Abstract
Principal component analysis (PCA) is one of the most popular tools in multivariate exploratory data analysis. Its probabilistic version (PPCA) based on the maximum likelihood procedure provides a probabilistic manner to implement dimension reduction. Recently, the bilinear PPCA (BPPCA) model, which assumes that the noise terms follow matrix variate Gaussian distributions, has been introduced to directly deal with two-dimensional (2-D) data for preserving the matrix structure of 2-D data, such as images, and avoiding the curse of dimensionality. However, Gaussian distributions are not always available in real-life applications which may contain outliers within data sets. In order to make BPPCA robust for outliers, in this paper, we propose a robust BPPCA model under the assumption of matrix variate t distributions for the noise terms. The alternating expectation conditional maximization (AECM) algorithm is used to estimate the model parameters. Numerical examples on several synthetic and publicly available data sets are presented to demonstrate the superiority of our proposed model in feature extraction, classification and outlier detection.
1. Introduction
High-dimensional data are increasingly collected for a variety of applications in the real world. However, high-dimensional data are not often distributed uniformly in their ambient space, instead of that the interesting structure inside the data often lies in a low-dimensional space [1]. One of the fundamental challenges is how to find the low-dimensional data representation for high-dimensional observed data in pattern recognition, machine learning and statistics [2,3]. Principal component analysis (PCA) [4] is arguably the most well-known dimension reduction method for high-dimensional data analysis, and it aims to find the first few principal eigenvectors corresponding to the first few largest eigenvalues of the covariance matrix, and then projects the high-dimensional data onto the low-dimensional subspace spanned by these principal eigenvectors to achieve the purpose of dimensionality reduction.
The traditional PCA is concerned with vectorial data, i.e., 1-D data. For 2-D image trained sample matrices, it is usual to first convert 2-D image matrices into 1-D image vectors. This transformation leads to higher dimensional image sample vectors and a larger covariance matrix, and thus suffers from the difficulty of accurately evaluating the principal eigenvectors of the large scale covariance matrix. Furthermore, such vectorizing of 2-D data destroys the natural matrix structure, and ignores potentially valuable information about the spatial relationships among 2-D data. Therefore, two-dimensional PCA (2DPCA) type algorithms [5,6,7] are proposed to compute principal component weight matrices directly based on 2-D image training with sample matrices instead of using vectorization.
These conventional PCA and 2DPCA algorithms are both derived and interpreted in the standard algebraic framework, thus they lack capability in handling issues of statistical inference or missing data. To remedy these drawbacks, a probabilistic PCA model (PPCA) has been proposed by Tipping and Bishop in [8], which is processed by assuming some Gaussian distributions on observations with introduced extra latent variables, and it has been successfully applied in many machine learning tasks [9]. Following PPCA, a probabilistic second-order PCA, called PSOPCA, is developed in [10] to directly model 2-D image matrices based on the so-called matrix variate Gaussian distributions.
Throughout this paper, is the set of all real matrices, and are the identity matrix and zero matrix, respectively. The superscript “” means transpose only, and denote the -norm and Frobenius norm of a matrix, respectively. Denoted by is the matrix variate Gaussian distribution [11] with the mean matrix , column covariance and row covariance . A random matrix is said to follow the matrix variate Gaussian distribution , i.e.,
where is the vectorization of a matrix obtained by stacking the columns of the matrix on top of one another. That means that the probability density function (pdf) of X is
where “⊗” is the Kronecker product of two matrices, and denotes the trace of a matrix. The last equality of (2) holds because of and
See ([11], Theorem 1.2.21) and ([11], Theorem 1.2.22) for more details.
PSOPCA in [10] considers the following two-sided latent matrix variable model
where and are the column and row factor loading matrices, respectively, and are the mean and error matrices, respectively, and is the latent core variable of X. The PSOPCA model is further extended to the bilinear probabilistic principal component analysis (BPPCA) model in [12] for better establishing the relationship with the 2DPCA algorithm [6], which is defined as
In contrast to the PSOPCA model (3), the column and row noise matrices and with different noise variances and , respectively, are included in the BPPCA model, and is represented as the common noise matrix. The model (4) improves the flexibility in capturing data uncertainty, and makes the marginal distribution to be the matrix variable Gaussian. In particular, we can see that if and are removed and , then (4) reduces to the PSOPCA model.
