


Hierarchical Mixed-Precision Post-Training Quantization for SAR Ship Detection Networks


Abstract
1. Introduction
2. Related Works
2.1. Synthetic Aperture Radar Ship Detection
2.2. Quantization
3. Methods
3.1. Problem Setting
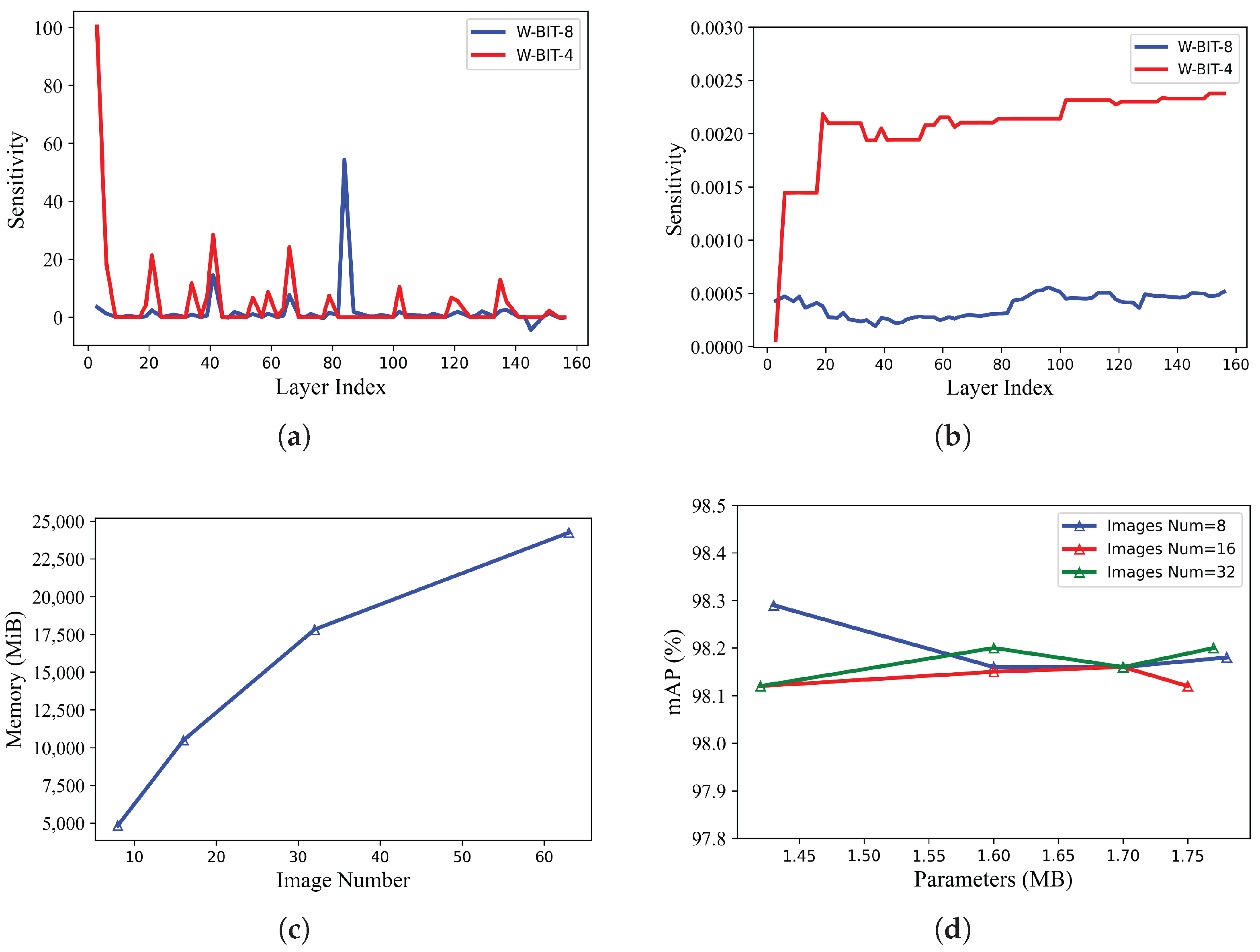
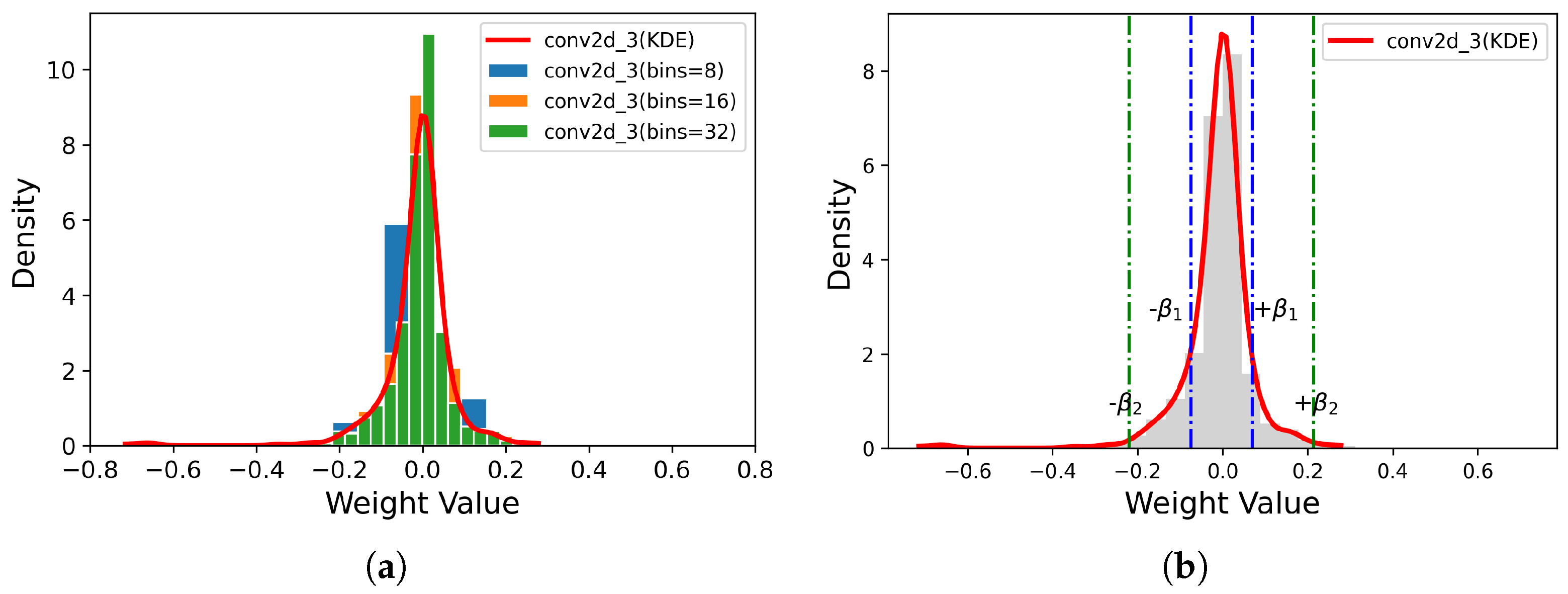
3.2. Reconstruction Error-Based Precision Configuration
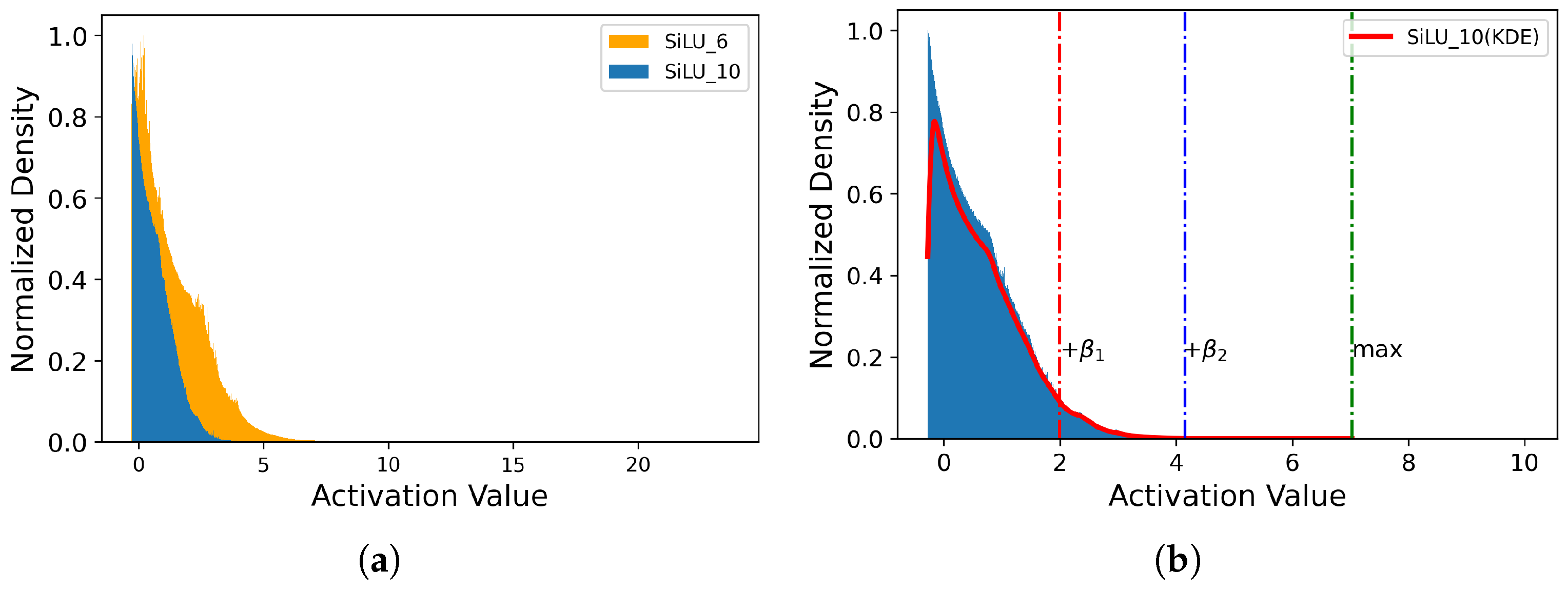
3.3. Intra-Layer Mixed-Precision Quantization
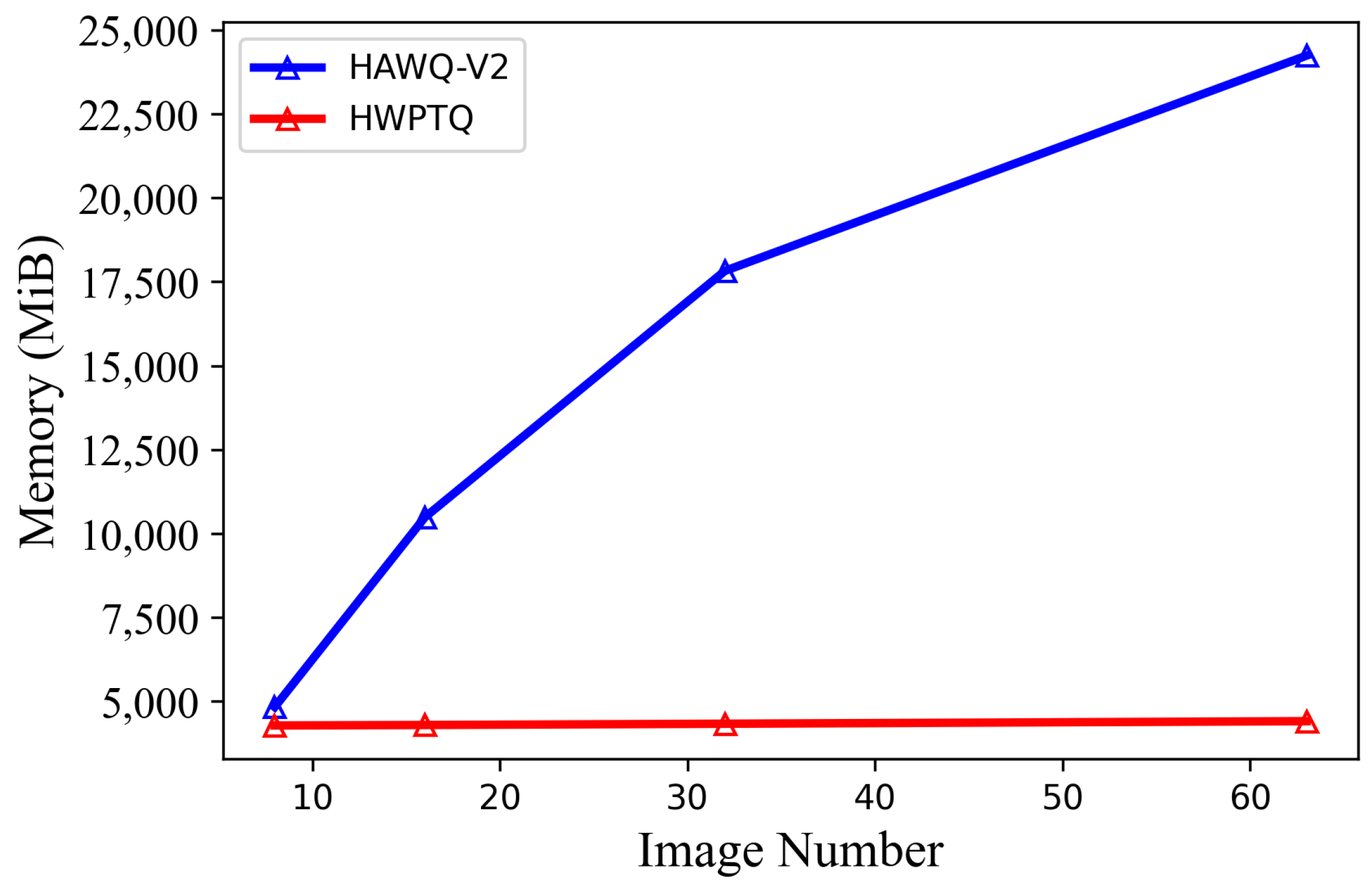
4. Experiment and Results
4.1. Dataset Description
4.2. Experimental Setting
4.3. Performance Evaluation
4.3.1. Experiments on Different Quantization Methods
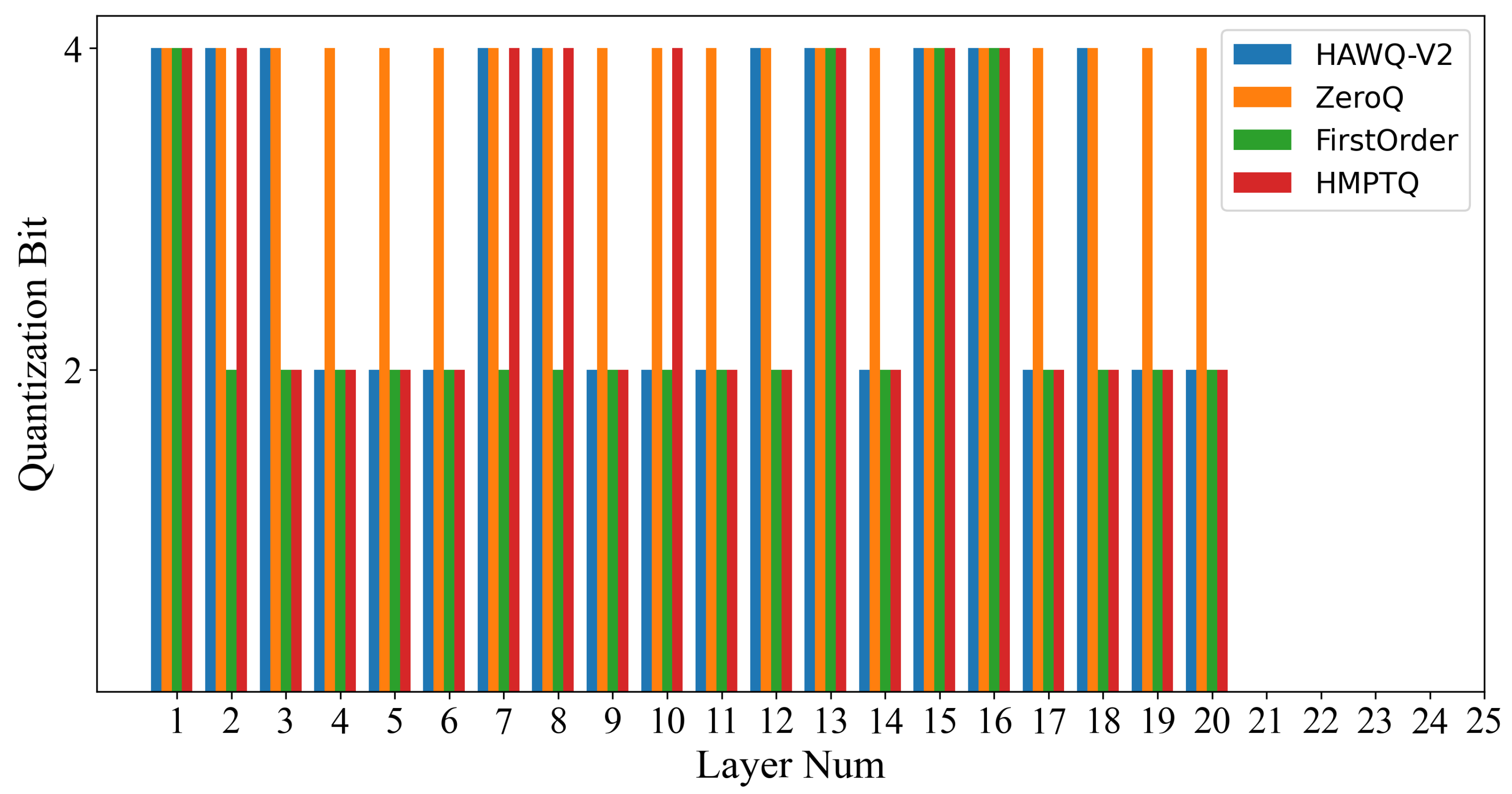
4.3.2. Experiments on Different Precision Allocation Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, S.; Zhan, R.; Wang, W.; Zhang, J. Learning Slimming SAR Ship Object Detector Through Network Pruning and Knowledge Distillation. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 1267–1282. [Google Scholar] [CrossRef]
- Ma, X.; Ji, K.; Xiong, B.; Zhang, L.; Feng, S.; Kuang, G. Light-YOLOv4: An Edge-Device Oriented Target Detection Method for Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 10808–10820. [Google Scholar] [CrossRef]
- Yang, Y.; Lang, P.; Yin, J.; He, Y.; Yang, J. Data Matters: Rethinking the Data Distribution in Semi-Supervised Oriented SAR Ship Detection. Remote Sens. 2024, 16, 2551. [Google Scholar] [CrossRef]
- Jeon, H.; Kim, D.j.; Kim, J. Water Body Detection using Deep Learning with Sentinel-1 SAR satellite data and Land Cover Maps. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Brussels, Belgium, 11–16 July 2021; pp. 8495–8498. [Google Scholar]
- Wang, Z.; Zhang, R.; Zhang, Q.; Zhu, Y.; Huang, B.; Lu, Z. An Automatic Thresholding Method for Water Body Detection from SAR Image. In Proceedings of the 2019 IEEE International Conference on Signal, Information and Data Processing (ICSIDP), Chongqing, China, 11–13 December 2019; pp. 1–4. [Google Scholar]
- Yadav, R.; Nascetti, A.; Ban, Y. Attentive Dual Stream Siamese U-Net for Flood Detection on Multi-Temporal Sentinel-1 Data. In Proceedings of the 2022 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 5222–5225. [Google Scholar]
