Abstract
Semantic code retrieval is the task of retrieving relevant codes based on natural language queries. Although it is related to other information retrieval tasks, it needs to bridge the gaps between the language used in the code (which is usually syntax-specific and logic-specific) and the natural language which is more suitable for describing ambiguous concepts and ideas. Existing approaches study code retrieval in a natural language for a specific programming language, however it is unwieldy and often requires a large amount of corpus for each language when dealing with multilingual scenarios.Using knowledge distillation of six existing monolingual Teacher Models to train one Student Model—MPLCS (Multi-Programming Language Code Search), this paper proposed a method to support multi-programing language code search tasks. MPLCS has the ability to incorporate multiple languages into one model with low corpus requirements. MPLCS can study the commonality between different programming languages and improve the recall accuracy for small dataset code languages. As for Ruby used in this paper, MPLCS improved its MRR score by 20 to 25%. In addition, MPLCS can compensate the low recall accuracy of monolingual models when perform language retrieval work on other programming languages. And in some cases, MPLCS’ recall accuracy can even outperform the recall accuracy of monolingual models when they perform language retrieval work on themselves.
1. Introduction
The research on code retrieval can be divided into two broad categories according to the methods used: Information Retrieval-Based Methods and Deep Learning Model-Based Methods. Information Retrieval-Based Methods are more based on traditional search methods, the main idea is to improve work based on text similarity, and to perform code retrieval through search techniques combined with code features. For example, Luan et al. [1] proposed a structured code recommendation tool called Aroma, which implements a method of searching code by using coding. They divide the retrieval process into two stages: stage 1, perform a small range lightweight search, and then stage 2, a further in-depth search based on the previous results searched in stage 1. On top of this, Lv et al. [2] discovered a way to better connect the characteristics of code by focusing on the API calls in coding. Standard APIs have specific functions and corresponding documentation descriptions, this enables them to turn code search tasks into simple similarity matches between natural language descriptions and API documentation. However, these information retrieval-based methods cannot uncover the deep connection between natural language and code language, this leads to the lack of accuracy in methods. With the rapid development of NLP, some scholars start using deep learning models to solve the problem of code retrieval to prove its accuracy.
The main strategy of the Deep Learning-Based Approach is to use a neural network approach to map code snippets and query statements in the same vector space. Husain et al. [3] came up with a plain and typical example to propose a basic framework where they simply consider the code as a text, encode it using several common methods for text embedding, and map the code and description to the same high-dimensional space for learning. Not long after, Gu et al. [4] went further in this direction, by not only considering the code text as features, but also function names and API (Application Programming Interface) sequences. After that, many scholars discovered more code-specific features to build new models. Haldar et al. [5] added both tokens and AST (Abstract Syntax Tree) information on the one hand, and improved join embedding, on the other hand, they argue that only calculating similarity in the last step (i.e., only the overall similarity is considered, not the local similarity) would cause information loss, so they fused both CAT (An AST-Based Model) and MP (A Multi-Perspective Model) methods and proposed the MP-CAT Model. Sachdev et al. [6] address an unsupervised learning task by proposing Neural Code Search (NCS), using features such as function names, function calls, enumerated quantities, string literals, annotations, TF-IDF weights, and word vectors to construct high-dimensional vectors for retrieval. Cambronero et al. [7] made improvements based on the NCS algorithm and proposed an improved idea of UNIF by adding a solution to the unsupervised learning algorithm NCS to improve model performance. With this model, a small number of supervised samples, can be comparable to some supervised learning algorithms. Meanwhile, some scholars are researching other issues related to code retrieval, for example, Yin and Neubig [8] investigated the task of code generation and argued that the current approach is to view it as a seq2seq generation task, but does not take into account that the code language has a specific syntactic structure. From this, an AST tree generation by natural language is proposed, and tools are used to convert the AST tree into code. Analogous to large pre-training models such as ELMo, GPT, BERT, and XLNet, Feng et al. [9] and Kanade et al. [10] proposed the pre-training models with codes studied.
