Abstract
The efficiency and the effectiveness of a machine learning (ML) model are greatly influenced by feature selection (FS), a crucial preprocessing step in machine learning that seeks out the ideal set of characteristics with the maximum accuracy possible. Due to their dominance over traditional optimization techniques, researchers are concentrating on a variety of metaheuristic (or evolutionary) algorithms and trying to suggest cutting-edge hybrid techniques to handle FS issues. The use of hybrid metaheuristic approaches for FS has thus been the subject of numerous research works. The purpose of this paper is to critically assess the existing hybrid FS approaches and to give a thorough literature review on the hybridization of different metaheuristic/evolutionary strategies that have been employed for supporting FS. This article reviews pertinent documents on hybrid frameworks that were published in the period from 2009 to 2022 and offers a thorough analysis of the used techniques, classifiers, datasets, applications, assessment metrics, and schemes of hybridization. Additionally, new open research issues and challenges are identified to pinpoint the areas that have to be further explored for additional study.
1. Introduction
Feature selection (FS) is a method that aims to choose the minimum required features that can represent a dataset by selecting those features that add the most to the estimation variable that falls within the user’s field of interest [1]. The volume of data available has risen significantly in recent years due to advancements in data gathering techniques in different fields, resulting in increased processing time and space complexity needed for the implementation of architectures in the realms of machine learning (ML). The collected data in many domains typically is of high dimensionality, making it impossible to select an optimum range of features and exclude unnecessary ones. The employed ML models are forced to learn insignificantly as a result of inappropriate features in the dataset, which leads to a poor recognition rate and a large drop in outcomes. By removing unnecessary and outdated features, FS reduces the dimensionality and improves the quality of the resulting attribute vector [2,3,4]. FS has been used for various purposes, including cancer classification (e.g., to improve the diagnosis of breast cancer and diabetes [5]), speech recognition [6], gene prediction [7], gait analysis [8], and text mining [9], etc.
FS has a pair of essential opposing goals, namely, reducing the number of needed characteristics and maximizing the performance of classification to overcome the curse of dimensionality. The three principal kinds of any FS strategy are filter, wrapper, and embedded methods, which integrate both filters and wrappers [10,11]. A filter technique is independent of any ML algorithm. It is appropriate for datasets containing fewer features, and it often requires low-performance computing capabilities. In filtering approaches, the association among classifiers and attributes is not considered, and thus filters often fail to detect the samples correctly during the learning process.
Many studies have used wrappers to address these problems. A wrapper technique frequently alters the training process and uses classifiers as assessment mechanisms. Thus, wrapper techniques for FS often affect the training algorithm and produce more precise results than filters. Wrappers put effort into training the employed ML algorithm by using only a subset of the features that are also needed for determining the training model performance. Depending on the selection accuracy determined in each preceding phase, a wrapper algorithm considers either adding or removing a feature from the selected number of features. As a result, wrapper methods are often more computationally complex and more expensive than most filtering techniques.
Conventional wrapper approaches [12] take a set of attributes and require the user to include arguments as parameters, after which the most informative attributes are chosen from a set of features proportional to the arguments provided by the user. The limitations of such techniques are that the selected feature vector is recursively evaluated, in which case certain characteristics are not included at the first level for assessment. In addition, arguments are specified by the user, and thus certain feature mixtures cannot be taken into account even with more precision. These issues may cause searching overhead along with overfitting. Evolutionary wrapper approaches, which are more common when the search area is very broad, have been created to address the drawbacks of classic wrapper methods. These approaches have many benefits over conventional wrapper methods, including the fact that they need fewer domain details. Evolutionary optimization techniques are population-based metaheuristic strategies that can solve a problem with multiple candidate solutions described by a group of individuals. Each entity in the FS tasks represents a part of the feature vector. An objective (target) function is employed to evaluate and assess the consistency of every candidate solution. The chosen individuals are exposed to the intervention of genetic operators in order to produce new entities that comprise the next generation [13].
A plethora of variations of metaheuristic methods has already been developed to support the FS tasks. When defining a metaheuristic approach, exploration and exploitation are two opposing aspects to take into account. In order to increase the effectiveness of these algorithms, it is essential to establish a good balance between these two aspects. This is because the algorithms perform well in some situations but poorly in others. Every nature-inspired approach has advantages and disadvantages of its own; hence it is not always practical to predict which algorithm is best for a given situation [14].
Researchers [15] now face a hurdle in the implementation and high-precision suggestion of modern metaheuristics for real-world applications. As a result, several researchers are working to solve FS challenges by using hybrid metaheuristics. By merging and coordinating the exploration and exploitation processes, hybridization aims to identify compatible alternatives to ensure the best possible output of the applied optimization methods [16]. A typical strategy for addressing such issues is to combine the advantages of various independent architectures through the hybridization of metaheuristic methods [15,17].
This review paper extends our previous work presented in [18]. The reasons for broadening and extending the research on hybrid FS are highlighted as follows.
- The initial work [18] only focused and reviewed a limited number of papers (only 10 in number) published from 2020–2021. In order to provide a more comprehensive overview of the field, the additional relevant research on hybrid FS from 2009–2022 is extremely important to include in the review study.
- The current review paper deepens the scope of our research on multiple domains covering a wide range of metaheuristic approaches and wrapper classifiers.
- The literature review presented in the current paper aims to fulfill the highly evolving nature of research in the field of FS, and it is very important to stay up to date with the latest developments in order to provide the most accurate and relevant information to the readers.
- Therefore, we believed it was important to design the current updated and extended review paper, which will be of interest to researchers in the FS domain.
We intend to address research issues and challenges that are open and interesting in terms of further research, and to provide a thorough overview of hybrid evolutionary techniques used to solve FS problems. This review draws the attention of scholars working with various metaheuristic frameworks, enabling them to further investigate enlightened approaches for tackling the complex FS problems often encountered in big data applications across many application domains.
The remaining parts of this review article include Section 2, which gives an outline of feature-collection processes and important contextual information. The details of the applied literature review on hybrid evolutionary methods for FS are presented in Section 3. Section 4 provides analysis and guidance for future research based on the literature studies. The last section contains the conclusions of this study. Table 1 summarizes the acronyms of all terms used in this paper (i.e., Table 1 presents the names of all presented FS selection methods, ML models, parameters, and corresponding evaluation metrics).

Table 1.
Acronyms of the reviewed FS methods and respective evaluation metrics.
2. Related Work
It is unusual for all properties in a considered dataset to be useful when designing an ML platform in real life. The inclusion of unwanted and redundant attributes lessens the model’s classification capability and accuracy. As more factors are added to an ML framework, its complexity increases [19,20]. By finding and assembling the ideal set of features, FS in ML aims to produce useful models of a problem under study and consideration [21]. Some important advantages of FS are [10,12]:
- reducing overfitting and eliminating redundant data,
- improving accuracy and reducing misleading results, and
- reducing the ML algorithm training time, dropping the algorithm complexity, and speeding up the training process.
