Abstract
Constructed neural networks with the assistance of grammatical evolution have been widely used in a series of classification and data-fitting problems recently. Application areas of this innovative machine learning technique include solving differential equations, autism screening, and measuring motor function in Parkinson’s disease. Although this technique has given excellent results, in many cases, it is trapped in local minimum and cannot perform satisfactorily in many problems. For this purpose, it is considered necessary to find techniques to avoid local minima, and one technique is the periodic application of local minimization techniques that will adjust the parameters of the constructed artificial neural network while maintaining the already existing architecture created by grammatical evolution. The periodic application of local minimization techniques has shown a significant reduction in both classification and data-fitting problems found in the relevant literature.
1. Introduction
Among the parametric machine learning models, one can find artificial neural networks (ANNs) [1,2], in which a set of parameters, also called weights, must be estimated in order for this model to adapt to classification or regression data. Neural networks have used problems derived from physics [3,4], problems involving differential equations [5], solar radiation prediction [6], agriculture problems [7], problems derived from chemistry [8,9], wind speed prediction [10], economics problems [11,12], problems related to medicine [13,14], etc. A common way to express a neural network is as a function . The vector represents the input pattern to the neural network, and the vector stands for the vector of parameters that must be computed. The set of parameters is calculated by minimizing the training error:
In Equation (1), the set stands for the train set. The values denote the target outputs for patterns . Recently, various methods have appeared that minimize this equation, such as the back propagation method [15], the RPROP method [16,17], the ADAM method [18], etc. Additionally, global optimization techniques were also used, such as the simulated annealing method [19], genetic algorithms [20], Particle Swarm Optimization (PSO) [21], Differential Evolution [22], Ant Colony Optimization [23], Gray Wolf Optimizer [24], Whale optimization [25], etc.
In many cases, especially when the data are large in volume or have a high number of features, significant times are observed during the process of training artificial neural networks. For this reason, techniques have been presented in recent years that exploit modern parallel computing structures for faster training of these machine learning models [26].
Another important aspect in artificial neural networks is the initialization of parameters. Various techniques have been proposed in this area, such as the usage of polynomial bases [27], initialization based on decision trees [28], usage of intervals [29], discriminant learning [30], etc. Also, recently, Chen et al. proposed a new weight initialization method [31].
Identifying the optimal architecture of an artificial neural network could be an extremely important factor to determine the generalization abilities of an artificial neural network. Networks with only a few neurons can be trained faster and may have good generalization abilities, but in many cases, the optimization method cannot escape from the local minima of the error function. Furthermore, networks with many neurons can have a significantly reduced training error but require a large computational time for their training and many times do not perform significantly when applied to data that are not present in the training set. In this direction, many researchers proposed various methods to discover the optimal architecture, such as the use of genetic algorithms [32,33], the Particle Swarm Optimization method [34], reinforcement learning [35], etc. Also, Islam et al. proposed a new adaptive merging and growing technique used to design the optimal structure of an artificial neural network [36].
Recently, a technique was presented that utilizes grammatical evolution [37] for the efficient construction of the architecture of an artificial neural network as well as the calculation of the optimal values of the parameters [38]. In this technique, the architecture of the neural network is identified. Also, the method performs feature selection, since only those features are selected which will reduce the training error. Using this technique, the number of features are reduced, leading to neural networks that are faster in response and have generalization abilities. The neural construction technique has been applied in a wide series of problems, such as the location of amide I bonds [39], solving differential equations [40], application in data collected for Parkinson’s disease [41], prediction of performance for higher education students [42], autism screening [43], etc. Software that implements the previously mentioned method can be downloaded freely from https://github.com/itsoulos/NNC (accessed on 28 September 2024) [44].
Although the neural network construction technique has been successfully used in a variety of applications and is able to identify the optimal structure of a neural network as well as find satisfactory values for the model parameters, it cannot avoid the local minima of the error function, which results in reduced performance. In this research paper, the periodic application of local optimization techniques is proposed in randomly selected artificial neural networks constructed by grammatical evolution. Local optimization does not alter the generated neural network structure but can more efficiently identify values of the network parameters with lower values of the training error. The current work was applied on many classification and data-fitting datasets, and it seems to reduce the test error obtained by the original neural construction technique.
2. Method Description
This section initiates with a short description of the grammatical evolution method and continues with a detailed description of the proposed algorithm.
2.1. Grammatical Evolution
Grammatical evolution can be considered as a genetic algorithm with integer chromosomes. These chromosomes stand for a series of production rules in a grammar expressed in the Backus–Naur (BNF) form [45]. The method was used in data fitting [46,47], trigonometric problems [48], automatic composition of music [49], production of numeric constants with an arbitrary number of digits [50], video games [51,52], energy problems [53], combinatorial optimization [54], cryptography [55], the production of decision trees [56], electronics [57], Wikipedia taxonomies [58], economics [59], bioinformatics [60], robotics [61], etc. A BNF grammar is commonly defined as a set . The following definitions hold for any BNF grammar:
- The set N contains the symbols denoted as non-terminal.
- The set T has the terminal symbols.
- The symbol stands for the start symbol of the grammar.
- The set P has all the production rules of the underlying grammar. These rules are used to produce terminal symbols from non-terminal symbols, and they are in the form or .
The production algorithm starts from the symbol S and moves through a series of steps, producing valid programs by replacing non-terminal symbols with the right hand of the selected production rule. The selection of the production rules is performed in two steps:
- Read the the next element V from the processed chromosome.
- Select the production rule that will be applied using the equation: Rule = V mod , where stands for the number of production rules that contains the current current non-terminal symbol.
The incorporated grammar for the neural construction method is outlined in Figure 1. The number in parentheses denotes the sequence number of each rule for every non-terminal symbol. The symbol n represents the number of features for the used dataset.

Figure 1.
The grammar used by the neural construction method.
This grammar can produce artificial neural networks in the following form:
The symbol H corresponds to the number of weights or processing units. The function denotes the sigmoid function, and it has the following definition:
The grammar of the present method can construct artificial neural networks with a hidden processing layer and with a variable number of computing units. This kind of architecture is sufficient to approach any problem, according to Hornik’s theorem [62], which states that an artificial neural network with a sufficient number of computing units and a processing level can approximate any function.
As an example, consider a problem with three inputs: . An example neural network that can be constructed by the grammatical evolution procedure could be the following:
The previously mentioned artificial neural network has two processing nodes, and not all inputs are necessarily connected to each processing node, since the grammatical evolution process may miss some connections.
2.2. The Proposed Algorithm
The steps of the current method are derived from the steps of the original neural network construction method with the addition of the periodical application of the local optimization algorithm as follows:
- 1.
- Initialization step.
- (a)
- Set as the generation counter.
- (b)
- Set as the maximum number of generations and as the number of chromosomes.
- (c)
- Set as the selection rate and as the mutation rate of the genetic algorithm.
- (d)
- Set as the number of chromosomes that will be selected to apply the local search optimization method on them.
