Highlights
What are the main findings?
- We propose GTA, the first weakly-supervised domain generalization framework for cross-platform (ground-to-altitude) point cloud segmentation.
- We develop a progressive domain-aware augmentation strategy with cross-scale semantic alignment to effectively mitigate domain shifts.
What are the implications of the main findings?
- We eliminate the dependency on annotated aerial point clouds by establishing a practical weakly supervised paradigm for ground-to-aerial collaborative perception.
- We significantly enhance cross-platform generalization capability in complex large-scale outdoor scenarios with diverse urban layouts.
Abstract
Collaborative sensing between low-altitude remote sensing and ground-based mobile mapping lays the theoretical foundation for multi-platform 3D data fusion. However, point clouds collected from Airborne Laser Scanners (ALSs) remain scarce due to high acquisition and annotation costs. In contrast, while autonomous driving datasets are more accessible, dense annotation remains a significant bottleneck. To address this, we propose Ground to Altitude (GTA), a weakly supervised domain generalization (DG) framework. GTA leverages sparse autonomous driving data to learn robust representations, enabling reliable segmentation on airborne point clouds under zero-label conditions. Specifically, we tackle cross-platform discrepancies through progressive domain-aware augmentation (PDA) and cross-scale semantic alignment (CSA). For PDA, we design a distance-guided dynamic upsampling strategy to approximate airborne point density and a cross-view augmentation scheme to model viewpoint variations. For CSA, we impose cross-domain feature consistency and contrastive regularization to enhance robustness against perturbations. A progressive training pipeline is further employed to maximize the utility of limited annotations and abundant unlabeled data. Our study reveals the limitations of existing DG methods in cross-platform scenarios. Extensive experiments demonstrate that GTA achieves state-of-the-art (SOTA) performance. Notably, under the challenging 0.1% supervision setting, our method achieves a 6.36% improvement in mIoU over the baseline on the SemanticKITTI → DALES benchmark, demonstrating significant gains across diverse categories beyond just structural objects.
1. Introduction
Three-dimensional LiDAR point cloud semantic segmentation is a fundamental task in scene understanding and plays a crucial role in various domains such as autonomous driving, human–computer interaction, and remote sensing. In recent years, advances in sensor acquisition technologies and data synthesis techniques have led to the emergence of several high-quality public datasets, such as SemanticKITTI [1] and SynLiDAR [2], which have significantly accelerated the progress of 3D point cloud semantic segmentation research.
However, most existing LiDAR datasets are collected from ground vehicles with a near-horizontal viewing perspective, resulting in data distributions and structural characteristics that are highly dependent on ground-level scenes. When models are deployed in typical aerial 3D applications—such as large-scale land-cover classification, building footprint extraction and reconstruction, vegetation and forest inventory analysis, agricultural field monitoring, disaster assessment, and city- or region-level geographic mapping—there is a notable lack of large-scale benchmark datasets tailored for these scenarios. Models trained on ground-view data typically exhibit limited generalization ability when transferred to aerial platforms due to substantial differences in viewpoint, point density distribution, and scene scale.
To improve model generalization, inspired by domain transfer studies in 2D vision tasks, several recent works in 3D point cloud semantic segmentation have begun exploring unsupervised domain adaptation (UDA) and domain generalization (DG) approaches. When handling large-scale outdoor datasets, fully annotating source domain data is prohibitively labor-intensive and often infeasible. Therefore, to address the challenge of cross-domain adaptation without significantly increasing data acquisition and labeling efforts, it is imperative to develop a cross-platform, weakly supervised 3D point cloud semantic segmentation framework that ensures stable scene perception across different sensing platforms. Such a capability not only facilitates multi-platform 3D data fusion but also lays a solid foundation for future intelligent systems to operate robustly in diverse and complex environments.
UDA methods typically rely on accessing target-domain data during training, which limits their generalization ability to only those domains observed during the training process. In contrast, DG aims to enhance model robustness in previously unseen domains without requiring any target-domain data. To achieve stable performance across heterogeneous platforms, this study adopts a DG-based research paradigm, with the objective of learning domain-invariant point cloud representations across data collected from different sensor platforms. However, even for the same semantic category, point clouds captured from different platforms may exhibit substantial discrepancies in both distribution and structural characteristics. As illustrated in Figure 1, airborne LiDAR typically preserves upper-layer geometry and global infrastructure while lacking interior and lateral surfaces, whereas ground-based autonomous driving datasets emphasize side-view structural details. These inherent differences pose significant challenges for constructing truly domain-invariant representations.

Figure 1.
Comparison of datasets captured from different perspectives. For better visualization, different colors denote distinct semantic categories. Point clouds from the airborne dataset DALES exhibit uniform density and typically preserve upper-layer geometry and overall infrastructure (top). In contrast, point clouds from the autonomous driving dataset SemanticKITTI decrease in density with distance and tend to emphasize side-view structures while underrepresenting upper-layer geometry (bottom).
To address this issue, we propose a cross-platform, weakly supervised 3D point cloud semantic segmentation framework based on DG. From a data-centric perspective, to reduce the model’s dependency on target-domain data, we employ progressive domain-aware augmentation (PDA), which applies stochastic transformations to source-domain point clouds based on a basic augmentation strategy. This encourages the model to learn more generalizable representations across varying samples without relying on domain-specific details, thereby enhancing generalization in the absence of target-domain data. Furthermore, we design platform-specific augmentation strategies tailored to the disparities between vehicle-mounted and airborne LiDAR data, improving the model’s adaptability to different platforms. From a label-centric perspective, weakly supervised methods provide limited annotations. To further enhance semantic refinement, our framework leverages a large number of unlabeled points without disturbing the learning of labeled point features. Specifically, we introduce cross-scale semantic alignment (CSA) to enforce semantic consistency between original and augmented samples across multiple feature scales.
Finally, we conduct a systematic evaluation and analysis of the proposed strategy. Experimental results on the SemanticKITTI, SynLiDAR, and DALES [3] datasets demonstrate that our method, even when trained under weak supervision, consistently outperforms all baseline approaches, thereby validating the effectiveness of the proposed framework.
To summarize, our key contributions are the following:
- We propose the first DG-based cross-platform weakly supervised 3D point cloud semantic segmentation framework, which effectively learns domain-invariant features from multi-platform data.
- We design a progressive data augmentation strategy, simulating airborne LiDAR data to enhance cross-platform generalization.
- We introduce CSA to fully leverage unlabeled points, enabling richer contextual feature learning and further improving generalizable 3D semantic scene understanding.
2. Related Work
2.1. LiDAR Semantic Segmentation
LiDAR semantic segmentation (LSS) aims to assign per-point semantic labels to LiDAR point clouds, serving as a crucial step for comprehensive 3D scene understanding. Depending on the amount of annotated data required, existing LSS approaches can be categorized into fully supervised, unsupervised, and weakly supervised methods.
2.1.1. Fully Supervised LiDAR Semantic Segmentation
With the increasing availability of datasets, fully supervised LSS has achieved remarkable progress. Existing approaches can generally be categorized into three groups according to their data processing strategies: projection-based, voxel-based, and point-based methods. Projection-based methods [4,5,6,7,8,9,10] project 3D points onto 2D images for subsequent semantic learning; however, both the projection and data processing may lead to the loss of geometric details. Voxel-based methods [11,12,13,14,15] convert point clouds into voxel grids and apply efficient sparse convolutional operations, yet the voxelization process inevitably obscures the inherent data characteristics of raw point clouds. Point-based methods [16,17,18,19,20,21,22], starting from the seminal PointNet [23], directly process raw point sets with multi-layer perceptrons (MLPs) and have since inspired a wide range of follow-up work. More recently, transformer-based architectures have emerged as powerful backbones. For instance, Hierarchical Point Cloud Transformer (HPCT) [24] introduces a hierarchical point cloud transformer to extract multi-scale semantic features for vegetation segmentation, while Point Transformer V3 (PTv3) [25] prioritizes simplicity and scale, achieving state-of-the-art efficiency and accuracy on large-scale datasets. However, despite their strong representation capabilities, fully supervised methods achieve high-precision results through high annotation costs.
