Our stream model has the following features: (1) Only one pass is needed to build the graph sketch; (2) A parameter, the Shrinking Factor, is introduced to allow users to directly control the size of a sketch. So, the users’ requirement can be used to build a sketch with much less space; (3) The graph stream sketch is divided into three different partitions (we also refer to the three independent small graphs as sub-sketches) and this method can help us to avoid global heterogeneity and skewness but take advantage of the local similarity; (4) Our sketch is expressed as a graph so the exact graph analysis method on a complete graph can also be used on our different sub-sketches; (5) A general multivariate linear regression model is used to generate the approximate solution based on the results from different sub-sketches. The regression method can be employed to support general graph analysis methods.
The framework of our stream model includes three parts: (1) Mapping a graph stream into a much smaller graph sketch in one pass. The sketch can have multiple independent partitions or sub-sketches; (2) Developing an exact algorithm on different sub-sketches to generate partial solutions; (3) Developing a regression model to generate an approximate solution based on different partial solutions.
5.1. Building the Sketch as a Multi-Partition Graph
5.1.1. Sliding Window Stream
We first describe our method when the stream comes from a sliding window, which means that only the last M edges falling into the given time window will be considered.
We define the shrinking factor
(a positive integer) to constrain the space allocation of a stream sketch. This means that the size of the edges and vertices of the graph sketch will be
of the original graph. The existing research on sketch building [
7] shows that multiple pairwise independent hash function [
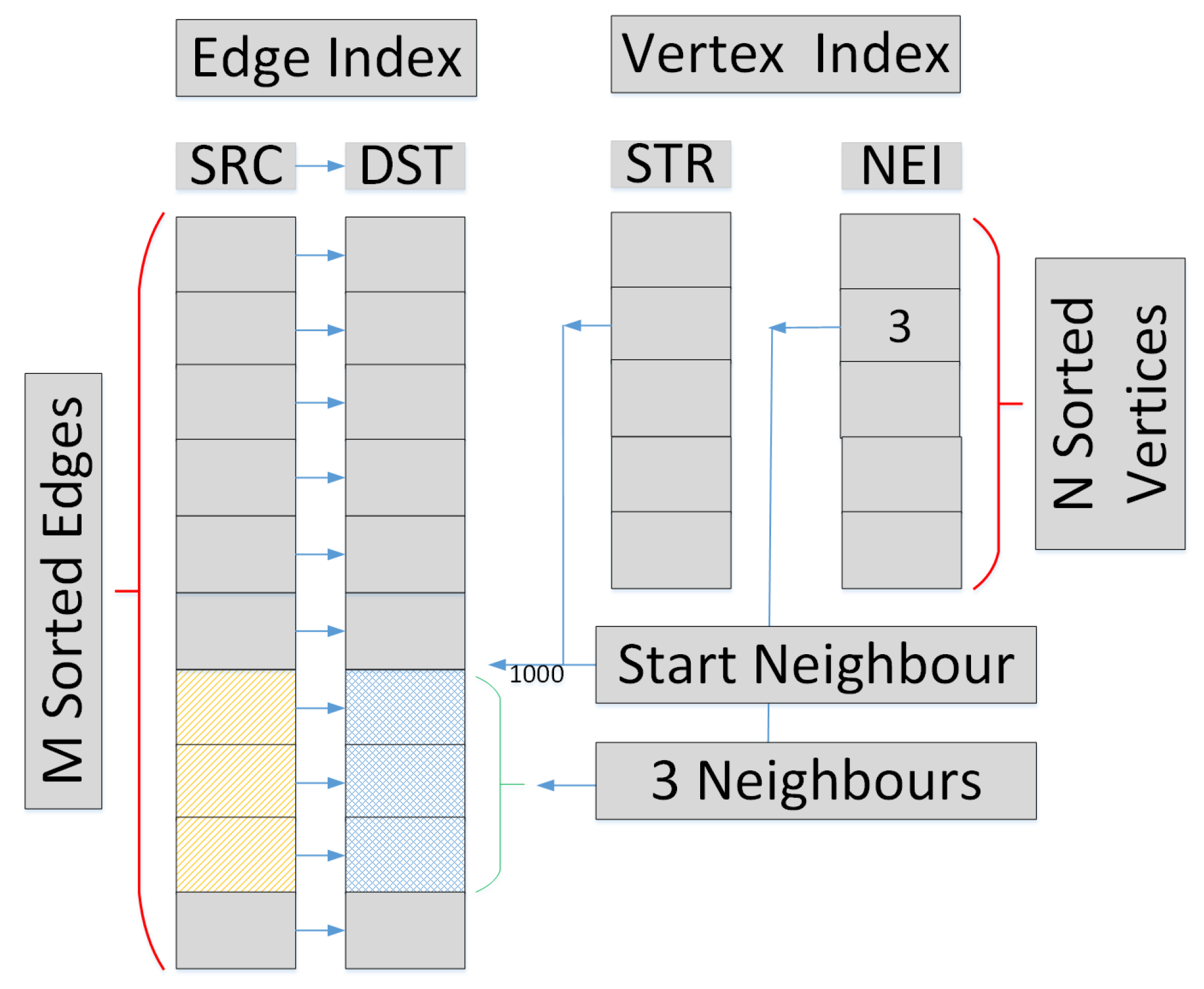
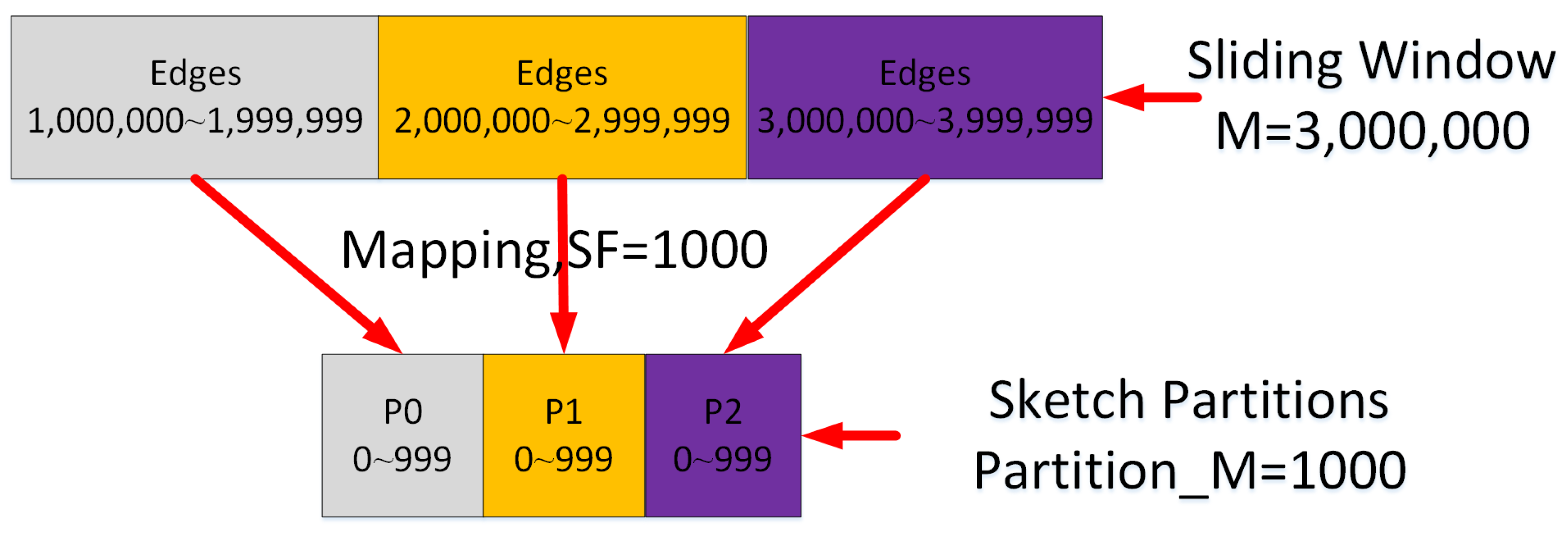
4] methods can often generate better estimation results because they can reduce the probability of hash collisions. In our solution, we sample at different parts of the given sliding window instead of the complete stream and then map the sampled edges into multiple (here three) independent partitions to completely avoid collisions. We name the three partitions Head, Mid, and Tail partitions or sub-sketches, respectively. Each partition will be assigned with
space of the original graph.
