Abstract
Land-Use/Land-Cover (LULC) products are a common source of information and a key input for spatially explicit models of ecosystem service (ES) supply and demand. Global, continental, and regional, readily available, and free land-cover products generated through Earth Observation (EO) data, can be potentially used as relevant to ES mapping and assessment processes from regional to national scales. However, several limitations exist in these products, highlighting the need for timely land-cover extraction on demand, that could replace or complement existing products. This study focuses on the development of a classification workflow for fine-scale, object-based land cover mapping, employed on terrestrial ES mapping, within the Greek terrestrial territory. The processing was implemented in the Google Earth Engine cloud computing environment using 10 m spatial resolution Sentinel-1 and Sentinel-2 data. Furthermore, the relevance of different training data extraction strategies and temporal EO information for increasing the classification accuracy was also evaluated. The different classification schemes demonstrated differences in overall accuracy ranging from 0.88% to 4.94% with the most accurate classification scheme being the manual sampling/monthly feature classification achieving a 79.55% overall accuracy. The classification results suggest that existing LULC data must be cautiously considered for automated extraction of training samples, in the case of new supervised land cover classifications aiming also to discern complex vegetation classes. The code used in this study is available on GitHub and runs on the Google Earth Engine web platform.
Keywords:
remote sensing; seasonal; Random Forests; OBIA; machine learning; big data; multispectral; radar; GEE; object 1. Introduction
Information on the spatial explicit distribution of ecosystem services (ES) is important for their conservation and management, policy design, implementation and monitoring, fulfillment of reporting processes to national and international mechanisms, as well as for communicating complex information to the public in order to increase awareness and engagement in biodiversity conservation and natural capital protection [1,2,3,4]. Land-Use/Land-Cover (LULC) mapping and thematic products are often used as proxies of ecosystem types, determine the delivery of ES, and are used as a key input for spatially explicit models of ES supply and demand [1,5]. Up-to-date LULC maps, with increased thematic resolution and accuracy are of high importance when it comes to mapping ecosystems and providing proxies to actual ES [6]. Furthermore, LULC information, when coupled with additional socioeconomic datasets, can also facilitate the transfer of relevant ES information across different spatial and temporal scales [7,8,9].
Remote sensing, providing synoptic, spatially continuous, and consistent observations at multiple scales, can provide timely and accurate spatially explicit information on Earth’s physical surface cover (i.e., land cover) [10], which is essential for ES related research and practice [11]. Global open-access land cover products generated through Earth Observation (EO) data e.g., GlobeLand30 [12], S2GLC [13], Copernicus Global Land Cover [14], as well as continental/regional products provided through the Copernicus land monitoring service, such as the Corine Land Cover [15], provide information that can be potentially used as relevant to ES mapping and assessment processes at global, national, regional, and local scales. However, such operational, land-cover efforts might present limitations related to the use of diverse input data, accuracy variability over different areas and different classes, coarse update intervals and outdatedness in comparison to the real world [16], coarse thematic resolution and/or class diversity, and coarse minimum mapping units (MMU). The above shortcomings raise the need for timely and on-demand land-cover datasets that could replace or complement available, freely distributed products, providing timely information to the end-users and addressing some, if not all, of the above shortcomings [17].
The recent availability of medium-high spatial resolution satellite imagery, such as the open-access Landsat-8 and Sentinel-2 (S2) data, can facilitate the development of finer scale, cost-effective land cover mapping datasets at national and supra-national scales [16,18,19], not only from public agencies and official organizations, but also from individual research groups [20]. This shift, leading to the “democratization” of a broad area mapping process, can also provide land cover information adhering to project-specific nomenclature needs. The improved temporal observation frequency of the aforementioned satellites can also provide enhanced information, related to the phenological differences and consequently intra-annual spectral variability. Such information has been proven to play an important part in land cover discrimination, especially for areas dominated by vegetation [21]. Freely available Synthetic Aperture Radar (SAR) data recording physical properties of terrestrial objects can be also used complementary to optical remote-sensing data, for enhancing land-cover class separation [22]. SAR can penetrate clouds and thus broad area land-cover mapping can be achieved in areas frequently covered by clouds [23]. Multi-seasonal analysis is also facilitated with SAR data, especially over LULC domains where the period of observation of is crucial (i.e., cropland mapping) [24]. Accordingly, earlier studies demonstrate that the integration of both Sentinel-1 (S1) and Sentinel-2 has been proven as an efficient approach for improving LULC map accuracies in many domains [25,26,27].
Beyond improved data availability during the last decade, the remote sensing community has also noticed advances in satellite data-processing methods along with rapid developments in computer hardware and software. In terms of data volume handling and computational power, products of national and supra-national scale can be more easily produced with the aid of cloud-computing platforms which provide access to numerous datasets and algorithms, great computing power, and cloud storage, free of charge for non-commercial use [28].
Information extraction about Earth’s surface is also facilitated from the availability of analysis-ready data with minimum pre-processing requirements, novel and robust classification algorithms enabling complex feature space relationships accommodation [20], as well as paradigm shifts in remote sensing analysis for a generation of geographic information. In regard to the latter, Object-Based Image Analysis (OBIA), involving delineation and analysis of image-objects instead of individual pixels [29], is a relatively new analysis paradigm that can contribute to overcoming traditional, per-pixel approaches [30]. Per-object analysis can minimize within-class spectral variability and classification inaccuracies from pixel artifacts due to spectral differences in atmospheric correction, incorrect cloud masking and misregistration problems [13]. In addition, regarding broad-area mapping, OBIA can reduce computational complexity [22], albeit the possible labor-intensive segmentation task. Although OBIA is rarely used in broad-area mapping, it has been used effectively in combination with Sentinel imagery, mostly in small scale studies, for crop [31] and urban land-cover mapping [22]. The upcoming “2nd generation CORINE Land Cover”, whose production has recently started, will be the first object-based pan-European LULC product relying on a high spatial resolution vector product (layer representing objects) called the “CLC+ Backbone”. This layer will be produced by incorporating Sentinel-1,2 and very-high resolution (VHR) imagery segmentation, as well as ancillary data (such as Open Street Map, EU-hydro, etc.) [32].
Nonetheless, and despite the aforementioned advances, a lot of challenges and open questions exist when it comes to the development of end-to-end automated or semi-automated workflows for land-cover information retrieval and wall-to-wall mapping over broad areas [17,18,33]. The synthesis of substantially large multi-sensor and multi-temporal EO datasets, in the form of large data cubes, along with the plethora of processing algorithms and approaches implies great challenges and bottlenecks for broad scale land cover mapping spanning from the selection of adequate, reliable reference data, to the proper synthesis of temporal EO information (i.e., compositing), and appropriate data fusion and feature extraction processes.
The main aim of the study is to develop a classification workflow for the production of a fine-scale, land-cover product that will be employed for terrestrial ecosystem condition and ES mapping in Greece, according to the provisions of European Union (EU) initiative for Mapping and Assessment of Ecosystem and their Services (MAES) as described in the EU Biodiversity Strategy to 2020 [34,35]. The complex classification nomenclature includes 21 classes linked to the 3rd level of the MAES ecosystem typology, classified through an object-based approach using 10 m spatial resolution Sentinel-1 and Sentinel-2 data along with additional geospatial information from national and EU’s Copernicus land cover products.
Additional research objectives of the study are:
- The evaluation of the relevance of different training data extraction strategies (i.e., manual and automated) to increase the classification accuracy.
- The evaluation of seasonal and monthly EO information to increase the classification accuracy.
- The assessment of the relative importance of the different features in the classification process, facilitating data dimensionality reduction and computational time and resources optimization.
2. Study Area
The study area is the terrestrial territory of Greece, including nearby coastal areas (2 km buffer). Greece covers an approximate area of 131,957 km2, with one of the largest coastlines in Europe of 15,021 km long, [19]. Geomorphologically, 78% of Greece’s area is covered by mountains [36] and has a highly diverse landscape. The climate, according to the Köppen–Geiger climate classification, is mainly temperate Mediterranean with large areas in northern Greece being classified as semi-arid and fewer areas, mostly in higher altitudes, classified as humid continental [37]. The combination of landscape and climate conditions together with Greece’s biological assets has led to the existence of a large ecosystem type variety, with forest habitats being the predominate habitat group covering 37% of the natural habitats in Greece [38].
The only currently-available, nation-wide, LULC information is the Corine Land Cover (CLC) dataset with a spatial resolution of 25 ha, while, in regard to ecosystem types, the new enhanced Ecosystem Type Map of Europe (v. 3.1) [39] with a spatial resolution of 1 ha is now available. The new version of the ecosystem map represents the terrestrial European Nature Information System (EUNIS) level 2 habitat classes, for the European Environment Agency (EEA) EEA-39 members. It was based on the 2012 CLC dataset, with further refinement with other products such as the High Resolution Layers (HRLs) (i.e., area of soil sealing, forest cover, grassland and wetness index), Urban Atlas, riparian zones, Natura 2000 (N2K), and the latest version of OpenStreetMap (OSM) [40].
3. Materials and Methods
3.1. Overall Workflow
Different classification schemes were implemented and tested in the present study, in order to identify the optimal processing workflow (Figure 1). Two different training sample extraction approaches (automated and manual), two different temporal composite strategies (seasonal, monthly), and two feature sets (Full, Reduced i.e., excluding Sentinel-2 original bands) were evaluated, forming in total six workflows and classification schemes (Table 1).