When modern software engineers develop a software product, it often requires more than just one programming language, thus developers are faced with the need to search for multiple code languages during the development process. A recent survey of open-source projects has shown that the use of multiple languages is rather universal, with a mean number of 5 languages used per project [11]. Thus, multilanguage software development (MLSD) seems to be common, at least in the open-source world [12]. As mentioned above, Both the information retrieval-based approaches and the deep learning-based approaches deal with the mapping from a single natural language to a single programming language. Thus this paper proposed the idea of mapping a single natural language to a multi-programming language, which is new in this field. The goal that we want to achieve here is, when a query of natural language is inputted, we were able to find multiple programming languages (such as Java, PHP, Go, etc.) codes that have the functionality that matches the natural language description. And this is done with the use of knowledge distillation.
Hinton et al. [13] proposed the concept of knowledge distillation, the core idea of knowledge distillation is to first train a complex model (known as the Teacher Model) and then use the output or intermediate state of this model to train a smaller model (known as the Student Model). The main contribution of knowledge distillation is model compression, which has been widely studied and utilized in many areas of deep learning, such as natural language processing, speech recognition, and computer vision. This technique is also used for natural language translation tasks. Many scholars have done a lot of exploratory work on multilingual translation models [14,15,16,17], and NMT-based multilingual translation models have been discovered. Xu et al. [18] proposed to transfer knowledge from individual models to multilingual models using knowledge distillation, which is commonly used for studying model compression and knowledge migration and mostly fits quite well with the multilingual code search environment. A large and deep Teacher Model (or an ensemble of multiple models) is usually trained first, and then a smaller and shallower Student Model is trained to mimic the behavior of the Teacher Model. The Student Model can approach or even outperform the accuracy of the complex Teacher Model by knowledge distillation. This paper uses knowledge distillation techniques to fuse six pre-trained monolingual models into one student model. By doing so, the size of the model is reduced significantly. At the same time, the student model’s performance is almost the same with each teacher model on the test set, on cases like Ruby and JavaScript, the student model even outperformed the teacher model. After redoing the experiments on different code and query encoders, we confirm that this method can be used on a wide range of encoders.
We summarize our contributions as follows:
- We propose a code search model that efficiently and accurately addresses multi-programming language fusion. A single model can solve the problem of searching for multiple programming languages.
- Compared to multiple models, our model has fewer parameters. Also, the data set requirements are lower because the data sets are complementary between different languages.
- The ability to uncover connections between different programming languages makes the model highly extensible, and this provides some support for languages with relatively small corpora.
Background
Joint Vector Representations, also known as Multimodal Embedding [19], are very common in code retrieval tasks and most deep-learning-based methods use this. Joint Vector Representations is a method to learn the connection between two heterogeneous structures, which maps data of two different structures into the same high-dimensional space [20], so that the corresponding data fall as close as possible to each other in the high-dimensional space, while making the non-corresponding data as far away from each other as possible. Such an approach also makes the query process more intuitive, and when performing a search, it is only necessary to find some points in the high-dimensional space that are closest to the target point, i.e., the nearest neighbor problem in the high-dimensional space.
This paper used joint embedding to learn the relevance between natural language description and code. As shown in Figure 1, code segments and natural language representations are mapped to the same high-dimensional space. The code for bubble sort and “bubble sort” is mapped to relatively close locations, as is the case for “quick sort”.
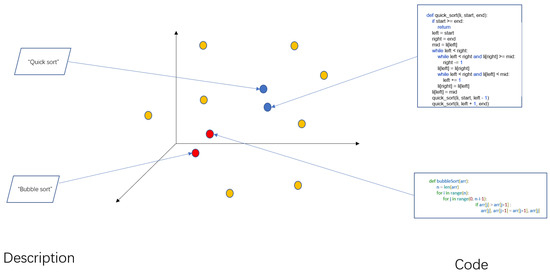
Figure 1.
Conceptual diagram of joint embedding in a code search task.
