
Peruvian Electrical Distribution Firms’ Efficiency Revisited: A Two-Stage Data Envelopment Analysis


Abstract
1. Introduction
2. First Stage Estimation: DEA Models, Data and Results
3. Two-Stage Data Envelopment Analysis
3.1. Brief and Critical Review of the Two-Stage DEA Literature
3.2. Review of the Two-Stage DEA Power Distribution Literature
4. Two-Stage Data Envelopment Analysis (DEA): Results
4.1. Two-Stage Drivers
4.2. Alternative Models and Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ariela, R.C. El Proceso de Privatizacines en el Perú Durante el Period 1991–2002; Serie de Gestión Pública; Instituto Latinoamericano de Planificación Económica y Social: Santiago, Chile, 2002. [Google Scholar]
- Zhang, Y.; Parker, D.; Kirkpatrick, C. Electricity sector reform in developing countries: An econometric assessment of the effects of privatization, competition and regulation. J. Regul. Econ. 2008, 33, 159–178. [Google Scholar] [CrossRef]
- Pérez-Reyes, R.; Tovar, B. Measuring efficiency and productivity change (PTF) in the Peruvian electricity distribution companies after reforms. Energy Policy 2009, 37, 2249–2261. [Google Scholar] [CrossRef]
- Coelli, T.; Prasada, D.S.; O’Donnell, C.; Battese, G. An Introduction to Efficiency and Productivity Analysis, 2nd ed.; Springer: New York, NY, USA, 2005. [Google Scholar]
- Simar, L.; Wilson, P.W. Estimation and inference in two stage semi-parametric models of production process. J. Econom. 2007, 136, 31–64. [Google Scholar] [CrossRef]
- Simar, L.; Wilson, P.W. Two-stage DEA: Caveat emptor. J. Product. Anal. 2011, 36, 205–218. [Google Scholar] [CrossRef]
- Da Silva, F.; Stasinakis, C.; Bardarova, V. Two-stage DEA-Truncated Regression: Application in banking efficiency and financial development. Expert Syst. Appl. 2018, 96, 284–301. [Google Scholar]
- Tovar, B.; Wall, A. Specialization, diversification, size and technical efficiency in ports: A empirical analysis using frontier techniques. Eur. J. Transp. Infrastruct. Res. 2017, 17, 279–303. [Google Scholar]
- Banker, R.D.; Natarajan, R. Evaluating contextual variables affecting productivity using data envelopment analysis. Oper. Res. 2008, 56, 48–58. [Google Scholar] [CrossRef]
- Ramalho, E.; Ramalho, J.S.; Henriques, P. Fractional regression models for second stage DEA efficiency analysis. J. Product. Anal. 2010, 34, 239–255. [Google Scholar] [CrossRef]
- Jamasb, T.; Pollitt, M. Benchmarking and regulation: International electricity experience. Util. Policy 2001, 9, 107–130. [Google Scholar] [CrossRef]
