
Adam Algorithm with Step Adaptation


Abstract
1. Introduction
2. Problem Statement and Background
| Algorithm 1 (Adam) |
| 1. Set β1, β2 ∈ [0, 1), ε > 0, step size α > 0, the initial point x0 ∈ Rn. The algorithm uses parameters β1 = 0.9, β2 = 0.999, ε = 10−8, α = 0.001. 2. Set k = 0, pk = 0, bk = 0, where pk, bk ∈ Rn. 3. Set k = k + 1, gk = ∇f(xk). 4. . 5. . 6. . 7. ). 8. Get the descent direction . 9. Find a new approximation of the minimum . 10. If the stopping criterion is met, then stop, else go to step 3. |
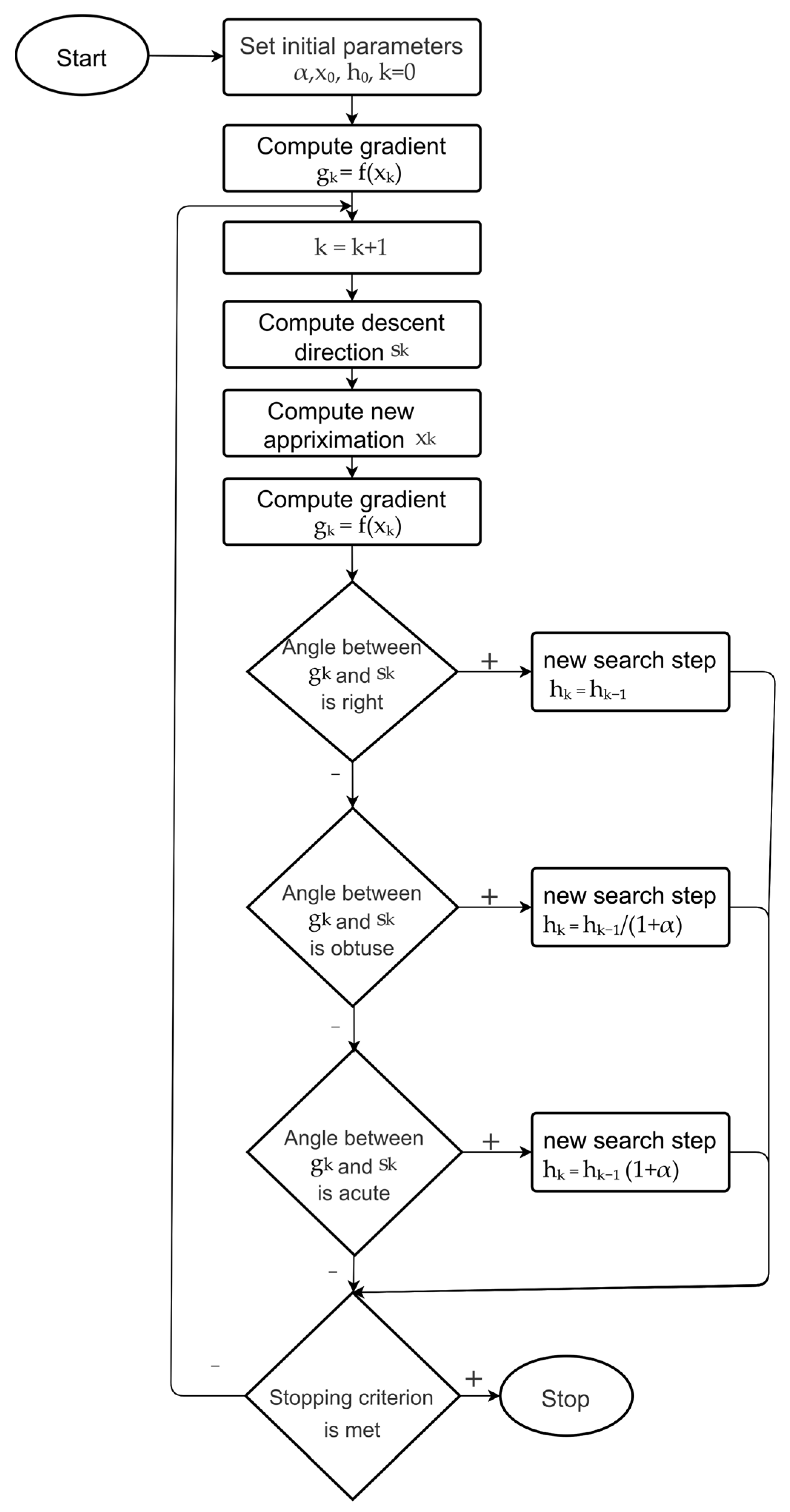
3. Algorithms with Step Adaptation
| Algorithm 2 (H_GR) |
| 1. Set the step adaptation parameter α > 0, the initial point x0 ∈ Rn and the initial step h0 ∈ R1. The algorithm uses parameter α = 0.01. 2. Set k = 0, compute gk = ∇f(xk). 3. Set k = k + 1. 4. Compute the descent direction. 5. Find a new approximation of minimum 6. Compute gk = ∇f(xk). 7. Compute a new search step 7.1 If |(gk, sk)|≤ 10−15 then hk = hk−1 else 7.2 If (gk, sk)≤ 0 then hk = hk−1/(1 + α) else 7.3 hk = hk−1(1 + α). 8. If the stopping criterion is met, then stop, else go to step 3. |
| Algorithm 3 (H_ MOMENTUM) |
| 1. Set the exponential smoothing parameter β1 ∈ [0, 1), ε > 0, step adaptation parameter α > 0, the initial point x0 ∈ Rn and the initial step h0 ∈ R1. The algorithm uses parameters β1 = 0.9, ε = 10−8, α = 0.01. 2. Set k = 0, pk = 0, bk = 0, where pk, bk ∈ Rn, compute gk = ∇f(xk). 3. Set k = k + 1. 4. Compute 5. Find a descent direction . 6. Find a new approximation of minimum 7. Compute gk = ∇f(xk). 8. Compute a new search step 8.1 If |(gk, sk)| ≤ 10−15 then hk = hk−1 else 8.2 If (gk, sk) ≤ 0 then hk = hk−1/(1 + α) else 8.3 hk = hk−1(1 + α). 9. If the stopping criterion is met, then stop, else go to step 3. |
