forest to Industrial Data. Polymers. 2022; 14(17):3500. https://doi.org/10.3390/polym14173500
Chicago/Turabian StyleJoo, Chonghyo, Hyundo Park, Hyukwon Kwon, Jongkoo Lim, Eunchul Shin, Hyungtae Cho, and Junghwan Kim. 2022. "Machine Learning Approach to Predict Physical Properties of Polypropylene Composites: Application of MLR, DNN, and Random Forest to Industrial Data" Polymers 14, no. 17: 3500. https://doi.org/10.3390/polym14173500
APA StyleJoo, C., Park, H., Kwon, H., Lim, J., Shin, E., Cho, H., & Kim, J. (2022). Machine Learning Approach to Predict Physical Properties of Polypropylene Composites: Application of MLR, DNN, and Random Forest to Industrial Data. Polymers, 14(17), 3500. https://doi.org/10.3390/polym14173500