


CViTF-Net: A Convolutional and Visual Transformer Fusion Network for Small Ship Target Detection in Synthetic Aperture Radar Images

Abstract
:1. Introduction
- 1.
- We constructed a new CViT backbone consisting of CNNs and visual transformers, which helped CViTF-Net obtain powerful feature representation capabilities. As a result, it significantly reduced the detector’s attention to the background and enhanced the robustness of small ship target detection.
- 2.
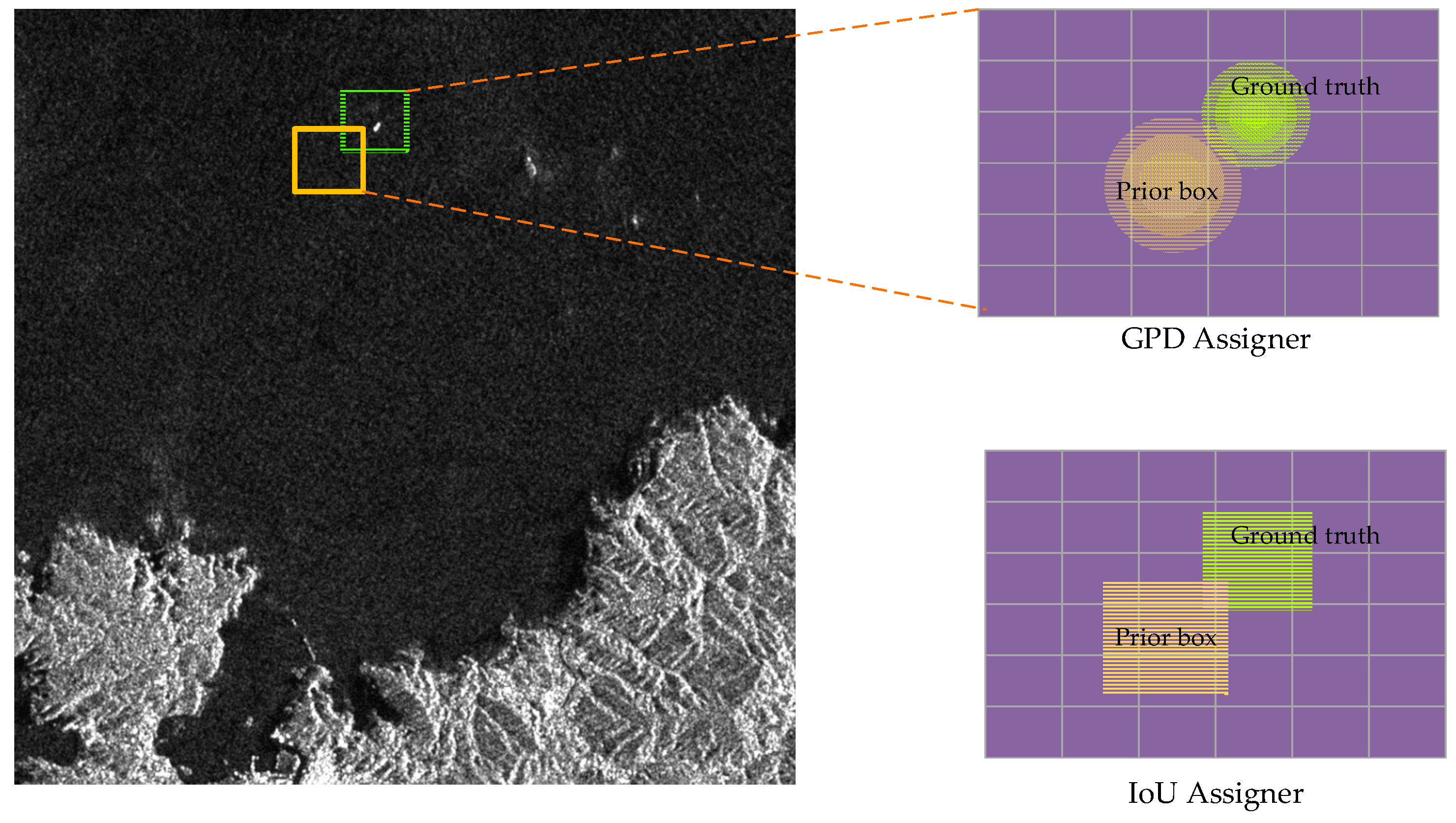
- We proposed a Gaussian prior discrepancy (GPD) assigner. This assigner leverages the discrepancy in two Gaussian distributions to judge the matching degree between the prior and ground truth. GPD helps CViTF-Net optimize the discrimination criteria for positive and negative samples.
- 3.
- We designed a level-sync attention mechanism (LSAM). It convolves and fuses multi-layer region of interest (RoI) feature maps, subsequently and adaptively allocating weights to different regions of the feature map. LSAM helps CViTF-Net better utilize low-level features for detecting small ship targets.