2.1.2. Unsupervised LiDAR Semantic Segmentation
Unsupervised methods eliminate the need for labeled data, and their research in image semantic segmentation [26,27,28,29] has become increasingly widespread and mature. In the 3D domain, several studies have attempted to transfer this concept to point cloud segmentation tasks. PointDC [30] integrates cross-modal distillation with super-voxel clustering to infer semantic structures in a fully label-free manner. GrowSP (Growing Superpoint) [31] progressively expands superpoints to discover semantic elements in 3D space. U3DS3 [32] performs iterative training based on superpoint and spatial clustering and improves voxelized features by exploiting the invariance and equivariance of volumetric representations, enabling more robust feature learning. AdaCo [33] introduces a cross-modal label generation module (CLGM) and leverages the strong reasoning capability of visual foundation models (VFMs) to provide cross-modal supervision. Despite their advantage of substantially reducing annotation costs, the segmentation accuracy of unsupervised approaches often remains insufficient for practical applications.
2.1.3. Weakly Supervised LiDAR Semantic Segmentation
Weakly supervised methods can substantially reduce annotation costs while preserving reasonable segmentation accuracy, and research in this field has been extensively advanced in recent years. According to the strategies to leverage training labels, existing methods can be categorized into four groups, namely two-dimensional label-based methods, cross-modulal methods, pseudo-3D label-based methods, and limited 3D label-based methods.
Two-dimensional label-based methods rely exclusively on more readily available 2D annotations to guide the training of 3D models. Inspired by 3D reconstruction approaches based on 2D projections such as CAPNET [34] and 3D image analysis methods leveraging graph convolution such as DGCNN [20], Wang et al. [35] proposed the first weakly supervised point cloud semantic segmentation method, which projects the segmentation results of truncated 3D point clouds onto a 2D plane and employs 2D ground truth images for supervised training. Subsequently, Wang et al. [36] extended the original framework by incorporating a decoder capable of capturing visual information; however, this approach only considers local projection cues, limiting its ability to model global semantics. To mitigate excessive interference from 2D information, 3DSS-VLG [37] explores the use of only 2D semantic cues during the training phase to assist 3D weakly supervised semantic segmentation tasks, representing the first work in this field to leverage semantic information from category text labels.
Cross-modal methods further leverage the complementarity between different types of data, introducing additional supervisory information on the basis of weakly annotated point clouds. BPNet [38] enables bidirectional interaction between 2D and 3D information across multiple structural levels, effectively combining the strengths of both modalities for improved scene understanding. Kweon and Yoon [39] leverage 2D class activation maps as self-supervision to enhance 3D semantic perception, while employing a point cloud feature similarity matrix to guide the training of an image classifier. MIT [40] adopts dual encoders to extract self-attention features from 3D point clouds and 2D multi-view images, respectively, and introduces a decoder to perform interleaved 2D–3D cross-attention, thereby achieving implicit feature fusion across the two modalities. Sun et al. [41] argue that cameras are commonly available in LiDAR-equipped scenarios and thus can synchronously capture both 2D and 3D information. By leveraging complementary cues from unlabeled images, they design a dual-branch network equipped with an active annotation strategy to directly enable cross-modal knowledge transfer between the two domains.
Pseudo-3D label-based methods do not rely on annotations from other modalities; instead, they generate pseudo labels for unlabeled points to replace ground-truth labels during training. Inspired by the Class Activation Map (CAM) [42], Wei et al. [43] introduced the Point Class Activation Map (PCAM) to facilitate pseudo-label generation and, for the first time, exploited subcloud-level labels for weakly supervised training. SSPC-Net [44] generates pseudo labels by leveraging superpoints together with a dynamic label propagation strategy. Liu et al. [45] constructed super-voxels from point clouds and adopted a graph propagation module for both training and label propagation. HybridCR [46] represents the first framework to simultaneously integrate point consistency, contrastive regularization, and pseudo-labeling for segmentation. To further optimize supervisory information and simplify label propagation, Liu et al. [47] designed a training strategy combining active learning with self-training, while Wu et al. [48] refined the selection of reliable pseudo labels based on predicted confidence and uncertainty. Additionally, Deng et al. [49] proposed an image-assisted pseudo-label generator to enhance pseudo-label quality.
Limited 3D label-based methods combine partially annotated point clouds with multiple constraints to train segmentation models. Xu and Lee [50] introduced three additional constraints to enhance the features of unlabeled points. Wei et al. [51] proposed a dense supervision propagation approach that transfers supervision information from labeled points to unlabeled ones. Observing significant intra-class variations in 3D data, Su et al. [52] designed a multi-prototype classifier along with two constraints to further discover subclasses within each semantic category. Cheng et al. [53] noted limitations of existing random sampling strategies in autonomous driving scenarios and proposed a novel Polar Cylinder Balanced Random Sampling method to achieve a more balanced point cloud distribution. To address large-scale scene segmentation, Zhang et al. [54] leveraged predictive consistency between perturbed and original branches to propagate information between labeled and unlabeled points. Lee et al. [55] further introduced the concept of cognitive uncertainty to filter reliable features prior to information propagation.
However, despite their strong representation capabilities, these LSS methods lack specific domain alignment mechanisms, making them susceptible to significant performance degradation when directly applied to cross-platform airborne domains.
2.2. Unsupervised Domain Adaptation
Research on LSS has achieved substantial progress; however, directly applying trained models across different domains often results in significant performance degradation. To address this challenge, researchers have explored UDA, which aims to transfer knowledge from labeled source-domain data to unlabeled target domains. To mitigate inter-domain discrepancies, SqueezeSegV2 [56] and Yi et al. [57] transformed point clouds into depth maps and 2D range images, enabling the use of 2D UDA techniques for model training. LiDAR-UDA [58] reduced inter-sensor differences by combining LiDAR beam subsampling with cross-frame aggregation, while MoDA [59] leveraged motion prior knowledge from video sequences to facilitate cross-domain alignment for segmentation tasks. To generate high-quality pseudo labels, Bian et al. [60] introduced a multi-level feature consistency framework, and Zhao et al. [61] designed a pseudo-label refinement network (PRN) to select highly reliable labels. VFMSeg [62] utilized a vision foundation model to encode prior knowledge and produce more accurate labels for unlabeled target-domain data, while CLIP2UDA [63] further incorporated cross-modal learning using the pre-trained Contrastive Language–Image Pre-training (CLIP) model to enrich supervisory signals. Mixing-based strategies have shown promise in bridging domain gaps. Compositional Semantic Mix (CoSMix) [64] introduces a cloud-mixing strategy for UDA by mixing source and target point clouds, while UniMix [65] proposes a unified mixing framework to create intermediate domains for both UDA and DG tasks. While effective for clear-to-adverse weather adaptation or similar viewpoints, these UDA methods primarily focus on mixing samples within similar sensor perspectives and often fail to address the severe geometric deformations caused by the drastic ground-to-air viewpoint shift.
2.3. Domain Generalization
Unlike UDA, DG places greater emphasis on the model’s ability to generalize to unseen target domains. It aims to achieve strong performance even when the model cannot access target domain data during the training phase, thereby partially overcoming the limitations of UDA. Data augmentation is a common strategy to enhance generalization. PointDR [66] was the first to apply DG to 3D semantic segmentation, proposing a domain randomization technique to study adaptation from normal-weather point clouds to adverse-weather point clouds. DGLSS [67] simulated target-domain data by randomly subsampling LiDAR scans and learned generalized representations through sparse invariant feature consistency and semantic-relevant consistency. Similarly, cross-modal learning can improve model generalization. BEV-DG [68] designed a density-preserving vector modeling scheme from a bird’s-eye view to extract domain-invariant features, while LiDOG [69] leveraged semantic priors from 2D BEV views in conjunction with 3D data for training. Autonomous driving tasks can further exploit multi-frame sequence information to enhance performance. LiDomAug [70] augmented data by combining ego-motion information and sequential frames and generating augmented samples via randomized LiDAR sensor configurations. Sanchez et al. [71] performed label propagation using multi-frame aggregation and object motion information. In addition, Kim et al. [72] proposed density-aware sparse convolution and a self-supervised density prediction auxiliary task to enhance the model’s density-awareness. However, these approaches focus solely on adaptation across different autonomous driving datasets, overlooking the critical need for cross-platform generalization across LiDAR-equipped platforms in real-world scenarios. Our work addresses this gap: considering the cross-platform differences from autonomous driving to airborne point clouds, as well as the labeling challenges of existing datasets, we propose Ground to Altitude (GTA).
