Abstract
In this work, we give provable sieving algorithms for the Shortest Vector Problem (SVP) and the Closest Vector Problem (CVP) on lattices in norm (). The running time we obtain is better than existing provable sieving algorithms. We give a new linear sieving procedure that works for all norm (). The main idea is to divide the space into hypercubes such that each vector can be mapped efficiently to a sub-region. We achieve a time complexity of , which is much less than the complexity of the previous best algorithm. We also introduce a mixed sieving procedure, where a point is mapped to a hypercube within a ball and then a quadratic sieve is performed within each hypercube. This improves the running time, especially in the norm, where we achieve a time complexity of , while the List Sieve Birthday algorithm has a running time of . We adopt our sieving techniques to approximation algorithms for SVP and CVP in norm () and show that our algorithm has a running time of , while previous algorithms have a time complexity of .
1. Introduction
A lattice is the set of all integer combinations of linearly independent vectors ,
We call n the rank of the lattice and d the dimension of the lattice. The matrix is called a basis of . A lattice is said to be full-rank if . In this work, we only consider full-rank lattices unless otherwise stated.
The two most important computational problems on lattices are the Shortest Vector Problem () and the Closest Vector Problem (). Given a basis for a lattice , the goal of is to compute the shortest non-zero vector in , while the goal of is to compute a lattice vector at a minimum distance to a given target vector . Typically, the length/distance is defined in terms of the norm, which is given by
These lattice problems have been mostly studied in the Euclidean norm (). Starting with the seminal work of [1], algorithms for solving these problems either exactly or approximately have been studied intensely. These algorithms have found applications in various fields, such as factoring polynomials over rationals [1], integer programming [2,3,4,5], cryptanalysis [6,7,8], checking the solvability by radicals [9], and solving low-density subset-sum problems [10]. More recently, many powerful cryptographic primitives have been constructed whose security is based on the worst-case hardness of these or related lattice problems [11,12,13,14,15,16,17,18,19].
1.1. Prior Work
The lattice algorithms that have been developed to solve and are either based on sieving techniques [20,21], enumeration methods [3,22], basis reduction [1,23], or Voronoi cell-based deterministic computation [4,24,25]. The fastest of these run in a time of , where n is the rank of the lattice and c is some constant. Since the aim of this paper is to improve time complexity of sieving algorithms, we mainly focus on these. For an overview of the other types of algorithms, interested readers can refer to the survey by Hanrot et al. [26].
1.1.1. Sieving Algorithms in the Euclidean Norm
The first algorithm to solve in the time exponential in the dimension of the lattice was given by Ajtai, Kumar, and Sivakumar [21] who devised a method based on “randomized sieving”, whereby exponentially many randomly generated lattice vectors are iteratively combined to create increasingly short vectors, eventually resulting in the shortest vector in the lattice. The time complexity of this algorithm was shown to be by Micciancio and Voulgaris [27]. This was later improved by Pujol and Stehle [28], who analyzed it with the birthday paradox and gave a time complexity of . In [27] the authors introduced List Sieve, which was modified in [28] (List Sieve Birthday) to give a time complexity of . The current fastest provable algorithm for exact SVP runs in a time of [20,29], and the fastest algorithm that gives a large constant approximation runs in a time of [30].
To make lattice sieving algorithms more practical for implementation, heuristic variants were introduced in [27,31]. Efforts have been made to decrease the asymptotic time complexity at the cost of using more space [32,33,34,35] and to study the trade-offs in reducing the space complexity [35,36,37,38]. Attempts have been made to make these algorithms competitive in high-performance computing environments [39,40,41,42,43]. The theoretically fastest heuristic algorithm that is conjectured to solve runs in a time of [33] (LDSieve).
The is considered to be a harder problem than since there is a simple dimension and approximation-factor preserving reduction from to [44]. Based on a technique due to Kannan [3], Ajtai, Kumar, and Sivakumar [45] gave a provable sieving based algorithm that gives a approximation of in time . Later, exact exponential time algorithms for CVP were discovered [24,46]. The current fastest algorithm for runs in a time of and is due to [46].
1.1.2. Algorithms in Other Norms
Blomer and Naewe [47] and then Arvind and Joglekar [48] generalized the AKS algorithm [21] to give exact provable algorithms for that run in a time of . Additionally, ref. [47] gave a approximation algorithm for for all norms that runs in a time of . For the special case when , Eisenbrand et al. [5] gave a algorithm for -approx CVP. Aggarwal and Mukhopadhyay [49] gave an algorithm for and approximate in the norm using a linear sieving technique that significantly improves the overall running time. In fact, for a large constant approximation factor, they achieved a running time of for . The authors have argued that it is not possible for any of the above-mentioned algorithms to achieve this running time in the norm.
1.1.3. Hardness Results
The first NP hardness result for in all norms and in the norm was given by Van Emde Boas [50]. Ajtai [51] proved that is NP-hard under randomized reductions. Micciancio [52] showed that is NP-hard to approximate within some constant approximation factor. Subsequently, it was shown that approximating in any norm and in norm up to a factor of is NP-hard [53,54]. This difficulty of the approximation factor has been improved to in [55], assuming the Projection Games Conjecture [56]. Furthermore, the difficulty of up to factor has been obtained assuming [57,58]. Recently, ref. [59] showed that for almost all , in the norm cannot be solved in of time under the strong exponential time hypothesis. A similar difficulty result has also been obtained for in the norm [60].
1.2. Our Results and Techniques
In this paper, we adopt the framework of [21,45] and give sieving algorithms for and in norm for . The primary difference between our sieving algorithm and the previous AKS-style algorithms such as those in [21,45,47,48] is in the sieving procedure—ours is a linear sieve, while theirs is a quadratic sieve. This results in an improvement in the overall running time.
Before describing our idea, we give an informal description of the sieving procedure of [21,45,47,48]. The algorithm starts by randomly generating a set S of lattice vectors with a length of at most . It then runs a sieving procedure a polynomial number of times. In the iteration, the algorithm starts with a list S of lattice vectors of a length of at most , for some parameter . The algorithm maintains and updates a list of “centers” C, which is initialized to be the empty set. Then, for each lattice vector in the list, the algorithm checks whether there is a center at a distance of at most from this vector. If there exists such a center, then the vector is replaced in the list by , and otherwise it is deleted from S and added to C. This results in lattice vectors which have a length of at most , where is the number of lattice vectors at the end of sieving iterations. We would like to mention here that this description hides many details and in particular, in order to show that this algorithm succeeds eventually in obtaining the shortest vector, we need to add a small perturbation to the lattice vectors to start with. The details of this can be found in Section 3.
A crucial step in this algorithm is to find a vector from the list of centers that is close to . This problem is called the nearest neighbor search (NNS) problem and has been well studied, especially in the context of heuristic algorithms for (see [33] and the references therein). A trivial bound on the running time for this is , but much effort has been dedicated to improving this bound under heuristic assumptions (see Section 1.1.1 for some references). Since they require heuristic assumptions, such improved algorithms for the NNS have not been used to improve the provable algorithms for .
One can also view such sieving procedures as a division of the “ambient” geometric space (consisting of all the vectors in the current list). In the iteration, the space of all vectors with a length of at most is divided into a number of sub-regions such that in each sub-region the vectors are within a distance of at most from a center. In the previous provable sieving algorithms such as those in [21,27,47,48] or even the heuristic ones, these sub-regions have been an ball of certain radius (if the algorithm is in norm) or some sections of it (spherical cap, etc.). Given a vector, one has to compare it with all the centers (and hence sub-regions formed so far) to determine in which of these sub-regions it belongs. If none is found, we make it a center and associate a new sub-region with it. Note that such a division of space depends on the order in which the vectors are processed.