- Baghermanesh, S.S.; Jabari, S.; McGrath, H. Urban Flood Detection Using Sentinel1-A Images. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Brussels, Belgium, 11–16 July 2021; pp. 527–530. [Google Scholar]
- Yang, Y.J.; Singha, S.; Mayerle, R. Fully Automated Sar Based Oil Spill Detection Using Yolov4. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Brussels, Belgium, 11–16 July 2021; pp. 5303–5306. [Google Scholar]
- Xu, F.Y.; An, X.Z.; Liu, W.Q. Oil Spill Detection in SAR Images based on Improved YOLOX-S. In Proceedings of the 2022 International Conference on Computer Engineering and Artificial Intelligence (ICCEAI), Shijiazhuang, China, 22–24 July 2022; pp. 261–265. [Google Scholar]
- Li, C.; Yang, Y.; Yang, X.; Chu, D.; Cao, W. A Novel Multi-Scale Feature Map Fusion for Oil Spill Detection of SAR Remote Sensing. Remote Sens. 2024, 16, 1684. [Google Scholar] [CrossRef]
- Tan, J.; Tang, Y.; Liu, B.; Zhao, G.; Mu, Y.; Sun, M.; Wang, B. A Self-Adaptive Thresholding Approach for Automatic Water Extraction Using Sentinel-1 SAR Imagery Based on OTSU Algorithm and Distance Block. Remote Sens. 2023, 15, 2690. [Google Scholar] [CrossRef]
- Ji, K.; Leng, X.; Wang, H.; Zhou, S.; Zou, H. Ship detection using weighted SVM and M-CHI decomposition in compact polarimetric SAR imagery. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort WOrth, TX, USA, 23–28 July 2017; pp. 890–893. [Google Scholar]
- Fang, J.; Shafiee, A.; Abdel-Aziz, H.; Thorsley, D.; Georgiadis, G.; Hassoun, J. Post-training Piecewise Linear Quantization for Deep Neural Networks. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Nagel, M.; Amjad, R.A.; van Baalen, M.; Louizos, C.; Blankevoort, T. Up or Down? Adaptive Rounding for Post-Training Quantization. arXiv 2020, arXiv:abs/2004.10568. [Google Scholar]
- Lin, C.; Peng, B.; Li, Z.; Tan, W.; Ren, Y.; Xiao, J.; Pu, S. Bit-shrinking: Limiting Instantaneous Sharpness for Improving Post-training Quantization. In Proceedings of the 2023 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 16196–16205. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.G.; Adam, H.; Kalenichenko, D. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]