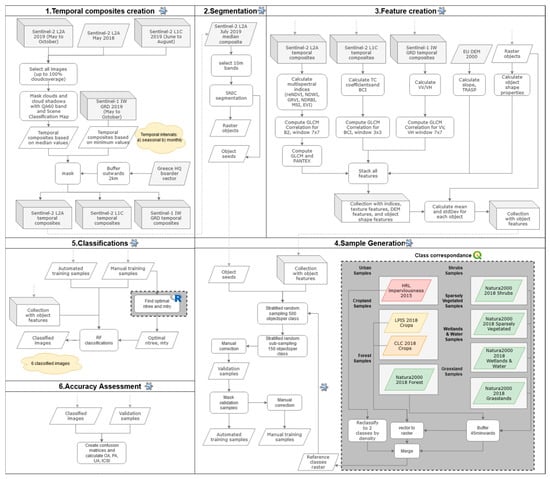
Figure 1.
The general processing chain with its data inputs, processing steps and final products. Items in grey boxes indicate processing done outside Google Earth Engine (GEE) and more specifically in R or QGIS software environments.

Table 1.
Feature sets and training sample extraction approaches adopted in the different classification experiments.
The general algorithm workflow followed is presented in Figure 1. Specifically, sections 1 (Composites creation), 3 (Feature creation), and 4 (Sample generation) differ in each scenario accordingly.
In all six workflows, temporal (seasonal or monthly), composites of S1 and S2 imagery were created at first, followed by image segmentation for object creation within Google Earth Engine (GEE). In the feature set creation step, different feature sets were generated per-object, considering either all available EO data or a reduced subset of features excluding the S2 original bands. Consequently, sample objects were identified based on a fully automated and a manual sample identification strategy. Finally, a Random Forest (RF) classification algorithm was used for class discrimination in the respective training objects set (six in total). The six classification schemes were evaluated by analyzing their confusion matrices and the derived standard accuracy measures, to find the best performing workflow. The JavaScript code used in this study is available on GitHub [41] and runs on the Google Earth Engine Code Editor, after signing-in to the service and following the instructions.
3.2. Satellite Data and Preprocessing
Sentinel-2 optical data and Sentinel-1 active data were jointly used in this study. The Sentinel-2 (S2) constellations carry the MSI multispectral optical sensor, which records 13 spectral bands in the visible, near-infrared, and short-wave infrared parts of the spectrum, with a spatial resolution of up to 10 m, and a revisit time of 5 days; in addition, compared to other free satellite imagery (e.g., Landsat imagery), it offers three bands in the red-edge region of the spectrum, that have been proven to play an important role in vegetation types species identification and vegetation status monitoring [31,42]. For the S2 data, both level-1C (L1C) and level-2A (L2A) processed data from the GEE data catalog were used in this study. The L1C products are top of atmosphere reflectance images while the L2A are produced from the L1C products, after applying atmospheric correction algorithms, providing bottom of atmosphere reflectance images. The L1C products were only used for computing the Tasseled Cap transformation [43], since the coefficients for the L2A Sentinel-2 products have not yet been calculated in literature.
The Sentinel-1 (S1) satellites are C-band active microwave Synthetic Aperture Radars (SAR), configured with dual polarization (VV, VH) interferometric wave modes, with an effective revisit of 6 days. The Ground Range-Detected (GRD) products are radiometrically calibrated and ortho-corrected, using SRTM 30 or ASTER DEM, and offered in geo-coded backscattering coefficients (σ0) in GEE [44].
Data from both satellites are available in Analysis Ready Data (ARD) format, through GEE, and were therefore retrieved from the corresponding collections. Regarding S2 L2A data, all images from May 2019 to October 2019 were used, along with May 2018 image acquisitions, to compensate for the increased cloud coverage observed in May 2019. S2 L1C data were only used for the 2019 summer period (June to August 2019). Finally, all S1 images in ascending and descending orbit from May 2019 to October 2019 were used. The one-year timeframe is considered as an adequate range for capturing yearly phenology and has been used in other national-scale LULC studies [17,33,45,46].
Subsequently, clouds were masked from optical images and all images (optical and SAR) were transformed to seasonal and monthly composites to achieve spatially homogenous and temporally equidistant images allowing a uniform processing framework for the whole county [47].
Clouds and cirrus in the S2 L1C images were masked using the QA60 band [48], while cloud shadow was masked using the solar azimuth, zenith, and possible cloud heights [49]. Clouds, cirrus, and cloud shadows from the S2 L2A images were masked using the scene classification map resulting from the application of the sen2cor processing algorithm [50]. S2 images temporal aggregation was based on the median reflectance values which has been proven to lead to more accurate LULC classifications [51,52]. S1 images composite creation was based on the minimum value instead of the median value, in order to overcome terrain and humidity effects. In GEE, S1 products are provided as sigma-naught (σ0) backscatter images, so, although terrain correction has already been applied in GEE using SRTM30, performing additional terrain flattening was not feasible.
3.3. Image Segmentation
The Simple Non-Iterative Clustering (SNIC) super-pixel segmentation, which is available in GEE was used in this study. The SNIC algorithm starts from seeds created on a regular grid and then, groups pixels into super-pixel clusters based on their distance from cluster centroids considering the normalized five-dimensional space of CIELAB color and spatial coordinates [53,54]. Subsequently, all image pixels are added to priority queues based on their connectivity to existing super-pixel clusters. Each time a pixel with the smallest distance to the cluster’s centroid is added, an updated centroid value and priority queue is generated for each growing cluster [53].
Parameters that need to be set in the SNIC segmentation are the seed distance, segment compactness, connectivity, and the neighborhood size [55]. Although inadvisable, numerous studies that apply segmentation for LULC mapping, rely on trial-and-error and visual inspection for finding optimal segmentation parameters [56]. Based on such an approach, SNIC parameters were selected after various experiments, based on visual inspection to produce the most homogeneous and meaningful objects within the experiment test sites and in accordance with the concept that “a good segmentation is one that shows little over-segmentation and no under-segmentation” by [29]. SNIC was applied on the 10 m S2 L2A July composite bands (B2, B3, B4, B8), for achieving the finest possible object detail since these were the bands with the highest spatial resolution. The July composite was chosen as it is one of the driest months in Greece, accompanied by vegetation growth peak. The SNIC parameters were set to a) seed distance of 10 pixels, b) segment compactness = 3, c) 8-pixel connectivity, and d) neighborhood size of 100 pixels.
3.4. Feature Extraction
A wide range of spectral and spatial features were considered in the classification process of the study and used to calculate descriptive statistics for each object (Table 2). Sentinel-1 bands, representing polarized (VV,VH) backscatter signals, along with the VV/VH ratio feature were incorporated in the classification process [22,54,57]. In addition to raw multispectral bands of Sentinel-2 imagery (considered only in the full feature set), spectral indices and multispectral transformations were employed to enhance class separability while limiting band correlation and data redundancy [21].
Besides spectral properties, the high spatial resolution of Sentinel imagery facilitates the use of texture features such as the gray-level co-occurrence matrix (GLCM) metrics [58] for improving LULC classifications. For enhancing urban areas, the so-called PANTEX index was employed, which highlights local contrast variations by keeping the minimum value of the energy computed on the GLCM in various directions [59].
Based on previous studies, the GLCM “correlation” metric [60] was calculated for enhancing separability of vegetation-covered classes over selected bands. The GLCM correlations for the Sentinel-2 blue band (B2) [61,62], the Biophysical Composition Index (BCI), and the VV and VH Sentinel-1 bands were used in order to improve separability in classes of this study which contain the same vegetation type and vary only in terms of height and density (i.e., classes “Sclerophyllous vegetation” and “Mediterranean sclerophyllous forests”) [63].
To further explore the strengths of the OBIA approach, for each object, the area and perimeter were extracted, along with shape metrics such as the form factor, square pixel metric, fractal dimension, and shape index [64] in order to describe polygon complexity.
Finally, ancillary information on the topography was derived from the EU-DEM v1.1, a hybrid pan-European product based mainly on SRTM and ASTER GDEM, with a 25 m spatial resolution [65]. More specifically, the variables used herein were elevation, slope and the Topographic Solar-Radiation Index (TRASP), which is a linear transformation of the circular aspect variable [66].
Table 2.
Features considered in the classification process.
Table 2.