The prime components of an FS process are presented in Figure 1 and they are [18] as follows.
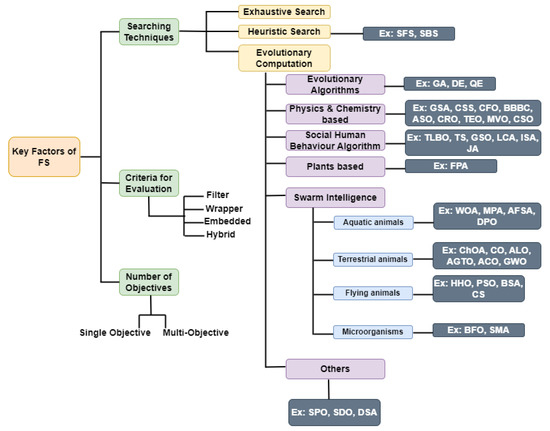
Figure 1.
Key factors of feature selection.
- 1.
- Searching Techniques: To obtain the best features with the highest accuracy, searching approaches are required to be applied in an FS process. Exhaustive search, heuristic search, and evolutionary computation are a few popular searching methods. An exhaustive search is explored in a few works [19,20]. Numerous heuristic strategies and greedy techniques, such as sequential forward selection (SFS) [22], and sequential backward selection (SBS), have therefore been used for FS [23]. However, in later parts of the FS process, it could be impossible to select or delete eliminated or selected features because both SFS and SBS suffer from the “nesting effect” problem. After being selected, features in the SFS method cannot be discarded later, while the features discarded in the SBS cannot be selected again. These two approaches can be compromised by using SFS l times and then applying SBS r times [24]. The nesting effect can be reduced by such a method, but the correct values of l and r must be determined carefully. Sequential backward and forward floating methods were presented to avoid this problem [22]. A two-layer cutting plane approach was recently suggested in [23] to evaluate the best subsets of characteristics. In [24], an exhaustive FS search with backtracking and a heuristic search was proposed.Various EC approaches have been proposed in recent years to tackle the challenges of the FS problems successfully. Some of them are differential evolution (DE) [25], genetic algorithms (GAs) [26], grey wolf optimization (GWO) [27,28], ant colony optimization (ACO) [29,30,31], binary Harris hawks optimization (BHHO) [32,33] and improved BHHO (IBHHO) [34], binary ant lion optimization (BALO) [35,36], salp swarm algorithm (SSA) [37], dragon algorithm (DA) [38], multiverse algorithm (MVA) [39], Jaya optimization algorithms such as the FS based on the Jaya optimization algorithm (FSJaya) [40] and the FS based on the adaptive Jaya algorithm (AJA) [41], grasshopper swarm intelligence optimization algorithm (GOA) and its binary versions [42], binary teaching learning-based optimization (BTLBO) [43], harmony search (HS) [44], and the vortex search algorithm (VSA) [45], etc. All these techniques have been applied for performing FS on various types of datasets, and they have been demonstrated to achieve high optimization rates and to increase the CA. EC techniques require no domain knowledge and do not presume whether the training dataset is linearly separable or not. Another valuable aspect of EC methods is that their population-based process can deliver several solutions in one cycle. However, EC approaches often entail considerable computational costs because they typically include a wide range of assessments. The stability of an EC approach is also a critical concern, as the respective algorithms often pick different features from various rounds. Further research study is required as the growing number of characteristics in large-scale datasets also raises computational costs and decreases the consistency of EC algorithm application [13] in certain real-world FS activities. A high-level description of the most used EC algorithms is given below.
- Genetic Algorithm (GA): A GA [46] is a metaheuristic influenced by natural selection that belongs to the larger class of evolutionary algorithms in computer science and operations research. GA relies on biologically inspired operators, such as mutation, crossover, and selection to develop high-quality solutions to optimization and search challenges. The GA is a mechanism that governs biological evolution and for tackling both constrained and unconstrained optimization issues. The GA adjusts a population of candidate solutions on a regular basis.
- Particle Swarm Optimization (PSO): PSO is a bioinspired algorithm that is straightforward to use while looking for the best alternative in the solution space. It differs from other optimization techniques in that it simply requires the objective function and is unaffected by the gradient or any differential form of the objective. It also has a small number of hyperparameters. Kennedy and Eberhart proposed PSO in 1995 [47]. Sociobiologists think that a school of fish or a flock of birds moving in a group “may profit from the experience of all other members”, as stated in the original publication. In other words, while a bird is flying around looking for food at random, all of the birds in the flock can share what they find and assist the entire flock to get the best hunt possible. While we may imitate the movement of a flock of birds, we can also assume that each bird is assisting us in locating the best solution in a high-dimensional solution space, with the flock’s best solution being the best solution in the space. This is a heuristic approach because we can never be certain that the true global optimal solution exists, and it rarely does. However, we frequently discover that the PSO solution is very close to the global optimum.
- Grey Wolf Optimizer (GWO): Mirjalili et al. [48] presented GWO as a new metaheuristic in 2014. The grey wolf’s social order and hunting mechanisms inspired the algorithm. First, there are four wolves, or degrees of the social hierarchy, to consider when creating GWO.
- –
- The wolf: the solution having best fitness value;
- –
- the wolf: the solution having second-best fitness value;
- –
- the wolf: the solution having third-best fitness value; and
- –
- the wolf: all other solutions.
As a result, the algorithm’s hunting mechanism is guided by the first three appropriate wolves, , , and . The remaining wolves are regarded as and follow them. Grey wolves follow a set of well-defined steps during hunting: encircling, hunting, and attacking. - Harris Hawk Optimization (HHO): Heidari and his team introduced HHO as a new metaheuristic algorithm in 2019 [49]. HHO uses Harris hawk principles to investigate the prey, surprise pounce, and diverse assault techniques used by Harris hawks in the environment. Hawks reflect alternatives in HHO, whereas prey represents the best solution. The Harris hawks use their keen vision to follow the target and then conduct a surprise pounce to seize the prey they have spotted. In general, HHO is divided into two phases: exploitation and exploration. The HHO algorithm can be switched from exploration to exploitation, and the exploration behaviour can then be adjusted depending on the fleeing prey’s energy.
- 2.
