1. Introduction
According to the Intergovernmental Panel on Climate Change (IPCC), the source of global warming is the result of human behavior, and its accumulated effects can severely affect life. Because human activities continue emitting greenhouse gases, the IPCC estimated that the average global temperature in 2100 will increase by 1 to 6.3 degrees Celsius. Furthermore, the sea level in 2100 is expected to increase 9 to 88 cm compared to current levels. This will have a huge impact on human habitats, tourism, fisheries, buildings near coastal areas, agricultural land, and wetlands. It is estimated that tens of millions of people will be forced to move, which will result in severe economic losses. The greenhouse gases regulated by the Kyoto Protocol include CO2, CH4, N2O, PFC, HFC, and SF6. In the growth of global greenhouse gas emissions, CO2 is the fastest growing and accounts for 94.77% of the total. Thus, countries across the globe have been focusing on the sources of the CO2 increase.
Previous studies on the amount of CO
2 emissions include factors that affect the amount of emissions [
1,
2,
3,
4] and carbon emission amount forecasting [
2,
5]. Previous studies on factors that affect the amount of carbon emissions considered different factors. Zakarya et al. [
1] used a panel cointegration test and Granger causality to analyze whether there is a correlation between total energy consumption, direct foreign investment, and economic growth. The major contribution in their study is the consideration of environmental pollution and the amount of carbon emissions caused by foreign investment. However, their study lacked consideration of the amount of carbon emissions caused by the population. Wu et al. [
2] explored the relationship between energy consumption, urban population, the economy, and CO
2 emissions in the BRICS countries (i.e., Brazil, Russia, India, China, and South Africa). Their study only used the grey model coefficient to conduct the correlation analysis and did not use the grey relation interpretation. In reality, uncertainty still exists when grey action is used as the standard, and this cannot accurately determine the mutual effect and correlation between the amount of carbon emissions and other factors. Their study considered the population factor and used urban population as its representative. However, the urban population does not represent the impact of a nation’s total population on the amount of CO
2 emissions. Wang et al. [
3] primarily explored the impact of China’s road cargo transportation on carbon emissions and used the least squares regression model and multiple linear regression analysis to build a forecast model. However, their study did not first conduct a correlation analysis between carbon emission pollution from road transportation, and only considered transportation. Thus, their study did not consider other factors that could cause and increase the amount of carbon emissions. Xu and Lin [
4] primarily analyzed the carbon emissions produced by China’s transportation industry. They used panel data to analyze the impact of the number of automobiles in different areas on the amount of CO
2 emissions. Again, they only considered transportation, but did not consider other factors that increased the carbon emissions.
Previous studies have used different forecast models to estimate the amount of CO
2 emissions. Belbute and Pereira [
5] forecasted global CO
2 emission amount based on the ARFIMA model. They defined the amount of carbon emissions as the CO
2 emitted from the burning of fossil fuels (petroleum, coal, and natural gas) and the production of cement. Aydin [
6] used regression
t-test, F-test, and residual analysis to examine the impact of Turkey’s national population, GDP, alternative energy, nuclear power consumption, combustible renewable energy, waste energy consumption, and fossil fuel consumption on CO
2 emissions. Aydin also used trend analysis to forecast future growth of CO
2 emissions. However, all the aforementioned forecast methods required a large amount of historic data samples to be able to build an accurate forecast model. In addition, most of these models did not consider other factors in the forecast model. These forecast methods have a common drawback that the selection of samples requires an assumption of some probability distribution, e.g., a normal distribution or Poisson distribution. In addition, most previous studies speculated and built forecast models based on raw CO
2 data. Thus, Wu et al. [
2] established a grey forecast model. The advantage of their method is that a small sample number and that the factors can be considered in the model. However, when the data has a non-linear trend, the grey forecast model can produce poorer forecast values. Although Wu et al. [
2] considered energy consumption, urban population, and economy as factors, they viewed the urban population as representative of the entire population. They did not consider the problem of transportation in the forecast model, which means that they still used incomplete factors.
In light of the above, this study considered all the factors that affect carbon emissions mentioned in previous works, and proposes an integrated forecasting model called hybrid multivariable grey forecasting and genetic programming model, which is divided into two stages. The first stage is the
multivariable grey forecasting method. The advantage of
multivariable grey forecasting is that different from conventional grey forecasting, it can introduce multiple factors that affect the forecast value into the forecast model, and it only requires a small number of samples (generally only four or more [
7]) to make an accurate forecast. However, when the data has a non-linear trend, the grey forecasting model can produce poorer forecast values. To improve the forecast accuracy, we combined grey forecasting with
genetic programming (GP) in the second stage to build an error correction model to lower the forecast error.
The greatest difference between this study and previous studies is that previous studies did not discuss multiple time periods and events to build their models for forecasting the amount of CO2 emissions. In addition, this study experimented with different combinations of factors in the forecast model, and scenario analysis was conducted to determine which combination of factors produced the most accurate CO2 emission forecast in terms of three error performance measures (i.e., MAPE, MAE, and PE). The primary contributions of this study include the following:
Previous studies did not consider at least three factors that affect carbon emissions. This study comprehensively considered all factors that affect carbon emissions to build a forecast model. We also conducted simulation analysis and scenario analysis to find the most suitable and accurate method to forecast carbon emissions.
Most previous forecast methods required a large amount of historic data to conform to statistical assumptions, and did not consider factors in the forecast model. This study introduced different factors that can affect the forecast value in the multivariable grey forecasting method into the forecast model. This produced a model that conforms better to changes while retaining the advantage of only needing a small quantity of observed samples to be able to accurately make forecasts.
The common methods for forecasting the amount of CO2 emissions include regression analysis and time series. However, these forecast methods do not consider factor in the forecast model, which can result in excessive forecast errors. When the data is a non-linear, the accuracy of the forecast value is also poor. Thus, this study proposes an integrated forecast method that includes a multivariable grey forecasting method and GP. The advantage of the multivariable grey forecasting method is that it introduces factors that can affect the forecast value into the forecast model. Only four or more observation samples are needed to accurately make forecasts. The GP can automatically produce a mathematical model to effectively solve complex non-linear mathematical problems. Mutual assistance within such a mixed forecast method makes this model an effective forecast tool.
After conducting a forecast using Taiwan’s carbon emissions as an example, the experimental result showed that the best model does not need to introduce all the factors or higher grey correlation factor into the forecast model. Factor arrangement combination showed that the model with the best accuracy for 2000–2015 CO2 emission amount used Taiwan population, energy consumption, and carbon emissions as factors (i.e., three factors are considered). Note that this work proposes a general forecasting model that uses multiple factors. Although the experiment results in this example show that the model performs best using three factors, the model used for other examples or applications may conclude that the model using a different number of factors performs best.
The rest of this paper is organized as follows:
Section 2 reviews the previous literature.
Section 3 introduces the mathematical model based on grey forecasting method and GP, describes the proposed improvements made on the grey forecasting method, and finally renders the complete flowchart of the proposed method.
Section 4 shows the simulation results using this method, and compares it with previous methods. Conventional statistical verification is used to compare whether there are significant differences between the proposed method and the previous methods and to determine the advantages/disadvantages of the two. Finally,
Section 4 analyzes the difference between single factor and multi-factors.
Section 5 concludes this study and gives some future research directions.
3. Methodology
Most of the forecasting methods commonly used in the previous studies adopted actual observed values to estimate the forecast value and did not consider other factors in the forecasting model. In addition, when the data shows a non-linear trend, the forecast value showed poor performance. To prevent these defects, we propose a mixed multivariable grey forecasting and GP model. This method is divided into two stages, the first stage is the multivariable grey forecasting method GM(1, N), in which the first parameter value 1 represents that the first-order derivative is applied in the forecasting model; and the second parameter represents that there are N − 1 associated series besides the predicted series. GM(1, N) has the advantage that it can introduce factors that can impact the forecast value into the forecasting model and only need four or more samples to accurately make forecasts. However, when the data is a non-linear trend, the grey forecasting model could show poorer forecast values. To improve the forecast accuracy, the second stage combines the grey forecasting with GP to build an error correction model with a lower forecast error.