- Kwak, J.; Kim, K.; Lee, S.S.; Jang, S.J.; Park, J. Quantization Aware Training with Order Strategy for CNN. In Proceedings of the IEEE Conference on Consumer Electronics-Asia, Yeosu, Republic of Korea, 26–28 October 2022; pp. 1–3. [Google Scholar]
- Shen, M.; Liang, F.; Gong, R.; Li, Y.; Li, C.; Lin, C.; Yu, F.; Yan, J.; Ouyang, W. Once Quantization-Aware Training: High Performance Extremely Low-bit Architecture Search. In Proceedings of the IEEE Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 5320–5329. [Google Scholar]
- Dong, Z.; Yao, Z.; Gholami, A.; Mahoney, M.; Keutzer, K. HAWQ: Hessian AWare Quantization of Neural Networks with Mixed-Precision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Republic of Korea, 27 Octobe–2 November 2019; pp. 293–302. [Google Scholar]
- Dong, Z.; Yao, Z.; Arfeen, D.; Gholami, A.; Mahoney, M.W.; Keutzer, K. HAWQ-V2: Hessian Aware trace-Weighted Quantization of Neural Networks. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Cai, Y.; Yao, Z.; Dong, Z.; Gholami, A.; Mahoney, M.W.; Keutzer, K. ZeroQ: A Novel Zero Shot Quantization Framework. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13166–13175. [Google Scholar]
- Wu, D.; Tang, Q.; Zhao, Y.; Zhang, M.; Fu, Y.; Zhang, D. EasyQuant: Post-training Quantization via Scale Optimization. arXiv 2020, arXiv:abs/2006.16669. [Google Scholar]
- Choukroun, Y.; Kravchik, E.; Yang, F.; Kisilev, P. Low-bit Quantization of Neural Networks for Efficient Inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Seoul, Republic of Korea, 27–28 October 2019; pp. 3009–3018. [Google Scholar]
- Guan, H.; Malevich, A.; Yang, J.; Park, J.; Yuen, H. Post-Training 4-bit Quantization on Embedding Tables. arXiv 2019, arXiv:abs/1911.02079. [Google Scholar]
- Oh, J.; Lee, S.; Park, M.; Walagaurav, P.; Kwon, K. Weight Equalizing Shift Scaler-Coupled Post-training Quantization. arXiv 2020, arXiv:abs/2008.05767. [Google Scholar]
- Hubara, I.; Nahshan, Y.; Hanani, Y.; Banner, R.; Soudry, D. Improving Post Training Neural Quantization: Layer-wise Calibration and Integer Programming. arXiv 2020, arXiv:abs/2006.10518. [Google Scholar]