- (e)
- Set as the number of generations that should pass before the application of the suggested local optimization technique.
- (f)
- Set as F the range of values within which the local optimization method can vary the parameters of the neural network.
- (g)
- Perform a random initialization of the chromosomes as sets of random integers.
- 2.
- Fitness Calculation step.
- (a)
- For do
- i.
- Produce the corresponding neural network for the chromosome , The production is performed using the procedure of Section 2.1. The vector denotes the set of parameters produced for the chromosome .
- ii.
- Set as the fitness of chromosome i. The set represents the train set.
- (b)
- EndFor
- 3.
- Genetic operations step.
- (a)
- Copy the best chromosomes according to their fitness values to the next generation.
- (b)
- Apply the crossover procedure. This procedure creates offsprings from the current population. Two chromosomes are selected through tournament selection for every created couple of ofssprings. These offsprings are created using the one-point crossover procedure, which is demonstrated in Figure 2.
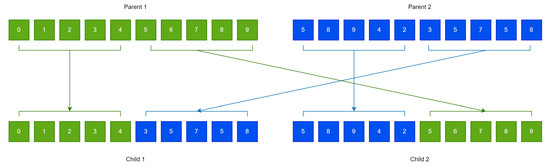 Figure 2. An example of the method of one-point crossover used in the grammatical evolution procedure.
Figure 2. An example of the method of one-point crossover used in the grammatical evolution procedure. - (c)
- Apply the mutation procedure. During this procedure, a random number is selected from uniform distribution for every element of each chromosome. If , then the current element is altered randomly.
- 4.
- Local search step.
- (a)
- If k mod = 0 then
- i.
- Set a set of chromosomes of the current population that are selected randomly.
- ii.
- For , apply the procedure described in Section 2.3 on chromosome .
- (b)
- Endif
- 5.
- Termination check step.
- (a)
- Set
- (b)
- If go to Fitness Calculation Step, else
- i.
- Obtain the chromosome that has the lowest fitness value among the population.
- ii.
- Produce the corresponding neural network for this chromosome. The vector denotes the set of parameters for the chromosome .
- iii.
- Obtain the corresponding test error for .
The flowchart for the proposed method is depicted in Figure 3.
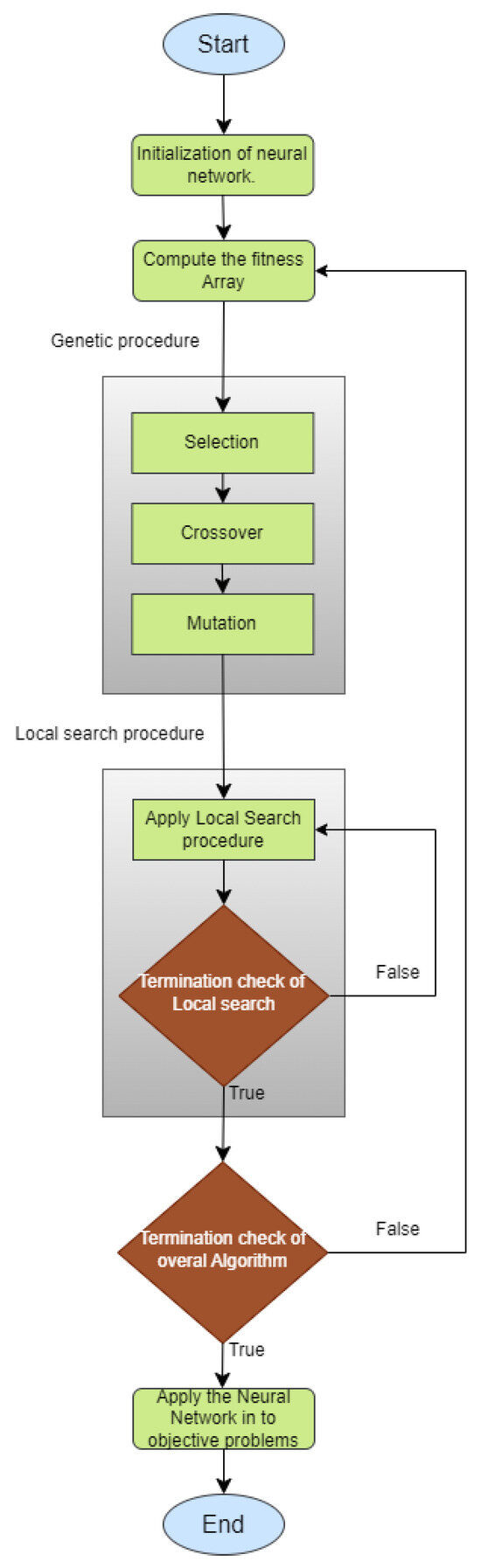
Figure 3.
The flowchart of the proposed algorithm.
2.3. The Local Search Procedure
The local search procedure initiates from the vector that is produced for any given chromosome g using the procedure described in Section 2.1. The procedure minimizes the error of Equation (1) with respect to vector . The minimization is performed within a value interval created around the initial point keeping the network structure intact. The main steps of this procedure are given below:
- 1.
- Set . This value denotes the total number of parameters for .
- 2.
- For do
- (a)
- Set , the left bound of the minimization for the parameter i.
- (b)
- Set , the right bound of the minimization for the parameter i.
- 3.
- EndFor
- 4.
- Minimize the error function of Equation (1) for vector inside the bounding box using a local optimization procedure . The BFGS method as modified by Powell [63] was incorporated in the conducted experiments.
As an example, consider a dataset with and the following constructed neural network:
where the number of nodes is . In this case, the vector has the elements . If the parameter F has the value then the bound vectors and are defined as
Hence, the minimization method could not change the elements and , and as a consequence, the architecture of the network remains intact.
3. Experimental Results
A series of classification and regression datasets was used in order to test the current work. Also, the suggested technique was compared against other established machine learning methods, and the results are reported. Furthermore, a series of experiments were executed to verify the sensitivity of the proposed technique with respect to the critical parameters presented earlier. The following URLs provide the used datasets:
- 1.
- The UCI dataset repository, https://archive.ics.uci.edu/ml/index.php (accessed on 28 September 2024) [64].
- 2.
- The Keel repository, https://sci2s.ugr.es/keel/datasets.php (accessed on 28 September 2024) [65].
- 3.
- The Statlib URL http://lib.stat.cmu.edu/datasets/ (accessed on 28 September 2024).
3.1. The Used Classification Datasets
The descriptions of the used datasets are also provided:
- 1.
- Appendictis, which is a dataset originated in [66].
- 2.
- Australian dataset [67], which is related to bank transactions.
- 3.
- Balance dataset [68], which has been used in a series of psychological experiments.
- 4.
- Circular dataset, which contains artificially generated data.
- 5.
- Cleveland dataset [69,70].
- 6.
- Dermatology dataset [71], which is a dataset that contains measurements of dermatological deceases.
- 7.
- Ecoli dataset, which is a dataset that contains measurements of proteins [72].
- 8.
