
HRBUST-LLPED: A Benchmark Dataset for Wearable Low-Light Pedestrian Detection

Abstract
:1. Introduction
- (1)
- We have expanded the focus of pedestrian detection to low-light images and have constructed a low-light pedestrian detection dataset using a low-light camera. The dataset contains denser pedestrian instances compared to existing pedestrian detection datasets.
- (2)
- We have provided lightweight, wearable, low-light pedestrian detection models based on the YOLOv5 and YOLOv8 frameworks, considering the lower computational power of wearable platforms when compared to GPUs. We have improved the model’s performance by modifying the activation layer and loss functions.
- (3)
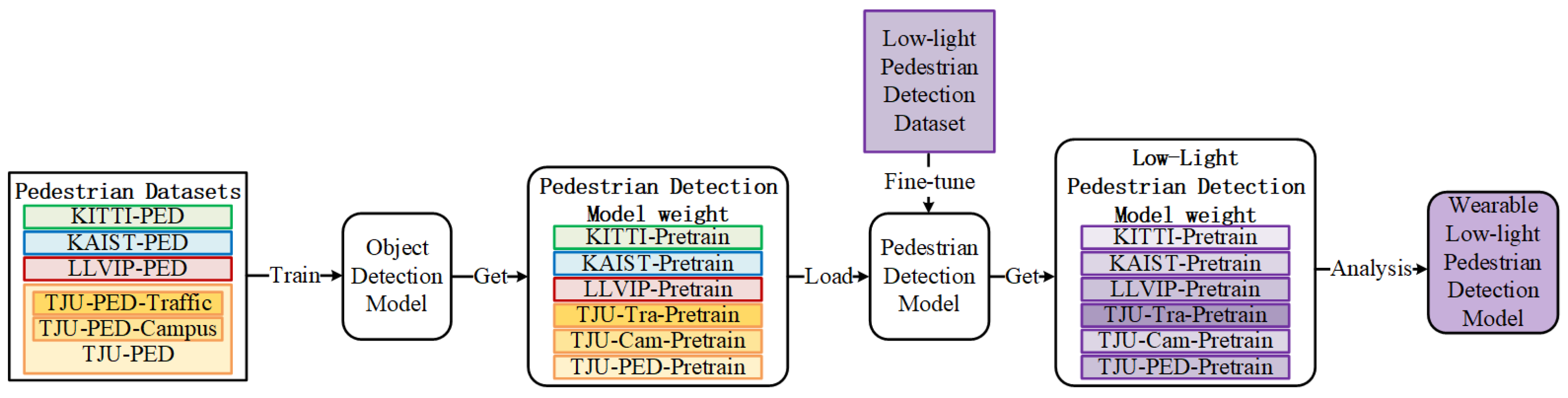
- We first pretrained our models on four visible light pedestrian detection datasets and then fine-tuned them on our constructed HRBUST-LLPED dataset. We achieved a performance of 69.90% in terms of AP@0.5:0.95 and an inference time of 1.6 ms per image.
2. Related Work
2.1. Pedestrian Detection Datasets
2.2. Object Detection
2.3. Object Detection on Wearable Devices
3. The HRBUST-LLEPD Dataset
3.1. Dataset Build
3.2. Dataset Analysis
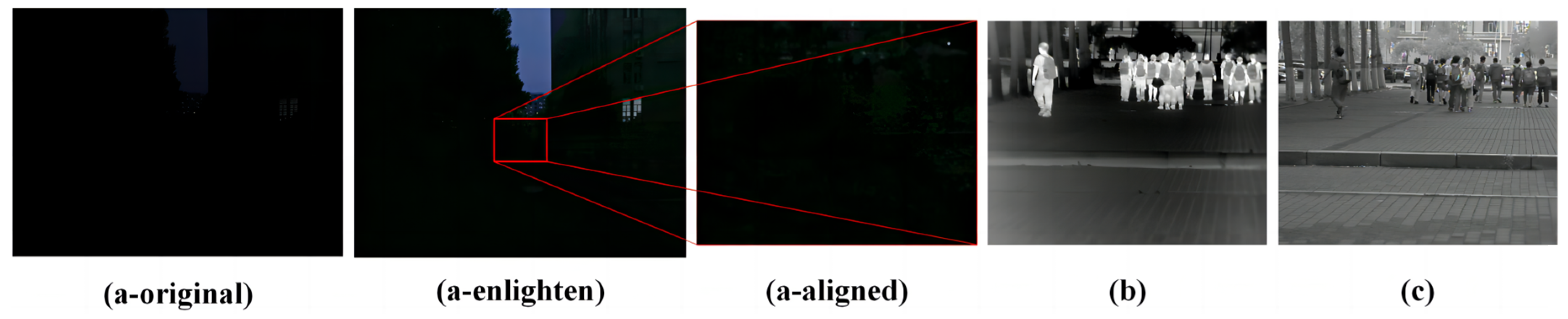
- HRBUST-LLPED is a pedestrian detection dataset for low-light conditions (starlight-level illumination). It captures clear images using low-light cameras, making it suitable for developing pedestrian detection algorithms in low-light environments.