The basic idea behind our sieving procedure (let us call it Linear Sieve) is similar to that used in [49] in the special case of the norm. In fact, our procedure is a generalization of this method for all norm (). We select these sub-regions as hypercubes and divide the ambient geometric space a priori (before we start processing the vectors in the current list) considering only the maximum length of a vector in the list. A diagrammatic representation of such a division of space in two dimensions has been given in Figure 1. It must be noted that in this figure (for ease of illustration), the radius of the small hypercube (square) is the same for , and balls (circles). However, in our algorithm, this radius depends on the norm. The advantage we obtain is that we can map a vector to a sub-region efficiently -in time; i.e., in a sense we obtain better “decodability” property. If the vector’s hypercube (sub-region) does not contain a center, we select this point as the center; otherwise, we subtract this vector from the center to obtain a shorter lattice vector. Thus, the time complexity of each sieving procedure is linear in the number of sampled vectors. Overall, we obtain an improved time complexity at the cost of increased space complexity compared to previous algorithms [26,47,48]. A more detailed explanation can be found in Section 3.1.
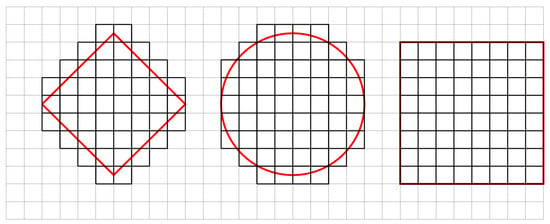
Figure 1.
Division of the area of a circle in , , and norm (respectively) into smaller squares.
Specifically, we obtain the following result.
Theorem 3 in Section 3.3
Let , and let . Given a full.rank lattice , there is a randomized algorithm for with a success probability of at least , space complexity of at most , and running time of at most , where and , where and .
A mixed sieving algorithm
In an attempt to gain as many advantages as possible, we introduce a mixed sieving procedure (let us call it Mixed Sieve). Here, we divide a hyperball into larger hypercubes so that we can map each point efficiently to a hypercube. Within a hypercube, we perform a quadratic sieving procedure such as AKS with the vectors in that region. This improves both time and space complexity, especially in the Euclidean norm.
Approximation algorithms for and
We have adopted our sieving techniques to approximation algorithms for and . The idea is quite similar to that described in [49] (where it was shown to work for only the norm). In Section 5.1, we have shown that our approximation algorithms are faster than those of [47,48], but again they require more space.
Remark 1.
It is quite straightforward to extend our algorithm to the Subspace Avoiding Problem () (or Generalized Shortest Vector Problem ) [47,48]: replace the quadratic sieve by any one of the faster sieves described in this paper. We thus obtain a similar improvement in running time. By Theorem 3.4 in [47], there are polynomial time reductions from other lattice problems such as the Successive Minima Problem () (given a lattice with rank n, the Successive Minima Problem () requires to find n linearly independent vectors such that .) and Shortest Independent Vector Problem () (given a rank n lattice the Shortest Independent Vector Problem () requires to find n linearly independent vectors such that . The definition of (and hence ) has been given in Section 2 (Definition ); c is the approximation factor) with approximation factor to with approximation factor . Thus, we can obtain a similar improvement in running time for both these problems. Since in this paper, we focus mainly on and , we do not delve into further details for these other problems.
Remark 2.
Our algorithm (and in that case any sieving algorithm) is quite different from deterministic algorithms such as those in [4,61]. They reduce the problem in any norm to a norm and compute an approximation of the shortest vector length (or distance of the closest lattice point to a target in case of ) using the Voronoi cell-based deterministic algorithm in [27]. Then, they enumerate all lattice points within a convex region to find the shortest one. Constructing ellipsoidal coverings, it has been shown that the lattice points within a convex body can be computed in a time proportional to the maximum number of lattice points that the body can contain in any translation of an ellipsoid. Note for norm that any smaller ball (where or ) can serve this purpose, and the bound on the number of translates comes from standard packing arguments. For these deterministic algorithms, the target would be to chose a shape so that the upper bound (packing bound) on the number of translates can be reduced. Thus, the authors chose small balls to cover a larger ball.
In contrast, in our sieving algorithm, we aimed to map each lattice point efficiently within a sub-region. Thus, we divided any arbitrary ball into smaller hypercubes. The result was an increase in space complexity, but due to the efficient mapping, we reduced the running time. To the best of our knowledge, this kind of sub-divisions has not been used before in any sieving algorithm. The focus of our paper is to develop randomized sieving algorithms. Thus, we will not delve further into the details of the above-mentioned deterministic algorithms. Clearly, these are different procedures.
1.3. Organization of the Paper
In Section 2, we give some preliminary definitions and results that are useful for this paper. In Section 3, we introduce the linear sieving technique, while in Section 4, we describe the mixed sieving technique. In Section 5, we discuss how to extend our sieving methods to approximation algorithms.
2. Preliminaries
2.1. Notations
We write to represent the logarithm to the base q, and simply log when the base is . We denote the natural logarithm by ln.
We use bold lowercase letters (e.g., ) for vectors and bold uppercase letters for matrices (e.g., ). We may drop the dimension in the superscript whenever it is clear from the context. Sometimes, we represent a matrix as a vector of column (vectors) (e.g., where each is an length vector). The co-ordinate of is denoted by .
Given a vector with , the representation size of with respect to is the maximum of n and the binary lengths of the numerators and denominators of the coefficients .
We denote the volume of a geometric body A by .
2.2. Norm and Ball
Definition 1.
The normof a vector is defined by
for and for .
Fact 1.
For for and
for .
Definition 2.
A ball is the set of all points within a fixed distance or radius (defined by a metric) from a fixed point or center. More precisely, we define the (closed) ball centered at with radius r as
The boundary of is the set
We may drop the first argument when the ball is centered at the origin and drop both arguments for a unit ball centered at the origin. Let
. We drop the first argument if the spherical shell or corona is centered at the origin.
Fact 2.
for all .
Fact 3.
. Specifically .
The algorithm of Dyer, Frieze, and Kannan [62] almost uniformly selects a point in any convex body in polynomial time if a membership oracle is given [63]. For the sake of simplicity, we ignore the implementation detail and assume that we are able to uniformly select a point in in polynomial time.
2.3. Lattice
Definition 3.
A lattice is a discrete additive subgroup of . Each lattice has a basis , where and
For algorithmic purposes, we can assume that . We call n the rank of and d the dimension. If , the lattice is said to be full-rank. Though our results can be generalized to arbitrary lattices, in the rest of the paper, we only consider full-rank lattices.
Definition 4.
For any lattice basis , we define the fundamental parallelepiped as
If , then , as can be easily seen by triangle inequality. For any , there exists a unique such that . This vector is denoted by and it can be computed in polynomial time given B and z.
Definition 5.
For , the ith successive minimum is defined as the smallest real number r such that contains i linearly independent vectors with a length of at most r:
Thus, the first successive minimum of a lattice is the length of the shortest non-zero vector in the lattice:
We consider the following lattice problems. In all the problems defined below, is some arbitrary approximation factor (usually specified as subscript), which can be a constant or a function of any parameter of the lattice (usually rank). For exact versions of the problems (i.e., ), we drop the subscript.