- Li, Y.; Gong, R.; Tan, X.; Yang, Y.; Hu, P.; Zhang, Q.; Yu, F.; Wang, W.; Gu, S. BRECQ: Pushing the Limit of Post-Training Quantization by Block Reconstruction. arXiv 2021, arXiv:abs/2102.05426. [Google Scholar]
- Wei, X.; Gong, R.; Li, Y.; Liu, X.; Yu, F. QDrop: Randomly Dropping Quantization for Extremely Low-bit Post-Training Quantization. arXiv 2022, arXiv:abs/2203.05740. [Google Scholar]
- Chauhan, A.; Tiwari, U.; R, V.N. Post Training Mixed Precision Quantization of Neural Networks using First-Order Information. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Paris, France, 2–6 October 2023; pp. 1335–1344. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. SAR Ship Detection Dataset (SSDD): Official Release and Comprehensive Data Analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Zhang, W.; Cai, M.; Zhang, T.; Zhuang, Y.; Mao, X. EarthGPT: A Universal Multimodal Large Language Model for Multisensor Image Comprehension in Remote Sensing Domain. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–20. [Google Scholar] [CrossRef]
- Zhang, W.; Cai, M.; Zhang, T.; Zhuang, Y.; Mao, X. EarthMarker: A Visual Prompt Learning Framework for Region-level and Point-level Remote Sensing Imagery Comprehension. arXiv 2024, arXiv:abs/2407.13596. [Google Scholar]
- Chen, Z.; Gao, X. An Improved Algorithm for Ship Target Detection in SAR Images Based on Faster R-CNN. In Proceedings of the 2018 Ninth International Conference on Intelligent Control and Information Processing (ICICIP), Wanzhou, China, 9–11 November 2018; pp. 39–43. [Google Scholar]
- Chai, B.; Chen, L.; Shi, H.; He, C. Marine Ship Detection Method for SAR Image Based on Improved Faster RCNN. In Proceedings of the 2021 SAR in Big Data Era (BIGSARDATA), Nanjing, China, 22–24 September 2021; pp. 1–4. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wang, H.; Wu, B.; Wu, Y.; Zhang, S.; Mei, S.; Liu, Y. An Improved YOLO-v3 Algorithm for Ship Detection in SAR Image Based on K-means++ with Focal Loss. In Proceedings of the 2022 3rd China International SAR Symposium (CISS), Shanghai, China, 2–4 November 2022; pp. 1–5. [Google Scholar]