- Fert dataset, which is used to detect the relation between sperm concentration and demographic data.
- 9.
- Haberman dataset, which is a medical dataset related to breast cancer.
- 10.
- Hayes roth dataset [73].
- 11.
- Heart dataset [74], which is a medical dataset used for the prediction of heart diseases.
- 12.
- HeartAttack dataset, which is used for the detection of heart diseases.
- 13.
- HouseVotes dataset [75].
- 14.
- Liverdisorder dataset [76], which is a medical dataset.
- 15.
- Ionosphere dataset, which is a climate dataset [77,78].
- 16.
- Mammographic dataset [79], which is a dataset related to the breast cancer.
- 17.
- Parkinsons dataset, which is used in the detection of Parkinson’s disease (PD) [80].
- 18.
- Pima dataset [81].
- 19.
- Popfailures dataset [82].
- 20.
- Regions2 dataset, which is used in the detection of hepatitis C [83].
- 21.
- Saheart dataset [84], which is a medical dataset used for the detection of heart diseases.
- 22.
- Segment dataset [85], which is a dataset related to image processing.
- 23.
- Spiral dataset, which is an artificial dataset.
- 24.
- Student dataset [86], which contains data from experiments conducted in Portuguese schools.
- 25.
- Transfusion dataset [87], which is a medical dataset.
- 26.
- Wdbc dataset [88].
- 27.
- Wine dataset, which is used for the detection of the quality of wines [89,90].
- 28.
- Eeg datasets, which is a dataset that contains EEG experiments [91]. The following distinct cases were used from this dataset: Z_F_S, Z_O_N_F_S, ZO_NF_S and ZONF_S.
- 29.
- Zoo dataset [92], which is used to classify animals.
The number of inputs and classes for every classification dataset is given in Table 1.

Table 1.
Number of inputs and distinct classes for every classification dataset.
3.2. The Used Regression Datasets
The descriptions for these datasets are provided below:
- 1.
- Abalone dataset [93].
- 2.
- Airfoil dataset, which is a dataset derived from NASA [94].
- 3.
- BK dataset [95], which contains data from various basketball games.
- 4.
- BL dataset, which contains data from an electricity experiment.
- 5.
- Baseball dataset, which is used to predict the average income of baseball players.
- 6.
- Concrete dataset [96].
- 7.
- Dee dataset, which contains measurements of the price of electricity.
- 8.
- FY, which is used to measure the longevity of fruit flies.
- 9.
- HO dataset, which appeared in the STALIB repository.
- 10.
- Housing dataset, which originated in [97].
- 11.
- Laser dataset, which contains data from physics experiments
- 12.
- LW dataset, which contains measurements of low weight babies.
- 13.
- MORTGAGE dataset, which is related to some economic measurements from the USA.
- 14.
- MUNDIAL, which appeared in the STALIB repository.
- 15.
- PL dataset, which is included in the STALIB repository.
- 16.
- QUAKE dataset, which contains data about earthquakes.
- 17.
- REALESTATE, which is included in the STALIB repository.
- 18.
- SN dataset, which contains measurements from an experiment related to trellising and pruning.
- 19.
- Treasury dataset, which deals with some factors of the USA economy.
- 20.
- VE dataset, which is included in the STALIB repository.
- 21.
- TZ dataset, which is included in the STALIB repository.
The number of inputs for each dataset is provided in Table 2.
Table 2.
Number of inputs for every regression dataset.
3.3. Experimental Results
All the methods used here were coded in ANSI C++. The freely available optimization of Optimus, which can be downloaded from https://github.com/itsoulos/GlobalOptimus/ (accessed on 28 September 2024), was also utilized for the optimization process. Each experiment was conducted 30 times, and the average classification or regression value was measured. In each run, a different seed for the random number generator was used, and the drand48() function of the C programming language was incorporated. For the case of classification datasets, the displayed classification error for a model and the test dataset T is calculated as
The test set T is defined as . For the case of regression problems, the regression error is defined as
The method of ten-fold cross-validation was incorporated to validate the experimental results. The experiments were carried out on an AMD Ryzen 5950X with 128 GB of RAM, running the Debian Linux operating system. The values for the parameters of the algorithms are shown in Table 3. In all tables, the bold font is used to mark the machine learning method that achieved the lowest classification or regression error.
Table 3.
The values of the parameters used in the experiments.
Table 4 contains the experimental results for the classification datasets and Table 5 contains the experimental results for the regression datasets. The neural network used in the experimental results has one processing unit with processing nodes and the sigmoid function as an activation function. The following notation was used in these tables:
Table 4.
Results from the application of machine learning models on the classification datasets. Numbers in cells represent average classification errors for the corresponding test set. The bold notation is used to mark the method with the lowest test error.
Table 5.
Results from the conducted experiments on the regression datasets. Numbers in cells denote average regression errors as calculated on the corresponding test sets. The bold notation is used to mark the method with the lowest test error.
- 1.
- The column BFGS represents the results obtained by the application of the BFGS method to train a neural network with processing nodes.
- 2.
- The column GENETIC represents the results produced by the training of a neural network with processing nodes using a genetic algorithm. The parameters of this algorithm are mentioned in Table 3.
- 3.
- The column NNC represents the results obtained by the neural construction technique.
- 4.
- The column INNC represents the results obtained by the proposed method.
- 5.
- The last row AVERAGE contains the average classification or regression error, as measured on all datasets.
The methods BFGS and GENETIC train the neural network by obtaining the global minimum of the error function defined in Equation (1).
The original technique of constructing artificial neural networks has significantly lower classification or regression errors than the other two techniques, and the proposed method managed to improve the performance of this technique in the majority of the datasets. The percentage improvement in error is even greater in regression problems. In some cases, the improvement exceeds 50% in the test error. This effect is evident in the box plots for classification and regression errors outlined in Figure 4 and Figure 5, respectively.
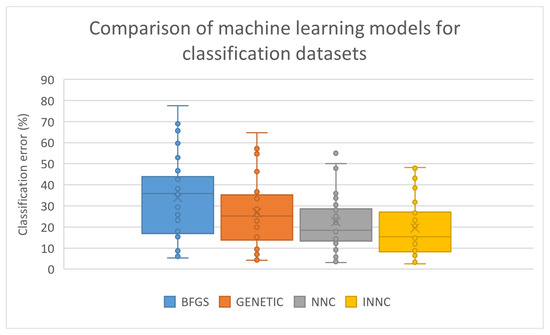
Figure 4.
Box plot for the comparison between the machine learning methods applied on the classification datasets.
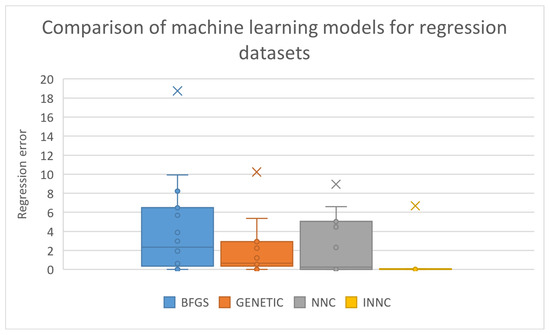
Figure 5.
