1. Introduction
Many biometrics exist to provide authentication for users while in a public setting [
1], such as personal identification numbers, passwords, cards, keys, and tokens [
2]. However, those methods can become compromised, lost, duplicated, stolen, or challenging to recall [
2]. The acquisition of face data [
3] is utilized for verification, authentication, identification, and recognition [
4], and has been a decades-old computer vision problem [
5]. The ability to accurately interpret a face allows for recognition to confirm an identity, associate a name with a face [
5] or interpret human feeling and expression [
6]. Facial recognition for humans is an easy task [
5], but becomes a complex task for a computer [
4] to perform like human perception [
5]. Although image analysis in real-time [
7,
8] is feasible for machines, and significant progress has been achieved recently [
9]. Automatic facial recognition remains a difficult task that is challenging, tough, and demanding [
2]. Many attempts to improve accuracy in data visualization [
3] still reach the same conclusion that artificial intelligence is not equal to human recognition when remembering a small sample size of faces [
10], and numerous questions and problems remain [
9].
A system needs to collect an image of a face to use as input to compare against a stored or previously recognized image for successful recognition. This step involves many variables that severely impact the capabilities for successful face recognition [
4]. Many users want authentication in a public setting and most likely, using a mobile device leads to unconstructed environments [
6] and non-controlled changes [
11]. These changes lead to limitations on nonlinear variations [
11], making data acquisition difficult [
1]. This problem has persisted for over fifty years [
6] and often contributes to differing results that cannot be replicated [
10]. Further complications include the approach taken because different techniques can yield different results [
10]. Some influences that contribute to these problems are the position, illumination, and expression [
1,
2,
3,
4,
8,
12,
13]. Other influences include pose angles [
1,
8], camera distance, head size, rotation, angle, and direction [
3,
5,
6]. The introduction of aging, scaling, accessories, occlusion [
1,
13], and hair [
5] makes capturing these varying scales more difficult [
14]. Limitations on the image quality such as noise, contrast [
15], resolution, compression, and blur [
12] also contribute to facial recognition inaccuracies.
Although image collection has some varying problems, machine and deep learning are relatively reliable [
16] learning algorithms capable of handling large datasets available for research and development [
17]. Plenty of facial recognition algorithm variants exist [
18,
19], and together these algorithms can improve human capabilities in security, medicine, social sciences [
17], marketing, and human–machine interface [
20]. These algorithms possess the ability to detect faces, sequence, gait, body, and gender determination [
19], but still, trained algorithms can produce skewed results [
16,
17]. These uneven results often lead to a significant drop in performance [
16] that can raise concerns about fairness [
20]. With the reputation of companies that use facial recognition at stake, many ethical concerns have been raised because of the underrepresentation of other races in existing datasets [
16]. Inconsistent model accuracy limits the applicability to non-white faces [
17], and the dataset contributes to demographic bias [
16]. Existing databases and algorithms are insufficient for training due to the low variability in race, ethnicity, and cultures [
20]. Most datasets are not labeled for ethnicity [
13], and unknown performance [
20] and controversial biased models are a result of utilizing these datasets [
13].
The use of limited models contributes to false matches, low adequacy, fairness, and reliability concerns [
20]. Many experiments have observed these results and marked present mostly in faces with a higher melanin presence [
16,
21]. Convolutional neural networks have improved the capabilities of algorithms [
13]. However, there is still much room for group fairness in datasets to mitigate the bias that has existed for decades leading to algorithms suffering from demographical performance bias that provides an imbalance to specific groups of individuals [
22]. As racist stereotypes exist, there is a need to avoid mislabeled faces and achieve greater race classification accuracy [
23]. Utmost importance should be placed on how human attributes are classified [
17] to build inclusive models while considering the need for diversity in datasets [
21]. Substantial importance should be emphasized that models need to be diverse due to being trained on large datasets with many variations [
13]. The results are algorithms and techniques that mitigate bias [
20].
The results include an imbalance for some races and demographical bias against specific ethnicities. Considering these inequalities, we investigate and evaluate racial discrimination in facial recognition across the various machine and deep learning models. The findings and results will allow us to discover existing bias with repeatable observations and if any algorithms outperform others while mitigating any bias.
Continuing previous research in [
23], we continue to measure and evaluate the observable bias resulting from utilizing the five traditional machine learning models and techniques. Replicating the initial approaches and datasets used with conventional algorithms, we repeat the previous steps and conduct similar experiments with the three deep learning algorithms. Collecting the results from the deep learning models, we perform identical evaluation and bias measurements. Collecting results for each algorithm used allows us to compare performance, accuracy, and bias to evaluate the efficiency of algorithms. We present our findings in hopes of making a meaningful contribution to the decades-old computer vision problem and facial recognition fields. Our collected contributions are:
Evaluation of racial bias across five machine learning algorithms using racially imbalanced and balanced datasets.
Evaluation of racial bias across three deep learning algorithms using racially imbalanced and balanced datasets.
Evaluation and comparison of accuracies and miss rates between tested algorithms.
Report the algorithms that mitigate the bias the most.
2. Background
As humans, we can quickly identify a face and recognize an individual within a short time. The idea of facial recognition is done daily, and with minimal effort that we may consider this task easy. As time passes, we may see a face that seems familiar, but may not recall the name of the individual even though we recognize them. The introduction of computers to assist with this computer vision problem allows the capabilities to expand to remember substantially more faces. However, once it seemed easy for a human, it is a much more complicated task for a machine. The initial concept of facial recognition was a straightforward task with an obvious solution. The solution involved obtaining an image and precisely identifying or determining if the image matched against a database of stored images. However, four main obstacles present unique problems for facial recognition to be completed successfully. The first problem is the complexity of the task itself, where the next problem is shown in the influences on the images themselves. The final problematic area for facial recognition lies within the algorithms and datasets. Together these problems combined present a unique problem that is observable in technology that is used every day.
2.1. Complexity
For a human to visually recognize a face, we first must observe a face with our eyes, and this image is introduced to the ocular nerve. The idea is then sent to the brain, where the brain retrieves the name that we associate with that face if it is recallable. Many systems are working in tandem, and we often do not realize the complexity of a task that appears so simple. For a computer to first remember an image, it must convert that image into a data structure to compare against others [
24]. In our case, we introduce a traditional photograph that we transform into an array of numbers to represent each image’s pixel. After converting the pictures, they are then stored for comparison against additional photos. Calculating values for each pixel is a complex task that can involve thousands or millions of steps to complete depending on image size and quality, especially if you consider that each pixel comprises values representing the red, green, and blue values within itself.
2.2. Influences
Influences are one of the most varying items that severely impact facial recognition. The typical three items referenced in the field are pose, illumination, and expression (PIE). Most conventional images are collected by a photographer using a fixed camera with a seated individual in precisely controlled lighting. However, if we suddenly consider any image as usable, then a candidate for recognition may be standing, seated, or involved in an action. The lighting could be too bright or too dark, depending on the location of the image collection. Considering expression is another barrier because viewing traditional images may have a subject smiling. However, your system would still need to recognize your face if you were in a bad mood or had a different expression such as surprise, shock, or pain. Additional items that present problems are aging, angle, scaling, accessories, and occlusion. As we age, our face has subtle changes that make facial recognition more difficult because the look is slightly different. Using a mobile device to collect images can allow individuals to manage their appearance. Still, there is no guarantee that they will hold the camera perfectly level or at an exact distance away from their face. Accessories such as jewelry, glasses, facial hair, hairstyles, and hair color can support the occlusion of a look, making this complex task even more difficult. During our research, the topic of masks as a new item that covers faces and their impact on systems was discussed. During the pandemic a mask was introduced as a new accessory that covers a considerable amount of a face.
2.3. Algorithms
Once a facial recognition system is in use and the influences and complexity issues have been considered. The next item that impacts the miss rates, hit rates, and the system’s accuracy is the algorithms themselves. Algorithms can contain several factors that may obtain results that are not precise. An algorithm is designed to do what it is programmed to do, and it will consistently execute as it is programmed. However, these algorithms are created by humans, and this underlying problem can surface within the intended results of an algorithm. Psychologists have studied this as something that humans instinctively do from childhood. Where humans interact with what they are familiar with or interact with more frequently. This phenomenon is observable in facial recognition algorithms designed in Eastern and Asian countries when compared against American counterparts. An algorithm designed in an Asian country will have some influence from its Asian designer and their daily interaction with other community members. This bias will likely result in a system that performs better for those types of individuals. Especially measuring results within that community when compared to other nations. Using inferior algorithms leads to skewed results, performance degradation, and applicability limitations. Biased algorithms can produce results that are not meaningful when considering other outside contributions. This bias demonstrates the need for careful thought when designing an algorithm to be inclusive for all intents and purposes.
2.4. Datasets
If the algorithm has carefully been planned during implementation, it is a particular assumption that it is only as good as the dataset it utilizes. Most datasets do not have labels for races, ethnicity, and demographics. Training of this type of dataset will yield an inaccurate model. This error would also lead to false matches and poor adequacy. Other obstacles in datasets include the fact that a nation may comprise many different races. Combining a similar race as one nationality complicates the accurate estimation of a specific demographic. For example, Malaysia is a multi-racial composition country with many races that all identify as Malaysian. Our dataset included more than 1000 test subjects, but we could only retrieve approximately twenty Black individuals with more than ten available images. There is an obvious imbalance and underrepresentation of specific races, ethnicities and, nationalities while surveying available datasets for research.
Many datasets exist and are available for research and development [
10]. However, facial recognition requires many images of each subject, creating an immediate complication for this type of research. Our study utilizes the FERET [
25,
26] dataset, a publicly available dataset with access granted from the National Institute of Standards and Technology (NIST). Our selected dataset contained 1208 subjects. However, when examining the available images, the number of subjects with many images was predominantly White. This imbalance immediately impacted our research methods and processes, and the limitations for other races were noticeable. Only a few datasets contain many images of the same individual, predominantly comprised of celebrities [
3]. Although many datasets are available, they lack the appropriate labeling and classifications that algorithms need to train and test against successfully. Properly documenting existing datasets would be a never-ending process, and still, the datasets would be insufficient for certain demographic and racial representations. An image revolution or campaign is needed to gather lots of images so that datasets become more diverse and inclusive with representations of all walks of life. Tuned datasets such as FairFace and DemogPairs successfully mitigated existing racial and demographic bias [
3,
7].
2.5. Machine Learning Algorithms
Machine learning algorithms make informed decisions by parsing data and learning from the collected data [
27]. Typically, these techniques are used to examine large databases to extract new information as a form of data mining. Many large companies use machine learning to provide an improved user experience in human–computer interaction. These improvements may include a recommendation based upon preferences or suggestions based on previous selections [
27]. Machine learning algorithms require outside exchange if corrections or adjustments are necessary. A general analogy to envision a machine learning algorithm can be demonstrated by using a flashlight. If we teach the flashlight with a machine learning model, it will understand light and dark. If provided with the word dark, the flashlight will come on. The opposite will occur if the word light is used. However, if presented with a word or phrase it has not learned, such as dim, it will not function and require additional adjustments to accommodate the new expression [
27]. Gwyn et al. [
23] studied traditional machine learning techniques prompting further research in facial recognition, specifically regarding racial bias. We have chosen Support Vector Classifier (SVC), Linear Discriminant Analysis (LDA), K-Nearest Neighbor (KNN), Decision Trees (DT), and Logistic Regression (LR) algorithms from [
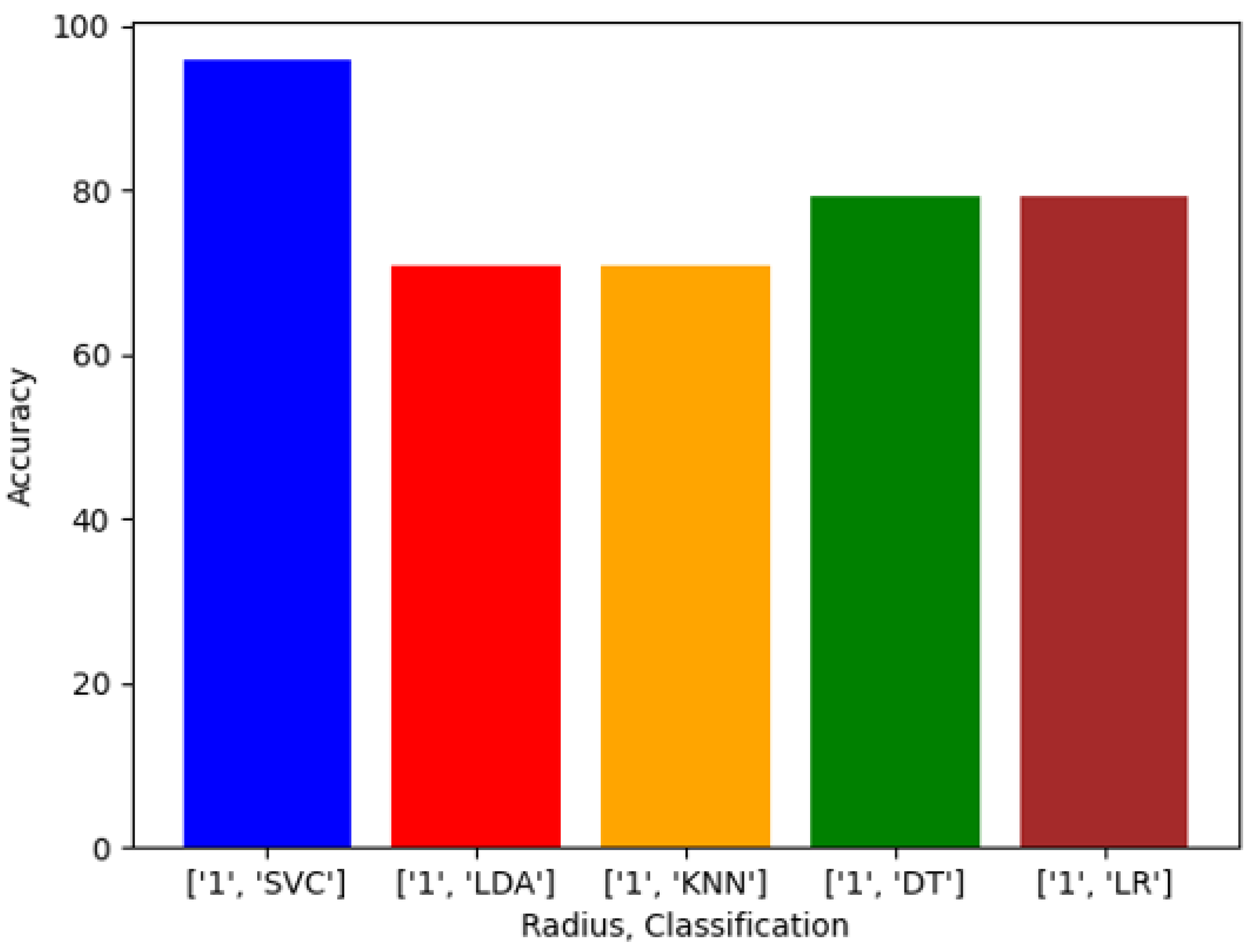
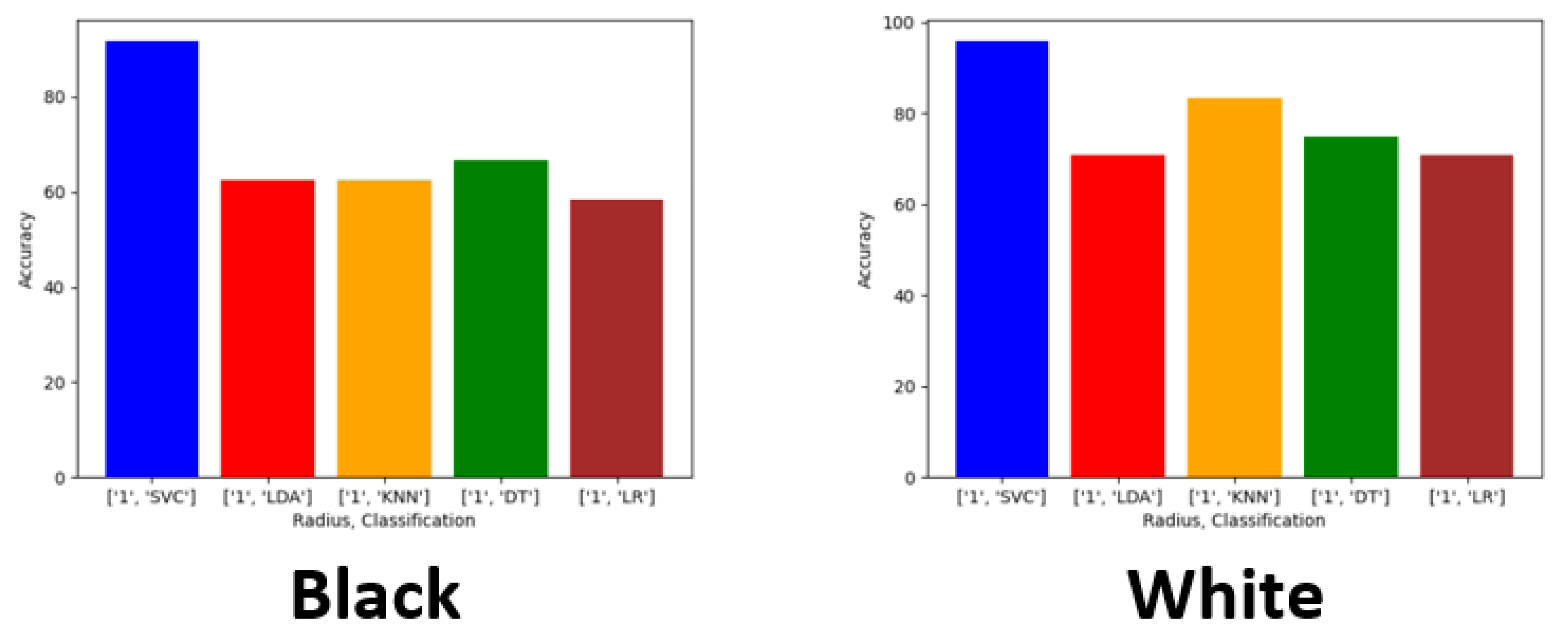
23]. These algorithms are used for several applications and the approaches can vary such as regression, clustering, dimension reduction and image classification. For our study, we choose to apply these algorithms using classification methods and do not combine or use them in tandem to produce observable results for each algorithm.