Paper structure
The remainder of the paper is organized as follows. Section 2 presents our proposed framework, this includes the teacher model network structure and the learning process of distilling knowledge using models to train student model. Section 3 describes the experimental setup and details. Section 4 presents an analysis of the experimental results. Section 5 concludes the paper.
2. Multi-Programming Language Code Search
Inspired by multilingual translation models, we propose a novel deep learning model, MPLCS, to solve the task of multi-programming language code search. Each programming language has its own syntactic structure and thus programming languages are heterogeneous from one another. For the heterogeneous problem, the method of joint embedding mentioned above is used to map them into the same high-dimensional space, and the semantic similarity of each heterogeneous data is measured by the similarity degree. For the problem of multi-model fusion, the solution we adopt is to use knowledge distillation to handle it.
2.1. Overview
There are two main parts, one for training the Teacher Model and one for training the Student Model. We will be discussing the network structure of the Teacher model in Section 2.2. As for the Student Model, it has the same structure of the Teacher Model and can take corresponding Teacher Model as input, then fuse the properties of different language models. The components are elaborated in Section 2.3.
2.2. Teacher Model
We follow Hamel et al’s study and use the same monolingual model structure, i.e., 1dCNN, NBOW, and self-attention, these are commonly used methods based on token sequences. In this paper, we will only introduce the model structure of self-attention and the subsequent experiments will be based on this model, since it performed best among the 3 methods. We embedded the code in the same way as embedding the natural language—an encoding of their token sequences with an added attention vector. In general, the model needs to be trained for the following parts as shown in Figure 2: code_vocab and query_vocab of the code and the description of the embedding layers, the fully connected layers of the corresponding code and description, and the attention vector.
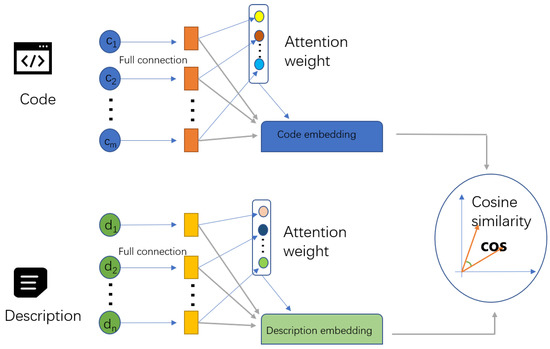
Figure 2.
Details in Teacher Models whose encoder is self-attentions.
Here, we define two embedding lexicons: code_vocab and query_vocab, each line corresponds to a specific code token or objects of the description token:
X is the set of code token dictionaries, Q is the set of natural language description dictionaries, and d is the dimension of the embedding, which we set to 128 in our experiments. Finding the embedding of a code or query is a simple matter of finding the corresponding line.
For a line of code and its corresponding natural language description , with the as code token and as description token. After embedding (random initialization) we can obtain:
And after going through a full connected layer, we have:
In which , is the hyperbolic tangent function, which is a common monotonous nonlinear activation function, taking the value from (−1, 1).
Finally, we use the attention vector to aggregate these token vectors, it is essentially a weighted average aggregation. The main process is to calculate the weight of each token in the current block of code or natural language sentence, in terms of goals, we naturally hope that the token that can represent the code or sentence will occupy a greater weight, and this is where “attention” comes into play. In the beginning, the attention vector will be randomly initialized and study the model simultaneously during the training process. The weight of each token is calculated by dotting the vector of the token with the attention vector and then normalizing it to ensure that the weights sum up to 1, the weights of each corresponding code token vector are calculated as follow:
The purpose of using exp is to ensure that the weights are positive, as in the standard softmax function, and we divide by the sum of all terms to ensure that the sum of the weights is 1, the calculation of natural language description token vector follows a similar pattern. Once is calculated, the final code vector can be obtained by summing the linear weights of the code token vectors . Code Vector represents the entire code segment, and it’s expressed as follow:
Similarity Model
After obtaining the code vector and the description vector, we want the code and description vectors to be co-embedding, so we measure the similarity between these two vectors. We measure this by using the cosine similarity formula, which is defined as
The higher the similarity, the higher the correlation between the code vector and the description vector. In summary, the MPLCS model takes a pair of ⟨codes, descriptions⟩ as input, and calculates their cosine similarity to measure the strength of their correlation.
