Abstract
The rapid digitalization of political campaigns has reshaped electioneering strategies, enabling political entities to leverage social media for targeted outreach. This study investigates the impact of digital political campaigning during the 2024 EU elections using machine learning techniques to analyze social media dynamics. We introduce a novel dataset—Political Popularity Campaign—which comprises social media posts, engagement metrics, and multimedia content from the electoral period. By applying predictive modeling, we estimate key indicators such as post popularity and assess their influence on campaign outcomes. Our findings highlight the significance of micro-targeting practices, the role of algorithmic biases, and the risks associated with disinformation in shaping public opinion. Moreover, this research contributes to the broader discussion on regulating digital campaigning by providing analytical models that can aid policymakers and public authorities in monitoring election compliance and transparency. The study underscores the necessity for robust frameworks to balance the advantages of digital political engagement with the challenges of ensuring fair democratic processes.
1. Introduction
In recent years, digital campaigning has emerged as a central element in political strategies, reshaping the landscape of electioneering across the globe [1,2,3]. In Italy, as in many other countries, political entities increasingly leverage digital platforms to reach and engage voters. However, the rapid integration of digital tools into political campaigns has outpaced the development of corresponding regulatory frameworks, leading to significant concerns regarding the integrity and fairness of the democratic process [4,5]. The role of digital platforms in political campaigning extends beyond voter engagement to include economic and structural dynamics, where factors such as financial constraints, agglomeration effects, and the proximity of innovative hubs influence the effectiveness and reach of online political strategies [5,6,7]. One of the primary concerns is the potential for interference through the purchase of political advertising on the Internet. Such activities can be utilized by external actors to influence election outcomes and may facilitate covert or illicit financing of political activities. The lack of transparency in online political advertising exacerbates these issues, as it becomes challenging to trace the origins and funding sources of digital campaign materials [4].
Observing and assessing public sentiment patterns on social media platforms has surfaced as a viable substitute for traditional opinion surveys, owing to its unprompted nature and reach to a vast audience [8,9]. Indeed, social media platforms have become the primary channels for digital campaigning, largely due to their capacity for targeted political propaganda, commonly referred to as micro-targeting. This approach allows campaigns to deliver tailored messages to specific segments of the electorate, enhancing engagement but also raising ethical and legal questions. The ability to micro-target voters can lead to the dissemination of misleading information and the reinforcement of echo chambers, thereby undermining informed democratic deliberation [7,10].
Considering this, over the past few years, the rise of social media has driven significant research into forecasting election results by analyzing sentiments expressed on these platforms. A key focus has been the precise assessment of sentiment scores from relevant social media content, often to predict the victorious candidate [6,8,11]. Traditional polling methods are not only costly but also require substantial time to conduct, whereas social media provides instant feedback, allowing for real-time analysis. Consequently, political figures have broadened the scope of participants influencing political discourse and have adapted their agendas to fit this digital landscape. Social media channels have become essential tools for candidates throughout their election campaigns. Platforms such as Facebook, Instagram, and Twitter empower politicians to engage directly with voters, rally support, and shape public perception [1,2,3]. These shifts in political communication have introduced new strategic considerations for candidates navigating the digital sphere [8,11].
Analyzing data from social media networks offers valuable insights into the dynamics of digital campaigning and the associated risks. Interactions on these platforms increasingly define the modern voter–representative relationship, with social media serving as a crucial medium for holding elected officials accountable [1,2,3]. However, the prevalence of bots, fake accounts, and algorithmic biases can distort public discourse and manipulate voter perceptions [12,13]. Nevertheless, as an initial and passive data source, social media information presents numerous analytical hurdles, including the extraction of pertinent details from unstructured and unsolicited content, the measurement of highly qualitative visual and textual communications, and the assurance of data representativeness concerning a specific subject [8].
Building upon this theoretical background, we defined a novel approach to estimate one key indicator (post-popularity) that could influence political elections. To this date, we have collected a new dataset, the Political Popularity campaign, comprising social media posts from the 2024 EU political elections. This dataset includes information on post content, like images, videos, engagement metrics (likes, shares, comments), and temporal data. By applying machine learning techniques to this dataset, we aim to predict key variables such as post popularity and assess their influence on campaign outcomes. This approach allows for a general understanding of how digital content resonates with the electorate and informs campaign strategies.
This work is part of a larger framework for the regulation of digital campaigning. By collecting and analyzing extensive campaign data from social networks—including interactions, advertising expenditures, and posts—through the collaborative efforts of data scientists and legal scholars, we seek to develop analytical models that can be utilized by public authorities responsible for monitoring compliance with legal regulations concerning election campaigns and the financing of political parties and candidates. While the entire framework aims at analyzing multiple social media, here, we focus on Instagram, which has been adopted in similar studies and has been demonstrated to be a rich source of data for the topic under analysis [14].
The main contributions of this study are as follows:
- Analysis of Micro-targeting Practices: The study delves into the use of micro-targeting on social media platforms, where tailored messages are delivered to specific voter segments. While this enhances engagement, it also raises ethical and legal questions, including the dissemination of misleading information and the reinforcement of echo chambers.
- Assessment of Social Media Dynamics: By analyzing data from major social media networks, the paper provides insights into how interactions on these platforms define modern voter–representative relationships.
