Abstract
Legal judgment prediction is an emerging application of artificial intelligence in the legal domain, offering significant potential to enhance legal decision support systems. Such systems can improve judicial efficiency, reduce burdens on legal professionals, and assist in early-stage case assessment. This study focused on predicting whether a legal case would be Accepted or Rejected using only the Fact section of court rulings. A key challenge lay in processing long legal documents, which often exceeded the input length limitations of transformer-based models. To address this, we proposed a two-step methodology: first, each document was segmented into sentence-level inputs compatible with AraBERT—a pretrained Arabic transformer model—to generate sentence-level predictions; second, these predictions were aggregated to produce a document-level decision using several methods, including Mean, Max, Confidence-Weighted, and Positional aggregation. We evaluated the approach on a dataset of 19,822 real-world cases collected from the Saudi Arabian Commercial Court. Among all aggregation methods, the Confidence-Weighted method applied to the AraBERT-based classifier achieved the highest performance, with an overall accuracy of 85.62%. The results demonstrated that combining sentence-level modeling with effective aggregation methods provides a scalable and accurate solution for Arabic legal judgment prediction, enabling full-length document processing without truncation.
Keywords:
Arabic NLP; AraBERT; classification; judgment prediction; legal judgment; LegalAI; LJP; segmentation 1. Introduction
Legal Artificial Intelligence (LegalAI) refers to the use of artificial intelligence methods in the legal domain. One prominent task in this area is legal judgment prediction (LJP), which aims to predict the outcome of a case by learning patterns from previously adjudicated cases. Such systems have the potential to save time and effort, reduce the burden on judges, lawyers, and plaintiffs, and provide a preliminary review of a case before it is initiated. One of the main challenges in LJP is language diversity, since these systems rely heavily on legal texts written in different languages. However, the challenge extends beyond language alone. Legal systems also vary significantly from one country to another, even among Arabic-speaking countries. Each country has its own legal rules, reasoning processes, and terminology, and this poses a challenge for developing universally effective models across different jurisdictions. Consequently, there is a growing need for Arabic-language, country-specific LJP systems that account for variations in both language and legal frameworks.
This need is particularly critical within the Kingdom of Saudi Arabia, where the number of filed cases increased by 23.56% between 2021 and 2024 [1]. Developing automated judgment prediction tools tailored to the Saudi legal system could play a vital role in enhancing judicial efficiency and reducing case backlogs.
Several studies have explored natural language processing (NLP) in the Arabic legal domain, but only a few have attempted LJP in the Saudi context. Al-Qurishi et al. [2] developed AraLegal-BERT, a domain-specific Arabic BERT model trained entirely from scratch on a large corpus of legal texts. While valuable for general NLP tasks such as classification and named entity recognition (NER), it was not designed for predicting legal outcomes. Almuzaini and Azmi [3] introduced TaSbeeb, a decision-support system for Saudi personal-status cases that retrieves relevant legal justifications, yet it does not perform outcome prediction.
Abbara et al. [4] proposed ALJP, focusing on custody and annulment rulings in personal-status cases. However, their dataset contained only 128 cases, making the study too limited in scale and scope to be generalizable. More recently, Ammar et al. [5] explored the use of large language models (LLaMA, JAIS, GPT-3.5) on Saudi commercial court data to generate complete rulings. Although their work demonstrated the potential of LLMs, their dataset was relatively small, and the generative approach achieved only modest alignment with human rulings.
Our study advances beyond these efforts in three ways. First, we build the largest dataset to date of Saudi commercial court cases for LJP, comprising 19,822 judgments. Second, we introduce a segmentation-and-aggregation framework that allows transformer models to process entire case documents without truncation, overcoming the 512-token input limit. Third, unlike prior approaches that either focused on legal retrieval, very small datasets, or generative text outputs, our method provides an outcome-focused prediction system (Accepted vs. Rejected) with interpretable sentence-level insights.
The key contributions of this study are as follows:
- We construct the largest dataset of Saudi commercial court rulings for LJP (19,822 cases), providing a resource that enables large-scale, reliable evaluation and significantly surpasses the size and scope of prior Arabic LJP datasets.
- We adapt and extend segmentation-and-aggregation methods for the Arabic legal domain, introducing Arabic-aware sentence segmentation and multiple aggregation strategies (mean, max, confidence-weighted, and positional) to effectively process long commercial court rulings without truncation.
- We deliver an outcome-focused and interpretable prediction framework (Accepted vs. Rejected) that achieves strong accuracy (85.62%), outperforms traditional baselines, and provides sentence-level insights that enhance transparency for practical judicial decision support.
This paper is structured as follows: Section 2 reviews the related work. Section 3 describes the dataset construction process and the classification model used. Section 4 presents the experimental results, while Section 5 provides a discussion of the findings. Finally, Section 6 concludes the paper.
2. Related Work
The task of predicting legal judgments can be traced back to the pioneering work of Kort [6], who, in 1957, applied quantitative methods to forecast decisions of the US Supreme Court in right-to-counsel cases. However, practical deployment of such systems has long been constrained by linguistic diversity, legal complexity, and limited access to large-scale annotated datasets. Over time, the field has progressed from traditional machine learning approaches to more sophisticated deep learning and multitask neural models.
Early methods relied on shallow textual features such as TF-IDF and topic models, achieving moderate performance on subsets of the European Court of Human Rights (ECHR) database [7,8]. These studies demonstrated that document structure and section-specific content significantly influenced prediction accuracy, laying the foundation for contemporary segmentation strategies. Similar approaches applied to US Supreme Court [9] and UK Supreme Court cases [10] yielded only moderate F1-scores (around 0.67–0.69), highlighting the difficulty of predicting appellate outcomes using shallow text representations, particularly in cases requiring nuanced legal reasoning.
The emergence of large-scale legal datasets and advances in natural language processing positioned deep learning as the dominant paradigm in legal judgment prediction. Early deep learning approaches, including convolutional and recurrent architectures, were designed to capture richer semantic and sequential information in legal texts. Long et al. [11] proposed AutoJudge, an end-to-end neural model for divorce judgment prediction in Chinese civil law. By combining a Bi-GRU encoder with pair-wise attention and a CNN classifier, the model outperformed both traditional baselines and earlier neural alternatives, demonstrating the benefit of modeling interactions across multiple legal text types. Extending deep learning to a multi-court system, Mumcuoğlu et al. [12] developed a prediction framework for the Turkish judiciary and found that recurrent networks, particularly LSTMs, consistently outperformed classical approaches across different court settings.
