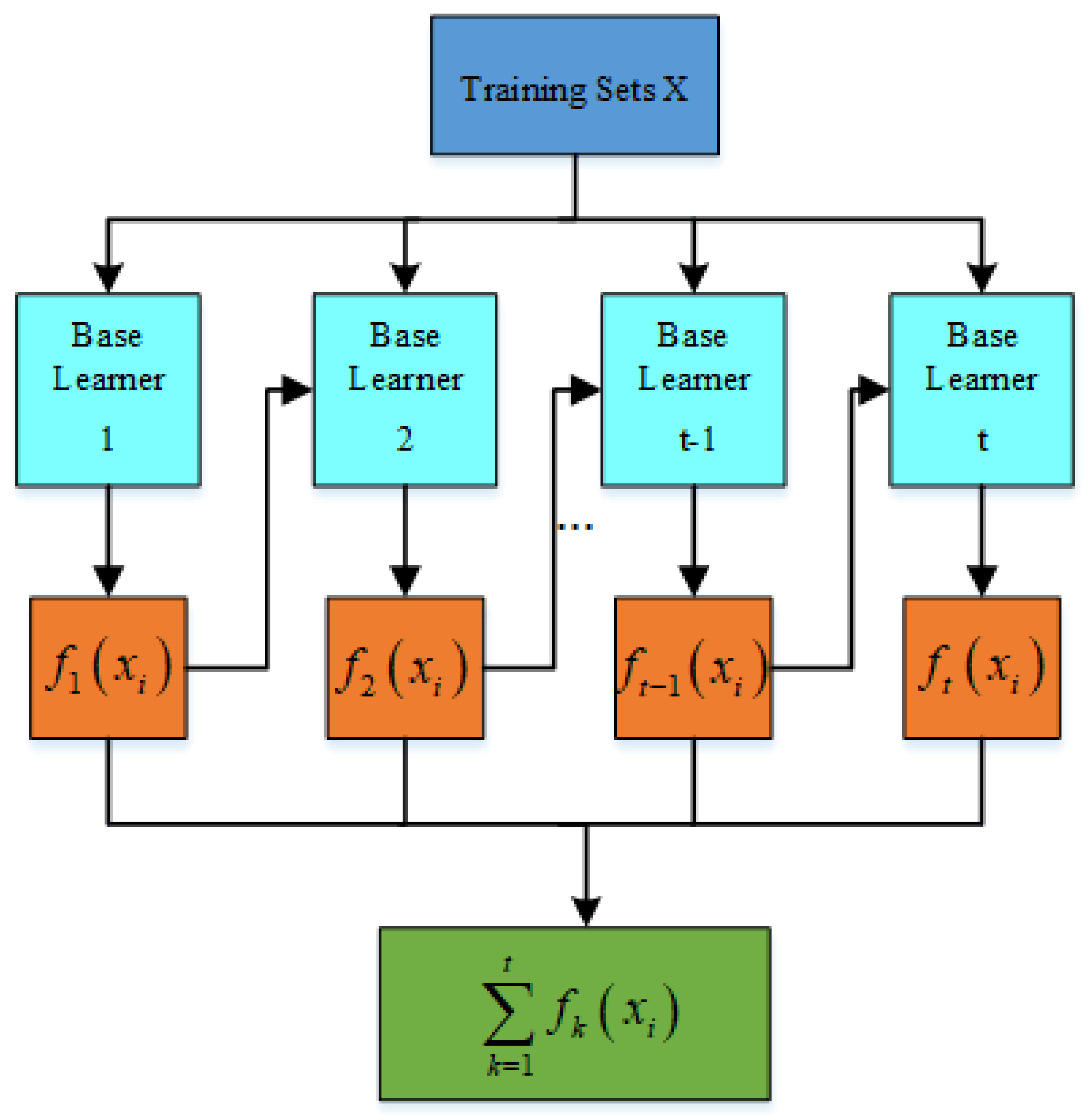
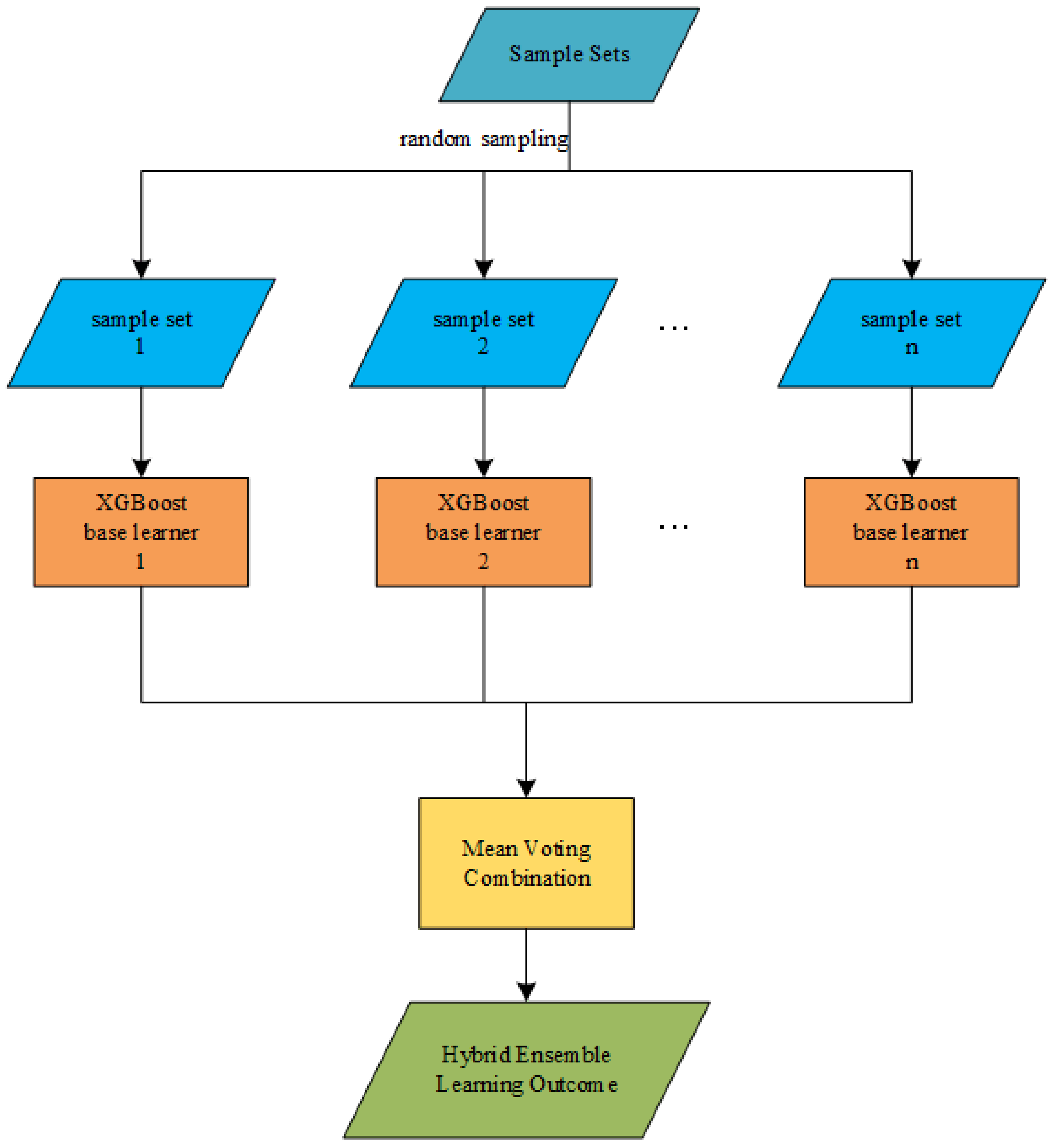
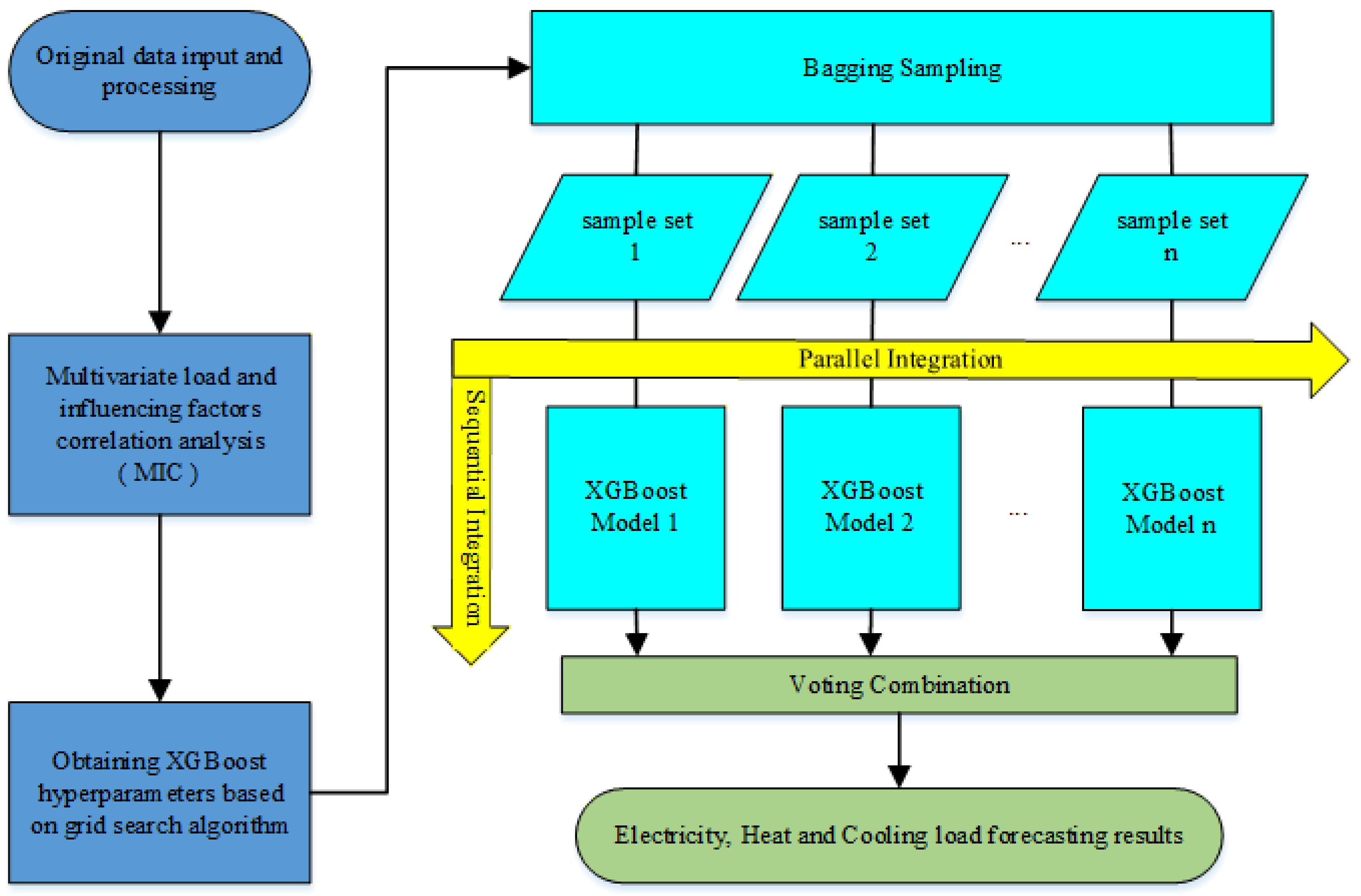
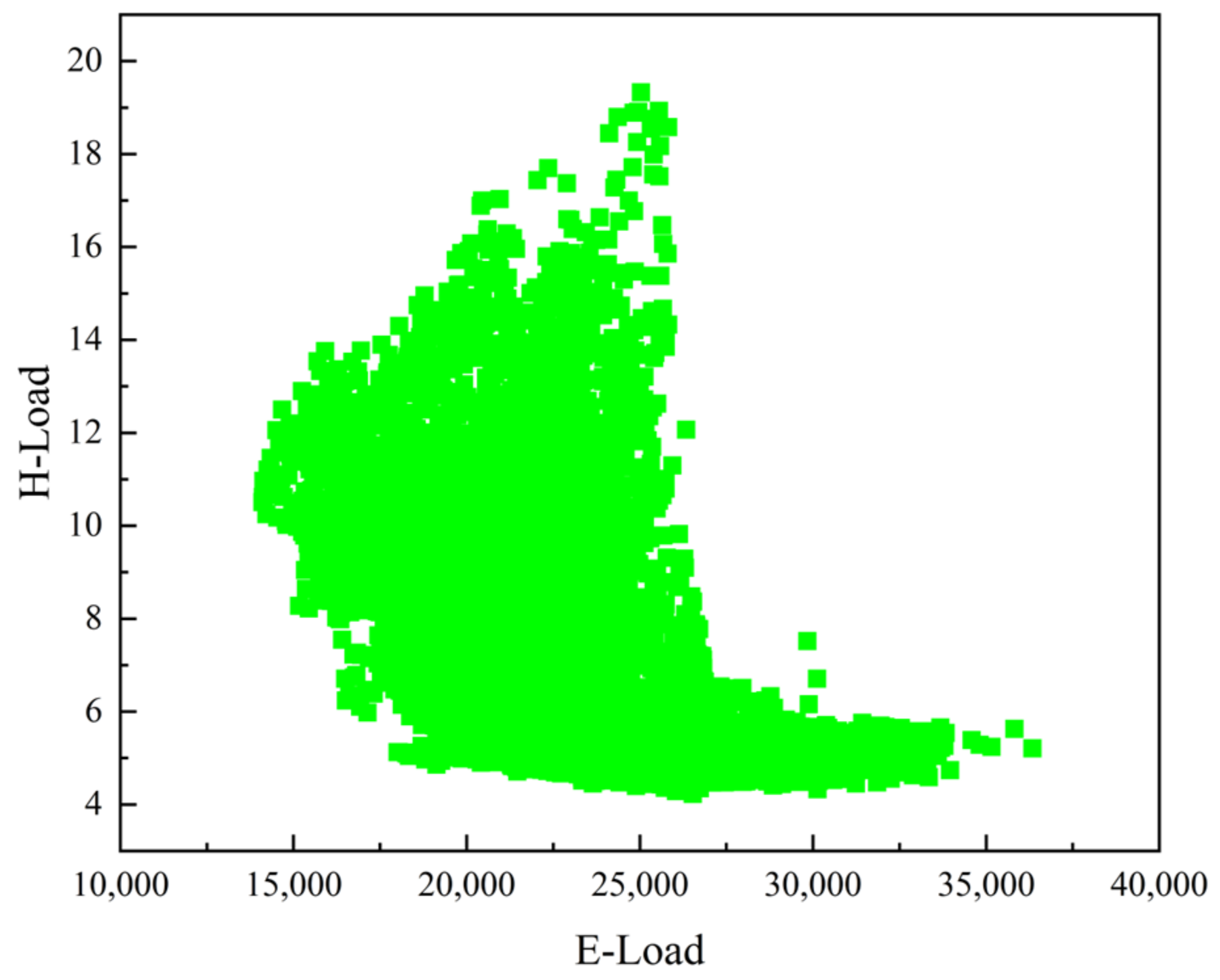
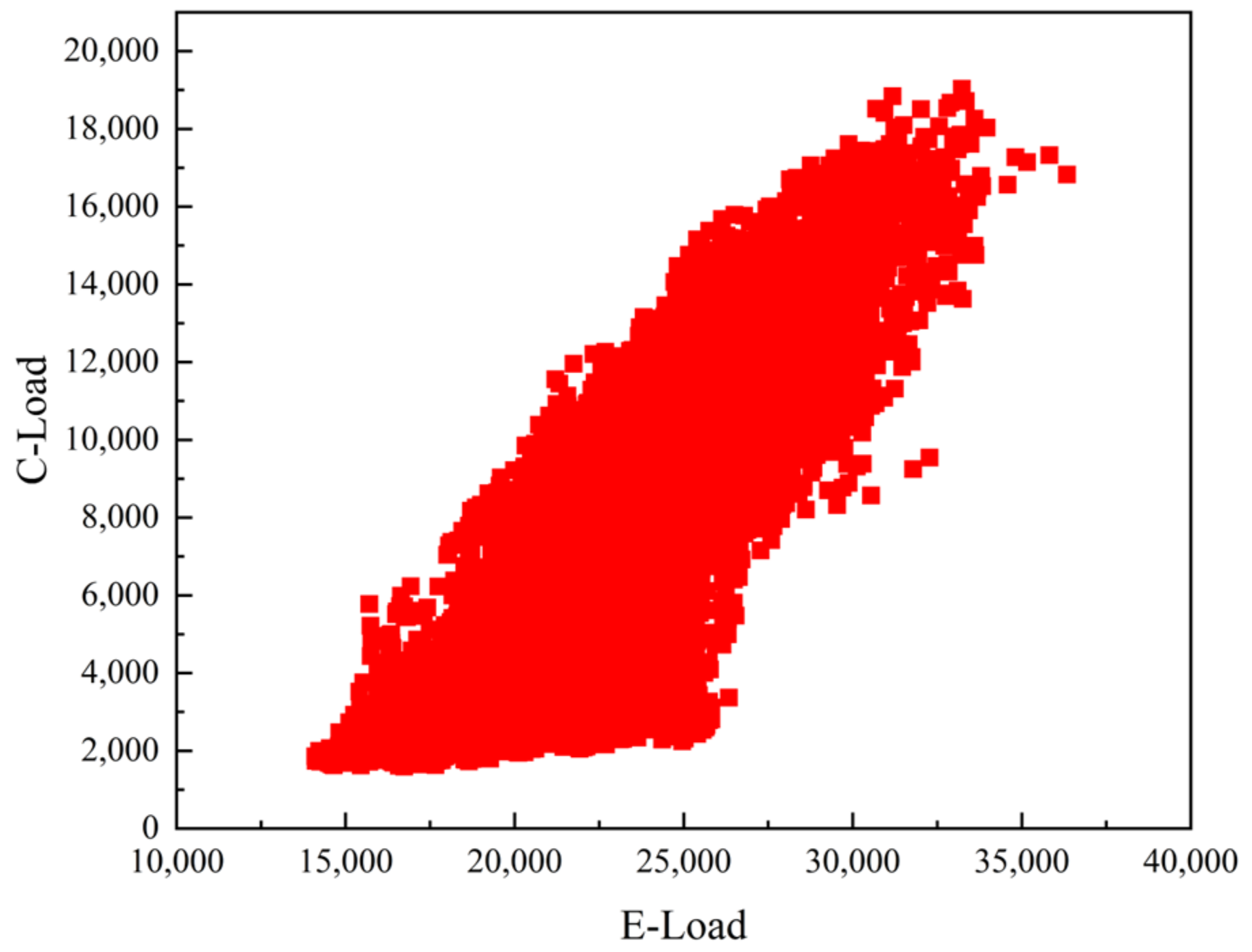
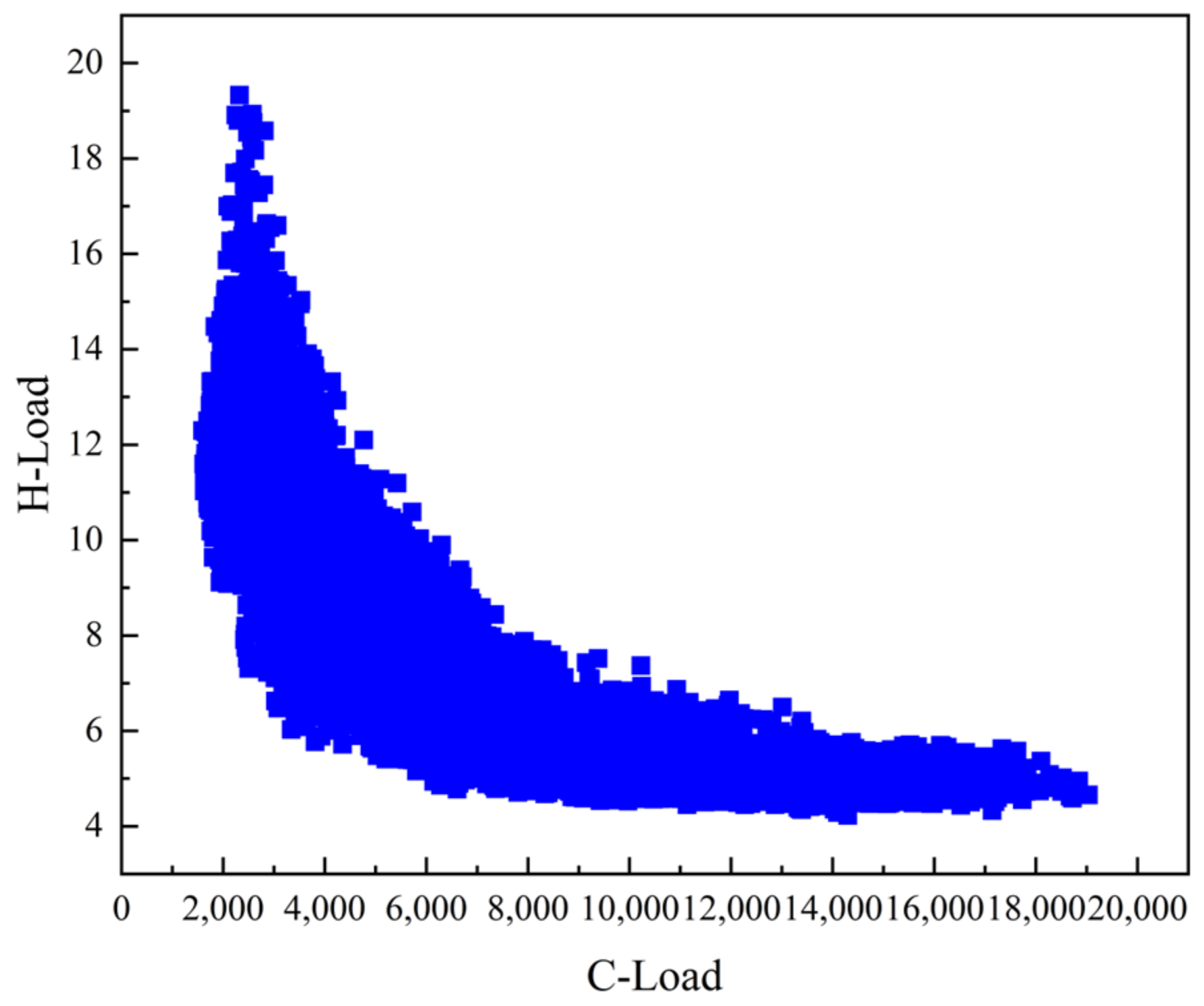
4.4.2. Comparison of Prediction Results of Different Models
