


Continuous Semi-Supervised Nonnegative Matrix Factorization

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Relation to Current Work and Contributions
3. Model
3.1. Formulation
3.2. Theoretical Results
3.3. Algorithm
| Algorithm 1: Overall CSSNMF algorithm. | |||||
| Input :A matrix , | |||||
| a vector , | |||||
| a positive integer , | |||||
| a scalar , | |||||
| a relative error tolerance , and | |||||
| a maximum number of iterations . | |||||
| Output:Minimizers of Equations (6)–(9): nonnegative matrix , | |||||
| nonnegative matrix , and | |||||
| vector | |||||
| 1 | |||||
| 2 | Elementwise, , , | ||||
| 3 | |||||
| 4 | while and do | ||||
| 5 | as per Algorithm 2 | ||||
| 6 | as per Algorithm 3 | ||||
| 7 | as per Algorithm 4 | ||||
| 8 | Normalize W, H, and as per Algorithm 5 | ||||
| 9 | |||||
| 10 | if then | ||||
| 11 | |||||
| 12 | end if | ||||
| 13 | |||||
| 14 | |||||
| 15 | end while | ||||
| 16 | return | ||||
| Algorithm 2: Updating W. |
 |
| Algorithm 3: Updating H. |
 |
| Algorithm 4: Updating . | ||
| Input | :A vector , and | |
| a matrix | ||
| Output | :A new value for . | |
| 1 | ||
| 2 | ||
| 3 | return | |
| Algorithm 5: Normalization process. | ||
| Input | :A matrix , | |
| a matrix , and | ||
| a vector | ||
| Output | :New values for W, H, and . | |
| 1 | a vector of row sums of H. | |
| 2 | ||
| 3 | . | |
| 4 | . | |
| 5 | ||
| 6 | return W, H, and . | |
- W and H fixed.
- and fixed.
- and fixed.