- Criteria for Evaluation: The common evaluation criteria for wrapper FS techniques are the classification efficiency and effectiveness by using the selected attributes. Decision trees (DTs), support vector machines (SVMs), naive Bayes (NB), k-nearest neighbor (KNN), artificial neural networks (ANNs), and linear discriminant analysis (LDA) are just a few examples of common classifiers that have been used as wrappers in FS applications [50,51,52]. In the domain of filter approaches, measurements from a variety of disciplines have been incorporated, particularly information theory, correlation estimates, distance metrics, and consistency criteria [53]. Individual feature evaluation, relying on a particular aspect, is a basic filter approach in which only the best tier features are selected [50]. Relief [54] is a distinctive case in which a distance metric is applied to assess the significance of features. Filter methods are often computationally inexpensive, but they do not consider attribute relationships, which often leads to complicated problems in case of repetitive feature sets, such as in the case of microarray gene data, where the genes are intrinsically correlated [21,53]. To overcome these issues, it is necessary to perform proper filter measurements to choose a suitable subset of relevant features in order to evaluate the whole feature set. Wang et al. [55] recently published a distance measure to assess the difference between the chosen feature space and the space spanned by all features in order to locate a subset of features that approximates all features. Peng et al. [56] introduced the minimum redundancy maximum relevance (MRMR) approach based on shared information, and recommended measures were added to the EC because of their powerful exploration capability [57,58]. A unified selection approach was proposed by Mao and Tsang [23], which optimizes multivariate performance measures but also results in an enormous search area for high-dimensional data, a problem that requires strong heuristic search methods for finding the best output. There are several relatively straightforward statistical methods, such as t-testing, logistic regression (LR), hierarchical clustering, and classification and regression tree (CART), which can be applied jointly to produce better classification results [59]. Recently, authors of [60] have applied sparse LR for FS problems including millions of features. Min et al. [24] developed a rough principle procedure to solve FS tasks under budgetary and schedule constraints. Many experiments show that most filter mechanisms are inefficient for cases with vast numbers of features [61].
- 3.
- Number of Objectives: Single-objective (SO) optimization frameworks are techniques which combine the classifier’s accuracy and the features quantity into a single optimization function. On the contrary, multiobjective (MO) optimization approaches entail techniques designed to find and balance the tradeoffs among alternatives. In an SO situation, a solution’s superiority over other solutions is determined by comparing the resulting fitness values, while in an MO optimization, the dominance notion is employed to get the best results [62]. In particular, to determine the significance of the derived feature sets, in an MO situation, multiple criteria need to be optimized by considering different parameters. MO strategies thus may be used to solve some challenging problems involving multiple conflicting goals [63], and MO optimization comprises fitness functions that minimize or maximize multiple conflicting goals. For example, a typical MO problem with minimization functions can be expressed mathematically as follows,where x is the decision variables vector, n is the number of objectives, is the objective function and and are the problem constraints.Finding the balance among the competing objectives is the process that identifies the dominance of an MO optimization approach. For example, a solution dominates another solution in a minimization problem if and only ifwhere .
3. A Brief Survey
Search Procedure
We adhere to the PRISMA principles for systematic reviews in our work (www.prisma-statement.org (accessed on 19 March 2023)). The relevant research questions are developed in accordance with these standards:
- 1.
- What are the search approaches that were utilised to find the best features?
- 2.
- What are the search algorithms utilised to choose the best features for classification?
- 3.
- What hybrid search approaches have been utilised to choose the best characteristics for classification?
The review began by searching for relevant research on Internet sites and in the University Teknologi PETRONAS online library. The Internet search was guided by the use of search engines to explore the electronic libraries and databases depicted in Figure 2. The terms “hybrid + feature selection”, “hybrid + search technique + feature selection”, and “hybrid + search technique + feature selection + classification” were the search parameters employed. There have been several studies on hybrid evolutionary FS. To ensure that the search was concentrated and controllable, the following inclusion and exclusion criteria were defined to select the publications for further study:
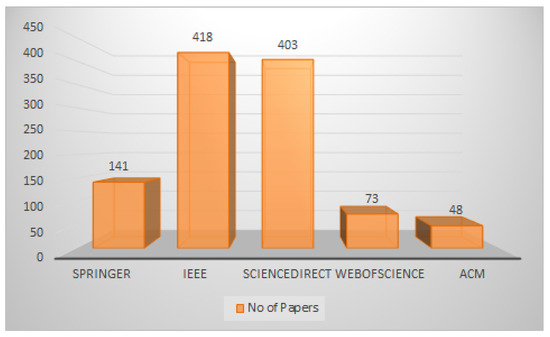
Figure 2.
Number of papers identified.
- Inclusion Criteria:
- –
- Research articles on hybrid evolutionary FS must have been published between 2009 and 2022.
- –
- Only research that has been published in peer-reviewed publications is included.
- –
- If the study had been published in more than one journal, we select the most complete version for inclusion.
- –
- Only related works utilised for classification are included.
- Exclusion Criteria:
- –
- Research articles prior to 2009 are not included.
- –
- Papers that are unrelated to the search topic are rejected.
- –
- Only items written in English are considered. Other languages are removed.
The papers chosen by the abovementioned search procedure were reviewed by title and abstract in accordance with the inclusion and exclusion criteria. Then, all of the studies identified as relevant to our topic were downloaded for information extraction and additional investigation. Figure 2 provides information on the number of research studies discovered during the search of the most popular computerised libraries and databases.
The next step was to prescreen the abstracts of the returning results. The primary goal of prescreening was to eliminate redundant data (some papers were returned in multiple databases) as well as incorrect findings. Improper findings were found in some studies where authors claimed to have employed the hybrid idea, but our research demonstrated that they hybridize filter and wrapper criteria rather than multiple search techniques.
Finally, studies of 35 publications on hybrid metaheuristic approaches that were presented between 2009 and 2022 are covered in this review report. Figure 3 presents the number of papers collected for each year.
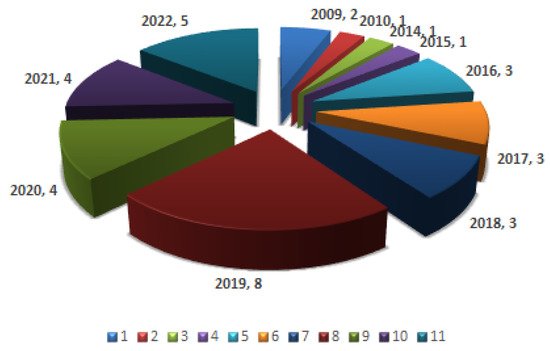
Figure 3.
Number of papers collected per year.
All identified articles were scrutinized by their title and abstract. The current review paper provides a thorough picture on the metaheuristics used for hybridization and also presents a range of various classifiers and datasets, the application fields of the corresponding techniques, their objective/fitness functions and assessment metrics, and the application fields of various hybridised approaches, in contrast to individual methods.
In Table 2, a brief introduction is given about each one of the collected papers in the relevant literature.
Table 2.
Introduction to the collected papers.
The search methods that have been fused together in each metaheuristic approach, the details of the corresponding fitness/objective function along with the respective means of hybridization which have been used in each approach are given in Table 3.
Table 3.
Search methods, their fitness function details, and means of hybridization.