- Tovar, B.; Wall, A. Can ports increase traffic while reducing inputs? Technical efficiency of Spanish port authorities using a directional distance function approach. Transp. Res. Part A 2015, 71, 128–144. [Google Scholar]
- Ramos-Real, F.; Tovar, B. Revisiting electric utilities’ efficiency in the Southern African Power Pool, 1998–2009. J. Energy South Afr. 2020, 31, 1–13. [Google Scholar] [CrossRef]
- Thanassoulis, E. Comparative performance measurement in regulation: The case of English and Welsh Sewerage Services. J. Oper. Res. Soc. 2002, 53, 292–302. [Google Scholar] [CrossRef]
- Pombo, C.; Taborda, R. Performance and efficiency in Colombia’s power distribution system: Effects of the 1994 reforms. Energy Econ. 2006, 28, 339–369. [Google Scholar] [CrossRef]
- Ramos-Real, F.; Tovar, B.; Iootty, M.; de Almeida, E.F.; Pinto, H.Q. The evolution and main determinants of productivity in Brazilian electricity distribution 1998–2005: An empirical analysis. Energy Econ. 2009, 31, 298–305. [Google Scholar] [CrossRef]
- Tovar, B.; Ramos-Real, F.; de Almeida, E.F. Firm size and productivity. Evidence from the electricity distribution industry in Brazil. Energy Policy 2011, 39, 826–833. [Google Scholar]
- Hjalmarsson, L.; Veiderpass, A. Productivity in Swedish electricity retail distribution. Scand. J. Econ. 1992, 94, 193–205. [Google Scholar] [CrossRef]
- Neuberg, L. Two issues in the municipal ownership of electric power distribution systems. Bell J. Econ. 1977, 8, 303–323. [Google Scholar] [CrossRef]
- Hattori, T.; Jamasb, T.; Pollit, M.G. The Performance of UK and Japanese Electricity Distribution System 1985–1998: A Comparative Efficiency Analysis; DAE Working Paper WP 0212; Department of Applied Economics, University of Cambridge: Cambridge, UK, 2003. [Google Scholar]
- McDonald, J. Using least squares and tobit in second stage DEA efficiency analyses. Eur. J. Oper. Res. 2009, 197, 792–798. [Google Scholar] [CrossRef]
- Papke, L.E.; Wooldridge, J.M. Econometric methods for fractional response variables with an application to 401(k) plan participation rates. J. Appl. Econ. 1996, 11, 619–632. [Google Scholar] [CrossRef]
- Gutierrez, E.; Lozano, S. Efficiency assessment and output maximization possibilities of European small and medium sized airports. Res. Transp. Econ. 2016, 56, 3–14. [Google Scholar] [CrossRef]
- Raheli, H.; Rezaei, R.M.; Jadidi, M.R.; Mobtaker, H.G. A two-stage DEA model to evaluate sustainability and energy efficiency of tomato production. Inf. Process. Agric. 2017, 4, 342–350. [Google Scholar] [CrossRef]
- Martins, A. Efficiency determinants in Portuguese banking industry: An application through fractional regression models. Tour. Manag. Stud. 2018, 14, 63–71. [Google Scholar] [CrossRef]