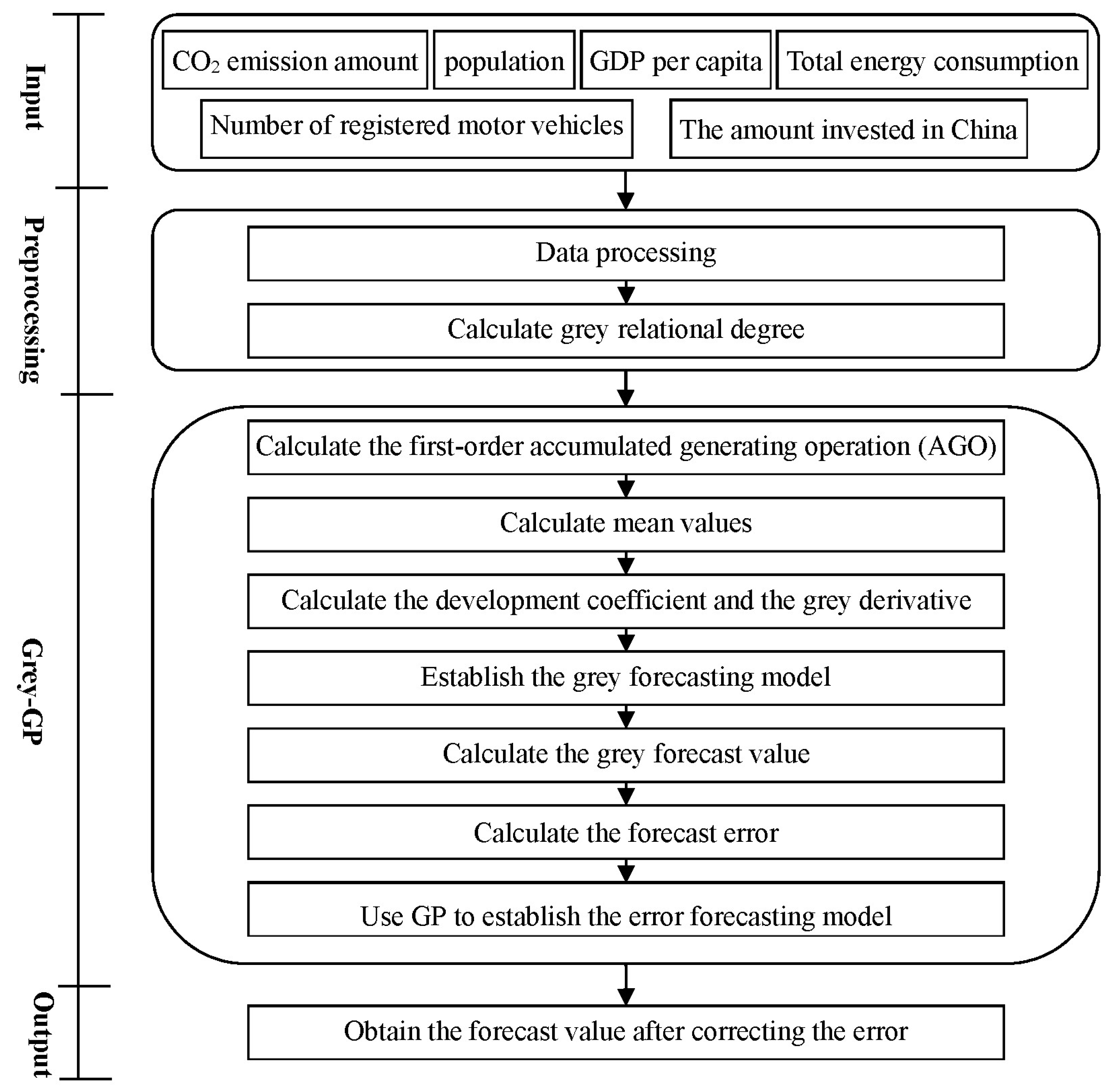
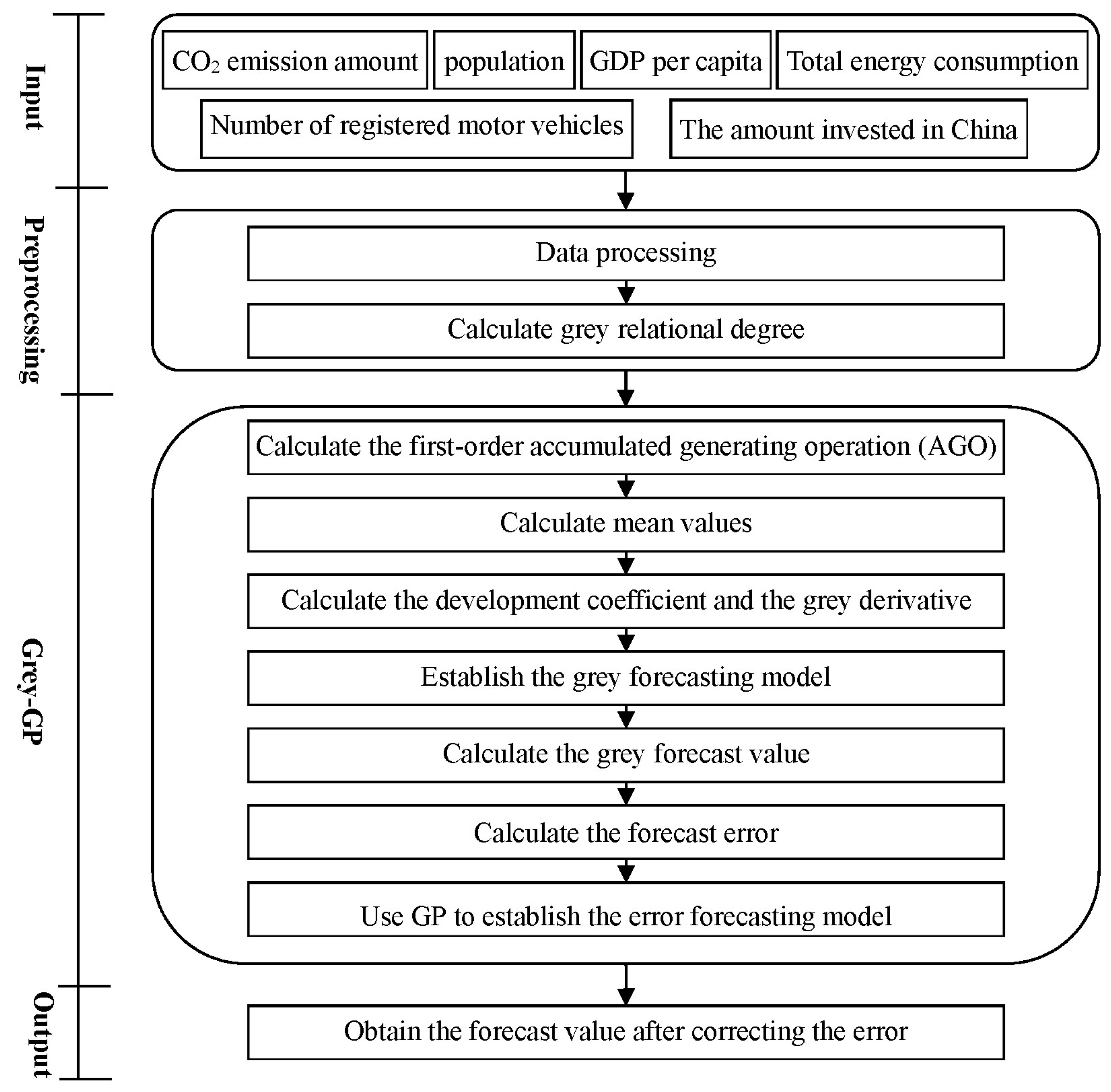
The detailed framework of the proposed two stages is shown in
Figure 1. This study considers multiple factors (e.g., population, GDP per capita, total energy consumption, number of registered motor vehicles, the amount invested in China, and so on) to forecast the amount of CO
2 emissions. First, the data of these factors are input. Then, the data is preprocessed, and then the grey relational analysis is used to calculate the grey relational degree between the primary factor (i.e., CO
2 emissions) and each of the other factors. After sorting the grey relational degrees, the important factors with a high degree of grey relation with CO
2 emissions are selected for later analysis. Then, GM(1,
N) considering these selected factors is used to build the forecast model and further calculate the grey forecast value. Then, the error between the actual value and the forecast value is calculated. Then, GP is used to build the error forecast model. The final forecast value is obtained by integrating the forecast value from GM(1,
N) and the error correction value from GP, to increase accuracy. The next section introduces the grey relational analysis, multivariable grey forecasting model, and GP used in the framework of the proposed method (
Figure 1).
