Detecting European Aspen (Populus tremula L.) in Boreal Forests Using Airborne Hyperspectral and Airborne Laser Scanning Data

 ,
,  , , , ,
, , , ,
Abstract
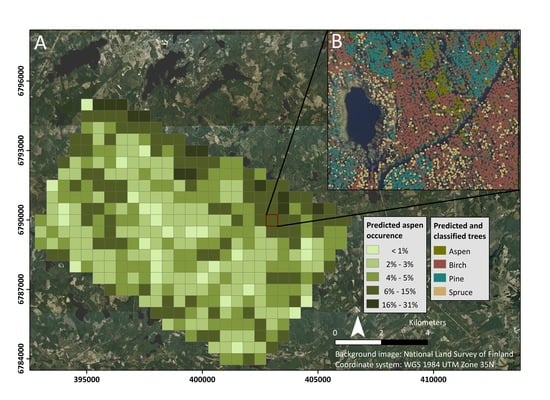
1. Introduction
- (1)
- Compare the performance of different hyperspectral data features in the tree species classification using SVM and RF classifiers, and
- (2)
- Find the most important spectral features to discriminate aspen from the other common tree species.
2. Materials and Methods
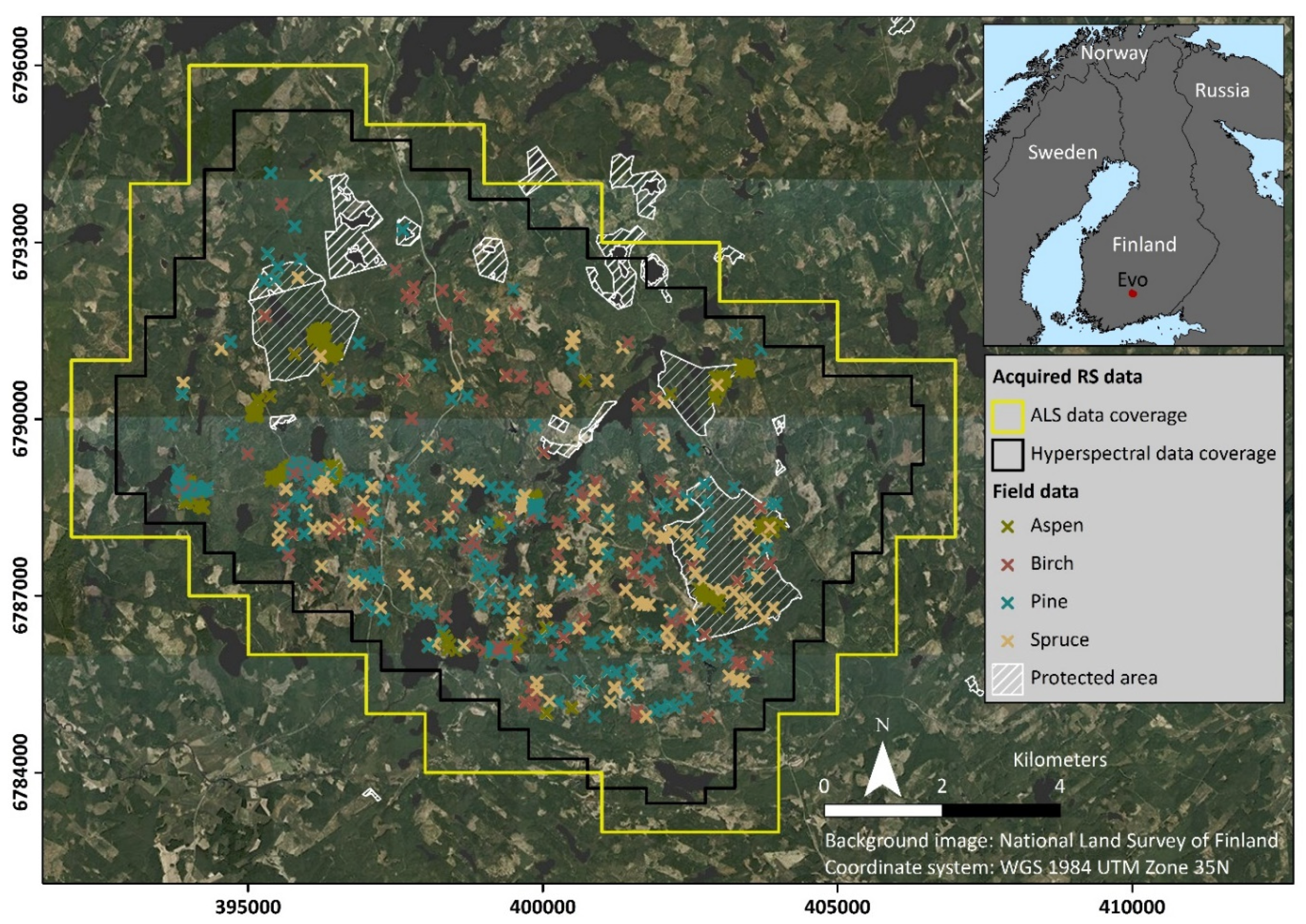
2.1. Study Area
2.2. Airborne Hyperspectral and LiDAR Data
2.3. Field Data
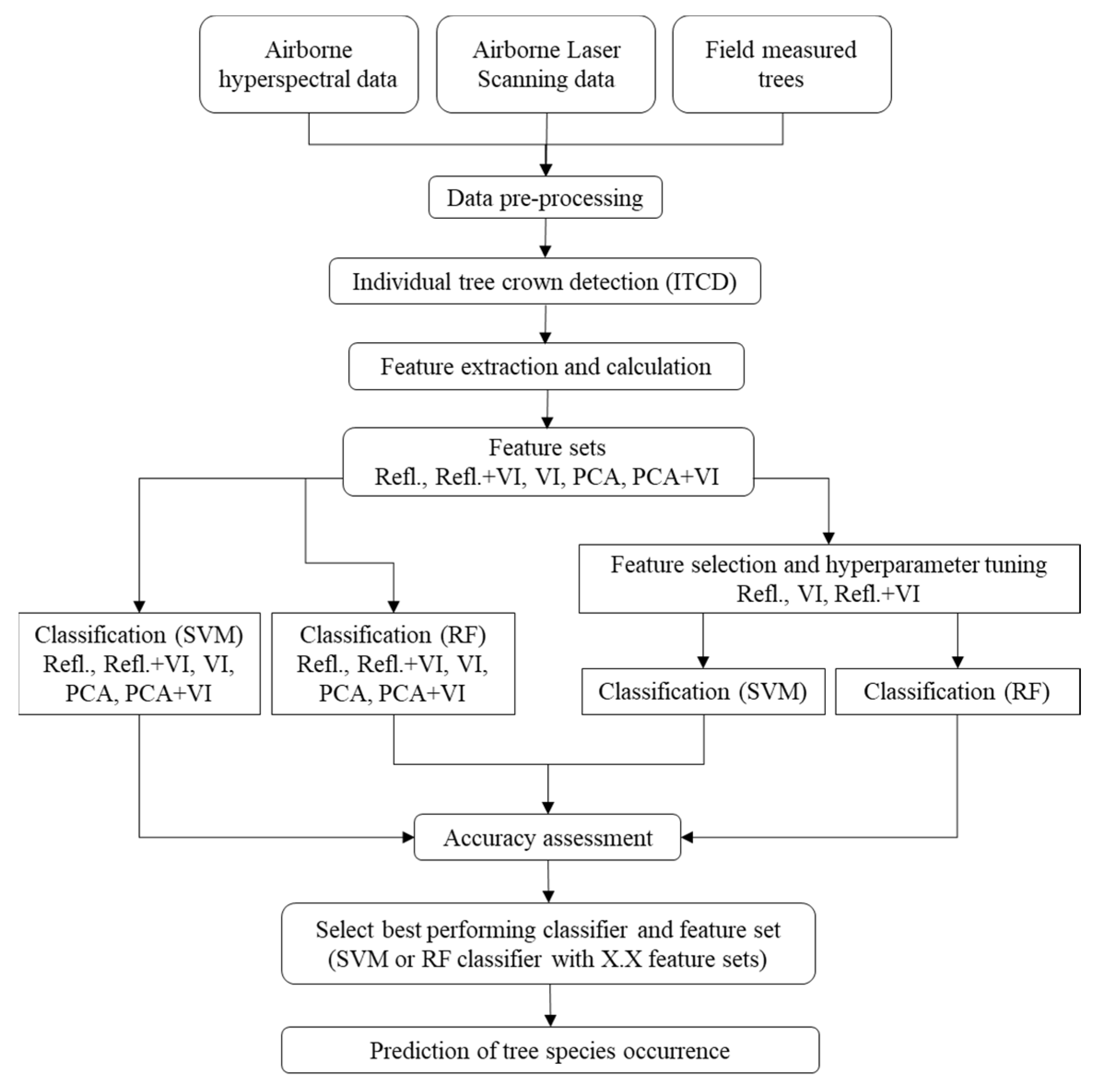
2.4. Individual Tree Crown Detection
2.5. Feature Extraction and Calculation
2.6. Machine Learning Classification Models
2.6.1. Feature Selection
2.6.2. Hyperparameter Tuning
2.6.3. Training, Prediction, and Accuracy Assessment
2.6.4. Model Interpretation
3. Results
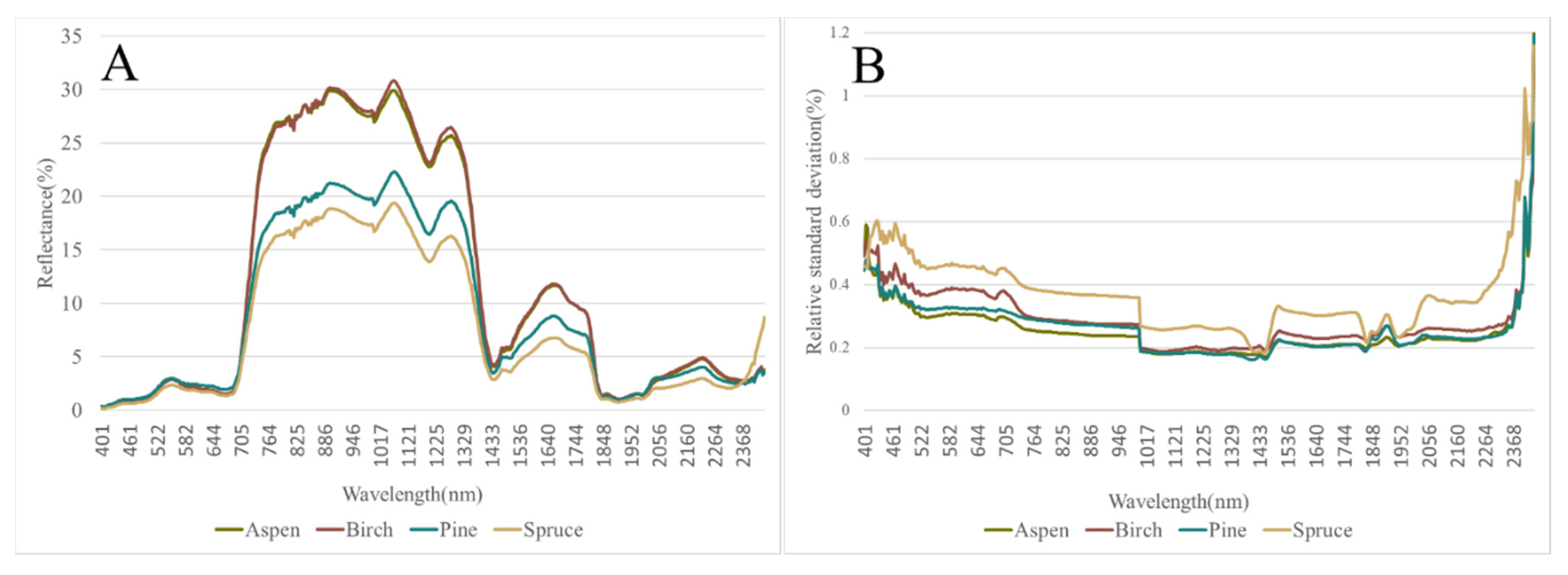
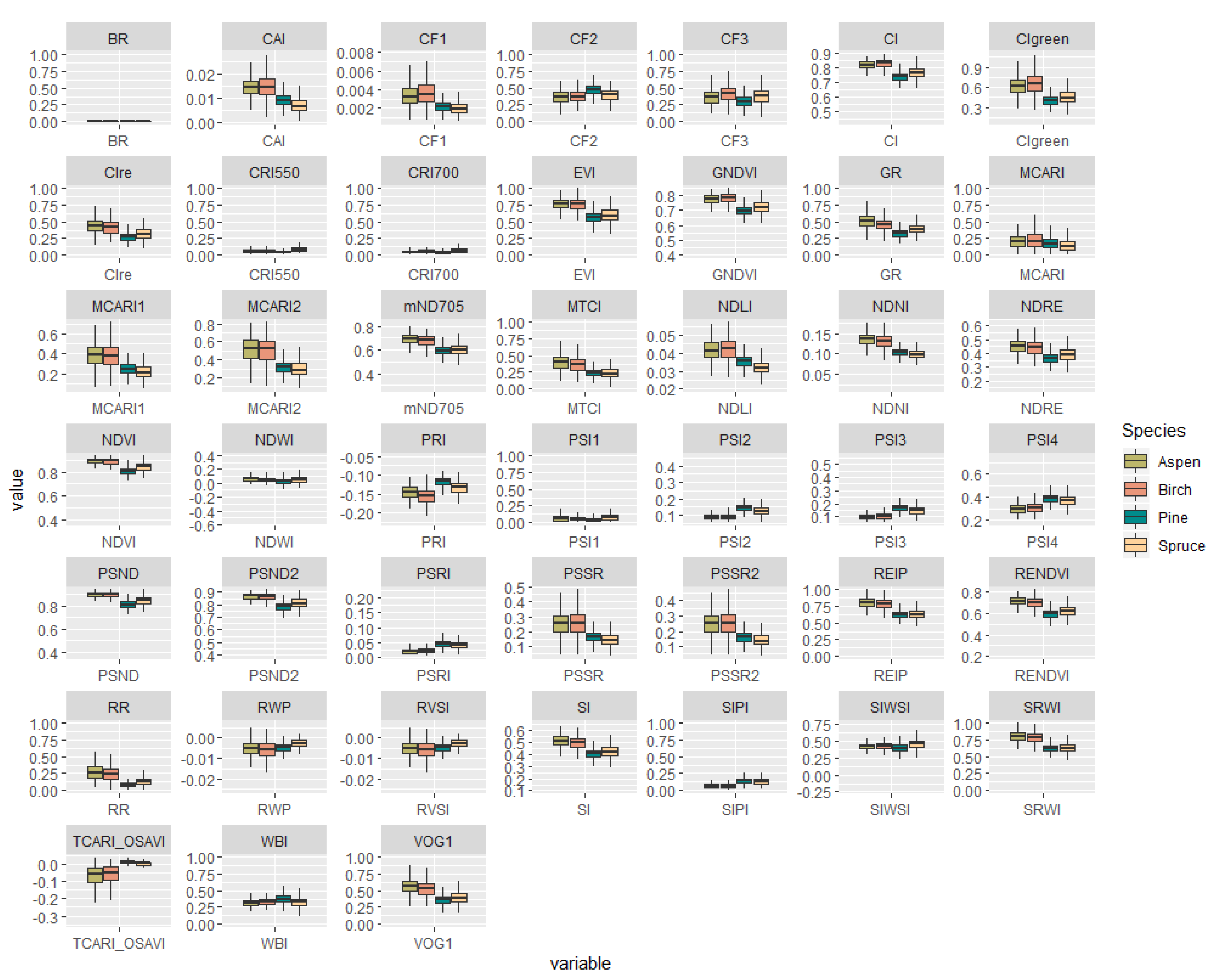