2. Materials and Methods
2.1. Method Motivation and Overview
2.2. CViT Backbone
2.2.1. Meta Conv Block
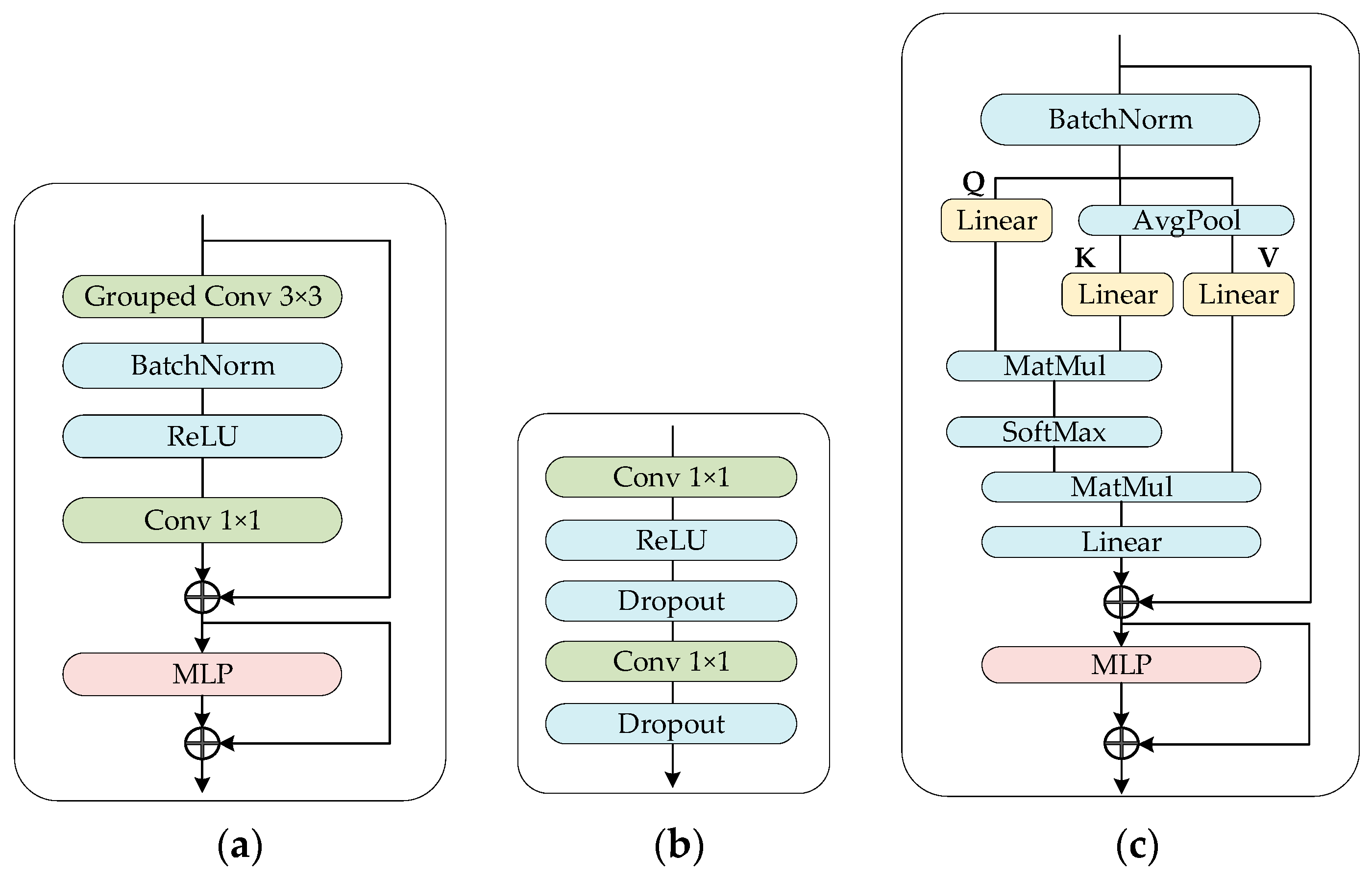
2.2.2. Meta ViT Block
2.3. Gaussian Prior Discrepancy (GPD) Assigner
| Algorithm 1. GPD assigner |
| //Calculate the similarity between a single ground truth and a single prior |
| function CalculateSimilarity(gt, prior) |
| x1 ← (gt [0] + gt [2])/2 |
| y1 ← (gt [1] + gt [3])/2 |
| x2 ← (prior [0] + prior [2])/2 |
| y2 ← (prior [1] + prior [3])/2 |
| w1 ← gt [2] − gt [0] + ϵ |
| h1 ← gt [3] − gt [1] + ϵ |
| w2 ← prior [2] − prior [0] + ϵ |
| h2 ← prior [3] − prior [1] + ϵ |
| kl ← Formula (7) |
| kld ←Formula (8) |
| return kld |
| end function |
| //Assign a ground truth index to each prior, the default index is 0, representing negative samples. |
| function AssignGtIndices(gts, priors) |
| //For each prior, the max kld of all gts, shape (length(priors),) prior_max_kld ← Call CalculateSimilarity() using gts and priors |
| assigned_gt_indices ← Create empty array, shape (length(priors),) |