- Ting, L.; Baijun, Z.; Yongsheng, Z.; Shun, Y. Ship Detection Algorithm based on Improved YOLO V5. In Proceedings of the 2021 6th International Conference on Automation, Control and Robotics Engineering (CACRE), Dalian, China, 15–17 July 2021; pp. 483–487. [Google Scholar]
- Ge, R.; Mao, Y.; Li, S.; Wei, H. Research On Ship Small Target Detection In SAR Image Based On Improved YOLO-v7. In Proceedings of the 2023 International Applied Computational Electromagnetics Society Symposium (ACES-China), Hangzhou, China, 15–18 August 2023; pp. 1–3. [Google Scholar]
- Congan, X.; Hang, S.; Jianwei, L.; Yu, L.; Libo, Y.; Long, G.; Wenjun, Y.; Taoyang, W. RSDD-SAR: Rotated Ship Detection Dataset in SAR Images. J. Radars 2022, 11, 581. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A High-Resolution SAR Images Dataset for Ship Detection and Instance Segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X.; Zhan, X.; JUN, S.; Wei, S.; Pan, D.; Li, J.; Su, H.; Zhou, Y.; et al. LS-SSDD-v1.0: A deep learning dataset dedicated to small ship detection from large-scale Sentinel-1 SAR images. Remote Sens. 2020, 12, 2997. [Google Scholar] [CrossRef]
- Ultralytics. YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 26 June 2020).
- Wang, C.Y.; Yeh, I.H.; Liao, H. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:abs/2402.13616. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| YOLOV5n | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SSDD | HRSID | LS-SSDD-v1.0 | |||||||||||
| Method | Bits | Params | mAP | Params↓ | mAP | Params | mAP | Params↓ | mAP | Params | mAP | Params↓ | mAP |
| (W/A) | (MB) | (%) | (%) | (%) | (MB) | (%) | (%) | (%) | (MB) | (%) | (%) | (%) | |
| Baseline | FP32 | 7.04 | 98.21 | - | - | 7.04 | 92.21 | - | - | 7.04 | 75.48 | - | - |
| Channel-wise | W84A8 | 1.60 | 98.18 | 77.30 | −0.03 | 1.60 | 92.25 | 77.33 | 0.04 | 1.56 | 72.70 | 77.86 | −2.78 |
| Channel-wise | W42A8 | 0.97 | 97.47 | 86.23 | −0.74 | 0.97 | 92.18 | 86.29 | −0.03 | 0.95 | 72.36 | 86.47 | −3.12 |
| Channel-wise | W8A84 | 2.02 | 97.67 | 71.33 | −0.54 | 2.02 | 91.85 | 71.33 | −0.36 | 2.02 | 73.22 | 71.33 | −2.26 |