Definition 6
(Shortest Vector Problem ()). Given a lattice , find a vector such that for any other .
Definition 7
(Closest Vector Problem ()). Given a lattice with rank n and a target vector , find such that for all other .
Lemma 1
([49]). The LLL algorithm [1] can be used to solve in polynomial time.
The following result shows that in order to solve , it is sufficient to consider the case when . This is done by appropriately scaling the lattice.
Lemma 2
(Lemma 4.1 in [47]). For all norms, if there is an algorithm A that for all lattices with solves in time , then there is an algorithm that solves for all lattices in time .
Thus, henceforth, we assume .
2.4. Some Useful Definitions and Results
In this section, we give some results and definitions which are useful for our analysis later.
Definition 8.
Let P and Q are two point sets in . The Minkowski sum of P and Q, denoted as , is the point set .
Lemma 3.
Let and such that and . Let .
If and are the volumes of D and , respectively, then
- [64]
- [26] When , further optimization can be done such that we get.
- [49] When then .
Theorem 1
(Kabatiansky and Levenshtein [65]). Let . If there exists such that for any , we have , then with .
Here, is the angle between the vectors and .
Below, we give some bounds which work for all norms. We especially mention the bounds obtained for the norm where some optimization has been performed using Theorem 1.
Lemma 4.
- [47] Let . If is a set of points in such that the distance between two points is at least , then .
- [26,27] When , we can have where .
Since the distance between two lattice vectors is at most , we obtain the following corollary.
Corollary 1.
Let be a lattice and R be a real number greater than the length of the shortest vector in the lattice.
- [64] where .
- [26,28] where .
3. A Faster Provable Sieving Algorithm in Norm
In this section, we present an algorithm for that uses the framework of the AKS algorithm [21] but uses a different sieving procedure that yields a faster running time. Using Lemma 1, we can obtain an estimate of such that . Thus, if we try polynomially many different values of , for , then for one of them, we have . For the rest of this section, we assume that we know an estimated of the length of the shortest vector in , which is correct up to a factor .
The AKS algorithm (or its norm generalization in [47,48]) initially uniformly samples a large number of perturbation vectors, , where , and for each such perturbation vector, it maintains a vector close to the lattice ( is such that ). Thus, initially, we have a set S of many such pairs for some . The desired situation is that after a polynomial number of such sieving iterations, we are left with a set of vector pairs such that . Finally, we take the pair-wise differences of the lattice vectors corresponding to these vector pairs and output the one with the smallest non-zero norm. It was shown in [21,47,48] that, with overwhelming probability, this is the shortest vector in the lattice.
One of the main and usually the most expensive steps in this algorithm is the sieving procedure, where given a list of vector pairs in each iteration, it outputs a list of vector pairs where . In each sieving iteration, a number of vector pairs (usually exponential in n) are identified as “center pairs”. The second element of each such center pair is referred to as the “center”. By a well-defined map, each of the remaining vector pairs is associated to a “center pair” such that after certain operations (such as subtraction) on the vectors, we obtain a pair with a vector difference yielding a lattice vector with a norm less than . If we start an iteration with say vector pairs and identify number of center pairs, then the output consists of vector pairs. An illustration is given in Figure 2. In [21] and most other provable variants or generalizations such as [47,48], the running time of this sieving procedure, which is the dominant part of the total running time of the algorithm, is roughly quadratic in the number of sampled vectors.
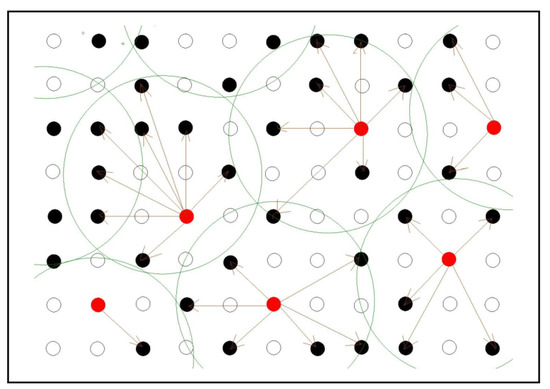
Figure 2.
One iteration of the quadratic AKS sieve in the norm. Each point represents a vector pair. The solid dots are the sampled ones, while the hollow dots are the unsampled ones. Among the sampled vector pairs, some are identified as centers (red dots) and the space is divided into a number of balls, centered around these red dots. Vector subtraction (denoted by arrow) is performed with the center pair in each ball, such that we obtain shorter lattice vectors in the next iteration.
Here, we propose a different sieving approach to reduce the overall time complexity of the algorithm. This can be thought of as a generalization of the sieving method introduced in [49] for the norm. We divide the space such that each lattice vector can be mapped efficiently into some desired division. In the following subsection, we explain this sieving procedure, whose running time is linear in the number of sampled vectors.
3.1. Linear Sieve
In the initial AKS algorithm [21,45] as well as in all its variants thereafter [27,47,48], in the sieving sub-routine, a space has been divided into sub-regions such that each sub-region is associated with a center. Then, given a vector, we map it to a sub-region and subtract it from the center so that we get a vector of length at most . We must aim to select these sub-regions such that we can (i) map a vector efficiently to a sub-region (ii) without increasing the number of centers “too much”. The latter factor is determined by the number of divisions of into these sub-regions and directly contributes to the space (and hence time) complexity.
In all the previous provable sieving algorithms, the sub-regions were small hyperballs (or parts of them) in norm. In this paper, our sub-regions are hypercubes. The choice of this particular sub-region makes the mapping very efficient. First, let us note that, in contrast with the previous algorithms (except [49]), we divide the space a priori. This can be done by dividing each co-ordinate axis into intervals of length so that the distance between any two vectors in the resulting hypercube is at most . In an ordered list, we store an appropriate index (say, co-ordinates of one corner) of only those hypercubes which have a non-zero intersection with . We can map a vector to a hypercube in time simply by looking at the intervals in which each of its co-ordinates belong. If the hypercube contains a center, then we subtract the vectors and store the difference; otherwise, we assign this vector as the center. An illustration is given in Figure 3.
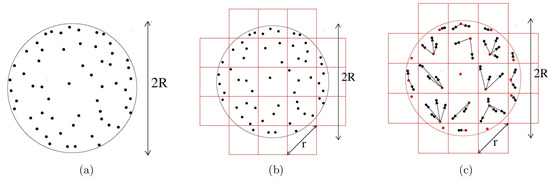
Figure 3.
One iteration of the linear sieve in the norm. (a) A number of vector pairs (solid black dots) with (Euclidean) length at most R are sampled. (b) The space is divided into a number of hypercubes with diagonal length r, and each vector pair is mapped into a hypercube. (c) Within each hypercube, a subtraction operation (denoted by arrow) is performed between a center (red dot) and the remaining vector pairs, such that we obtain shorter lattice vectors in the next iteration.
The following lemma gives a bound on the number of hypercubes or centers we obtain by this process. Such a volumetric argument can be found in [66].
Lemma 5.
Let and . The number of translates of required to cover is at most .
Proof.
Let be the number of translates of required to cover . These translates are all within . In addition, noting that , we have
Plugging in the value of r, we have .
Using Fact 3, we have . □
Note that the above lemma implies a sub-division where one hypercube is centered at the origin. Thus, along each axis, we can have the following -length intervals:
We do not know whether this is the most optimal way of sub-dividing into smaller hypercubes. In [49], it has been shown that if we divide from one corner—i.e., place one small hypercube at one corner of the larger hypercube —then copies of hypercubes of radius r suffices.
