Abstract
A variety of strategies are used to construct algorithms for solving equations. However, higher order derivatives are usually assumed to calculate the convergence order. More importantly, bounds on error and uniqueness regions for the solution are also not derived. Therefore, the benefits of these algorithms are limited. We simply use the first derivative to tackle all these issues and study the ball analysis for two sixth order algorithms under the same set of conditions. In addition, we present a calculable ball comparison between these algorithms. In this manner, we enhance the utility of these algorithms. Our idea is very general. That is why it can also be used to extend other algorithms as well in the same way.
1. Introduction
We consider two Banach spaces and with an open and convex subset of . Let us denote the set by . Suppose is Fréchet derivable. Equations of the kind
are often utilized in science and other applied areas to solve several highly challenging problems. We should not ignore the fact that solving these equations is a difficult process, as the solution could only be discovered analytically on rare instances. This is why iterative processes are generally used for solving these equations. However, it is an arduous task to develop an effective iterative approach for addressing (1). The classical Newton’s iterative strategy is most typically employed for this issue. In addition, a lot of studies on higher order modifications of conventional processes like Newton’s, Jarratt’s, Chebyshev’s, etc. are presented in [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15]. Wang et al. [16] presented a sixth order variant of Jarratt’s algorithm, which adds the evaluation of the function at an additional point in the iteration procedure of Jarratt’s method [12]. Grau-Sánchez and Gutiérrez [10] by applying Obreshkov-like techniques described two families of zero-finding iterative approaches. An efficient family of nonlinear system algorithms is suggested by Cordero et al. [8] using a reduced composition technique on Newton’s and Jarratt’s algorithm. Sharma et al. [17] composed two weighted-Newton steps to construct an efficient fourth order weighted-Newton method to solve nonlinear systems. Sharma and Arora [18] constructed iterative algorithms of fourth and sixth convergence order for solving nonlinear systems. Two bi-parametric fourth order families of predictor-corrector iterative algorithms are discussed in [9]. Newton-like iterative approaches of fifth and eighth rate of convergence are also designed by Sharma and Arora [19]. Additional studies on other algorithms with their convergence and dynamics are available in [20,21,22,23,24,25].
Notice that higher convergence order algorithms using Taylor expansions suffer from the following problems:
- (1’)
- Higher order derivatives (not on the algorithms) should exist although convergence may be possible without these conditions.
- (2’)
- We do not know in advance how many iterations should be performed to reach a certain error tolerance.
- (3’)
- The choice of initial points is limited, since we do not know a convergence ball.
- (4’)
- No information is provided on the uniqueness of .
- (5’)
- Results are limited on the multidimensional Euclidean space.
Hence, there is a need to address these problems. The novelty of our article lies in the fact that we handle (1’)–(5’) as follows.
- (1”)
- We only use the derivative that actually appears on these algorithms. The convergence order is recovered again, since we by pass Taylor series, (which require the higher order derivatives) and use instead the computational order of convergence (COC) given byand the approximate computational order of convergence (ACOC) given byThese formulae use the algorithms (which depend on the first derivative). In the case of ACOC no knowledge of is needed.
- (2”)
- We use generalized Lipschitz-type conditions which allow us to provide upper bounds on which in turn can be used to determine the smallest number of iterations to reach the error tolerance.
- (3”)
- Under our local convergence analysis a convergence ball is determined. Hence, we know from where to pick the stater so that convergence to the solution can be achieved.
- (4”)
- A uniqueness ball is provided.
- (5”)
- The results are presented in the more general setting of Banach space valued operators.
In this article, to demonstrate our technique, we selected the following sixth convergence order algorithms to expand their utility. However, our technique is so general that it can be applied on other algorithms [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26]. We also compare their convergence balls and dynamical properties. Define algorithms for all by
- SM1:
- SM2:
For , these algorithms are described in [26] (see also [11]), where the benefits over other algorithm are well explained. Conditions on derivatives of the seventh order and Taylor series expansion have been employed in [11,26] to determine their convergence rate. Because of such results needing derivatives of higher order, these algorithms are very difficult to implement, as their utility is reduced although they may converge. In order to justify this, we have the following function
where and is defined on . Then, it is crucial to highlight that is not bounded. Hence, the existing convergence results for methods SM1 and SM2 based on do not work in this scenario, although these algorithms may still converge with convergence order six. Clearly this is the case, since the conditions in the aforementioned studies are only sufficient.
The other parts of this work can be summarized as: In Section 2, the main convergence theorems on the ball convergence of SM1 and SM2 are discussed. Section 3 deals with comparison of the attraction basins for these procedures. Numerical applications are placed in Section 4. This study is concluded with final comments in Section 5.
2. Ball Convergence
Our ball convergence analysis is requires the development of some scalar parameters and functions. Set .
Suppose function:
- (i)
- has a smallest root in for some function which is non-decreasing and continuous. Set .
- (ii)
- has a smallest root in for some functions , which are non-decreasing and continuous with defined by
- (iii)
- has a smallest root in . Set and .
- (iv)
- has a smallest root in , where
- (v)
- has a smallest root in . Set and .
- (vi)
- has a smallest root in , where
The scalar given as
shall be shown to be a convergence radius for SM1. Set . It is implied by (5) that
and
hold for each s in T.
The notation stands for the closure of a ball of radius and center .
We suppose from now on that is a simple root of , scalar functions are as given previously and is differentiable. Further, conditions hold:
- For eachSet .
- For eachand
- for some to be defined later.
- There exists satisfyingSet .Next, the main convergence result for SM1 is developed utilizing conditions .
Theorem 1.
Suppose that the conditions hold for . Then, iteration given by SM1 exists in , stays in and converges to provided the initial guess is in . Moreover, we have
and
where radius r and functions are as given previously. Furthermore, is the only zero of in the set given in is .
Proof.
Mathematical induction shall be used to show the existence of iteration so that items (10)–(12) hold. Let . Using , (5) and (6) we get
leading to by a lemma due to Banach for mappings [5] that are invertible, and
The iterate exists by (14) for , and we can write
Using (5), (9) (for ), (14) (for ), () and (15), we have in turn
showing and (10) holds if . Notice also that , and exists, so we can write
By (5), (9) (for ), (14) (for ), (16) and (17), we obtain in turn
showing and (11) if . Notice also that , exists, and we can write
In view of (5), (9) (for ), (14) (for ), (16), (18) and (19), we have
showing , and (12) if .
Simply switch , , , by , , , in the previous calculations to finish the induction for items (10)–(12). Then, the estimation
where is in implies and .
Finally, set for with .
By and , we obtain
leading to , since and . □
Next, the convergence analysis of algorithm SM2 is developed in an analogous fashion. But this time the functions are:
Suppose functions have least positive solutions , respectively as before, and set
Then, under conditions for , the choice of the functions is justified by the estimates
so
so
Hence, we arrived at the ball convergence result for SM2.
Theorem 2.
Suppose that the conditions hold with . Then, the conclusions of Theorem 1 hold for SM2 with , , replacing ρ, , respectively.
