Abstract
Municipal solid waste (MSW) refers to solid and semi-solid waste generated during human production and daily activities. The process of incinerating such waste, known as municipal solid waste incineration (MSWI), serves as a critical method for reducing waste volume and recovering resources. Automatic online recognition of flame combustion status during MSWI is a key technical approach to ensuring system stability, addressing issues such as high pollution emissions, severe equipment wear, and low operational efficiency. However, when manually selecting optimized features and hyperparameters based on empirical experience, the MSWI flame combustion state recognition model suffers from high time consumption, strong dependency on expertise, and difficulty in adaptively obtaining optimal solutions. To address these challenges, this article proposes a method for constructing a flame combustion state recognition model optimized based on reinforcement learning (RL), long short-term memory (LSTM), and parallel differential evolution (PDE) algorithms, achieving collaborative optimization of deep features and model hyperparameters. First, the feature selection and hyperparameter optimization problem of the ViT-IDFC combustion state recognition model is transformed into an encoding design and optimization problem for the PDE algorithm. Then, the mutation and selection factors of the PDE algorithm are used as modeling inputs for LSTM, which predicts the optimal hyperparameters based on PDE outputs. Next, during the PDE-based optimization of the ViT-IDFC model, a policy gradient reinforcement learning method is applied to determine the parameters of the LSTM model. Finally, the optimized combustion state recognition model is obtained by identifying the feature selection parameters and hyperparameters of the ViT-IDFC model. Test results based on an industrial image dataset demonstrate that the proposed optimization algorithm improves the recognition performance of both left and right grate recognition models, with the left grate achieving a 0.51% increase in recognition accuracy and the right grate a 0.74% increase.
1. Introduction
Pollution control and prevention are crucial for the sustainable development of the global economy, the protection of the environment, and the safeguarding of public health, making them a global priority [1,2]. Municipal solid waste (MSW) is growing annually by 8% to 10% worldwide [3,4]. In developing countries such as China, many cities are at risk of being overwhelmed by MSW, leading to significant environmental challenges [5]. MSW incineration (MSWI) is a complex system that converts waste into energy (WTE) and plays a key role in addressing urban environmental issues [6,7,8] while supporting renewable energy recycling [9]. Although MSWI is a scientifically validated waste treatment method, emissions from these plants are a major source of pollution [10,11], often facing opposition due to the “Not in My Backyard” (NIMBY) effect [12,13]. The combustion stage of the MSWI process is the primary source of environmental indicators (EIs) such as NOx, CO, HCl, and SO2 [14]. Flame combustion state recognition technology enables early detection of abnormal combustion conditions, thereby guiding the control system to promptly adjust operational parameters such as grate speed and facilitating a rapid return to normal combustion. Under abnormal conditions, incomplete fuel combustion leads to increased carbon monoxide emissions, a significantly higher risk of dioxin formation due to suboptimal combustion environments, and reduced power generation efficiency [3]. Furthermore, deteriorating conditions may even cause unplanned shutdowns and equipment wear. Therefore, accurate identification of flame combustion states is crucial for pollution reduction and optimized control.
Due to differences in operating equipment, the uncertainty in the maintenance of MSWI plants, fluctuations in the composition of MSW, and strong interference from the environment within the incinerator, accurately identifying the flame combustion state is challenging [3]. Additionally, the reliance on experts for manual recognition of combustion status lacks stability, making it difficult to ensure consistent operational efficiency and pollution reduction in the MSWI process [15]. The process of expert manual identification is intelligently modeled by constructing a data-driven mapping function from image space to state space, thereby transforming human visual experience based on prior knowledge into a computable and optimizable mathematical model. Leveraging the powerful representational learning capability of deep neural networks, discriminative deep-level information is automatically extracted from raw data, and high-precision modeling is achieved by learning the underlying complex patterns and decision boundaries. By building a high-accuracy artificial intelligence-based combustion state recognition model, limitations of human experts—such as subjectivity, limited experience, and cognitive biases—are overcome in terms of generalization, robustness, and judgment consistency. This provides effective support for the intelligent operation of the MSWI process.
Extensive research has been conducted on the identification of MSWI flame combustion states. Zhou et al. proposed a PCA-K-means clustering approach to distinguish between abnormal and normal flames, using only two states for classification [16]. Huang, on the other hand, extracted key parameters—such as the grayscale mean, flame area ratio, and flame high-temperature rate—from combustion images through image processing technology. These parameters were then input into K-nearest neighbor (KNN) and convolutional neural network (CNN) models for partial burning state recognition [17]. However, this approach relies on only a few physical features. Zhou also extracted 12 physical features from flame images based on expert knowledge and used a backpropagation neural network (BPNN) for combustion state recognition [18]. Additionally, Qiao et al. constructed a combustion state recognition model based on flame image color moment features and applied the least squares support vector machine (LS-SVM) [19]. Guo et al. took a different approach by generating abnormal working condition images using deep convolutional adversarial networks (DCGANs) to construct a CNN for combustion state recognition. This method addresses the issue of limited abnormal combustion images [20]. However, it only classifies combustion states based on the position of the combustion line, which provides limited local information. In contrast, Pan et al. created a flame combustion state recognition database using global image features and employed an improved visual transformer-based deep forest classification (ViT-IDFC) algorithm for state recognition [21]. The key limitation of the research on MSWI flame state recognition models mentioned above is that determining hyperparameters often requires expert experience and repeated experimentation, which is time-consuming, resource-intensive, and computationally expensive. Furthermore, these methods do not guarantee that the model will achieve optimal recognition performance.
To address these issues, this article conducts research on flame combustion state recognition through the collaborative optimization of deep features and model hyperparameters. Evolutionary algorithms (EAs) are commonly used to solve the aforementioned optimization problems [22]. Among all possible combinations, EAs can achieve the search for a globally optimal or near-optimal solution, thereby enabling the model to reach its best performance. The optimization process simulates the mechanisms of “natural selection” and “genetic inheritance” observed in biological systems. Each “population” consists of multiple potential solutions, and the algorithm iteratively performs operations such as selection, crossover, and mutation. Based on the evaluation results of each solution, superior individuals are retained while inferior ones are eliminated, gradually evolving solutions with progressively improved performance. Among these, the Differential Evolution (DE) algorithm is a heuristic optimization technique primarily used to solve continuous problems in real space. Due to its automatic adaptation and ease of implementation, DE has been widely adopted. For example, Dilbag et al. optimized the hyperparameters of a remote sensing image visibility restoration model using dynamic DE [23], Singh et al. adjusted the initial parameters of a CNN using multi-objective DE [24], and Chen et al. introduced Gaussian–Cauchy mutation and parameter adaptation strategies in DE to solve the economic scheduling problem of large-scale cogeneration systems [25]. These studies achieved improved results by optimizing model parameters using the DE algorithm. However, DE faces challenges such as stagnation and premature convergence during the optimization process, which are closely linked to the control parameters and the crossover rate of the algorithm. Clearly, for different optimization problems, the most suitable parameter settings must strike a balance between maintaining population diversity and enhancing convergence speed. Typically, the control parameters of DE are set based on optimization experience obtained through repeated experiments.
