1. Introduction
Energy storage is a crucial question for the usage of photovoltaic (PV) energy because of its time-varying behavior. In the ÉcoBioH2 project [
1], we consider a building with solar panels providing different usages. The building includes a datacenter that is constrained to be powered by solar energy. It has a low carbon footprint building with lead and hydrogen storage capabilities. Our goal is to monitor this hybrid energy storage system with a goal of low carbon impact.
The building [
1] is partially islanded with a datacenter that can only be powered by the energy produced by the building’s solar panels. The proportion of energy produced by the PV in the energy consumed by the building, including the datacenter, defines the self-consumption. The EcoBioH2 project requests the self-consumption to be at least 35%. Demand flexibility, where the load is adjusted to meet production, is not an option in this building so that energy storage will be needed to power the datacenter. Daily variations of the energy production can be mitigated using lead or lithium batteries. However, due to their low capacity density such technologies cannot be used for interseasonal storage. Hydrogen energy storage, on the other hand, is a promising solution to this problem, enabling yearly low-volume, high-capacity, low-carbo-emission energy storage. Unfortunately, it is plagued by its low storage efficiency. Combining hydrogen storage with lead batteries in a hybrid energy storage system enables us to leverage the advantages of both energy storages [
2]. Hybrid storage has been shown to perform well in islanded emergency situations [
3]. Lead batteries can deliver a big load but not for long. On the other hand, hydrogen storage only supports a small load but has a higher capacity than lead or lithium batteries allowing a longer discharge. The question becomes how to monitor the charge and discharge of each storage and to balance between the short-term battery and the long-term hydrogen storage?
We encounter therefore several short and long-term goals and constraints in opposition summarized in
Table 1. Minimizing the carbon impact discourages from using batteries, as batteries emit carbon during their lifecycle. It also encourages using
storage when needed, as less carbon is emitted per kW·h than battery storage. The less energy is stored, the less energy is lost in storage efficiency. This results in more energy available to the building. Thus, in the short-term, self-consumption increases. However, the datacenter is not guaranteed to have enough energy available for the long-term. Keeping the datacenter powered by solar energy requires storing as much energy as possible. Nevertheless, some energy is lost during charge and discharge leading to a lower self-consumption. This energy should be stored in the battery first since less energy is lost in efficiency, resulting in higher emissions. Keeping the datacenter powered is a long-term objective as previous decisions impact the current state that constraints our capacity to power the datacenter in the future. Nonetheless, because of their capacities our energy storage systems perform in opposition. Battery storage has a limited capacity. It allows the withstanding of short-term production variations. Hydrogen storage has an enormous capacity. It helps with long-term, interseasonal variations.
Managing a long-term storage system means that the control system needs to choose actions (charge or discharge and storage type) depending on their long-term consequences. We consider a duration of several months. We want to minimize the carbon impact while having enough energy for a complete year at least, under the constraints of the datacenter being powered by solar energy. Using convex optimization to solve this problem requires precise forecasting of the energy production and consumption for the whole year. One cannot have months of such forecasts in advance [
4,
5]. In [
6], the authors try to minimize the cost and limit their study to 3 days only. Methods based on genetic algorithms, as [
7], require a detailed model of the building usages and energy production which is not realistic in our case since all parts are not known in advance. We also want to allow flexible usages. Therefore, we propose to adopt a solution that can cope with light domain expertise. If the input and output data of the problem are accessible, supervised learning and deep learning can be considered [
8]. Having contradicting goals with different horizons, reinforcement learning is an interesting approach [
9]. The solution we are looking for should provide a suitable control policy for our hybrid storage system. Most reinforcement learning methods quantize the action space to avoid having interdependent action space bounds [
10]. However, such a solution comes with a loss in precision in the action’s selection. It requires more data for learning.
Taking into account theses aspects, we address in the sequel our problem formulation allowing the deployment of non-quantized Deep Reinforcement Learning (DRL) [
11] to learn the storage decision policy. DRL learns a long-term evaluation of actions and uses it to train an actor that for each state of the building gives the best action. In our case, the action is the charge or discharge of the lead and hydrogen storages. Learning the policy could even improve controlling the efficiency in the short-term [
12]. Existing works focus on non-islanded settings [
13] where no state causes a failure. Since our building is partially islanded, this approach would yield to a failure where the islanded portion is not powered anymore. Existing DRL for hybrid energy storage systems focuses on minimizing the energy cost [
14]. It does not consider the minimization of carbon emission in a partially islanded building.