3. Method
In this section, we first introduce the overall framework of the proposed method in Section 3.1. We then elaborate on the PDA and the CSA in Section 3.2 and Section 3.3, respectively. Finally, the detailed loss functions are presented in Section 3.4.
3.1. Overview
The overview of GTA is illustrated in Figure 2. To mitigate the challenges introduced by domain shift, the proposed framework is designed to enhance weakly supervised 3D point cloud semantic segmentation. It integrates two complementary components: PDA and CSA. Working jointly, these modules improve robustness against distributional variations and enforce semantic consistency across different feature scales and domains.
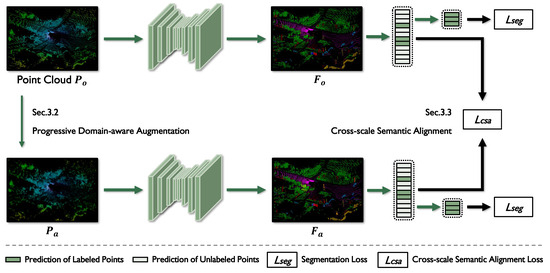
Figure 2.
The architecture of GTA. The original point cloud is first processed by PDA to generate an augmented point cloud, . Both and are then fed into the 3D semantic segmentation network to extract their corresponding features, and . These features are passed through a series of multilayer perceptrons to produce initial semantic predictions, which are subsequently used to compute the CSA loss , integrating contrastive regularization and consistency supervision. This loss enforces semantic consistency across scales and domains. Meanwhile, only the labeled points contribute to the cross-entropy segmentation loss , guiding the network to learn accurate predictions from sparse annotations.
First, the PDA module applies stage-wise domain-aware transformations to the input point clouds, including basic augmentations—mirroring, random rotation, and jittering—as well as perceptual augmentations, such as distance-guided upsampling and geometry-aware selection. Unlike conventional random augmentation strategies that may distort inherent spatial structures, PDA dynamically adjusts the augmentation intensity based on the training stage. During early training, the model focuses on learning fundamental geometric patterns under mild perturbations; as training progresses, it is gradually exposed to more complex geometric variations and density shifts. The distance-guided upsampling and geometry-aware selection operations increase point density while preserving top points, facade points, and a portion of original samples, thereby enriching training diversity without compromising structural integrity. This progressive strategy facilitates the learning of feature representations that are robust to domain variations while maintaining structural and semantic consistency.
Next, with the features extracted, MLPs are applied to generate initial semantic predictions. These predictions are further refined by the CSA module, which enforces semantic consistency across multiple spatial scales. Specifically, CSA constrains both coarse- and fine-grained semantic responses to maintain local coherence while preserving high-frequency structural details. This strategy effectively mitigates semantic drift caused by the significant geometric perturbations introduced by PDA, enabling the network to exploit complementary contextual cues and ensuring reliable CSA.
Finally, the initial predictions at weakly annotated points are leveraged to compute the segmentation loss, which is jointly optimized with the cross-scale alignment loss. Taken together, these objectives constitute a unified augmentation–alignment learning paradigm that progressively improves DG and semantic stability under weak supervision.
3.2. Progressive Domain-Aware Augmentation
Autonomous driving and aerial LiDAR point clouds exhibit significant discrepancies in feature distributions due to differences in acquisition viewpoints, sensor configurations, and scanning trajectories. Traditional data augmentation techniques fail to effectively simulate the structured geometric variations that naturally occur across domains. To address this challenge, we propose a PDA strategy. Built upon conventional geometric perturbations, PDA gradually increases perturbation complexity and diversity, generating multiple semantically consistent point cloud variants. This progressive scheduling enables the model to smoothly transition from learning local perturbation invariance to global domain shift robustness, thereby effectively narrowing the cross-domain gap.
Specifically, PDA consists of two stages: a basic augmentation stage and a domain-aware augmentation stage. In the early training phase, lightweight geometric perturbations such as mirroring, rotation, and jittering are applied to improve robustness against local spatial noise while preserving the overall topological layout. As training proceeds, PDA progressively activates domain-aware augmentations that mimic characteristics commonly observed in aerial LiDAR, including uniform density distribution, vertical view-angle bias, and geometric discontinuities caused by occlusions.
Motivated by the observation that autonomous driving point clouds become sparser with increasing distance, while aerial point clouds generally maintain uniform density, we introduce a distance-aware density compensation strategy. For each point , its ground-projected distance is computed as
where denotes the relative compensation weight applied to enhance density in distant regions. Furthermore, we define a vertical structural saliency term based on local height differences:
which captures geometric discontinuities on building rooftops and façades, thereby reinforcing occlusion patterns present from aerial viewpoints. To avoid semantic distortion, ground surfaces are preserved while façade structures are sparsely retained.
We unify density compensation, structural saliency, and training scheduling into a continuous piecewise augmentation formulation:
where denotes the duplication of point with a duplication factor of n for local density augmentation. Here, is a monotonic curriculum coefficient, increases domain shift intensity in the later training stages, and and control the contributions of density and saliency, respectively. Here,
is a façade saliency mask introducing sparse discontinuities in structurally significant regions.
This unified formulation enables joint geometric modeling of domain discrepancies: simulates uniform density at long ranges, captures vertical structural deviations, and introduces façade sparsity. The exponential scheduling term ensures a smooth transition from mild to strong domain perturbations, preventing early training instability. After applying PDA, the original point cloud and the augmented point cloud are fed into the network to extract features. The obtained representations correspond to structurally consistent yet geometrically diverse inputs, significantly improving spatial robustness under cross-domain scenarios. By progressively exposing the model to increasingly challenging geometric variations, PDA enhances generalization while preserving semantic stability, laying a solid foundation for subsequent cross-domain feature alignment.
3.3. Cross-Scale Semantic Alignment
While PDA effectively increases cross-domain geometric diversity, it inevitably introduces feature mismatches between the original and augmented samples. Under weak supervision, where point-level annotations are limited, local geometric perturbations are prone to induce semantic drift and accumulate in the feature space, ultimately degrading class discriminability. Moreover, features at different scales exhibit varying sensitivities to local structures and global semantics, which can further exacerbate potential alignment bias.
To address these challenges, we propose a CSA module that enforces semantic consistency and contrastive regularization across multiple feature scales to achieve robust alignment under diverse geometric perturbations. Specifically, lower-level features capture fine-grained local geometry, while higher-level features focus on global semantic stability. In addition, contrastive regularization explicitly pulls semantically consistent samples closer and pushes away potentially misaligned instances, effectively mitigating distributional deviation introduced by PDA.
With CSA, the network learns semantically invariant representations across geometry-diverse domains, thereby substantially improving the generalization and discriminative capability of the feature space, and providing robust support for weakly supervised scenarios lacking dense annotations.
3.3.1. Semantic Consistency Constraint
Directly imposing supervision on augmented point clouds may lead the model to overfit perturbation-induced biases, resulting in degraded segmentation performance. To address this issue, we introduce a semantic consistency constraint that enforces alignment between the predictive distributions of the original and augmented point clouds, thereby enhancing robustness against structural perturbations.