Reinforcement learning (RL) achieves task goals through interactive learning between agents and the environment [26]. Unlike supervised and unsupervised learning, RL focuses on decision-making based on environmental feedback. In the RL framework, agents learn to maximize long-term cumulative rewards through interaction with the environment. Its advantages include the ability to make sequential decisions, adapt to environmental changes, balance exploration and exploitation, not requiring large amounts of labeled data, and having high generalizability [27]. Currently, RL is gradually becoming an important tool for solving model hyperparameter optimization. For example, Pan et al. designed a deep neural network, PFSPNet [28], to achieve an end-to-end output model that is not limited by problem size, aimed at solving the schedule ng problem in an assembly line workshop. They applied a deep RL execution evaluation strategy to optimize the network parameters of the model. The results showed that this approach outperformed existing heuristic algorithms. Tian et al. addressed the exploration and exploitation challenges faced by EAs in operator selection during the search process [29]. They treated decision variables as states and candidate operators as actions, using deep neural networks to learn and estimate the Q-value strategy for each action in a given state. Based on reinforcement learning, their proposed method was used for operator selection. Experimental results demonstrated that the method could successfully identify the optimal operator for each parent.
Furthermore, some scholars are focused on exploring how to combine RL with DE in the search process to achieve adaptive selection of optimal parameters. For example, Hu et al. proposed integrating RL with DE in photovoltaic models [30], evaluating fitness function values during iterations to determine action rewards for adjusting parameter values, and then using RL to adjust these parameters to identify the most suitable algorithm settings for the environmental model. Tan et al. introduced a hybrid mutation strategy DE algorithm based on deep Q-network (DQN) [31], called DEDQN, which implements adaptive selection of mutation strategies during the evolutionary process through RL. Sun et al. used Long Short-Term Memory (LSTM) as the parameter controller for DE and employed an RL algorithm to optimize the parameters of the LSTM [32]. These studies leverage the reward/punishment mechanism of RL, enabling agents to continuously learn the optimal parameter combinations through trial and error, thereby improving model performance. However, there is a lack of research on improving the operational efficiency of the DE algorithm and on performing deep feature and model hyperparameter collaborative optimization in the context of flame combustion state recognition.
In the MSWI process, variations in process parameters such as MSW heating value and air supply volume directly influence the flame combustion state, which manifests as differences in flame image data distribution. Building on prior knowledge from field experts, reference [21] proposed a global feature-oriented flame combustion state image dataset and introduced the ViT-IDFC recognition algorithm. However, the multilayer feature selection and hyperparameter determination of this model mainly depend on manual experience. When the distribution of the flame combustion state dataset changes, the effectiveness of manual parameter selection decreases significantly. Thus, there is a need to develop a method capable of adaptively selecting hyperparameters based on changes in dataset distribution. This approach ensures that when process parameter variations such as MSW heating value or air supply volume cause a decline in model recognition accuracy, this performance degradation signal promptly triggers the optimization framework, driving it to automatically adjust feature selection parameters and model hyperparameters to regain adaptation to new operating conditions. To improve the performance of the flame global characterization information combustion state recognition model for MSWI processes, it is crucial to address the following: (1) how to select appropriate feature selection parameters and recognition model hyperparameters for encoding, and (2) how to optimize the control parameters of the parallel DE (PDE) algorithm to accommodate changes in the image dataset distribution. parameters of the parallel differential evolution algorithm to adapt to changes in image dataset distribution.
In response to the above challenges, this article proposes a ViT-IDFC recognition model optimized by RL-LSTM-PDE. First, the hyperparameter selection process of the ViT-IDFC combustion state recognition model is encoded as a PDE optimization problem. Next, control parameters—such as the mutation factor and crossover factor of PDE—are modeled using LSTM, with the LSTM output providing the optimal hyperparameters for the ViT-IDFC combustion state recognition model. Finally, the network parameters of the LSTM model are derived through PDE during the empirical learning process, which optimizes both ViT features and IDFC model hyperparameters. The innovations of this article are as follows: (1) a novel optimization modeling strategy for deep features and model hyperparameters, which formalizes the selection process as an observable Markov Decision Process (MDP); (2) the use of a multi-layer optimization approach, combining PDE for model parameter optimization, LSTM for predicting the evolutionary parameters of PDE, and RL for optimizing PDE parameters based on model generalization performance, to solve the MDP problem; (3) the collaborative optimization of ViT-IDFC model features and hyperparameters in the MSWI process, which improves the model’s generalization performance.
2. Flame State Recognition Description for MSWI Process
The process flow of grate furnace type MSWI is shown in Figure 1.
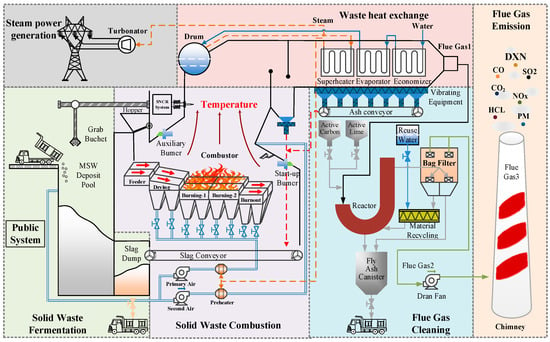
Figure 1.
MSWI process flow.
As shown in Figure 1, the MSWI process is a complex, serial system consisting of six stages: solid waste fermentation, solid waste combustion, waste heat exchange, steam power generation, flue gas treatment, and flue gas emissions. These stages are interrelated and together form the overall framework of the MSWI process. Among them, solid waste combustion is the core of the entire MSWI process, and the assessment of the on-site MSW combustion status is generally based on domain experts’ visual observation of flame images. Correspondingly, the combustion control strategy is adjusted based on the combustion status.
The schematic diagram of the four combustion states of MSW based on global information is shown in Figure 2.

Figure 2.
Typical flame combustion states during MSWI process.
In Figure 2, the blue line represents the burnout line of the flame, the red line represents the edge of the flame, and the red arrow indicates the direction and height of the flame. As shown in Figure 2, the combustion state of the MSWI is primarily classified into four categories: channeling burning, smoldering, partial burning, and normal burning. Significant differences are observed in the distribution of burnout lines, flame edges, direction, and height across the different combustion states, which result from the combined effects of the current combustion control strategies and the components of the MSW.
3. Optimization Modeling Strategy
The optimization modeling strategy proposed in this article is shown in Figure 3.