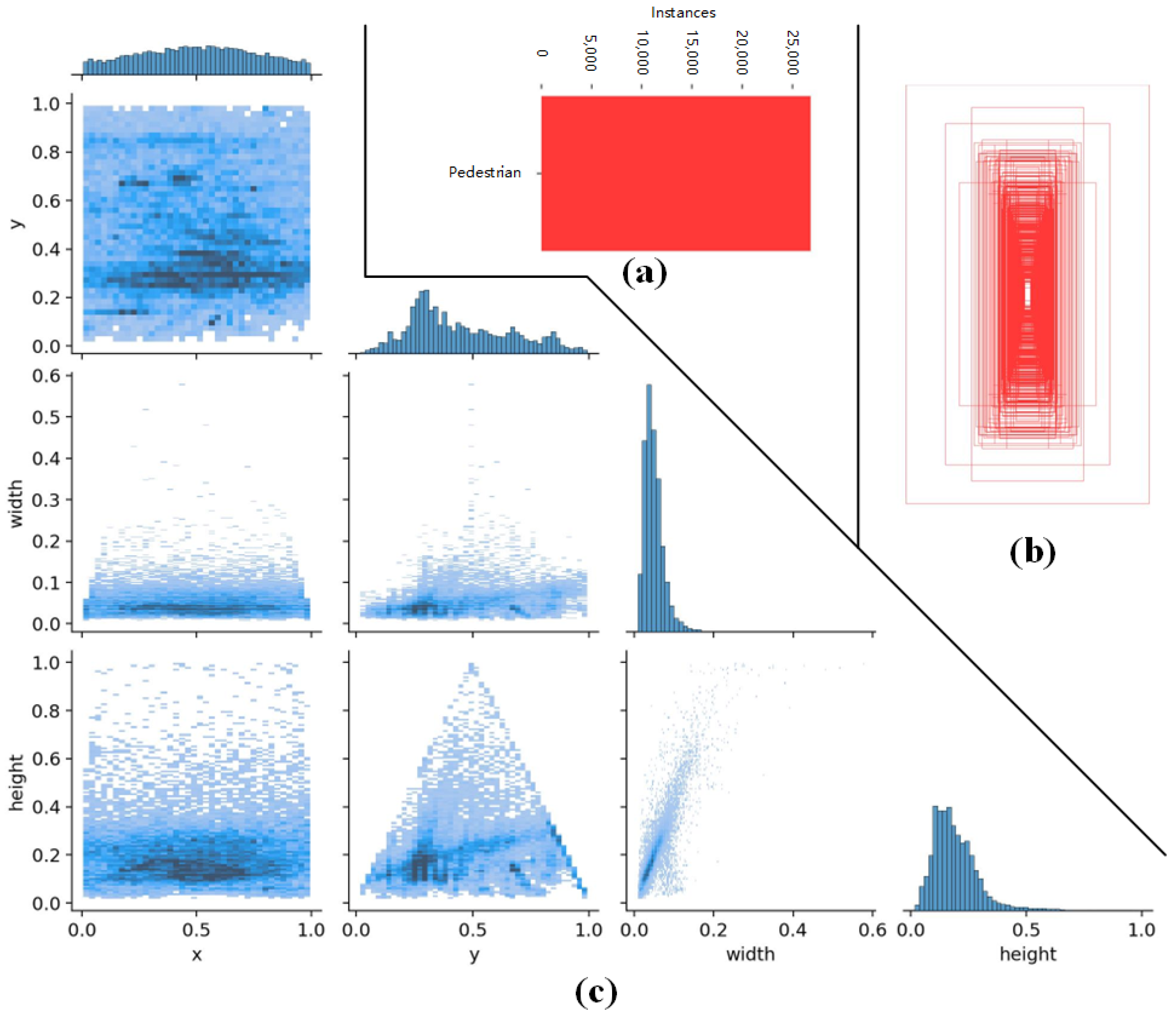
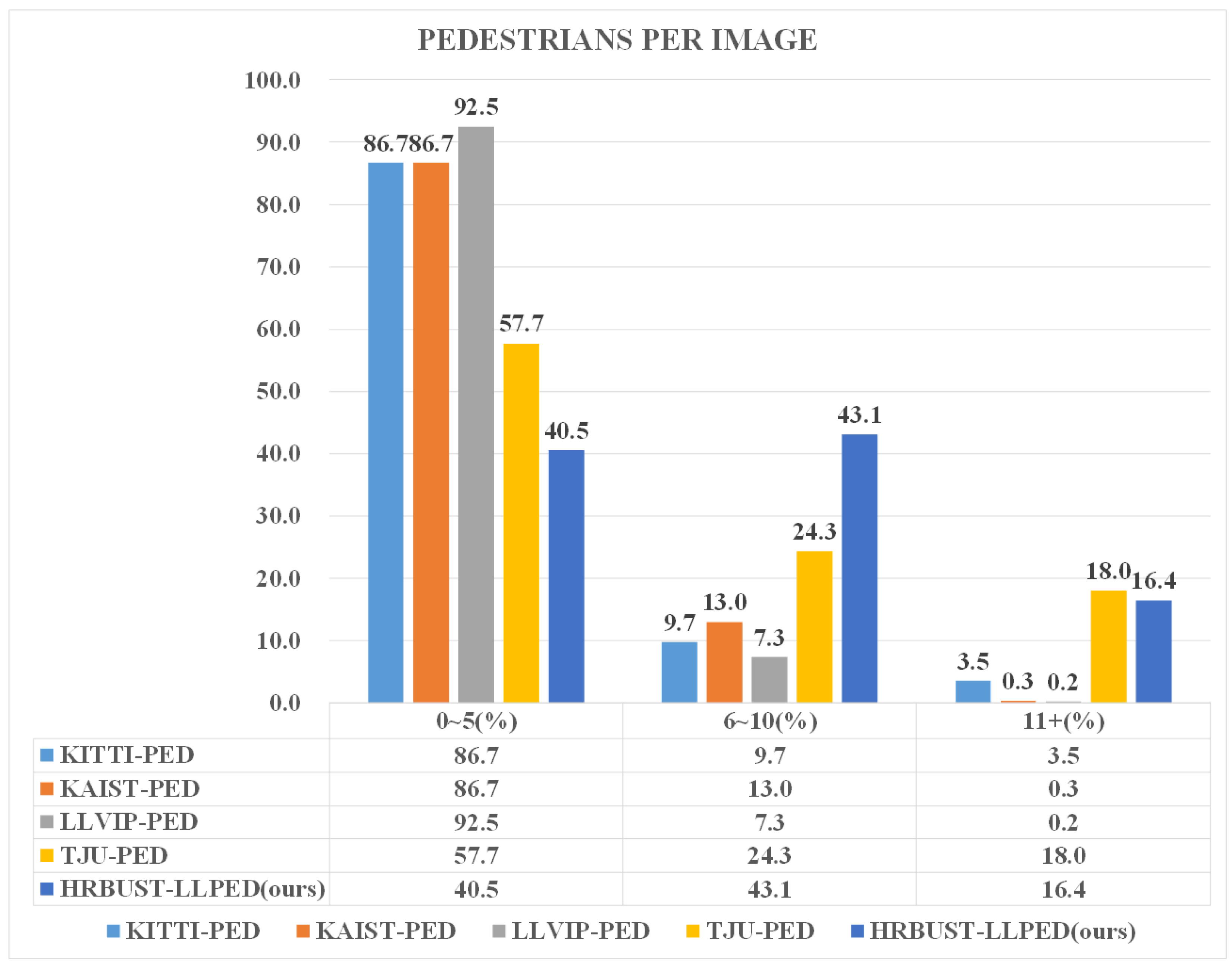
- The dataset contains abundant pedestrian annotations, covering pedestrians of various sizes. Each image includes a substantial number of pedestrians, with significant occlusion between the pedestrians and between the pedestrians and the background. This enables comprehensive training and evaluation of the model’s pedestrian recognition capability.
- The dataset captures scenes from different seasons, ranging from winter to summer, and includes weather conditions such as snow, sunny, and cloudy. This diversity in weather conditions ensures the model’s robustness across different weather scenarios.
