
Transfer Learning for Operator Selection: A Reinforcement Learning Approach




Abstract
:1. Introduction
2. Background and Related Work
2.1. Artificial Bee Colony Algorithm
2.2. Reinforcement Learning
2.3. Adaptive Operator Selection
2.4. Transfer Learning
2.5. Related Work
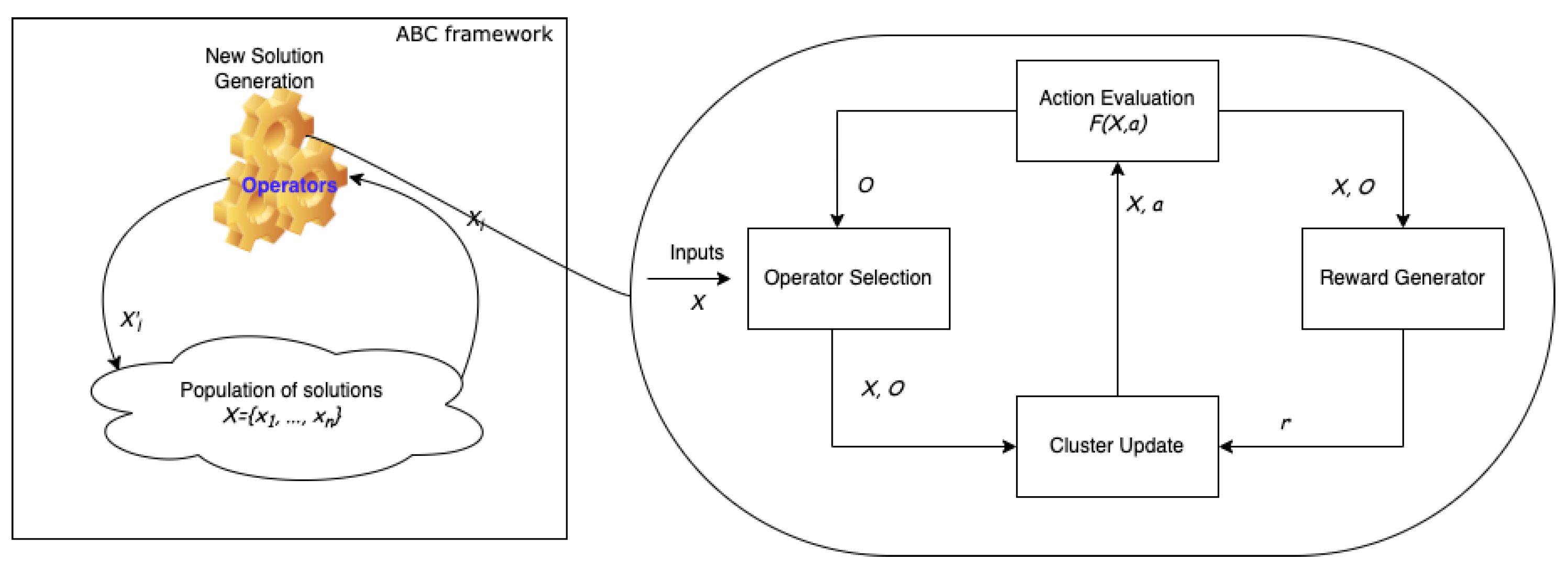
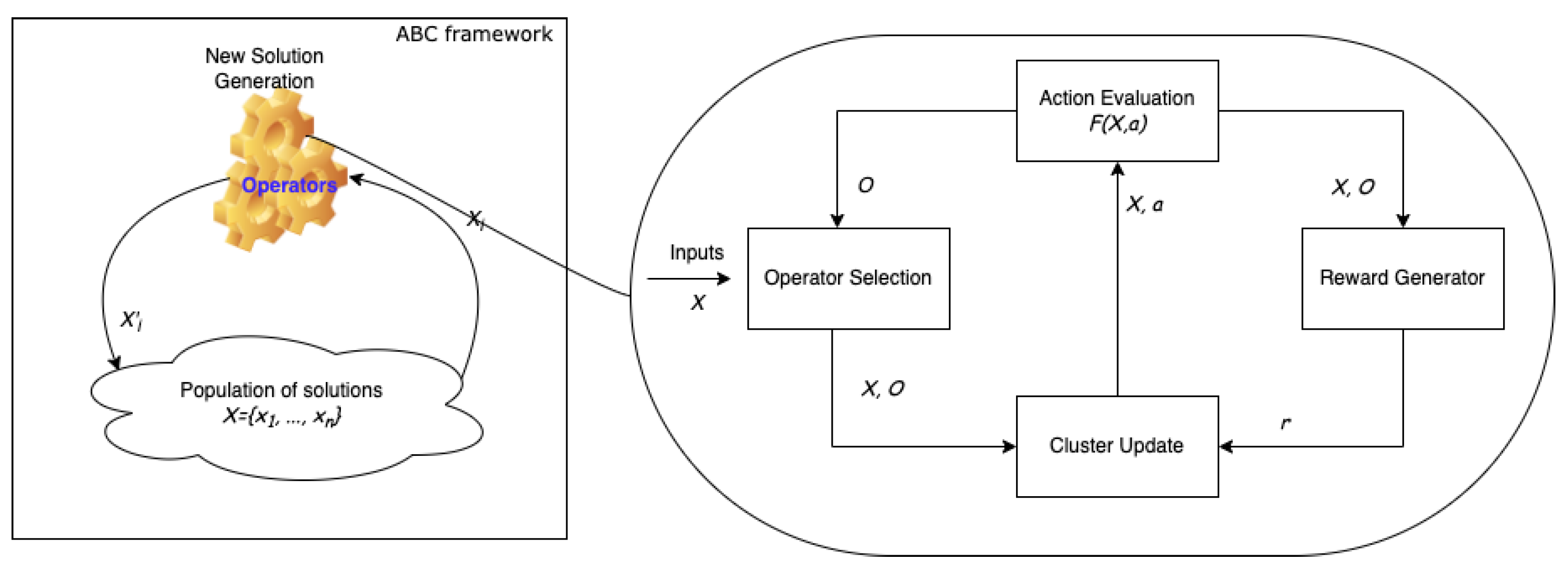
3. Proposed Approach for Transfer Learning with RL
| Algorithm 1 General overview of RL-AOS |
|
4. Experimental Results
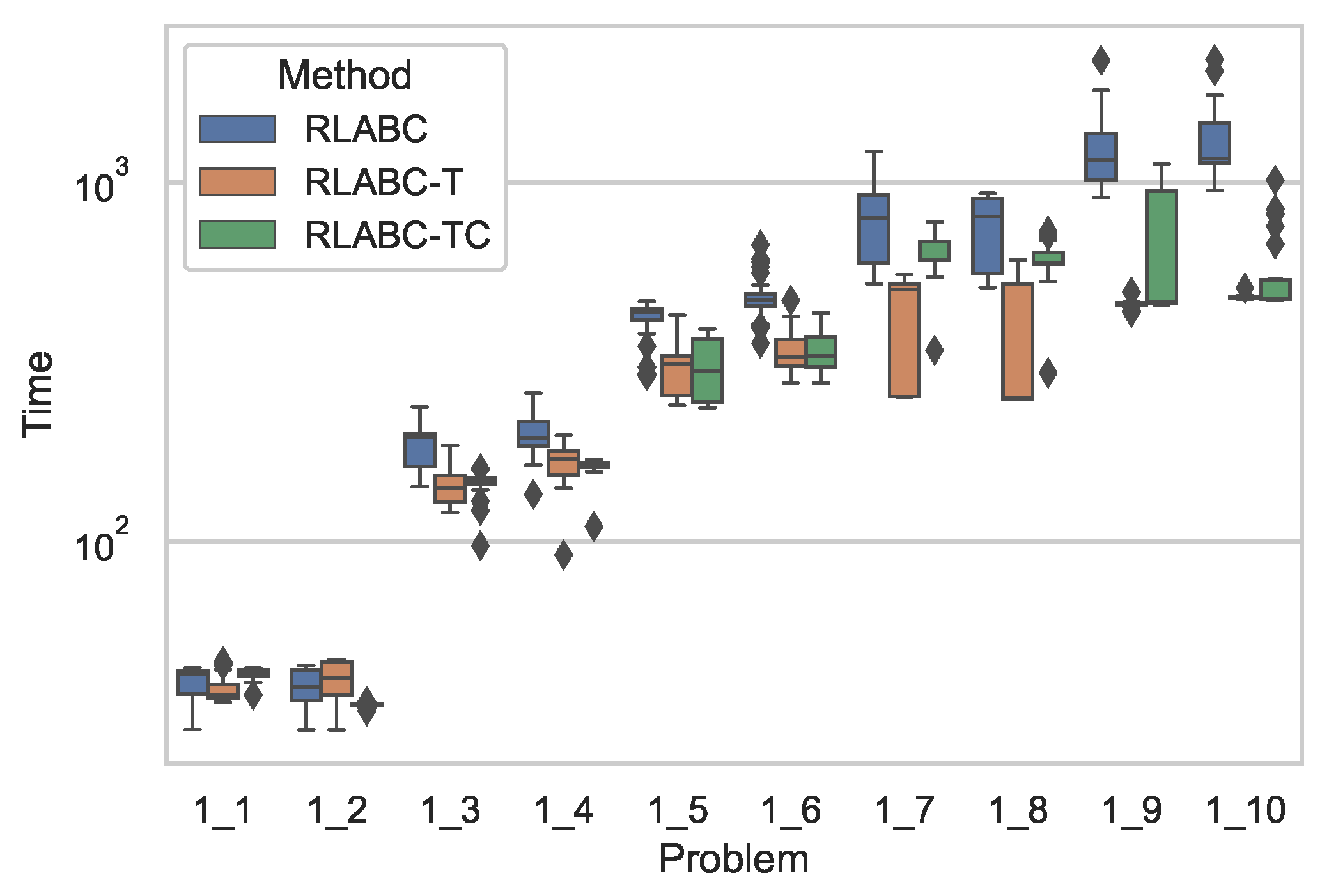
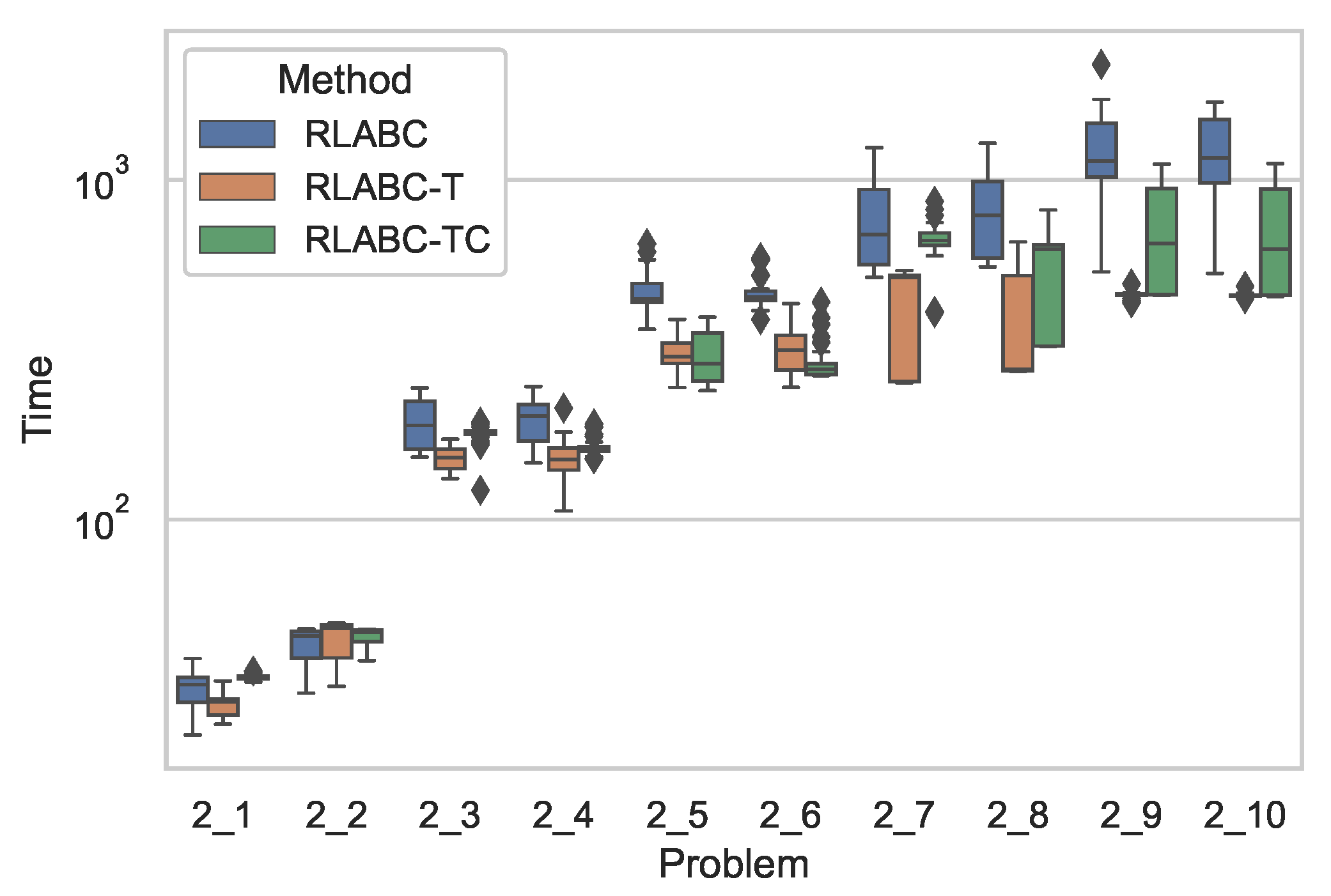
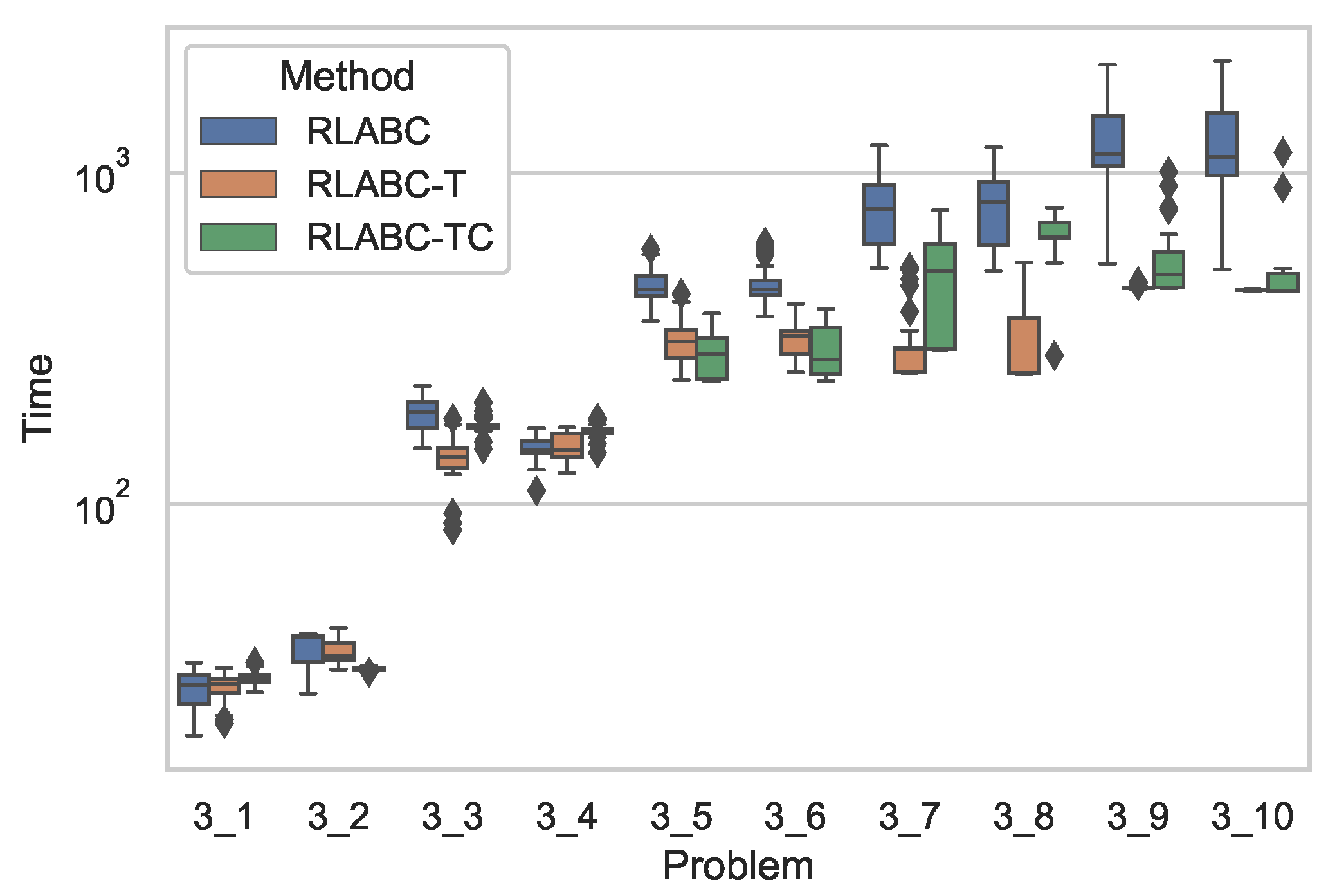
4.1. The Problem and Datasets
4.2. Experimental Settings
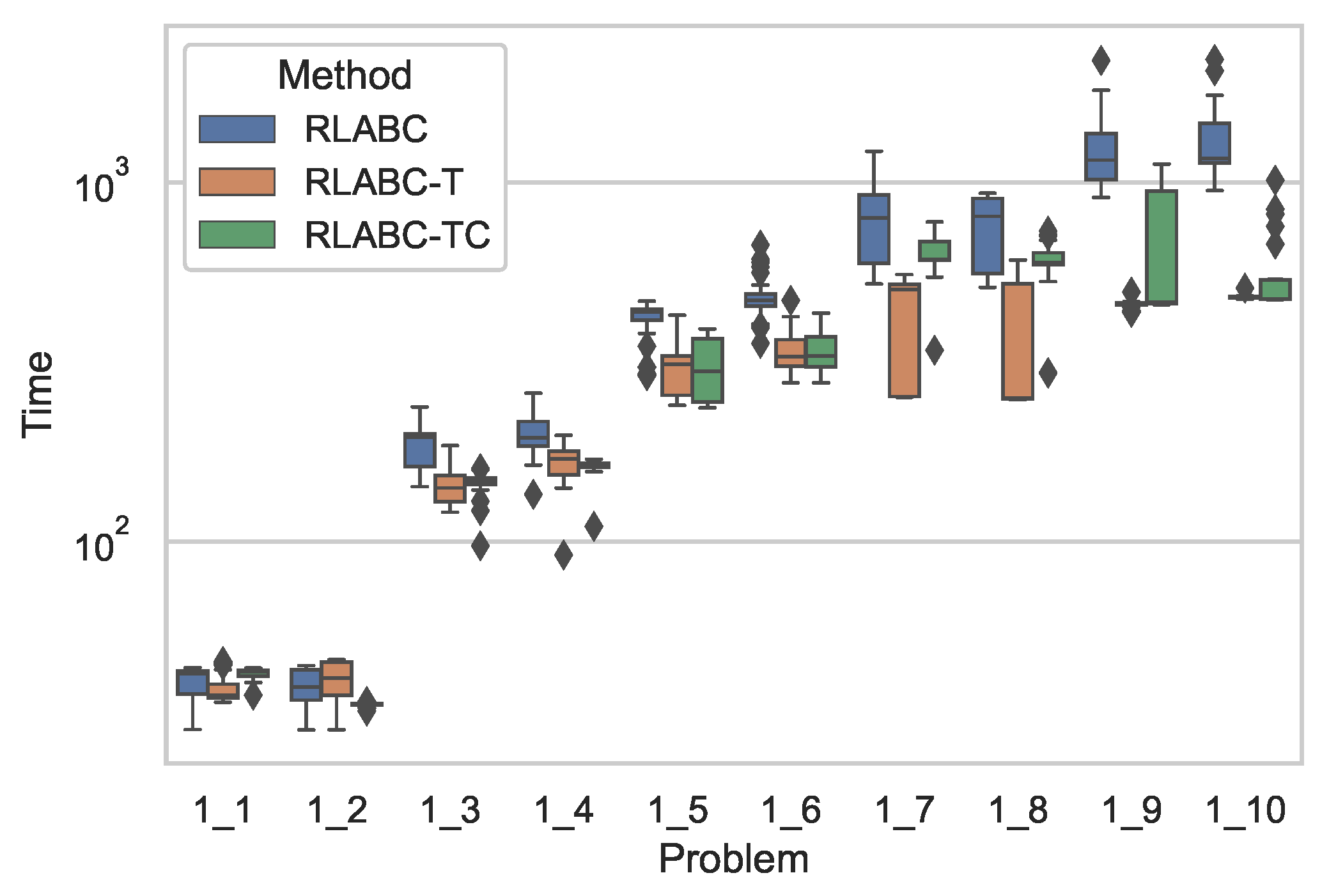
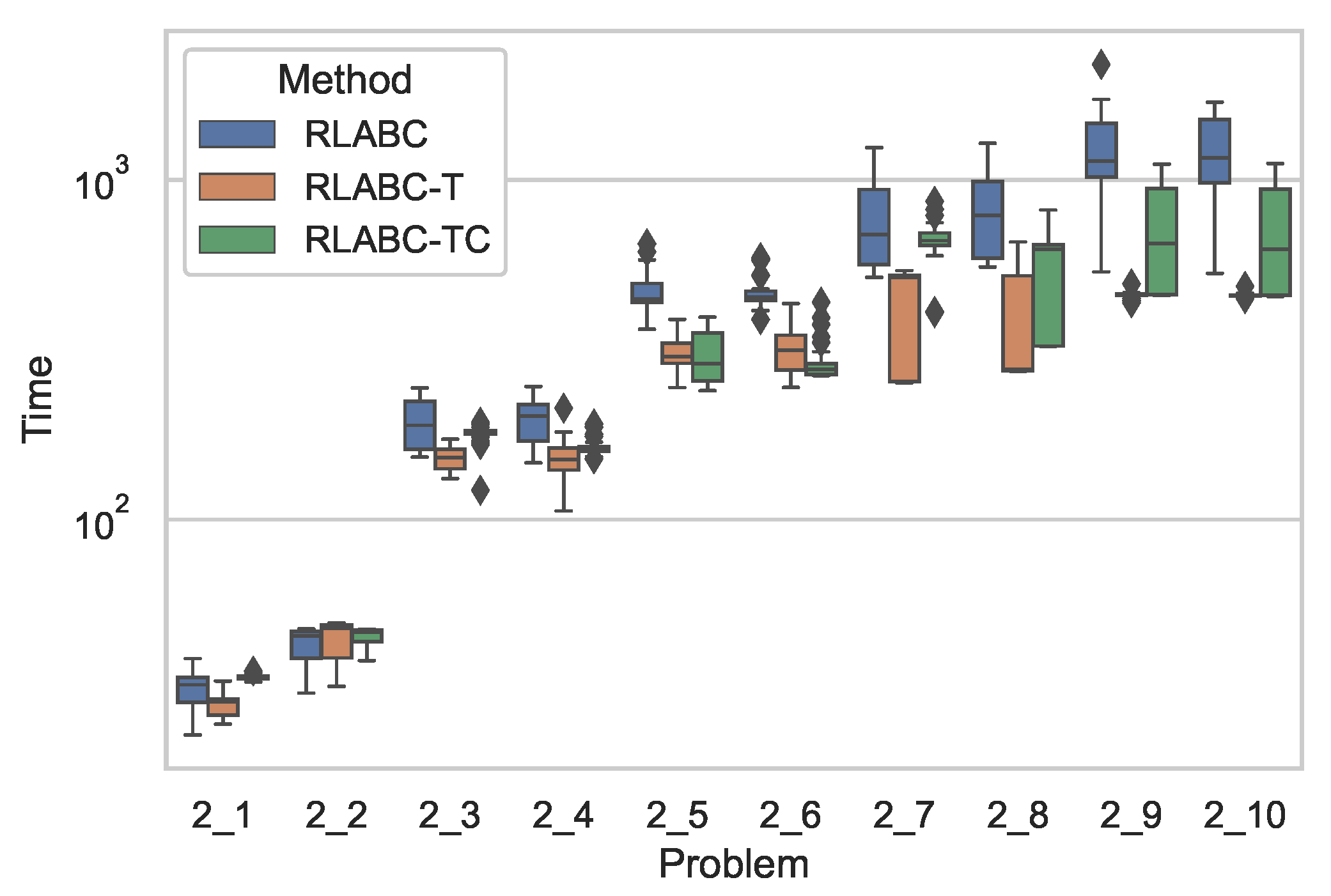
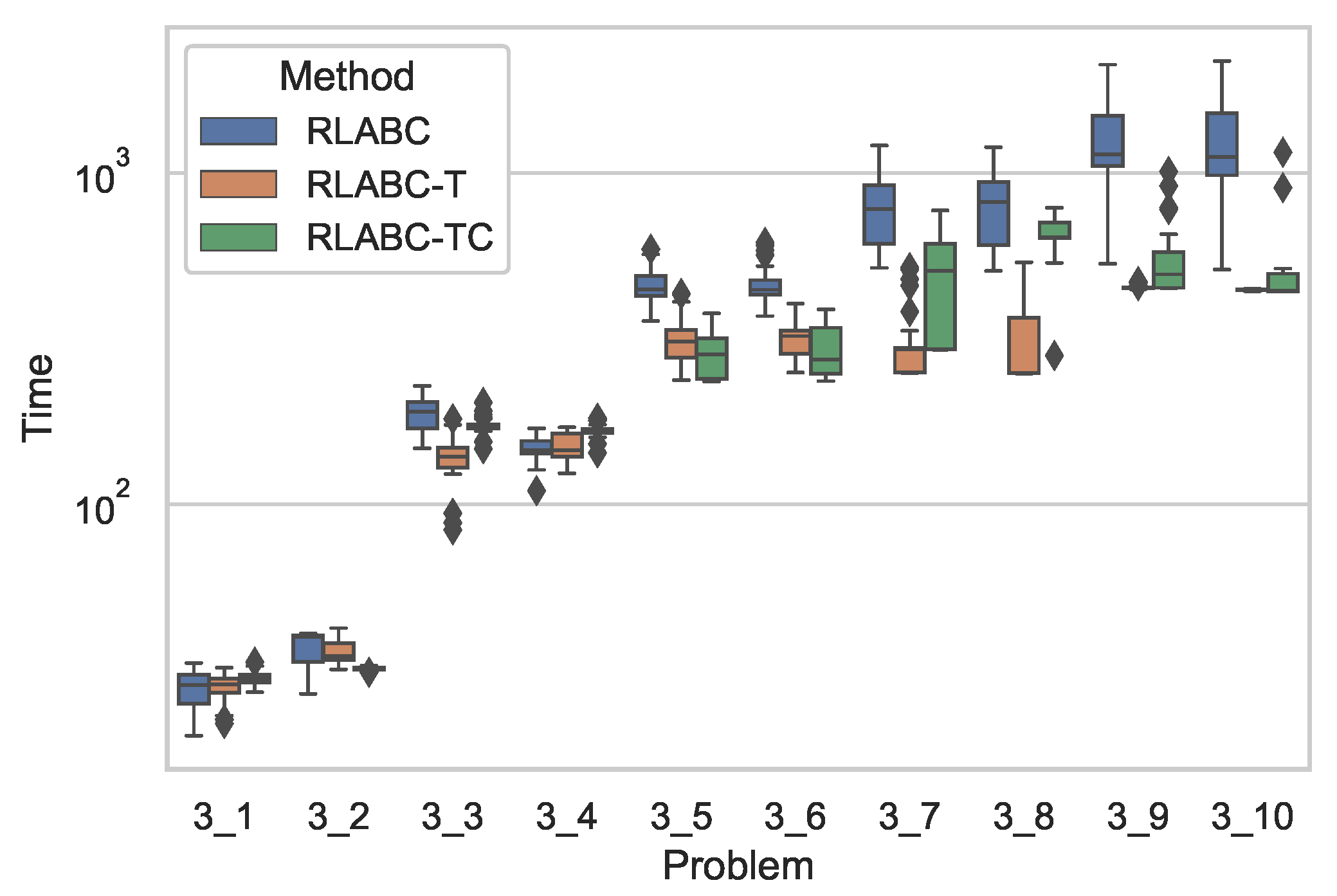
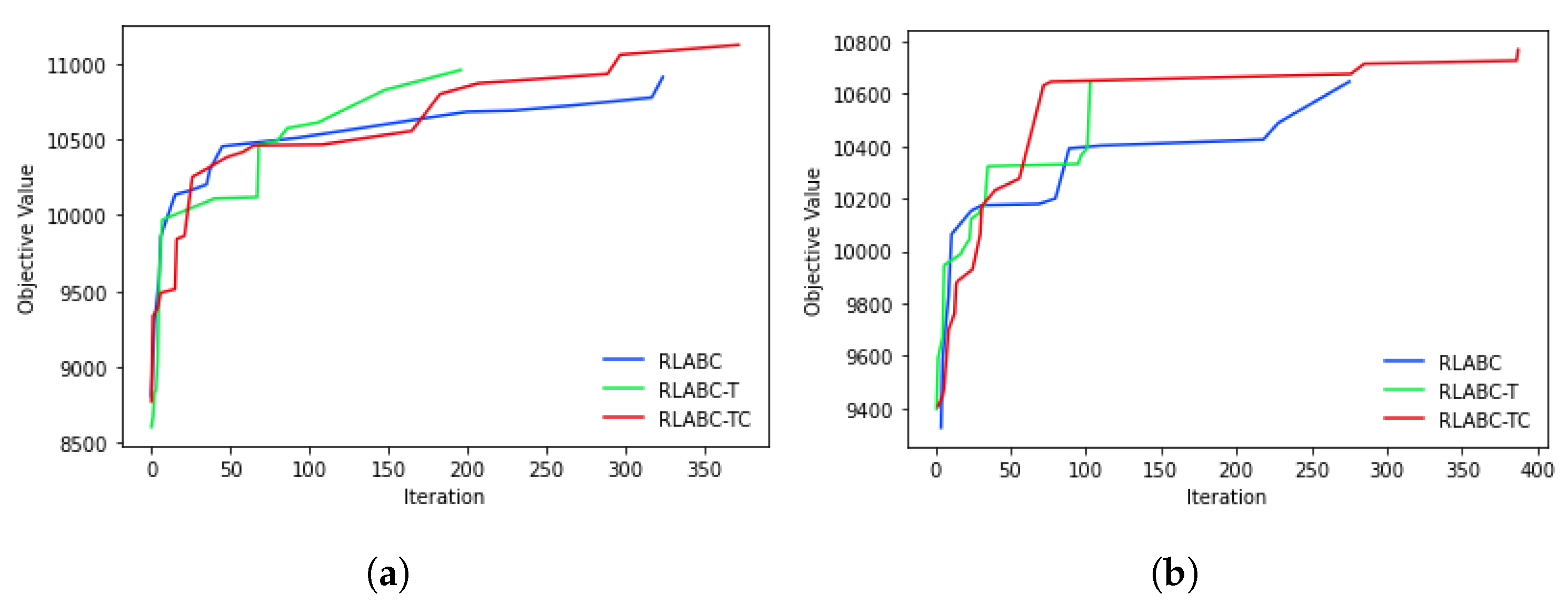
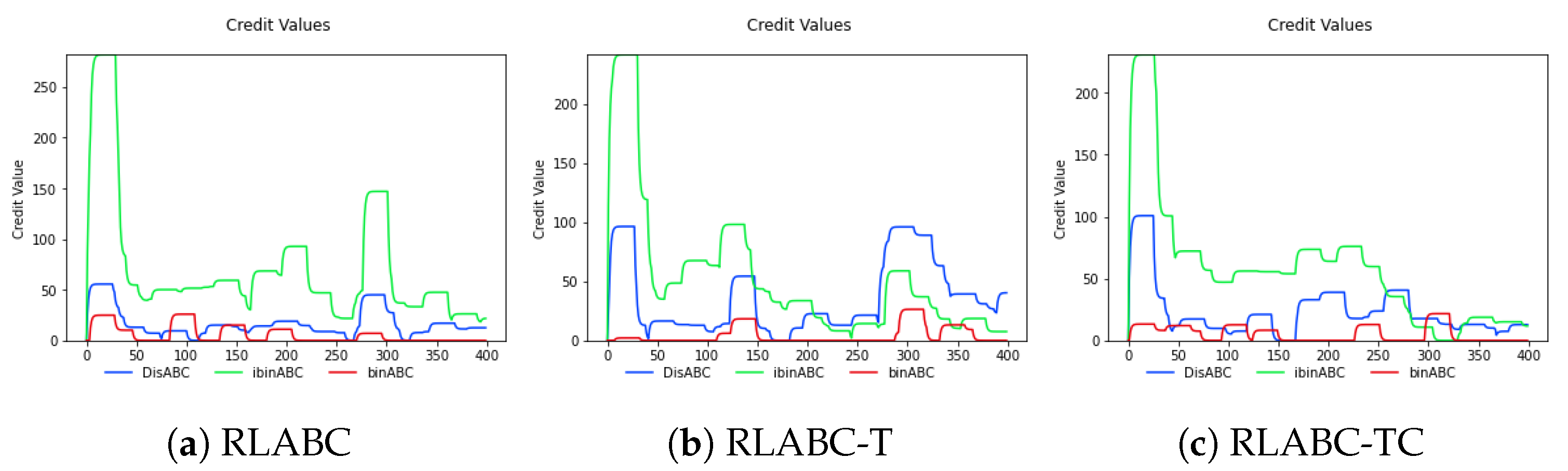
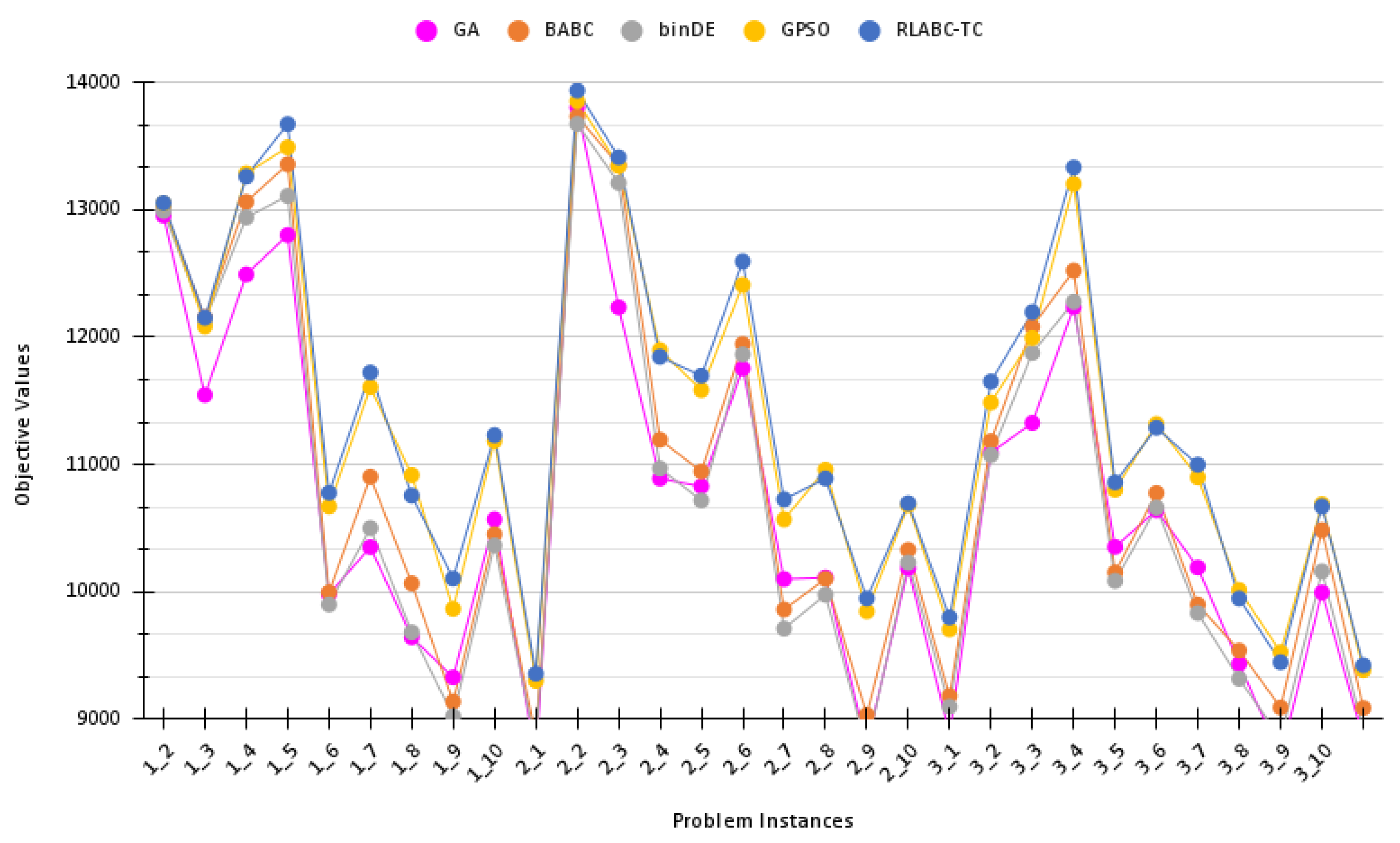
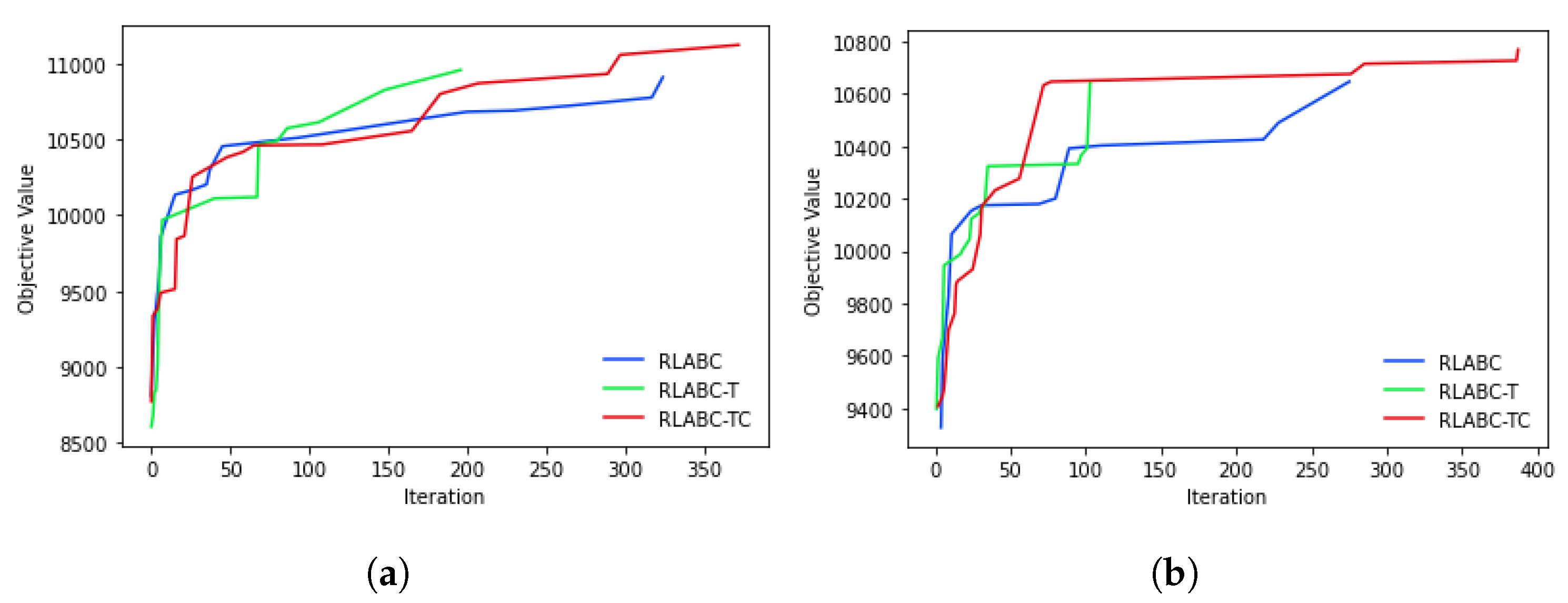
4.3. Results and Discussions
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Davis, L. Adapting operator probabilities in genetic algorithms. In Proceedings of the Third International Conference on Genetic Algorithms, San Francisco, CA, USA, 4–7 June 1989; pp. 61–69. [Google Scholar]
- Goldberg, D.E. Probability matching, the magnitude of reinforcement, and classifier system bidding. Mach. Learn. 1990, 5, 407–425. [Google Scholar] [CrossRef] [Green Version]
- Durgut, R.; Aydin, M.E. Adaptive binary artificial bee colony algorithm. Appl. Soft Comput. 2021, 101, 107054. [Google Scholar] [CrossRef]
- Durgut, R.; Aydin, M.E.; Atli, I. Adaptive operator selection with reinforcement learning. Inf. Sci. 2021, 581, 773–790. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A survey on deep transfer learning. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 270–279. [Google Scholar]
