
The Evolution of Wikipedia’s Norm Network

Abstract
:
1. Introduction
2. Methods
2.1. Centrality and Attention Measures
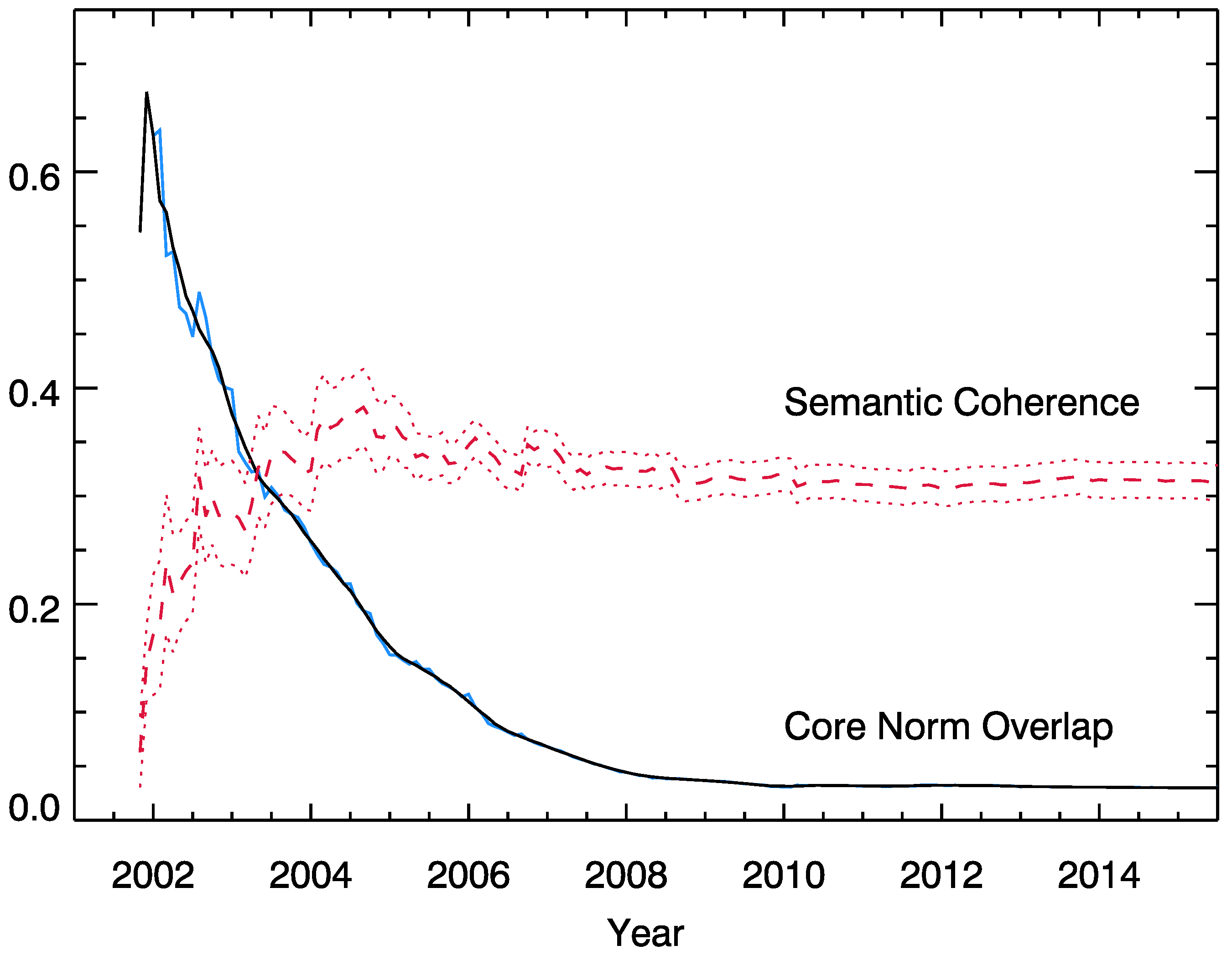
2.2. Influence and Overlap
2.3. Semantic Coherence
2.4. Community Detection
3. Results
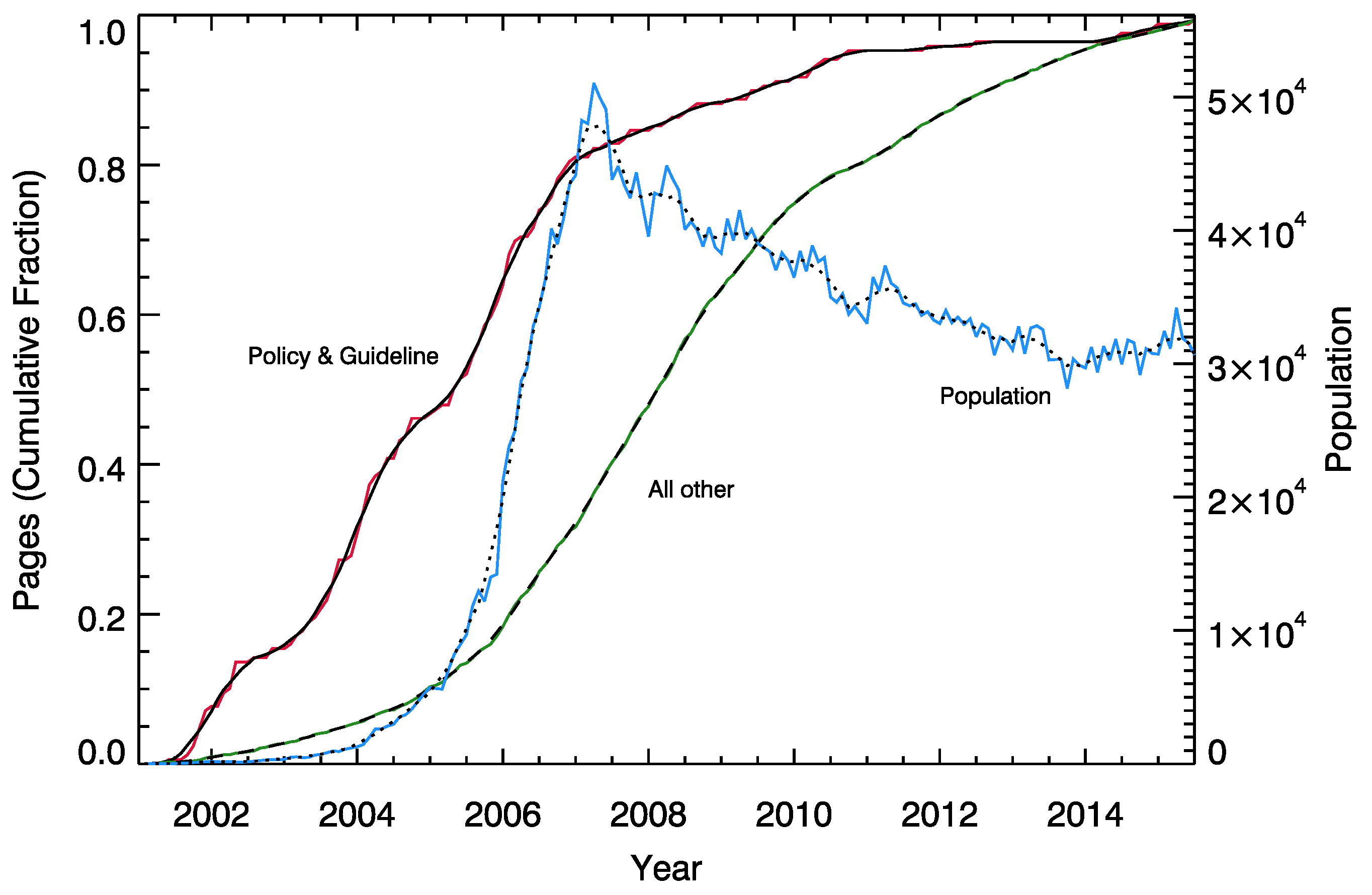
3.1. Network Construction
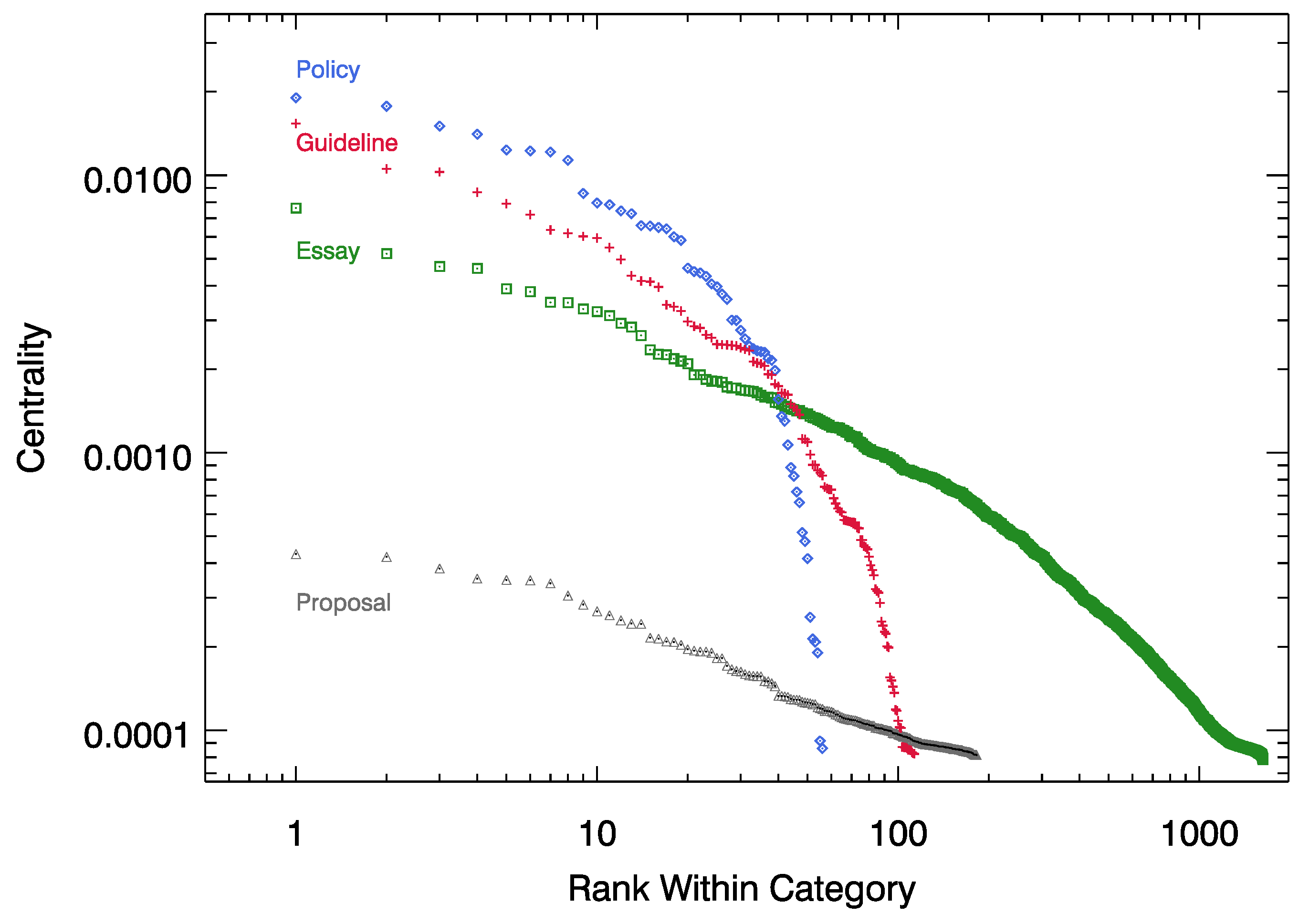
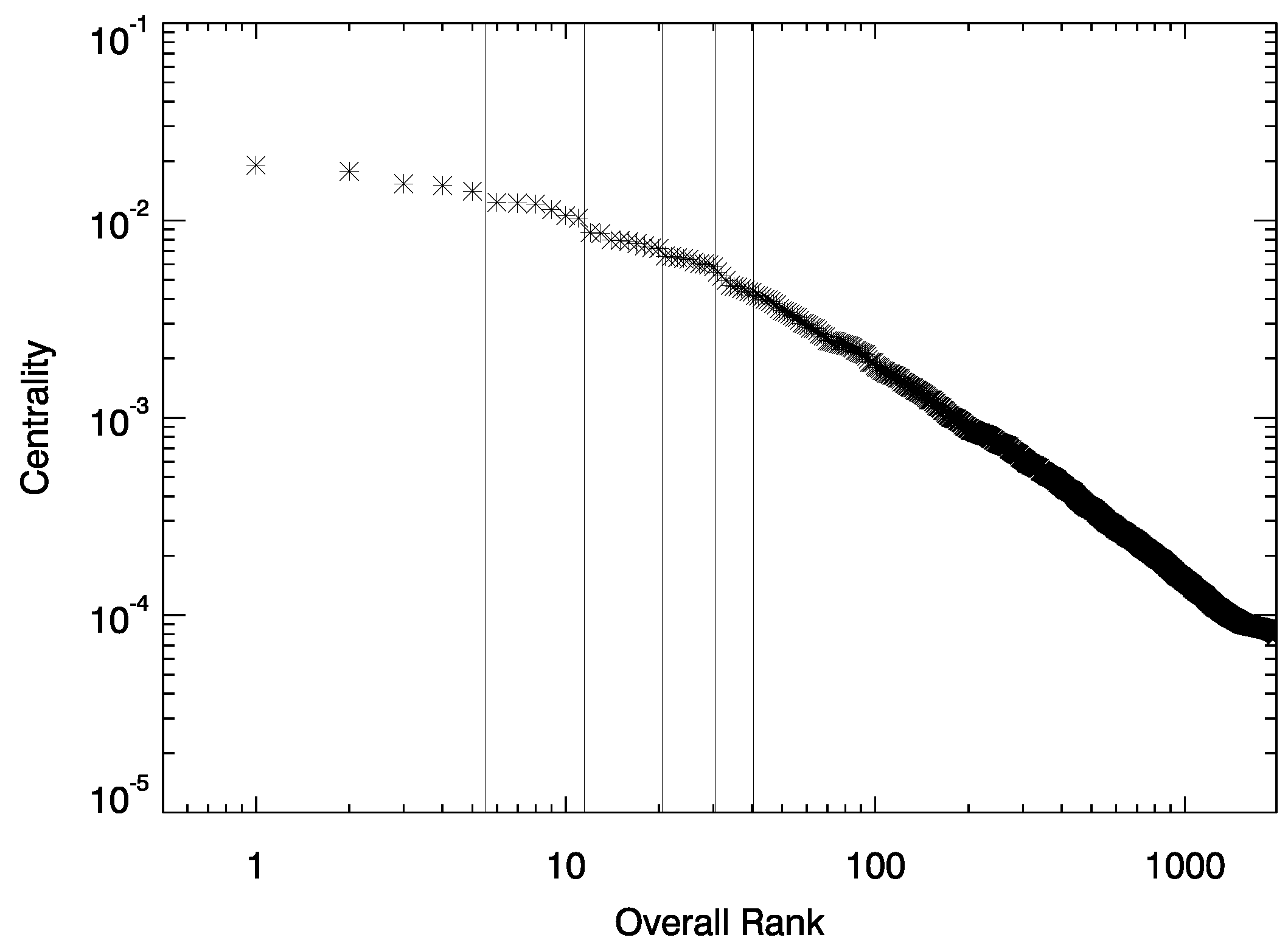
3.2. Core Norms
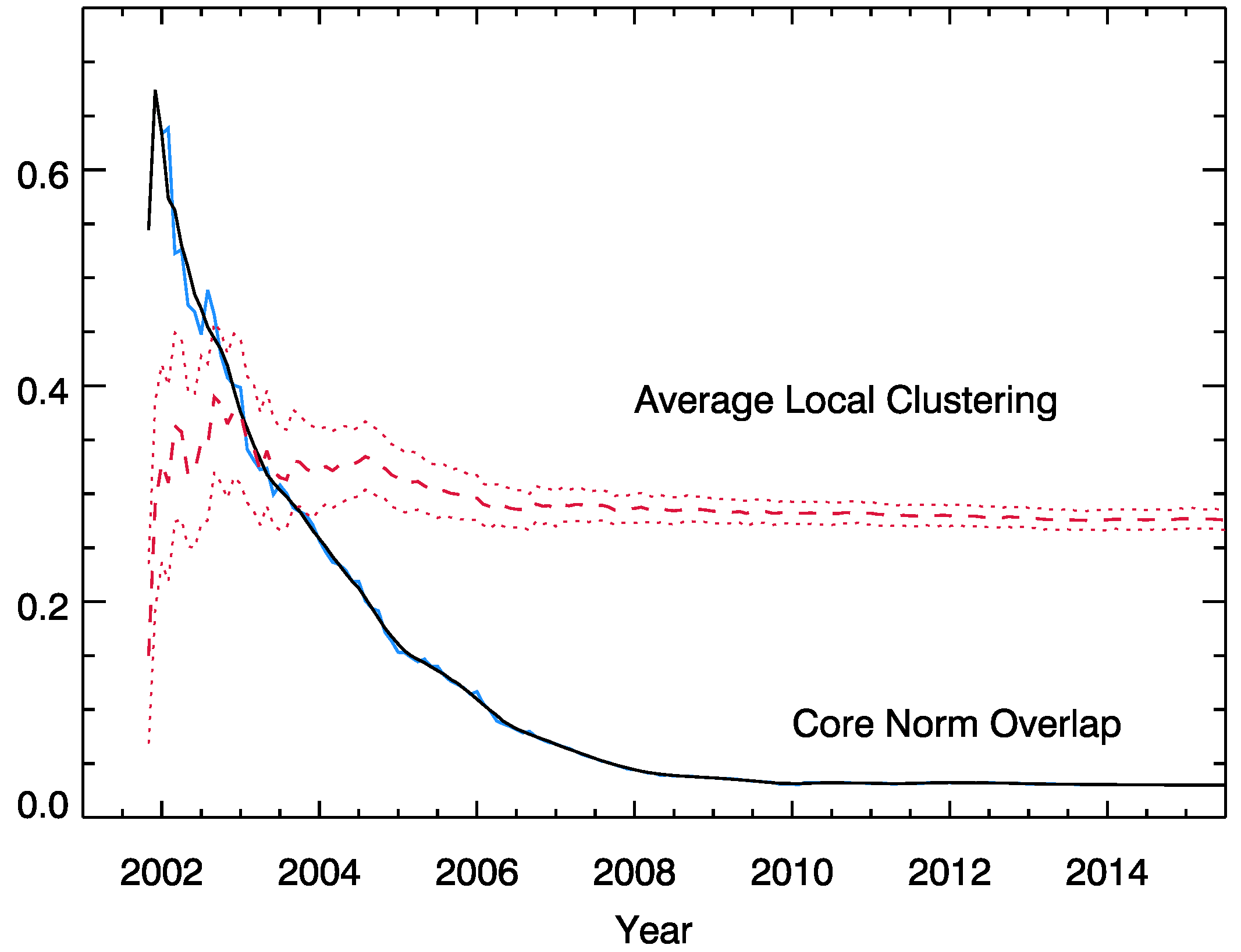
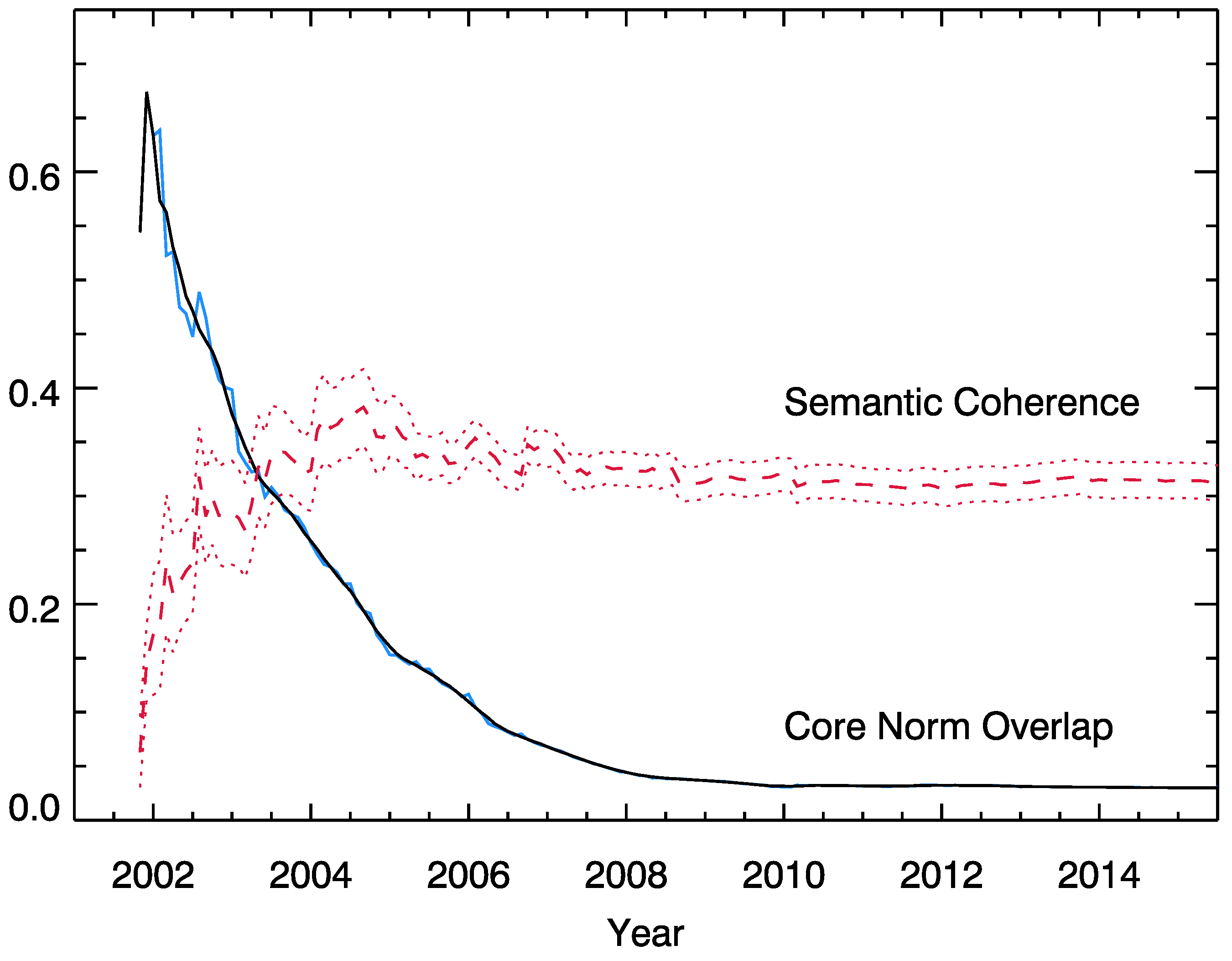
3.3. Overlap and Semantic Coherence
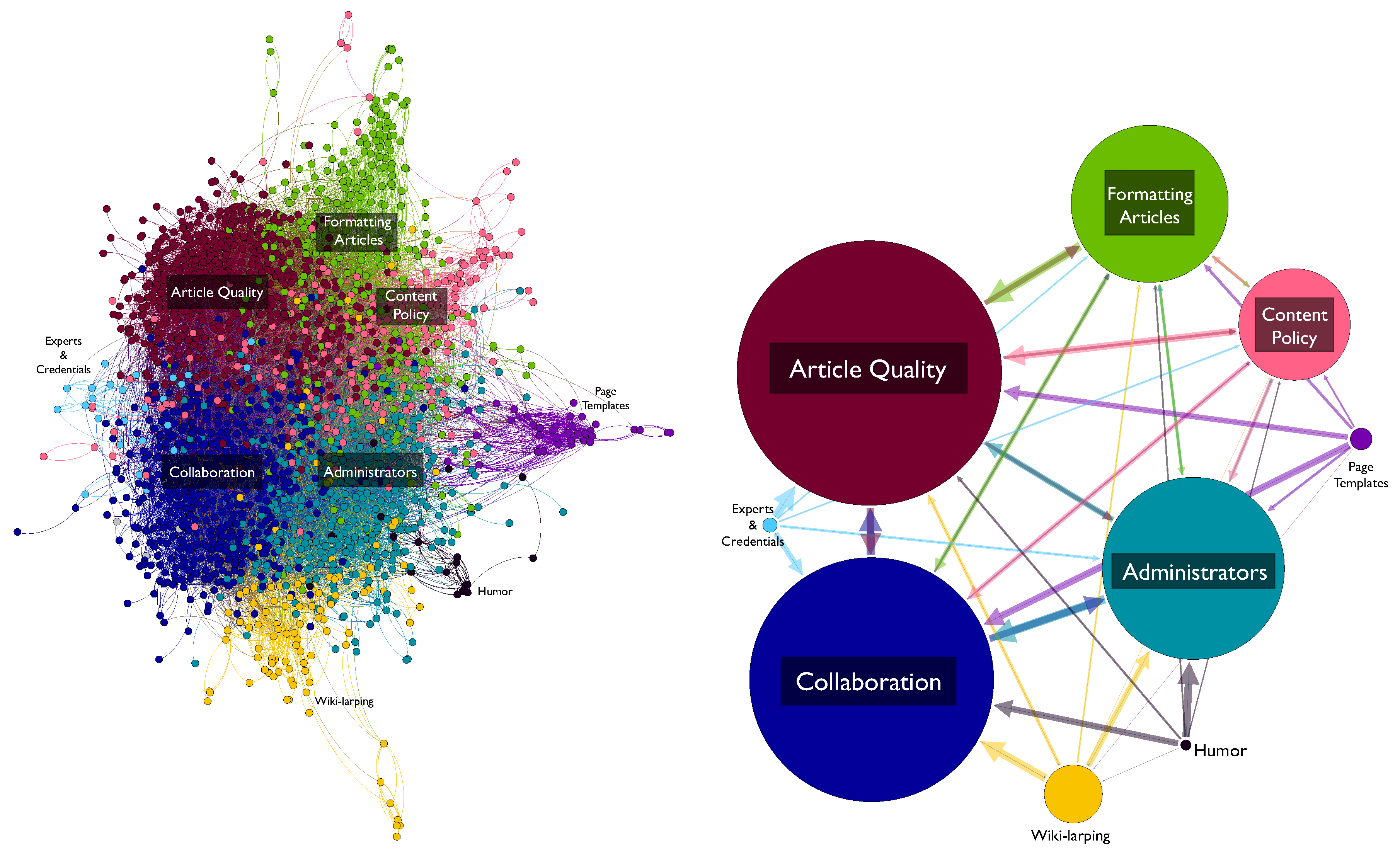
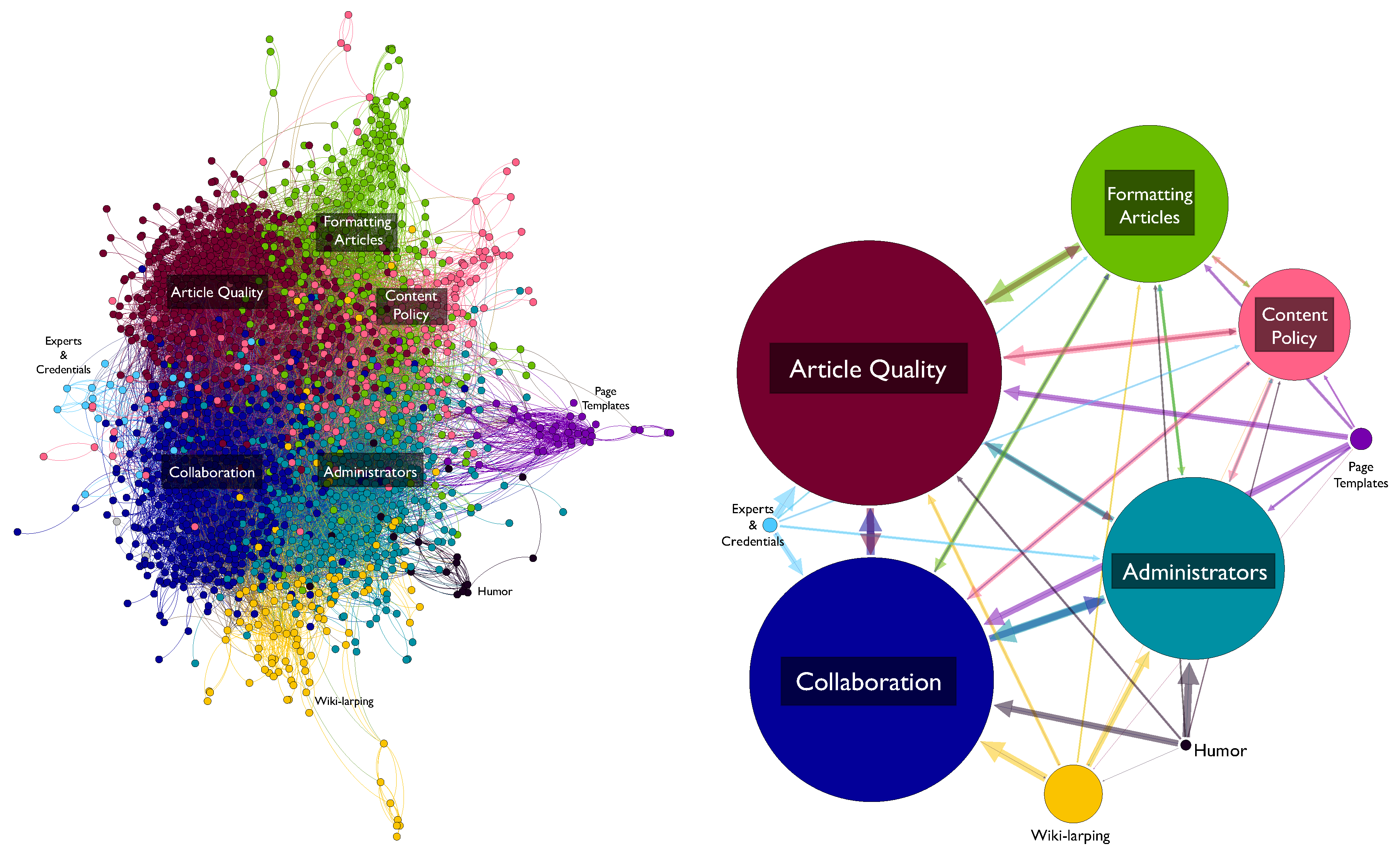
3.4. Emergent Clusters
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Corpus Construction
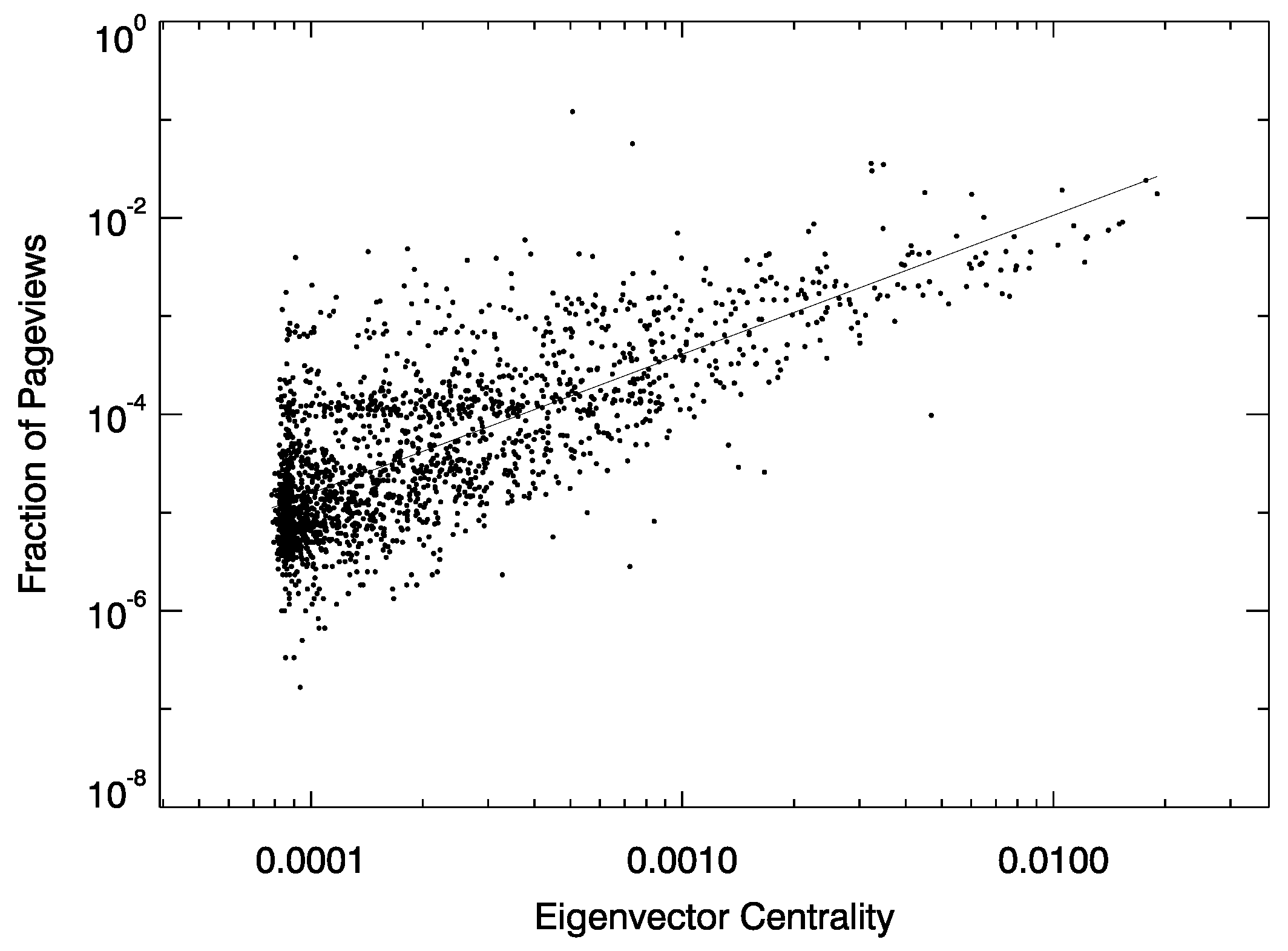
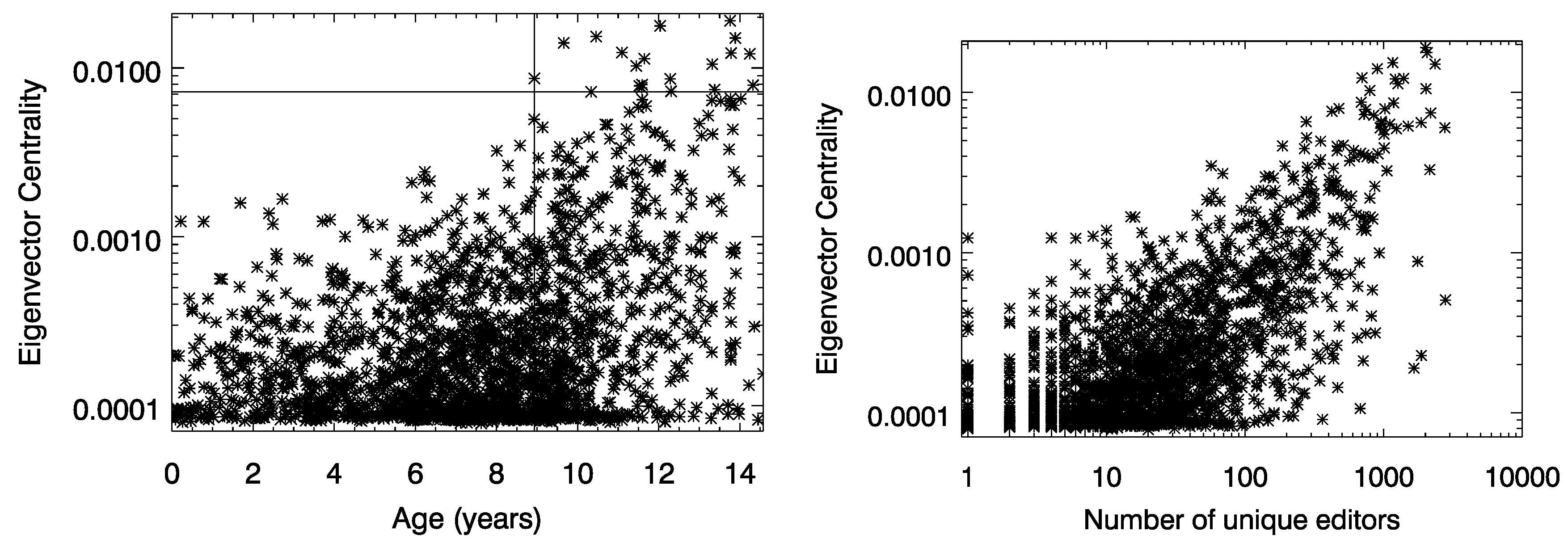
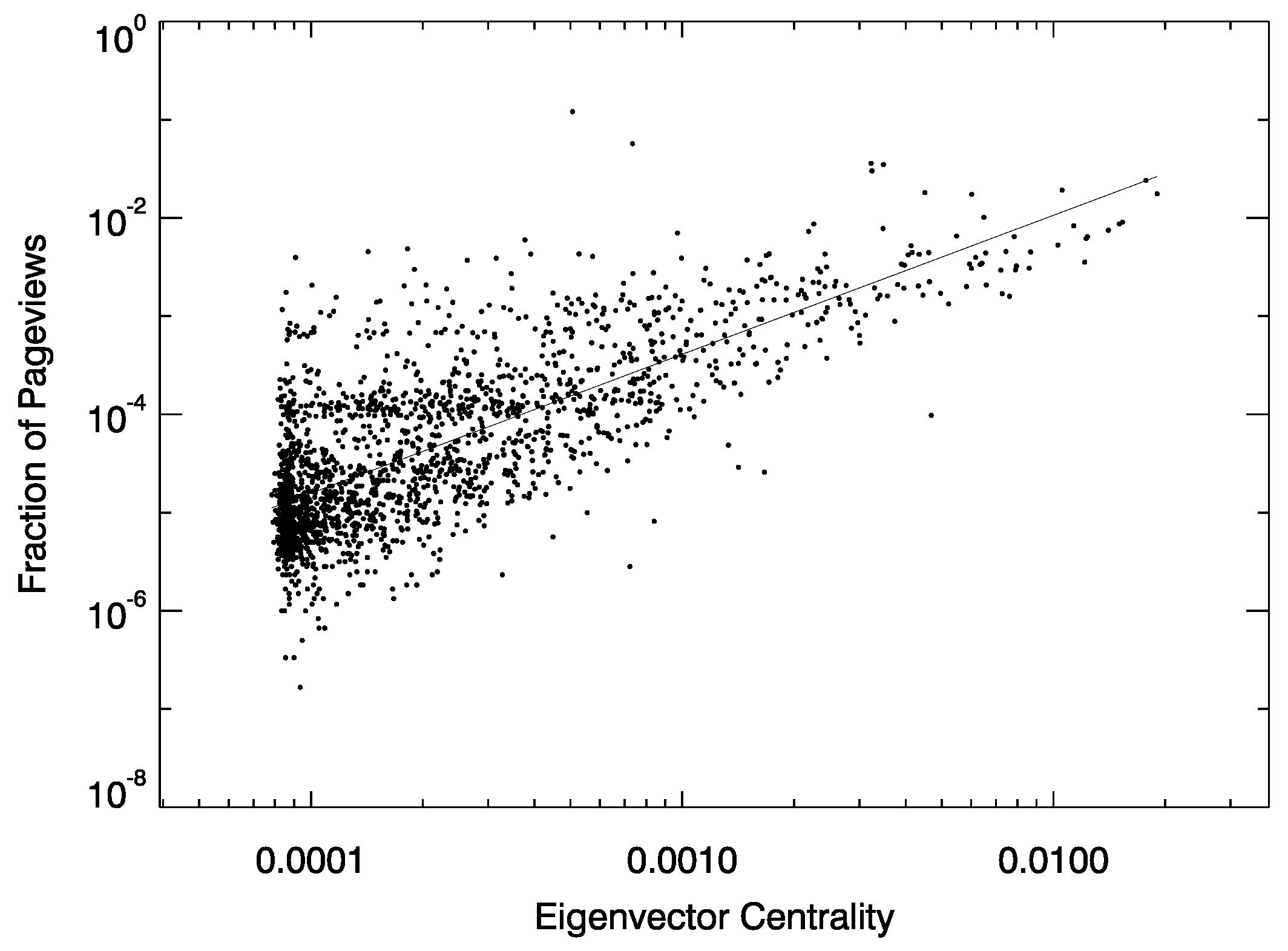
Appendix B. Relationship between Eigenvector Centrality and Attention Measures

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attention Measure | r | p Value |
|---|---|---|
| Page views | 0.32 | <10−3 |
| Number of edits | 0.70 | <10−3 |
| Number of talk page edits | 0.63 | <10−3 |
| Number of editors | 0.72 | <10−3 |
Appendix C. Regression on Age and Edits
| Predictor | Coefficient × 10−5 | p Value |
|---|---|---|
| Number of editors | 95 ± 6 | <10−3 |
| Number of talk edits | 46 ± 3 | <10−3 |
| Page size | 2 ± 2 | n.d. |
| Age | 2 ± 2 | n.d. |
| Number of edits | −30 ± 7 | <10−3 |

Appendix D. Combined Scree Plot
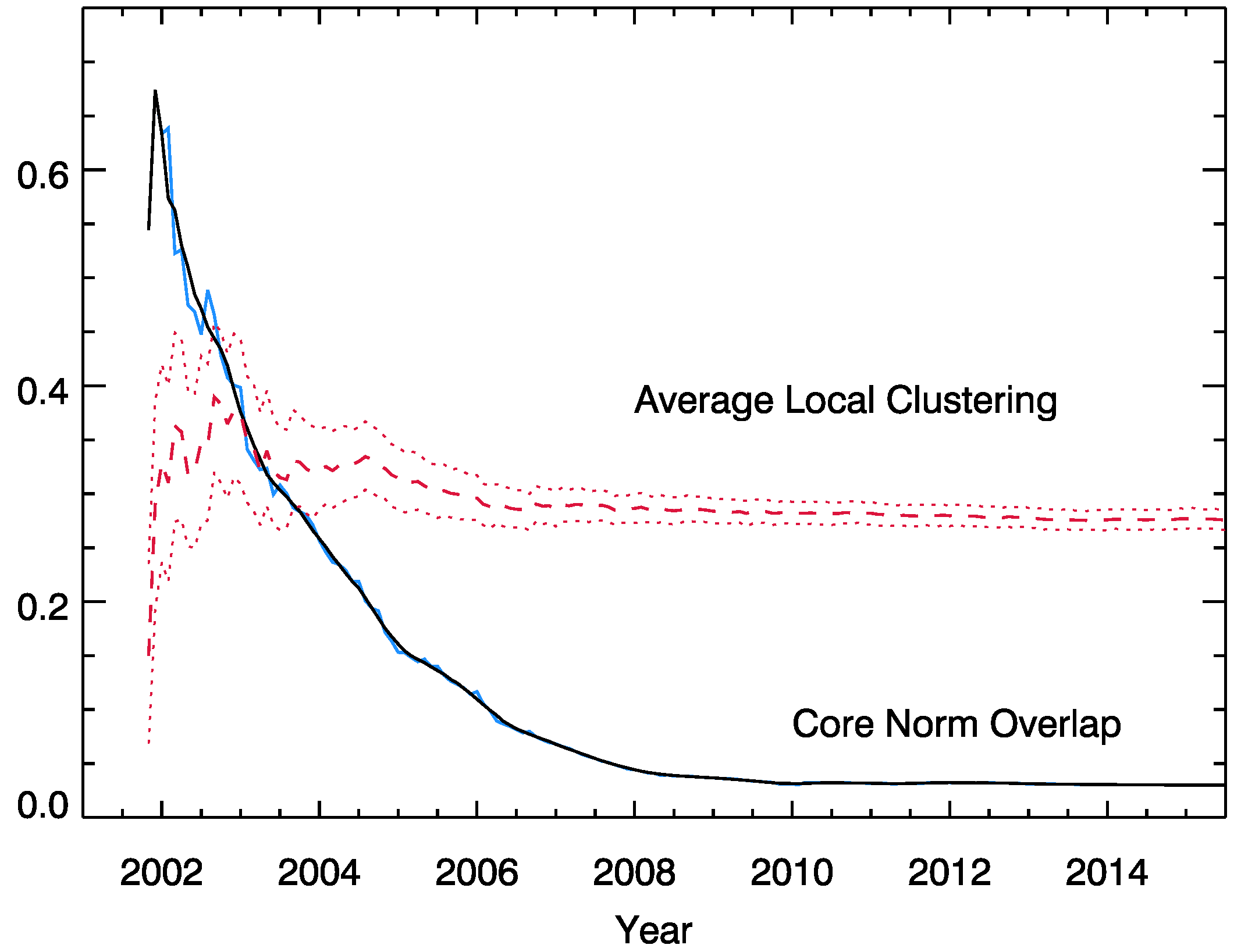
Appendix E. Local Clustering Coefficient
Appendix F. Clusters and Topic Modeling
| Rank | Fraction | Louvain Community | Representative Words |
|---|---|---|---|
| 1 | 11.4% | Collaboration | editor, edit, dont, good, people, make, editing, policy, page, talk, |