| Algorithm 6: Prediction process. | ||
| Input | :A matrix , | |
| a vector , | ||
| and a vector . | ||
| Output | :Model prediction for response variable, . | |
| 1 | Compute . | |
| 2 | Compute . | |
| 3 | return | |
4. Synthetic Datasets
4.1. Generating Synthetic Data
- We fix values of , , and
- We then define
- We pick such that each entry is . We likewise choose
- We set .
- We pick such that each element is
- We set
- We perturb X with noise and Y with noise .
- Any negative X-entries are set to 0.
- Being elementwise and or
- Being elementwise and .
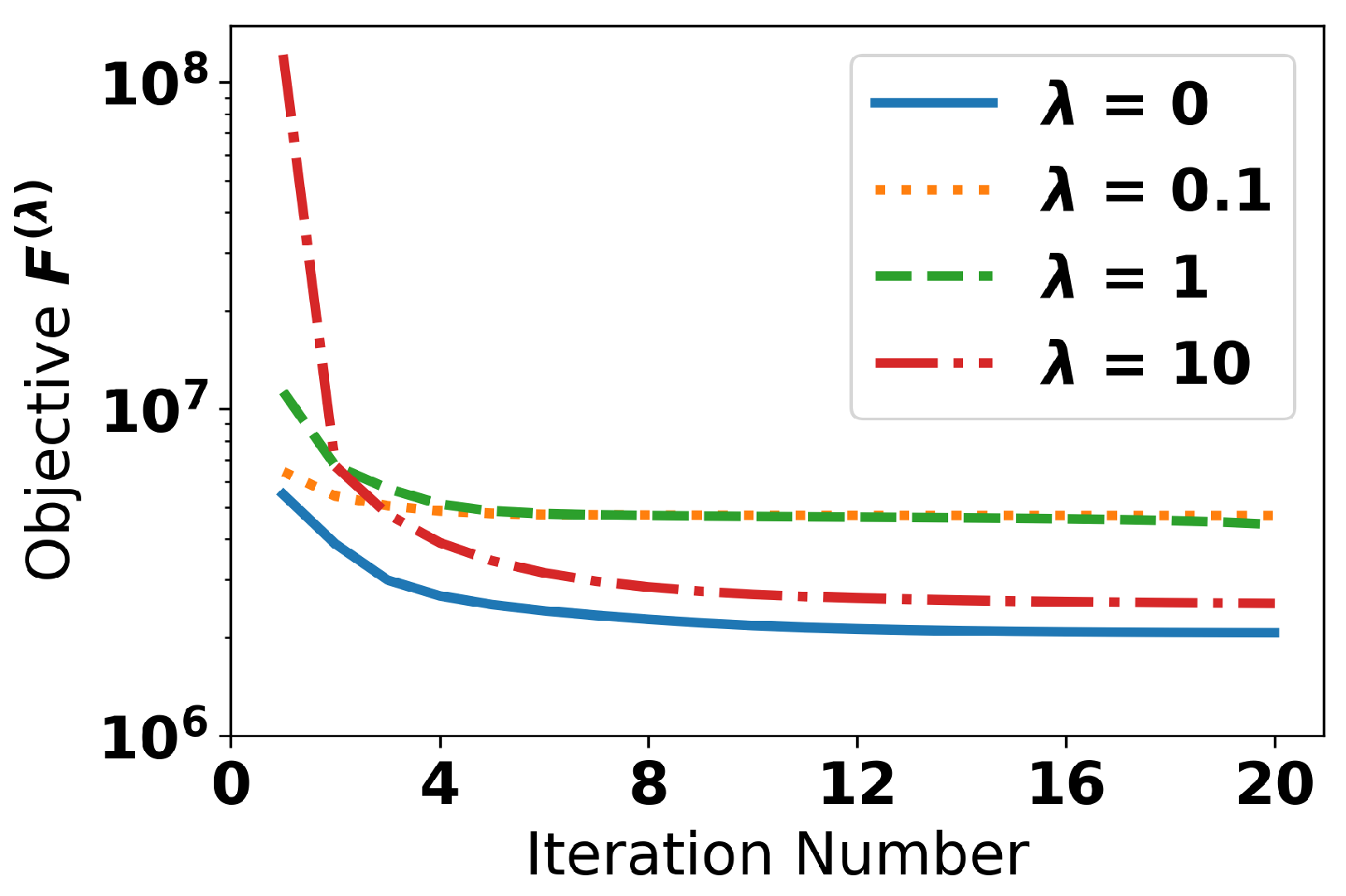
4.2. Investigation
5. Rate My Professors Dataset
5.1. Pre-Processing
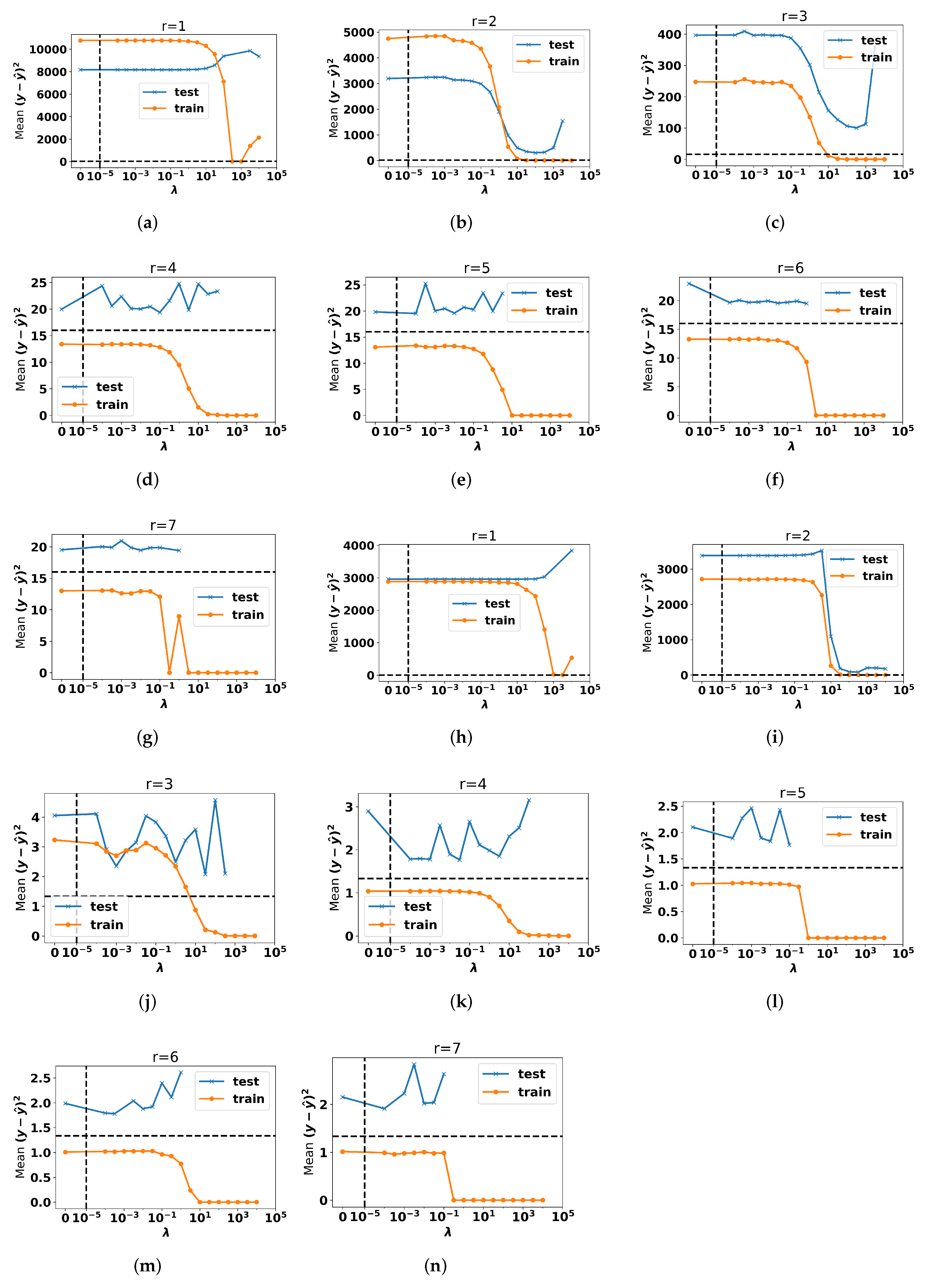