- Introduction of a Novel Dataset and Predictive Modeling: The research introduces a new dataset comprising social media posts from the 2024 political elections, including post content, engagement metrics, and temporal data. By applying machine learning techniques, the study aims to predict variables such as post popularity and assess their influence on campaign outcomes, offering a nuanced understanding of how digital content resonates with the electorate.
The rest of the paper is organized as follows: Section 2 provides an overview of related works, discussing prior research on digital political campaigning, sentiment analysis, and machine learning applications in election forecasting. Section 3 describes the dataset, preprocessing steps, and the machine learning models applied to analyze digital political campaigns. Section 4 presents the experimental results, highlighting key findings regarding the impact of social media engagement on political popularity. Finally, Section 5 discusses the implications of our findings, outlines the limitations, and suggests future research directions.
2. Related Works
2.1. Political Campaign Analysis
The evolution of political campaigns in the digital era has necessitated a re-evaluation of traditional strategies and the adoption of data-driven approaches. Political campaigns are concerted efforts to sway the opinions of a certain group of people, commonly used in democracies to elect legislators or determine referendums [15,16]. The increasing availability of microtargeted advertising and the accessibility of generative artificial intelligence (AI) tools have transformed political campaigns, enabling more precise targeting and message customization [16,17].
The European Democracy Action Plan, introduced by the EU Commission, aims to foster free and fair elections while countering disinformation and ensuring transparency in political advertising. Recent regulatory initiatives, such as the Regulation (EU) 2022/2065 on a Single Market for Digital Services, acknowledge the systemic risks that digital platforms pose to democratic processes, particularly through the spread of misleading information via automated bots and coordinated operations. These risks have been recognized in Horizon Europe, Cluster 2, which emphasizes the dual potential of digital environments to either support or threaten democracy.
The role of social media in political engagement is well documented, with scholars highlighting both its ability to enhance civic participation and its potential to undermine democratic discourse through microtargeting and misinformation [16,18]. The European Parliament’s resolution on foreign interference in democratic processes underscores the need for stricter regulations to govern online political campaigning. However, national frameworks, such as those in Italy, remain largely outdated, lacking specific regulations for online political advertising.
Legal scholars have examined digital constitutionalism and the responsibilities of private actors in safeguarding fundamental rights, alongside issues of co-regulation and algorithmic censorship [18,19]. Despite these discussions, limited attention has been paid to the enforcement of electoral regulations in digital spaces [20,21]. Additionally, interdisciplinary collaboration between legal experts and data scientists remains insufficient, even though social media analytics could provide valuable insights into political sentiment and regulatory needs [22].
In fact, the increasing reliance on digital platforms in political campaigning raises concerns regarding the manipulation of public perception through AI-driven content generation and targeted messaging strategies [23,24]. Advances in deep learning and extended reality have the potential to reshape political discourse by enabling the creation of hyper-realistic synthetic media, influencing voter behavior, and altering the dynamics of political engagement [25,26,27,28]. Moreover, the application of AI in analyzing public sentiment and voter preferences introduces ethical challenges related to transparency and democratic accountability [29,30].
2.2. Machine Learning Analysis
Machine learning (ML) techniques have been extensively used to analyze political communication, particularly in monitoring public sentiment during election campaigns. The increasing availability of social media data has made it possible to forecast election outcomes by analyzing digital interactions [31]. Traditional polling methods, while effective, are often costly and time-consuming, whereas sentiment analysis and network-based approaches allow real-time monitoring of political discourse [8,31,32].
A key aspect of digital political campaigning is microtargeting, where machine learning algorithms tailor campaign messages to specific voter groups based on behavioral data [12,33]. This strategy raises ethical and regulatory concerns, particularly regarding misinformation and the reinforcement of echo chambers. To address these issues, research efforts have explored methods to assess the influence of digital campaign strategies on public opinion.
Recent studies, such as [8], have proposed social media intelligence frameworks (SocMINT) to analyze election-related discourse. Their research demonstrated how sentiment analysis and network-based KPIs can be leveraged to predict electoral trends. Building on such methods, this work integrates machine learning techniques to predict political post popularity and assess their impact on campaign outcomes. By analyzing engagement metrics from platforms like Facebook, Instagram, and Twitter, this study seeks to inform both policymakers and scholars on how digital campaign strategies shape electoral behavior.
A recent literature review [31] further highlights the growing role of machine learning in political science. Their study systematically analyzed 339 political science articles using machine learning and found that political communication and electoral studies are the most common application areas. The most frequently applied methods include topic modeling, support vector machines, and random forests, indicating a strong preference for supervised learning approaches in predictive political science research [1,2,3]. The review also notes the increasing use of causal inference techniques in ML, aiming to bridge the gap between predictive accuracy and explanatory power in political analysis. Moreover, it highlights that while ML applications in political science have expanded rapidly, challenges remain in model interpretability, ethical considerations, and the necessity for interdisciplinary collaboration [31].
In sum, while significant research has explored the role of digital media in elections, there remains a gap in interdisciplinary methodologies combining computational analysis with legal scholarship. This study aims to bridge that gap by leveraging social media analytics and ML to inform regulatory strategies aligned with the European Democracy Action Plan.
3. Materials and Methods
The methodologies of this work are based on an interdisciplinary collaboration between scholars from the legal field and computer science engineers. This approach ensures that both technical and legal perspectives are integrated throughout the work lifecycle. The Computer Science (CS) team and the Legal team will work in close coordination to develop, analyze, and evaluate the AI-based system while considering legal and constitutional implications.