Further advances came through attention and multitask learning. Luo et al. [13] introduced a framework for jointly ranking relevant law articles and predicting charges, showing that attention mechanisms significantly improved accuracy. Building on this line of work, Xiao et al. [14] released the large-scale CAIL2018 dataset covering millions of Chinese criminal cases and compared early deep learning models with traditional baselines. Interestingly, TF-IDF with SVM outperformed CNNs, illustrating that well-designed feature engineering could rival early neural approaches.
A key limitation identified in this work was severe class imbalance in charge prediction. Related to this challenge, Hu et al. [15] proposed a few-shot learning framework tailored for low-resource legal settings, achieving substantial gains on rare charges. Zhong et al. [16] subsequently introduced TOPJUDGE, a topological multitask framework that jointly predicted charges, law articles, and penalties, and consistently outperformed both single-task and prior multitask baselines on large-scale Chinese datasets.
Together, these studies established the value of attention, multitask learning, and meta-learning in legal judgment prediction, demonstrating clear improvements over shallow feature-based methods. Nevertheless, early deep learning models remained constrained by difficulties in handling very long documents and persistent class imbalance, motivating the subsequent shift toward transformer-based architectures.
Transformer-based models have further advanced legal judgment prediction. On ECHR data, Chalkidis et al. [17] compared traditional baselines with BiGRU, HAN, BERT, and Hierarchical BERT (HIER-BERT). The hierarchical variant achieved the highest performance, with F1-scores of 0.82 for binary prediction and 0.60 for multi-label tasks, demonstrating the effectiveness of hierarchical architectures in capturing the structure of long legal texts. In Brazil, Lage-Freitas et al. [18] evaluated cases from the State Supreme Court of Alagoas, comparing traditional classifiers with several deep learning models, including BERT-Imbau, a Portuguese-language transformer. Interestingly, traditional approaches such as XGBoost rivaled or even outperformed deep models when combined with careful preprocessing and class rebalancing, underscoring that preprocessing quality remains a critical factor in low-resource legal settings.
In the US, Semo et al. [19] compiled a dataset of class-action lawsuits and evaluated multiple transformer variants under different input configurations. CaseLawBERT, a domain-specific model pretrained on US case law, outperformed generic BERT and even long-context models such as Longformer, indicating that domain-specific pretraining can be more valuable than extended sequence capacity. However, overall performance remained modest, suggesting that both pretraining and effective handling of long case contexts are necessary for robust prediction.
In contrast to prior studies in other jurisdictions, our work focuses on Arabic commercial court cases and introduces a segmentation-based strategy to address the challenge of long legal documents, thereby adapting transformer models to a novel language and legal system. Despite the rapid growth of LJP research in English, Chinese, and European contexts, Arabic legal NLP remains underexplored. The complexity of Arabic morphology, syntactic variability, and rich inflectional structure pose unique challenges for standard NLP models. Legal documents in Arabic also exhibit domain-specific characteristics, such as highly formal language, long nested sentence structures, and frequent use of legal jargon and rhetorical expressions. Moreover, many Arabic legal systems, including the Saudi judiciary, follow civil law traditions, which involve detailed reasoning grounded in codified laws and make judgment prediction particularly intricate.
Several efforts have begun addressing this gap. Al-Qurishi et al. [2] introduced AraLegal-BERT, the first Arabic BERT model pretrained entirely from scratch on a large corpus of Arabic legal texts, showing the effectiveness of domain-specific pretraining for tasks such as text classification, NER, and keyword extraction. However, the model was not evaluated for legal judgment prediction and is not publicly available, limiting its direct applicability to this task. Almuzaini and Azmi [3] proposed TaSbeeb, a decision-support system for Saudi courts that assists legal professionals by retrieving relevant judicial reasoning from sources such as the Qur’an, Sunnah, and legal principles. While important for judicial reasoning, its focus differs from outcome prediction.
On a smaller scale, Abbara et al. [4] developed ALJP, a system for personal-status cases (e.g., custody and annulment) using just 128 cases, including 49 collected from the Saudi Ministry of Justice and 79 simulated cases prepared by legal experts. Traditional and deep learning models were evaluated, with SVM and AraVec embeddings performing best, but the dataset’s limited size restricted scalability. More recently, Ammar et al. [5] investigated large language models (LLaMA, JAIS, and GPT-3.5) for predicting rulings in Arabic commercial court cases. While GPT-3.5 achieved the best alignment with reference rulings, overall performance was modest, highlighting the difficulty of generating full legal decisions in Arabic.
Together, these studies show the potential of domain-specific pretraining, retrieval-based decision support, and emerging LLMs for Arabic legal NLP, but they also reveal gaps in large-scale, outcome-focused prediction systems. Our work addresses this need by constructing a comprehensive dataset of Saudi commercial court cases and applying segmentation-based transformer models to predict case acceptance or rejection.
The deployment of AI in judicial contexts raises significant ethical and ontological considerations that must be carefully addressed. As Barbierato et al. [20] demonstrate, the broader integration of machine learning technologies demands fundamental examination of fairness, transparency, and explainability principles. Such concerns are particularly acute in high-stakes applications such as legal systems, where decisions carry profound consequences. They are further compounded by semantic bias embedded in historical judicial data, which can lead to unethical and discriminatory predictions [21].
Beyond technical fairness, AI deployment in legal systems raises broader human rights concerns. Rodrigues [22] emphasizes that AI technologies can disproportionately impact vulnerable individuals and groups, creating accountability gaps in existing frameworks. Recital 61 of the EU AI Act (Regulation (EU) 2024/1689) similarly classifies AI for judicial decision-making as a “high-risk” application, underscoring the necessity of fairness, accountability, and human oversight in this domain [23]. The ontological question of the role of AI in legal reasoning, whether as an augmentative tool or a substitute for human judgment, remains central to responsible implementation.
Our segmentation-based approach seeks to address these ethical imperatives by maintaining human oversight and providing granular, interpretable predictions that allow legal practitioners to examine which specific aspects of case documents influence model recommendations. This transparency mechanism supports rather than replaces human judicial reasoning, contributing to more equitable and accountable legal AI systems.
3. Materials and Methods
This section presents the overall methodology adopted in this study, which consists of several key phases: data collection and preprocessing, sentence-level segmentation, prediction using a fine-tuned AraBERT model, and final document-level classification through aggregation. We begin by describing the construction and labeling of the dataset, followed by the segmentation process used to prepare the Fact section of each legal document for model input. Next, we explain how sentence-level predictions are generated and, finally, how various aggregation methods are applied to derive a single document-level outcome.