| Algorithm 4 (H_ADAM) |
| 1. Set β1, β2 ∈ [0, 1), ε > 0, step adaptation parameter α > 0, the initial point x0 ∈ Rn, the initial step h0 ∈ R1. The algorithm uses parameters β1 = 0.9, β2 = 0.999, ε = 10−8, α = 0.01. 2. Set k = 0, pk = 0, bk = 0, where pk, bk ∈ Rn. Compute gk = ∇f(xk). 3. Set k = k + 1. 4. . 5. . 6. Get the descent direction . 7. Find a new approximation of the minimum . 8. Compute gk = ∇f(xk). 9. Compute a new search step 9.1 If |(gk, sk)| ≤ 10−15 then hk = hk−1 else 9.2 If (gk, sk) ≤ 0 then hk = hk−1/(1 + α) else 9.3 hk = hk−1(1 + α). 10. If the stopping criterion is met, then stop, else go to step 3. |
4. Numerical Results and Discussion
4.1. Preliminary Analysis of Algorithm Parameters
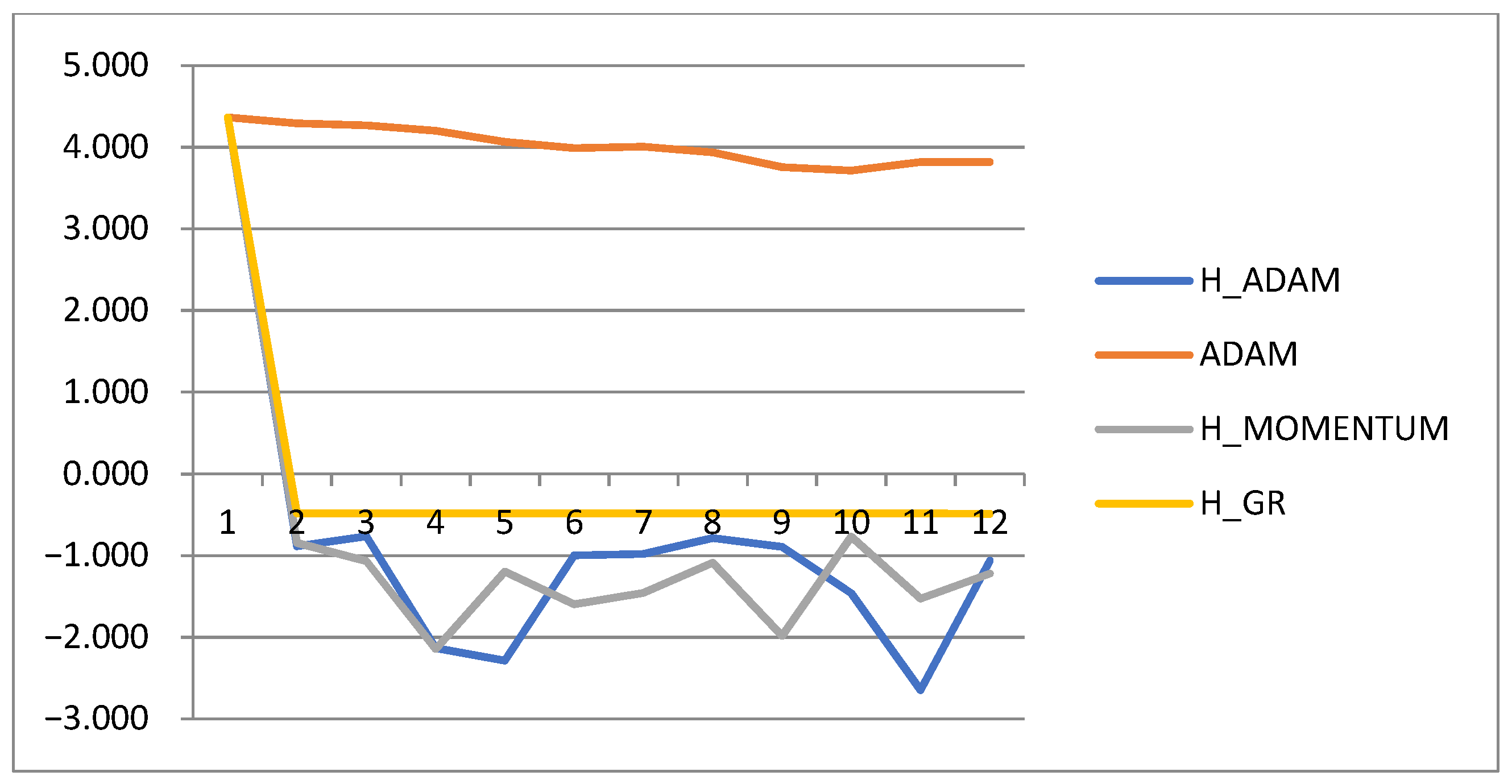
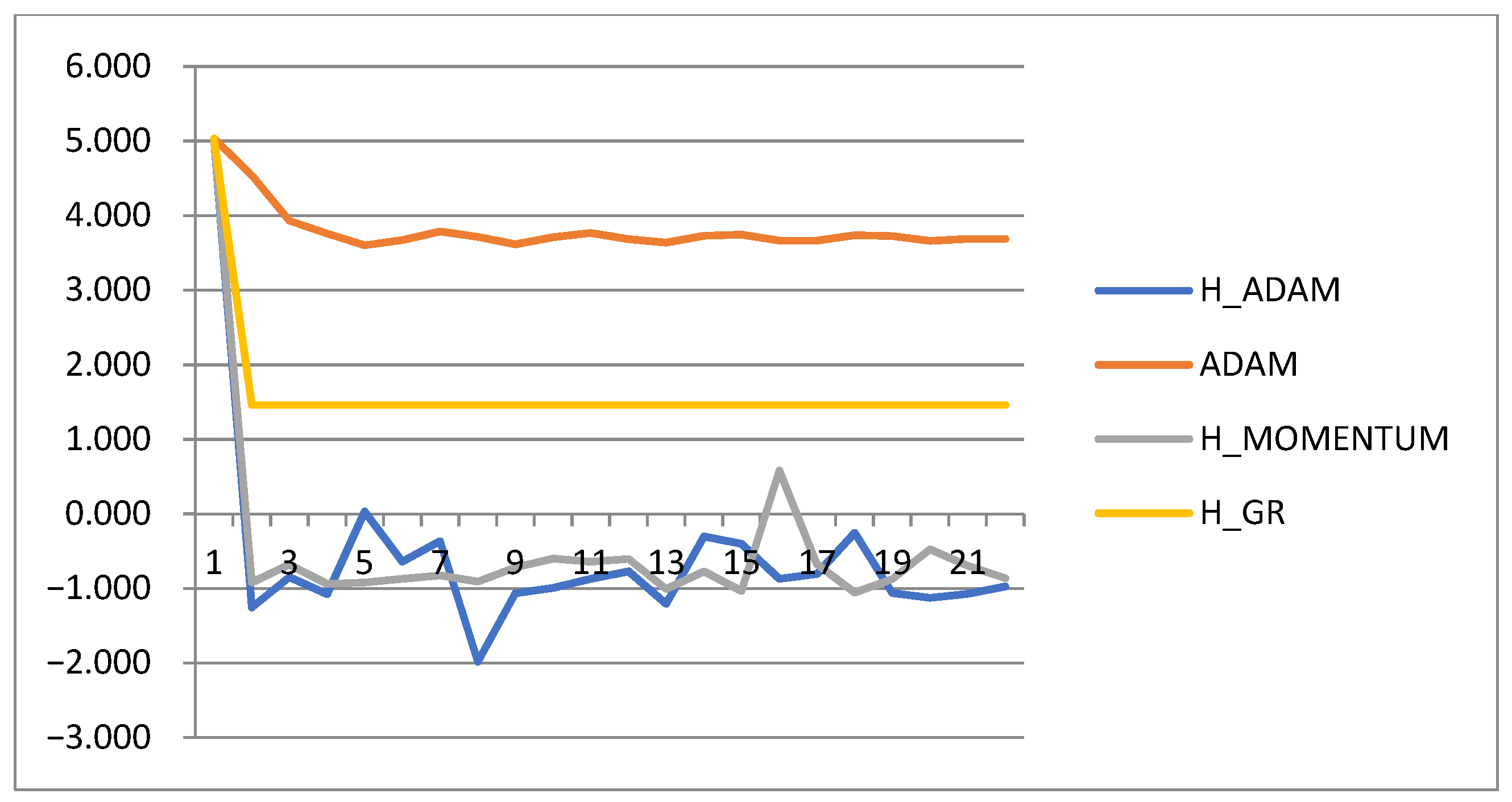
4.1.1. Convergence Rate Analysis
4.1.2. Analysis of Step Adaptation Parameter
4.1.3. Analysis of Exponential Smoothing Parameters
4.2. Test Functions
4.2.1. Rosenbrock Function
4.2.2. Quadratic Functions
4.2.3. Functions with Ellipsoidal Ravine
4.2.4. Non-Quadratic Function
4.3. Application Problem (Regression)
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Designation | Meaning |
|---|---|
| gk,∇f | Gradient of a function |
| hk | Minimization step |
| hk* | Optimal value of minimization step |
| pk | Exponentially smoothed gradients |
| bk | Exponentially smoothed squares of gradients |
| sk | Descent direction |
| xk | Approximation of minimum |
| E | Mathematical expectation |
| Exponential decay rates for the moment estimates | |
| α | Stepsize parameter |
| ε | Small value |
| (a,b) | Scalar product for vectors a and b |