- Neves, S.A.; Marquesa, A.C.; Moutinhoa, V. Two-stage DEA model to evaluate technical efficiency on deployment of battery electric vehicles in the EU countries. Transp. Res. Part D 2020, 86, 102489. [Google Scholar] [CrossRef]
- Leme, R.C.; Paiva, A.P.; Santos, P.E.S.; Balestrassi, P.P.; Galvão, L.D.L. Design of experiments applied to environmental variables analysis in electricity utilities efficiency: The Brazilian case. Energy Econ. 2014, 45, 111–119. [Google Scholar] [CrossRef]
- Da Silva, A.V.; Costa, M.A.; Lopes, A.L.M.; do Carmo, G.M. A close look at second stage data envelopment analysis using compound error models and the Tobit model. Socio-Econ. Plan. Sci. 2019, 65, 111–126. [Google Scholar] [CrossRef]
- Kwoka, J.E.; Pollitt, M.G. Do mergers improve efficiency? Evidence from restructuring the US electric power sector. Int. J. Ind. Organ. 2010, 28, 645–656. [Google Scholar]
- Kwoka, J.E.; Ozturk, S.; Sergici, S. Divestiture policy and operating efficiency in U. S. electric power distribution. J. Regul. Econ. 2010, 38, 86–109. [Google Scholar] [CrossRef][Green Version]
- Miguéis, V.; Camanho, A.; Bjørndal, E.; Bjørndal, M. Productivity change and innovation in Norwegian electricity distribution companies. J. Oper. Res. Soc. 2012, 63, 982–990. [Google Scholar] [CrossRef]
- Çelen, A. Efficiency and productivity (TFP) of the Turkish electricity distributioncompanies: An application of two-stage (DEA &Tobit) analysis. Energy Police 2013, 63, 300–310. [Google Scholar]
- Yu, W.; Jamasb, T.; Pollitt, M. Does weather explain cost and quality performance? An analysis of UK electricity distribution companies. Energy Police 2009, 37, 4177–4188. [Google Scholar]
- Bobde, S.; Tanaka, M. Efficiency evaluation of electricity distribution utilities in India: A two-stage DEA with bootstrap estimation. J. Oper. Res. Soc. 2018, 69. [Google Scholar] [CrossRef]
- Lee, B.L.; Wilson, C.; Simshauser, P.; Majiwa, E. Deregulation, efficiency and policy determination: An analysis of Australia’s electricity distribution sector. Energy Econ. 2021, 98, 105210. [Google Scholar] [CrossRef]
- Badunenko, O.; Tauchmann, H. Simar and Wilson Two-Stage Efficiency Analysis for Stata; FAU Discussion Papers in Economics, No. 08/2018; Friedrich-Alexander-Universität Erlangen-Nürnberg, Institute for Economics: Nürnberg, Germany, 2018. [Google Scholar]
- Berg, S.; Lin Ch Tsaplin, V. Regulation of State-Owned and Privatized Utilities: Ukraine Electricity Distribution Company Performance. J. Regul. Econ. 2005, 28, 259–287. [Google Scholar] [CrossRef]
