Hierarchical Structures and Leadership Design in Mean-Field-Type Games with Polynomial Cost

 ,
,
Abstract
1. Introduction
- A single decision-maker can have a strong impact on the mean-field terms;
- The expected payoffs are not necessarily linear with respect to the state distribution;
- The number of decision-makers is not necessarily infinite.
2. The Setup
2.1. Games with Polynomial Cost
2.2. Hierarchical Leader Design and Algorithmic Approach
| Algorithm 1: Finding the best hierarchical structure |
 |
3. Nash Mean-Field-Type Equilibrium
- Let I be an arbitrary integer and , the system in η becomes linear and has a unique solution if, and only if the determinant of the matrix M is non-zero, with and When the determinant is zero, the resulting control strategies become non-admissible and the costs become infinite.
- For , and the system in η becomes a binary cubic polynomial, given byFor , there is a unique solution, given byFor , we derive from the first equation thatBy substituting it to the second equation, we arrive atThe latter equation is a polynomial of odd degree “9”. It has a unique real root in if its derivative has a constant sign. Its derivative isIt has a constant sign if and have opposite signs. If and are positive, then the condition is reduced to
- and arbitrary . Thus, a sufficiency condition is that and have opposite signs. In particular if , then the condition reduces to
- The same reasoning applies to the system in , and has a unique real solution if
- For decision-makers and arbitrary , the system can be rewritten as a fixed-point equation which fulfils a contraction mapping condition if the norms of r and ϵ are sufficiently small. In this case, there is a unique solution.
4. Multiple Leaders and Multiple Followers
4.1. No Control-Coupling within Classes
4.1.1. No Leader and All Followers
4.1.2. One Leader and Multiple Followers
4.1.3. Multiple Leaders and One Follower
4.1.4. All Leaders and No Follower
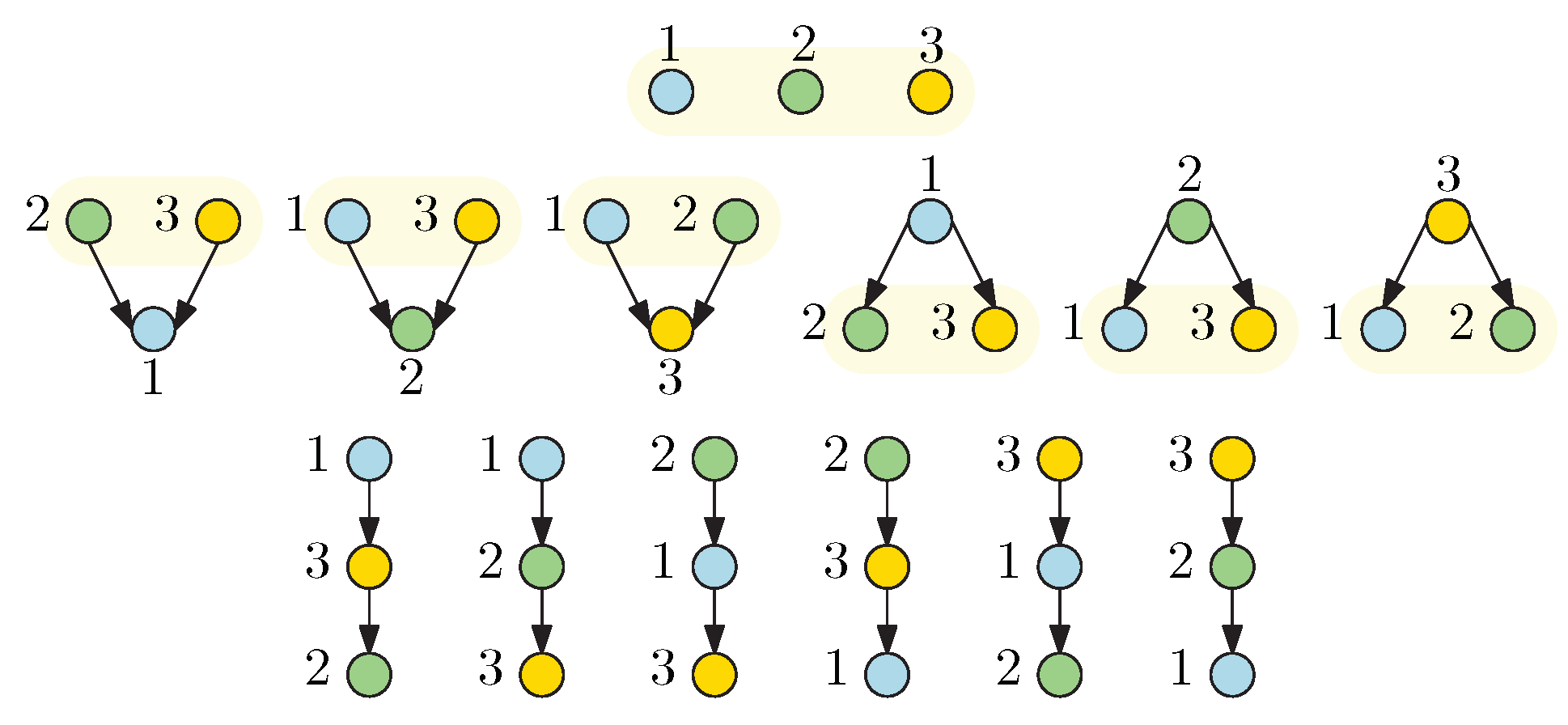
5. Fully Hierarchical Game
- For the order of the play matters because of the informational difference between the decision-makers at different levels of hierarchy in (8). One open question that we leave for future investigation is: How to determine the optimal ordering among all permutations of heterogenous decision-makers?
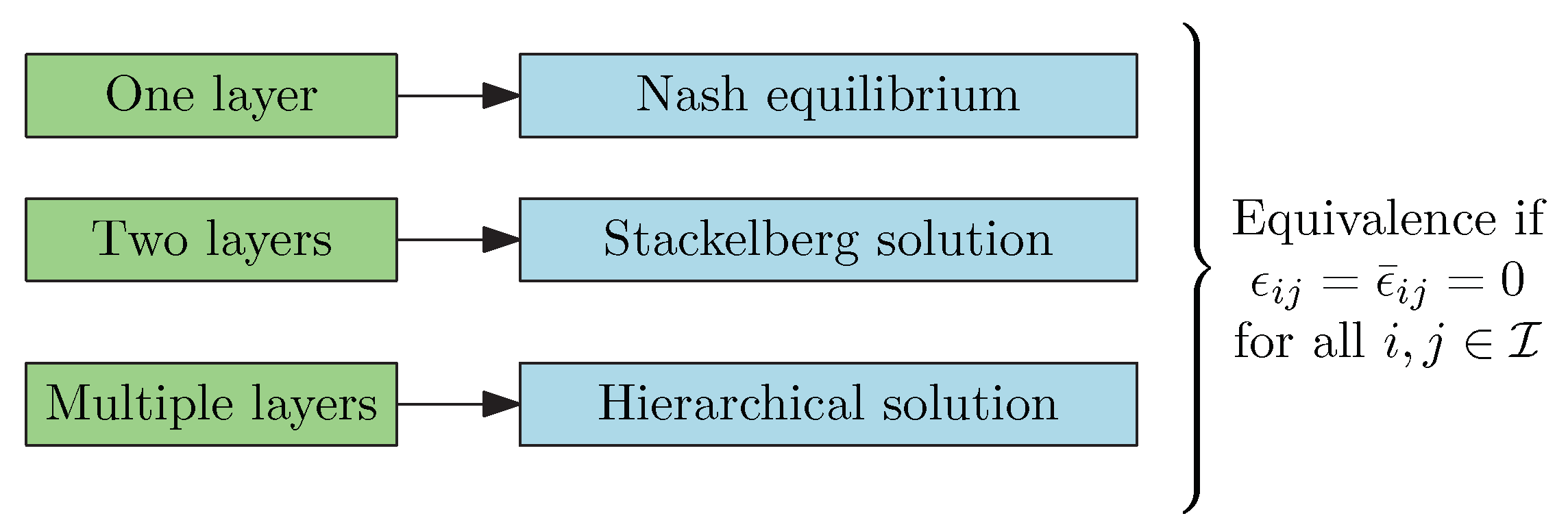
- When all the and are zero, the Nash equilibrium coincides with the bi-level solution, which coincides with any level of hierarchical solution. The order of the play and the informational difference do not generate an extra advantage for the first mover in this particular case. Consequently, the hierarchical leader design is only performed when the parameters .