3.1. Spectral Signatures of the Analyzed Tree Species
3.2. Impact of the Principal Component Analysis to Classification
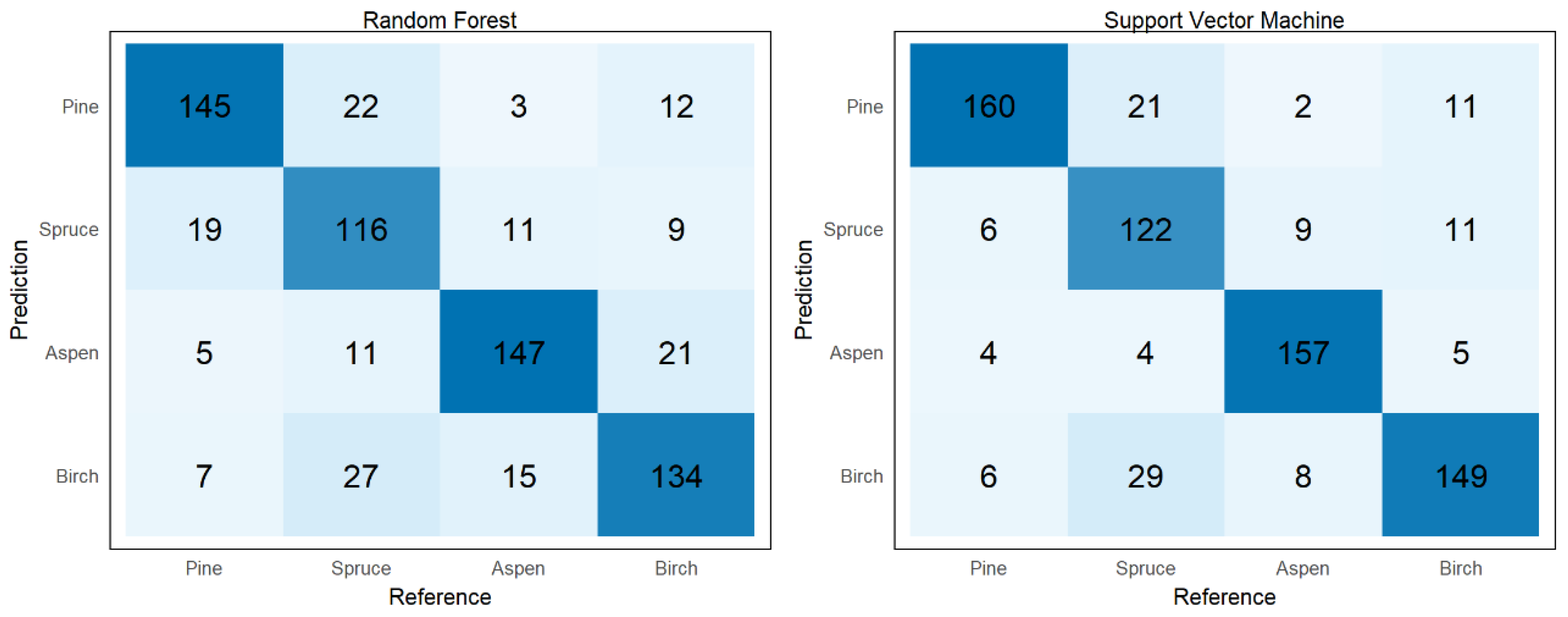
3.3. Accuracy Assessment and Statistical Comparison of Feature Sets and Models
3.4. Accuracy Assessment and Statistical Comparison of Feature Sets and Models after Feature Selection
3.4.1. Impact of the Feature Selection and Model Tuning to Classification
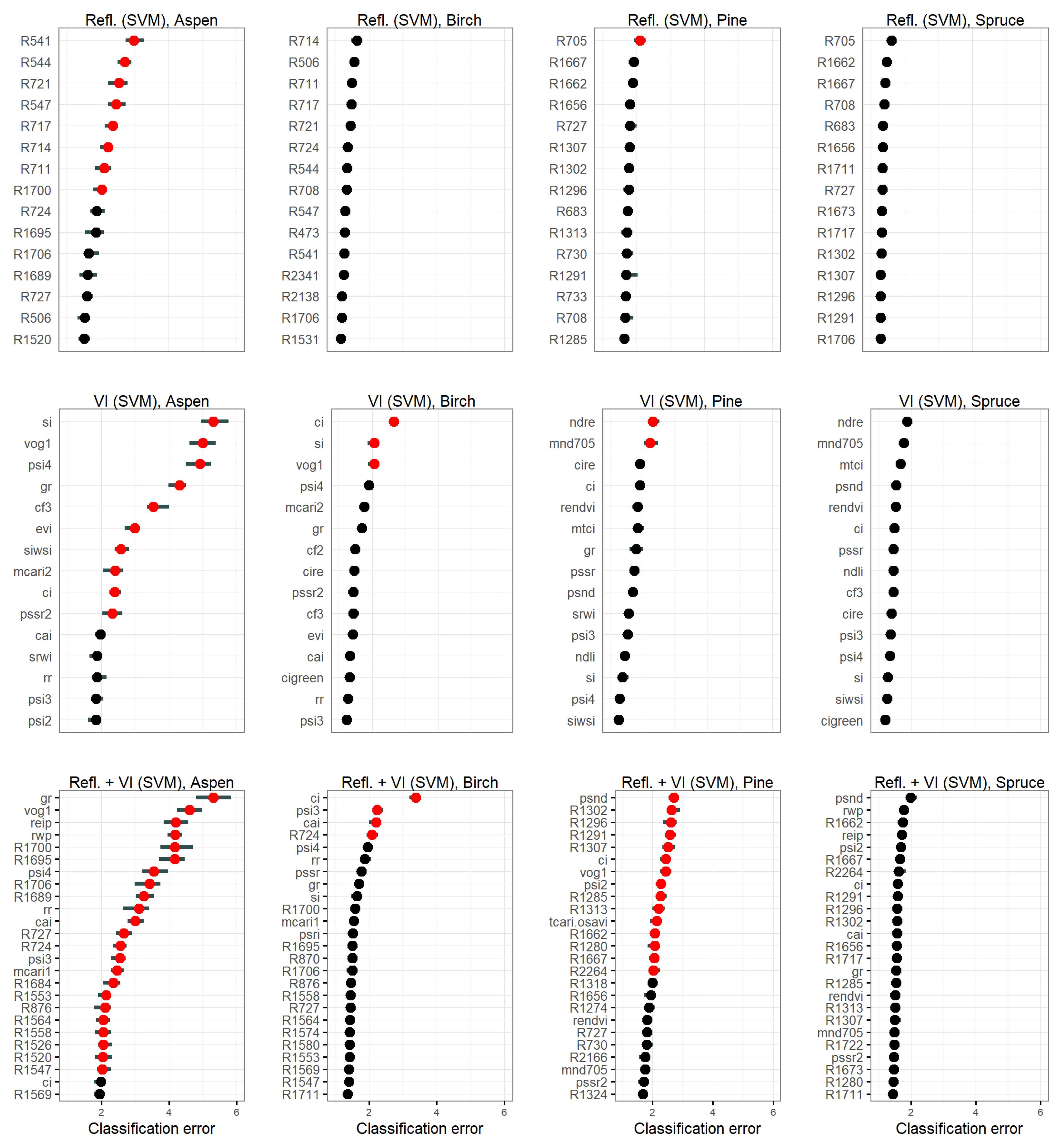
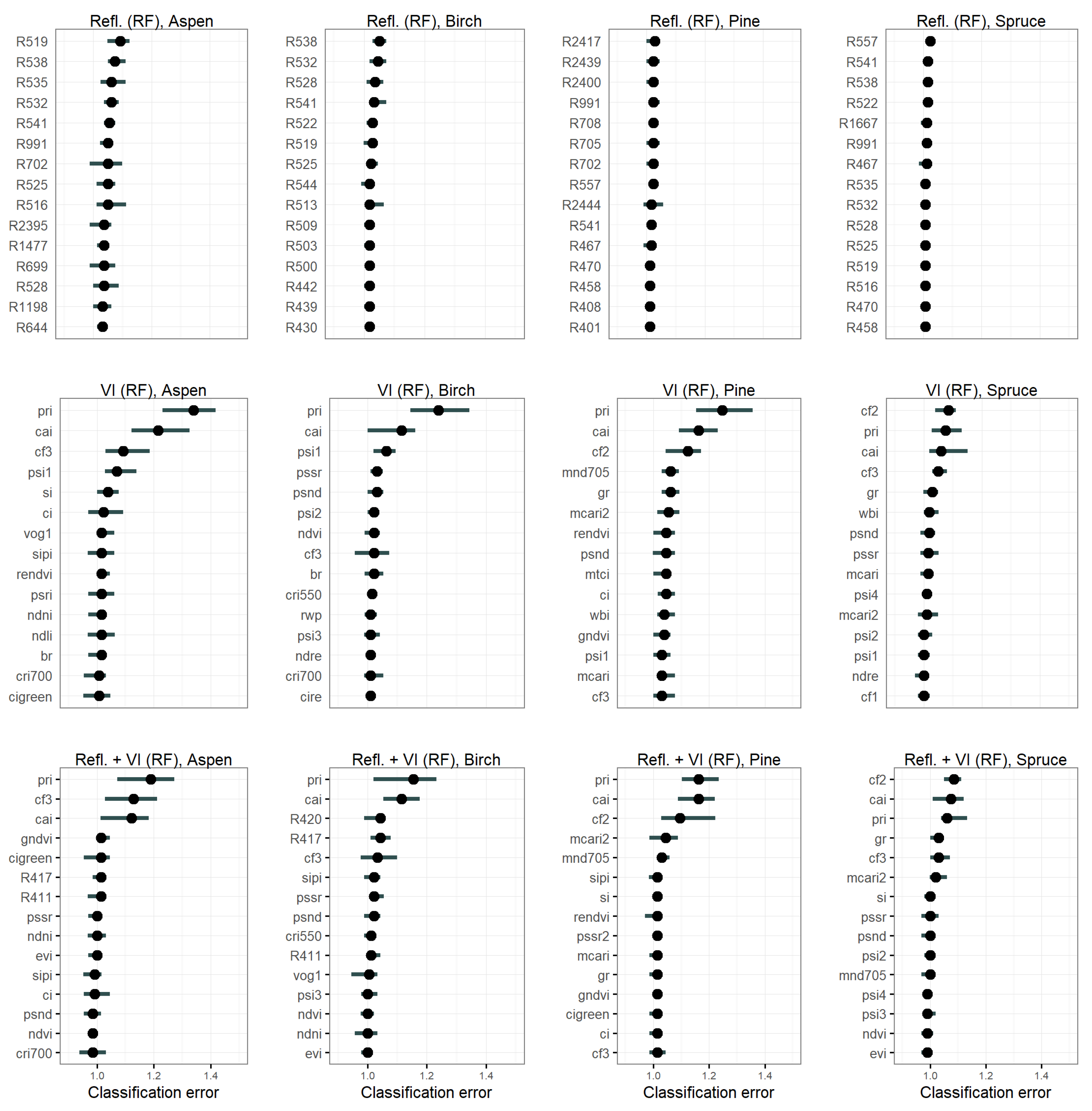
3.4.2. Feature Importance