Remark 1.
The continuity assumption
on is employed in existing studies. But then, since , we have
This is a significant achievement. All results, which are obtained earlier, can be presented in terms of λ, since . This is a more specific location about . This improves the convergence radii; tightens the upper error and produces a better knowledge about . To demonstrate this, let us take the example for . Then, we have
and using Rheinboldt or Traub [14,15] (for ), we get , previous studies by Argyros [5] (for ), and with this study , so
3. Comparison of Attraction Basins
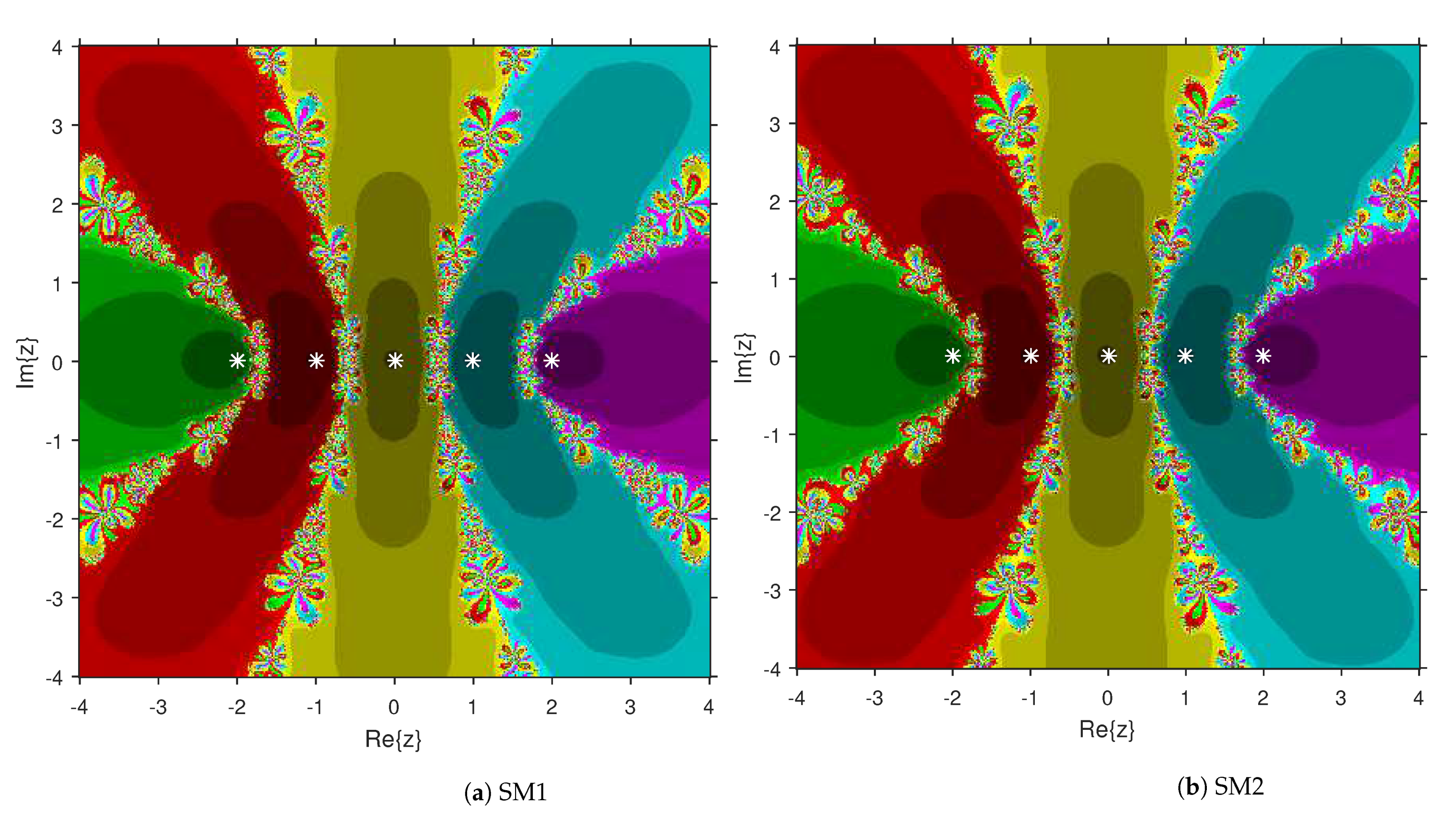
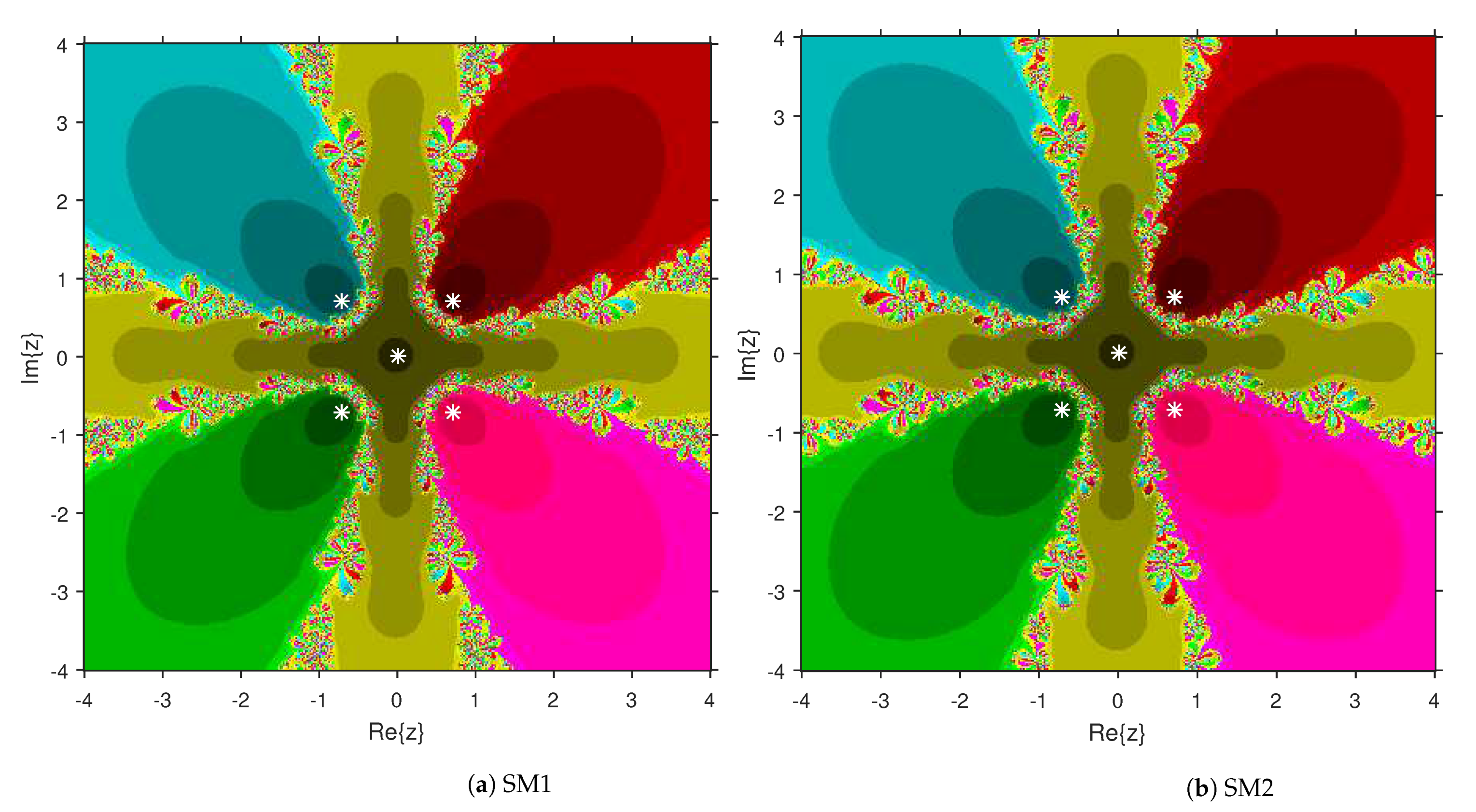
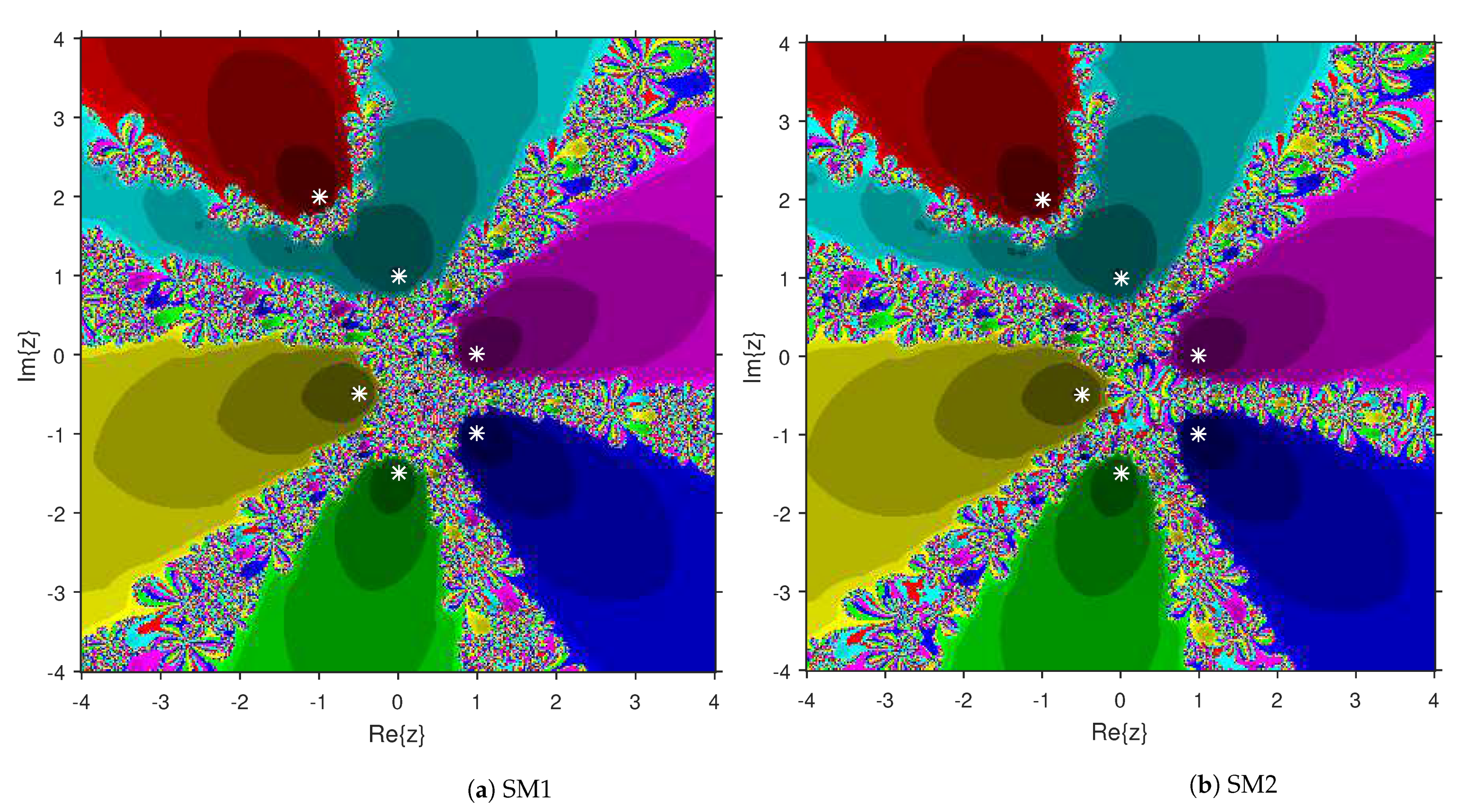
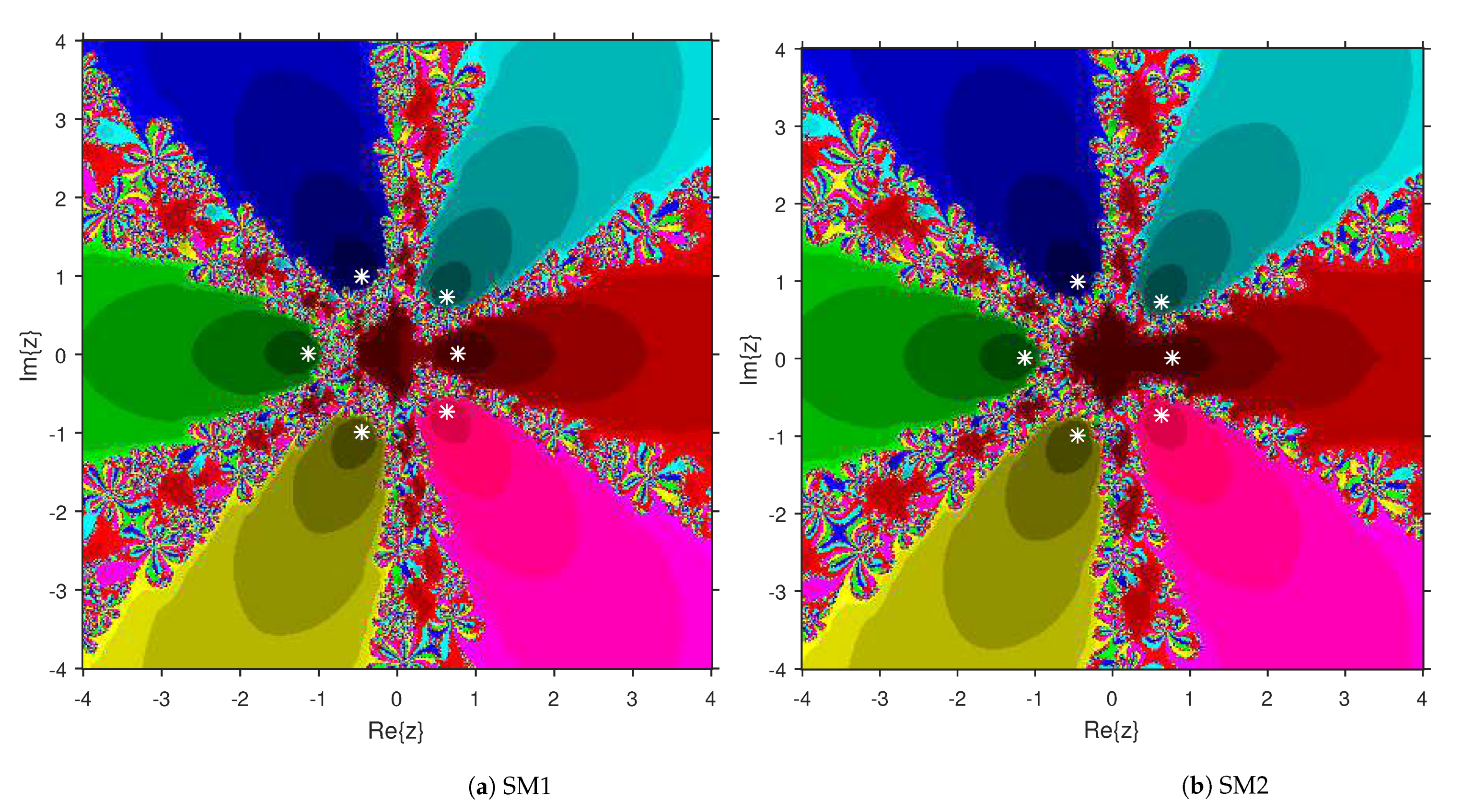