In this paper, we formulate the carbon impact minimization of the partially islanded building to learn a hybrid storage policy using DRL. We will reformulate this problem to reduce the action space dimension and therefore improve the DRL performance.
The contributions of this paper are as follows:
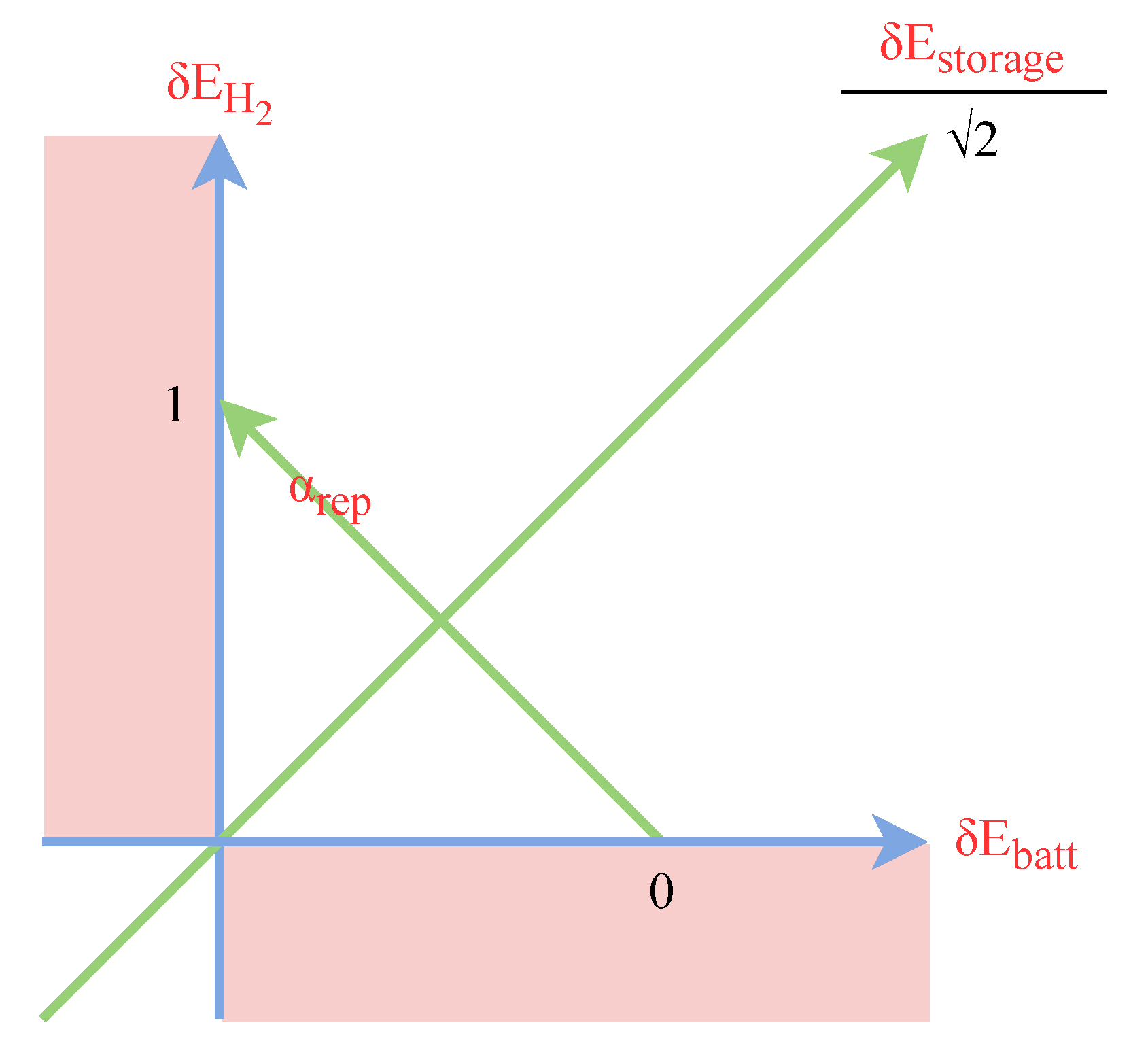
We redefine the action space so that the action bounds are not interdependent.
We use this reformulation to reduce the action space to a single dimension.
From this analysis, we deduce a fixed up to a projection (but not learned) repartition policy between the lead and hydrogen.