6. Numerical Investigation
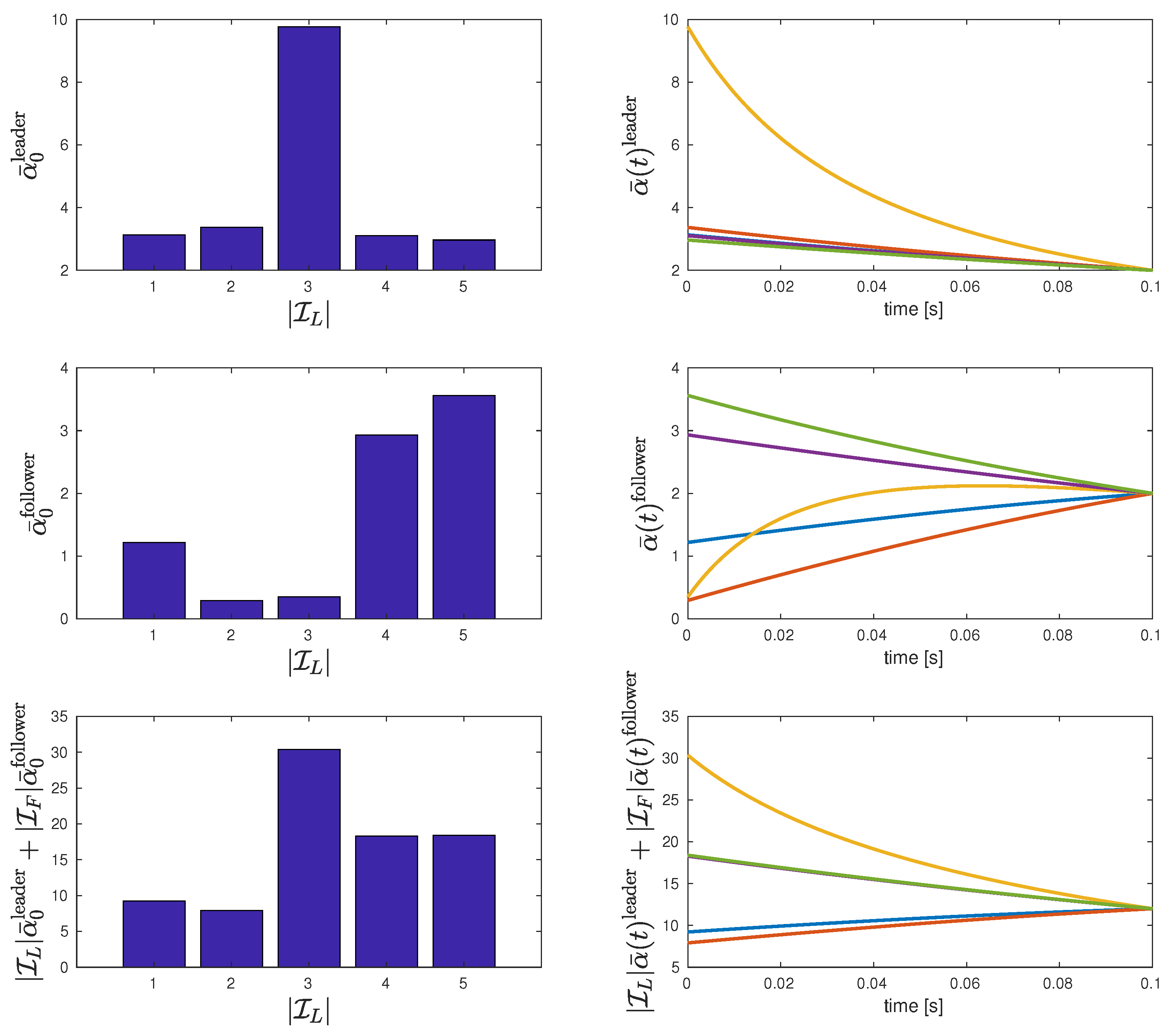
6.1. Effect of the Number of Leaders on the Total Cost
6.1.1. Uniform Coupling and Homogeneous Players
6.1.2. Uniform Coupling and Heterogeneous Players
6.2. Impact of the Hierarchical Structures
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. I-th Hierarchical Level
Appendix A.2. (I − 1)-th Hierarchical Level
Appendix A.3. i-th Hierarchical Level
Appendix A.4. 1-st Hierarchical Level
References
- Stackelberg, H.V. The Theory of the Market Economy; Peacock, A.J.; Hodge, W., Translators; Originally Published as Grundlagen der Theoretischen Volkswirtschaftlehre; Oxford University Press: Oxford, UK, 1948. [Google Scholar]
- Simaan, M.; Cruz, J.B. On the Stackelberg strategy in nonzero-sum games. J. Optim. Theory Appl. 1973, 11, 533–555. [Google Scholar] [CrossRef]
- Bagchi, A.; Basar, T. Stackelberg strategies in linear-quadratic stochastic differential games. J. Optim. Theory Appl. 1981, 35, 443–464. [Google Scholar] [CrossRef]
- Bensoussan, A.; Chen, S.; Sethi, S.P. The maximum principle for global solutions of stochastic Stackelberg differential games. SIAM J. Control Optim. 2015, 53, 1956–1981. [Google Scholar] [CrossRef]
- Pan, L.; Yong, J. A differential game with multi-level of hierarchy. J. Math. Anal. Appl. 1991, 161, 522–544. [Google Scholar] [CrossRef]
- Simaan, M.; Cruz, J. A Stackelberg solution for games with many players. IEEE Trans. Autom. Control 1973, 18, 322–324. [Google Scholar] [CrossRef]