| time, article, faith, point, policies, encyclopedia, consensus, community, personal, user | |||
| 2 | 8.67% | Article Quality | source, reliable, article, material, information, research, primary, view, original, editors, |
| subject, published, secondary, policy, neutral, point, scientific, content, topic, claims | |||
| 3 | 8.56% | — | article, deletion, page, deleted, discussion, content, delete, speedy, talk, tag, |
| subject, information, policy, user, guidelines, criteria, notability, afd, time, essay | |||
| 4 | 8.26% | Experts and Credentials | article, information, content, encyclopedia, editors, people, wikipedias, subject, featured, quality, |
| good, list, topic, readers, time, work, project, knowledge, number, lead | |||
| 5 | 6.65% | — | consensus, policy, discussion, community, process, committee, arbitration, editors, administrator, user, |
| request, policies, admin, block, dispute, page, wikimedia, proposal, information, made | |||
| 6 | 5.80% | Formatting Articles | article, names, title, page, english, disambiguation, naming, redirect, conventions, common, |
| term, style, citation, word, language, topic, book, usage, examples, cases | |||
| 7 | 5.69% | Administrators | user, edit, page, vandalism, account, ip, editing, talk, editors, bot, |
| address, protection, administrators, userboxes, username, blocked, block, request, sock, template | |||
| 8 | 5.36% | — | notable, article, notability, list, sources, coverage, criteria, information, subject, reliable, |
| emojif, guideline, film, event, university, significant, general, topic, independent, inclusion | |||
| 9 | 5.03% | — | page, link, text, image, file, wikimedia, search, commons, web, information, |