- Karaboga, D.; Akay, B. A comparative study of Artificial Bee Colony algorithm. Appl. Math. Comput. 2009, 214, 108–132. [Google Scholar] [CrossRef]
- Dorigo, M.; Birattari, M.; Stutzle, T. Ant colony optimization. IEEE Comput. Intell. Mag. 2006, 1, 28–39. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning, Second Edition: An Introduction: An Introduction; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Sigaud, O.; Buffet, O. Markov Decision Processes in Artificial Intelligence; Wiley-IEEE Press: Hoboken, NJ, USA, 2010. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef] [Green Version]
- Simon, D. Evolutionary Optimization Algorithms; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2013. [Google Scholar]
- Verheul, J. The Influence of Using Adaptive Operator Selection in a Multiobjective Evolutionary Algorithm Based on Decomposition. Master’s Thesis, Utrecht University, Utrecht, The Netherlands, 2020. [Google Scholar]
- Li, K.; Fialho, A.; Kwong, S.; Zhang, Q. Adaptive Operator Selection With Bandits for a Multiobjective Evolutionary Algorithm Based on Decomposition. IEEE Trans. Evol. Comput. 2014, 18, 114–130. [Google Scholar] [CrossRef]
- Torrey, L.; Shavlik, J. Transfer Learning. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; Olivas, E.S., Guerrero, J.D.M., Martinez-Sober, M., Magdalena-Benedito, J.R., López, A.J.S., Eds.; IGI Global: Hershey, PA, USA, 2010; Chapter 11; pp. 242–264. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Lin, Q.; Liu, Z.; Yan, Q.; Du, Z.; Coello, C.A.C.; Liang, Z.; Wang, W.; Chen, J. Adaptive composite operator selection and parameter control for multiobjective evolutionary algorithm. Inf. Sci. 2016, 339, 332–352. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition. Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Bischl, B.; Mersmann, O.; Trautmann, H.; Preuß, M. Algorithm selection based on exploratory landscape analysis and cost-sensitive learning. In Proceedings of the 14th Annual Conference on Genetic and Evolutionary Computation, Philadelphia, PA, USA, 7–11 July 2012; pp. 313–320. [Google Scholar]
- Hansen, N.; Auger, A.; Finck, S.; Ros, R. Real-Parameter Black-Box Optimization Benchmarking 2009: Experimental Setup; Research Report RR-6828; INRIA: Paris, France, 2009. [Google Scholar]
- Sallam, K.M.; Elsayed, S.M.; Sarker, R.A.; Essam, D.L. Landscape-based adaptive operator selection mechanism for differential evolution. Inf. Sci. 2017, 418, 383–404. [Google Scholar] [CrossRef]
- Handoko, S.D.; Nguyen, D.T.; Yuan, Z.; Lau, H.C. Reinforcement Learning for Adaptive Operator Selection in Memetic Search Applied to Quadratic Assignment Problem. In GECCO Comp’ 14, Proceedings of the Companion Publication of the 2014 Annual Conference on Genetic and Evolutionary Computation, Vancouver, BC, Canada, 12–16 July 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 193–194. [Google Scholar]
- Chen, B.; Qu, R.; Bai, R.; Laesanklang, W. A variable neighborhood search algorithm with reinforcement learning for a real-life periodic vehicle routing problem with time windows and open routes. RAIRO-Oper. Res. 2020, 54, 1467–1494. [Google Scholar] [CrossRef]
- Aydin, M.E.; Öztemel, E. Dynamic job-shop scheduling using reinforcement learning agents. Robot. Auton. Syst. 2000, 33, 169–178. [Google Scholar] [CrossRef]
- Kiran, M.S.; Gündüz, M. XOR-based artificial bee colony algorithm for binary optimization. Turk. J. Electr. Eng. Comput. Sci. 2013, 21, 2307–2328. [Google Scholar] [CrossRef] [Green Version]