All of the above mentioned probabilistic models assume that the noise terms follow Gaussian distributions. It is a well-known issue that Gaussian noises will lead to a serious drawback while dealing with anomalous observations. Thus, the probabilistic PCA models based on Gaussian distributions are not robust to outliers. To make probabilistic models which are insensitive to outliers, one prefers heavy-tailed distributions, such as the Student t distribution or centered Laplacian distribution with -norm. Using the t distribution or centered Laplacian distribution instead of the Gaussian distribution in the PPCA model [8] results in tPPCA [13,14] and probabilistic L1-PPCA [15] algorithms, respectively. Similarly, a robust version of PSOPCA, called L1-2DPPCA, is introduced in [16] based on the Laplacian distribution combined with variational EM-type algorithms to learn parameters. However, it is difficult to generalize a robust version of the BPPCA algorithm based on the Laplacian distribution. The reason is that if the error term in the PSOPCA model is a Laplacian distribution, then the condition distribution is also a Laplacian distribution, but it does not hold in the BPPCA model. Fortunately, the same goal can be achieved by using the t distribution. In fact, the Gaussian distribution is a special t distribution. Compared to the Gaussian distribution, the t distribution has significantly heavier tails and contains one more free parameter. Recently, some robust probabilistic models under the assumption of the t distribution have already been done successfully by a number of researchers in [17,18,19,20,21,22]. Motivated by these facts, we will continue the effort to develop a robust BPPCA model from matrix variate t distributions to handle 2-D data sets in the presence of outliers.
The remainder of the paper is organized as follows. Section 2 introduces some notations and a matrix variate t distribution which are essential to our later development. The robust BPPCA model and its associated parameters estimation based on the AECM algorithm are given and analyzed in detail in Section 3. Section 4 is dedicated to present some numerical examples for showing the behaviors of our proposed model and to support our analysis. Finally, conclusions are made in Section 5.
2. Preliminaries
Let , , and , and the probability density function of the random variable having a Gamma distribution with parameters and , i.e., , be
where is the Gamma function, i.e.,
Analogously to the process of tPPCA in [14], we derive the matrix variate t distribution in this paper by considering
where . Let . We have
Let . Then, and . Therefore, (7) can be rewritten as
In this paper, if the pdf of the random matrix X is
then the random matrix X is said to follow the matrix variate t distribution with degrees of freedom , and is denoted by
In particular, if or , then the matrix variate t distribution degenerates to the multivariate t distribution. As the classical multivariate t distribution, another favorite perspective on the matrix variate t distribution which is critical to our later developments, is to treat as a latent variable, then the conditional distribution of is a matrix variate Gaussian distribution by (8), i.e.,
where . Notice that, despite the non-uniqueness in the factorization , in (10) always returns the same pdf of X.
3. Robust BPPCA
3.1. The Model
In this section, we develop a robust model by replacing the matrix variate Gaussian distribution in BPPCA with the matrix variate t distribution with degrees of freedom defined in (9) to deal with 2-D data sets. Specifically, the proposed robust bilinear probabilistic principal analysis model (RBPPCA for short) is defined as
As BPPCA [12], in the RBPPCA model (11), , and are the column, row and common noise matrices, respectively, is the latent matrix, and these are assumed to be independent of each other, and the mean matrix, and the column and row factor loading matrices are , and , respectively. Similarly to BPPCA [12], the parameters C, R, and can not be uniquely identified, but the interested subspaces spanned by the columns of C and R are unique. The reader is referred to ([12], Appendix B) for details. The difference from BPPCA is that the noise matrices , and and latent matrix variate Z in the RBPPCA model (11) are supposed matrix variate t distributions by (10), i.e.,
It follows by (11) that
Consequently, where
That means the random matrix X follows the matrix variate t distribution, i.e., . In addition, as shown in [23], the conditional distribution which is also required in our later estimation of model parameters is a Gamma distribution, i.e.,
where .