| external, software, content, article, site, add, click, wiki, edit, make | |||
| 10 | 4.38% | — | talk, edit, page, user, war, im, article, dont, people, time, |
| contribs, good, contributions, back, long, list, things, make, day, ive | |||
| 11 | 4.04% | Content Policies | copyright, image, public, nonfree, free, work, content, license, domain, law, |
| fair, article, copyrighted, published, states, pma, united, subject, permission, media | |||
| 12 | 3.81% | — | page, talk, template, namespace, user, link, article, text, category, section, |
| special, edit, title, list, signature, ut, mediawiki, redirect, move, navbox | |||
| 13 | 3.28% | Humor | list, chart, people, united, war, town, world, man, england, states, |
| british, top, hot, songs, women, city, ireland, music, number, death | |||
| 14 | 3.04% | — | category, day, categories, article, tip, stub, list, page, people, categorization, |
| main, link, year, created, red, featured, create, template, sort, subcategories | |||
| 15 | 2.97% | Wiki-larping | people, user, time, status, wikidragon, truth, wikifauna, wikipuma, credentials, names, |
| editathon, work, turkish, years, page, make, real, history, group, greek | |||
| 16 | 2.83% | — | support, oppose, policy, people, user, proposal, talk, userboxes, dont, image, |
| offensive, pov, namespace, page, content, article, censorship, vote, npov, agree | |||
| 17 | 2.79% | — | ban, topic, editing, indefinite, talk, sanctions, article, page, user, edit, |
| discussion, banned, paid, related, editor, contribs, interest, coi, community, broadly | |||
| 18 | 2.55% | — | quotation, style, citing, punctuation, american, mos, ads, dash, manual, inactive, |
| en, english, issue, sentence, dashes, election, text, space, british, jumped | |||