3.1. Grey Relational Analysis
The relation among factors can be evaluated according to similarity or difference among the development trends of factors. Through the grey relational analysis between the primary factor (i.e., carbon emissions in this study) and multiple factors, we can understand the correlation between the two as time or space changes. When system decision and forecast provide usable information or more reliable basis, this type of analysis model can clearly show the correlation between factors. The grey relational analysis procedures are as follows:
When calculating the grey relation, a time series is established based on the original observed value of each period. Let
denote the primary series and
,
i = 1, 2, …,
N denote the associated series, where
k denotes the index of the period such as week, month, or year:
The maximum difference and minimum difference between the primary series and the other associated series are calculated as follows:
The grey relational coefficient
between the primary series and the associated series in period
k is calculated as follows:
where
ζ is the identification coefficient; and
. Generally speaking, the identification coefficient value should be 0.5. However, to magnify the difference of the results, this value can be adjusted according to the actual need.
The grey relational degree between the primary series and the associated series is the mean of all grey relational coefficients as calculated as follows:
The importance level of each factor can be obtained by comparing the grey relational degree between the primary factor and each other factor and then sorting them. The ordering of the grey relational degrees can then be used as the basis for the entire system’s decision making.
3.2. Multivariable Grey Forecasting Method GM(1, N)
In the grey forecasting model, GM(h, n) is a type of dynamic model, where h is the order number of the differential equation that characterizes the dynamic model; and n is the number of variables (i.e., factors in this study). GM(1, 1) and GM(1, N) are the most commonly used modes. The GM(1, 1) model uses the historical data of one variable to forecast the future behavior of the same variable. Differently, the GM(1, N) model has only one behavior variable, but has multiple variables that affect the behavior. Therefore, to consider multiple factors in forecasting carbon emissions, this study method uses GM(1, N).
The GM(1, N) model is introduced as follows: In the grey system, is the observed value of the primary factor in period k; and , i = 2, …, N, is the associated factor.
After the first-order accumulation generating operation (1-AGO) on the observed series
of each factor
i, we obtain
where:
Similar to whitening the GM(1, 1) model to obtain the general differential equation
, the differential equation for the GM(1,
N) model is expressed as follows:
where
a is the grey development coefficient, which is the major parameter that reflects development trends;
bi is the grey action coefficient corresponding to the associated series
i; and the mean series is obtained as follows:
Transform Equation (6) into the following matrix form:
The above matrix is solved by the least-squares method to obtain coefficient
a and coefficient
bi. Then,
where:
We substitute coefficients
a and
bi into Equation (6) to obtain the following series:
Conduct inverse accumulation generation to obtain the forecast value:
When the forecast value is obtained, the future dynamic status of the factors can be understood. Then, the error series between original values and forecast values is calculated. We then used the GP to estimate the error series, and conduct error correction to improve the accuracy.
3.3. Genetic Programing
GP is a type of automated function production method. Given a set of parameters, GP can automatically find a function that conforms to the parameters. The basic concept is based on GA, which includes reproduction, crossover, and mutation. The difference between GP and GA is that GA is expressed in an encoded string, but GP is expressed as a program tree diagram. Using GA to solve a problem suffers from the solution representation, with a fixed length that restricts the solution searching ability. In addition, it is not intuitive to decode the calculation results. Differently, GP is not limited by a fixed length, and can directly express the calculation results, which makes it easier to understand by decision makers.
The main architecture of GP includes a terminal set and function set. The former expresses variables or constants; and the latter expresses mathematical or calculation symbols (formed from addition, subtraction, multiplication, division, polynomials, trigonometric function, or other types of function). After the two sets are confirmed, it is required to define the fitness function to be optimized, set control parameters, and decide termination conditions of the GP algorithm. Then, GP is used to obtain the optimal function that best conform to actual objectives.
This study uses GP to correct the forecast error between actual values and forecast values. First, GM(1,
N) is used to obtain the forecast values, and then calculate the error series:
Then, GP is used to find the function characterizing the above error series as follows:
The architecture of GP is set as follows: the terminal set is {
ei(1),
ei(2), …,
ei(
k)}. The function set is {+, −, ×, /, log, sin, cos, exp}. The fitness function is defined as
for
i = 1, 2, …,
N. That is, the difference between the error estimation value produced by GP and the error obtained from the GM(1,
N) model is used to evaluate fitness. The parameters used in GP include the population size, evolution size, the maximal depth for the evolutionary tree, crossover rate, and mutation rate. These parameter values are set through repeated experiments and exploration. The final forecast value is obtained by summing the forecast value
obtained by GM(1,
N) and the forecast error value
obtained by GP, as calculated as follows:
4. Results
This section built a forecasting model and conducted experimental analysis based on the amount of CO
2 emissions in Taiwan, and considered the factors that affect the amount of CO
2 emissions. Among the factors that affect the amount of CO
2 emissions mentioned in the literature review in
Section 2 [
1,
2,
3,
4], the factors that had a higher correlation with the amount of emissions include population, GDP per capita, total energy consumption, number of registered motor vehicles, and foreign investment.
The experiment in this study used the data of Taiwan as an example. Based on data from the Department of Statistics, Ministry of Economic Affairs, Taiwan, 50% percent of Taiwan’s foreign investment is in China. In addition, the data on the amount of CO2 emissions from 2000 to 2015 shows that in 2009 the amount of carbon emissions significantly decreased. From the historic events, the cause of the CO2 emission decrease during that year may be the financial crisis caused by the American subprime mortgage crisis at the end of 2007. At that time, the global stock market reached a new low, and banks in different countries faced collapse. This had a significant impact on Taiwan’s economy. Affected by the financial crisis, economic development encountered obstructions, and factories were closed.
We collected and compiled the amount of CO2 emissions data and the factors from 2006 to 2011 (the year before Taiwan faced the financial crisis) for the grey relational analysis, as well as compared forecasts from different GM(1, N) models. We also found that growth of the amount of carbon emissions from 2010 to 2014 was gentle. Data showed that Taiwan’s investment in China increased. As manufacturers moved out from Taiwan, this study attempts to investigate whether this movement slowed down the carbon emission growth in Taiwan. This study analyzed and explored carbon emissions during this period. Data on the amount of CO2 emissions and the factors in Taiwan for the period from 2010 to 2014 (the year when a large number of Taiwan businessmen moved factories to China) were compiled for grey relational analysis. Forecasts of different GM(1, N) models were compared.
In this section, the first subsection compiled the amount of CO2 emissions and the factor data for the period from 2000 to 2015 for the grey relational analysis. Then, we further consider two periods. The second subsection analyzed the period from 2006 to 2011 (when Taiwan faced the financial crisis), and the third subsection analyzed the period from 2009 to 2015 (when a large number of Taiwan businessmen moved their factories to China). For the grey forecasting model, N = 2, 3, 4, 5, 6 was substituted to compare different GM(1, N) models.
4.1. Forecast and Analysis of the CO2 Emission Amount in Taiwan
For the factors that affect Taiwan’s amount of CO
2 emissions, we collected data on Taiwan’s population, GDP per capita, total energy consumption, number of registered motor vehicles, and the amount invested in China for the period from 2000–2015, as shown in
Table 2. We then applied the grey relational analysis to understand the importance ordering of the factors and the correlation(s) between them. The key to the analysis lay in the correlation coefficient between the factors.
The grey relational degree between the amount of CO
2 emissions and the factors is shown in
Table 3, in which the highest correlation of the amount of CO
2 emissions is with the number of registered motor vehicles. The second highest correlation is with the GDP per capita, followed by population, total energy consumption, and amount invested in China. The relational degree between each pair of factors is not significant. The key to the analysis is the correlation ordering between the factors.
The data from 2000–2013 includes a total of 14 sets of observations. The forecast model was built to obtain the simulation value and calculate the simulation value errors. The model forecast value and forecast value error were obtained from 2014 and 2015 data.
N = 2, 3, 4, 5 was substituted into GM(1,
N) to produce 31 sets of models. Based on the aforementioned method, we separately calculated the models built using different combinations of factors to show their error value and accuracy (
Table 4).
Table 4 shows that GM(1, 3) includes the population and the total energy consumption, and its accuracy rate was the highest at 96.63%. Overall, 18 combinations had accuracy higher than 96%. The two combinations with the lowest accuracy were GM(1, 2) using GDP and GM(1, 2) using the amount invested in China. Both had an accuracy rate lower than 30%.