Since we divide the sketch into three independent partitions, we select a very simple hash function. For a given sliding window, we let the total number of edges and vertices in this window be M and N. Then, the size of each partition will have edges and vertices. For any edge from the original graph, we will map the edge ID e to . At the same time, its two vertices i and j will be mapped to and . If , then we will map to the Head partition. If , we will map to the Tail partition. Otherwise, we will map to the Mid partition.
Figure 4 is an example that shows how we map, completely, 3,000,000 edges in a given sliding window into a sketch with three partitions. The edges from 1,000,000 to 1999,999 are mapped to the Head partition p0 that has 1000 edges. The edges from 2,000,000 to 2,999,999 are mapped to the Mid partition p1 and the edges from 3,000,000 to 3,999,999 are mapped to the Tail partition p2. Each partition is expressed as a graph.
After the three smaller partitions are built, we sort the edges and create the DI data structure to store the partition graphs.
We map different parts of a stream into corresponding sub-sketches and this is very different from the existing sketch building methods. They map the same stream into different sketches with independent pairwise hash functions so each sketch is an independent summarization of the stream. However, in our method, one sub-sketch can only stand for a part of the stream and we use different sub-sketches to capture the different local features in a stream. Our regression model (see
Section 5.3) will be responsible for generating the final approximate solution.
More partitions will help to capture more local features of a stream. However, we aim for a regression model that is as simple as possible. Too many partitions will make our regression model have more variables and become complicated. We select three as the default number of partitions because this can achieve sufficient accuracy based on our experimental results. Of course, for some special cases, we may choose more partitions but use the same proposed framework.
5.1.2. Insert-Only and Insert-Delete Streams
For the sliding window stream, we only need to care about the edges in the given window. However, for insert-only and insert-delete streams, we need to consider the edges that will come in the future. Here, we will describe the sketch updating mechanism in our stream model.
For the insert-delete stream, we will introduce a new weight array in the sketch. If the total number of edges that can be held in one partition is , then we will introduce a weight array with size to store the latest updated information of each edge. The initial value of will be zero. If a new insert edge is mapped to e, then we will let . If a deleted edge is mapped to e, then we will let . So, for any edge in the partition, if , it means that the edge has been deleted so we can safely remove this edge from our sketch. If , it means that there are multiple edges in the stream that have been mapped to this edge. For the insert-only stream, it is similar to the insert-delete stream but we never reduce the value of .
To improve the sketch update performance, we will use the bulk updating mechanism for the two streams. If B new edges have arrived (they can be insert edges or delete edges), we will divide B into three parts and map them into the three different partitions just as in the method used in the sliding window stream. After the new edges are updated, we need to resort the edges and update the DI data structure to express the updated sub-sketches.
5.2. Edge–Vertex Iterator Based Triangle Counting Algorithm
We can directly employ existing exact graph algorithms in our sketch because the sketch is also expressed as a graph. Here, we will use a typical graph analysis algorithm—triangle counting—to show how we can develop optimized exact algorithms based on our data structure.
To improve the performance of a distributed triangle counting algorithm, two important problems are maintaining load balancing and avoiding remote access or communication as much as possible.