3.1. Data Collection
The dataset was constructed using publicly available court decisions published by the Ministry of Justice of the Kingdom of Saudi Arabia [24]. The Ministry maintains a large corpus of legal cases on its official website, primarily covering decisions from the Commercial Court and its appellate divisions. The Commercial Court is a specialized tribunal responsible for adjudicating business and financial disputes, including contractual, commercial, and corporate matters, while its appellate branches handle legal challenges to first-instance rulings. This online repository includes over 65,000 legal cases, offering a valuable resource for Arabic legal text processing and related NLP tasks. The platform organizes cases using a hierarchical taxonomy that supports thematic categorization. At the top level, categories include lawsuits, rights, personal status, enforcement, rules and regulations, and commercial matters. At the time of data collection, the website featured a structured taxonomy classifying cases by legal type. This structure has since been updated and no longer includes explicit case-type labels.
To balance diversity with consistency, specific case types were selected for inclusion in the dataset. From the Commercial category, Renting and Selling cases were chosen due to their frequency and relevance to common commercial disputes. From the Lawsuit category, Proceedings of the Case was selected, as it provides a comprehensive view of procedural legal reasoning. These selections aimed to ensure a representative sampling of legal subjects while also enabling focused evaluation of models on relatively homogeneous categories.
Each court ruling on the Ministry of Justice website consists of multiple sections. The first section presents essential case metadata, including the court type, city, case number, and date of judgment. The second section displays a set of tags used to categorize the case by type. The third section contains a summary of the case, typically outlining key facts and legal arguments. In some instances, a fourth section is included, presenting the appellate ruling if an appeal was filed.
Web scraping methods were employed in accordance with publicly accessible content and the terms of use outlined by the Ministry of Justice of the Kingdom of Saudi Arabia [25]. In line with the Ministry’s open data policy, which permits the reuse of non-confidential public data for research purposes, only publicly available court rulings were collected. No private or personally identifiable information was scraped or stored. Attribution to the Ministry of Justice is provided, and the resulting dataset is securely stored and available upon request to ensure ethical compliance.
Figure 1 illustrates the data extraction pipeline. Selenium was used to extract hyperlinks to individual case pages by targeting specific HTML elements. A cleaning step was applied to filter out invalid or duplicate links, ensuring the quality and consistency of the extracted data. In the second stage, BeautifulSoup was used to retrieve detailed information from each case page.
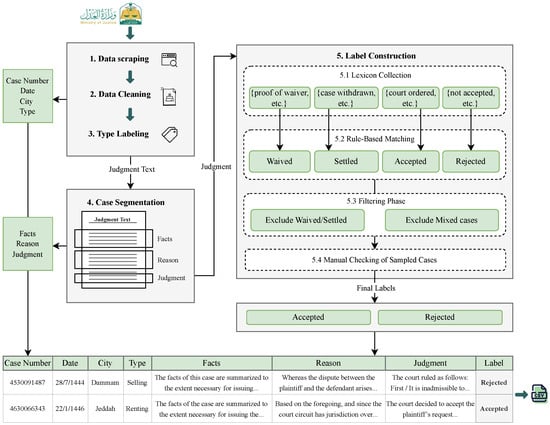
Figure 1.
Data collection pipeline for Saudi legal cases, including web scraping, cleaning, segmentation, and rule-based labeling.
The extracted dataset was compiled into a structured CSV format, with each row representing a unique legal case. The fields include ‘Case Number’ (numeric), ‘Date’ (Hijri calendar, formatted as DD/MM/YYYY), ‘City’ (string), and ‘Judgment Text’ (UTF-8 encoded Arabic text).
3.2. Data Preprocessing
After data collection, several issues were identified in the raw dataset that required attention prior to model development. The most prominent issue was the presence of missing values, particularly in the Judgment Text column, where some entries were completely blank. These incomplete records posed risks to data consistency and could negatively impact model training. In addition, duplicate entries were discovered, likely due to repeated scraping or overlapping records at the source. Structural and formatting inconsistencies were also identified within the judgment text.
A set of preprocessing steps was performed on the Judgment Text:
- Removal of Tashkeel (diacritical marks):All Arabic diacritical marks were removed to standardize the text across entries.
- Removal of HTML tags:Any embedded HTML tags were stripped to retain only clean, plain text.
- Whitespace normalization: Redundant whitespace characters, including tabs, multiple spaces, and newline characters, were removed to sanitize the text.
Following these cleaning steps, each case was labeled with its corresponding case type.
Although most cases exhibited a recognizable structure comprising facts, legal reasoning, and the final judgment, approximately 6.4% of the documents lacked clear formatting or contained irregular section markers. These cases were excluded from further processing due to the difficulty of reliably segmenting their content. To improve consistency, each remaining Judgment Text was segmented into three distinct columns: Facts, Reasons, and Judgment, using predefined legal keywords that typically precede each section. These structured records were then consolidated into a single, organized dataset to facilitate downstream analysis and model training.
3.3. Rule-Based Labeling
Following data collection and cleaning, each case was labeled in accordance with the research objectives, based on the court’s final ruling. This was achieved through a rule-based (lexicon-driven) labeling approach applied to the Judgment section of each case. The method relies on detecting specific keywords or phrases indicative of the court’s decision.
Upon analyzing a large sample of cases, the most common outcomes fell into five categories: Accepted, Rejected, Waived, Settled, and Mixed. The first two categories represent formal court rulings, whereas the latter two typically refer to cases resolved outside of court proceedings. For instance, a waiver indicates that the plaintiff voluntarily withdrew the case, while a settlement reflects an amicable resolution between the parties. As these categories do not reflect judicial rulings, they were excluded from the final dataset.
The Mixed category refers to cases where multiple claims were filed and different rulings were obtained, such as some claims being Accepted and others Rejected within the same case. These cases were excluded from our dataset to eliminate ambiguity. Table 1 provides examples of typical phrases used to assign cases to each category.

Table 1.
Arabic legal phrases used for rule-based labeling with English translations and assigned labels.
The initial labeling process yielded a total of 32,174 cases, distributed across five categories: 12,995 Accepted, 10,498 Rejected, 7258 Mixed, 1263 Waived, and 160 Settled, as summarized in Table 2.
Table 2.
Initial distribution of labeled case outcomes.
To assess labeling accuracy, a stratified random sample of 500 cases was selected based on both case type and label to ensure representative coverage of all categories. A manual review of these cases revealed that 492 out of 500 labels (98.4%) were consistent with the final court rulings, while only 8 cases (1.6%) were mislabeled. This high agreement demonstrates the reliability and robustness of the rule-based labeling approach.