- Cruz, J. Leader-follower strategies for multilevel systems. IEEE Trans. Autom. Control 1978, 23, 244–255. [Google Scholar] [CrossRef]
- Gardner, B.; Cruz, J. Feedback Stackelberg strategy for M-level hierarchical games. IEEE Trans. Autom. Control 1978, 23, 489–491. [Google Scholar] [CrossRef]
- Basar, T.; Selbuz, H. Closed-loop Stackelberg strategies with applications in the optimal control of multilevel systems. IEEE Trans. Autom. Control 1979, 24, 166–179. [Google Scholar] [CrossRef]
- Lin, Y.; Jiang, X.; Zhang, W. An Open-Loop Stackelberg Strategy for the Linear Quadratic Mean-Field Stochastic Differential Game. IEEE Trans. Autom. Control 2019, 64, 97–110. [Google Scholar] [CrossRef]
- Du, K.; Wu, Z. Linear-Quadratic Stackelberg Game for Mean-Field Backward Stochastic Differential System and Application. Math. Probl. Eng. 2019, 2019, 1798585. [Google Scholar] [CrossRef]
- Moon, J.; Basar, T. Linear-quadratic stochastic differential Stackelberg games with a high population of followers. In Proceedings of the 54th IEEE Conference on Decision Control, Osaka, Japan, 15–18 December 2015; pp. 2270–2275. [Google Scholar]
- Bensoussan, A.; Chau, M.H.M.; Yam, S.C.P. Mean-field Stackelberg games: Aggregation of delayed instructions. SIAM J. Control Optim. 2015, 53, 2237–2266. [Google Scholar] [CrossRef]
