
On the Use of Machine Learning Models for Prediction of Compressive Strength of Concrete: Influence of Dimensionality Reduction on the Model Performance




Abstract
1. Introduction
- Models with original features (i.e., without any feature reduction) to act as a baseline for comparison.
- Models with reduced dimensionality after PCA, trained and tested with PCA-selected features.
- Models with the equal number of manually selected features as that in scenario 2.
2. Data Source and Theories of Machine Learning Models
2.1. Data Source
2.2. Introduction of the Utilized ML Models
2.2.1. Linear Regression (LR)
2.2.2. Support Vector Regression (SVR)
2.2.3. Extreme Gradient Boosting (XGBoost)
2.2.4. Artificial Neural Network (ANN)
3. Prediction Process with Different ML Models
3.1. Data Preprocessing
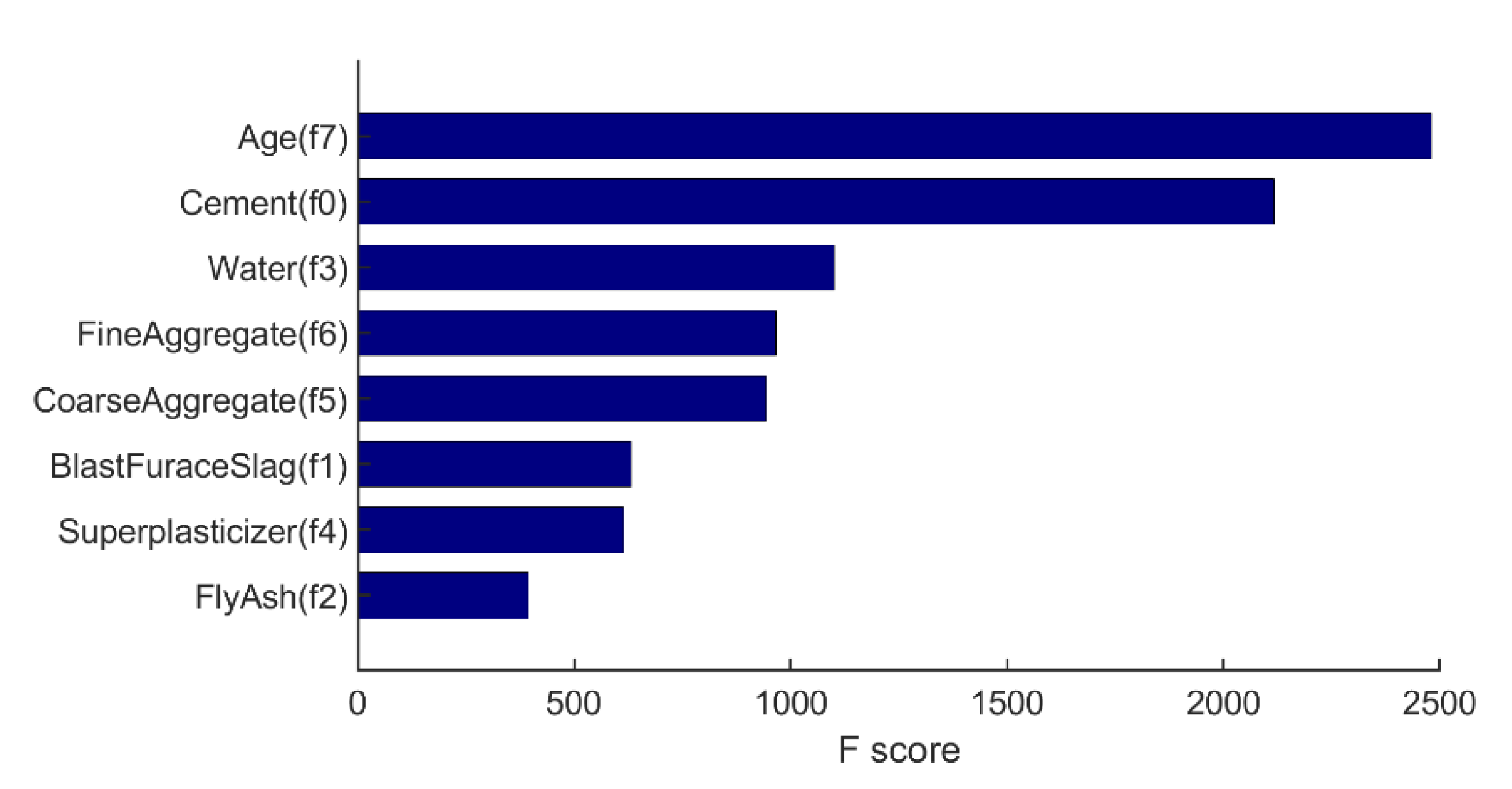
3.1.1. Feature Selection and Extraction