- Ngo, T.; Tsui, K.W.H. Estimating the confidence intervals for DEA efficiency scores of Asia-Pacific airlines. Oper. Res. 2021. [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Variable | Sales (MWh) | Customers (Number) | Workers (Number) | Net Fixed Assets (Thousands of Soles in 1994) | Losses (MWh) |
|---|---|---|---|---|---|
| Mean | 971,650 | 302,945 | 264 | 434,214 | 96,808 |
| Minimum | 33,327 | 19,743 | 19 | 22,784 | 4675 |
| Maximum | 7,185,542 | 1,293,552 | 787 | 2,088,524 | 536,922 |
| Standard deviat. | 1,553,483 | 280,244 | 188 | 460,151 | 121,545 |
| Company | ET CRS | ET VRS | ES | |||
|---|---|---|---|---|---|---|
| 1996 | 2014 | 1996 | 2014 | 1996 | 2014 | |
| Edecañete | 1.000 | 0.651 | 1.000 | 1.000 | 1.000 | 0.651 |
| Edelnor | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
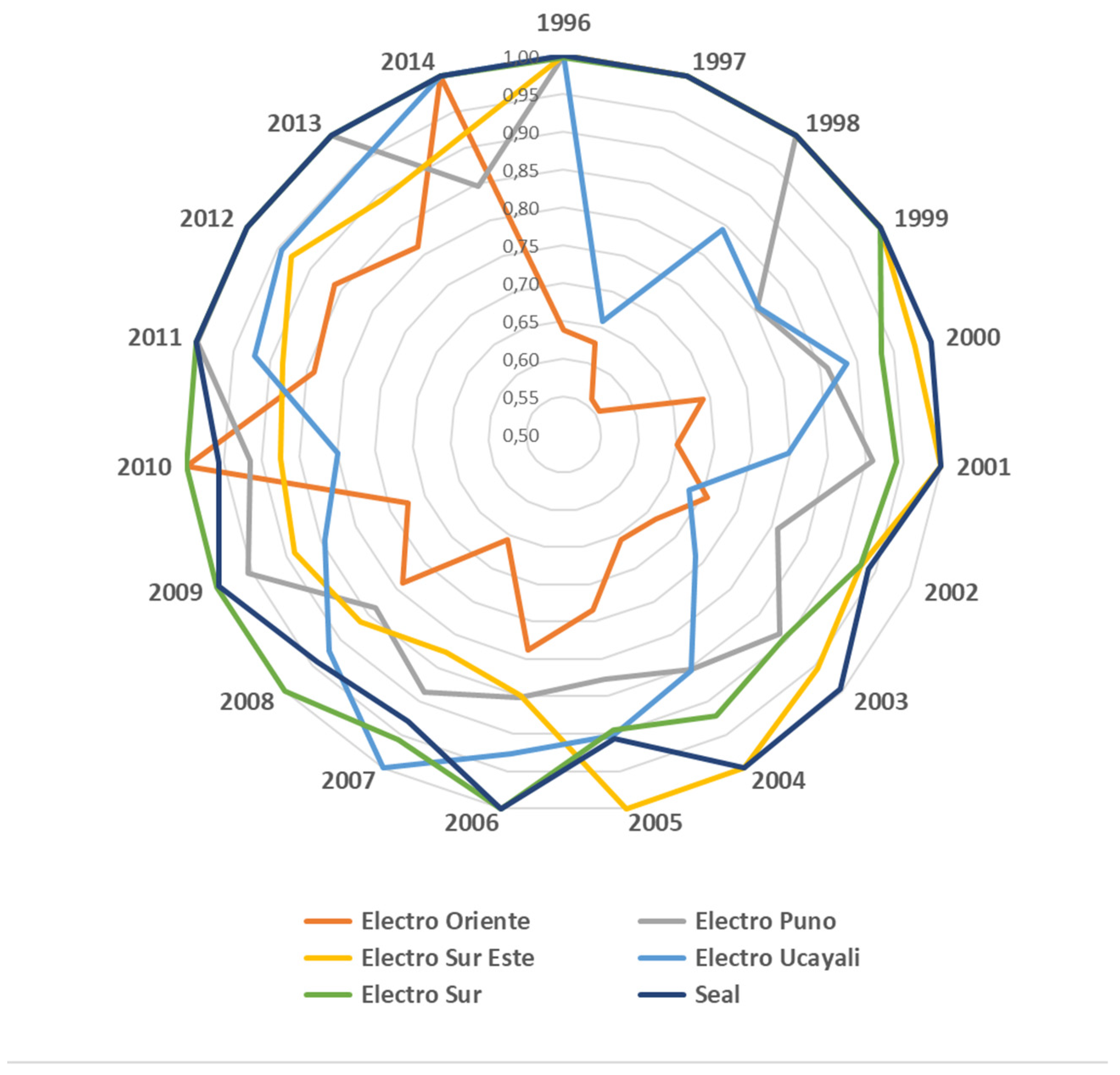
| Electro Oriente | 0.632 | 1.000 | 0.638 | 1.000 | 0.991 | 1.000 |
| Electro Puno | 1.000 | 0.799 | 1.000 | 0.847 | 1.000 | 0.943 |
| Electro Sur Este | 1.000 | 0.915 | 1.000 | 0.916 | 1.000 | 0.998 |
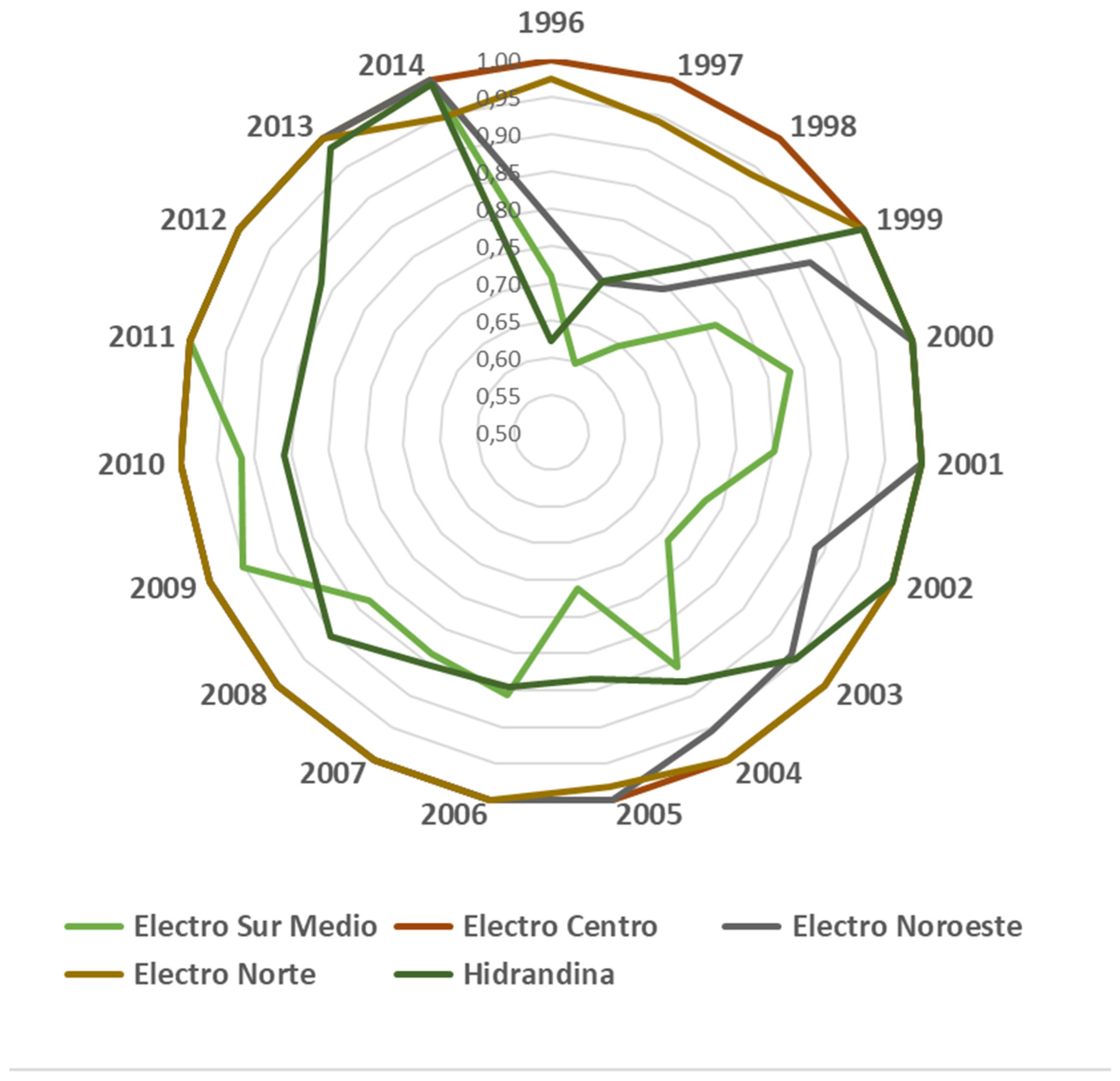
| Electro Sur Medio | 0.697 | 1.000 | 0.711 | 1.000 | 0.980 | 1.000 |
| Electro Ucayali | 0.838 | 1.000 | 1.000 | 1.000 | 0.838 | 1.000 |
| Electro Centro | 0.864 | 1.000 | 1.000 | 1.000 | 0.864 | 1.000 |
| Electro Noroeste | 0.780 | 0.963 | 0.784 | 1.000 | 0.995 | 0.963 |
| Electro Norte | 0.961 | 0.945 | 0.975 | 0.947 | 0.986 | 0.998 |
| Electro Sur | 0.948 | 1.000 | 0.997 | 1.000 | 0.950 | 1.000 |
| Hidrandina | 0.572 | 0.868 | 0.623 | 0.993 | 0.918 | 0.874 |
| Luz del Sur | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| Seal | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| Average | 0.878 | 0.939 | 0.909 | 0.979 | 0.966 | 0.959 |
| Study | Data | Method | FS Variables | SE Regression Variables |
|---|---|---|---|---|
| [15] | NDF = 12 C = Colombia P = 1985–2001 | FS: lnput-oriented DEA CRS & VRS model SE: OLS pooled; Tobit pooled and Tobit random-effects panel regressions | I: Worker in distribution & commercialization (number), Transformer & Substations (number), Network (km); Regional GDP per capita, Installed generation capacity O: Sales (GWh), Customers (number), Area served (Km2) | DVSE: DEA TE CRS & SE scores depending on the model. CVSE: Sales-GWh/Transf; Sales-GWh/lines; Subscribers per Km2; Urban Area (Km2); Industrial/residential sales; Log PPE; Log (sales/PPE); Oper-income/net worth; Loss index; Industry-adjusted loss index; Regulation; Business |