Comparison of the dynamical qualities of SM1 and SM2 are provided in this section by employing the tool attraction basin. Suppose is the notation for a second or higher degree complex polynomial. Then, the set represents the attraction basin corresponding to a zero of , where is formed by an iterative algorithm with a starting choice . Let us select a region × on with a grid of points. To prepare attraction basins, we apply SM1 and SM2 on variety of complex polynomials by selecting every point as a stater. The point remains in the basin of a zero of a considered polynomial if . Then, we display with a fixed color corresponding to . As per the number of iterations, we employ the light to dark colors to each . Black color is the sign of non-convergence zones. The terminating condition of the iteration is with the maximum limit of 300 iterations. We used MATLAB 2019a to design the fractal pictures.
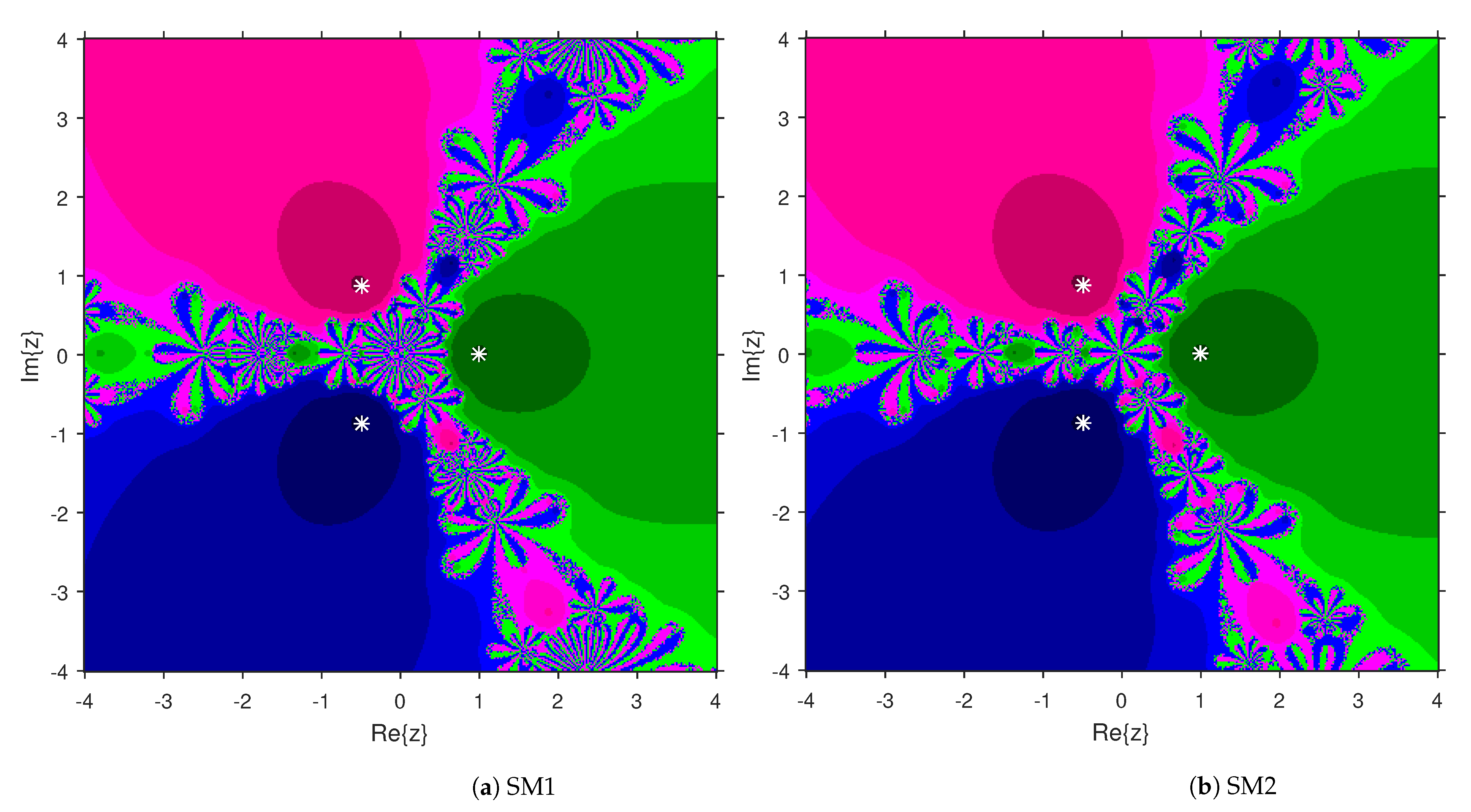
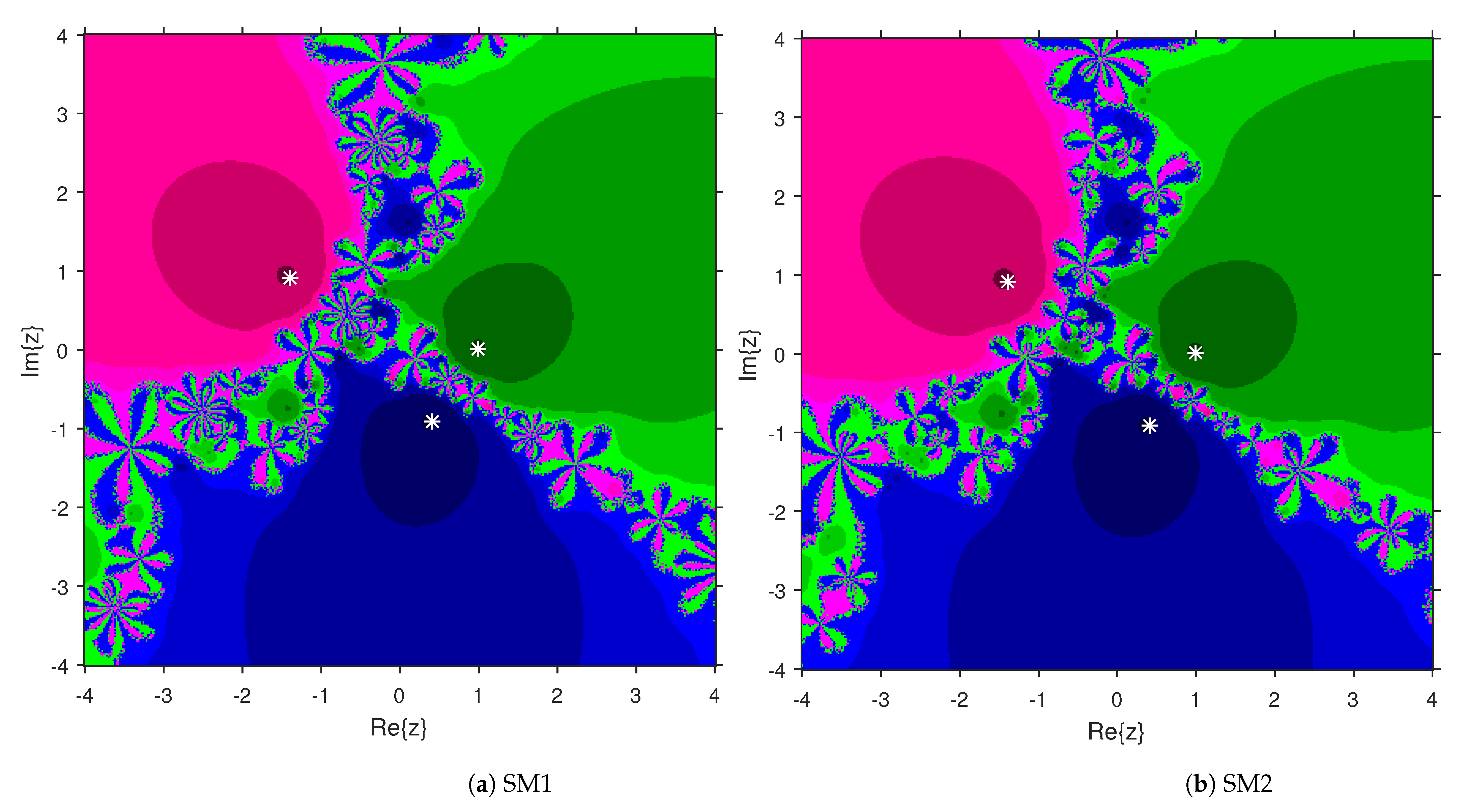
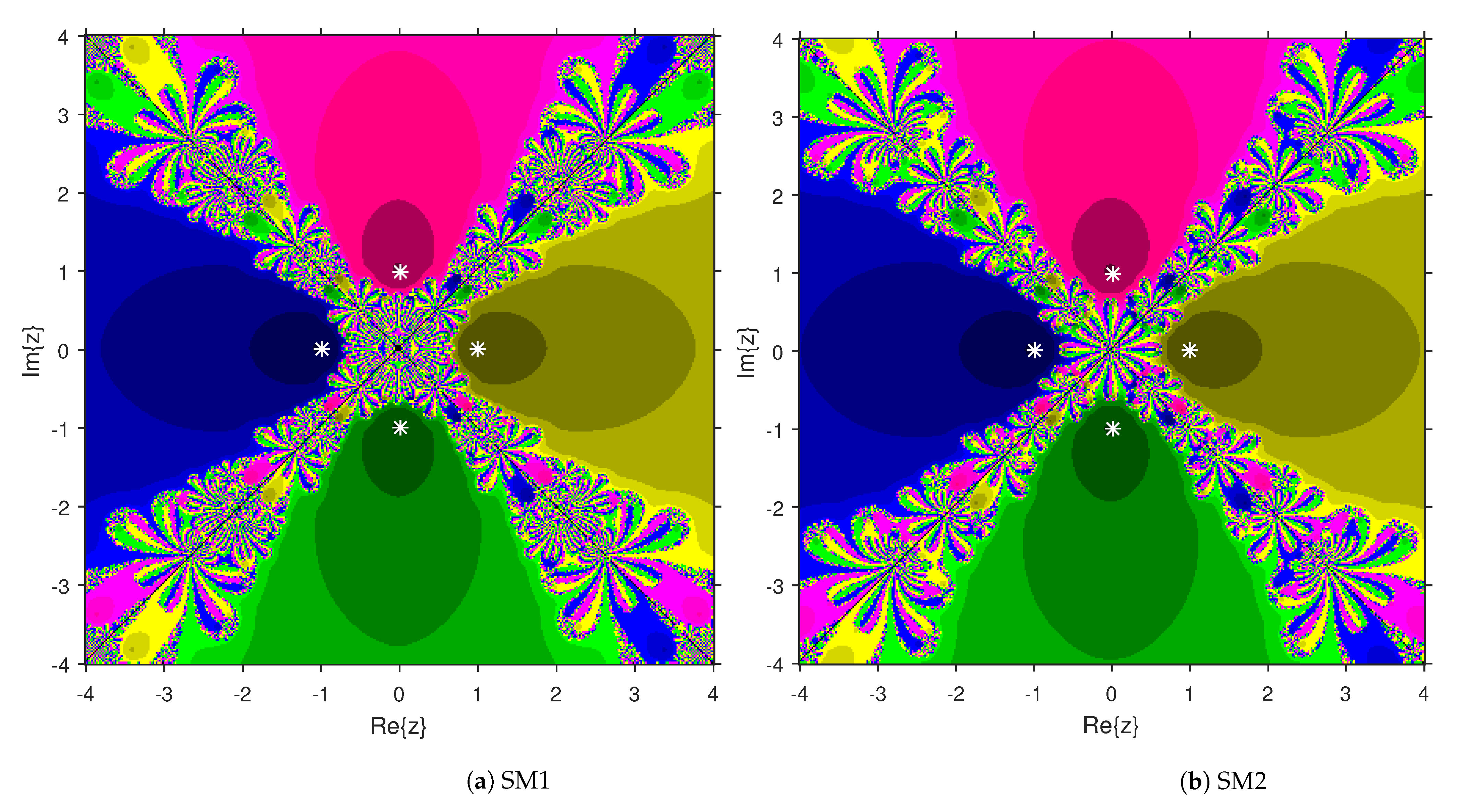
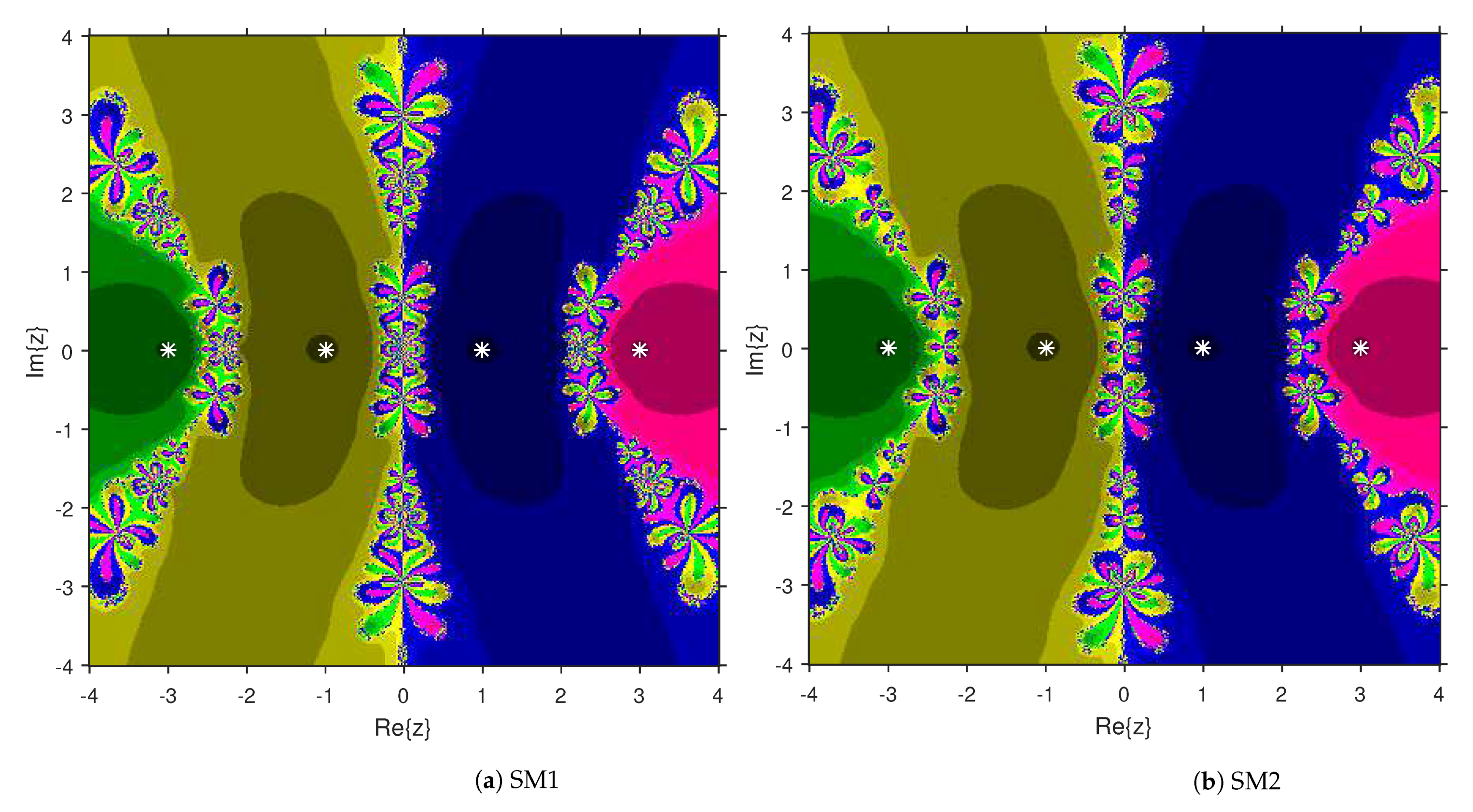
This numerical experiment begins with polynomials and of degree two. These polynomials are used to compare the attraction basins for SM1 and SM2. The results of comparison are displayed in Figure 1 and Figure 2. In Figure 1, green and pink areas indicate the attraction basins corresponding to the zeros and 1, respectively, of . The basins of the solutions and of are shown in Figure 2 by applying pink and green colors, respectively. Figure 3 and Figure 4 offer the attraction basins for SM1 and SM2 associated to the zeros of and . In Figure 3, the basins of the solutions , 1 and of are painted in blue, green and pink, respectively. The basins