4. Discussion
4.1. Impact of Classifiers, Features, Feature Selection, and Segmentation
4.2. Impact of Spectral Features for Aspen Discrimination
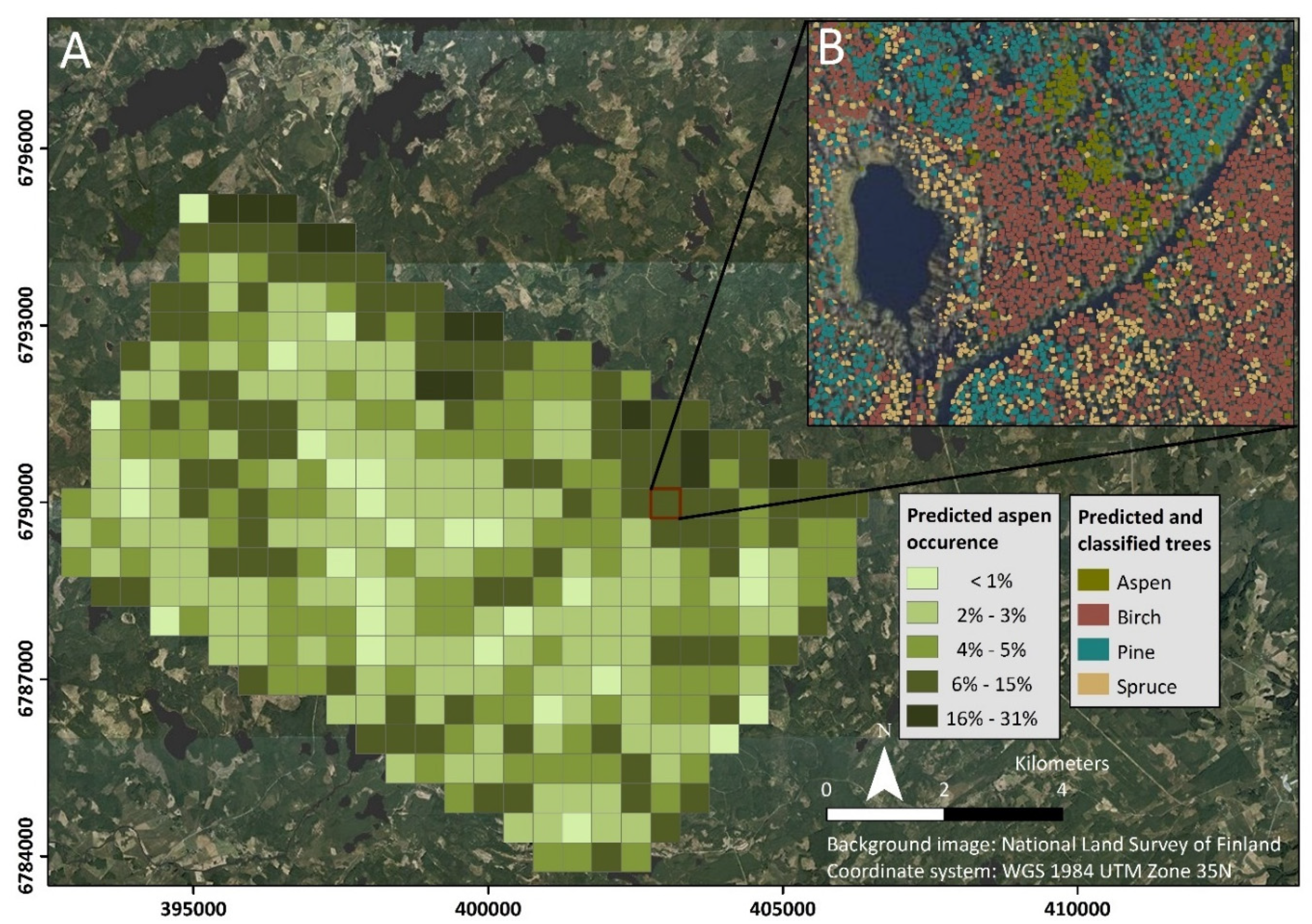
4.3. Considerations for Cost-Effectiveness and Upscaling the Results
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Esseen, P.A.; Ehnström, B.; Ericson, L.; Sjöberg, K. Boreal forests. Ecol. Bull. 1997, 46, 16–47. Available online: https://www.jstor.org/stable/20113207 (accessed on 13 November 2019).