| neg_inds ← Indices of prior where 0 ≤ prior_max_kld < 0.8 assigned_gt_indices[neg_inds] ← 0 for i ← 1 to length(gts) do pos_indices ← Indices of top 3 klds related to gts[i] in prior_max_kld assigned_gt_indices[pos_indices] ← i end for return assigned_gt_indices |
| end function |
2.4. Level-Sync Attention Mechanism (LSAM)
| Algorithm 2. Level Sync Attention |
| function LevelSyncAttention(input_features) //Preprocessing Stage conv_features ← Create empty array |
| for scale ← 1 to length(input_features) do |
| conv_features[scale] ← Conv2D(input_features[scale],5,5) |
| end for combined_features ← Sum of conv_features //Postprocessing Stage |
| query, key, value ← Conv2D(combined_features,1,1) |
| attention_scores ← Softmax(query) |
| context_vector ← Weighted sum of key and attention_scores |
| weighted_features ← ReLU(value)·context_vector |
| output_features ← Conv2D(weighted_features,1,1) |
| return output_features |
| end function |
3. Results
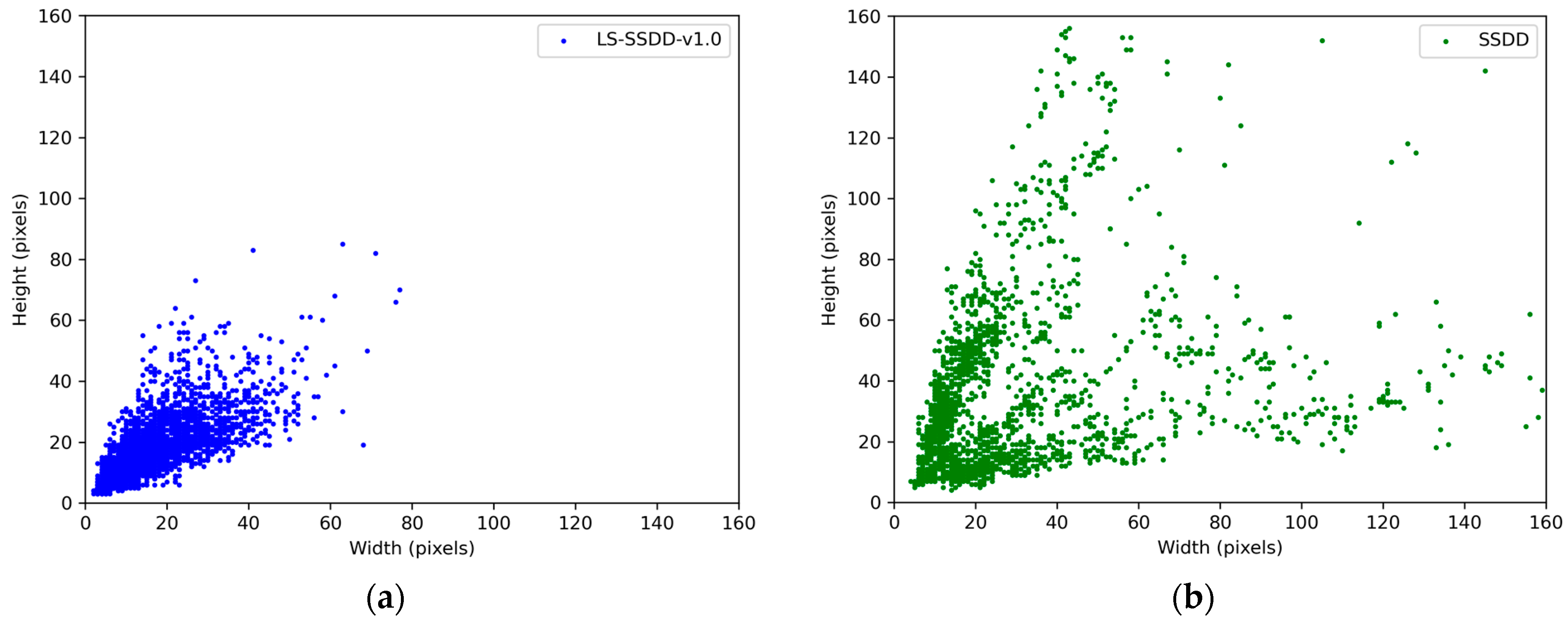
3.1. Introduction of the Datasets
3.2. Evaluation Criterions
3.3. Implementation Details
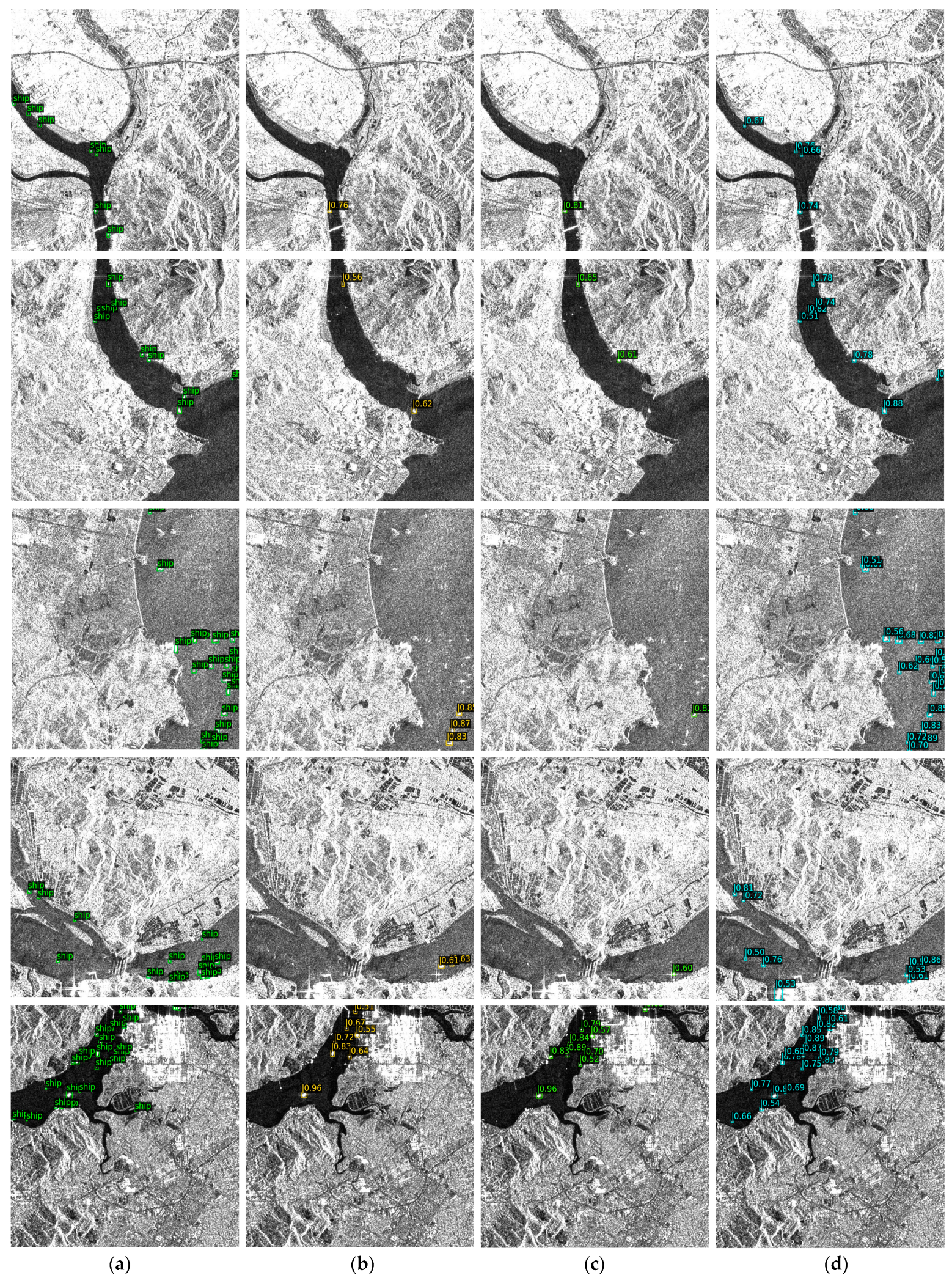
3.4. Results for LS-SSDD-v1.0
3.5. Results on SSDD
- 1.