By introducing two latent matrix variates and , the RBPPCA model (11) can be rewritten as
where and are the row projected intermediate and residual matrices, respectively. By (11), we have the conditional distributions
where is given by (12). In addition, by using (15c) and the Bayes’ rule, the conditional distributions and can be calculated as
where
In (14), the bilinear projection in the RBPPCA model is split into two stages by first projecting the latent matrix Z in the row direction to obtain , then being projected in the column direction to finally generate X. Similarly, we can also consider the decomposition of the bilinear projection by first projecting column and then row directions to rewrite (11) as
where and with and . Furthermore,
3.2. Estimation of the Parameters
In the model (11), the parameter set to be estimated is . We will introduce how to calculate the parameters by using the alternating expectation conditional maximization (AECM) algorithm in this subsection. The AECM algorithm [12,24,25] is a two stage iterative optimization technique for finding maximum likelihood solutions. To apply it to the AECM algorithm, we divide the parameter set into two subsets and .
In the first stage, we consider the AECM algorithm for the model (14) to compute . Let with be a set of 2-D sample observations. The latent variables’ data are treated as “missing data”, and the “complete” data log-likelihood is
In E-step, given the parameter set which is obtained from the i-th iteration, we compute the expectation of with respect to the condition distribution , i.e.,
where the constant contains those terms without referring the parameters in the set . We denote and for convenience. It is noted by (13) and (16b) that given the parameter set , the conditional distributions of and are known. That is, for ,
where , , , and with . Then, it is easy to obtain that
In addition, based on the conditional distributions of and , in (20), the condition expectations by [13] where is the digamma function, and
which is detailed in Appendix A.
In the subsequent conditional maximization (CM) step of the first stage, given the condition , we maximize with respect to . It follows by (20) that
Therefore, by successively solving the equations , and , we can iteratively update the parameters W, C and . Specifically, by , we have
That means
Thus, an iterative updating of W can be obtained by
Similarly, based on and , we have
The last equality (24b) holds because of (22) and (24a). Finally, we update by maximizing the scalar nonlinear function defined in (20) on v, which can be solved numerically by most scientific computation software packages [26,27], to obtain .
In the second stage, the AECM algorithm is used for the model (18) to update . In such a case, we consider the latent variables’ data as “missing data”. Then, by (19b), the “complete” data log-likelihood is
Similarly, in E-step of the second stage, given the updated parameter set
where , , and are calculated from the first stage, we compute the expectation of with respect to the condition distribution , denoted by . Based on (19) and the current parameter set , we define
We have, up to a constant,
where and
See Appendix A for the derivation of (27). At last, in CM-step of the second stage, based on , similarly to (23) and (24), we maximize with respect to to update
and then solve the scalar nonlinear maximization problem (26) on to get .
We summarize what we do in this subsection in Algorithm 1. A few remarks regarding Algorithm 1 are in order:
- (1)
- In Algorithm 1, it is not necessarily to explicitly compute and . The reason is that the calculation of and can be more efficiently performed by usingIn its per-iteration of Algorithm 1, the most expensive computational cost is appearing on the formation of with . Owing to introducing the new latent variable , RBPPCA is a little more time complex than BPPCA having a calculation cost of . However, it will be shown in our numerical example that the RBPPCA algorithm presents less sensitivity to outliers.
- (2)
- Compared with the AECM algorithm of BPPCA in [12] which uses the centered data and estimates and based on the model and , respectively, two more parameters and W are needed to be computed in the AECM iteration of RBPPCA. Notice that both the models (14) and (18) contain the parameters and W. Thus, we split the parameter set into and which naturally leads to the parameters and W being calculated twice in each loop of Algorithm 1. Though other partitions of the set , such as and , are also available for the estimation of parameters, we prefer and , because updating and W one more time in each iteration can be obtained by adding a little more computational cost.
- (3)
- As stated in Section 3.3 of [24], any AECM sequence increases at each iteration, and converges to a stationary point of . Notice that the convergence results of the AECM algorithm proved in Section 3.3 of [24] do not depend on the distributions of the data sets. Therefore, up to set a limit on the maximum number of steps , we use the following relative change of log-likelihood as the stopping criterion, i.e.,where is a specified tolerance used, which by default is set to in our numerical examples.