Box plot for the comparison between the machine learning methods applied on the regression datasets.
Furthermore, the same reduction in test error is validated from the statistical tests performed for classification and regression problems. These tests are depicted in Figure 6 and Figure 7.
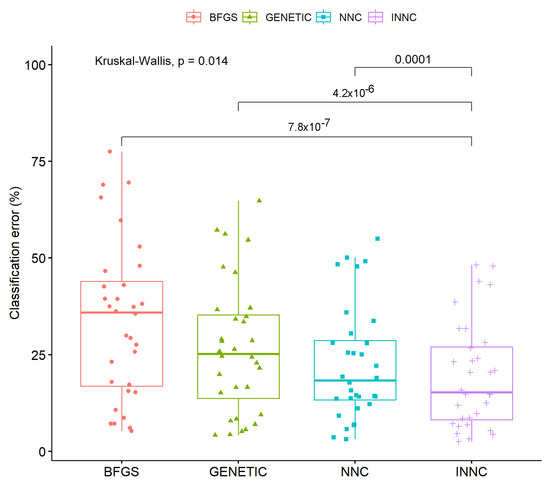
Figure 6.
Statistical test for all machine learning models that was applied on the classification datasets.
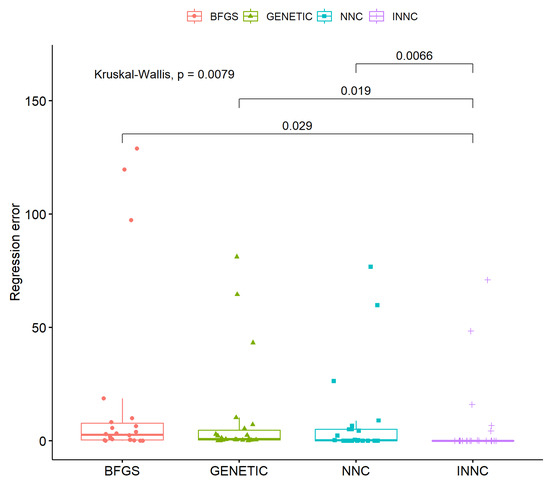
Figure 7.
Statistical test for all machine learning models that was applied on the regression datasets.
3.3.1. Experiments with the Parameter
To verify the robustness of the proposed technique as well as its sensitivity to parameter changes, a new experiment was carried out in which the critical parameter was varied from 5 to 20. This parameter determines the number of generations intervening before the local optimization method is executed on randomly selected chromosomes. The results from this experiment for the classification datasets are depicted in Table 6, and the results for the regression datasets are depicted in Table 7.
Table 6.
Experimental results using a variety of values for the parameter of the current work with application on the classification datasets. The bold notation marks the method with the lowest test error.
Table 7.
Experimental results with a variety of values for the parameter . The current work was applied on the regression datasets. The bold notation marks the method with the lowest test error.
The method appears to have similar results for each variation of the critical parameter. In some cases, the error is smaller for low values of this parameter but not to a great extent. This effect is also evident in the box plot presented for the classification datasets in Figure 8 as well as in the statistical comparison of Figure 9.
Figure 8.
Box plot for the experiments with the parameter and the current work. The method was applied on the classification datasets.
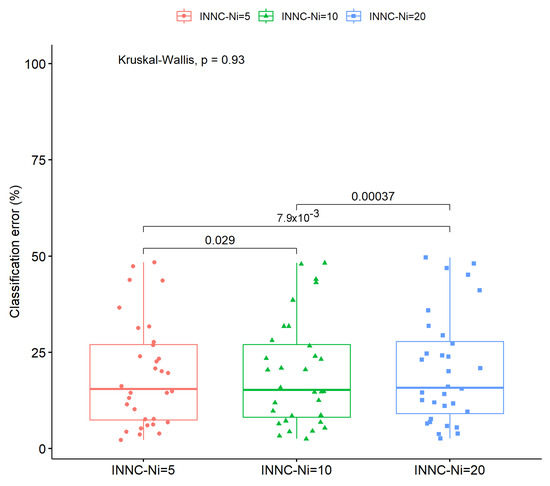
Figure 9.
Statistical comparison of the experiment with the current work and a variety of values for parameter . The method was applied on the classification datasets.
In addition, the average execution time of the methods was recorded for the various values of the parameter , and the results are shown in Figure 10 and Figure 11 for classification and regression problems, respectively.
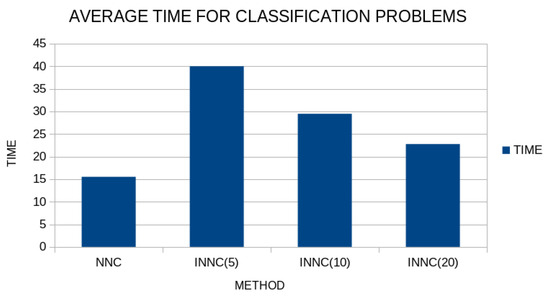
Figure 10.
Average execution time for the original method and the modified one. The time was recorded for different values of the parameter and for the classification datasets.
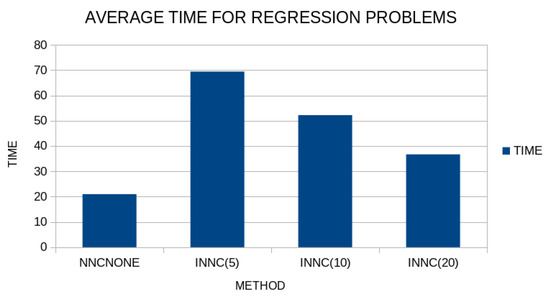
Figure 11.
Average execution time for the original method and the modified one. The time was measured for different values of the parameter . The execution times were recorded for the regression problems.
As expected, the method requires more computational time than the original one, and in fact, the smaller the value of the parameter the more time has to be spent since more local optimizations have to be performed. Of course, this additional computing time can be significantly reduced by using parallel computing techniques.
3.3.2. Experiments with the Parameter F
Another important parameter for the proposed method is parameter F. This parameter identifies the range of changes that the local optimization method can cause on randomly selected chromosomes. In this experiment, the parameter F changed from 1.5 to 8.0, and the results for the classification datasets are depicted in Table 8, while the experimental results for the regression datasets are presented in Table 9.
Table 8.
Experimental results with a variety of values for the parameter F with application on the classification datasets. The bold notation marks the method with the lowest test error.
Table 9.
Experimental results using a variety of values for the parameter F with application on the the regression datasets. The bold notation marks the method with the lowest test error.
Once again, there are no significant differences in the performance of the proposed technique as the critical factor F varies. In the case of the classification data, however, there is a small increase in the classification error as this factor increases, which may be due to the fact that as we move away from the solution created by the method of creating neural networks, the performance of the method decreases. Also, the box plot for the classification datasets is depicted in Figure 12.