| a·b = a ʘ b | Hadamard product for vectors a and b |
| ‖ ‖ | Vector norm |
| r | Noise level |
| n_max | Maximum number of iterations |
References
- Alamir, N.; Kamel, S.; Abdelkader, S. Stochastic multi-layer optimization for cooperative multi-microgrid systems with hydrogen storage and demand response. Int. J. Hydrogen Energy 2025, 100, 688–703. [Google Scholar] [CrossRef]
- Fan, J.; Yan, R.; He, Y.; Zhang, J.; Zhao, W.; Liu, M.; An, S.; Ma, Q. Stochastic optimization of combined energy and computation task scheduling strategies of hybrid system with multi-energy storage system and data center. Renew. Energy 2025, 242, 122466. [Google Scholar] [CrossRef]
- Wu, Y.; Chen, Z.; Chen, R.; Chen, X.; Zhao, X.; Yuan, J.; Chen, Y. Stochastic optimization for joint energy-reserve dispatch considering uncertain carbon emission. Renew. Sustain. Energy Rev. 2025, 211, 115297. [Google Scholar] [CrossRef]
- Duan, F.; Bu, X. Stochastic optimization of a hybrid photovoltaic/fuel cell/parking lot system incorporating cloud model. Renew. Energy 2024, 237, 121727. [Google Scholar] [CrossRef]
- Zheng, H.; Ye, J.; Luo, F. Two-stage stochastic robust optimization for capacity allocation and operation of integrated energy systems. Electr. Power Syst. Res. 2025, 239, 111253. [Google Scholar] [CrossRef]
- Malik, A.; Devarajan, G. A momentum-based stochastic fractional gradient optimizer with U-net model for brain tumor segmentation in MRI. Digit. Signal Process. 2025, 159, 104983. [Google Scholar] [CrossRef]
- Hikima, Y.; Takeda, A. Stochastic approach for price optimization problems with decision-dependent uncertainty. Eur. J. Oper. Res. 2025, 322, 541–553. [Google Scholar] [CrossRef]