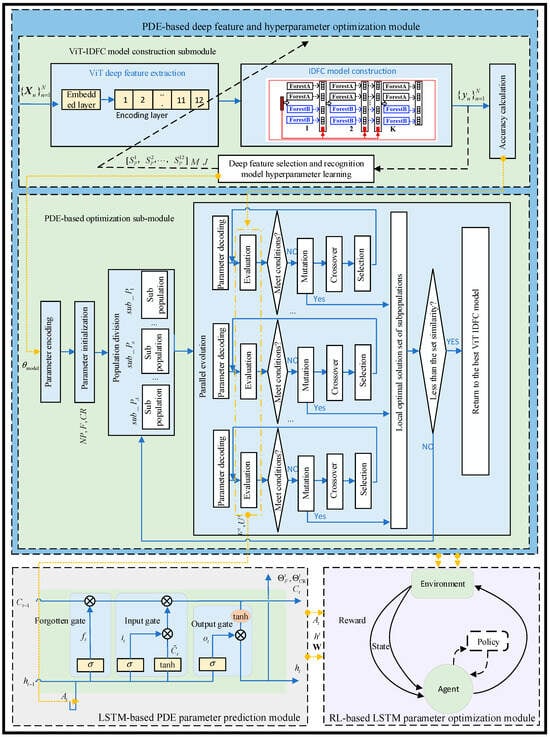
Figure 3.
Optimization modeling strategy.
In Figure 3, and represent the flame image dataset and its corresponding combustion state, respectively; represents the deep feature selection parameters of the ViT-IDFC combustion state recognition model submodule; and represent model hyperparameters such as the number of decision trees and the minimum number of partition samples for leaf nodes in IDFC; and represent the mutation factor and crossover factor of PDE; and represents the network parameter of LSTM.
The functions of each module are as follows:
- (1)
- PDE-based deep feature and hyperparameter optimization module: encodes the feature selection parameters and recognition model hyperparameters and of ViT-IDFC as decision variables for PDE optimization, and the fitness is characterized by the recognition;
- (2)
- LSTM-based PDE parameter prediction module: an LSTM model is constructed, with the mutation factor and crossover factor of PDE as inputs, and optimized and as the outputs;
- (3)
- RL-based LSTM parameter optimization module: treating LSTM as a Markov decision process and using RL optimization based on policy gradient algorithm to obtain the optimized control parameters of PDE.
Therefore, the optimization modeling process is as follows. Firstly, based on RL agents that can learn from experience, we obtain the network parameters of LSTM. Then, based on LSTM, we determine the and parameters of PDE. Next, based on PDE, we determine the parameters of the ViT-IDFC model, such as , and . Finally, we obtain the optimized recognition model.
4. Algorithm Implementation
4.1. PDE-Based Deep Feature and Hyperparameter Optimization Module
4.1.1. ViT-IDFC Model Construction Submodule
Firstly, a combustion state recognition model based on ViT-IDFC is constructed, and the collected flame images on site are classified to obtain a flame image dataset, which is denoted as (where represents the image, , and respectively represent its height, width, and number of channels, represents the label, and represents the sample size of the dataset). On this basis, pre-training of ViT is carried out based on the ImageNet dataset, and the ViT model is iteratively optimized until the network performance meets the predetermined requirements. The weights and bias parameters of the model are saved. Based on the above image dataset, transfer feature extraction is performed by inputting the flame image dataset into the ViT model. Further, the feature sequences extracted by each encoding layer based on Transformer is represented using the following equation:
where represents the ViT deep feature extraction model composed of an embedding layer and an encoding layer.
Next, transfer feature selection is performed based on expert experience, and the selected flame image depth features are denoted as . Furthermore, we construct the IDFC module and concatenate obtained by reducing and to obtain the following features:
where represents the image flattening operation.
Finally, the recognition result is obtained by inputting into the IDFC model as follows:
where represents the constructed IDFC model.
4.1.2. PDE-Based Optimization Sub-Module
DE is widely used to solve global optimal solutions in multidimensional spaces. To improve the problem of long optimization time in DE, the PDE algorithm uses multiple population parallelization and reduces the size of subpopulations to reduce evolution time, while further improving evolution efficiency by constraining the direction of subpopulation evolution in iterations [33]. It can be divided into four parts, i.e., optimization parameter encoding, parameter initialization, population partition, and parallel evolution. Details are shown as follows.
Step (1) Optimization parameter encoding. The deep feature in the ViT-IDFC recognition model represents the 12 layers of features extracted by the ViT model. Obviously, relying on expert experience to select features has a certain degree of subjective arbitrariness. To further select deep features that can represent global information, is used as the parameter for selecting deep features. We take the first layer feature as example; the criterion is defined as follows: when is present, it is selected; when occurs, it is deleted. In addition, the number of decision trees and the minimum number of leaf nodes of the base learner RF in the IDFC recognition model are encoded as model hyperparameters.
Step (2) Parameter initialization. Four PDE parameters, including population size , number of subpopulations , subpopulation mutation factor , and subpopulation crossover probability , need to be initialized, where and are used to partition subpopulations; and are used for the evolutionary process of each subpopulation. We use prediction accuracy as the fitness function to evaluate the fitness of the population, which is as follows:
where represents the fitness evaluation function.
Step (3) population partition. Randomly dividing the initial population into subpopulations can be expressed as:
The size of the subpopulation is obtained as follows:
Step (4) Parallel evolution. We execute DE in parallel pools for different subpopulations based on their partitioning results. The following sections describe the process from two aspects such as independent evolution of subpopulations and overall evolution of the population.
- a.
- Independent evolution of subpopulations
The evolutionary strategy of subpopulations is consistent with the standard DE strategy and can be divided into three parts such as “mutation”, “crossover”, and “selection”. The following section takes the generation of the subpopulation as an example.
Firstly, we adopt the DE/current to best/1 strategy for mutation operation. Specifically, two different individuals are differentiated and added to a third individual to obtain a mutated individual, as shown below:
where represents the variable factor, ; represents the mutant individual of the generation; represents the individual of the generation; and represent two random individuals of the generation; and is the optimal individual of the generation.
Here, the mutation operation of the PDE algorithm is referred to as a function , and the generation process of the generation mutation heterogeneous group is as follows:
Next, we perform crossover operations on each individual and their offspring’s mutated individuals. Here, the individual of the is represented as:
where is obtained through cross recombination of and . Taking allele as an example, its crossover process is executed as follows:
where is the cross factor, .
When the set crossover probability is less than the generated random floating-point number in , the crossover reassembly operation is performed.
Here, if we denote the crossover operation as a function , the process of generating can be expressed as follows:
Finally, the fitness function evaluates and selects and , with the criterion of selecting the individual with a high score as the individual of the generation, as follows:
Here, the selection operation is denoted as function . Correspondingly, the fitness value corresponding to the generation population can be expressed as:
Finally, the local optimal solution obtained after the evolution of each subpopulation can be expressed as:
- b.
- Overall evolution of the population
First, after completing a parallel evolution, the local optimal solutions of each subpopulation are summarized to obtain a set of local optimal solutions , as follows:
Then, based on the local optimal solution set , each subpopulation is updated by adding the optimal individual of each subpopulation to obtain a new population .
Finally, based on whether the number of previous iterations has reached the pre-set threshold , perform the corresponding operations:
If not achieved, re-divide the population and perform the evolutionary process, i.e., return to step (3);
If reached, the model stops iterating. Based on the local optimal solution set , the optimal solution with the highest fitness value is selected as the optimal solution of the model, as shown below:
where .