Suppose in one sieving iteration, we have a set S of lattice vectors of length at most R; i.e., they all lie in (Figure 3a). We would like to combine points so that we are left with vectors in . We divide each axis into intervals of length and store in an ordered set () co-ordinates of one corner of the resulting hypercubes that have a non-zero intersection with (Figure 3b). Note that this can be done in a time of , where is the maximum number of hypercube translates as described in Lemma 5.
We maintain a list of pairs, where the first entry of each pair is an n-tuple in (let us call it “index-tuple”) and the second one, initialized as empty set, is for storing a center pair. Given , we map it to its index-tuple as follows: we calculate the interval in which each of its co-ordinates belong (steps 10–13 in Algorithm 2). This can be done in time. This is equivalent to storing information about the hypercube (in Figure 3b) in which it belongs or is mapped to. We can access in constant time. For each , if there exists a —i.e., (implying )—then we add to the output set (Figure 3c). Otherwise, we add vector pair to as a center pair. This implies that if there exists a center in the hypercube, then we perform subtraction operations to obtain a shorter vector. Otherwise, we make the center for its hypercube. Finally, we return .
More details of this sieving procedure (Linear Sieve) can be found in Algorithm 2.
3.2. AKS Algorithm with a Linear Sieve
Algorithm 1 describes an exact algorithm for with a linear sieving procedure (Linear Sieve) (Algorithm 2).
| Algorithm 1: An exact algorithm for |
 |
| Algorithm 2: Linear Sieve for norm |
 |
Lemma 6.
Let . The number of center pairs in Algorithm 2 always satisfies where .
Proof.
This follows from Lemma 5 in Section 3.1.
□
Claim 1.
The following two invariants are maintained in Algorithm 1:
1. 2. .
Proof.
- The first invariant is maintained at the beginning of the sieving iterations in Algorithm 1 due to the choice of at step 4 of Algorithm 1.Since each center pair once belonged to S, . Thus, at step 15 of the sieving procedure (Algorithm 2), we have .
- The second invariant is maintained in steps 2–6 of Algorithm 1 because and hence .We claim that this invariant is also maintained in each iteration of the sieving procedure.Consider a pair and let be its index-tuple. Let be its associated center pair. By Algorithm 2, we have ; i.e., . Thus, and henceThe claim follows by the re-assignment of variable R at step 10 in Algorithm 1. □
In the following lemma, we bound the length of the remaining lattice vectors after all the sieving iterations are over. The proof is similar to that given in [49], so we write it briefly.
Lemma 7.
At the end of k iterations in Algorithm 1, the length of lattice vectors .
Proof.
Let be the value of R after k iterations, where
.
Then,
Thus, after k iterations, , and hence after k iterations,
□
Using Corollary 1 and assuming , we obtain an upper bound on the number of lattice vectors of a length of at most ; i.e.,
, where .
The above lemma along with the invariants implies that at the beginning of step 12 in Algorithm 1, we have “short” lattice vectors; i.e., vectors with a norm bounded by . We want to start with a “sufficient number” of vector pairs so that we do not end up with all zero vectors at the end of the sieving iterations. For this, we work with the following conceptual modification proposed by Regev [67].
Let such that (where ), and . Define a bijection on that maps to , to and to itself:
For the analysis of the algorithm, we assume that for each perturbation vector chosen by our algorithm, we replace by with probability and that it remains unchanged with probability . We call this procedure tossing the vector . This does not change the distribution of the perturbation vectors . Further, we assume that this replacement of the perturbation vectors happens at the step where this has any effect on the algorithm for the first time. In particular, at step 17 in Algorithm 2, after we have identified a center pair , we apply on with probability . Then, at the beginning of step 12 in Algorithm 1, we apply to for all pairs . The distribution of remains unchanged by this procedure because and . A somewhat more detailed explanation of this can be found in the following result of [47].
Lemma 8
(Theorem 4.5 in [47] (re-stated)). The modification outlined above does not change the output distribution of the actual procedure.
Note that since this is just a conceptual modification intended for ease in analysis, we should not be concerned with the actual running time of this modified procedure. Even the fact that we need a shortest vector to begin the mapping does not matter.
The following lemma will help us to estimate the number of vector pairs to sample at the beginning of the algorithm.
Lemma 9
(Lemma 4.7 in [47]). Let and q denote the probability that a random point in is contained in . If N points are chosen uniformly at random in , then with a probability larger than , there are at least points with the property .
From Lemma 3, we have
Thus, with a probability of at least , we have at least pairs before the sieving iterations such that .
Lemma 10.
If , then with a probability of at least , Algorithm 1 outputs a shortest non-zero vector in with respect to norm for .
Proof.
Of the N vector pairs sampled in steps 2–6 of Algorithm 1, we consider those such that . We have already seen there are at least such pairs with a probability of at least . We remove vector pairs in each of the k sieve iterations. Thus, at step 12 of Algorithm 1, we have pairs to process.
By Lemma 7, each of them is contained within a ball of radius which can have at most lattice vectors. Thus, there exists at least one lattice vector for which the perturbation is in , and it appears twice in S at the beginning of step 12. With a probability of , it remains , or with the same probability, it becomes either or . Thus, after taking pair-wise difference at step 12 with a probability of at least , we find the shortest vector. □
Theorem 2.
Let , and let . Given a full rank lattice , there is a randomized algorithm for with a success probability of at least , a space complexity of at most , and running time of at most , where and , where and .
Proof.
If we start with N pairs (as stated in Lemma 10), then the space complexity is at most with .
In each iteration of the sieving Algorithm 2, it takes at most time to initialize and index (Lemmas 5 and 6). For each vector pair , it takes a time of at most n to calculate its index-tuple . Thus, the time taken to process each vector pair is at most , and the total time taken per iteration of Algorithm 2 is at most , which is at most , and there are at most such iterations.
If , then the time complexity for the computation of the pairwise differences is at most .
Thus, the overall time complexity is at most where
. □
3.3. Improvement Using the Birthday Paradox
We can obtain a better running time and space complexity if we use the birthday paradox to decrease the number of sampled vectors but obtain at least two vector pairs corresponding to the same lattice vector after the sieving iterations [26,28]. For this, we have to ensure that the vectors are independent and identically distributed before step 12 of Algorithm 1. Thus, we incorporate the following modification, as discussed in [26]. Very briefly, the trick is to set aside many uniformly distributed vector pairs as centers for each sieving step, even before the sieving iterations begin. In each sieving iteration, the probability that a vector pair is not within the required distance of any center pair decreases. Now, if we sample enough vectors, then with a good probability at step 12, we have at least two vectors whose perturbation is in , implying that with a probability of at least 1/2, we obtain the shortest vector.
In the analysis of [26], the authors simply stated that the required center pairs can be sampled uniformly at the beginning. In our linear sieving algorithm, we have an advantage. Unlike the AKS-style algorithms, in which the center pairs are selected and then the space is divided, in our case, we can divide the space a priori. We take advantage of this and conduct a number of random divisions of the space. Since in each iteration, the length of the vectors decreases, the size of the hypercubes also decreases, and this can be calculated. Thus, for each iteration we have a number of divisions of the space into hypercubes of a certain size. For this, we need to divide the axes into intervals of a fixed size. Simply by shifting the intervals in each axis, we can make this division random. Then, among the uniformly sampled vectors, we select a center for each hypercube.
Assume we start with sampled pairs. After the initial sampling, for each of the k sieving iterations, we fix pairs to be used as center pairs in the following way.