| 19 | 2.41% | Page Templates | text, template, page, line, article, gt, section, lt, enforcement, table, |
| footnote, law, summary, infobox, style, agencies, synth, color, work, data | |||
| 20 | 2.32% | — | article, station, number, year, state, route, highway, time, road, points, |
| date, railway, britannica, ship, include, information, eb, county, class, official |
| Rank | Cluster Name | Top Pages |
|---|---|---|
| 1 | Article Quality | Neutral_point_of_view; Verifiability; Identifying_reliable_sources; What_Wikipedia_is_not; Biographies_of_living_persons; No_original_research; Citing_sources |
| 2 | Collaboration | Consensus; Policies_and_guidelines; Assume_good_faith; Dispute_resolution; Civility; Edit_warring; Talk_page_guidelines |
| 3 | Administrators | Administrators; Blocking_policy; Arbitration_Committee; Vandalism; User_pages; Sock_puppetry; User_access_levels |
| 4 | Formatting Articles | Redirect; Article_titles; Disambiguation; Manual_of_Style; Namespace; What_is_an_article?; Categorization |
| 5 | Content Policies | Copyrights; Copyright_violations; Non-free_content; Image_use_policy; General_disclaimer; Non-Wikipedia_disclaimers; Substitution |
| 6 | Wiki-larping | Citation_needed; Wikibreak; WikiGnome; Wikipediholic; Talk_page_stalker; Wikipedia_is_a_volunteer_service; WikiDragon |
| 7 | Page Templates | Overlink_crisis; Pruning_article_revisions; Disinfoboxes; Thinking_outside_the_infobox; Advanced_template_coding; Advanced_article_editing; Advanced_footnote_formatting |
| 8 | Experts and Credentials | Expert_editors; Honesty; Expert_retention; Randy_in_Boise; Ten_Simple_Rules_for_Editing_Wikipedia; Conflicts_of_interest_(medicine); There_is_no_credential_policy |