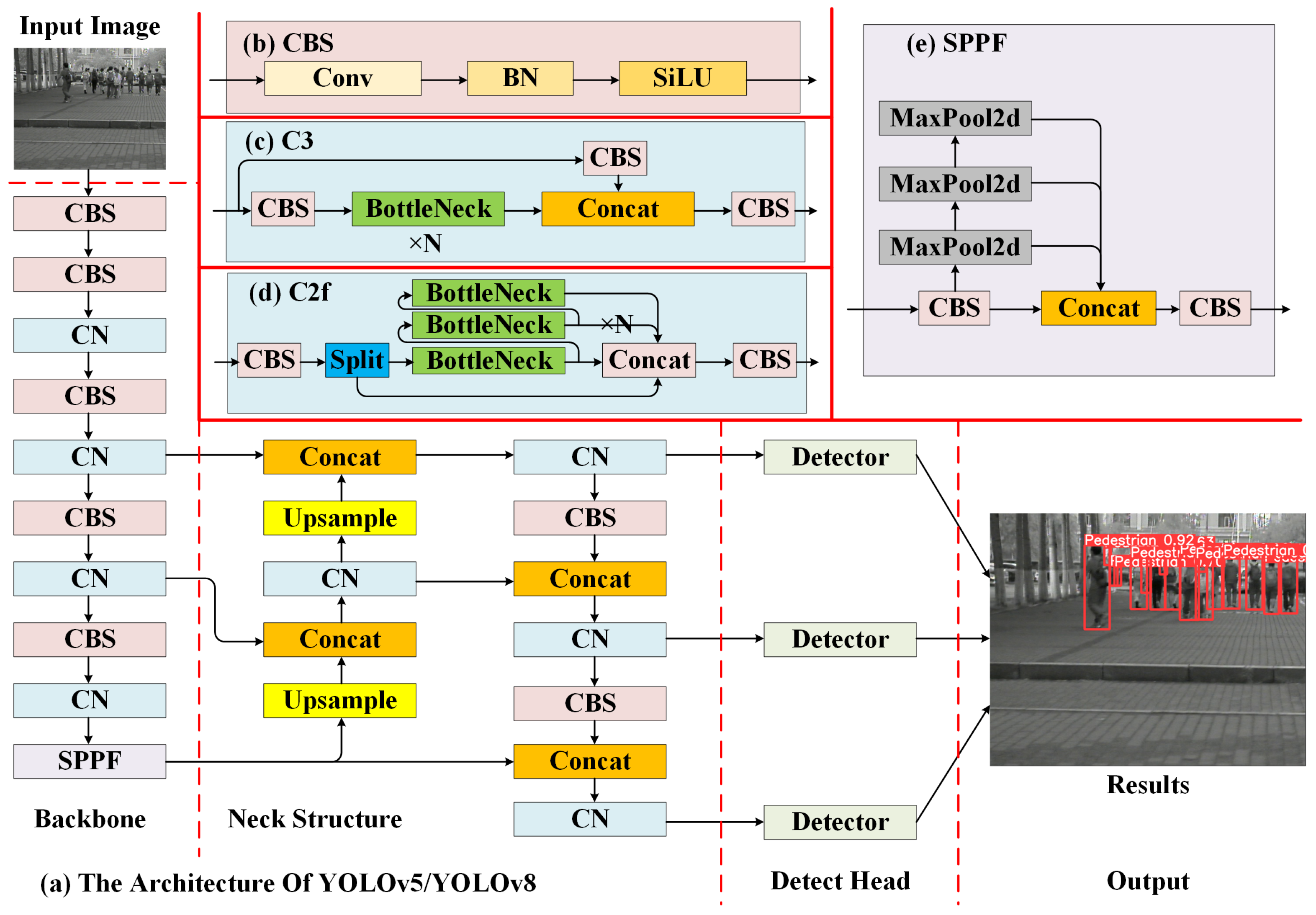
4. Wearable Low-Light Pedestrian Detection
5. Experiments
5.1. Evaluate Metric
5.2. Implementation Details
5.3. Experimental Results
- The model with the highest detection of precious is based on YOLOv5s pretrained on the TJU-PED dataset, with an accuracy of 95.15%. The model with the highest recall rate and AP@0.5 is based on YOLOv8s pretrained on the TJU-PED-Campus dataset, with 91.66% in terms of recall and 96.34% in terms of AP@0.5. The models with the highest AP@0.5:0.95 are based on YOLOv8s pretrained on the TJU-PED dataset, achieving a value of 69.90%. The fastest model is based on YOLOv8n, with an inference speed of 1.6 ms per image.