1. Let . We maintain k lists of pairs, , where each list is similar to (), as described in Algorithm 2. In the list, we store the indices (co-ordinates of a corner) of translates of that have a non-zero intersection with where and . For such a division, we can obtain center pairs in each list. To meet our requirement, we maintain such lists for each i. We call these lists the “sibling lists” of .
2. For each (where S is the set of sampled pairs), we first calculate to check in which list group it can potentially belong, say . That is, corresponds to the smallest hyperball containing . Then, we map it to its index-tuple , as has already been described before. We add to a list in or any of its sibling lists if it was empty before. Since we sampled uniformly, this ensures we obtain the required number of (initially) fixed centers, and no other vector can be used as a center throughout the algorithm.
Having set aside the centers, now we repeat the following sieving operations k times. For each vector pair , we can check which list (or its sibling lists) it can belong to from . Then, if a center pair is found, we subtract as in step 15 of Algorithm 2. Otherwise, we discard it and consider it “lost”.
Let us call this modified sieving procedure LinearSieveBirthday. We obtain the following improvement in the running time.
Theorem 3.
Let , and let . Given a full rank lattice , there is a randomized algorithm for with a success probability of at least , a space complexity of at most , and running time of at most , where and , where and .
Proof.
This analysis has been taken from [26]. At the beginning of the algorithm, among the pairs set aside as centers for the first step, there are pairs such that the perturbation is in with high probability (Lemma 9). We call them good pairs. After fixing these pairs as centers, the probability that the distance between the next perturbed vector and the closest center is more than decreases. The sum of these probabilities is bounded from above by . As a consequence, once all centers have been processed, the probability for any of the subsequent pairs to be lost is . By induction, it can be proved that the same proportion of pairs is lost at each step of the sieve with high probability. As a consequence, no more than pairs are lost during the whole algorithm. This means that in the final ball, there are probabilistically independent lattice points corresponding to good pairs with high probability. As in the proof of Lemma 10 this implies that the algorithm returns a shortest vector with a probability of at least 1/2. □
Comparison of Linear Sieve with provable sieving algorithms [21,45,47,48]
For , the number of centers obtained by [47] is
, where (Lemma 4). If we conducted a similar analysis for their algorithm, we would obtain space and time complexities of and , respectively, where
We can incorporate modifications to apply the birthday paradox, as has been done in [26] (for norm). This would improve the exponents to
Clearly, the running time of our algorithm is less since for all . In [47], the authors did not specify the constant in the exponent of running time. However, using the above formulae, we found out that their algorithm can achieve a time complexity of and space complexity of at parameters (without the birthday paradox, the algorithm in [47] can achieve time and space complexities of and , respectively, at parameters ). In comparison, our algorithm can achieve a time and space complexity of at parameters .
For , we can use Theorem 1 to obtain a better bound on the number of lattice vectors that remain after all sieving iterations. This is reflected in the quantity , which is then given by (Corollary 1). Furthermore, (Lemma 3). At parameters and , we obtain . The AKS algorithm with the birthday paradox manages to achieve a time complexity of and space complexity of when and [26]. Thus, our algorithm achieves a better time complexity at the cost of more space.
For , we can reduce the space complexity by using the sub-division mentioned in Section 3.1 and achieve a space and time complexity of at parameters (in [49], the authors mentioned a time and space complexity of in norm. We obtain a slightly better running time by using , as mentioned in this paper). Again, this is better than the time complexity of [47] (which is for all norms).
4. A Mixed Sieving Algorithm
The main advantage in dividing the space (hyperball) into hypercubes (as we did in Linear Sieve) is the efficient “decodability” in the sense that a vector can be mapped to a sub-region (and thus be associated with a center) in time. However, the price we pay is in space complexity, because the number of hypercubes required to cover a hyperball is greater than the number of centers required if we used smaller hyperballs like in [21,47,48]. To reduce the space complexity, we perform a mixed sieving procedure. Double sieving techniques have been used for heuristic algorithms as in [32], where the rough idea is the following. There are two sets of centers: the first set consists of centers of larger radius balls, and for each such center, there is another set of centers of smaller radius balls within the respective large ball. In each sieving iteration, each non-center vector is mapped to the larger balls by comparing with the centers in the first set. Then, they are mapped to a smaller ball by comparing with the second set of centers. Thus, in both levels, a quadratic sieve is applied.
In our mixed sieving, the primary difference is the fact that in the two levels, we use two types of sieving methods: a linear sieve in the first level and then a quadratic sieve such as AKS in the next level. The overall outline of the algorithm is the same as in Algorithm 1, except at step 9, where we apply the following sieving procedure, which we call Mixed Sieve. An illustration is given in Figure 4.
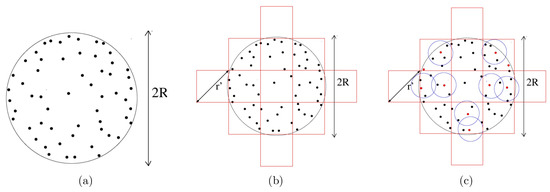
Figure 4.
One iteration of the mixed sieve in the norm. (a) A number of vector pairs (solid black dots) with a (Euclidean) length of at most R are sampled. (b) The space is divided into hypercubes with diagonal length , and the vector pairs are mapped into each hypercube. (c) Within each hypercube, some vector pairs are selected as centers (red dots) and a hypercube is further sub-divided into a number of balls, centered around these red dots. Then, vector subtraction is performed between the center and the vector pairs in each ball (like AKS).
The input to Mixed Sieve is a set of vectors of length R, and the output is a set of smaller vectors of length .
- We divide the whole space into large hypercubes of length , where A is some constant. In time, we map a vector to a large hypercube by comparing its co-ordinates. This has been explained in Section 3.1. We do not assign centers yet and do not perform any vector operation at this step. The distance between any two vectors mapped to the same hypercube is at most (Figure 4b).
- Next, we perform the AKS sieving procedure within each hypercube. For each hypercube, we have a set (initially null) of centers. When a vector is mapped to a hypercube, we check if it is within distance of any center (within that hypercube). If yes, then we subtract it from the center and add the resultant shorter vector to output set. If no, then we add this vector to the set of centers (Figure 4c).
Using the same kind of counting method as in Section 3.1, we can say we need large hypercubes, where . The maximum distance between any two vectors in each hypercube is , and we want to get vectors of length at most by applying the AKS sieve. Thus, the number of centers (let us call these “AKS sieve-centers”) within each hypercube is where (in the special case of Euclidean norm, we have ). (and ) are obtained by applying Lemma 4. Note that the value of A must ensure the non-negativity of . Thus, the total number of centers is where .
To use the birthday paradox, we apply similar methods as given in Section 3.3 and [26]. Assume that we initially sample vectors. Then, using similar arguments as in Section 3, we can conclude that, with high probability, we end up with the shortest vector in the lattice. We are not re-writing the proof since it is similar to that in Theorem 3. The only thing that is slightly different is the number of center pairs set aside at the beginning of the sieving iterations. As in Section 3, we randomly divide the space times into hypercubes. Then, among the uniformly sampled vectors, we set aside vector pairs as centers for each hypercube. Thus, in Theorem 3, we replace by .
Thus, space complexity is where . It takes time to map each vector to a large hypercube, and then at most time to compare it with the “AKS sieve-centers” within each hypercube. Thus, the time complexity is where .
Theorem 4.
Let and A be some constant. Given a full-rank lattice , there is a randomized algorithm for with a success probability of at least , a space complexity of at most , and a running time of at most . Here, and . , , and .