In order to verify the effectiveness and reliability of the proposed method, the model is compared with the LSTM model of deep learning, the XGBoost model of single sequential integration of ensemble learning, the RF model of single parallel integration, and the Bagging-GBDT model of ensemble learning. The load forecasting results are shown in
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15 and
Figure 16.
(1) Comparison between Bagging-XGBoost model and the LSTM model
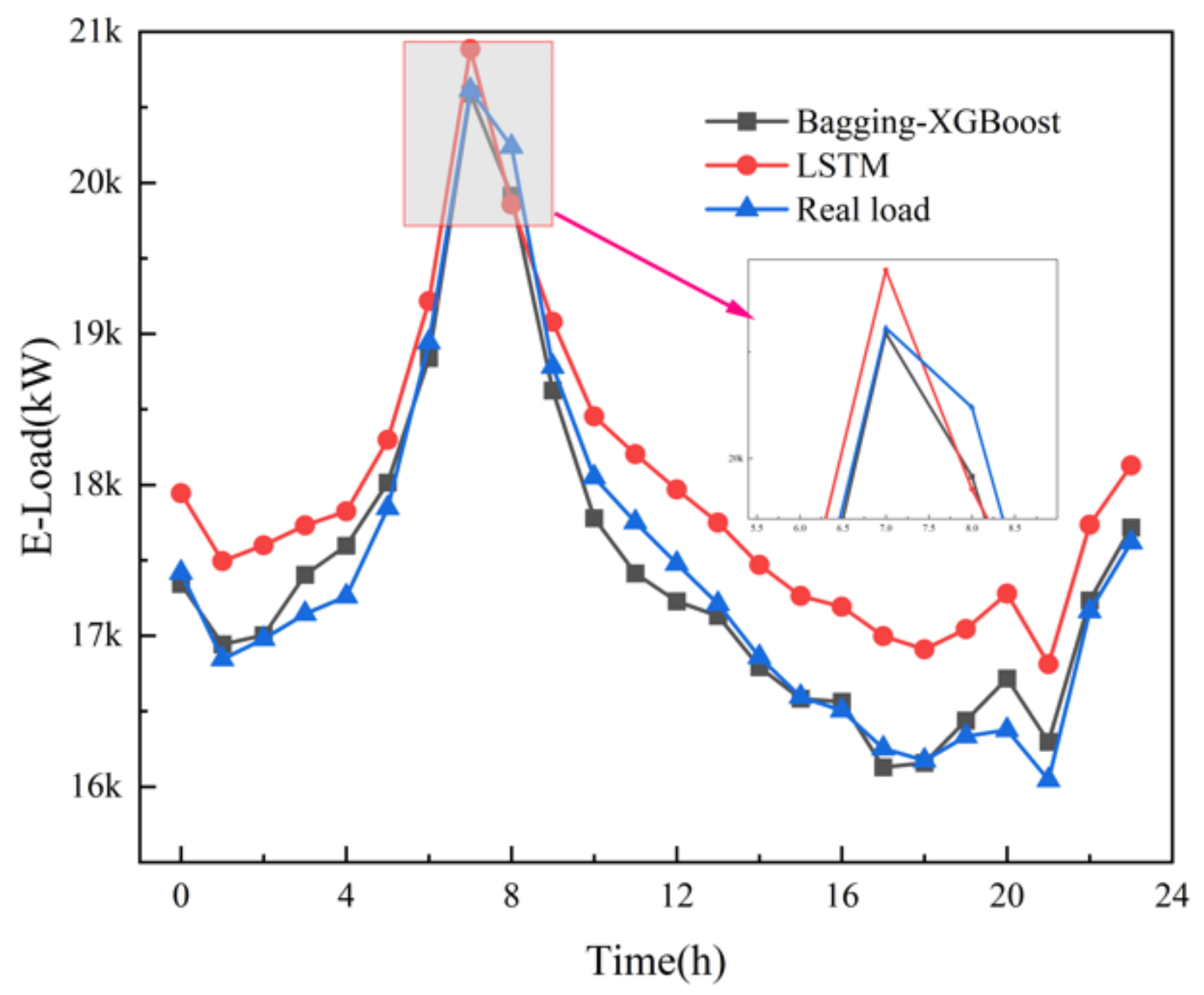
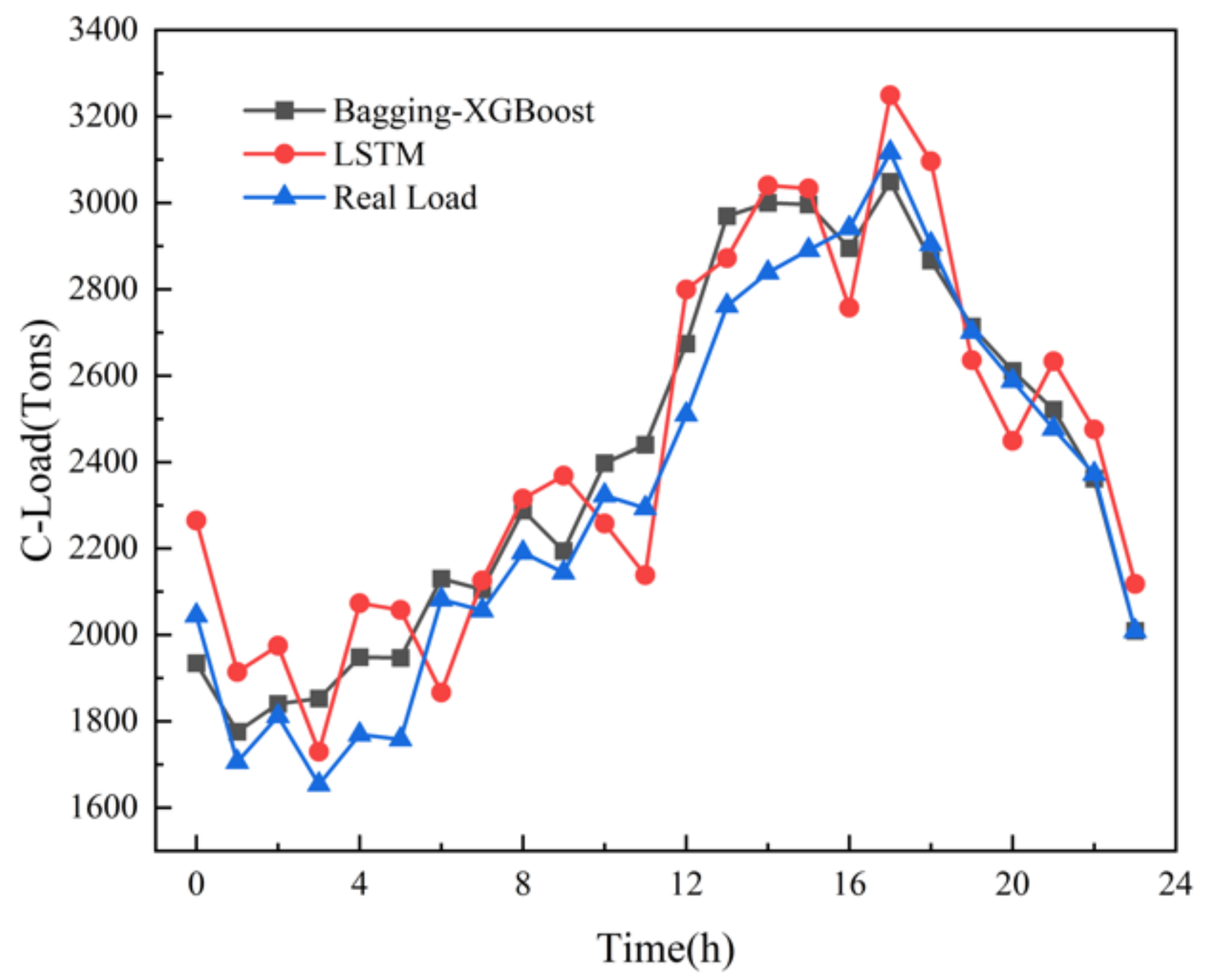
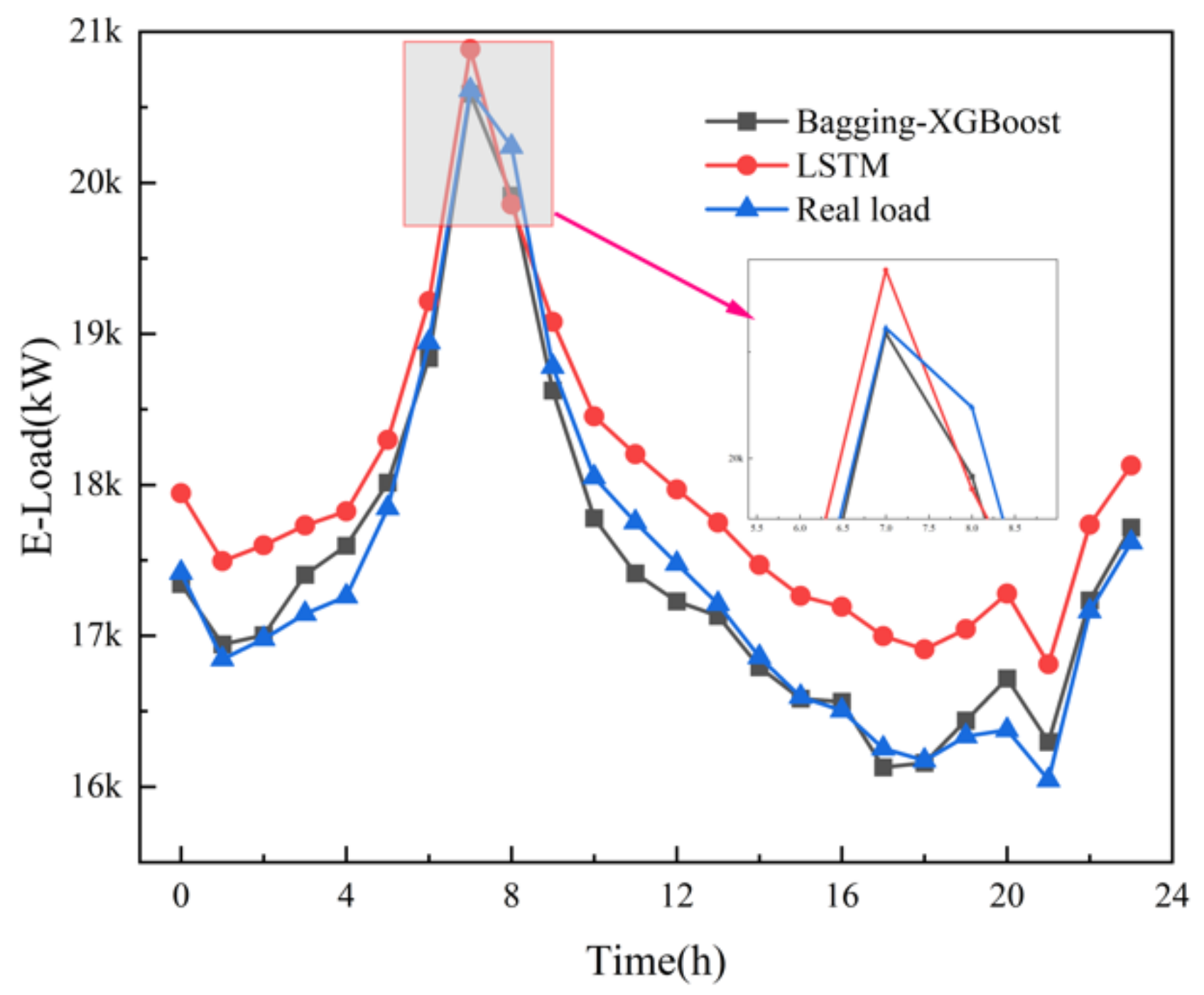
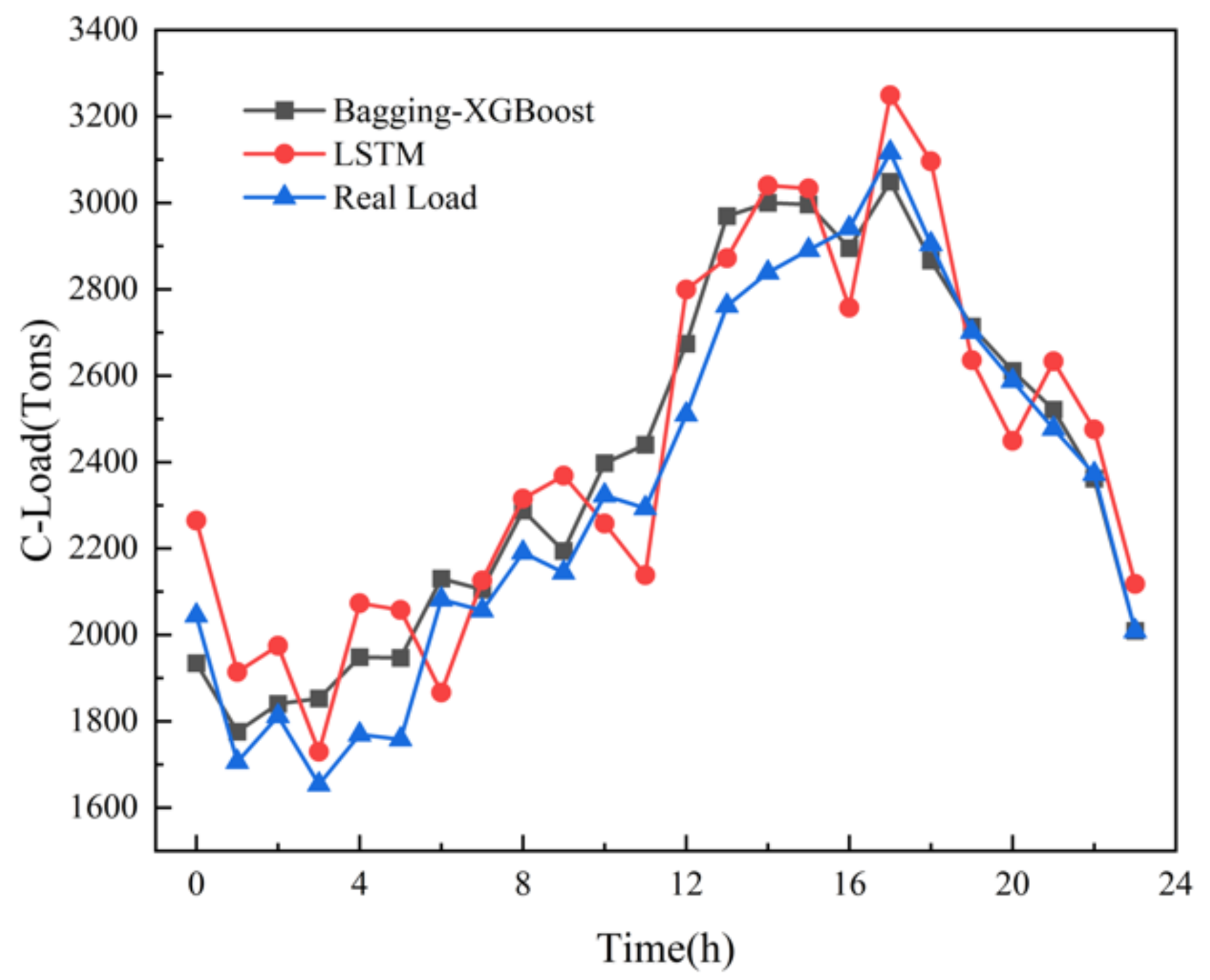
The LSTM algorithm is called Long short-term memory, which was first proposed in 1997. It is a specific form of RNN (Recurrent neural network) and has been widely used in the field of multi-load forecasting of integrated energy systems. Electric, cooling and heat multivariate load forecasting is shown in the following figures.