3.4. Dataset Composition
To prevent data leakage and ensure unique representation, duplicate entries were removed both at the combined level (Fact, Reason, and Judgment together) and within each column individually. After this step, we balanced the dataset by undersampling the Rejected class, which was slightly larger than the Accepted class. The reduction was drawn primarily from the Proceedings of the Case category, as it constituted the largest proportion of cases. The final dataset consists of 19,822 cases, with 9911 Accepted and 9911 Rejected cases. These cases span various legal types, including Renting, Selling, and Proceedings of the Case. Table 3 summarizes the distribution of Accepted and Rejected cases across these legal categories.
Table 3.
Distribution of Accepted and Rejected cases by type.
3.5. Classification
A transformer-based language model tailored to the Arabic language was adopted to classify the legal document. Pretrained on large-scale Arabic corpora, this model is well-suited for capturing the linguistic structure and semantics of Arabic legal texts. A transformer-based model can process a maximum of 512 tokens per input, which limits their ability to handle long documents. This poses a significant challenge in our task, as the Fact sections in our legal cases average 1210 tokens, with some reaching up to 10,940 tokens. Figure 2 illustrates the token length distribution within the Fact section, revealing that most cases exceed 500 tokens.
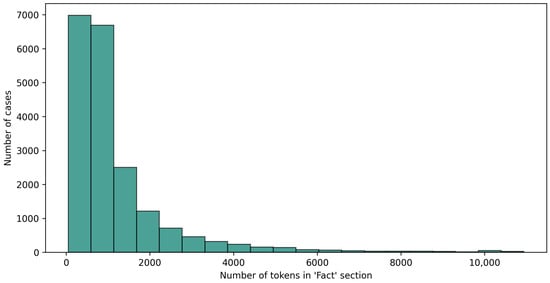
Figure 2.
Token length distribution of the Fact section.
To address this limitation, our method introduces a text-splitting strategy based on commas and periods to maintain logical and meaningful sentence boundaries. If the sentence reached 510 tokens and no comma or period appeared, we searched backward within a window of 50 tokens for punctuation. If none were found, the sentence was split at the nearest space upon reaching 510 tokens, while ensuring subword tokens remained intact. An overlap of 20 tokens was added to preserve contextual continuity.
This approach resulted in 40,823 sentence segments using punctuation and 16,442 segments split by token limit, totaling 57,265 sentences. The number of sentence segments per case ranged from 1 to 22, depending on the length of the case. After reviewing short segments, those with 50 tokens or fewer were removed due to their low informational value. Each case was assigned a unique document ID along with an internal segment index to preserve order. Figure 3 provides an overview of the full modeling pipeline, including text segmentation, sentence-level classification, and document-level aggregation.
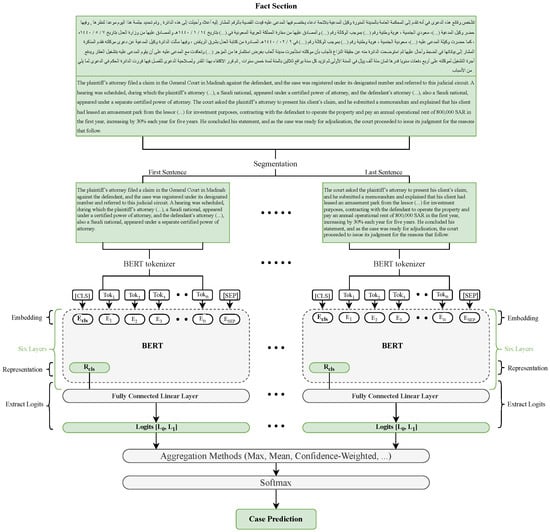
Figure 3.
Overview of the proposed methodology: segmentation, sentence-level classification, and document-level aggregation. Here, refers to logits for the class Rejected, and refers to logits for the class Accepted.
The Fact sections were tokenized using an Arabic-specific tokenizer, with a maximum sequence length of 512 tokens and dynamic padding. The resulting input sequences included token IDs, attention masks, and corresponding labels. These inputs were then converted into contextual embeddings and passed through a pretrained Arabic transformer-based model, where only 6 out of the 12 transformer layers were fine-tuned to reduce overfitting. A linear classification layer was applied on top of the [CLS] token to produce two-class logits (Rejected and Accepted) for each sentence segment.
During inference, each segment was processed independently, generating a matrix of shape per document. To convert these sentence-level outputs into a single document-level prediction, we implemented several aggregation methods that operate on the raw logits (i.e., before softmax activation). This preserves relative confidence across segments and avoids distortions introduced by applying softmax prematurely. The softmax function is applied only once after aggregation to yield the final document-level probabilities.
We experimented with multiple aggregation strategies. Baseline methods included maximum, mean, top-3 mean, and median pooling. More advanced methods incorporated structural and contextual weighting, such as length-weighted, confidence-weighted, and positional (early and late) pooling. The following section details each aggregation method and its corresponding mathematical formulation.
- Max pooling: Selects the segment with the highest logit score.
- Mean Pooling: Averages the logits across all segments equally.
- Top-3 Mean: Averages the logits from the three most confident segments (based on maximum softmax probability). If fewer than three segments are available, all are averaged. Unlike Mean Pooling, which treats all segments equally, top-3 mean assumes the most confident predictions are the most informative and downweights noisy or irrelevant content.
- Median pooling: Takes the element-wise median of all segment logits.
- Length-Weighted: Computes a weighted average where each segment’s contribution is proportional to its token length.
- Confidence-Weighted: Computes a weighted average using each segment’s softmax confidence as the weight.
- Positional-early and positional-late: Apply linearly decaying or increasing weights across segment positions to emphasize early or late segments, respectively.
where is the logit for segment i, n is the total number of segments in the document, denotes the indices of the top-k segments ranked by confidence, is the token length of segment i, is the softmax confidence of segment i, and , are the positional weights for early and late emphasis, respectively.
To obtain the final document-level prediction, we first apply one of the aggregation methods to the sentence-level logits , resulting in a single document-level logit vector. This aggregated vector is then passed through a softmax function to convert the raw logits into class probabilities. Finally, we select the class index c with the highest probability using the argmax function. Formally, the prediction is defined as:
Here, denotes the predicted class label for the document, is the raw logit vector for segment i, and represents the chosen aggregation method (e.g., mean, max, or confidence-weighted). The softmax function ensures the output is a valid probability distribution over the classes, and c ranges over all possible class labels.