Features considered in the classification process.
| Feature Name | Statistic per Object | Brief Index Formula | Data Source | Reference |
|---|---|---|---|---|
| Original Bands | ||||
| -B2, B3, B4, B5, B6, B7, B8, B8A, B11, B12 | Mean, stdDev | - | S2 L2A | |
| -VV, VH | Mean, stdDev | - | S1 IW GRD | |
| Spectral indices | ||||
| -reNDVI | Mean, stdDev | S2 L2A | [67] | |
| -NDWI | Mean, stdDev | S2 L2A | [68] | |
| -GRVI | Mean, stdDev | S2 L2A | [69] | |
| -NDRBI | Mean, stdDev | S2 L2A | [70] | |
| -MSI | Mean, stdDev | S2 L2A | [71] | |
| -EVI | Mean, stdDev | S2 L2A | [72] | |
| -TC Brightness | Mean, stdDev | S2 L1C | [43] | |
| -TC Greenness | Mean, stdDev | S2 L1C | ||
| -TC Wetness | Mean, stdDev | S2 L1C | ||
| -BCI | Mean, stdDev | S2 L1C | [73] | |
| -VV/VH ratio | Mean, stdDev | S1 IW GRD | ||
| Texture indices | ||||
| -B2 7 7 GLCM Correlation | Mean | S2 L2A | [62] | |
| -PANTEX | Mean | S2 L2A | [74] | |
| -BCI 3 3 GLCM Correlation | Mean | S2 L1C | - | |
| -VV 7 7 GLCM Correlation | Mean | S1 IW GRD | [63] | |
| VH 7 7 GLCM Correlation | Mean | S1 IW GRD | ||
| Object shape properties | ||||
| -Perimeter, -Area | ||||
| -Form factor | [64] | |||
| -Square pixel metric | ||||
| -Fractal dimension | ||||
| -Shape index | ||||
| Ancillary data | ||||
| -Elevation, -Slope, -TRASP | Mean | EU-DEM | [66] | |
3.5. Classification Scheme
For the identification and mapping of ecosystem types, a typology allowing the correspondence of all terrestrial habitat types to the MAES Level 3 ecosystem type classes is used on the basis of the habitat types’ interpretation [4,38,75]. Marine ecosystems were represented in MAES level 1 category and were mapped in a distance of 2 km away from the shore. The final classification scheme consisted of 21 classes and is presented in Table 3.
Table 3.
Study classification scheme and class correspondence table, following earlier studies [4,38,75].
Because of the ecological interpretation of most classes, it was challenging to harmonize them with the LULC classification schemes of the different reference data sets used. Urban classes were straightforward and based on the Impervious HRL density and the two subclasses were split according the thresholds used in the Corine Land Cover nomenclature [76] (i.e., density higher than 30% and lower than 30%). Cropland classes were assigned to homogenous LPIS classes that also agreed in the CLC in LULC type. Complex and heterogeneous agricultural parcels from the LPIS where not used in this study. Woodland and forest classes were split into multiple sub classes following their ecological characteristics of the different forest types of Greece and based on the corresponding habitat types [38]. On the other hand, grasslands engulf a broad range of ecological and land use categories; in terms of land use, they span from natural grasslands to managed rangelands and pastures and furthermore they vary based on their tree-cover densities. These aspects imply difficulties in separating grasslands from other land cover classes based on their spectral and temporal characteristics and were therefore depicted in one single class, in align with [46].
3.6. Reference Data
Relying only on in-situ procedures for reference data collection would require tremendous efforts for national-scale mapping. However, existing geospatial national and EU’s Copernicus datasets, can be used for collecting reference data with a proper class correspondence and a careful sampling procedure. The Natura 2000 (N2K) product is a pan-European LULC dataset providing information about both status and change, for the protected areas under the N2K network, covering approximately 630,000 sq km [77]. The detailed N2K classification scheme, including 55 thematic LC/LU classes, allowed us to identify class correspondence with MAES level 3 classes with natural cover (Table 3). A large scale (1:5000) habitat map of Νatura 2000 terrestrial areas by the National Cadastre and Mapping Agency was used for sample identification, assuming that land cover inside protected areas remains stable throughout a 2-year period [17].
The Land Parcel Information System (LPIS) used to validate eligibility of agricultural subsidies under the EU’s Common Agriculture Policy, has been applied for generating crop-related samples similar to previous studies [33,46]. In this study, the 2018 Greek LPIS layer (scale 1:5000) was used to generate crop land cover samples by making the assumption that minor changes happen in major agriculture type classes from year to year. Samples extracted from LPIS, were further refined using information from the Corine Land Cover 2018 dataset in order to identify and select only the areas with a high probability of belonging to the assigned class [52] (Table 3).
Reference samples regarding built-up areas were initially extracted from the Copernicus Imperviousness High Resolution Layer (HRL) [17,46]. The Imperviousness layer is 20 m spatial resolution product depicting the proportion of sealed soil per pixel. The product is generated using a semi-automated classification of maximum Normalized Difference Vegetation Index (NDVI) mosaics. The 2015 version is used herein, with the assumption that built-up areas rarely convert back to natural surfaces [59].
A 3-step sampling was implemented, for reference data extraction, relying on the N2K, LPIS, and HRL maps. In step 1, a reference sample collection, for training and validation, was created, by performing a stratified random sampling, in order to identify 650 reference objects per class.
In order to derive the validation sub-sample from the reference dataset (i.e., step 2), the approach of Mack et al. [45] was followed. More specifically, we applied a random shuffling of the reference samples selected in step 1 for each class, in order to identify a sub-sample of 150 objects per class for the validation task. Subsequently, these objects were visually checked and corrected using Google Earth Engine imagery and ESA’s VHR IMAGE 2018 dataset (providing VHR orthorectified multispectral products over Europe) in order to create a highly reliable validation dataset [78]. The reliability was ensured through a sequential visual check for each validation object to verity its purity and homogeneity relative to the reference class assigned. In case of erroneous or ambiguous class assignments, the object was replaced from the original sample until 150 validation samples were selected for each class.
Finally, for rare classes (e.g., Peat bogs–7.2.1), where the total number of sample objects did not reach 150 objects, only half of the samples were kept for validation, allowing the rest to be assigned as training and thus having a balanced dataset.
The validation objects from step 2 were then excluded from the initial reference sample collection and the remaining objects were used for developing two different training datasets (i.e., step 3). The first training dataset (automated) contained the objects withheld outside the reference sample collection, without any modification. On the other hand, for the second training dataset (manual), a manual correction procedure to the withheld objects was followed, by interpreting the available very high-resolution imagery. In the case of training objects with erroneous or ambiguous class assignments, the respective object was replaced by introducing to the training sample, the nearest object belonging to the same class. Finally, few additional sample objects were added to classes that were noticed to require a large number of replacements (e.g., floodplain forest-class 3.2.1).
3.7. Classification Algorithm and Accuracy Assessment
Random Forests (RF) is a popular supervised machine learning algorithm that is nonparametric and fits several decision tree classifiers on various subsamples of the dataset using averaging to improve the predictive accuracy and control over-fitting [79]. The model uses only a part of the samples for training and keeps the remaining (called out-of-the bag samples) for an internal error estimate, called out-of-bag (OOB) error. RF has been proven to be robust to reference data errors up to 15%, works fairly well with small sample sizes and highly dimensional feature spaces and, in addition, has a small execution time compared to other classification methods [33,80]. For the above reasons, RF has been widely used in LULC classification studies and has shown the best performance in object-based classification [56].
In the present study, RF classification was accomplished within the GEE environment. Important parameters that must be specified for the implementation of the RF algorithm are (a) the number of trees in the forest (Ntree) and (b) the number of input variables randomly chosen at each split (Mtry). Optimal values of Ntree and Mtry were calculated locally, instead of GEE, in the R environment [81], using the “tuneRF” function in the “randomForest” package.
An additional by-product of the RF classification, which is calculated internally, is the variable importance. RF in GEE works by using the so-called Gini Index as a measure for the best split selection. Variable importance is measured by the OOB error increase and the Gini Index decrease, when switching one of the input random variables while keeping the rest constant. This measure helps identify the most influential predictor features in the classification and can sometimes be useful for model reduction [82,83].
For each classification experiment the validation objects were used for generating a confusion matrix and the derived standard accuracy measures, i.e., overall accuracy (OA), producer’s (PA) accuracy, user’s accuracy (UA) [84]. The OA shows the proportion of the total correctly classified objects, providing a general understanding of the overall classification algorithm effectiveness. The PA expresses how well the samples for each class were identified (omission error) while the UA indicates the probability that a sample actually represents that class on the ground (commission error) [33,57]. An additional metric used for assessing individual class accuracy and classification effectiveness was the Individual Classification Success Index (ICSI), [85], for each as class i:
4. Results
4.1. Classification Schemes
With respect to the achieved accuracy levels under different training data sampling approaches (Table 4), the manual sampling procedures presented the highest overall accuracy (77.33%–79.55%) for all feature sets evaluated.
Table 4.
Overall, producer’s (%) and user’s (%) accuracy, and ICSI (%) for the six different classification experiments. Higher red color saturation indicate ICSI values further below the ICSI average, while higher green color saturation indicate ICSI values further above the average.
On the other hand, the automation of the training sample extraction procedure for all three feature/composite sets, resulted to the lowest overall accuracies (74.89%–75.64%).
Regarding the different feature sets evaluated, high accuracy was achieved when the monthly features both using the manual (M-M-R) and automated (A-M-R) training sample approaches (overall accuracy 75.64% and 79.55%, respectively) were employed. On the other hand, the use of all features, including S2 original bands through seasonal composites presented the least satisfactory results for both manual (M-S-F) and automated (A-S-F) training (overall accuracy 74.89% and 77.33%, respectively).
The highest accuracy was noted in the classification scheme considering the monthly indices set and the manually identified training samples (M-M-R) (Figure 2).
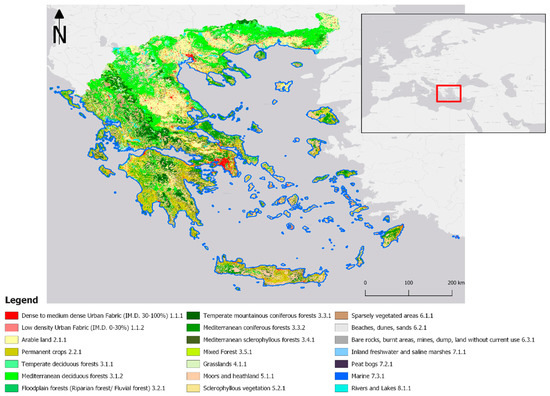
Figure 2.