Teacher Model Learning
Contrastive representation learning is often used for code retrieval tasks [4,5,21,22,23], and our experiment will use the contrastive loss function as the loss function of the model.We now describe how to train the MPLCS model in two stages, the first stage is to train the six Teacher Models. Both codes and descriptions are embedded into a unified vector space. The ultimate goal of joint embedding is that if a code fragment and a description have similar semantics, their embedding vectors should be close to each other. In other words, given an arbitrary code fragment C and an arbitrary description D, we want it to predict high similarity (close to 1) if D is the correct description of C, otherwise, it will only little similarity (close to 0).
Therefore, we need to use negative samples to construct our loss function. Essentially we consider this problem: we construct each training instance as a triad : for each code fragment C, there is a positive description (the correct description of C) and a negative description (the wrong description of C) chosen randomly from a pool of all (negative samples are derived from positive samples). When trained on the set, MPLCS predicts the cosine similarity of the and pairs and minimizes the rank loss, that is, minimizing the following equation.
In this formula, represents positive description, represents negative description. In practice, we use the strategy of obtaining the cosine between two of the N code vectors and the N corresponding description vectors. This gives us an matrix, with positive sample values on the main diagonal and negative sample values everywhere else. We want the positive sample value to be as large as possible and the negative sample value to be as small as possible, so we subtract the value on each diagonal by 1, and the main goal is to make all values as small as possible. The formula is described as follows:
2.3. Student Model
After training the six Teacher Models, we begin to train the Student Model. Every language input will obtain two sets of vectors during the encoding step, one set constructed by the Student Model and the other one constructed by the Teacher Model for the corresponding language, as shown in Figure 3. The composition of the loss function consists of three parts: (1) STUDENT’s code vector and STUDENT’s description vector, (2) the code vector of the TEACHER and the description vector of the STUDENT, (3) the code vector of the STUDENT and the description vector of the TEACHER.
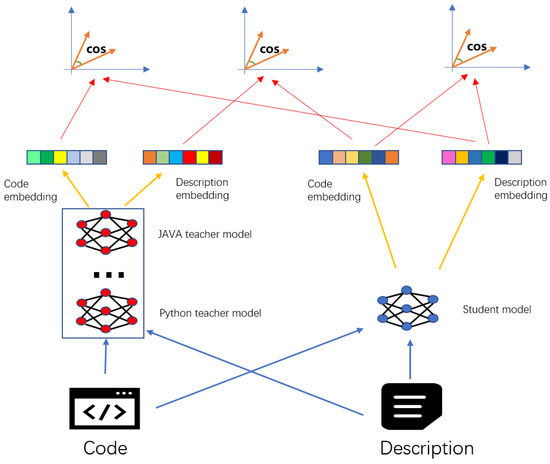
Figure 3.
Schematic diagram of the overall model.
In the formula, is the set of Teacher Models, which is the set of six Teacher Models in this paper. For each of the Teacher Models, two additional sets of loss functions are computed, as shown in , we replace code vector to the loss function in Teacher Model’s and replace description vector to Teacher Models’. The parameter is used to adjust the contribution of the teacher model in the student model. We explore the effect of this parameter on Teacher Models in our experiment. Even the two parts of can be scaled differently to serve as a focus for one part of the work, and this part of the work can be further elaborated for future studies.