| 9 | Humor | Silly_Things; Rules_for_Fools; April_Fools; April_Fool’s_Main_Page; Unusual_articles; Yet_more_Best_of_BJAODN; Best_of_BJAODN |
References
- Sherif, M. The Psychology of Social Norms; Harper: New York, NY, USA, 1936. [Google Scholar]
- Durkheim, E. The Rules of Sociological Method; Free Press: New York, NY, USA, 1938. [Google Scholar]
- Akerlof, G. The economics of caste and of the rat race and other woeful tales. Q. J. Econ. 1976, 90, 599–617. [Google Scholar] [CrossRef]
- Geertz, C. Thick description: Toward an interpretive theory of culture. In Readings in the Philosophy of Social Science; Martin, M., McIntyre, L.C., Eds.; MIT Press: Cambridge, MA, USA, 1994; pp. 213–231. [Google Scholar]
- Ellickson, R.C.; Ellickson, R.C. Order without Law: How Neighbors Settle Disputes; Harvard University Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Bowles, S. Microeconomics: Behavior, Institutions, and Evolution; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Simon, H.A. A formal theory of the employment relationship. Econometrica 1951, 19, 293–305. [Google Scholar] [CrossRef]
- Brennan, G.; Buchanan, J.M. The reason of rules; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Tyler, T.R. Psychological perspectives on legitimacy and legitimation. Annu. Rev. Psychol. 2006, 57, 375–400. [Google Scholar] [CrossRef] [PubMed]
- Tyler, T.R.; Fagan, J. Legitimacy and cooperation: Why do people help the police fight crime in their communities. Ohio State J. Crim. Law 2008, 6, 231. [Google Scholar] [CrossRef]
- Elias, N. The Civilizing Process: Sociogenetic and Psychogenetic Investigations, 2nd ed.; Dunning, E., Goudsblom, J., Mennell, S., Eds.; Wiley: New York, NY, USA, 2000. [Google Scholar]
- Pinker, S. The Better Angels of Our Nature: Why Violence Has Declined; Penguin Group: New York, NY, USA, 2011. [Google Scholar]