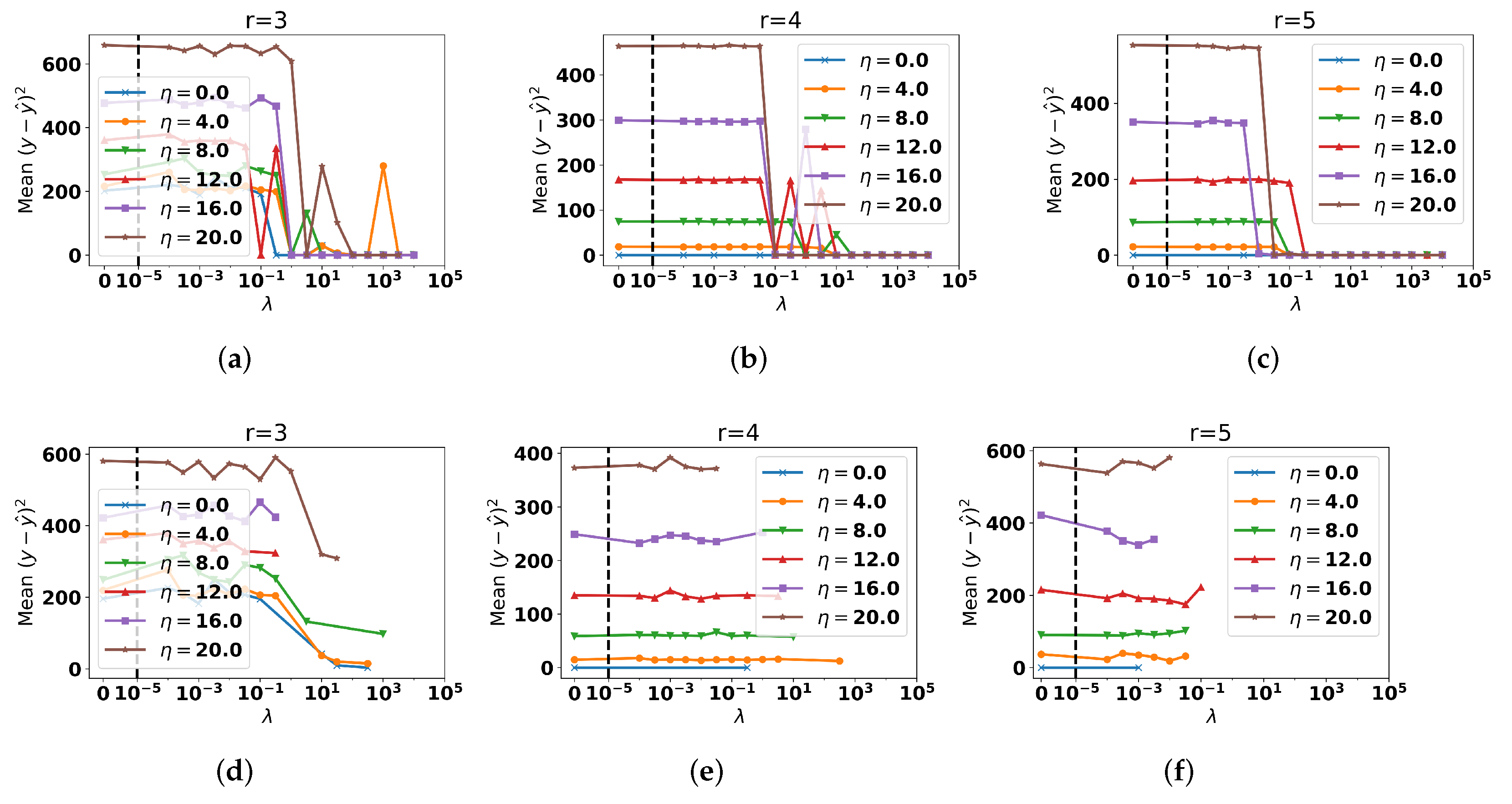
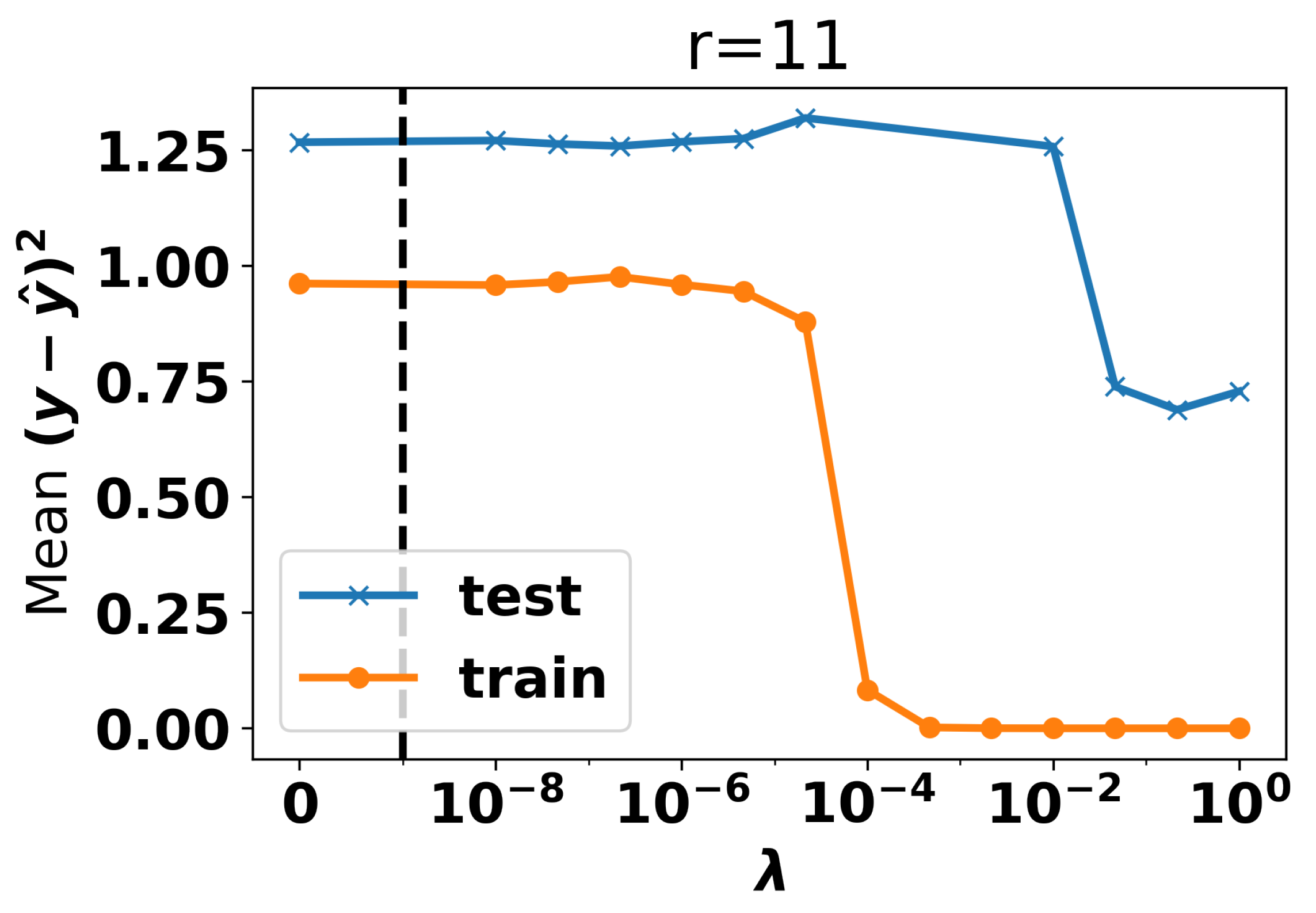
5.2. Choice of Topic Number and Regression Weight
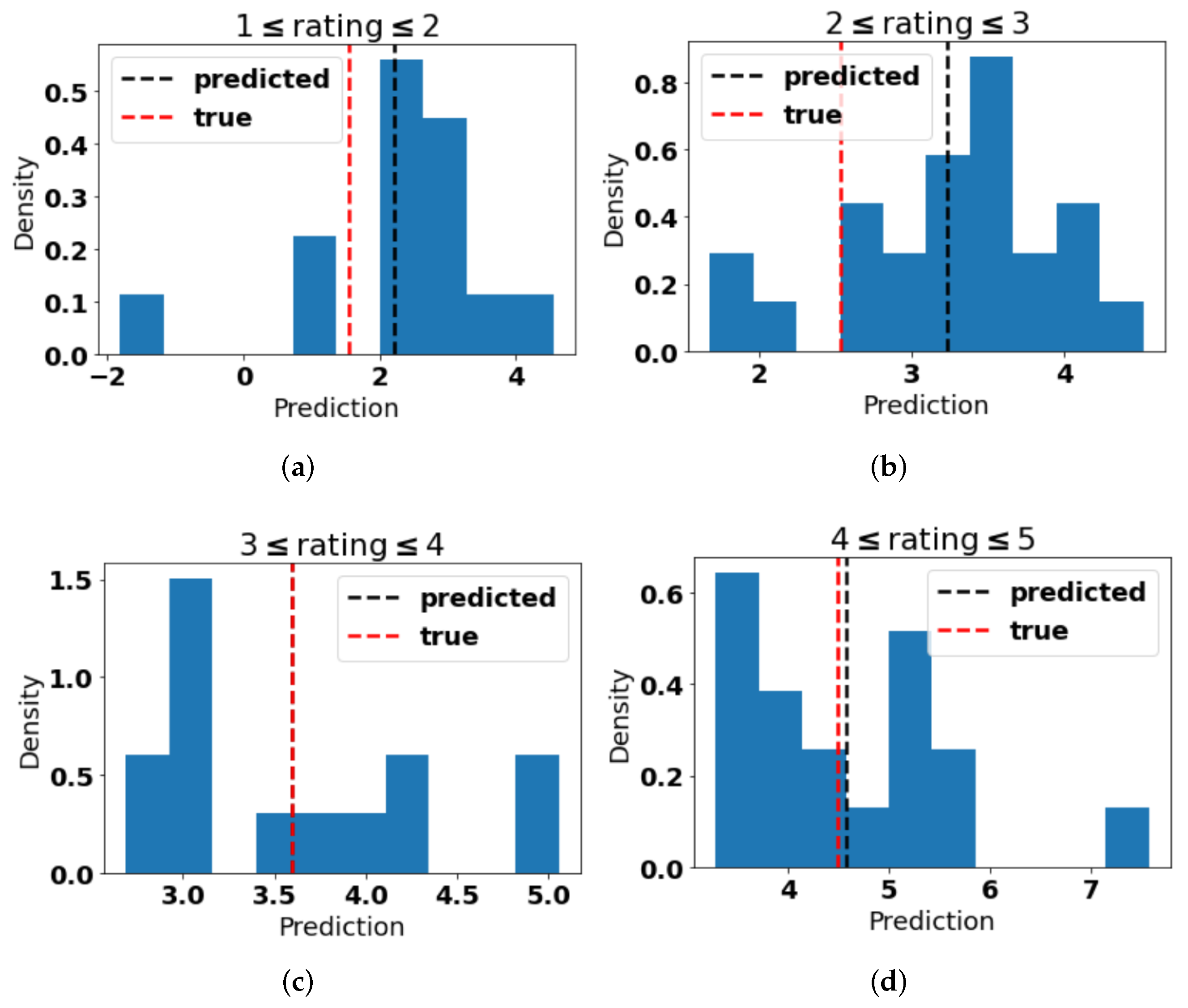
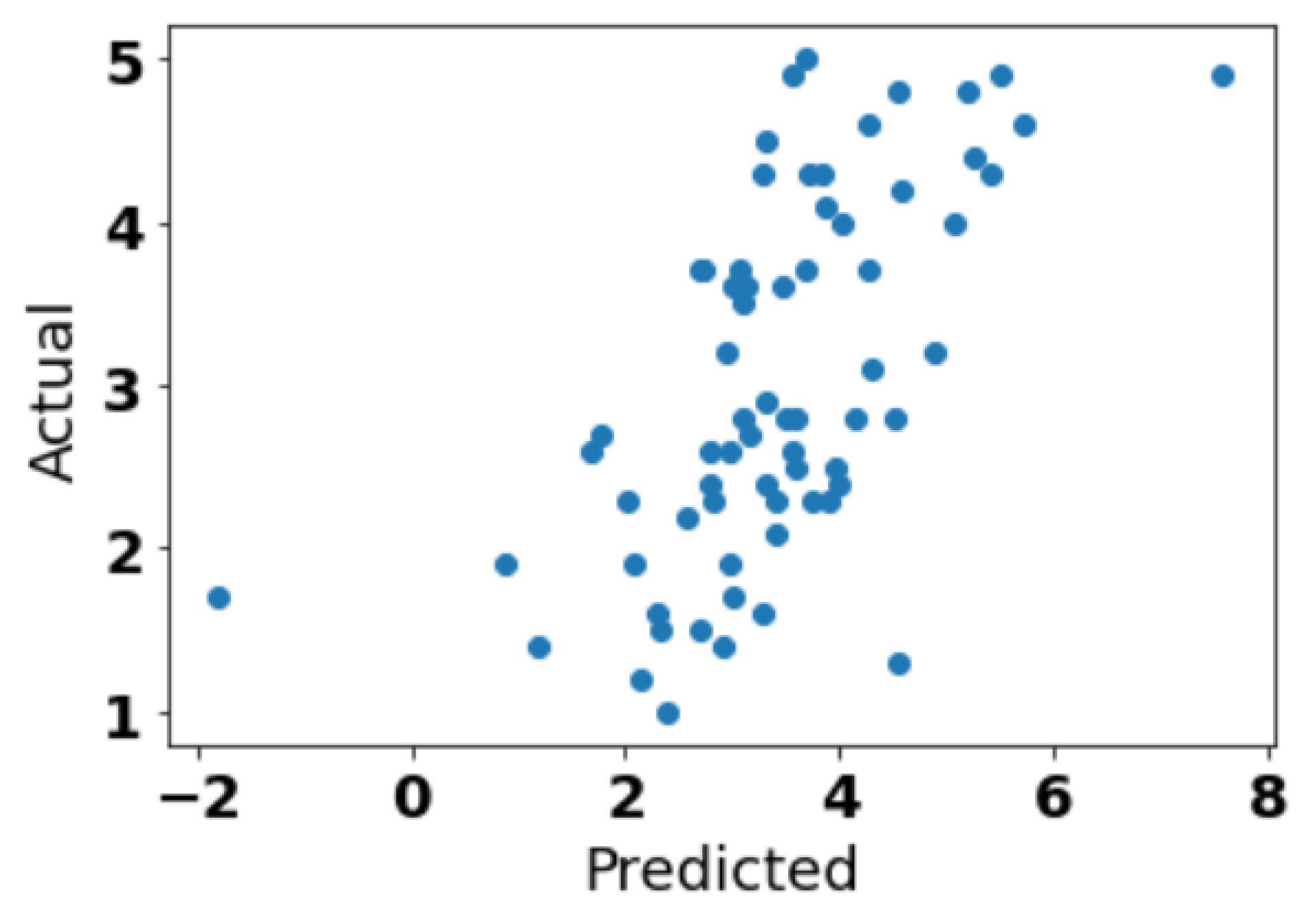
5.3. Prediction
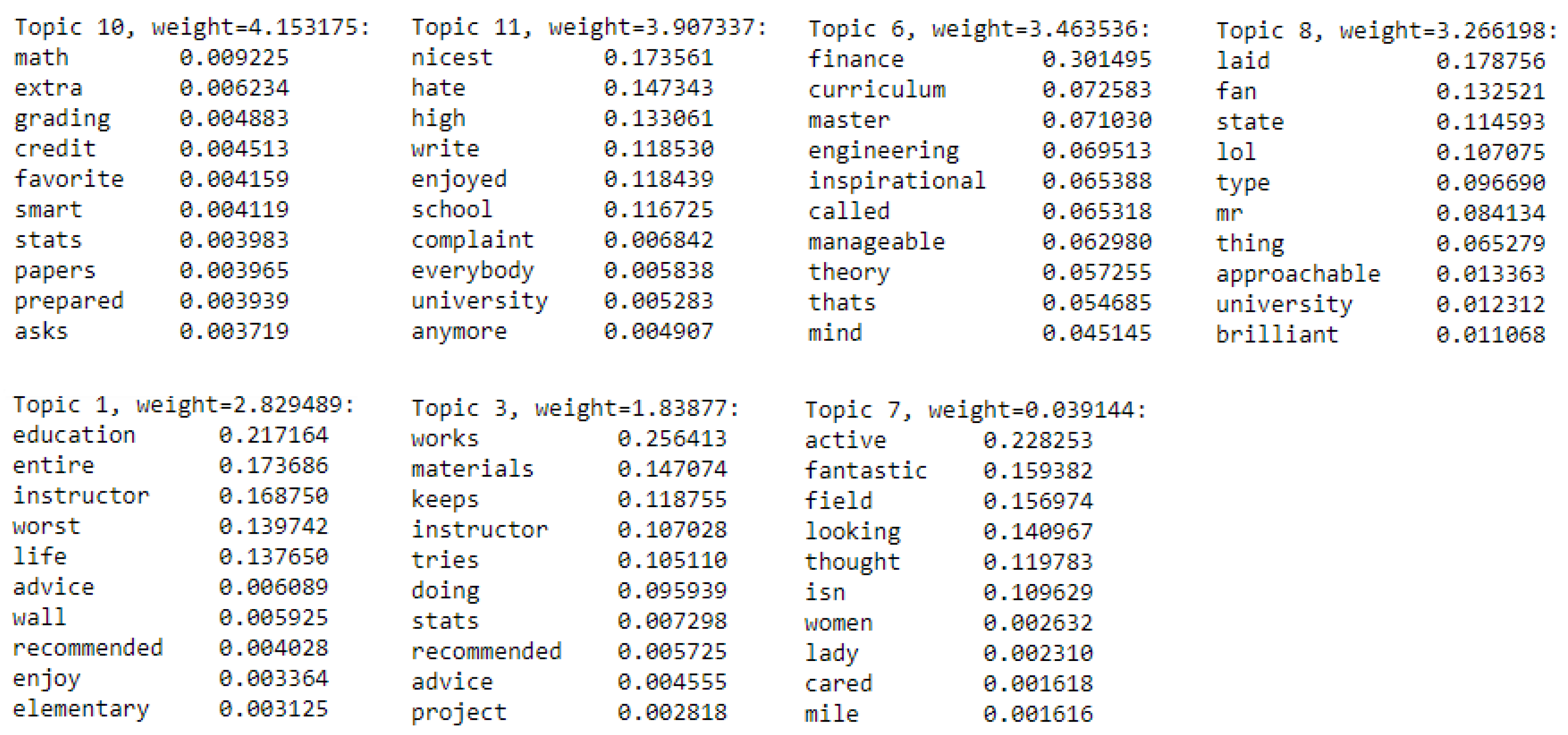
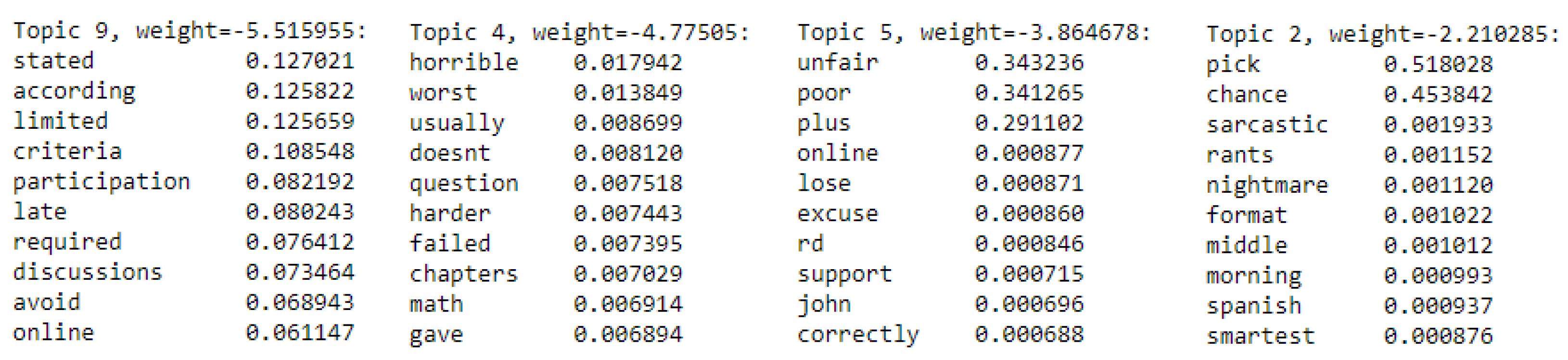
5.4. Topics Identified
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, Y.; Zhang, H.; Liu, R.; Ye, Z.; Lin, J. Experimental explorations on short text topic mining between LDA and NMF based Schemes. Knowl.-Based Syst. 2019, 163, 1–13. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef] [PubMed]
- Lao, H.; Zhang, X. Regression and Classification of Alzheimer’s Disease Diagnosis Using NMF-TDNet Features From 3D Brain MR Image. IEEE J. Biomed. Health Inform. 2021, 26, 1103–1115. [Google Scholar] [CrossRef] [PubMed]