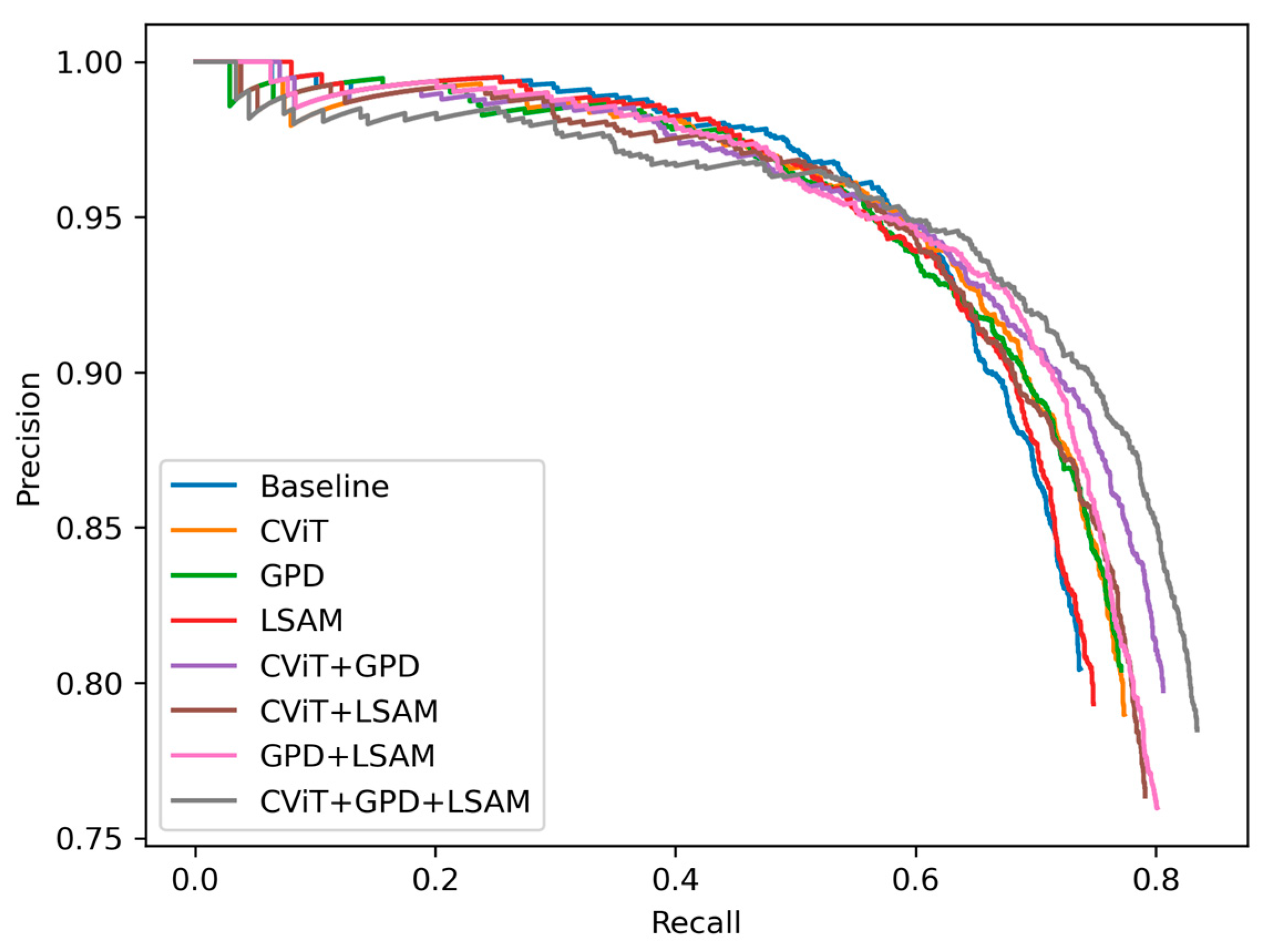
- Design of CViTF-Net: The architecture of CViTF-Net is configured such that the global feature information extracted by the CViT backbone aids the model in effectively managing background interference, consequently elevating the true positive rate for object detection, thereby augmenting recall. The GPD assigner leverages a two-dimensional Gaussian distribution centered on the target’s position, with the variance representing the uncertainty in the target’s location. This approach allows for more accurate matching of targets to prior boxes, even in cases of slight positional offsets or blurriness, thereby reducing the false negative rate and enhancing recall. The LSAM component excels in capturing intricate target details and contextual information, further reducing the false negative rate and enhancing recall.
- 2.
- Precision–recall trade-off: Typically, when a model endeavors to increase recall (i.e., reduce false negatives), it may inadvertently classify some non-target regions as targets, leading to a decrease in precision (an increase in false positives). This phenomenon represents a common trade-off.
- 3.
- Comprehensive evaluation with F1 and mAP: The F1 score takes both precision and recall into account simultaneously, while mAP provides a comprehensive assessment of the model’s performance at various thresholds. Consequently, even though CViTF-Net may exhibit relatively lower precision, its overall performance remains outstanding.