We propose an actor–critic approach to control the partially islanded hybrid energy storage of the building, to be named DDPG.
Simulations will show the importance of the hydrogen efficiency and carbon impact normalization in the reward, for the learned policy to be effective.
4. Learning the Policy with DDPG
In the reformulation
reformulation, we want to select
given the state
. The function that provides
given
is referred to as the policy. We want to learn the policy using DRL with an actor–critic policy-based approach: the Deep Deterministic Policy Gradient (DDPG) [
19]. Experts may want to skip
Section 4.2 and
Section 4.3.
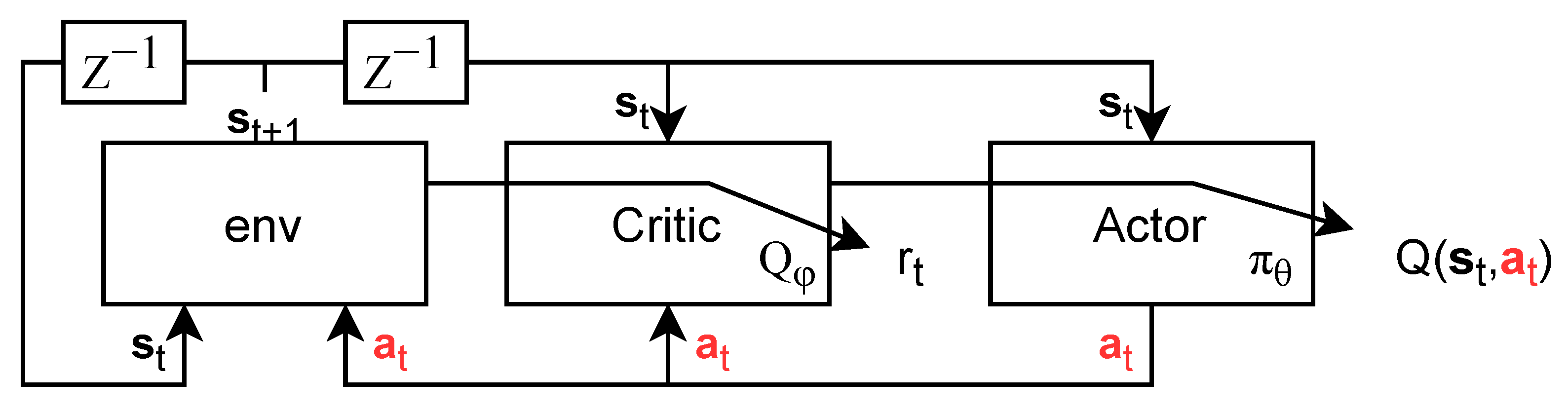
4.1. Actor–Critic Approach
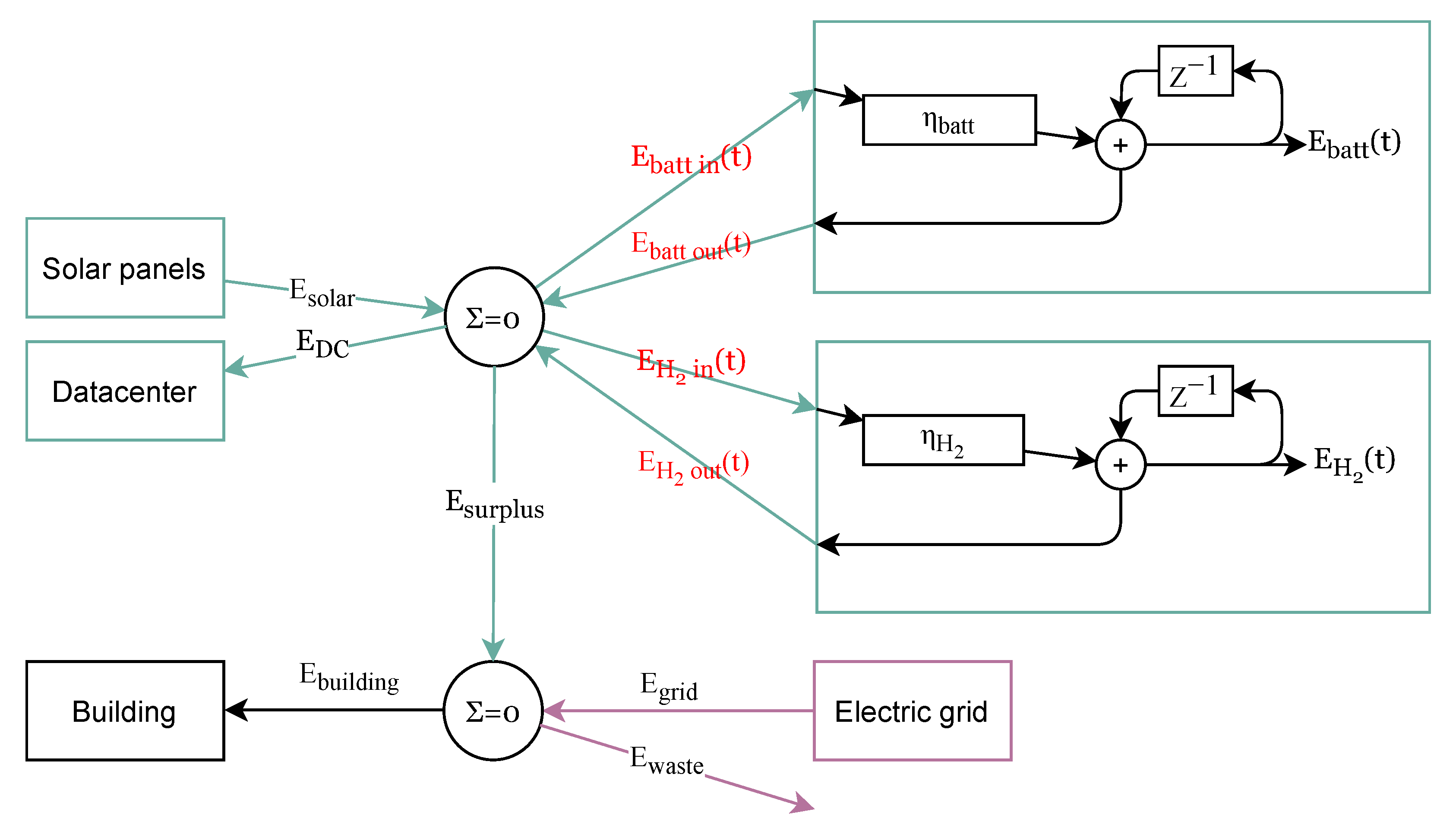
We call
for the environment, the set of equations: (
1) and its battery variant that allows the obtaining of
from
and
,
. Its corresponding reward, the short-term evaluation function, is defined as a function of
and
,
. We use [
19], an actor–critic approach, where the estimated best policy for a given environment
is learned through a critic as in
Figure 4. The critic transforms this short-term evaluation into a long-term evaluation, the Q-values
, through learning. It will be detailed in
Section 4.2. The actor
is the function that selects the best possible action
possible. It uses the critic as to know what is the best action in a given state (as detailed in
Section 4.3).
In
Section 2.4, we set our objective to minimize the long-term carbon impact (
13). However, in reinforcement learning we try to maximize a score, defined as the sum of all rewards:
To remove this difference, we maximize the negative carbon impact
. However, the more negative terms you add, the lower the sum is. This leads to a policy trying to stop the simulation as fast as possible, in contradiction to our goal to always provide the datacenter in energy. To counter this, we propose, inspired by [
20], to add a living incentive of 1 at each instant. Therefore, we propose to define the reward as:
The reward accounting for the carbon impact is now normalized between 0 and 1 so that the reward is always positive. Still in this reward the normalization depends on the state
. When the normalization depends on the state, two identical actions can have different rewards associated with them. Therefore, the reward is not proportional to the carbon impact (
45) making the reward harder to interpret. To alleviate this problem, we propose to use the global maximum instead of the worst case for the current state:
By convention is set to zero after the simulation ends.
The actor and critic are parameterized using artificial neural networks, respectively denoted and . They will be learned alternatively and iteratively. Two stabilization networks are also used for the critic supervision with weights and .
4.2. Critic Learning
Now that we have defined a reward, we can use the critic to transform it into a long-term metric. As time goes, we have less and less trust in the future. Therefore, we discount the future rewards using a discount factor
. We define the critic
. It estimates the weighted long-term returns of taking an action
in a given state
. This weighted version of (
50) also allows the binding of the infinite sum to learn it.