Given the softmax distributions of the original prediction and the augmented prediction , the cross-cloud consistency loss is defined as
where N denotes the number of points and represents the Jensen–Shannon divergence, computed as
where denotes the Kullback–Leibler divergence:
The computation is analogous for , with and .
Since the model is highly sensitive to noisy perturbations during early training, we apply a parameterized multi-stage scheduling strategy to gradually activate the consistency objective:
where t denotes the current epoch, T is the maximum number of epochs, and , , and are tunable hyper-parameters. Consistent with the multi-stage PDA pipeline, we assign weaker consistency strength in early phases and gradually increase it as training stabilizes, effectively suppressing distributional drift introduced by aggressive geometry perturbations.
The final semantic consistency loss is defined as
3.3.2. Contrastive Regularization
Relying solely on consistency constraints in the prediction space may cause feature representations of structurally distinct points to collapse over time, leading to inter-class confusion under aggressive geometric perturbations. To enhance class separability in the embedding space, we further introduce a point-level contrastive regularization term.
Given the original embedding features and the augmented embedding features , we apply normalization along the feature dimension for both. For each anchor embedding , its corresponding positive sample is the augmented counterpart , while all other embeddings are considered as negatives. Based on a temperature parameter, , the point-level contrastive regularization loss is formulated as
where denotes the cosine similarity, is a temperature hyperparameter, and N is the number of sampled points.
This regularization term encourages anchor embeddings to be pulled closer to their corresponding positive samples while suppressing similarity to negatives in the embedding space, thus complementing the semantic consistency constraint imposed in the prediction space. We jointly define the cross-domain semantic alignment loss as
By simultaneously optimizing output-space consistency and embedding-space discrimination, the model effectively mitigates feature collapse, strengthens structural robustness, and yields domain-invariant 3D semantic representations.
3.4. Loss Functions
Based on the aforementioned module designs, we propose GTA, a weakly supervised domain-generalizable LSS framework. The framework jointly optimizes the weakly supervised segmentation loss together with the semantic alignment regularization introduced by PDA and CSA, thereby improving classification accuracy and cross-domain robustness. The overall loss function is defined as
where controls the contribution of the semantic alignment regularization term.
The weakly supervised segmentation loss is computed by applying cross-entropy between the predicted probability and weak annotations, defined as
where denotes the weak supervision signal, denotes the model prediction, and represents the set of weakly annotated points.
During training, the model further optimizes semantic consistency in the prediction space and semantic alignment in the embedding space, effectively mitigating distributional discrepancies caused by domain shift. Consequently, the model achieves enhanced generalization capability and more stable semantic discrimination across diverse scenarios.
4. Experimental Results
To evaluate the semantic segmentation performance of our model under a DG setting, we restricted the training process to a single annotated autonomous-driving dataset as the source domain and subsequently deployed the trained model on previously unseen airborne LiDAR data for target-domain testing. Using the DALES dataset, we constructed two DG benchmark test sets to rigorously assess how the proposed GTA framework facilitates cross-platform generalization. In addition, we compared our approach against several state-of-the-art (SOTA) point cloud segmentation generalization networks to provide a comprehensive performance analysis.
4.1. Implementation Details
We selected seven shared evaluation categories based on the semantic taxonomy of the DALES dataset for both DG benchmarks. Since SemanticKITTI and SynLiDAR contain more fine-grained class definitions, several categories were merged accordingly, and all dataset annotations were remapped to a unified label space. For SemanticKITTI and SynLiDAR, we adopted point-level weak supervision by randomly selecting a fixed proportion of points as labeled samples. Specifically, we tailored the labeled ratio to the distinct characteristics of each source domain. For SemanticKITTI, we strictly adhered to the standard protocol of the baseline Semantic Query Network (SQN) [73] by fixing the labeled ratio at 0.1% to ensure a fair comparison and isolate the contribution of our domain-aware modules. Conversely, for SynLiDAR, we adopted a 1% labeled setting. This adjustment compensated for the lower point density of the synthetic dataset compared to that of real-world LiDAR, ensuring sufficient supervision signals for effective learning. All experiments were conducted on a workstation equipped with an Intel CoreTM i9-12900KF CPU and an NVIDIA RTX 3090Ti GPU with 24 GB of memory.
4.2. Evaluation Metrics
To quantitatively evaluate and analyze the performance of the model, we performed assessments on all points of the target-domain test-set DALES. We adopted the Intersection over Union (IoU) for each segmentation class and the mean Intersection over Union (mIoU) across all classes as evaluation metrics. Let K denote the total number of classes, TP the number of true positives, FP the number of false positives, FN the number of false negatives, and TN the number of true negatives [74]. The two evaluation metrics are computed as follows:
4.3. Comparison with SOTA Methods
To provide a realistic evaluation of our model’s performance, we selected several closely related methods as baselines. First, we considered data augmentation-based approaches, including Pointcutmix [75]—which generates augmented samples by mixing two point clouds selected from the training set—and Mix3D [76], which constructs hybrid scenes by concatenating points and labels from different scenes. Second, we included domain-adaptive methods such as RayCast [77] and fully supervised DG approaches for all-weather scenarios like PointDR [66], which employs a domain randomization strategy during segmentation training. Finally, we also evaluated the generalization performance of SQN, a weakly supervised method designed for large-scale 3D point cloud semantic segmentation. Notably, the implementations of the baseline methods were based on the relevant code from the LiDOG [69] project.
4.3.1. Evaluation on SemanticKITTI → DALES
SemanticKITTI is a densely annotated autonomous-driving dataset collected by the Mobile Laser Scanning (MLS) platform at the University of Bonn, Germany. It comprises 45.49 million points and 28 semantic categories, which we further consolidated into seven categories for our study.
We trained the model on the SemanticKITTI dataset and evaluated its generalization performance on the DALES dataset, with the results summarized in Table 1. Under a fully supervised training regime, the data augmentation method Mix3D achieved the best generalization performance, reaching 22.61% mIoU. The DG method for all-weather scenarios, PointDR, performed poorly, achieving only 14.71% mIoU, with the lowest performance observed on the ground category. The weakly supervised method SQN attained 20.54% mIoU, surpassing Pointcutmix, RayCast, and PointDR. Notably, GTA achieved the SOTA segmentation performance. Using only 0.1% of the training data, it attained 26.9% mIoU, outperforming PointCutMix and Mix3D by 7.23% and 4.29%, respectively, and surpassing RayCast by 9.02%. Furthermore, compared to SQN under the same 0.1% annotation setting, our method yielded a significant performance gain of 6.36%. These results demonstrate GTA’s capability to learn more robust representations when addressing cross-platform domain generalization tasks.

Table 1.
Performance comparison on SemanticKITTI → DALES.
The qualitative results of transferring from SemanticKITTI to DALES using only 0.1% annotations are illustrated in Figure 3. The first column shows the raw input point clouds, which are visualized using a Scalar Field Visualization technique since the DALES dataset does not provide RGB information. The second column presents the ground-truth labels, while the third column displays the predictions generated by our method. The last column shows the predictions of SQN [73], which serves as the backbone network of our framework. Regions where our method achieves superior predictions are highlighted in purple. As can be observed, our method yields substantial improvements over SQN on the DALES dataset, particularly in the more accurate identification of buildings and cars, thereby demonstrating the effectiveness of the proposed approach.

Figure 3.
Visualization results of cross-DG from SemanticKITTI to DALES. From left to right, we show the raw point cloud, the ground-truth annotations, the predictions of our method, and those of the comparison method. Regions where our approach outperforms SQN are highlighted with purple circles. Note that the ground truth (GT) is provided as a reference to highlight the significant structural improvements of GTA compared to the baseline (SQN), particularly in recovering geometric details.
4.3.2. Evaluation on SynLiDAR → DALES
SynLiDAR is a large-scale synthetic dataset collected and annotated by Nanyang Technological University from diverse virtual environments with rich scene content and layouts. It contains over 19 billion points across 32 semantic categories, which we further consolidated into seven test categories for evaluation.
