
Scattering-Point-Guided RPN for Oriented Ship Detection in SAR Images

Abstract
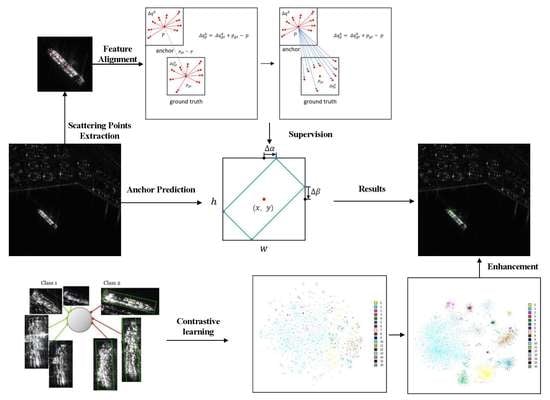
1. Introduction
- In this article, a novel method of ship detection named SPG-OSD in SAR images is proposed. According to the characteristics of SAR images, this method combines the features and distribution information of key scattering points to guide the network. The experiments with the dataset demonstrate the superiority of our methodology;
- Key scattering points are innovatively used to guide RPN to solve the problem of foreground and background misclassification, which effectively alleviates the false alarm and missing ship. The Scattering-Point-Guided RPN (SPG RPN) can predict the position of key scattering points and apply location information to the deformable convolution module to better extract the features near the key scattering points;
- In order to ease ship misclassification issues in SAR images, we augment a Region-of-Interest (RoI) head with a contrast branch where proposals are encoded as contrast features. RoI contrastive (RIC) loss is introduced into the ship detection network, which can enhance instance-level intra-class compactness and inter-class variance.
2. Related Works
2.1. Deep-Learning-Based Object Detection in SAR Images
2.2. Oriented Object Detection
2.3. Improved RPN
2.4. Contrastive Learning
3. Material and Methodology
3.1. Dataset
3.2. Overview Network Structure
3.3. Scattering-Point-Guided RPN
3.3.1. Scattering Point Extraction
3.3.2. Feature Alignment
3.3.3. Loss Calculation and Feature Guidance
3.4. RoI Contrastive Loss
4. Results
4.1. Implementation Details
4.2. Evaluation Metric
4.3. Comparison with Other Methods
4.4. Ablation Studies
4.4.1. Effect of Scattering-Point-Guided RPN
4.4.2. Effect of RoI Contrastive Loss
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Snapir, B.; Waine, T.W.; Biermann, L. Maritime Vessel Classification to Monitor Fisheries with SAR: Demonstration in the North Sea. Remote Sens. 2019, 11, 353. [Google Scholar] [CrossRef]
- Leng, X.; Ji, K.; Zhou, S.; Xing, X.; Zou, H. An Adaptive Ship Detection Scheme for Spaceborne SAR Imagery. Sensors 2016, 16, 1345. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. SAR Ship Detection Dataset (SSDD): Official Release and Comprehensive Data Analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Kurekin, A.A.; Loveday, B.R.; Clements, O.; Quartly, G.D.; Miller, P.I.; Wiafe, G.; Adu Agyekum, K. Operational Monitoring of Illegal Fishing in Ghana through Exploitation of Satellite Earth Observation and AIS Data. Remote Sens. 2019, 11, 293. [Google Scholar] [CrossRef]
- Ai, J.; Yang, X.; Song, J.; Dong, Z.; Jia, L.; Zhou, F. An adaptively truncated clutter-statistics-based two-parameter CFAR detector in SAR imagery. IEEE J. Ocean. Eng. 2017, 43, 267–279. [Google Scholar] [CrossRef]
- Wu, F.; Wang, C.; Jiang, S.; Zhang, H.; Zhang, B. Classification of Vessels in Single-Pol COSMO-SkyMed Images Based on Statistical and Structural Features. Remote Sens. 2015, 7, 5511–5533. [Google Scholar] [CrossRef]
- Wang, J.; Yang, J.; Yu, K.; Lv, F.; Huang, T.; Gong, Y. Locality-constrained linear coding for image classification. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 3360–3367. [Google Scholar]
- Bahmanyar, R.; Cui, S.; Datcu, M. A comparative study of bag-of-words and bag-of-topics models of EO image patches. IEEE Geosci. Remote. Sens. Lett. 2015, 12, 1357–1361. [Google Scholar] [CrossRef]
- Gu, M.; Wang, Y.; Liu, H.; Wang, P. PolSAR Ship Detection Based on a SIFT-like PolSAR Keypoint Detector. Remote Sens. 2022, 14, 2900. [Google Scholar] [CrossRef]
- Hwang, J.-I.; Jung, H.-S. Automatic Ship Detection Using the Artificial Neural Network and Support Vector Machine from X-Band Sar Satellite Images. Remote Sens. 2018, 10, 1799. [Google Scholar] [CrossRef]