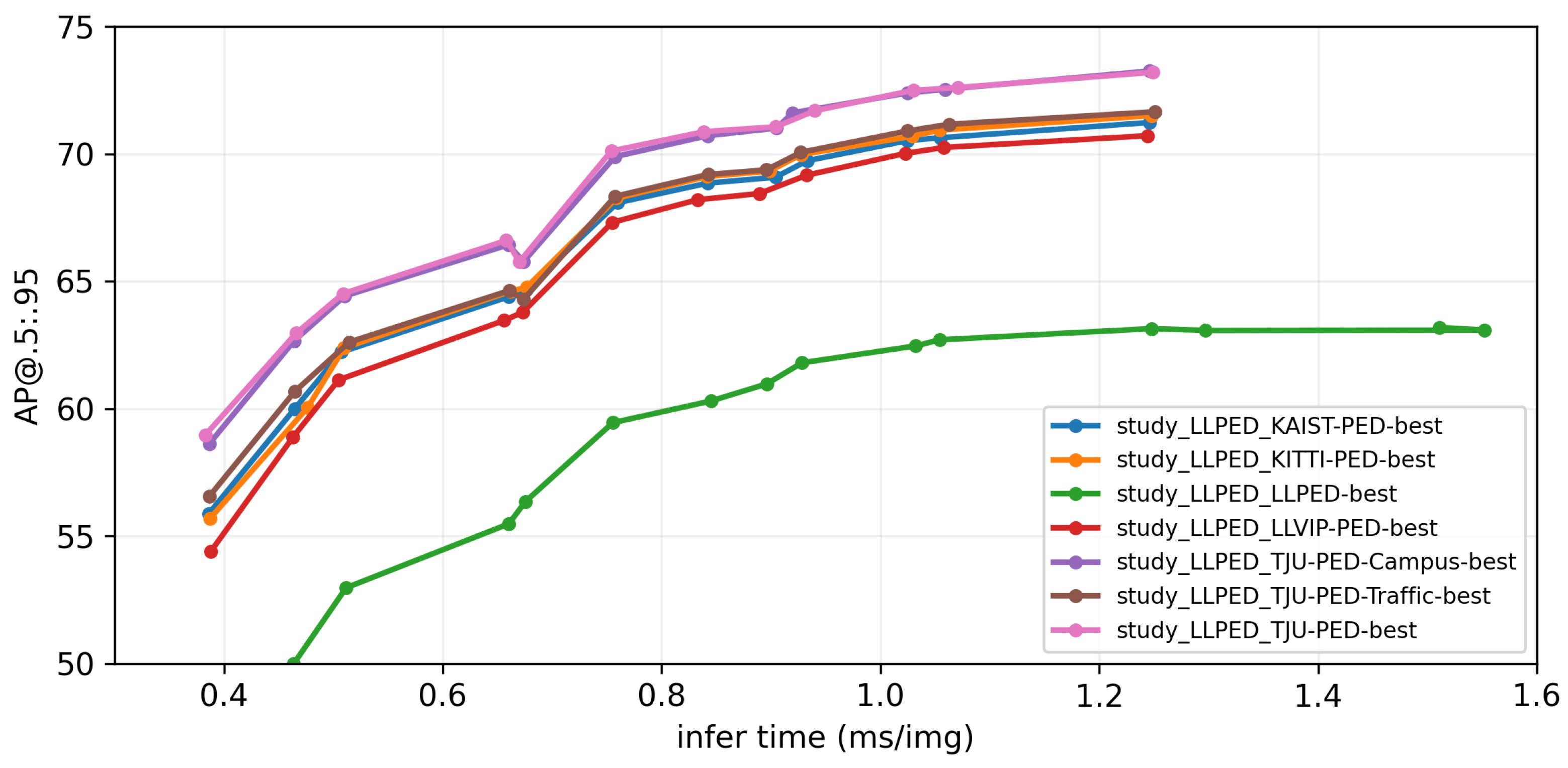
- Among the four selected models, YOLOv8s performs the best, achieving approximately a 3% higher for AP@0.5:0.95 than YOLOv5s. YOLOv8n and YOLOv5s have similar accuracies, but YOLOv8n is approximately 1.5 ms faster.