- Krizhevsky, A. One weird trick for parallelizing convolutional neural networks. arXiv 2024, arXiv:1404.5997. Available online: https://arxiv.org/abs/1404.5997v2 (accessed on 29 January 2025).
- Güçlü, U.; van Gerven, M.A.J. Deep Neural Networks Reveal a Gradient in the Complexity of Neural Representations across the Ventral Stream. J. Neurosci. 2015, 35, 10005–10014. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Kingsbury, B.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar] [CrossRef]
- Chevalier, S. A parallelized, Adam-based solver for reserve and security constrained AC unit commitment. Electr. Power Syst. Res. 2024, 235, 110685. [Google Scholar] [CrossRef]
- Cheng, W.; Pu, R.; Wang, B. AMC: Adaptive Learning Rate Adjustment Based on Model Complexity. Mathematics 2025, 13, 650. [Google Scholar] [CrossRef]
- Taniguchi, S.; Harada, K.; Minegishi, G.; Oshima, Y.; Jeong, S.; Nagahara, G.; Iiyama, T.; Suzuki, M.; Iwasawa, Y.; Matsuo, Y. ADOPT: Modified Adam Can Converge with Any β2 with the Optimal Rate. In Proceedings of the 38th Conference on Neural Information Processing Systems (NeurIPS 2024), Vancouver, BC, Canada, 16 December 2024. [Google Scholar]
- Loizou, N.; Vaswani, S.; Laradji, I.; Lacoste-Julien, S. Stochastic Polyak step-size for SGD: An adaptive learning rate for fast convergence. In Proceedings of the 24th International Conference on Artificial Intelligence and Statistics (AISTATS-2021), Virtual, 13–15 April 2021; Volume 130, pp. 1306–1314. [Google Scholar] [CrossRef]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. arXiv 2012, arXiv:1212.5701. Available online: https://arxiv.org/abs/1212.5701 (accessed on 8 February 2025).