The algorithm flowchart is shown in Figure 4.
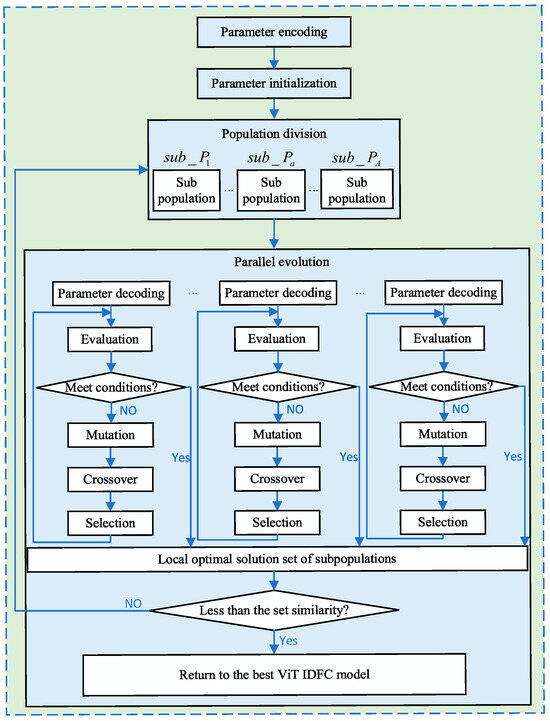
Figure 4.
PDE algorithm flowchart.
4.2. LSTM-Based PDE Parameter Prediction Module
In the evolution process of PDE, the information of its generation population is determined from the 1st generation to the generation. Due to the randomness of and , the evolutionary process of PDE can also be viewed as a random time series. Therefore, to adapt to its temporal dependence, an LSTM network is used here to obtain the and through online prediction.
Specifically, the fitness value (denoted as ) of PDE and its statistical data are combined to form as the input for LSTM. Among them, is composed of the normalized histogram and the moving average of the histogram vectors from the past generation, denoted as . The calculation process is shown below in detail.
Firstly, we normalize to obtain as follows:
Then, we calculate the histogram of as follows:
where is the number of bars in the histogram.
Furthermore, the moving average value of the histogram vector of the previous generation is calculated as follows:
Finally, the input of the LSTM network is obtained to predict .
The LSTM network introduces gate structures including forget gates, input gates, and output gates, as well as a memory unit to selectively receive information input into the neural network. The gate structure is responsible for connecting other parts of the neural network to the memory unit to complete weight setting.
Specifically, the forget gate receives information from the previous moment to the current moment, and calculates the degree of information retention based on the output from the previous moment and the input from the current moment as follows:
where is the sigmoid activation function.
The input gate first calculates its activation value based on and , as follows:
Next, we calculate the candidate values that may be added to the cell state as follows,
Then, based on the results of the first two steps, we calculate the updated unit status as follows,
where represents Hadamard product.
The output gate calculates the degree of information output based on and as follows:
The short-term memory value at the current time is obtained as follows:
Finally, the current prediction result output by the network is as follows:
where is the output hidden layer weight.
Therefore, LSTM can be formalized as follows:
where , represents long-term memory value, and represents short-term memory value.
The algorithm flowchart is shown in Figure 5.
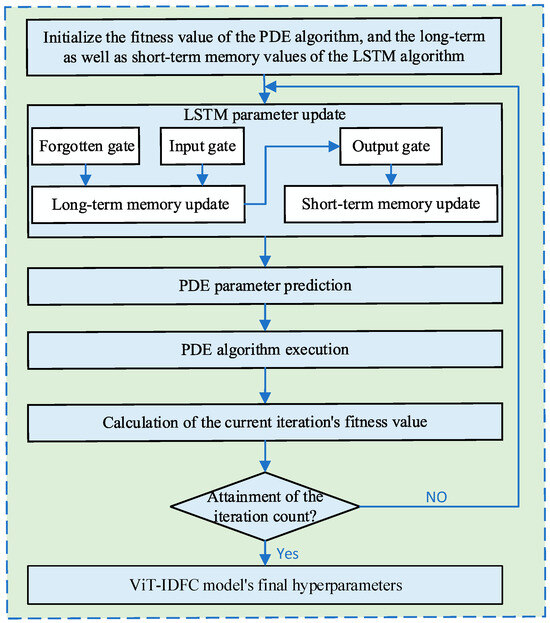
Figure 5.
LSTM algorithm flowchart.
4.3. RL-Based LSTM Parameter Optimization Module
To optimize the evolutionary parameters of PDE, the LSTM used for PDE parameter prediction is first modeled as a Markov decision process (MDP). The definitions of environment, state, action, strategy, reward, and transfer are as follows.
- (1)
- Environment: Optimize the ViT-IDFC combustion state recognition model;
- (2)
- Status: Use fitness values , statistics , and short-term memory values as the status ;
- (3)
- Action: Define PDE parameters as actions, i.e., ;
- (4)
- Strategy: Determined by LSTM parameters, as follows:
- (5)
- Reward: Refers to the relative improvement of the best fitness value, as follows:
- (6)
- Transition: Represented as a probability distribution . Here, the RL based variant algorithm Policy Gradient (PG) is used to handle the situation where the transition probability is unknown. The principle of this algorithm is to update policy parameters through random gradient ascent to maximize the expected value of rewards. In this way, algorithms can optimize the behavior of agents to adapt to unknown transition probability environments, as follows:
For the proposed MDP, the joint probability of trajectory is as follows,
Furthermore, the cumulative reward gradient can be obtained as follows:
where is the cumulative reward of .
The expected value of the above equation can be obtained through trajectory samples, as follows:
where represents the action value of the agent at time of the trajectory, and represents the state of the agent at time of the trajectory.
Therefore, according to Equation (29), it can be calculated to evaluate the actions taken by the agent in the current state .
The algorithm flowchart is shown in Figure 6.
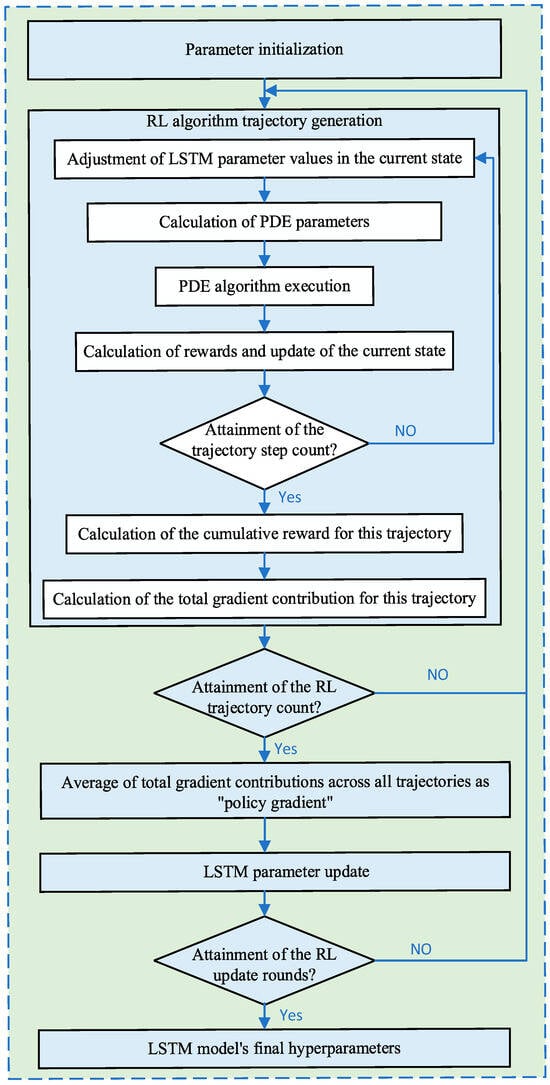
Figure 6.