3.1. Data Acquisition
To collect data, we leveraged the Apify API (https://apify.com/apify/instagram-scraper, accesed on 12 February 2025) to extract Instagram posts during the 2024 EU election period (from 1 May 2024 to 30 June 2024). The selection criteria focused on posts relevant to electoral propaganda, ensuring that only content published at least 24 h before the election was included. To capture a more representative measure of engagement and audience interaction, all metrics were recorded at least 48 h after the posts were published, allowing sufficient time for organic propagation across the platform. Our final dataset comprised 364 images sourced from the official Instagram accounts of major political leaders, candidates, and their respective parties.
The subjects considered were the following:
- Più Europa
- Italia Viva
- Azione
- Lega
- Fratelli d’Italia
- Forza Italia
- Bonaccini
- Movimento 5 Stelle
- Alleanza
- Elly
- Partito Democratico
These political parties were collected in a balanced and representative way to minimize possible sources of bias. The next step was to collect the different discrete variables into a dataframe. These are the so-called feature variables essential for our ML-based approach. The variables collected and calculated are listed in Table 1.

Table 1.
Variables collected for each post through APIFY and their descriptions.
3.2. Data Processing and Aggregation
The collected data, including both posts and structured tabular data, underwent preprocessing to filter out irrelevant content. We specifically retained variables of interest such as likes, comments, and shares. From these metrics, we calculated engagement levels for each post. To convert the engagement rates into a categorical variable (for classification), we sorted posts based on engagement scores and defined three popularity categories based on threshold values: low, medium, and high. Specifically, the metrics used for class division were the total sum of interactions received for each post (likes + comments + shares), which were categorized as follows:
- Low popularity: value from 0 to 1000,
- Medium popularity: value from 1000 to 5000,
- High popularity: value above 5000.
A novel dataset was then constructed by categorizing each image into one of these classes. The report categorizes posts into low, medium, and high popularity, providing insights into the factors influencing audience interaction.
For instance, posts in the low popularity category include content such as a campaign message from Daniela Di Cosmo and a taxation policy statement (“Tassiamo i super ricchi”), both of which rely heavily on text and lack visually compelling elements. Another example in this category is a post criticizing Giorgia Meloni’s alleged association with anti-vaccine movements, indicating that negative framing alone does not guarantee high engagement. Conversely, medium popularity posts include critiques of political figures, such as one portraying Ursula von der Leyen with the hashtag #NoUrsulaBis, as well as a statement about the growth of Giorgia Meloni’s party (“FdI continua a crescere”), suggesting that posts with a mix of polarization and ideological reinforcement tend to attract moderate engagement. In the high popularity category, posts that highlight economic contrasts—such as the one emphasizing a EUR 209 billion gain from a European agreement compared to a EUR 13 billion loss—stand out for their effective use of visual contrast and numerical impact, which likely enhances shareability. Similarly, a post from the Partito Democratico stating “Sotto i 9 euro l’ora non è lavoro, è sfruttamento” (“Below 9 euros per hour is not work, it is exploitation”) benefits from a strong moral and emotional appeal, which is a recurring feature in highly engaging political content. At first glance, these observations suggest that clear contrasts, numerical evidence, emotional triggers, and visually engaging layouts contribute significantly to social media post popularity in political discourse.
3.3. Machine Learning Framework
For the classification and analysis of engagement, we developed an ML pipeline employing the Pytorch framework (v2.0.0), using Python (v3.8).
We defined an automated deep-learning pipeline for image feature extraction and classification head fine-tuning. This fine-tuning process was previously adopted for our use case and domain of analysis [34,35]. In our approach, we leveraged pre-trained convolutional neural networks (CNNs) and Vision Transformers (ViT) [36,37,38,39] to extract meaningful numerical representations (embeddings) from raw image data. Given an input image , a CNN or ViT model () extracts feature embeddings :
where represents the vision backbone function parameterized by weights , and d is the dimensionality of the extracted features.
Before feeding our images into each of the selected models, in our preprocessing stage, each input image was resized to a fixed resolution of pixels, ensuring compatibility with the input requirements of convolutional neural networks (CNNs) and Vision Transformers (ViTs). We applied pixel intensity normalization by scaling the RGB values to the range and further standardizing them using channel-wise mean and standard deviation values computed from the ImageNet dataset, a common practice to improve model generalization and convergence.
The extracted embeddings serve as input for various machine learning classifiers, including logistic regression, neural networks, gradient boosting, and support vector machines (SVMs) [40,41]. The classification models learn decision boundaries using these features. For each classifier g with parameters , the classification function is defined as
where represents the predicted class label.
To optimize , models are trained by minimizing a loss function , such as cross-entropy loss for multi-class classification:
where N is the number of training samples, is the true class label, and is the predicted probability.
To evaluate model performance, the Test and Score module performs cross validation. The classification performance metrics include the following:
- Accuracy:
- Precision:
- Recall:
- F1-score:
- Matthews correlation coefficient (MCC):
- Area under the curve (AUC):where , , , and are true positives, true negatives, false positives, and false negatives, respectively.
The trained models are applied to unseen images using the Predictions module:
The classification results are analyzed both quantitatively through confusion matrices and single predictions while examining them qualitatively.
4. Results
In this Section, we report our experimental setting and obtained results.