for SM1 and SM2 associated to the zeros 1, and of are given in Figure 4 by means of green, pink and blue regions, respectively. Next, we use polynomials and of degree four to compare the attraction basins for SM1 and SM2. Figure 5 provides the comparison of basins for these algorithms associated to the solutions 1, , i and of , which are denoted in yellow, green, pink and blue regions. The basins for SM1 and SM2 corresponding to the zeros , 3, and 1 of are demonstrated in Figure 6 using yellow, pink, green and blue colors, respectively. Moreover, we select polynomials and of degree five to design and compare the attraction basins for SM1 and SM2. Figure 7 gives the basins of zeros 0, 2, , and 1 of in yellow, magenta, red, green and cyan colors, respectively. In Figure 8, green, cyan, red, pink and yellow regions illustrate the attraction basins of the solutions , , , and 0, respectively, of . Lastly, sixth degree complex polynomials and are considered. In Figure 9, the attraction basins for SM1 and SM2 corresponding to the zeros , , , 1, i and of are given in blue, yellow, green, magenta, cyan and red colors, respectively. In Figure 10, green, pink, red, yellow, cyan and blue colors are applied to illustrate the basins related to the solutions , , , , and of , respectively. In these Figure 1, Figure 2, Figure 3, Figure 4, Figure 5, Figure 6, Figure 7, Figure 8, Figure 9 and Figure 10, the roots of the considered polynomials are displayed using white *.
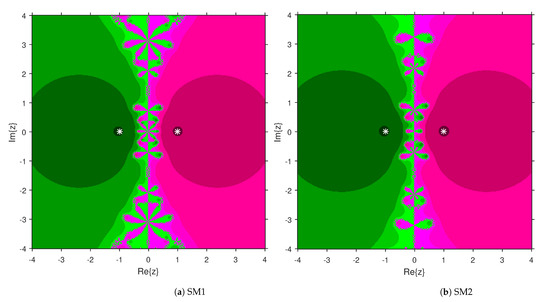
Figure 1.
Attraction basins comparison between SM1 and SM2 related to .
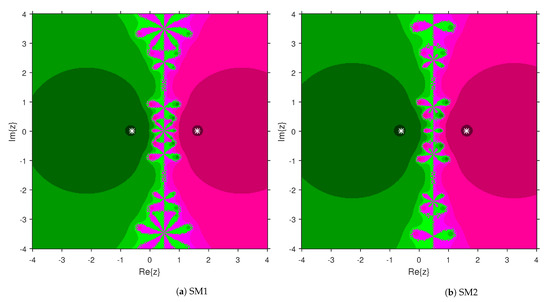
Figure 2.