- Kuuluvainen, T. Natural variability of forests as a reference for restoring and managing biological diversity in boreal Fennoscandia. Silva Fenn. 2002, 36, 97–125. [Google Scholar] [CrossRef]
- Brockerhoff, E.G.; Barbaro, L.; Castagneyrol, B.; Forrester, D.I.; Gardiner, B.; González-Olabarria, J.R.; Lyver, P.O.; Meurisse, N.; Oxbrough, A.; Taki, H.; et al. Forest biodiversity, ecosystem functioning and the provision of ecosystem services. Biodivers. Conserv. 2017, 26, 3005–3035. [Google Scholar] [CrossRef]
- Lindenmayer, D.B.; Margules, C.R.; Botkin, D.B. Indicators of biodiversity for ecologically sustainable forest management. Conserv. Biol. 2000, 14, 941–950. [Google Scholar] [CrossRef]
- Kouki, J.; Arnold, K.; Martikainen, P. Long-term persistence of aspen—A key host for many threatened species–is endangered in old-growth conservation areas in Finland. J. Nat. Conserv. 2004, 12, 41–52. [Google Scholar] [CrossRef]
- Kivinen, S.; Koivisto, E.; Keski-Saari, S.; Poikolainen, L.; Tanhuanpää, T.; Kuzmin, A.; Viinikka, A.; Heikkinen, R.K.; Pykälä, J.; Virkkala, R.; et al. A keystone species, European aspen (Populus tremula L.), in boreal forests: Ecological role, knowledge needs and mapping using remote sensing. For. Ecol. Manag. 2020, 462, 118008. [Google Scholar] [CrossRef]
- Jonsell, M.; Weslien, J.; Ehnström, B. Substrate requirements of red-listed saproxylic invertebrates in Sweden. Biodivers. Conserv. 1998, 7, 749–764. [Google Scholar] [CrossRef]
- Tikkanen, O.P.; Martikainen, P.; Hyvärinen, E.; Junninen, K.; Kouki, J. Red-listed boreal forest species of Finland: Associations with forest structure, tree species, and decaying wood. Ann. Zool. Fenn. 2006, 43, 373–383. Available online: https://www.jstor.org/stable/23736858 (accessed on 19 December 2019).
- Latva-Karjanmaa, T.; Penttilä, R.; Siitonen, J. The demographic structure of European aspen (Populus tremula) populations in managed and old-growth boreal forests in eastern Finland. Can. J. For. Res. 2007, 37, 1070–1081. [Google Scholar] [CrossRef]
- Maltamo, M.; Packalén, P. Species specific management inventory in Finland. In Forestry Applications of Airborne Laser Scanning—Concepts and Case Studies. Managing Forest Ecosystems; Maltamo, M., Naesset, E., Vauhkonen, J., Eds.; Springer: Dordrecht, The Netherlands, 2014; Volume 7, pp. 241–252. [Google Scholar] [CrossRef]
- Vehmas, M.; Kouki, J.; Eerikäinen, K. Long-term spatio-temporal dynamics and historical continuity of European aspen (Populus tremula L.) stands in the Koli National Park, eastern Finland. For. Int. J. For. Res. 2008, 82, 135–148. [Google Scholar] [CrossRef][Green Version]
- Hardenbol, A.A.; Junninen, K.; Kouki, J. A key tree species for forest biodiversity, European aspen (Populus tremula), is rapidly declining in boreal old-growth forest reserves. For. Ecol. Manag. 2020, 462, 118009. [Google Scholar] [CrossRef]
- White, J.C.; Coops, N.C.; Wulder, M.A.; Vastaranta, M.; Hilker, T.; Tompalski, P. Remote Sensing Technologies for Enhancing Forest Inventories: A Review. Can. J. Remote Sens. 2016, 42, 619–641. [Google Scholar] [CrossRef]
- Næsset, E. Area-based inventory in Norway—From innovation to an operational reality. In Forestry Applications of Airborne Laser Scanning. Managing Forest Ecosystems; Maltamo, M., Næsset, E., Vauhkonen, J., Eds.; Springer: Dordrecht, The Netherlands, 2014; Volume 7, pp. 215–240. [Google Scholar] [CrossRef]
- Nilsson, M.; Nordkvist, K.; Jonzén, J.; Lindgren, N.; Axensten, P.; Wallerman, J.; Egberth, M.; Larsson, S.; Nilsson, L.; Eriksson, J.; et al. A nationwide forest attribute map of Sweden predicted using airborne laser scanning data and field data from the National Forest Inventory. Remote Sens. Environ. 2017, 194, 447–454. [Google Scholar] [CrossRef]
- Kangas, A.; Astrup, R.; Breidenbach, J.; Fridman, J.; Gobakken, T.; Korhonen, K.T.; Maltamo, M.; Nilsson, M.; Nord-Larsen, T.; Næsset, E.; et al. Remote sensing and forest inventories in Nordic countries–roadmap for the future. Scand. J. For. Res. 2018, 33, 397–412. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; Latifi, H.; Stereńczak, K.; Modzelewska, A.; Lefsky, M.; Waser, L.T.; Straub, C.; Ghosh, A. Review of studies on tree species classification from remotely sensed data. Remote Sens. Environ. 2016, 186, 64–87. [Google Scholar] [CrossRef]
- Wulder, M.A.; Hall, R.J.; Coops, N.C.; Franklin, S.E. High spatial resolution remotely sensed data for ecosystem characterization. BioScience 2004, 54, 511–521. [Google Scholar] [CrossRef]
- Carlson, K.M.; Asner, G.P.; Hughes, R.F.; Ostertag, R.; Martin, R.E. Hyperspectral Remote Sensing of Canopy Biodiversity in Hawaiian Lowland Rainforests. Ecosystems 2007, 10, 536–549. [Google Scholar] [CrossRef]
- Corona, P.; Chirici, G.; McRoberts, R.E.; Winter, S.; Barbati, A. Contribution of large-scale forest inventories to biodiversity assessment and monitoring. For. Ecol. Manag. 2011, 262, 2061–2069. [Google Scholar] [CrossRef]
- Wang, R.; Gamon, J.A. Remote sensing of terrestrial plant biodiversity. Remote Sens. Environ. 2019, 231, 111218. [Google Scholar] [CrossRef]
- Packalén, P.; Maltamo, M. The k-MSN method for the prediction of species-specific stand attributes using airborne laser scanning and aerial photographs. Remote Sens. Environ. 2007, 109, 328–341. [Google Scholar] [CrossRef]
- Holmgren, J.; Persson, Å.; Söderman, U. Species identification of individual trees by combining high resolution LiDAR data with multi-spectral images. Int. J. Remote Sens. 2008, 29, 1537–1552. [Google Scholar] [CrossRef]
- Korpela, I.; Ørka, O.H.; Maltamo, M.; Tokola, T.; Hyyppä, J. Tree species classification using airborne LiDAR—Effects of stand and tree parameters, downsizing of training set, intensity normalization, and sensor type. Silva Fenn. 2010, 44, 319–339. [Google Scholar] [CrossRef]
- Ørka, H.O.; Næsset, E.; Bollandsås, O.M. Effects of different sensors and leaf-on and leaf-off canopy conditions on echo distributions and individual tree properties derived from airborne laser scanning. Remote Sens. Environ. 2010, 114, 1445–1461. [Google Scholar] [CrossRef]
- Nevalainen, O.; Honkavaara, E.; Tuominen, S.; Viljanen, N.; Hakala, T.; Yu, X.; Hyyppä, J.; Saari, H.; Pölönen, I.; Imai, N.N.; et al. Individual tree detection and classification with UAV-based photogrammetric point clouds and hyperspectral imaging. Remote Sens. 2017, 9, 185. [Google Scholar] [CrossRef]