- Ji, Y.; Zeng, P.; Zhang, W.; Zhao, L. Forest Biomass Inversion based on KNN-FIFS with Different Alos Data. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Brussels, Belgium, 12–16 July 2021; pp. 4540–4543. [Google Scholar]
- Chen, S.; Wang, H. SAR target recognition based on deep learning. In Proceedings of the 2014 International Conference on Data Science and Advanced Analytics (DSAA), Shanghai, China, 30 October–1 November 2014; pp. 541–547. [Google Scholar]
- Chen, S.; Zhang, J.; Zhan, R. R2FA-Det: Delving into High-Quality Rotatable Boxes for Ship Detection in SAR Images. Remote Sens. 2020, 12, 2031. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, B.; Tian, Z.; Xu, C.; Wu, F.; Sun, C. An Anchor-Free Method for Arbitrary-Oriented Ship Detection in SAR Images. In Proceedings of the 2021 SAR in Big Data Era (BIGSARDATA), Nanjing, China, 22–24 September 2021; pp. 1–4. [Google Scholar]
- Han, J.; Ding, J.; Xue, N.; Xia, G.-S. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 2786–2795. [Google Scholar]
- He, B.; Zhang, Q.; Tong, M.; He, C. Oriented Ship Detector for Remote Sensing Imagery Based on Pairwise Branch Detection Head and SAR Feature Enhancement. Remote Sens. 2022, 14, 2177. [Google Scholar] [CrossRef]
- Xu, Z.; Gao, R.; Huang, K.; Xu, Q. Triangle Distance IoU Loss, Attention-Weighted Feature Pyramid Network, and Rotated-SARShip Dataset for Arbitrary-Oriented SAR Ship Detection. Remote Sens. 2022, 14, 4676. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, C.; Zhang, H.; Zhang, B.; Tian, S. An efficient object-oriented method of Azimuth ambiguities removal for ship detection in SAR images. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 2275–2278. [Google Scholar]
- Sun, X.; Lv, Y.; Wang, Z.; Fu, K. SCAN: Scattering Characteristics Analysis Network for Few-Shot Aircraft Classification in High-Resolution SAR Images. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Vu, T.; Jang, H.; Pham, T.X.; Yoo, C. Cascade RPN: Delving into High-Quality Region Proposal Network with Adaptive Convolution. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 15210–15219. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017. [Google Scholar]
- Kang, M.; Leng, X.; Lin, Z.; Ji, K. A modified faster R-CNN based on CFAR algorithm for SAR ship detection. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–4. [Google Scholar]
- Qian, Y.; Liu, Q.; Zhu, H.; Fan, H.; Du, B.; Liu, S. Mask R-CNN for object detection in multitemporal SAR images. In Proceedings of the 2019 10th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Shanghai, China, 5–7 August 2019; pp. 1–4. [Google Scholar]
- Tang, G.; Zhuge, Y.; Claramunt, C.; Men, S. N-YOLO: A SAR Ship Detection Using Noise-Classifying and Complete-Target Extraction. Remote Sens. 2021, 13, 871. [Google Scholar] [CrossRef]
- Sun, Z.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. BiFA-YOLO: A Novel YOLO-Based Method for Arbitrary-Oriented Ship Detection in High-Resolution SAR Images. Remote Sens. 2021, 13, 4209. [Google Scholar] [CrossRef]
- Zhou, L.-Q.; Piao, J.-C. A Lightweight YOLOv4 Based SAR Image Ship Detection. In Proceedings of the 2021 IEEE 4th International Conference on Computer and Communication Engineering Technology (CCET), Beijing, China, 13–15 August 2021; pp. 28–31. [Google Scholar]
- Zheng, T.; Wang, J.; Lei, P. Deep learning based target detection method with multi-features in SAR imagery. In Proceedings of the 2019 6th Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), Xiamen, China, 26–29 November 2019; pp. 1–4. [Google Scholar]
- Song, T.; Kim, S.; Sohn, K. Shape-Robust SAR Ship Detection via Context-Preserving Augmentation and Deep Contrastive RoI Learning. IEEE Geosci. Remote. Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Fu, K.; Fu, J.; Wang, Z.; Sun, X. Scattering-keypoint-guided network for oriented ship detection in high-resolution and large-scale SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2021, 14, 11162–11178. [Google Scholar] [CrossRef]