Using SVC, image classification for a multi-class approach is achieved by constructing linear decision surfaces using high-dimensional features mapped by non-linear input [
23]. LDA is used as a classifying approach by using a normally distributed dataset and projecting the input to maximize the separation of the classes [
23]. Classification utilizing KNN is achieved by assigning classes to the output. The designation is concluded by the overall counts of its nearest cohorts, and the class assignment goes to the class with the most common neighbors [
23]. The DT approach yields its classifications as a structure and treats each child or leaf as a subset without statistical reasoning [
23]. The LR approach reaches the classification by considering the probability that a class exists where the outcome is that a training image and a test image belong to the same class [
23].
2.6. Deep Learning Algorithms
Much like machine learning was a form of data mining, deep learning algorithms are a subset of machine learning that functions similarly, but with differing capabilities [
27]. If a deep learning algorithm returns an incorrect prediction, the model itself will correct it internally. These algorithms may also use selections and preferences initially, but once deployed, they learn solely on the model and what it was trained on to predict and correct upon [
27]. Vehicles that drive automatically or features on them that make lane corrections, braking, and accident avoidance autonomously are some examples of deep learning algorithms in use. We can continue the flashlight analogy to better assist with understanding deep learning algorithms. The light would not need a keyword to associate with action because it would compute from its model and learn to be on or off when required [
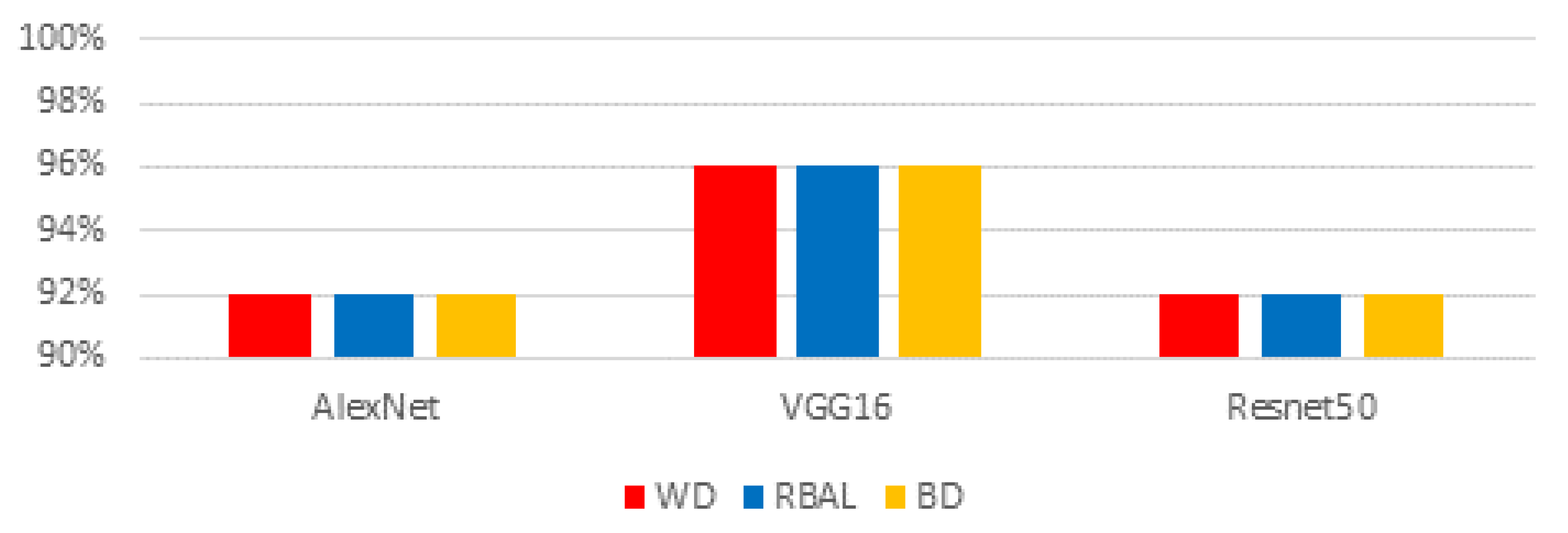
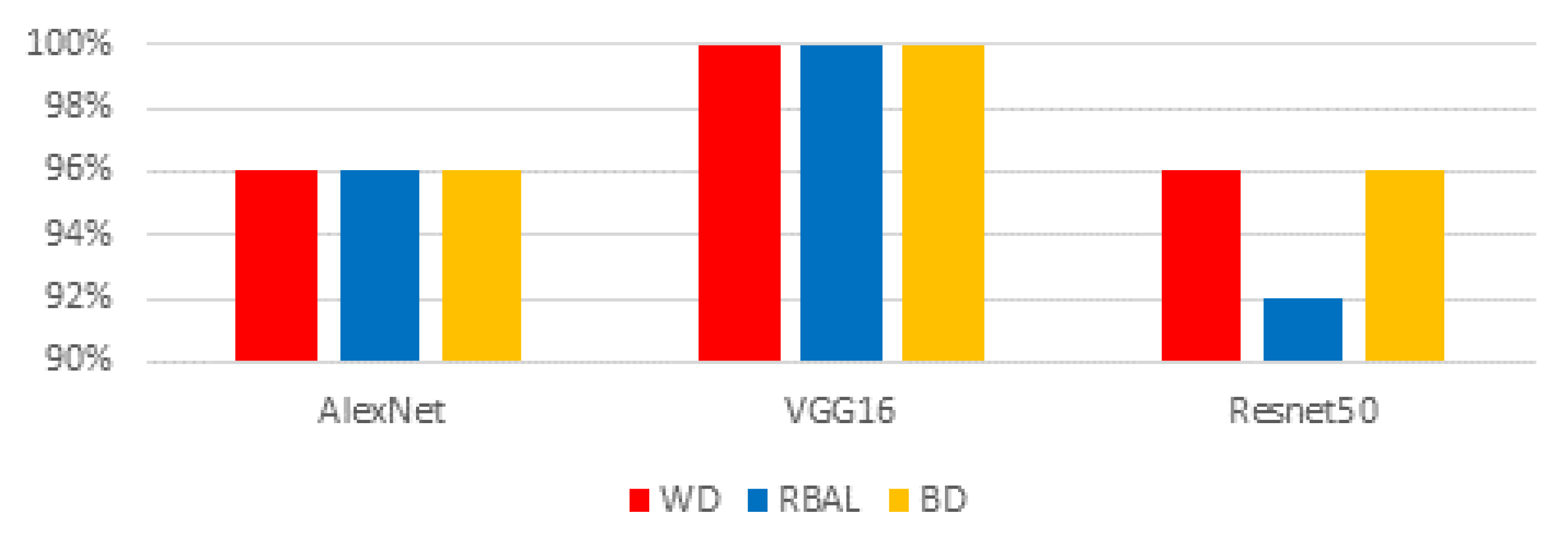
27]. For our continuing research, we have chosen AlexNet, VGG16, and ResNet50 deep learning algorithms.