- (4)
- Based on the computed results of Algorithm 1, and similar to PPCA [8] and BPPCA [12], it is known thatcan be considered as the compressed representation of X. Hence, we can reconstruct X as
| Algorithm 1 Robust bilinear probabilistic PCA algorithm (RBPPCA). |
| Input: Initialization , and sample matrices . Compute . Output: the converged {}
|
4. Numerical Examples
In this section, we conduct several numerical examples based on synthetic problems and three real-world data sets to demonstrate the effectiveness of our proposed RBPPCA algorithm. All experiments were run by using MATLAB (2016a) with machine epsilon on a Windows 10 (64 bit) Laptop with an Intel Core i7-8750H CPU (2.20GHz) and 8GB memory. Each random experiment was repeated 20 times independently, then the average numerical results were reported.
Example 1
(Experiments on the synthetic data).In this example, we only compare ours with the BPPCA algorithm [12] to illustrate the significant improvement of the RBPPCA algorithm. We take N data matrices for with and , of which are generated by
where C, R and W are simply synthesized by MATLAB as
, , and are sampled from matrix variate normal distributions , , , and with , respectively. The other data matrices, i.e., for , are regarded as outliers of which each entry is sampled from the uniform distribution over the range of 0 to 10. In order to demonstrate the quality of computed approximations and , we calculate the arc length distance between the two subspaces and , which is used in [12] and defined as
to monitor the numerical performance of the RBPPCA and BPPCA method, where and are the column space of and , respectively, and Q and are the orthogonal base matrices of and , respectively. In fact, by ([28], Definition 4.2.1), the computational result of (31) is the largest canonical angle between the estimated subspace and the true .
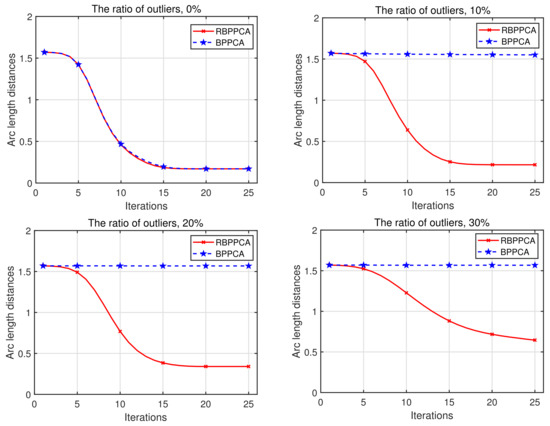
In this test, we start with , , , and , then consider the effect of the ratio of outliers, i.e., , which is varied from 0 to 30% with a stride length of 10% in this example. In these cases, the estimated values of are all . If we use other initial values here, the computed also converges to one as iterations increase. The corresponding numerical results of arc length distances are plotted in Figure 1. Figure 1 shows that the RBPPCA and BPPCA methods almost perform with the same convergence behavior when the data matrices are without outliers.
Figure 1.
Convergence behaviors of RBPPCA and BPPCA with the ratio of outliers being 0%, 10%, 20% and 30%, respectively.
As the ratio of outliers goes to 30%, it is reasonable that more iterations are required for the RBPPCA method to achieve a satisfactory accuracy. Unlike the BPPCA method, the presented RBPPCA method is more robust to outliers because the arc length distances of the BPPCA method are always held to approximately when the data includes outliers.
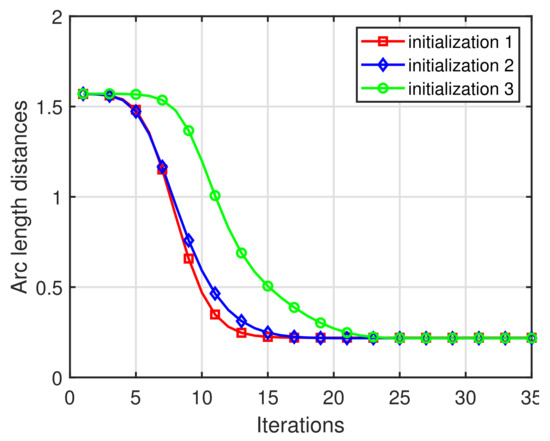
In this example, we also test the impact of the initializations on and , and the sample size N, respectively, based on the synthetic data having 10% outliers. Three different types of initializations of and are set as follows:
- (1)
- initialization 1: and ;
- (2)
- initialization 2: and ;
- (3)
- initialization 3:
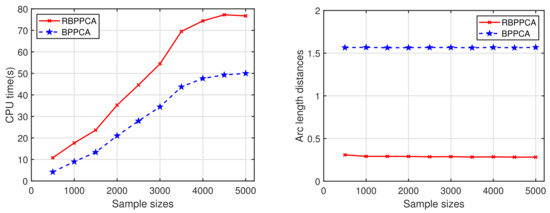
and other parameters are fixed to be the same. The results associated with the different initializations are shown in Figure 2. Inspection of the plot illustrates that our RBPPCA method appears to be insensitive to different initializations, since the convergence behaviors of the RBPPCA method based on different initializations do not have a significant difference. Figure 3 presents the required CPU time in seconds and the quantities of arc length distances of the BPPCA and RBPPCA methods with the number of iterations being 25 with respect to the number of samples, where the sample size N varies from 200 to 5000 with a stride length of 200. Such graphs covey the fact that with the increase of the sample size N, the BPPCA and RBPPCA methods both required more CPU time for 25 iterations, and the BPPCA method needs less time complexity than RBPPCA as we stated in the remarks of Algorithm 1. However, the bigger N does not lead to the improved arc length distances of the BPPCA method.