3.6. Experimental Setup
To prepare the data for training, the dataset was split into 64% for training (12,686 cases), 16% for validation (3172 cases), and 20% for testing (3964 cases). This split was obtained by initially allocating 80% of the data for training and 20% for testing, then reserving 20% of the training portion for validation (i.e., 16% of the total dataset), a standard practice in deep learning to enable reliable model tuning and unbiased evaluation.
To prevent data leakage during the segmentation step, each case was assigned a unique Document_ID to ensure that all sentence segments from the same case remained within the same subset. This process resulted in 36,702 training sentences, 8927 validation sentences, and 11,636 test sentences. We used a transformer-based model pretrained on Arabic text, specifically AraBERT v2, introduced by Antoun et al. [26].
AraBERT is based on the BERT architecture and was pretrained on a large corpus of Arabic text, including news articles and Wikipedia, using a customized preprocessing pipeline tailored to the morphology and orthography of Arabic. Text normalization was performed using the ArabertPreprocessor as a base, with additional custom preprocessing steps. These included the removal of punctuation (except for single commas and periods), repetitive dot sequences (e.g., …) used to cover sensitive information such as ID numbers, and English terms such as company names and URLs. The Fact sections were then tokenized using the AraBERT tokenizer with a maximum sequence length of 512 tokens and dynamic padding. During training, we fine-tuned only the top six layers of AraBERT, as noted above.
The model was fine-tuned using the Hugging Face Trainer API. The final layer architecture consisted of the [CLS] representation from the transformer, followed by a dropout layer (rate = 0.1) and a fully connected linear layer projecting to the output label space. Table 4 summarizes the key hyperparameters used in training. We initially adopted the default values commonly reported in prior BERT fine-tuning studies (e.g., a learning rate of , three epochs, and standard configurations for batch size, weight decay, evaluation strategy, and mixed precision training). We then tuned the most influential parameters, reducing the learning rate to , increasing the number of epochs to 8, and setting the warm-up ratio to 0.06. These adjustments were made based on empirical validation to improve stability and overall performance.
Table 4.
Key hyperparameters used for fine-tuning the AraBERT classifier.
4. Results
This section presents the evaluation results of the proposed legal judgment prediction model. Performance was assessed using standard metrics, including accuracy, precision, recall, and F1-score. All metrics were computed using macro averaging since the dataset is balanced. Equations (10)–(13) define the evaluation metrics used:
where
- TP—True Positives: correctly predicted positive cases.
- TN—True Negatives: correctly predicted negative cases.
- FP—False Positives: incorrectly predicted as positive.
- FN—False Negatives: incorrectly predicted as negative.
To produce document-level predictions, sentence-level outputs were aggregated based on Document_ID, ensuring that aggregation was performed independently within each predefined data split. Table 5 summarizes the results on the test set across various aggregation methods. The Confidence-Weighted aggregation achieved the best performance, with an accuracy of 85.62% and an F1-score of 85.61%. The Max, Mean, Median, and Top-3 Mean methods also demonstrated strong results, each achieving an F1-score of approximately 84.98–85.41%. In contrast, the Length-Weighted method lagged behind at 84.41%, suggesting that document length alone was not a strong indicator of case outcome. The Positional-Early method underperformed at 81.38%, suggesting that emphasizing earlier segments is less effective for document-level classification. In contrast, the Positional-Late method achieved an F1-score of 84.90%, closely matching the performance of the max-based strategies.
Table 5.
Document-level classification performance on the test set using macro-averaged metrics for different aggregation methods (all metrics reported in %).
Figure 4 presents the confusion matrix for the best-performing method, Confidence-Weighted, highlighting its ability to distinguish between Accepted and Rejected cases. Confusion matrices for the remaining aggregation methods are included in Figure A1.
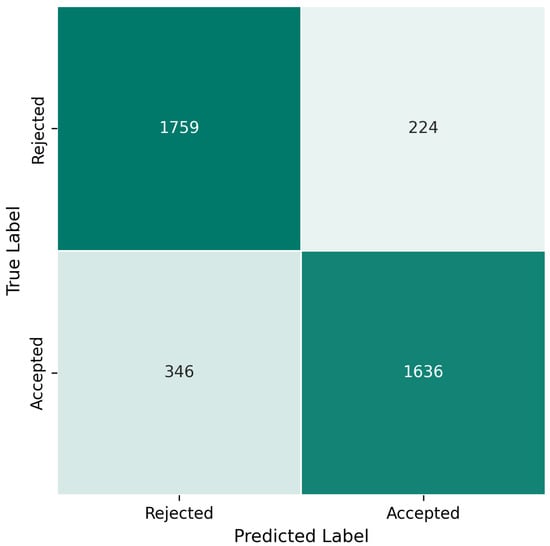
Figure 4.
Confusion matrix for the confidence-weighted aggregation method.
These findings indicate that the model generalizes well across multiple aggregation methods and that the prediction pipeline, from sentence-level outputs to final document-level decisions, is robust and reliable.
To further evaluate our approach, we implemented traditional and neural baselines. The traditional baseline was a linear Support Vector Machine (SVM) [27] trained with unigram and bigram TF-IDF [28] features restricted to the top 5000 n-grams. For neural baselines, we fine-tuned AraBERT v2 [26] on sequences truncated to the default maximum length of 512 tokens, using the same preprocessing and training hyperparameters as our segmentation-based model, except that all transformer layers were fine-tuned rather than partially frozen. In addition, we evaluated XLM-RoBERTa-base (XLM-R) [29], a multilingual model pretrained on 100 languages, fine-tuned with the default maximum sequence length of 512 tokens, and Longformer (base-4096) [30], which supports sequences up to 4096 tokens via sliding-window attention. Longformer was trained with gradient accumulation, gradient checkpointing, and a global attention mask on the first token. Table 6 summarizes the baseline setups.
Table 6.
Summary of baseline models and their configurations.
The performance of all baselines is shown in Table 7. The TF-IDF + SVM baseline achieved an F1-score of 82.98%, demonstrating competitive performance for a non-transformer approach. AraBERT v2, limited to the first 512 tokens, underperformed (F1-score = 78.55%), highlighting both the limited informativeness of early segments and the shortcomings of relying on truncation instead of processing the full document, as achieved by our segmentation-based approach.
Table 7.
Baseline model performance on the test set using macro-averaged metrics (all metrics reported in %).