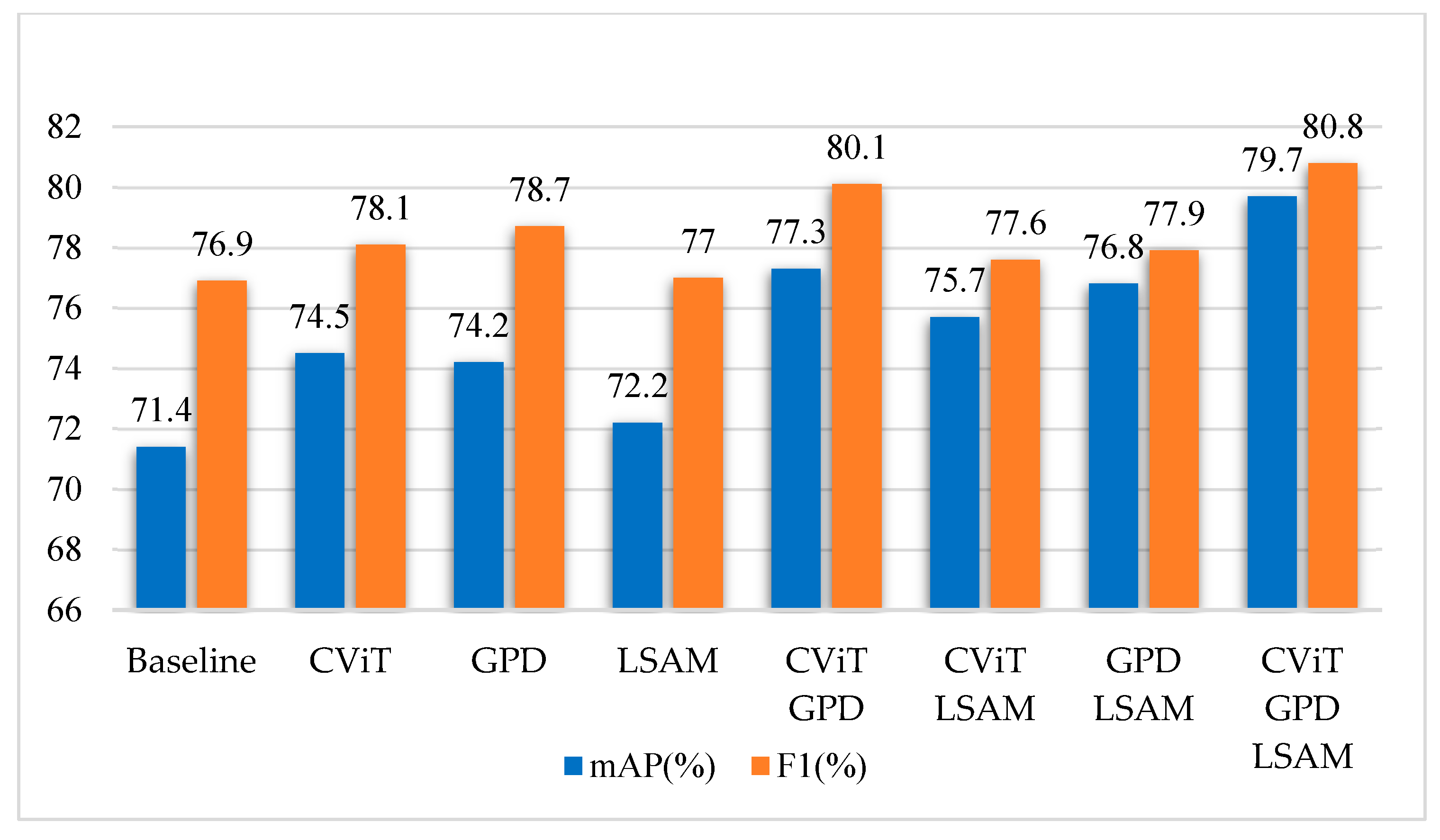
4. Ablation Experiment
- 1.
- CViT backbone (CViT): The detector’s recall, mAP, and F1 improved when only the CViT was enabled compared to not enabling any components, especially the recall and mAP, which increased by 3.6% and 3.1%, respectively. However, a slight decrease was observed in the precision, which can be attributed to CViT’s proficiency in capturing global information, possibly at the expense of some detail features. Despite this, the CViT significantly improves the overall performance of the detector.
- 2.
- GPD assigner (GPD): When only the GPD was enabled, compared to not enabling any components, the detector’s recall increased by 3.4%, the mAP increased by 2.8%, and the F1 increased by 1.8%, while maintaining the same precision. Meanwhile, compared to enabling the CViT and LSAM, but not the GPD, the precision rose from 0.763 to 0.802. This finding indicates that the GPD’s utilization of the two-dimensional Gaussian prior notably optimizes the sample discrimination criteria. It plays a crucial role in boosting the performance of the detector. Since the GPD assigner is an optimization strategy for allocating positive and negative samples and does not involve changes to the model architecture, the model’s GFLOPs and Params(M) are not affected by the GPD.
- 3.
- LSAM: When only the LSAM was enabled, and not the CViT or GPD, compared to not enabling any components, the impact on the precision was slightly insufficient. The recall and mAP improved, but the F1 remained essentially unchanged. This finding suggests that the LSAM played a positive role in processing the RoI feature maps, helping the detector reduce the missed detection rate.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Y.; Yang, W.; Chen, J.; Kuang, H.; Liu, W.; Li, C. Azimuth Sidelobes Suppression Using Multi-Azimuth Angle Synthetic Aperture Radar Images. Sensors 2019, 19, 2764. [Google Scholar] [CrossRef] [PubMed]
- Chang, W.; Tao, H.; Sun, G.; Wang, Y.; Bao, Z. A Novel Multi-Angle SAR Imaging System and Method Based on an Ultrahigh Speed Platform. Sensors 2019, 19, 1701. [Google Scholar] [CrossRef] [PubMed]
- Sonkar, A.; Kumar, S.; Kumar, N. Spaceborne SAR-Based Detection of Ships in Suez Gulf to Analyze the Maritime Traffic Jam Caused Due to the Blockage of Egypt’s Suez Canal. Sustainability 2023, 15, 9706. [Google Scholar] [CrossRef]
- Malyszko, M. Fuzzy Logic in Selection of Maritime Search and Rescue Units. Appl. Sci. 2022, 12, 21. [Google Scholar] [CrossRef]
- Bai, L.; Yao, C.; Ye, Z.; Xue, D.; Lin, X.; Hui, M. Feature Enhancement Pyramid and Shallow Feature Reconstruction Network for SAR Ship Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1042–1056. [Google Scholar] [CrossRef]
- Chen, S.; Li, X. A New CFAR Algorithm Based on Variable Window for Ship Target Detection in SAR Images. Signal Image Video Process. 2019, 13, 779–786. [Google Scholar] [CrossRef]
- Ai, J.; Mao, Y.; Luo, Q.; Xing, M.; Jiang, K.; Jia, L.; Yang, X. Robust CFAR Ship Detector Based on Bilateral-Trimmed-Statistics of Complex Ocean Scenes in SAR Imagery: A Closed-Form Solution. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 1872–1890. [Google Scholar] [CrossRef]
- Liu, T.; Yang, Z.; Yang, J.; Gao, G. CFAR Ship Detection Methods Using Compact Polarimetric SAR in a K-Wishart Distribution. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3737–3745. [Google Scholar] [CrossRef]
- Li, N.; Pan, X.; Yang, L.; Huang, Z.; Wu, Z.; Zheng, G. Adaptive CFAR Method for SAR Ship Detection Using Intensity and Texture Feature Fusion Attention Contrast Mechanism. Sensors 2022, 22, 8116. [Google Scholar] [CrossRef]
- Yasir, M.; Jianhua, W.; Mingming, X.; Hui, S.; Zhe, Z.; Shanwei, L.; Colak, A.T.I.; Hossain, M.S. Ship Detection Based on Deep Learning Using SAR Imagery: A Systematic Literature Review. Soft Comput. 2023, 27, 63–84. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Li, J.; Qu, C.; Shao, J. Ship Detection in SAR Images Based on an Improved Faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Yu, Y.; Yang, X.; Li, J.; Gao, X. A Cascade Rotated Anchor-Aided Detector for Ship Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Su, N.; He, J.; Yan, Y.; Zhao, C.; Xing, X. SII-Net: Spatial Information Integration Network for Small Target Detection in SAR Images. Remote Sens. 2022, 14, 442. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Li, X.; Li, D.; Liu, H.; Wan, J.; Chen, Z.; Liu, Q. A-BFPN: An Attention-Guided Balanced Feature Pyramid Network for SAR Ship Detection. Remote Sens. 2022, 14, 3829. [Google Scholar] [CrossRef]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 821–830. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 9626–9635. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. Available online: https://arxiv.org/abs/1512.02325v5 (accessed on 21 August 2023).