| [3] | NDF = 14 C = Peru P = 1996–2006 | FS: lnput-oriented DEA VRS model SE: Tobit random-effects panel regression and Mann-Whitney Test | I: Worker (number), Net Assets (000 Soles), Losses (MWh) O: Sales (MWh), Customers (number) | DVSE: DEA TE VRS scores CVSE: Investment per client; Low-medium voltage sales ratio; Mountains and Jungle indexes; Reform; DProp. |
| [33] | NDF = 12 C = UK P = 1996/06–2002/03 | FS: Cost minimization DEA VRS model SE: Tobit pooled regression | I: OPEX; TOTEX; Duration of interruptions; Losses (GWh) IP: 1 (for TOTEX & OPEX), Willingness-to-pay (Duration of interruptions); Energy price (Losses) O: Customers (number); Network length; Energy delivered | DVSE: DEA ET & EE scores depending on model CVSE: Weather index I (Minimum temperature, air frost, ground frost and concrete temperature); Weather index II (maximum temperature, thunder, hail land gale) |
| [30] | NDF = 73 C = USA P = 1994–2003 | FS: lnput-oriented DEA CRS model SE: GLS estimation with fixed effects. | I: OPEX or TCEX depending on the model O: Sales (MWh); Customers (number); Network length | DVSE: DEA CRS scores CVSE: POST-DIVEST = dummy for major divestiture or series of timing dummies POST1, POST2, POST6 for successive years after the particular utility’s major divestiture, depending on the model; POST-MAND = if divesture was mandated; POST-NON = if divesture was not mandated; Residential-total sales ratio |
| [29] | NDF = 73 C = USA P = 1994–2003 | FS: lnput-oriented DEA CRS model SE: GLS with random effects. | I: OPEX or TCEX depending on the model O: Sales (MWh); Customers (number); Network length | DVSE: DEA CRS scores CVSE: PRE = sets of years before merger; POST = sets of years after merger; GROUP subsets of utilities (buyers vs. sellers, buyers vs. non-merging utilities, etc.); Residential-total sales ratio; Distribution output generated by the utility itself (%); Adjacent dummy (physical proximity of the merging units); Twomergers dummy |
| [31] | NDF = 127 C = Norway P = 2004–2007 | FS: DEA VRS model with weight restrictions related to environmental conditions SE: Tobit regression | I: TOTEX (including the interruptions’ costs) O: Cottage customers (number); Regular customers (except cottages) (number); Energy delivered (MWh); High voltage lines (Km); Network stations transformers (number), Interface Environmental conditions: forest, snow and coast/wind. | DVSE: DEA TE VRS scores CVSE: Firm remaining life span, Size (total cost); Environmental conditions (Forest, Coast and Snow indexes). |