RL algorithm flowchart.
4.4. Pseudocode
Table 1 shows the pseudocode of the proposed algorithm.

Table 1.
Pseudocode for flame combustion state recognition model based on deep feature and hyperparameter collaborative optimization.
The proposed algorithm flowchart is shown in Figure 7.
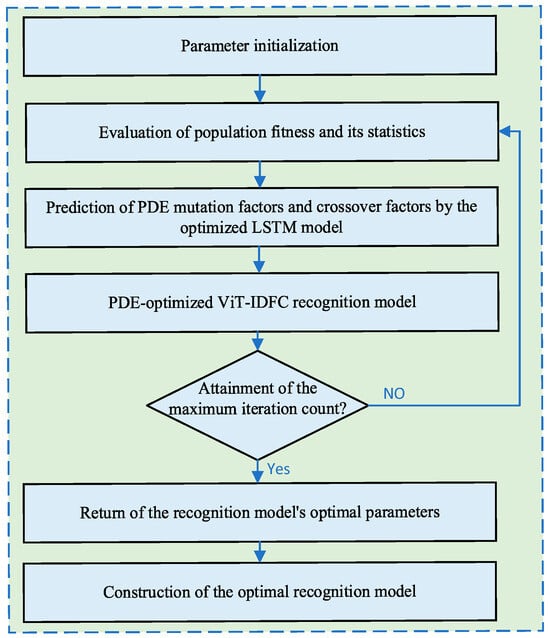
Figure 7.
Algorithm flowchart.
5. Experimental Study
5.1. Hardware Configuration and Evaluation Indicators
The recognition model described in this article is built on Python 3.9 and Pytorch 1.12.0 GPU framework. The training and testing hardware environments are shown in Table 2.
Table 2.
Hardware configuration.
To evaluate the performance of the model, we used evaluation metrics such as confusion matrix, accuracy, precision, recall, F1-score and ROC-AUC. Table 3 shows the confusion matrix of the classification results, providing specific data for performance evaluation. Among them, TP represents the number of samples correctly predicted as positive by the model; FP denotes the number of samples incorrectly predicted as positive; TN indicates the number of samples correctly predicted as negative; and FN refers to the number of samples incorrectly predicted as negative.
Table 3.
Classification result confusion matrix.
Accuracy measures the proportion of correct predictions among all predictions made by the model, reflecting its overall performance; Precision measures the proportion of truly positive samples among those predicted as positive, indicating the accuracy of positive predictions; Recall measures the proportion of successfully predicted positive samples among all actual positive samples, reflecting the model’s ability to identify all relevant instances; F1-score reflects the model’s comprehensive performance in identifying positive-class samples, balancing both the accuracy of positive predictions and the coverage capability for positive instances; ROC-AUC indicates the model’s ability to distinguish between positive and negative samples across different classification thresholds. The value ranges of the above five metrics are all [0, 1], with higher values indicating better model performance. The definitions of Accuracy, Precision, Recall, F1-score and ROC-AUC are as follows.
5.2. Data Description
The flame image data used in this study was sourced from a MSWI power plant in Beijing. Due to the limited field of view of industrial cameras, one camera was installed at each end of the grate to capture flame videos.
We collected left and right single-channel flame videos from an MSWI power plant at a frame rate of 25 frames per second. Guided by expert experience, representative combustion state segments were then selected from the collected videos. The selected segment duration was 54 h and 49 min for the left grate and 44 h and 45 min for the right grate. These segments were sampled at a rate of one frame per minute to generate flame images. The specific distribution of the various typical combustion states is shown in Table 4, yielding 3289 images for the left grate and 2685 images for the right grate. These images cover flame states under multiple working conditions, including different waste input volumes, different grate speeds, and different air velocities, to ensure sample diversity and dataset representativeness. After randomly shuffling the dataset, it was split into training and testing sets in a 7:3 ratio.
Table 4.
Flame image dataset.
Remark 1.
The composition of waste shows significant variability due to residents’ living habits and seasonal consumption patterns. During combustion, water evaporation results in relatively low flame temperatures, which typically appear as low-brightness features in images. In contrast, dry waste produces higher image brightness and more dynamic flame contours. This variability in the dataset directly impacts the feature extraction logic of the model, affecting recognition stability across different scenarios. To mitigate the impact of such variability on the model’s generalization capability, future research will expand the dataset coverage to ensure a comprehensive sample distribution that accounts for fluctuations in seasonal waste composition and environmental conditions.
5.3. Experimental Result
5.3.1. Deep Features and Hyperparameter Selection Results
Table 5 shows the deep features and hyperparameter optimization results of ViT-IDFC based on PDE.
Table 5.
Hyperparameter optimization results.
According to Table 5, after PDE optimization, both the feature selection parameters and model hyperparameters of the left and right grate recognition models have undergone changes. Among them, the feature selection parameters for both grates have selected 7 layers of deep features as input to the recognition model. However, the specific deep feature layers selected differ between the left and right grates, which is related to the distribution differences in the flame images from the two grates.
5.3.2. PDE Parameter Optimization Results
The optimization results of PDE parameters based on LSTM network are shown in Figure 8.
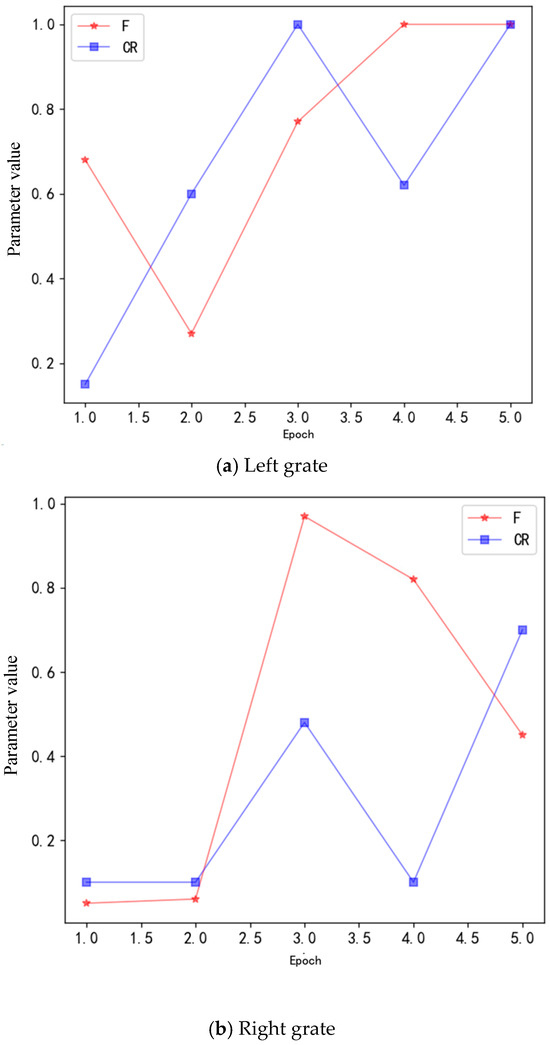
Figure 8.