3.1.2. Feature Normalization
3.2. Prediction Process with Original Features
3.2.1. Linear Regression (LR)
3.2.2. Support Vector Regression (SVR)
3.2.3. Extreme Gradient Boosting (XGBoost)
3.2.4. Artificial Neural Network (ANN)
3.3. Prediction Process with Manually Selected Features and PCA-Reduced Features
4. Prediction Process with different ML Models
4.1. Performance on Training Set and Test Set
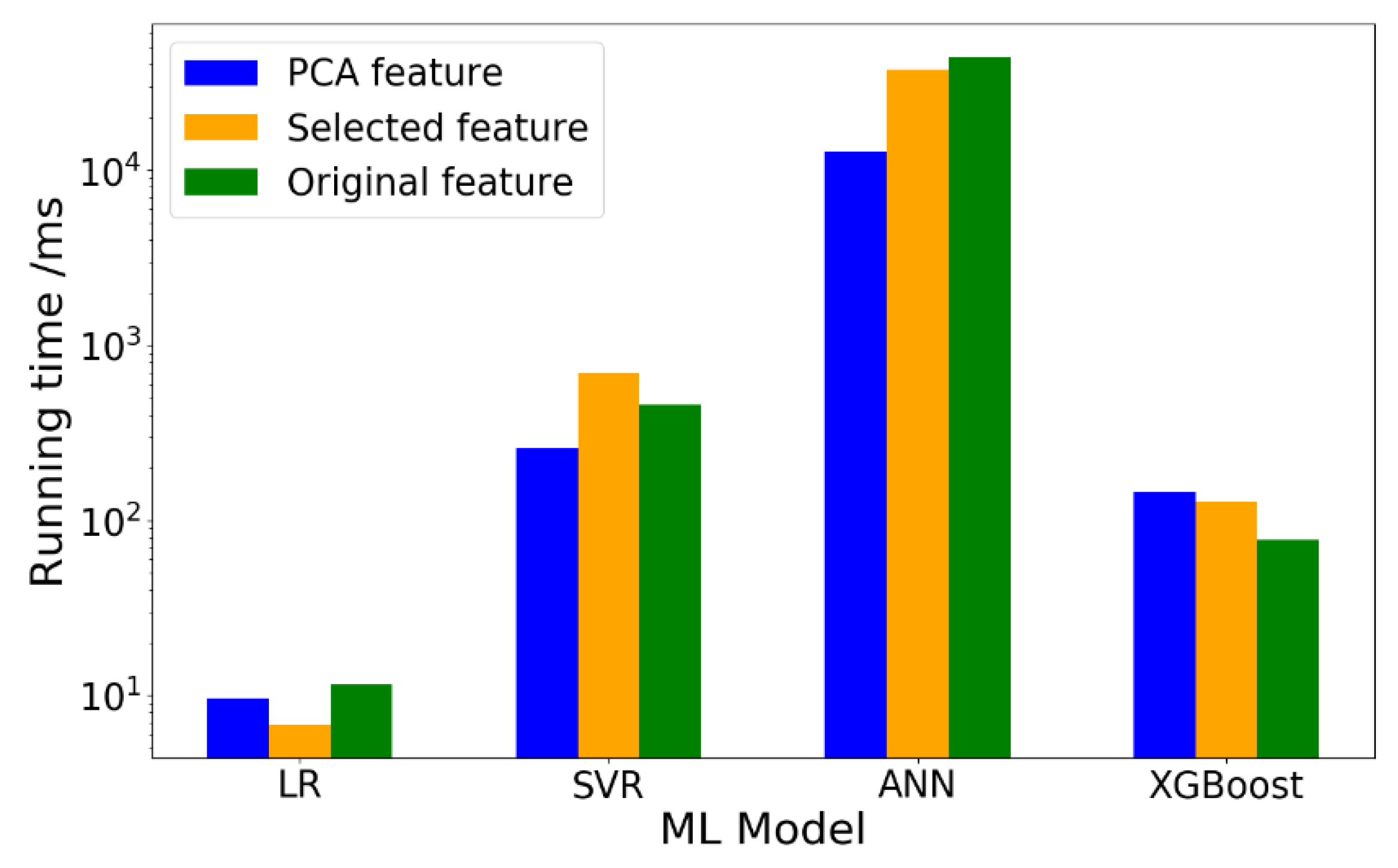
4.2. Training Speed
5. Conclusions
- Among the four ML models, linear regression has the poorest performance with an R-square of less than 0.90, while the other 3 ML models have an R-square of over 0.90. Therefore, it is possible to make an accurate prediction of the compressive strength using some ML models such as Support Vector Regression (SVR), Extreme Gradient Boosting (XGBoost), and Artificial Neural Network (ANN).