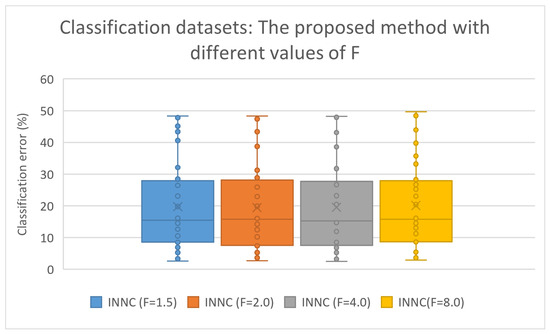
Figure 12.
Box plot for the experiments using the current work and different values of the parameter F. The experiments were conducted on the classification datasets.
3.3.3. Experiments with the Used Local Search Optimizer
An important issue of the proposed method is the selection of the local search optimizer, that will be applied periodically to chromosomes selected randomly. In the current work, a modified version of the BFGS method [63] was chosen, since it can satisfactorily handle the constraints placed on the network parameters for the optimization. However, an additional experiment was executed using different local optimization techniques. The results for the classification datasets are presented in Table 10, and the results for the regression datasets are shown in Table 11. The following notation is used in the experimental tables:
Table 10.
Experimental results with different local optimization techniques in the proposed method with application on the classification datasets. The bold notation marks the method with the lowest test error.
Table 11.
Experimental results with local optimization techniques in the current work with application on the regression datasets. The bold notation marks the method with the lowest test error.
- 1.
- The column ADAM denotes the incorporation of the ADAM local optimization method [18] in the current technique.
- 2.
- The column LBFGS denotes the incorporation of the Limited Memory BFGS (L-BFGS) method [98] as the local search procedure.
- 3.
- The column BFGS represents the incorporation of the BFGS method, modified by Powell [63], as the local search procedure.
The BFGS method achieved lower values for the test error in the majority of cases, and this is also evident in Figure 13, where a box plot is depicted for the classification datasets.
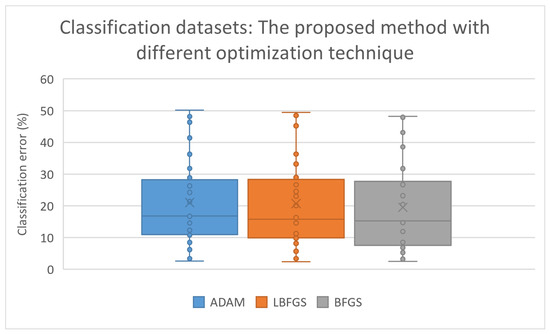
Figure 13.
Box plot for the experiment with the proposed method and different local optimization methods. The current work was executed on the classification datasets.
4. Conclusions
An extension of the artificial neural network construction technique was presented in the present work, in which the continuous application of a local optimization method to chromosomes that were selected randomly was introduced. The local optimization method was applied in such a way as not to alter the architecture of the neural network constructed by grammatical evolution. The proposed modified method was applied on a series of benchmark datasets found in the relevant literature and, judging from the experimental results, it reduced significantly the test error of the original method in most datasets.
Moreover, to establish the stability of the proposed technique, additional experiments were carried out in which a number of critical parameters were varied over a range of values. After the completion of these experiments, it became clear that there is no significant difference in the effectiveness of the proposed method even if these critical parameters change significantly from execution to execution. The only case where a significant difference in the effectiveness of the proposed technique was found was when different local optimization techniques were used, where the BFGS variant appeared to achieve the best results in the majority of cases.
Nevertheless, one major drawback of the current work is the additional execution time required from the execution of the local search optimization techniques. Since the grammatical evolution procedure is a modified genetic algorithm, the generated artificial neural networks are independent of themselves, and parallel programming techniques may be used in order to improve the speed of the method, such as the usage of MPI [99] or the OpenMP library [100].
Author Contributions
V.C. and I.G.T. performed the mentioned experiments. I.G.T. wrote the used software and D.T., A.T. and V.C. executed all the statistical comparisons and prepared the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research has been financed by the European Union: Next Generation EU through the Program Greece 2.0 National Recovery and Resilience Plan, under the call RESEARCH–CREATE–INNOVATE, project name “iCREW: Intelligent small craft simulator for advanced crew training using Virtual Reality techniques” (project code: TAEDK-06195).
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef]
- Suryadevara, S.; Yanamala, A.K.Y. A Comprehensive Overview of Artificial Neural Networks: Evolution, Architectures, and Applications. Rev. Intel. Artif. Med. 2021, 12, 51–76. [Google Scholar]
- Baldi, P.; Cranmer, K.; Faucett, T.; Sadowski, P.; Whiteson, D. Parameterized neural networks for high-energy physics. Eur. Phys. J. C 2016, 76, 1–7. [Google Scholar] [CrossRef]
- Carleo, G.; Troyer, M. Solving the quantum many-body problem with artificial neural networks. Science 2017, 355, 602–606. [Google Scholar] [CrossRef]
- Khoo, Y.; Lu, J.; Ying, L. Solving parametric PDE problems with artificial neural networks. Eur. J. Appl. Math. 2021, 32, 421–435. [Google Scholar] [CrossRef]
- Kumar Yadav, A.; Chandel, S.S. Solar radiation prediction using Artificial Neural Network techniques: A review. Renew. Sustain. Energy Rev. 2014, 33, 772–781. [Google Scholar] [CrossRef]
- Escamilla-García, A.; Soto-Zarazúa, G.M.; Toledano-Ayala, M.; Rivas-Araiza, E.; Gastélum-Barrios, A. Applications of Artificial Neural Networks in Greenhouse Technology and Overview for Smart Agriculture Development. Appl. Sci. 2020, 10, 3835. [Google Scholar] [CrossRef]