PDE parameter optimization results.
As shown in Figure 8, during the optimization process of PDE mutation factor and crossover factor based on LSTM network, F and CR gradually approach 1 in the optimization process of the left grate recognition model, while F and CR gradually approach 0.5 in the optimization process of the right grate recognition model. In the process of learning LSTM parameters based on RL, the reward value of RL is consistent with the accuracy value of the model and shows an increasing trend. This indicates that the agent gradually masters the experience of making the recognition model achieve the best performance during the learning process, and ultimately achieves the best recognition performance through parameter optimization.
5.3.3. Optimize Model Recognition Results
Table 6 shows the recognition results of the optimized model before and after deep feature and hyperparameter optimization.
Table 6.
Results of hyperparameter optimization.
As shown in Table 6, the RL-LSTM-PDE optimization algorithm has improved the recognition performance for both the left and right grate models through multi-level optimization based on the integration of RL, LSTM, and PDE. Specifically, the recognition accuracy increased by 0.51% for the left grate and 0.74% for the right grate.
The trend of RL reward value and recognition model accuracy value changing with epoch is shown in.
As shown in Figure 9, during the process of learning LSTM parameters based on RL, the reward value of RL is consistent with the accuracy value of the model and shows an increasing trend. This indicates that the agent gradually obtains the experience of achieving the optimal recognition effect of the model during the learning process, and ultimately achieves the best recognition effect through parameter optimization.
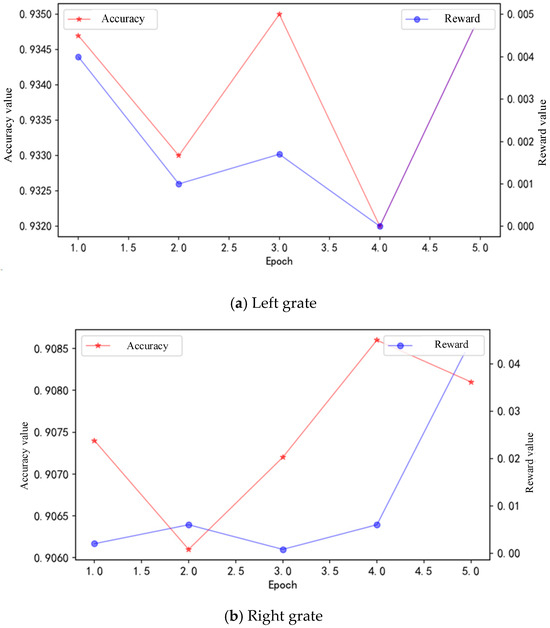
Figure 9.
Relation between values of RL reward and recognition model accuracy and learning epoch.
Figure 10 shows the confusion matrix of the optimized left/right grate recognition results.
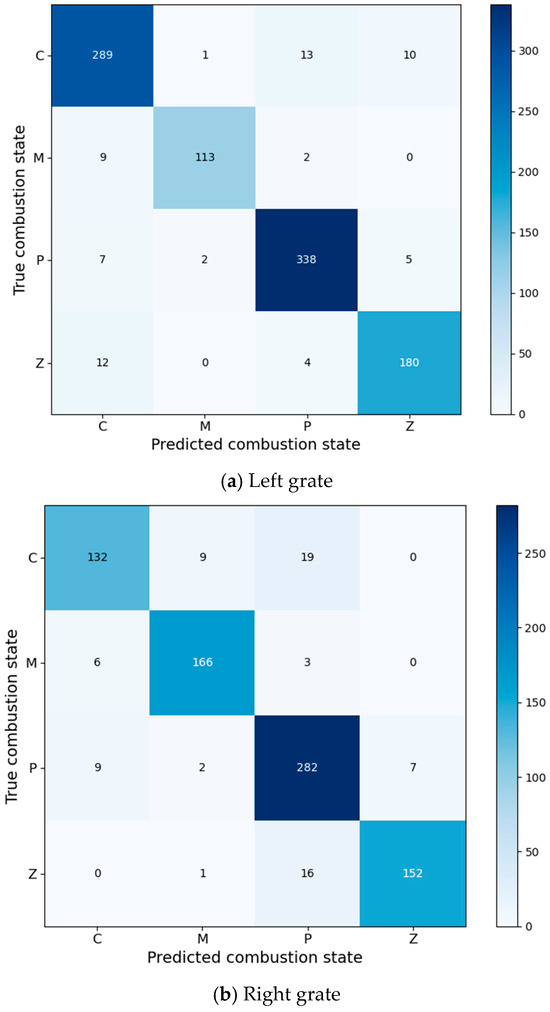
Figure 10.
Confusion matrix of model recognition results.
In the matrix shown in Figure 10, C, M, P, and Z represent the four flame combustion states: Channeling burning, Smoldering, Partial burning, and Normal burning, respectively. The rows of the matrix correspond to the predicted combustion states, while the columns represent the true combustion states by the model.
The numbers along the diagonal indicate the count of correctly predicted samples. For example, the value in the first row and first column represents the number of samples correctly predicted as Channeling burning. The off-diagonal elements represent misclassified samples. For instance, the value in the first row and second column indicates the number of samples where Channeling burning was incorrectly predicted as Smoldering. The misclassification count for each combustion state is calculated by summing the off-diagonal elements in each row of the matrix. The optimal combustion state is determined as the category with the highest diagonal value and the lowest misclassification count.
From Figure 10, the combustion categories of both the left and right grate are prone to misidentification. This is because the combustion state often occurs in the transition stage of other combustion states, and therefore the flame image features are coupled with other categories. The Partial burning state is the least prone to misidentification, as its flame image features are relatively simple and differ significantly from other states.
5.3.4. Computational Complexity Analysis
The computational complexity of a single forward pass of the ViT-IDFC model is ; the computational complexity of the PDE algorithm is ; the computational complexity of the LSTM model is , where is the size of the hidden layer; and the computational complexity of RL is .
During the training phase, the computational complexity of the LSTM model is significantly lower than that of RL and can be neglected. Therefore, the overall computational complexity of the proposed RL-LSTM-PDE method is denoted . During the inference phase, the time cost is completely decoupled from the optimization framework and is equivalent to the computational cost of a single ViT-IDFC model, denoted as .