Table 4 gives the details of the classifiers used in the fitness-assessment process, datasets taken for the experiment, and the applications of the mentioned research.
Table 4.
Classifiers, datasets used, and application.
Finally, the descriptions of the classifiers used by the aforementioned articles as wrappers are given in Table 5.
Table 5.
Summary of classifiers used.
4. Analysis and Discussion
According to the analysis of the mentioned articles, the majority of studies employed the wrapper strategy mainly due to its supremacy in terms of higher accuracy compared to filter techniques, which have consistently been shown through experimentation that perform inaccurate filtration. In an effort to utilize all the advantages from both approaches, numerous researchers have tried to integrate and hybridize filter and wrapper methods. Figure 4 displays the number of papers broken down by the evolutionary methods that were employed in the corresponding studies.
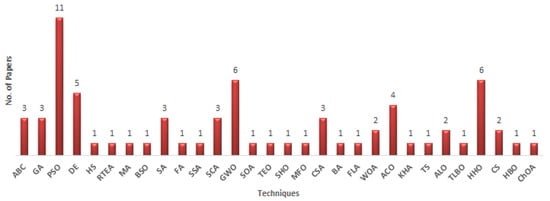
Figure 4.
Number of papers per technique.
These results demonstrate unequivocally that PSO is utilised for fusion in the most number of research articles (11). This is most likely caused by the PSO’s lack of derivatives and its simpler concept and coding technology compared to other evolutionary methods. In particular, in contrast to the other competing evolutionary methods, PSO uses two acceleration coefficients (i.e., the cognitive and social parameters, respectively) and an inertia weight, and thus in PSO there are few parameters required to be adjusted. Furthermore, on average the convergence rate of PSO is faster than other stochastic algorithms [96].
Feature-selection techniques can be applicable to any area where there is a chance of facing the “curse of dimensionality problem”. However, after studying the presented works (Figure 5), we found that most of the hybrid FS techniques (54%) have verified their performance by considering some benchmark datasets. Only 22% of the total articles have applied their technique to the biomedical area (microarray gene selection, disease diagnosis etc.).
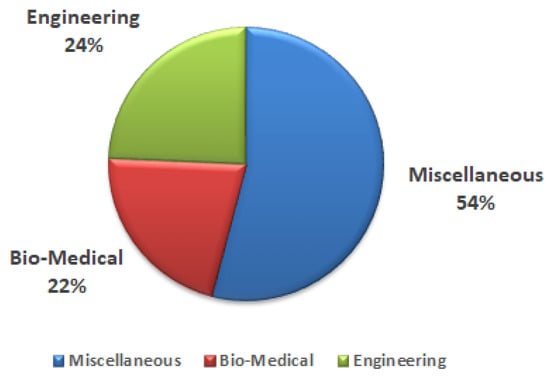
Figure 5.
Distribution of papers according to application area.
Additionally, Figure 6 displays the quantity of papers by using different standard classifiers as wrappers. Because it is simple to grasp and requires less calculation time, 21 out of 35 research employed KNN as a wrapper in their fitness computation procedure. KNN’s training procedure is also incredibly fast because it makes decisions without using any training data.
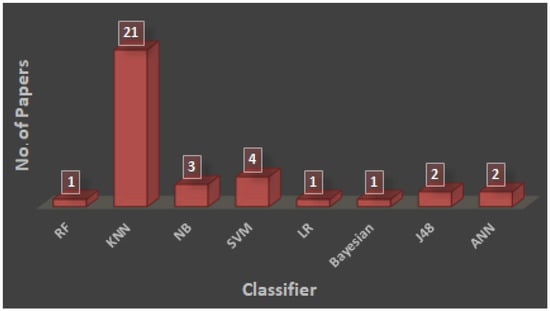
Figure 6.
Number of papers vs. classifier.
Additionally, the bulk of FS researchers using hybrid evolutionary techniques have the goal of reducing both the number of features and the error rate. This is a challenging task, despite the inadequacies of many ECs. The recommended hybrid approaches, however, surpass the current FS methodology after hybridization, which looks for comparable alternatives to produce the best results when tackling optimization tasks, according to tests performed on various datasets. By combining and merging the exploration and exploitation processes, this is achieved. Overall, the previous studies have led to several enhancements and alterations, and, in short, each specific research approach requires the employment of unique approaches in order to provide the required outcomes. The solution model may change over time because there is no one technique that can be used to solve every problem.
After investigating the abovementioned works on hybrid evolutionary algorithms for FS in classification, we are able to list out the following advantages of hybridization.
- Efficiency of the base algorithm can be improved (P1 [64], P4 [67], P8 [71], P11 [74], P14 [77], P20 [9], P22 [83], P25 [86], P26 [87], P28 [89], P35 [17]).
- Premature convergence and the local optimum trap issue can be addressed (P2 [65], P5 [68], P6 [69], P11 [74], P15 [78], P31 [92], P32 [93], P33 [94], P34 [95], P35 [17]).
- Balance between both exploration and exploitation can be maintained (P3 [66], P7 [70], P8 [71], P19 [81], P29 [90]).
- The poor exploitation capability of some of the base methods can be improved (P9 [72], P21 [82], P23 [84], P30 [91], P35).
- The optimal solution identified in each iteration can be enhanced (P10 [73], P12 [75], P16 [79], P18 [80]).
- The searching procedure can converge to the best global solution (P12 [75], P13 [76], P17 [6], P24 [85], P27 [88]).
Although the presented articles are able to improve the performance of the FS techniques, they still have some limitations that point in the direction of future research.
- They are not verified with real-world applications like the biomedical domain (P1 [64], P3 [66], P8 [71], P10 [73], P12 [75], P13 [76], P15 [78], P16 [79], P31 [92], P32 [93]).
- They are not tested with high-dimensional datasets (P1 [64], P3 [66], P4 [67], P6 [69], P7 [70], P8 [71], P9 [72], P10 [73], P11 [74], P12 [75], P13 [76], P15 [78], P16 [79], P18 [80], P19 [81], P24 [85], P27 [88], P29 [90], P32 [93], P33 [94]).
- In some cases, the proposed algorithm is unable to find the global optimum (P3 [66], P14 [77], P27 [88]).
- The fitness value focused only on the error rate and not on the number of features (P5 [68]).
- They take longer to execute (P35 [17]).
- The performance of the proposed approach is not compared with other existing hybrid approaches (P6 [69], P7 [70], P10 [73], P11 [74], P12 [75], P15 [78], P16 [79], P17 [6], P18 [80], P19 [81], P20 [9], P21 [82], P22 [83], P23 [84], P25 [86], P26 [87], P27 [88], P28 [89], P30 [91], P34 [95]).
- They are verified with a few datasets (P14 [77], P17 [6], P20 [9], P21 [82]).
As hybrid models for FS are becoming more effective and more efficient solutions, the following concerns have to be analysed by performing further enhancement.