- Klingenstein, S.; Hitchcock, T.; DeDeo, S. The civilizing process in London’s Old Bailey. Proc. Natl. Acad. Sci. USA 2014, 111, 9419–9424. [Google Scholar] [CrossRef] [PubMed]
- Ehrlich, P.R.; Levin, S.A. The evolution of norms. PLoS Biol. 2005, 3, 943. [Google Scholar] [CrossRef] [PubMed]
- Ostrom, E.; Hess, C. A framework for analyzing the knowledge commons. In Understanding Knowledge as a Commons; Hess, C., Ostrom, E., Eds.; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Benkler, Y. The Wealth of Networks: How Social Production Transforms Markets and Freedom; Yale University Press: New Haven, CT, USA, 2006. [Google Scholar]
- Bollier, D. The growth of the commons paradigm. In Understanding Knowledge as a Commons; Hess, C., Ostrom, E., Eds.; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Frischmann, B.; Madison, M.; Strandburg, K. Governing Knowledge Commons; Oxford University Press: Oxford, UK, 2014. [Google Scholar]
- Ostrom, E. Governing the Commons: The Evolution of Institutions for Collective Action; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Hess, C.; Ostrom, E. Understanding Knowledge as a Commons: From Theory to Practice; MIT Press: Cambridge, MA, USA, 2011. [Google Scholar]
- West, J.; Lakhani, K.R. Getting clear about communities in open innovation. Ind. Innov. 2008, 15, 223–231. [Google Scholar] [CrossRef]
- O’Mahony, S. The governance of open source initiatives: What does it mean to be community managed? J. Manag. Gov. 2007, 11, 139–150. [Google Scholar] [CrossRef]
- Beschastnikh, I.; Kriplean, T.; McDonald, D.W. Wikipedian self-governance in action: Motivating the policy lens. In Proceedings of the ICWSM, Seattle, WA, USA, 30 March–2 April 2008.