From the comparison of load forecasting curves and load forecasting results, it can be seen that the prediction accuracy of Bagging-XGBoost model is higher than that of the LSTM model. From the results of electric load forecasting, the MAPE% value of the Bagging-XGBoost model is 1.169 lower than that of the LSTM model, the MAE value is reduced by 145.908, and the RMSE value is reduced by 153.666. Based on the prediction results of cooling load and heat load, the prediction performance index of the proposed model is better than that of the LSTM model.
The structure of the LSTM model itself is relatively complex and the training is time-consuming. In addition, the network structure characteristics determine that it cannot process data in parallel. Taking the electric load as an example, when the prediction step size is 24 h, the Bagging-XGBoost model takes 42.29 s, and the LSTM model takes 39.86 s. Although the LSTM model takes less time, the speed advantage is not particularly obvious. Considering the prediction accuracy and training time, the Bagging-XGBoost model better achieves a good balance between prediction accuracy and training time.
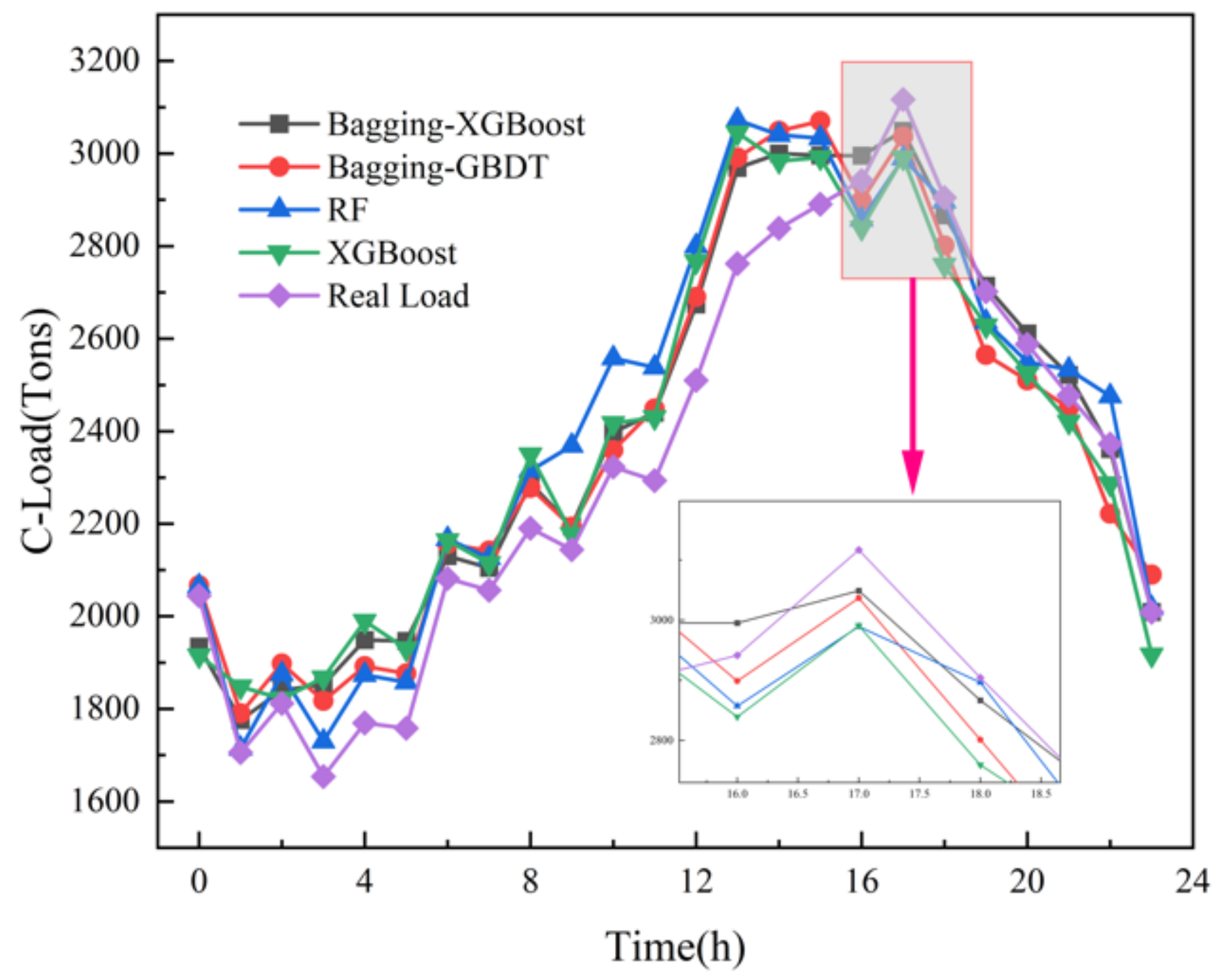
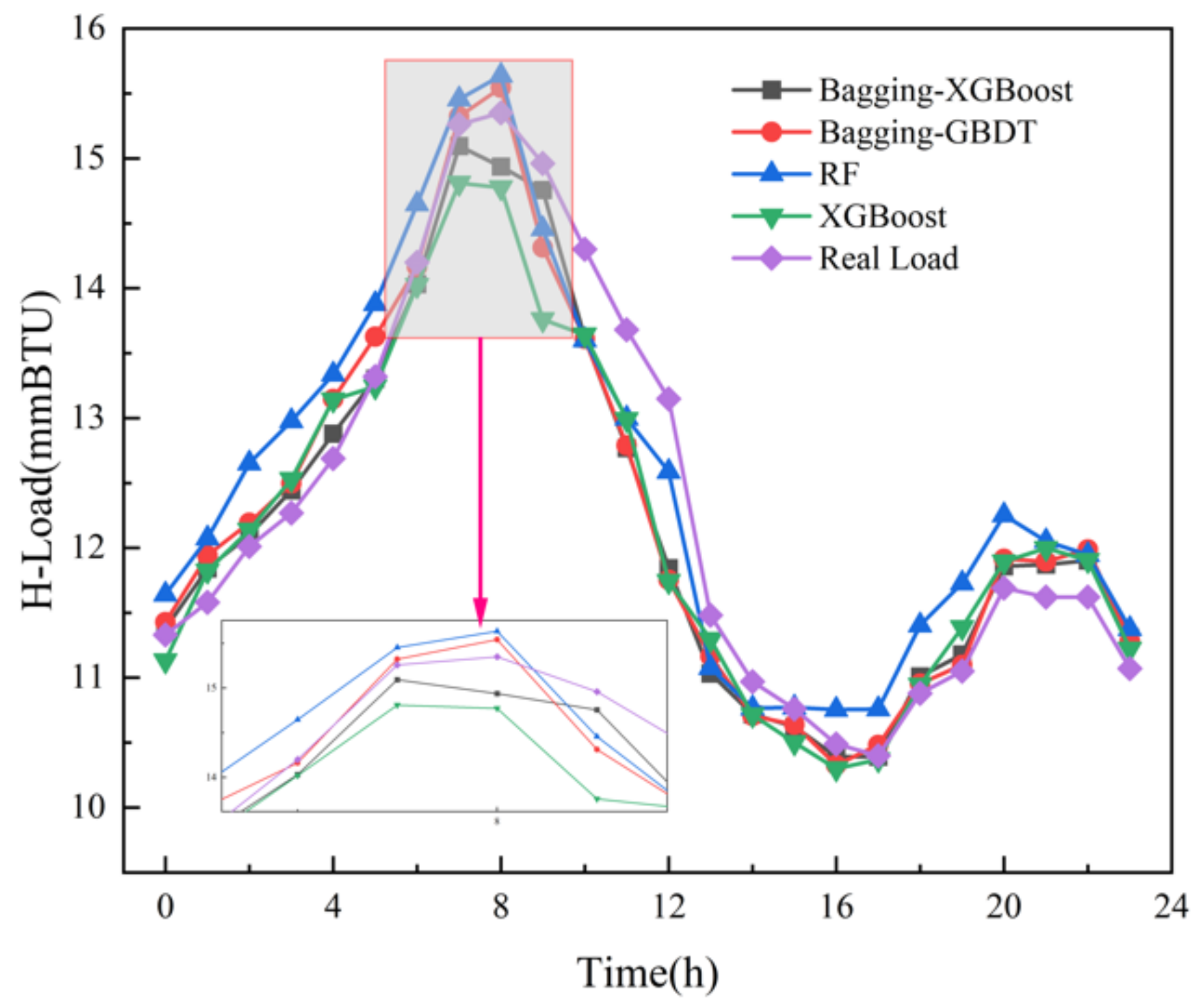
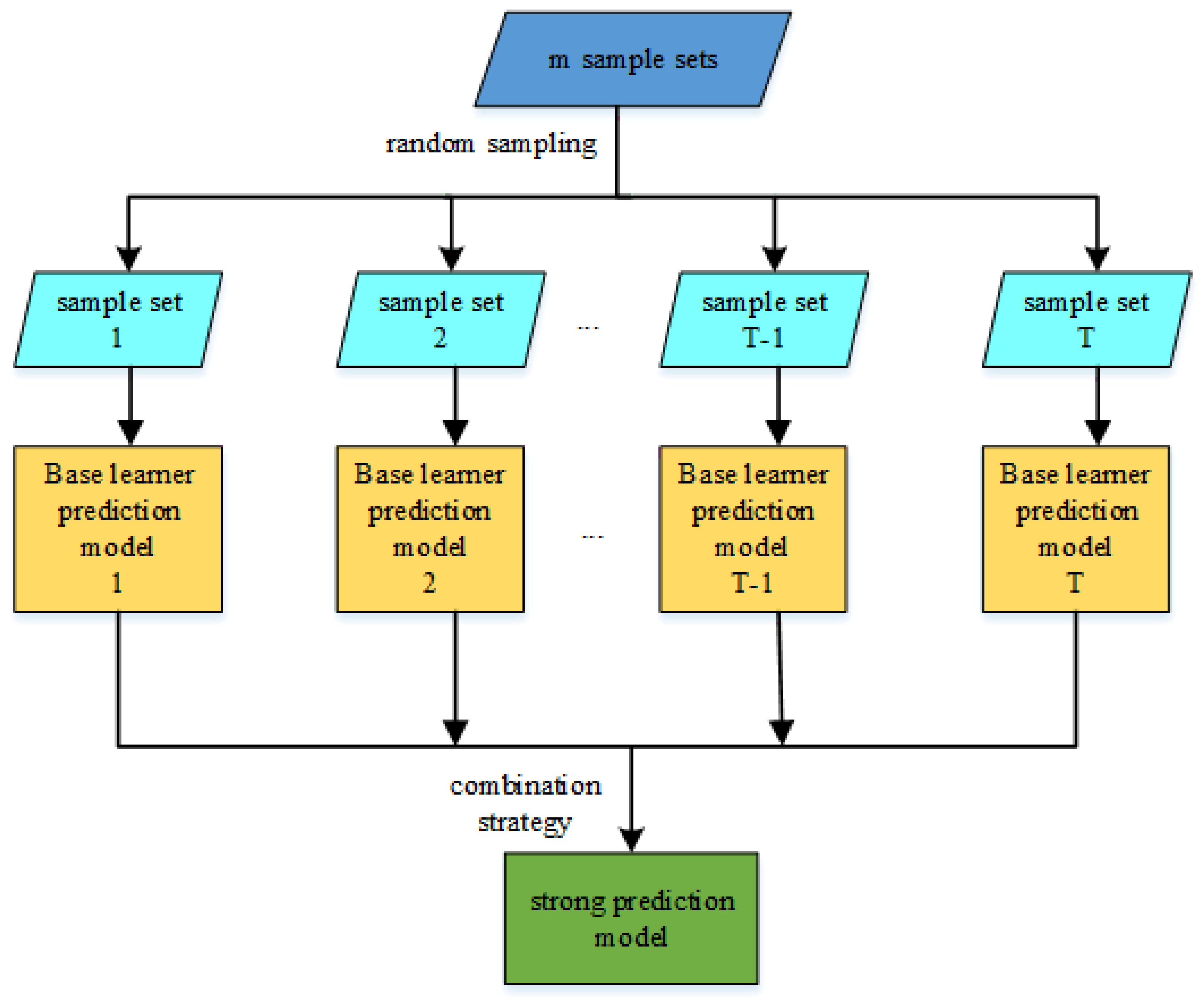
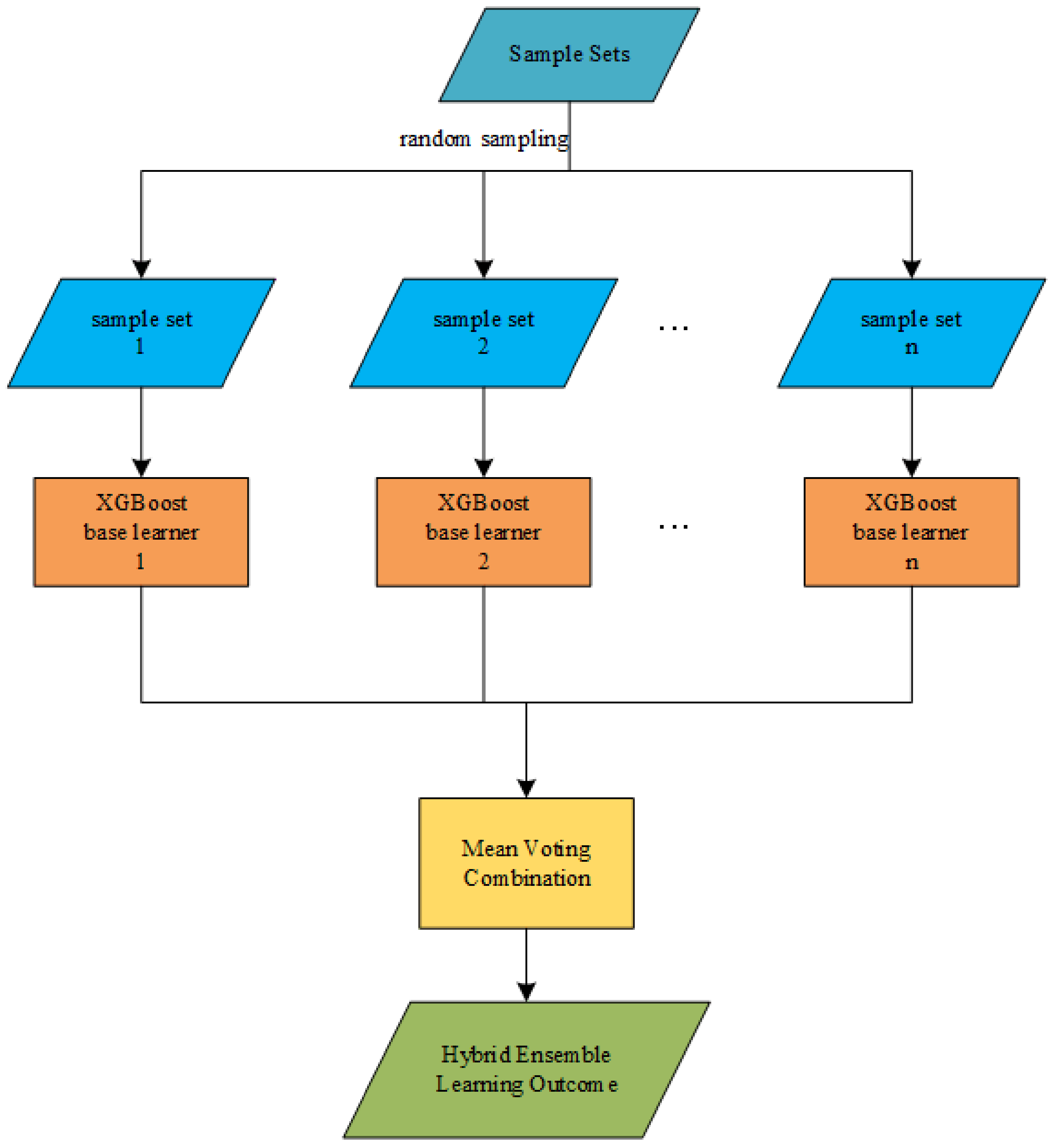
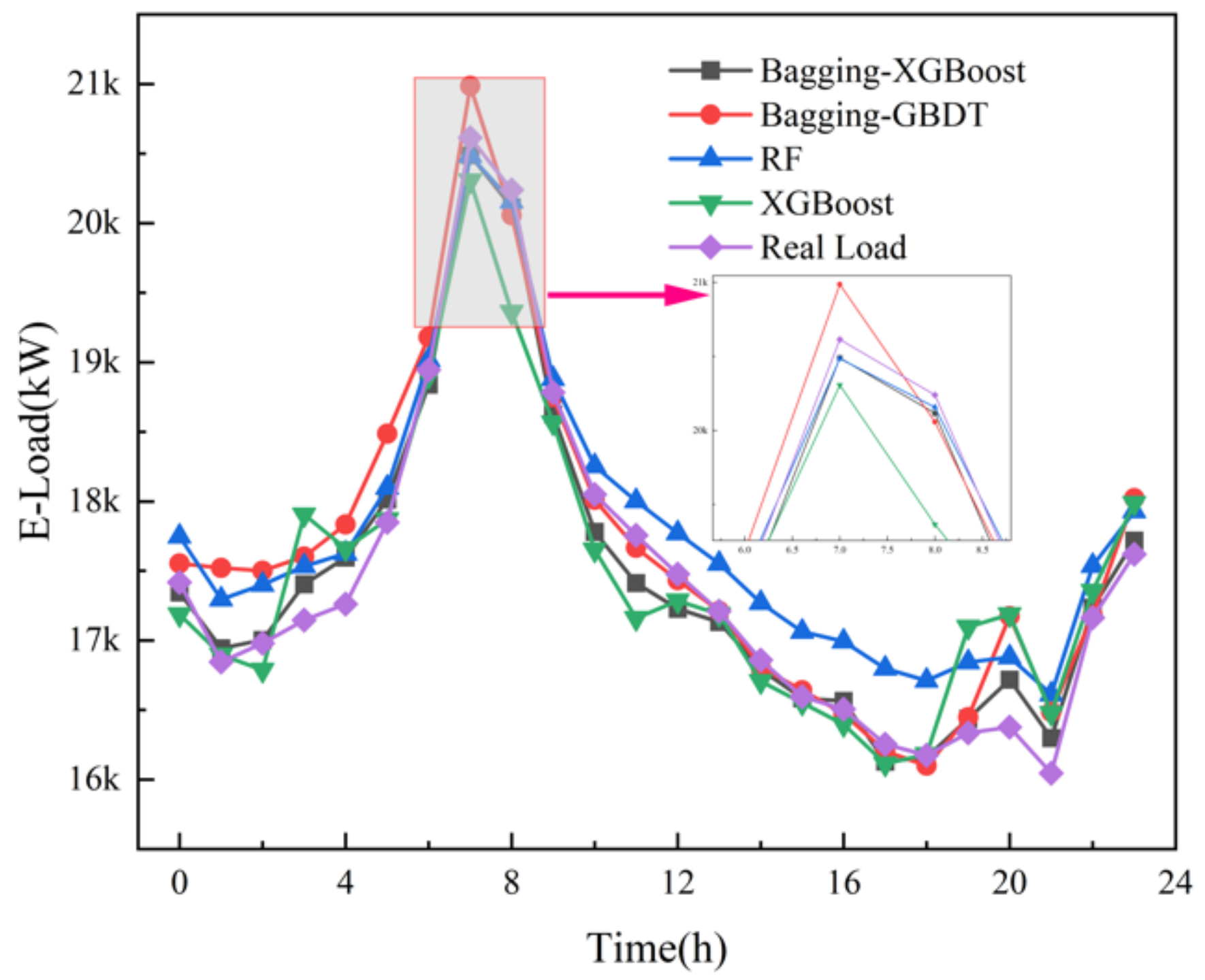
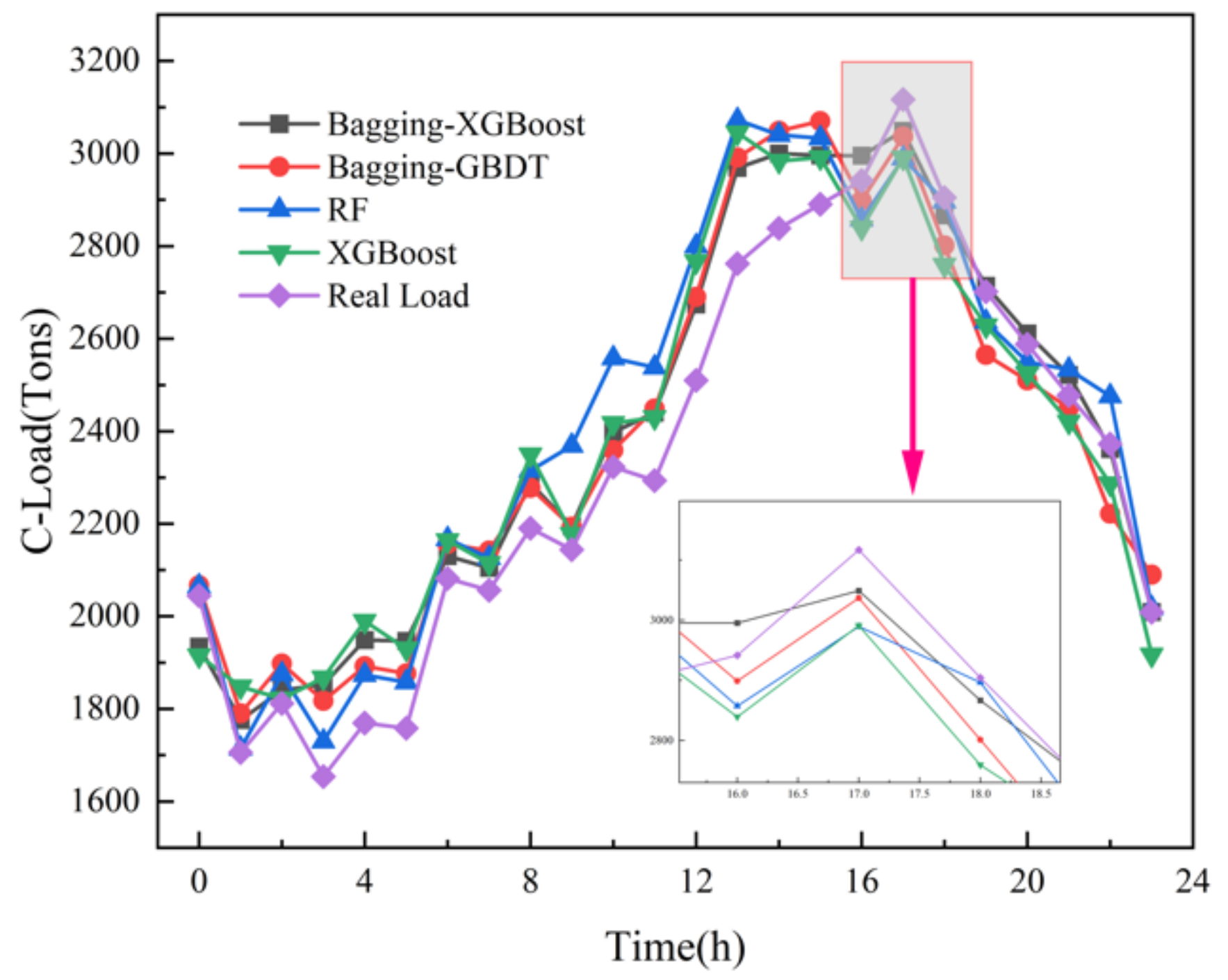
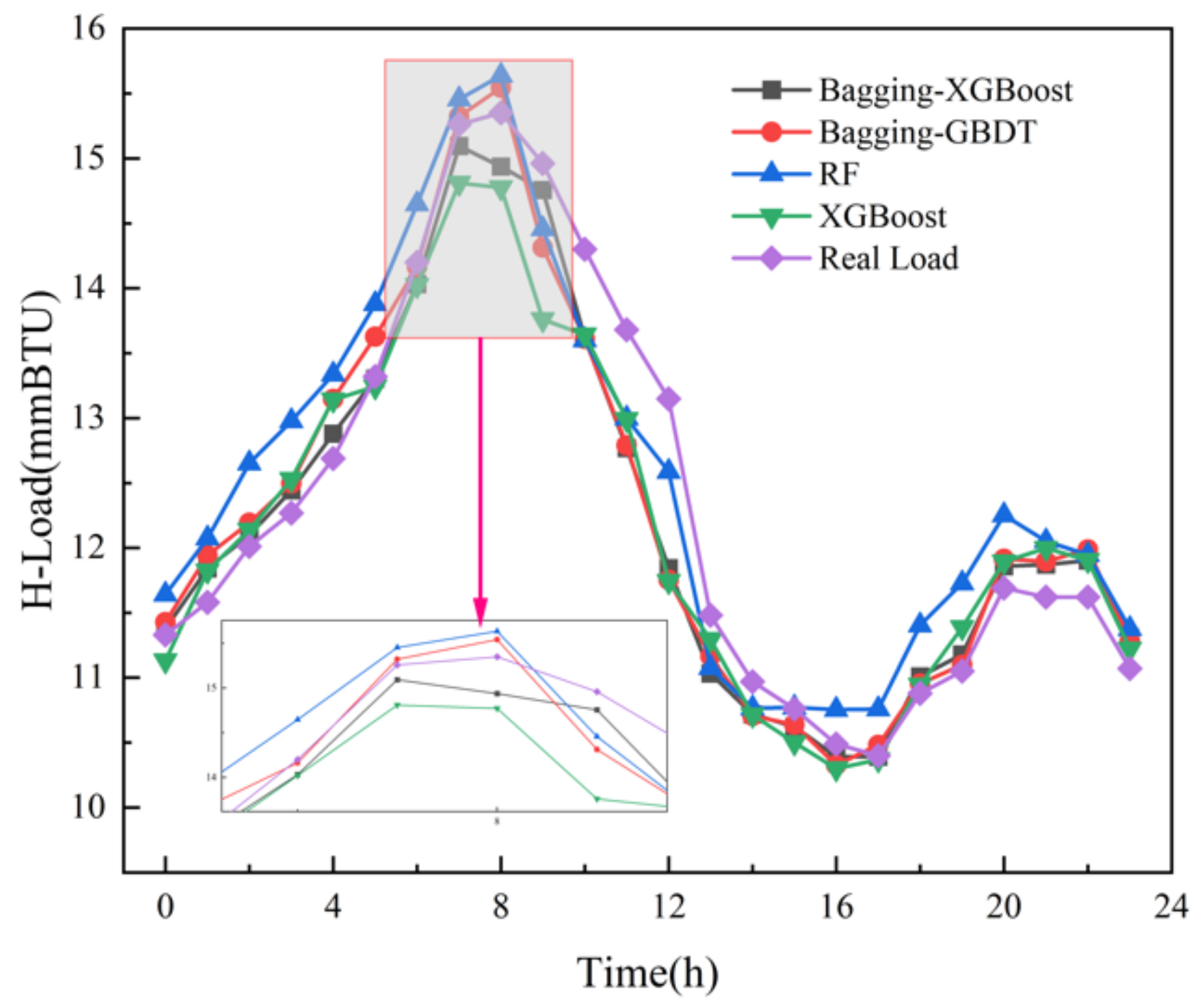
(2) Comparison of Bagging-XGBoost model with RF model and XGBoost model
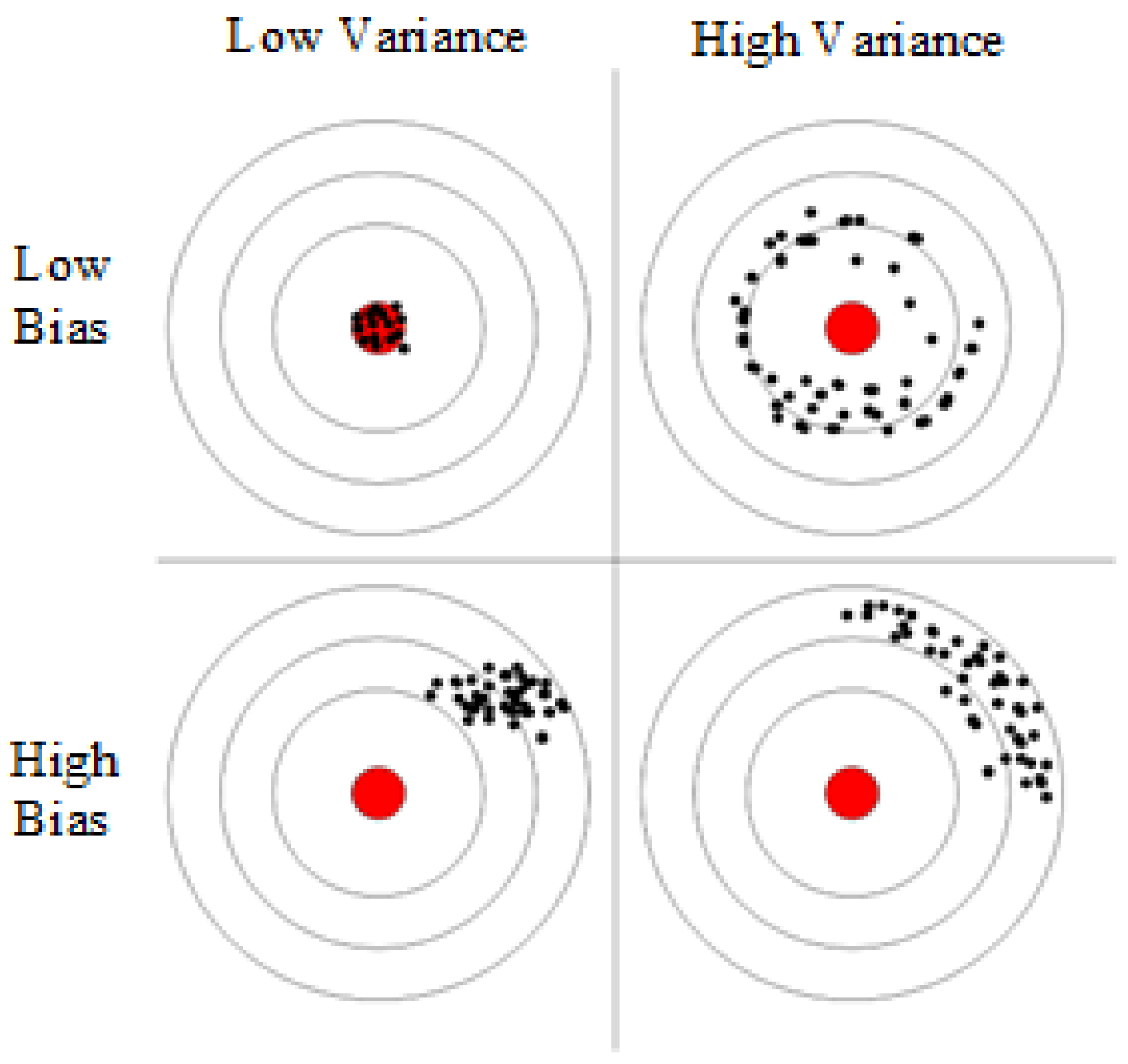