- Durgut, R. Improved binary artificial bee colony algorithm. Front. Inf. Technol. Electron. Eng. 2021, 22, 1080–1091. [Google Scholar] [CrossRef]
- Kashan, M.H.; Nahavandi, N.; Kashan, A.H. DisABC: A new artificial bee colony algorithm for binary optimization. Appl. Soft Comput. 2012, 12, 342–352. [Google Scholar] [CrossRef]
- Goldschmidt, O.; Nehme, D.; Yu, G. Note: On the set-union knapsack problem. Naval Res. Logist. (NRL) 1994, 41, 833–842. [Google Scholar] [CrossRef]
- Wu, C.; He, Y. Solving the set-union knapsack problem by a novel hybrid Jaya algorithm. Soft Comput. 2020, 24, 1883–1902. [Google Scholar] [CrossRef]
- He, Y.; Xie, H.; Wong, T.L.; Wang, X. A novel binary artificial bee colony algorithm for the set-union knapsack problem. Future Gener. Comput. Syst. 2018, 78, 77–86. [Google Scholar] [CrossRef]
- Ozsoydan, F.B.; Baykasoglu, A. A swarm intelligence-based algorithm for the set-union knapsack problem. Future Gener. Comput. Syst. 2019, 93, 560–569. [Google Scholar] [CrossRef]
- Ozturk, C.; Hancer, E.; Karaboga, D. A novel binary artificial bee colony algorithm based on genetic operators. Inf. Sci. 2015, 297, 154–170. [Google Scholar] [CrossRef]
- Engelbrecht, A.P.; Pampara, G. Binary differential evolution strategies. In Proceedings of the 2007 IEEE Congress on Evolutionary Computation, Singapore, 25–28 September 2007; pp. 1942–1947. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
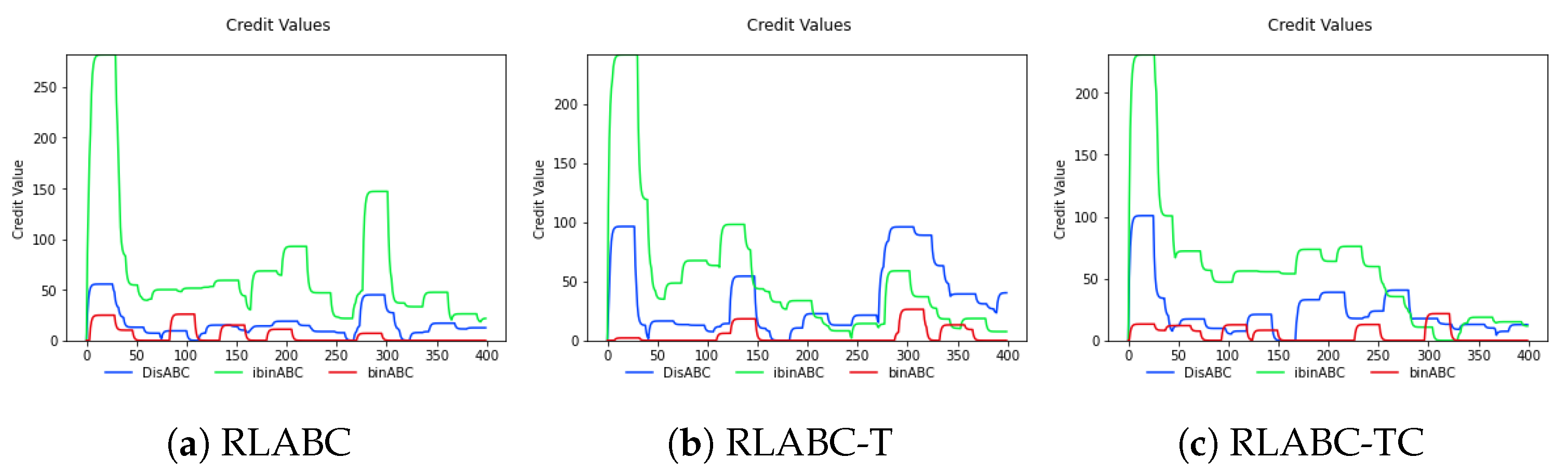{kind=link}
{kind=link}
| ID | m | n | w | y | ID | m | n | w | y | ID | m | n | w | y |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1_1 | 100 | 85 | 0.10 | 0.75 | 2_1 | 100 | 100 | 0.10 | 0.75 | 3_1 | 85 | 100 | 0.10 | 0.75 |
