
A Domain Adaptive Person Re-Identification Based on Dual Attention Mechanism and Camstyle Transfer


 ,
, 
Abstract
:
1. Introduction
- StarGAN is introduced into pedestrian image processing to reduce the distribution deviation between different sub-domains in the target dataset. Fast style conversion is applied to multi-domain images. The dataset is expanded while generating high-quality images.
- A dual-channel attention network is integrated to the feature extraction network. More discriminative features are obtained without affecting domain style. The feature dependence from both spatial and channel dimensions is obtained to further enhance feature representation.
- The effectiveness of the proposed method is verified by comparing with state-of-the-art methods on both Market-1501 and DukeMTMC-reID datasets.
2. Related Work
2.1. Unsupervised Domain Adaptation
2.2. Generative Adversarial Networks
2.3. Self-Attention Modules
3. The Proposed Method
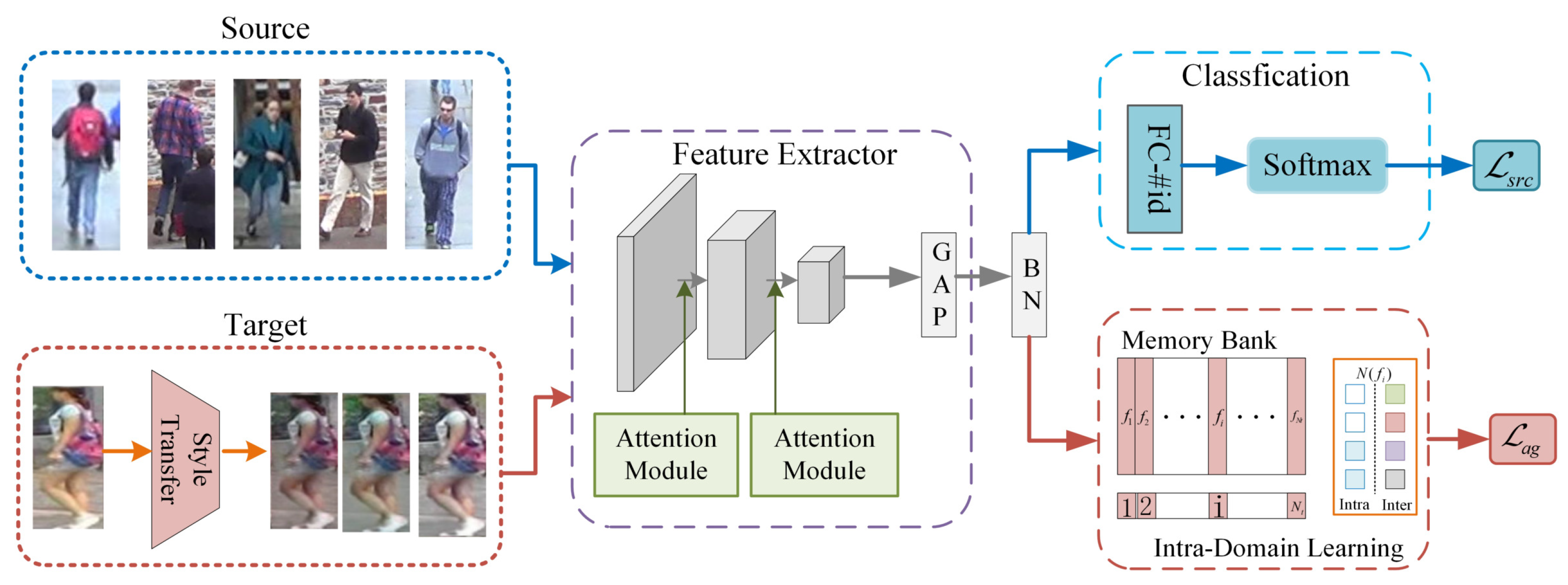
3.1. Overview of the Proposed Framework
3.2. Supervised Learning for Source Domain
3.3. Intra-Domain Learning
3.4. Camera-Aware Neighborhood Invariance
3.5. Style Transfer
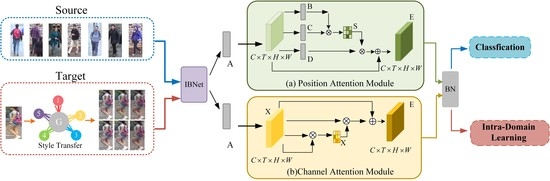
3.6. Dual Attention Network
3.6.1. Position Attention Module
3.6.2. Channel Attention Module
4. Experiments
4.1. Dataset and Evaluation Metrics
4.2. Deep Re-ID Model
4.3. Parameter Analysis
4.4. Ablation Study
4.5. Comparison with State-of-the-Art Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 17–35. [Google Scholar]
- Qi, G.; Hu, G.; Wang, X.; Mazur, N.; Zhu, Z.; Haner, M. EXAM: A Framework of Learning Extreme and Moderate Embeddings for Person Re-ID. J. Imaging 2021, 7, 6. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Chen, S.; Qi, G.; Zhu, Z.; Haner, M.; Cai, R. A GAN-Based Self-Training Framework for Unsupervised Domain Adaptive Person Re-Identification. J. Imaging 2021, 7, 62. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Luo, H.; Jiang, W.; Gu, Y.; Liu, F.; Liao, X.; Lai, S.; Gu, J. A strong baseline and batch normalization neck for deep person re-identification. IEEE Trans. Multimed. 2019, 22, 2597–2609. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Wang, X.; Zhu, Z.; Huang, X.; Li, P.; Qi, G.; Rong, Y. A Novel Person Re-ID Method based on Multi-Scale Feature Fusion. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 7154–7159. [Google Scholar]
- Jin, X.; Lan, C.; Zeng, W.; Chen, Z. Global distance-distributions separation for unsupervised person re-identification. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 735–751. [Google Scholar]
- Yu, H.X.; Zheng, W.S.; Wu, A.; Guo, X.; Gong, S.; Lai, J.H. Unsupervised person re-identification by soft multilabel learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2148–2157. [Google Scholar]
- Li, H.; Chen, Y.; Tao, D.; Yu, Z.; Qi, G. Attribute-Aligned Domain-Invariant Feature Learning for Unsupervised Domain Adaptation Person Re-Identification. IEEE Trans. Inf. Forensics Secur. 2021, 16, 1480–1494. [Google Scholar] [CrossRef]
- Li, H.; Dong, N.; Yu, Z.; Tao, D.; Qi, G. Triple Adversarial Learning and Multi-View Imaginative Reasoning for Unsupervised Domain Adaptation Person Re-Identification. Available online: https://ieeexplore.ieee.org/abstract/document/9495801 (accessed on 5 November 2021).