Q can be expressed recursively:
We learn the
Q-function using an artificial neural network of weights
. At the
iteration of our learning algorithm and for a given value of
and
, we define a reference value
from the recursive expression (
53). Since we do not know
, we need to select the best action possible at
. The best estimator of this action is provided by the policy
, so that we define the reference as:
where
has been estimated by
.
The squared difference between the estimated value
, and the reference value
[
21] is defined as:
To update
, we minimize
in (
55) using a simple gradient descent:
where
is the gradient of
in (
55) with respect to
taken at the value
.
is a small positive step-size. To stabilize the learning [
19] suggests updating the reference network
slower, so that:
at weight initialization.
4.3. Actor Learning
Since we alternate the updates of the critic and of the actor, we address next the learning of the actor. To learn what is the best action to select, we need a loss function that grades different actions
. Using the reward function (
52), as a loss function, the policy would select the best short-term, instantaneous, action. Since the critic
depends on the action
, we replace
by
. At iteration
i, to update the actor network
, we use the gradient ascent of the average
taken at
. This can be expressed as:
where
is a small positive step-size.
To learn the critic a stabilized actor is used. Like the stabilized critic,
is updated by:
with
at the beginning.
During learning, an Ornstein–Uhlenbeck noise [
22],
n, is added to the policy decision to make sure we explore the action space:
4.4. Proposition: DDPG Algorithm to Learn the Policy
From the previous section, we propose the DDPG Algorithm 1. This algorithm alternates the learning of the networks of the actor and of the critic. We select randomly the initial instant t to avoid learning time patterns. We start each run with full energy storage.
Once learned, we use the last weights of the neural network parameterizing the actor to select the action using directly.
To learn well an artificial neural network needs the different samples of learning data to be uncorrelated. In reinforcement learning two consecutive states tends to be close, i.e., correlated. To overcome this problem, we store all experiences
in a memory and use a tiny random subset as the learning batch [
23]. The random selection of a batch from the memory is called
.
| Algorithm 1: DDPG |
![Energies 14 04706 i001]() |
5. Simulation
We have just proposed DDPG to learn how to choose with respect to the environment. In this section, we display the simulations settings and results.
5.1. Simulation Settings
Production data are computed using (
48) from real irradiance data [
17,
18] measured at the building location in Avignon, France. The building has
of solar panels with
opacity and an efficiency of
. Those solar panels can produce a maximum of
kW·h per hour.
Consumption data comes from projections of the engineering office [
16]. It consists of powering housing units with an electricity demand fluctuating daily between 30 kW·h (1 a.m. to 6 a.m.) and 90 kW·h. The weekly variations of the consumption varies with a factor between 1 and 1.4 during awake hours between workdays and the weekend. There is little interseasonal variation, standard deviation of 0.6 kW·h (0.01% of yearly mean) between seasons, as heating uses wood pellets. In those simulations, the datacenter is consuming a fixed amount of
kW·h. The datacenter consumption adds up to 87.6 MW·h per year, around 17% of the 496 MW·h that the entire building consumes in a year. To power this datacenter, our building’s solar panels produce an average of 53.8 kW·h/h during the
sunny hours on average day counts, for a yearly total of 249 MW·h/year. This covers a maximum of 2.8 times the consumption of our datacenter, but lowers to 99% if all energy goes through the hydrogen storage. The same solar production covers at most 50% of the building yearly consumption. When accounting for hydrogen efficiency, the solar production covers at most 17% of the building consumption.
We only use half of the lead battery capacity to preserve the battery health longer
kW·h. The lead battery carbon intensity is split between the charge and discharge
·h. Since the charge quantity comes before the efficiency, its carbon intensity must account for efficiency:
·h. The carbon intensity of the electrolysers, accounting for the efficiency, is used for
·h. The carbon intensity of the fuel cells corresponds to
·h.
account for both the electrolysers and fuel cells efficiency.
·h uses the average French grid carbon intensity. All those values are reported in
Table 3.
The simulations use an hourly simulation step t.
We train on the production data from year 2005, validate and select hyperparameters, using best score (
50) values, on the year 2006 and test finally on year 2007. Each year lasts 8760 h.
To improve learning, we normalize between
and 1 all state and action inputs and outputs. For a given value
d bounded between
and
:
is then used as an input for the networks.