| Channel-wise | W8A42 | 2.02 | 16.65 | 71.33 | −81.56 | 2.02 | 21.04 | 71.33 | −71.17 | 2.02 | 31.93 | 71.3 | −43.55 |
| Channel-wise | W84A84 | 1.56 | 97.62 | 77.83 | −0.59 | 1.60 | 91.97 | 77.30 | −0.24 | 1.56 | 73.56 | 77.88 | −1.92 |
| Channel-wise | W42A84 | 0.96 | 97.32 | 86.38 | −0.89 | 0.97 | 92.04 | 86.26 | −0.17 | 0.95 | 72.48 | 86.47 | −3.00 |
| Channel-wise | W42A42 | 0.94 | 11.48 | 86.64 | −86.73 | 0.97 | 25.38 | 86.24 | −66.83 | 0.95 | 30.54 | 86.47 | −44.94 |
| HMPTQ | WP84A8 | 1.62 | 98.27 | 77.04 | 0.06 | 1.67 | 92.19 | 76.28 | −0.02 | 1.67 | 73.39 | 76.26 | −2.09 |
| HMPTQ | WP42A8 | 1.13 | 98.38 | 84.01 | 0.17 | 1.14 | 92.07 | 83.80 | −0.14 | 1.14 | 73.53 | 83.88 | −1.93 |
| HMPTQ | W8AP84 | 2.02 | 98.09 | 71.33 | −0.12 | 2.02 | 92.16 | 71.33 | −0.05 | 2.02 | 73.77 | 71.33 | −2.71 |
| HMPTQ | W8AP42 | 2.02 | 96.89 | 71.33 | −1.32 | 2.02 | 89.30 | 71.33 | −1.91 | 2.02 | 70.17 | 71.33 | −5.31 |
| HMPTQ | WP84AP84 | 1.64 | 97.90 | 76.70 | −0.31 | 1.67 | 92.12 | 76.33 | −0.09 | 1.65 | 72.63 | 76.63 | −2.85 |
| HMPTQ | WP42AP84 | 1.11 | 98.18 | 84.21 | −0.03 | 1.14 | 92.14 | 83.74 | −0.07 | 1.14 | 72.80 | 83.88 | −2.68 |
| HMPTQ | WP42AP42 | 1.11 | 96.86 | 84.21 | −1.35 | 1.14 | 90.25 | 83.74 | −1.96 | 1.14 | 70.29 | 83.88 | −5.19 |
| YOLOV9c | |||||||||||||
| Baseline | FP32 | 100.91 | 97.64 | - | - | 100.91 | 91.93 | - | - | 100.91 | 77.13 | − | - |
| Channel-wise | W84A8 | 27.87 | 97.71 | 72.38 | 0.07 | 27.84 | 92.04 | 72.41 | 0.11 | 27.84 | 77.0 | 72.41 | −0.13 |
| Channel-wise | W42A8 | 19.45 | 97.68 | 80.72 | 0.04 | 19.43 | 92.01 | 80.74 | 0.08 | 19.43 | 76.78 | 80.74 | −0.35 |
| Channel-wise | W8A84 | 33.50 | 97.05 | 66.80 | −0.59 | 33.50 | 89.73 | 66.80 | −2.20 | 33.50 | 76.70 | 66.80 | −0.43 |
| Channel-wise | W8A42 | 33.50 | 96.15 | 66.80 | −1.49 | 33.50 | 87.88 | 66.80 | −4.05 | 33.50 | 70.52 | 66.80 | −6.61 |
| Channel-wise | W84A84 | 27.87 | 97.02 | 72.38 | −0.62 | 27.84 | 89.60 | 72.41 | −2.33 | 27.84 | 76.56 | 72.41 | −0.57 |
| Channel-wise | W42A84 | 19.45 | 97.14 | 80.72 | −0.50 | 19.43 | 89.60 | 80.74 | −2.33 | 19.43 | 77.14 | 80.74 | 0.01 |