Figure 2.
Convergence behaviors of RBPPCA for three different types of initialization.
Figure 3.
CPU time in seconds (left) and arc length distances (right) of BPPCA and RBPPCA with the number of iterations being 25 with the sample size N from 200 to 5000.
Example 2





(Experiments on face image databases).In this example, all of the experiments are based on two publicly available face image databases: the Yale face database ( Available from http://vision.ucsd.edu/content/yale-face-database) (accessed on 22 September 2021), and the Yale B face database (Available from http://vision.ucsd.edu/~leekc/ExtYaleDatabase/ExtYaleB.html) (accessed on 22 September 2021).The Yale face database includes different face orientations, facial expression, and whether there exist glasses, and the Yale B face database is collected under different illumination conditions. We select 265 face images of 15 individuals for each database. Each person has 11 images, and these images are cropped to pixels. For each individual, eight images are randomly selected as the training set, and the rest are the test set. Then, we randomly select two and four images from the eight images in the training set to be corrupted as outliers, respectively. Half of the corrupted images are generated by replacing part of the original image with a rectangle of noise, and the other half of corrupted images use a rectangle of noise to replace it. Within each rectangle, the pixel value comes from a uniform distribution on the interval . Then, we rescale the images from the range of [0, 255] to the range [0, 1]. Some original and corrupted images of the Yale and Yale B databases are shown in Figure 4, Figure 5, Figure 6 and Figure 7, respectively. The iteration of BPPCA and RBPPCA is stopped when their corresponding relative changes of the log-likelihood defined in (29) are smaller than .
Figure 4.
One set of processed samples from the Yale face database.
Figure 5.
Some generated outlier face images in the training set from the Yale face database.
Figure 6.
Eleven images of an individual from the Yale B face database.
Figure 7.
Some corrupted face images in the training set of the Yale B face database.
We run the BPPCA and RBBPCA algorithms for the original data set and the corrupted data set, respectively, with the order of Z in (11) being , and consider the reconstructed images defined in (30) based on the computed results. A comparison of the reconstructed images based on the original data set and corrupted data set with two corrupted images for each individual is shown in Figure 8. In Figure 8, the first, second and third columns are the original images, the reconstructed images of RBPPCA, and the reconstructed images of BPPCA for the Yale (left) and Yale B (right) databases, respectively, and the images of the first, second and third rows are shown based on the original, corrupted data sets with rectangles of noise, and corrupted data sets with rectangles of noise, respectively. The BPPCA and RBPPCA almost perform the same as the reconstructed images on the original data set. However, for corrupted data sets, the reconstructed performance of RBPPCA presents better images than BPPCA because it tries to explain noise information.
Figure 8.
Original images (the first column), reconstructed images by RBPPCA (the second column), and reconstructed images by BPPCA (the third column) of the Yale (left) and Yale B (right) databases, respectively.