- The capability of newly developed methods has not been thoroughly explored, particularly in terms of their scalability, and therefore additional research is suggested for FS in high-dimensional real-world applications.
- Since computation complexity is one of the key issues in most hybrid approaches for FS, it is recommended that more appropriate measures to reduce computational complexity should be proposed. Two key considerations must be weighed in order to do so: (1) more efficient ways to perform searching in the large solution spaces and (2) faster evaluation tools.
- The FS priorities, such as computational burden and space complexity, can indeed be viewed in combination with the two main objectives of the hybrid FS problem (i.e., exploration and exploitation).
- Proposing new methodologies that soften the fitness landscape will significantly reduce the problem’s complexities and motivate the development of more effective search strategies.
- Most of the existing studies in the literature used only one fitness function. However, FS can be viewed as an MO problem and thus, the application of hybridization in multiobjective FS tasks is an open research domain for researchers.
- As hybrid FS techniques are time-consuming as compared to the others, employing parallel processing during the FS phase is also an area of research to be explored.
- Most of the abovementioned articles are wrapper-based; however, the optimal solutions generated by wrapper approaches are less generic. Therefore, a hybrid–hybrid approach (i.e., hybridising filter and wrapper criteria while mixing evolutionary techniques) for FS is a challenging research domain.
- Feature selection plays a vital role in the biomedical area due to the high dimensionality of the data. However, very few works (22%) explored their techniques in this field. Therefore, the application of hybrid FS techniques to biomedical data is a very good research area for the future.
5. Conclusions and Future Work
Over the years, academics conducting knowledge extraction and elicitation research have emphasized hybrid metaheuristic approaches for optimal feature identification and selection. The “No Free Lunch” (NFL) theorem states that there has never been and will never be an optimization method that can adequately handle all problems. Therefore, in this paper we tried a systematized analysis of the literature, taking into account research works released from 2009 to 2022, to point out the key difficulties and strategies for hybrid FS and provide a comprehensive investigation of the metaheuristic approaches employed in the development of hybridized FS techniques. According to the survey’s findings, substantial efforts have been made to improve metaheuristic wrapper FS methods’ performance through hybridization in terms of the precision and the size of the considered feature subsets, paving the path for potential advancements. Finally, since there is still room for further development, any hybrid evolutionary FS technique should be extended into a variety of hybridization strategies and variations based on the needs of the specific problems under consideration. As a result, researchers studying hybrid evolutionary methods for addressing FS tasks could use the results of this review study to further investigate more effective and efficient techniques for solving the latest challenges in FS.
Author Contributions
J.P., P.M., R.D., B.A., V.C.G. and A.K.; methodology, J.P., P.M., R.D., B.A., V.C.G. and A.K.; validation, J.P., P.M., R.D., B.A., V.C.G. and A.K.; formal analysis, J.P., P.M., R.D., B.A., V.C.G. and A.K.; investigation, J.P., P.M., R.D., B.A., V.C.G. and A.K.; writing—original draft preparation, J.P., P.M., R.D., B.A., V.C.G. and A.K.; writing—review and editing, J.P., P.M., R.D., B.A., V.C.G. and A.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Piri, J.; Mohapatra, P.; Dey, R. Fetal Health Status Classification Using MOGA—CD Based Feature Selection Approach. In Proceedings of the IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 2–4 July 2020; pp. 1–6. [Google Scholar]
- Bhattacharyya, T.; Chatterjee, B.; Singh, P.K.; Yoon, J.H.; Geem, Z.W.; Sarkar, R. Mayfly in Harmony: A New Hybrid Meta-Heuristic Feature Selection Algorithm. IEEE Access 2020, 8, 195929–195945. [Google Scholar] [CrossRef]
- Piri, J.; Mohapatra, P. Exploring Fetal Health Status Using an Association Based Classification Approach. In Proceedings of the IEEE International Conference on Information Technology (ICIT), Bhubaneswar, India, 19–21 December 2019; pp. 166–171. [Google Scholar]
- Piri, J.; Mohapatra, P.; Acharya, B.; Gharehchopogh, F.S.; Gerogiannis, V.C.; Kanavos, A.; Manika, S. Feature Selection Using Artificial Gorilla Troop Optimization for Biomedical Data: A Case Analysis with COVID-19 Data. Mathematics 2022, 10, 2742. [Google Scholar] [CrossRef]
- Jain, D.; Singh, V. Diagnosis of Breast Cancer and Diabetes using Hybrid Feature Selection Method. In Proceedings of the 5th International Conference on Parallel, Distributed and Grid Computing (PDGC), Solan, India, 20–22 December 2018; pp. 64–69. [Google Scholar]
- Mendiratta, S.; Turk, N.; Bansal, D. Automatic Speech Recognition using Optimal Selection of Features based on Hybrid ABC-PSO. In Proceedings of the IEEE International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–27 August 2016; Volume 2, pp. 1–7. [Google Scholar]
- Naik, A.; Kuppili, V.; Edla, D.R. Binary Dragonfly Algorithm and Fisher Score Based Hybrid Feature Selection Adopting a Novel Fitness Function Applied to Microarray Data. In Proceedings of the International IEEE Conference on Applied Machine Learning (ICAML), Bhubaneswar, India, 27–28 September 2019; pp. 40–43. [Google Scholar]
- Monica, K.M.; Parvathi, R. Hybrid FOW—A Novel Whale Optimized Firefly Feature Selector for Gait Analysis. Pers. Ubiquitous Comput. 2021, 1–13. [Google Scholar] [CrossRef]