Attraction basins comparison between SM1 and SM2 corresponding to .
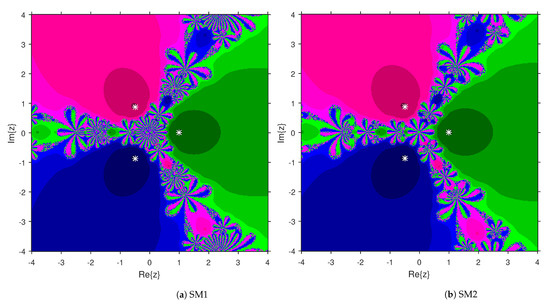
Figure 3.
Attraction basins comparison between SM1 and SM2 related to .
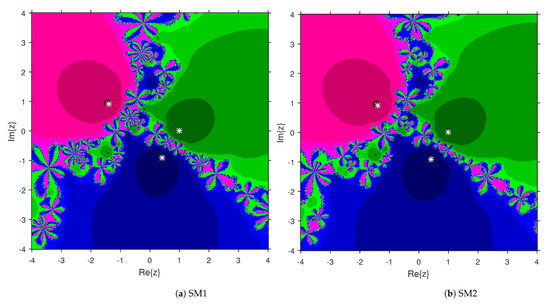
Figure 4.
Attraction basins comparison between SM1 and SM2 corresponding to .
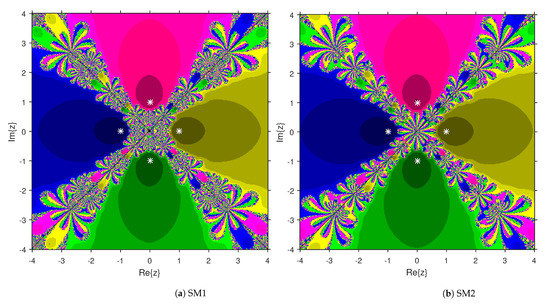
Figure 5.
Attraction basins comparison between SM1 and SM2 related to .
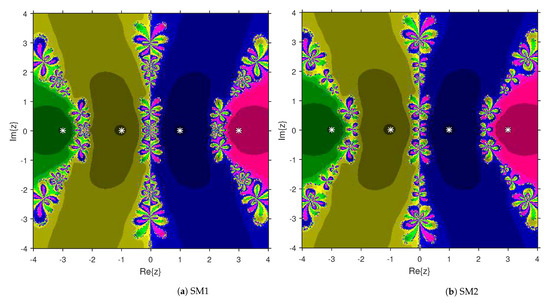
Figure 6.
Attraction basins comparison between SM1 and SM2 corresponding to .
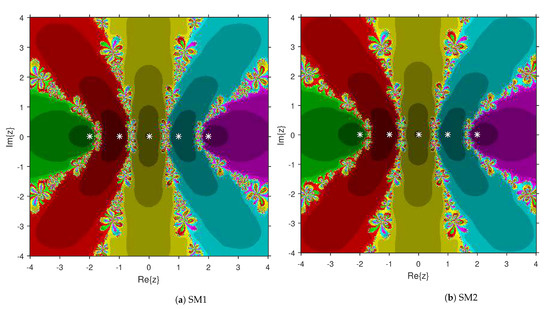
Figure 7.
Attraction basins comparison between SM1 and SM2 related to .
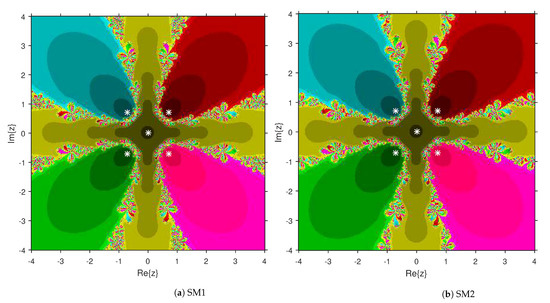
Figure 8.
Attraction basins comparison between SM1 and SM2 corresponding to .
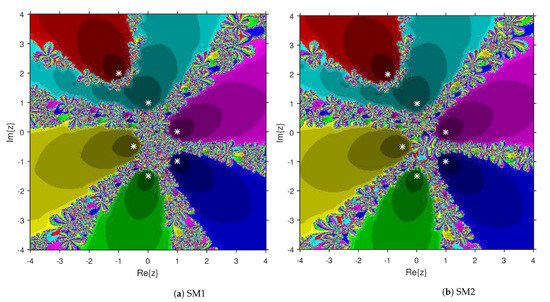
Figure 9.
Attraction basins comparison between SM1 and SM2 related to .
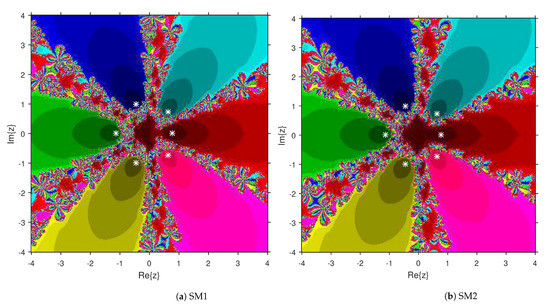
Figure 10.
Attraction basins comparison between SM1 and SM2 corresponding to .
4. Numerical Examples
We apply the proposed techniques to estimate the convergence radii for SM1 and SM2 when .
Example 1.

Let us consider and . Define on by
where . We have . In addition, , and . The values of ρ and are produced by the application of proposed theorems and summarized in Table 1.
Table 1.
Comparison of convergence radii for Example 1.
Example 2.
Let and . Consider on for as
We have . In addition, , and . Using the newly proposed theorems the values of ρ and are calculated and displayed in Table 2.
Table 2.
Comparison of convergence radii for Example 2.
Example 3.
Finally, the motivational problem described in the first section is addressed with , and . We apply the suggested theorems to compute ρ and . These values are shown in Table 3.
Table 3.
Comparison of convergence radii for Example 3.
It is worth noticing that if we stop at the first iterate in both algorithms (i.e., restrict ourselves to the first substep of Jarratt’s algorithm), then the radius is largest (see and ). Moreover, if we increase the convergence order to four (i.e., consider only the first two substeps of the algorithms), then the radii get smaller (see and ). Furthermore, if we increase the order to six (i.e., use all the substeps of these algorithms), then, we obtain the smallest radii (see and ). This is expected when the order increases. Concerning the corresponding error estimates we see clearly that fewer iterates are needed to reach as order increases. We solved Example 3 with using these algorithms and the results are presented in Table 4 and Table 5. In addition, we executed four iterations of these schemes ten times in MATLAB 2019a. Then, we obtained the average elapsed time and average CPU time (in seconds) for SM1 and SM2 and these values are presented in Table 6.
Table 4.
for algorithm SM1.
Table 5.
for algorithm SM2.
Table 6.
Elapsed time and CPU time comparison between SM1 and SM2.