- Shen, L.; Wu, J.; Yang, W. Multiscale Quantum Mechanics/Molecular Mechanics Simulations with Neural Networks. J. Chem. Theory Comput. 2016, 12, 4934–4946. [Google Scholar] [CrossRef]
- Wei, J.N.; Duvenaud, D.; Aspuru-Guzik, A. Neural Networks for the Prediction of Organic Chemistry Reactions. ACS Cent. Sci. 2016, 2, 725–732. [Google Scholar] [CrossRef]
- Khosravi, A.; Koury, R.N.N.; Machado, L.; Pabon, J.J.G. Prediction of wind speed and wind direction using artificial neural network, support vector regression and adaptive neuro-fuzzy inference system. Sustain. Energy Technol. Assess. 2018, 25, 146–160. [Google Scholar] [CrossRef]
- Falat, L.; Pancikova, L. Quantitative Modelling in Economics with Advanced Artificial Neural Networks. Procedia Econ. Financ. 2015, 34, 194–201. [Google Scholar] [CrossRef]
- Namazi, M.; Shokrolahi, A.; Sadeghzadeh Maharluie, M. Detecting and ranking cash flow risk factors via artificial neural networks technique. J. Bus. Res. 2016, 69, 1801–1806. [Google Scholar] [CrossRef]
- Baskin, I.I.; Winkler, D.; Tetko, I.V. A renaissance of neural networks in drug discovery. Expert Opin. Drug Discov. 2016, 11, 785–795. [Google Scholar] [CrossRef]
- Bartzatt, R. Prediction of Novel Anti-Ebola Virus Compounds Utilizing Artificial Neural Network (ANN). Chem. Fac. Publ. 2018, 49, 16–34. [Google Scholar]
- Vora, K.; Yagnik, S. A survey on backpropagation algorithms for feedforward neural networks. Int. J. Eng. Dev. Res. 2014, 1, 193–197. [Google Scholar]
- Pajchrowski, T.; Zawirski, K.; Nowopolski, K. Neural speed controller trained online by means of modified RPROP algorithm. IEEE Trans. Ind. Inform. 2014, 11, 560–568. [Google Scholar] [CrossRef]
- Hermanto, R.P.S.; Nugroho, A. Waiting-time estimation in bank customer queues using RPROP neural networks. Procedia Comput. Sci. 2018, 135, 35–42. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. ADAM: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Kuo, C.L.; Kuruoglu, E.E.; Chan, W.K.V. Neural Network Structure Optimization by Simulated Annealing. Entropy 2022, 24, 348. [Google Scholar] [CrossRef]
- Reynolds, J.; Rezgui, Y.; Kwan, A.; Piriou, S. A zone-level, building energy optimisation combining an artificial neural network, a genetic algorithm, and model predictive control. Energy 2018, 151, 729–739. [Google Scholar] [CrossRef]
- Das, G.; Pattnaik, P.K.; Padhy, S.K. Artificial neural network trained by particle swarm optimization for non-linear channel equalization. Expert Syst. Appl. 2014, 41, 3491–3496. [Google Scholar] [CrossRef]
- Wang, L.; Zeng, Y.; Chen, T. Back propagation neural network with adaptive differential evolution algorithm for time series forecasting. Expert Syst. Appl. 2015, 42, 855–863. [Google Scholar] [CrossRef]
- Salama, K.M.; Abdelbar, A.M. Learning neural network structures with ant colony algorithms. Swarm Intell. 2015, 9, 229–265. [Google Scholar] [CrossRef]
- Mirjalili, S. How effective is the Grey Wolf optimizer in training multi-layer perceptrons. Appl. Intell. 2015, 43, 150–161. [Google Scholar] [CrossRef]
- Aljarah, I.; Faris, H.; Mirjalili, S. Optimizing connection weights in neural networks using the whale optimization algorithm. Soft Comput. 2018, 22, 1–15. [Google Scholar] [CrossRef]
- Zhang, M.; Hibi, K.; Inoue, J. GPU-accelerated artificial neural network potential for molecular dynamics simulation. Comput. Phys. Commun. 2023, 285, 108655. [Google Scholar] [CrossRef]
- Varnava, T.M.; Meade, A.J. An initialization method for feedforward artificial neural networks using polynomial bases. Adv. Adapt. Data Anal. 2011, 3, 385–400. [Google Scholar] [CrossRef]
- Ivanova, I.; Kubat, M. Initialization of neural networks by means of decision trees. Knowl.-Based Syst. 1995, 8, 333–344. [Google Scholar] [CrossRef]
- Sodhi, S.S.; Chandra, P. Interval based Weight Initialization Method for Sigmoidal Feedforward Artificial Neural Networks. AASRI Procedia 2014, 6, 19–25. [Google Scholar] [CrossRef]
- Chumachenko, K.; Iosifidis, A.; Gabbouj, M. Feedforward neural networks initialization based on discriminant learning. Neural Netw. 2022, 146, 220–229. [Google Scholar] [CrossRef]
- Chen, Q.; Hao, W.; He, J. A weight initialization based on the linear product structure for neural networks. Appl. Math. Comput. 2022, 415, 126722. [Google Scholar] [CrossRef]
- Arifovic, J.; Gençay, R. Using genetic algorithms to select architecture of a feedforward artificial neural network. Phys. A Stat. Mech. Its Appl. 2001, 289, 574–594. [Google Scholar] [CrossRef]
- Benardos, P.G.; Vosniakos, G.C. Optimizing feedforward artificial neural network architecture. Eng. Appl. Artif. Intell. 2007, 20, 365–382. [Google Scholar] [CrossRef]
- Garro, B.A.; Vázquez, R.A. Designing Artificial Neural Networks Using Particle Swarm Optimization Algorithms. Comput. Intell. Neurosci. 2015, 2015, 369298. [Google Scholar] [CrossRef]
- Baker, B.; Gupta, O.; Naik, N.; Raskar, R. Designing neural network architectures using reinforcement learning. arXiv 2016, arXiv:1611.02167. [Google Scholar]
- Islam, M.M.; Sattar, M.A.; Amin, M.F.; Yao, X.; Murase, K. A New Adaptive Merging and Growing Algorithm for Designing Artificial Neural Networks. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2009, 39, 705–722. [Google Scholar] [CrossRef] [PubMed]
- O’Neill, M.; Ryan, C. Grammatical evolution. IEEE Trans. Evol. Comput. 2001, 5, 349–358. [Google Scholar] [CrossRef]
- Tsoulos, I.G.; Gavrilis, D.; Glavas, E. Neural network construction and training using grammatical evolution. Neurocomputing 2008, 72, 269–277. [Google Scholar] [CrossRef]