Ecosystem Types Map for the best performing classification relying on the manually extracted samples and monthly features composites (M-M-R).
The classification accuracy of individual classes (PAs and UAs) are provided in Table 4. The manual training sample extraction provides a better balance of commission and omission errors, presenting lower mean absolute differences between producer’s and user’s accuracy across all three feature sets (7.84%), compared to the automated (13.85%) approaches. Again, the classification experiment relying on the monthly indices feature set and visually identified training samples (M-M-R) classification experiment, presented the lowest mean absolute difference (7.43%) between PA and UA.
The manual training sample extraction also addressed the large differences in omission/commission errors evident in the discrimination of the objects covered by urban fabric (1.1.1 and 1.2.1), agricultural areas (2.1.1 and 2.2.1), bare rocks (6.3.1), and peat bogs (7.2.1). However, a negative effect in error balance was evident when it came to Mediterranean sclerophyllous forest class (3.4.1), mixed forest (3.5.1), and moors and heathlands (6.1.1).
The ICSI also indicated that the manual training sample extraction, compared to the automated one, lowered the classification result in 10 out the 21 classes, predominantly in the Mediterranean sclerophyllous forest class (3.4.1) by 19% and inland freshwater and saline marshes (7.1.1) by 15 %, when relying on the full feature set (M-S-F). However, when the monthly feature set was employed (M-M-R), the manual training sample extraction improved the ICSI in 13 out of the 21 classes.
The use of the monthly instead of the seasonal indices feature set, when considering the manual training samples (i.e., M-M-R instead of M-S-R), also improved the ICSI in 13 out of the 21 classes while the improvement was even higher when compared to the full seasonal feature (M-S-F) set (16 out of the 21 classes).
Nevertheless, in all classification schemes, moderate to low accuracies (lower than 30%) in terms of the ICSI, were attained for the sclerophyllous vegetation (5.2.1), moors and heathland (5.1.1), and Mediterranean sclerophyllous forest (3.4.1).
Classes exhibiting the highest accuracies, while remaining stable among the two sampling techniques, where temperate mountainous coniferous forests (3.3.1) Mediterranean coniferous forests (3.3.2), grasslands (4.1.1), marine areas (7.3.1), and rivers and lakes (8.1.1).
Table 5 and Table 6 depict the confusion matrices of the best (M-M-R) and worst (A-S-F) performing classifications, respectively. In the A-S-F classification experiment (Table 6), low density urban fabric (1.1.2) had high confusion with dense urban fabric (1.1.1), bare area (6.3.1) was frequently confused with dense urban fabric (1.1.1), and peat bogs (7.2.1) exhibited high confusion with inland freshwater and saline marshes (7.1.1). All these misclassifications were minimized with the manual sampling and monthly feature approach (M-M-R) (Table 5).
Table 5.
Confusion matrix for the best performing classification (M-M-R). Values are given in percentage of reference objects (normalized per row).
Table 6.
Confusion matrix for the worst performing classification (A-S-F). Values are given in percentage of reference objects (normalized per row).
In addition, one can observe the confusion between the classes which had low accuracies in all classification experiments. Mediterranean sclerophyllous forest (3.4.1) is often classified as sclerophyllous vegetation (5.2.1) and vice versa, mixed forest (3.5.1) as temperate deciduous forests (3.1.1) or temperate mountainous coniferous forests (3.3.1), and last, moors and heathland (5.1.1) is confused with grasslands (4.1.1) and sparsely vegetated areas (6.1.1).
4.2. Visual Assessment of the Results
Landscape complexity in large-scale LULC mapping generates errors that are not always evident in the classification quantitative assessments using the confusion matrix and derived standard accuracy measures. Visual assessments are always essential for gaining an insight on the final product accuracy and for revealing errors that were not highlighted in the accuracy measures [33].
In general, the visual comparison of classifications revealed minor differences between different feature sets, but considerable differences for classifications of different sampling techniques.
Particularly, the automated sampling classifications resulted to an overestimation of mixed forests (5.3.1) and Mediterranean coniferous forests (3.3.2) (Figure 3a–c). On the contrary, low density urban fabric (1.1.2) was underestimated, an observation also consistent with the PA and UA of the automated sampling classification (Table 4). As it can be seen in image subsets included in the second row of Figure 3, areas surrounding the dense urban fabric, are classified as permanent crops (2.2.1), in the A-M-R experiment, instead of low density urban fabric, in the M-M-R approach. This effect is mainly caused by the automated LPIS samples containing greenhouses, which mixes the crop spectra with artificial materials.
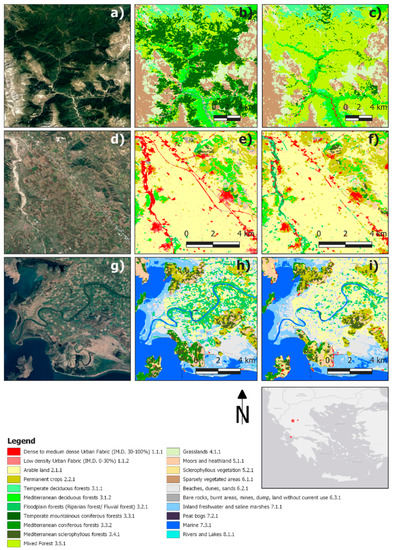
Figure 3.
Closeup of classifications for the different sampling techniques, in a forest, agricultural and wetland area. First column (a,d,g): Google Earth imagery, second column (b,e,h): M-M-R classifications, third column (c,f,i): A-M-R classifications.
Manual samples classifications, although reaching higher accuracy values, also demonstrated problems in specific areas. Particularly, in the manual sampling classifications, arable land (2.1.1) was frequently classified as floodplain forests (3.2.1), an effect noticed mostly in high moisture agriculture areas, such as river estuaries and can be explained by the additional number of manual floodplain samples obtained, for solving the spectral confusion with riverbanks in the automated sampling (Figure 3g–i).
Riverbank areas identification was challenging in both automated and manual sampling approaches, being classified as either dense urban fabric (1.1.1) or floodplain forests (3.2.1). In Figure 3a–c the riverbank of the river crossing the forest in the south, is mistakenly classified as floodplain forests in the manual sampling classification and as dense urban fabric in the automated sampling classification. Conversely, in Figure 3d–f one can see the riverbank in the west, mistakenly classified as dense urban fabric in the manual sampling classification and as floodplain forests in the automated sampling classification. These errors can be explained by the large temporal variations of moisture in riverbanks, throughout seasons and between years, caused by differences in precipitation.
Regarding the visual inspection between the different feature set classifications, a noticeable effect was the classification of arable land areas (2.1.1) as inland freshwater and saline marshes (7.1.1), evident in several high-moisture agriculture areas (Figure 4). This effect was minimized with the use of seasonal features, excluding the S2 L2A bands (M-S-R and A-S-R classifications).
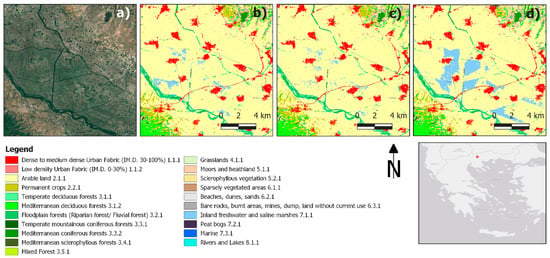
Figure 4.
Closeup of manual sampling classifications for the different feature sets in an agricultural area: (a) Google Earth imagery, (b) M-S-F, (c) M-S-R, and (d) M-M-R classification experiments.
Finally, besides the errors produced by the classifiers, artefacts created by the preprocessing steps were also observed. These errors had a negligible effect in the different classification schemes’ overall accuracy; however, they are noticeable on the local level. The cloud masking using the Cloud Probability and Scene Classification of S2 L2A images resulted in no-data values in artificial surfaces, due to constant misclassification of artificial areas in the Scene product and therefore constant masking in the compositing process. In addition, some mountain areas which were probably covered by clouds and snow most of the time also had no-data values due to constant masking in the compositing process.
4.3. Variable Importance
Variable importance was measured in GEE by the OOB error increase and the Gini Index decrease, when permuting one of the input random variables while keeping the rest constant. The 20 most important predictor features are presented in Figure 5, averaged over the two sampling methods, for each feature set. In all feature set cases, the feature mean values instead of the standard deviations for each object were among the most important features. Moreover, in all cases, the two most important variables were topographic features, namely the mean value of elevation and slope, followed by TRASP in the third and fourth position. Object properties, in specific, area, form factor, and fractal dimension were also found to be among the 20 most important variables in all cases. SAR VV/VH ratio was found in all feature combinations among the top 10 features, unlike SAR bands which appeared much lower in the total feature lists and therefore do not exist in these figures. Regarding the original S2 spectral bands, only the first Short-Wave InfraRed (SWIR) (B11) was found to be an important feature, while in respect to texture features, only the PANTEX index was found important, though only for seasonal composites. According to the output of the variable importance, the most informative spectral indices in all classifications were BCI, GRVI, MSI, the TC components, reNDVI, and NDRBI. Finally, features from all the available months and seasons were selected as optimal in all six classification experiments.