- Orabona, F.; Pál, D. Scale-Free Algorithms for Online Linear Optimization. In Algorithmic Learning Theory; Chaudhuri, K., Gentile, C., Zilles, S., Eds.; ALT 2015, Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9355. [Google Scholar] [CrossRef]
- Vaswani, S.; Laradji, I.; Kunstner, F.; Meng, S.Y.; Schmidt, M.; Lacoste-Julien, S. Adaptive Gradient Methods Converge Faster with Over-Parameterization (But You Should Do a Line-Search). arXiv 2020, arXiv:2006.06835. Available online: https://arxiv.org/abs/2006.06835 (accessed on 5 February 2025).
- Vaswani, S.; Mishkin, A.; Laradji, I.; Schmidt, M.; Gidel, G.; Lacoste-Julien, S. Painless Stochastic Gradient: Interpolation, Line-Search, and Convergence Rates. arXiv 2019, arXiv:1905.09997. Available online: https://arxiv.org/abs/1905.09997 (accessed on 8 February 2025).
- Reddi, S.J.; Kale, S.; Kumar, S. On the convergence of Adam and beyond. In Proceedings of the 6th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Tan, C.; Ma, S.; Dai, Y.-H.; Qian, Y. Barzilai-Borwein step size for stochastic gradient descent. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 685–693. [Google Scholar]
- Chen, J.; Zhou, D.; Tang, Y.; Yang, Z.; Cao, Y.; Gu, Q. Closing the Generalization Gap of Adaptive Gradient Methods in Training Deep Neural Networks. arXiv 2018, arXiv:1806.06763. Available online: https://arxiv.org/abs/1806.06763 (accessed on 8 February 2025).
- Ward, R.; Wu, X.; Bottou, L. AdaGrad stepsizes: Sharp convergence over nonconvex landscapes. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR. Volume 97, pp. 6677–6686. [Google Scholar]
- Xie, Y.; Wu, X.; Ward, R. Linear convergence of adaptive stochastic gradient descent. In Proceedings of the 33 International Conference on Artificial Intelligence and Statistics, Online, 26–28 August 2020; PMLR. Volume 108, pp. 1475–1485. [Google Scholar]
- Li, X.; Orabona, F. On the convergence of stochastic gradient descent with adaptive stepsizes. In Proceedings of the 22 International Conference on Artificial Intelligence and Statistics (AISTATS) 2019, Naha, Japan, 16–18 April 2019; PMLR. Volume 89, pp. 983–992. [Google Scholar]
- Wang, Q.; Su, F.; Dai, S.; Lu, X.; Liu, Y. AdaGC: A Novel Adaptive Optimization Algorithm with Gradient Bias Correction. Expert Syst. Appl. 2024, 256, 124956. [Google Scholar] [CrossRef]
- Zhuang, J.; Tang, T.; Ding, Y.; Tatikonda, S.; Dvornek, N.; Papademetris, X.; Duncan, J. AdaBelief Optimizer: Adapting Stepsizes by the Belief in Observed Gradients. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020; Volume 33, pp. 1–12. [Google Scholar]
- Zou, W.; Xia, Y.; Cao, W. AdaDerivative optimizer: Adapting step-sizes by the derivative term in past gradient information. Eng. Appl. Artif. Intell. 2023, 119, 105755. [Google Scholar] [CrossRef]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the Variance of the Adaptive Learning Rate and Beyond. arXiv 2019, arXiv:1908.03265. Available online: https://arxiv.org/abs/1908.03265 (accessed on 8 February 2025).
- Shao, Y.; Yang, J.; Zhou, W.; Sun, H.; Xing, L.; Zhao, Q.; Zhang, L. An Improvement of Adam Based on a Cyclic Exponential Decay Learning Rate and Gradient Norm Constraints. Electronics 2024, 13, 1778. [Google Scholar] [CrossRef]