The training process is shown in Algorithm 1. L is the number of language varieties, which is taken as 6 in this paper, denotes the language number, denotes the training set for the language with the number l, represents the parameter of the multilingual Student Model, the corresponding represents a parameter of Teacher Model for the language with the number l. Our algorithm takes the pre-trained Teacher Models as input. It is important to note that the training set for the Teacher Model can either be shared with the Student training set for that language or choose a separate training set. Similarly, the structure of the student network model can be set to be the same or different from that of the teacher network model. For convenience, the same data set and network model structure are chosen in this paper. Notice that lines 7–10 of Algorithm 1 made a loss function selection. This is based on the strategy that: if the Student Model is already performing better than the Teacher Model for a particular language, the Teacher Model will not be introduced, but this setting is not fixed, and the accuracy of this language may be reduced later when training other languages, that is then the Teacher Model will be reintroduced. The setting of whether or not to introduce a Teacher Model involves parameter , as described in lines 14–22, where the accuracy of the Student Model is higher than that of the Teacher Model, then the Teacher Model is not introduced.
| Algorithm 1. Knowledge distillation in multiple code languages |
|
| 1: Randomly initialized Student Model parameters , current step count set to , cumulative gradient , For each Teacher Model, mark |
| 2: while do |
| 3: |
| 4: |
| 5: for do |
| 6: Randomly select a batch of data from the training set |
| 7: if then |
| 8: Calculating gradient on loss function, |
| 9: else |
| 10: Calculating gradient on loss function, |
| 11: end if |
| 12: end for |
| 13: Update model parameter: |
| 14: if then |
| 15: for do |
| 16: if then |
| 17: |
| 18: else |
| 19: |
| 20: end if |
| 21: end for |
| 22: end if |
| 23: end while |
3. Experiments
3.1. Data Preparation
The experimental data was selected from the publicly available dataset collected by Hamel et al. [3]. They collected corpus from publicly available open-source GitHub repositories, and to weed out a portion of low-quality project code, libraries.io was used to identify all projects that were quoted by at least one other project, and were ranked by the number of stars and forks indicated by “popularity” ranking. The statistic information of the database is listed in Table 1. Data set is divided into training set, validation set, and test set according to an 80:10:10 ratio.

Table 1.
Sample size.
However, the obtained data through the corpus cleaning is still unsatisfied. First of all, function annotation is essentially different from inquired sentences, so the format of language is not the same.
Code and annotations are often written by the same author at the same time and therefore they appear to be the same vocabulary, unlike search queries which cover many different terms. Secondly, despite we put enough effect on data cleaning, the extent to which each annotation accurately describes its relevant code fragment is still uncertain. For example, some annotations are obsolete in terms of the code they describe or the object of the comment is a localized part that the author wants to focus on rather than the whole function. Finally, we are aware of some annotations are written in other languages such as Japanese and Russian, and that our evaluation dataset focuses on English queries. In order to address this issue, some scholars have chosen to add some other conditional features to strengthen the characteristics of samples. When collecting and sorting corpus, they tend to select previously available code and corresponding descriptive annotations, and in addition, they also collect relevant query information, such as gathering asked questions from Stack Overflow and attracting the code and corresponding annotations from the answers, this method can help to propose some models that make good use of this new information, whereas this type of data is not mainstream (most codes do not have query information) For example, a company’s internal code does not have relevant query questions, so this paper is still experimenting with the original dataset.
3.2. Vocabulary
For a fixed-size dictionary, the traditional tokenization based technique of simply segmenting the text with spaces and symbols has many drawbacks, such as the inability to deal well with unknown or rare words (the OOV out-of-vocabulary problem); the nature of the language’s own lexical construction, and the difficulty of learning the root word associations with the traditional method. This leads to the lack of generalization ability with the traditional approach. Byte-Pair-Encoding (BPE) is a method for solving such issues. unknown or rare words can be classified as unregistered words. Unregistered is known as words that do not appear in the training corpus, but appear in the test corpus. When we work with NLP tasks, we usually generate a vocabulary list (dictionary) based on the corpus, for the words in the corpus that have a frequency greater than a certain threshold, they will be put into the dictionary, and encode all words below that threshold as "#UNK". The advantage of this approach is its simplicity, but the problem is that it’s difficult for our model to handle unregistered words if they appear in the test corpus. Usually, our dictionaries are word-level, meaning that they are based on words or phrases, but this inevitably leads to the problem of unregistered words, because it is impossible to design a very large dictionary that covers all words. In addition, another type of lexicon is character-level, which is to design a lexicon with a single letter or Chinese character as the basic word. This approach can theoretically solve the problem of unregistered words because all words are composed of letters, but the disadvantage of this is that the model granularity is too fine and lacks semantic information. Rico et al. [24] proposed a sub-word based approach to generate lexicon, which combines the advantages of word-level and character-level by learning the substrings of characters with high frequency in all words from the corpus and then merging these substrings of characters with high frequency into a lexicon, this dictionary contains both word-level substrings and character-level substrings. We used the BPE technique to generate both query and code vocabulary.