- Wu, A.; Zheng, W.S.; Lai, J.H. Unsupervised person re-identification by camera-aware similarity consistency learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October 2019; pp. 6922–6931. [Google Scholar]
- Lin, S.; Li, H.; Li, C.T.; Kot, A.C. Multi-task mid-level feature alignment network for unsupervised cross-dataset person re-identification. arXiv 2018, arXiv:1807.01440. [Google Scholar]
- Wang, J.; Zhu, X.; Gong, S.; Li, W. Transferable joint attribute-identity deep learning for unsupervised person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2275–2284. [Google Scholar]
- Zou, Y.; Yang, X.; Yu, Z.; Kumar, B.V.; Kautz, J. Joint disentangling and adaptation for cross-domain person re-identification. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 87–104. [Google Scholar]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person transfer gan to bridge domain gap for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 79–88. [Google Scholar]
- Zhong, Z.; Zheng, L.; Zheng, Z.; Li, S.; Yang, Y. Camera style adaptation for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5157–5166. [Google Scholar]
- Lin, Y.; Dong, X.; Zheng, L.; Yan, Y.; Yang, Y. A bottom-up clustering approach to unsupervised person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8738–8745. [Google Scholar]
- Fan, H.; Zheng, L.; Yan, C.; Yang, Y. Unsupervised person re-identification: Clustering and fine-tuning. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2018, 14, 1–18. [Google Scholar] [CrossRef]
- Zhai, Y.; Lu, S.; Ye, Q.; Shan, X.; Chen, J.; Ji, R.; Tian, Y. Ad-cluster: Augmented discriminative clustering for domain adaptive person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9021–9030. [Google Scholar]
- Zhu, Z.; Luo, Y.; Chen, S.; Qi, G.; Mazur, N.; Zhong, C.; Li, Q. Camera style transformation with preserved self-similarity and domain-dissimilarity in unsupervised person re-identification. J. Vis. Commun. Image Represent. 2021, 80, 103303. [Google Scholar] [CrossRef]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Zhong, Z.; Zheng, L.; Luo, Z.; Li, S.; Yang, Y. Invariance matters: Exemplar memory for domain adaptive person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 598–607. [Google Scholar]
- Yang, Q.; Yu, H.X.; Wu, A.; Zheng, W.S. Patch-based discriminative feature learning for unsupervised person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3633–3642. [Google Scholar]
- Ding, Y.; Fan, H.; Xu, M.; Yang, Y. Adaptive exploration for unsupervised person re-identification. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2020, 16, 1–19. [Google Scholar] [CrossRef]
- Zhong, C.; Jiang, X.; Qi, G. Video-based Person Re-identification Based on Distributed Cloud Computing. J. Artif. Intell. Technol. 2021, 1, 110–120. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Zhu, Z.; Luo, Y.; Wei, H.; Li, Y.; Qi, G.; Mazur, N.; Li, Y.; Li, P. Atmospheric Light Estimation Based Remote Sensing Image Dehazing. Remote Sens. 2021, 13, 2432. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Chen, Y.; Zhu, X.; Gong, S. Person re-identification by deep learning multi-scale representations. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2590–2600. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Zhu, Z.; Luo, Y.; Qi, G.; Meng, J.; Li, Y.; Mazur, N. Remote Sensing Image Defogging Networks Based on Dual Self-Attention Boost Residual Octave Convolution. Remote Sens. 2021, 13, 3104. [Google Scholar] [CrossRef]