- Lu, X.; Li, Q.; Li, B.; Yan, J. MimicDet: Bridging the Gap Between One-Stage and Two-Stage Object Detection. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; Volume 12359, pp. 541–557. ISBN 978-3-030-58567-9. [Google Scholar]
- Yang, Y.; Ju, Y.; Zhou, Z. A Super Lightweight and Efficient SAR Image Ship Detector. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Ultralytics. YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 25 March 2023).
- Yasir, M.; Shanwei, L.; Mingming, X.; Hui, S.; Hossain, M.S.; Colak, A.T.I.; Wang, D.; Jianhua, W.; Dang, K.B. Multi-Scale Ship Target Detection Using SAR Images Based on Improved Yolov5. Front. Mar. Sci. 2023, 9, 1086140. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, Y.; Qian, L.; Zhang, X.; Diao, S.; Liu, X.; Cao, J.; Huang, H. A Lightweight Ship Target Detection Model Based on Improved YOLOv5s Algorithm. PLoS ONE 2023, 18, e0283932. [Google Scholar] [CrossRef]
- Zhang, J.; Sheng, W.; Zhu, H.; Guo, S.; Han, Y. MLBR-YOLOX: An Efficient SAR Ship Detection Network with Multilevel Background Removing Modules. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 5331–5343. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- Yang, S.; An, W.; Li, S.; Wei, G.; Zou, B. An Improved FCOS Method for Ship Detection in SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8910–8927. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H.; Zhang, C.; Fu, Q. Combing Single Shot Multibox Detector with Transfer Learning for Ship Detection Using Chinese Gaofen-3 Images. In Proceedings of the 2017 Progress in Electromagnetics Research Symposium—Fall (PIERS—FALL), Singapore, 19–22 November 2017; pp. 712–716. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H. Combining a Single Shot Multibox Detector with Transfer Learning for Ship Detection Using Sentinel-1 SAR Images. Remote Sens. Lett. 2018, 9, 780–788. [Google Scholar] [CrossRef]
- Bao, W.; Huang, M.; Zhang, Y.; Xu, Y.; Liu, X.; Xiang, X. Boosting Ship Detection in SAR Images with Complementary Pretraining Techniques. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8941–8954. [Google Scholar] [CrossRef]
- Ganesh, V.; Kolluri, J.; Maada, A.R.; Ali, M.H.; Thota, R.; Nyalakonda, S. Real-Time Video Processing for Ship Detection Using Transfer Learning. In Proceedings of the Third International Conference on Image Processing and Capsule Networks, Bangkok, Thailand, 20–21 May 2022; pp. 685–703. [Google Scholar]
- Zong, C.; Wan, Z. Container ship cell guide accuracy check technology based on improved 3D point cloud instance segmentation. Brodogradnja 2022, 73, 23–35. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Q.; Peng, W.; Xu, H.; Li, X.; Xu, W. Disparity-Based Multiscale Fusion Network for Transportation Detection. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18855–18863. [Google Scholar] [CrossRef]
- Yang, M.; Wang, H.; Hu, K.; Yin, G.; Wei, Z. IA-Net: An Inception–Attention-Module-Based Network for Classifying Underwater Images from Others. IEEE J. Ocean. Eng. 2022, 47, 704–717. [Google Scholar] [CrossRef]
- Zhou, L.; Ye, Y.; Tang, T.; Nan, K.; Qin, Y. Robust Matching for SAR and Optical Images Using Multiscale Convolutional Gradient Features. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Gong, Y.; Zhang, Z.; Wen, J.; Lan, G.; Xiao, S. Small Ship Detection of SAR Images Based on Optimized Feature Pyramid and Sample Augmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 7385–7392. [Google Scholar] [CrossRef]
- Qian, L.; Zheng, Y.; Li, L.; Ma, Y.; Zhou, C.; Zhang, D. A New Method of Inland Water Ship Trajectory Prediction Based on Long Short-Term Memory Network Optimized by Genetic Algorithm. Appl. Sci. 2022, 12, 4073. [Google Scholar] [CrossRef]
- Zheng, Y.; Li, L.; Qian, L.; Cheng, B.; Hou, W.; Zhuang, Y. Sine-SSA-BP Ship Trajectory Prediction Based on Chaotic Mapping Improved Sparrow Search Algorithm. Sensors 2023, 23, 704. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A Survey of Modern Deep Learning Based Object Detection Models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Lin, Z.; Wang, H.; Li, S. Pavement Anomaly Detection Based on Transformer and Self-Supervised Learning. Autom. Constr. 2022, 143, 104544. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Xia, R.; Chen, J.; Huang, Z.; Wan, H.; Wu, B.; Sun, L.; Yao, B.; Xiang, H.; Xing, M. CRTransSar: A Visual Transformer Based on Contextual Joint Representation Learning for SAR Ship Detection. Remote Sens. 2022, 14, 1488. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. MetaFormer Is Actually What You Need for Vision. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Hershey, J.R.; Olsen, P.A. Approximating the Kullback Leibler Divergence between Gaussian Mixture Models. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing—ICASSP ’07, Honolulu, HI, USA, 15–20 April 2007; pp. IV-317–IV-320. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zhang, T.; Zhang, X.; Ke, X.; Zhan, X.; Shi, J.; Wei, S.; Pan, D.; Li, J.; Su, H.; Zhou, Y.; et al. LS-SSDD-v1.0: A Deep Learning Dataset Dedicated to Small Ship Detection from Large-Scale Sentinel-1 SAR Images. Remote Sens. 2020, 12, 2997. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. SAR Ship Detection Dataset (SSDD): Official Release and Comprehensive Data Analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar] [CrossRef]
- Wu, Y.; Chen, Y.; Yuan, L.; Liu, Z.; Wang, L.; Li, H.; Fu, Y. Rethinking Classification and Localization for Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10183–10192. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Wei, S.; Su, H.; Ming, J.; Wang, C.; Yan, M.; Kumar, D.; Shi, J.; Zhang, X. Precise and Robust Ship Detection for High-Resolution SAR Imagery Based on HR-SDNet. Remote Sens. 2020, 12, 167. [Google Scholar] [CrossRef]
- Yu, N.; Ren, H.; Deng, T.; Fan, X. A Lightweight Radar Ship Detection Framework with Hybrid Attentions. Remote Sens. 2023, 15, 2743. [Google Scholar] [CrossRef]
- Jiang, Z.; Wang, Y.; Zhou, X.; Chen, L.; Chang, Y.; Song, D.; Shi, H. Small-Scale Ship Detection for SAR Remote Sensing Images Based on Coordinate-Aware Mixed Attention and Spatial Semantic Joint Context. Smart Cities 2023, 6, 1612–1629. [Google Scholar] [CrossRef]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and Excitation Rank Faster R-CNN for Ship Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 751–755. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X. Quad-FPN: A Novel Quad Feature Pyramid Network for SAR Ship Detection. Remote Sens. 2021, 13, 2771. [Google Scholar] [CrossRef]
- Li, D.; Liang, Q.; Liu, H.; Liu, Q.; Liu, H.; Liao, G. A Novel Multidimensional Domain Deep Learning Network for SAR Ship Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | LS-SSDD-v1.0 | SSDD |
|---|---|---|
| Satellite | Sentinel-1 | RadarSat-2, TerraSAR-X, Sentinel-1 |
| Image size (pixel) | 800 × 800 | 500 × 333 |
| Image number | 9000 | 1160 |
| Train/test ratio | 6000/3000 | 928/232 |
| Ship number | 6015 | 2456 |
| Avg. ship size (pixel2) | 381 | 1882 |
| Scenes | Inshore and offshore | Inshore and offshore |
| Configuration | Parameter |
|---|---|
| CPU | AMD EPYC 7543 32-Core Processor |
| GPU | NVIDIA RTX A5000 ×4 |
| Operating system | Ubuntu 20.04.4 LTS |
| Development tools | Python 3.10.8, Pytorch 1.13.0+cu117 |
| Method | Precision | Recall | mAP | F1 |
|---|---|---|---|---|
| FPN [12] | 0.805 | 0.706 | 0.680 | 0.752 |
| Cascade R-CNN [15] | 0.822 | 0.700 | 0.694 | 0.756 |
| Libra R-CNN [20] | 0.821 | 0.690 | 0.678 | 0.749 |
| Double Head R-CNN [58] | 0.815 | 0.704 | 0.685 | 0.755 |
| DCN [59] | 0.766 | 0.730 | 0.700 | 0.747 |
| YOLOX-L [30] | 0.687 | 0.732 | 0.698 | 0.708 |
| YOLOv7-X [60] | 0.690 | 0.728 | 0.686 | 0.708 |
| HR-SDNet [61] | 0.849 | 0.705 | 0.688 | 0.770 |
| MHASD [62] | 0.834 | 0.679 | 0.755 | 0.748 |
| SII-Net [16] | 0.682 | 0.793 | 0.761 | 0.733 |
| A-BFPN [19] | 0.850 | 0.736 | 0.766 | 0.788 |
| CMA-SSJC [63] | 0.704 | 0.803 | 0.772 | 0.750 |
| CViTF-Net | 0.784 | 0.834 | 0.797 | 0.808 |
| Method | Precision | Recall | mAP | F1 |
|---|---|---|---|---|
| FPN [12] | 0.698 | 0.376 | 0.341 | 0.488 |
| Cascade R-CNN [15] | 0.739 | 0.369 | 0.358 | 0.492 |
| Libra R-CNN [20] | 0.734 | 0.342 | 0.313 | 0.466 |
| Double Head R-CNN [58] | 0.743 | 0.373 | 0.338 | 0.496 |
| DCN [59] | 0.683 | 0.408 | 0.364 | 0.510 |
| YOLOX-L [30] | 0.686 | 0.431 | 0.392 | 0.529 |
| YOLOv7-X [60] | 0.504 | 0.414 | 0.327 | 0.454 |
| HR-SDNet [61] | 0.760 | 0.378 | 0.348 | 0.504 |
| MHASD [62] | 0.576 | 0.422 | 0.438 | 0.487 |
| SII-Net [16] | 0.461 | 0.554 | 0.469 | 0.503 |
| A-BFPN [19] | 0.770 | 0.545 | 0.471 | 0.638 |
| CMA-SSJC [63] | 0.502 | 0.586 | 0.522 | 0.540 |
| CViTF-Net | 0.643 | 0.656 | 0.579 | 0.649 |
| Method | Precision | Recall | mAP | F1 |
|---|---|---|---|---|
| FPN [12] | 0.836 | 0.901 | 0.876 | 0.867 |