- The highest R-square of test set of ML model with original features, PCA-selected features and manually selected features are 0.9331 (ANN), 0.9160 (ANN), and 0.9339 (XGBoost) respectively. Therefore, the performance of XGBoost model with manually selected features is the model with the best performance of all models.
- The prediction accuracy of SVR model with manually selected features (R-square = 0.9080) or PCA-selected features (R-square = 0.9134) is better than the model with original features (R-square = 0.9003) without dramatic running time change, indicating that dimensionality reduction has an admirable influence on SVR model.
- Compared with the XGBoost model with original features and manually selected features, the model with PCA-selected features has a relatively poorer performance (R-square = 0.8787). The possible reason for this is inferred that the PCA-selected features are not as distinguishable as the manually selected features in this study.
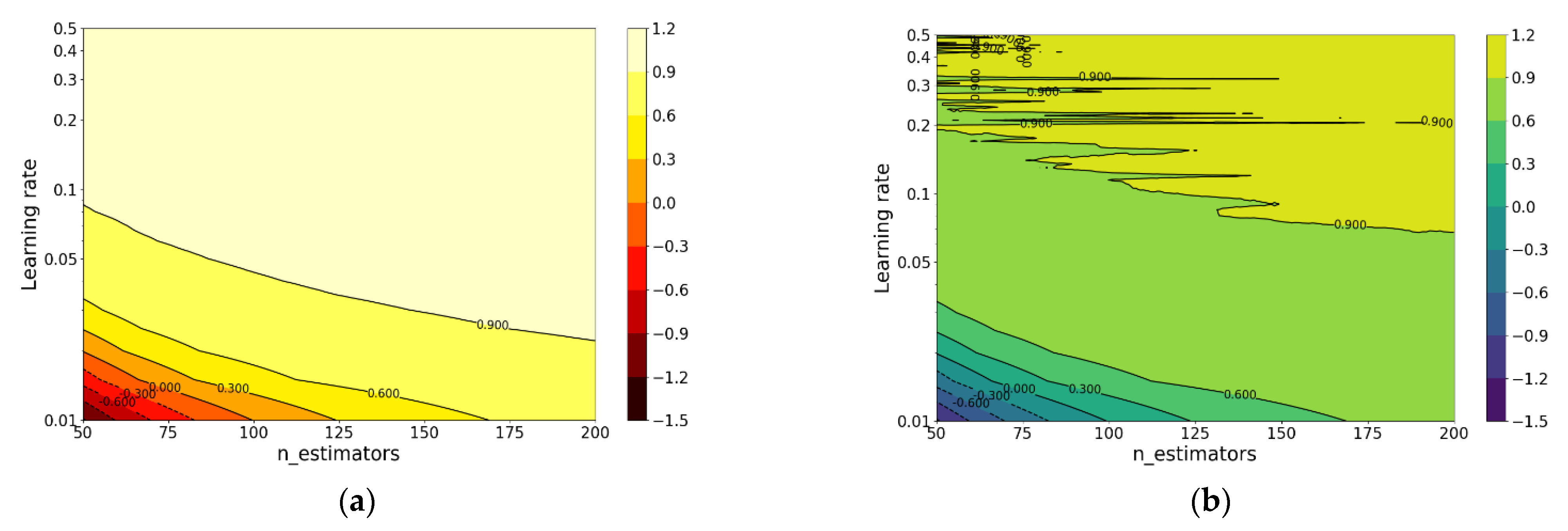
- The running time of XGBoost model with PCA-selected features or manually selected features is longer than XGBoost model with original features. In this work, dimensionality reduction by PCA seems to have an adverse effect both on the performance and the running time for XGBoost model.