3. System and Experimental Design
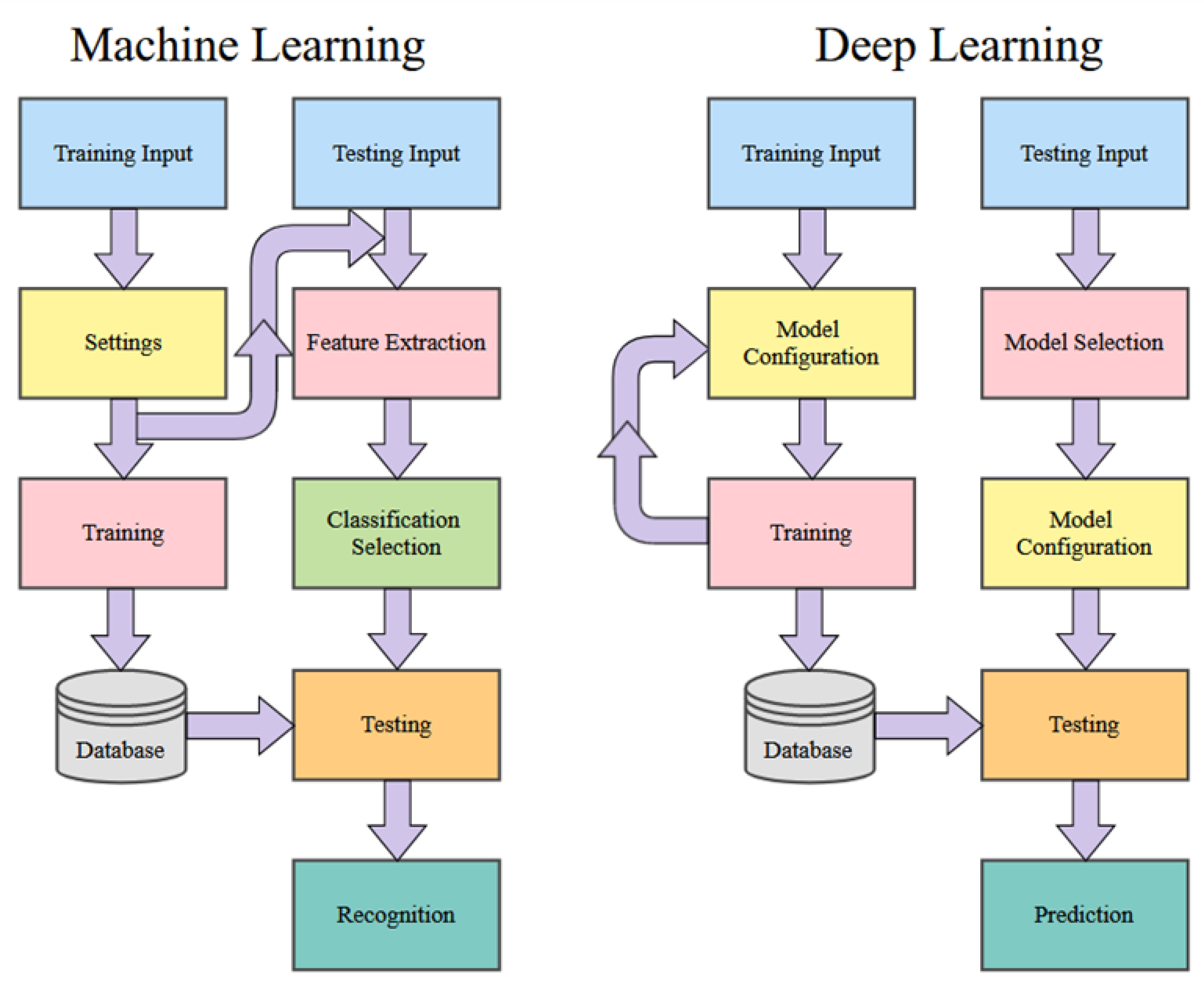
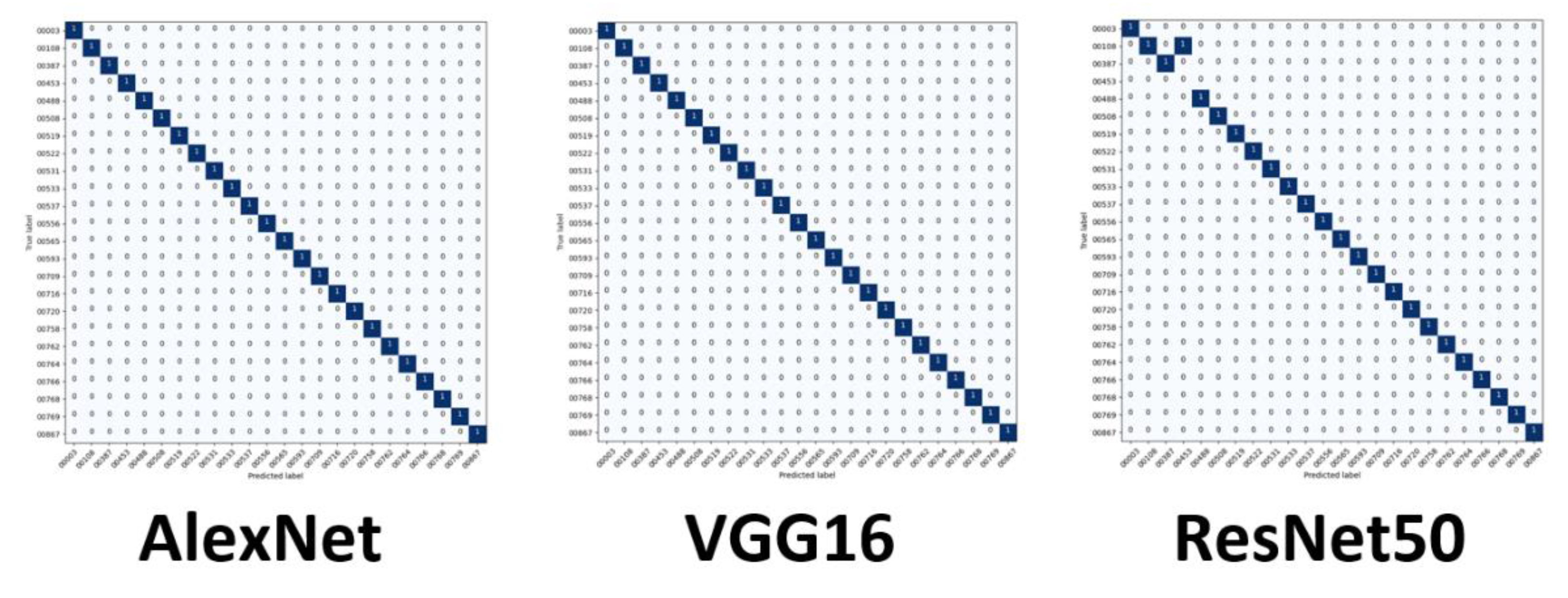
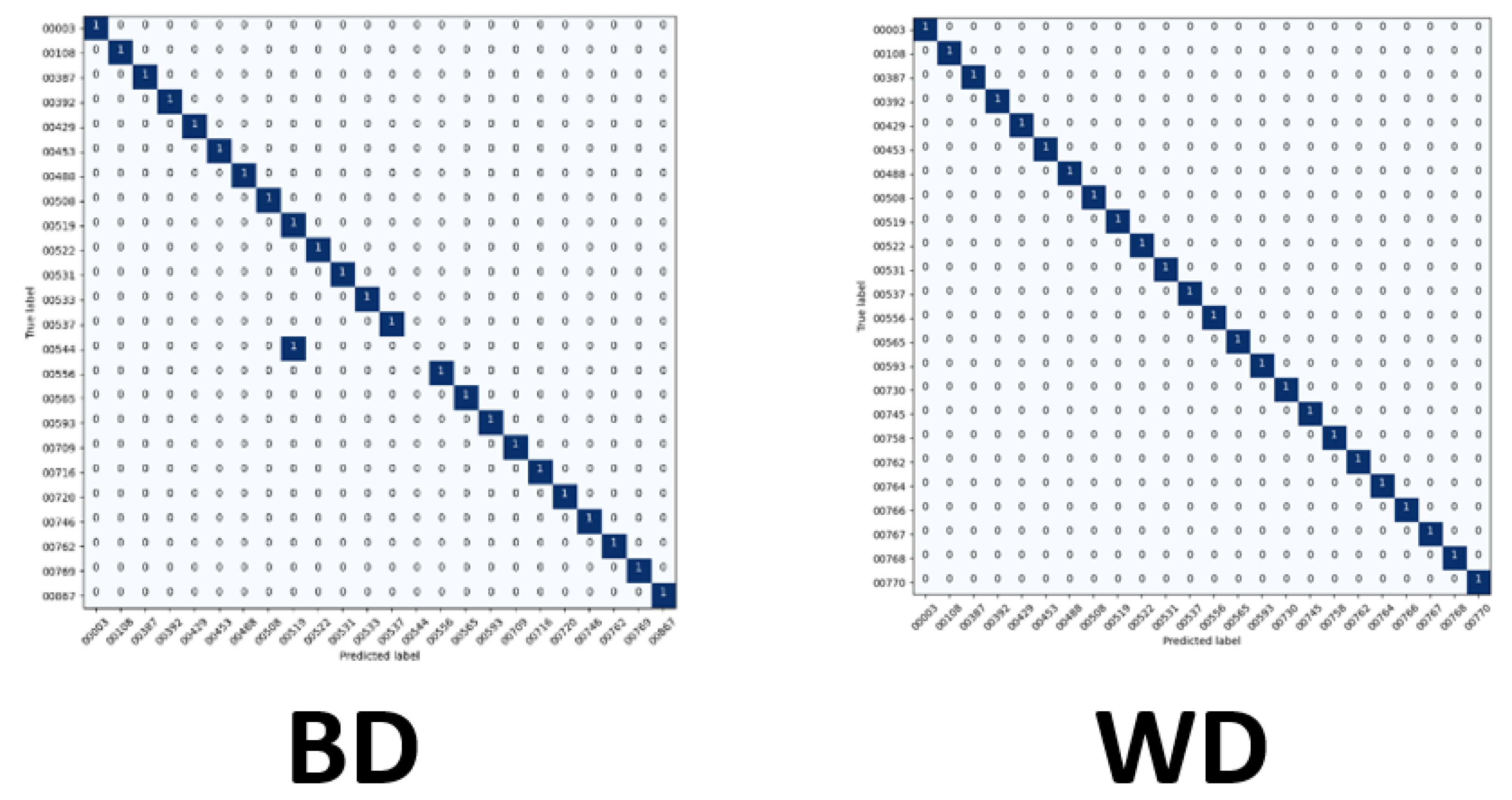
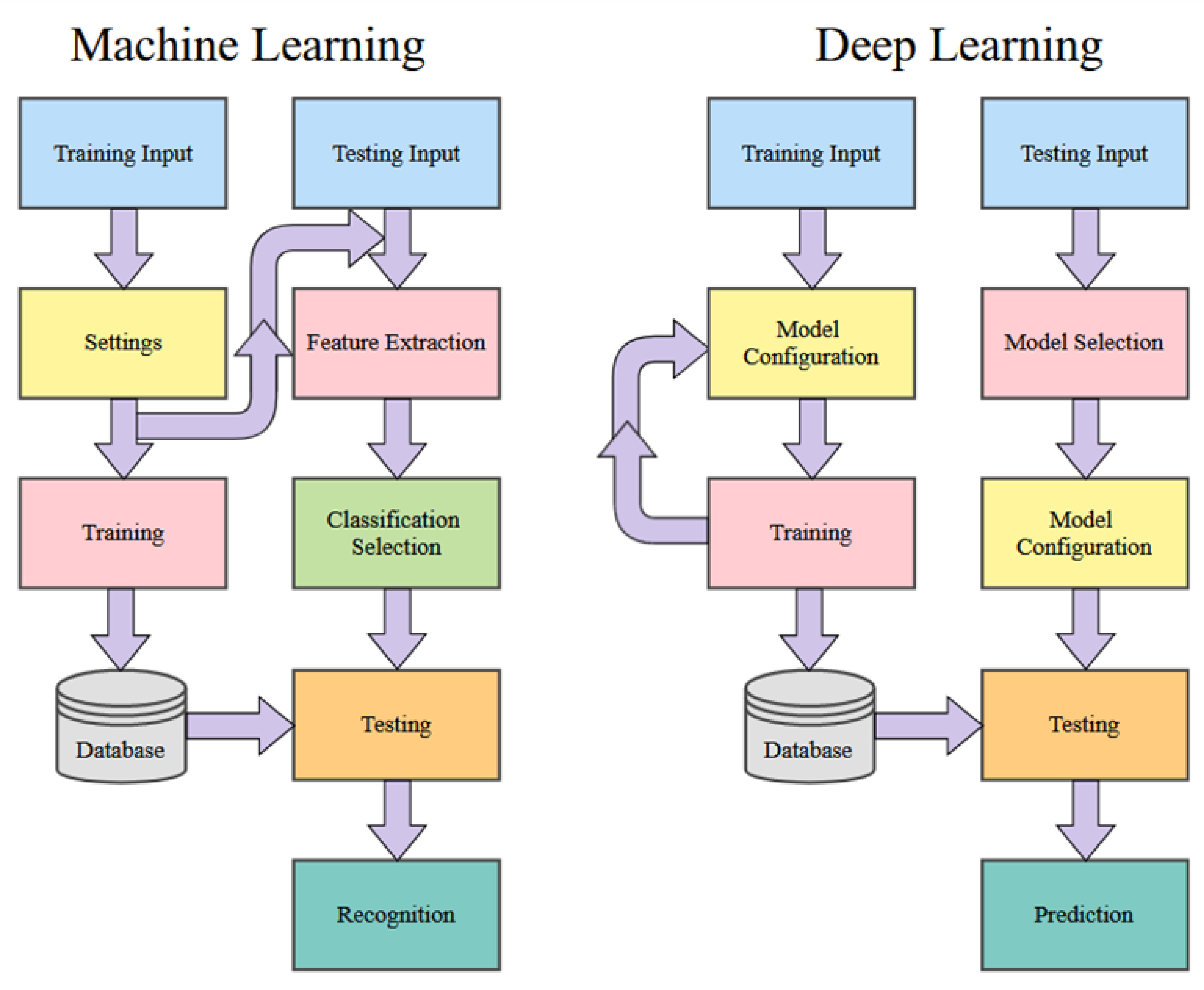
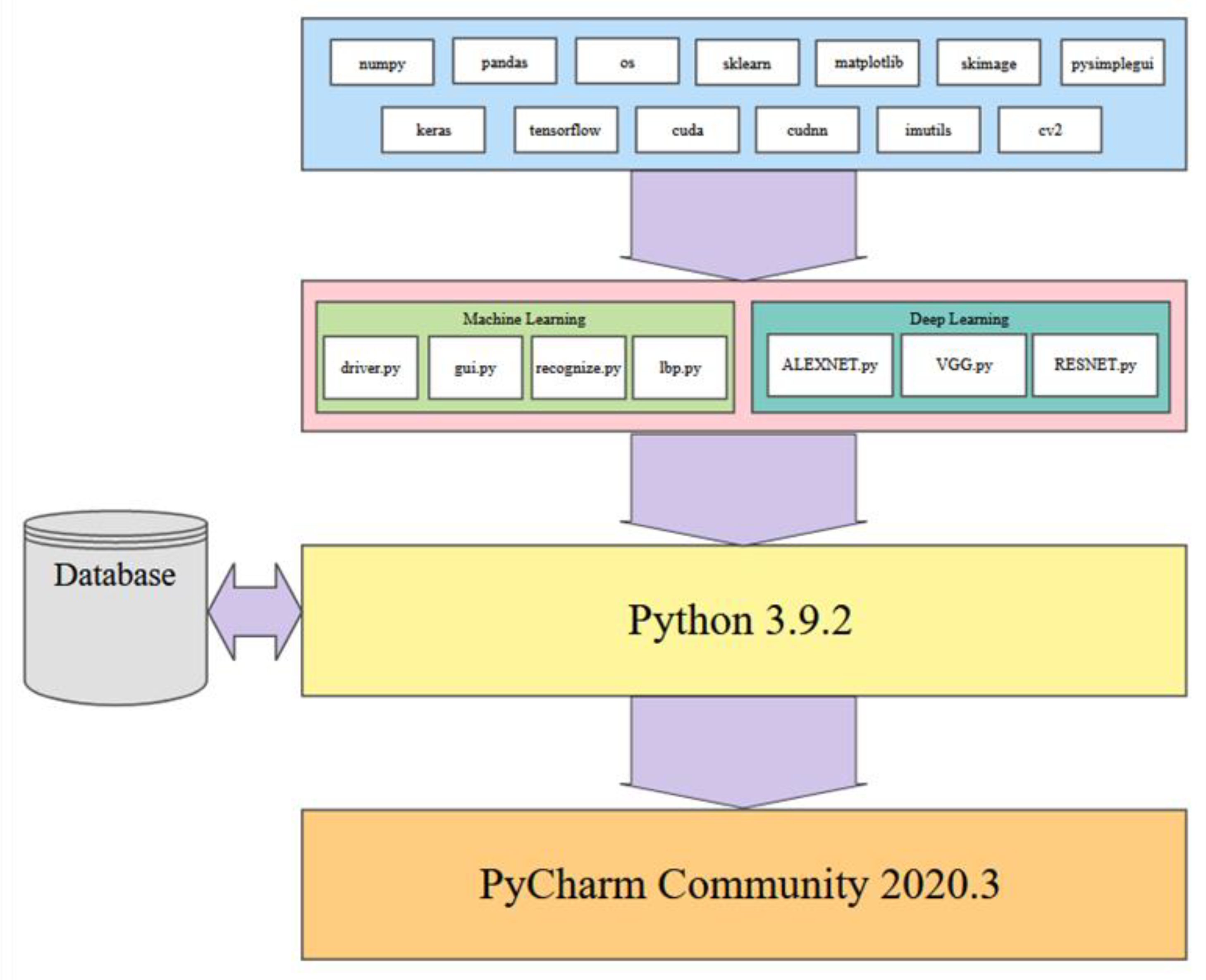
The similarities in the construction of our machine learning and deep learning algorithms, as shown in
Figure 1, denotes the similarities between the two. Both algorithms follow a similar route for execution and use inputs to test for successful recognition. Both algorithms store the results of their training for future comparison and testing. Still, the most notable differences are the number of iterations or epochs that deep learning uses to learn and perform better. Machine learning algorithms take input and apply the settings and execute a mathematically complex algorithm once.
3.1. System Design and Architecture
Our machine learning algorithms take images and use them as input to train the system, as shown in
Figure 1. After initialization, the graphical user interface (GUI) collects testing variables, so identical approaches are used. The following steps are for the system to train on inputs of balanced or imbalanced datasets and save them to a datastore. During the testing portion, the system takes the images as input and applies the same setting used for training. The system extracts the features and brings the classification selection for the desired algorithms. The testing phase compares the calculated image to the saved training images to recognize.
A similar approach is used for the deep learning algorithms where input is used for training. The model of the algorithm to be used is constructed. The training iterates or cycles for a selected number of epochs. During the revolutions of each period, the system can validate the training for accuracy and improve predictions on each iteration. Once the training is completed, the datastore is used to save the trained model, as shown in
Figure 1.