3.3. Evaluation
Mean Reciprocal Rank (MRR)
MRR is commonly used in the recommended system as an evaluation metric. It evaluates the performance of the retrieval system by using the ranking of the correct retrieval results in retrieval results. The formula is as follows.
SuccessRate@k
SuccessRate@k is a common metric to evaluate whether an approach can retrieve the correct answer in the top k returning results. It is widely used by many studies on the code search task. The metric is calculated as follows:
where Q denotes the set of queries, denotes the highest rank of the hit snippets in the returned snippet list for the query; denotes an indicator function that returns 1 if the Rank of the qth query () is smaller than k otherwise returns 0. SuccessRate@k is important because a better code search engine should allow developers to find the desired snippet by inspecting fewer results.
3.4. Experiment Setup
3.4.1. Data Pre-Processing
First, we tokenize the code and description of the training set for all six languages and use the BPE method to construct a code dictionary and a description dictionary, the size of both dictionaries is set to 30,000. Then, codes and descriptions in the dataset are then transformed into index sequences, the code length is set to 200, the description length is set to 30, and a pad operation is used if the length is insufficient.
3.4.2. Teacher Model Training
We shuffle the training set, the batch size is set to 512, the epoch limit is set to 500, the optimization algorithm is Adam, and the learning rate is 0.1. Early Stop mechanism is used during the training process, i.e., setting a tolerance value of patience = 5, when a model trained on one epoch performed better on the validation set than a model trained on the next 5 epochs, stop training and save the model corresponding to this epoch. After training for each language, six teacher models are obtained. In addition, in order to establish that the method of knowledge distillation is indeed effective, We also set up a dataset that fused six languages together to train a model, which is shown by the ALL rows in Table 2 and Table 3.
Table 2.
MRR for each monolingual model and MPLCS model on different language test sets.
Table 3.
SuccessRate@k for each monolingual model and MPLCS model on different language test sets.
3.4.3. Student Model Training
The network structure of the student model is consistent with that of the teacher model. The results of the teacher models’ encoder are used to guide the student model during the training process. The details are described in Algorithm 1 in the previous section.
3.4.4. Eevaluation Setting
The evaluation method for the teacher model and the student model was described in the previous section. The batch size for both MRR and SuccessRate@k is set to 1000, that is for SuccessRate@k.
3.4.5. Lambda Parameter Exploration
In order to find out the magnitude of impact the teacher model has on the student model, the parameters in Equation (12) were set to different values, to explore the effect of different weightings of the teacher model on the student model. As the results under different encoders show a similar pattern, We explore the problem of only for the teacher model and student model that both code and query encoder are self-attention.
3.4.6. Experiment Equipment
The equipment uses 3 RTX 1080Ti 11 GB, and the training time per epoch is around 200–400 s. The number of epochs for a teacher model or student model is around 20–40.