- Azmi, R.; Pishgoo, B.; Norozi, N.; Koohzadi, M.; Baesi, F. A Hybrid GA and SA Algorithms for Feature Selection in Recognition of Hand-printed Farsi Characters. In Proceedings of the IEEE International Conference on Intelligent Computing and Intelligent Systems, Xiamen, China, 29–31 October 2010; Volume 3, pp. 384–387. [Google Scholar]
- Al-Tashi, Q.; Abdulkadir, S.J.; Rais, H.M.; Mirjalili, S.; Alhussian, H. Approaches to Multi-Objective Feature Selection: A Systematic Literature Review. IEEE Access 2020, 8, 125076–125096. [Google Scholar] [CrossRef]
- Brezočnik, L.; Fister, I.; Podgorelec, V. Swarm Intelligence Algorithms for Feature Selection: A Review. Appl. Sci. 2018, 8, 1521. [Google Scholar] [CrossRef]
- Venkatesh, B.; Anuradha, J. A Review of Feature Selection and Its Methods. Cybern. Inf. Technol. 2019, 19, 3–26. [Google Scholar] [CrossRef]
- Abd-Alsabour, N. A Review on Evolutionary Feature Selection. In Proceedings of the IEEE European Modelling Symposium, Pisa, Italy, 21–23 October 2014; pp. 20–26. [Google Scholar]
- Wolpert, D.H.; Macready, W.G. No Free Lunch Theorems for Optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Cheng, M.Y.; Prayogo, D. Symbiotic Organisms Search: A new Metaheuristic Optimization Algorithm. Comput. Struct. 2014, 139, 98–112. [Google Scholar] [CrossRef]
- Singh, N.; Son, L.H.; Chiclana, F.; Magnot, J.P. A new Fusion of Salp Swarm with Sine Cosine for Optimization of Non-Linear Functions. Eng. Comput. 2020, 36, 185–212. [Google Scholar] [CrossRef]
- Piri, J.; Mohapatra, P.; Singh, H.K.R.; Acharya, B.; Patra, T.K. An Enhanced Binary Multiobjective Hybrid Filter-Wrapper Chimp Optimization Based Feature Selection Method for COVID-19 Patient Health Prediction. IEEE Access 2022, 10, 100376–100396. [Google Scholar] [CrossRef]
- Piri, J.; Mohapatra, P.; Dey, R.; Panda, N. Role of Hybrid Evolutionary Approaches for Feature Selection in Classification: A Review. In Proceedings of the International Conference on Metaheuristics in Software Engineering and its Application, Marrakech, Morocco, 27–30 October 2022; pp. 92–103. [Google Scholar]
- Blum, A.; Langley, P. Selection of Relevant Features and Examples in Machine Learning. Artif. Intell. 1997, 97, 245–271. [Google Scholar] [CrossRef]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discovery and Data Mining; The Springer International Series in Engineering and Computer Science; Springer: Berlin/Heidelberg, Germany, 1998; Volume 454. [Google Scholar]
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Pudil, P.; Novovicová, J.; Kittler, J. Floating Search Methods in Feature Selection. Pattern Recognit. Lett. 1994, 15, 1119–1125. [Google Scholar] [CrossRef]
- Mao, Q.; Tsang, I.W. A Feature Selection Method for Multivariate Performance Measures. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2051–2063. [Google Scholar] [CrossRef]
- Min, F.; Hu, Q.; Zhu, W. Feature Selection with Test Cost Constraint. Int. J. Approx. Reason. 2014, 55, 167–179. [Google Scholar] [CrossRef]
- Vivekanandan, T.; Iyengar, N.C.S.N. Optimal Feature Selection using a Modified Differential Evolution Algorithm and its Effectiveness for Prediction of Heart Disease. Comput. Biol. Med. 2017, 90, 125–136. [Google Scholar] [CrossRef]
- Sahebi, G.; Movahedi, P.; Ebrahimi, M.; Pahikkala, T.; Plosila, J.; Tenhunen, H. GeFeS: A Generalized Wrapper Feature Selection Approach for Optimizing Classification Performance. Comput. Biol. Med. 2020, 125, 103974. [Google Scholar] [CrossRef]
- Al-Tashi, Q.; Rais, H.; Jadid, S. Feature Selection Method Based on Grey Wolf Optimization for Coronary Artery Disease Classification. In Proceedings of the International Conference of Reliable Information and Communication Technology, Kuala Lumpur, Malaysia, 23–24 July 2018; pp. 257–266. [Google Scholar]
- Too, J.; Abdullah, A.R. Opposition based Competitive Grey Wolf Optimizer for EMG Feature Selection. Evol. Intell. 2021, 14, 1691–1705. [Google Scholar] [CrossRef]
- Aghdam, M.H.; Ghasem-Aghaee, N.; Basiri, M.E. Text Feature Selection using Ant Colony Optimization. Expert Syst. Appl. 2009, 36, 6843–6853. [Google Scholar] [CrossRef]
- Erguzel, T.T.; Tas, C.; Cebi, M. A Wrapper-based Approach for Feature Selection and Classification of Major Depressive Disorder-Bipolar Disorders. Comput. Biol. Med. 2015, 64, 127–137. [Google Scholar] [CrossRef]
- Huang, H.; Xie, H.; Guo, J.; Chen, H. Ant Colony Optimization-based Feature Selection Method for Surface Electromyography Signals Classification. Comput. Biol. Med. 2012, 42, 30–38. [Google Scholar] [CrossRef]
- Piri, J.; Mohapatra, P. An Analytical Study of Modified Multi-objective Harris Hawk Optimizer towards Medical Data Feature Selection. Comput. Biol. Med. 2021, 135, 104558. [Google Scholar] [CrossRef] [PubMed]
- Too, J.; Abdullah, A.R.; Saad, N.M. A New Quadratic Binary Harris Hawk Optimization for Feature Selection. Electronics 2019, 8, 1130. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, R.; Wang, X.; Chen, H.; Li, C. Boosted Binary Harris Hawks Optimizer and Feature Selection. Eng. Comput. 2021, 37, 3741–3770. [Google Scholar] [CrossRef]
- Emary, E.; Zawbaa, H.M.; Hassanien, A.E. Binary Ant Lion Approaches for Feature Selection. Neurocomputing 2016, 213, 54–65. [Google Scholar] [CrossRef]
- Piri, J.; Mohapatra, P.; Dey, R. Multi-objective Ant Lion Optimization Based Feature Retrieval Methodology for Investigation of Fetal Wellbeing. In Proceedings of the 3rd IEEE International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 21–23 September 2021; pp. 1732–1737. [Google Scholar]
- Hegazy, A.E.; Makhlouf, M.A.A.; El-Tawel, G.S. Improved Salp Swarm Algorithm for Feature Selection. J. King Saud Univ.-Comput. Inf. Sci. 2020, 32, 335–344. [Google Scholar] [CrossRef]
- Mafarja, M.M.; Aljarah, I.; Heidari, A.A.; Faris, H.; Fournier-Viger, P.; Li, X.; Mirjalili, S. Binary Dragonfly Optimization for Feature Selection using Time-varying Transfer Functions. Knowl. Based Syst. 2018, 161, 185–204. [Google Scholar] [CrossRef]