4.1. Experimental Setting
We partitioned our dataset into training and testing sets, allocating 70% for training and 30% for testing while ensuring class balance in both sets.
To extract deep feature representations from images, we utilized five pre-trained CNN models: ResNet-50, VGG-16, SqueezeNet, Inception-v3, and ViT-B/16 (Vision Transformer). Each model was modified by removing its final fully connected (FC) classification layer to retain high-level feature representations. The extracted feature vectors were then flattened into one-dimensional arrays and stored for subsequent classification.
Following feature extraction, we trained four machine learning classifiers to categorize social media posts based on engagement levels: logistic regression, a linear classifier optimized for high-dimensional data; support vector machine (SVM), a kernel-based model effective for non-linear decision boundaries; gradient boosting classifier, an ensemble method leveraging boosting for improved predictive performance; and multilayer perceptron (MLP), a shallow artificial neural network trained via backpropagation.
The logistic regression model was configured with a maximum iteration limit of 1000 (max_iter = 1000) to ensure convergence during optimization. The support vector machine (SVM) utilized a linear kernel (kernel = ‘linear’) for efficient classification of linearly separable data, with probability estimation enabled (probability = True) to facilitate probabilistic predictions. The gradient boosting classifier was initialized with 100 boosting iterations (n_estimators = 100), balancing model complexity and performance. The multilayer perceptron (MLP) architecture comprised a single hidden layer with 100 neurons (hidden_layer_sizes = (100,)), employing the rectified linear unit (ReLU) activation function (activation = ‘relu’) to introduce non-linearity, with weight optimization managed via the Adam solver (solver = ‘adam’). The training process was constrained to a maximum of 1000 iterations (max_iter = 1000) to ensure convergence, with a fixed random seed (random_state = 42) to promote reproducibility. Following model training, performance was assessed on the standardized test set, leveraging the optimized hyperparameters to maximize predictive accuracy.
All the classifiers were trained using supervised learning, with the dataset split into 70% training and 30% testing subsets. Extracted features were standardized to optimize classifier performance.
All experiments were conducted on a machine equipped with an Intel Core i9-13980HX processor (13th Gen, 2.20 GHz, Manufacturer: Intel Corporation, Santa Clara, CA, USA), 16 GB of RAM, and an NVIDIA GeForce RTX 4070 GPU with 8 GB of VRAM (Manufacturer: NVIDIA Corporation, Santa Clara, CA, USA), running a 64-bit operating system with the latest WDDM drivers (Manufacturer: Microsoft Corporation, Redmond, WA, USA).
4.2. Obtained Results
The results obtained with our ML approach for political post popularity prediction are reported in Table 2.
Table 2.
Performance comparison of models using different vision backbones and machine learning classifiers. The best results for each backbone are highlighted in bold.
To clarify and properly visualize the performance of each model and classifier, we report in Figure 1 a barplot comparison of the F1-scores according to backbones and selected classifiers.
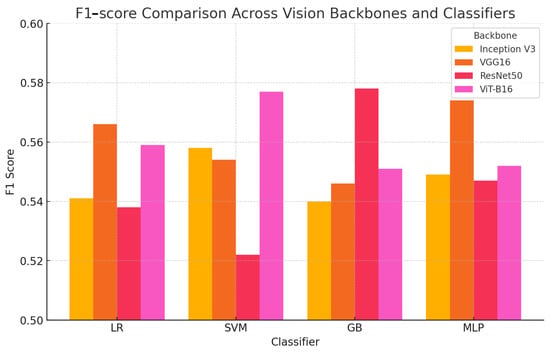
Figure 1.
Barplot comparison of F1-scores across backbones and classifiers.
According to both Table 2 and Figure 1, the evaluation of different network backbones and classification models reveals important insights into the relationship between feature extraction quality and predictive performance. Among the architectures tested, ViT-B16 demonstrated competitive performance, particularly in F1-score and precision, when paired with SVM and gradient boosting (GB), respectively. This suggests that Vision Transformers, while typically requiring large datasets, can still provide effective feature representations for specific classification tasks. Notably, ViT-B16 achieved the highest F1-score (0.577) with SVM and the highest precision (0.704) with GB, indicating that its tokenized representations can be leveraged effectively when paired with appropriate classifiers.
However, while ViT-B16 demonstrated strengths in precision and F1-score, its overall classification accuracy (0.611) remained on par with other models, particularly CNN-based architectures like VGG16 and ResNet50, which achieved comparable results. This aligns with findings in other domains where Vision Transformers may not always outperform convolutional architectures unless trained on significantly large-scale datasets. The moderate MCC scores obtained by the ViT-B16 classifiers further support this, suggesting that while the representations contribute meaningfully to predictive performance, they do not necessarily lead to a significant increase in overall classification reliability compared to CNN-based alternatives.
Across classification models, GB emerged as the best-performing classifier for ViT-B16, particularly in precision (0.704), indicating its ability to reduce false positives, making it a suitable choice for applications where precision is a priority. SVM, on the other hand, achieved the highest F1-score (0.577), balancing precision and recall more effectively. However, MLP matched GB in overall accuracy (0.611), further demonstrating that neural network classifiers can effectively leverage ViT-B16 embeddings.