We trained the model solely on the SynLiDAR dataset and evaluated its target-domain performance on the DALES dataset, with the results summarized in Table 2. Under a fully supervised training regime, the data augmentation method Pointcutmix achieved the best generalization performance, attaining 22.19% mIoU, surpassing Mix3D, RayCast, and PointDR. The weakly supervised 3D point cloud segmentation method SQN performed poorly, achieving only 14.34% mIoU, and struggled particularly with distinguishing the vegetation category.
Table 2.
Performance comparison on SynLiDAR → DALES.
The proposed method, GTA, achieved the highest segmentation performance, reaching 24.02% mIoU using only 1% of the training data. This corresponded to improvements of 1.83% and 8.61% over the data augmentation methods Pointcutmix and Mix3D, respectively, and an increase of 7.51% compared to the domain-adaptive method RayCast. Furthermore, compared to SQN, which also used 1% labeled data, GTA achieved a 9.68% higher mIoU. These results demonstrate the ability of GTA to learn more robust representations for cross-platform tasks and for generalizing from synthetic to real-world data. Notably, the performance gap of SQN between synthetic and autonomous-driving datasets highlights the inherent difficulty of synthetic-to-real generalization, whereas GTA maintained strong performance, confirming its effectiveness.
The qualitative results of transferring from SynLiDAR to DALES using only 1% annotations are presented in Figure 4. The first column shows the raw input point clouds, which were visualized using the Scalar Field Visualization technique for the DALES dataset. The second column depicts the ground-truth labels, while the third column displays the predictions produced by our method. The last column shows the predictions of SQN, which serves as the backbone network of our framework. Regions where our method achieves superior predictions are highlighted in purple. As observed, our method exhibits substantial improvements over SQN on the DALES dataset, particularly in the more accurate identification of buildings and vegetation, demonstrating the effectiveness of the proposed approach.
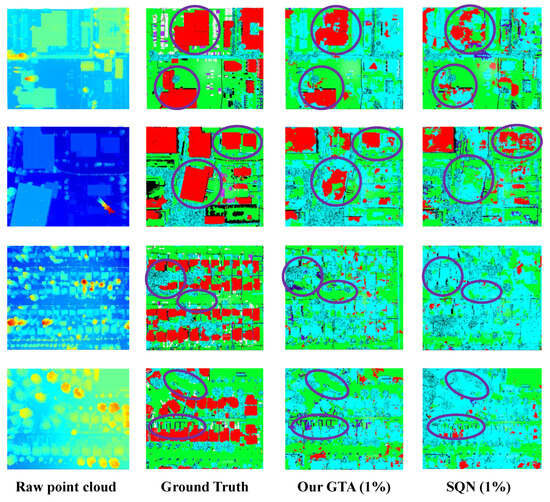
Figure 4.
Visualization results of cross-DG from SynLiDAR to DALES. From left to right, we show the raw point cloud, the ground-truth annotations, the predictions of our method, and those of the comparison method. Regions where our approach outperforms SQN are highlighted with purple circles. Note that the ground truth (GT) is provided as a reference to highlight the significant structural improvements of GTA compared to the baseline (SQN), particularly in recovering geometric details.
5. Discussion
5.1. Ablation Study
To thoroughly evaluate the individual contributions of the key components in our GTA framework, we conducted a systematic analysis combining quantitative metrics and qualitative visualization. The experiments were performed on the cross-domain SemanticKITTI → DALES scenario under the 0.1% weakly supervised setting. The quantitative results are summarized in Table 3.
Table 3.
Ablation study (removing modules) on SemanticKITTI → DALES.
5.1.1. Effectiveness of Progressive Domain-Aware Augmentation
Removing the PDA module resulted in a 7.76% decrease in mIoU. This metric drop indicates that the model struggles to adapt to the geometric characteristics of the target airborne point clouds without progressive perturbations. Operating at the input level, PDA introduces data augmentation in a staged manner to progressively align the geometric statistics of source samples with the target distribution, thereby enabling the model to learn more discriminative and structured semantic features. These ablation results align with existing theoretical analyses of DG and staged adaptation mechanisms, further validating the positive contribution of PDA in robust feature extraction.
5.1.2. Effectiveness of the Cross-Scale Semantic Alignment
Table 3 reveals that removing the CSA module precipitated the most substantial performance decline of 8.82%. This sharp drop underscores that merely utilizing PDA is insufficient to bridge the severe domain gap without explicit feature-level alignment. As corroborated by the t-SNE visualization in Figure 5, the baseline features exhibit severe entanglement, whereas the full framework incorporating CSA establishes clear decision boundaries. This confirms that CSA effectively operates on the embedding space by enforcing consistency constraints across scales. Particularly under extremely sparse supervision, CSA compensates for the semantic uncertainty and enhances class separability, playing a decisive role in constructing a discriminative semantic structure.
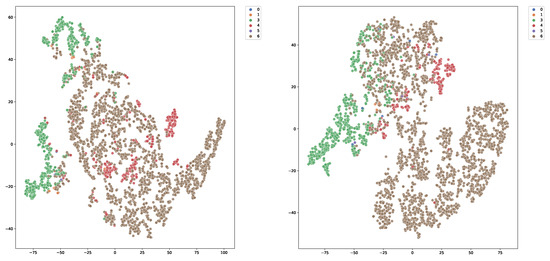
Figure 5.
The t-SNE visualization of feature distributions on the DALES dataset. The numbers in the legend correspond to different semantic classes. (Left): The baseline features exhibit severe entanglement between classes, indicating poor semantic discriminability. (Right): In contrast, our GTA framework produces compact intra-class clusters and clear inter-class separation, demonstrating that the PDA and CSA modules effectively refine the feature space.
5.1.3. Synergistic Effects
The complete GTA model achieved optimal performance when both PDA and CSA were incorporated, indicating a complementary relationship between the two components at different spatial levels. PDA bridges the geometric gap at the data level, while CSA bridges the semantic gap at the feature level. Comparing the visual results in Figure 5, we observe that our full framework transforms the chaotic feature space of the baseline into compact, well-separated clusters. This proves that the two modules mutually reinforce each other: PDA provides a diverse and robust input distribution, which facilitates CSA in learning more discriminative structural features, ultimately forming a closed loop for cross-domain robustness.
5.1.4. Computational Complexity Analysis
To evaluate the practical efficiency of our GTA framework, we compared the model parameters and inference speed with those of the baseline SQN. All experiments were conducted on a single NVIDIA RTX 3090 Ti GPU with a batch size of 2. As summarized in Table 4, our method introduced only a marginal increase in model size from 1.05 M to 1.11 M parameters. This indicates that the proposed PDA and CSA modules are parameter-efficient and do not impose a heavy memory burden. Significantly, the inference speed remained consistent at 10.0 FPS, comparable to that of the baseline. This demonstrates that GTA significantly improves segmentation performance without compromising the real-time capability of the network, highlighting its potential for efficient deployment in resource-constrained autonomous systems.
Table 4.
Comparison of computational complexity and performance on DALES.
5.2. Performance Analysis
5.2.1. Quantitative Error Analysiss
To further investigate the limitations and failure modes of our method in the airborne scenario, we conducted a quantitative error analysis on the DALES dataset.
As shown in Figure 6 (left), the confusion matrix reveals a systematic misclassification where various structural objects are erroneously predicted as Vegetation. Specifically, the model exhibited high error rates for Buildings (81%), Trucks (64%), and Cars (56%) being misclassified as Vegetation. This widespread confusion is primarily attributed to the drastic viewpoint shift. The model, trained on ground-based LiDAR dataset SemanticKITTI, learned to recognize these classes largely by their vertical facades. However, in the airborne target domain, these objects predominantly present as roofs (horizontal or sloped planes) while vertical facades are largely occluded or missing. Consequently, the model failed to identify the characteristic vertical geometric features and erroneously categorized these elevated roof points as Vegetation.
