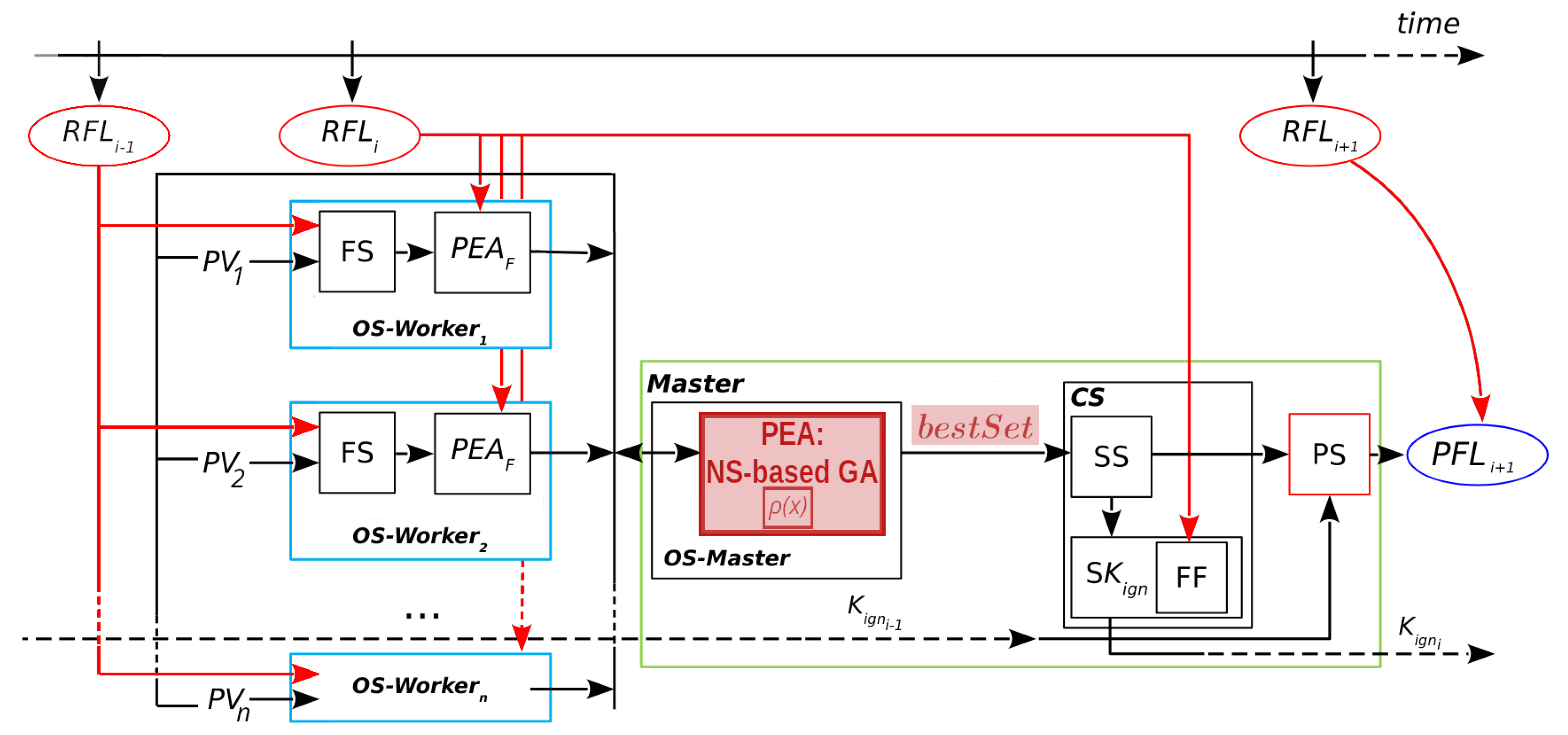
2.1. ESS Framework
The systems referred to in this paper fit into the DDM-MOS category, given that they perform multiple simulations, each based on a different scenario, and rely on a number of simulations in order to yield a fire spread prediction. Previous approaches showed limitations, either caused by the use of a single simulation for the predictions or by the complexity of considering a large space of possibilities, which includes redundant or unfeasible scenarios. To overcome these limitations, the Evolutionary Statistical System (ESS) was developed. Its core idea is to produce a reduced selection of results with the aid of an evolutionary algorithm that searches over the space of all possible scenarios. The objective is to reduce the complexity of the computations while considering a sample of scenarios that may produce better prediction results. In order to understand the scheme of the method proposed in this paper and of its other, more recent competitors, it is necessary to have a general comprehension of how ESS works, since they all share a similar framework.