| 1_2 | 100 | 85 | 0.15 | 0.85 | 2_2 | 100 | 100 | 0.15 | 0.85 | 3_2 | 85 | 100 | 0.15 | 0.85 |
| 1_3 | 200 | 185 | 0.10 | 0.75 | 2_3 | 200 | 200 | 0.10 | 0.75 | 3_3 | 185 | 200 | 0.10 | 0.75 |
| 1_4 | 200 | 185 | 0.15 | 0.85 | 2_4 | 200 | 200 | 0.15 | 0.85 | 3_4 | 185 | 200 | 0.15 | 0.85 |
| 1_5 | 300 | 285 | 0.10 | 0.75 | 2_5 | 300 | 300 | 0.10 | 0.75 | 3_5 | 285 | 300 | 0.10 | 0.75 |
| 1_6 | 300 | 285 | 0.15 | 0.85 | 2_6 | 300 | 300 | 0.15 | 0.85 | 3_6 | 285 | 300 | 0.15 | 0.85 |
| 1_7 | 400 | 385 | 0.10 | 0.75 | 2_7 | 400 | 400 | 0.10 | 0.75 | 3_7 | 385 | 400 | 0.10 | 0.75 |
| 1_8 | 400 | 385 | 0.15 | 0.85 | 2_8 | 400 | 400 | 0.15 | 0.85 | 3_8 | 385 | 400 | 0.15 | 0.85 |
| 1_9 | 500 | 485 | 0.10 | 0.75 | 2_9 | 500 | 500 | 0.10 | 0.75 | 3_9 | 485 | 500 | 0.10 | 0.75 |
| 1_10 | 500 | 485 | 0.15 | 0.85 | 2_10 | 500 | 500 | 0.15 | 0.85 | 3_10 | 485 | 500 | 0.15 | 0.85 |
| RLABC | RLABC-T | RLABC-TC | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Best | Mean | Std | R | Best | Mean | Std | R | S | Best | Mean | Std | R | S | |
| 1_1 | 13,251 | 13,071.4 | 53.5 | 1 | 13,283 | 13,070.5 | 61.80 | 2 | − | 13,167 | 13,054.9 | 38.1 | 3 | − |
| 1_2 | 12,274 | 12,143.2 | 73.1 | 2 | 12,238 | 12,090.8 | 80.25 | 3 | + | 12,272 | 12,153.9 | 62.5 | 1 | − |
| 1_3 | 13,402 | 13,271.7 | 100.2 | 2 | 13,405 | 13,283 | 67.74 | 1 | − | 13,405 | 13,262.8 | 88.2 | 3 | − |
| 1_4 | 14,215 | 13,680.6 | 251.4 | 1 | 13,777 | 13,451.8 | 201.02 | 3 | + | 14,215 | 13,674.8 | 232.0 | 2 | − |
| 1_5 | 11,065 | 10,717.5 | 141.1 | 2 | 10,900 | 10,661.5 | 110.45 | 3 | − | 11,073 | 10,777.1 | 166.0 | 1 | − |
| 1_6 | 12,245 | 11,672.6 | 269.3 | 3 | 12,245 | 11,734.5 | 285.05 | 1 | − | 12,245 | 11,722.8 | 272.0 | 2 | − |