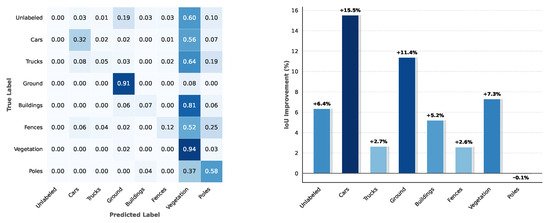
Figure 6.
Quantitative error analysis on the DALES dataset. (Left): The normalized confusion matrix reveals a severe misclassification of structural objects as Vegetation, highlighted by the high values in the “Vegetation” column. (Right): The per-class IoU comparison demonstrates that our GTA framework achieves significant gains in structural categories compared to the baseline SQN.
However, as shown in Figure 6 (right), our method still demonstrated superior robustness compared to the baseline. The GTA framework significantly improved the IoU of structural classes, boosting Ground by 11.4% and Cars by 15.5%. These results verify that although geometric ambiguity persisted, our domain-aware modules effectively recovered a substantial portion of semantic information lost by the baseline.
5.2.2. Qualitative Visualization
Complementing the quantitative metrics, we present a visualization study to intuitively demonstrate the generalization capability of GTA. Due to the distinct geometric characteristics of different categories, generalization strategies are often challenged by specific class-level variances, particularly under the drastic viewpoint shift between domains.
As shown in Figure 7, we visualize the segmentation results of the SemanticKITTI → DALES scenario under the 0.1% labeled setting. We specifically highlight four representative categories: Vegetation, Poles, Cars, and Buildings. The red bounding boxes in raw point clouds highlight the regions of interest.
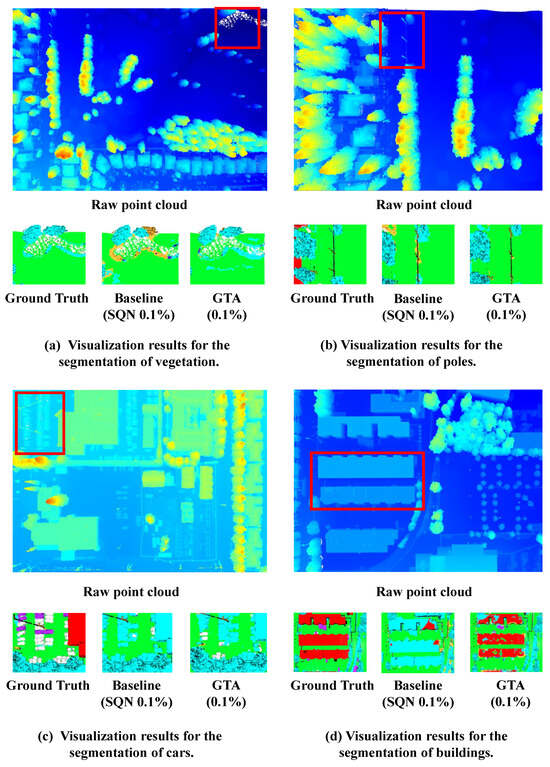
Figure 7.
Visualization results of generalizing the SemanticKITTI training set to the DALES dataset. Each group of results includes the raw point cloud, the ground-truth annotations within the red bounding boxes, the predictions of baseline methods, and the results of our approach. With only 0.1% labeled points, the baseline methods exhibit noticeable discrepancies from the ground-truth annotations, whereas the proposed GTA method produces segmentation results that are much closer to the ground truth.
It is evident that our GTA produces predictions much closer to the ground truth compared to those of the baseline SQN. A critical observation can be made in the building case: the baseline model, struggling with the top-down view, fails to recognize the building structure and misclassifies the roof points as vegetation. In contrast, GTA successfully captures the geometric consistency of the building despite the missing vertical facades. Similarly, for small objects like poles and cars, our method preserves fine-grained structural details that are lost by the baseline. This visual evidence confirms that our DG strategy effectively learns robust, viewpoint-invariant features.
6. Conclusions
In this paper, we introduced GTA, a weakly supervised DG framework for LSS that bridges the gap between autonomous driving and airborne point clouds, enabling zero-label deployment in the target domain. To accommodate distributional differences across heterogeneous LiDAR platforms, we proposed a distance-guided dynamic upsampling strategy and a cross-view augmentation scheme within the PDA module, supported by a progressive training pipeline that ensures stable optimization. Furthermore, the semantic consistency and contrastive regularization of CSA enhance robustness against perturbations and improve the discriminability of learned representations. Extensive experiments demonstrate that, although a performance gap remains compared to the ground truth (the theoretical upper bound), GTA achieves SOTA performance among weakly supervised methods for cross-platform 3D semantic segmentation. Error analysis reveals that domain viewpoint shifts lead to geometric ambiguity between structural objects and vegetation. In the absence of vertical facade features, models relying on sparse geometric cues struggle to distinguish flat rooftops from vegetation canopies. In future work, we plan to address this by incorporating cross-modal data to provide complementary texture information, or by exploring geometric-aware pre-training strategies to learn more viewpoint-invariant representations, to further close this performance gap.
Author Contributions
Conceptualization, J.W., X.X., J.L., Y.L. and C.C.; Methodology, J.W. and X.X.; Validation, J.W., J.L. and Q.L.; Formal analysis, C.C.; Investigation, J.W. and Y.L.; Resources, Y.L.; Data curation, J.L., Q.L. and C.C.; Writing – original draft, J.W.; Writing – review & editing, J.W. and X.X.; Visualization, J.W. and Q.L.; Supervision, X.X., Y.L. and C.C.; Project administration, X.X., J.L., Y.L. and C.C.; Funding acquisition, C.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original data presented in this study are openly available from SemanticKITTI, SynLiDAR and DALES: www.semantic-kitti.org (accessed on 1 June 2023), https://github.com/xiaoaoran/SynLiDAR (accessed on 28 June 2021) and https://sites.google.com/a/udayton.edu/vasari1/research/earth-vision/dales (accessed on 19 June 2020) or [1,2,3].