- Lai, Y.; Hayashida, M.; Akutsu, T. Survival analysis by penalized regression and matrix factorization. Sci. World J. 2013, 2013. [Google Scholar] [CrossRef]
- Stewart, G.W. On the early history of the singular value decomposition. SIAM Rev. 1993, 35, 551–566. [Google Scholar] [CrossRef]
- Shahnaz, F.; Berry, M.W.; Pauca, V.P.; Plemmons, R.J. Document clustering using nonnegative matrix factorization. Inf. Process. Manag. 2006, 42, 373–386. [Google Scholar] [CrossRef]
- Joyce, J.M. Kullback-leibler divergence. In International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 720–722. [Google Scholar]
- Marler, R.T.; Arora, J.S. The weighted sum method for multi-objective optimization: New insights. Struct. Multidiscip. Optim. 2010, 41, 853–862. [Google Scholar] [CrossRef]
- Freijeiro-González, L.; Febrero-Bande, M.; González-Manteiga, W. A critical review of LASSO and its derivatives for variable selection under dependence among covariates. Int. Stat. Rev. 2022, 90, 118–145. [Google Scholar] [CrossRef]
- Austin, W.; Anderson, D.; Ghosh, J. Fully supervised non-negative matrix factorization for feature extraction. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 5772–5775. [Google Scholar]
- Zhu, W.; Yan, Y. Joint linear regression and nonnegative matrix factorization based on self-organized graph for image clustering and classification. IEEE Access 2018, 6, 38820–38834. [Google Scholar] [CrossRef]
- Haddock, J.; Kassab, L.; Li, S.; Kryshchenko, A.; Grotheer, R.; Sizikova, E.; Wang, C.; Merkh, T.; Madushani, R.; Ahn, M.; et al. Semi-supervised Nonnegative Matrix Factorization for Document Classification. In Proceedings of the 2021 55th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 31 October–3 November 2021; pp. 1355–1360. [Google Scholar]
- Li, P.; Tseng, C.; Zheng, Y.; Chew, J.A.; Huang, L.; Jarman, B.; Needell, D. Guided Semi-Supervised Non-negative Matrix Factorization on Legal Documents. Algorithms 2022, 15, 136. [Google Scholar] [CrossRef]
- Rate My Professors. Available online: https://www.ratemyprofessors.com/ (accessed on 17 February 2023).