| 1_7 | 11,289 | 10,742.4 | 252.1 | 3 | 11,244 | 10,812.7 | 250.80 | 1 | − | 11,294 | 10,755.3 | 216.8 | 2 | − |
| 1_8 | 10,168 | 10,027.1 | 145.2 | 3 | 10,175 | 10,123.9 | 84.43 | 1 | + | 10175 | 10,103.8 | 82.4 | 2 | + |
| 1_9 | 11,427 | 11,188.1 | 140.5 | 3 | 11,490 | 11,196.1 | 134.66 | 2 | − | 11,490 | 11,230.6 | 151.2 | 1 | − |
| 1_10 | 9734 | 9359.3 | 195.2 | 2 | 9817 | 9475.3 | 154.50 | 1 | + | 10,022 | 9355.3 | 208.8 | 3 | - |
| Mean: | 2.2 | Mean: | 1.8 | Mean: | 2 | |||||||||
| RLABC | RLABC-T | RLABC-TC | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Best | Mean | Std | R | Best | Mean | Std | R | S | Best | Mean | Std | R | S | |
| 2_1 | 14,044 | 13,949 | 85.05 | 1 | 14,044 | 13,943.2 | 86.3631 | 2 | − | 14,044 | 13,938.5 | 92.7598 | 3 | − |
| 2_2 | 13,508 | 13,442.1 | 88.2756 | 2 | 13,508 | 13,465.9 | 48.2438 | 1 | − | 13,508 | 13,414 | 99.4093 | 3 | − |
| 2_3 | 12,211 | 11,833.3 | 178.218 | 3 | 12,328 | 11,944.3 | 201.902 | 1 | − | 12,328 | 11,845.8 | 212.621 | 2 | − |
| 2_4 | 12,019 | 11,652 | 163.042 | 2 | 11,821 | 11,627.4 | 201.362 | 3 | − | 12,187 | 11,697.1 | 222.437 | 1 | − |
| 2_5 | 12,646 | 12,535 | 167.639 | 3 | 12,695 | 12,623.3 | 72.6071 | 1 | + | 12,655 | 12,595.2 | 114.05 | 2 | − |
| 2_6 | 11,410 | 10,679.6 | 176.845 | 3 | 11,054 | 10,759.6 | 144.579 | 1 | + | 11,251 | 10,725.8 | 137.088 | 2 | + |
| 2_7 | 11,193 | 10,855.3 | 132.626 | 3 | 11,310 | 10,924.2 | 170.308 | 1 | − | 11,249 | 10,889.6 | 156.932 | 2 | − |
| 2_8 | 10,355 | 9882.63 | 234.754 | 2 | 10,382 | 9871.07 | 233.87 | 3 | − | 10,382 | 9947.37 | 214.996 | 1 | − |
| 2_9 | 10,770 | 10,647.2 | 65.2152 | 3 | 10,885 | 10,688.7 | 60.1216 | 2 | + | 10,885 | 10,694.9 | 73.2702 | 1 | + |
| 2_10 | 10,194 | 9851.07 | 209.2 | 1 | 10,176 | 9845.03 | 186.539 | 2 | - | 10,176 | 9798.8 | 229.578 | 3 | - |