In the Euclidean norm, we have ,
, and .
Comparison with previous provable sieving algorithms [20,27,28]
In the Euclidean norm with parameters and , we obtain a space and time complexity of , while the List Sieve Birthday [26,28] has space and time complexities of and , respectively. We can also use a different sieve in the second level, such as List Sieve [27], etc., which works in norm and is faster than the AKS sieve. We can therefore expect to achieve a better running time.
The Discrete Gaussian-based sieving algorithm of Aggarwal et al. [20] with a time complexity of performs better than both our sieving techniques. However, their algorithm works for the Euclidean norm and, to the best of our knowledge, it has not been generalized to any other norm.
5. Approximation Algorithms for and
In this section, we show how to adopt our sieving techniques to approximation algorithms for and . The analysis and explanations are similar to that given in [49]. For completeness, we give a brief outline.
5.1. Algorithm for Approximate
We note that at the end of the sieving procedure in Algorithm 1, we obtain lattice vectors of length at most . Thus, if we can ensure that one of the vectors obtained at the end of the sieving procedure is non-zero, we obtain a -approximation of the shortest vector. Consider a new algorithm (let us call it Approx-SVP) that is identical to Algorithm 1, except that Step 12 is replaced by the following:
- Find a non-zero vector in .
We now show that if we start with sufficiently many vectors, we must obtain a non-zero vector.
Lemma 11.
If , then with a probability of at least , Algorithm outputs a non-zero vector in of a length of at most with respect to norm.
Proof.
Of the N vector pairs sampled in steps 2–6 of Algorithm , we consider those such that . We have already seen there are at least such pairs. We remove vector pairs in each of the k sieve iterations. Thus, at step 12 of Algorithm 1, we have pairs to process.
With a probability of , , and hence is replaced by either or . Thus, the probability that this vector is the zero vector is at most . □
We thus obtain the following result.
Theorem 5.
Let , and , Assume we are given a full-rank lattice . There is a randomized algorithm that τ approximates with a success probability of at least and a space and time complexity , where , and .
Note that while presenting the above theorem, we assumed that we are using the Linear Sieve in Algorithm 1. We can also use the Mixed Sieve procedure as described in Section 4. Then, we will obtain space and time complexities of and , respectively, where and , respectively (in the Euclidean norm, the parameters are as described in Theorem 4).
Comparison with provable approximation algorithms [30,47,48]
We have mentioned in Section 1 that [47,48] gave approximation algorithms for lattice problems that work for all norms and use the quadratic sieving procedure (as has been described before). Using our notations, the space and time complexities of their approximate algorithms are and , respectively, where
The authors did not mention any explicit value of the constant in the exponent. Using the above formulae, we conclude that [47,48] can achieve time and space complexities of and , respectively, at parameters with a large constant approximation factor. In comparison, we can achieve a space and time complexity of with a large constant approximation factor at the same parameters.
In norm, using the mixed sieving procedure, we obtain a time and space complexity of and a large constant approximation factor at parameters ,. In [30], the best running time reported is for a large approximation factor.
Using a similar linear sieve, a time and space complexity of i.e., can be achieved for the norm for a large constant approximation factor [49].
5.2. Algorithm for Approximate
Given a lattice and a target vector , let d denote the distance of the closest vector in to . Just as in Section 3.2, we assume that we know the value of d within a factor of . We can get rid of this assumption by using Babai’s [68] algorithm to guess the value of d within a factor of and then run our algorithm for polynomially many values of d.
For , define the following dimensional lattice
Let be the lattice vector closest to .
Then for some .
We sample N vector pairs (8–12 of Algorithm 3), where is a basis for . Next, we run a number of iterations of the sieving Algorithm 2 to obtain a number of vector pairs such that . Further details can be found in Algorithm 3. Note that in the algorithm, is the dimensional vector obtained by restricting to the first n co-ordinates (with respect to the computational basis).
| Algorithm 3: Approximate algorithm for |
 |
From Lemma 7, we have seen that after iterations (where ), . Thus, after the sieving iterations, the set consists of vector pairs such that the corresponding lattice vector has .
Selecting ensures that our sieving algorithm does not return vectors from for some such that . Then, every vector has , and so either or for some lattice vector .
With similar arguments as in [49] (using the tossing argument outlined in Section 3.2), we can conclude that with some non-zero probability we have at least one vector in after the sieving iterations.
Thus, we obtain the following result.
Theorem 6.
Let , and for any let . Given a full-rank lattice , there is a randomized algorithm that, for
, approximates with a success probability of at least and a space and time complexity of , where and .
Again, using Mixed Sieve in Algorithm 1, we obtain space and time complexities of and , respectively, where
and , respectively (in the Euclidean norm, the parameters are as described in Theorem 4).
6. Discussions
In this paper, we have designed new sieving algorithms that work for any norm. A comparative performance evaluation has been given in Table 1. We achieve a better time complexity at the cost of space complexity for every , except for the algorithm in [20] that employs a Discrete Gaussian-based sieving algorithm and has better space and time complexity in the Euclidean norm. To the best of our knowledge, this algorithm does not work for any other norm.

Table 1.
Comparison of the performance of various sieving algorithms in different norms. In the last row, DGS stands fro Discrete Gaussian Sampling-based sieve.
Future Work
An obvious direction for further research would be to design heuristic algorithms on these kind of sieving techniques and to study if these can be adapted to other computing environments like parallel computing.
The major difference between our algorithm and the others like [21,47] is in the choice of the shape of the sub-regions in which we divide the ambient space (as has already been explained before). Due to this we get superior “decodability” in the sense that a vector can be efficiently mapped to a sub-region, at the cost of inferior space complexity, as described before. It might be interesting to study what other shapes of these sub-regions might be considered and what are the trade-offs we get.
It might be possible to improve the bound on the number of hypercubes required to cover the hyperball. At least in the norm we have seen that the number of hypercubes may depend on the initial position of the smaller hypercube, whose translates cover the bigger hyperball. In fact it might be possible to get some lower bound on the complexity of this kind of approach.
Funding
Research at IQC was supported in part by the Government of Canada through Innovation, Science and Economic Development Canada, Public Works and Government Services Canada, and Canada First Research Excellence Fund.