- Kang, Y.; Wang, Z.; Fu, J.; Sun, X.; Fu, K. SFR-Net: Scattering feature relation network for aircraft detection in complex SAR images. IEEE Trans. Geosci. Remote. Sens. 2021, 60, 1–17. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, Z.; Sun, X.; Fu, K. SPAN: Strong Scattering Point Aware Network for Ship Detection and Classification in Large-Scale SAR Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2022, 15, 1188–1204. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.-S.; Lu, Q. Learning RoI transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2849–2858. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.-S.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Yan, J. Arbitrary-oriented object detection with circular smooth label. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 677–694. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 3163–3171. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.-S. Align Deep Features for Oriented Object Detection. IEEE Trans. Geosci. Remote. Sens. 2021, 60, 1–11. [Google Scholar] [CrossRef]
- Li, W.; Chen, Y.; Hu, K.; Zhu, J. Oriented reppoints for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 1829–1838. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 3520–3529. [Google Scholar]
- Yang, X.; Zhou, Y.; Zhang, G.; Yang, J.; Wang, W.; Yan, J.; Zhang, X.; Tian, Q. The KFIoU Loss for Rotated Object Detection. arXiv 2022, arXiv:2201.12558. [Google Scholar]
- He, Y.; Gao, F.; Wang, J.; Li, X. Learning Polar Encodings for Arbitrary-Oriented Ship Detection in SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3846–3859. [Google Scholar] [CrossRef]
- Lu, H.; Wu, W.; Zhang, Q.; Huang, X.; Li, H.; Zhang, L. Deep Learning for the Detection of Bridges in Synthetic Aperture Radar Images. Remote Sens. 2019, 11, 830. [Google Scholar]
- Zhang, J.; Yang, Z.; Liu, H.; Li, Y.; Li, D.; Li, X. SAR Vehicle Detection with Double-Path Multi-Scale Object Detection Network. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2399–2403. [Google Scholar]
- Zhang, Y.; Cao, X.; Wang, M.; Dong, J.; Zhang, X. Building Extraction from High-Resolution SAR Images Based on Deep Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5668–5685. [Google Scholar]
- Xu, C.; Su, H.; Li, J.; Li, L.; Wang, P. RSDD-SAR: Rotated Ship Detection Dataset in SAR Images. J. Radars 2021, in press.
- Lu, H.; Zhang, Q.; Wu, W.; Li, H.; Zhang, L. Dual-Branch Dual-Resolution Network for Oriented Ship Detection in SAR Images. Remote Sens. 2020, 12, 837. [Google Scholar]
- Yang, L.; Song, Y.; Zhang, H.; Liu, S.; Gao, S.; Ma, Y. Ship Detection in SAR Images via Multi-Scale Convolutional Neural Networks. In Proceedings of the 2018 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spain, 22–27 July 2018; pp. 5943–5946. [Google Scholar]
- Gidaris, S.; Komodakis, N. Attend refine repeat: Active box proposal generation via in-out localization. arXiv 2016, arXiv:1606.04446. [Google Scholar]
- Zhong, Q.; Li, C.; Zhang, Y.; Xie, D.; Yang, S.; Pu, S.J.N. Cascade region proposal and global context for deep object detection. Neurocomputing 2020, 395, 170–177. [Google Scholar] [CrossRef]
- Fan, H.; Ling, H. Siamese cascaded region proposal networks for real-time visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7952–7961. [Google Scholar]