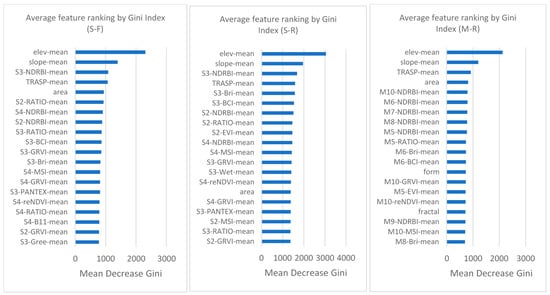
Figure 5.
Averaged feature importance (for manual and automated sampling), for the full, seasonal (S-F), for the reduced, seasonal (S-R) and the monthly, reduced (M-R) feature sets. Letters “S” and “M” stand for “season” and “month” respectively, while the number next to them indicates the season and month in ascending order starting from S2 = spring and M5 = May, till S4 = autumn and M10 = October.
5. Discussion
5.1. Classification Accuracy
The overall goal of this study was the development of a classification workflow for fine scale object-based land cover mapping, using a 21-class scheme, facilitating ecosystem condition and ES mapping, within the Greek territory, towards MAES implementation in Greece. Efforts for national scale LULC mapping using RS for Greece have been made in the past [19,86], using a lower thematic resolution that cannot harmonize with the EUNIS habitat classes and relying on manually interpretation of samples. A more complex classification scheme of 27 classes was used by Karakizi et al. [87], for mapping a relatively small area over Northern Greece, covered by a single Landsat tile.
Object-based image analysis, which mimics the way the human brain interprets images, by grouping pixels into homogenous and meaningful objects through image segmentation [29] has been predominantly employed for image classification having pixel sizes larger than 2 m and small (i.e., smaller than 300 ha) study areas [56]. However, it has been used recently in LULC classification with lower spatial resolution images including data from Sentinel-1 and Sentinel-2 satellites [22,54,55]. An object-based approach can account for geolocation offset errors that in linear shaped objects (such as roads and rivers), can affect classification results when adopting a pixel-based approach [88]. Furthermore, OBIA methods have been found to improve classification accuracy by reducing “salt and pepper” noise that occurs in pixel-based LULC classifications [54]. This effect is amplified by artifacts caused by inadequate cloud masking and atmospheric correction, in best pixel compositing strategies, like the median method used in this study [46]. Lastly, although all processing was performed on the powerful GEE cloud environment, OBIA helps reduce computational complexity caused mainly due to the large study area extent [22]. OBIA applied in this study would not be fully beneficial without the exploitation of object spatial properties. Among the few recent national-scale LULC studies that applied OBIA [54,55,89], there is little evidence of object shape properties use. Specifically, only Tu et al. [55] used the area property of each object as an input feature in the classification. The appearance of object shape properties in the most important variables in all the classification experiments, underlines the strength of the object-based approach used in this study.
Six classification schemes were developed, using automated and manual sampling techniques and different multi-temporal feature combinations. Among the six schemes, 0.88% to 4.94% differences in OA were observed. The most accurate classification scheme was the classification considering the monthly features (excluding S2 original bands) and manually identified samples (M-M-R), achieving an OA of 79.55%. Previous nation-wide land cover studies achieved higher accuracies than our study, which can be likely related to the less detailed classification scheme incorporating fewer classes [48]. However, comparing the accuracy attained in the current study with earlier national scale land cover maps is not straightforward, not only due to the complex classification scheme used here, but also due to the phyto-sociological criteria used for defining some of the classes.
In all classification experiments, almost all land cover classes (17 out of 21 classes) exhibited high accuracies in terms of PA and UA. Lower accuracies are particularly noticeable for Mediterranean sclerophyllous forests (3.4.1), mixed forest (3.5.1), moors and heathland (5.1.1), and sclerophyllous vegetation (5.2.1). The lower accuracy observed for these classes is mainly explained by the large similarities in spectral responses these ecosystem types have. It is not a surprise that mapping of moors and heathland which cover such an broad ecological and land use gradient is challenging [18]. Likewise, mixed forest was hard to capture because of the different types of vegetation combinations in this category. The confusion of Mediterranean sclerophyllous forests with sclerophyllous vegetation was expected, since conceptually, the only differences between the two are vegetation height, structure, and density. Ecological modeling, regarding each forest class presence is needed to meliorate classification into the different MAES level 3 classes (e.g., presence in specific phytogeographical regions of Greece, altitude, slope, distance from shore etc.).
5.2. Automated Sampling Potential with Available LULC Products
Besides mapping land cover in large scales in the finest MMU and highest accuracy possible, there is still a need for a framework for mapping in regular intervals. One of the key aspects of regular large-scale land cover mapping, relies on the ability to generate samples in an automated manner. Several studies, have used available national or regional products as a basis to obtain samples, thus avoiding the tedious work of manual sample collection for nation-wide LULC. Automated sampling is often followed by a “data cleansing” procedure. However, a simpler classification scheme is observed in these studies. In specific, Griffiths et al. [46] used automated sampling deriving from LPIS for national crop mapping, while Mack et al. [45] used only LUCAS points in a 9-class classification scheme. Inglada et al. [33] relied on a 17-class scheme, though they obtained samples from additional local products.
In our study, the visual comparison of different classification schemes as well as the examination of the respective confusion matrices, revealed minor differences among classification schemes using different feature sets, but considerable differences in the maps resulting from the different sampling procedures. Specifically, the manual sampling procedure presented higher accuracy when compared with the automated, regardless the feature set evaluated. Although the Copernicus program and national scale readily available LULC products (i.e., N2K) provide detailed thematic information datasets at large map scales, it seems that visual interpretation is a prerequisite for training sample extraction and mapping when it comes to complex and ecological-relevant classification schemes. For example, the intrinsic heterogeneity of N2K habitats types and the spectral variability of the different land cover components of each habitat type, result in non-systematic high spectral intra-variability of habitat patches, as well as the low inter-variability between different habitat types, [90,91].
Even governmental, official products, with less complex nomenclature, created through on-screen digitization, such as LPIS, can contain errors e.g., due to false claims or digitization errors [46]. In addition, several national sub-contractors are employed from governmental organizations for LPIS and N2K creation across EU countries, likely resulting in inconsistencies and product heterogeneity nationwide. Furthermore, in the case of the Copernicus datasets, previous studies had observed underestimates of imperviousness density and omission errors in the HRL Imperviousness dataset [92]. Furthermore, introduction of location-based constraints during automated sample extraction (i.e., creation of buffers of a certain distance around polygon limits), does not guarantee for the assignment of correct land cover labels or the prevention of mixed objects or pixels [17]. Training data characteristics and quality, therefore, are of key importance in LULC classification, an observation also in line with [52,93].
5.3. Multi-Temporal Features and Variable Importance
Despite using a large number of features (multi-temporal and multi-sensor) evaluated in the study’s classification schemes, the relatively high accuracy attained at all cases, supports the RF classifier ability in the handling and identification of the most important features when used with highly correlated multidimensional data [80].
The RF variable importance analysis revealed that in all cases, the most important features were elevation and slope, followed by spectral indices, shape variables, and texture variables.
Topography-derived variables (i.e., elevation, slope), which had the highest rank in importance, have been related in numerous studies to physical and environmental factors that influence vegetation distribution [94,95]. In particular, elevation has been proven to be one of the most important parameters affecting vegetation phenology in [96] and forest mapping in [97] and has been found to be considerably important for wetland identification [57]. Slope also influences vegetation by affecting soil, water, and nutrient quantities [98].
With respect to the highest ranking spectral indices, the GRVI has been reported also in other studies using multitemporal data for its effectiveness in vegetation mapping, for instance in [99] for crop mapping and in [100] for monitoring forest phenological variations. Furthermore, the large significance of the reNDVI, which in this study uses B5 of S2, can be explained with the reported importance of B5 among the red-edge bands, for crop and tree species classification [31,101]. The MSI index appeared as most important in all classification experiments due to being one of the few water-sensitive indices employed, with the advantage of differentiating total chlorophyll and water concentration at the canopy level [71]. The appearance of all the TC components in the highest ranking features, verifies a statement by [21], that dimensionality reduction methods is crucial for retaining important information in data compression, especially when utilizing time series. The importance of multiple month NDRBI can be explained by its capability of separating vegetative from non-vegetative areas [102]. The variable importance measures, in terms of temporal-interval choice, further revealed the value of multi-temporal data in LULC mapping [21], since all seasons appeared in the 20 most important variables for classification.
6. Conclusions
In this paper, different classification schemes were evaluated for fine-scale, land-cover mapping at a national scale, following a fine-scale (21 classes) classification nomenclature.
Our approach integrates cloud-based analysis, a machine learning classification algorithm and freely available multi-sensor and multi-seasonal earth observation data, in order to develop a cost-effective, country-level, land-cover map that will be subsequently used for ecosystem condition and ES mapping and assessment, i.e., for the MAES implementation in Greece, at the national scale.
We have analyzed different approaches considering different feature sets and training sample extraction methods. The random forest classification algorithm is assumed to be relatively robust to reference data inaccuracies; however, our results also support earlier research findings that the refinement of the automated selected training samples leads to higher classification accuracies.
