
Multi-Objective Task Scheduling Optimization in Spatial Crowdsourcing


Abstract
1. Introduction
2. Related Work
2.1. Task Matching in SC
2.2. Task Scheduling Problem in SC
2.3. The Binary-Objective Optimization Problem in SC
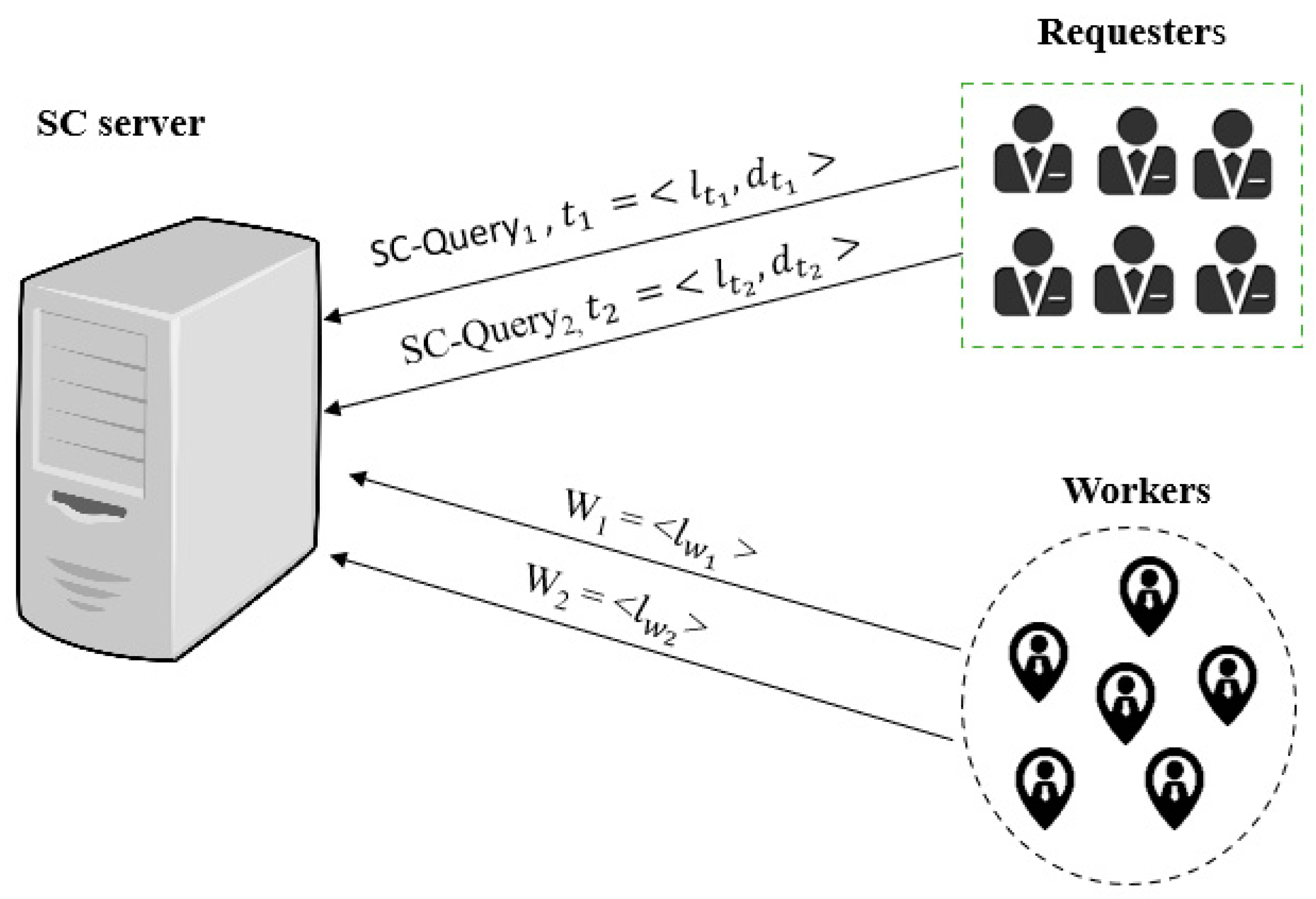
3. The MOTSO Model in SC
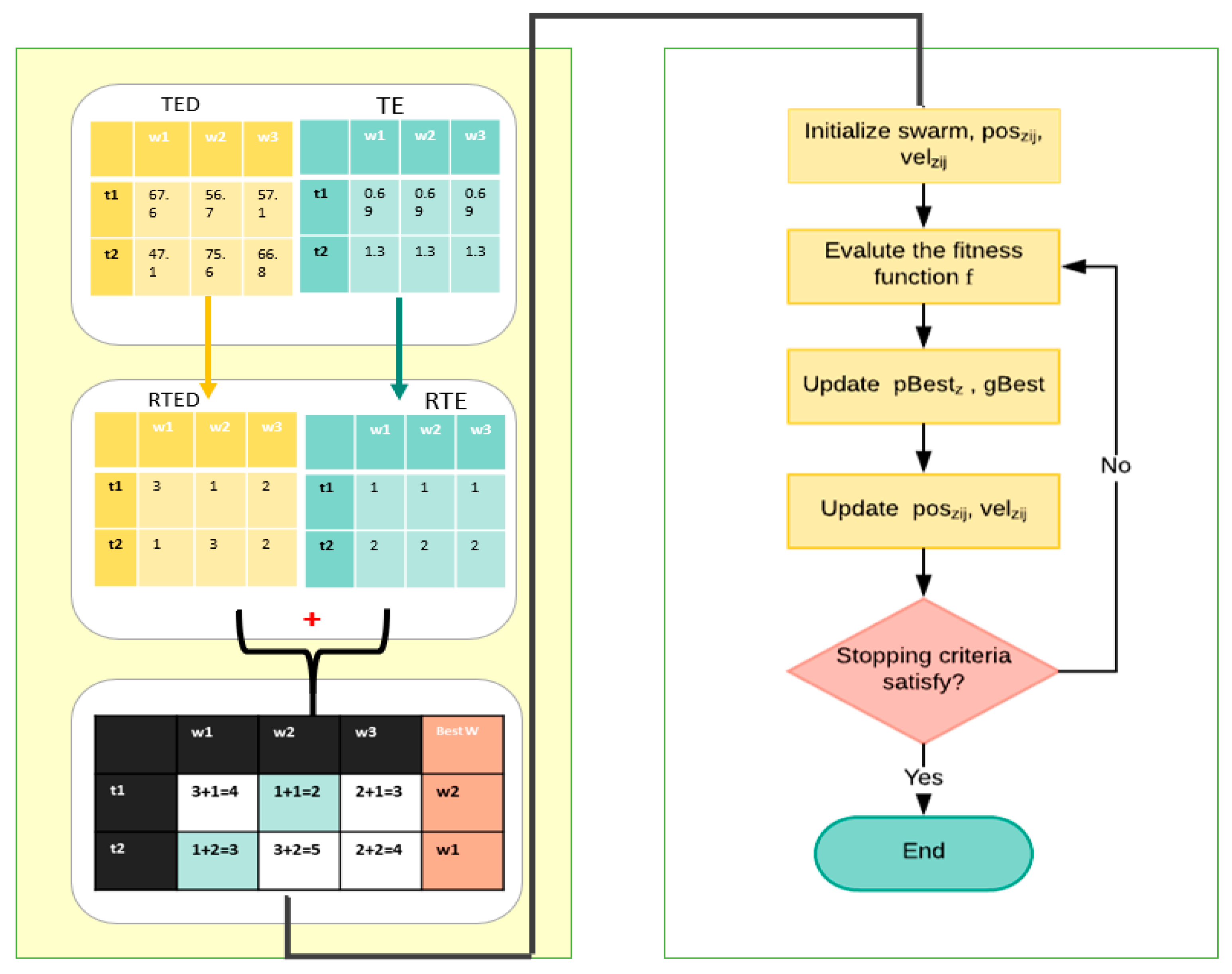
3.1. The Ranking Strategy Algorithm
| Algorithm 1. Pseudo code for algorithm pre-computation. |
| // Pre-computation |
| Input: set of tasks T and set of workers W |
| Output: |
| Initialize TE, TC, TED, RTED, RTE, Ranked with size [|T|][|W|] |
| Foreach task do |
| Foreach worker do |
| = computeTC(t,w) // compute travel duration using (1). |
| = computeTED (t,w) // compute task execution duration using (2). |
| = computeTE(t,w) // compute task entropy using (3). |
| End Foreach |
| End Foreach |
| RTED = Rank(TED); // sort ascending and rank each worker for each task. |
| RTE = Rank(TE); // sort ascending and rank each task for each worker |
| Foreach task do |
| Foreach worker do |
| = + |
| End Foreach |
| End Foreach |
| = Rank () //sort ascending and rank |
| Return |
3.1.1. Task Execution Duration (TED) and Ranked Task Execution Duration (RTED)
3.1.2. Task Entropy (TE) and Ranked Task Entropy (RTE)
3.1.3. The Ranked Tables
3.2. Multi-Objective Particle Swarm Optimization
4. Performance Evaluation
- N is the inertia weight;
- P is population number;
- I is iteration number;
- D is duration max;
- C1 and C2 are acceleration coefficients;
- r1 and r2 are random numbers;
- S is the speed of workers;
- No.w is the number of workers;
- No.t is the number of tasks.