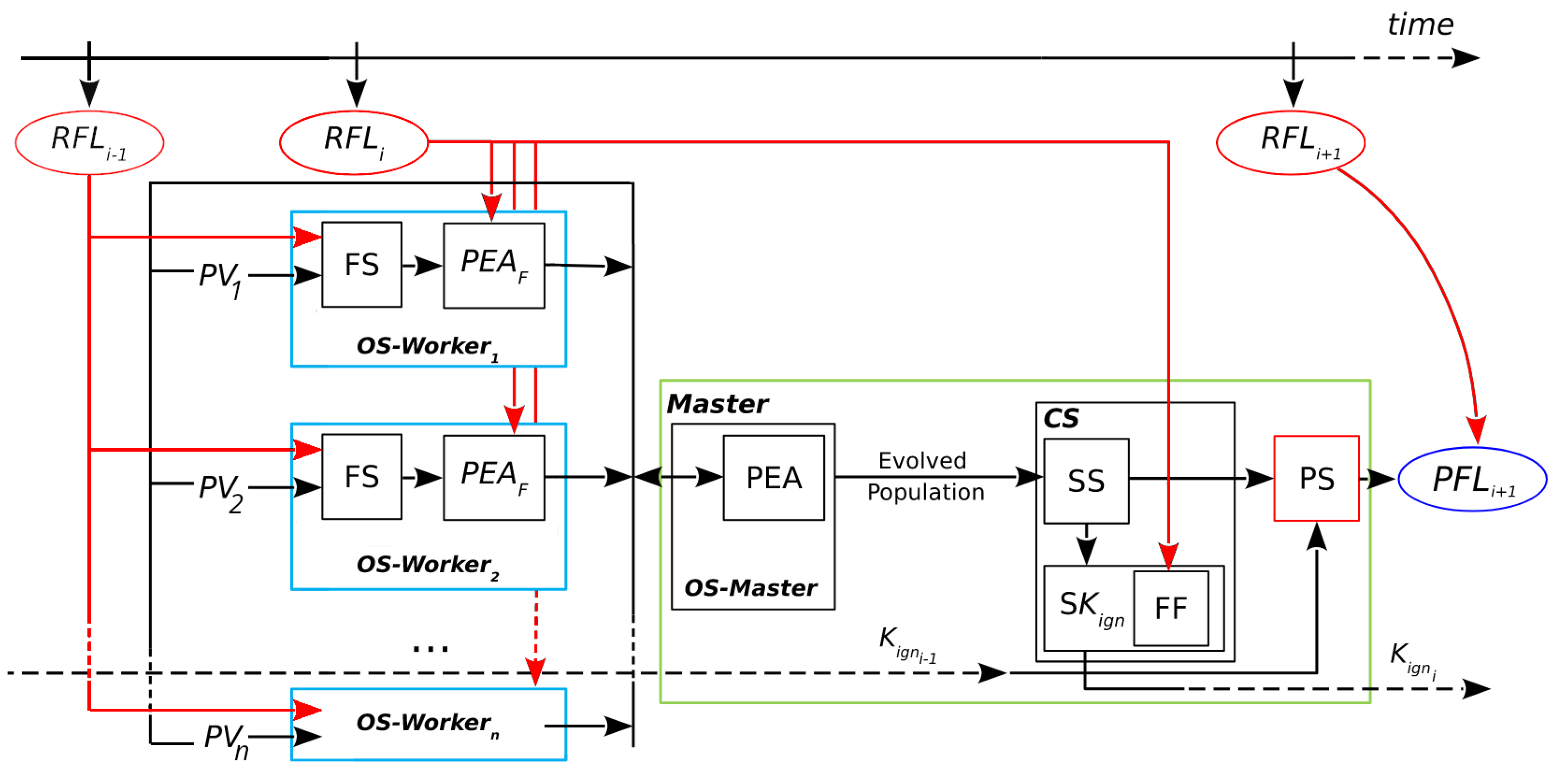
A general scheme of the operation of ESS can be seen in
Figure 2 (reproduced and modified with permission from [
11]). ESS takes advantage of parallelization with the objective of reducing computation times. This is achieved by implementing a
Master/Worker parallel hierarchy for carrying out the optimization of scenarios. During the fire, the whole prediction process is repeated for different discrete time instants. These instants are called
prediction steps, and in each of them, four main stages take place: Optimization Stage (divided into Master and Workers, respectively:
OS-Master and
OS-Worker), Statistical Stage (
SS), Calibration Stage (
CS), and Prediction Stage (
PS).
At each prediction step, the process aims to estimate the growth of the fire line from
to
. For every step, a new optimization starts with the
OS. This involves a search through the space of scenarios guided by a fitness function. The process is a classic evolutionary algorithm that starts with the initialization of the population, performs the evolution of the population (selection, reproduction, and replacement), and then finishes when a termination condition is reached. This parallel evolutionary process is divided into the Master and Workers, shown in
Figure 2 as
OS-Master and
OS-Worker, respectively. The
OS-Master block involves the initialization and modification of the population of scenarios, represented by a set of parameter vectors
PV. The Master distributes these scenarios to the Workers processes (shown as
to
).
The Workers evaluate each scenario that they receive by sending it as input to a fire behavior simulator FS. In the FS block, the information from the Real Fire Line at the previous instant, , is used together with the scenario to produce a simulated map for that scenario. Then, this simulated map and the information from are passed into the block . As represented in the figure, two inputs from the fire line are needed at the OS-Worker (i.e., and ): the first one to produce the simulations, and the second one to evaluate the fitness of those simulations. Such evaluations are needed for guiding the search and producing an adequate result for the next stage (the SS). Therefore, the fitness is obtained by comparing the simulated map with the real state of the fire at the last known instant of time. The Master process receives these evaluations (the simulated maps with their fitness) and uses them to continue with the evolution, i.e., to perform selection, reproduction, and replacement of the population.
Although not shown in the figure for clarity, it is important to note that the OS is iterative in two ways. Firstly, the Master must divide all scenarios in the population into a number of vectors according to the number of Worker processes; e.g., if there are 200 scenarios and 50 Workers, the Master must send a different (each containing 50 scenarios ) for evaluation four times in order to complete the 200 evaluations. Secondly, the Master will repeat this process for each generation of the until a stopping condition is reached.
Once the OS-Master has finished, the following stages are CS and PS. These stages involve the computation of the overlapped result. For the CS, the general idea is to use a collection of simulated maps resulting from the evolutionary algorithm and produce as output an aggregated map and a threshold value; then, for the PS, a final map is produced as a matrix of burned and unburned cells, and this constitutes the prediction for .
In the case of ESS, the collection of simulated maps is equivalent to the evolved population, and the complete
CS is performed by the Master. This is represented by the
CS block in
Figure 2, which involves several steps. The first step is the Statistical Stage or
SS. The purpose of this step is to take into consideration a number of solutions for the prediction. For this, the Master aggregates the resulting maps obtained from the evolved population, producing a matrix in which each cell is the sum of cells that are ignited according to each simulated map from the input. These frequencies are interpreted as probabilities of ignition. Although in this case the selection of maps is straightforward, other criteria can be used to consider different simulations with different results regarding the reduction of uncertainty.