- Although the running time of ANN model is much longer than the other three models (less than 1s) in 3 scenarios, dimensionality reduction has an obviously positive influence on running time without losing much prediction accuracy for ANN model.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- British Standards Institution. Eurocode 2: Design of Concrete Structures: Part 1-1: General Rules and Rules for Buildings; British Standards Institution: London, UK, 2015. [Google Scholar]
- CMC. Code for Design of Concrete Structures (GB50010-2010); China Ministry of Construction: Beijing, China, 2010. [Google Scholar]
- Pereira, P.; Evangelista, L.M.F.D.R.; De Brito, J.M.C.L. The effect of superplasticizers on the mechanical performance of concrete made with fine recycled concrete aggregates. Cem. Concr. Compos. 2012, 34, 1044–1052. [Google Scholar] [CrossRef]
- Poon, C.S.; Shui, Z.; Lam, L.; Fok, H.; Kou, S. Influence of moisture states of natural and recycled aggregates on the slump and compressive strength of concrete. Cem. Concr. Res. 2004, 34, 31–36. [Google Scholar] [CrossRef]
- Kaplan, M.F. The effects of age and water/cement ratio upon the relation between ultrasonic pulse velocity and compressive strength of concrete. Mag. Concr. Res. 1959, 11, 85–92. [Google Scholar] [CrossRef]
- Oner, A.; Akyuz, S.; Yildiz, R. An experimental study on strength development of concrete containing fly ash and optimum usage of fly ash in concrete. Cem. Concr. Res. 2005, 35, 1165–1171. [Google Scholar] [CrossRef]
- Juenger, M.C.; Siddique, R. Recent advances in understanding the role of supplementary cementitious materials in concrete. Cem. Concr. Res. 2015, 78, 71–80. [Google Scholar] [CrossRef]
- Snellings, R.; Mertens, G.; Elsen, J. Supplementary cementitious materials. Rev. Mineral. Geochem. 2012, 74, 211–278. [Google Scholar] [CrossRef]
- Chung, K.L.; Ghannam, M.; Zhang, C. Effect of Specimen Shapes on Compressive Strength of Engineered Cementitious Composites (ECCs) with Different Values of Water-to-Binder Ratio and PVA Fiber. Arab. J. Sci. Eng. 2017, 43, 1825–1837. [Google Scholar] [CrossRef]
- Park, J.J.; Kang, S.T.; Koh, K.T.; Kim, S.W. Influence of the ingredients on the compressive strength of UHPC as a fundamental study to optimize the mixing pro-portion. In Proceedings of the Second International Symposium on Ultra High Performance Concrete, Kassel, Germany, 5–7 March 2008. [Google Scholar]
- Tziviloglou, E.; Wiktor, V.; Jonkers, H.; Schlangen, E. Bacteria-based self-healing concrete to increase liquid tightness of cracks. Constr. Build. Mater. 2016, 122, 118–125. [Google Scholar] [CrossRef]
- Kim, J.J.; Fan, T.; Taha, M.R. Homogenization Model Examining the Effect of Nanosilica on Concrete Strength and Stiffness. Transp. Res. Rec. J. Transp. Res. Board 2010, 2141, 28–35. [Google Scholar] [CrossRef]
- Pichler, B.L.; Hellmich, C. Upscaling quasi-brittle strength of cement paste and mortar: A multi-scale engineering mechanics model. Cem. Concr. Res. 2011, 41, 467–476. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, Y.; Gan, Y.; Chang, Z.; Schlangen, E.; Šavija, B. Microstructure informed micromechanical modelling of hydrated cement paste: Techniques and challenges. Constr. Build. Mater. 2020, 251, 118983. [Google Scholar] [CrossRef]