| [32] | NDF = 21 C = Turkey P = 2002–2009 | FS: lnput-oriented DEA VRS modelSE: Tobit pooled regression | I: Worker (number); Network length (km); Transformer capacity (MVA); Outage hours per customer; Loss & theft ratio. O: Energy delivered (MWh); Customers (number) | DVSE: DEA TE VRS scores CVSE: Customer density; Customer structure (%); Restructuring; ownership; Loss & theft ratio |
| [27] | NDF = 61 C = Brazil P = 2003–2009 | FS: lnput-oriented DEA-NDRS model SE: Simar and Wilson (2007) bootstrapped truncated regression | I: OPEX ($) O: Energy Delivered (MWh); Customers (number); Network length (Km) | DVSE: DEA TE NDRS scores CVSE: MS = Mean Salary; PI = natural logarithm of precipitation index; CI = Complexity index; CA = natural logarithm of consumer per area |
| [34] | NDF = 13 C = India P = 2005–2012 | FS: Conventional & Boostrap DEA model SE: FGLS and Pooled OLS regression | I: Model 1: Worker (number); Transformer capacity (MVA), Network (km)Model 2: Worker (number); Total Assests ($) O: Electricity delivered (GWh); Customers (number) | DVSE: Conventional & bias-correctedbootstrap efficiency estimates of DEA depending on model CVSE: Tariff ratio; consumer structure (%); Log of Population density (person per Km2); Ownership dummy; Log of Subsidy; Population density x ownership |
| [28] | NDF = 61 C = Brazil P = 2015 | FS: lnput-oriented DEA-NDRS model with weight restrictions. SE: OLS and Tobit regresions | I: Mean operational cost O: Underground network; Overhead network; High voltage network; Consumers (number); Weighted energy market; Non-technical losses; Consumer-hour interrupted energy.(Mean values were calculated using 2011 to 2013) | DVSE: DEA TE CRS & VRS scores depending on the model CVSE: Density of consumers; Network density; Complexity index; Precipitation index; Lightning rate; Low vegetation index; Medium vegetation index; High vegetation index; Mean declivity index; Proportion of paved roads; Concession area (km2); Average duration of interruptions; Frequency of interruptions; e-factor |
| [35] | NDF = 14 C = Australia P for FS = 2009–2017P for SE = 2017 | FS: lnput-oriented VRS DEA model. SE: Simar and Wilson’s(2007) double bootstrap truncated regression | I: Operating Expenditure; Network capacity; Network length (km) O: Electricity delivered (GWh) | DVSE: DEA TE scores CVSE: Reliability; Average age of poles; Customers (number) |
| Present Study | NDF = 14 C = Peru P = 1996–2014 | FS: lnput-oriented DEA VRS model SE: all model proposed in the literature, including fractional models | I: Worker (number), Net Assets (000 Soles), Losses (MWh) O: Sales (MWh), Customers (number) | DVSE: DEA TE scores CVSE: Investment per client; Low-medium voltage sales ratio; Mountains and Jungle indexes; Reform; DProp |