The processing chain of the different classification schemes evaluated, adopts an object-based perspective instead of the traditional per-pixel classification paradigm. This approach, not only facilitates integration of earth observation data from sensors with different characteristics, such as the active Sentinel-1 and passive Sentinel-2 satellite images used in our study, but also addresses challenges related to excessive computational and time demands, an issue that must be treated even in cloud-computing environments.
Assessment of variable importance in all classification schemes highlighted that EO data alone, are not adequate for predicting and mapping the complex Mediterranean landscape, especially when it comes to broad, diverse area mapping. Incorporation of auxiliary data related to the ecological factors seemed to have the highest impact in the classification process, indicating that this information is necessary for discriminating ambiguous habitat patches.
Seasonal and monthly spectral information features were also very important, quantifying phenological differences among map classes. In the future, additional spectral-temporal features, capturing habitat phenology, should be evaluated for further improving classification accuracy.
The present study acts as a roadmap for the further development of an end-to-end, automated workflow, for annual land-cover mapping in Greece, providing up-to-date estimates of ecosystem extent, condition, ES supply (or potential supply), and ES bundles, nationwide. The resulting map will be available to the public through the webGIS portal of the LIFE-IP 4 Natura project (currently under development).
Author Contributions
Conceptualization and research design, G.M. and N.V.; methodology G.M., N.V., I.P.K. and P.D.; analysis implementation, N.V.; writing—original draft preparation, N.V. and G.M.; review and editing, N.V., I.P.K., C.G., P.D. and G.M.; resources, D.K.; supervision, G.M.; funding acquisition, I.M., G.M. and P.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the European Commission LIFE Integrated Project, LIFE-IP 4 NATURA“Integrated Actions for the Conservation and Management of Natura 2000 sites, species, habitats and ecosystems in Greece”, Grant Number: LIFE 16 IPE/G/000002.
Acknowledgments
The study was conducted within the framework of the National Mapping and Assessment of Ecosystem and their Services project, under the LIFE-IP 4 NATURA project. We would like to thank the Hellenic Ministry of the Environment and Energy and the Hellenic Ministry of Rural Development and Food, for the provision of nation-wide geospatial material. The VHR IMAGE 2018 dataset is provided at no-cost from European Space Agency. The authors are grateful to Ass. Professor Georgios Korakis for his contribution in reference data selection.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Andrew, M.E.; Wulder, M.A.; Nelson, T.A.; Coops, N.C. Spatial data, analysis approaches, and information needs for spatial ecosystem service assessments: A review. GIScience Remote Sens. 2015, 52, 344–373. [Google Scholar] [CrossRef]
- Cowling, R.M.; Egoh, B.; Knight, A.T.; O’Farrell, P.J.; Reyers, B.; Rouget, M.; Roux, D.J.; Welz, A.; Wilhelm-Rechman, A. An operational model for mainstreaming ecosystem services for implementation. Proc. Natl. Acad. Sci. USA 2008, 105, 9483–9488. [Google Scholar] [CrossRef] [PubMed]
- Maes, J.; Egoh, B.; Willemen, L.; Liquete, C.; Vihervaara, P.; Schägner, J.P.; Grizzetti, B.; Drakou, E.G.; La Notte, A.; Zulian, G.; et al. Mapping ecosystem services for policy support and decision making in the European Union. Ecosyst. Serv. 2012, 1, 31–39. [Google Scholar] [CrossRef]
- Kokkoris, I.; Mallinis, G.; Bekri, E.; Vlami, V.; Zogaris, S.; Chrysafis, I.; Mitsopoulos, I.; Dimopoulos, P. National Set of MAES Indicators in Greece: Ecosystem Services and Management Implications. Forests 2020, 11, 595. [Google Scholar] [CrossRef]
- Cord, A.F.; Brauman, K.A.; Chaplin-, R.; Huth, A.; Ziv, G.; Seppelt, R. Priorities to Advance Monitoring of Ecosystem Services Using Earth Observation. Trends Ecol. Evol. 2017, 32, 416–428. [Google Scholar] [CrossRef] [PubMed]
- Grêt-Regamey, A.; Weibel, B.; Bagstad, K.J.; Ferrari, M.; Geneletti, D.; Klug, H.; Schirpke, U.; Tappeiner, U. On the effects of scale for ecosystem services mapping. PLoS ONE 2014, 9, e112601. [Google Scholar] [CrossRef]
- Burkhard, B.; Kroll, F.; Nedkov, S.; Müller, F. Mapping ecosystem service supply, demand and budgets. Ecol. Indic. 2012, 21, 17–29. [Google Scholar] [CrossRef]
- Mapping Ecosystem Services; Burkhard, B., Maes, J., Eds.; Pensoft Publishers: Sofia, Bulgaria, 2017; ISBN 978-954-642-830-1. [Google Scholar]
- Jacobs, S.; Burkhard, B.; Van Daele, T.; Staes, J.; Schneiders, A. “The Matrix Reloaded”: A review of expert knowledge use for mapping ecosystem services. Ecol. Modell. 2015, 295, 21–30. [Google Scholar] [CrossRef]
- Mallinis, G.; Georgiadis, C. Editorial of Special Issue “Remote Sensing for Land Cover/Land Use Mapping at Local and Regional Scales”. Remote Sens. 2019, 11, 2202. [Google Scholar] [CrossRef]
- De Araujo, C.C.; Atkinson, P.M.; Dearing, J.A.; De Araujo Barbosa, C.C.; Atkinson, P.M.; Dearing, J.A.; De Araujo, C.C.; Atkinson, P.M.; Dearing, J.A.; De Araujo Barbosa, C.C.; et al. Remote sensing of ecosystem services: A systematic review. Ecol. Indic. 2015, 52, 430–443. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover mapping at 30m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Kukawska, E.; Lewinski, S.; Krupinski, M.; Malinowski, R.; Nowakowski, A.; Rybicki, M.; Kotarba, A. Multitemporal Sentinel-2 data-remarks and observations. In Proceedings of the 2017 9th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Brugge, Belgium, 27–29 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar]
- Buchhorn, M.; Lesiv, M.; Tsendbazar, N.-E.; Herold, M.; Bertels, L.; Smets, B. Copernicus Global Land Cover Layers—Collection 2. Remote Sens. 2020, 12, 1044. [Google Scholar] [CrossRef]
- Büttner, G. CORINE land cover and land cover change products. Remote Sens. Digit. Image Process. 2014, 18, 55–74. [Google Scholar]
- Grekousis, G.; Mountrakis, G.; Kavouras, M. An overview of 21 global and 43 regional land-cover mapping products. Int. J. Remote Sens. 2015, 36, 5309–5335. [Google Scholar] [CrossRef]
- Leinenkugel, P.; Deck, R.; Huth, J.; Ottinger, M.; Mack, B. The Potential of Open Geodata for Automated Large-Scale Land Use and Land Cover Classification. Remote Sens. 2019, 11, 2249. [Google Scholar] [CrossRef]
- Pflugmacher, D.; Rabe, A.; Peters, M.; Hostert, P. Mapping pan-European land cover using Landsat spectral-temporal metrics and the European LUCAS survey. Remote Sens. Environ. 2019, 221, 583–595. [Google Scholar] [CrossRef]
- Gounaridis, D.; Apostolou, A.; Koukoulas, S. Land cover of Greece, 2010: A semi-automated classification using random forests. J. Maps 2016, 12, 1055–1062. [Google Scholar] [CrossRef]
- Wulder, M.A.; Coops, N.C.; Roy, D.P.; White, J.C.; Hermosilla, T. Land cover 2.0. Int. J. Remote Sens. 2018, 39, 4254–4284. [Google Scholar] [CrossRef]
- Gómez, C.; White, J.C.; Wulder, M.A. Optical remotely sensed time series data for land cover classification: A review. ISPRS J. Photogramm. Remote Sens. 2016, 116, 55–72. [Google Scholar] [CrossRef]
- Stromann, O.; Nascetti, A.; Yousif, O.; Ban, Y. Dimensionality Reduction and Feature Selection for Object-Based Land Cover Classification based on Sentinel-1 and Sentinel-2 Time Series Using Google Earth Engine. Remote Sens. 2019, 12, 76. [Google Scholar] [CrossRef]
- Lehmann, E.A.; Caccetta, P.; Lowell, K.; Mitchell, A.; Zhou, Z.-S.; Held, A.; Milne, T.; Tapley, I. SAR and optical remote sensing: Assessment of complementarity and interoperability in the context of a large-scale operational forest monitoring system. Remote Sens. Environ. 2015, 156, 335–348. [Google Scholar] [CrossRef]
- Hütt, C.; Waldhoff, G.; Waldhoff, G. Multi-data approach for crop classification using multitemporal, dual-polarimetric TerraSAR-X data, and official geodata. Eur. J. Remote Sens. 2018, 51, 62–74. [Google Scholar] [CrossRef]
- Ienco, D.; Interdonato, R.; Gaetano, R.; Ho Tong Minh, D. Combining Sentinel-1 and Sentinel-2 Satellite Image Time Series for land cover mapping via a multi-source deep learning architecture. ISPRS J. Photogramm. Remote Sens. 2019, 158, 11–22. [Google Scholar] [CrossRef]
- Van Tricht, K.; Gobin, A.; Gilliams, S.; Piccard, I. Synergistic use of radar sentinel-1 and optical sentinel-2 imagery for crop mapping: A case study for Belgium. Remote Sens. 2018, 10, 1642. [Google Scholar] [CrossRef]
- Slagter, B.; Tsendbazar, N.-E.; Vollrath, A.; Reiche, J. Mapping wetland characteristics using temporally dense Sentinel-1 and Sentinel-2 data: A case study in the St. Lucia wetlands, South Africa. Int. J. Appl. Earth Obs. Geoinf. 2020, 86, 102009. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Hay, G.J.; Castilla, G. Geographic Object-Based Image Analysis (GEOBIA): A new name for a new discipline. In Object-Based Image Analysis; Springer Berlin Heidelberg: Berlin, Heidelberg, 2008; ISBN 978-3-540-77057-2. [Google Scholar]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First experience with Sentinel-2 data for crop and tree species classifications in central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- EEA Technical Specifications for Implementation of a New land-Monitoring Concept Based on EAGLE. Public Consultation document for CLC+ Core. Available online: https://land.copernicus.eu/user-corner/technical-library/clc-core-consultations-for-the-technical-specifications (accessed on 9 October 2020).