This study applied three types of error evaluation methods as the evaluation indicators of the forecast model. The smaller the error value, the higher the forecast model’s accuracy rate. The first type of error evaluation method is the mean absolute percentage error (MAPE) calculated as follows:
where
fk is the forecast value of period
k, and
ok is the original actual value of period
k. This method divided the accuracy rate into four levels, as shown in
Table 5.
The second type of error evaluation method is the mean absolute error (MAE), which uses error to indicate accuracy, and is calculated is as follows:
The third type of error evaluation method is the percentage error (PE), which is represented in percentage form. This method can directly compare the difference between the forecast value and actual value, as calculated as follows:
To prove the accuracy of the proposed method, we built the following forecast models based on the data from 2000 to 2015: regression forecast, time series forecast, GP, Hybrid GM(1, 1), and the proposed hybrid GM(1, 3). The built forecast models were trained with 14 sets of data from 2000–2013, and then were tested with two sets of data from 2014–2015.
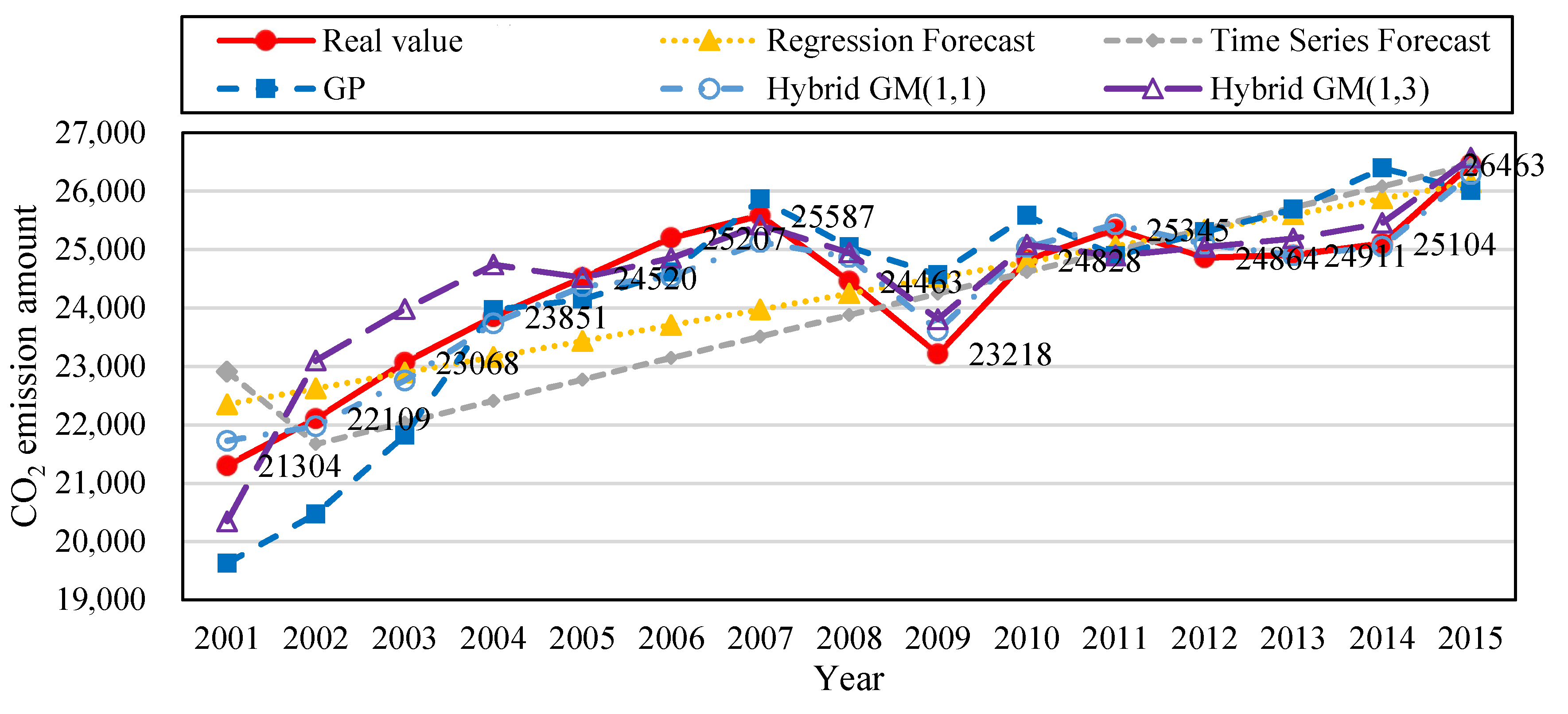
Table 6 shows that the MAPE of regression forecast, time series forecast, GP, Hybrid GM(1, 1), and the proposed hybrid GM(1, 3) during training data was 3.07%, 4.44%, 4.42%, 2.64%, and 2.14%; and their MAE during training data was 768.78, 1,067.38, 1,079.89, 248.67, and 457.399, respectively. Their MAPE during testing data was 2.13%, 1.79%, 2.80%, 2.65%, and 0.91%, respectively; and their MAE during testing data was 544.54, 1,061.42, 708.921, 205.09, and 119.101, respectively.
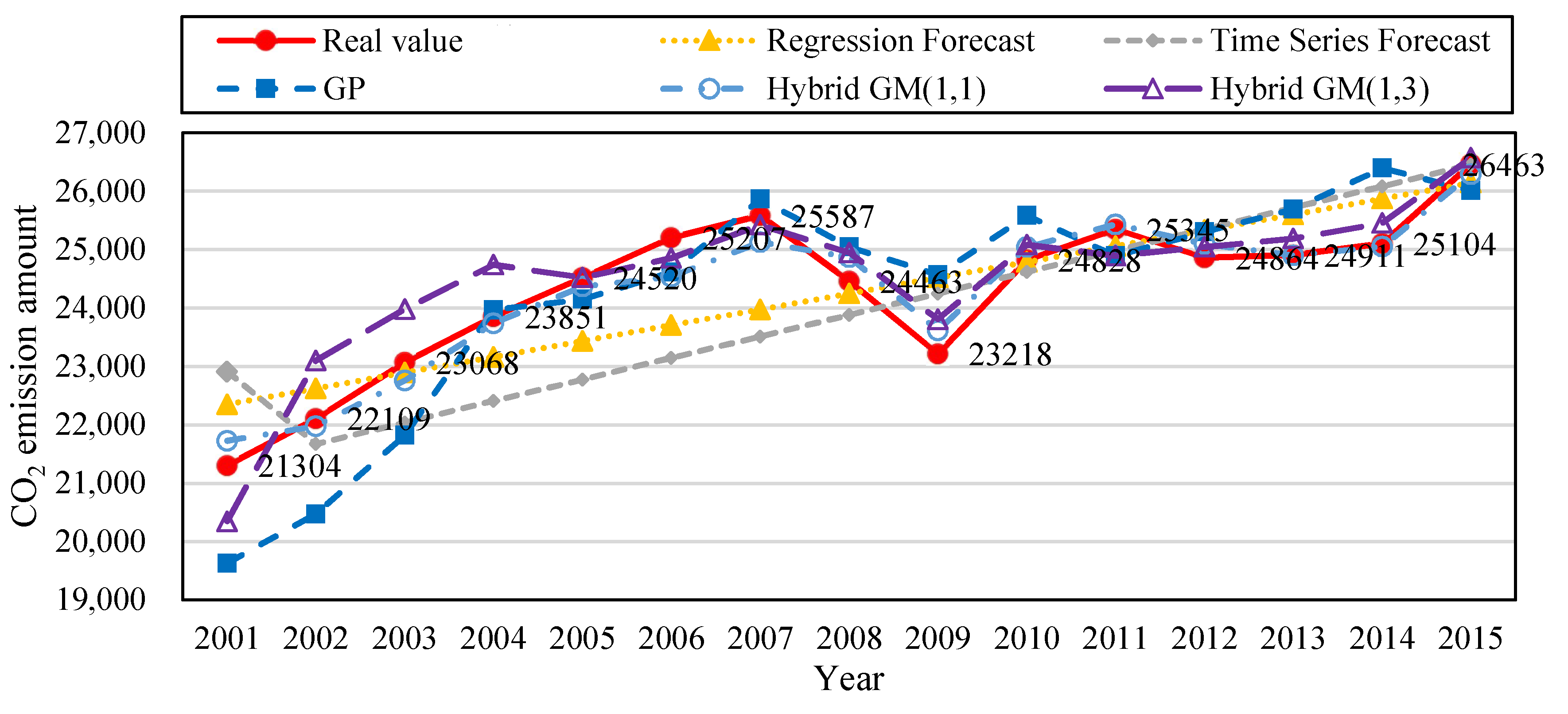
Figure 2 shows the trend of the amount of CO
2 emissions established with the simulation value and forecast value of the five types of forecast models from
Table 6.