3.2. System Software
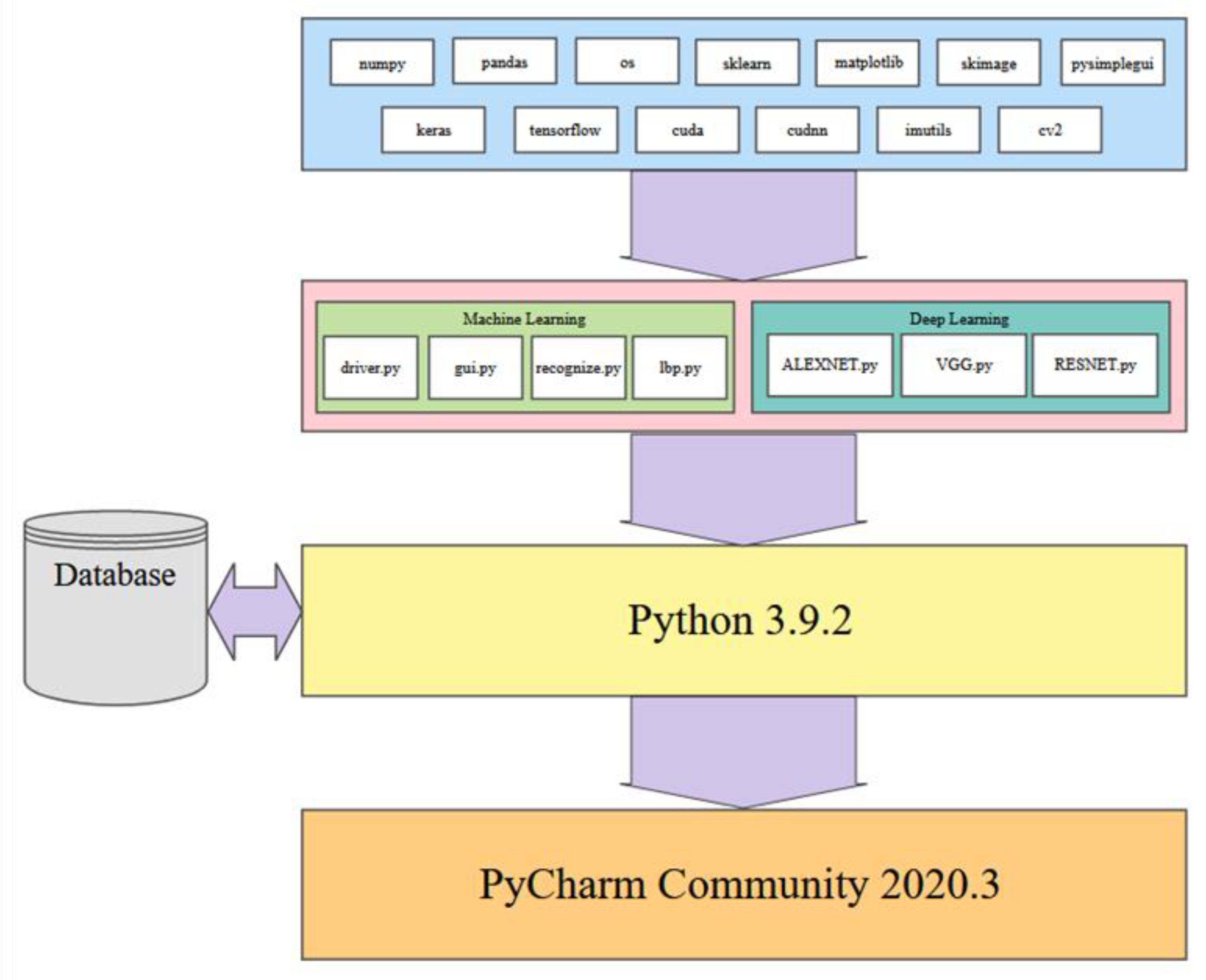
Continuing prior research [
23], Python
® was the language used, which was a requirement for our continuing research and experimentation. Python is a powerful programming tool that granted us access to many libraries that assisted with implementing this project. Those imported libraries include Pandas, NumPy, OS, Scikit-Learn, Matplotlib, Keras, TensorFlow, CUDA, and cuDNN, as shown in
Figure 2.
Pandas is a powerful utility to collect DataFrame information, and NumPy was successful in data structure manipulation. Tools included by importing Scikit-Learn include confusion matrices and built-in metrics reporting. Matplotlib was utilized for feedback and graphing during code execution. The subsequent imports were the game changers for this project. The Keras neural network library has an extensive catalog of tools built on the open-source library of TensorFlow. These high-level Application Programming Interfaces (APIs) assisted in layering, pooling, metric reporting, model construction, and optimization. The addition of the CUDA and cuDNN imports is where the significant drop in runtime occurred. After configuring them properly, they allow the GPU to be utilized in tandem with the CPU. Overall runtimes significantly drop by more than 75%. Each of our model interpretations is paired with some of these imports and our FERET dataset compilation. The existing code implementations for our experimentation are conducted in Python 3.9.2 using PyCharm Community Edition 2020.3.
3.3. Evaluation Plan
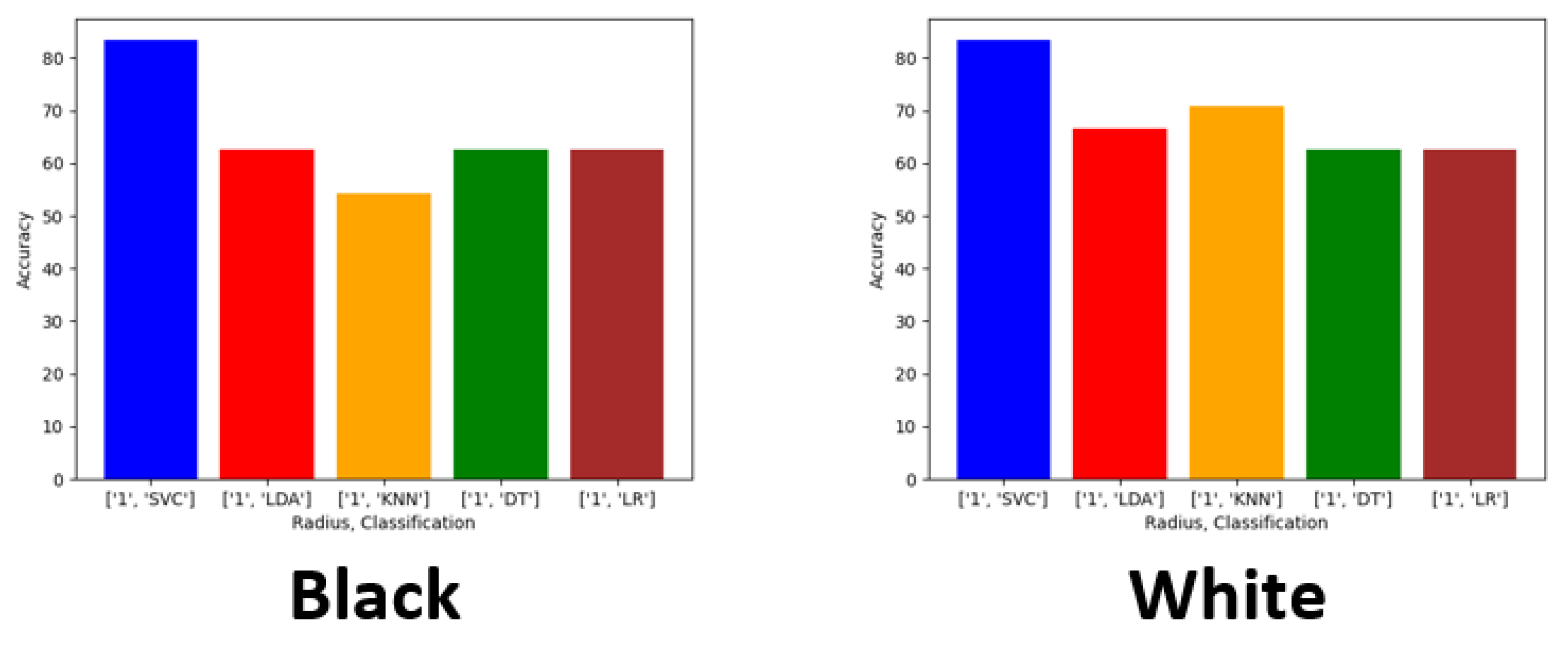
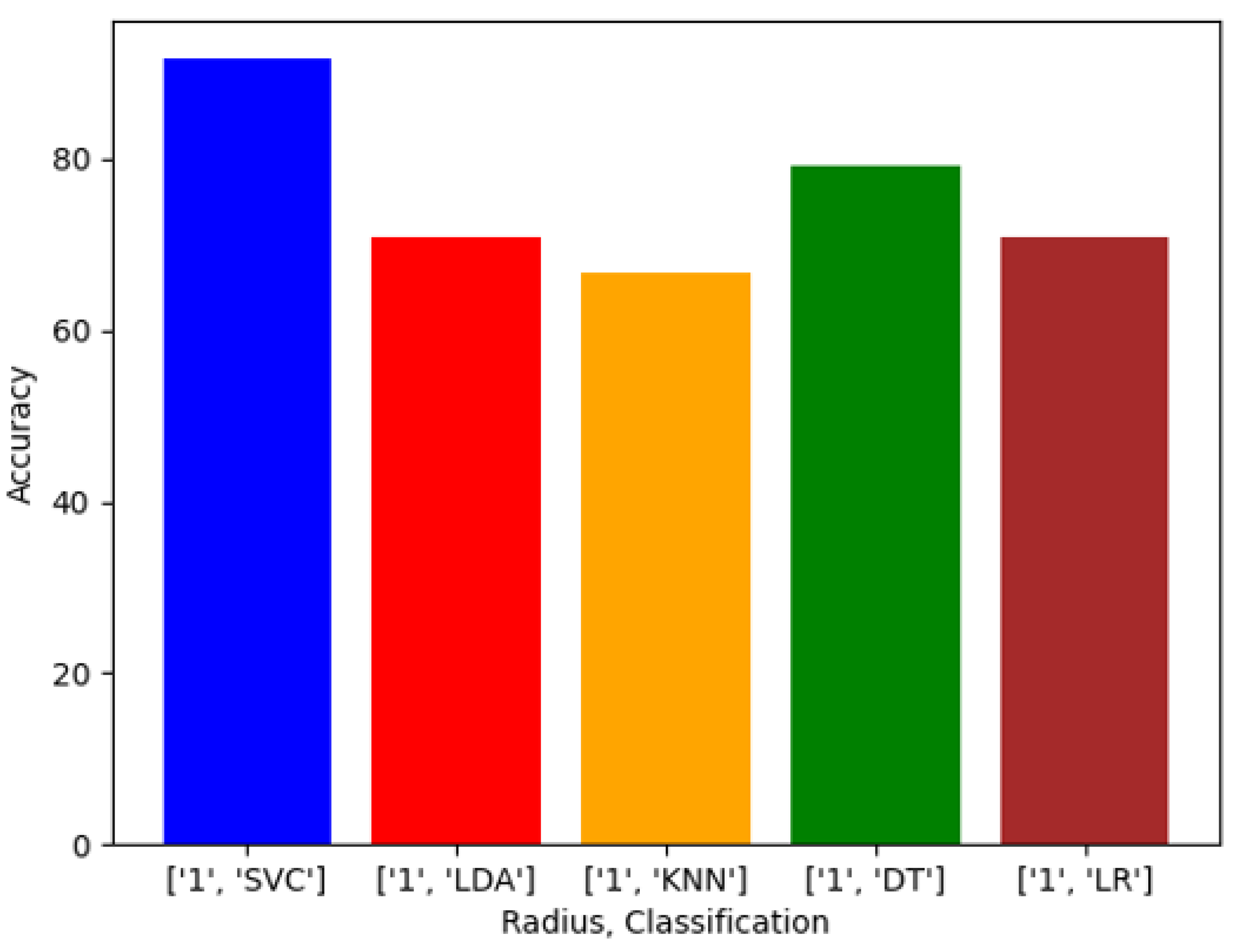
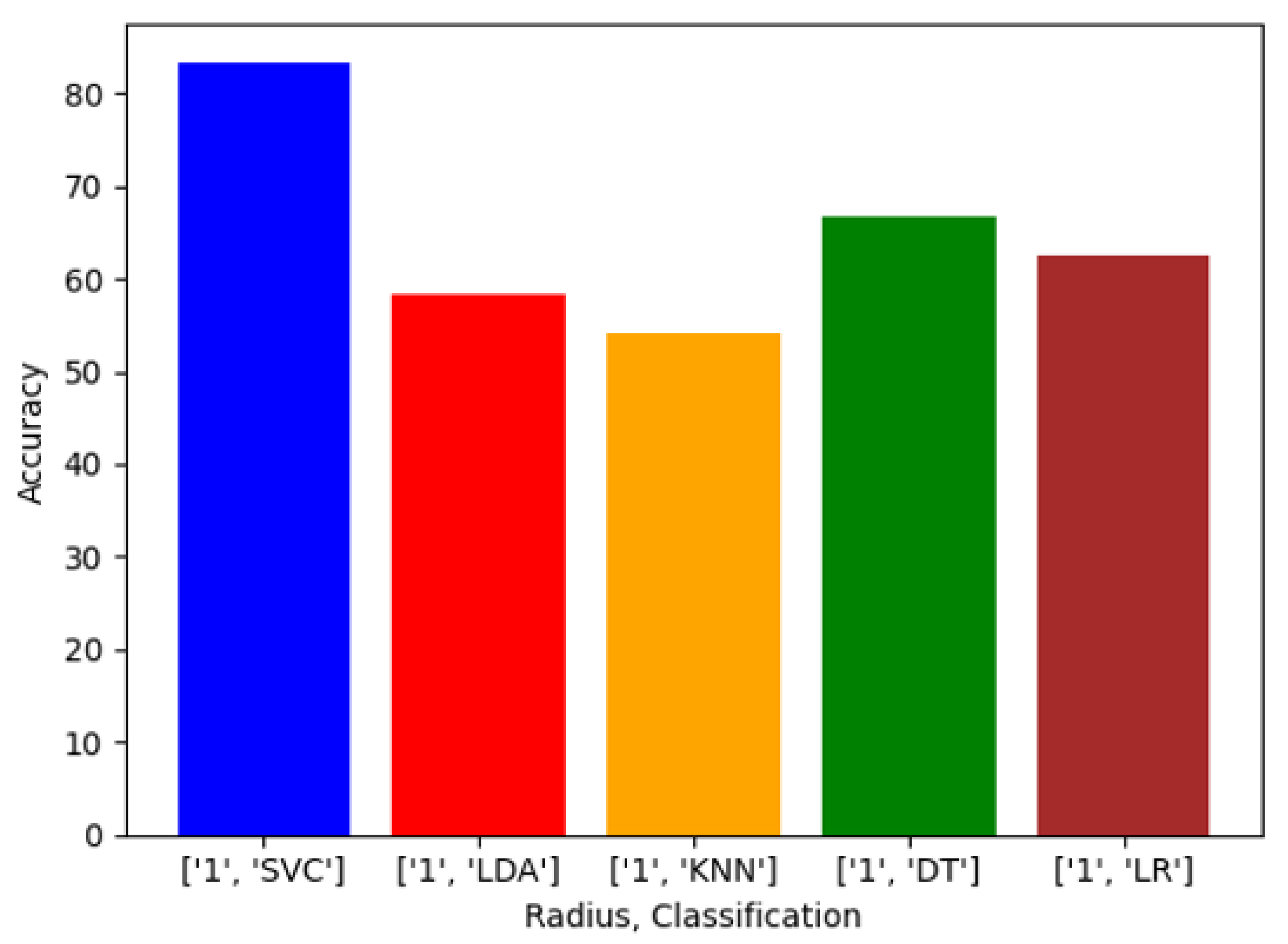
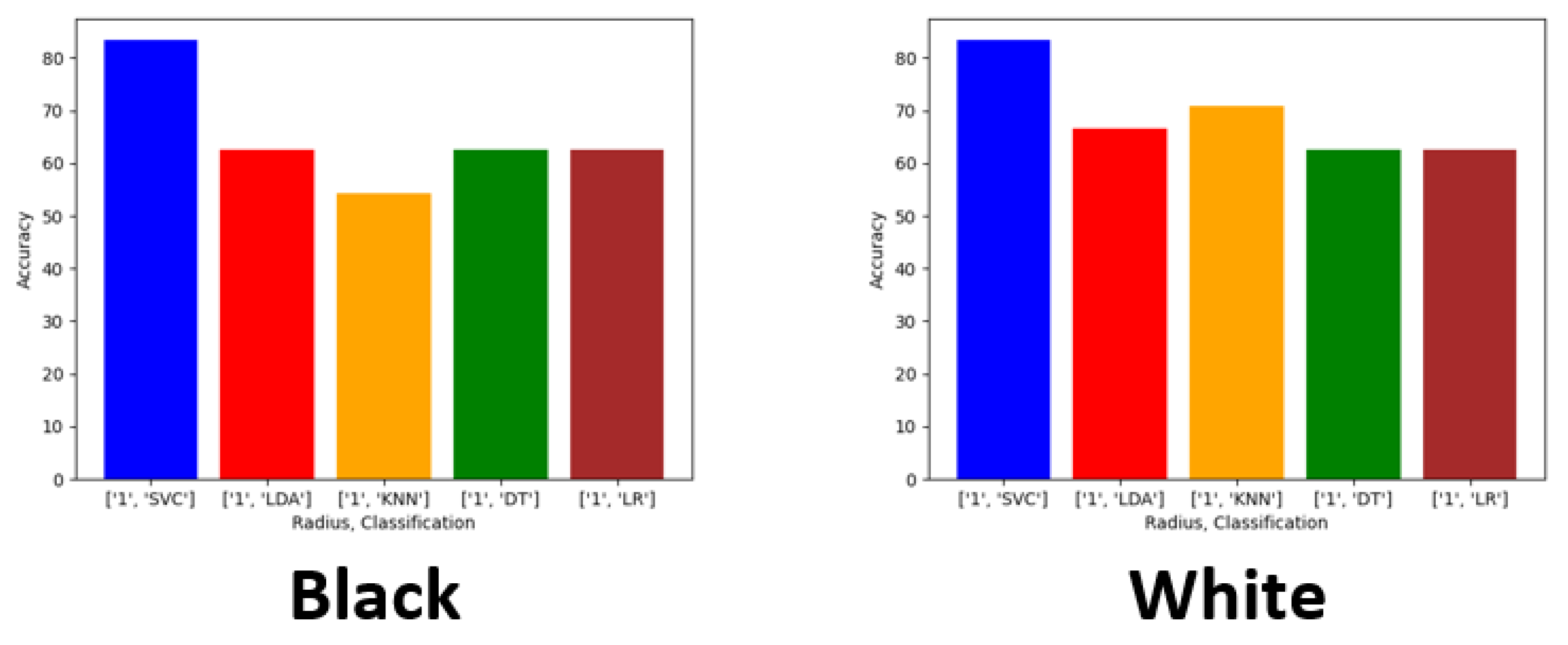
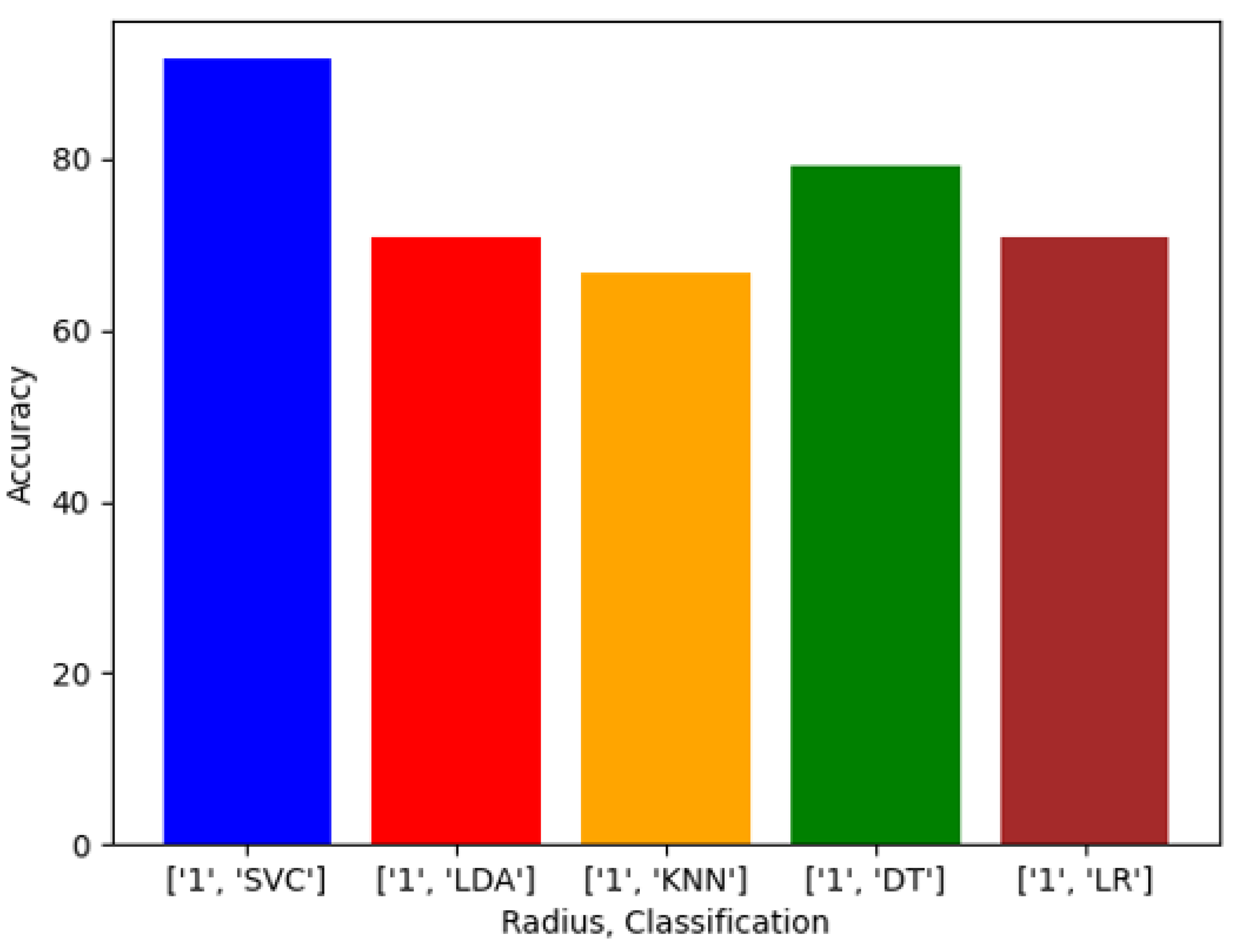
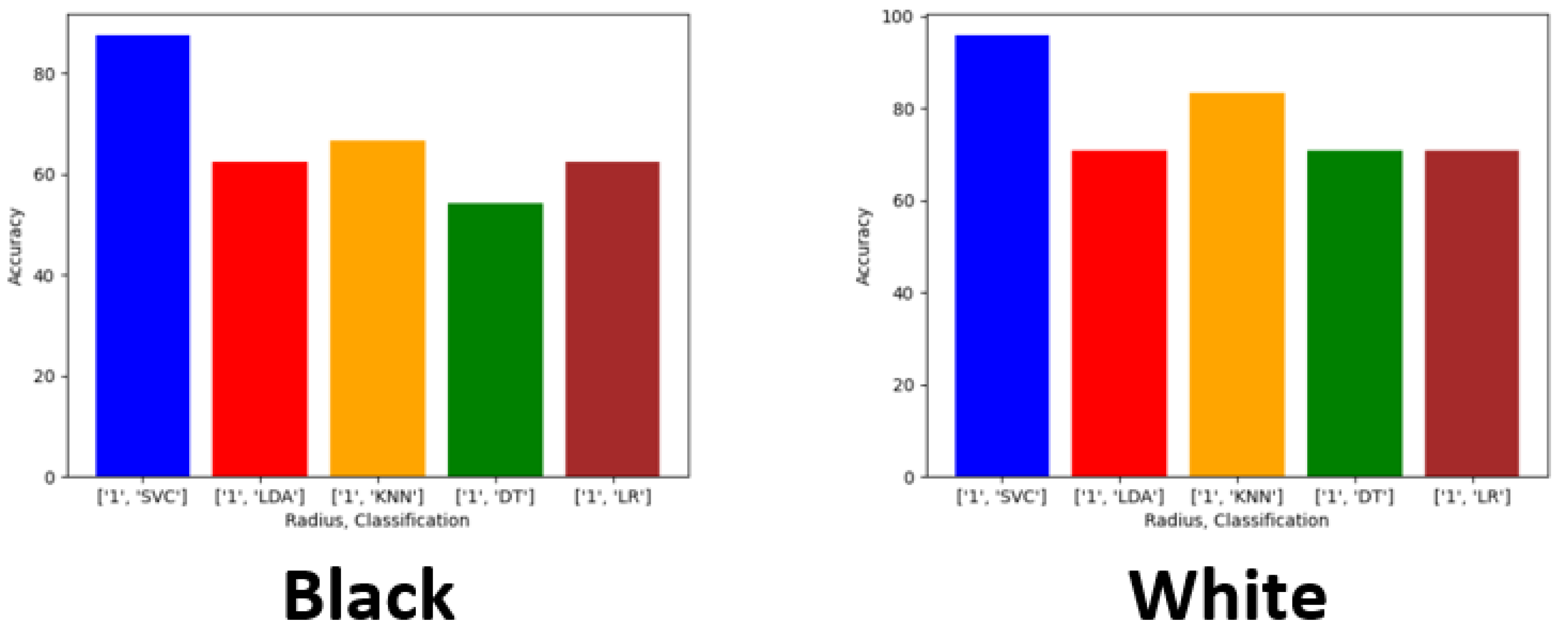
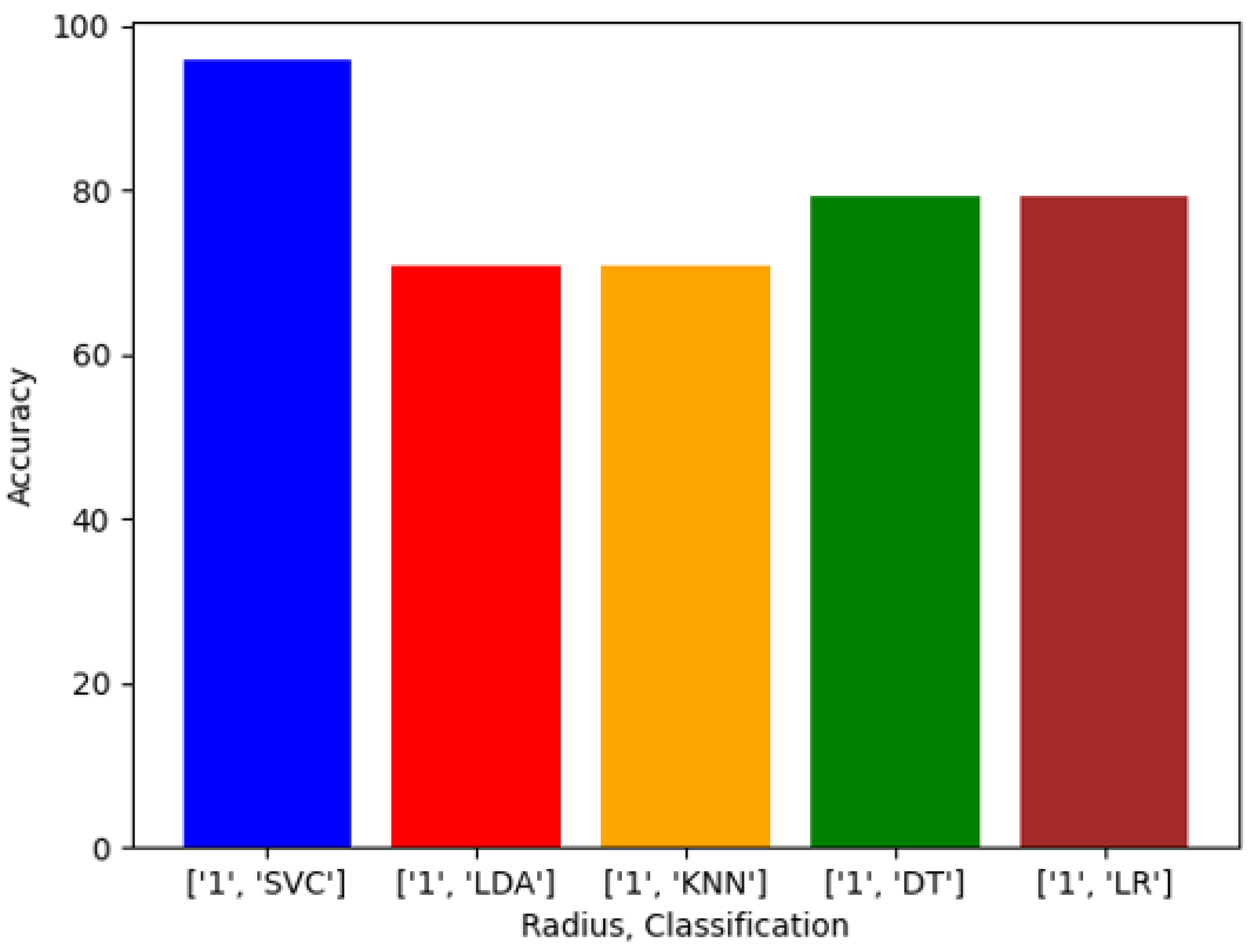
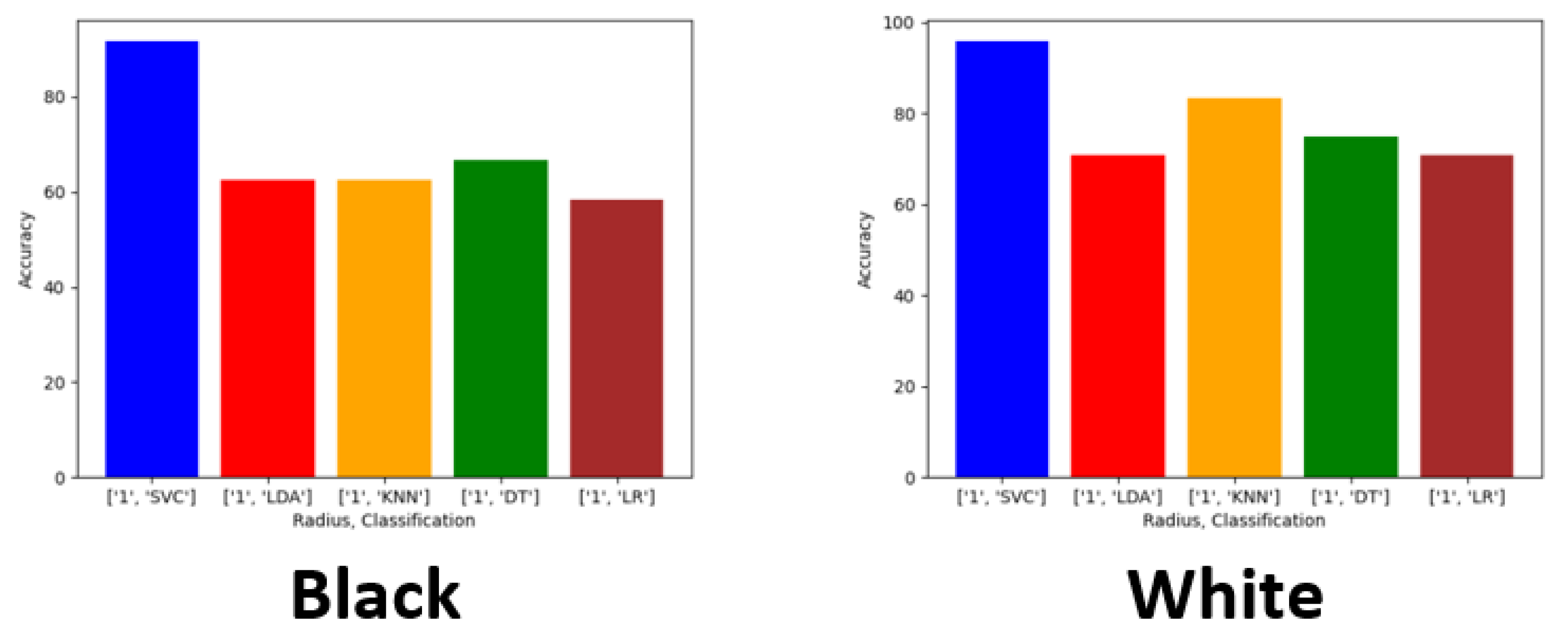
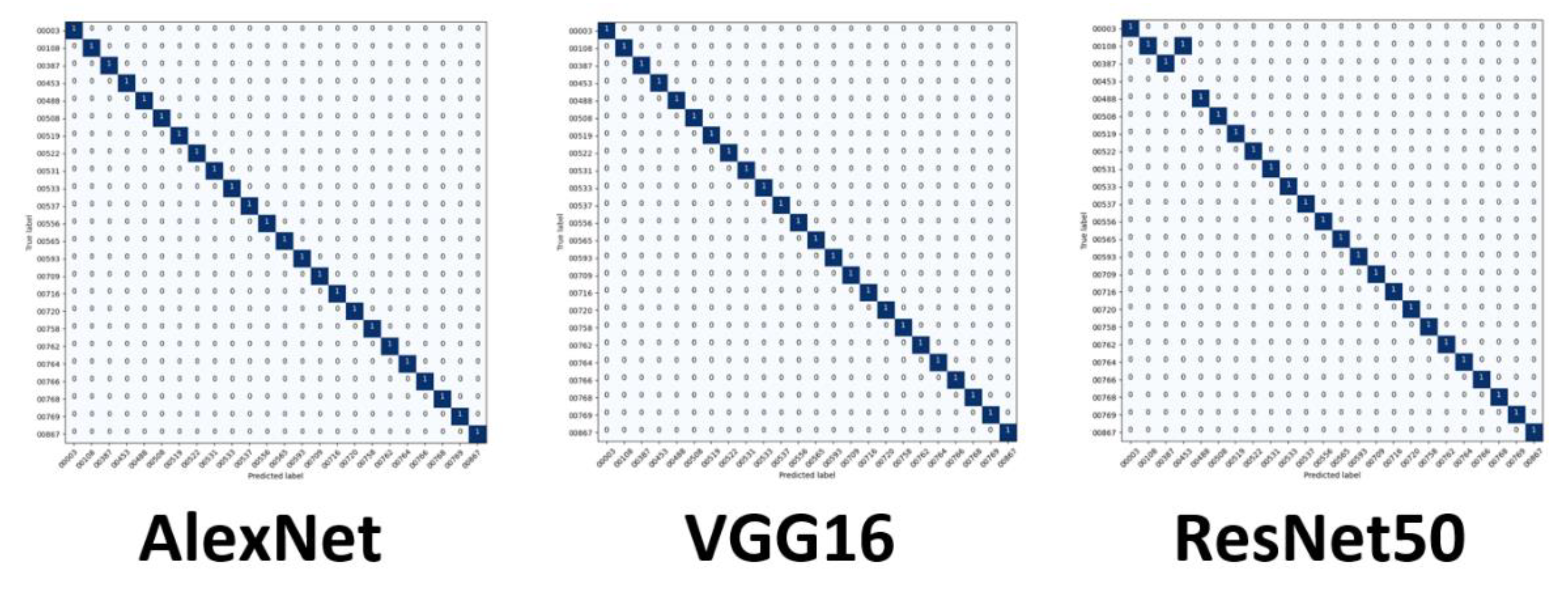
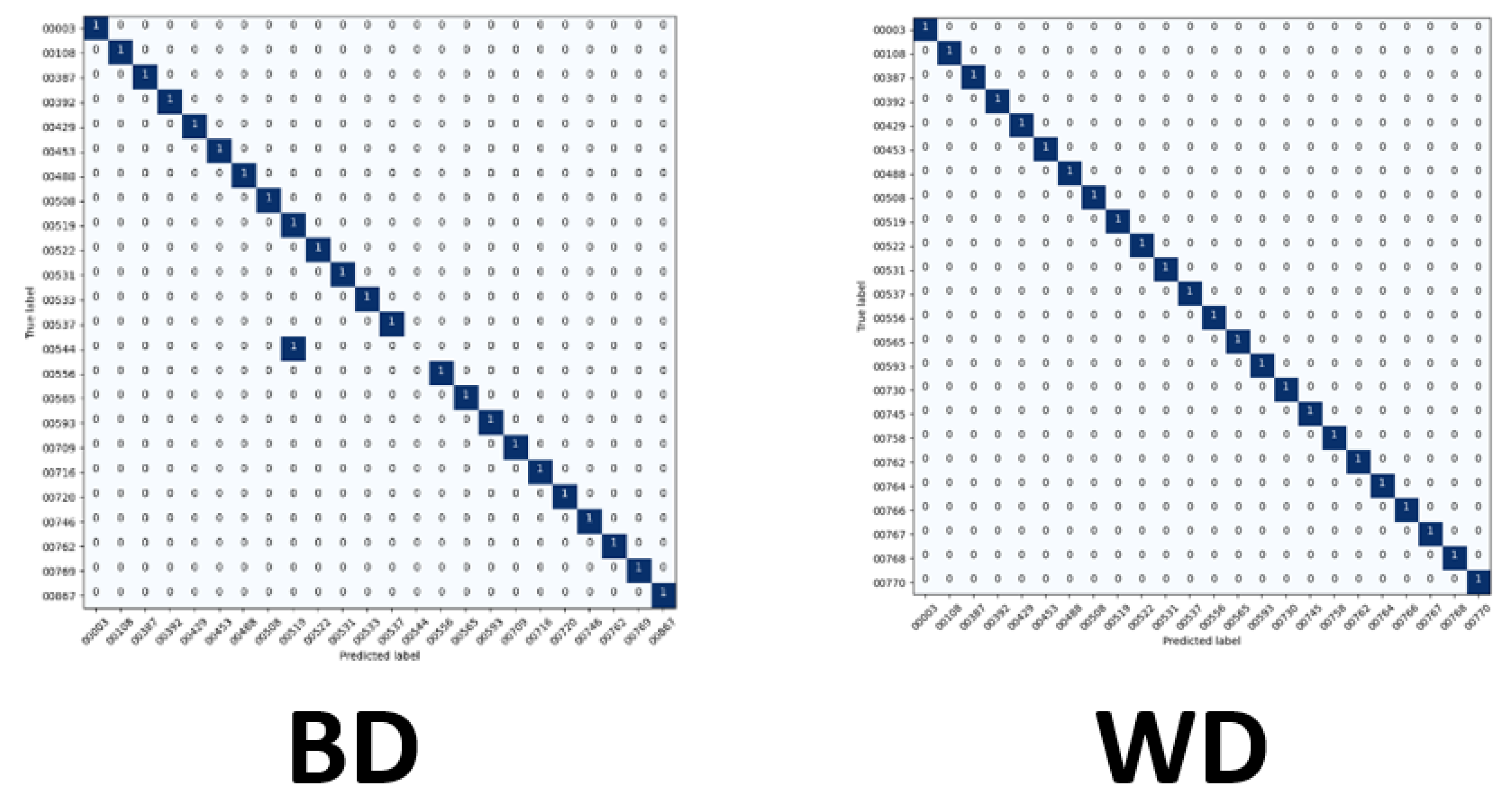
Exploring this topic requires three generated datasets and machine learning algorithms to compare performance and results against each. We conducted a plethora of research to collect images and place them into groups that will yield observable results that hopefully will have a meaningful contribution to the facial recognition field. Sampling is sourced from the FERET dataset emphasizing