- Sherzer, G.L.; Schlangen, E.; Ye, G.; Gal, A. Evaluating compressive mechanical LDPM parameters based on an upscaled multiscale approach. Constr. Build. Mater. 2020, 251, 118912. [Google Scholar] [CrossRef]
- Ni, H.-G.; Wang, J.-Z. Prediction of compressive strength of concrete by neural networks. Cem. Concr. Res. 2000, 30, 1245–1250. [Google Scholar] [CrossRef]
- Azimi-Pour, M.; Eskandari-Naddaf, H.; Pakzad, A. Linear and non-linear SVM prediction for fresh properties and compressive strength of high volume fly ash self-compacting concrete. Constr. Build. Mater. 2020, 230, 117021. [Google Scholar] [CrossRef]
- Ouyang, B.; Li, Y.; Song, Y.; Wu, F.; Yu, H.; Wang, Y.; Bauchy, M.; Sant, G. Learning from Sparse Datasets: Predicting Concrete’s Strength by Machine Learning. arXiv 2020, arXiv:2004.14407. [Google Scholar]
- Yeh, I.-C. Modeling of strength of high-performance concrete using artificial neural networks. Cem. Concr. Res. 1998, 28, 1797–1808. [Google Scholar] [CrossRef]
- Yeh, I.-C. Modeling Concrete Strength with Augment-Neuron Networks. J. Mater. Civ. Eng. 1998, 10, 263–268. [Google Scholar] [CrossRef]
- Kotsiantis, S.B.; Kanellopoulos, D.; Pintelas, P.E. Data preprocessing for supervised leaning. Int. J. Comput. Sci. 2006, 1, 111–117. [Google Scholar]
- Van Der Maaten, L.; Postma, E.; Van den Herik, J. Dimensionality reduction: A comparative. J. Mach. Learn. Res. 2009, 10, 13. [Google Scholar]
- Khademi, F.; Jamal, S.M.; Deshpande, N.; Londhe, S. Predicting strength of recycled aggregate concrete using Artificial Neural Network, Adaptive Neuro-Fuzzy Inference System and Multiple Linear Regression. Int. J. Sustain. Built Environ. 2016, 5, 355–369. [Google Scholar] [CrossRef]
- Abd, A.M.; Abd, S.M. Modelling the strength of lightweight foamed concrete using support vector machine (SVM). Case Stud. Constr. Mater. 2017, 6, 8–15. [Google Scholar] [CrossRef]
- Lu, X.; Zhou, W.; Ding, X.; Shi, X.; Luan, B.; Li, M. Ensemble Learning Regression for Estimating Unconfined Compressive Strength of Cemented Paste Backfill. IEEE Access 2019, 7, 72125–72133. [Google Scholar] [CrossRef]
- Suykens, J.A.K.; Vandewalle, J. Least Squares Support Vector Machine Classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Lange, R.; Männer, R. Quantifying a Critical Training Set Size for Generalization and Overfitting using Teacher Neural Networks. In Proceedings of the International Conference on Artificial Neural Networks, Sorrento, Italy, 26–29 May 1994; Springer Nature: Berlin, Germany, 1994; pp. 497–500. [Google Scholar]
- Nguyen-Sy, T.; Wakim, J.; To, Q.-D.; Vu, M.-N.; Nguyen, T.-D.; Nguyen, T.-T. Predicting the compressive strength of concrete from its compositions and age using the extreme gradient boosting method. Constr. Build. Mater. 2020, 260, 119757. [Google Scholar] [CrossRef]