After obtaining this probability matrix, it will be used for two purposes: on the one hand, it is provided as input for the
PS; on the other hand, it is used in the next step of the
CS: the search for the
Key Ignition Value, or
. This is a simple search represented by the block
. These two parts are interrelated: the
PS at
depends on the output of the
CS at
, which is
. Up to this point, we have a probability map, but the predicted fire line
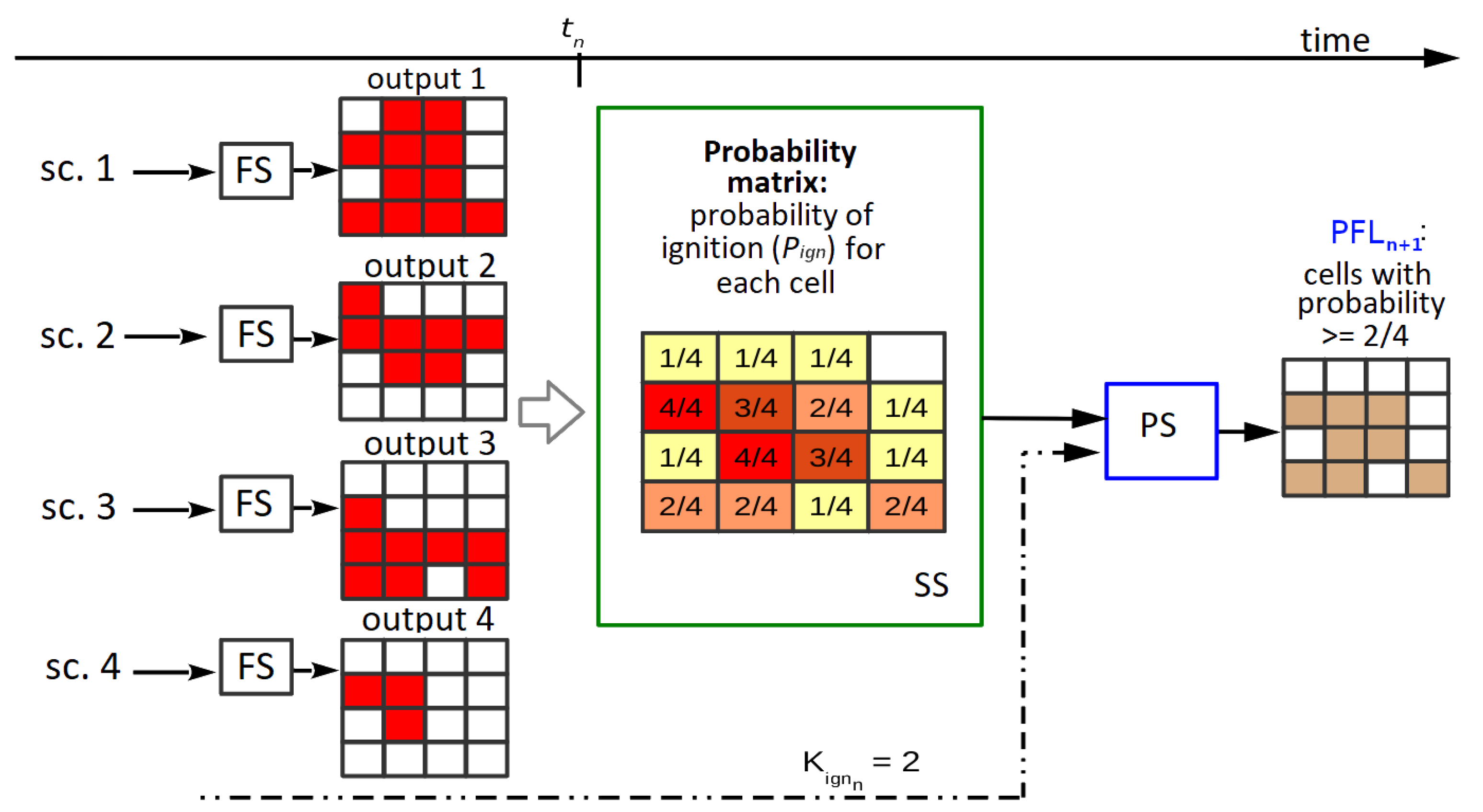
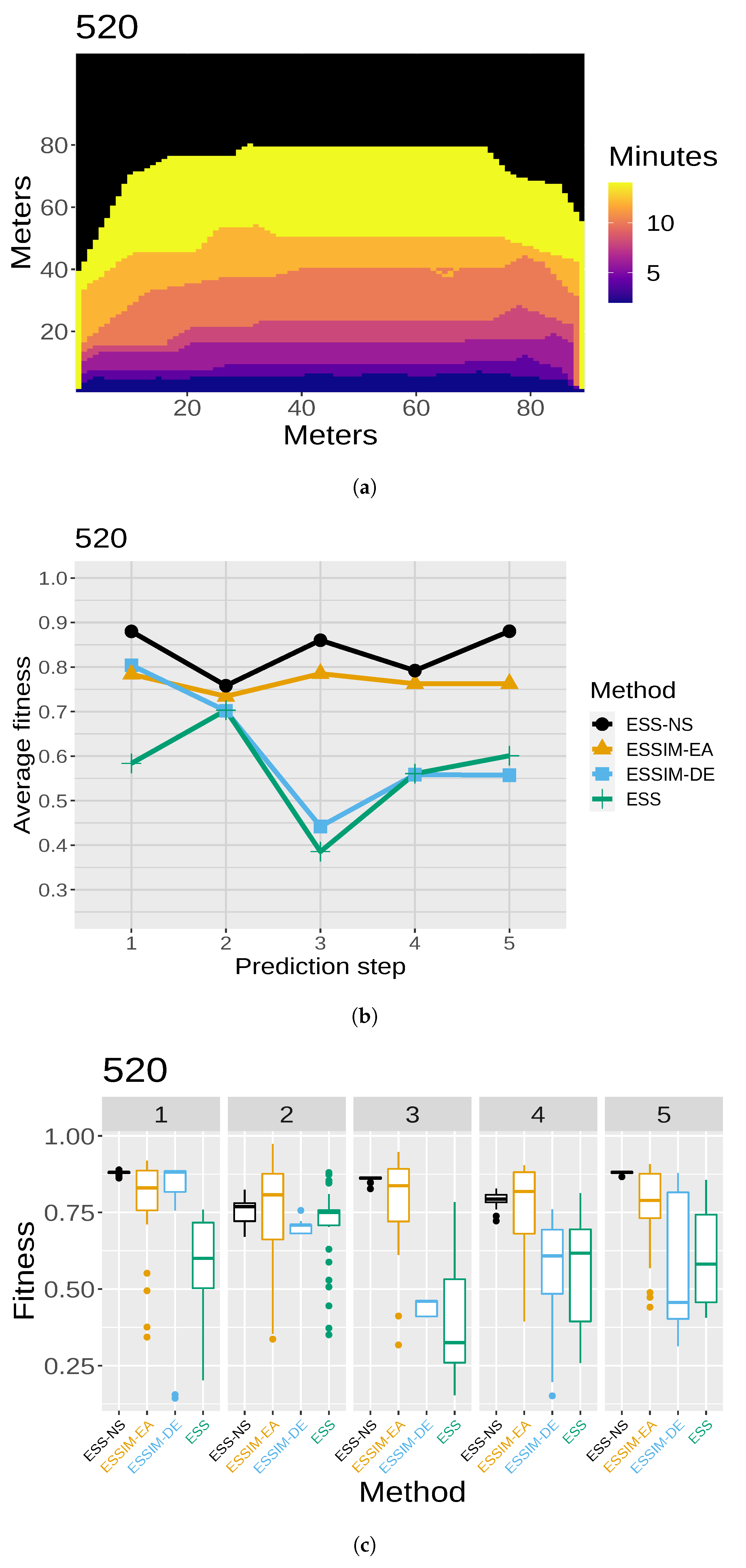
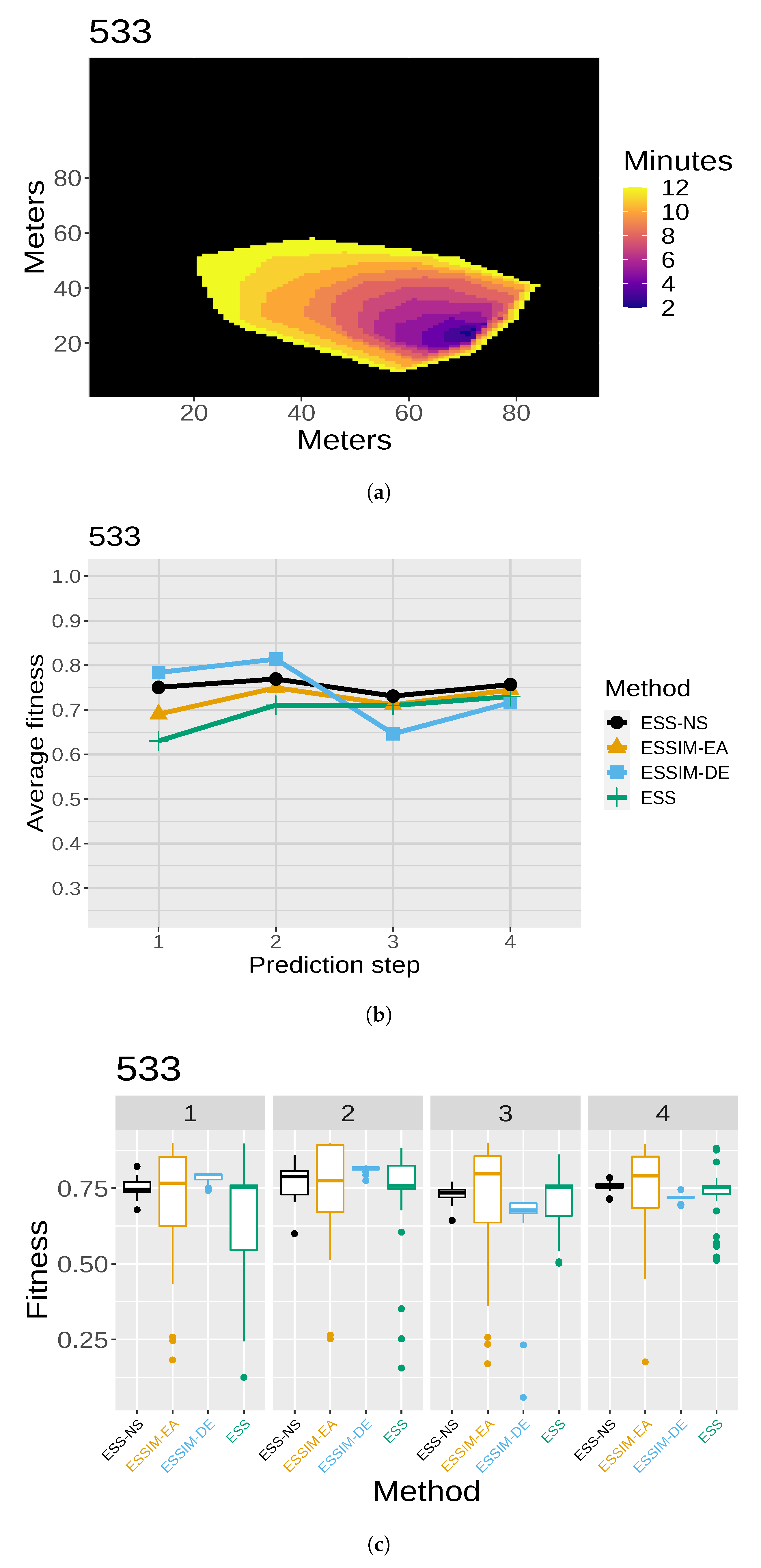
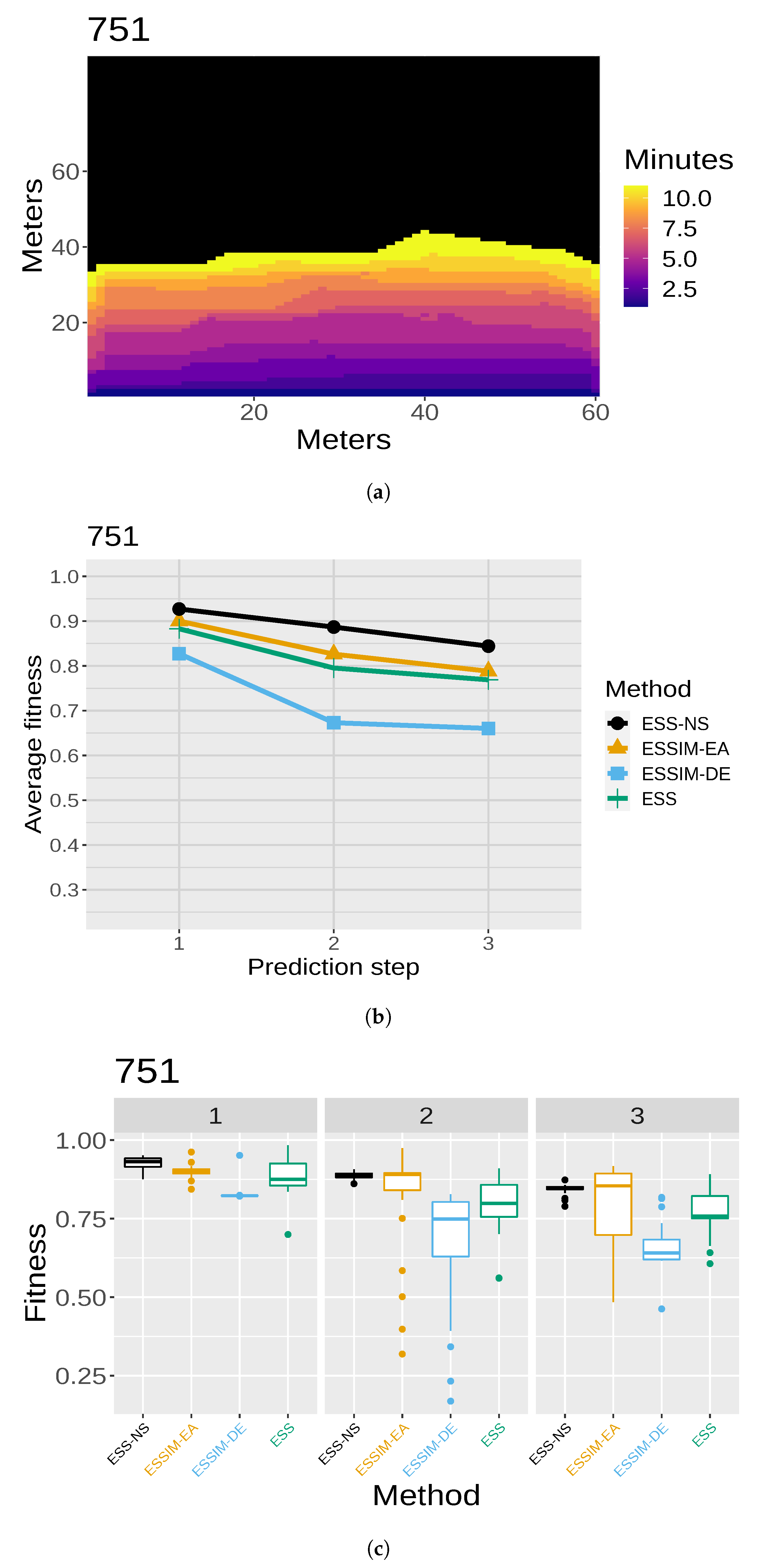
consists of cells that are marked as either burned or unburned. Then, we need a threshold for establishing which cells of the probability map are going to be considered as ignited. In other words, the threshold establishes how many simulated maps must have each cell as ignited in order for that cell to appear as ignited in the final map. A more detailed diagram of the first use of the matrix is illustrated in