Acknowledgments
The author would like to acknowledge the anonymous reviewers for their helpful comments that have helped to improve the manuscript significantly.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Lenstra, A.K.; Lenstra, H.W., Jr.; Lovász, L. Factoring polynomials with rational coefficients. Math. Ann. 1982, 261, 515–534. [Google Scholar] [CrossRef]
- Lenstra, H.W., Jr. Integer programming with a fixed number of variables. Math. Oper. Res. 1983, 8, 538–548. [Google Scholar] [CrossRef] [Green Version]
- Kannan, R. Minkowski’s convex body theorem and integer programming. Math. Oper. Res. 1987, 12, 415–440. [Google Scholar] [CrossRef] [Green Version]
- Dadush, D.; Peikert, C.; Vempala, S. Enumerative lattice algorithms in any norm via m-ellipsoid coverings. In Proceedings of the 2011 IEEE 52nd Annual Symposium on Foundations of Computer Science, Palm Springs, CA, USA, 22–25 October 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 580–589. [Google Scholar]
- Eisenbrand, F.; Hähnle, N.; Niemeier, M. Covering cubes and the closest vector problem. In Proceedings of the Twenty-Seventh Annual Symposium on Computational Geometry, Paris, France, 13–15 June 2011; ACM: New York, NY, USA, 2011; pp. 417–423. [Google Scholar]
- Odlyzko, A.M. The rise and fall of knapsack cryptosystems. Cryptol. Comput. Number Theory 1990, 42, 75–88. [Google Scholar]
- Joux, A.; Stern, J. Lattice reduction: A toolbox for the cryptanalyst. J. Cryptol. 1998, 11, 161–185. [Google Scholar] [CrossRef]
- Nguyen, P.Q.; Stern, J. The two faces of lattices in cryptology. In Cryptography and Lattices; Springer: Berlin/Heidelberg, Germany, 2001; pp. 146–180. [Google Scholar]
- Landau, S.; Miller, G.L. Solvability by radicals is in polynomial time. In Proceedings of the Fifteenth Annual ACM Symposium on Theory of Computing; ACM: New York, NY, USA, 1983; pp. 140–151. [Google Scholar]
- Coster, M.J.; Joux, A.; LaMacchia, B.A.; Odlyzko, A.M.; Schnorr, C.; Stern, J. Improved low-density subset sum algorithms. Comput. Complex. 1992, 2, 111–128. [Google Scholar] [CrossRef] [Green Version]
- Ajtai, M. Generating hard instances of lattice problems. In Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing, Philadelphia, PA, USA, 22–24 May 1996; ACM: New York, NY, USA, 1996; pp. 99–108. [Google Scholar]
- Micciancio, D.; Regev, O. Worst-case to average-case reductions based on Gaussian measures. SIAM J. Comput. 2007, 37, 267–302. [Google Scholar] [CrossRef] [Green Version]
- Gentry, C. Fully homomorphic encryption using ideal lattices. In Proceedings of the STOC’09—Proceedings of the 2009 ACM International Symposium on Theory of Computing, Bethesda, MD, USA, 31 May–2 June 2009; ACM: New York, NY, USA, 2009; pp. 169–178. [Google Scholar]
- Regev, O. On lattices, learning with errors, random linear codes, and cryptography. J. ACM 2009, 56, 34. [Google Scholar] [CrossRef]
- Brakerski, Z.; Vaikuntanathan, V. Efficient fully homomorphic encryption from (standard) LWE. In Proceedings of the FOCS, Palm Springs, CA, USA, 23–25 October 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 97–106. [Google Scholar]
- Brakerski, Z.; Langlois, A.; Peikert, C.; Regev, O.; Stehlé, D. Classical hardness of learning with errors. In Proceedings of the STOC, Palo Alto, CA, USA, 1–4 June 2013; pp. 575–584. [Google Scholar]
- Brakerski, Z.; Vaikuntanathan, V. Lattice-based FHE as secure as PKE. In Proceedings of the ITCS, Princeton, NJ, USA, 12–14 January 2014; pp. 1–12. [Google Scholar]
- Peikert, C. A decade of lattice cryptography. Found. Trends Theor. Comput. Sci. 2016, 10, 283–424. [Google Scholar] [CrossRef]
- Ducas, L.; Lepoint, T.; Lyubashevsky, V.; Schwabe, P.; Seiler, G.; Stehlé, D. Crystals–Dilithium: Digital Signatures from Module Lattices. IACR Transactions on Symmetric Cryptology. 2018, pp. 238–268. Available online: https://repository.ubn.ru.nl/bitstream/handle/2066/191703/191703.pdf (accessed on 8 December 2021).
- Aggarwal, D.; Dadush, D.; Regev, O.; Stephens-Davidowitz, N. Solving the Shortest Vector Problem in 2n time via Discrete Gaussian sampling. In Proceedings of the STOC, Portland, OR, USA, 14–17 June 2015. [Google Scholar]
- Ajtai, M.; Kumar, R.; Sivakumar, D. A sieve algorithm for the shortest lattice vector problem. In Proceedings of the STOC, Heraklion, Greece, 6–8 July 2001; pp. 601–610. [Google Scholar]
- Fincke, U.; Pohst, M. Improved methods for calculating vectors of short length in a lattice, including a complexity analysis. Math. Comput. 1985, 44, 463–471. [Google Scholar] [CrossRef]
- Schnorr, C.-P. A hierarchy of polynomial time lattice basis reduction algorithms. Theor. Comput. Sci. 1987, 53, 201–224. [Google Scholar] [CrossRef] [Green Version]
- Micciancio, D.; Voulgaris, P. A deterministic single exponential time algorithm for most lattice problems based on Voronoi cell computations. SIAM J. Comput. 2013, 42, 1364–1391. [Google Scholar] [CrossRef]
- Dadush, D.; Vempala, S.S. Near-optimal deterministic algorithms for volume computation via m-ellipsoids. Proc. Natl. Acad. Sci. USA 2013, 110, 19237–19245. [Google Scholar] [CrossRef] [Green Version]
- Hanrot, G.; Pujol, X.; Stehlé, D. Algorithms for the shortest and closest lattice vector problems. In International Conference on Coding and Cryptology; Springer: Berlin/Heidelberg, Germany, 2011; pp. 159–190. [Google Scholar]
- Micciancio, D.; Voulgaris, P. Faster exponential time algorithms for the shortest vector problem. In Proceedings of the SODA, Austin, TX, USA, 17–19 January 2010; pp. 1468–1480. [Google Scholar]
- Pujol, X.; Stehlé, D. Solving the shortest lattice vector problem in time 22.465n. IACR Cryptol. ePrint Arch. 2009, 2009, 605. [Google Scholar]
- Aggarwal, D.; Stephens-Davidowitz, N. Just take the average! an embarrassingly simple 2n-time algorithm for SVP (and CVP). arXiv 2017, arXiv:1709.01535. [Google Scholar]
- Liu, M.; Wang, X.; Xu, G.; Zheng, X. Shortest lattice vectors in the presence of gaps. IACR Cryptol. Eprint Arch. 2011, 2011, 139. [Google Scholar]
- Nguyen, P.Q.; Vidick, T. Sieve algorithms for the shortest vector problem are practical. J. Math. Cryptol. 2008, 2, 181–207. [Google Scholar] [CrossRef]
- Wang, X.; Liu, M.; Tian, C.; Bi, J. Improved Nguyen-Vidick heuristic sieve algorithm for shortest vector problem. In Proceedings of the AsiaCCS, Hong Kong, China, 22–24 March 2011; pp. 1–9. [Google Scholar]
- Becker, A.; Ducas, L.; Gama, N.; Laarhoven, T. New directions in nearest neighbor searching with applications to lattice sieving. In Proceedings of the Twenty-Seventh Annual ACM-SIAM Symposium on Discrete Algorithms, Arlington, VA, USA, 10–12 January 2016; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2016; pp. 10–24. [Google Scholar]
- Laarhoven, T.; de Weger, B. Faster sieving for shortest lattice vectors using spherical locality-sensitive hashing. In International Conference on Cryptology and Information Security in Latin America; Springer: Berlin/Heidelberg, Germany, 2015; pp. 101–118. [Google Scholar]