5. Conclusions
Major problems appear when studying high convergence order algorithms for solving equations. One of them is that the order is shown assuming the existence of higher order derivatives that do not appear on the algorithms. In particular in the case of SM1 ans SM2 derivatives up to the order seven have been utilized. Hence (see also our example in the introduction) these derivative restrict the utilization of these algorithms. We also do not know how many iterates needed to arrive at a prearranged accuracy. Moreover, no uniqueness of the solution is known about a certain ball. This is not only the case for the algorithms we studied but all the high convergence algorithms whose convergence order is shown using Taylor series. That is why we addressed all these concerns in the more general situation of a Banach space, under generalized continuity conditions and using only the derivative appearing on these algorithms. Our technique can be applied to extend the utilization of other algorithms since it is so general. We also present the convergence ball and dynamical comparison between these schemes.
Author Contributions
Conceptualization, I.K.A. and D.S.; methodology, I.K.A., D.S., C.I.A., S.K.P., S.K.S. and M.I.A.; software, I.K.A., C.I.A. and D.S.; validation, I.K.A., D.S., C.I.A., S.K.P. and S.K.S.; formal analysis, I.K.A., D.S., C.I.A. and M.I.A.; investigation, I.K.A., D.S., C.I.A., S.K.P. and S.K.S.; resources, I.K.A., D.S., C.I.A., S.K.P. and S.K.S.; data curation, C.I.A., S.K.P., S.K.S. and M.I.A.; writing—original draft preparation, I.K.A., D.S., C.I.A., S.K.P., S.K.S. and M.I.A.; writing—review and editing, I.K.A. and D.S.; visualization, I.K.A., D.S., C.I.A., S.K.P., S.K.S. and M.I.A.; supervision, I.K.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
This study did not report any data.
Conflicts of Interest
The researchers have no conflict of interest.
References
- Abro, H.A.; Shaikh, M.M. A new time-efficient and convergent nonlinear solver. Appl. Math. Comput. 2019, 355, 516–536. [Google Scholar] [CrossRef]
- Cordero, A.; Torregrosa, J.R.; Vassileva, M.P. Design, Analysis, and Applications of Iterative Methods for Solving Nonlinear Systems. In Nonlinear Systems-Design, Analysis, Estimation and Control; IntechOpen: Rijeka, Croatia, 2016. [Google Scholar]
- Waseem, M.; Noor, M.A.; Noor, K.I. Efficient method for solving a system of nonlinear equations. Appl. Math. Comput. 2016, 275, 134–146. [Google Scholar] [CrossRef]
- Said Solaiman, O.; Hashim, I. Efficacy of optimal methods for nonlinear equations with chemical engineering applications. Math. Probl. Eng. 2019, 2019, 1728965. [Google Scholar] [CrossRef] [Green Version]
- Argyros, I.K.; Hilout, S. Computational Methods in Nonlinear Analysis; World Scientific Publishing House: New Jersey, NJ, USA, 2013. [Google Scholar]
- Argyros, I.K.; Magreñán, Á.A. Iterative Methods and Their Dynamics with Applications: A Contemporary Study; CRC Press: New York, NY, USA, 2017. [Google Scholar]
- Argyros, I.K.; Magreñán, Á.A. A Contemporary Study of Iterative Methods; Elsevier: New York, NY, USA, 2018. [Google Scholar]
- Cordero, A.; Hueso, J.L.; Martínez, E.; Torregrosa, J.R. A modified Newton-Jarratt’s composition. Numer. Algor. 2010, 55, 87–99. [Google Scholar] [CrossRef]
- Cordero, A.; García-Maimó, J.; Torregrosa, J.R.; Vassileva, M.P. Solving nonlinear problems by Ostrowski-Chun type parametric families. J. Math. Chem. 2015, 53, 430–449. [Google Scholar] [CrossRef] [Green Version]
- Grau-Sánchez, M.; Gutiérrez, J.M. Zero-finder methods derived from Obreshkovs techniques. Appl. Math. Comput. 2009, 215, 2992–3001. [Google Scholar]
- Hueso, J.L.; Martínez, E.; Teruel, C. Convergence, efficiency and dynamics of new fourth and sixth order families of iterative methods for nonlinear systems. J. Comput. Appl. Math. 2015, 275, 412–420. [Google Scholar] [CrossRef]
- Jarratt, P. Some fourth order multipoint iterative methods for solving equations. Math. Comp. 1966, 20, 434–437. [Google Scholar] [CrossRef]
- Petković, M.S.; Neta, B.; Petković, L.; Džunić, D. Multipoint Methods for Solving Nonlinear Equations; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Rheinboldt, W.C. An adaptive continuation process for solving systems of nonlinear equations. Math. Model. Numer. Methods 1978, 3, 129–142. [Google Scholar] [CrossRef]
- Traub, J.F. Iterative Methods for Solution of Equations; Prentice-Hall: Englewood Cliffs, NJ, USA, 1964. [Google Scholar]
- Wang, X.; Kou, J.; Li, Y. A variant of Jarratt method with sixth-order convergence. Appl. Math. Comput. 2008, 204, 14–19. [Google Scholar] [CrossRef]
- Sharma, J.R.; Guna, R.K.; Sharma, R. An efficient fourth order weighted-Newton method for systems of nonlinear equations. Numer. Algor. 2013, 62, 307–323. [Google Scholar] [CrossRef]
- Sharma, J.R.; Arora, H. Efficient Jarratt-like methods for solving systems of nonlinear equations. Calcolo 2014, 51, 193–210. [Google Scholar] [CrossRef]
- Sharma, J.R.; Arora, H. Improved Newton-like methods for solving systems of nonlinear equations. SeMA J. 2016, 74, 1–7. [Google Scholar] [CrossRef]
- Argyros, I.K.; George, S. Local convergence of Jarratt-type methods with less computation of inversion under weak conditions. Math. Model. Anal. 2017, 22, 228–236. [Google Scholar] [CrossRef]
- Argyros, I.K.; Sharma, D.; Argyros, C.I.; Parhi, S.K.; Sunanda, S.K. A Family of Fifth and Sixth Convergence Order Methods for Nonlinear Models. Symmetry 2021, 13, 715. [Google Scholar] [CrossRef]
- Kou, J.; Li, Y. An improvement of the Jarratt method. Appl. Math. Comput. 2007, 189, 1816–1821. [Google Scholar] [CrossRef]
- Magreñán, Á.A. Different anomalies in a Jarratt family of iterative root-finding methods. Appl. Math. Comput. 2014, 233, 29–38. [Google Scholar]
- Sharma, D.; Parhi, S.K.; Sunanda, S.K. Extending the convergence domain of deformed Halley method under ω condition in Banach spaces. Bol. Soc. Mat. Mex. 2021, 27, 32. [Google Scholar] [CrossRef]
- Soleymani, F.; Lotfi, T.; Bakhtiari, P. A multi-step class of iterative methods for nonlinear systems. Optim. Lett. 2014, 8, 1001–1015. [Google Scholar] [CrossRef]
- Chun, C.; Neta, B. Developing high order methods for the solution of systems of nonlinear equations. Appl. Math. Comput. 2019, 342, 178–190. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).