- Huang, Y.; Wu, Q.; Xu, J.; Zhong, Y. SBSGAN: Suppression of inter-domain background shift for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October 2019; pp. 9527–9536. [Google Scholar]
- Liu, J.; Zha, Z.J.; Chen, D.; Hong, R.; Wang, M. Adaptive transfer network for cross-domain person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7202–7211. [Google Scholar]
- Sun, J.; Qi, G.; Mazur, N.; Zhu, Z. Structural Scheduling of Transient Control Under Energy Storage Systems by Sparse-Promoting Reinforcement Learning. IEEE Trans. Ind. Inform. 2022, 18, 744–756. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Huang, H.; Yang, W.; Chen, X.; Zhao, X.; Huang, K.; Lin, J.; Huang, G.; Du, D. Eanet: Enhancing alignment for cross-domain person re-identification. arXiv 2018, arXiv:1812.11369. [Google Scholar]
- Zhu, Z.; Wei, H.; Hu, G.; Li, Y.; Qi, G.; Mazur, N. A Novel Fast Single Image Dehazing Algorithm Based on Artificial Multiexposure Image Fusion. IEEE Trans. Instrum. Meas. 2021, 70, 1–23. [Google Scholar] [CrossRef]
- Zheng, M.; Qi, G.; Zhu, Z.; Li, Y.; Wei, H.; Liu, Y. Image Dehazing by an Artificial Image Fusion Method Based on Adaptive Structure Decomposition. IEEE Sens. J. 2020, 20, 8062–8072. [Google Scholar] [CrossRef]
- Wu, J.; Liao, S.; Wang, X.; Yang, Y.; Li, S.Z. Clustering and dynamic sampling based unsupervised domain adaptation for person re-identification. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 886–891. [Google Scholar]
- Zhang, X.; Cao, J.; Shen, C.; You, M. Self-training with progressive augmentation for unsupervised cross-domain person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October 2019; pp. 8222–8231. [Google Scholar]
- Fu, Y.; Wei, Y.; Wang, G.; Zhou, Y.; Shi, H.; Huang, T.S. Self-similarity grouping: A simple unsupervised cross domain adaptation approach for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October 2019; pp. 6112–6121. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Liu, M.Y.; Tuzel, O. Coupled generative adversarial networks. Adv. Neural Inf. Process. Syst. 2016, 29, 469–477. [Google Scholar]
- Ning, X.; Gong, K.; Li, W.; Zhang, L.; Bai, X.; Tian, S. Feature Refinement and Filter Network for Person Re-Identification. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3391–3402. [Google Scholar] [CrossRef]
- Xia, B.N.; Gong, Y.; Zhang, Y.; Poellabauer, C. Second-order non-local attention networks for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3760–3769. [Google Scholar]
- Zheng, L.; Huang, Y.; Lu, H.; Yang, Y. Pose-invariant embedding for deep person re-identification. IEEE Trans. Image Process. 2019, 28, 4500–4509. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Deng, W.; Hu, J. Mixed high-order attention network for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October 2019; pp. 371–381. [Google Scholar]
- Zhong, Z.; Zheng, L.; Li, S.; Yang, Y. Generalizing a person retrieval model hetero-and homogeneously. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 172–188. [Google Scholar]
- Jia, X.; Wang, X.; Mi, Q. An unsupervised person re-identification approach based on cross-view distribution alignment. IET Image Process. 2021, 15, 2693–2704. [Google Scholar] [CrossRef]
- Deng, W.; Zheng, L.; Ye, Q.; Kang, G.; Yang, Y.; Jiao, J. Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 994–1003. [Google Scholar]