Figure 3 (reproduced, modified, and translated with permission from [
22]). In the example from this figure, if there are four simulated maps and
, then for a cell to be predicted as burned in the aggregated map, it must be present as such in at least two of the simulated maps. Note that instead of being the result of one simulation, this final map,
(shown at the right in
Figure 3, after the
PS), aggregates information from the collection of simulated maps obtained as the output of the
OS (simplified in the l.h.s. of the figure). In order to choose an appropriate value of
, it is assumed that a value that was found to be a good predictor for the current known fire line will still be a reasonable choice for the next step due to the fact that propagation phenomena have certain regularities. Therefore, the search for this value involves evaluating the fitness of different maps generated with different threshold values. Going back to
Figure 2, the fitness is computed between each of these maps and the
in the
block. For the
PS to take place at a given prediction step, the best
must have been found at the previous iteration. This is represented by the arrows going from the previous iteration into the
PS (
) and from
towards the next iteration (
). For instance, at step
, the value
is chosen to be used within the
PS of
. The
CS begins in the second fire instant since it depends on the knowledge of the real fire line at the first instant. Once the first result from the calibration has been obtained, that is, starting from the third fire instant, then a prediction from the aggregated map can be obtained.
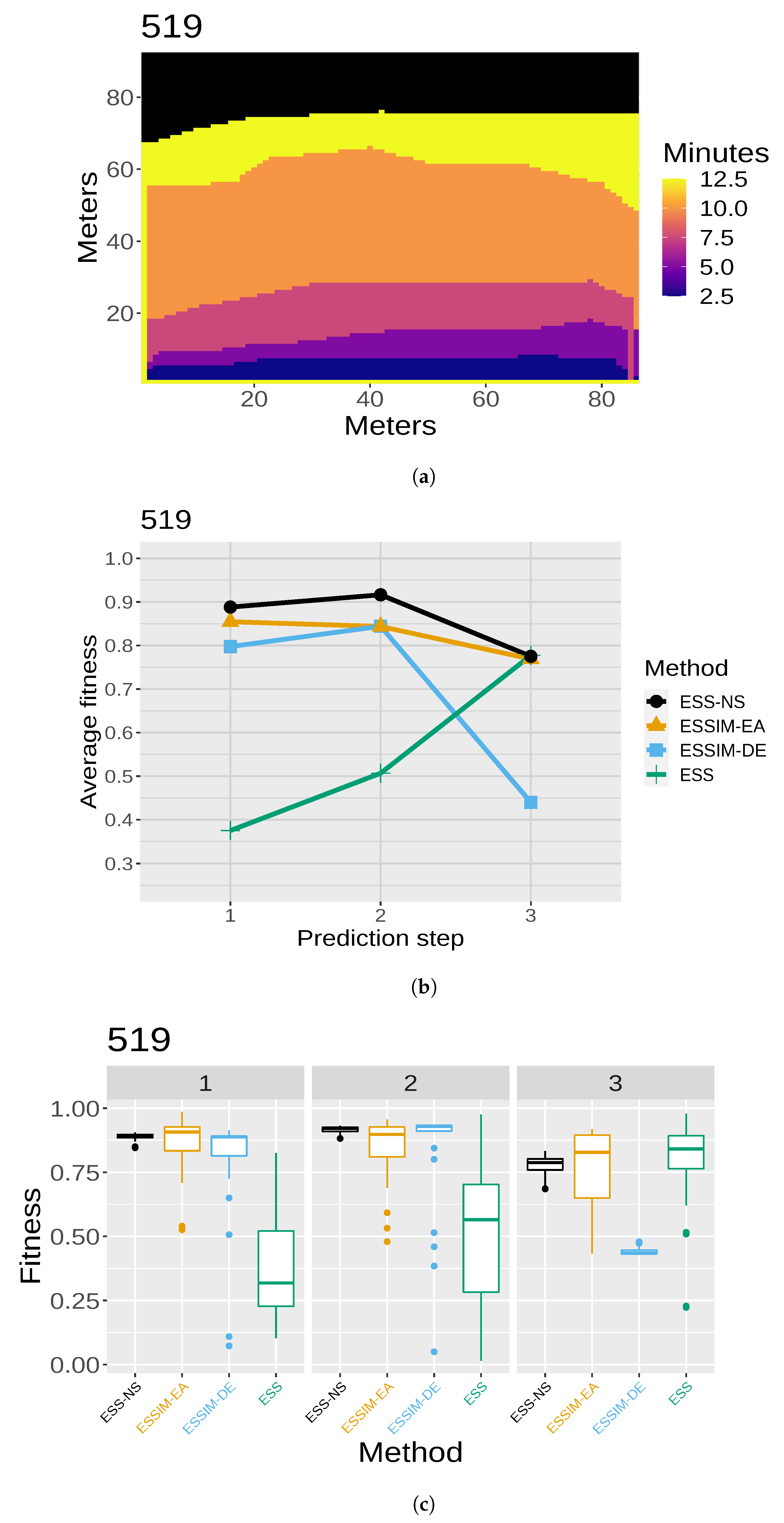
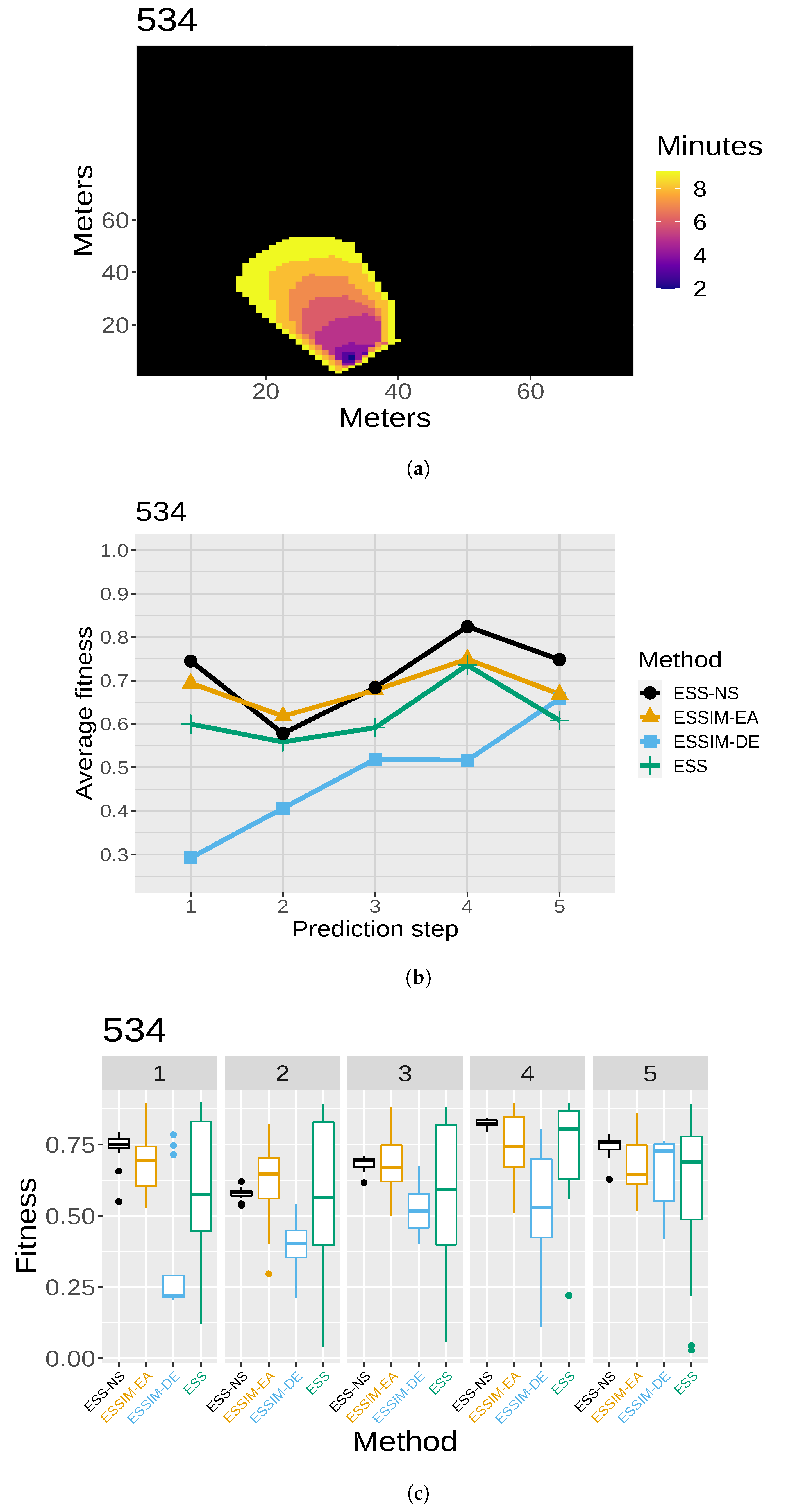
After each prediction step, and when the is known for that step, the can be compared if needed. For this, one can once again use the fitness function, this time in order to evaluate the final predictions (represented by the connection between and ). In our experiments, this evaluation is performed statically after each complete run, given that the cases under consideration are controlled fires for which the is known for all steps. A real-time evaluation could also be achieved by computing this fitness iteratively after obtaining the for the previous instant and after each prediction map has been obtained.
2.2. ESSIM-EA and ESSIM-DE Frameworks
This section summarizes the operation of the more recently developed systems, ESSIM-EA and ESSIM-DE, which are both based on ESS and are also included in our comparison against our new method in
Section 4.
ESSIM-EA stands for Evolutionary Statistical System with Island Model based on evolutionary algorithms, while ESSIM-DE is ESSIM based on Differential Evolution. Both systems fit into the category of DDM-MOS, since they employ a method for selecting multiple solutions from the space of possible scenarios and producing an overlapped result in order to perform the prediction of fire propagation.