- Wang, J.; Chen, K.; Yang, S.; Loy, C.C.; Lin, D. Region proposal by guided anchoring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2965–2974. [Google Scholar] [CrossRef]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F.J.T. A survey on contrastive self-supervised learning. Technologies 2020, 9, 2. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, R.; Shen, C.; Kong, T.; Li, L. Dense contrastive learning for self-supervised visual pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 3024–3033. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Lei, S.; Lu, D.; Qiu, X.; Ding, C. SRSDD-v1.0: A High-Resolution SAR Rotation Ship Detection Dataset. Remote Sens. 2021, 13, 5104. [Google Scholar] [CrossRef]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Wang, R.; Shivanna, R.; Cheng, D.; Jain, S.; Lin, D.; Hong, L.; Chi, E. Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. In Proceedings of the Web Conference (WWW), Ljubljana, Slovenia, 19–23 April 2021; pp. 1785–1797. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Tan, J.; Lu, X.; Zhang, G.; Yin, C.; Li, Q. Equalization loss v2: A new gradient balance approach for long-tailed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 1685–1694. [Google Scholar]
- Harris, C.G.; Stephens, M.J. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988. [Google Scholar]
- Fan, H.; Su, H.; Guibas, L.J. A point set generation network for 3d object reconstruction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 605–613. [Google Scholar]
- Butt, M.A.; Maragos, P. Optimum Design of Chamfer Distance Transforms. IEEE Trans. Image Process. 1998, 7, 1477–1484. [Google Scholar] [CrossRef]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Zhou, Y.; Yang, X.; Zhang, G.; Wang, J.; Liu, Y.; Hou, L.; Jiang, X.; Liu, X.; Yan, J.; Lyu, C. Mmrotate: A rotated object detection benchmark using pytorch. In Proceedings of the 30th ACM International Conference on Multimedia (MM), Lisboa, Portugal, 10–14 October 2022. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target | Train Dataset Size | Test Dataset Size |
|---|---|---|
| ore-oil | 142 | 28 |
| Container | 1744 | 393 |
| Fishing | 229 | 46 |
| LawEnforce | 20 | 3 |
| Dredger | 186 | 53 |
| Cell-Container | 103 | 28 |
| Type1 | 27 | 7 |
| Type2 | 26 | 8 |
| Type3 | 371 | 149 |
| Type4 | 40 | 10 |
| Type5 | 31 | 10 |
| Type6 | 140 | 52 |
| Type7 | 68 | 18 |
| Type8 | 284 | 119 |
| Type9 | 48 | 14 |
| Type10 | 174 | 63 |
| Total | 3633 | 999 |
| Method | Precision | Recall | F1 | ||
|---|---|---|---|---|---|
| Gliding Vertex | 0.2982 | 0.6197 | 0.4026 | 0.5319 | 0.1501 |
| RoI Transformer | 0.4393 | 0.6730 | 0.5316 | 0.5608 | 0.1305 |
| R3Det | 0.0633 | 0.6769 | 0.1158 | 0.4096 | 0.1479 |
| CSL | 0.0465 | 0.6388 | 0.0867 | 0.2758 | 0.0756 |
| S2ANet | 0.1093 | 0.7203 | 0.1898 | 0.5751 | 0.1459 |
| KFIoU | 0.0831 | 0.8304 | 0.1511 | 0.5303 | 0.1852 |
| Oriented RepPoints | 0.0343 | 0.8951 | 0.0661 | 0.4828 | 0.0951 |
| Oriented-RCNN | 0.3665 | 0.7406 | 0.4903 | 0.6447 | 0.1885 |
| Baseline (ours) | 0.3891 | 0.7717 | 0.5173 | 0.6590 | 0.2048 |
| SPG-OSD (ours) | 0.4669 | 0.7859 | 0.5858 | 0.6934 | 0.2437 |
| SPG RPN | RIC Loss | Precision | Recall | F1 | ||
|---|---|---|---|---|---|---|
| × | × | 0.3891 | 0.7717 | 0.5173 | 0.6590 | 0.2048 |
| √ | × | 0.4486 | 0.7798 | 0.5696 | 0.6805 | 0.2319 |
| × | √ | 0.4448 | 0.7754 | 0.5653 | 0.6707 | 0.2313 |
| √ | √ | 0.4669 | 0.7859 | 0.5858 | 0.6934 | 0.2437 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Lu, D.; Qiu, X.; Li, F. Scattering-Point-Guided RPN for Oriented Ship Detection in SAR Images. Remote Sens. 2023, 15, 1411. https://doi.org/10.3390/rs15051411
Zhang Y, Lu D, Qiu X, Li F. Scattering-Point-Guided RPN for Oriented Ship Detection in SAR Images. Remote Sensing. 2023; 15(5):1411. https://doi.org/10.3390/rs15051411
Chicago/Turabian StyleZhang, Yipeng, Dongdong Lu, Xiaolan Qiu, and Fei Li. 2023. "Scattering-Point-Guided RPN for Oriented Ship Detection in SAR Images" Remote Sensing 15, no. 5: 1411. https://doi.org/10.3390/rs15051411
APA StyleZhang, Y., Lu, D., Qiu, X., & Li, F. (2023). Scattering-Point-Guided RPN for Oriented Ship Detection in SAR Images. Remote Sensing, 15(5), 1411. https://doi.org/10.3390/rs15051411