In Chapel, the locale type refers to a unit of the machine resources on which the program is running. Locales have the capability to store variables and to run Chapel tasks. In practice, for a standard distributed memory architecture, a single multicore/SMP node is typically considered a locale. Shared memory architectures are typically considered a single locale. In this work, we will develop a multiple-locale exact triangle counting algorithm for distributed memory clusters.
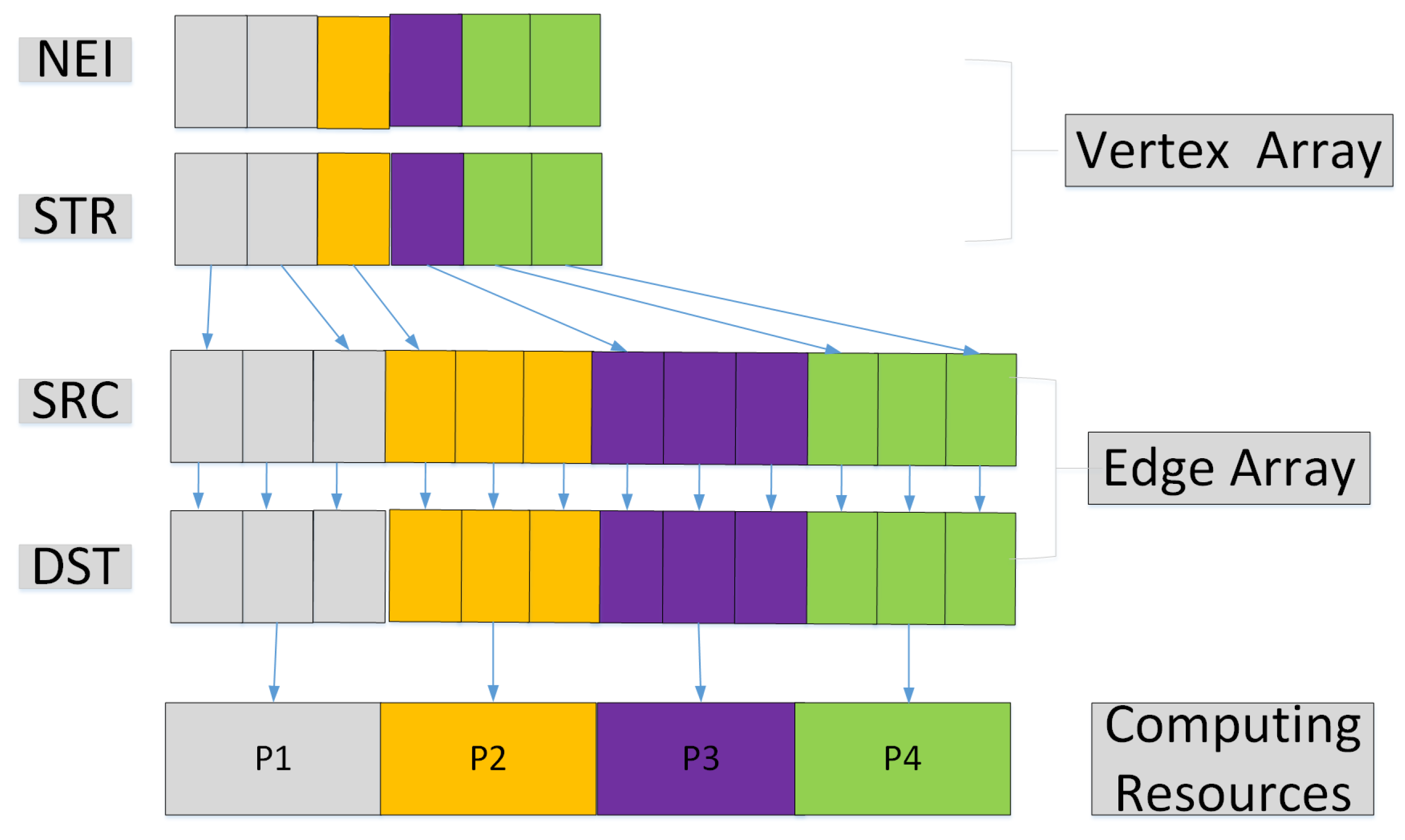
For power law graphs, a small number of vertices may have a high degree. So, if we divide the data based on number of vertices, it is easy to cause an unbalanced load. Our method divides the data based on the number of edges. At the same time, our DI data structure will keep the edges connected with the same vertex together. So, the edge partition method will result in good load balancing and data access locality.