Under the standard hardware configuration specified in Table 2, tests conducted on the left grate model demonstrated that completing the ViT-IDFC parameter optimization required approximately 4.2 h when the training epoch was set to 5. During this process, hardware resources were dedicated to core computational tasks including feature extraction, LSTM parameter inference, and PDE population optimization, with no redundant computations. This resource allocation aligns with the conventional load capacity of such hardware systems.
5.4. Method Comparison
To verify the superiority of the proposed method, it was compared with some other methods. The parameter settings are shown in Table 7, and the recognition results of the left/right grate flame images are shown in Table 8 and Table 9.
Table 7.
Parameter setting statistics of comparison methods.
Table 8.
Comparative experimental results of left grate flame image models.
Table 9.
Comparative experimental results of right grate flame image models.
According to Table 8 and Table 9, compared to other methods, the method proposed in this article has the best optimization effect on the recognition model. The multi-level collaborative optimization architecture adopted in the proposed method achieves a three-layer interaction among RL, LSTM, and PDE. RL globally guides the optimization direction through a reward mechanism; LSTM dynamically interprets the optimization status and finely adjusts the hyperparameters of PDE; and PDE collaboratively explores the solution space with multiple subpopulations. This deeply coupled mechanism significantly enhances global optimization capability and model expressiveness, leading to comprehensive performance that surpasses compared models. Furthermore, the proposed method employs a parallel differential evolution framework, which significantly enhances operational efficiency compared to the RL-LSTM-DE approach. However, due to the incorporation of RL-LSTM networks for parameter prediction and optimization, the computational complexity of the proposed method is higher than that of conventional DE and PDE algorithms. Despite this increased complexity, the method achieves a substantial improvement in recognition accuracy. These results demonstrate that the proposed approach strikes an effective balance between computational efficiency and model performance.
5.5. Ablation Experiment
Table 10 and Table 11 present the ablation experimental results of the RL-LSTM-PDE method proposed in this study, based on the left and right grate flame images, respectively.
Table 10.
Experimental results of left grate ablation.
Table 11.
Results of right grate ablation experiment.
According to Table 10 and Table 11, when optimizing the recognition model parameters based on PDE and LSTM-PDE algorithms, the performance improvement is very limited, and even the model performance decreases, indicating that its global search ability is still very limited. When optimizing the recognition model based on the proposed RL-LSTM-PDE algorithm, the model performance can reach its optimal level.
6. Conclusions
To address the challenges of time consumption, high dependency, and difficulty in adaptively achieving optimal results when manually selecting optimization features and hyperparameters based on experience for the MSWI flame combustion state recognition model, an optimization method for collaboratively optimizing deep features and model hyperparameters is proposed. The optimization framework of the proposed method is essentially a general-purpose adaptive model optimizer, whose design is independent of the inherent characteristics of any specific species or dataset. By replacing the target dataset and correspondingly adjusting the preprocessing parameters of the model’s input layer, the framework can be quickly adapted to a variety of application scenarios, such as plant species recognition and combustion state classification in coal-fired power plants, demonstrating its capability for cross-scene migration and adaptation.
The main contributions of this study are as follows: (1) proposing a deep feature and hyperparameter optimization strategy for the recognition model based on RL-LSTM-PDE, which reduces the time-consuming process and inconsistencies caused by reliance on manual experience for feature and hyperparameter selection; (2) transforming the deep feature selection and hyperparameter optimization problem of the combustion state recognition model into a coding design and optimization problem for the PDE algorithm, reinterpreting the determination of mutation and selection factors for the PDE algorithm as an LSTM model prediction task, and framing the optimization of LSTM parameters as an RL problem within the context of optimizing the ViT-IDFC combustion state recognition model; (3) implementing the optimization of deep features and model hyperparameters for the ViT-IDFC combustion state recognition model based on the proposed strategy, and validating its effectiveness using real process data.
In the field of industrial AI applications, the integration of interpretable AI methods has become a crucial component for building trustworthy systems. The ViT-IDFC model used in this article not only visually identifies the key regions of flame images with varying depth features but also demonstrates intrinsic recognition causality through a decision tree-based recognition algorithm that offers traceability and interpretability. These features make the inference process of complex models transparent and traceable, helping operators understand the decision logic behind AI. This transparency is critical in enhancing the reliability of human–machine collaboration, particularly in industrial environments.
Future research should focus on reducing the time cost associated with the operation of this strategy. Additionally, we will collect flame image data under various operating conditions from multiple MSWI facilities and validate the methodology through extendable testing.
Author Contributions
Conceptualization, J.T.; methodology, J.T.; software, X.Y. and J.R.; validation, J.R.; formal analysis, J.T.; investigation, X.Y.; resources, X.Y. and J.R.; data curation, X.Y.; writing—original draft preparation, X.Y.; writing—review and editing, J.T. and W.W.; visualization, X.Y.; supervision, J.T. and W.W.; project administration, J.T.; funding acquisition, W.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded in part by the General Scientific Research Projects of Liaoning Province Science and Technology Joint Plan Project under Grant 2024JH2/102600083, and in part by Liaoning Provincial Department of Education under Grant JYTMS20230489.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gómez-Sanabria, A.; Kiesewetter, G.; Klimont, Z.; Schoepp, W.; Haberl, H. Potential for future reductions of global GHG and air pollutants from circular waste management systems. Nat. Commun. 2022, 13, 106. [Google Scholar] [CrossRef]