The comparison between Vision Transformers and traditional CNN-based feature extractors suggests that while ViT-B16 was able to achieve competitive performance, it did not consistently outperform convolutional networks. This reinforces the importance of dataset characteristics in determining the effectiveness of different feature extractors. ViT-B16’s moderate performance suggests that while self-attention mechanisms provide useful feature representations, they may not always translate into superior classification results unless combined with larger-scale data or further fine-tuning.
Qualitatively, we selected the best vision backbone (Vit/B) and ML classifier (SVM) and analyzed the wrongly classified examples to find common patterns that may have misled the model itself. We then analyzed the confusion matrix of its prediction, as reported in Figure 2.
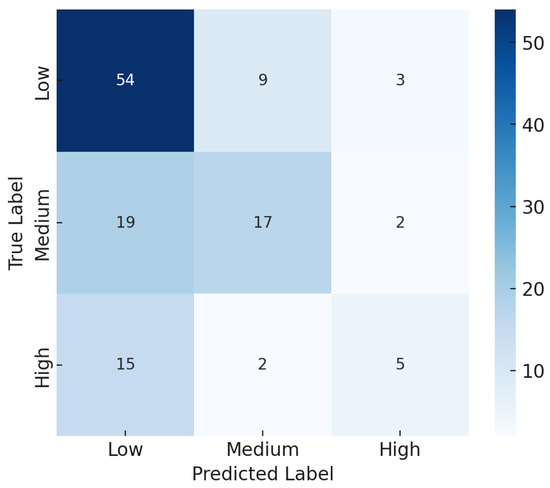
Figure 2.
Confusion matrix of the best-selected model.
The confusion matrix provides valuable insights into the classification performance of the model trained to distinguish between three categories: High, Low, and Medium. Overall, the model demonstrates the highest classification accuracy for the “Medium” category, correctly identifying 54 instances, suggesting that the features distinguishing this class are well captured. However, the misclassification rates for the “High” and “Low” classes are substantial, indicating that the decision boundaries between these categories may not be well defined. Specifically, the “High” class is often misclassified as “Medium”, with 15 incorrect predictions compared to only 5 correct ones, suggesting significant feature overlap between these two categories. Similarly, the model struggles with the “Low” class, correctly classifying 17 instances but misclassifying nearly half (19 cases) as “Medium”. These results indicate that the decision boundary between “Low” and “Medium” is not sufficiently clear, potentially due to overlapping feature representations in the dataset.
A notable trend in misclassification patterns is that incorrect predictions tend to be biased toward “Medium” rather than “High” or “Low”. This suggests that the “Medium” category may serve as a central cluster in the feature space, causing instances from the other classes to be incorrectly mapped to it. Additionally, if the dataset contains a greater proportion of "Medium" samples, the model may have developed a bias favoring this category, increasing the likelihood of false positives at the expense of correctly identifying “High” and “Low”. Given these observations, several improvements can be considered to enhance the classification performance. Feature engineering should be explored to identify more discriminative attributes that can effectively separate “High” and “Low” from ”Medium”. Additionally, resampling techniques, such as oversampling the underrepresented classes or undersampling “Medium”, may help mitigate the class imbalance and improve the classification boundaries. Alternative classification models, including ensemble methods or fine-tuned neural networks, could also be tested to refine decision boundaries and reduce misclassification rates.
Overall, while the model achieves a strong performance in classifying “Medium”, it struggles to differentiate between “High” and “Low”, leading to significant misclassification. The results highlight the importance of refining decision boundaries, either through improved feature selection, data augmentation, or alternative classification strategies, to achieve a more balanced and reliable classification model.
5. Discussions and Conclusions
The findings of this study highlight the growing influence of digital political campaigning, particularly through social media, in shaping voter engagement and election outcomes. The application of machine learning techniques to assess social media dynamics provided insightful results, demonstrating the significance of post popularity in predicting electoral impact.
Our analysis confirmed that digital campaigns increasingly rely on micro-targeting practices, where tailored messages reach specific voter segments, thereby enhancing engagement. However, this also raises ethical concerns related to misinformation, echo chambers, and algorithmic biases, which can distort democratic discourse [1,2,3]. The study further revealed that social media sentiment and engagement metrics could serve as viable alternatives to traditional polling methods, offering real-time insights into public opinion.
However, the model performance results indicate that distinguishing between high, medium, and low engagement posts remains a challenge, as observed in the misclassification trends. Vision Transformers, while demonstrating competitive performance in feature extraction, did not consistently outperform CNN-based architectures, suggesting that dataset characteristics and feature representation play a crucial role in classification effectiveness. However, distinguishing between posts with low and medium popularity is still complex. This issue can be attributed not only to the model’s performances but also to overlapping engagement patterns, which hindered classification performance. As a potential solution, we propose future work exploring binary classification (popular vs. non-popular) rather than a multi-class approach to improve predictive accuracy. Considering possible model improvements, clustering methods such as density-based clustering and feature engineering enhancements could be explored. Additionally, integrating models based on energy functions, as suggested in the FEM analysis study [42], could enhance classification robustness and provide new insights into engagement modeling. At the same time, the potential for numerical-analytical methodologies to optimize decision models was also highlighted. As suggested in the recent literature [43], combining mathematical models and simulations could refine feature selection and enhance predictive performance.
Another point of analysis amounts to the interpretability of ML predictions. Future work should incorporate interpretability methods such as LIME [44] to better understand the key features influencing engagement. This will also support bias analysis in our dataset, which, although efforts were made to ensure balanced representation among major political parties and leaders, may still arise due to the nature of political communication strategies and post types (e.g., infographics, speech photos, crowd images).