From the overall prediction results, it can be seen that the prediction accuracy of the sequential-parallel integration model (Bagging-XGBoost) is greatly improved compared with the sequential integration model (XGBoost) and parallel integration model (RF). Compared with the XGBoost model, the MAPE index of the electric, cooling, and heat load forecasting results of the Bagging-XGBoost model is reduced by 74.8%, 35.7%, and 57.7%, respectively. Compared with the RF model, it decreased by 86.9%, 66.8%, and 34.2%. From the perspective of bias and variance, the prediction results of the Bagging-XGBoost model also achieve the desired results. Taking the electrical load as an example, the MAE index and RMSE index of the Bagging-XGBoost model are reduced by 192.665 and 189.257 kW compared with the RF model. Compared with the XGBoost model, it is reduced by 148.747 and 215.342 kW. It can be seen that sequential-parallel hybrid ensemble learning can better balance bias and variance than single sequential ensemble learning or single parallel ensemble learning to achieve the best prediction results.
(3) Comparison between the Bagging-XGBoost model and Bagging-GBDT model
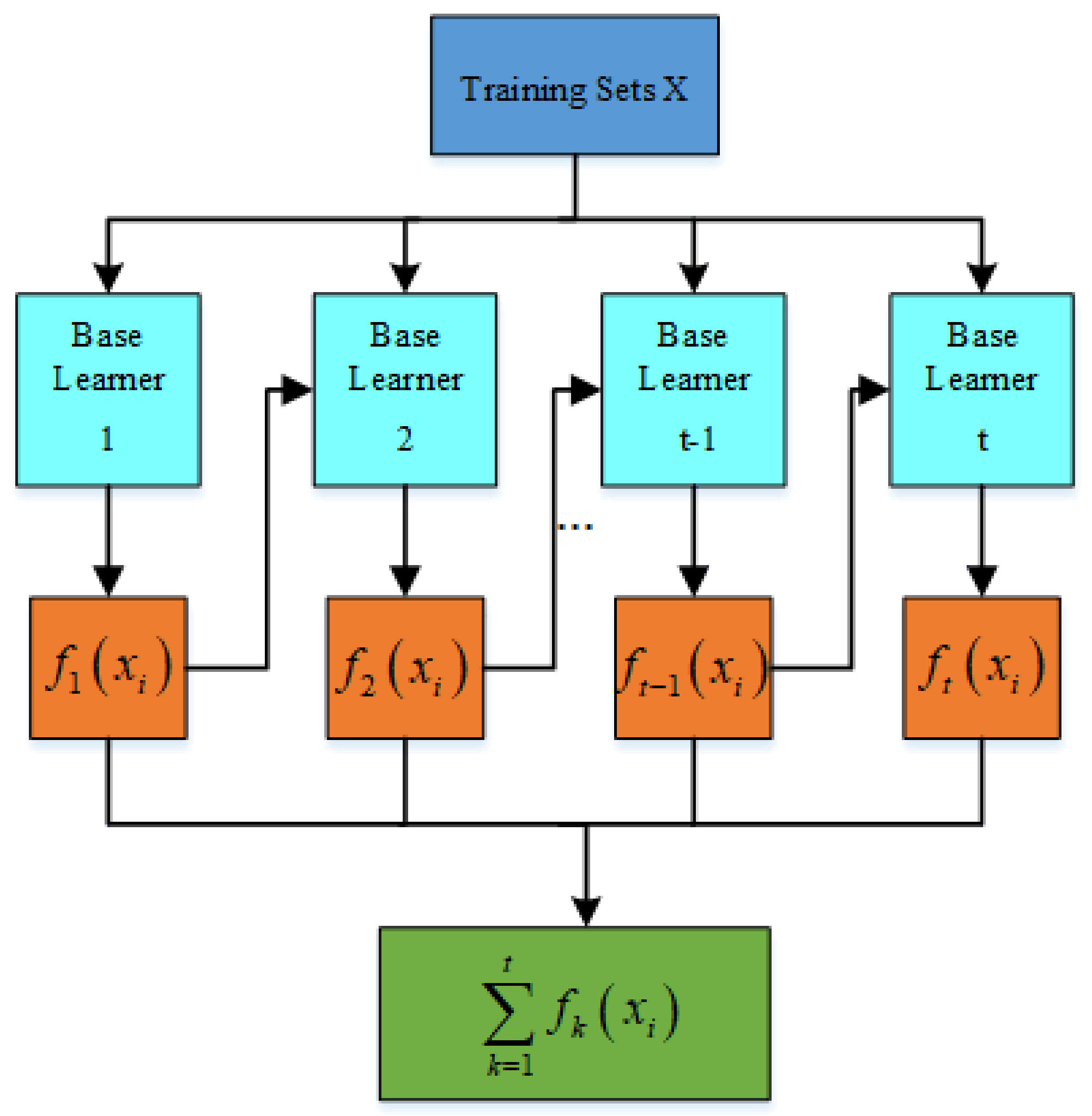
Both XGBoost and GBDT are sequential ensemble learning algorithms. Because XGBoost is an improved algorithm of GBDT, XGBoost performs second-order Taylor expansion on the loss function and can apply first-order and second-order derivatives at the same time. It can quickly find the splitting point so that it has a strong ability to prevent overfitting. However, GBDT only applies first-order derivative information during training, and the model training is not sufficient, resulting in lower prediction accuracy than XGBoost. From