- Weisberg, S. Applied Linear Regression; John Wiley & Sons: Hoboken, NJ, USA, 2005; Volume 528. [Google Scholar] [CrossRef]
- Khademi, F.; Akbari, M.; Jamal, S.M.; Nikoo, M. Multiple linear regression, artificial neural network, and fuzzy logic prediction of 28 days compressive strength of concrete. Front. Struct. Civ. Eng. 2017, 11, 90–99. [Google Scholar] [CrossRef]
- Cook, R.; Lapeyre, J.; Ma, H.; Kumar, A. Prediction of Compressive Strength of Concrete: Critical Comparison of Performance of a Hybrid Machine Learning Model with Standalone Models. J. Mater. Civ. Eng. 2019, 31, 04019255. [Google Scholar] [CrossRef]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Duchesnay, E. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Breiman, L.; Ihaka, R. Nonlinear Discriminant Analysis via Scaling and ACE; Department of Statistics, University of California: Davis One Shields Avenue Davis, CA, USA, 1984. [Google Scholar]
- Verhaegh, W.; Aarts, E.; Korst, J. Algorithms in Ambient Intelligence; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2004; Volume 2. [Google Scholar] [CrossRef]
- Alnaggar, M.; Bhanot, N. A machine learning approach for the identification of the Lattice Discrete Particle Model parameters. Eng. Fract. Mech. 2018, 197, 160–175. [Google Scholar] [CrossRef]
- Ben Chaabene, W.; Flah, M.; Nehdi, M.L. Machine learning prediction of mechanical properties of concrete: Critical review. Constr. Build. Mater. 2020, 260, 119889. [Google Scholar] [CrossRef]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Harris, C.R.; Millman, K.J.; Van Der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Kim, Y.; Ryu, S.; Gu, G.X. Prediction of composite microstructure stress-strain curves using convolutional neural networks. Mater. Des. 2020, 189, 108509. [Google Scholar] [CrossRef]
- Zheng, A.; Casari, A. Feature Engineering for Machine Learning: Principles and Techniques for Data Scientists; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2018. [Google Scholar]
- Ketkar, N.; Santana, E. Deep Learning with Python; Springer: Berlin, Germany, 2017; Volume 1. [Google Scholar] [CrossRef]
- Amari, S.; Wu, S. Improving support vector machine classifiers by modifying kernel functions. Neural Netw. 1999, 12, 783–789. [Google Scholar] [CrossRef]
- Liu, Z.; Zuo, M.J.; Zhao, X.; Xu, H. An Analytical Approach to Fast Parameter Selection of Gaussian RBF Kernel for Support Vector Machine. J. Inf. Sci. Eng. 2015, 31, 691–710. [Google Scholar]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V. Package ‘xgboost’. In R version; The R Foundation: Vienna, Austria, 2019; Volume 90. [Google Scholar]
- Oner, A.; Akyuz, S. An experimental study on optimum usage of GGBS for the compressive strength of concrete. Cem. Concr. Compos. 2007, 29, 505–514. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cement (kg/m3) | Blast Furnace Slag (kg/m3) | Fly Ash (kg/m3) | Water (kg/m3) | Superplasticizer (kg/m3) | Coarse Aggregate (kg/m3) | Fine Aggregate (kg/m3) | Age (day) | Compressive Strength (MPa) | |
|---|---|---|---|---|---|---|---|---|---|
| Mean | 281.168 | 73.896 | 54.188 | 181.567 | 6.205 | 972.919 | 773.580 | 45.662 | 35.818 |