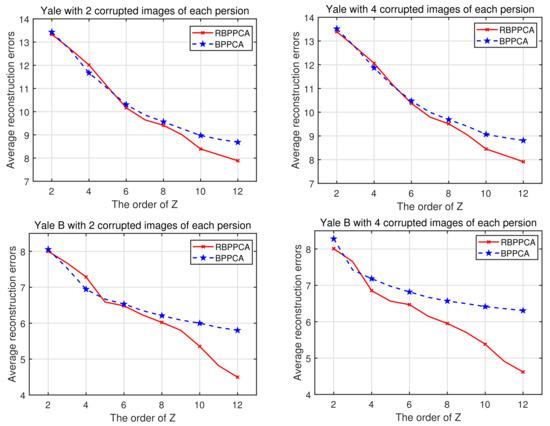
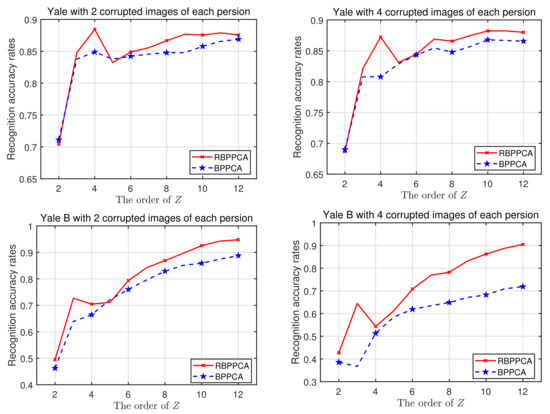
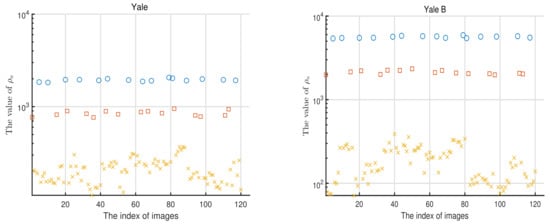
We also compare the average reconstruction errors and the recognition accuracy rates for the RBPPCA and BPPCA algorithms in the cases where each person has two corrupted images and four corrupted images, respectively, where recognition accuracy rates are calculated based on the nearest neighbor classifier (1-NN) which is employed for the classification. The average reconstruction errors and recognition accuracy rates versus the order of Z are plotted in Figure 9 and Figure 10, respectively. As expected, the average reconstruction errors decrease, while the recognition accuracy rates rise as the order of Z increases. In these cases, our proposed RBPPCA algorithm outperforms the BPPCA algorithm in reducing average reconstruction errors and enhancing the recognition accuracy. In addition, another advantage of robust probabilistic algorithms based on t distributions is outlier detection. By [14], we can compute as the standard of outlier detection. Figure 11 is the scatter chart for of all the images in the training set of the Yale and Yale B databases with two corrupted images for one person, respectively. It is exhibited that the quantity of can be divided into three parts. Notice that these three parts correspond to the images with no noise, a rectangle of noise, and a rectangle of noise, respectively. Hence, the comparison of provides a method for judging the outliers.
Figure 9.
Average reconstruction errors of the BPPCA and RBPPCA algorithms vs. the order of Z for the Yale and Yale B databases with 2 and 4 corrupted images of each individual, respectively.
Figure 10.
Recognition accuracy rates of the BPPCA and RBPPCA algorithms vs. the order of Z for the Yale and Yale B databases with 2 and 4 corrupted images of each individual, respectively.
Figure 11.
of each image in the Yale (left) and Yale B (right) databases, respectively, with 2 corrupted images of each individual.
Example 3


(Experiments on the MNIST dataset).In Example 2, it is shown that RBPPCA is superior to BPPCA when the data sets contain outliers. In this example, we compare the RBPPCA algorithm to the tPPCA [14] and L1-PPCA [15] algorithms based on handwritten digit images from the MNIST (Available from http://yann.lecun.com/exdb/mnist) (accessed on 22 September 2021) database in which each image has pixels. We choose 59 images of the digit 4 as the training data set, and randomly select nine of them to be corrupted as outliers. The way of corrupting the images is to add noise from a uniform distribution on the interval, and then normalize all images to the range. The normalized corrupted images of the digit 4 are shown in Figure 12. The RBPPCA, tPPCA [14] and L1-PPCA [15] algorithms are implemented with 100 iterations for the original data set of the digit 4 and the corrupted data set, respectively.
Figure 12.
The normalized corrupted images of the digit 4.