These findings underscore the importance of refining machine learning methodologies for political analysis. Indeed, as digital electioneering continues to evolve, interdisciplinary collaborations between legal scholars, data scientists, and policymakers are essential to developing frameworks that safeguard democratic integrity while leveraging technological advancements. Future research should explore the integration of multimodal data sources, such as textual, visual, and network-based features, to enhance the predictive accuracy and better capture the complexities of digital political communication.
Moreover, while Instagram has been identified as a powerful political communication medium [8], future work should extend the analysis to other platforms, such as Twitter/X, Facebook, TikTok, and Google search, to assess model generalizability across different social media environments and analyze whether different posts from different environments could lead to different pattern discovery.
Additionally, investigating the role of automated bots, deepfake content, and emerging generative AI technologies in campaign strategies can further inform regulatory measures and should be part of future works. Moreover, a key limitation is the potential for algorithmic and data-driven biases in AI models, which may inadvertently favor certain political perspectives or topics. While efforts are made to ensure neutrality, inherent biases in training data and content selection can shape responses in subtle ways. Future research should focus on systematically auditing AI-generated political discourse using benchmarking techniques to assess and mitigate these biases, ensuring greater transparency and fairness in digital political analysis. In fact, in this regard, the regulation of digital campaigns remains insufficient in ensuring transparency, particularly in areas such as algorithmic targeting, disinformation control, and platform accountability. Key regulatory priorities should include stricter transparency requirements for political advertising, ensuring that voters can easily identify who funds and targets them with specific messages. The recent European Regulation 2024/900 mandates disclosure of political ad sponsors and targeting criteria, aiming to safeguard voter autonomy by preventing manipulative advertising strategies [45,46]. Additionally, greater oversight of disinformation campaigns is crucial, particularly regarding foreign interference. For example, the European Union has imposed sanctions on state-sponsored media linked to Russian propaganda, demonstrating the need for a balanced approach between security and media freedom [47]. Moreover, stronger enforcement mechanisms for platform responsibility under frameworks like the Digital Services Act (DSA) are needed to mitigate algorithmic amplification of harmful content, as these platforms have become primary spaces for political discourse and potential manipulation [45,46].
Finally, it is important to note that no tests were conducted to generalize the results to other and different elections, and future work will focus on validating the proposed methodology across different electoral contexts to assess its broader applicability.
Overall, this study provides a foundational step in bridging computational political analysis with legal and ethical considerations, emphasizing the need for continued interdisciplinary efforts to ensure fair and transparent electoral processes in the digital era.
Author Contributions
Conceptualization, G.D.C., A.C. and E.F.; methodology, P.S.; software, P.S.; validation, E.F.; data curation, P.S. and E.F.; writing—original draft preparation, P.S., G.D.C., A.C. and E.F.; writing—review and editing, G.D.C., A.C. and E.F.; supervision, G.D.C. and E.F. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the European Union—Next Generation EU under the Prin 2022 PNRR call, Mission 4, Component 2, Investment 1.1, P2022MCYCK, CUP D53D23022340001.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Acknowledgments
This article was produced within the framework of the project ‘Normative and Digital Solutions to Counter Threats during National Election Campaigns—RightNets’, funded by the European Union—Next Generation EU under the Prin 2022 PNRR call, Mission 4, Component 2, Investment 1.1, P2022MCYCK, CUP D53D23022340001. The views and opinions expressed are, however, those of the author(s) only and do not necessarily reflect those of the European Union or the European Commission. Neither the European Union nor the European Commission can be held responsible for them.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| EU | European Union |
| ML | Machine Learning |
| AI | Artificial Intelligence |
| CNN | Convolutional Neural Network |
| ViT | Vision Transformer |
| SVM | Support Vector Machine |
| GB | Gradient Boosting |
| MLP | Multilayer Perceptron |
| MCC | Matthews Correlation Coefficient |
| AUC | Area Under the Curve |
| LR | Logistic Regression |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
| KPI | Key Performance Indicator |
| API | Application Programming Interface |
| CS | Computer Science |
| GPU | Graphics Processing Unit |
| RTX | Ray Tracing Texel eXtreme |
| APIFY | API-based Web Scraping Framework |
| URL | Uniform Resource Locator |
| FC | Fully Connected |
| CCDCOE | NATO Cooperative Cyber Defence Centre of Excellence |
References
- Haq, E.U.; Braud, T.; Kwon, Y.D.; Hui, P. A survey on computational politics. IEEE Access 2020, 8, 197379–197406. [Google Scholar]
- Singh, L.; Kamboj, S.; Kaur, T.; Singh, P. Exploring Changes in Public Opinion, Political Campaigns, and Political Behavior Through Data Science and Machine Learning. In Proceedings of the 2024 2nd International Conference on Artificial Intelligence and Machine Learning Applications Theme: Healthcare and Internet of Things (AIMLA), Tiruchengode, India, 15–16 March 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–5. [Google Scholar]
- Boratyn, D.; Brzyski, D.; Kosowska-Gąstoł, B.; Rybicki, J.; Słomczyński, W.; Stolicki, D. Machine learning and statistical approaches to measuring similarity of political parties. arXiv 2023, arXiv:2306.03079. [Google Scholar]
- Bradshaw, S.; Howard, P.N. Government Responses to Malicious Use of Social Media; The NATO Cooperative Cyber Defence Centre of Excellence (CCDCOE): 2018. Available online: https://demtech.oii.ox.ac.uk/wp-content/uploads/sites/12/2019/01/Nato-Report.pdf (accessed on 12 February 2025).