| Std | 104.456 | 86.237 | 63.966 | 21.344 | 5.971 | 77.716 | 80.137 | 63.139 | 16.698 |
| Min | 102 | 0 | 0 | 121.8 | 0 | 801 | 594 | 1 | 2.33 |
| Max | 540 | 359.4 | 200.1 | 247 | 32.2 | 1145 | 992.6 | 365 | 82.6 |
| Range | 358 | 359.4 | 200.1 | 125.2 | 32.2 | 344 | 398.6 | 364 | 80.26 |
| Component | Component 1 | Component 2 | Component 3 | Component 4 | Component 5 | Component 6 | Component 7 | Component 8 |
|---|---|---|---|---|---|---|---|---|
| Explained variance ratio | 3.2577 × 10−1 | 2.4887 × 10−1 | 1.8480 × 10−1 | 1.0766 × 10−1 | 1.0095 × 10−1 | 2.9845 × 10−2 | 1.8180 × 10−3 | 2.8770 × 10−4 |
| Cumulative explained variance | 0.32577 | 0.57464 | 0.75944 | 0.86710 | 0.96805 | 0.997895 | 0.999713 | 1.00000 |
| Degree | Dimensionality of New Features | R-Square | |
|---|---|---|---|
| Training Set | Test Set | ||
| 1 | 8 | 0.6133 | 0.6162 |
| 2 | 44 | 0.8114 | 0.7916 |
| 3 | 164 | 0.9269 | 0.8914 |
| 4 | 494 | 0.9834 | −596.344 |
| ML Model | R-Square | MSE | Hyperparameters | ||
|---|---|---|---|---|---|
| Trainset | Testset | Trainset | Testset | ||
| LR | 0.8803 | 0.8496 | 32.3600 | 44.9011 | Polynomial Degree = 3 |
| SVR | 0.9563 | 0.9134 | 11.8244 | 25.8550 | C = 550 |
| γ = 0.23 | |||||
| XGBoost | 0.9916 | 0.8787 | 2.3397 | 33.8782 | n_estimators = 190 |
| learning_rate = 0.07 | |||||
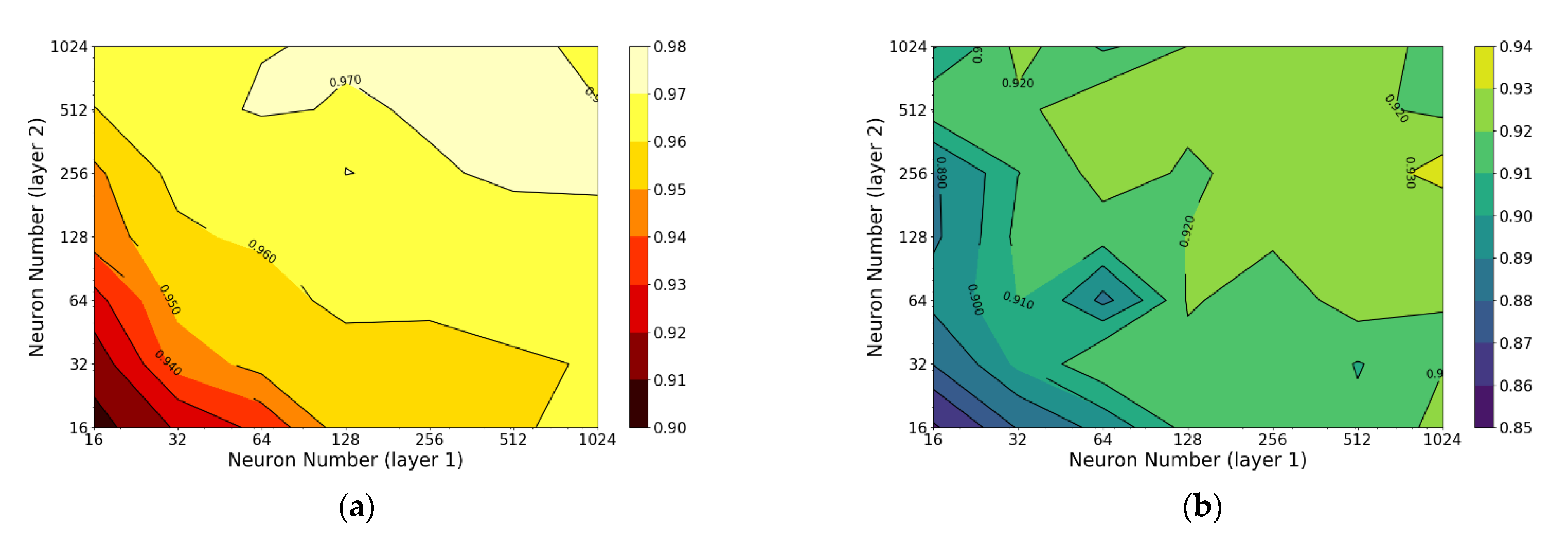
| ANN | 0.9602 | 0.9160 | 13.2096 | 26.4843 | #neuron = 128 (layer1) |
| #neuron = 128 (layer2) learning_rate = 0.0003 | |||||
| ML Model | R-Square | MSE | Hyperparameters | ||
|---|---|---|---|---|---|
| Trainset | Testset | Trainset | Testset | ||
| LR | 0.8803 | 0.8496 | 32.3600 | 44.9011 | Polynomial Degree = 4 |
| SVR | 0.9563 | 0.9134 | 11.8244 | 25.8550 | C = 2000 |
| γ = 0.27 | |||||
| XGBoost | 0.9916 | 0.8787 | 2.3397 | 33.8782 | n_estimators = 140 |
| learning_rate = 0.23 | |||||
| ANN | 0.9602 | 0.9160 | 13.2096 | 26.4843 | #neuron = 512 (layer1) |
| #neuron = 512 (layer2) learning_rate = 0.1 | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, Z.; Xu, Y.; Šavija, B. On the Use of Machine Learning Models for Prediction of Compressive Strength of Concrete: Influence of Dimensionality Reduction on the Model Performance. Materials 2021, 14, 713. https://doi.org/10.3390/ma14040713
Wan Z, Xu Y, Šavija B. On the Use of Machine Learning Models for Prediction of Compressive Strength of Concrete: Influence of Dimensionality Reduction on the Model Performance. Materials. 2021; 14(4):713. https://doi.org/10.3390/ma14040713
Chicago/Turabian StyleWan, Zhi, Yading Xu, and Branko Šavija. 2021. "On the Use of Machine Learning Models for Prediction of Compressive Strength of Concrete: Influence of Dimensionality Reduction on the Model Performance" Materials 14, no. 4: 713. https://doi.org/10.3390/ma14040713
APA StyleWan, Z., Xu, Y., & Šavija, B. (2021). On the Use of Machine Learning Models for Prediction of Compressive Strength of Concrete: Influence of Dimensionality Reduction on the Model Performance. Materials, 14(4), 713. https://doi.org/10.3390/ma14040713