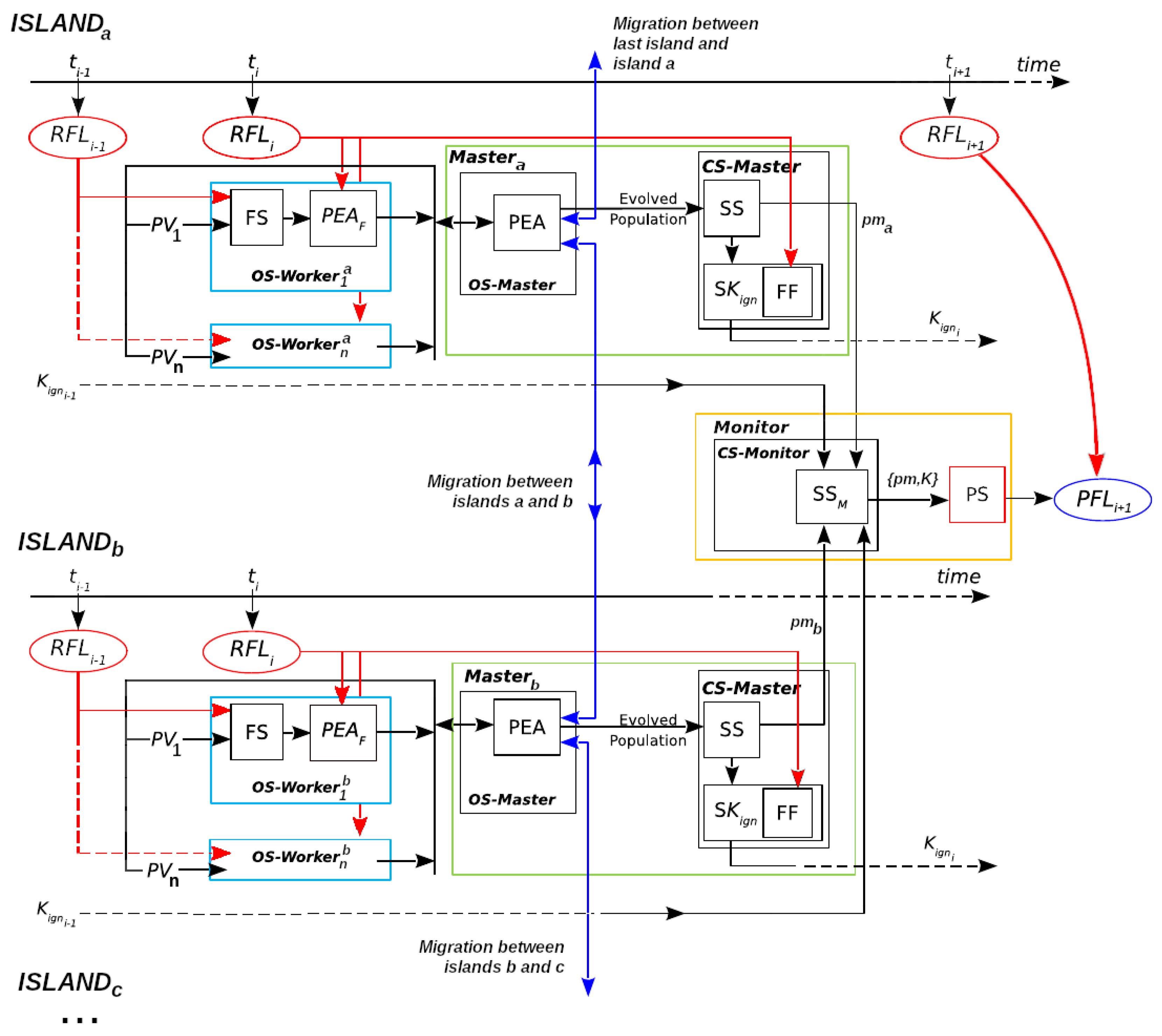
ESSIM-EA and ESSIM-DE are summarized in
Figure 4, reproduced and modified from [
11] (Published under a Creative Commons Attribution-NonCommercial-No Derivatives License (CC BY NC ND). See
https://creativecommons.org/licenses/by-nc-nd/4.0/, accessed on 13 October 2022). The four main stages in these systems are the same as in ESS: Optimization Stage (
OS), Statistical Stage (
SS), Calibration Stage (
CS), and Prediction Stage (
PS). Because both ESSIM systems use a hierarchical scheme of processes, these stages are subdivided to carry out the different processes in the hierarchy. The Master/Worker hierarchy of ESS is augmented with a more complex hierarchy that consists of one Monitor, which handles multiple Masters, and, in turn, each Master manages a number of Workers. Essentially, the system uses a number of islands where each island implements a Master/Worker scheme; the Monitor then acts as the Master process for the Masters of the islands. On each island, the Master/Worker process operates as described in
Section 2.1 for ESS: the Master distributes scenarios among the Workers for performing the simulations in the
OS.
The process begins with the Monitor, which sends the initial information to each island to carry out the different stages. The Master process of each island performs the
OS: it controls the evolution of its population and the migration process. On each island during each iteration of the evolutionary algorithm, the Master sends individuals to the Worker processes, which are in charge of their evaluation. For more details on the operation of the island model, see [
11].
After the evolutionary process, the SS takes place in which the Master performs the computation of the probability matrix that is required for the CS and PS. In this new scheme, the SS is carried out by the Master, the CS is performed by both the Master and the Monitor, and the PS is handled only by the Monitor. The CS starts with the CS-Master block, where each Master generates a probability matrix and provides its value. The block CS-Monitor represents the final part of the calibration in which the Monitor receives all matrices sent by the Masters and then selects the best candidate based on their fitness (these fitness values have already been computed by the Masters). The matrix selected by the Monitor is used for producing the current step prediction.
Experimentally, when ESSIM-EA was introduced, it was shown to be able to reach predictions of similar or higher quality than ESS but with a higher cost in execution times. Later, ESSIM-DE was developed, and it significantly reduced response times, but the quality did not improve in general. Subsequent works have improved the performance of the ESSIM-DE method by embedding tuning strategies into the process [
23]. Tuning strategies are methods for improving the performance of an application by calibrating critical aspects. Application tuning can be automatic (when the techniques are transparently incorporated in the application) and/or dynamic (adjustments occur during execution) [
24]. For ESSIM-DE, there are two automatic and dynamic tuning metrics which have been shown to mitigate the issues of premature convergence and population stagnation present in the case of application of the algorithm. One metric is a population restart operator [
13], and the other involves the analysis of the IQR factor of the population throughout generations [
25]. The results showed that ESSIM-DE enhanced with these metrics achieved better quality and response times with respect to the same method without tuning.