XLM-RoBERTa achieved an F1-score of 77.24%, closely matching AraBERT v2. This small difference indicates that the primary limitation arises from the low informativeness of early document segments and highlights the importance of processing full documents for tasks such as LJP, with multilingual pretraining contributing only modestly to weaker performance on Arabic legal text. Longformer, despite its ability to process longer inputs, obtained the lowest overall performance (an F1-score of 75.65%), showing that longer input capacity alone cannot compensate for the absence of language-specific pretraining. Collectively, these results demonstrate that both processing full documents and language-specific pretraining are decisive for accurate Arabic legal judgment prediction.
5. Discussion
This study developed a framework for predicting legal judgment outcomes in Arabic court cases by combining sentence-level classification with document-level aggregation. The approach addresses the challenge of modeling long legal documents within the input constraints of transformer-based architectures.
The results of the study showed that the model achieved comparable performance using all the proposed aggregation methods with accuracies ranging from 81% to 86% and corresponding error rates between 14% and 19%. As shown in Figure 4, the best-performing method, Confidence-Weighted, misclassified over 100 Accepted cases as Rejected. Other methods showed similar misclassification rates for Accepted cases, indicating a consistent bias across all methods toward predicting rejection.
While the dataset is balanced at the document level, with an equal number of Accepted and Rejected cases (9911 each), this balance does not hold at the sentence level. The Rejected class comprises 30,819 segments, whereas the Accepted class contains only 26,446 segments. This sentence-level imbalance may have contributed to a higher false negative rate for Accepted cases. Across all aggregation methods, a total of 372 cases were consistently misclassified, including 236 false negatives and 136 false positives. This pattern indicates a bias toward incorrectly predicting Accepted cases as Rejected. Notably, the Positional-Early and Positional-Late methods exhibited a higher number of uniquely misclassified cases not shared with any other method, as shown in Table 8. In contrast, the Mean and Confidence-Weighted methods did not produce any uniquely misclassified cases.
Table 8.
Unique false positives and false negatives by aggregation method.
Figure 5 illustrates that, under the Confidence-Weighted aggregation method, the error rate increases with document length (measured in tokens). Documents containing fewer than 500 tokens exhibit the lowest error rate (8%), while those exceeding 2000 tokens show the highest (24%). This pattern suggests that longer documents may pose additional challenges for the model, potentially due to increased complexity, noise, or difficulties in aggregating a larger number of sentence-level predictions. Notably, this trend was consistent across all other aggregation methods.
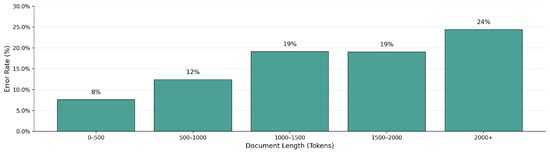
Figure 5.
Error rate by document length using the Confidence-weighted aggregation method.
As shown in Figure 6, which presents the average prediction confidence for correct and incorrect predictions across aggregation methods, the Mean and Positional-Late methods demonstrated the widest confidence gaps. They achieved high confidence for correct predictions (approximately 0.865–0.878) and maintained lower confidence for incorrect ones (approximately 0.696–0.711). Although the Confidence-Weighted method, overall the best performer in terms of macro-F1, also produced high confidence for correct predictions (approximately 0.874) and lower confidence for incorrect ones (approximately 0.714), its separation of 0.160 was close to, though slightly below, the leading methods. In contrast, several other approaches achieved comparable or slightly wider gaps than Confidence-Weighted, while Positional-Early performed the worst, showing the smallest separation.
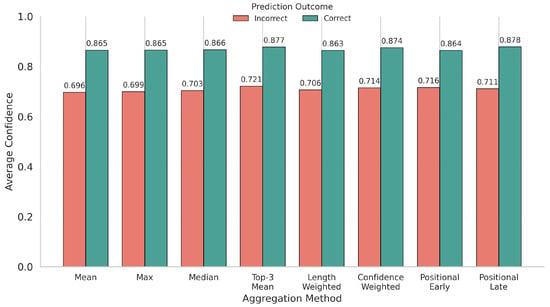
Figure 6.
Average prediction confidence for correct and incorrect predictions across aggregation methods.
Overall, the classification performance appears to be more influenced by the type of legal case than by the specific aggregation method used. As shown in Figure 7, Proceedings of the Case consistently achieved the highest accuracy across all methods (reaching up to 88%), while Renting cases exhibited lower performance, with a minimum accuracy of 77% using the Positional-Early method. This suggests that the inherent characteristics and linguistic patterns of each case type may play a more substantial role in prediction accuracy than the choice of aggregation method.
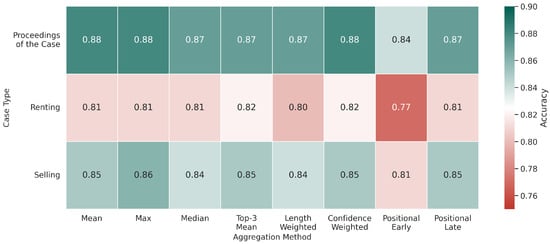
Figure 7.
Heatmap showing classification accuracy across different case types and aggregation methods.
The observations revealed several consistent trends across aggregation methods, including higher accuracy in predicting Rejected cases, an increasing error rate with longer documents, and notable differences in performance across case types. These findings suggest that sentence-level imbalances, contextual dispersion, and inherent differences in case characteristics pose challenges for accurate legal judgment prediction. While aggregation methods like Confidence-Weighted improved overall performance, the classification of Accepted cases remains more error-prone, indicating the need for further refinement.
The baseline results highlight important insights into modeling Arabic legal texts. The relatively strong performance of TF-IDF + SVM (F1 = 82.98%) shows that surface-level lexical cues remain predictive, yet this approach lacks generalization beyond shallow features. The weaker results of AraBERT v2 truncated to the first 512 tokens (F1 = 78.55%) and XLM-R (F1 = 77.24%) emphasize that relying only on early segments is insufficient for capturing the full legal reasoning process. Longformer’s poor performance (F1 = 75.65%) further demonstrates that longer input capacity alone is not beneficial without language- and domain-specific pretraining. Collectively, these patterns confirm that accurate LJP requires both full-document coverage and representations tuned to the legal and linguistic characteristics of Arabic. Our segmentation-and-aggregation framework directly addresses these gaps, providing both predictive accuracy and interpretable insights at the sentence level.
Compared to prior work in Arabic legal NLP, our approach offers distinct advantages in scalability, document coverage, and interpretability. Our sentence-level AraBERT classification with Confidence-Weighted aggregation achieved 85.62% accuracy and an 85.61% F1-score, addressing key methodological limitations observed in earlier studies.