- Papamokos, G.V.; Tsoulos, I.G.; Demetropoulos, I.N.; Glavas, E. Location of amide I mode of vibration in computed data utilizing constructed neural networks. Expert Syst. Appl. 2009, 36, 12210–12213. [Google Scholar] [CrossRef]
- Tsoulos, I.G.; Gavrilis, D.; Glavas, E. Solving differential equations with constructed neural networks. Neurocomputing 2009, 72, 2385–2391. [Google Scholar] [CrossRef]
- Tsoulos, I.G.; Mitsi, G.; Stavrakoudis, A.; Papapetropoulos, S. Application of Machine Learning in a Parkinson’s Disease Digital Biomarker Dataset Using Neural Network Construction (NNC) Methodology Discriminates Patient Motor Status. Front. ICT 2019, 6, 10. [Google Scholar] [CrossRef]
- Christou, V.; Tsoulos, I.G.; Loupas, V.; Tzallas, A.T.; Gogos, C.; Karvelis, P.S.; Antoniadis, N.; Glavas, E.; Giannakeas, N. Performance and early drop prediction for higher education students using machine learning. Expert Syst. Appl. 2023, 225, 120079. [Google Scholar] [CrossRef]
- Toki, E.I.; Pange, J.; Tatsis, G.; Plachouras, K.; Tsoulos, I.G. Utilizing Constructed Neural Networks for Autism Screening. Appl. Sci. 2024, 14, 3053. [Google Scholar] [CrossRef]
- Tsoulos, I.G.; Tzallas, A.; Tsalikakis, D. NNC: A tool based on Grammatical Evolution for data classification and differential equation solving. SoftwareX 2019, 10, 100297. [Google Scholar] [CrossRef]
- Backus, J.W. The Syntax and Semantics of the Proposed International Algebraic Language of the Zurich ACM-GAMM Conference. In Proceedings of the International Conference on Information Processing, UNESCO, Paris, France, 15–20 June 1959; pp. 125–132. [Google Scholar]
- Ryan, C.; Collins, J.; O’Neill, M. Grammatical evolution: Evolving programs for an arbitrary language. In Genetic Programming. EuroGP 1998; Banzhaf, W., Poli, R., Schoenauer, M., Fogarty, T.C., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1998; Volume 1391. [Google Scholar]
- O’Neill, M.; Ryan, M.C. Evolving Multi-line Compilable C Programs. In Genetic Programming. EuroGP 1999; Poli, R., Nordin, P., Langdon, W.B., Fogarty, T.C., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1999; Volume 1598. [Google Scholar]
- Ryan, C.; O’Neill, M.; Collins, J.J. Grammatical Evolution: Solving Trigonometric Identities. In Proceedings of the Mendel 1998: 4th International Mendel Conference on Genetic Algorithms, Optimisation Problems, Fuzzy Logic, Neural Networks, Rough Sets, Brno, Czech Republic, 1–2 November 1998. [Google Scholar]
- Puente, A.O.; Alfonso, R.S.; Moreno, M.A. Automatic composition of music by means of grammatical evolution. In APL ’02: Proceedings of the 2002 Conference on APL: Array Processing Languages: Lore, Problems, and Applications Madrid, Spain, 22–25 July 2002; Association for Computing Machinery: New York, NY, USA, 2002; pp. 148–155. [Google Scholar]
- Dempsey, I.; Neill, M.O.; Brabazon, A. Constant creation in grammatical evolution. Int. J. Innov. Comput. Appl. 2007, 1, 23–38. [Google Scholar] [CrossRef]
- Galván-López, E.; Swafford, J.M.; O’Neill, M.; Brabazon, A. Evolving a Ms. PacMan Controller Using Grammatical Evolution. In Applications of Evolutionary Computation. EvoApplications 2010; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6024. [Google Scholar]
- Shaker, N.; Nicolau, M.; Yannakakis, G.N.; Togelius, J.; O’Neill, M. Evolving levels for Super Mario Bros using grammatical evolution. In Proceedings of the 2012 IEEE Conference on Computational Intelligence and Games (CIG), Granada, Spain, 11–14 September 2012; pp. 304–331. [Google Scholar]
- Martínez-Rodríguez, D.; Colmenar, J.M.; Hidalgo, J.I.; Micó, R.J.V.; Salcedo-Sanz, S. Particle swarm grammatical evolution for energy demand estimation. Energy Sci. Eng. 2020, 8, 1068–1079. [Google Scholar] [CrossRef]
- Sabar, N.R.; Ayob, M.; Kendall, G.; Qu, R. Grammatical Evolution Hyper-Heuristic for Combinatorial Optimization Problems. IEEE Trans. Evol. Comput. 2013, 17, 840–861. [Google Scholar] [CrossRef]
- Ryan, C.; Kshirsagar, M.; Vaidya, G.; Cunningham, A.; Sivaraman, R. Design of a cryptographically secure pseudo random number generator with grammatical evolution. Sci. Rep. 2022, 12, 8602. [Google Scholar] [CrossRef]
- Pereira, P.J.; Cortez, P.; Mendes, R. Multi-objective Grammatical Evolution of Decision Trees for Mobile Marketing user conversion prediction. Expert Syst. Appl. 2021, 168, 114287. [Google Scholar] [CrossRef]
- Castejón, F.; Carmona, E.J. Automatic design of analog electronic circuits using grammatical evolution. Appl. Soft Comput. 2018, 62, 1003–1018. [Google Scholar] [CrossRef]
- Araujo, L.; Martinez-Romo, J.; Duque, A. Discovering taxonomies in Wikipedia by means of grammatical evolution. Soft Comput. 2018, 22, 2907–2919. [Google Scholar] [CrossRef]
- Martín, C.; Quintana, D.; Isasi, P. Grammatical Evolution-based ensembles for algorithmic trading. Appl. Soft Comput. 2019, 84, 105713. [Google Scholar] [CrossRef]
- Moore, J.H.; Sipper, M. Grammatical Evolution Strategies for Bioinformatics and Systems Genomics. In Handbook of Grammatical Evolution; Ryan, C., O’Neill, M., Collins, J., Eds.; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Peabody, C.; Seitzer, J. GEF: A self-programming robot using grammatical evolution. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Powell, M.J.D. A Tolerant Algorithm for Linearly Constrained Optimization Calculations. Math. Program. 1989, 45, 547–566. [Google Scholar] [CrossRef]
- Kelly, M.; Longjohn, R.; Nottingham, K. The UCI Machine Learning Repository. 2023. Available online: https://archive.ics.uci.edu (accessed on 18 February 2024).