| Cascade R-CNN [15] | 0.845 | 0.895 | 0.889 | 0.869 |
| Libra R-CNN [20] | 0.843 | 0.897 | 0.869 | 0.869 |
| Double Head R-CNN [58] | 0.835 | 0.899 | 0.870 | 0.865 |
| DCN [59] | 0.792 | 0.920 | 0.892 | 0.851 |
| YOLOX-L [30] | 0.687 | 0.909 | 0.877 | 0.782 |
| YOLOv7-X [60] | 0.766 | 0.913 | 0.882 | 0.833 |
| HR-SDNet [61] | 0.875 | 0.899 | 0.883 | 0.886 |
| MHASD [62] | 0.905 | 0.857 | 0.915 | 0.880 |
| SII-Net [16] | 0.819 | 0.934 | 0.916 | 0.872 |
| A-BFPN [19] | 0.921 | 0.889 | 0.921 | 0.904 |
| CMA-SSJC [63] | 0.827 | 0.931 | 0.909 | 0.875 |
| CViTF-Net | 0.875 | 0.939 | 0.923 | 0.905 |
| Method | Precision | Recall | mAP | F1 |
|---|---|---|---|---|
| FPN [12] | 0.884 | 0.941 | 0.936 | 0.911 |
| Cascade R-CNN [15] | 0.914 | 0.939 | 0.934 | 0.926 |
| Libra R-CNN [20] | 0.861 | 0.946 | 0.939 | 0.901 |
| Double Head R-CNN [58] | 0.905 | 0.945 | 0.942 | 0.924 |
| DCN [59] | 0.931 | 0.952 | 0.950 | 0.941 |
| YOLOX-L [30] | 0.797 | 0.965 | 0.950 | 0.872 |
| YOLOv7-X [60] | 0.843 | 0.917 | 0.899 | 0.878 |
| HR-SDNet [61] | 0.964 | 0.909 | 0.908 | 0.935 |
| SER Faster R-CNN [64] | 0.861 | 0.922 | 0.915 | 0.890 |
| Quad-FPN [65] | 0.895 | 0.957 | 0.952 | 0.924 |
| RIF [66] | 0.946 | 0.932 | 0.962 | 0.938 |
| SII-Net [16] | 0.861 | 0.968 | 0.955 | 0.911 |
| A-BFPN [19] | 0.975 | 0.944 | 0.968 | 0.959 |
| CViTF-Net | 0.943 | 0.981 | 0.978 | 0.961 |
| Method | Precision | Recall | mAP | F1 |
|---|---|---|---|---|
| FPN [12] | 0.741 | 0.848 | 0.823 | 0.790 |
| Cascade R-CNN [15] | 0.786 | 0.837 | 0.810 | 0.810 |
| Libra R-CNN [20] | 0.686 | 0.854 | 0.817 | 0.760 |
| Double Head R-CNN [58] | 0.769 | 0.854 | 0.838 | 0.809 |
| DCN [59] | 0.862 | 0.877 | 0.869 | 0.869 |
| YOLOX-L [30] | 0.626 | 0.924 | 0.874 | 0.746 |
| YOLOv7-X [60] | 0.655 | 0.808 | 0.748 | 0.723 |
| HR-SDNet [61] | 0.907 | 0.744 | 0.736 | 0.817 |
| SER Faster R-CNN [64] | 0.663 | 0.790 | 0.745 | 0.720 |
| Quad-FPN [65] | 0.747 | 0.877 | 0.846 | 0.806 |
| RIF [66] | 0.903 | 0.762 | 0.852 | 0.826 |
| A-BFPN [19] | 0.935 | 0.756 | 0.883 | 0.836 |
| CViTF-Net | 0.883 | 0.965 | 0.958 | 0.922 |
| Method | Precision | Recall | mAP | F1 |
|---|---|---|---|---|
| FPN [12] | 0.958 | 0.984 | 0.982 | 0.970 |
| Cascade R-CNN [15] | 0.976 | 0.986 | 0.985 | 0.980 |
| Libra R-CNN [20] | 0.958 | 0.989 | 0.988 | 0.973 |
| Double Head R-CNN [58] | 0.973 | 0.986 | 0.986 | 0.979 |
| DCN [59] | 0.963 | 0.986 | 0.985 | 0.974 |
| YOLOX-L [30] | 0.904 | 0.984 | 0.977 | 0.942 |
| YOLOv7-X [60] | 0.940 | 0.967 | 0.961 | 0.953 |
| HR-SDNet [61] | 0.986 | 0.986 | 0.985 | 0.986 |
| SER Faster R-CNN [64] | 0.968 | 0.983 | 0.982 | 0.975 |
| Quad-FPN [65] | 0.973 | 0.994 | 0.993 | 0.983 |
| RIF [66] | 0.985 | 0.982 | 0.992 | 0.983 |
| A-BFPN [19] | 0.989 | 0.987 | 0.995 | 0.987 |
| CViTF-Net | 0.983 | 0.994 | 0.993 | 0.988 |
| CViT | GPD | LSAM | Precision | Recall | mAP | F1 | GFLOPs | Params(M) |
|---|---|---|---|---|---|---|---|---|
| - | - | - | 0.804 | 0.737 | 0.714 | 0.769 | 171.94 | 79.62 |
| √ | - | - | 0.789 | 0.773 | 0.745 | 0.780 | 205.74 | 90.97 |
| - | √ | - | 0.802 | 0.771 | 0.742 | 0.786 | 171.94 | 79.62 |
| - | - | √ | 0.793 | 0.748 | 0.722 | 0.769 | 191.76 | 83.3 |
| √ | √ | - | 0.797 | 0.806 | 0.773 | 0.801 | 205.74 | 90.97 |
| √ | - | √ | 0.763 | 0.791 | 0.757 | 0.776 | 225.56 | 94.65 |
| - | √ | √ | 0.759 | 0.801 | 0.768 | 0.779 | 191.76 | 83.3 |
| √ | √ | √ | 0.784 | 0.834 | 0.797 | 0.808 | 225.56 | 94.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, M.; Liu, T.; Chen, Y. CViTF-Net: A Convolutional and Visual Transformer Fusion Network for Small Ship Target Detection in Synthetic Aperture Radar Images. Remote Sens. 2023, 15, 4373. https://doi.org/10.3390/rs15184373
Huang M, Liu T, Chen Y. CViTF-Net: A Convolutional and Visual Transformer Fusion Network for Small Ship Target Detection in Synthetic Aperture Radar Images. Remote Sensing. 2023; 15(18):4373. https://doi.org/10.3390/rs15184373
Chicago/Turabian StyleHuang, Min, Tianen Liu, and Yazhou Chen. 2023. "CViTF-Net: A Convolutional and Visual Transformer Fusion Network for Small Ship Target Detection in Synthetic Aperture Radar Images" Remote Sensing 15, no. 18: 4373. https://doi.org/10.3390/rs15184373
APA StyleHuang, M., Liu, T., & Chen, Y. (2023). CViTF-Net: A Convolutional and Visual Transformer Fusion Network for Small Ship Target Detection in Synthetic Aperture Radar Images. Remote Sensing, 15(18), 4373. https://doi.org/10.3390/rs15184373