- Bensoussan, A.; Chau, M.; Lai, Y.; Yam, S. Linear-quadratic mean field Stackelberg games with state and control delays. SIAM J. Control Optim. 2017, 55, 2748–2781. [Google Scholar] [CrossRef]
- Averboukh, A.Y. Stackelberg solution for first-order mean-field game with a major player. Izv. Inst. Mat. Inform. Udmurt. 2018, 52. [Google Scholar] [CrossRef]
- Moon, J.; Basar, T. Linear quadratic mean field Stackelberg differential games. Automatica 2018, 97, 200–213. [Google Scholar] [CrossRef]
- Shi, J.; Wang, G.; Xiong, J. Leader-follower stochastic differential game with asymmetric information and applications. Automatica 2016, 63, 60–73. [Google Scholar] [CrossRef]
- Nourian, M.; Caines, P.; Malhamé, R.P.; Huang, M. Mean Field LQG Control in Leader-Follower Stochastic Multi-Agent Systems: Likelihood Ratio Based Adaptation. IEEE Trans. Autom. Control 2012, 57, 2801–2816. [Google Scholar] [CrossRef]
- Cai, H.; Hu, G. Distributed Tracking Control of an Interconnected Leader-Follower multi-agent System. IEEE Trans. Autom. Control 2017, 62, 3494–3501. [Google Scholar] [CrossRef]
- Li, Y.; Shi, D.; Chen, T. False Data Injection Attacks on Networked Control Systems: A Stackelberg Game Analysis. IEEE Trans. Autom. Control 2018, 63, 3503–3509. [Google Scholar] [CrossRef]
- Barreiro-Gomez, J.; Ocampo-Martinez, C.; Quijano, N. Partitioning for large-scale systems: A sequential distributed MPC design. In Proceedings of the 20th IFAC World Congress, Toulouse, France, 9–14 July 2017; pp. 8838–8843. [Google Scholar]