Even though the two approaches described provide improvements over ESS, they are still limited in several fundamental aspects. The first aspect has to do with the design of the metaheuristics that were adapted for use in the OS of the ESSIM systems. These are population-based algorithms that are traditionally used with the objective of selecting a single solution: the best individual from the final population, obtained from the last iteration of the evolution process. Instead, the adaptations implemented use the final population to select a set of solutions for the CS and PS. Since evolutionary metaheuristics tend to converge to a population of similar genotypes, that is, of individuals which are similar in their representation, the population evolved for each prediction step may consist of a set of scenarios that are similar to each other and therefore produce similar simulations. This may be a limiting factor for the uncertainty reduction objective. To understand this, it must be noted that complex problems do not usually have a smooth fitness landscape, which may imply that individuals that are genotypically far apart in the search space may still have acceptable fitness values and could be valuable solutions. Thus, the metaheuristics implemented in the ESSIM systems may leave out these promising candidates. The second aspect is that in the case of ESSIM-DE, the baseline version performs worse than ESS and ESSIM-EA with respect to quality, which led to the design of the previously mentioned tuning mechanisms. These variants produced better results in quality than the original version of ESSIM-DE but did not significantly outperform ESSIM-EA. Such findings seem to support the idea that this particular application problem could benefit from a greater exploration power, combined with a strategy that could take better advantage of the solutions found during the search. From this reasoning, we arrived at the idea of applying a paradigm that maximizes exploration, while keeping solutions in a way that is compatible by design with a DDM-MOS, that is, a system that is based on multiple overlapped solutions.
2.3. Novelty Search: Paradigm and Applications
The limitations observed in existing systems led us to consider the selection of other search approaches that may yield improvements in the quality of predictions. Given the particular problems observed in the experimental results of previous works, we determined that a promising approach for this problem could be the Novelty Search (NS) paradigm. In this section, we explain the main ideas and describe related works behind this approach.
Metaheuristic search algorithms reward the degree of progress toward a solution, measured by an objective function, usually referred to as a
score or
fitness function depending on the type of algorithm. This function, together with the neighborhood operators of a particular method, produces what is known as the
fitness landscape [
26]. By changing the algorithm, the fitness function, or both, a given problem may become easier or more difficult to solve, depending on the shape and features of the landscape that they generate. In highly complex problems, the fitness landscape often has features that make the objective function inefficient in guiding the search or may even lead the search away from good solutions [
17]. This has led to the creation of alternative strategies that address the limitations inherent to objective-based methods [
27]. One of these strategies is NS, introduced in [
19]. In this paradigm, the search is driven by a characterization of the behavior of individuals that rewards the dissimilarity of new solutions with respect to other solutions found before. As a consequence, the search process never converges but rather explores many different regions of the space of solutions, which allows the algorithms to discover high fitness solutions that may not be reachable by traditional methods. This exploration power differs from metaheuristic approaches in that it is not driven by randomness, but rather by explicitly searching for novel behaviors. NS has been applied with good results to multiple problems from diverse fields [
18,
19,
28,
29,
30,
31].
Initially, the main area of interest for applications of NS consisted of open-ended problems. In this area, the objective is to generate increasingly complex, novel, or creative behaviors; there is no fixed, predetermined solution to be reached. Interestingly, NS has also been proven useful for optimization problems in general, finding global optima in many cases and outperforming traditional metaheuristics when the problems have the quality of being
deceptive, that is, when the combination of solutions of high fitness leads to solutions of lower fitness and vice versa [
31].
In order to guide the search by novelty, all algorithms following this paradigm need to implement a function to evaluate the novelty score of the solutions. Therefore, a novelty measure of the solutions must be defined in the space of behaviors of the solutions. This measure, usually called in the literature, is problem-dependent; an example can be the difference between values of the fitness function of two individuals.
A frequently used novelty score function is the one presented by [
19], which, for an individual
x, computes the average distance to its
k closest neighbors:
where
is the
i-th nearest neighbor of the individual
x according to the distance function
. In the literature, the parameter
k is usually selected experimentally, but the entire population can also be used [
18,
32].
To perform this evaluation, it is not sufficient to select close individuals by considering only the current population; it is also necessary to consider the set of individuals that have been novel in past iterations. To this end, the search incorporates an archive of novel solutions that allows it to keep track of the most novel solutions discovered so far and uses it to compute the novelty score. The novelty values obtained are used to guide the search, replacing the traditional fitness-based score. This design allows the search to be unaffected by the fitness function landscape, directly preventing problems such as those found in the systems described in the previous section.
When using conventional metaheuristics, due to the randomness involved in the algorithms, it is possible that some high fitness solutions may be lost in intermediate iterations with no record of them remaining in the final population. In contrast, NS can avoid this issue because when applied to optimization problems it makes use of a memory of the best performing solution(s), as measured, for example, by the fitness function. In this way, even though NS never converges to populations of high fitness, it is possible to keep track of the best solutions (with respect to the fitness function or any characterization of the behavior of the solutions) found throughout the search.
Different metaheuristics have already been implemented using the NS paradigm, such as a
Genetic Algorithm [
33] and
Particle Swarm Optimization [
34]. Additionally, multiple hybrid approaches that combine fitness and novelty exist in the literature and have been shown to be effective in solving practical problems. Among some of the approaches used, there are weighted sums between fitness and novelty-based goals [
35], different goals in a multi-objective search [
36], and independent searches with some type of mutual interaction [
29], among others [
19,
28,
30,
37,
38,
39].
Metaheuristics can generally be parallelized in different ways and at different levels. For example, one can run an instance of an algorithm that parallelizes the computation of the fitness function, or one can have a process that manages many instances of the whole algorithm in parallel. The advantages of parallelization are better execution times, more efficient use of resources, and/or improvements in the performance of the algorithm. Just as NS can be implemented by adapting existing metaheuristics to the NS paradigm, existing parallel metaheuristics can also be used as a template for new parallel novelty-based approaches. However, it must be considered that novelty-based criteria, together with the archive mechanism, may warrant additional efforts in order to design an adequate solution. In the particular case of NS, parallelization can be a way to enhance the search, giving it a greater exploration capacity without excessively affecting the execution time. Examples of parallel algorithms containing an NS component can be found in [
40,
41].







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