- Krutikov, V.; Tovbis, E.; Gutova, S.; Rozhnov, I.; Kazakovtsev, L. Gradient Method with Step Adaptation. Mathematics 2025, 13, 61. [Google Scholar] [CrossRef]
- Krutikov, V.; Gutova, S.; Tovbis, E.; Kazakovtsev, L.; Semenkin, E. Relaxation Subgradient Algorithms with Machine Learning Procedures. Mathematics 2022, 10, 3959. [Google Scholar] [CrossRef]
- Polyak, B.T. Gradient methods for the minimization of functional. USSR Comput. Math. Math. Phys. 1963, 3, 864–878. [Google Scholar] [CrossRef]




| Authors | Reference | Publication Years | Method |
|---|---|---|---|
| D.P.Kingma, J.P. Ba | [13] | 2015 | Adam |
| J.Duchi, E.Hazan, Y.Singer, | [20] | 2011 | AdaGrad |
| M.D.Zeiler | [21] | 2012 | AdaDelta |
| S.J.Reddi, S.Kale, S.Kumar | [16] | 2018 | AMSGrad |
| J.Chen et al. | [26] | 2020 | Padam |
| R.Ward, X.Wu, L.Bottou | [27] | 2019 | AdaGrad-Norm |
| Q.Wang et al. | [30] | 2024 | AdaGC |
| J.Zhuang et al. | [31] | 2020 | AdaBelief |
| W.Zou, Y.Xia, W.Cao | [32] | 2023 | AdaDerivative |
| L.Liu et al. | [33] | 2020 | RAdam |
| Shao, Y. et al. | [34] | 2024 | CN-Adam |
| amax | ||||||||
|---|---|---|---|---|---|---|---|---|
| ADAM | H_GR | H_MOMENTUM | H_ADAM | ADAM | H_GR | H_MOMENTUM | H_ADAM | |
| 10 | 5307 | 216 | 489 | 607 | 5307 | 944 | 79,147 | 12,679 |
| 102 | 5307 | 720 | 418 | 5143 | 5307 | 1407 | 60,540 | 11,498 |
| 103 | 5307 | 4451 | 854 | 4167 | 5307 | 7892 | 1243 | 4917 |
| 104 | 5307 | 44,442 | 2205 | 891 | 5307 | 78,882 | 3892 | 1572 |
| α | amax = 104, n_max = 200,000 | amax = 10, n_max = 100,000 | ||||||
|---|---|---|---|---|---|---|---|---|
| ADAM | H_GR | H_MOMENTUM | H_ADAM | ADAM | H_GR | H_MOMENTUM | H_ADAM | |
| 0.1 | 2253 × 10−5 | 78,107 | 5835 | 2804 | 109,253 | 169 | 359 | 343 |
| 0.01 | 2253 × 10−5 | 78,882 | 3892 | 1572 | 109,253 | 944 | 79,147 | 12,679 |
| 0.001 | 2253 × 10−5 | 78,889 | 15,769 | 17,992 | 109,253 | 3011 | 12,475 | 19,522 |
| β2 | ADAM | H_ADAM |
|---|---|---|
| 0.3 | 1901 × 10−2 | 1934 |
| 0.5 | 1063 × 10−3 | 1684 |
| 0.7 | 1379 × 10−4 | 1533 |
| 0.9 | 6094 × 10−5 | 1502 |
| 0.999 | 2253 × 10−5 | 1572 |
| r | ADAM | H_GR | H_MOMENTUM | H_ADAM |
|---|---|---|---|---|
| 0 | 12,315 | 11,252 | 2094 | 10,001 |
| 1 | 13,721 | 11,269 | 7140 | 11,021 |
| 2 | 116,779 | 31,477 | 18,938 | 18,921 |
| 3 | 44,111 | 29,050 | 38,862 | 41,404 |
| 4 | 260,210 | 147,051 | 1064 | 148,752 |
| 5 | 934,950 | 168,840 | 112,545 | 112,284 |
| 6 | 1301 × 10−5 | 429,597 | 83,790 | 80,820 |
| 7 | 2872 × 10−4 | 571,974 | 152,464 | 182,693 |
| 8 | 71,419 | 3233 × 10−9 | 662,428 | 288,912 |
| 9 | 3868 × 10−5 | 761,875 | 350,220 | 256,479 |
| 10 | 1231 × 10−3 | 499,957 | 58,956 | 347,315 |
| r | ADAM | H_GR | H_MOMENTUM | H_ADAM |
|---|---|---|---|---|
| 0 | 108,850 | 1272 | 1729 × 10−3 | 3222 |
| 1 | 253,080 | 1795 | 2231 | 2368 |
| 2 | 1133 × 10−3 | 1994 | 5124 | 5534 |
| 3 | 3678 × 10−3 | 2953 | 10,878 | 11,133 |
| 4 | 5230 × 10−3 | 4517 | 16,731 | 18,416 |
| 5 | 7113 × 10−3 | 6725 | 28,560 | 29,747 |
| 6 | 1226 × 10−3 | 9448 | 48,540 | 48,546 |
| 7 | 1448 × 10−3 | 12,240 | 71,915 | 70,744 |