- Inglada, J.; Vincent, A.; Arias, M.; Tardy, B.; Morin, D.; Rodes, I. Operational High Resolution Land Cover Map Production at the Country Scale Using Satellite Image Time Series. Remote Sens. 2017, 9, 95. [Google Scholar] [CrossRef]
- European Commision. Our Life Insurance, Our Natural Capital: An EU Biodiversity Strategy to 2020. Communication from the Commission to the European Parliament, the Council, the Economic and Social Committee and the Committee of the Regions; European Commision: Brussels, Belgium, 2011. [Google Scholar]
- Maes, J.; Teller, A.; Erhard, M.; Liquete, C.; Braat, L.; Berry, P.; Egoh, B.; Puydarrieux, P.; Fiorina, C.; Santos, F.; et al. Mapping and Assessment of Ecosystems and their Services; Publications office of the European Union: Luxembourg, 2013; ISBN 9789279293696. [Google Scholar]
- Schuler, M.; Stucki, E.; Roque, O.; Perlik, M. Mountain Areas in Europe: Analysis of Mountain Areas in EU Member States, Acceding and Other European Countries; European Commission: Brussels, Belgium, 2004. [Google Scholar]
- Beck, H.E.; Zimmermann, N.E.; McVicar, T.R.; Vergopolan, N.; Berg, A.; Wood, E.F. Present and future köppen-geiger climate classification maps at 1-km resolution. Sci. Data 2018, 5, 1–12. [Google Scholar] [CrossRef]
- Kokkoris, I.; Dimopoulos, P.; Xystrakis, F.; Tsiripidis, I. National scale ecosystem condition assessment with emphasis on forest types in Greece. One Ecosyst. 2018, 3. [Google Scholar] [CrossRef]
- Weiss, M.; Banko, G. Ecosystem Type Map v3.1—Terrestrial and marine ecosystems; EEA-European Topic Centre on Biological Diversity: Paris, France, 2018. [Google Scholar]
- EEA Mapping Europe’s Ecosystems. Available online: https://www.eea.europa.eu/themes/biodiversity/mapping-europes-ecosystems (accessed on 9 October 2020).
- LIFE-IP 4 NATURA GitHub Page. Available online: https://github.com/n-verde/LIFE-IP_4_NATURA (accessed on 9 October 2020).
- Shoko, C.; Mutanga, O. Examining the strength of the newly-launched Sentinel 2 MSI sensor in detecting and discriminating subtle differences between C3 and C4 grass species. ISPRS J. Photogramm. Remote Sens. 2017, 129, 32–40. [Google Scholar] [CrossRef]
- Shi, T.; Xu, H. Derivation of Tasseled Cap Transformation Coefficients for Sentinel-2 MSI At-Sensor Reflectance Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 4038–4048. [Google Scholar] [CrossRef]
- d’Andrimont, R.; Lemoine, G.; van der Velde, M. Targeted Grassland Monitoring at Parcel Level Using Sentinels, Street-Level Images and Field Observations. Remote Sens. 2018, 10, 1300. [Google Scholar] [CrossRef]
- Mack, B.; Leinenkugel, P.; Kuenzer, C.; Dech, S. A semi-automated approach for the generation of a new land use and land cover product for Germany based on Landsat time-series and Lucas in-situ data. Remote Sens. Lett. 2017, 8, 244–253. [Google Scholar] [CrossRef]
- Griffiths, P.; Nendel, C.; Hostert, P. Intra-annual reflectance composites from Sentinel-2 and Landsat for national-scale crop and land cover mapping. Remote Sens. Environ. 2019, 220, 135–151. [Google Scholar] [CrossRef]
- Griffiths, P.; Nendel, C.; Pickert, J.; Hostert, P. Towards national-scale characterization of grassland use intensity from integrated Sentinel-2 and Landsat time series. Remote Sens. Environ. 2019, 1–12. [Google Scholar] [CrossRef]
- Weigand, M.; Staab, J.; Wurm, M.; Taubenböck, H. Spatial and semantic effects of LUCAS samples on fully automated land use/land cover classification in high-resolution Sentinel-2 data. Int. J. Appl. Earth Obs. Geoinf. 2020, 88, 102065. [Google Scholar] [CrossRef]
- Evans, M.J.; Malcom, J.W. Automated Change Detection Methods for Satellite Data that can Improve Conservation Implementation. bioRxiv 2020. [Google Scholar] [CrossRef]
- Main-Knorn, M.; Pflug, B.; Louis, J.; Debaecker, V.; Müller-Wilm, U.; Gascon, F. Sen2Cor for Sentinel-2. In Proceedings of the Image and Signal Processing for Remote Sensing XXIII, Warsaw, Poland, 11–14 September 2017; Volume 10427, p. 3. [Google Scholar] [CrossRef]
- Xie, S.; Liu, L.; Zhang, X.; Yang, J.; Chen, X.; Gao, Y. Automatic land-cover mapping using landsat time-series data based on google earth engine. Remote Sens. 2019, 11, 3023. [Google Scholar] [CrossRef]
- Carrasco, L.; O’Neil, A.W.; Daniel Morton, R.; Rowland, C.S. Evaluating combinations of temporally aggregated Sentinel-1, Sentinel-2 and Landsat 8 for land cover mapping with Google Earth Engine. Remote Sens. 2019, 11, 288. [Google Scholar] [CrossRef]
- Achanta, R.; Süsstrunk, S. Superpixels and polygons using simple non-iterative clustering. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 4895–4904. [Google Scholar]
- Mahdianpari, M.; Salehi, B.; Mohammadimanesh, F.; Brisco, B.; Homayouni, S.; Gill, E.; DeLancey, E.R.; Bourgeau-Chavez, L. Big Data for a Big Country: The First Generation of Canadian Wetland Inventory Map at a Spatial Resolution of 10-m Using Sentinel-1 and Sentinel-2 Data on the Google Earth Engine Cloud Computing Platform. Can. J. Remote Sens. 2020, 46, 15–33. [Google Scholar] [CrossRef]
- Tu, Y.; Chen, B.; Zhang, T.; Xu, B. Regional Mapping of Essential Urban Land Use Categories in China: A Segmentation-Based Approach. Remote Sens. 2020, 12, 1058. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Amani, M.; Brisco, B.; Afshar, M.; Mirmazloumi, S.M.; Mahdavi, S.; Mirzadeh, S.M.J.; Huang, W.; Granger, J. A generalized supervised classification scheme to produce provincial wetland inventory maps: An application of Google Earth Engine for big geo data processing. Big Earth Data 2019, 3, 378–394. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man. Cybern. 1973, 3, 610–621. [Google Scholar] [CrossRef]
- Lefebvre, A.; Sannier, C.; Corpetti, T. Monitoring urban areas with Sentinel-2A data: Application to the update of the Copernicus High Resolution Layer Imperviousness Degree. Remote Sens. 2016, 8, 606. [Google Scholar] [CrossRef]
- Culbert, P.D.; Pidgeon, A.M.; St. Louis, V.; Radeloff, V.C.; Bash, D.; St.-Louis, V.; Bash, D.; Radeloff, V.C. The Impact of Phenological Variation on Texture Measures of Remotely Sensed Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2009, 2, 299–309. [Google Scholar] [CrossRef]
- Vaglio Laurin, G.; Puletti, N.; Hawthorne, W.; Liesenberg, V.; Corona, P.; Papale, D.; Chen, Q.; Valentini, R. Discrimination of tropical forest types, dominant species, and mapping of functional guilds by hyperspectral and simulated multispectral Sentinel-2 data. Remote Sens. Environ. 2016, 176, 163–176. [Google Scholar] [CrossRef]
- Pandit, S.; Tsuyuki, S.; Dube, T. Exploring the inclusion of Sentinel-2 MSI texture metrics in above-ground biomass estimation in the community forest of Nepal. Geocarto Int. 2019, 6049, 1–18. [Google Scholar] [CrossRef]
- Morin, D.; Planells, M.; Guyon, D.; Villard, L.; Mermoz, S.; Bouvet, A.; Thevenon, H.; Dejoux, J.-F.; Le Toan, T.; Dedieu, G. Estimation and Mapping of Forest Structure Parameters from Open Access Satellite Images: Development of a Generic Method with a Study Case on Coniferous Plantation. Remote Sens. 2019, 11, 1275. [Google Scholar] [CrossRef]
- Jiao, L.; Liu, Y.; Li, H. Characterizing land-use classes in remote sensing imagery by shape metrics. ISPRS J. Photogramm. Remote Sens. 2012, 72, 46–55. [Google Scholar] [CrossRef]
- García, J.C.; Antonio, J.; Garzón, A. EU-DEM Upgrade Documentation EEA User Manual; Indra Systems S.A.: Madrid, Spain, 2015. [Google Scholar]
- Roberts, D.W.; Cooper, S. V Concepts and techniques of vegetation mapping. In Proceedings of the Land Classifications Based on Vegetation: Applications for Resource Management, Moscow, ID, USA, 17–19 November 1987; Intermountain Research Station publications: Ogden, UT, USA, 1989; pp. 90–96. [Google Scholar]
- Forkuor, G.; Dimobe, K.; Serme, I.; Tondoh, J.E. Landsat-8 vs. Sentinel-2: Examining the added value of sentinel-2′s red-edge bands to land-use and land-cover mapping in Burkina Faso. GIScience Remote Sens. 2018, 55, 331–354. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Motohka, T.; Nasahara, K.N.; Oguma, H.; Tsuchida, S. Applicability of Green-Red Vegetation Index for remote sensing of vegetation phenology. Remote Sens. 2010, 2, 2369–2387. [Google Scholar] [CrossRef]
- Mallinis, G.; Karteris, M.; Theodoridou, I.; Tsioukas, V.; Karteris, M. Development of a nationwide approach for large scale estimation of green roof retrofitting areas and roof-top solar energy potential using VHR natural colour orthoimagery and DSM data over Thessaloniki, Greece. Remote Sens. Lett. 2014, 5, 548–557. [Google Scholar] [CrossRef]
- Dotzler, S.; Hill, J.; Buddenbaum, H.; Stoffels, J. The potential of EnMAP and sentinel-2 data for detecting drought stress phenomena in deciduous forest communities. Remote Sens. 2015, 7, 14227–14258. [Google Scholar] [CrossRef]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.; Gao, X.; Ferreira, L. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Deng, C.; Wu, C. BCI: A biophysical composition index for remote sensing of urban environments. Remote Sens. Environ. 2012, 127, 247–259. [Google Scholar] [CrossRef]
- Pesaresi, M.; Gerhardinger, A.; Kayitakire, F. A robust built-up area presence index by anisotropic rotation-invariant textural measure. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2008, 1, 180–192. [Google Scholar] [CrossRef]
- EEA Linkages of Species and Habitat Types to MAES Ecosystems. Available online: https://www.eea.europa.eu/data-and-maps/data/linkages-of-species-and-habitat (accessed on 9 October 2020).