| Channel-wise | W42A42 | 19.45 | 96.04 | 80.72 | −1.60 | 19.43 | 85.47 | 80.74 | −6.46 | 19.43 | 71.80 | 80.74 | −5.33 |
| HMPTQ | WP84A8 | 28.93 | 97.67 | 71.33 | 0.03 | 28.91 | 92.09 | 71.35 | 0.16 | 28.91 | 77.04 | 71.36 | −0.09 |
| HMPTQ | WP42A8 | 21.85 | 97.60 | 78.35 | −0.04 | 21.83 | 92.08 | 78.37 | 0.15 | 21.88 | 76.79 | 78.31 | −0.34 |
| HMPTQ | W8AP84 | 33.50 | 97.54 | 66.80 | −0.10 | 33.50 | 91.97 | 66.80 | 0.04 | 33.50 | 77.14 | 66.80 | 0.01 |
| HMPTQ | W8AP42 | 33.50 | 97.44 | 66.80 | −0.20 | 33.50 | 91.31 | 66.80 | −0.62 | 33.50 | 75.52 | 66.80 | −1.61 |
| HMPTQ | WP84AP84 | 28.93 | 97.66 | 71.33 | 0.02 | 28.91 | 92.04 | 71.35 | 0.11 | 28.91 | 76.89 | 71.36 | −0.24 |
| HMPTQ | WP42AP84 | 21.85 | 97.69 | 78.35 | 0.05 | 21.83 | 91.91 | 78.37 | −0.02 | 21.88 | 76.93 | 78.31 | −0.20 |
| HMPTQ | WP42AP42 | 21.85 | 97.36 | 78.35 | −0.28 | 21.83 | 91.48 | 78.37 | −0.45 | 21.88 | 74.72 | 78.31 | −2.41 |
| SSDD | HRSID | LS-SSDD-v1.0 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Bits | Params | mAP | Params↓ | mAP | Params | mAP | Params↓ | mAP | Params | mAP | Params↓ | mAP |
| (W/A) | (MB) | (%) | (%) | (%) | (MB) | (%) | (%) | (%) | (MB) | (%) | (%) | (%) | |
| Baseline | FP32 | 7.04 | 98.21 | - | - | 7.04 | 92.21 | - | - | 7.04 | 75.48 | - | - |
| PWLQ [13] | W84A8 | 1.58 | 98.02 | 77.60 | −0.19 | 1.57 | 91.88 | 77.64 | −0.33 | 1.56 | 69.61 | 77.86 | −5.86 |
| PWLQ [13] | W42A8 | 0.96 | 56.0 | 86.36 | −42.21 | 0.97 | 65.75 | 86.18 | −26.46 | 0.95 | 44.26 | 86.47 | −31.22 |
| AdaRound [14] | W84A8 | 1.60 | 98.19 | 77.33 | −0.02 | 1.58 | 92.14 | 77.62 | −0.07 | 1.56 | 71.77 | 77.86 | −3.71 |
| AdaRound [14] | W42A8 | 0.95 | 96.49 | 86.52 | −1.72 | 0.97 | 92.37 | 86.26 | −0.16 | 0.95 | 73.28 | 86.47 | −2.20 |
| Bit−Shrinking [15] | W84A8 | 1.60 | 98.25 | 77.32 | 0.04 | 1.60 | 92.18 | 77.29 | −0.03 | 1.56 | 73.94 | 77.86 | −1.54 |
| Bit−Shrinking [15] | W42A8 | 0.96 | 98.25 | 86.36 | 0.04 | 0.97 | 91.89 | 86.29 | −0.32 | 0.95 | 73.03 | 86.47 | −2.45 |
| HMPTQ | WP84A8 | 1.62 | 98.27 | 77.04 | 0.06 | 1.67 | 92.19 | 76.28 | −0.02 | 1.67 | 73.39 | 76.26 | −2.09 |
| HMPTQ | WP42A8 | 1.13 | 98.38 | 84.01 | 0.17 | 1.14 | 92.07 | 83.80 | −0.14 | 1.14 | 73.53 | 83.88 | −1.93 |