| Variable | TE (VRS) | LV/MV | K/N | Jungle | Mountain | Property | Reform |
|---|---|---|---|---|---|---|---|
| Average | 0.932 | 2.035 | 1.482 | 0.143 | 0.286 | 0.327 | 0.523 |
| Minimum | 0.557 | 0.584 | 0.726 | 0.000 | 0.000 | 0.000 | 0.000 |
| Maximum | 1.000 | 6.175 | 4.573 | 1.000 | 1.000 | 1.000 | 1.000 |
| Standard Deviation | 0.105 | 1.224 | 0.578 | 0.351 | 0.453 | 0.470 | 0.500 |
| Variables | Y1 | Y2 | X1 | X2 | X3 | Θ | Z1 | Z2 | Z3 | Z4 | Z5 | Z6 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Users | Sales | Employees | Loss | Capital (K) | Vrs | LV/MV | (K/N) | Mountain | Jungle | Reform | T | ||
| y1 | users | 1 | |||||||||||
| y2 | sales | 0.9040 | 1 | ||||||||||
| x1 | employees | 0.8748 | 0.8318 | 1 | |||||||||
| x2 | loss | 0.9202 | 0.9534 | 0.879 | 1 | ||||||||
| x3 | capital (K) | 0.9565 | 0.9376 | 0.8581 | 0.925 | 1 | |||||||
| θ | vrs | 0.3213 | 0.2699 | 0.1725 | 0.228 | 0.2178 | 1 | ||||||
| z1 | LV/MV | 0.0146 | −0.169 | 0.0412 | −0.17 | −0.0269 | 0.1577 | 1 | |||||
| z2 | (K/N) | −0.091 | 0.0459 | −0.0556 | 0.032 | 0.1104 | −0.5402 | −0.0662 | 1 | ||||
| z3 | mountain | −0.085 | −0.25 | −0.1391 | −0.252 | −0.1476 | 0.1496 | 0.6736 | −0.1772 | 1 | |||
| z4 | jungle | −0.297 | −0.2 | −0.2862 | −0.223 | −0.2157 | −0.5118 | −0.1333 | 0.5344 | −0.2582 | 1 | ||
| z5 | reform | 0.4801 | 0.4266 | 0.4249 | 0.415 | 0.4337 | 0.347 | −0.2449 | −0.1935 | −0.3951 | −0.4271 | 1 | |
| z6 | t | 0.2686 | 0.2007 | 0.0289 | 0.079 | 0.1742 | 0.227 | −0.145 | −0.367 | 0 | 0 | 0.1443 | 1 |
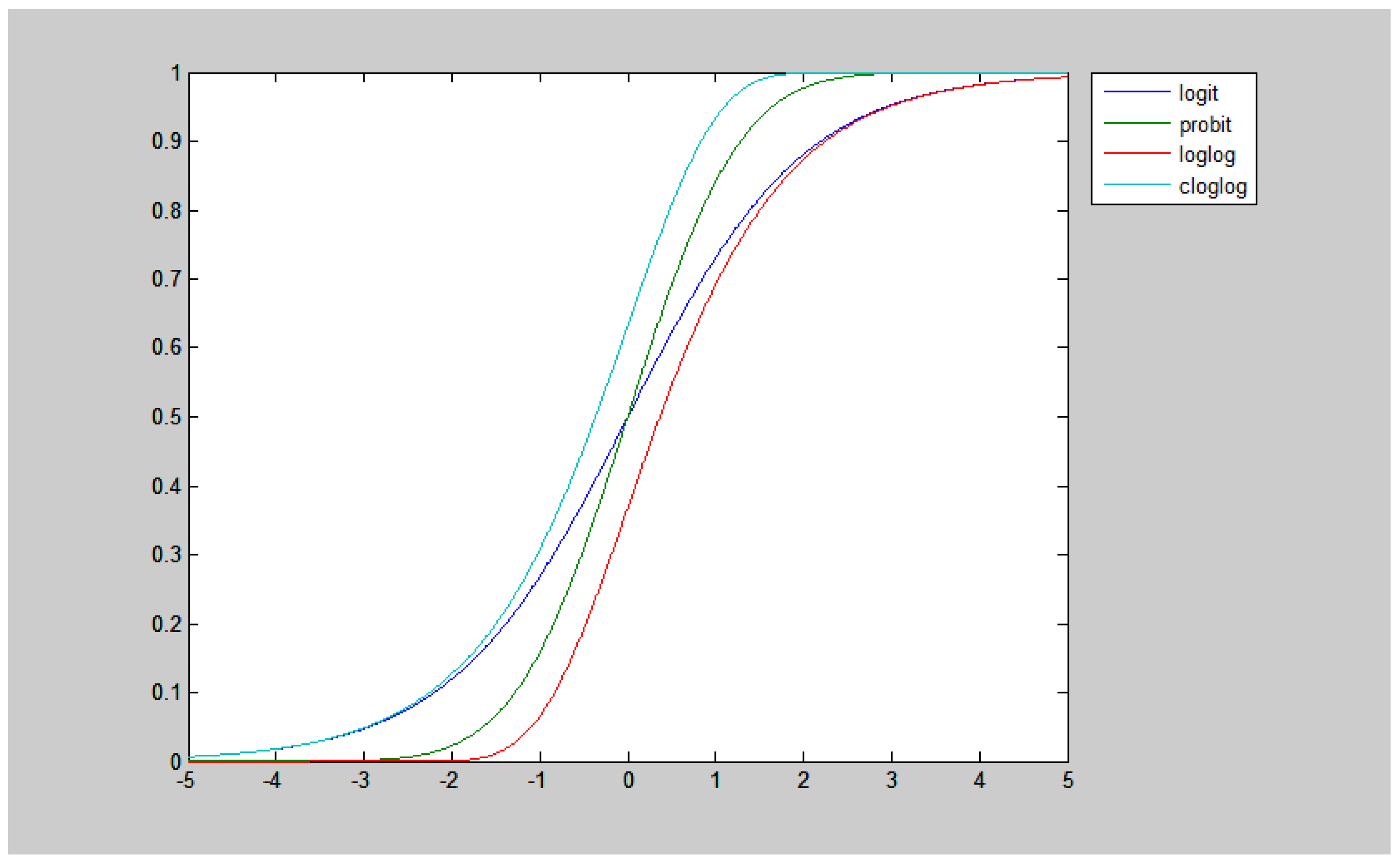
| Variable | Logit | Probit | LogLog | Cloglog | ||||
|---|---|---|---|---|---|---|---|---|
| Coefficient | APE | Coefficient | APE | Coefficient | APE | Coefficient | APE | |
| Constant | 1.99 | 1.28 | 2.01 | 0.946 | ||||
| (4.346) | (5.449) | (4.437) | (5.679) | |||||
| LV/MV | 0.395 | 0.023 | 0.202 | 0.023 | 0.35 | 0.022 | 0.149 | 0.023 |
| (3.204) | (3.006) | (3.527) | (3.293) | (3.106) | (2.864) | (3.988) | (3.802) | |
| K/N | −0.502 | −0.029 | −0.31 | −0.036 | −0.419 | −0.026 | −0.293 | −0.045 |
| (−2.922) | (−2.915) | (−3.52) | (−3.486) | (−2.626) | (−2.583) | (−4.275) | (−4.188) | |
| Mountain | 0.224 | 0.013 | 0.066 | 0.008 | 0.26 | 0.016 | 0.014 | 0.002 |
| (0.875) | (0.876) | (0.491) | (0.492) | (0.987) | (0.996) | (0.148) | (0.148) | |
| Jungle | −0.322 | −0.019 | −0.167 | −0.019 | −0.298 | −0.019 | −0.134 | −0.021 |
| (−1.016) | (−1.012) | (−1.028) | (−1.027) | (−0.982) | (−0.976) | (−1.120) | (−1.12) | |
| Trend | 0.031 | 0.002 | 0.013 | 0.002 | 0.029 | 0.002 | 0.008 | 0.001 |