- Falavigna, G.; Giannini, V.; Ippoliti, R. Internationalization and financial constraints: Opportunities, obstacles, and strategies. Int. Econ. 2024, 179, 100510. [Google Scholar] [CrossRef]
- Cainelli, G.; Giannini, V.; Iacobucci, D. Agglomeration, networking and the Great Recession. Reg. Stud. 2019, 53, 951–962. [Google Scholar] [CrossRef]
- Micozzi, A.; Giannini, V. How Does the Localization of Innovative Start-ups Near the Universities Influence Their Performance? Industria 2023, 44, 129–151. [Google Scholar] [CrossRef]
- Mameli, M.; Paolanti, M.; Morbidoni, C.; Frontoni, E.; Teti, A. Social media analytics system for action inspection on social networks. Soc. Netw. Anal. Min. 2022, 12, 33. [Google Scholar]
- Stacchio, L.; Angeli, A.; Lisanti, G.; Marfia, G. Analyzing cultural relationships visual cues through deep learning models in a cross-dataset setting. Neural Comput. Appl. 2024, 36, 11727–11742. [Google Scholar] [CrossRef]
- Chester, J.; Montgomery, K.C. The Role of Digital Marketing in Political Campaigns. Internet Policy Rev. 2017, 6. [Google Scholar] [CrossRef]
- Liu, R.; Yao, X.; Guo, C.; Wei, X. Can we forecast presidential election using twitter data? An integrative modelling approach. Ann. Gis 2021, 27, 43–56. [Google Scholar]
- Tufekci, Z. Engineering the Public: Big Data, Surveillance and Computational Politics. First Monday 2014, 19. Available online: https://firstmonday.org/ojs/index.php/fm/article/view/4901/4097 (accessed on 12 February 2025).
- Paolanti, M.; Pierdicca, R.; Pietrini, R.; Martini, M.; Frontoni, E. SeSAME: Re-identification-based ambient intelligence system for museum environment. Pattern Recognit. Lett. 2022, 161, 17–23. [Google Scholar] [CrossRef]
- Bossetta, M. The digital architectures of social media: Comparing political campaigning on Facebook, Twitter, Instagram, and Snapchat in the 2016 US election. J. Mass Commun. Q. 2018, 95, 471–496. [Google Scholar]
- Smith, J.; Doe, J. Political Campaigns: Strategies and Implications. J. Sci. Res. 2020, 10, 123–145. [Google Scholar]
- Mersy, G.; Santore, V.; Rand, I.; Kleinman, C.; Wilson, G.; Bonsall, J.; Edwards, T. A comparison of machine learning algorithms applied to american legislature polarization. In Proceedings of the 2020 IEEE 21st International Conference on Information Reuse and Integration for Data Science (IRI), Las Vegas, NV, USA, 11–13 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 451–456. [Google Scholar]
- Brown, A.; Green, B. Digital Campaigning: The Rise of Data-Driven Strategies; Oxford University Press: Oxford, UK, 2019. [Google Scholar]
- Albert, K.; Penney, J.; Schneier, B.; Kumar, R.S.S. Politics of adversarial machine learning. arXiv 2020, arXiv:2002.05648. [Google Scholar]
- Suzor, N.P. Digital Constitutionalism: Using the Rule of Law to Evaluate the Legitimacy of Governance by Platforms. Soc. Media Soc. 2018, 4, 1–11. [Google Scholar] [CrossRef]
- Kofi Annan Foundation. Kofi Annan Commission on Elections and Democracy in the Digital Age: Protecting Electoral Integrity in the Digital Age; Kofi Annan Foundation: Geneva, Switzerland, 2020. [Google Scholar]
- Stacchio, L.; Angeli, A.; Lisanti, G.; Calanca, D.; Marfia, G. Toward a Holistic Approach to the Socio-historical Analysis of Vernacular Photos. Acm Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–23. [Google Scholar] [CrossRef]
- Trasys International. Study on the Impact of New Technologies on Free and Fair Elections (’Elections Study’) Literature Review Version 3.0. European Commission, March 2021. Available online: https://commission.europa.eu/system/files/2022-12/Annex%20I_LiteratureReview_20210319_clean_dsj_v3.0_a.pdf (accessed on 12 February 2025).
- Brennan Center for Justice. Generative AI in Political Advertising. Available online: https://www.brennancenter.org/our-work/research-reports/generative-ai-political-advertising (accessed on 12 February 2025).
- Stacchio, L.; Scorolli, C.; Marfia, G. Evaluating Human Aesthetic and Emotional Aspects of 3D Generated Content through eXtended Reality. In Proceedings of the CEUR Workshop Proceedings, Örebro, Sweden, 15–17 June 2022; Volume 3519, pp. 38–49. [Google Scholar]
- Groh, M.; Sankaranarayanan, A.; Singh, N.; Kim, D.Y.; Lippman, A.; Picard, R. Human Detection of Political Speech Deepfakes across Transcripts, Audio, and Video. arXiv 2022, arXiv:2202.12883. [Google Scholar] [CrossRef]
- YORD Studio. How AI is Shaping the Future of Extended Reality (XR). 21 October 2024. Available online: https://yordstudio.com/how-ai-is-shaping-the-future-of-extended-reality-xr/ (accessed on 12 February 2025).