4. Experiment Results
We have prepared several different sets of code and query encoding methods and combined them into different models, including the common 1dCNN, NBOW, and self-attention. We have also prepared a test set for each language and tested it on each monolingual model and MPLCS respectively, the MRR results and SuccessRate@k results are shown in Table 2 and Table 3 respectively. The results indicate that the monolingual model’s prediction performed better only for its own language, however, it did not perform well for other languages (Ruby is because the training set is too small). Such a result holds in all models. Otherwise, we can observe the similarity between programming languages through this table, for example between Python and PHP. Notice that the ALL model trained by fusing the six data, has consistent test results across various languages. Although the accuracy rate is not as high as monolingual to itself, it is more accurate than monolingual to other languages. Our model outperforms ALL on almost every language. It can be confirmed that the student model does indeed study the knowledge of the teacher model through knowledge distillation techniques. Notice that MPLCS is superior to the teacher model on the Ruby and JavaScript test sets. This is due to the fact that the training sets for both languages are relatively small, and the multilingual fusion model can compensate for the small training set to some extent.
The effect of on the student model can be seen in Table 4. We can see that as increases from 0 and the student model receives more guidance from the teacher model, which leads to the gradual increase in MMR across all models. When , The average MRR for the six languages reached a maximum, relatively close to the MMR when and . The results indicate that as more teacher models are instructed, the more knowledge student models are learned.
Table 4.
The effect of on the student model.
5. Conclusions
In this paper we present a new idea for semantic code retrieval-multi-code language code retrieval. By introducing the knowledge distillation technique, we established a Multi-Programming Language Code Search (MPLCS) model. The model can fuse several monolingual teacher models into a single student model, it supports multi-language code retrieval and also compensates for the deficiencies for languages where the training set is too small. In addition, MPLCS has no restrictions on the encoding method, it can be applied using a variety of different encoding methods. This paper only applied a general knowledge distillation technique and used only the results encoded from the teacher’s model, thus the model is not significant in terms of accuracy improvement. However, this paper could have an intriguing effect on multi-code language code retrieval tasks.
Open Questions
- In this paper, only the simplest features of the code are obtained, which treats it as a new natural language, other features such as API sequences, information from AST trees were not used in this paper, further research on these features could better improve the accuracy.
- As mentioned before, a high-quality training set can also greatly improve the practical meaning of the conclusions.
- Translation between different programming languages is also a very interesting research direction.
- Multi-natural language to multi-programming language is also a valuable research direction, but it will require a more comprehensive dataset as support.
Author Contributions
Conceptualization, W.L.; Data curation, W.L.; Formal analysis, W.L. and J.X.; Funding acquisition, Q.C.; Investigation, W.L. and J.X.; Methodology, W.L.; Project administration, Q.C.; Resources, W.L.; Software, W.L.; Supervision, J.X. and Q.C.; Validation, W.L. and J.X.; Visualization, W.L.; Writing—original draft, W.L.; Writing—review & editing, W.L. and J.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research is funded by the National Key Research and Development Program of China, grant number 2018YFB2101200.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Dataset is available on https://s3.amazonaws.com/code-search-net/CodeSearchNet/v2/python.zip. The content in brackets is the programming language name, such as java.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Luan, S.; Yang, D.; Barnaby, C.; Sen, K.; Chandra, S. Aroma: Code recommendation via structural code search. Proc. ACM Program. Lang. 2019, 3, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Lv, F.; Zhang, H.; Lou, J.g.; Wang, S.; Zhang, D.; Zhao, J. Codehow: Effective code search based on api understanding and extended boolean model (e). In Proceedings of the 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lincoln, NE, USA, 9–13 November 2015; pp. 260–270. [Google Scholar]