- Becker, A.; Laarhoven, T. Efficient (ideal) lattice sieving using cross-polytope LSH. In International Conference on Cryptology in Africa; Springer: Berlin/Heidelberg, Germany, 2016; pp. 3–23. [Google Scholar]
- Herold, G.; Kirshanova, E. Improved algorithms for the approximate k-list problem in Euclidean norm. In IACR International Workshop on Public Key Cryptography; Springer: Berlin/Heidelberg, Germany, 2017; pp. 16–40. [Google Scholar]
- Herold, G.; Kirshanova, E.; Laarhoven, T. Speed-ups and time–memory trade-offs for tuple lattice sieving. In IACR International Workshop on Public Key Cryptography; Springer: Berlin/Heidelberg, Germany, 2018; pp. 407–436. [Google Scholar]
- Laarhoven, T.; Mariano, A. Progressive lattice sieving. In International Conference on Post-Quantum Cryptography; Springer: Berlin/Heidelberg, Germany, 2018; pp. 292–311. [Google Scholar]
- Mariano, A.; Bischof, C. Enhancing the scalability and memory usage of hash sieve on multi-core CPUs. In Proceedings of the 2016 24th Euromicro International Conference on Parallel, Distributed, and Network-Based Processing (PDP), Heraklion, Greece, 17–19 February 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 545–552. [Google Scholar]
- Mariano, A.; Laarhoven, T.; Bischof, C. A parallel variant of LD sieve for the SVP on lattices. In Proceedings of the 2017 25th Euromicro International Conference on Parallel, Distributed and Network-based Processing (PDP), St. Petersburg, Russia, 6–8 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 23–30. [Google Scholar]
- Yang, S.-Y.; Kuo, P.-C.; Yang, B.-Y.; Cheng, C.-M. Gauss sieve algorithm on GPUs. In Cryptographers’ Track at the RSA Conference; Springer: Berlin/Heidelberg, Germany, 2017; pp. 39–57. [Google Scholar]
- Ducas, L. Shortest vector from lattice sieving: A few dimensions for free. In Annual International Conference on the Theory and Applications of Cryptographic Techniques; Springer: Berlin/Heidelberg, Germany, 2018; pp. 125–145. [Google Scholar]
- Albrecht, M.R.; Ducas, L.; Herold, G.; Kirshanova, E.; Postlethwaite, E.W.; Stevens, M. The general sieve kernel and new records in lattice reduction. In Annual International Conference on the Theory and Applications of Cryptographic Techniques; Springer: Berlin/Heidelberg, Germany, 2019; pp. 717–746. [Google Scholar]
- Goldreich, O.; Micciancio, D.; Safra, S.; Seifert, J.-P. Approximating shortest lattice vectors is not harder than approximating closest lattice vectors. Inf. Process. Lett. 1999, 71, 55–61. [Google Scholar] [CrossRef]
- Ajtai, M.; Kumar, R.; Sivakumar, D. Sampling short lattice vectors and the closest lattice vector problem. In Proceedings of the CCC, Beijing, China, 15–20 April 2002; pp. 41–45. [Google Scholar]
- Aggarwal, D.; Dadush, D.; Stephens-Davidowitz, N. Solving the closest vector problem in 2n time–the Discrete Gaussian strikes again! In Proceedings of the Foundations of Computer Science (FOCS), 2015 IEEE 56th Annual Symposium, Berkeley, CA, USA, 18–20 October 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 563–582. [Google Scholar]
- Blömer, J.; Naewe, S. Sampling methods for shortest vectors, closest vectors and successive minima. Theor. Comput. Sci. 2009, 410, 1648–1665. [Google Scholar] [CrossRef] [Green Version]
- Arvind, V.; Joglekar, P.S. Some sieving algorithms for lattice problems. In LIPIcs-Leibniz International Proceedings in Informatics; Schloss Dagstuhl-Leibniz-Zentrum für Informatik: Wadern, Germany, 2008; Volume 2. [Google Scholar]
- Aggarwal, D.; Mukhopadhyay, P. Improved algorithms for the shortest vector problem and the closest vector problem in the infinity norm. arXiv 2018, arXiv:1801.02358. [Google Scholar]
- van Emde Boas, P. Another NP-Complete Partition Problem and the Complexity of Computing Short Vectors in a Lattice; Technical Report; Department of Mathematics, University of Amsterdam: Amsterdam, The Netherlands, 1981. [Google Scholar]
- Ajtai, M. The shortest vector problem in ℓ2 is NP-hard for randomized reductions. In Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, Dallas, TX, USA, 24–26 May 1998; ACM: New York, NY, USA, 1998; pp. 10–19. [Google Scholar]
- Micciancio, D. The shortest vector problem is NP-hard to approximate to within some constant. SIAM J. Comput. 2001, 30, 2008–2035. [Google Scholar] [CrossRef] [Green Version]
- Dinur, I.; Kindler, G.; Raz, R.; Safra, S. Approximating CVP to within almost-polynomial factors is NP-hard. Combinatorica 2003, 23, 205–243. [Google Scholar] [CrossRef]
- Dinur, I. Approximating SVP∞ to within almost-polynomial factors is NP-hard. In Italian Conference on Algorithms and Complexity; Springer: Berlin/Heidelberg, Germany, 2000; pp. 263–276. [Google Scholar]
- Mukhopadhyay, P. The projection games conjecture and the hardness of approximation of SSAT and related problems. J. Comput. Syst. Sci. 2021, 123, 186–201. [Google Scholar] [CrossRef]
- Moshkovitz, D. The projection games conjecture and the NP-hardness of ln n-approximating Set-Cover. Theory Comput. 2015, 11, 221–235. [Google Scholar] [CrossRef]
- Khot, S. Hardness of approximating the shortest vector problem in lattices. J. ACM 2005, 52, 789–808. [Google Scholar] [CrossRef]
- Haviv, I.; Regev, O. Tensor-based hardness of the shortest vector problem to within almost polynomial factors. Theory Comput. 2012, 8, 513–531. [Google Scholar] [CrossRef]
- Bennett, H.; Golovnev, A.; Stephens-Davidowitz, N. On the quantitative hardness of CVP. arXiv 2017, arXiv:1704.03928. [Google Scholar]
- Aggarwal, D.; Stephens-Davidowitz, N. (gap/S)ETH hardness of SVP. In Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing, Los Angeles, CA, USA, 25–29 June 2018; ACM: New York, NY, USA, 2018; pp. 228–238. [Google Scholar]
- Dadush, D.; Kun, G. Lattice sparsification and the approximate closest vector problem. In Proceedings of the Twenty-Fourth annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 6–8 January 2013; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2013; pp. 1088–1102. [Google Scholar]
- Dyer, M.; Frieze, A.; Kannan, R. A random polynomial-time algorithm for approximating the volume of convex bodies. J. ACM 1991, 38, 1–17. [Google Scholar] [CrossRef]
- Goldreich, O.; Goldwasser, S. On the limits of nonapproximability of lattice problems. J. Comput. Syst. Sci. 2000, 60, 540–563. [Google Scholar] [CrossRef] [Green Version]
- Blömer, J.; Naewe, S. Sampling methods for shortest vectors, closest vectors and successive minima. In International Colloquium on Automata, Languages, and Programming; Springer: Berlin/Heidelberg, Germany, 2007; pp. 65–77. [Google Scholar]
- Kabatiansky, G.A.; Levenshtein, V.I. On bounds for packings on a sphere and in space. Probl. Peredachi Informatsii 1978, 14, 3–25. [Google Scholar]
- Pisier, G. The Volume of Convex Bodies and Banach Space Geometry; Cambridge University Press: Cambridge, UK, 1999; Volume 94. [Google Scholar]
- Regev, O. Lecture Notes on Lattices in Computer Science; New York University: New York, NY, USA, 2009. [Google Scholar]
- Babai, L. On Lovász’ lattice reduction and the nearest lattice point problem. Combinatorica 1986, 6, 1–13. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).