- Saarinen, N.; Vastaranta, M.; Näsi, R.; Rosnell, T.; Hakala, T.; Honkavaara, E.; Wulder, M.A.; Luoma, V.; Tommaselli, A.M.G.; Imai, N.N.; et al. Assessing biodiversity in boreal forests with UAV-based photogrammetric point clouds and hyperspectral imaging. Remote Sens. 2018, 10, 338. [Google Scholar] [CrossRef]
- Tuominen, S.; Näsi, R.; Honkavaara, E.; Balazs, A.; Hakala, T.; Viljanen, N.; Pölönen, I.; Saari, H.; Ojanen, H. Assessment of classifiers and remote sensing features of hyperspectral imagery and stereo-photogrammetric point clouds for recognition of tree species in a forest area of high species diversity. Remote Sens. 2018, 10, 714. [Google Scholar] [CrossRef]
- Sothe, C.; Dalponte, M.; Almeida, C.M.D.; Schimalski, M.B.; Lima, C.L.; Liesenberg, V.; Takahashi Miyoshi, G.; Tommaselli, A.M.G. Tree Species Classification in a Highly Diverse Subtropical Forest Integrating UAV-Based Photogrammetric Point Cloud and Hyperspectral Data. Remote Sens. 2019, 11, 1338. [Google Scholar] [CrossRef]
- Takahashi Miyoshi, G.; Imai, N.N.; Tommaselli, A.M.G.; Antunes de Moraes, M.V.; Honkavaara, E. Evaluation of hyperspectral multitemporal information to improve tree species identification in the highly diverse Atlantic forest. Remote Sens. 2020, 12, 244. [Google Scholar] [CrossRef]
- Clark, M.L.; Roberts, D.A.; Clark, D.B. Hyperspectral discrimination of tropical rain forest tree species at leaf to crown scales. Remote Sens. Environ. 2005, 96, 375–398. [Google Scholar] [CrossRef]
- Jones, T.G.; Coops, N.C.; Sharma, T. Assessing the utility of airborne hyperspectral and LiDAR data for species distribution mapping in the coastal Pacific Northwest, Canada. Remote Sens. Environ. 2010, 114, 2841–2852. [Google Scholar] [CrossRef]
- Dalponte, M.; Ørka, H.O.; Ene, L.T.; Gobakken, T.; Næsset, E. Tree crown delineation and tree species classification in boreal forests using hyperspectral and ALS data. Remote Sens. Environ. 2014, 140, 306–317. [Google Scholar] [CrossRef]
- Richter, R.; Reu, B.; Wirth, C.; Doktor, D.; Vohland, M. The use of airborne hyperspectral data for tree species classification in a species-rich Central European forest area. Int. J. Appl. Earth Obs. Geoinf. 2016, 52, 464–474. [Google Scholar] [CrossRef]
- Maschler, J.; Atzberger, C.; Immitzer, M. Individual tree crown segmentation and classification of 13 tree species using airborne hyperspectral data. Remote Sens. 2018, 10, 1218. [Google Scholar] [CrossRef]
- Modzelewska, A.; Fassnacht, F.E.; Stereńczak, K. Tree species identification within an extensive forest area with diverse management regimes using airborne hyperspectral data. Int. J. Appl. Earth Obs. Geoinf. 2020, 84, 101960. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, X. Object-Based tree species classification using airborne hyperspectral images and LiDAR data. Forests 2020, 11, 32. [Google Scholar] [CrossRef]
- Liang, X.; Hyyppä, J.; Matikainen, L. Deciduous-coniferous tree classification using difference between first and last pulse laser signatures. IAPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2007, 36, 253–257. [Google Scholar]
- Kaartinen, H.; Hyyppä, J.; Yu, X.; Vastaranta, M.; Hyyppä, H.; Kukko, A.; Holopainen, M.; Heipke, C.; Hirschmugi, M.; Morsdorf, F.; et al. An international comparison of individual tree detection and extraction using airborne laser scanning. Remote Sens. 2012, 4, 950–974. [Google Scholar] [CrossRef]
- Ghosh, A.; Fassnacht, F.E.; Joshi, P.K.; Koch, B. A framework for mapping tree species combining hyperspectral and LiDAR data: Role of selected classifiers and sensor across three spatial scales. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 49–63. [Google Scholar] [CrossRef]
- Roth, K.L.; Roberts, D.A.; Dennison, P.E.; Peterson, S.H.; Alonzo, M. The impact of spatial resolution on the classification of plant species and functional types within imaging spectrometer data. Remote Sens. Environ. 2015, 171, 45–57. [Google Scholar] [CrossRef]
- Dalponte, M.; Reyes, F.; Kandare, K.; Gianelle, D. Delineation of Individual Tree Crowns from ALS and Hyperspectral data: A comparison among four methods. Eur. J. Remote Sens. 2017, 48, 365–382. [Google Scholar] [CrossRef]
- Piiroinen, R.; Heiskanen, J.; Maeda, E.E.; Viinikka, A.; Pellikka, P. Classification of tree species in a diverse African agroforestry landscape using imaging spectroscopy and laser scanning. Remote Sens. 2017, 9, 875. [Google Scholar] [CrossRef]
- Kalacska, M.; Bohlman, S.; Sanchez-Azofeifa, G.A.; Castro-Esau, K.; Caelli, T. Hyperspectral discrimination of tropical dry forest lianas and trees: Comparative data reduction approaches at the leaf and canopy levels. Remote Sens. Environ. 2007, 109, 406–415. [Google Scholar] [CrossRef]
- Clark, M.L.; Roberts, D.A. Species level differences in hyperspectral metrics among tropical rainforest trees as determined by a tree-based classifier. Remote Sens. 2012, 4, 1820–1855. [Google Scholar] [CrossRef]
- Hovi, A.; Raitio, P.; Rautiainen, M. A spectral analysis of 25 boreal tree species. Silva Fenn. 2017, 51, 7753. [Google Scholar] [CrossRef]
- Ahti, T.; Hämet-Ahti, L.; Jalas, J. Vegetation zones and their sections in northwestern Europe. Ann. Bot. Fenn. 1968, 5, 169–211. [Google Scholar]
- Schläpfer, D.; Richter, R. Geo-atmospheric Processing of Airborne Imaging Spectrometry Data Part 1: Parametric Orthorectification. Int. J. Remote Sens. 2002, 23, 2609–2630. [Google Scholar] [CrossRef]
- Richter, R.; Schläpfer, D. Geo-atmospheric processing of airborne imaging spectrometry data. Part 2: Atmospheric/Topographic Correction. Int. J. Remote Sens. 2002, 23, 2631–2649. [Google Scholar] [CrossRef]
- Dalponte, M. itcSegment: Individual Tree Crowns Segmentation. R Package Version 0.8. 2018. Available online: https://CRAN.R-project.org/package=itcSegment (accessed on 5 August 2019).
- Hughes, J. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef]
- Rodarmel, C.; Shan, J. Principal Component Analysis for Hyperspectral Image Classification. Surv. Land Inf. Syst. 2002, 62, 115–122. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019. [Google Scholar]
- Bro, R.; Smilde, A.K. Principal component analysis. Tutorial review. Anal. Methods 2014, 6, 2812–2831. [Google Scholar] [CrossRef]
- Kuhn, M. Caret: Classification and Regression Training. R Package Versionv6.0-84 2019, (contributions from Jed Wing, Steve Weston, Andre Williams, Chris Keefer, Allan Engelhardt, Tony Cooper, Zachary Mayer, Brenton Kenkel, the R Core Team, Michael Benesty, Reynald Lescarbeau, Andrew Ziem, Luca Scrucca, Yuan Tang, Can Candan, and Tyler Hunt). Available online: http://CRAN.R-project.org/package=caret (accessed on 4 April 2020).