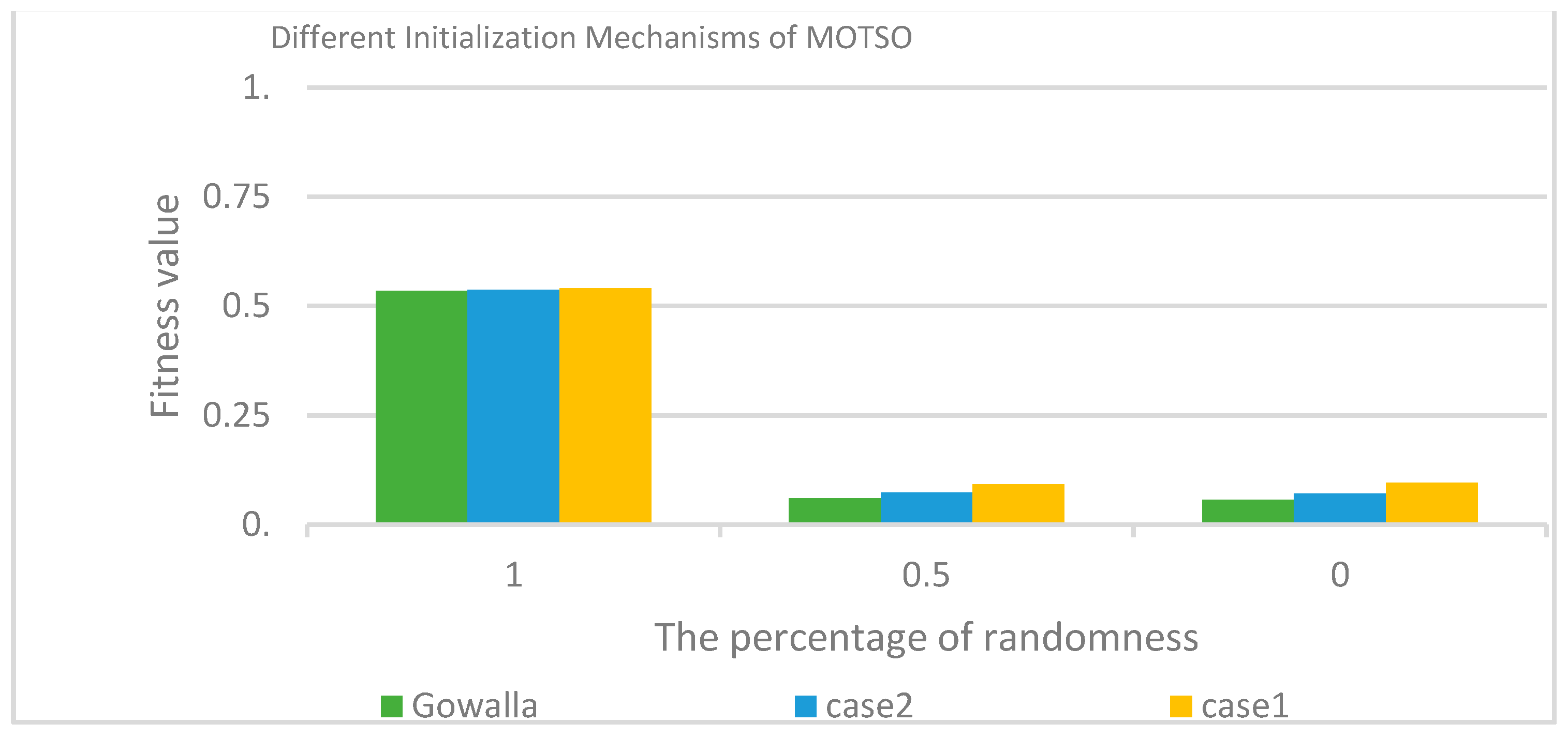
4.1. The Performance of the Ranking Strategy Algorithm
- Initializing the position of a particle randomly (the percentage of randomness is 100%);
- Initializing the position of a hybrid particle, both randomly and from the ranked table (the percentage of randomness is 50%);
- Initializing the positions of all particles from the ranked table (the percentage of randomness is 0%).
- Initializing the positions of all particles randomly;
- Initializing the positions of all particles using the output of the ranking strategy stage.