Our results are reasonably close to the F1-score of 0.92 achieved by Abbara et al. [4] for multi-class personal-status case prediction. However, our framework demonstrates superior scalability by processing 19,822 cases, compared to their evaluation on only 128 instances. Unlike Ammar et al.’s generative approach [5], which produced full legal ruling text but showed limited effectiveness in evaluation, our binary classification framework predicts whether cases will be Accepted or Rejected, providing clear, categorical outcomes and objective performance metrics.
While Al-Qurishi et al.’s AraLegal-BERT [2] achieved higher performance (0.92 F1) in legal text classification, their approach applied a “head & tail” truncation strategy and was not designed for judgment prediction tasks. In contrast, our framework processes complete document content while maintaining competitive performance, specifically for judgment prediction.
The key advantage of our approach lies in its balance between classification accuracy, complete document processing, and interpretable sentence-level insights, addressing the limitations of both truncation-based methods and resource-intensive generative approaches.
However, this approach has several limitations. First, it relies on sentence-level segmentation, which may disrupt the contextual flow of long legal narratives and fragment semantic coherence, particularly when legal reasoning spans multiple sentences or sections. To mitigate this issue, we introduced splitting based on periods and commas to maintain sentence integrity, as well as overlapping windows of 20 tokens when no clear boundary markers were present. Nevertheless, the coherence problem is not completely eliminated and may partially explain certain misclassifications observed in our experiments.
This limitation may also contribute to the performance ceiling observed in our results, where achieving accuracy beyond approximately 85% proves challenging without models capable of processing longer contexts and preserving discourse continuity. To address this, future work could investigate the development or adaptation of Arabic long-context transformer architectures capable of processing larger portions of text without segmentation. While such models (e.g., Longformer and BigBird) exist for English and other languages, equivalent models for Arabic remain underexplored, highlighting an important direction for future research.
Second, while AraBERT is a powerful Arabic language model, it was not pretrained on legal-domain texts, which may limit its ability to interpret legal terminology and reasoning accurately. Future work should consider pretraining or domain-adapting Arabic transformer models on large-scale legal corpora to enhance domain-specific understanding.
6. Conclusions
This study proposed a two-step framework for LJP in Arabic commercial court cases. The Fact section of each legal document was first segmented into sentence-level inputs and classified using AraBERT v2. Then, sentence-level predictions were aggregated to generate a final document-level decision.
Experimental results on the test set demonstrated that all aggregation methods performed competitively, with Confidence-Weighted aggregation achieving the highest accuracy (85.62%) and F1-score (85.61%). Error analysis revealed higher precision for Rejected cases, increased error rates in longer documents, and performance variations across case types. These findings highlight the potential of aggregation-based methods for modeling long Arabic legal documents, while also revealing persistent challenges in classifying Accepted outcomes.
The proposed framework could serve as a reliable LJP assistant, enhancing judicial efficiency by reducing case screening time and providing early insights into likely verdicts. In practice, such a system may assist judges and lawyers by estimating potential outcomes based on historical patterns. However, it should be viewed strictly as a decision-support tool rather than a replacement for human judgment, as final legal decisions must remain the responsibility of judges.
This work also addresses a critical research gap by enabling large-scale modeling of long Arabic legal documents and providing interpretable, outcome-focused predictions. Unlike prior approaches that focused on narrower tasks, smaller datasets, or different legal domains, our method targets binary judgment prediction for commercial court cases using a large dataset of 19,822 documents. These contributions advance Arabic LJP by providing a scalable, accurate, and practical framework tailored to the Saudi judicial context.
Although the results provide an advancement over existing studies, they underscore the need for further refinement and expansion. Future research should focus on developing models capable of capturing long-range context in Arabic legal texts and extending evaluation to diverse legal domains, thereby enhancing generalizability and applicability in real-world judicial settings. In addition, future work could address more complex prediction tasks, such as handling cases labeled as “Mixed” where multiple outcomes occur within the same judgment, or extracting the specific legal articles referenced in the court’s decision. Finally, incorporating domain-adaptive pretraining using large-scale Arabic legal corpora could further improve the model’s ability to understand legal terminology and reasoning.
Author Contributions
Conceptualization, A.A.; methodology, A.A., S.A., and N.M.A.; software, A.A.; validation, S.A. and N.M.A.; formal analysis, A.A.; investigation, A.A.; resources, A.A.; data curation, A.A.; writing—original draft preparation, A.A.; writing—review and editing, S.A. and N.M.A.; visualization, A.A.; supervision, S.A. and N.M.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding. The APC was funded by the authors.
Data Availability Statement
Data available on request.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| LegalAI | Legal Artificial Intelligence |
| ML | Machine Learning |
| NLP | Natural Language Processing |
| LJP | Legal Judgment Prediction |
| BERT | Bidirectional Encoder Representations from Transformers |
| AraBERT | Arabic BERT |
| CLS | Classification Token |
Appendix A. Additional Results: Confusion Matrices

Figure A1.
Confusion matrices for each aggregation method on the test set. These visualizations support the claim that Accepted cases are more frequently misclassified than Rejected ones across all methods.
References
- Ministry of Justice of the Kingdom of Saudi Arabia. Judicial Reports. 2025. Available online: https://www.moj.gov.sa/ar/OpenData/PowerBIReport/Pages/BIReportJud.aspx (accessed on 18 August 2025).