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Hurskainen, P.; Adhikari, H.; Siljander, M.; Pellikka, P.; Hemp, A. Auxiliary datasets improve accuracy of object-based land use/land cover classification in heterogeneous savanna landscapes. Remote Sens. Environ. 2019, 233, 111354. [Google Scholar] [CrossRef]
- Wang, K.; Wang, T.; Liu, X. A Review: Individual Tree Species Classification Using Integrated Airborne LiDAR and Optical Imagery with a Focus on the Urban Environment. Forests 2019, 10, 1. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăgut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Fox, E.W.; Hill, R.A.; Leibowitz, S.G.; Olsen, A.R.; Thornbrugh, D.J.; Weber, M.H. Assessing the accuracy and stability of variable selection methods for random forest modeling in ecology. Environ. Monit. Assess. 2017, 189, 316. [Google Scholar] [CrossRef]
- Kuhn, M. The Caret Package Documentation, 2019-03-27. Available online: http://topepo.github.io/caret/index.html (accessed on 27 April 2020).
- Dalponte, M.; Bruzzone, L.; Gianelle, D. Tree species classification in the Southern Alps based on the fusion of very high geometrical resolution multispectral/hyperspectral images and LiDAR data. Remote Sens. Environ. 2012, 123, 258–270. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Smits, P.C.; Dellepiane, S.G.; Schowengerdt, R.A. Quality assessment of image classification algorithms for land-cover mapping: A review and a proposal for a cost-based approach. Int. J. Remote Sens. 1999, 20, 1461–1486. [Google Scholar] [CrossRef]
- Agresti, A. An Introduction to Categorical Data Analysis; Wiley: New York, NY, USA, 1996. [Google Scholar]
- Momeni, R.; Aplin, P.; Boyd, D.S. Mapping Complex Urban Land Cover from Spaceborne Imagery: The Influence of Spatial Resolution, Spectral Band Set and Classification Approach. Remote Sens. 2016, 8, 88. [Google Scholar] [CrossRef]
- Fisher, A.; Rudin, C.; Dominici, F. All models are wrong, but many are useful: Learning a variable’s importance by studying an entire class of prediction models simultaneously. J. Mach. Learn. Res. 2019, 20, 1–81. Available online: http://www.jmlr.org/papers/v20/18-760.html (accessed on 3 March 2020).
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Strobl, C.; Boulesteix, A.L.; Zeileis, A.; Hothorn, T. Bias in random forest variable importance measures: Illustrations, sources and a solution. BMC Bioinform. 2007, 8, 25. [Google Scholar] [CrossRef]
- Strobl, C.; Boulesteix, A.-L.; Kneib, T.; Augustin, T.; Zeileis, A. Conditional variable importance for random forests. BMC Bioinform. 2008, 9, 307. [Google Scholar] [CrossRef]
- Molnar, C.; Casalicchio, G.; Bischl, B. iml: An R package for interpretable machine learning. J. Open Source Softw. 2018, 3, 786. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning. A Guide for Making Black Box Models Explainable 2019. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 5 March 2020).
- Waser, L.T.; Küchler, M.; Jütte, K.; Stampfer, T. Evaluating the Potential of WorldView-2 Data to Classify Tree Species and Different Levels of Ash Mortality. Remote Sens. 2014, 6, 4515–4545. [Google Scholar] [CrossRef]
- Roth, K.L.; Roberts, D.A.; Dennison, P.E.; Alonzo, M.; Peterson, S.H.; Beland, M. Differentiating plant species within and across diverse ecosystems with imaging spectroscopy. Remote Sens. Environ. 2015, 167, 135–151. [Google Scholar] [CrossRef]
- Buitrago, M.F.; Groen, T.A.; Hecker, C.A.; Skidmore, A.K. Spectroscopic determination of leaf traits using infrared spectra. Int. J. Appl. Earth Obs. Geoinf. 2018, 69, 237–250. [Google Scholar] [CrossRef]
- Ballanti, L.; Blesius, L.; Hines, E.; Kruse, B. Tree species classification using hyperspectral imagery: A comparison of two classifiers. Remote Sens. 2016, 8, 445. [Google Scholar] [CrossRef]
- Raczko, E.; Zagajewski, B. Comparison of support vector machine, random forest and neural network classifiers for tree species classification on airborne hyperspectral APEX images. Eur. J. Remote Sens. 2017, 50, 144–154. [Google Scholar] [CrossRef]
- Björklund, M. Be careful with your principal components. Evolution 2019, 73, 2151–2158. [Google Scholar] [CrossRef] [PubMed]
- Ollinger, S.V. Sources of variability in canopy reflectance and the convergent properties of plants. New Phytol. 2011, 189, 375–394. [Google Scholar] [CrossRef]
- Blackburn, G.A. Quantifying Chlorophylls and Caroteniods at Leaf and Canopy Scales: An Evaluation of Some Hyperspectral Approaches. Remote Sens. Environ. 1998, 66, 273–285. [Google Scholar] [CrossRef]
- Vogelmann, J.E.; Rock, B.N.; Moss, D.M. Red edge spectral measurements from sugar maple leaves. Int. J. Remote Sens. 1993, 14, 1563–1575. [Google Scholar] [CrossRef]
- Le Maire, G.; François, C.; Dufrêne, E. Towards universal deciduous broad leaf chlorophyll indices using PROSPECT simulated database and hyperspectral reflectance measurements. Remote Sens. Environ. 2004, 89, 1–28. [Google Scholar] [CrossRef]
- Minocha, R.; Martinez, G.; Lyons, B.; Long, S. Development of a standardized methodology for quantifying total chlorophyll and carotenoids from foliage of hardwood and conifer tree species. Can. J. For. Res. 2009, 39, 849–861. [Google Scholar] [CrossRef]
- Croft, H.; Chen, J.M.; Zhang, Y. The applicability of empirical vegetation indices for determining leaf chlorophyll content over different leaf and canopy structures. Ecol. Complex. 2014, 17, 119–130. [Google Scholar] [CrossRef]
- Daughtry, G.S.T. Discriminating crop residues from soil by shortwave infrared reflectance. Agronomy 2001, 93, 125–131. [Google Scholar] [CrossRef]
- Trier, Ø.D.; Salberg, A.B.; Kermit, M.; Rudjord, Ø.; Gobakken, T.; Næsset, E.; Aarsten, D. Tree species classification in Norway from airborne hyperspectral and airborne laser scanning data. Eur. J. Remote Sens. 2018, 51, 336–351. [Google Scholar] [CrossRef]
- Carter, G.A. Ratios of leaf reflectances in narrow wavebands as indicators of plant stress. Int. J. Remote Sens. 1994, 15, 697–703. [Google Scholar] [CrossRef]
- Sims, D.A.; Gamon, J.A. Relationships between leaf pigment content and spectral reflectance across a wide range of species, leaf structures and developmental stages. Remote Sens. Environ. 2002, 81, 337–354. [Google Scholar] [CrossRef]
- Zarco-Tejada, P.J.; Berni, J.A.J.; Suárez, L.; Sepulcre-Cantó, G.; Morales, F.; Miller, J.R. Imaging chlorophyll fluorescence with an airborne narrow-band multispectral camera for vegetation stress detection. Remote Sens. Environ. 2009, 113, 1262–1275. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015. Lecture Notes in Computer Science; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Springer: Cham, Switzerland, 2015. [Google Scholar] [CrossRef]