- Sreejith, S.; Nehemiah, H.K.; Kannan, A. Clinical Data Classification using an Enhanced SMOTE and Chaotic Evolutionary Feature Selection. Comput. Biol. Med. 2020, 126, 103991. [Google Scholar] [CrossRef]
- Das, H.; Naik, B.; Behera, H.S. A Jaya Algorithm based Wrapper Method for Optimal Feature Selection in Supervised Classification. J. King Saud Univ.-Comput. Inf. Sci. 2020, 34, 3851–3863. [Google Scholar] [CrossRef]
- Tiwari, V.; Jain, S.C. An Optimal Feature Selection Method for Histopathology Tissue Image Classification using Adaptive Jaya Algorithm. Evol. Intell. 2021, 14, 1279–1292. [Google Scholar] [CrossRef]
- Haouassi, H.; Merah, E.; Rafik, M.; Messaoud, M.T.; Chouhal, O. A new Binary Grasshopper Optimization Algorithm for Feature Selection Problem. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 316–328. [Google Scholar]
- Mohan, A.; Nandhini, M. Optimal Feature Selection using Binary Teaching Learning based Optimization Algorithm. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 329–341. [Google Scholar]
- Dash, R. An Adaptive Harmony Search Approach for Gene Selection and Classification of High Dimensional Medical Data. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 195–207. [Google Scholar] [CrossRef]
- Gharehchopogh, F.S.; Maleki, I.; Dizaji, Z.A. Chaotic Vortex Search Algorithm: Metaheuristic Algorithm for Feature Selection. Evol. Intell. 2022, 15, 1777–1808. [Google Scholar] [CrossRef]
- Mitchell, M. An Introduction to Genetic Algorithms; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the IEEE International Conference on Neural Networks (ICNN), Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.M.; Chen, H. Harris Hawks Optimization: Algorithm and Applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Liu, H.; Zhao, Z. Manipulating Data and Dimension Reduction Methods: Feature Selection. In Encyclopedia of Complexity and Systems Science; Springer: Berlin/Heidelberg, Germany, 2009; pp. 5348–5359. [Google Scholar]
- Liu, H.; Motoda, H.; Setiono, R.; Zhao, Z. Feature Selection: An Ever Evolving Frontier in Data Mining. In Proceedings of the 4th International Workshop on Feature Selection in Data Mining (FSDM), Hyderabad, India, 21 June 2010; Volume 10, pp. 4–13. [Google Scholar]
- Xue, B.; Zhang, M.; Browne, W.N. Particle Swarm Optimization for Feature Selection in Classification: A Multi-Objective Approach. IEEE Trans. Cybern. 2013, 43, 1656–1671. [Google Scholar] [CrossRef]
- Dash, M.; Liu, H. Feature Selection for Classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Kira, K.; Rendell, L.A. A Practical Approach to Feature Selection. In Proceedings of the 9th International Workshop on Machine Learning (ML), San Francisco, CA, USA, 1–3 July 1992; Morgan Kaufmann: Burlington, MA, USA, 1992; pp. 249–256. [Google Scholar]
- Wang, S.; Pedrycz, W.; Zhu, Q.; Zhu, W. Subspace learning for unsupervised feature selection via matrix factorization. Pattern Recognit. 2015, 48, 10–19. [Google Scholar] [CrossRef]
- Peng, H.; Long, F.; Ding, C.H.Q. Feature Selection Based on Mutual Information: Criteria of Max-Dependency, Max-Relevance, and Min-Redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Cervante, L.; Xue, B.; Zhang, M.; Shang, L. Binary Particle Swarm Optimisation for Feature Selection: A Filter based Approach. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC), Brisbane, Australia, 10–15 June 2012; pp. 1–8. [Google Scholar]
- Ünler, A.; Murat, A.E.; Chinnam, R.B. mr2PSO: A Maximum Relevance Minimum Redundancy Feature Selection Method based on Swarm Intelligence for Support Vector Machine Classification. Inf. Sci. 2011, 181, 4625–4641. [Google Scholar] [CrossRef]
- Tan, N.C.; Fisher, W.G.; Rosenblatt, K.P.; Garner, H.R. Application of Multiple Statistical Tests to Enhance Mass Spectrometry-based Biomarker Discovery. BMC Bioinform. 2009, 10, 144. [Google Scholar] [CrossRef]
- Tan, M.; Tsang, I.W.; Wang, L. Minimax Sparse Logistic Regression for Very High-Dimensional Feature Selection. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1609–1622. [Google Scholar] [CrossRef] [PubMed]
- Zhai, Y.; Ong, Y.; Tsang, I.W. The Emerging “Big Dimensionality”. IEEE Comput. Intell. Mag. 2014, 9, 14–26. [Google Scholar] [CrossRef]
- Thiele, L.; Miettinen, K.; Korhonen, P.J.; Luque, J.M. A Preference-Based Evolutionary Algorithm for Multi-Objective Optimization. Evol. Comput. 2009, 17, 411–436. [Google Scholar] [CrossRef] [PubMed]
- Bui, L.T.; Alam, S. Multi-Objective Optimization in Computational Intelligence: Theory and Practice; IGI Global: Hershey, PA, USA, 2008. [Google Scholar]
- Al-Wajih, R.; Abdulkadir, S.J.; Alhussian, H.; Aziz, N.; Al-Tashi, Q.; Mirjalili, S.; Alqushaibi, A. Hybrid Binary Whale with Harris Hawks for Feature Selection. Neural Comput. Appl. 2022, 34, 19377–19395. [Google Scholar] [CrossRef]
- Ajibade, S.S.M.; Ahmad, N.B.B.; Zainal, A. A Hybrid Chaotic Particle Swarm Optimization with Differential Evolution for Feature Selection. In Proceedings of the IEEE Symposium on Industrial Electronics & Applications (ISIEA), Kristiansand, Norway, 9–13 November 2020; pp. 1–6. [Google Scholar]
- Ahmed, S.; Ghosh, K.K.; Singh, P.K.; Geem, Z.W.; Sarkar, R. Hybrid of Harmony Search Algorithm and Ring Theory-Based Evolutionary Algorithm for Feature Selection. IEEE Access 2020, 8, 102629–102645. [Google Scholar] [CrossRef]
- Bezdan, T.; Zivkovic, M.; Bacanin, N.; Chhabra, A.; Suresh, M. Feature Selection by Hybrid Brain Storm Optimization Algorithm for COVID-19 Classification. J. Comput. Biol. 2022, 29, 515–529. [Google Scholar] [CrossRef]
- Lee, C.; Le, T.; Lin, Y. A Feature Selection Approach Hybrid Grey Wolf and Heap-Based Optimizer Applied in Bearing Fault Diagnosis. IEEE Access 2022, 10, 56691–56705. [Google Scholar] [CrossRef]