- He, J. Big Data Set from RateMyProfessor.com for Professors’ Teaching Evaluation. 2020. Available online: https://doi.org/10.17632/fvtfjyvw7d.2 (accessed on 21 February 2023).
- Kim, H.; Park, H. Nonnegative matrix factorization based on alternating nonnegativity constrained least squares and active set method. SIAM J. Matrix Anal. Appl. 2008, 30, 713–730. [Google Scholar] [CrossRef]
- Lee, D.; Seung, H.S. Algorithms for non-negative matrix factorization. Adv. Neural Inf. Process. Syst. 2000, 13. [Google Scholar]
- Klein, C.A.; Huang, C.H. Review of pseudoinverse control for use with kinematically redundant manipulators. IEEE Trans. Syst. Man Cybern. 1983, 2, 245–250. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- scipy.optimize.nnls. Available online: https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.nnls.html (accessed on 17 February 2023).
- Bro, R.; De Jong, S. A fast non-negativity-constrained least squares algorithm. J. Chemom. J. Chemom. Soc. 1997, 11, 393–401. [Google Scholar] [CrossRef]
- Luo, Y.; Duraiswami, R. Efficient parallel nonnegative least squares on multicore architectures. SIAM J. Sci. Comput. 2011, 33, 2848–2863. [Google Scholar] [CrossRef]
- Berry, M.W.; Browne, M.; Langville, A.N.; Pauca, V.P.; Plemmons, R.J. Algorithms and applications for approximate nonnegative matrix factorization. Comput. Stat. Data Anal. 2007, 52, 155–173. [Google Scholar] [CrossRef]
- Joachims, T. A Probabilistic Analysis of the Rocchio Algorithm with TFIDF for Text Categorization. Technical Report, Carnegie-Mellon Univ Pittsburgh pa Dept of Computer Science. 1996. Available online: https://apps.dtic.mil/sti/citations/ADA307731 (accessed on 21 February 2023).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Bleske-Rechek, A.; Fritsch, A. Student Consensus on RateMyProfessors Com. Pract. Assess. Res. Eval. 2011, 16, 18. [Google Scholar]
- Hartman, K.B.; Hunt, J.B. What ratemyprofessors. com reveals about how and why students evaluate their professors: A glimpse into the student mind-set. Mark. Educ. Rev. 2013, 23, 151–162. [Google Scholar]
- Moon, G.E.; Ellis, J.A.; Sukumaran-Rajam, A.; Parthasarathy, S.; Sadayappan, P. ALO-NMF: Accelerated locality-optimized non-negative matrix factorization. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; pp. 1758–1767. [Google Scholar]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lindstrom, M.R.; Ding, X.; Liu, F.; Somayajula, A.; Needell, D. Continuous Semi-Supervised Nonnegative Matrix Factorization. Algorithms 2023, 16, 187. https://doi.org/10.3390/a16040187
Lindstrom MR, Ding X, Liu F, Somayajula A, Needell D. Continuous Semi-Supervised Nonnegative Matrix Factorization. Algorithms. 2023; 16(4):187. https://doi.org/10.3390/a16040187
Chicago/Turabian StyleLindstrom, Michael R., Xiaofu Ding, Feng Liu, Anand Somayajula, and Deanna Needell. 2023. "Continuous Semi-Supervised Nonnegative Matrix Factorization" Algorithms 16, no. 4: 187. https://doi.org/10.3390/a16040187
APA StyleLindstrom, M. R., Ding, X., Liu, F., Somayajula, A., & Needell, D. (2023). Continuous Semi-Supervised Nonnegative Matrix Factorization. Algorithms, 16(4), 187. https://doi.org/10.3390/a16040187