Table 6 and
Figure 7 to
Figure 9, it can be seen that the overall prediction effect of the Bagging-XGBoost model is better, and the prediction accuracy is higher than that of the Bagging-GBDT model. Among them, the prediction accuracy of electric, cooling, and heat load is increased by 28.6%, 6.9%, and 13.1%, respectively, and all three loads achieve the ideal prediction effect.
From the load forecasting results, the Bagging-XGBoost model has the best effect in the prediction of electric load and cooling load, and the heat load is slightly inferior in the prediction effect, and the prediction accuracy is significantly improved. From the load forecasting curve, the overall error fluctuation of the Bagging-XGBoost model is relatively stable during the forecasting process, while the error fluctuation of the other three forecasting models is more severe. In summary, the Bagging-XGBoost hybrid ensemble learning model adopted in this paper can reduce the bias and variance, enhance the generalization performance of the model, and greatly improve the multi-load forecasting accuracy of the integrated energy system.
In order to verify the feasibility and effectiveness of the Bagging-XGBoost hybrid integration algorithm, avoid too single training set to make the prediction result accidental. Taking the electric load as an example, the data set is divided into a training set, verification set and test set according to 6:2:2, and then the data with prediction steps of one week, one month, and one quarter are tested. The average absolute percentage error and training time of the prediction results are obtained, as shown in the following
Table 7.
From the data analysis in
Table 8, with the increase in the prediction step size, the data is more complex. While the prediction difficulty increases, the training time will also increase, and the prediction accuracy of the model will generally decrease. This shows that the more data, the more information it contains. Under the influence of various factors, the full learning ability of the model is insufficient, and the generalization performance is not strong. The Bagging-XGBoost model not only has higher prediction accuracy than other models but also has a more stable prediction performance. In terms of training time, the representative RF model in parallel integration has a shorter training time than the typical sequential integrated XGBoost model because the parallel integration algorithm is faster than the sequential integration algorithm. While the Bagging-XGBoost model ensures higher prediction accuracy, the training time is not much different from other models, which reflects the superiority of the sequential-parallel hybrid integration algorithm and has better application prospects in the field of load forecasting.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}