| Mean: | 2.3 | Mean: | 1.7 | Mean: | 2 | |||||||||
| RLABC | RLABC-T | RLABC-TC | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Best | Mean | Std | R | Best | Mean | Std | R | S | Best | Mean | Std | R | S | |
| 3_1 | 12,045 | 11,632 | 191.489 | 3 | 12,020 | 11,697.3 | 148.956 | 1 | − | 12,020 | 11,651.9 | 152.747 | 2 | − |
| 3_2 | 12,369 | 12,205.2 | 149.614 | 1 | 12,369 | 12,101 | 263.167 | 3 | − | 12,369 | 12,196.8 | 201.196 | 2 | − |
| 3_3 | 13,609 | 13,352.2 | 130.039 | 2 | 13,609 | 13,399 | 99.6629 | 1 | − | 13,609 | 13,334.8 | 127.075 | 3 | − |
| 3_4 | 10,973 | 10,856.3 | 105.533 | 2 | 11,021 | 10,852.4 | 86.8795 | 3 | − | 11,298 | 10,859.1 | 140.543 | 1 | − |
| 3_5 | 11,538 | 11,240 | 169.691 | 3 | 11,538 | 11,308.8 | 210.61 | 1 | − | 11,538 | 11,287.8 | 194.904 | 2 | − |
| 3_6 | 11,377 | 11,077.2 | 189.324 | 1 | 11,377 | 11,017.5 | 178.618 | 2 | − | 11,377 | 10,997.4 | 202.552 | 3 | + |
| 3_7 | 10,181 | 9951.63 | 80.973 | 1 | 10,069 | 9932.27 | 67.0159 | 3 | − | 10,087 | 9946.9 | 76.4209 | 2 | − |
| 3_8 | 10,075 | 9403.8 | 177.593 | 3 | 10,077 | 9517.33 | 193.699 | 1 | + | 9749 | 9445.77 | 146.641 | 2 | − |
| 3_9 | 10,877 | 10,647.3 | 101.085 | 2 | 10,831 | 10,626.4 | 90.5375 | 3 | − | 10,987 | 10,668.8 | 122.98 | 1 | − |
| 3_10 | 9745 | 9426.57 | 136.45 | 2 | 10,220 | 9433.83 | 234.262 | 1 | - | 9649 | 9421.17 | 117.068 | 3 | - |
| Mean: | 2 | Mean: | 1.9 | Mean: | 2.1 | |||||||||
| RLABC | RLABC-T | RLABC-TC | |||
|---|---|---|---|---|---|
| Instance No | Rank | Rank | Sign | Rank | Sign |
| 1_1 | 2 | 3 | + | 1 | − |
| 1_2 | 2 | 1 | + | 3 | − |
| 1_3 | 3 | 2 | + | 1 | + |
| 1_4 | 3 | 1 | + | 2 | + |
| 1_5 | 3 | 1 | + | 2 | + |
| 1_6 | 3 | 1 | + | 2 | + |