4.2. Performance of the MOTSO Model
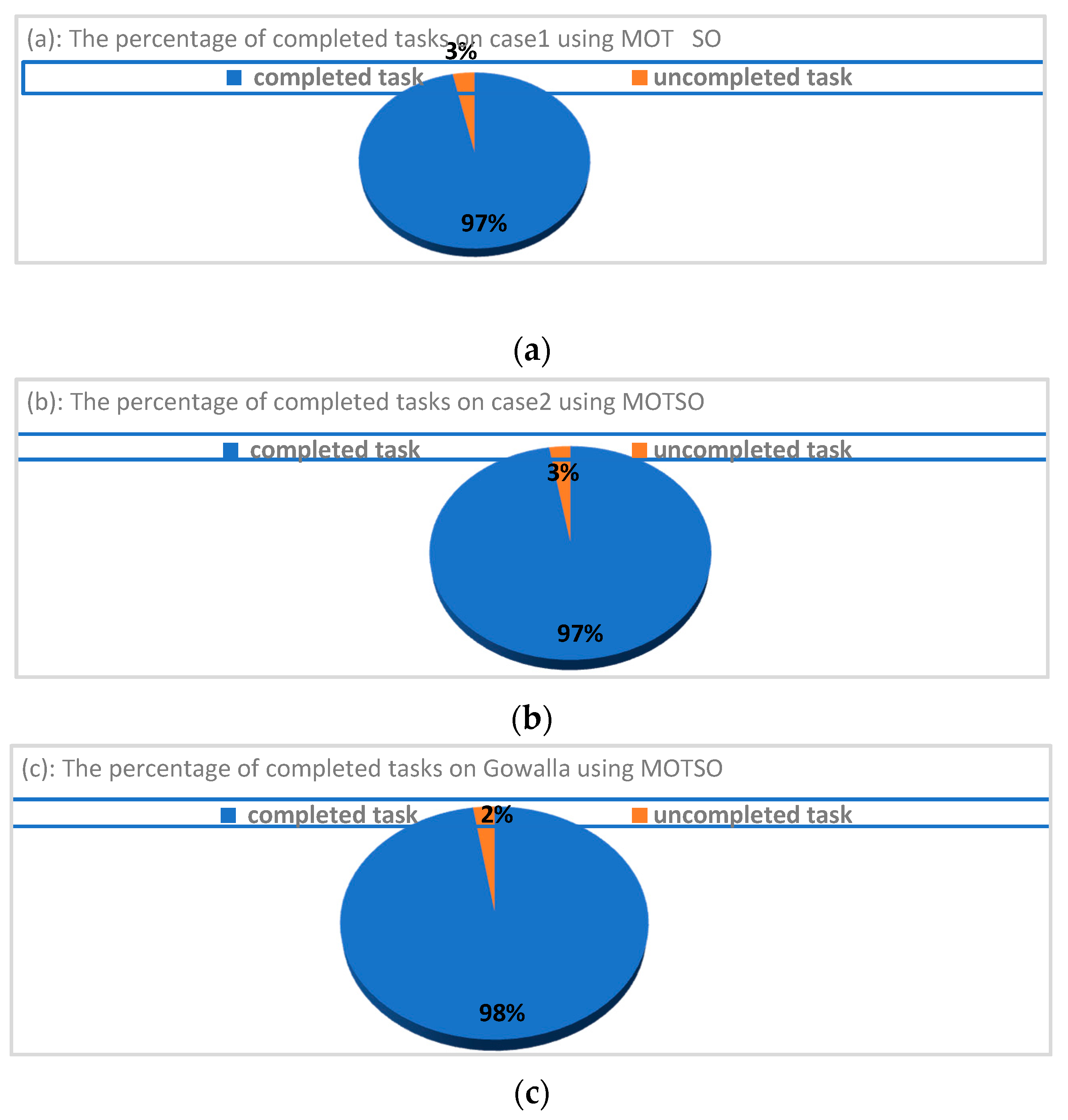
4.2.1. Maximizing the Number of Completed Tasks
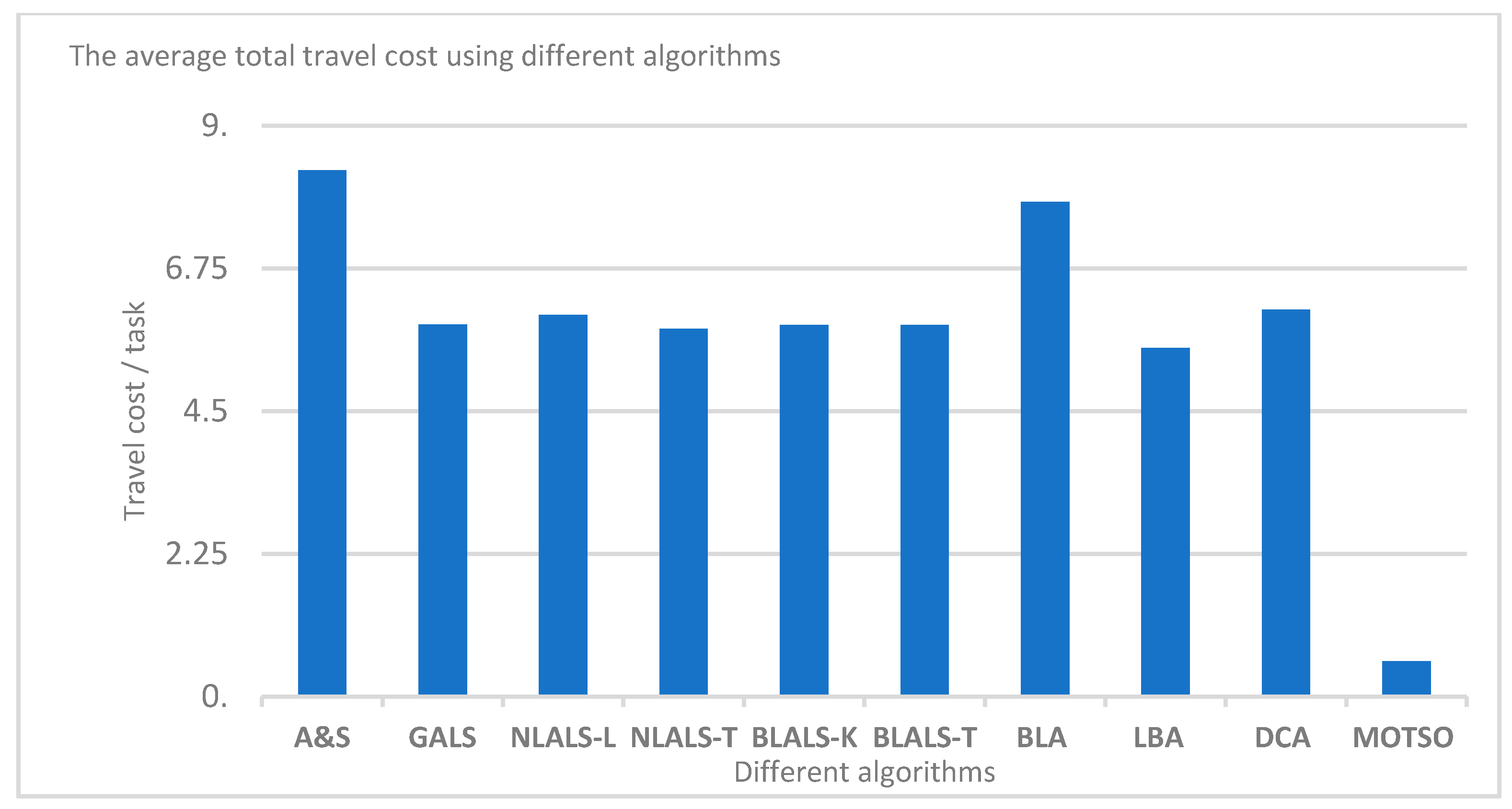
4.2.2. Minimizing the Total Travel Costs (TTCs)
4.2.3. Minimizing the Standard Deviation of the Workload Balance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Symbol | Name of Algorithm |
| A&S | Baseline algorithm |
| GALS | Global assignment and local scheduling algorithm |
| NLALA-L | Naïve local assignment local scheduling based on location |
| NLALS-T | Naïve local assignment local scheduling based on task-oriented partitioning |
| BLALS-K | Bisection-based local assignment and local scheduling based on K-means |
| BLALS-T | Bisection-based local assignment and local scheduling—task-oriented partitioning |
| BLA | Baseline algorithm |
| LBA | Load-balancing algorithm |
| DCA | Divide-and-conquer algorithm |
| MOTSO | Multi-objective task scheduling optimization |
References
- Wang, Y.; Jia, X.; Jin, Q.; Ma, J. Mobile crowdsourcing: Framework, challenges, and solutions. Concurr. Comput. Pr. Exp. 2016, 29, e3789. [Google Scholar] [CrossRef]
- Sun, D.; Gao, Y.; Yu, D. Efficient and Load Balancing Strategy for Task Scheduling in Spatial Crowdsourcing. In Web-Age Information Management; Song, S., Tong, Y., Eds.; Springer: Berlin, Germany, 2016; pp. 161–173. [Google Scholar]
- Tong, Y.; She, J.; Ding, B.; Wang, L.; Chen, L. Online mobile Micro-Task Allocation in spatial crowdsourcing. In Proceedings of the 2016 IEEE 32nd International Conference on Data Engineering (ICDE), Helsinki, Finland, 16–20 May 2016; pp. 49–60. [Google Scholar]
- Song, T.; Tong, Y.; Wang, L.; She, J.; Yao, B.; Chen, L.; Xu, K. Trichromatic Online Matching in Real-Time Spatial Crowdsourcing. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; pp. 1009–1020. [Google Scholar]