- Al-Qurishi, M.; Alqaseemi, S.; Souissi, R. AraLegal-BERT: A Pretrained Language Model for Arabic Legal Text. In Proceedings of the Natural Legal Language Processing Workshop, Abu Dhabi, United Arab Emirates, 8 December 2022; Aletras, N., Chalkidis, I., Barrett, L., Goanță, C., Preoțiuc-Pietro, D., Eds.; Hybrid: Abu Dhabi, United Arab Emirates, 2022; pp. 338–344. [Google Scholar] [CrossRef]
- Almuzaini, H.A.; Azmi, A.M. TaSbeeb: A Judicial Decision Support System Based on Deep Learning Framework. J. King Saud-Univ.-Comput. Inf. Sci. 2023, 35, 101695. [Google Scholar] [CrossRef]
- Abbara, S.; Hafez, M.; Kazzaz, A.; Alhothali, A.; Alsolami, A. ALJP: An Arabic Legal Judgment Prediction in Personal Status Cases Using Machine Learning Models. arXiv 2023, arXiv:2309.00238. [Google Scholar] [CrossRef]
- Ammar, A.; Koubaa, A.; Benjdira, B.; Nacar, O.; Sibaee, S. Prediction of Arabic Legal Rulings Using Large Language Models. Electronics 2024, 13, 764. [Google Scholar] [CrossRef]
- Kort, F. Predicting Supreme Court decisions mathematically: A quantitative analysis of the “right to counsel” cases. Am. Political Sci. Rev. 1957, 51, 1–12. [Google Scholar] [CrossRef]
- Aletras, N.; Tsarapatsanis, D.; Preoţiuc-Pietro, D.; Lampos, V. Predicting judicial decisions of the European Court of Human Rights: A natural language processing perspective. PeerJ Comput. Sci. 2016, 2, e93. [Google Scholar] [CrossRef]
- Medvedeva, M.; Vols, M.; Wieling, M. Using machine learning to predict decisions of the European Court of Human Rights. Artif. Intell. Law 2020, 28, 237–266. [Google Scholar] [CrossRef]
- Alali, M.; Syed, S.; Alsayed, M.; Patel, S.; Bodala, H. JUSTICE: A Benchmark Dataset for Supreme Court’s Judgment Prediction. arXiv 2021, arXiv:2112.03414. [Google Scholar] [CrossRef]
- Strickson, B.; De La Iglesia, B. Legal Judgement Prediction for UK Courts. In Proceedings of the 3rd International Conference on Information Science and Systems (ICISS’20), New York, NY, USA, 19–22 March 2020; pp. 204–209. [Google Scholar] [CrossRef]
- Long, S.; Tu, C.; Liu, Z.; Sun, M. Automatic Judgment Prediction via Legal Reading Comprehension. In Proceedings of the Chinese Computational Linguistics, Kunming, China, 18–20 October 2019; Sun, M., Huang, X., Ji, H., Liu, Z., Liu, Y., Eds.; Springer: Cham, Switzerland, 2019; pp. 558–572. [Google Scholar] [CrossRef]
- Mumcuoğlu, E.; Öztürk, C.E.; Ozaktas, H.M.; Koç, A. Natural language processing in law: Prediction of outcomes in the higher courts of Turkey. Inf. Process. Manag. 2021, 58, 102684. [Google Scholar] [CrossRef]
- Luo, B.; Feng, Y.; Xu, J.; Zhang, X.; Zhao, D. Learning to Predict Charges for Criminal Cases with Legal Basis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 2727–2736. [Google Scholar] [CrossRef]
- Xiao, C.; Zhong, H.; Guo, Z.; Tu, C.; Liu, Z.; Sun, M.; Feng, Y.; Han, X.; Hu, Z.; Wang, H.; et al. CAIL2018: A Large-Scale Legal Dataset for Judgment Prediction. arXiv 2018, arXiv:1807.02478. [Google Scholar] [CrossRef]
- Hu, Z.; Li, X.; Tu, C.; Liu, Z.; Sun, M. Few-Shot Charge Prediction with Discriminative Legal Attributes. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; Bender, E.M., Derczynski, L., Isabelle, P., Eds.; Association for Computational Linguistics: Santa Fe, NM, USA, 2018; pp. 487–498. [Google Scholar]
- Zhong, H.; Guo, Z.; Tu, C.; Xiao, C.; Liu, Z.; Sun, M. Legal Judgment Prediction via Topological Learning. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP 2018), Brussels, Belgium, 31 October–4 November 2018; Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J., Eds.; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 3540–3549. [Google Scholar] [CrossRef]
- Chalkidis, I.; Androutsopoulos, I.; Aletras, N. Neural Legal Judgment Prediction in English. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Korhonen, A., Traum, D., Màrquez, L., Eds.; Association for Computational Linguistics: Florence, Italy, 2019; pp. 4317–4323. [Google Scholar] [CrossRef]
- Lage-Freitas, A.; Allende-Cid, H.; Santana, O.; Oliveira-Lage, L. Predicting Brazilian Court Decisions. PeerJ Comput. Sci. 2022, 8, e904. [Google Scholar] [CrossRef] [PubMed]
- Semo, G.; Bernsohn, D.; Hagag, B.; Hayat, G.; Niklaus, J. ClassActionPrediction: A Challenging Benchmark for Legal Judgment Prediction of Class Action Cases in the US. In Proceedings of the Natural Legal Language Processing Workshop 2022, Abu Dhabi, United Arab Emirates, 8 December 2022; Aletras, N., Chalkidis, I., Barrett, L., Goanță, C., Preoțiuc-Pietro, D., Eds.; Association for Computational Linguistics: Abu Dhabi, United Arab Emirates, 2022; pp. 31–46. [Google Scholar] [CrossRef]
- Barbierato, E.; Gatti, A.; Incremona, A.; Pozzi, A.; Toti, D. Breaking Away from AI: The Ontological and Ethical Evolution of Machine Learning. IEEE Access 2025, 13, 55627–55647. [Google Scholar] [CrossRef]
- Javed, K.; Li, J. Artificial intelligence in judicial adjudication: Semantic biasness classification and identification in legal judgement (SBCILJ). Heliyon 2024, 10, e30184. [Google Scholar] [CrossRef] [PubMed]
- Rodrigues, R. Legal and human rights issues of AI: Gaps, challenges and vulnerabilities. J. Responsible Technol. 2020, 4, 100005. [Google Scholar] [CrossRef]
- European Parliament and Council of the European Union. Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 Laying down Harmonised Rules on Artificial Intelligence (Artificial Intelligence Act), Recital 61. 2024. Available online: https://eur-lex.europa.eu/eli/reg/2024/1689/oj/eng (accessed on 12 September 2025).
- Ministry of Justice of the Kingdom of Saudi Arabia. Judicial Decisions. 2025. Available online: https://laws.moj.gov.sa/ar/JudicialDecisionsList/1 (accessed on 18 August 2025).
- Ministry of Justice of the Kingdom of Saudi Arabia. Open Data Policy. 2025. Available online: https://www.moj.gov.sa/english/OpenData/Pages/OpenDataPolicy.aspx (accessed on 18 August 2025).
- Antoun, W.; Baly, F.; Hajj, H. AraBERT: Transformer-based Model for Arabic Language Understanding. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools (OSACT4), Marseille, France, 11–16 May 2020; Al-Khalifa, H., Magdy, W., Darwish, K., Elsayed, T., Mubarak, H., Eds.; European Language Resources Association (ELRA): Marseille, France, 2020; pp. 9–15. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020), Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J., Eds.; Association for Computational Linguistics: Online, 2020; pp. 8440–8451. [Google Scholar] [CrossRef]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).