- Sutter, M.; Rivas, M.F. Leadership, Reward and Punishment in Sequential Public Goods Experiments. In Reward and Punishment in Social Dilemmas; Lange, P.A.V., Rockenbach, B., Yamagishi, T., Eds.; Oxford University Press: Oxford, UK, 2014; pp. 1–39. [Google Scholar]
- Andersson, D.; Djehiche, B. A Maximum Principle for SDEs of mean-field-type. Appl. Math. Optim. 2011, 63, 341–356. [Google Scholar] [CrossRef]
- Buckdahn, R.; Djehiche, B.; Li, J. A General Stochastic Maximum Principle for SDEs of mean-field-type. Appl. Math. Optim. 2011, 64, 197–216. [Google Scholar] [CrossRef]
- Tembine, H. Risk-sensitive mean-field-type games with Lp-norm drifts. Automatica 2015, 59, 224–237. [Google Scholar] [CrossRef]
- Tcheukam, A.; Tembine, H. mean-field-type Games for Distributed Power Networks in Presence of Prosumers. In Proceedings of the 2016 28th Chinese Control and Decision Conference (CCDC), Yinchuan, China, 28–30 May 2016; pp. 446–451. [Google Scholar]
- Djehiche, B.; Tcheukam, A.; Tembine, H. mean-field-type Games in Engineering. AIMS Electron. Electr. Eng. 2017, 1, 18. [Google Scholar] [CrossRef]
- Tembine, H. mean-field-type games. AIMS Math. 2017, 2, 706–735. [Google Scholar] [CrossRef]
- Duncan, T.; Tembine, H. Linear-Quadratic mean-field-type Games: A Direct Method. Games 2018, 9, 7. [Google Scholar] [CrossRef]