- For most pretrained datasets, training the model with pedestrian sizes closer to the target dataset leads to better performance when transferring the model.
- For the YOLOv5 models, the input image resolution does not affect the inference speed, whereas for the YOLOv8 models, the input image resolution impacts the model’s speed.
5.4. Further Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, H.; Liu, H.; Li, Z.; Li, C.; Meng, Z.; Gao, N.; Zhang, Z. Adaptive Threshold Based ZUPT for Single IMU Enabled Wearable Pedestrian Localization. IEEE Internet Things J. 2023, 10, 11749–11760. [Google Scholar] [CrossRef]
- Tang, Z.; Zhang, L.; Chen, X.; Ying, J.; Wang, X.; Wang, H. Wearable supernumerary robotic limb system using a hybrid control approach based on motor imagery and object detection. IEEE Trans. Neural Syst. Rehabil. Eng. 2022, 30, 1298–1309. [Google Scholar] [CrossRef] [PubMed]
- Han, Y.; Yarlagadda, S.K.; Ghosh, T.; Zhu, F.; Sazonov, E.; Delp, E.J. Improving food detection for images from a wearable egocentric camera. arXiv 2023, arXiv:2301.07861. [Google Scholar] [CrossRef]
- Li, X.; Holiday, S.; Cribbet, M.; Bharadwaj, A.; White, S.; Sazonov, E.; Gan, Y. Non-Invasive Screen Exposure Time Assessment Using Wearable Sensor and Object Detection. In Proceedings of the 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Glasgow, UK, 11–15 July 2022; pp. 4917–4920. [Google Scholar]
- Kim, J.; Moon, N. Dog behavior recognition based on multimodal data from a camera and wearable device. Appl. Sci. 2022, 12, 3199. [Google Scholar] [CrossRef]
- Park, K.B.; Choi, S.H.; Lee, J.Y.; Ghasemi, Y.; Mohammed, M.; Jeong, H. Hands-free human–robot interaction using multimodal gestures and deep learning in wearable mixed reality. IEEE Access 2021, 9, 55448–55464. [Google Scholar] [CrossRef]
- Dimitropoulos, N.; Togias, T.; Michalos, G.; Makris, S. Operator support in human–robot collaborative environments using AI enhanced wearable devices. Procedia CIRP 2021, 97, 464–469. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 743–761. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Zhang, S.; Benenson, R.; Schiele, B. Citypersons: A diverse dataset for pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3213–3221. [Google Scholar]
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. Crowdhuman: A benchmark for detecting human in a crowd. arXiv 2018, arXiv:1805.00123. [Google Scholar]
- Zhang, S.; Xie, Y.; Wan, J.; Xia, H.; Li, S.Z.; Guo, G. Widerperson: A diverse dataset for dense pedestrian detection in the wild. IEEE Trans. Multimed. 2019, 22, 380–393. [Google Scholar] [CrossRef]
- Braun, M.; Krebs, S.; Flohr, F.; Gavrila, D.M. Eurocity persons: A novel benchmark for person detection in traffic scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1844–1861. [Google Scholar] [CrossRef] [PubMed]
- Pang, Y.; Cao, J.; Li, Y.; Xie, J.; Sun, H.; Gong, J. TJU-DHD: A diverse high-resolution dataset for object detection. IEEE Trans. Image Process. 2020, 30, 207–219. [Google Scholar] [CrossRef]
- Davis, J.W.; Sharma, V. OTCBVS Benchmark Dataset Collection. 2007. Available online: https://vcipl-okstate.org/pbvs/bench/ (accessed on 2 September 2023).