However, if each locale directly employs the existing edge iterator [
13] on its edges, the reverse edges of the undirected graphs are often not in the same locale. This will cause a new load balancing problem. So, we will first generate the vertices based on the edges distributed to different locales. Then, each locale will employ the vertex iterator to calculate the number of triangles. The combined edge–vertex iterator method is the major innovation for our triangle counting method on distributed systems.
When we employ the high level parallel language Chapel to design the parallel exact triangle counting algorithm, there are two additional advantages: (1) Our DI data structure can work together with the coforall or forall parallel construct of Chapel to exploit the parallelism; (2) We can take advantage of the high level module Set provided by Chapel to implement the parallel set operation easily and efficiently.
At a high level, our proposed algorithm takes advantage of the multi-locale feature of Chapel to handle very large graphs in distributed memory. The distributed data are processed at their locales or their local memory. Furthermore, each shared memory compute node can also process their own data in parallel. The following steps are needed to implement the multi-locale exact triangle counting algorithm: (1) The DI graph data should be distributed evenly onto the distributed memory to balance the load; (2) Each distributed node only counts the triangle including the vertices assigned to the current node; (3) All the triangles calculated by different nodes should be summed together to obtain the exact number of triangles.
Our multi-locale exact triangle counting algorithm is described in Algorithm 1. For a given graph sketch partition , we will use an array to keep each locale’s result (line 2). Here in line 3, we use coforall instead of forall to allow each in to execute the following code in parallel so we can fully exploit the distributed computing resources. The code between line 3 and line 17 will be executed in parallel on each locale. Each locale will use a local variable to store the number of triangles (line 5). Line 6 and line 7 are important for implementing load balancing. Assume edges from to are assigned to the current locale, we can obtain the corresponding vertex ID and as the vertices interval that the current locale will handle. Since different locales may have different edges with the same starting vertex, the interval of different locales may overlap. At the same time, some starting vertex in the index array may not appear in , so we should also make sure there is no “hole” in the complete interval . In line 7, we will make sure all the intervals will cover all the vertices without overlapping.
Our method includes the following steps: (1) If the current locale’s is the same as the previous locale’s , this means that one vertex’s edges have been partitioned into two different locales. We will set to avoid two locales executing the counting on the same vertex; (2) If the current locale’s is different from the previous locale’s , and the difference is larger than 1, this means that there is a “hole” between the last locale’s vertices and the current locale’s vertices. So we will let the current locale’s last locale’s ; (3) If the current locale is the last locale, we will let its the last vertex ID. If the current locale is the first locale, we will let .
From line 8 to line 14 we will count all the triangles starting from the vertices assigned to the current locale in parallel. In line 9 we will generate all the adjacent vertices
of the current vertex
u and its vertex ID is larger than
u. From line 10 to line 12, for any vertex
, we will generate all the adjacent vertices
of current vertex
v and its vertex ID is larger than
v. So the number of vertices in
is the number of triangles having edge
. Since we only calculate the triangles whose vertices meet
, we will not count the duplicate triangles. In this way, we can avoid the unnecessary calculation. In line 15, each locale will assign its total number of triangles to the corresponding position of array
. At the end in line 18, when we sum all the number of triangles of different locales, we will obtain the total number of triangles.
| Algorithm 1: Edge–vertex Iterator triangle counting algorithm |
 |
5.3. Real-World Graph Distribution Based Regression Model
Instead of developing different specific methods for different graph analysis problems, we propose a general regression method to generate the approximate solution based on the results of different sub-sketches.