To accelerate the learning, all gradient descents are performed using Adam [
24]. During training, we use the following step sizes
to learn the critic and
for the actor. For the stabilization networks,
. To learn, we sample batches of 64 experiences from a memory of
experiences. The actor and critic both have 2 hidden layers with a ReLU activation function. Hidden layers have respectively 400 and 300 units in them. The output layer uses a tanh activation to bound its output. The discount factor,
in (
54) is optimized as a hyperparameter between 0.995 and 0.9999. We found the best value for the discount factor to be 0.9979.
5.2. Simulation Metrics
We name duration and note
N the average length of the simulations. When all simulations last the whole year, the hourly carbon impact is evaluated as in (
49). To select the best policy, the average score is computed using (
50). Self-consumption, defined as the energy provided by the solar panels, directly or indirectly using one of the storages, over the consumption, is computed using:
Per the ÉcoBioH2 project, the goal is to reach 35% of self-consumption: .
5.3. Simulation Results
The following learning algorithms are simulated on data from Avignon from 2007 and our building:
DDPGTwoBatts: DDPG with actions
DDPGRepartition: DDPG with actions
proposed DDPG with action
where
DDPGTwoBatts and
DDPGRepartition are algorithms similar to
DDPG with action spaces of the corresponding formulations respectively (
11) and (
17). The starting time is randomly selected from any hour of the year.
To test the learned policies, the duration, hourly impact (
49), score (
50) and self-consumption (
62) metrics are computed on the 2007 irradiance data and averaged over all runs. We compute those metrics over 365 different runs, starting each 2007 day at midnight. For the sake of comparison, we also compute those metrics when applicable for the preselected values
and
using (
47) on the same data. Recall that the fixed
values are bounded to (
43) and (
44) to ensure the long-term duration.
The metrics over the different runs are displayed in
Table 4.
We can see in
Table 4 that
DDPGTwoBatts and
DDPGRepartition do not last the whole year. This shows the importance of our reformulations to reduce the action space dimensions. We observe that all policies using the
reformulation last the whole year (
). This validates our proposed reformulations and dimension reduction.