- Zhao, Y.; Han, Q. Spatial crowdsourcing: Current state and future directions. IEEE Commun. Mag. 2016, 54, 102–107. [Google Scholar] [CrossRef]
- Kazemi, L.; Shahabi, C. GeoCrowd: Enabling Query Answering with Spatial Crowdsourcing. In Proceedings of the 20th International Conference on Intelligent User Interfaces, Redondo Beach, CA, USA, 6–9 November 2012; pp. 189–198. [Google Scholar]
- Chen, L.; Shahabi, C. Spatial Crowdsourcing: Challenges and Opportunities. IEEE Data Eng. Bull. 2016, 39, 14–25. [Google Scholar]
- Cheng, P.; Lian, X.; Chen, L.; Han, J.; Zhao, J. Task Assignment on Multi-Skill Oriented Spatial Crowdsourcing. IEEE Trans. Knowl. Data Eng. 2016, 28, 2201–2215. [Google Scholar] [CrossRef]
- Kazemi, L.; Shahabi, C.; Chen, L. GeoTruCrowd: Trustworthy Query Answering with Spatial Crowdsourcing. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013; pp. 314–323. [Google Scholar]
- Deng, D.; Shahabi, C.; Zhu, L. Task matching and scheduling for multiple workers in spatial crowdsourcing. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, DC, USA, 3–6 November 2015; p. 21. [Google Scholar]
- Deng, D.; Shahabi, C.; Demiryurek, U. Maximizing the number of worker’s self-selected tasks in spatial crowdsourcing. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013; pp. 324–333. [Google Scholar]
- Tran, L.; To, H.; Fan, L.; Shahabi, C. A Real-Time Framework for Task Assignment in Hyperlocal Spatial Crowdsourcing. ACM Trans. Intell. Syst. Technol. 2018, 9, 1–26. [Google Scholar] [CrossRef]
- Tsai, J.-T.; Fang, J.-C.; Chou, J.-H. Optimized task scheduling and resource allocation on cloud computing environment using improved differential evolution algorithm. Comput. Oper. Res. 2013, 40, 3045–3055. [Google Scholar] [CrossRef]