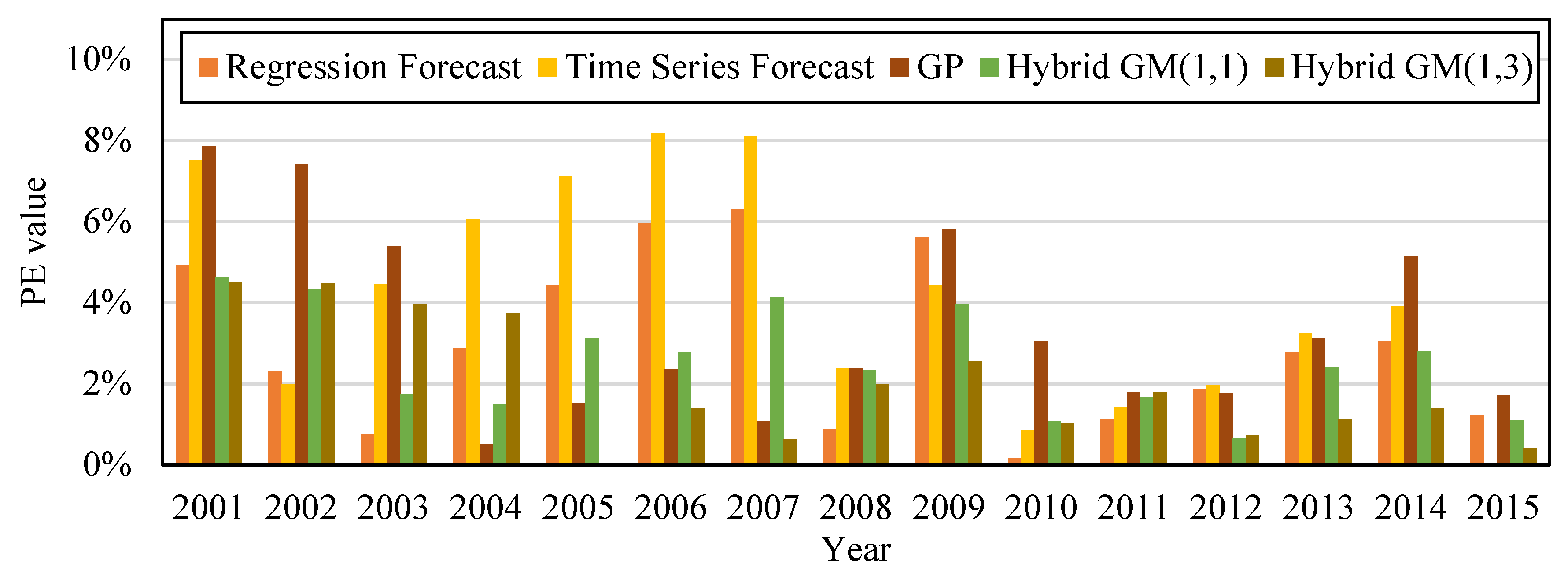
Figure 3 is the bar chart built from the PE values of the five forecast models in
Table 6. It can be observed that compared with other forecast models, the method proposed by this study had better accuracy for forecasting the amount of CO
2 emissions.
4.2. Analysis of the Amount of CO2 Emissions in Taiwan during the Financial Crisis
The financial crisis caused by the American subprime mortgage crisis at the end of 2007 resulted in new lows in the global stock markets. Many banks faced bankruptcy and the crisis produced a significant impact on Taiwan’s economy. As the financial crisis hit, the news often reported factory shutdowns and company layoffs. The unemployment rate hit a historic high, as the labor market rapidly worsened to a level not seen before. To analyze the factors that affected Taiwan’s amount of CO
2 emissions during the financial crisis, we collected data on population, GDP per capita, total energy consumption, number of registered motor vehicles, and the amount invested in China for the period from 2006–2011, as shown in
Table 4. We then applied the grey relational analysis to understand the importance of factors and the relational degrees of factors. The key to the analysis is the relational degrees of factors.
The grey relation degrees of all factors was sorted from large to small.
Table 7 shows that Taiwan’s population has the highest correlation with the amount of CO
2 emissions, followed by total energy consumption, the number of registered motor vehicles, GDP per capita, and the amount invested in China.
Simulation values were obtained from the forecast model built with the data from 2006 to 2010, and the simulation value error was calculated. The model forecast value and forecast value error were obtained from the data in 2011.
N = 2, 3, 4, 5 was substituted in GM(1,
N) to produce 31 sets of models. Based on the aforementioned method, we separately calculated the models built from different combinations of factors. The error values and accuracy were also calculated, as shown in
Table 8. Results show that GM(1, 5), which included Taiwan’s population, total energy consumption, number of registered motor vehicles, and the amount invested in China had an accuracy rate of 97.15%, which is the combination with the highest accuracy. Among all combinations, three combinations had accuracies higher than 97%, and 14 combinations had accuracies higher than 96%.
We built the following forecast models based on data from 2006 to 2011: regression analysis forecast, time series forecast, GP, hybrid GM(1, 1), and our proposed hybrid GM(1, 5). Five sets of data from 2006–2010 were used to train the forecast models, and then tested with data from 2011.
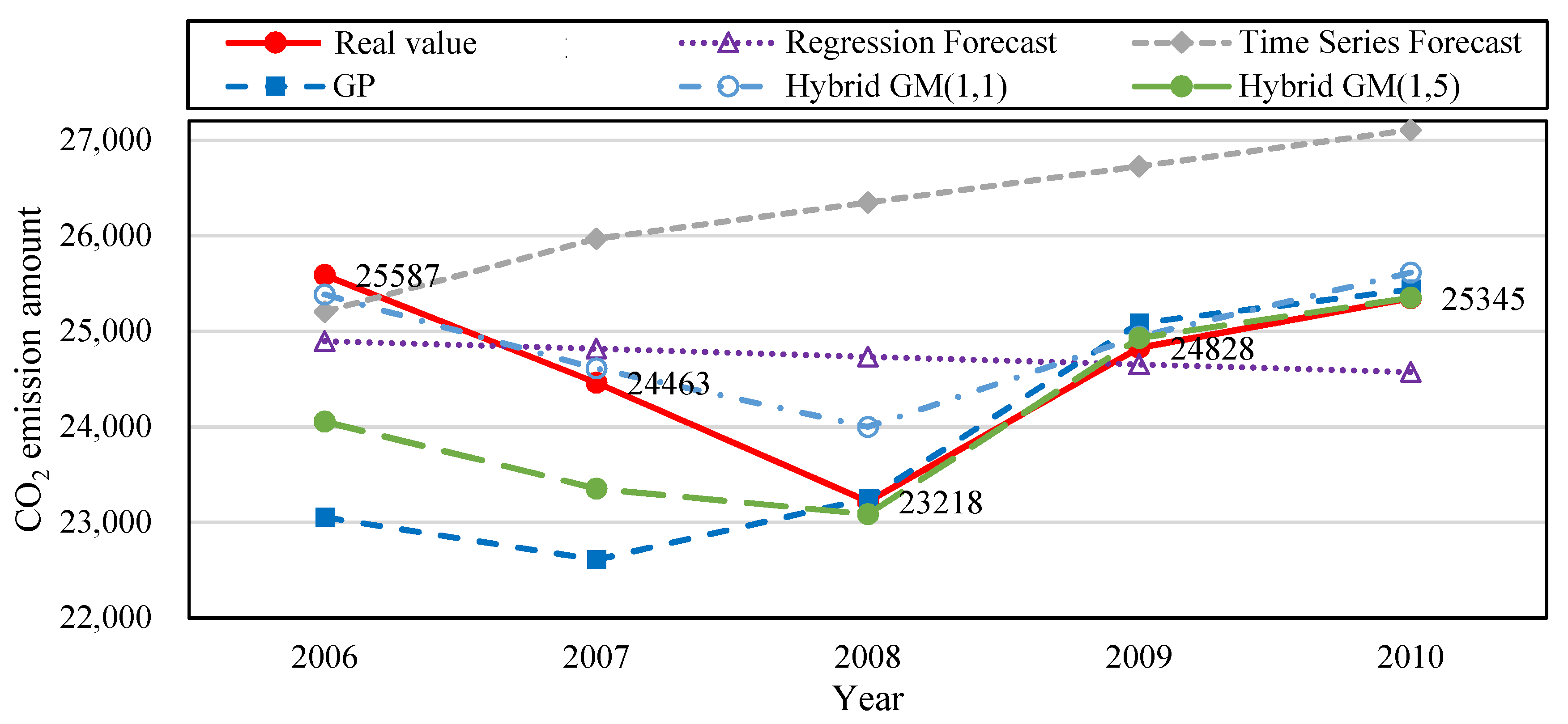
Table 9 shows that the MAPE during training data for regression analysis forecast, time series forecast, GP, hybrid GM(1, 1), the proposed hybrid GM(1, 5) was 2.84%, 7.19%, 4.66%, 1.74%, and 2.88%, respectively. Their MAE during training data was 592.8, 1728, 1168.48, 250.25, and 602.46, respectively. Their MAPE during testing data was 3.05%, 6.95%, 0.36%, 3.86%, and 0.02%, respectively. The MAE during training data was 592.8, 1762, 92.31, 951.03, and 5.54, respectively.