| (1.484) | (1.449) | (1.243) | (1.224) | (1.475) | (1.435) | (1.094) | (1.089) | |
| Reform | 1.14 | 0.067 | 0.556 | 0.065 | 1.1 | 0.069 | 0.4 | 0.062 |
| (4.239) | (4.324) | (4.38) | (4.452) | (4.043) | (4.170) | (4.577) | (4.687) | |
| Log-likelihood | −44.884 | −44.617 | −45.026 | −44.329 | ||||
| R2 | 0.366 | 0.379 | 0.358 | 0.394 | ||||
| Bootstrap replications | 1000 | 1000 | 1000 | 1000 | ||||
| Variable | OLS | Fixed Effect | Random Effect | Tobit | Simar-Wilson | |
|---|---|---|---|---|---|---|
| Bootstrap | Bootstrap | Bootstrap | Algorithms #2 | |||
| Coefficient | Marginal Effects | Coefficient | ||||
| Constant | −0.039 | −0.12 | −0.105 | 0.903 | 0.682 | |
| (−1.171) | (−1.543) | (−1.214) | (26.885) | (17.942) | ||
| LV/MV | 0.016 | 0.029 | 0.026 | 0.023 | 0.013 | 0.025 |
| (2.445) | (1.178) | (1.111) | (2.66) | (2.604) | (3.688) | |
| K/N | −0.076 | −0.066 | −0.067 | −0.052 | −0.03 | −0.101 |
| (−4.422) | (−3.118) | (−3.858) | (−5.381) | (−4.948) | (−7.276) | |
| Mountain | 0.005 | − | 0.015 | 0.01 | 0.006 | −0.038 |
| (0.275) | (0.217) | (0.252) | (0.252) | (−1.634) | ||
| Jungle | −0.077 | − | −0.047 | −0.042 | −0.024 | 0.004 |
| (−2.547) | (−0.526) | (−0.9) | (−0.908) | (0.145) | ||
| Trend | 0.002 | 0.002 | 0.002 | 0.002 | 0.001 | 0.013 |
| (1.932) | (1.092) | (1.072) | (2.219) | (2.184) | (9.312) | |
| Reform | 0.052 | 0.109 | 0.099 | 0.084 | 0.048 | 0.109 |
| (3.457) | (1.618) | (1.584) | (4.465) | (4.225) | (5.123) | |
| Log-likelihood | 247.941 | 321.310 | − | 343.670 | 276.165 | |
| ρ | 0.423* | 0.48 | 0.518 | 0.423 | ||
| χ2 | 247.941 | 13.976 | 20.512 | 108.715 | 405.517 | |
| Bootstrap replications | 1000 | 1000 | 1000 | 100/1000 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pérez-Reyes, R.; Tovar, B. Peruvian Electrical Distribution Firms’ Efficiency Revisited: A Two-Stage Data Envelopment Analysis. Sustainability 2021, 13, 10066. https://doi.org/10.3390/su131810066
Pérez-Reyes R, Tovar B. Peruvian Electrical Distribution Firms’ Efficiency Revisited: A Two-Stage Data Envelopment Analysis. Sustainability. 2021; 13(18):10066. https://doi.org/10.3390/su131810066
Chicago/Turabian StylePérez-Reyes, Raúl, and Beatriz Tovar. 2021. "Peruvian Electrical Distribution Firms’ Efficiency Revisited: A Two-Stage Data Envelopment Analysis" Sustainability 13, no. 18: 10066. https://doi.org/10.3390/su131810066
APA StylePérez-Reyes, R., & Tovar, B. (2021). Peruvian Electrical Distribution Firms’ Efficiency Revisited: A Two-Stage Data Envelopment Analysis. Sustainability, 13(18), 10066. https://doi.org/10.3390/su131810066