- Ali, K.; Kausar, N.; Amir, M. Impact of pollution prevention strategies on environment sustainability: Role of environmental management accounting and environmental proactivity. Environ. Sci. Pollut. Res. 2023, 30, 88891–88904. [Google Scholar] [CrossRef]
- Tang, J.; Xia, H.; Yu, W.; Qiao, J.F. Research status and prospects of intelligent optimization control for municipal solid waste incineration process. Acta Autom. Sin. 2023, 49, 2019–2059. [Google Scholar]
- Song, Y.; Xian, X.; Zhang, C.; Zhu, F.; Yu, B.; Liu, J. Residual municipal solid waste to energy under carbon neutrality: Challenges and perspectives for China. Resour. Conserv. Recycl. 2023, 198, 107177. [Google Scholar] [CrossRef]
- Tang, L.; Guo, J.; Wan, R.; Jia, M.; Qu, J.; Li, L.; Bo, X. Air pollutant emissions and reduction potentials from municipal solid waste incineration in China. Environ. Pollut. 2023, 319, 121021. [Google Scholar] [CrossRef] [PubMed]
- Walser, T.; Limbach, L.K.; Brogioli, R.; Erismann, E.; Flamigni, L.; Hattendorf, B.; Juchli, M.; Krumeich, F.; Ludwig, C.; Prikopsky, K.; et al. Persistence of engineered nanoparticles in a municipal solid-waste incineration plant. Nat. Nanotechnol. 2012, 7, 520–524. [Google Scholar] [CrossRef] [PubMed]
- Istrate, I.R.; Galvez-Martos, J.L.; Vázquez, D.; Guillén-Gosálbez, G.; Dufour, J. Prospective analysis of the optimal capacity, economics and carbon footprint of energy recovery from municipal solid waste incineration. Resour. Conserv. Recycl. 2023, 193, 106943. [Google Scholar] [CrossRef]
- Fernando, Y.; Tseng, M.L.; Aziz, N.; Ikhsan, R.B.; Wahyuni-TD, I.S. Waste-to-energy supply chain management on circular economy capability: An empirical study. Sustain. Prod. Consum. 2022, 31, 26–38. [Google Scholar] [CrossRef]
- Kalyani, K.A.; Pandey, K.K. Waste to energy status in India: A short review. Renew. Sustain. Energy Rev. 2014, 31, 113–120. [Google Scholar] [CrossRef]
- Liu, J.; Hu, L.; Tang, L.; Ren, J. Utilisation of municipal solid waste incinerator (MSWI) fly ash with metakaolin for preparation of alkali-activated cementitious material. J. Hazard. Mater. 2021, 402, 123451. [Google Scholar] [CrossRef]
- Fan, C.; Wang, B.; Qi, Y.; Liu, Z. Characteristics and leaching behavior of MSWI fly ash in novel solidification/stabilization binders. Waste Manag. 2021, 131, 277–285. [Google Scholar] [CrossRef]
- Song, L.; Sun, Y.; Song, J.; Feng, Z.; Gao, J.; Yao, Q. From “not in my backyard” to “please in my backyard”: Transforming the local responses toward a waste-to-energy incineration project in China. Sustain. Prod. Consum. 2024, 45, 104–114. [Google Scholar] [CrossRef]
- Liang, X.; Kurniawan, T.A.; Goh, H.H.; Zhang, D.; Dai, W.; Liu, H.; Goh, K.C.; Othman, M.H.D. Conversion of landfilled waste-to-electricity (WTE) for energy efficiency improvement in Shenzhen (China): A strategy to contribute to resource recovery of unused methane for generating renewable energy on-site. J. Clean. Prod. 2022, 369, 133078. [Google Scholar] [CrossRef]
- Liang, D.; Wang, F.; Lv, G. The resource utilization and environmental assessment of MSWI fly ash with solidification and stabilization: A review. Waste Biomass Valorization 2024, 15, 37–56. [Google Scholar] [CrossRef]
- Cao, C.; Zhang, Q.; Li, M.H.; Wang, S.Y. Flame combustion state recognition in municipal solid waste incineration processes based on image multi-threshold segmentation and DQN-PL model. Energy 2025, 331, 136967. [Google Scholar] [CrossRef]
- Zhou, C.; Cao, Y.; Yang, S. Video Based Combustion State Identification for Municipal Solid Waste Incineration. IFAC-Pap. 2020, 53, 13448–13453. [Google Scholar] [CrossRef]
- Huang, S. Research on the Diagnosis Method of Large scale Household Waste Incineration Process Based on Machine Vision. Zhejiang University: Hangzhou, China, 2020. [Google Scholar]
- Zhou, Z.C. Research on Combustion State Diagnosis of Garbage Incinerator Based on Image Processing and Artificial Intelligence. Southeast University: Nanjing, China, 2015. [Google Scholar]
- Qiao, J.F.; Duan, H.S.; Tang, J.; Meng, X. MSWI combustion condition recognition based on flame image color features. Control Eng. 2022, 29, 1153–1161. [Google Scholar]
- Guo, H.T.; Tang, J.; Ding, H.X.; Qiao, J.F. Combustion states recognition method of MSWI process based on mixed data enhancement. Acta Autom. Sin. 2024, 50, 560–575. [Google Scholar]
- Pan, X.T.; Tang, J.; Xia, H.; Yu, W.; Qiao, J.F. Combustion state identification of MSWI processes using ViT-IDFC. Eng. Appl. Artif. Intell. 2023, 126, 106893. [Google Scholar] [CrossRef]
- Bian, C.; Zhou, Y.W.; Li, M.Q.; Qian, C. Stochastic population update can provably be helpful in multi-objective evolutionary algorithms. Artif. Intell. 2025, 341, 104308. [Google Scholar] [CrossRef]
- Singh, D.; Kaur, M.; Jabarulla, M.Y.; Kumar, V.; Lee, H. Evolving fusion-based visibility restoration model for hazy remote sensing images using dynamic differential evolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Singh, D.; Kumar, V.; Vaishali; Kaur, M. Classification of COVID-19 patients from chest CT images using multi-objective differential evolution–based convolutional neural networks. Eur. J. Clin. Microbiol. Infect. Dis. 2020, 39, 1379–1389. [Google Scholar] [CrossRef]
- Chen, X.; Shen, A. Self-adaptive differential evolution with Gaussian–Cauchy mutation for large-scale CHP economic dispatch problem. Neural Comput. Appl. 2022, 34, 11769–11787. [Google Scholar] [CrossRef]
- Liang, X.X.; Feng, Y.H.; Ma, Y.; Cheng, G.Q.; Huang, J.C.; Wang, Q.; Zhou, Y.Z. Deep multi-agent reinforcement learning: A survey. Acta Autom. Sin. 2020, 46, 2537–2557. [Google Scholar]
- Zhou, P.; Wang, X.; Chai, T. Multiobjective operation optimization of wastewater treatment process based on reinforcement self-learning and knowledge guidance. IEEE Trans. Cybern. 2022, 53, 6896–6909. [Google Scholar] [CrossRef]
- Pan, Z.X.; Wang, L.; Wang, J.J.; Lu, J.W. Deep reinforcement learning based optimization algorithm for permutation flow-shop scheduling. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 7, 983–994. [Google Scholar] [CrossRef]
- Tian, Y.; Li, X.P.; Ma, H.P.; Zhang, X.Y.; Tian, K.C.; Jin, Y.C. Deep reinforcement learning based adaptive operator selection for evolutionary multi-objective optimization. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 7, 1051–1064. [Google Scholar] [CrossRef]
- Hu, Z.; Gong, W.; Li, S. Reinforcement learning-based differential evolution for parameters extraction of photovoltaic models. Energy Rep. 2021, 7, 916–928. [Google Scholar] [CrossRef]
- Tan, Z.P.; Li, K.S. Differential evolution with mixed mutation strategy based on deep reinforcement learning. Appl. Soft Comput. 2021, 111, 107678. [Google Scholar] [CrossRef]
- Sun, J.; Liu, X.; Bäck, T.; Xu, Z. Learning Adaptive Differential Evolution Algorithm From Optimization Experiences by Policy Gradient. IEEE Trans. Evol. Comput. 2021, 25, 666–680. [Google Scholar] [CrossRef]
- Li, T.L.; Li, Y.F.; Wang, F.; Gong, C.; Zhang, J.R.; Ma, H. Improved parallel differential evolution algorithm with small population for multi-period optimal dispatch problem of microgrids. Energies 2025, 18, 3852. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).