- Barreiro-Gomez, J.; Duncan, T.E.; Tembine, H. Linear-Quadratic mean-field-type Games: Jump-Diffusion Process with Regime Switching. IEEE Trans. Autom. Control 2019, 64, 4329–4336. [Google Scholar] [CrossRef]
- Barreiro-Gomez, J.; Duncan, T.E.; Tembine, H. Linear-Quadratic mean-field-type Games with Multiple Input Constraints. IEEE Control Syst. Lett. 2019, 3, 511–516. [Google Scholar] [CrossRef]
- Beardsley, X.W.; Field, B.; Xiao, M. Mean-variance-skewness-kurtosis portfolio optimization with return and liquidity. Commun. Math. Financ. 2012, 1, 13–49. [Google Scholar]
- Theodossiou, P.; Savva, C.S. Skewness and the Relation Between Risk and Return. Manag. Sci. 2016, 62, 1598–1609. [Google Scholar] [CrossRef]
- Sun, J.; Yong, J. Linear Quadratic Stochastic Differential Games: Open-Loop and Closed-Loop Saddle Points. SIAM J. Control. Optim. 2014, 52, 4082–4121. [Google Scholar] [CrossRef]
- Bensoussan, A.; Djehiche, B.; Tembine, H.; Yam, S.C.P. mean-field-type Games with Jump and Regime Switching. Dyn. Games Appl. 2020. [Google Scholar] [CrossRef]









{kind=link}
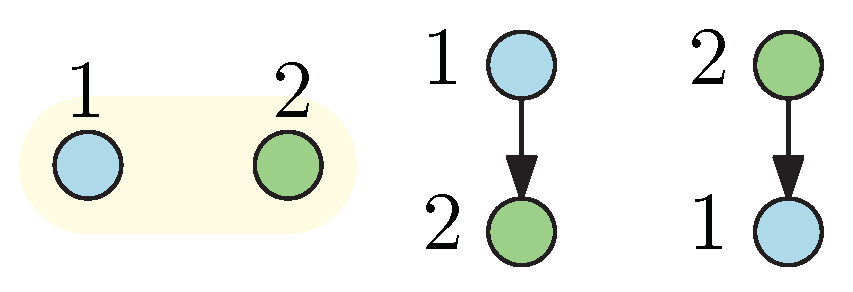{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Leader(s)-Follower(s) Structure |  |  |  |  |  |
|---|---|---|---|---|---|
| Individual leader cost | 3.132 | 3.37 | 9.772 | 3.107 | 2.968 |
| Individual follower cost | 1.217 | 0.2931 | 0.3481 | 2.933 | 3.562 |
| Total cost | 9.219 | 7.911 | 30.36 | 18.29 | 18.4 |
| Leader(s)-Follower(s) Structure |  |  |  |  |  |  |