- Zhang, G.; Zuo, X. Deadline Constrained Task Scheduling Based on Standard-PSO in a Hybrid Cloud. In Advances in Swarm Intelligence; Tan, Y., Shi, Y., Mo, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7928, pp. 200–209. [Google Scholar]
- Jana, B.; Chakraborty, M.; Mandal, T. A Task Scheduling Technique Based on Particle Swarm Optimization Algorithm in Cloud Environment. In Soft Computing: Theories and Applications; Ray, K., Sharma, T.K., Rawat, S., Saini, R.K., Bandyopadhyay, A., Eds.; Springer: Singapore, 2019; Volume 742, pp. 525–536. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar] [CrossRef]
- Wang, D.; Tan, D.; Liu, L. Particle swarm optimization algorithm: An overview. Soft Comput. 2018, 22, 387–408. [Google Scholar] [CrossRef]
- Coello, C.C.; Lechuga, M. MOPSO: A proposal for multiple objective particle swarm optimization. In Proceedings of the 2002 Congress on Evolutionary Computation, 2002. CEC ’02, Honolulu, HI, USA, 12–17 May 2003; Volume 2, pp. 1051–1056. [Google Scholar]
- Alabbadi, A.A.; Abulkhair, M.F. Task-Scheduling Based on Multi-Objective Particle Swarm Optimization in Spatial Crowdsourcing. J. King Abdulaziz Univ. Comput. Inf. Technol. Sci. 2019, 8, 45–57. [Google Scholar] [CrossRef]
- Chen, Z.; Fu, R.; Zhao, Z.; Liu, Z.; Xia, L.; Chen, L.; Cheng, P.; Cao, C.C.; Tong, Y.; Zhang, C.J. gMission: A General Spatial Crowdsourcing Platform. Proc. VLDB Endow. 2014, 7, 1629–1632. [Google Scholar] [CrossRef]
- Uber. Available online: https://www.uber.com// (accessed on 22 November 2018).
- Google Maps. Available online: https://www.google.com/maps (accessed on 22 November 2018).
- Free Driving Directions, Traffic Reports & GPS Navigation App by Waze. Available online: https://www.waze.com/ (accessed on 22 November 2018).
- Restaurants, Dentists, Bars, Beauty Salons, Doctors—Yelp. Available online: https://www.yelp.com/ (accessed on 22 November 2018).