| 1_7 | 3 | 2 | + | 1 | + |
| 1_8 | 3 | 2 | + | 1 | + |
| 1_9 | 3 | 2 | + | 1 | + |
| 1_10 | 3 | 2 | + | 1 | + |
| Mean: | 2.8 | 1.7 | 1.5 | ||
| RLABC | RLABC-T | RLABC-TC | |||
|---|---|---|---|---|---|
| Rank | Rank | Sign | Rank | Sign | |
| 2_1 | 2 | 3 | + | 1 | + |
| 2_2 | 1 | 3 | − | 2 | − |
| 2_3 | 3 | 2 | + | 1 | + |
| 2_4 | 3 | 2 | + | 1 | + |
| 2_5 | 3 | 1 | + | 2 | + |
| 2_6 | 3 | 1 | + | 2 | + |
| 2_7 | 3 | 2 | + | 1 | + |
| 2_8 | 3 | 2 | + | 1 | + |
| 2_9 | 3 | 2 | + | 1 | + |
| 2_10 | 3 | 2 | + | 1 | + |
| Mean: | 2.7 | 2 | 1.3 | ||
| RLABC | RLABC-T | RLABC-TC | |||
|---|---|---|---|---|---|
| Rank | Rank | Sign | Rank | Sign | |
| 3_1 | 1 | 3 | + | 2 | − |
| 3_2 | 3 | 1 | + | 2 | − |
| 3_3 | 3 | 2 | + | 1 | + |
| 3_4 | 1 | 3 | + | 2 | − |
| 3_5 | 3 | 1 | + | 2 | + |
| 3_6 | 3 | 1 | + | 2 | + |
| 3_7 | 3 | 2 | + | 1 | + |
| 3_8 | 3 | 2 | + | 1 | + |
| 3_9 | 3 | 2 | + | 1 | + |
| 3_10 | 3 | 2 | + | 1 | + |
| Mean: | 2.6 | 1.9 | 1.5 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Durgut, R.; Aydin, M.E.; Rakib, A. Transfer Learning for Operator Selection: A Reinforcement Learning Approach. Algorithms 2022, 15, 24. https://doi.org/10.3390/a15010024
Durgut R, Aydin ME, Rakib A. Transfer Learning for Operator Selection: A Reinforcement Learning Approach. Algorithms. 2022; 15(1):24. https://doi.org/10.3390/a15010024
Chicago/Turabian StyleDurgut, Rafet, Mehmet Emin Aydin, and Abdur Rakib. 2022. "Transfer Learning for Operator Selection: A Reinforcement Learning Approach" Algorithms 15, no. 1: 24. https://doi.org/10.3390/a15010024
APA StyleDurgut, R., Aydin, M. E., & Rakib, A. (2022). Transfer Learning for Operator Selection: A Reinforcement Learning Approach. Algorithms, 15(1), 24. https://doi.org/10.3390/a15010024