| 8 | 2727 × 10−3 | 15,898 | 97,062 | 97,362 |
| 9 | 4985 × 10−3 | 19,896 | 120,143 | 119,395 |
| 10 | 8304 × 10−3 | 23,851 | 148,182 | 148,132 |
| r | ADAM | H_GR | H_MOMENTUM | H_ADAM |
|---|---|---|---|---|
| 0 | 108,962 | 7990 | 2924 | 3394 |
| 1 | 384,327 | 8213 | 2383 | 2648 |
| 2 | 2662 × 10−2 | 13,472 | 5939 | 6371 |
| 3 | 2008 × 10−2 | 24,502 | 12,370 | 12,485 |
| 4 | 2365 × 10−2 | 39,925 | 21,904 | 20,613 |
| 5 | 5215 × 10−2 | 58,929 | 36,407 | 36,566 |
| 6 | 3275 × 10−2 | 82,361 | 56,038 | 57,183 |
| 7 | 2305 × 10−2 | 110,098 | 79,388 | 83,536 |
| 8 | 3421 × 10−2 | 144,175 | 112,980 | 113,497 |
| 9 | 4754 × 10−2 | 181,752 | 153,109 | 155,566 |
| 10 | 6556 × 10−2 | 221,429 | 185,665 | 189,573 |
| r | ADAM | H_GR | H_MOMENTUM | H_ADAM |
|---|---|---|---|---|
| 0 | 109,074 | 79,052 | 4089 | 3608 |
| 1 | 6556 × 10−3 | 221,429 | 12,035 | 13,846 |
| 2 | 1078 × 10−2 | 117,260 | 40,889 | 42,857 |
| 3 | 1520 × 10−1 | 204,209 | 88,205 | 89,771 |
| 4 | 1134 × 10−1 | 327,993 | 157,061 | 158,273 |
| 5 | 3526 × 10−1 | 482,820 | 242,504 | 245,092 |
| 6 | 4876 × 10−1 | 674,838 | 347,052 | 352,129 |
| 7 | 2193 × 10−1 | 898,724 | 473,565 | 473,565 |
| 8 | 3171 × 10−1 | 1,153,451 | 617,978 | 625,033 |
| 9 | 4271 × 10−1 | 1,450,025 | 789,082 | 800,510 |
| 10 | 5659 × 10−1 | 1,762,557 | 986,144 | 995,597 |
| r | ADAM | H_GR | H_MOMENTUM | H_ADAM |
|---|---|---|---|---|
| 0 | 123,881 | 4704 × 10−4 | 3670 | 5592 |
| 1 | 232,563 | 4480 × 10−4 | 445,481 | 41,511 |
| 2 | 398,545 | 3654 × 10−4 | 560,187 | 77,574 |
| 3 | 717,788 | 3654 × 10−4 | 994,309 | 205,299 |
| 4 | 1,723,520 | 4125 × 10−4 | 1,110,249 | 320,391 |
| 5 | 6009 × 10−4 | 5028 × 10−4 | 1,187,059 | 364,720 |
| 6 | 6163 × 10−4 | 6156 × 10−4 | 1,687,797 | 720,857 |
| 7 | 9079 × 10−4 | 7666 × 10−4 | 1,922,210 | 1,010,981 |
| 8 | 9766 × 10−4 | 9447 × 10−4 | 2,830,218 | 1,877,945 |
| 9 | 1941 × 10−3 | 1165 × 10−3 | 1809 × 10−4 | 2,257,204 |
| 10 | 2129 × 10−3 | 1417 × 10−3 | 2446 × 10−4 | 3,023,663 |
| r | ADAM | H_GR | H_MOMENTUM | H_ADAM |
|---|---|---|---|---|
| 0 | 125,914 | 3,982,257 | 200,396 | 7183 |
| 1 | 5456 × 10−5 | 3,880,233 | 281,489 | 137,671 |
| 2 | 1320 × 10−4 | 3,536,635 | 407,108 | 206,566 |
| 3 | 4690 × 10−4 | 3,502,361 | 565,846 | 309,788 |
| 4 | 9978 × 10−4 | 3,747,585 | 775,680 | 467,366 |
| 5 | 5281 × 10−4 | 1449 × 10−10 | 1,057,342 | 661,454 |
| 6 | 1434 × 10−3 | 1731 × 10−9 | 1,346,356 | 897,082 |
| 7 | 2083 × 10−3 | 1738 × 10−8 | 1,704,643 | 1,104,140 |
| 8 | 1612 × 10−3 | 1264 × 10−7 | 1,682,106 | 1,420,716 |
| 9 | 4059 × 10−3 | 6793 × 10−7 | 2,210,826 | 1,854,261 |
| 10 | 6697 × 10−3 | 2897 × 10−6 | 2,724,228 | 2,357,420 |
| r | ADAM | H_GR | H_MOMENTUM | H_ADAM |
|---|---|---|---|---|
| 0 | 42,027 | 29,774 | 22,993 | 1347 |
| 1 | 58,005 | 30,091 | 4894 | 4500 |
| 2 | 59,829 | 45,441 | 17,907 | 17,888 |
| 3 | 74,718 | 79,189 | 39,133 | 38,062 |
| 4 | 1022 × 10−4 | 3758 × 10−8 | 69,850 | 68,934 |
| 5 | 1258 × 10−1 | 4687 × 10−5 | 1785 × 10−9 | 110,252 |
| 6 | 2943 × 10−1 | 3656 × 10−3 | 1657 × 10−5 | 161,151 |
| 7 | 1271 × 102 | 6545 × 10−2 | 4047 × 10−3 | 224,008 |
| 8 | 5060 | 4938 × 10−1 | 1643 × 10−1 | 291,613 |