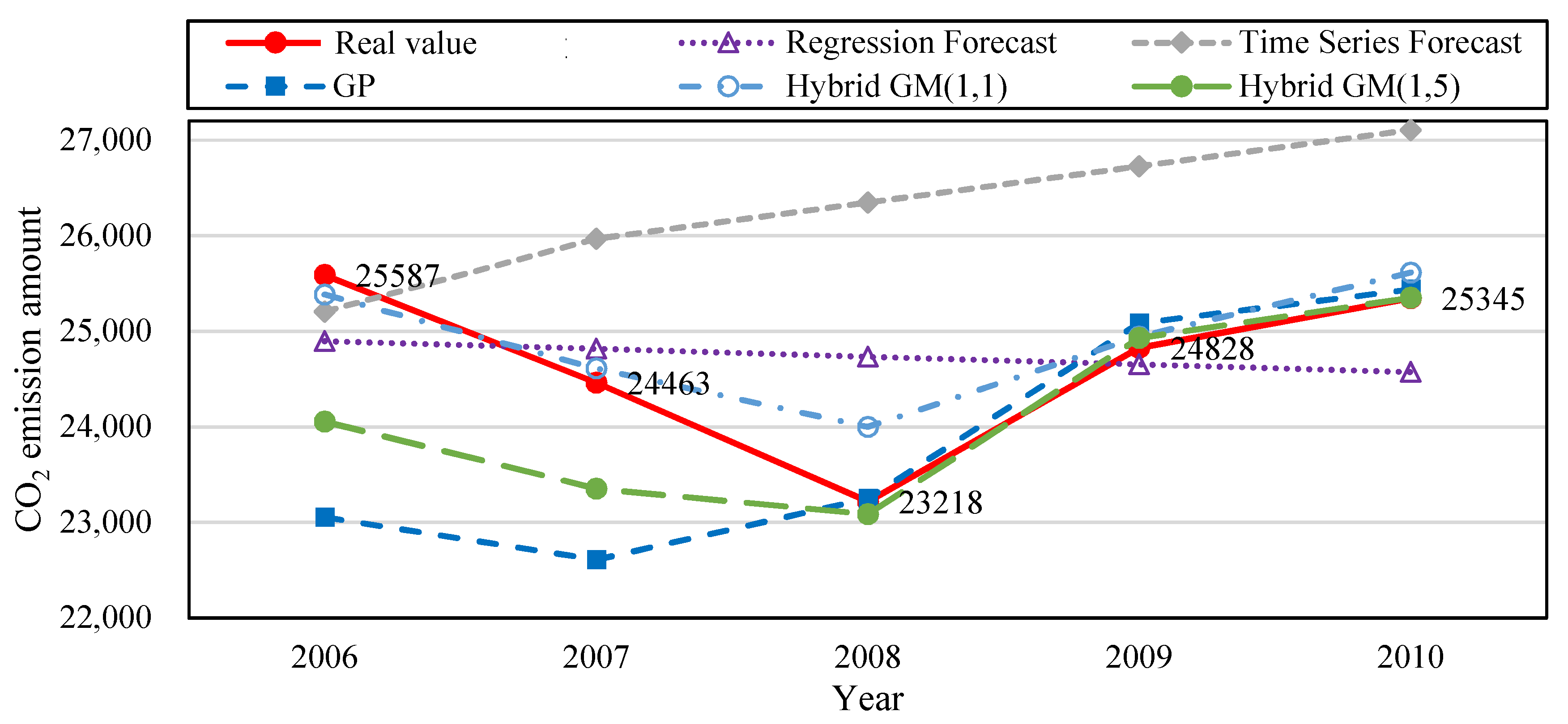
Figure 4 is the CO
2 emission amount trend produced from the simulation value and forecast value of the five forecast models in
Table 9 for the financial crisis period.
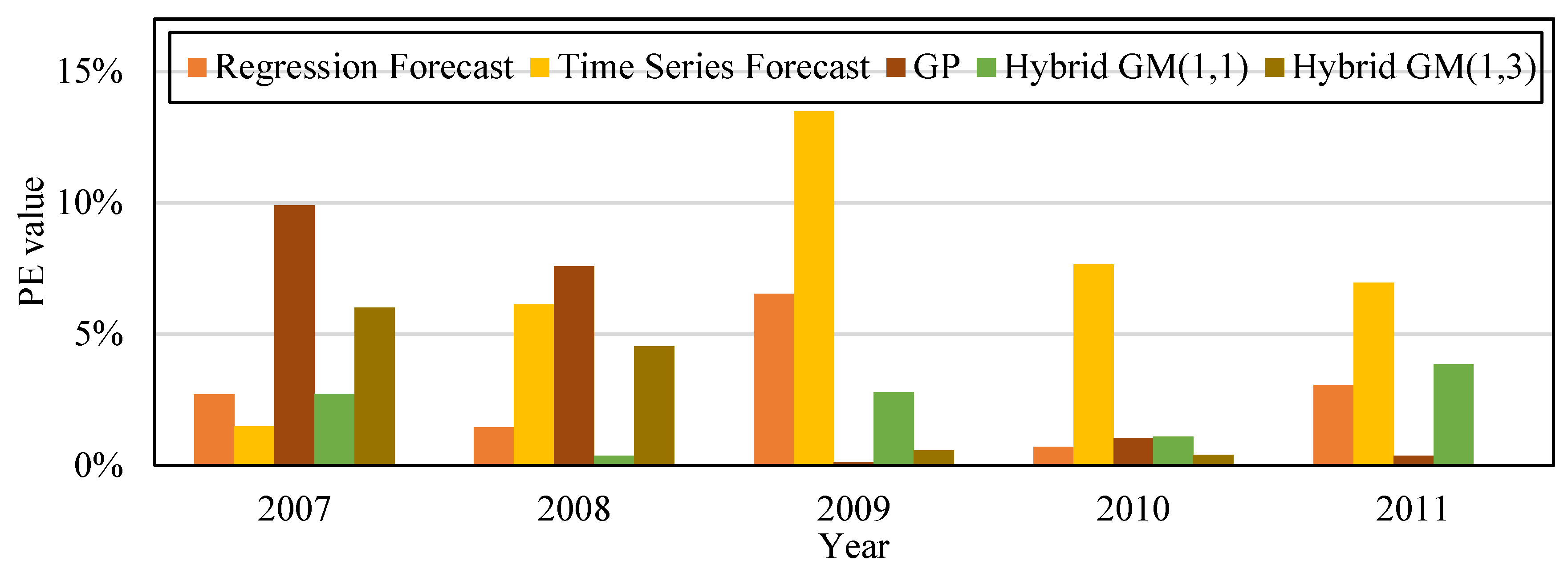
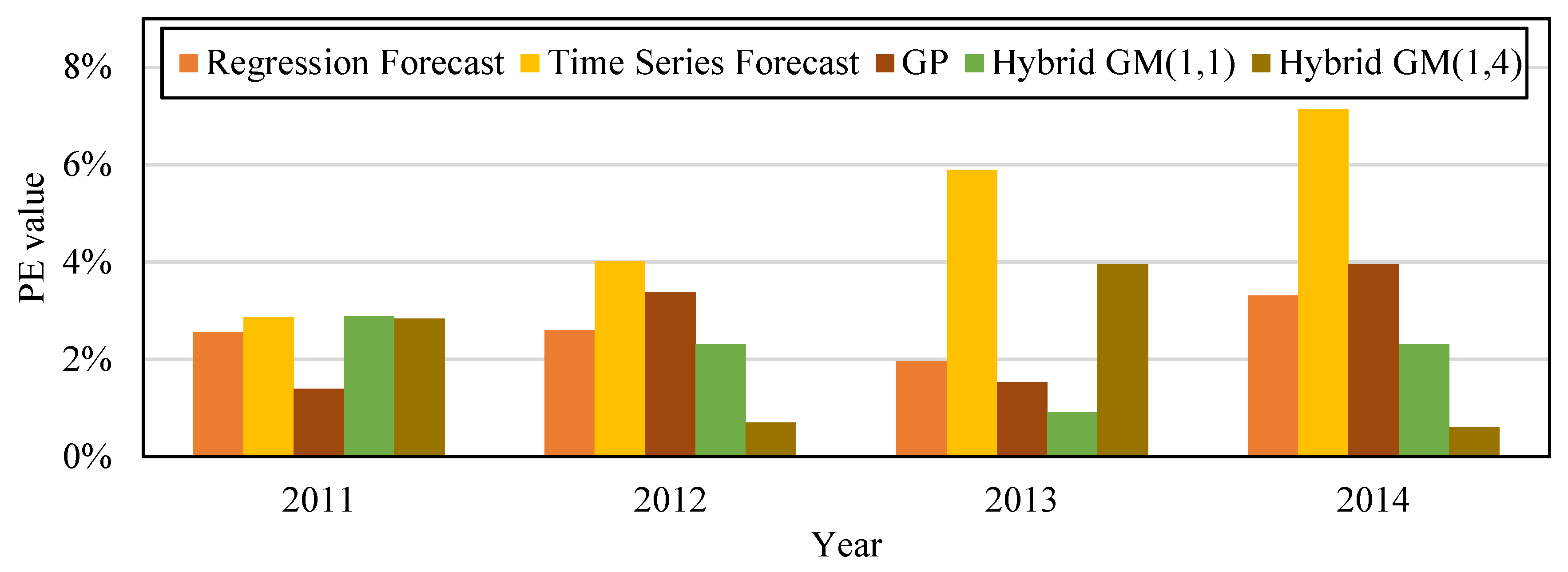
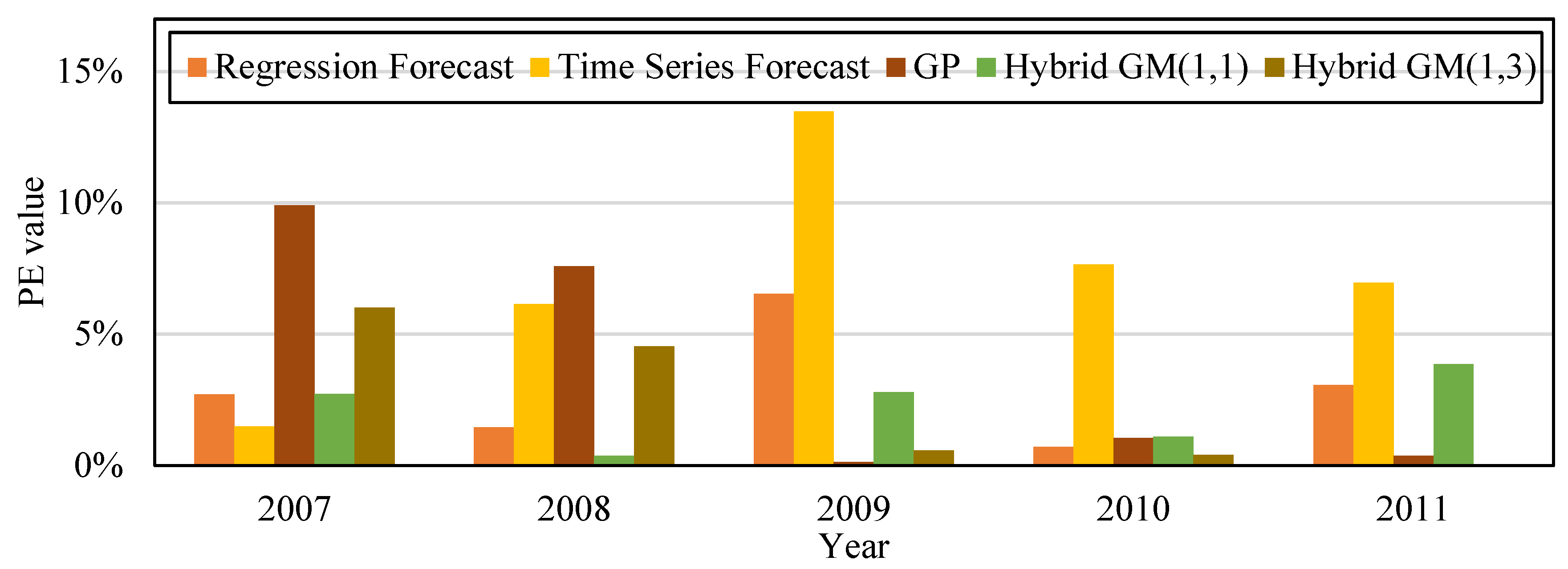
Figure 5 is the bar chart that compares the PE values from the five forecast model from
Table 9. The original actual value in the data and chart clearly shows that after the financial crisis occurred in 2008, the amount of CO
2 emissions decreased significantly. CO
2 emissions gradually rose with the revival of the economy. Compared with other forecast models, the proposed model has superior fitness and variability, and is more accurate in forecasting CO
2 emission amount.
4.3. The Impact of Taiwan Businessmen Moving Overseas on Taiwan’s CO2 Emission Amount
When Taiwan began allowing Taiwan businessmen to invest in China in 1990, the first people to invest in China were from the manufacturing industry and labor-intensive industries. Investments in the manufacturing industry accounted for 90% of all investments in China. China is large and full of resources, so small and medium-size industries can achieve economies of scale in production and sales. In addition, the land, equipment, factory, and labor were cheap in China, which gave small and medium-size companies an advantage in growth. Considering the popularity of investing in China in recent years, we collected factors that impacted CO
2 emissions in Taiwan during the period that Taiwan businessmen were moving overseas. We collected data on population, GDP per capita, total energy consumption, number of registered motor vehicles, and amount invested in China for the period between 2010 and 2014. We then applied grey relational analysis to understand the importance of factors and the relational degree between factors. The key to the analysis is the relational degree between factors. The grey relational degrees of all factors was sorted from large to small.