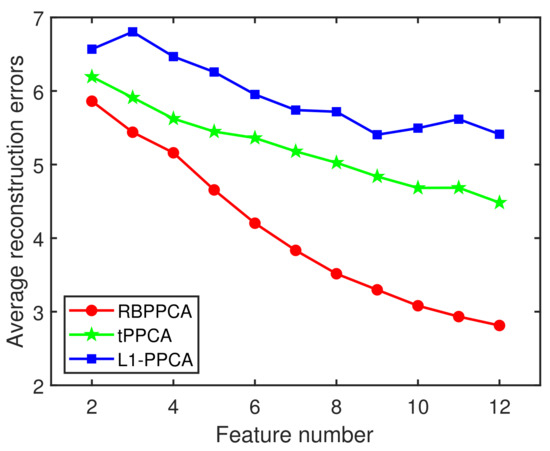
Figure 13 presents the average reconstruction errors of the RBBPCA, tPPCA and L1-PPCA algorithms where the feature number is the order of Z for the RBBPCA algorithm and is the dimension of the low-dimensional representation for the tPPCA and L1-PPCA algorithms. It is observed that the performance of our RBPPCA algorithm is superior to other algorithms. The reconstructed behaviors of different algorithms based on the original data set of the digit 4 and the corrupted data set with are shown in Figure 14. In Figure 14, the first column is the original images, and the second, third and fourth columns are the reconstructed images by the RBBPCA, tPPCA and L1-PPCA algorithms, respectively. As shown in Figure 14, compared to the tPPCA and L1-PPCA algorithms, the RBPPCA algorithm performs better reconstruction outcomes in such a case.
Figure 13.
Average reconstruction errors of the RBPPCA, tPPCA and L1-PPCA algorithms vs. feature number on the MINST database.
Figure 14.
Original images of the digit 4 (the first column), images reconstructed by RBPPCA (the second column), images reconstructed by tPPCA (the third column), and images reconstructed by L1-PPCA (the fourth column). The images shown in the first and second rows are based on the original and corrupted image data sets, respectively.
5. Conclusions
To remedy the problem that data are assumed to follow a matrix variate Gaussian distribution which is sensitive to outliers, in this paper, we proposed a robust BPPCA algorithm (RBPPCA), i.e., Algorithm 1, by replacing the matrix variate Gaussian distribution with the matrix variate t distribution for noise. Compared to BPPCA, owing to the matrix variate t distribution having a significantly heavy tail property, our proposed RBPPCA method combined with AECM for estimating parameters can deal with 2-D data sets in the presence of outliers. The numerical examples based on a synthetic and two publicly available real data sets, Yale and Yale B, are presented to state that Algorithm 1 is far superior to the BPPCA algorithm in computational accuracy, reconstruction performance, average reconstruction errors, recognition accuracy rates, and outlier detection. It is also shown by numerical examples based on the MNIST database that our RBPPCA method outperforms the tPPCA and L1-PPCA algorithms.
Author Contributions
Writing—original draft, Y.L.; Writing—review and editing, Z.T. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported in part by the research fund for distinguished young scholars of Fujian Agriculture and Forestry University No. xjq201727, and the science and technology innovation special fund project of Fujian Agriculture and Forestry University No. CXZX2020105A.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
We first consider the conditional expectation of with respect to the condition distribution , which will be applied in our derivations of (22). That is
where and are given by (21). In addition, for symmetric matrices and , we have
Notice that (22) can be rewritten as
Then, we give the calculation results of the terms on the right hand side of (A3) from below. It is clear that
References
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Burges, C.J.C. Dimension Reduction: A Guided Tour; Now Publishers Inc.: Noord-Brabant, The Netherlands, 2010. [Google Scholar]
- Ma, Y.; Zhu, L. A review on dimension reduction. Int. Stat. Rev. 2013, 81, 134–150. [Google Scholar]
- Jolliffe, I.T. Principal Component Analysis; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Yang, J.; Zhang, D.; Frangi, A.F.; Yang, J. Two-dimensional PCA: A new approach to appearance-based face representation and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 131–137. [Google Scholar]
