1. Introduction
Synthetic aperture radar (SAR) is an active microwave imaging radar which can realize all-weather and all-day observation of the ground. Therefore, it has been widely used in the field of target reconstruction, target detection, and disaster and environmental monitoring [
1,
2,
3,
4]. Among these applications, automatic ship detection in SAR images plays an essential role in both military and civilian fields, such as national defense and security, fishing vessel monitoring, and maritime transport supervision and rescue [
1,
5,
6,
7]. However, compared with optical imagery, SAR images acquired from satellite and airborne platforms usually have lower resolutions and are more susceptible to background clutter and noise. In addition, ships of different sizes are displayed as objects with different pixels in SAR images. Therefore, it is still a significant challenge to accurately detect SAR ships with multi-scale features.
Traditional SAR ship detection methods usually rely on experience to manually select features, such as grayscale, texture, contrast, histogram statistics, and scattering properties [
8,
9,
10]. Generally, they are only suitable for SAR ship detection with simple backgrounds. The constant false alarm rate (CFAR) detection method is widely utilized in SAR ship detection [
11]. It sets the threshold according to the contrast between the target and the sea clutter background, which can achieve better detection performance in high-contrast scenes. However, when the surrounding environment is complex, it is difficult to use statistical data to describe the scattering mechanism of the ship target, and the detection performance will decline.
In recent years, deep learning methods have been widely used in target detection and recognition, target localization, image segmentation, and so on. They have the advantages of self-learning, self-improvement, and weight sharing. It is possible to realize automatic detection and recognition of ships in SAR images by using deep learning methods, which have become the new methods of choice to tackle the problem of SAR ship detection. Nie et al. [
12] improved the accuracy of ship detection and segmentation by adding a bottom-up structure to the FPN model in Mask-RCNN and applying an attention mechanism to the network. Ke et al. [
13] replaced conventional convolution kernels with deformable convolution in Faster RCNN to better model the geometric transformation of ships. In order to tackle the problem of multi-scale ship detection, You et al. [
14] proposed a wide-area target search system to integrate different ship detection methods. Lv et al. [
15] designed a two-step detector for ship detection, which utilized the complex information of a single-look SAR image to characterize the ship features. Li et al. [
16] proposed a novel RADet algorithm to obtain the rotating boundary boxes of objects with shape masks. To solve the problem of multi-scale SAR ship detection in complex environments, Li et al. [
17] proposed a multidimensional domain fusion network which fused low-level and high-level features to improve detection accuracy. Furthermore, to improve the accuracy of neural networks, attention mechanisms are widely used in target detection and recognition. A squeeze and excitation (SE) attention mechanism is proposed to focus on channel relationships, which recalibrates channel characteristic responses by simulating interdependencies between channels [
18]. An attention receptive pyramid network embedded in a convolutional block attention module (CBAM) [
19] is proposed to suppress the background interference in [
20]. Zha et al. [
21] proposed a ship detection method using multi-feature transformation and fusion to improve the detection accuracy for small targets in complex backgrounds. In the proposed ship detection model, a modified CBAM attention mechanism and SE attention mechanism are utilized to reduce the noise interference. Li et al. [
22] proposed an SAR ship detection model, A-BFPN, based on attention-guided balanced feature pyramid networks, and constructed a channel attention fusion module to acquire the multiscale features. Zhang et al. [
23] proposed a regional predictive perception network for SAR ship detection, which constructed a cross-scale self-attention module to restrain the background interference and improve the SAR ship target detection accuracy. All of these methods have achieved good results in SAR ship detection tasks. However, they mainly focus on the improvement of detection accuracy, ignoring that the complexity and computation of the model will increase with the deepening of the network. This issue can be a significant obstacle to deploying ship detection on aircraft or satellite platforms.