diverse, inclusive images with racial variations. Three datasets are distributed to yield a balance of equal amounts of image representations for each race. The other two sets are distributed to weigh heavier towards a particular race or ethnicity. The datasets are then analyzed with algorithms, and performance is rated on the accuracy of prediction modeling. Additional metric measurements include precision, recall, and F1 scoring. Algorithms and models utilized are Support Vector Classifier (SVC), Linear Discriminant Analysis (LDA), K-Nearest Neighbors (KNN), Decision Trees (DT), Logistic Regression (LR), AlexNet, VGG16, and ResNet50. In the initial testing on the sample of 24 subjects, we then alter the dataset to be biased towards a particular race. For dominant set 1, we choose 16 topics to represent the Black classification and 8 subjects to describe the White variety. We make a similar comparison for the next phase in experimentation, but this time we complement experiment 2. For dominant set 2, we choose 16 subjects to represent the White and 8 subjects to define the Black classification.
The weighting for each scenario is as follows:
Balanced—12 Black subjects vs. 12 White subjects;
Dominant Set 1—16 Black subjects vs. 8 White subjects;
Dominant Set 2—8 Black subjects vs. 16 White subjects.
Everyone has an available 12 images because of the limitations of our dataset. Initially, we select 11 ideas for those available algorithms to train on and set the remaining image as the image to test against for accuracy. We then remove 3 photos to eliminate influences of position, illumination, expression, or occlusion to explore accuracy. This setup allows us to test on the original image, but train on only 8 images. To mitigate the limitations of our dataset, we then revisited our initial training set that contained 11 images and augmented them. This method allows us to create additional pictures by inverting the original copies and giving us 22 photos to train.
The dataset configurations for each experimental scenario are:
Eight images for training and 1 image for testing per subject;
Eleven images for training and 1 image for testing per subject;
Twenty-two Images for training and 1 image for testing per subject.
3.4. Evaluation Procedure
The evaluation involves careful consideration to continue previous research conducted in [