- Toet, A. The TNO multiband image data collection. Data Brief 2017, 15, 249–251. [Google Scholar] [CrossRef] [PubMed]
- González, A.; Fang, Z.; Socarras, Y.; Serrat, J.; Vázquez, D.; Xu, J.; López, A.M. Pedestrian detection at day/night time with visible and FIR cameras: A comparison. Sensors 2016, 16, 820. [Google Scholar] [CrossRef] [PubMed]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A visible-infrared paired dataset for low-light vision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3496–3504. [Google Scholar]
- Papageorgiou, C.; Poggio, T. A trainable system for object detection. Int. J. Comput. Vis. 2000, 38, 15–33. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Cision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Enzweiler, M.; Gavrila, D.M. Monocular pedestrian detection: Survey and experiments. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 2179–2195. [Google Scholar] [CrossRef]
- Wojek, C.; Walk, S.; Schiele, B. Multi-cue onboard pedestrian detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 794–801. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings Part IV 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 354–370. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Yifu, Z.; Wong, C.; Montes, D.; et al. ultralytics/yolov5: v3.0. Zenodo. Available online: https://ui.adsabs.harvard.edu/abs/2022zndo...3908559J/abstract (accessed on 6 November 2023).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Eckert, M.; Blex, M.; Friedrich, C.M. Object detection featuring 3D audio localization for Microsoft HoloLens. In Proceedings of the 11th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2018), Funchal, Portugal, 19–21 January 2018; Volume 5, pp. 555–561. [Google Scholar]
- Bahri, H.; Krčmařík, D.; Kočí, J. Accurate object detection system on hololens using yolo algorithm. In Proceedings of the 2019 International Conference on Control, Artificial Intelligence, Robotics and Optimization (ICCAIRO), Athens, Greece, 8–10 December 2019; pp. 219–224. [Google Scholar]
- Park, K.B.; Kim, M.; Choi, S.H.; Lee, J.Y. Deep learning-based smart task assistance in wearable augmented reality. Robot. Comput.-Integr. Manuf. 2020, 63, 101887. [Google Scholar] [CrossRef]
- Arifando, R.; Eto, S.; Wada, C. Improved YOLOv5-Based Lightweight Object Detection Algorithm for People with Visual Impairment to Detect Buses. Appl. Sci. 2023, 13, 5802. [Google Scholar] [CrossRef]
- Maya-Martínez, S.U.; Argüelles-Cruz, A.J.; Guzmán-Zavaleta, Z.J.; Ramírez-Cadena, M.d.J. Pedestrian detection model based on Tiny-Yolov3 architecture for wearable devices to visually impaired assistance. Front. Robot. AI 2023, 10, 1052509. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Num. of Train Images | Num. of Test Images | Num. of Train Instances | Num. of Test Instances | Resolution | Image Type | Day/ Night | Pedestrians per Image | |
|---|---|---|---|---|---|---|---|---|
| KITTI-PED | 1796 | - | 4708 | - | 1238 × 374 | Visible | Day | 2.62 |
| KAIST-PED | 7595 | 1383 | 24,304 | 4163 | 640 × 512 | Visible | Day | 3.17 |
| LLVIP-PED | 12,025 | 3463 | 34,135 | 8302 | 1280 × 1024 | Visible | Night | 2.74 |
| TJU-PED -Traffic | 13,858 | 2136 | 27,650 | 5244 | 1624 × 1200 | Visible | Day, Night | 2.06 |
| TJU-PED -Campus | 39,727 | 5204 | 234,455 | 36,161 | 640 × 480 ∼ 5248 × 3936 | Visible | Day, Night | 6.02 |
| TJU-PED | 53,585 | 7340 | 262,105 | 41,405 | 640 × 480 ∼ 5248 × 3936 | Visible | Day, Night | 4.98 |
| HRBUST- LLPED (ours) | 3558 | 711 | 26,774 | 5374 | 720 × 576 | Low-light | Night | 7.53 |
| Method | Input Resolution | Train to LLPED, Test on LLPED | Infer Time (ms) | |||
|---|---|---|---|---|---|---|
| P (%) | R (%) | AP50 (%) | AP (%) | |||
| YOLOv5s-o | 640 × 640 | 93.05 | 84.17 | 92.91 | 59.04 | 3.5 |
| YOLOv8s-o | 640 × 640 | 92.41 | 83.12 | 92.35 | 61.82 | 4.3 |
| YOLOv5n-o | 640 × 640 | 90.98 | 80.67 | 90.57 | 55.88 | 2.9 |