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| GTA | Ground to Altitude; |
| MLPs | Multilayer perceptrons; |
| SOTA | State of the art; |
| CE | Cross-entropy. |
References
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9297–9307. [Google Scholar]
- Xiao, A.; Huang, J.; Guan, D.; Zhan, F.; Lu, S. Transfer learning from synthetic to real LiDAR point cloud for semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 22 February–1 March 2022; Volume 36, pp. 2795–2803. [Google Scholar]
- Varney, N.; Asari, V.K.; Graehling, Q. DALES: A large-scale aerial LiDAR data set for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Utrecht, The Netherlands, 7–11 December 2020; pp. 186–187. [Google Scholar]
- Xiao, A.; Yang, X.; Lu, S.; Guan, D.; Huang, J. FPS-Net: A convolutional fusion network for large-scale LiDAR point cloud segmentation. Isprs J. Photogramm. Remote Sens. 2021, 176, 237–249. [Google Scholar] [CrossRef]
- Cortinhal, T.; Tzelepis, G.; Aksoy, E.E. Salsanext: Fast, uncertainty-aware semantic segmentation of LiDAR point clouds. In Proceedings of the International Symposium on Visual Computing (ISVC), San Diego, CA, USA, 5–7 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 207–222. [Google Scholar]
- Peng, K.; Fei, J.; Yang, K.; Roitberg, A.; Zhang, J.; Bieder, F.; Heidenreich, P.; Stiller, C.; Stiefelhagen, R. MASS: Multi-attentional semantic segmentation of LiDAR data for dense top-view understanding. IEEE Trans. Intell. Transp. Syst. 2022, 23, 15824–15840. [Google Scholar] [CrossRef]
- Ando, A.; Gidaris, S.; Bursuc, A.; Puy, G.; Boulch, A.; Marlet, R. RangeViT: Towards vision transformers for 3D semantic segmentation in autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 5240–5250. [Google Scholar]
- Cheng, H.X.; Han, X.F.; Xiao, G.Q. TransRVNet: LiDAR semantic segmentation with transformer. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5895–5907. [Google Scholar] [CrossRef]
- Lin, F.; Lin, T.; Yao, Y.; Ren, H.; Wu, J.; Cai, Q. VPA-Net: A visual perception assistance network for 3D LiDAR semantic segmentation. Pattern Recognit. 2025, 158, 111014. [Google Scholar] [CrossRef]
- Li, R.; Li, S.; Chen, X.; Ma, T.; Gall, J.; Liang, J. TFNet: Exploiting temporal cues for fast and accurate LiDAR semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 17–21 June 2024; pp. 4547–4556. [Google Scholar]
- Wang, X.; Feng, W.; Kong, L.; Wan, L. NUC-Net: Non-uniform cylindrical partition network for efficient LiDAR semantic segmentation. IEEE Trans. Circuits Syst. Video Technol. 2025, 35, 9090–9104. [Google Scholar] [CrossRef]
- Zhu, X.; Zhou, H.; Wang, T.; Hong, F.; Ma, Y.; Li, W.; Li, H.; Lin, D. Cylindrical and asymmetrical 3D convolution networks for LiDAR segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19 November 2021; pp. 9939–9948. [Google Scholar]
- Hou, Y.; Zhu, X.; Ma, Y.; Loy, C.C.; Li, Y. Point-to-voxel knowledge distillation for LiDAR semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 5 June 2022; pp. 8479–8488. [Google Scholar]
- Choy, C.; Gwak, J.; Savarese, S. 4D spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3075–3084. [Google Scholar]
- Graham, B.; Engelcke, M.; Van Der Maaten, L. 3D semantic segmentation with submanifold sparse convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9224–9232. [Google Scholar]
- Wang, Z.; Chen, H.; Liu, J.; Qin, J.; Sheng, Y.; Yang, L. Multilevel intuitive attention neural network for airborne LiDAR point cloud semantic segmentation. Int. J. Appl. Earth Obs. Geoinf. 2024, 132, 104020. [Google Scholar] [CrossRef]
- Zhou, Y.; Xie, Z.; Zhao, J.; Du, W.; Yao, R.; El Saddik, A. Multi-modal LiDAR point cloud semantic segmentation with salience refinement and boundary perception. ACM Trans. Multimed. Comput. Commun. Appl. 2024, 20, 1–20. [Google Scholar]
- Qiu, S.; Li, X.; Xue, X.; Pu, J. PC-BEV: An efficient polar-Cartesian BEV fusion framework for LiDAR semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; Volume 39, pp. 6612–6620. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar]
- Phan, A.V.; Le Nguyen, M.; Nguyen, Y.L.H.; Bui, L.T. Dgcnn: A convolutional neural network over large-scale labeled graphs. Neural Netw. 2018, 108, 533–543. [Google Scholar] [CrossRef] [PubMed]
- Lai, X.; Liu, J.; Jiang, L.; Wang, L.; Zhao, H.; Liu, S.; Qi, X.; Jia, J. Stratified transformer for 3D point cloud segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8500–8509. [Google Scholar]
- Ma, Y.; Guo, Y.; Liu, H.; Lei, Y.; Wen, G. Global context reasoning for semantic segmentation of 3D point clouds. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 2931–2940. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qiang, X.; He, W.; Chen, S.; Lv, Q.; Huang, F. Hierarchical Point Cloud Transformer: A Unified Vegetation Semantic Segmentation Model for Multisource Point Clouds Based on Deep Learning. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Wu, X.; Jiang, L.; Wang, P.-S.; Liu, Z.; Liu, X.; Qiao, Y.; Ouyang, W.; He, T.; Zhao, H. Point Transformer V3: Simpler Faster Stronger. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 4840–4851. [Google Scholar]
- Chen, Y.; Liu, J.; Ni, B.; Wang, H.; Yang, J.; Liu, N.; Li, T.; Tian, Q. Shape self-correction for unsupervised point cloud understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8382–8391. [Google Scholar]
- Cho, J.H.; Mall, U.; Bala, K.; Hariharan, B. Picie: Unsupervised semantic segmentation using invariance and equivariance in clustering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16794–16804. [Google Scholar]
- Hoang, C.M.; Kang, B. Pixel-level clustering network for unsupervised image segmentation. Eng. Appl. Artif. Intell. 2024, 127, 107327. [Google Scholar] [CrossRef]
- Niu, D.; Wang, X.; Han, X.; Lian, L.; Herzig, R.; Darrell, T. Unsupervised universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 22744–22754. [Google Scholar]
- Chen, Z.; Xu, H.; Chen, W.; Zhou, Z.; Xiao, H.; Sun, B.; Xie, X. PointDC: Unsupervised Semantic Segmentation of 3D Point Clouds via Cross-modal Distillation and Super-Voxel Clustering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 14290–14299. [Google Scholar]
- Zhang, Z.; Yang, B.; Wang, B.; Li, B. Growsp: Unsupervised semantic segmentation of 3D point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Paris, France, 2–3 October 2023; pp. 17619–17629. [Google Scholar]
- Liu, J.; Yu, Z.; Breckon, T.P.; Shum, H.P.H. U3DS3: Unsupervised 3D semantic scene segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2024; pp. 3759–3768. [Google Scholar]
- Zou, P.; Zhao, S.; Huang, W.; Xia, Q.; Wen, C.; Li, W.; Wang, C. AdaCo: Overcoming visual foundation model noise in 3D semantic segmentation via adaptive label correction. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; Volume 39, pp. 11086–11094. [Google Scholar]
- Navaneet, K.L.; Mandikal, P.; Agarwal, M.; Babu, R.V. CapNet: Continuous approximation projection for 3D point cloud reconstruction using 2D supervision. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8819–8826. [Google Scholar]
- Wang, H.; Rong, X.; Yang, L.; Wang, S.; Tian, Y. Towards Weakly Supervised Semantic Segmentation in 3D Graph-Structured Point Clouds of Wild Scenes. In Proceedings of the BMVC, Cardiff, UK, 9–12 September 2019; p. 284. [Google Scholar]
- Wang, H.; Rong, X.; Yang, L.; Feng, J.; Xiao, J.; Tian, Y. Weakly supervised semantic segmentation in 3D graph-structured point clouds of wild scenes. arXiv 2020, arXiv:2004.12498. [Google Scholar] [CrossRef]
- Xu, X.; Yuan, Y.; Li, J.; Zhang, Q.; Jie, Z.; Ma, L.; Tang, H.; Sebe, N.; Wang, X. 3D weakly supervised semantic segmentation with 2D vision-language guidance. In Proceedings of the European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 87–104. [Google Scholar]
- Hu, W.; Zhao, H.; Jiang, L.; Jia, J.; Wong, T.-T. Bidirectional projection network for cross dimension scene understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14373–14382. [Google Scholar]
- Kweon, H.; Yoon, K.-J. Joint learning of 2D-3D weakly supervised semantic segmentation. Adv. Neural Inf. Process. Syst. (Neurips) 2022, 35, 30499–30511. [Google Scholar]