To achieve real-time ship detection in remote sensing images, many lightweight models based on one-stage detectors have been explored. The Single Shot MultiBox Detector (SSD) [
24] model is a detection method that directly predicts target categories and bounding boxes and does not generate a proposal process. This makes SSD easy to train and integrate and suitable for fast SAR ship detection [
25]. Zhou et al. [
26] designed a lightweight SAR ship detection method based on anchor free networks, which utilized a single-stage model FCOS to reduce the model parameter and decrease the computational complexity. Miao et al. [
27] designed an SAR ship detection model based on an improved RetinaNet network. The backbone of RetinaNet was replaced by a ghost module to decrease the number of convolutional layers, which could effectively reduce the model parameters and the floating-point operations. Guo et al. [
28] proposed an improved YOLOv5 network for SAR ship detection. The proposed network used a CBAM module to extract features of the channel and spatial dimensions and employed a BiFPN module to fuse multi-scale features. Zhang et al. [
29] designed a ShipDeNet-20 network for real-time SAR application by introducing a scale share feature pyramid module. Zhao et al. [
30] constructed a single-stage model to detect arbitrarily oriented ships through stepwise regression from coarse-grained to fine-grained detection. Moreover, shallow texture features and deep semantic features are also fused in this model to improve the accuracy. Chang et al. [
31] developed a new architecture with fewer layers based on You Only Look Once version 2 (YOLOv2) to reduce the computational time. An attention mechanism is imposed into YOLOv3 in [
32]. Sun et al. [
33] designed a YOLO-based arbitrary orientation SAR ship detector, which can detect multi-scale ships through bi-directional information interaction. Guo et al. [
34] combined the adaptive activation function and convolutional block attention model in YOLOX-SAR to improve the feature extraction ability. Van Etten [
35] proposed an end-to-end object detection framework You Only Look Twice (YOLT) for satellite imagery, which can rapidly detect objects with relatively little training data. Nina et al. [
36] studied the ship detection performance of YOLOv3 and YOLT on satellite imagery. Although YOLO series can be regarded as the first choice for real-time ship detection, their detection accuracy still needs to be improved. Due to the imaging characteristics of SAR systems, the obtained SAR images are much different from the nature scenes, which are obviously influenced by background interference and the morphological changes of the targets. Especially in the nearshore area, some ships in SAR images have scattering mechanisms that are similar to the surrounding areas, or a large number of ships are densely distributed, which can easily cause missed detections and false detections. In addition, the existing methods of SAR ship detection often ignore the position information loss of small ships in high-level features, which limits the detection performance. Furthermore, most methods improve accuracy by adding modules or increasing the network depth, resulting in complex models and slow detection speeds, which are not conducive to the application of real-time ship detection.
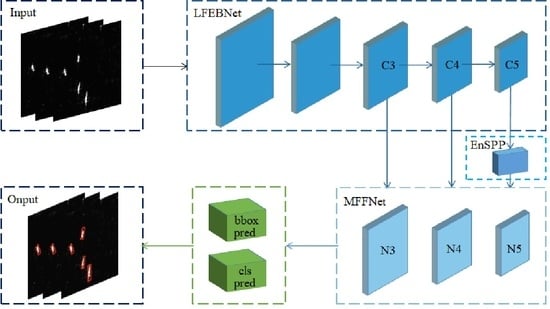
In order to better balance the accuracy and speed of SAR ship detection, we propose an efficient lightweight SAR ship detection model YOLO-Lite in this paper. The main contributions of the proposed model are as follows:
1. We design a lightweight feature enhancement backbone (LFEBNet) to reduce computational costs. Moreover, a channel and position enhancement attention (CPEA) module is constructed and integrated into the LFEBNet architecture to more accurately locate the target location by capturing the positional information.
2. To enhance the expression ability of features and address the position information loss of small SAR ships in high-level features, an enhanced spatial pyramid pooling (EnSPP) module is designed to aggregate the output feature more fully.
3. To overcome the multi-scale features of SAR ship targets, an effective multi-scale feature fusion network (MFFNet) is customized to obtain feature maps with more position and semantic information.
4. Considering the imbalance between negative and positive samples, we introduce weights to control negative and positive samples and the sample classification difficulty to obtain a novel confidence loss function, which can effectively improve the SAR ship target detection accuracy.
The remainder of this paper is organized as follows. The overall network structure and details are introduced in
Section 2. In
Section 3, the experiment results and performance analysis are presented. Ablation experiments are conducted in
Section 4. Finally,
Section 5 gives a brief conclusion.
5. Conclusions
Aiming at the problem of inaccurate target location and complex background interference in SAR ship detection, an efficient lightweight network YOLO-Lite is proposed in this paper. It can better balance the accuracy and speed of SAR ship detection. Specifically, a lightweight feature enhancement backbone (LFEBNet) is designed to reduce the computational costs. Additionally, a CPEA module is constructed to help the backbone network obtain more accurate position information. An EnSPP module is designed to enhance the expression ability of features and address the position information loss of small SAR ships in high level features. Moreover, an effective MFFNet network is customized to overcome the multi-scale features of SAR ship targets. In addition, a novel confidence loss function is proposed to effectively improve the SAR ship target detection accuracy. The experimental results on the SSDD dataset show that the precision, mAP, and F1 of our YOLO-Lite reach 96.28%, 94.36%, and 93.39%, respectively. Meanwhile, the number of model parameters and FPS are 7.64 M and 103.5, respectively. With respect to the SAR ship dataset, our model is still stable, and the precision, mAP, and F1 are 94.86%, 92.13%, and 91.39%, respectively, which is superior to other detection methods. The quantitative and visualization results confirm the effectiveness of the proposed YOLO-Lite.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}