- Stacchio, L.; Vallasciani, G.; Augello, G.; Carrador, S.; Cascarano, P.; Marfia, G. WiXaRd: Towards a Holistic Distributed Platform for Multi-Party and Cross-Reality WebXR Experiences. In Proceedings of the 2024 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW 2024), Orlando, FL, USA, 16–21 March 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 264–272. [Google Scholar] [CrossRef]
- Bononi, L.; Donatiello, L.; Longo, D.; Massari, M.; Montori, F.; Stacchio, L.; Marfia, G. Digital Twin Collaborative Platforms: Applications to Humans-in-the-Loop Crafting of Urban Areas. IEEE Consum. Electron. Mag. 2023, 12, 38–46. [Google Scholar] [CrossRef]
- Paolanti, M.; Tiribelli, S.; Giovanola, B.; Mancini, A.; Frontoni, E.; Pierdicca, R. Ethical framework to assess and quantify the trustworthiness of artificial intelligence techniques: Application case in remote sensing. Remote Sens. 2024, 16, 4529. [Google Scholar] [CrossRef]
- Stacchio, L.; Pierdicca, R.; Paolanti, M.; Zingaretti, P.; Frontoni, E.; Giovanola, B.; Tiribelli, S. XRAI-Ethics: Towards a Robust Ethical Analysis Framework for Extended Artificial Intelligence. In Proceedings of the 2024 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Bellevue, WA, USA, 21–25 October 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 214–219. [Google Scholar]
- de Slegte, S.; van der Veer, H.; Jacobs, K. The Use of Machine Learning Methods in Political Science. Political Stud. Rev. 2024, 23, 456–472. [Google Scholar] [CrossRef]
- Stacchio, L.; Garzarella, S.; Cascarano, P.; De Filippo, A.; Cervellati, E.; Marfia, G. DanXe: An extended artificial intelligence framework to analyze and promote dance heritage. Digit. Appl. Archaeol. Cult. Herit. 2024, 33, e00343. [Google Scholar] [CrossRef]
- Pietrini, R.; Galdelli, A.; Mancini, A.; Zingaretti, P. Embedded Vision System for Real-Time Shelves Rows Detection for Planogram Compliance Check. In Proceedings of the International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Boston, MA, USA, 20–24 August 2023; American Society of Mechanical Engineers: New York, NY, USA, 2023; Volume 87356, p. V007T07A003. [Google Scholar]
- Joo, J.; Steinert-Threlkeld, Z.C. Image as Data: Automated Visual Content Analysis for Political Science. arXiv 2018, arXiv:1810.01544. [Google Scholar]
- Anastasopoulos, L.J.; Whitford, A.B. Photographic home styles in Congress: A computer vision approach. arXiv 2016, arXiv:1611.09942. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. arXiv 2016, arXiv:1602.07360,. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar]
- Sen, P.C.; Hajra, M.; Ghosh, M. Supervised classification algorithms in machine learning: A survey and review. In Emerging Technology in Modelling and Graphics: Proceedings of the IEM Graph 2018, Kolkata, India, 6–8 September 2018; Springer: Berlin/Heidelberg, Germany, 2020; pp. 99–111. [Google Scholar]
- Stacchio, L.; Angeli, A.; Lisanti, G.; Marfia, G. Applying deep learning approaches to mixed quantitative-qualitative analyses. In Proceedings of the 2022 ACM Conference on Information Technology for Social Good, New York, NY, USA, 7–9 September 2022; GoodIT ’22. pp. 161–166. [Google Scholar] [CrossRef]
- Versaci, M.; Laganà, F.; Morabito, F.C.; Palumbo, A.; Angiulli, G. Adaptation of an Eddy Current Model for Characterizing Subsurface Defects in CFRP Plates Using FEM Analysis Based on Energy Functional. Mathematics 2024, 12, 2854. [Google Scholar] [CrossRef]
- Laganà, F.; Pullano, S.A.; Angiulli, G.; Versaci, M. Optimized Analytical–Numerical Procedure for Ultrasonic Sludge Treatment for Agricultural Use. Algorithms 2024, 17, 592. [Google Scholar] [CrossRef]
- Bhattacharya, A. Applied Machine Learning Explainability Techniques: Make ML Models Explainable and Trustworthy for Practical Applications Using LIME, SHAP, and More; Packt Publishing Ltd.: Birmingham, UK, 2022. [Google Scholar]
- Caterina, E. Verso il nuovo regolamento Ue in materia di pubblicità politica: Mercato delle idee o della propaganda? Quad. Cost. Riv. Ital. Dirit. Cost. 2024, 1, 207–209. [Google Scholar] [CrossRef]
- Licastro, A. La regolazione dello spazio informativo disintermediato dinanzi alla progressiva avanzata della ’synthetic media technology’ in tempo di tornate elettorali. Dirit. Pubblico 2024, 3, 577–619. [Google Scholar] [CrossRef]
- Cossiri, A. Le campagne di disinformazione nell’arsenale di guerra: Strumenti giuridici per contrastare la minaccia alla prova del bilanciamento. Riv. Ital. Inform. Dirit. 2024, 5, 77–85. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).