| 9 | 8679 | 2199 | 3565 | 372,003 |
| 10 | 65,182 | 7184 | 41,457 | 483,712 |
| Nb | ADAM | H_GR | H_MOMENTUM | H_ADAM |
|---|---|---|---|---|
| N | 5257 | 1086 | 18,595 | 347 |
| 1 | 3638 | 6559 × 10−4 | 90,588 | 15,283 |
| 10 | 11,708 | 4266 × 10−9 | 8321 | 2564 |
| 100 | 7691 | 1646 | 1984 | 580 |
| 200 | 6873 | 1652 | 1704 | 464 |
| 300 | 6462 | 1650 | 1666 | 432 |
| Nb | ADAM | H_GR | H_MOMENTUM | H_ADAM |
|---|---|---|---|---|
| N | 8088 | 75,539 | 29,697 | 407 |
| 1 | 1300 × 102 | 3887 × 102 | 2894 × 102 | 60,993 |
| 10 | 4913 × 10−1 | 1509 × 102 | 6066 × 10−9 | 5961 |
| 100 | 11,134 | 8891 | 19,917 | 1332 |
| 200 | 10,219 | 8735 | 18,731 | 1087 |
| 300 | 9611 | 11,955 | 18,566 | 1028 |
| Nb | ADAM | H_GR | H_MOMENTUM | H_ADAM |
|---|---|---|---|---|
| N | 4436 | 812 | 331 | 328 |
| 1 | 5581 | 72,841 | 39,493 | 35,781 |
| 10 | 9172 | 3437 | 3657 | 2500 |
| 100 | 6107 | 1874 | 558 | 621 |
| 200 | 5517 | 1877 | 460 | 488 |
| 300 | 5108 | 1877 | 408 | 432 |
| Nb | ADAM | H_GR | H_MOMENTUM | H_ADAM |
|---|---|---|---|---|
| N | 16,672 | 951 | 465 | 429 |
| 1 | 4240 | 2465 × 10−9 | 2766 × 10−8 | 74,608 |
| 10 | 33,813 | 6911 × 10−8 | 9100 | 5173 |
| 100 | 21,740 | 1879 | 2266 | 990 |
| 200 | 19,755 | 1882 | 1951 | 723 |
| 300 | 18,700 | 1877 | 1878 | 669 |
| Nb | ADAM | H_GR | H_MOMENTUM | H_ADAM |
|---|---|---|---|---|
| N | 5175 | 1178 | 4183 × 10−2 | 10,724 |
| 1 | 5634 | 9368 × 10−2 | 68,302 | 69,690 |
| 10 | 1050 | 6372 | 9896 | 11,785 |
| 100 | 5776 | 983 | 2298 | 2865 |
| 200 | 4982 | 836 | 1612 | 1824 |
| 300 | 4584 | 681 | 1166 | 1609 |
| Nb | ADAM | H_GR | H_MOMENTUM | H_ADAM |
|---|---|---|---|---|
| N | 8087 | 75,528 | 2519 × 105 | 7238 |
| 1 | 51,086 | 6138 × 103 | 5805 × 103 | 68,925 |
| 10 | 14,699 | 7495 × 103 | 7080 × 102 | 11,874 |
| 100 | 9516 | 18,633 | 88,183 | 2496 |
| 200 | 8301 | 17,451 | 30,213 | 1747 |
| 300 | 7671 | 3999 × 103 | 1096 | 1386 |
| r | ADAM | H_GR | H_MOMENTUM | H_ADAM |
|---|---|---|---|---|
| 0 | 109,068 | 70,843 | 3009 × 10−1 | 9187 |
| 1 | 4325 × 10−3 | 74,703 | 13,264 | 6375 |
| 2 | 2676 × 10−2 | 115,024 | 41,756 | 29,302 |
| 3 | 1615 × 10−1 | 197,074 | 88,530 | 81,751 |
| 4 | 1104 × 10−1 | 307,960 | 154,555 | 148,360 |
| 5 | 3113 × 10−1 | 450,904 | 237,077 | 230,640 |
| 6 | 5663 × 10−1 | 638,927 | 334,401 | 327,220 |
| 7 | 2156 × 10−1 | 870,161 | 451,562 | 442,835 |
| 8 | 3331 × 10−1 | 1,117,565 | 590,216 | 582,402 |
| 9 | 4333 × 10−1 | 1,391,424 | 755,477 | 756,073 |
| 10 | 5623 × 10−1 | 1,694,334 | 950,169 | 942,084 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krutikov, V.; Tovbis, E.; Kazakovtsev, L. Adam Algorithm with Step Adaptation. Algorithms 2025, 18, 268. https://doi.org/10.3390/a18050268
Krutikov V, Tovbis E, Kazakovtsev L. Adam Algorithm with Step Adaptation. Algorithms. 2025; 18(5):268. https://doi.org/10.3390/a18050268
Chicago/Turabian StyleKrutikov, Vladimir, Elena Tovbis, and Lev Kazakovtsev. 2025. "Adam Algorithm with Step Adaptation" Algorithms 18, no. 5: 268. https://doi.org/10.3390/a18050268
APA StyleKrutikov, V., Tovbis, E., & Kazakovtsev, L. (2025). Adam Algorithm with Step Adaptation. Algorithms, 18(5), 268. https://doi.org/10.3390/a18050268