- TaskRabbit Connects You to Safe and Reliable Help in Your Neighborhood. Available online: https://www.taskrabbit.com/ (accessed on 22 November 2018).
- Gigwalk: We’ve Got Your Brand’s Back—Gigwalk. Available online: http://www.gigwalk.com/ (accessed on 22 November 2018).
- To, H. Task Assignment in Spatial Crowdsourcing: Challenges and Approaches. In Proceedings of the 3rd ACM SIGSPATIAL PhD Symposium, Burlingame, CA, USA, 31 October 2016; Volume 1, pp. 1–4. [Google Scholar]
- Cheng, P.; Jian, X.; Chen, L. Task Assignment on Spatial Crowdsourcing (Technical Report). arXiv 2016, arXiv:1605.09675. [Google Scholar]
- Gummidi, S.R.B.; Xie, X.; Pedersen, T.B. A Survey of Spatial Crowdsourcing. ACM Trans. Database Syst. 2019, 44, 1–46. [Google Scholar] [CrossRef]
- Tong, Y.; Zhou, Z.; Zeng, Y.; Chen, L.; Shahabi, C. Spatial crowdsourcing: A survey. VLDB J. 2019, 29, 217–250. [Google Scholar] [CrossRef]
- To, H.; Shahabi, C.; Kazemi, L. A Server-Assigned Spatial Crowdsourcing Framework. ACM Trans. Spat. Algorithms Syst. 2015, 1, 1–28. [Google Scholar] [CrossRef]
- To, H.; Fan, L.; Tran, L.; Shahabi, C. Real-time task assignment in hyperlocal spatial crowdsourcing under budget constraints. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communications (PerCom), Sydney, NSW, Australia, 14–19 March 2016; pp. 1–8. [Google Scholar]
- Alfarrarjeh, A.; Emrich, T.; Shahabi, C. Scalable Spatial Crowdsourcing: A Study of Distributed Algorithms. In Proceedings of the 2015 16th IEEE International Conference on Mobile Data Management, Pittsburgh, PA, USA, 15–18 June 2015; Volume 1, pp. 134–144. [Google Scholar]
- Hassan, U.U.; Curry, E. Efficient task assignment for spatial crowdsourcing: A combinatorial fractional optimization approach with semi-bandit learning. Expert Syst. Appl. 2016, 58, 36–56. [Google Scholar] [CrossRef]
- Wang, L.; Yu, Z.; Han, Q.; Guo, B.; Xiong, H. Multi-Objective Optimization Based Allocation of Heterogeneous Spatial Crowdsourcing Tasks. IEEE Trans. Mob. Comput. 2017, 17, 1637–1650. [Google Scholar] [CrossRef]
- SNAP: Network Datasets: Gowalla. Available online: http://snap.stanford.edu/data/loc-gowalla.html (accessed on 17 January 2017).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Task Assignment Problem | Optimization | ||
|---|---|---|---|---|
| Matching | Scheduling | Single Objective | Binary Objective | |
| [6] | √ | √ | ||
| [9] | √ | √ | ||
| [31] | √ | √ | ||
| [8] | √ | √ | ||
| [3] | √ | √ | ||
| [12] | √ | √ | ||
| [4] | √ | √ | ||
| [32] | √ | √ | ||
| [33] | √ | √ | ||
| [11] | √ | √ | ||
| [7] | √ | √ | ||
| [10] | √ | √ | √ | |
| [2] | √ | √ | ||
| [34] | √ | √ | ||
| [35] | √ | √ | ||
| w1 | w2 | w3 | w4 | w5 | |
|---|---|---|---|---|---|
| t1 | 137.5286391016494 | 140.77934794265565 | 140.83953070394318 | 132.77599556103092 | 156.88627234146358 |
| t2 | 47.12959736369906 | 85.88725867729572 | 75.65173447900676 | 77.63439324242962 | 66.8175097791553 |
| t3 | 92.55306850854014 | 130.09070678927753 | 92.66485742716874 | 101.97479734391655 | 88.3209190565524 |
| w1 | w2 | w3 | w4 | w5 | |
|---|---|---|---|---|---|
| t1 | 2 | 3 | 4 | 1 | 5 |
| t2 | 1 | 5 | 3 | 4 | 2 |
| t3 | 2 | 5 | 3 | 4 | 1 |
| t4 | 1 | 2 | 3 | 5 | 4 |
| w1 | w2 | w3 | w4 | w5 | |
|---|---|---|---|---|---|