- Husain, H.; Wu, H.H.; Gazit, T.; Allamanis, M.; Brockschmidt, M. Codesearchnet challenge: Evaluating the state of semantic code search. arXiv 2019, arXiv:1909.09436. [Google Scholar]
- Gu, X.; Zhang, H.; Kim, S. Deep code search. In Proceedings of the 2018 IEEE/ACM 40th International Conference on Software Engineering (ICSE), Gothenburg, Sweden, 27 May–3 June 2018; pp. 933–944. [Google Scholar]
- Haldar, R.; Wu, L.; Xiong, J.; Hockenmaier, J. A multi-perspective architecture for semantic code search. arXiv 2020, arXiv:2005.06980. [Google Scholar]
- Sachdev, S.; Li, H.; Luan, S.; Kim, S.; Sen, K.; Chandra, S. Retrieval on source code: A neural code search. In Proceedings of the 2nd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, Philadelphia, PA, USA, 18 June 2018; pp. 31–41. [Google Scholar]
- Cambronero, J.; Li, H.; Kim, S.; Sen, K.; Chandra, S. When deep learning met code search. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Tallinn, Estonia, 26–30 August 2019; pp. 964–974. [Google Scholar]
- Yin, P.; Neubig, G. A syntactic neural model for general-purpose code generation. arXiv 2017, arXiv:1704.01696. [Google Scholar]
- Feng, Z.; Guo, D.; Tang, D.; Duan, N.; Feng, X.; Gong, M.; Shou, L.; Qin, B.; Liu, T.; Jiang, D.; et al. Codebert: A pre-trained model for programming and natural languages. arXiv 2020, arXiv:2002.08155. [Google Scholar]
- Kanade, A.; Maniatis, P.; Balakrishnan, G.; Shi, K. Learning and evaluating contextual embedding of source code. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 5110–5121. [Google Scholar]
- Mayer, P.; Bauer, A. An empirical analysis of the utilization of multiple programming languages in open source projects. In Proceedings of the 19th International Conference on Evaluation and Assessment in Software Engineering, Nanjing, China, 27–29 April 2015; pp. 1–10. [Google Scholar]
- Mayer, P.; Kirsch, M.; Le, M.A. On multi-language software development, cross-language links and accompanying tools: A survey of professional software developers. J. Softw. Eng. Res. Dev. 2017, 5, 1–33. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Johnson, M.; Schuster, M.; Le, Q.V.; Krikun, M.; Wu, Y.; Chen, Z.; Thorat, N.; Viégas, F.; Wattenberg, M.; Corrado, G.; et al. Google’s multilingual neural machine translation system: Enabling zero-shot translation. Trans. Assoc. Comput. Linguist. 2017, 5, 339–351. [Google Scholar] [CrossRef] [Green Version]
- Firat, O.; Cho, K.; Bengio, Y. Multi-way, multilingual neural machine translation with a shared attention mechanism. arXiv 2016, arXiv:1601.01073. [Google Scholar]
- Ha, T.L.; Niehues, J.; Waibel, A. Toward multilingual neural machine translation with universal encoder and decoder. arXiv 2016, arXiv:1611.04798. [Google Scholar]
- Lu, Y.; Keung, P.; Ladhak, F.; Bhardwaj, V.; Zhang, S.; Sun, J. A neural interlingua for multilingual machine translation. arXiv 2018, arXiv:1804.08198. [Google Scholar]
- Tan, X.; Ren, Y.; He, D.; Qin, T.; Zhao, Z.; Liu, T.Y. Multilingual neural machine translation with knowledge distillation. arXiv 2019, arXiv:1902.10461. [Google Scholar]
- Xu, R.; Xiong, C.; Chen, W.; Corso, J. Jointly modeling deep video and compositional text to bridge vision and language in a unified framework. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Wan, Y.; Shu, J.; Sui, Y.; Xu, G.; Zhao, Z.; Wu, J.; Yu, P.S. Multi-modal attention network learning for semantic source code retrieval. arXiv 2019, arXiv:1909.13516. [Google Scholar]
- Zeng, C.; Yu, Y.; Li, S.; Xia, X.; Wang, Z.; Geng, M.; Xiao, B.; Dong, W.; Liao, X. deGraphCS: Embedding Variable-based Flow Graph for Neural Code Search. arXiv 2021, arXiv:2103.13020. [Google Scholar]
- Gu, J.; Chen, Z.; Monperrus, M. Multimodal Representation for Neural Code Search. In Proceedings of the 2021 IEEE International Conference on Software Maintenance and Evolution (ICSME), Luxembourg, 27 September–1 October 2021; pp. 483–494. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. arXiv 2015, arXiv:1508.07909. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).