| YOLOv8n-o | 640 × 640 | 91.82 | 80.01 | 89.89 | 59.20 | 2.4 |
| YOLOv5s | 640 × 640 | 92.72 | 85.83 | 93.93 | 61.49 | 3.1 |
| YOLOv8s | 640 × 640 | 92.20 | 85.59 | 93.44 | 63.64 | 3.4 |
| YOLOv5n | 640 × 640 | 92.19 | 82.58 | 91.86 | 57.91 | 2.6 |
| YOLOv8n | 640 × 640 | 92.01 | 82.32 | 91.50 | 60.99 | 1.6 |
| Method | Input Resolution | Trained and Tested on LLVIP-PED Dataset | Transfered to and Tested on HRBUST-LLPED Dataset | Infer Time (ms) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P (%) | R (%) | AP50 (%) | AP (%) | P (%) | R (%) | AP50 (%) | AP (%) | |||
| YOLOv5s-o | 640 × 640 | 90.35 | 80.60 | 88.59 | 48.93 | 93.76 | 87.35 | 95.61 | 65.22 | 3.5 |
| 1280 × 1280 | 88.63 | 81.84 | 89.09 | 50.27 | 92.79 | 88.33 | 95.51 | 65.19 | 3.6 | |
| YOLOv8s-o | 640 × 640 | 85.78 | 82.07 | 87.36 | 50.12 | 92.52 | 90.74 | 95.76 | 68.44 | 4.3 |
| 1280 × 1280 | 91.63 | 80.08 | 88.22 | 50.44 | 93.04 | 90.29 | 95.83 | 68.59 | 15.4 | |
| YOLOv5n-o | 640 × 640 | 92.36 | 79.23 | 88.04 | 47.89 | 92.82 | 86.42 | 94.41 | 61.63 | 2.9 |
| 1280 × 1280 | 85.12 | 83.36 | 87.90 | 48.63 | 93.28 | 87.40 | 95.04 | 63.58 | 2.9 | |
| YOLOv8n-o | 640 × 640 | 90.74 | 79.33 | 88.15 | 50.17 | 92.57 | 89.77 | 95.57 | 67.85 | 2.1 |
| 1280 × 1280 | 90.95 | 80.39 | 88.66 | 51.57 | 92.20 | 89.69 | 95.42 | 67.18 | 7.3 | |
| YOLOv5s | 640 × 640 | 93.30 | 84.05 | 91.14 | 51.05 | 93.62 | 89.83 | 95.74 | 67.27 | 3.2 |
| 1280 × 1280 | 91.47 | 83.91 | 90.66 | 52.31 | 94.19 | 89.00 | 95.68 | 66.98 | 3.2 | |
| YOLOv8s | 640 × 640 | 89.62 | 79.24 | 87.37 | 49.96 | 92.67 | 90.62 | 95.96 | 69.29 | 3.5 |
| 1280 × 1280 | 91.58 | 82.55 | 89.54 | 52.29 | 92.43 | 91.50 | 96.01 | 69.50 | 12.6 | |
| YOLOv5n | 640 × 640 | 93.27 | 77.58 | 87.84 | 49.55 | 93.75 | 86.02 | 94.56 | 64.34 | 2.6 |
| 1280 × 1280 | 89.54 | 82.16 | 89.10 | 50.64 | 93.38 | 87.12 | 94.70 | 64.27 | 2.7 | |
| YOLOv8n | 640 × 640 | 89.72 | 82.09 | 89.16 | 51.68 | 92.61 | 89.43 | 95.56 | 67.69 | 1.7 |
| 1280 × 1280 | 90.97 | 82.60 | 89.68 | 52.04 | 92.30 | 89.32 | 95.44 | 67.51 | 5.6 | |
| Method | Input Resolution | Trained and Tested on KITTI-PED Dataset | Transfered to and Tested on HRBUST-LLPED Dataset | Infer Time (ms) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P (%) | R (%) | AP50 (%) | AP (%) | P (%) | R (%) | AP50 (%) | AP (%) | |||
| YOLOv5s | 640 × 640 | 93.91 | 83.72 | 92.85 | 62.56 | 93.80 | 89.17 | 95.74 | 67.51 | 3.2 |
| 1280 × 1280 | 99.04 | 91.16 | 97.29 | 75.69 | 93.16 | 89.41 | 95.77 | 67.58 | 3.2 | |
| YOLOv8s | 640 × 640 | 94.61 | 88.43 | 95.12 | 74.85 | 93.30 | 91.05 | 96.30 | 69.73 | 3.4 |
| 1280 × 1280 | 98.07 | 93.34 | 97.76 | 82.85 | 92.73 | 91.38 | 96.15 | 69.57 | 12.6 | |
| YOLOv5n | 640 × 640 | 79.22 | 68.46 | 78.57 | 39.98 | 93.14 | 86.90 | 94.76 | 64.12 | 2.6 |
| 1280 × 1280 | 96.59 | 85.82 | 94.87 | 66.18 | 92.53 | 87.37 | 94.71 | 64.17 | 2.6 | |
| YOLOv8n | 640 × 640 | 92.30 | 79.69 | 90.93 | 66.31 | 92.49 | 89.36 | 95.44 | 67.90 | 1.7 |
| 1280 × 1280 | 92.59 | 90.30 | 96.34 | 77.03 | 92.45 | 89.21 | 95.49 | 68.21 | 5.6 | |
| Method | Input Resolution | Trained and Tested on KAIST-PED Dataset | Transfered to and Tested on HRBUST-LLPED Dataset | Infer Time (ms) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P (%) | R (%) | AP50 (%) | AP (%) | P (%) | R (%) | AP50 (%) | AP (%) | |||
| YOLOv5s | 640 × 640 | 36.09 | 28.22 | 32.41 | 13.09 | 94.31 | 88.74 | 95.74 | 67.42 | 3.2 |
| YOLOv8s | 640 × 640 | 37.40 | 26.50 | 30.41 | 13.84 | 93.36 | 90.53 | 95.98 | 69.30 | 3.4 |
| YOLOv5n | 640 × 640 | 37.23 | 28.52 | 30.06 | 12.58 | 93.21 | 86.92 | 94.50 | 64.04 | 2.6 |
| YOLOv8n | 640 × 640 | 36.86 | 26.98 | 29.63 | 12.73 | 92.99 | 88.67 | 95.59 | 68.01 | 1.6 |
| Method | Input Resolution | Trained and Tested on TJU-PED-Traffic Dataset | Transfered to and Tested on HRBUST-LLPED Dataset | Infer Time (ms) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P (%) | R (%) | AP50 (%) | AP (%) | P (%) | R (%) | AP50 (%) | AP (%) | |||