23]. Initial research performed was explicitly applied to the field of facial recognition in general. Moving forward, we aim to use that research to observe existing bias and identify approaches to mitigate these inaccuracies. Metrics involved in these evaluations will include accuracy, precision, recall, F1 score, hit rates, and miss rates.
Our experimentation involves very precise steps that must be repeated, so the collected results are free from uncontrolled changes. The steps we have followed for each algorithm are:
3.5. Experimental Design
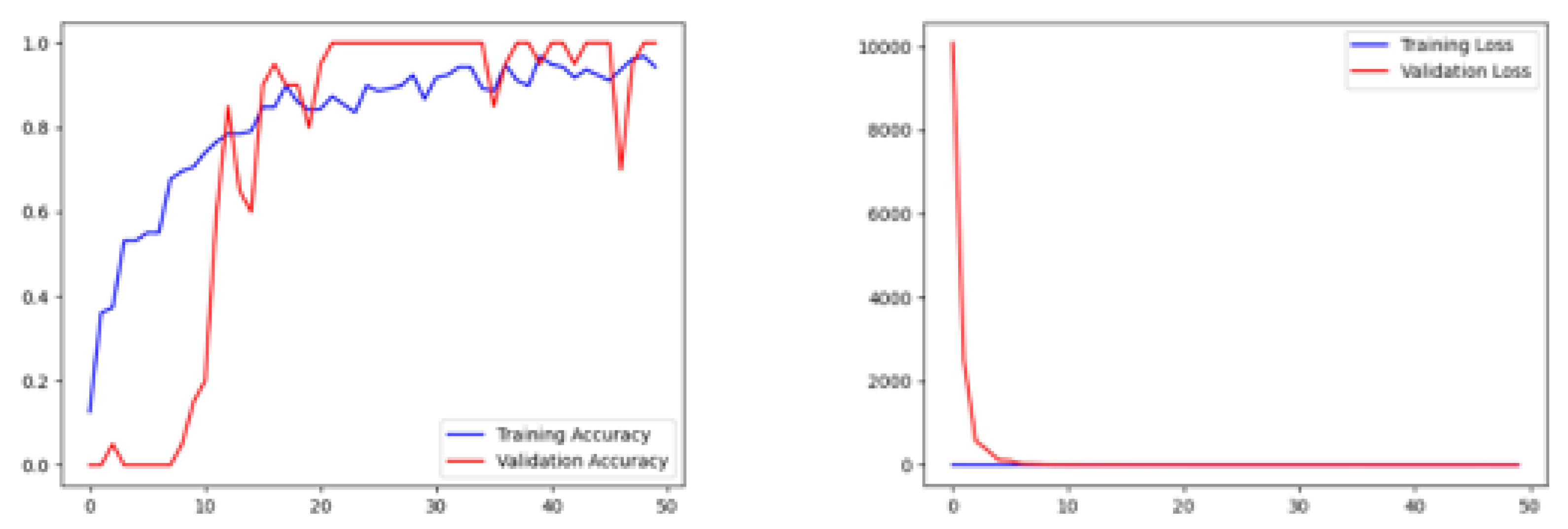
Details regarding machine specifics and methodologies are provided in this section to give an insight into the technology used. These details will serve as a gauge for others to compare to when considering turn-around and runtimes. Our experimentation was performed on a Dell® Alienware® Aurora® Ryzen® machine running a Windows 10® operating system. The Central Processing Unit (CPU) is an AMD® Ryzen® 9 3900XT 12-Core Processor 3.79 GHz. The available memory includes a 512 Gigabytes (GB) Solid State Drive (SSD) and 32 Gigabytes Random Access Memory (RAM). It consists of an NVIDIA® GeForce® RTX 2070 8GB GD DR6 for graphics that significantly contributed to expediting experimentation after installing the required libraries. The Integrated Development Environment (IDE) used was PyCharm Community Edition 2020.3®, a product of JetBrains®. Code implementation for our project was designed using Python 3.9.2 using our IDE. Importing TensorFlow, CUDA and cuDNN allows the machine to use the stream executor to create dynamic libraries that utilize the graphics card for CPU support. The addition of these dynamic libraries significantly reduced the overall runtimes of all algorithms. Before optimizing the configurations, runtimes for the machine learning algorithms took approximately 180 s to complete depending on the number of images utilized. With the optimization configuration, the runtimes are reduced to about 32 s for each selected model. The deep learning algorithms use a sizeable learning epoch, so overall runtimes depend on that setting. Our generalized settings of 50 periods yield runtimes of approximately 18 min, where our optimized settings reduce that time to around 4 min. Taking averages of our three deep learning algorithms produces an average of 7 s per epoch.