- Pu, R.; Gong, P.; Biging, G.S.; Larrieu, M.R. Extraction of red edge optical parameters from Hyperion data for estimation of forest leaf area index. IEEE Trans. Geosci. Remote Sens. 2003, 41, 916–921. [Google Scholar] [CrossRef]
- Buitrago, M.F.; Skidmore, A.K.; Groen, T.A.; Hecker, C.A. Connecting infrared spectra with plant traits to identify species. ISPRS J. Photogramm. Remote Sens. 2018, 139, 183–200. [Google Scholar] [CrossRef]
- Singh, J.; Suhag, M.; Dhaka, A. Augmented digestion of lignocellulose by steam explosion, acid and alkaline pretreatment methods: A review. Carbohydr. Polym. 2015, 117, 624–631. [Google Scholar] [CrossRef]
- Couture, J.J.; Singh, A.; Rubert-Nason, K.F.; Serbin, S.P.; Lindroth, R.L.; Townsend, P.A. Spectroscopic determination of ecologically relevant plant secondary metabolites. Methods Ecol. Evol. 2016, 7, 1402–1412. [Google Scholar] [CrossRef]
- Rubert-Nason, K.F.; Holeski, L.M.; Couture, J.J.; Gusse, A.; Undersander, D.J.; Lindroth, R.L. Rapid phytochemical analysis of birch (Betula) and poplar (Populus) foliage by near-infrared reflectance spectroscopy. Anal. Bioanal. Chem. 2012, 405, 1333–1344. [Google Scholar] [CrossRef]
- Kokaly, F.R.; Skidmore, A.K. Plant phenolics and absorption features in vegetation reflectance spectra near 1.66 μm. Int. J. Appl. Earth Obs. Geoinf. 2015, 43, 55–83. [Google Scholar] [CrossRef]
- Ekö, P.M.; Johansson, U.; Pettersson, N.; Bergqvist, J.; Elfving, B.; Frisk, J. Current growth differences of Norway spruce (Picea abies), Scots pine (Pinus sylvestris) and birch (Betula pendula and Betula pubescens) in different regions in Sweden. Scand. J. For. Res. 2008, 23, 307–318. [Google Scholar] [CrossRef]
- Lehtomäki, J.; Tomppo, E.; Kuokkanen, P.; Hanski, I.; Moilanen, A. Applying spatial conservation prioritization software and high-resolution GIS data to a national-scale study in forest conservation. For. Ecol. Manag. 2009, 258, 2439–2449. [Google Scholar] [CrossRef]
- Grigorieva, O.; Brovkina, O.; Saidov, A. An original method for tree species classification using multitemporal multispectral and hyperspectral satellite data. Silva Fenn. 2020, 54, 10143. [Google Scholar] [CrossRef]
- Persson, M.; Lindberg, E.; Reese, H. Tree species classification with multi-temporal Sentinel-2 data. Remote Sens. 2018, 10, 1794. [Google Scholar] [CrossRef]
- Guanter, L.; Kaufmann, H.; Foerster, S.; Brosinsky, A.; Wulf, H.; Bochow, M.; Boesche, N.; Brell, M.; Buddenbaum, H.; Chabrillat, S.; et al. EnMAP Science Plan; EnMAP Technical Report 2016; GFZ Data Services: Potsdam, Germany, 2016. [Google Scholar] [CrossRef]
- Lee, C.M.; Cable, M.L.; Hook, S.J.; Green, R.O.; Ustin, S.L.; Mandl, D.J.; Middleton, E.M. An Introduction to the Nasa Hyperspectral Infrared Imager (Hyspiri) Mission and Preparatory Activities. Remote Sens. Environ. 2015, 167, 6–19. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time of Data Capture | 2018.07.16 08:27–11:14 |
|---|---|
| VNIR camera VNIR spectral range | HySpex 1800–SN00827 406–995 nm, 186 bands, bandwidth 3.26 nm |
| SWIR camera SWIR spectral range | HySpex 384me–SN3126 956–2525 nm, 288 bands, bandwidth 5.45 nm |
| LiDAR scanner Pulse density | Leica ALS70-HP–SN7204 10.2 p/m2 |
| Maximum flight altitude | 1500 m above ground level |
| Total imaged area | 82.94 km2 |
| Maximum flight speed | 240.76 km/h |
| Species Name | Species Count | Species Percentage | Single Tree |
|---|---|---|---|
| Scots pine (Pinus sylvestris L.) | 2570 | 38.9 | 688 |
| Norway spruce (Picea abies (L.) Karst) | 2045 | 31 | 495 |
| Birch (Betula sp.) * | 1267 | 19.2 | 474 |
| Aspen (Populus tremula L.) | 717 | 10.9 | 599 |
| All species | 6599 | 100 | 2256 |
| Species Name | Tree Count | Training Data (N) | Test Data (N) |
|---|---|---|---|
| Scots pine (Pinus sylvestris L.) | 1052 | 406 | 181 |
| Norway spruce (Picea abies (L.) Karst) | 750 | 406 | 181 |
| Birch (incl. downy birch Betula pubescens silver birch Betula pendula) | 587 | 406 | 181 |
| Aspen (Populus tremula L.) | 611 | 406 | 181 |
| All species | 3025 | 1624 | 724 |
| Feature Set | F1-Score | Kappa | Overall Accuracy | |||
|---|---|---|---|---|---|---|
| Aspen | Birch | Pine | Spruce | |||
| Reflectance (SVM) | 91% | 82% | 84% | 78% | 0.78 | 84% |
| Reflectance (RF) | 72% | 65% | 74% | 67% | 0.59 | 70% |
| Reflectance + VI (SVM) | 92% | 80% | 82% | 75% | 0.77 | 83% |
| Reflectance + VI (RF) | 82% | 72% | 82% | 76% | 0.71 | 78% |
| VI (SVM) | 89% | 80% | 83% | 77% | 0.76 | 82% |
| VI (RF) | 82% | 73% | 81% | 76% | 0.70 | 78% |
| PCA (SVM) | 91% | 81% | 82% | 74% | 0.76 | 82% |
| PCA (RF) | 88% | 78% | 82% | 75% | 0.75 | 81% |
| PCA + VI (SVM) | 90% | 79% | 83% | 76% | 0.76 | 82% |
| PCA + VI (RF) | 88% | 78% | 81% | 75% | 0.74 | 81% |
| Feature Set | Features | F1-Score | Kappa | Overall Accuracy | |||
|---|---|---|---|---|---|---|---|
| Aspen | Birch | Pine | Spruce | ||||
| Reflectance (SVM) | 370 | 90% | 80% | 87% | 75% | 0.77 | 83% |
| Reflectance (RF) | 144 | 77% | 69% | 76% | 62% | 0.61 | 71% |
| VI (SVM) | 44 | 90% | 80% | 86% | 76% | 0.77 | 83% |
| VI (RF) | 43 | 81% | 74% | 82% | 70% | 0.69 | 77% |
| Reflectance + VI (SVM) | 290 | 91% | 81% | 86% | 75% | 0.78 | 84% |
| Reflectance + VI (RF) | 37 | 82% | 75% | 81% | 70% | 0.69 | 77% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Viinikka, A.; Hurskainen, P.; Keski-Saari, S.; Kivinen, S.; Tanhuanpää, T.; Mäyrä, J.; Poikolainen, L.; Vihervaara, P.; Kumpula, T. Detecting European Aspen (Populus tremula L.) in Boreal Forests Using Airborne Hyperspectral and Airborne Laser Scanning Data. Remote Sens. 2020, 12, 2610. https://doi.org/10.3390/rs12162610
Viinikka A, Hurskainen P, Keski-Saari S, Kivinen S, Tanhuanpää T, Mäyrä J, Poikolainen L, Vihervaara P, Kumpula T. Detecting European Aspen (Populus tremula L.) in Boreal Forests Using Airborne Hyperspectral and Airborne Laser Scanning Data. Remote Sensing. 2020; 12(16):2610. https://doi.org/10.3390/rs12162610
Chicago/Turabian StyleViinikka, Arto, Pekka Hurskainen, Sarita Keski-Saari, Sonja Kivinen, Topi Tanhuanpää, Janne Mäyrä, Laura Poikolainen, Petteri Vihervaara, and Timo Kumpula. 2020. "Detecting European Aspen (Populus tremula L.) in Boreal Forests Using Airborne Hyperspectral and Airborne Laser Scanning Data" Remote Sensing 12, no. 16: 2610. https://doi.org/10.3390/rs12162610
APA StyleViinikka, A., Hurskainen, P., Keski-Saari, S., Kivinen, S., Tanhuanpää, T., Mäyrä, J., Poikolainen, L., Vihervaara, P., & Kumpula, T. (2020). Detecting European Aspen (Populus tremula L.) in Boreal Forests Using Airborne Hyperspectral and Airborne Laser Scanning Data. Remote Sensing, 12(16), 2610. https://doi.org/10.3390/rs12162610