- Alcalá-Fdez, J.; Fernandez, A.; Luengo, J.; Derrac, J.; García, S.; Sánchez, L.; Herrera, F. KEEL Data-Mining Software Tool: Data Set Repository, Integration of Algorithms and Experimental Analysis Framework. J. Mult.-Valued Log. Soft Comput. 2011, 17, 255–287. [Google Scholar]
- Weiss, S.M.; Kulikowski, C.A. Computer Systems That Learn: Classification and Prediction Methods from Statistics, Neural Nets, Machine Learning, and Expert Systems; Morgan Kaufmann Publishers Inc.: San Mateo, CA, USA, 1991. [Google Scholar]
- Quinlan, J.R. Simplifying Decision Trees. Int. J. Man-Mach. Stud. 1987, 27, 221–234. [Google Scholar] [CrossRef]
- Shultz, T.; Mareschal, D.; Schmidt, W. Modeling Cognitive Development on Balance Scale Phenomena. Mach. Learn. 1994, 16, 59–88. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Jiang, Y. NeC4.5: Neural ensemble based C4.5. IEEE Trans. Knowl. Data Eng. 2004, 16, 770–773. [Google Scholar] [CrossRef]
- Setiono, R.; Leow, W.K. FERNN: An Algorithm for Fast Extraction of Rules from Neural Networks. Appl. Intell. 2000, 12, 15–25. [Google Scholar] [CrossRef]
- Demiroz, G.; Govenir, H.A.; Ilter, N. Learning Differential Diagnosis of Eryhemato-Squamous Diseases using Voting Feature Intervals. Artif. Intell. Med. 1998, 13, 147–165. [Google Scholar]
- Horton, P.; Nakai, K. A Probabilistic Classification System for Predicting the Cellular Localization Sites of Proteins. Int. Conf. Intell. Syst. Mol. Biol. 1996, 4, 109–115. [Google Scholar]
- Hayes-Roth, B.; Hayes-Roth, B.F. Concept learning and the recognition and classification of exemplars. J. Verbal Learn. Verbal Behav. 1977, 16, 321–338. [Google Scholar] [CrossRef]
- Kononenko, I.; Šimec, E.; Robnik-Šikonja, M. Overcoming the Myopia of Inductive Learning Algorithms with RELIEFF. Appl. Intell. 1997, 7, 39–55. [Google Scholar] [CrossRef]
- French, R.M.; Chater, N. Using noise to compute error surfaces in connectionist networks: A novel means of reducing catastrophic forgetting. Neural Comput. 2002, 14, 1755–1769. [Google Scholar] [CrossRef] [PubMed]
- Garcke, J.; Griebel, M. Classification with sparse grids using simplicial basis functions. Intell. Data Anal. 2002, 6, 483–502. [Google Scholar] [CrossRef]
- Dy, J.G.; Brodley, C.E. Feature Selection for Unsupervised Learning. J. Mach. Learn. Res. 2004, 5, 845–889. [Google Scholar]
- Perantonis, S.J.; Virvilis, V. Input Feature Extraction for Multilayered Perceptrons Using Supervised Principal Component Analysis. Neural Process. Lett. 1999, 10, 243–252. [Google Scholar] [CrossRef]
- Elter, M.; Schulz-Wendtland, R.; Wittenberg, T. The prediction of breast cancer biopsy outcomes using two CAD approaches that both emphasize an intelligible decision process. Med. Phys. 2007, 34, 4164–4172. [Google Scholar] [CrossRef]
- Little, M.A.; McSharry, P.E.; Hunter, E.J.; Spielman, J.; Ramig, L.O. Suitability of dysphonia measurements for telemonitoring of Parkinson’s disease. IEEE Trans. Biomed. Eng. 2009, 56, 1015–1022. [Google Scholar] [CrossRef]
- Smith, J.W.; Everhart, J.E.; Dickson, W.C.; Knowler, W.C.; Johannes, R.S. Using the ADAP learning algorithm to forecast the onset of diabetes mellitus. In Proceedings of the Symposium on Computer Applications and Medical Care; IEEE Computer Society Press: New York, NY, USA, 1988; pp. 261–265. [Google Scholar]
- Lucas, D.D.; Klein, R.; Tannahill, J.; Ivanova, D.; Brandon, S.; Domyancic, D.; Zhang, Y. Failure analysis of parameter-induced simulation crashes in climate models. Geosci. Model Dev. 2013, 6, 1157–1171. [Google Scholar] [CrossRef]
- Giannakeas, N.; Tsipouras, M.G.; Tzallas, A.T.; Kyriakidi, K.; Tsianou, Z.E.; Manousou, P.; Hall, A.; Karvounis, E.C.; Tsianos, V.; Tsianos, E. A clustering based method for collagen proportional area extraction in liver biopsy images. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBS), Milan, Italy, 25–29 August 2015; pp. 3097–3100. [Google Scholar]
- Hastie, T.; Tibshirani, R. Non-parametric logistic and proportional odds regression. JRSS-C (Appl. Stat.) 1987, 36, 260–276. [Google Scholar] [CrossRef]
- Dash, M.; Liu, H.; Scheuermann, P.; Tan, K.L. Fast hierarchical clustering and its validation. Data Knowl. Eng. 2003, 44, 109–138. [Google Scholar] [CrossRef]
- Cortez, P.; Gonçalves Silva, A.M. Using data mining to predict secondary school student performance. In Proceedings of the 5th FUture BUsiness TEChnology Conference (FUBUTEC 2008), EUROSIS-ETI, Porto Alegre, Brazil, 9–11 April 2008; pp. 5–12. [Google Scholar]
- Yeh, I.C.; Yang, K.J.; Ting, T.M. Knowledge discovery on RFM model using Bernoulli sequence. Expert Syst. Appl. 2009, 36, 5866–5871. [Google Scholar] [CrossRef]
- Wolberg, W.H.; Mangasarian, O.L. Multisurface method of pattern separation for medical diagnosis applied to breast cytology. Proc. Natl. Acad. Sci. USA 1990, 87, 9193–9196. [Google Scholar] [CrossRef] [PubMed]
- Raymer, M.; Doom, T.E.; Kuhn, L.A.; Punch, W.F. Knowledge discovery in medical and biological datasets using a hybrid Bayes classifier/evolutionary algorithm. IEEE Trans. Syst. Man Cybern. Part B Cybern. Publ. IEEE Syst. Man Cybern. Soc. 2003, 33, 802–813. [Google Scholar] [CrossRef]
- Zhong, P.; Fukushima, M. Regularized nonsmooth Newton method for multi-class support vector machines. Optim. Methods Softw. 2007, 22, 225–236. [Google Scholar] [CrossRef]
- Andrzejak, R.G.; Lehnertz, K.; Mormann, F.; Rieke, C.; David, P.; Elger, C.E. Indications of nonlinear deterministic and finite-dimensional structures in time series of brain electrical activity: Dependence on recording region and brain state. Phys. Rev. E 2001, 64, 1–8. [Google Scholar] [CrossRef]
- Koivisto, M.; Sood, K. Exact Bayesian Structure Discovery in Bayesian Networks. J. Mach. Learn. Res. 2004, 5, 549–573. [Google Scholar]
- Nash, W.J.; Sellers, T.L.; Talbot, S.R.; Cawthor, A.J.; Ford, W.B. The Population Biology of Abalone (Haliotis Species) in Tasmania. I. Blacklip Abalone (H. rubra) from the North Coast and Islands of Bass Strait; Sea Fisheries Division, Technical Report 48; Sea Fisheries Division, Department of Primary Industry and Fisheries: Orange, NSW, Australia, 1994.
- Brooks, T.F.; Pope, D.S.; Marcolini, A.M. Airfoil Self-Noise and Prediction; Technical Report, NASA RP-1218; NASA: Washington, DC, USA, 1989.
- Simonoff, J.S. Smooting Methods in Statistics; Springer: Berlin/Heidelberg, Germany, 1996. [Google Scholar]
- Cheng Yeh, I. Modeling of strength of high performance concrete using artificial neural networks. Cem. Concr. Res. 1998, 28, 1797–1808. [Google Scholar]
- Harrison, D.; Rubinfeld, D.L. Hedonic prices and the demand for clean ai. Environ. Econ. Manag. 1978, 5, 81–102. [Google Scholar] [CrossRef]
- Liu, D.C.; Nocedal, J. On the Limited Memory Method for Large Scale Optimization. Math. Program. B 1989, 45, 503–528. [Google Scholar] [CrossRef]
- Gropp, W.; Lusk, E.; Doss, N.; Skjellum, A. A high-performance, portable implementation of the MPI message passing interface standard. Parallel Comput. 1996, 22, 789–828. [Google Scholar] [CrossRef]
- Chandra, R. Parallel Programming in OpenMP; Morgan Kaufmann: Cambridge, MA, USA, 2001. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).