achieves the lowest carbon impact; however, it cannot ensure the target of self-consumption. On the other hand, achieves the target self-consumption at the price of a higher carbon impact. The proposed DDPG provides a good trade-off between the two by adapting to the state . It reaches the target self-consumption minus 0.1% and lowers the carbon impact with respect to . The carbon emission gain over the intuitive policy , using hydrogen only as a last resort, is of 43.8 gCOeq/year. This shows the interest of learning the policy once the problem is well formulated.
5.4. Reward Normalization Effect
In
Section 4.1, we presented two ways to normalize the carbon impact in the reward. In this section, we show that the proposed global normalization (
52) yields better results than the local state-specific normalization (
51).
In
Table 5, we display the duration for both normalizations. We see that policies that use the locally normalized reward have a lower duration than the ones using a globally normalized reward. This confirms that the local normalization is harder to learn as two identical actions have different rewards in different states.
Therefore, the higher dynamic of the local normalization is not worth the variability induced by this normalization. This validates our choice of the global normalization (
52) for the proposed
DDPG algorithm.
5.5. Hydrogen Storage Efficiency Impact
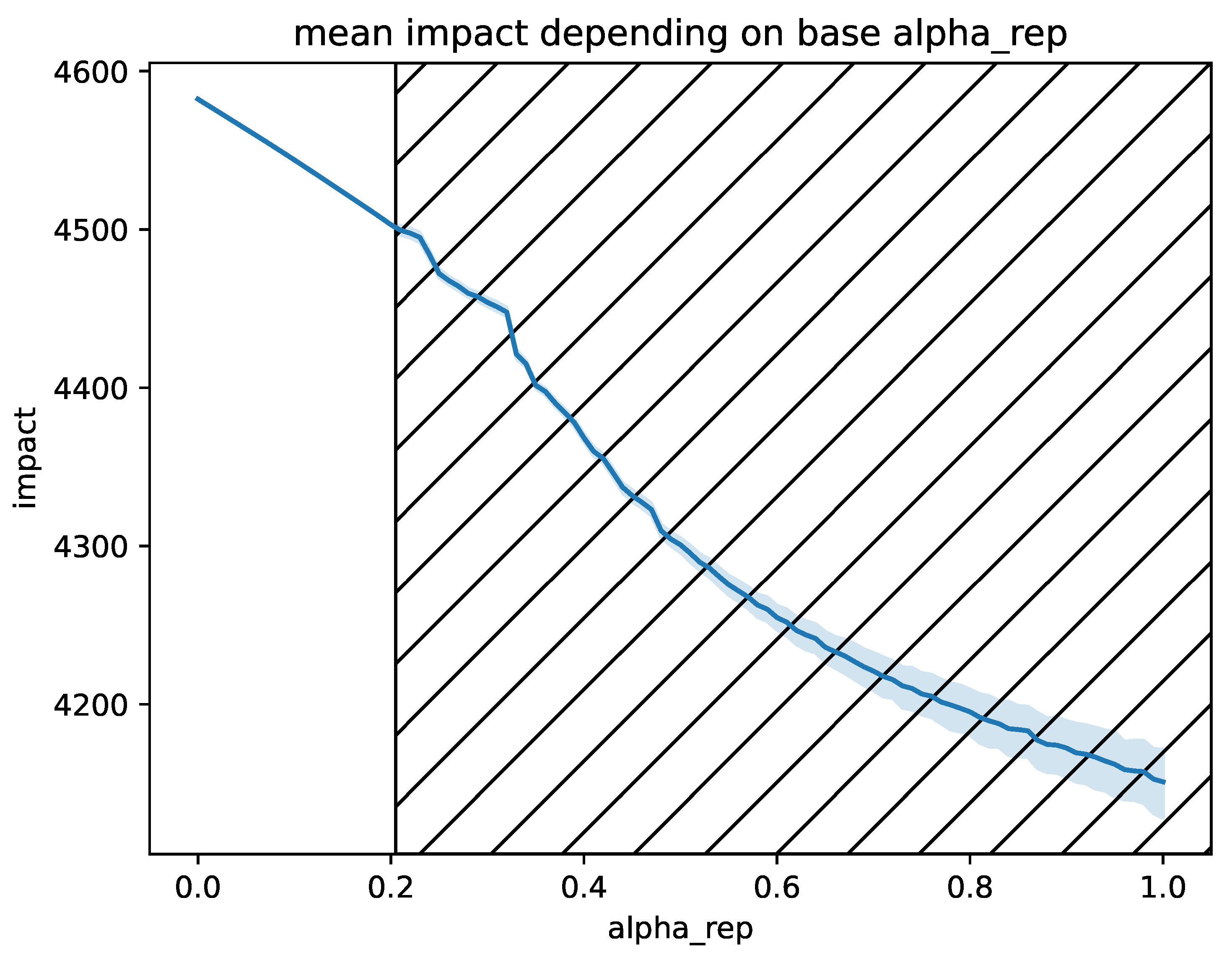
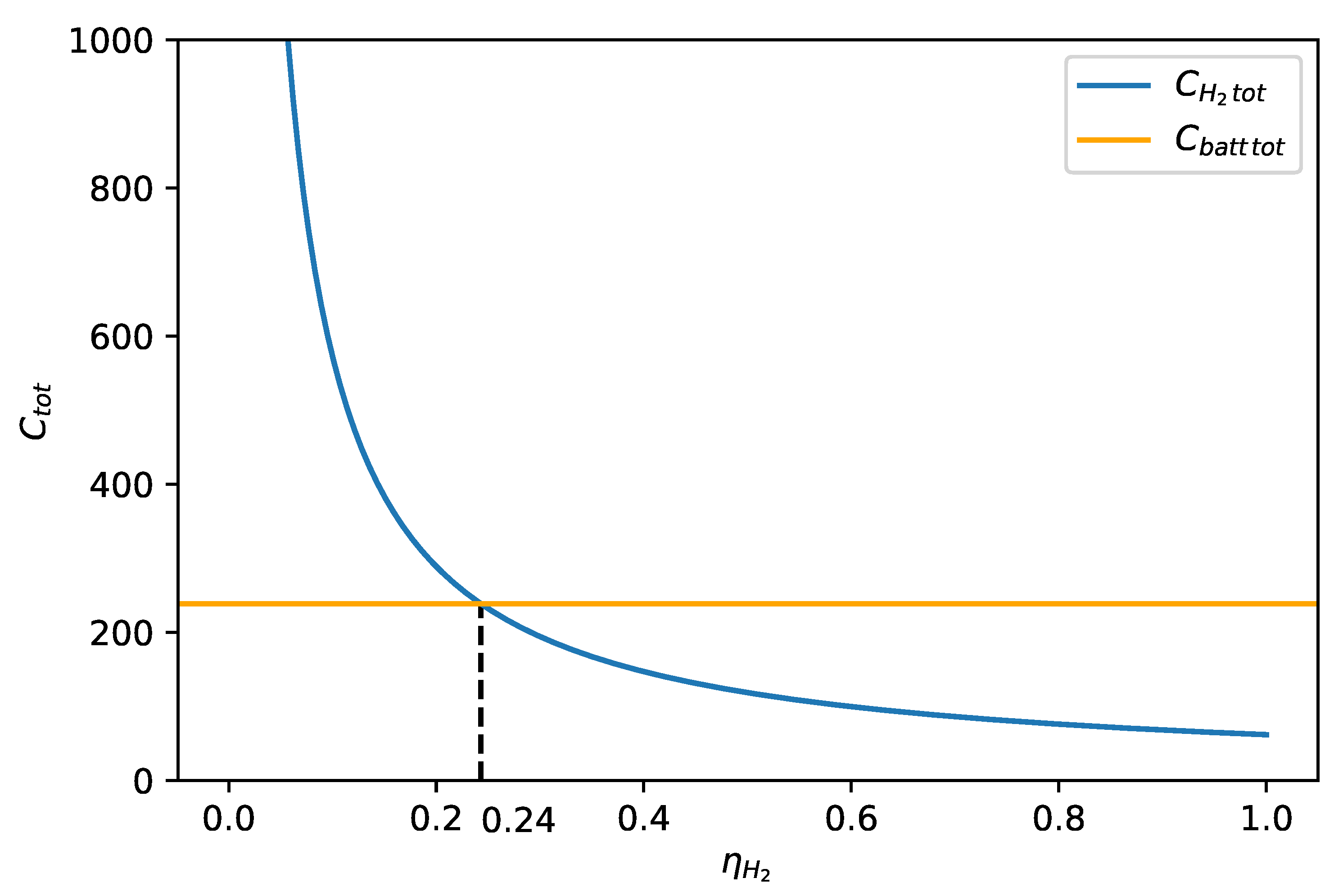
In our simulations, we have seen the sensibility of our carbon impact results to the parameters in
Table 3. Indeed, the efficiency of the storage has a great impact on the system behavior. Hydrogen storage yields lower carbon emissions when its efficiency
is higher than some threshold. The greater is
, the greater
could be and so the range for adapting
via learning is more important. To find the threshold in
, we first compute the total carbon intensity of storing one kW·h in a given storage, including the carbon intensity of energy production. For
, we obtain:
We display the value of (
63) of both storages in
Figure 5 with respect to
, the other parameters are taken from
Table 3. When
learning is useful since the policy must balance the lower carbon impact (using the hydrogen storage) with the low efficiency (using the battery storage). When
the learned policy converges to