- Thawkar, S. Feature Selection and Classification in Mammography using Hybrid Crow Search Algorithm with Harris Hawks Optimization. Biocybern. Biomed. Eng. 2022, 42, 1094–1111. [Google Scholar] [CrossRef]
- El-Kenawy, E.S.; Eid, M. Hybrid Gray Wolf and Particle Swarm Optimization for Feature Selection. Int. J. Innov. Comput. Inf. Control 2020, 16, 831–844. [Google Scholar]
- Al-Tashi, Q.; Abdulkadir, S.J.; Rais, H.M.; Mirjalili, S.; Alhussian, H. Binary Optimization Using Hybrid Grey Wolf Optimization for Feature Selection. IEEE Access 2019, 7, 39496–39508. [Google Scholar] [CrossRef]
- Jia, H.; Xing, Z.; Song, W. A New Hybrid Seagull Optimization Algorithm for Feature Selection. IEEE Access 2019, 7, 49614–49631. [Google Scholar] [CrossRef]
- Jia, H.; Li, J.; Song, W.; Peng, X.; Lang, C.; Li, Y. Spotted Hyena Optimization Algorithm with Simulated Annealing for Feature Selection. IEEE Access 2019, 7, 71943–71962. [Google Scholar] [CrossRef]
- Aziz, M.A.E.; Ewees, A.A.; Ibrahim, R.A.; Lu, S. Opposition-based Moth-flame Optimization Improved by Differential Evolution for Feature Selection. Math. Comput. Simul. 2020, 168, 48–75. [Google Scholar]
- Arora, S.; Singh, H.; Sharma, M.; Sharma, S.; Anand, P. A New Hybrid Algorithm Based on Grey Wolf Optimization and Crow Search Algorithm for Unconstrained Function Optimization and Feature Selection. IEEE Access 2019, 7, 26343–26361. [Google Scholar] [CrossRef]
- Tawhid, M.A.; Dsouza, K.B. Hybrid Binary Bat Enhanced Particle Swarm Optimization Algorithm for Solving Feature Selection Problems. Appl. Comput. Inform. 2018, 16, 117–136. [Google Scholar] [CrossRef]
- Rajamohana, S.P.; Umamaheswari, K. Hybrid Approach of Improved Binary Particle Swarm Optimization and Shuffled Frog Leaping for Feature Selection. Comput. Electr. Eng. 2018, 67, 497–508. [Google Scholar] [CrossRef]
- Elaziz, M.E.A.; Ewees, A.A.; Oliva, D.; Duan, P.; Xiong, S. A Hybrid Method of Sine Cosine Algorithm and Differential Evolution for Feature Selection. In Proceedings of the 24th International Conference on Neural Information Processing (ICONIP), Guangzhou, China, 14–18 November 2017; Volume 10638, pp. 145–155. [Google Scholar]
- Mafarja, M.M.; Mirjalili, S. Hybrid Whale Optimization Algorithm with Simulated Annealing for Feature Selection. Neurocomputing 2017, 260, 302–312. [Google Scholar] [CrossRef]
- Menghour, K.; Souici-Meslati, L. Hybrid ACO-PSO Based Approaches for Feature Selection. Int. J. Intell. Eng. Syst. 2016, 9, 65–79. [Google Scholar] [CrossRef]
- Hafez, A.I.; Hassanien, A.E.; Zawbaa, H.M.; Emary, E. Hybrid Monkey Algorithm with Krill Herd Algorithm optimization for Feature Selection. In Proceedings of the 11th IEEE International Computer Engineering Conference (ICENCO), Cairo, Egypt, 29–30 December 2015; pp. 273–277. [Google Scholar]
- Nemati, S.; Basiri, M.E.; Ghasem-Aghaee, N.; Aghdam, M.H. A Novel ACO-GA Hybrid Algorithm for Feature Selection in Protein Function Prediction. Expert Syst. Appl. 2009, 36, 12086–12094. [Google Scholar] [CrossRef]
- Chuang, L.; Yang, C.; Yang, C. Tabu Search and Binary Particle Swarm Optimization for Feature Selection Using Microarray Data. J. Comput. Biol. 2009, 16, 1689–1703. [Google Scholar] [CrossRef] [PubMed]
- Kumar, L.; Bharti, K.K. A Novel Hybrid BPSO-SCA Approach for Feature Selection. Nat. Comput. 2021, 20, 39–61. [Google Scholar] [CrossRef]
- Moslehi, F.; Haeri, A. A Novel Hybrid Wrapper-filter Approach based on Genetic Algorithm, Particle Swarm Optimization for Feature Subset Selection. J. Ambient Intell. Humaniz. Comput. 2020, 11, 1105–1127. [Google Scholar] [CrossRef]
- Zawbaa, H.M.; Emary, E.; Grosan, C.; Snásel, V. Large-dimensionality Small-instance Set Feature Selection: A Hybrid Bio-inspired Heuristic Approach. Swarm Evol. Comput. 2018, 42, 29–42. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Diabat, A. A Novel Hybrid Antlion Optimization Algorithm for Multi-objective Task Scheduling Problems in Cloud Computing Environments. Clust. Comput. 2021, 24, 205–223. [Google Scholar] [CrossRef]
- Adamu, A.; Abdullahi, M.; Junaidu, S.B.; Hassan, I.H. An Hybrid Particle Swarm Optimization with Crow Search Algorithm for Feature Selection. Mach. Learn. Appl. 2021, 6, 100108. [Google Scholar] [CrossRef]
- Thawkar, S. A Hybrid Model using Teaching-learning-based Optimization and Salp Swarm Algorithm for Feature Selection and Classification in Digital Mammography. J. Ambient Intell. Humaniz. Comput. 2021, 12, 8793–8808. [Google Scholar] [CrossRef]
- Houssein, E.H.; Hosney, M.E.; Elhoseny, M.; Oliva, D.; Mohamed, W.M.; Hassaballah, M. Hybrid Harris Hawks Optimization with Cuckoo Search for Drug Design and Discovery in Chemoinformatics. Sci. Rep. 2020, 10, 1–22. [Google Scholar] [CrossRef]
- Hussain, K.; Neggaz, N.; Zhu, W.; Houssein, E.H. An Efficient Hybrid Sine-cosine Harris Hawks Optimization for Low and High-dimensional Feature Selection. Expert Syst. Appl. 2021, 176, 114778. [Google Scholar] [CrossRef]
- Al-Wajih, R.; Abdulkadir, S.J.; Aziz, N.; Al-Tashi, Q.; Talpur, N. Hybrid Binary Grey Wolf With Harris Hawks Optimizer for Feature Selection. IEEE Access 2021, 9, 31662–31677. [Google Scholar] [CrossRef]
- Shunmugapriya, P.; Kanmani, S. A Hybrid Algorithm using Ant and Bee Colony Optimization for Feature Selection and Classification (AC-ABC Hybrid). Swarm Evol. Comput. 2017, 36, 27–36. [Google Scholar] [CrossRef]
- Zorarpaci, E.; Özel, S.A. A Hybrid Approach of Differential Evolution and Artificial Bee Colony for Feature Selection. Expert Syst. Appl. 2016, 62, 91–103. [Google Scholar] [CrossRef]
- Jona, J.B.; Nagaveni, N. Ant-cuckoo Colony Optimization for Feature Selection in Digital Mammogram. Pak. J. Biol. Sci. PJBS 2014, 17, 266–271. [Google Scholar] [CrossRef] [PubMed]
- Abdmouleh, Z.; Gastli, A.; Ben-Brahim, L.; Haouari, M.; Al-Emadi, N.A. Review of Optimization Techniques applied for the Integration of Distributed Generation from Renewable Energy Sources. Renew. Energy 2017, 113, 266–280. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).