- Zhong, Z.; Zheng, L.; Zheng, Z.; Li, S.; Yang, Y. Camstyle: A novel data augmentation method for person re-identification. IEEE Trans. Image Process. 2018, 28, 1176–1190. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.J.; Yang, F.E.; Liu, Y.C.; Yeh, Y.Y.; Du, X.; Frank Wang, Y.C. Adaptation and re-identification network: An unsupervised deep transfer learning approach to person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–178. [Google Scholar]
- Song, L.; Wang, C.; Zhang, L.; Du, B.; Zhang, Q.; Huang, C.; Wang, X. Unsupervised domain adaptive re-identification: Theory and practice. Pattern Recognit. 2020, 102, 107173. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| s | Duke to Market | Market to Duke | ||||||
|---|---|---|---|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-10 | mAP | Rank-1 | Rank-5 | Rank-10 | mAP | |
| 6 | 68.5 | 82.3 | 86.6 | 38.3 | 61.8 | 72.6 | 76.4 | 39.3 |
| 8 | 75.1 | 86.4 | 89.7 | 45.6 | 65.9 | 75.9 | 80.4 | 44.2 |
| 10 | 80.1 | 89.9 | 93.2 | 60.1 | 68.1 | 79.1 | 82.3 | 46.9 |
| 12 | 78.8 | 88.9 | 91.9 | 54.3 | 69.5 | 80.4 | 83.4 | 48.5 |
| 14 | 76.6 | 87.4 | 90.6 | 53.5 | 68.9 | 80.7 | 84.3 | 53.0 |
| Method | Duke to Market | |||
|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-10 | mAP | |
| None | 77.8 | 88.1 | 91.7 | 48.4 |
| Channel | 78.8 | 88.3 | 91.7 | 48.6 |
| Position | 78.7 | 88.9 | 92 | 48.5 |
| Position-Channel | 77.9 | 88 | 91.5 | 50.5 |
| Channel-Position | 79.1 | 88.7 | 92.5 | 53.5 |
| Channel+Position | 80.5 | 89.5 | 93.2 | 60.1 |
| Method | Market1501 | DukeMTMC-reID | ||||||
|---|---|---|---|---|---|---|---|---|
| R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 | mAP | |
| PTGAN [16] | 38.6 | - | 66.1 | - | 27.4 | - | 50.7 | - |
| SPGAN [52] | 51.5 | 70.1 | 76.8 | 22.8 | 41.1 | 56.6 | 63 | 22.3 |
| CamStyle [53] | 58.8 | 78.2 | 84.3 | 27.4 | 48.4 | 62.5 | 68.9 | 25.1 |
| HHL [50] | 62.2 | 78.8 | 84 | 31.4 | 46.9 | 61 | 66.7 | 27.2 |
| MAR [9] | 67.7 | 81.9 | - | 40 | 67.1 | 79.8 | - | 48 |
| PAUL [24] | 68.5 | 82.4 | 87.4 | 40.1 | 72 | 82.7 | 86 | 53.2 |
| ARN [54] | 70.3 | 80.4 | 86.3 | 39.4 | 60.2 | 73.9 | 79.5 | 33.4 |
| ECN [23] | 75.1 | 87.6 | 91.6 | 43 | 63.3 | 75.8 | 80.4 | 40.4 |
| UDA [55] | 75.8 | 89.5 | 93.2 | 53.7 | 68.4 | 80.1 | 83.5 | 49 |
| PAST [41] | 78.4 | - | - | 54.6 | 72.4 | - | - | 54.3 |
| SSG [42] | 80 | 90 | 92.4 | 58.3 | 73 | 80.6 | 83.2 | 53.4 |
| CV-DA [51] | 79.7 | 89 | 91.4 | 59.8 | 71.1 | 81.2 | 84.2 | 52.6 |
| Ours | 80.5 | 89.9 | 93.2 | 60.1 | 71.2 | 81.7 | 84.3 | 53.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, C.; Qi, G.; Mazur, N.; Banerjee, S.; Malaviya, D.; Hu, G. A Domain Adaptive Person Re-Identification Based on Dual Attention Mechanism and Camstyle Transfer. Algorithms 2021, 14, 361. https://doi.org/10.3390/a14120361
Zhong C, Qi G, Mazur N, Banerjee S, Malaviya D, Hu G. A Domain Adaptive Person Re-Identification Based on Dual Attention Mechanism and Camstyle Transfer. Algorithms. 2021; 14(12):361. https://doi.org/10.3390/a14120361
Chicago/Turabian StyleZhong, Chengyan, Guanqiu Qi, Neal Mazur, Sarbani Banerjee, Devanshi Malaviya, and Gang Hu. 2021. "A Domain Adaptive Person Re-Identification Based on Dual Attention Mechanism and Camstyle Transfer" Algorithms 14, no. 12: 361. https://doi.org/10.3390/a14120361
APA StyleZhong, C., Qi, G., Mazur, N., Banerjee, S., Malaviya, D., & Hu, G. (2021). A Domain Adaptive Person Re-Identification Based on Dual Attention Mechanism and Camstyle Transfer. Algorithms, 14(12), 361. https://doi.org/10.3390/a14120361