, as both objectives (minimizing the carbon impact and continuous powering of the datacenter) align.
We calculate from (
63) and its battery variant, the threshold point where
to be at efficiency:
Using values in
Table 3 on (
64), hydrogen improves the carbon impact only when
. The current value is
, learning is also useful as shown in the simulations
Table 4. We can also suggest that when the hydrogen storage efficiency will improve in the future, the impact of learning will be even more important.
6. Conclusions
We have addressed the problem of monitoring the hybrid energy storage of a partially islanded building with a goal of carbon impact minimization and self-consumption. We have reformulated the problem to reduce the number of components of the action to one, , the proportion of hydrogen storage given the building state . To learn the policy, , we propose a new DRL algorithm using a reward tailored to our problem, DDPG. The simulation results show that when the hydrogen storage efficiency is large enough, learning of allows a decrease to the carbon impact while lasting at least one year and maintaining of self-consumption. As hydrogen storage technologies improve, the proposed algorithm should have even more impact.
Learning the policy using the proposed DDPG can also be done when the storage model includes non-linearities. Learning can also adapt to climate changes in time using more recent data for learning. To measure such benefits, we will use in the future the ÉcoBioH2 real data to be measured in the sequel of the project. Learning from real data will reduce the gap between the model and the real system. Reducing this gap should improve performance. The proposed approach could also be used to optimize other environmental metrics with a multi-objective cost in .
With our current formulation, policies cannot assess what day and hour it is as they only have two state variables to compute the hour: and . They cannot differentiate between 1 a.m. and 4 a.m. at night as those two times have the same consumption and no PV production. They also cannot differentiate between a cloudy summer and a clear winter as production and consumption are close in those two cases. In the future, we will consider taking into account the knowledge of the current time to enable the learned policy to adapt its behavior to the time of the day and month of the year.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}