- Ye, J. Generalized low rank approximations of matrices. Mach. Learn. 2005, 61, 167–191. [Google Scholar]
- Zhang, D.; Zhou, Z.H. (2D) 2PCA: Two-directional two-dimensional PCA for efficient face representation and recognition. Neurocomputing 2005, 69, 224–231. [Google Scholar]
- Tipping, M.E.; Bishop, C.M. Probabilistic principal component analysis. J. R. Stat. Soc. Ser. B Stat. Methodol. 1999, 61, 611–622. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Yu, S.; Bi, J.; Ye, J. Matrix-variate and higher-order probabilistic projections. Data Min. Knowl. Discov. 2011, 22, 372–392. [Google Scholar]
- Gupta, A.K.; Nagar, D.K. Matrix Variate Distributions; CRC Press: Boca Raton, FL, USA, 2018; Volume 104. [Google Scholar]
- Zhao, J.; Philip, L.H.; Kwok, J.T. Bilinear probabilistic principal component analysis. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 492–503. [Google Scholar]
- Zhao, J.; Jiang, Q. Probabilistic PCA for t distributions. Neurocomputing 2006, 69, 2217–2226. [Google Scholar]
- Chen, T.; Martin, E.; Montague, G. Robust probabilistic PCA with missing data and contribution analysis for outlier detection. Comput. Stat. Data Anal. 2009, 53, 3706–3716. [Google Scholar]
- Gao, J. Robust L1 principal component analysis and its Bayesian variational inference. Neural Comput. 2008, 20, 555–572. [Google Scholar] [CrossRef] [PubMed]
- Ju, F.; Sun, Y.; Gao, J.; Hu, Y.; Yin, B. Image outlier detection and feature extraction via L1-norm-based 2D probabilistic PCA. IEEE Trans. Image Process. 2015, 24, 4834–4846. [Google Scholar] [CrossRef] [PubMed]
- Galimberti, G.; Soffritti, G. A multivariate linear regression analysis using finite mixtures of t distributions. Comput. Stat. Data Anal. 2014, 71, 138–150. [Google Scholar] [CrossRef]
- Morris, K.; McNicholas, P.D.; Scrucca, L. Dimension reduction for model-based clustering via mixtures of multivariate t-distributions. Adv. Data Anal. Classif. 2013, 7, 321–338. [Google Scholar] [CrossRef]
- Pesevski, A.; Franczak, B.C.; McNicholas, P.D. Subspace clustering with the multivariate-t distribution. Pattern Recognit. Lett. 2018, 112, 297–302. [Google Scholar] [CrossRef] [Green Version]
- Teklehaymanot, F.K.; Muma, M.; Zoubir, A.M. Robust Bayesian cluster enumeration based on the t distribution. Signal Process. 2021, 182, 107870. [Google Scholar] [CrossRef]
- Wei, X.; Yang, Z. The infinite Student’s t-factor mixture analyzer for robust clustering and classification. Pattern Recognit. 2012, 45, 4346–4357. [Google Scholar] [CrossRef]
- Zhou, X.; Tan, C. Maximum likelihood estimation of Tobit factor analysis for multivariate t-distribution. Commun. Stat. Simul. Comput. 2009, 39, 1–16. [Google Scholar] [CrossRef]
- Lange, K.L.; Little, R.J.A.; Taylor, J.M.G. Robust statistical modeling using the t distribution. J. Am. Stat. Assoc. 1989, 84, 881–896. [Google Scholar] [CrossRef] [Green Version]
- Meng, X.L.; Van Dyk, D. The EM algorithm—An old folk-song sung to a fast new tune. J. R. Stat. Soc. Ser. B Stat. Methodol. 1997, 59, 511–567. [Google Scholar] [CrossRef]
- Zhou, Y.; Lu, H.; Cheung, Y. Bilinear probabilistic canonical correlation analysis via hybrid concatenations. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 5–9 October 2017; Volume 31. [Google Scholar]
- Coleman, T.; Branch, M.A.; Grace, A. Optimization toolbox. In For Use with MATLAB. User’s Guide for MATLAB 5, Version 2, Relaese II; 1999; Available online: https://www.dpipe.tsukuba.ac.jp/~naito/optim_tb.pdf (accessed on 20 September 2021).
- Schrage, L. LINGO User’s Guide; LINDO System Inc.: Chicago, IL, USA, 2006. [Google Scholar]
- Stewart, G.W. Matrix Algorithms: Volume II: Eigensystems; SIAM: Philadelphia, PA, USA, 2001. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).