|---|---|---|---|---|---|---|
| Leaders | ||||||
| Followers | ||||||
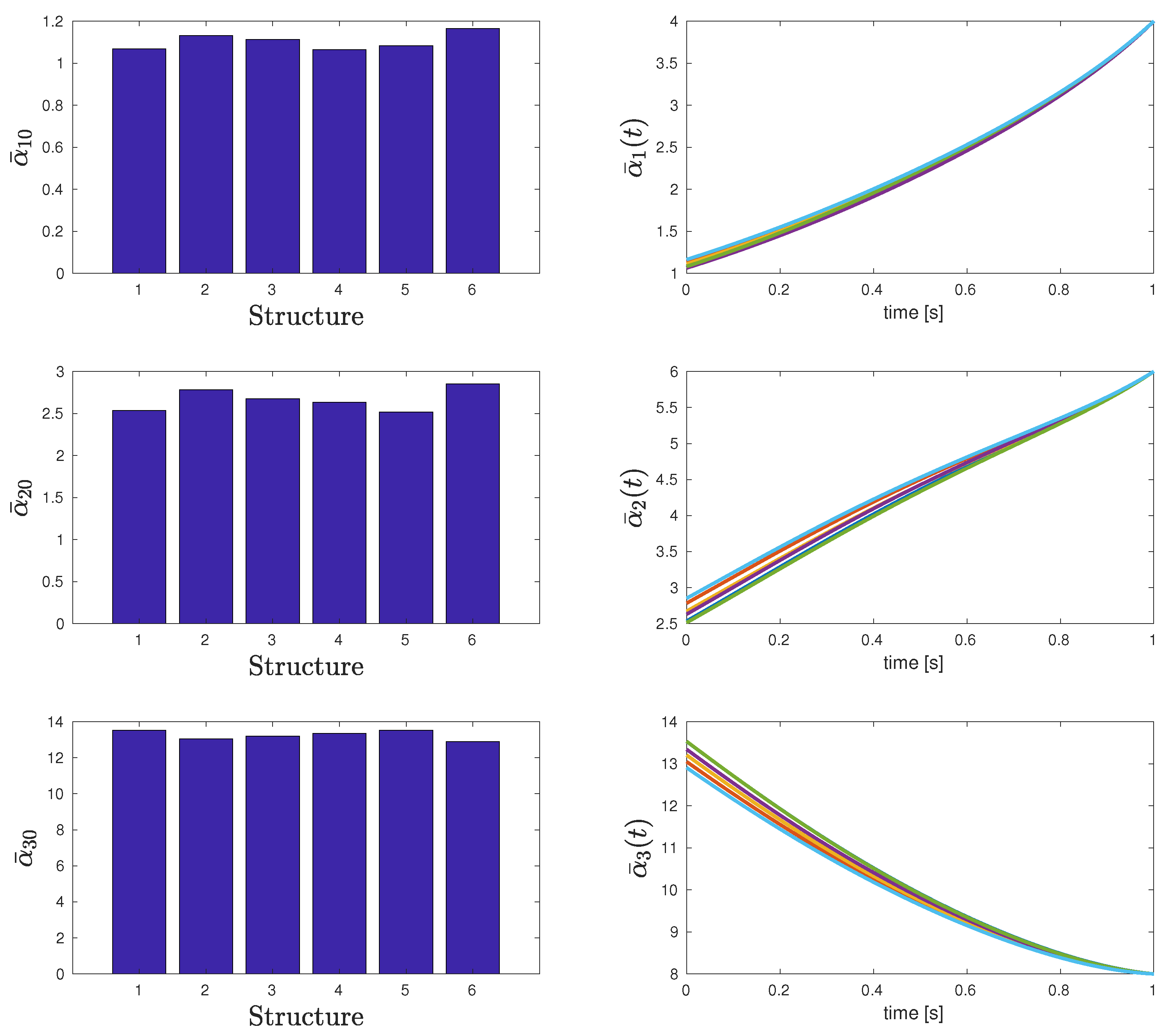
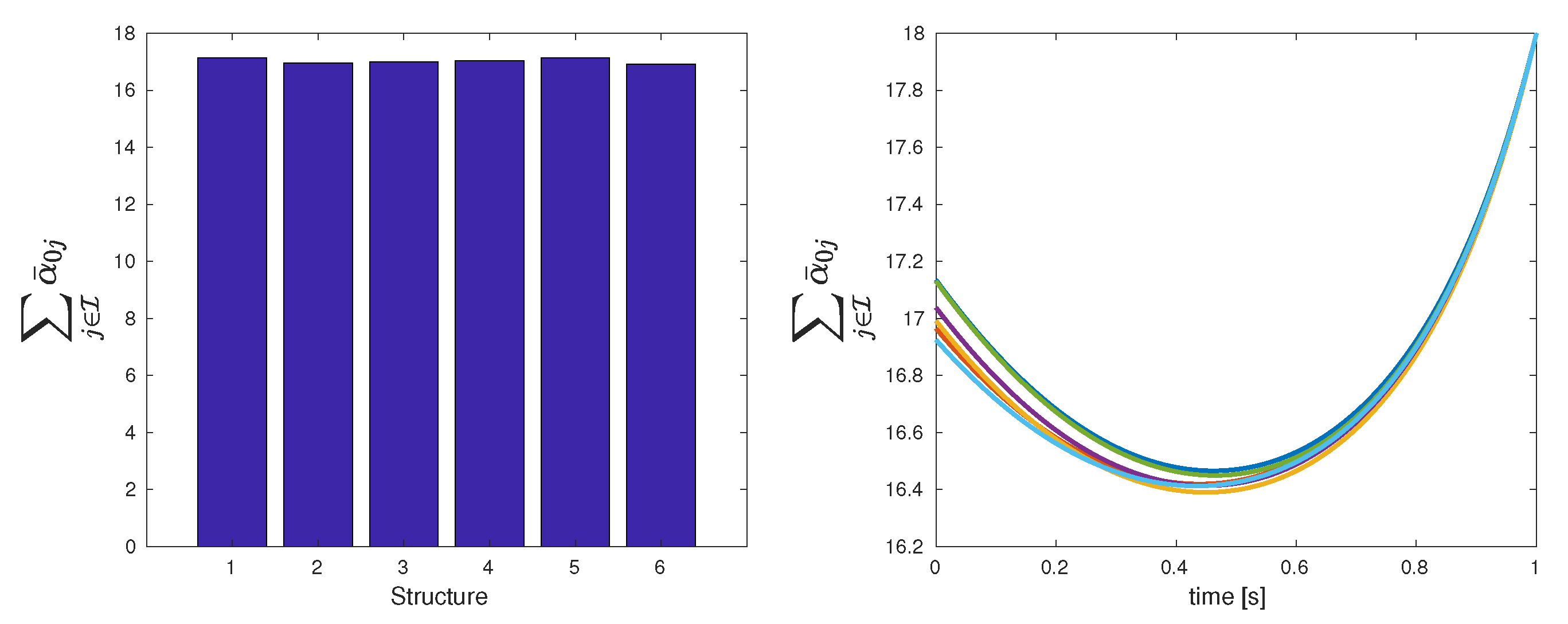
| Total cost | 17.14 | 16.96 | 16.99 | 17.04 | 17.13 | 16.92 |
| Hierarchical Structure |  |  |  |  |  |  |
|---|---|---|---|---|---|---|
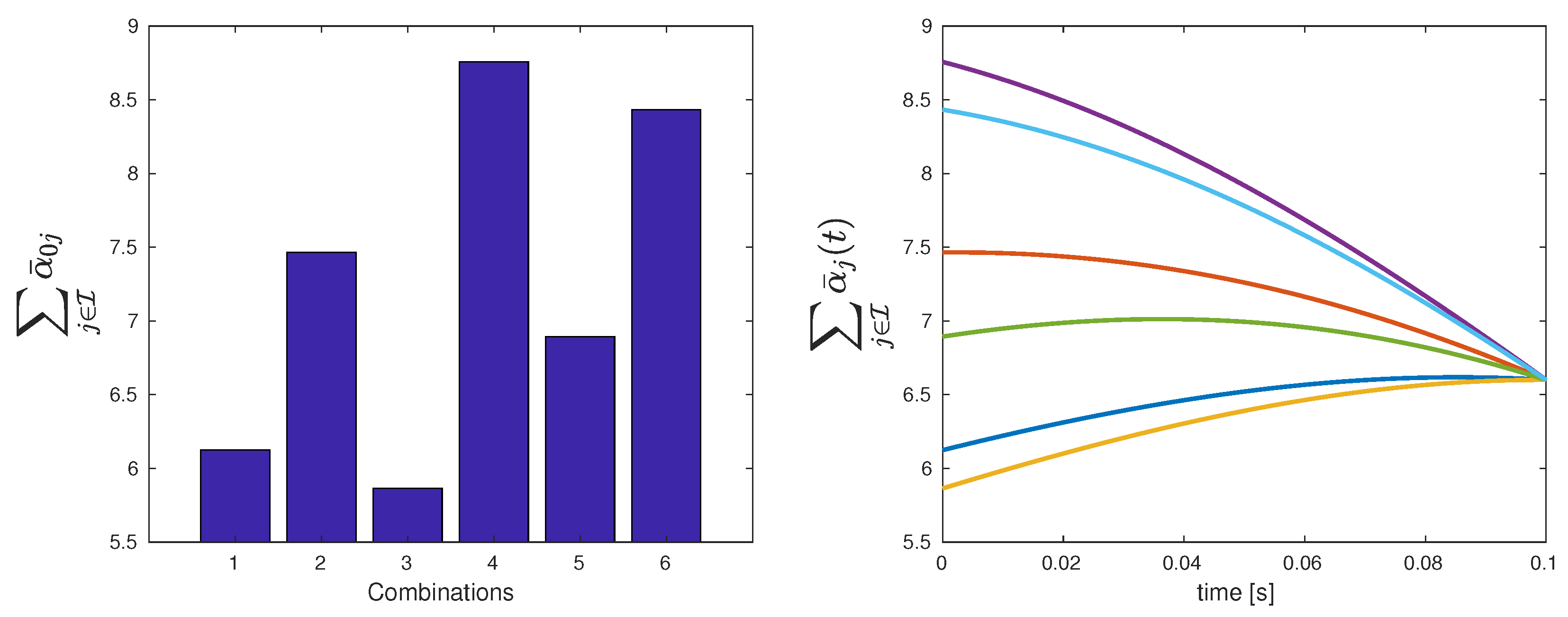
| Combination label | 1 | 2 | 3 | 4 | 5 | 6 |
| Hierarchical order | ||||||
| Total cost | 6.124 | 7.464 | 5.864 | 8.757 | 6.894 | 8.433 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
El Oula Frihi, Z.; Barreiro-Gomez, J.; Eddine Choutri, S.; Tembine, H. Hierarchical Structures and Leadership Design in Mean-Field-Type Games with Polynomial Cost. Games 2020, 11, 30. https://doi.org/10.3390/g11030030
El Oula Frihi Z, Barreiro-Gomez J, Eddine Choutri S, Tembine H. Hierarchical Structures and Leadership Design in Mean-Field-Type Games with Polynomial Cost. Games. 2020; 11(3):30. https://doi.org/10.3390/g11030030
Chicago/Turabian StyleEl Oula Frihi, Zahrate, Julian Barreiro-Gomez, Salah Eddine Choutri, and Hamidou Tembine. 2020. "Hierarchical Structures and Leadership Design in Mean-Field-Type Games with Polynomial Cost" Games 11, no. 3: 30. https://doi.org/10.3390/g11030030
APA StyleEl Oula Frihi, Z., Barreiro-Gomez, J., Eddine Choutri, S., & Tembine, H. (2020). Hierarchical Structures and Leadership Design in Mean-Field-Type Games with Polynomial Cost. Games, 11(3), 30. https://doi.org/10.3390/g11030030