- Kosztra, B.; Büttner, G.; Hazeu, G.; Arnold, S. Updated CLC Illustrated Nomenclature Guidelines; European Environment Agency: Wien, Austria, 2017. [Google Scholar]
- EEA NOMENCLATURE and MAPPING GUIDELINE. Copernicus Land Monitoring Service Local Component: Natura 2000 Mapping. Available online: https://land.copernicus.eu/local/natura/resolveuid/aa66ae0cd4fe4270bd5d354f145498ee (accessed on 9 October 2020).
- Radoux, J.; Lamarche, C.; Van Bogaert, E.; Bontemps, S.; Brockmann, C.; Defourny, P. Automated training sample extraction for global land cover mapping. Remote Sens. 2014, 6, 3965–3987. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăgu, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- R Core Team R: A Language and Environment for Statistical Computing. Available online: https://www.r-project.org (accessed on 9 October 2020).
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Koukoulas, S.; Blackburn, G.A. Introducing new indices for accuracy evaluation of classified images representing semi-natural woodland environments. Photogramm. Eng. Remote Sens. 2001, 67, 499–510. [Google Scholar]
- Karantzalos, K.; Bliziotis, D.; Karmas, A. A Scalable Geospatial Web Service for Near Real-Time, High-Resolution Land Cover Mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4665–4674. [Google Scholar] [CrossRef]
- Karakizi, C.; Karantzalos, K.; Vakalopoulou, M.; Antoniou, G. Detailed Land Cover Mapping from Multitemporal Landsat-8 Data of Different Cloud Cover. Remote Sens. 2018, 10, 1214. [Google Scholar] [CrossRef]
- Pereira-Pires, J.E.; Aubard, V.; Ribeiro, R.A.; Fonseca, J.M.; Silva, J.M.N.; Mora, A. Semi-automatic methodology for fire break maintenance operations detection with sentinel-2 imagery and artificial neural network. Remote Sens. 2020, 12, 909. [Google Scholar] [CrossRef]
- Uddin, K.; Shrestha, H.L.; Murthy, M.S.R.; Bajracharya, B.; Shrestha, B.; Gilani, H.; Pradhan, S.; Dangol, B. Development of 2010 national land cover database for the Nepal. J. Environ. Manag. 2015, 148, 82–90. [Google Scholar] [CrossRef] [PubMed]
- Haest, B.; Vanden Borre, J.; Spanhove, T.; Thoonen, G.; Delalieux, S.; Kooistra, L.; Mücher, C.A.; Paelinckx, D.; Scheunders, P.; Kempeneers, P. Habitat mapping and quality assessment of NATURA 2000 heathland using airborne imaging spectroscopy. Remote Sens. 2017, 9, 266. [Google Scholar] [CrossRef]
- Vanden Borre, J.; Paelinckx, D.; Mücher, C.A.; Kooistra, L.; Haest, B.; De Blust, G.; Schmidt, A.M. Integrating remote sensing in Natura 2000 habitat monitoring: Prospects on the way forward. J. Nat. Conserv. 2011, 19, 116–125. [Google Scholar] [CrossRef]
- Smith, G.; Pennec, A.; Sannier, C.; Dufourmont, H. HRL Imperviousness Degree 2015 Validation Report; European Environment Agency: Brussels, Belgium, 2018. [Google Scholar]
- Heydari, S.S.; Mountrakis, G. Effect of classifier selection, reference sample size, reference class distribution and scene heterogeneity in per-pixel classification accuracy using 26 Landsat sites. Remote Sens. Environ. 2018, 204, 648–658. [Google Scholar] [CrossRef]
- José Vidal-Macua, J.; Ninyerola, M.; Zabala, A.; Domingo-Marimon, C.; Pons, X. Factors affecting forest dynamics in the Iberian Peninsula from 1987 to 2012. The role of topography and drought. For. Ecol. Manag. 2017, 406, 290–306. [Google Scholar] [CrossRef]
- Tomaselli, V.; Adamo, M.; Veronico, G.; Sciandrello, S.; Tarantino, C.; Dimopoulos, P.; Medagli, P.; Nagendra, H.; Blonda, P. Definition and application of expert knowledge on vegetation pattern, phenology, and seasonality for habitat mapping, as exemplified in a Mediterranean coastal site. Plant Biosyst. Int. J. Deal. Asp. Plant Biol. 2017, 151, 887–899. [Google Scholar] [CrossRef]
- Hwang, T.; Song, C.; Vose, J.M.; Band, L.E. Topography-mediated controls on local vegetation phenology estimated from MODIS vegetation index. Landsc. Ecol. 2011, 26, 541–556. [Google Scholar] [CrossRef]
- Fernández-Landa, A.; Algeet-Abarquero, N.; Fernández-Moya, J.; Guillén-Climent, M.L.; Pedroni, L.; García, F.; Espejo, A.; Villegas, J.F.; Marchamalo, M.; Bonatti, J.; et al. An operational framework for land cover classification in the context of REDD+ mechanisms: A case study from costa rica. Remote Sens. 2016, 8, 593. [Google Scholar] [CrossRef]
- Robinson, C.; Saatchi, S.; Clark, D.; Astaiza, J.H.; Hubel, A.F.; Gillespie, T.W. Topography and three-dimensional structure can estimate tree diversity along a tropical elevational gradient in Costa Rica. Remote Sens. 2018, 10, 629. [Google Scholar] [CrossRef]
- Siachalou, S.; Mallinis, G.; Tsakiri-Strati, M. Analysis of Time-Series Spectral Index Data to Enhance Crop Identification Over a Mediterranean Rural Landscape. IEEE Geosci. Remote Sens. Lett. 2017, 1–5. [Google Scholar] [CrossRef]
- Nagai, S.; Ishii, R.; Bin Suhaili, A.; Kobayashi, H.; Matsuoka, M.; Ichie, T.; Motohka, T.; Kendawang, J.J.; Suzuki, R. Usability of noise-free daily satellite-observed green–red vegetation index values for monitoring ecosystem changes in Borneo. Int. J. Remote Sens. 2014, 35, 7910–7926. [Google Scholar] [CrossRef]
- Delegido, J.; Verrelst, J.; Alonso, L.; Moreno, J. Evaluation of sentinel-2 red-edge bands for empirical estimation of green LAI and chlorophyll content. Sensors 2011, 11, 7063–7081. [Google Scholar] [CrossRef] [PubMed]
- Stow, D.A.; Toure, S.I.; Lippitt, C.D.; Lippitt, C.L.; Lee, C.R. Frequency distribution signatures and classification of within-object pixels. Int. J. Appl. Earth Obs. Geoinf. 2012, 15, 49–56. [Google Scholar] [CrossRef] [PubMed]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).