| YOLOv5s | 640 × 640 | 83.68 | 71.93 | 80.95 | 45.73 | 93.84 | 89.02 | 95.62 | 67.11 | 3.2 |
| 1280 × 1280 | 88.52 | 77.84 | 87.89 | 53.62 | 94.69 | 88.97 | 95.88 | 67.75 | 3.2 | |
| YOLOv8s | 640 × 640 | 84.76 | 73.20 | 82.87 | 48.43 | 92.65 | 90.97 | 96.08 | 69.56 | 3.4 |
| 1280 × 1280 | 86.84 | 81.00 | 89.30 | 56.44 | 92.55 | 91.11 | 96.28 | 69.30 | 12.7 | |
| YOLOv5n | 640 × 640 | 83.53 | 64.12 | 74.85 | 39.67 | 94.43 | 86.19 | 94.81 | 64.25 | 2.6 |
| 1280 × 1280 | 85.91 | 77.64 | 86.26 | 50.62 | 92.91 | 87.55 | 94.91 | 64.70 | 2.6 | |
| YOLOv8n | 640 × 640 | 83.51 | 67.82 | 78.27 | 44.28 | 92.65 | 89.71 | 95.67 | 67.95 | 1.7 |
| 1280 × 1280 | 85.34 | 80.01 | 87.68 | 53.78 | 92.50 | 89.49 | 95.60 | 68.17 | 5.6 | |
| Method | Input Resolution | Trained and Tested on TJU-PED-Campus Dataset | Transfered to and Tested on HRBUST-LLPED Dataset | Infer Time (ms) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P (%) | R (%) | AP50 (%) | AP (%) | P (%) | R (%) | AP50 (%) | AP (%) | |||
| YOLOv5s | 640 × 640 | 84.95 | 63.04 | 72.23 | 46.55 | 94.60 | 89.17 | 96.16 | 68.83 | 3.2 |
| 1280 × 1280 | 89.57 | 73.77 | 84.36 | 57.33 | 93.91 | 90.43 | 96.27 | 69.19 | 3.2 | |
| YOLOv8s | 640 × 640 | 88.13 | 64.71 | 74.39 | 51.02 | 93.35 | 90.64 | 96.17 | 69.73 | 3.4 |
| 1280 × 1280 | 90.39 | 76.00 | 85.43 | 61.15 | 92.96 | 91.66 | 96.34 | 69.87 | 12.6 | |
| YOLOv5n | 640 × 640 | 85.31 | 57.11 | 66.84 | 40.91 | 93.69 | 88.18 | 95.40 | 65.87 | 2.6 |
| 1280 × 1280 | 87.40 | 69.97 | 80.25 | 51.93 | 93.91 | 87.35 | 95.24 | 66.01 | 2.6 | |
| YOLOv8n | 640 × 640 | 85.97 | 59.92 | 69.49 | 46.07 | 93.06 | 89.82 | 95.73 | 68.77 | 1.7 |
| 1280 × 1280 | 89.68 | 71.49 | 81.80 | 57.21 | 92.89 | 90.19 | 96.00 | 68.71 | 5.6 | |
| Method | Input Resolution | Trained and Tested on TJU-PED Dataset | Transfered to and Tested on HRBUST-LLPED Dataset | Infer Time (ms) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P (%) | R (%) | AP50 (%) | AP (%) | P (%) | R (%) | AP50 (%) | AP (%) | |||
| YOLOv5s | 640 × 640 | 82.89 | 65.00 | 73.61 | 46.79 | 95.15 | 88.72 | 96.03 | 68.83 | 3.2 |
| 1280 × 1280 | 89.20 | 74.13 | 84.87 | 57.05 | 94.56 | 89.19 | 96.06 | 68.97 | 3.2 | |
| YOLOv8s | 640 × 640 | 87.27 | 66.56 | 75.88 | 51.04 | 93.46 | 90.66 | 96.24 | 69.59 | 3.4 |
| 1280 × 1280 | 90.02 | 76.89 | 86.09 | 60.67 | 93.25 | 91.27 | 96.29 | 69.90 | 12.6 | |
| YOLOv5n | 640 × 640 | 83.41 | 58.75 | 68.14 | 40.94 | 92.96 | 87.81 | 95.26 | 65.69 | 2.6 |
| 1280 × 1280 | 87.24 | 70.49 | 80.96 | 51.84 | 93.19 | 88.68 | 95.36 | 65.81 | 2.6 | |
| YOLOv8n | 640 × 640 | 85.35 | 60.88 | 70.80 | 45.82 | 92.67 | 90.27 | 95.75 | 68.53 | 1.6 |
| 1280 × 1280 | 89.28 | 72.22 | 82.51 | 56.82 | 93.09 | 90.52 | 96.04 | 68.74 | 5.6 | |
| Method | Input Resolution | MR (%) | FDR (%) | ILR (%) |
|---|---|---|---|---|
| YOLOv5s | 640 × 640 | 6.77 | 10.04 | 2.71 |
| 1280 × 1280 | 6.66 | 9.53 | 2.66 | |
| YOLOv8s | 640 × 640 | 7.66 | 9.27 | 2.92 |
| 1280 × 1280 | 6.98 | 8.72 | 2.51 | |
| YOLOv5n | 640 × 640 | 9.03 | 10.22 | 3.62 |
| 1280 × 1280 | 8.66 | 10.49 | 3.15 | |
| YOLOv8n | 640 × 640 | 8.13 | 9.03 | 2.92 |
| 1280 × 1280 | 7.88 | 8.67 | 2.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Sun, G.; Yu, L.; Zhou, K. HRBUST-LLPED: A Benchmark Dataset for Wearable Low-Light Pedestrian Detection. Micromachines 2023, 14, 2164. https://doi.org/10.3390/mi14122164
Li T, Sun G, Yu L, Zhou K. HRBUST-LLPED: A Benchmark Dataset for Wearable Low-Light Pedestrian Detection. Micromachines. 2023; 14(12):2164. https://doi.org/10.3390/mi14122164
Chicago/Turabian StyleLi, Tianlin, Guanglu Sun, Linsen Yu, and Kai Zhou. 2023. "HRBUST-LLPED: A Benchmark Dataset for Wearable Low-Light Pedestrian Detection" Micromachines 14, no. 12: 2164. https://doi.org/10.3390/mi14122164
APA StyleLi, T., Sun, G., Yu, L., & Zhou, K. (2023). HRBUST-LLPED: A Benchmark Dataset for Wearable Low-Light Pedestrian Detection. Micromachines, 14(12), 2164. https://doi.org/10.3390/mi14122164