Table 10 shows that Taiwan’s energy consumption has the highest correlation with the amount of CO
2 emissions, followed by population, the number of registered motor vehicles, GDP per capita, and the amount invested in China.
Simulation values were obtained from forecast model built with the data from 2010 to 2013, and the simulation value errors were calculated. Model forecast value and forecast value error were obtained with the data from 2014.
N = 2, 3, 4, 5 was substituted in GM(1,
N) to produce 31 combinations of factors used in the grey model. Based on the aforementioned method, we separately calculated models built from different factor combinations. The error values and accuracy were also calculated, as shown in
Table 11. Result show that GM(1, 4), which included Taiwan’s population, number of registered motor vehicles, and amount invested in China had an accuracy rate of 97.87%, which is the highest accuracy. Four combinations had accuracy higher than 96%.
We built the following forecast models based on data from 2010 to 2014: regression forecast, time series forecast, GP, hybrid GM(1, 1), and the proposed hybrid GM(1, 4). Four sets of data from 2010 to 2013 were used to train the forecast models, and then were tested with data from 2014.
Table 12 shows that the MAPE during training data for the regression forecast, time series forecast, GP, hybrid GM(1, 1), and the proposed hybrid GM(1, 4) was 2.24%, 3.38%, 3.77%, 2.03%, and 2.49%, respectively. Their MAE during training data was 560.1, 843.75, 946.49, 511.5, and 408.9, respectively. Their MAPE during testing data was 3.31%, 7.14%, 0.49%, 2.3%, and 0.61%, respectively. Their MAE during training data was 830, 1792, 123.71, 598.43, and 153.58, respectively.