- Yang, C.-K.; Chen, M.-H.; Chuang, Y.-Y.; Lin, Y.-Y. 2D–3D interlaced transformer for point cloud segmentation with scene-level supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Hsinchu City, Taiwan, 19 October 2023; pp. 977–987. [Google Scholar]
- Sun, T.; Zhang, Z.; Tan, X.; Qu, Y.; Xie, Y. Image understands point cloud: Weakly supervised 3D semantic segmentation via association learning. IEEE Trans. Image Process. 2024, 33, 1838–1852. [Google Scholar] [CrossRef] [PubMed]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Wei, J.; Lin, G.; Yap, K.H.; Hung, T.Y.; Xie, L. Multi-path region mining for weakly supervised 3D semantic segmentation on point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4384–4393. [Google Scholar]
- Cheng, M.; Hui, L.; Xie, J.; Yang, J. Sspc-net: Semi-supervised semantic 3D point cloud segmentation network. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 9–21 May 2021; Volume 35, pp. 1140–1147. [Google Scholar]
- Liu, Z.; Qi, X.; Fu, C.W. One thing one click: A self-training approach for weakly supervised 3D semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1726–1736. [Google Scholar]
- Li, M.; Xie, Y.; Shen, Y.; Ke, B.; Qiao, R.; Ren, B.; Lin, S.; Ma, L. Hybridcr: Weakly-supervised 3D point cloud semantic segmentation via hybrid contrastive regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14930–14939. [Google Scholar]
- Liu, G.; van Kaick, O.; Huang, H.; Hu, R. Active self-training for weakly supervised 3D scene semantic segmentation. Comput. Vis. Media 2024, 10, 425–438. [Google Scholar] [CrossRef]
- Wu, Z.; Wu, Y.; Lin, G.; Cai, J. Reliability-Adaptive Consistency Regularization for Weakly-Supervised Point Cloud Segmentation. Int. J. Comput. Vis. 2024, 132, 2276–2289. [Google Scholar] [CrossRef]
- Deng, J.; Lu, J.; Zhang, T. Quantity-Quality Enhanced Self-Training Network for Weakly Supervised Point Cloud Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 3580–3596. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Lee, G.H. Weakly supervised semantic point cloud segmentation: Towards 10× fewer labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13706–13715. [Google Scholar]
- Wei, J.; Lin, G.; Yap, K.H.; Liu, F.; Hung, T.Y. Dense supervision propagation for weakly supervised semantic segmentation on 3D point clouds. arXiv 2021, arXiv:2107.11267. [Google Scholar] [CrossRef]
- Su, Y.; Xu, X.; Jia, K. Weakly supervised 3D point cloud segmentation via multi-prototype learning. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7723–7736. [Google Scholar] [CrossRef]
- Han, X.F.; Cheng, H.; Jiang, H.; He, D.; Xiao, G. Pcb-randnet: Rethinking random sampling for lidar semantic segmentation in autonomous driving scene. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 4435–4441. [Google Scholar]
- Zhang, Y.; Qu, Y.; Xie, Y.; Li, Z.; Zheng, S.; Li, C. Perturbed self-distillation: Weakly supervised large-scale point cloud semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15520–15528. [Google Scholar]
- Lee, M.S.; Yang, S.W.; Han, S.W. Gaia: Graphical information gain based attention network for weakly supervised point cloud semantic segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 582–591. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar]
- Yi, E.; Yang, J.; Kim, J. Enhanced Prototypical Learning for Unsupervised Domain Adaptation in LiDAR Semantic Segmentation. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 1–7. [Google Scholar]
- Shaban, A.; Lee, J.; Jung, S.; Meng, X.; Boots, B. LiDAR-UDA: Self-ensembling Through Time for Unsupervised LiDAR Domain Adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Honolulu, HI, USA, 24 September 2023; pp. 19784–19794. [Google Scholar]
- Pan, F.; Yin, X.; Lee, S.; Niu, A.; Yoon, S.; Kweon, I.S. MoDA: Leveraging Motion Priors from Videos for Advancing Unsupervised Domain Adaptation in Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Denver, CO, USA, 21 September 2024; pp. 2649–2658. [Google Scholar]
- Bian, Y.; Xie, J.; Qian, J. Unsupervised domain adaptive point cloud semantic segmentation. In Proceedings of the Asian Conference on Pattern Recognition, Jeju Island, Republic of Korea, 9–12 November 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 285–298. [Google Scholar]
- Zhao, X.; Mithun, N.C.; Rajvanshi, A.; Chiu, H.-P.; Samarasekera, S. Unsupervised Domain Adaptation for Semantic Segmentation With Pseudo Label Self-Refinement. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2024; pp. 2399–2409. [Google Scholar]
- Xu, J.; Yang, W.; Kong, L.; Liu, Y.; Zhou, Q.; Zhang, R.; Li, Z.; Chen, W.-M.; Fei, B. Visual foundation models boost cross-modal unsupervised domain adaptation for 3D semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2025, 26, 20287–20301. [Google Scholar] [CrossRef]
- Wu, Y.; Xing, M.; Zhang, Y.; Xie, Y.; Qu, Y. CLIP2UDA: Making frozen CLIP reward unsupervised domain adaptation in 3D semantic segmentation. In Proceedings of the 32nd ACM International Conference on Multimedia (MM), Melbourne VIC, Australia, 28 October–1 November 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 8662–8671. [Google Scholar] [CrossRef]
- Saltori, C.; Galasso, F.; Fiameni, G.; Sebe, N.; Ricci, E.; Poiesi, F. CoSMix: Compositional Semantic Mix for Domain Adaptation in 3D LiDAR Segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 586–602. [Google Scholar]
- Zhao, H.; Zhang, J.; Chen, Z.; Zhao, S.; Tao, D. UniMix: Towards Domain Adaptive and Generalizable LiDAR Semantic Segmentation in Adverse Weather. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 16–22 June 2024; pp. 14781–14791. [Google Scholar]
- Xiao, A.; Huang, J.; Xuan, W.; Ren, R.; Liu, K.; Guan, D.; El Saddik, A.; Lu, S.; Xing, E.P. 3D semantic segmentation in the wild: Learning generalized models for adverse-condition point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 10–17 June 2023; pp. 9382–9392. [Google Scholar]
- Kim, H.; Kang, Y.; Oh, C.; Yoon, K.-J. Single domain generalization for LiDAR semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 17587–17598. [Google Scholar]
- Li, M.; Zhang, Y.; Ma, X.; Qu, Y.; Fu, Y. BEV-DG: Cross-modal learning under bird’s-eye view for domain generalization of 3D semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 11632–11642. [Google Scholar]
- Saltori, C.; Osep, A.; Ricci, E.; Leal-Taixé, L. Walking your LiDoG: A journey through multiple domains for LiDAR semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 196–206. [Google Scholar]
- Ryu, K.; Hwang, S.; Park, J. Instant domain augmentation for LiDAR semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–23 June 2023; pp. 9350–9360. [Google Scholar]
- Sanchez, J.; Deschaud, J.-E.; Goulette, F. Domain generalization of 3D semantic segmentation in autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 18077–18087. [Google Scholar]
- Kim, J.; Woo, J.; Shin, U.; Oh, J.; Im, S. Density-aware domain generalization for LiDAR semantic segmentation. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024; pp. 9573–9580. [Google Scholar]
- Hu, Q.; Yang, B.; Fang, G.; Guo, Y.; Leonardis, A.; Trigoni, N.; Markham, A. Sqn: Weakly-supervised semantic segmentation of large-scale 3D point clouds. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXVII. Springer: Berlin/Heidelberg, Germany, 2022; pp. 600–619. [Google Scholar]
- Hu, Q.; Yang, B.; Khalid, S.; Xiao, W.; Trigoni, N.; Markham, A. Sensaturban: Learning semantics from urban-scale photogrammetric point clouds. Int. J. Comput. Vis. 2022, 130, 316–343. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, L.; Ouyang, B.; Liu, B.; Zhu, J.; Chen, Y.; Meng, Y.; Wu, D. PointCutMix: Regularization strategy for point cloud classification. Neurocomputing 2022, 505, 58–67. [Google Scholar] [CrossRef]
- Nekrasov, A.; Schult, J.; Litany, O.; Leibe, B.; Engelmann, F. Mix3D: Out-of-context data augmentation for 3D scenes. In Proceedings of the 2021 International Conference on 3D Vision (3DV), London, UK, 1–3 December 2021; IEEE: New York, NY, USA, 2021; pp. 116–125. [Google Scholar]
- Langer, F.; Milioto, A.; Haag, A.; Behley, J.; Stachniss, C. Domain transfer for semantic segmentation of LiDAR data using deep neural networks. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 10 February 2020; IEEE: New York, NY, USA, 2020; pp. 8263–8270. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.