One essential objective of a stream model is generating an accurate estimation based on the query results from its sketch. The basic idea of our method is to exploit the real-world graph distribution information to build an accurate regression model. Then we can use the regression model to generate approximate solutions for different queries.
Specifically, for the triangle counting problem, when we know the exact number of triangles in each sub-sketch (see
Table 1), the key problem is how we can estimate the total number of triangles.
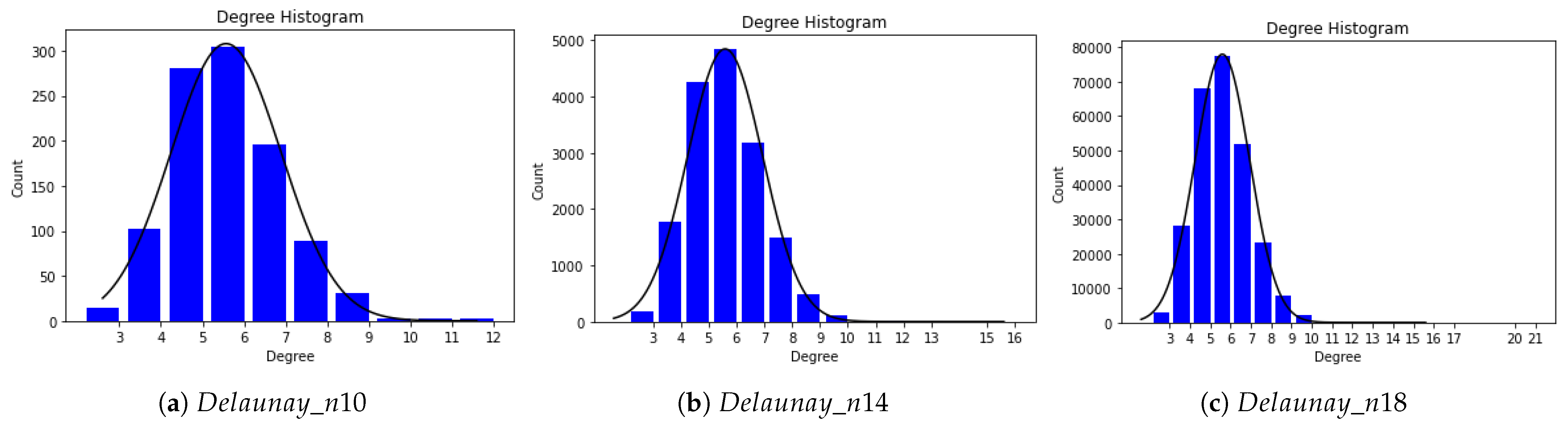
To achieve user-required accuracy for different real-world applications, our method exploits the features of real-world graph distributions. Many sparse networks—social networks in particular—have an important property; their degree distribution follows the power law distribution. Normal distributions are often used in the natural and social sciences to represent real-valued random variables whose distributions are not known. So, we develop two regression models for the two different graph degree distributions.
We let
be the exact number of triangles in the Head, Mid and Tail sub-sketches. The exact triangle counting algorithm is given in
Section 5.2.
For normal degree distribution graphs, we assume that the total number of triangles has a linear relationship with the number of triangles in each sub-sketch. We take
as three randomly sampled results of the original stream graph to build our multivariate linear regression model.
is the estimated number of triangles and the regression model is given in Equation (
1).
For power law graphs, the sampling results of
can be significantly different because of the skewness in degree distribution. A power law distribution has the property that its log–log plot is a straight line. So we assume the logarithmic value of the total number of triangles in a stream graph should have a linear relationship with the logarithmic values of the exact number of triangles in different degree sub-sketches. Then we have two ways to build the regression model. One is unordered and the other is ordered. The unordered model can be expressed as in Equation (
2). In this model, the relative order information of sampling results cannot be captured.
where
is the logarithmic value of the estimated value
;
and
;
and
are the logarithmic values of
and
, respectively.