5. Conclusions and Future Work
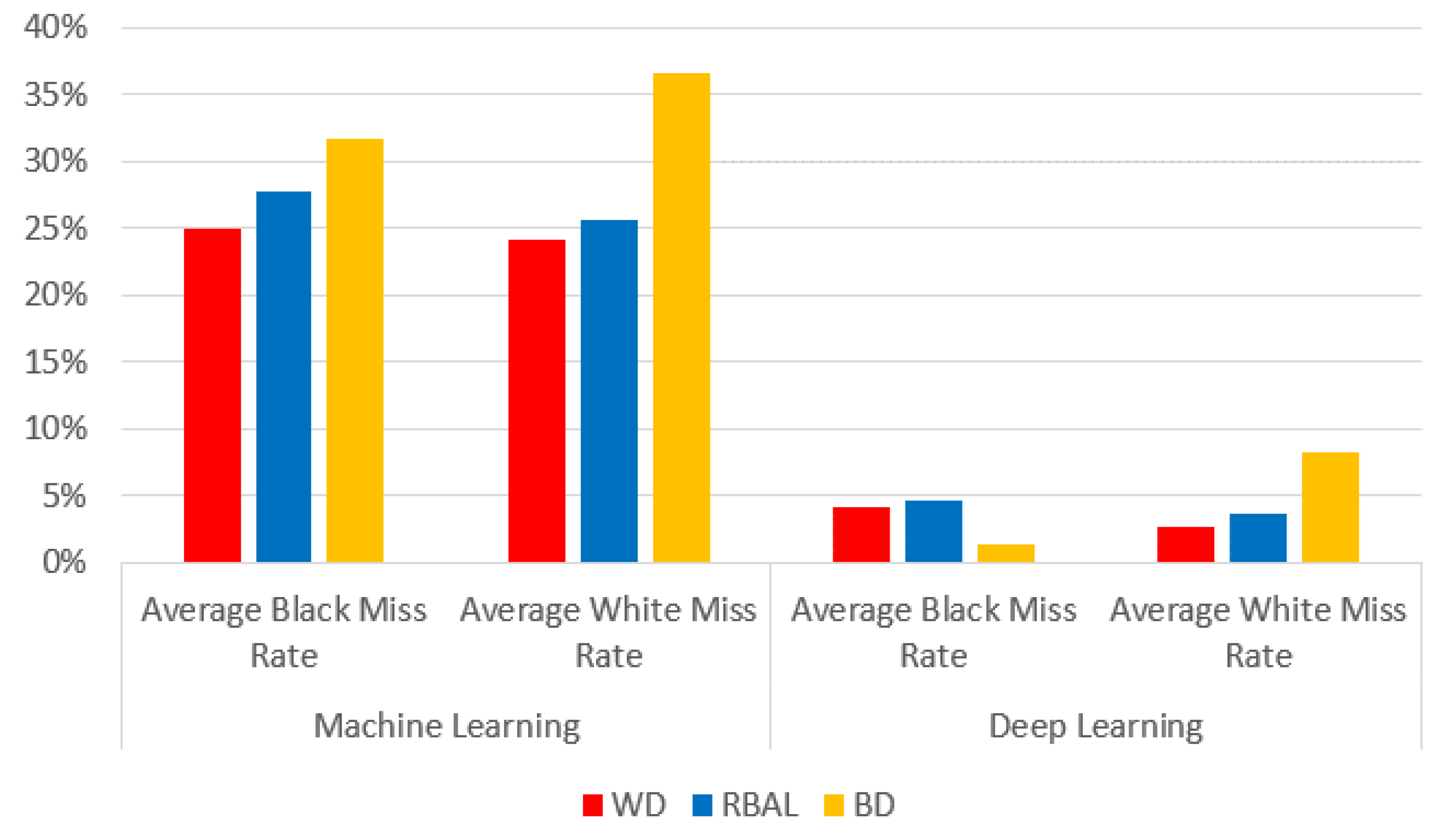
We have conducted thorough coverage throughout our research covered in this document. We first gave a little insight into facial recognition with our introduction, preliminaries, and problem statement. We provided four problems related to facial recognition during our problem statement, and we laid out our contributions to the scientific community. Additional issues related to race, ethnicity, algorithms, and datasets followed to provide an encompassing generalized view of our research. Next, we reviewed our system design, development, and architectures. We gave an in-depth evaluation plan for each type of algorithm, dataset, and a look into the software and its architecture. Concluding those informative items, we then thoroughly explained the result and findings of our experimentation. We provided analysis for the machine learning algorithms and compared them across the differing dataset configurations. We then replicated those experiments using deep learning algorithms and explored their performance across the different dataset types. Concluding the analysis, we compared the results of two kinds of algorithms and compared their accuracy, metrics, miss rates, and performances.
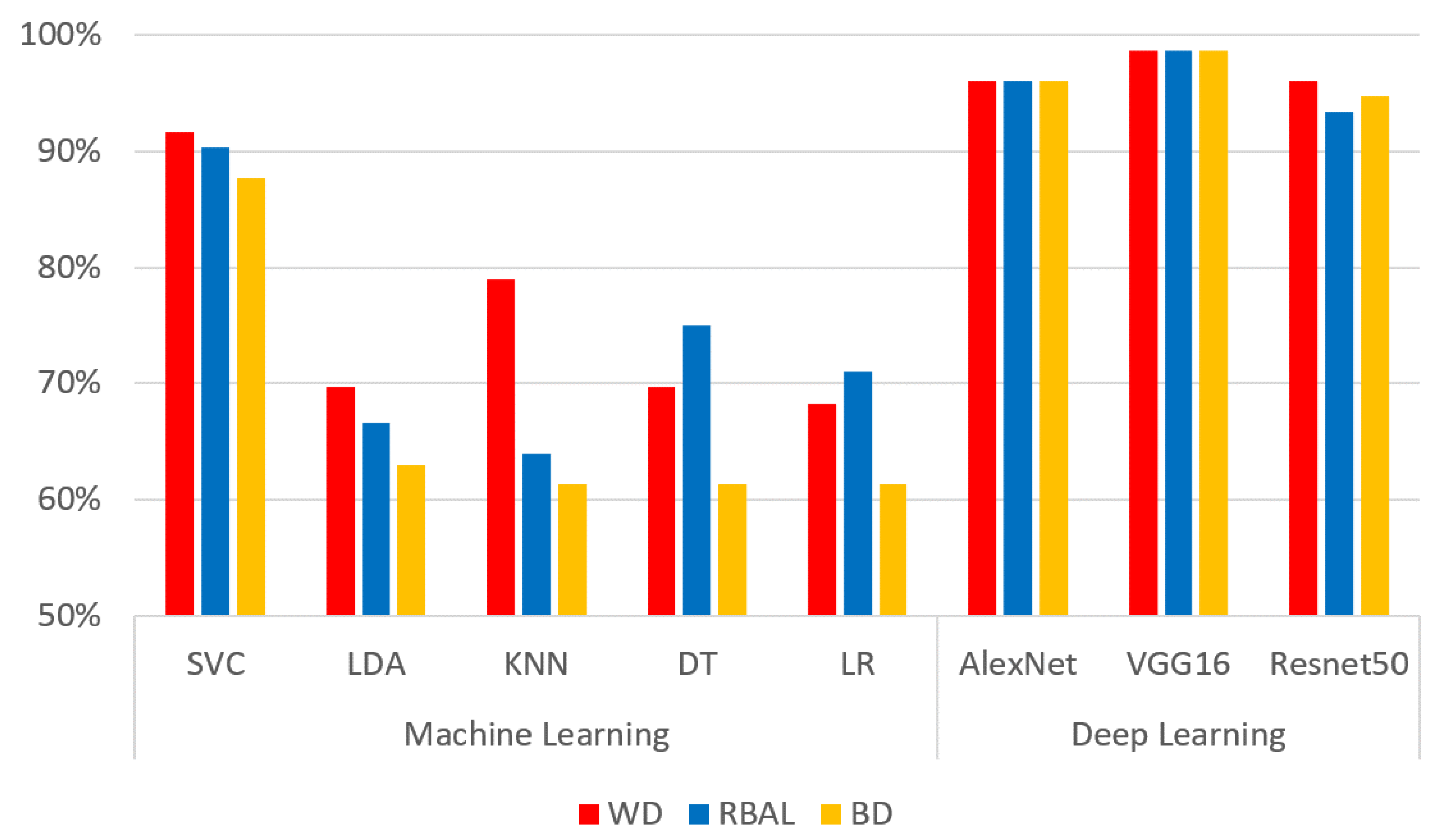
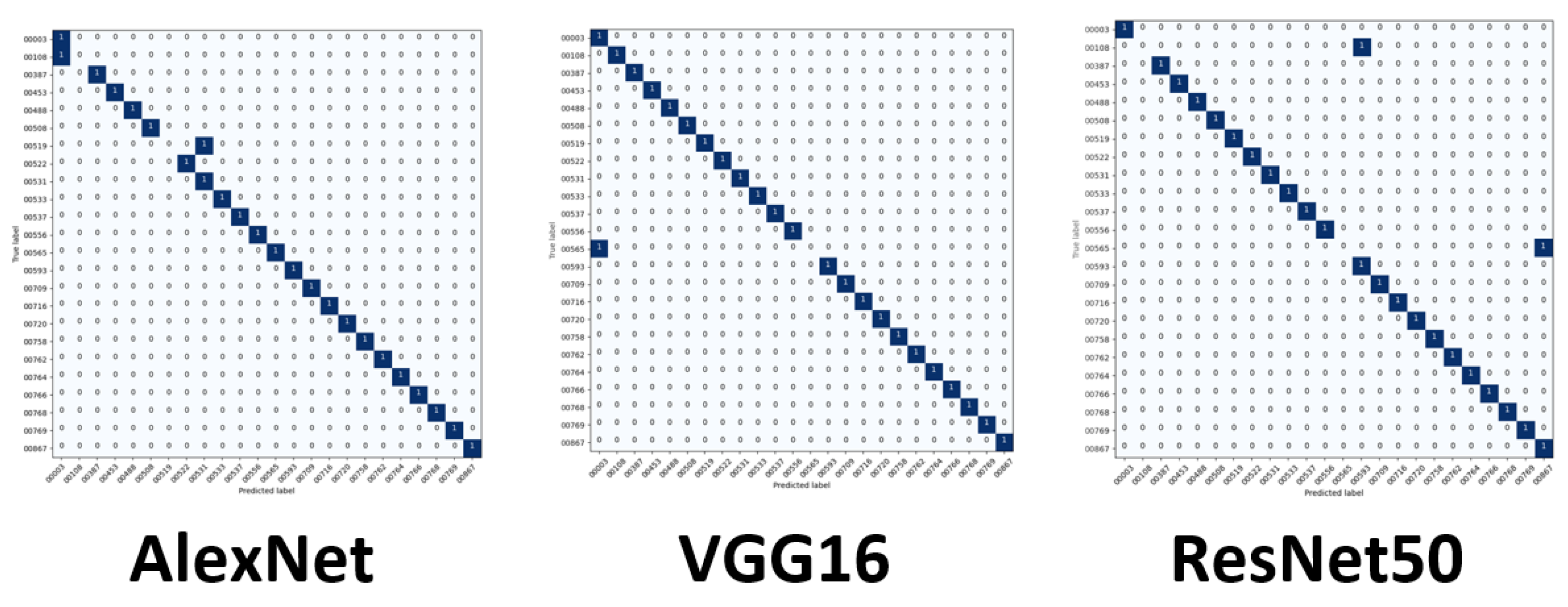
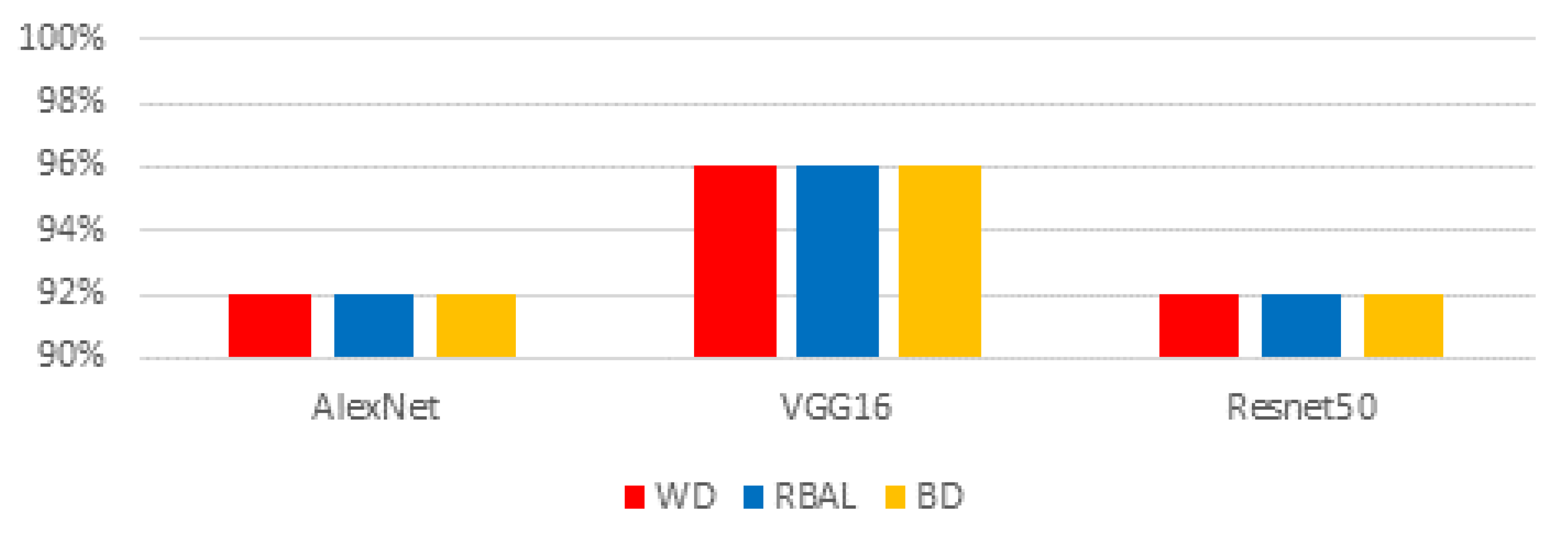
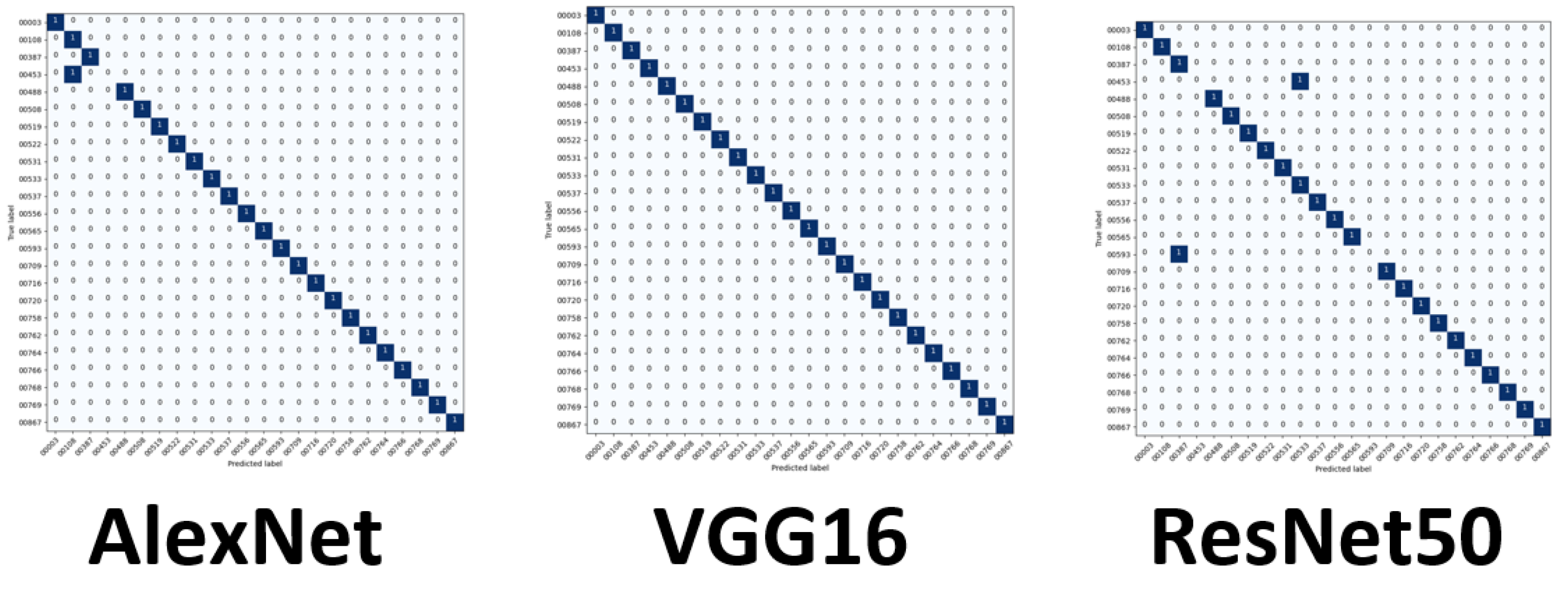
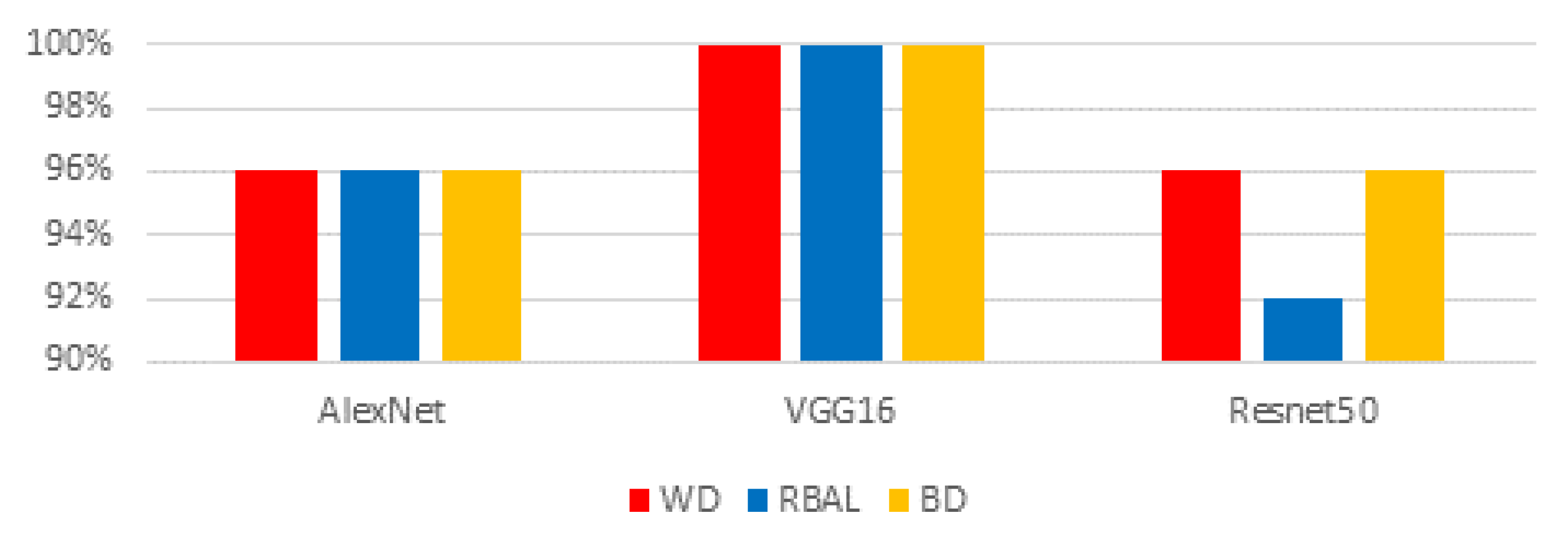
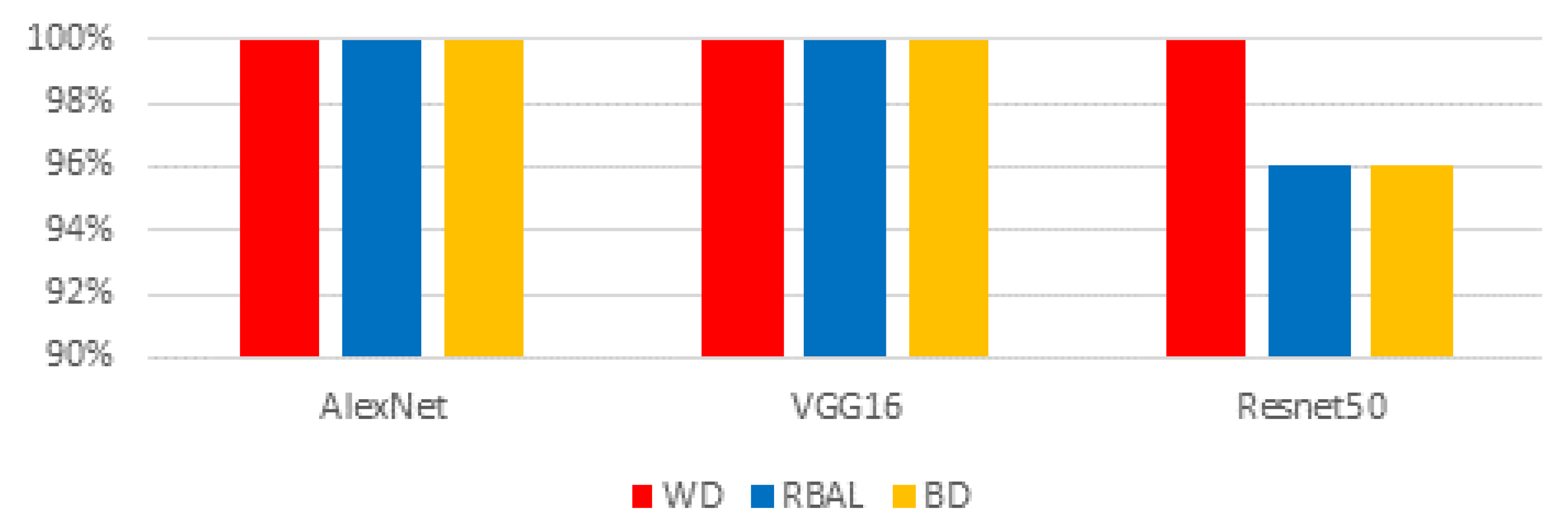
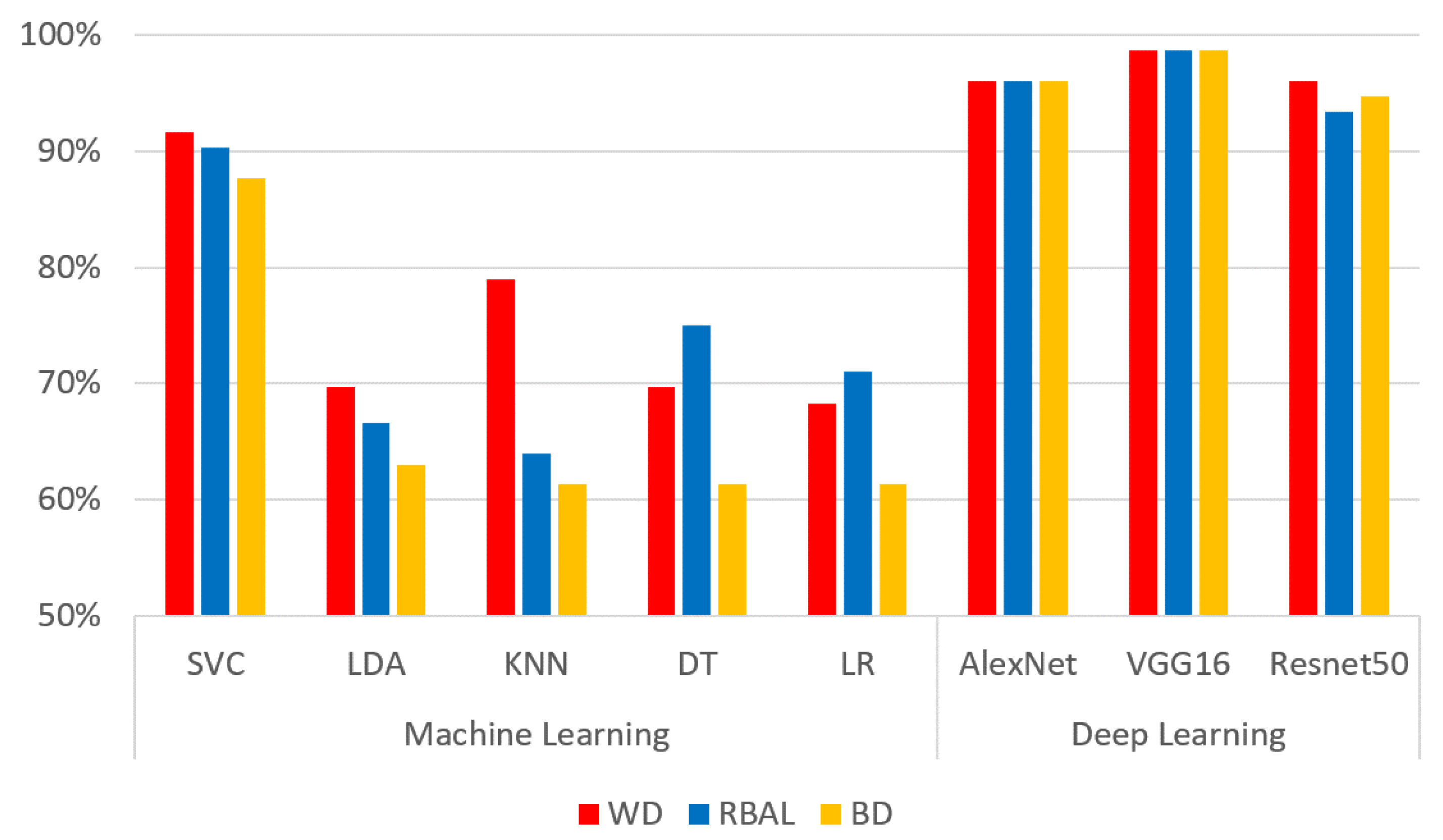
We evaluated racial bias across five machine learning algorithms using racially imbalanced and balanced datasets. The five machine learning algorithms explored were Support Vector Classifier (SVC), Linear Discriminant Analysis (LDA), K-Nearest Neighbor (KNN), Decision Trees (DT), and Logistic Regression (LR). We evaluated racial bias across three deep learning algorithms using racially imbalanced and balanced datasets. The three deep learning algorithms explored were AlexNet, VGG16, and ResNet50. We evaluated and compared the accuracy and miss rates between all tested algorithms and reported that SVC is the superior machine learning algorithm and VGG16 is the best deep learning algorithm based on our experimental study. Our findings conclude the algorithm that mitigates the bias the most is VGG16, and all our deep learning algorithms outperformed their machine learning counterparts.
The deep learning algorithms utilized for this study all have layering as a commonality. This layering is what assists these algorithms in performing significantly better than their machine learning counterparts. While comparing these models the significant difference between them are the numbers of layers, their connections, strides, pooling, and density. The number of layers for each algorithm yields the trainable parameters [
29]. AlexNet uses 8 layers resulting in 60 million trainable parameters where VGG16 has 16 layers resulting in 138 million parameters [
29]. ResNet50 uses 50 layers that yield 23 million trainable parameters but using significantly more layers requires additional time to train and geometric fallout likely led to our findings.
Our research has barely scratched the surface as it relates to facial recognition. Our future work can be expanded in many directions towards the approaches we used here. Our team is currently investigating similar research about the impacts of genders and ages across algorithms. There are plenty of other algorithms that can be explored, including variants of the ones we have used. VGG16 and ResNet50 have variants that could expand on our research. Different algorithms such as Xception and Inception also have variants that could develop this research even further. Expansion for this research does not end with algorithm approaches as other datasets may also be helpful. We considered experimenting with more datasets such as FairFace or DemogPairs as potential future work. These datasets are focused on mitigating bias and would have served as an excellent addition to this research. A final consideration for research expansion should include many racial representations, as this research focuses on two ethnicities.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}