| t1 | 0.6931471805599453 | 0.6931471805599453 | 0.6931471805599453 | 0.6931471805599453 | 0.6931471805599453 |
| t2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| t3 | 1.386943611198906 | 1.386943611198906 | 1.386943611198906 | 1.386943611198906 | 1.386943611198906 |
| t4 | 0.6931471805599453 | 0.6931471805599453 | 0.6931471805599453 | 0.6931471805599453 | 0.6931471805599453 |
| w1 | w2 | w3 | w4 | w5 | |
|---|---|---|---|---|---|
| t1 | 2 | 2 | 2 | 2 | 2 |
| t2 | 1 | 1 | 1 | 1 | 1 |
| t3 | 4 | 4 | 4 | 4 | 4 |
| t4 | 3 | 3 | 3 | 3 | 3 |
| w1 | w2 | w3 | w4 | w5 | The Optimal Worker | |
|---|---|---|---|---|---|---|
| t1 | 2 + 2 = 4 | 3 + 2 = 5 | 4 + 2 = 6 | 1 + 2 = 3 | 5 + 2 = 7 | w4 |
| t2 | 1 + 1 = 2 | 5 + 1 = 6 | 3 + 1 = 4 | 4 + 1 = 5 | 2 + 1 = 3 | w1 |
| t3 | 2 + 4 = 6 | 5 + 4 = 9 | 3 + 4 = 7 | 4 + 4 = 8 | 1 + 4 = 5 | w5 |
| t4 | 1 + 3 = 4 | 2 + 3 = 5 | 3 + 3 = 6 | 5 + 3 = 8 | 4 + 3 = 7 | w1 |
| Parameter | Parameter Value | |
|---|---|---|
| MOPSO configuration | P | 50 |
| I | 80 | |
| N | [0,1] | |
| C1, C2 | 2.00, 2.00 | |
| r1, r2 | [0,1] | |
| SC configuration | No.w | Case1 = 600 Case2 = 1200 Gowalla = 2400 |
| No.t | Case1 = 600 Case2 = 1200 Gowalla = 2400 | |
| S | 80 | |
| D | 90 |
| Dataset | Fitness Function Value | ||
|---|---|---|---|
| 100% (Randomly) | 50% (Hybrid) | 0% (Ranked table) | |
| Case 1 | 0.540143 | 0.092286 | 0.096544 |
| Case 2 | 0.537479 | 0.073181 | 0.071633 |
| Gowalla | 0.535224 | 0.060976 | 0.056781 |
| Normalization Values for Each Objective in Terms of Minimization | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| NWLB | NTTC | ||||||||
| 100% | 50% | 0% | 100% | 50% | 0% | 100% | 50% | 0% | |
| Case 1 | 0.34853 | 0.026923 | 0.034188 | 0.039943 | 0.048828 | 0.051251 | 0.15167 | 0.016535 | 0.011105 |
| Case 2 | 0.35715 | 0.026961 | 0.027024 | 0.028998 | 0.034157 | 0.036681 | 0.151331 | 0.012063 | 0.007929 |
| Gowalla | 0.365401 | 0.026474 | 0.024522 | 0.020456 | 0.024455 | 0.026705 | 0.149367 | 0.010047 | 0.005554 |
| Dataset | Total Travel Cost Using MOTSO |
|---|---|
| TTCs | |
| Case 1 | 637.2025 |
| Case 2 | 917.3457 |
| Gowalla | 1292.929 |
| Using Gowalla | |
|---|---|
| Name of algorithm | ATC value |
| A&S | 8.30 |
| GALS | 5.87 |
| NLALA-L | 6.02 |
| NLALS-T | 5.80 |
| BLALS-K | 5.86 |
| BLALS-T | 5.86 |
| BLA | 7.8 |
| LBA | 5.5 |
| DCA | 6.1 |
| MOTSO (our model) | 0.5527457 |
| Dataset | Workload Balancing Using MOTSO |
|---|---|
| WLB | |
| Case 1 | 55.58566 |
| Case 2 | 56.42424 |
| Gowalla | 58.01609 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alabbadi, A.A.; Abulkhair, M.F. Multi-Objective Task Scheduling Optimization in Spatial Crowdsourcing. Algorithms 2021, 14, 77. https://doi.org/10.3390/a14030077
Alabbadi AA, Abulkhair MF. Multi-Objective Task Scheduling Optimization in Spatial Crowdsourcing. Algorithms. 2021; 14(3):77. https://doi.org/10.3390/a14030077
Chicago/Turabian StyleAlabbadi, Afra A., and Maysoon F. Abulkhair. 2021. "Multi-Objective Task Scheduling Optimization in Spatial Crowdsourcing" Algorithms 14, no. 3: 77. https://doi.org/10.3390/a14030077
APA StyleAlabbadi, A. A., & Abulkhair, M. F. (2021). Multi-Objective Task Scheduling Optimization in Spatial Crowdsourcing. Algorithms, 14(3), 77. https://doi.org/10.3390/a14030077