- March, J.G.; Schulz, M.; Zhou, X. The Dynamics of Rules: Change in Written Organizational Codes; Stanford University Press: Palo Alto, CA, USA, 2000. [Google Scholar]
- Butler, B.; Joyce, E.; Pike, J. Don’t look now, but we’ve created a bureaucracy: The nature and roles of policies and rules in wikipedia. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Florence, Italy, 5–10 April 2008; ACM: New York, NY, USA, 2008; pp. 1101–1110. [Google Scholar]
- Schneider, J.; Passant, A.; Breslin, J. A qualitative and quantitative analysis of how Wikipedia talk pages are used. In Proceedings of the 2010 ACM Conference on Web Science, Raleigh, NC, USA, 26–27 April 2010; ACM: New York, NY, USA, 2010. [Google Scholar]
- Kriplean, T.; Beschastnikh, I.; McDonald, D.W.; Golder, S.A. Community, consensus, coercion, control: CS*W or how policy mediates mass participation. In Proceedings of the 2007 International ACM Conference on Supporting Group Work, Sanibel Island, FL, USA, 4–7 November 2007; ACM: New York, NY, USA, 2007; pp. 167–176. [Google Scholar]
- Park, H.W.; Thelwall, M. Hyperlink analyses of the World Wide Web: A review. J. Comput. Med. Commun. 2003, 8, 4. [Google Scholar] [CrossRef]
- Gonzalez-Bailon, S. Opening the black box of link formation: Social factors underlying the structure of the web. Soc. Netw. 2009, 31, 271–280. [Google Scholar] [CrossRef]
- Strube, M.; Ponzetto, S.P. WikiRelate! Computing semantic relatedness using Wikipedia. In Proceedings of the AAAI 21st National Conference on Artificial Intelligence, Boston, MA, USA, 16–20 July 2006; Volume 6, pp. 1419–1424.
- Witten, I.; Milne, D. An effective, low-cost measure of semantic relatedness obtained from Wikipedia links. In Proceedings of the AAAIWorkshop onWikipedia and Artificial Intelligence: An Evolving Synergy, Chicago, IL, USA, 13 July 2008; AAAI Press: Menlo Park, CA, USA, 2008; pp. 25–30. [Google Scholar]
- Bellomi, F.; Bonato, R. Network analysis for Wikipedia. In Proceedings of the Wikimania, Frankfurt am Main, Germany, 4–8 August 2005.
- Lizorkin, D.; Medelyan, O.; Grineva, M. Analysis of community structure in Wikipedia. In Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009; ACM: New York, NY, USA, 2009; pp. 1221–1222. [Google Scholar]
- Fowler, J.H.; Jeon, S. The authority of Supreme Court precedent. Soc. Netw. 2008, 30, 16–30. [Google Scholar] [CrossRef]
- Walsh, D.J. On the meaning and pattern of legal citations: Evidence from state wrongful discharge precedent cases. Law Soc. Rev. 1997, 31, 337–361. [Google Scholar] [CrossRef]
- Caldeira, G.A. The transmission of legal precedent: A study of state Supreme Courts. Am. Political Sci. Rev. 1985, 79, 178–194. [Google Scholar] [CrossRef]
- Henrich, J.; Boyd, R.; Richerson, P.J. Five misunderstandings about cultural evolution. Hum. Nat. 2008, 19, 119–137. [Google Scholar] [CrossRef] [PubMed]
- Shirky, C. Here Comes Everybody: The Power of Organizing without Organizations; Penguin: New York, NY, USA, 2008. [Google Scholar]
- Konieczny, P. Governance, Organization, and Democracy on the Internet: The Iron Law and the Evolution of Wikipedia. Sociol. Forum 2009, 24, 162–192. [Google Scholar] [CrossRef]
- Konieczny, P. Adhocratic governance in the Internet age: A case of Wikipedia. J. Inf. Technol. Politics 2010, 7, 263–283. [Google Scholar] [CrossRef]
- Meyer, J.W.; Rowan, B. Institutionalized organizations: Formal structure as myth and ceremony. Am. J. Sociol. 1977, 83, 340–363. [Google Scholar] [CrossRef]
- Open Data for the paper the Evolution of Wikipedia’s Norm Network. Available online: https://bit.ly/wikinorm (accessed on 21 August 2015).
- Morgan, J.T.; Zachry, M. Negotiating with angry mastodons: The wikipedia policy environment as genre ecology. In Proceedings of the 16th ACM International Conference on Supporting Group Work, Sanibel, FL, USA, 7–10 November 2010; ACM: New York, NY, USA, 2010; pp. 165–168. [Google Scholar]
- Template:Policy. Available online: https://en.wikipedia.org/wiki/Template:Policy (accessed on 17 April 2016).
- Template:Guideline. Available online: https://en.wikipedia.org/wiki/Template:Guideline (accessed on 17 April 2016).
- Template:Essay. Available online: https://en.wikipedia.org/wiki/Template:Essay (accessed on 17 April 2016).
- Template:Proposed. Available online: https://en.wikipedia.org/wiki/Template:Proposed (accessed on 17 April 2016).