Then, we refine the regression model for power law distribution as follows. We get
and
by sorting
and
. They mean the minimum, median and maximum sampling values of the number of triangles. They will be used to stand for the sampling results of a power law distribution at the right (low possibility), middle (a little bit high possibility) and left part (very high possibility). We let
and
. Our ordered multivariate linear regression model for power law graphs is given in Equation (
3).
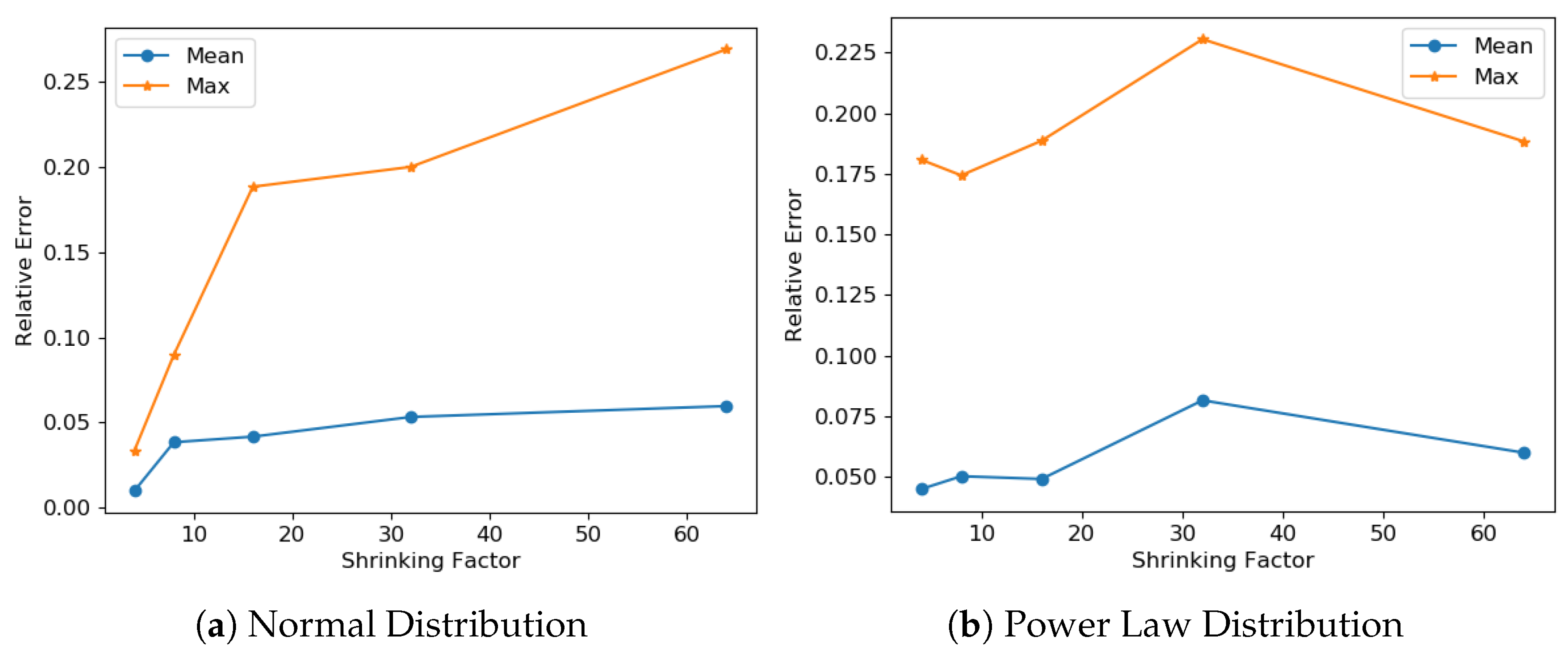
The accuracy of our multivariate linear regression model is given in in
Section 7.3.1 and we can see that the ordered regression model is better than the unordered regression model. Both of our normal and ordered power law regression models achieve a very high accuracy.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}