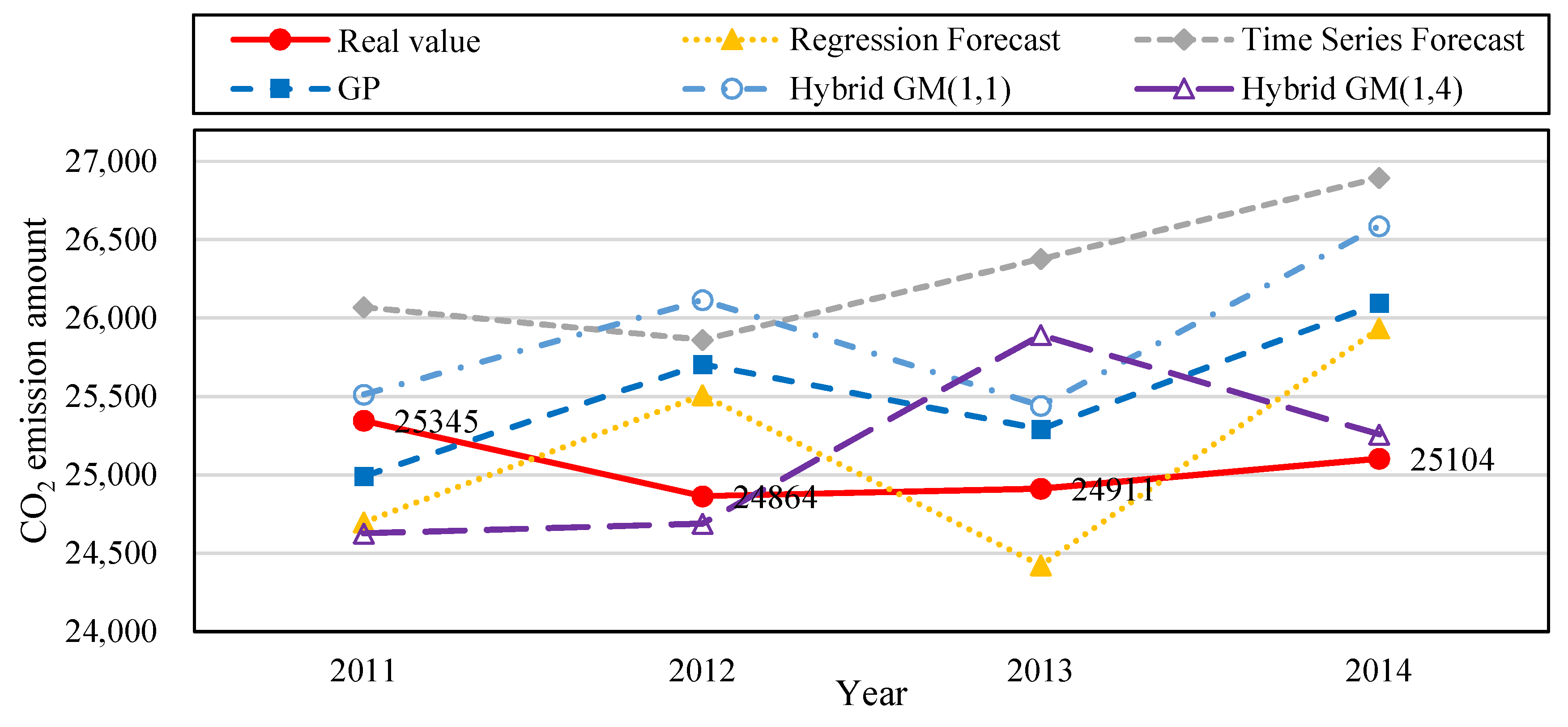
Figure 6 is the trend if the amount of CO
2 emissions produced with the simulation value and forecast value of the five forecast model in
Table 12 for the period when Taiwan businessmen were moving overseas.
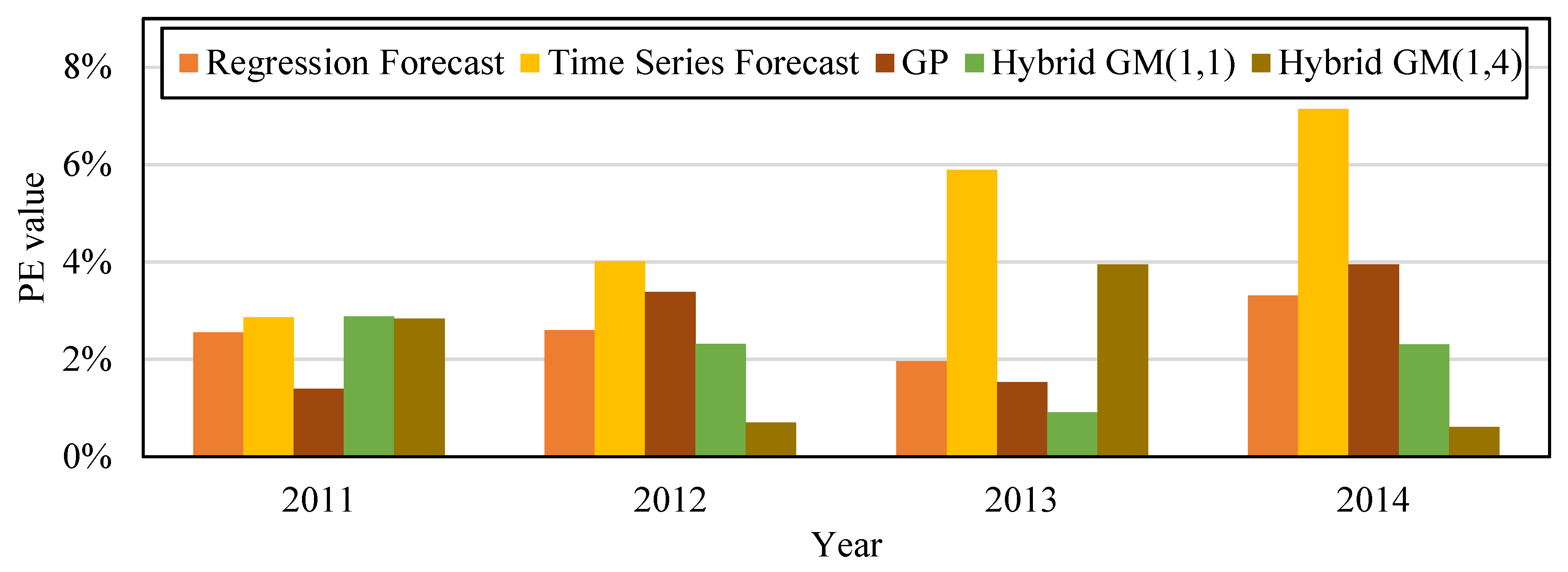
Figure 7 is the bar chart that compares the PE values from the five forecast models in
Table 12. The original actual value in the data and chart clearly shows that the amount of CO
2 emissions in 2010 dropped after Taiwan businessmen moved overseas. Compared with other forecast models, the proposed model has superior fitness and variability, and is more accurate in forecasting the amount of CO
2 emissions.
6. Conclusions
This work has proposed an approach that integrates multivariable grey forecasting and GP to consider multiple factors to forecast carbon emissions. Multivariable grey forecasting model is suitable for making predictions based on multiple factors with only four or more samples; and GP is used to create the error correction model for the prediction error of multivariable grey forecasting model. The performance of the proposed approach was tested on a case study for forecasting the carbon dioxide emissions in Taiwan from 2000 to 2015. The experimental result showed that the proposed approach with three factors (i.e., population, energy consumption, and carbon emissions) performed best among various combinations of six factors in this case. Note that the proposed approach applied in different examples may conclude that considering a different number of factors performs best. In addition, compared with previous approaches, the proposed approach also showed higher accuracy.
The possible limitation of the proposed approach is as follows. Inherited from the limitation of grey forecasting as indicated in a lot of previous literature (e.g., [
7,
20,
21]), the proposed method includes the grey forecasting method that adopts the least-squares method in estimation, so the predictions of the proposed method may be biased when the data samples have a lot of noise or show a sudden peak/valley owing to some sudden events or external factors. For example, when some country or region starts to implement a series of regulations and methods to prohibit or reduce CO
2 emissions in some year, the data that year may have a large drop. However, those regulations and methods may not be effective or stable in the following years, and hence the data of these years may demonstrate great vibration. Most forecasting methods suffer from this kind of noisy data.
In the future, we will use different types of data, such as electricity consumption and market sales data, for forecasting. The use of different types of problems and parameters will be more challenging for the mixed multivariable grey forecasting model designed in this study. Because factors for actual values are directly reflected in the forecast model, we can determine what kind of problem is suitable for what type of mathematical model. If we can put this model to good use, we can effectively solve instability and improve problem solving efficiency.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}