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Halfaker, A.; Geiger, R.S.; Morgan, J.T.; Riedl, J. The rise and decline of an open collaboration system: How Wikipedia’s reaction to popularity is causing its decline. Am. Behav. Sci. 2013, 57, 664–688. [Google Scholar] [CrossRef]
- Wikipedia Statistics: Active Wikipedians. Available online: https://stats.wikimedia.org/EN/TablesWikipediansEditsGt5.htm (accessed on 21 August 2015).
- Brush, E.R.; Krakauer, D.C.; Flack, J.C. A family of algorithms for computing consensus about node state from network data. PLoS Comput. Biol. 2013, 9, e1003109. [Google Scholar] [CrossRef] [PubMed]
- StatsGrok. Available online: http://stats.grok.se (accessed on 17 April 2016). Data from service created by Domas Mituzas, visualized by Wikipedia User Henrik.
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- DeDeo, S.; Hawkins, R.X.; Klingenstein, S.; Hitchcock, T. Bootstrap methods for the empirical study of decision-making and information flows in social systems. Entropy 2013, 15, 2246–2276. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- Yan, E.; Ding, Y. Scholarly network similarities: How bibliographic coupling networks, citation networks, cocitation networks, topical networks, coauthorship networks, and coword networks relate to each other. J. Am. Soc. Inf. Sci. Technol. 2012, 63, 1313–1326. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef]
- Jacomy, M.; Venturini, T.; Heymann, S.; Bastian, M. ForceAtlas2, a Continuous Graph Layout Algorithm for Handy Network Visualization Designed for the Gephi Software. PLoS ONE 2014, 9, e98679. [Google Scholar] [CrossRef] [PubMed]
- Merton, R.K. The Matthew effect in science. Science 1968, 159, 56–63. [Google Scholar] [CrossRef] [PubMed]
- Shaw, A.; Hill, B.M. Laboratories of oligarchy? How the Iron Law extends to peer production. J. Commun. 2014, 64, 215–238. [Google Scholar] [CrossRef]
- Forte, A.; Larco, V.; Bruckman, A. Decentralization in Wikipedia governance. J. Manag. Inf. Syst. 2009, 26, 49–72. [Google Scholar] [CrossRef]
- Cohen, J. A power primer. Psychol. Bull. 1992, 112, 155. [Google Scholar] [CrossRef] [PubMed]
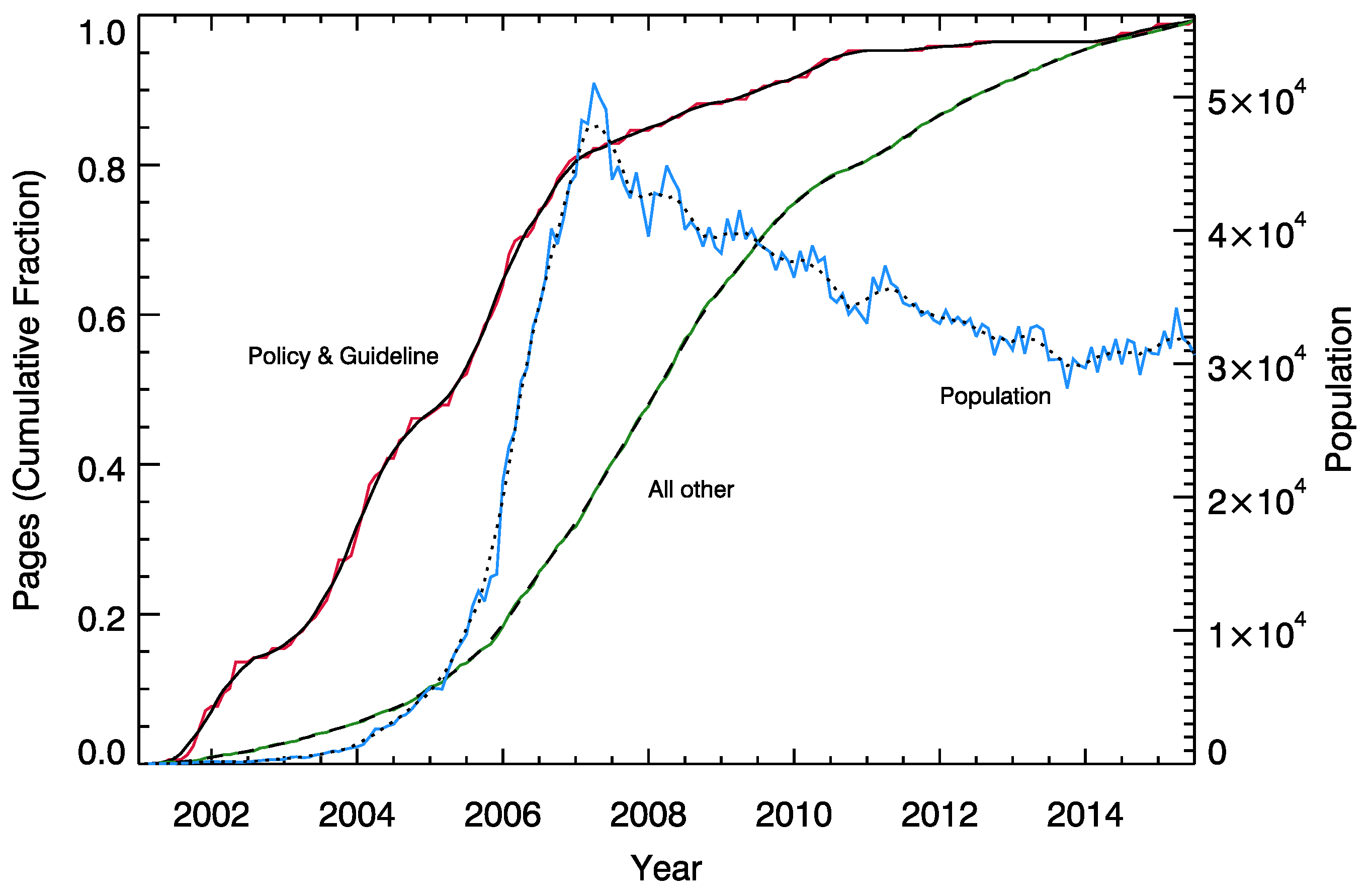
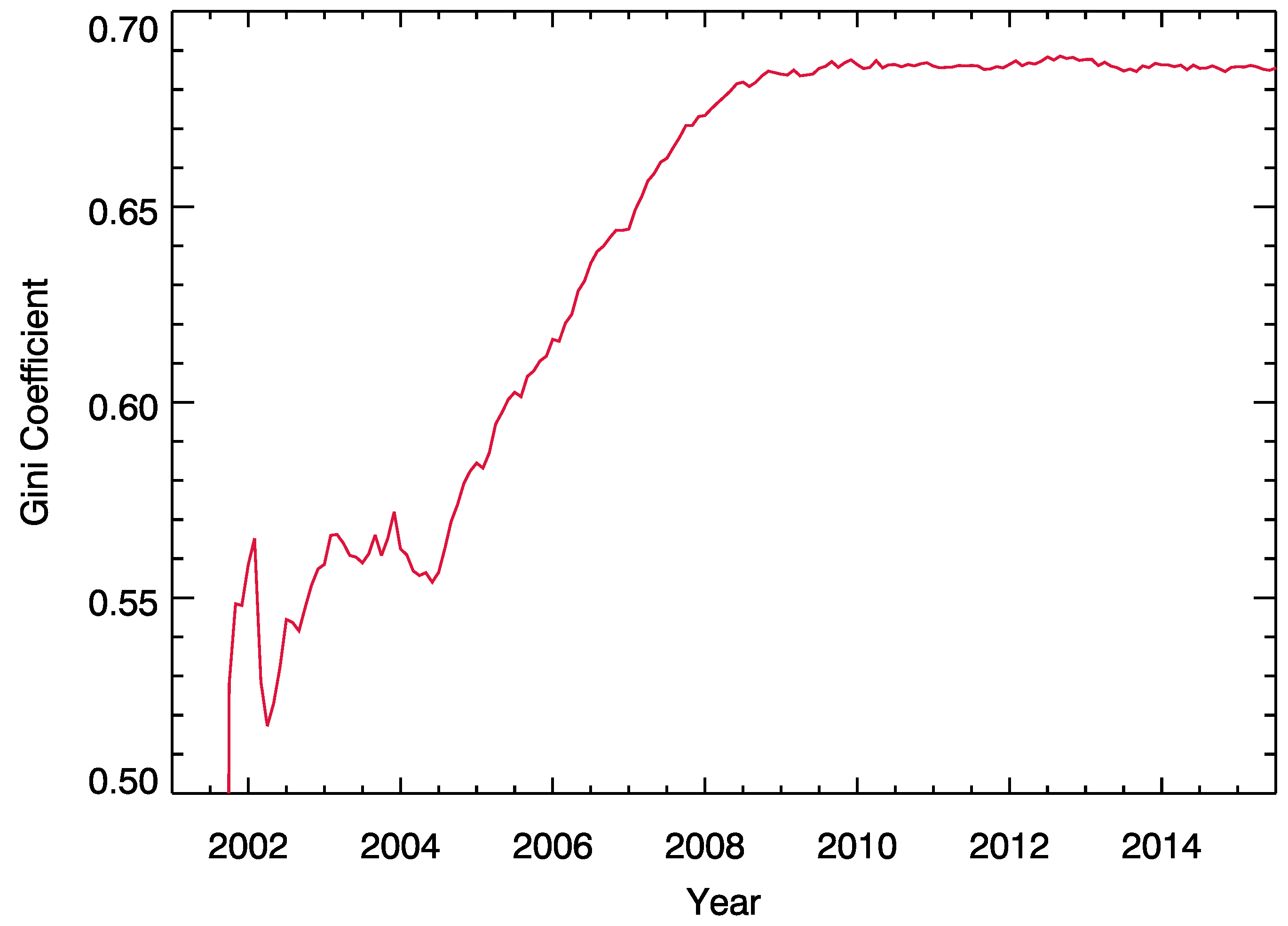
| Rank | Name | Classification | Creation Date |
|---|---|---|---|
| 1 | Neutral_point_of_view | User-content | 24 December 2001 |
| 2 | Verifiability | User-content | 2 August 2003 |
| 3 | Identifying_reliable_sources | User-content | 28 February 2005 |
| 4 | What_Wikipedia_is_not | User-user/user-content | 24 September 2001 |
| 5 | Biographies_of_living_persons | User-content | 17 December 2005 |
| 6 | Consensus | User-user | 11 July 2004 |
| 7 | Policies_and_guidelines | User-user/user-content | 1 November 2001 |
| 8 | Administrators | User-admin | 16 May 2001 |
| 9 | No_original_research | User-content | 21 December 2003 |
| 10 | Citing_sources | User-content | 19 April 2002 |
| 11 | Assume_good_faith | User-user | 3 March 2004 |
| 12 | Notability | User-content | 7 September 2006 |
| 13 | Blocking_policy | User-admin | 8 June 2003 |
| 14 | Dispute_resolution | User-user/user-admin | 12 January 2004 |
| 15 | Redirect | User-content | 25 February 2002 |
| 16 | Civility | User-user | 5 February 2004 |
| 17 | Arbitration_Committee | User-admin | 16 January 2004 |
| 18 | Vandalism | User-content | 29 March 2002 |
| 19 | Edit_warring | User-user | 26 April 2003 |
| 20 | Talk_page_guidelines | User-user | 15 April 2005 |
| Rank | Fraction of System | Classification | Topic |
|---|---|---|---|
| 1 | 24.8% | User-Content | Article Quality |
| 2 | 22.9% | User-User | Collaboration |
| 3 | 17.1% | User-Administration | Administrators |
| 4 | 14.7% | User-Content | Formatting Articles |
| 5 | 10.5% | User-Content | Content Policies |
| 6 | 5.4% | User-User | Wiki-larping |
| 7 | 2.0% | User-Content | Page Templates |
| 8 | 1.3% | User-User/User-Content | Experts and Credentials |
| 9 | 1.0% | User-User | Humor |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Heaberlin, B.; DeDeo, S. The Evolution of Wikipedia’s Norm Network. Future Internet 2016, 8, 14. https://doi.org/10.3390/fi8020014
Heaberlin B, DeDeo S. The Evolution of Wikipedia’s Norm Network. Future Internet. 2016; 8(2):14. https://doi.org/10.3390/fi8020014
Chicago/Turabian StyleHeaberlin, Bradi, and Simon DeDeo. 2016. "The Evolution of Wikipedia’s Norm Network" Future Internet 8, no. 2: 14. https://doi.org/10.3390/fi8020014
APA StyleHeaberlin, B., & DeDeo, S. (2016). The Evolution of Wikipedia’s Norm Network. Future Internet, 8(2), 14. https://doi.org/10.3390/fi8020014