| SSDD | HRSID | LS-SSDD-v1.0 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Bits | Params | mAP | Params↓ | mAP | Params | mAP | Params↓ | mAP | Params | mAP | Params↓ | mAP |
| (W/A) | (MB) | (%) | (%) | (%) | (MB) | (%) | (%) | (%) | (MB) | (%) | (%) | (%) | |
| Baseline | FP32 | 7.04 | 98.21 | - | - | 7.04 | 92.21 | - | - | 7.04 | 75.48 | - | - |
| HAWQ−V2 [20] | WP84A8 | 1.68 | 98.17 | 76.17 | −0.04 | 1.68 | 92.11 | 76.19 | −0.10 | 1.61 | 72.79 | 77.12 | −2.69 |
| HAWQ−V2 [20] | WP42A8 | 1.15 | 98.34 | 83.73 | 0.13 | 1.15 | 91.93 | 83.67 | −0.28 | 1.12 | 72.45 | 84.12 | −3.03 |
| ZeroQ [21] | WP84A8 | 1.68 | 97.46 | 76.09 | −0.75 | 1.68 | 92.07 | 76.19 | −0.14 | 1.69 | 72.92 | 75.93 | −2.56 |
| ZeroQ [21] | WP42A8 | 1.18 | 78.24 | 83.22 | −19.97 | 1.19 | 26.58 | 83.11 | −65.63 | 1.09 | 63.51 | 84.57 | −11.97 |
| FirstOrder [29] | WP84A8 | 1.71 | 98.38 | 75.76 | 0.17 | 1.67 | 92.16 | 76.24 | −0.05 | 1.67 | 73.39 | 76.26 | −2.09 |
| FirstOrder [29] | WP42A8 | 1.16 | 98.00 | 83.49 | −0.21 | 1.16 | 92.01 | 83.52 | −0.20 | 1.14 | 71.81 | 83.76 | −3.67 |
| HMPTQ | WP84A8 | 1.62 | 98.27 | 77.04 | 0.06 | 1.67 | 92.19 | 76.28 | −0.02 | 1.67 | 73.39 | 76.26 | −2.09 |
| HMPTQ | WP42A8 | 1.13 | 98.38 | 84.01 | 0.17 | 1.14 | 92.07 | 83.80 | −0.14 | 1.14 | 73.53 | 83.88 | −1.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, H.; Wang, Z.; Ni, Y. Hierarchical Mixed-Precision Post-Training Quantization for SAR Ship Detection Networks. Remote Sens. 2024, 16, 4042. https://doi.org/10.3390/rs16214042
Wei H, Wang Z, Ni Y. Hierarchical Mixed-Precision Post-Training Quantization for SAR Ship Detection Networks. Remote Sensing. 2024; 16(21):4042. https://doi.org/10.3390/rs16214042
Chicago/Turabian StyleWei, Hang, Zulin Wang, and Yuanhan Ni. 2024. "Hierarchical Mixed-Precision Post-Training Quantization for SAR Ship Detection Networks" Remote Sensing 16, no. 21: 4042. https://doi.org/10.3390/rs16214042
APA StyleWei, H., Wang, Z., & Ni, Y. (2024). Hierarchical Mixed-Precision Post-Training Quantization for SAR Ship Detection Networks. Remote Sensing, 16(21), 4042. https://doi.org/10.3390/rs16214042